Syntactic Comprehension of Relative Clauses and Center Embedding Using Pseudowords

 ,
,
Abstract
1. Introduction
2. Experiment 1
2.1. Materials and Methods
2.1.1. Participants
2.1.2. Experimental Design
2.1.3. Materials
2.1.4. Procedure
2.1.5. Data Analysis
2.2. Results
2.2.1. Comprehension Questions
2.2.2. Reading Times
2.3. Discussion
3. Experiment 2
3.1. Materials and Methods
3.1.1. Participants
3.1.2. Materials
3.1.3. Procedure
3.1.4. Data Analysis
3.2. Results
3.2.1. Comprehension Questions
3.2.2. Reading times
3.3. Discussion
4. General Discussion
4.1. Disambiguation in Korean RC
4.2. Surprisal and Its Relation to Reading Times in RC
4.3. On-Line Constraints of a Memory Load and Its Relation to Reading Times in CE
4.4. Advantages of the Self-Paced Pseudoword Reading Task
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Chomsky, N. Lectures on Government and Binding: The Pisa Lectures; Walter de Gruyter: Berlin, Germany, 1993. [Google Scholar]
- Kayne, R.S. The Antisymmetry of Syntax; MIT Press: Cambridge, MA, USA, 1994. [Google Scholar]
- Sag, I.A. English relative clause constructions. J. Linguist. 1997, 33, 431–483. [Google Scholar] [CrossRef]
- Chomsky, N. The Minimalist Program; MIT Press: Cambridge, MA, USA, 2014. [Google Scholar]
- Gibson, E. Linguistic complexity: Locality of syntactic dependencies. Cognition 1998, 68, 1–76. [Google Scholar] [CrossRef]
- Gibson, E. The dependency locality theory: A distance-based theory of linguistic complexity. Image Lang. Brain 2000, 2000, 95–126. [Google Scholar]
- Hale, J. Proceedings of the Second Meeting of the North American Chapter of the Association for Computational Linguistics on Language Technologies; Association for Computational Linguistics: Stroudsburg, PA, USA, 2001; pp. 1–8. [Google Scholar]
- Warren, T.; Gibson, E. The influence of referential processing on sentence complexity. Cognition 2002, 85, 79–112. [Google Scholar] [CrossRef]
- Hale, J. The information conveyed by words in sentences. J. Psycholinguist. Res. 2003, 32, 101–123. [Google Scholar] [CrossRef]
- Keller, F. The entropy rate principle as a predictor of processing effort: An evaluation against eye-tracking data. In Proceedings of the 2004 Conference on Empirical Methods in Natural Language Processing, Barcelona, Spain, 25–26 July 2004. [Google Scholar]
- Lewis, R.L.; Vasishth, S. An activation-based model of sentence processing as skilled memory retrieval. Cogn. Sci. 2005, 29, 375–419. [Google Scholar] [CrossRef]
- Lewis, R.L.; Vasishth, S.; Van Dyke, J.A. Computational principles of working memory in sentence comprehension. Trends Cogn. Sci. 2006, 10, 447–454. [Google Scholar] [CrossRef]
- Vasishth, S.; Lewis, R.L. Argument-head distance and processing complexity: Explaining both locality and antilocality effects. Language 2006, 82, 767–794. [Google Scholar] [CrossRef]
- Demberg, V.; Keller, F. Data from eye-tracking corpora as evidence for theories of syntactic processing complexity. Cognition 2008, 109, 193–210. [Google Scholar] [CrossRef]
- Levy, R. Expectation-based syntactic comprehension. Cognition 2008, 106, 1126–1177. [Google Scholar] [CrossRef]
- Staub, A. Eye movements and processing difficulty in object relative clauses. Cognition 2010, 116, 71–86. [Google Scholar] [CrossRef] [PubMed]
- Kwon, N.; Gordon, P.C.; Lee, Y.; Kluender, R.; Polinsky, M. Cognitive and linguistic factors affecting subject/object asymmetry: An eye-tracking study of prenominal relative clauses in Korean. Language 2010, 86, 546–582. [Google Scholar] [CrossRef]
- Vasishth, S.; Drenhaus, H. Locality in german. Dialogue Discourse 2011, 2, 59–82. [Google Scholar] [CrossRef]
- Levy, R.P.; Keller, F. Expectation and locality effects in German verb-final structures. J. Mem. Lang. 2013, 68, 199–222. [Google Scholar] [CrossRef] [PubMed]
- Levy, R.; Fedorenko, E.; Gibson, E. The syntactic complexity of Russian relative clauses. J. Mem. Lang. 2013, 69, 461–495. [Google Scholar] [CrossRef]
- Husain, S.; Vasishth, S.; Srinivasan, N. Strong expectations cancel locality effects: Evidence from Hindi. PLoS ONE 2014, 9, e100986. [Google Scholar] [CrossRef]
- Boston, M.F.; Hale, J.; Kliegl, R.; Patil, U.; Vasishth, S. Parsing costs as predictors of reading difficulty: An evaluation using the Potsdam Sentence Corpus. J. Eye Mov. Res. 2008, 2. [Google Scholar] [CrossRef]
- Roark, B.; Bachrach, A.; Cardenas, C.; Pallier, C. Proceedings of the 2009 Conference on Empirical Methods in Natural Language Processing: Volume 1-Volume 1; Association for Computational Linguistics: Pittsburgh, PA, USA, 2009; pp. 324–333. [Google Scholar]
- Bresnan, J.; Ford, M. Predicting syntax: Processing dative constructions in American and Australian varieties of English. Language 2010, 86, 168–213. [Google Scholar] [CrossRef]
- Levy, R.; Fedorenko, E.; Breen, M.; Gibson, E. The processing of extraposed structures in English. Cognition 2012, 122, 12–36. [Google Scholar] [CrossRef]
- Smith, N.J.; Levy, R. The effect of word predictability on reading time is logarithmic. Cognition 2013, 128, 302–319. [Google Scholar] [CrossRef]
- Hirschberg, J.; Manning, C.D. Advances in natural language processing. Science 2015, 349, 261–266. [Google Scholar] [CrossRef] [PubMed]
- Linzen, T.; Jaeger, T.F. Uncertainty and expectation in sentence processing: Evidence from subcategorization distributions. Cogn. Sci. 2016, 40, 1382–1411. [Google Scholar] [CrossRef] [PubMed]
- Kuperberg, G.R.; Jaeger, T.F. What do we mean by prediction in language comprehension? Lang. Cogn. Neurosci. 2016, 31, 32–59. [Google Scholar] [CrossRef] [PubMed]
- Wu, F.; Kaiser, E.; Vasishth, S. Effects of Early Cues on the Processing of Chinese Relative Clauses: Evidence for Experience-Based Theories. Cogn. Sci. 2018, 42, 1101–1133. [Google Scholar] [CrossRef]
- Mansbridge, M.; Park, S.; Tamaoka, K. Disambiguation and integration in Korean relative clause processing. J. Psycholinguist. Res. 2017, 46, 827–845. [Google Scholar] [CrossRef]
- Fitch, W.T.; Hauser, M.D. Computational constraints on syntactic processing in a nonhuman primate. Science 2004, 303, 377–380. [Google Scholar] [CrossRef]
- Karlsson, F. Constraints on multiple center-embedding of clauses. J. Linguist. 2007, 43, 365–392. [Google Scholar] [CrossRef]
- King, J.; Just, M.A. Individual differences in syntactic processing: The role of working memory. J. Mem. Lang. 1991, 30, 580–602. [Google Scholar] [CrossRef]
- Just, M.A.; Carpenter, P.A. A capacity theory of comprehension: Individual differences in working memory. Psychol. Rev. 1992, 99, 122. [Google Scholar] [CrossRef]
- Lewis, R.L. Interference in short-term memory: The magical number two (or three) in sentence processing. J. Psycholinguist. Res. 1996, 25, 93–115. [Google Scholar] [CrossRef]
- Christiansen, M.H.; Chater, N. Toward a connectionist model of recursion in human linguistic performance. Cogn. Sci. 1999, 23, 157–205. [Google Scholar] [CrossRef]
- Gordon, P.C.; Hendrick, R.; Johnson, M. Memory interference during language processing. J. Exp. Psychol. Learn. Mem. Cogn. 2001, 27, 1411. [Google Scholar] [CrossRef]
- Kiss, T. Semantic constraints on relative clause extraposition. Nat. Lang. Linguist. Theory 2005, 23, 281–334. [Google Scholar] [CrossRef]
- Levinson, S.C. Recursion in pragmatics. Language 2013, 89, 149–162. [Google Scholar] [CrossRef]
- Gibson, E.; Piantadosi, S.T.; Brink, K.; Bergen, L.; Lim, E.; Saxe, R. A noisy-channel account of crosslinguistic word-order variation. Psychol. Sci. 2013, 24, 1079–1088. [Google Scholar] [CrossRef] [PubMed]
- Jäger, L.; Engelmann, F.; Vasishth, S. Similarity-based interference in sentence comprehension: Literature review and Bayesian meta-analysis. J. Mem. Lang. 2017, 94, 316–339. [Google Scholar] [CrossRef]
- Bates, E. Processing complex sentences: A cross-linguistic study. Lang. Cogn. Process. 1999, 14, 69–123. [Google Scholar] [CrossRef]
- Nakayama, M.; Lee, S.-H.; Lewis, R.L. Difficulty of processing Japanese and Korean center-embedding constructions. Stud. Lang. Sci. 2005, 4, 99–118. [Google Scholar]
- Comrie, B. Rethinking the typology of relative clauses. Lang. Des. J. Theor. Exp. Linguist. 1998, 1, 59–85. [Google Scholar]
- Kwon, N. Processing of Syntactic and Anaphoric Gap-Filler Dependencies in Korean: Evidence from Self-Paced Reading Time, ERP and Eye-Tracking Experiments; UC San Diego: La Jolla, CA, USA, 2008. [Google Scholar]
- Kim, I. Rethinking “island effects” in Korean relativization. Lang. Sci. 2013, 38, 59–82. [Google Scholar] [CrossRef]
- Kim, J.-B. A Head-Driven and Constraint-Based Analysis of Korean Relative Clause Constructions. Lang. Res. 1998, 34, 767–808. [Google Scholar]
- Cha, J.-Y. Constraints on Clausal Complex Noun Phrases in Korean with Focus on the Gapless Relative Clause Construction; University of Illinois at Urbana-Champaign: Champaign, IL, USA, 2005. [Google Scholar]
- Monsalve, I.F.; Frank, S.L.; Vigliocco, G. Lexical surprisal as a general predictor of reading time. In Proceedings of the 13th Conference of the European Chapter of the Association for Computational Linguistics, Avignon, France, 23 April 2012; Association for Computational Linguistics: Avignon, France, 2012; pp. 398–408. [Google Scholar]
- Daneman, M.; Carpenter, P.A. Individual differences in working memory and reading. J. Verbal Learn. Verbal Behav. 1980, 19, 450–466. [Google Scholar] [CrossRef]
- Yoo, H.-J.; Lee, J.-M.; Kim, M.-R. Individual differences in working memory: Inhibition of irrelevant information. Korean J. Cogn. Sci. 2004, 17, 207–229. [Google Scholar]
- Oldfield, R.C. The assessment and analysis of handedness: The Edinburgh inventory. Neuropsychologia 1971, 9, 97–113. [Google Scholar] [CrossRef]
- Lee, I.; Ramsey, S.R. The Korean Language; Suny Press: Albany, NY, USA, 2000. [Google Scholar]
- Chae, H.-R. Tense Markers and -ko Constructions in Korean. In Proceedings of the 20th Pacific Asia Conference on Language, Information and Computation, Wuhan, China, 1–3 November 2006; He, T., Sun, M., Chen, Q., Eds.; Tsinghua University Press: Beijing, China, 2006; pp. 191–197. [Google Scholar]
- Gamallo, P. The Meaning of Syntactic Dependencies. Linguist. Online 2008, 35, 33–53. [Google Scholar]
- Weskott, T.; Fanselow, G. On the informativity of different measures of linguistic acceptability. Language 2011, 87, 249–273. [Google Scholar] [CrossRef]
- Gang, H.-S.; Yang, M.-H.; Park, D.-G. A Sociolinguistic Study on Characteristics of Names of Korean People and their Transitional Aspects. Soc. Korean Lang. Lit. Res. 2012, 73, 33–60. [Google Scholar]
- Lee, Y.; Lee, H.; Gordon, P.C. Linguistic complexity and information structure in Korean: Evidence from eye-tracking during reading. Cognition 2007, 104, 495–534. [Google Scholar] [CrossRef] [PubMed][Green Version]
- Kim, H. Korean national corpus in the 21st century Sejong project. In Proceedings of the 13th NIJL International Symposium, Tokyo, Japan, March 2006; pp. 49–54. [Google Scholar]
- Kwon, N.; Polinsky, M.; Kluender, R. Subject preference in Korean. In Proceedings of the 25th West Coast Conference on Formal Linguistics; Cascadilla Proceedings Project: Somerville, MA, USA, 2006; pp. 1–14. [Google Scholar]
- Martin, S.E. A Reference Grammar of Korean: A Complete Guide to the Grammar and History of the Korean Language; Tuttle Publishing: Tokyo, Japan, 1992. [Google Scholar]
- Peirce, J.W. PsychoPy—Psychophysics software in Python. J. Neurosci. Methods 2007, 162, 8–13. [Google Scholar] [CrossRef]
- Luce, R.D. Response Times: Their Role in Inferring Elementary Mental Organization; Oxford University Press on Demand: New York, NY, USA, 1986. [Google Scholar]
- Loftus, G.R.; Masson, M.E. Using confidence intervals in within-subject designs. Psychon. Bull. Rev. 1994, 1, 476–490. [Google Scholar] [CrossRef]
- Cousineau, D. Confidence intervals in within-subject designs: A simpler solution to Loftus and Masson’s method. Tutor. Quant. Methods Psychol. 2005, 1, 42–45. [Google Scholar] [CrossRef]
- Morey, R.D. Confidence intervals from normalized data: A correction to Cousineau (2005). Reason 2008, 4, 61–64. [Google Scholar] [CrossRef]
- Bates, D.; Mächler, M.; Bolker, B.; Walker, S. Fitting linear mixed-effects models using lme4. arXiv 2014, arXiv:1406.5823. [Google Scholar]
- Bates, D.; Mächler, M.; Bolker, B.; Walker, S. Fitting Linear Mixed-Effects Models Using lme4. J. Stat. Softw. 2015, 67, 1–48. [Google Scholar] [CrossRef]
- Baayen, R.H.; Davidson, D.J.; Bates, D.M. Mixed-effects modeling with crossed random effects for subjects and items. J. Mem. Lang. 2008, 59, 390–412. [Google Scholar] [CrossRef]
- Barr, D.J.; Levy, R.; Scheepers, C.; Tily, H.J. Random effects structure for confirmatory hypothesis testing: Keep it maximal. J. Mem. Lang. 2013, 68, 255–278. [Google Scholar] [CrossRef]
- Bates, D.; Kliegl, R.; Vasishth, S.; Baayen, H. Parsimonious mixed models. arXiv 2015, arXiv:1506.04967. [Google Scholar]
- Matuschek, H.; Kliegl, R.; Vasishth, S.; Baayen, H.; Bates, D. Balancing Type I error and power in linear mixed models. J. Mem. Lang. 2017, 94, 305–315. [Google Scholar] [CrossRef]
- Mitchell, D.C. An evaluation of subject-paced reading tasks and other methods for investigating immediate processes in reading. In New Methods in Reading Comprehension Research; Kieras, D., Just, M.A., Eds.; Erlbaum: Hillsdale, NJ, USA, 1984; pp. 69–89. [Google Scholar]
- Ferreira, F.; Clifton, C. The independence of syntactic processing. J. Mem. Lang. 1986, 25, 348–368. [Google Scholar] [CrossRef]
- Jaeger, T.F. Categorical data analysis: Away from ANOVAs (transformation or not) and towards logit mixed models. J. Mem. Lang. 2008, 59, 434–446. [Google Scholar] [CrossRef]
- Kuznetsova, A.; Brockhoff, P.B.; Christensen, R.H.B. lmerTest package: Tests in linear mixed effects models. J. Stat. Softw. 2017, 82. [Google Scholar] [CrossRef]
- Kwon, N.; Kluender, R.; Kutas, M.; Polinsky, M. Subject/object processing asymmetries in Korean relative clauses: Evidence from ERP data. Language 2013, 89, 537. [Google Scholar] [CrossRef]
- Cho, S.W. The acquisition of word order in Korean. Calg. Work. Pap. Linguist. 1982, 7, 53–116. [Google Scholar]
- Frenck-Mestre, C.; Kim, S.K.; Choo, H.; Ghio, A.; Herschensohn, J. Koh, SLook and listen! The online processing of Korean case by native and non-native speakers. Lang. Cogn. Neurosci. 2019, 34, 385–404. [Google Scholar] [CrossRef]
- Keenan, E.L.; Comrie, B. Noun phrase accessibility and universal grammar. Linguist. Inq. 1977, 8, 63–99. [Google Scholar]
- Chae, H.-R. Are There Relative Clauses in Korean?: A Participle Clause Analysis. Korean J. Linguist. 2012, 37, 1043–1065. [Google Scholar] [CrossRef]
- Yi, K.; Koo, M.; Nam, K.; Park, K.; Park, T.; Bae, S.; Lee, C.H. The Korean Lexicon Project—A Lexical Decision Study on 30,930 Korean Words and Nonwords. Korean J. Cogn. Biol. Psychol. 2017, 29, 395–410. [Google Scholar]
- Nakatani, K.; Gibson, E. Distinguishing theories of syntactic expectation cost in sentence comprehension: Evidence from Japanese. Linguistics 2008, 46, 63–87. [Google Scholar] [CrossRef]
- Jegerski, J.; VanPatten, B. (Eds.) Self-paced reading. In Research Methods in Second Language Psycholinguistics; Routledge: New York, NY, USA, 2014; pp. 20–49. [Google Scholar]
- Just, M.A.; Carpenter, P.A.; Woolley, J.D. Paradigms and processes in reading comprehension. J. Exp. Psychol. Gen. 1982, 111, 228. [Google Scholar] [CrossRef]
- Gibson, E.; Wu, H.-H.I. Processing Chinese relative clauses in context. Lang. Cogn. Process. 2013, 28, 125–155. [Google Scholar] [CrossRef]
- Rayner, K.; Carlson, M.; Frazier, L. The interaction of syntax and semantics during sentence processing: Eye movements in the analysis of semantically biased sentences. J. Verbal Learn. Verbal Behav. 1983, 22, 358–374. [Google Scholar] [CrossRef]
- Hagoort, P. Interplay between syntax and semantics during sentence comprehension: ERP effects of combining syntactic and semantic violations. J. Cogn. Neurosci. 2003, 15, 883–899. [Google Scholar] [CrossRef] [PubMed]
- Keenan, E.L. Relative clauses. Lang. Typol. Syntact. Descr. 1985, 2, 141–170. [Google Scholar]
- Kjellmer, G. Conjunctional/Adverbial Which in Substandard English. Stud. Angl. Posnan. 1988, 21, 125–137. [Google Scholar]
- Loock, R. Appositive Relative Clauses in Contemporary Written and Spoken English: Discourse Functions and Competitive Structures. Ph.D. Thesis, University of Lille III (UMR 8528 SILEX, CNRS), Villeneuve-d’Ascq, France, 2005. [Google Scholar]
- Loock, R. ‘Are you a good which or a bad which?’The relative pronoun as. Connect. Discourse Landmarks 2007, 161, 71. [Google Scholar]
- Loock, R. Appositive Relative Clauses in English: Discourse Functions and Competing Structures; John Benjamins Publishing: Amsterdam, The Netherlands, 2010; Volume 22. [Google Scholar]
- Yoon, J.-H. Different Semantics for Different Syntax: Relative Clauses in Korean. In Working Papers in Linguistics; Ohio State University: Columbus, OH, USA, 1993; Volume 42, pp. 199–226. [Google Scholar]
- Lee, S.-H. A Lexical Analysis of Select Unbounded Dependency Constructions in Korean. Ph.D. Thesis, The Ohio State University, Columbus, OH, USA, 2004. [Google Scholar]
- Cha, J.-Y. (Ed.) Type-hierarchical analysis of gapless relative clauses in Korean. In Proceedings of the 4th International Conference on HPSG, Ithaca, NY, USA, 18–20 July 1997; Cornell University: Ithaca, NY, USA, 1997. [Google Scholar]
- Cha, J.-Y. Semantics of Korean Gapless Relative Clause Constructions. 1999. [Google Scholar]
- Matsumoto, Y. Noun-Modifying Constructions in Japanese: A Frame Semantic Approach; John Benjamins Publishing: Philadelphia, PA, USA, 1997; Volume 35. [Google Scholar]
- Murasugi, K. Noun Phrases in Japanese and English: A Study in Syntax, Learnability and Acquisition. Ph.D. Thesis, University of Connecticut, Mansfield, CT, USA, 1991. [Google Scholar]
- Tsai, W.-T.D. On the absence of island effects. Tsing Hua J. Chin. Stud. 1997, 27, 125–149. [Google Scholar]
- Chang, C.H. Gapless Relative Clause Constructions in Mandarin Chinese. Master’s Thesis, National Chung Cheng University, Minxiong, Chiayi, Taiwan, 2006. [Google Scholar]
- Zhang, N. Gapless relative clauses as clausal licensors of relational nouns. Lang. Linguist. 2008, 9, 1003–1026. [Google Scholar]
- Yeom, J.-I. Gapless Adnominal Clauses in Korean and their Interpretations. Lang. Res. 2015, 51, 597–627. [Google Scholar]
- Steson, L.; Andrews, S. To Transform or Not to Transform: Using Generalized Linear Mixed Models to Analyse Reaction Time Data. Front. Psychol. 2015, 6, 1171. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
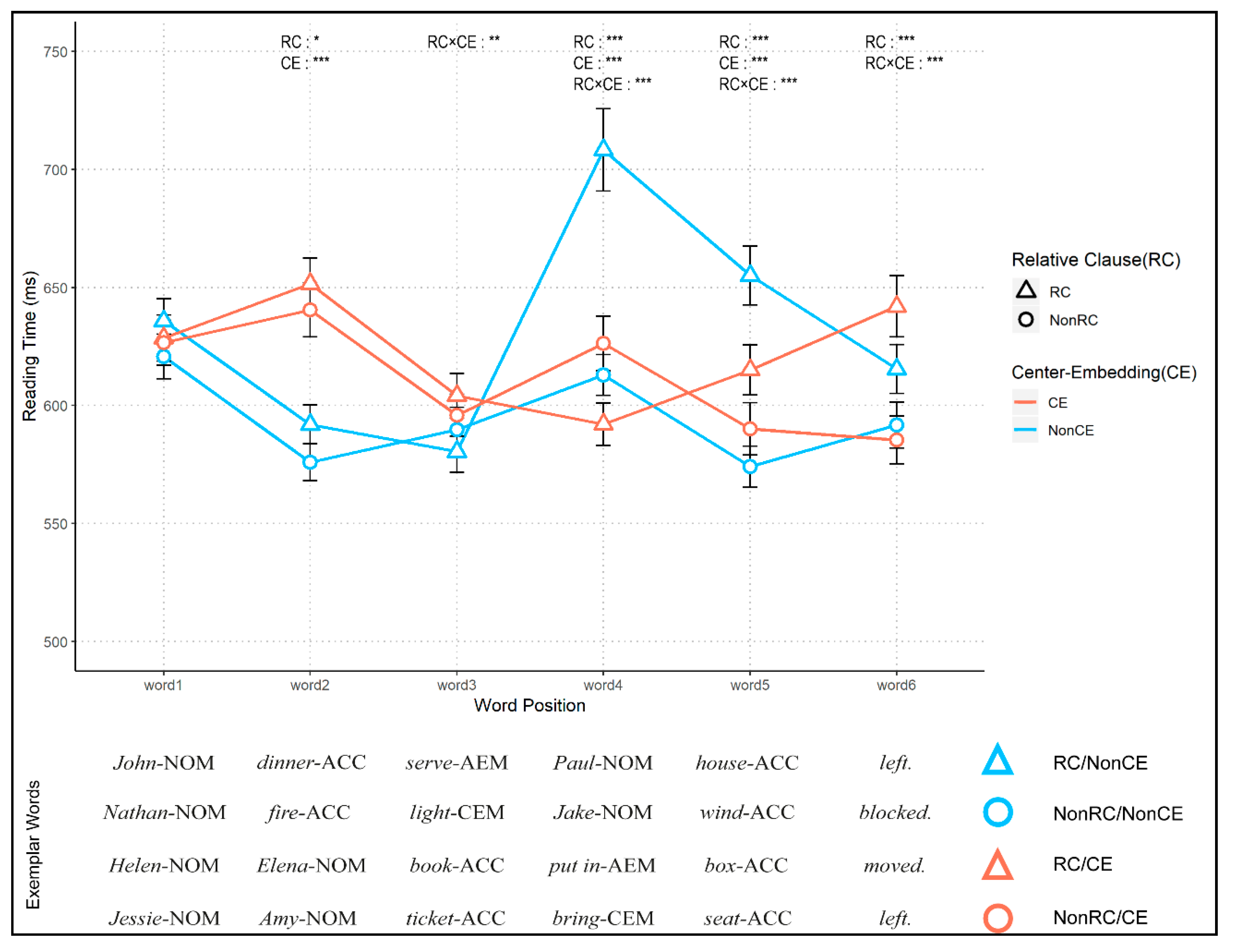
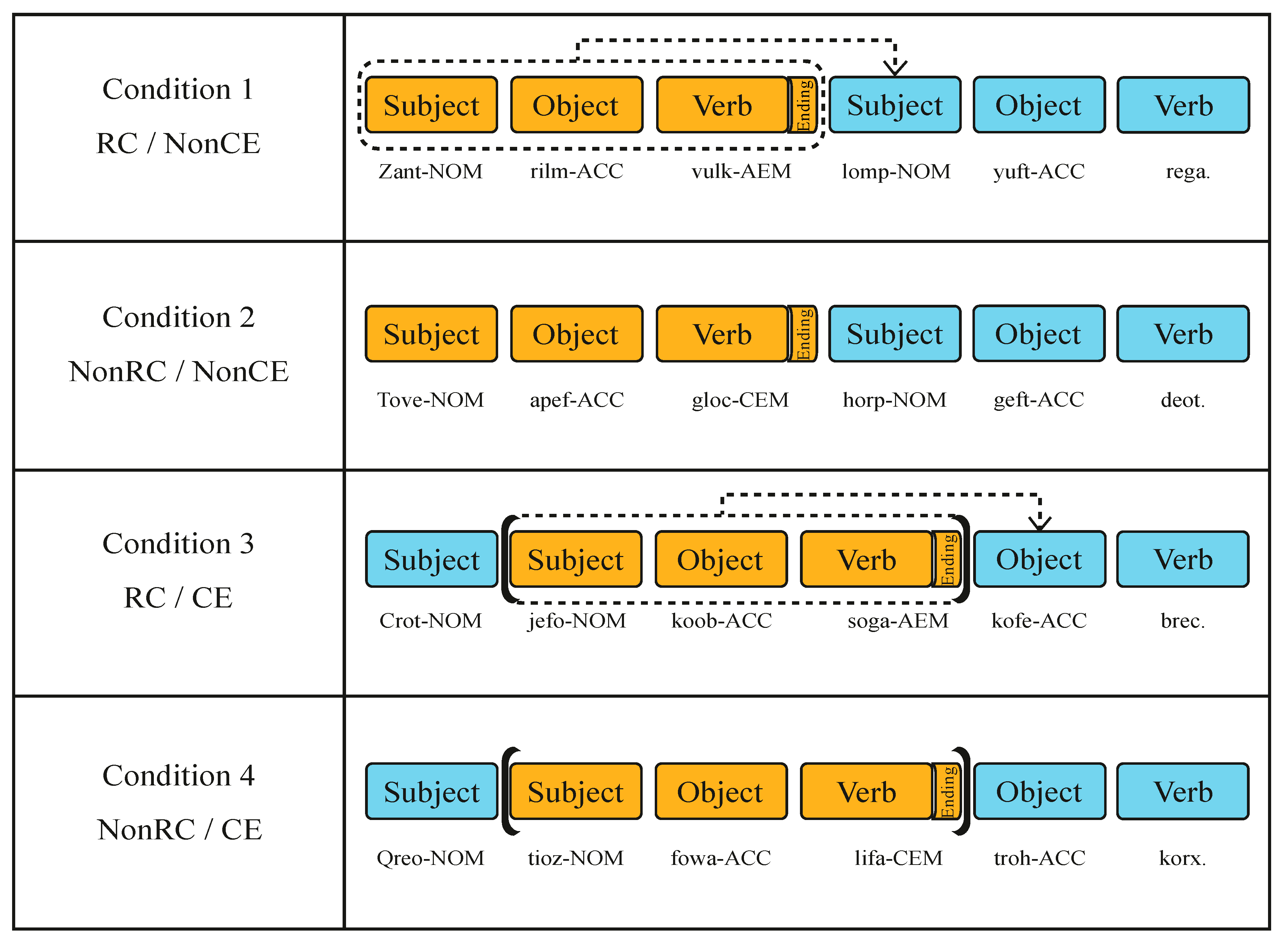
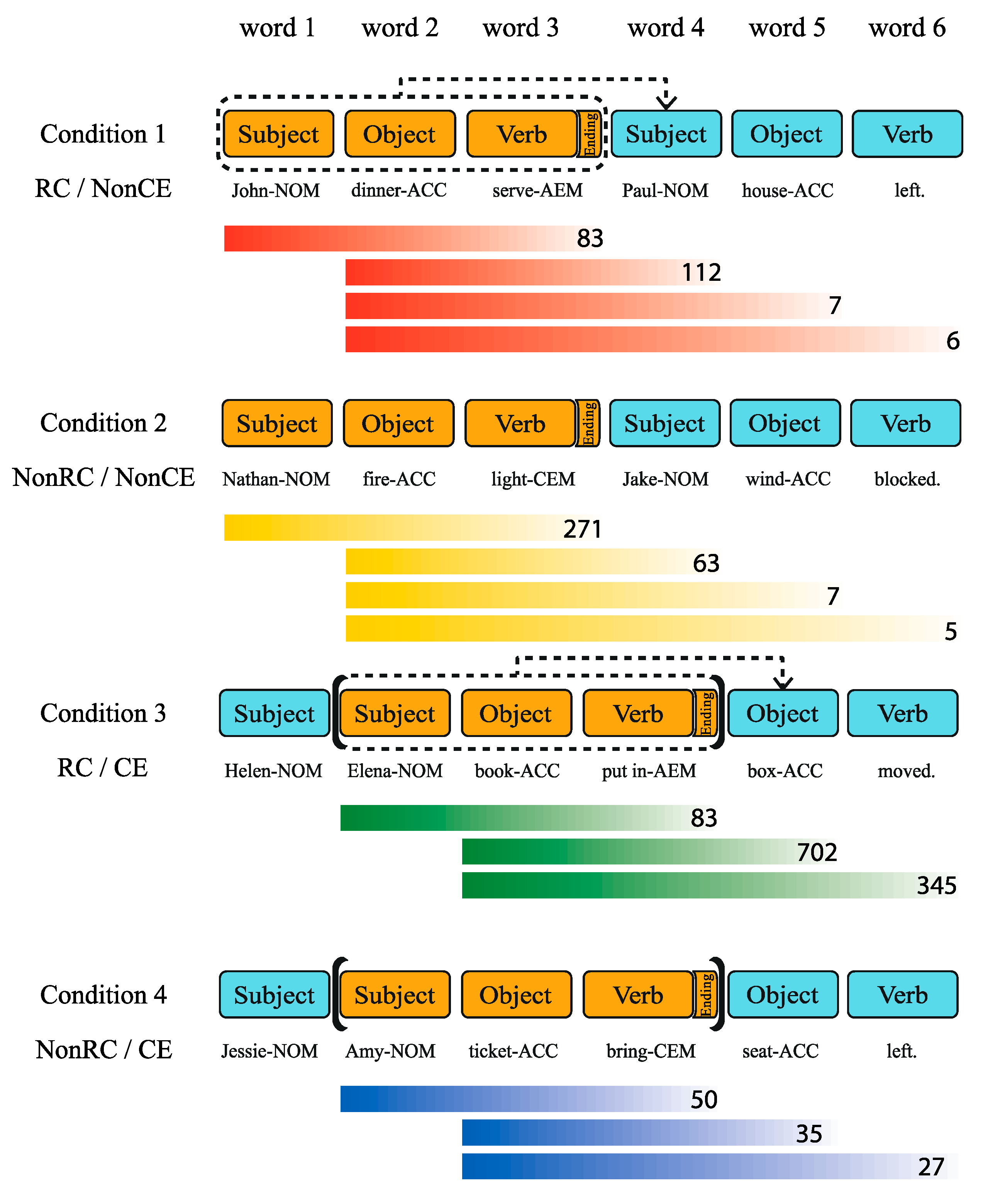
| RC/NonCE: | John이 | 저녁을 | 사준 | Paul이 | 집을 | 나섰다. |
| John-i | cenyek-ul | sacwu-n | Paul-i | cip-ul | na-sess-ta. | |
| NonRC/NonCE: | Nathan이 | 불을 | 켰고 | Jake가 | 바람을 | 막았다. |
| Nathan-i | pwul-ul | Khyess-ko | Jake-ka | Palam-ul | mak-ass-ta. | |
| RC/CE: | Helen이 | Elena가 | 책을 | 넣은 | 상자를 | 옮겼다. |
| Helen-i | Elena-ka | chayk-ul | neh-un | sangca-lul | olm-kyess-ta. | |
| NonRC/CE: | Jessie가 | Amy가 | 표를 | 가져오자 | 자리를 | 떴다. |
| Jessie-ka | Amy-ka | phyo-lul | kacyeo-ca | cali-lul | ttenass-ta. |
| Conditions | RC/NonCE | NonRC/NonCE | RC/CE | NonRC/CE |
|---|---|---|---|---|
| RT (ms) | 1178.008 (12.259) | 1175.367 (11.319) | 1200.645 (11.814) | 1175.217 (11.265) |
| Accuracy (%) | 91 (0.01) | 91 (0.01) | 92 (0.01) | 91 (0.01) |
| Words | Effects | Estimate | t-Value | p-Value |
|---|---|---|---|---|
| Word 1 | RC | −1.984 | −0.982 | 0.326 |
| CE | 0.100 | 0.050 | 0.960 | |
| RC × CE | 2.566 | 1.270 | 0.204 | |
| Word 2 | RC | −4.156 | −2.026 | 0.043* |
| CE | 28.575 | 12.325 | < 2 × 10−16*** | |
| RC × CE | −1.005 | −0.490 | 0.624 | |
| Word 3 | RC | 3.066 | 1.582 | 0.114 |
| CE | −0.294 | −0.145 | 0.885 | |
| RC × CE | −5.267 | −2.680 | 0.007** | |
| Word 4 | RC | −14.314 | −5.280 | 1.36 × 10−7*** |
| CE | −27.023 | −8.491 | < 2 × 10−16*** | |
| RC × CE | 30.140 | 11.065 | < 2 × 10−16*** | |
| Word 5 | RC | −22.834 | −9.729 | < 2 × 10−16*** |
| CE | −10.675 | −4.379 | 1.22 × 10−5*** | |
| RC × CE | 10.917 | 4.585 | 4.68 × 10−6*** | |
| Word 6 | RC | −10.482 | −4.436 | 9.39 × 10−6*** |
| CE | 4.451 | 1.862 | 0.063 | |
| RC × CE | −11.769 | −5.009 | 5.71 × 10−7*** |
| Conditions | RC/NonCE | NonRC/NonCE | RC/CE | NonRC/CE |
|---|---|---|---|---|
| RT (ms) | 1644.465 (23.489) | 1515.466 (18.451) | 1760.705 (23.807) | 1673.426 (21.209) |
| Accuracy (%) | 75.875 (0.015) | 88.125 (0.011) | 62.75 (0.017) | 76.25 (0.015) |
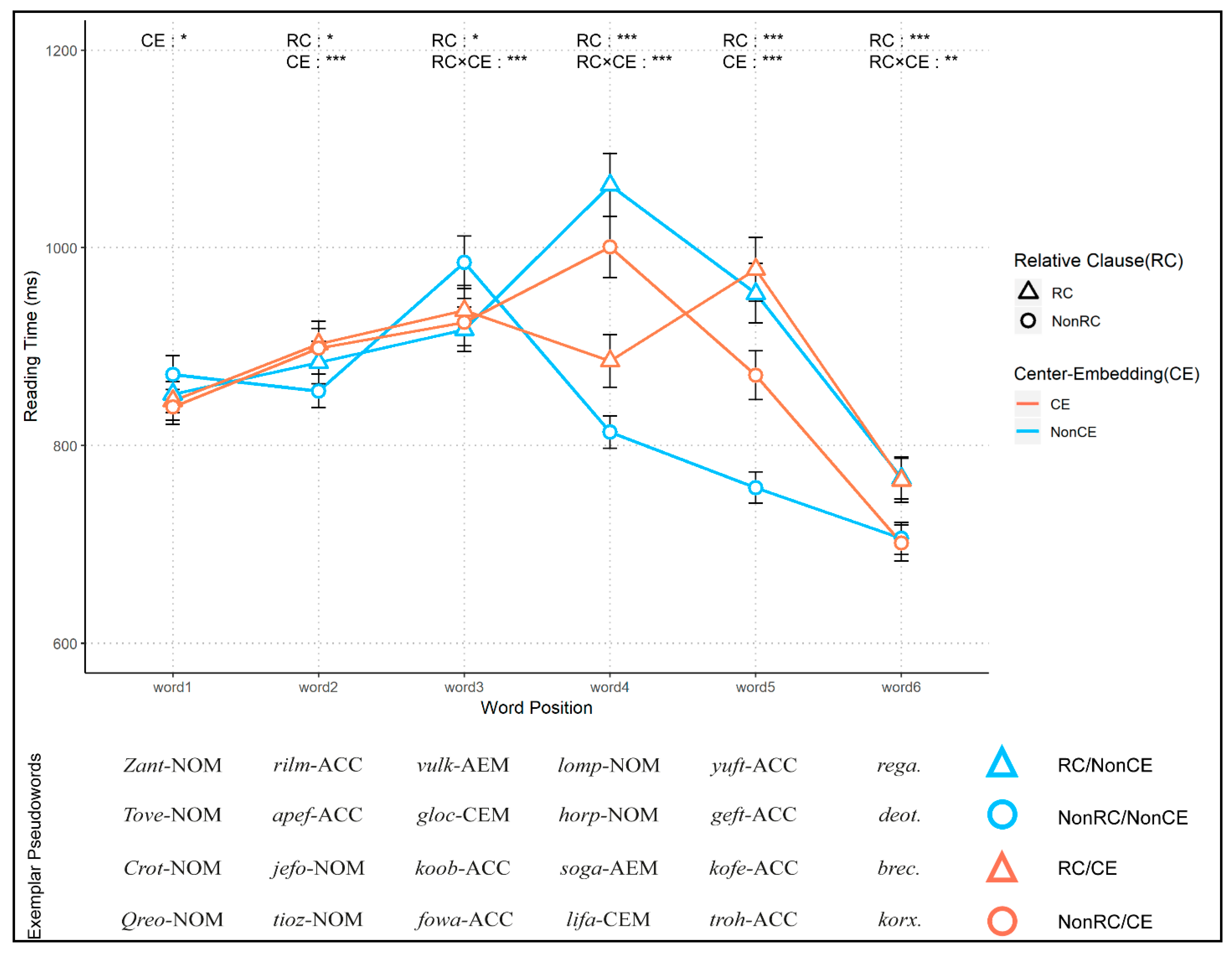
| Words | Effects | Estimate | t-Value | p-Value |
|---|---|---|---|---|
| Word 1 | RC | 0.614 | 0.144 | 0.886 |
| CE | −9.005 | −2.112 | 0.035* | |
| RC × CE | −7.045 | −1.653 | 0.099 | |
| Word 2 | RC | −10.124 | −2.329 | 0.020* |
| CE | 20.123 | 4.626 | 3.93 × 10−6*** | |
| RC × CE | 6.336 | 1.458 | 0.145 | |
| Word 3 | RC | 13.012 | 2.350 | 0.019* |
| CE | −10.364 | −1.865 | 0.062 | |
| RC × CE | −20.626 | −3.729 | 0.0002*** | |
| Word 4 | RC | −32.893 | −5.430 | 6.25 × 10−8*** |
| CE | 1.286 | 0.212 | 0.832 | |
| RC × CE | 91.230 | 15.050 | < 2 × 10−16*** | |
| Word 5 | RC | −69.145 | −11.615 | < 2 × 10−16*** |
| CE | 33.287 | 5.608 | 2.3 × 10−8*** | |
| RC × CE | −0.024 | −0.004 | 0.997 | |
| Word 6 | RC | −21.075 | −4.912 | 9.67 × 10−7*** |
| CE | −6.558 | −1.566 | 0.117 | |
| RC × CE | −12.431 | −2.857 | 0.004** |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cheon, K.-H.; Kim, Y.; Yoon, H.-D.; Nam, K.-C.; Lee, S.-Y.; Jeon, H.-A. Syntactic Comprehension of Relative Clauses and Center Embedding Using Pseudowords. Brain Sci. 2020, 10, 202. https://doi.org/10.3390/brainsci10040202
Cheon K-H, Kim Y, Yoon H-D, Nam K-C, Lee S-Y, Jeon H-A. Syntactic Comprehension of Relative Clauses and Center Embedding Using Pseudowords. Brain Sciences. 2020; 10(4):202. https://doi.org/10.3390/brainsci10040202
Chicago/Turabian StyleCheon, Kyung-Hwan, Youngjoo Kim, Hee-Dong Yoon, Ki-Chun Nam, Sun-Young Lee, and Hyeon-Ae Jeon. 2020. "Syntactic Comprehension of Relative Clauses and Center Embedding Using Pseudowords" Brain Sciences 10, no. 4: 202. https://doi.org/10.3390/brainsci10040202
APA StyleCheon, K.-H., Kim, Y., Yoon, H.-D., Nam, K.-C., Lee, S.-Y., & Jeon, H.-A. (2020). Syntactic Comprehension of Relative Clauses and Center Embedding Using Pseudowords. Brain Sciences, 10(4), 202. https://doi.org/10.3390/brainsci10040202