Abstract
The essential use of natural language processing is to analyze the sentiment of the author via the context. This sentiment analysis (SA) is said to determine the exactness of the underlying emotion in the context. It has been used in several subject areas such as stock market prediction, social media data on product reviews, psychology, judiciary, forecasting, disease prediction, agriculture, etc. Many researchers have worked on these areas and have produced significant results. These outcomes are beneficial in their respective fields, as they help to understand the overall summary in a short time. Furthermore, SA helps in understanding actual feedback shared across different platforms such as Amazon, TripAdvisor, etc. The main objective of this thorough survey was to analyze some of the essential studies done so far and to provide an overview of SA models in the area of emotion AI-driven SA. In addition, this paper offers a review of ontology-based SA and lexicon-based SA along with machine learning models that are used to analyze the sentiment of the given context. Furthermore, this work also discusses different neural network-based approaches for analyzing sentiment. Finally, these different approaches were also analyzed with sample data collected from Twitter. Among the four approaches considered in each domain, the aspect-based ontology method produced 83% accuracy among the ontology-based SAs, the term frequency approach produced 85% accuracy in the lexicon-based analysis, and the support vector machine-based approach achieved 90% accuracy among the other machine learning-based approaches.
1. Introduction
Sentiment analysis (SA) refers to uncovering the human emotion that is conveyed within a context. It makes it possible to predict the emotion, attitude, or even the personality of a person which is expressed in the form of different aspects. Sentiment analysis identifies the human emotion underlined in the context which enables machines to understand these emotions accurately. Initially, knowledge or opinions were shared among family members, neighbors, friends, relatives, etc. in person. Now, with the evolution of technology, most of these exchanges happen online where SA plays a significant role. Technology has provided a platform for one to be exposed to thousands of opinions in minutes [1]. For example, a person can post their views on a social issue or on a product they have recently bought. These reviews also extend to movies, hotels, and restaurants [2]. Now, people are fonder of online communication; hence, both the opinions of individuals and the need for sentiment prediction in business areas have increased in order to understand the common people’s needs easily and their likes and dislikes [3]. Sentiment analysis and opinion mining (OM) are among the fields that are highly profited by these innovative approaches, and they involve an automated procedure of perceiving and recognizing human feelings [4].
This paper intended to provide a wide range of analyses on various studies on AI-driven SA and OM of emotion. In addition, this paper serves as a comprehensive review of SA and OM based on multiple approaches and methodologies, including the implicit and explicit extraction of data. This review paper includes a taxonomy of analyses on sentiment and the pros and cons of SA based on previous research works. The various levels of SA, open issues, research issues, as well as future directions on the study of sentiment and OM and their various applications are further highlighted in this review article.
1.1. Emotion AI-Driven Sentiment Analysis: Taxonomy
Sentiment analysis is sorted into the following three dimensions: the document level (DL), sentence level (SL), and feature level or angle level which is shown in Figure 1. At the DL, all the words related to emotions in the entire document are analyzed [5]. The positive or negative outcomes of the sentences are analyzed without focusing on every viewpoint. This analysis provides a general assessment of the report. At the DL, the examination supposes that the whole document has one specific theme [6]. Afterwards, it is estimated whether the tone of the entire report is positive or negative. This kind of SA is used for applications such as social and mental examinations by casual associations, client satisfaction analyses, and analyses of patients in therapeutic settings [7].
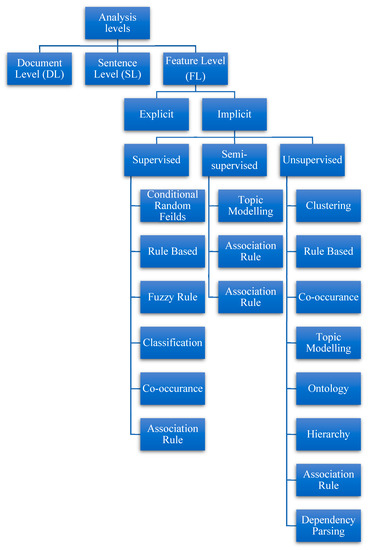
Figure 1.
Taxonomy: emotion AI-driven sentiment analysis.
Similarly, at the SL, the aim is to discover the limit of the sentence, and the result is given at the general sentence level. It determines whether the real sentence is exceptional or objective. Also, it interprets whether the general inclination of the sentence is positive or negative in energetic sentences that are viewed as small records. It is widely used for tweets, Facebook posts, and short messages [8].
1.2. Sentiment Analysis (SA) Process
The main objective of SA is to obtain the emotion from the context. The context might be data from an online review or document; it can be anything in a large amount where human beings could delay the process while dealing with it. There are numerous steps to be followed to uncover the exact meaning and the sentiment oriented to it. Hence, this section explains the various methods of SA [9]. The process of emotion AI-driven sentiment analysis is illustrated in Figure 2.
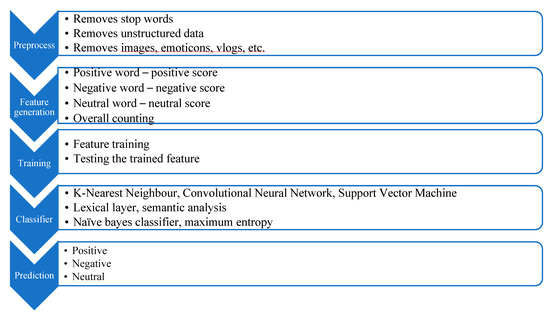
Figure 2.
Process of emotion AI-driven sentimental analysis, K-Nearest Neighbour (KNN), Convolutional Neural Network (CNN), Support Vector Machine (SVM).
1.2.1. Step 1: Data Collection
A dataset needs to be collected. For example, tweets as a dataset can be gathered by utilizing the Twitter API; ROAuth is required to approve the application [10]. The dataset could be of more than 5000 tweets that vary in size according to the data needed. It should include all three types of data, where structured data are in an organized format in the repository [11], semi-structured data are formatted in the form of structured data, and unstructured data are not organized and do not contain any pre-defined models [12]. The types of data are depicted in Figure 3.
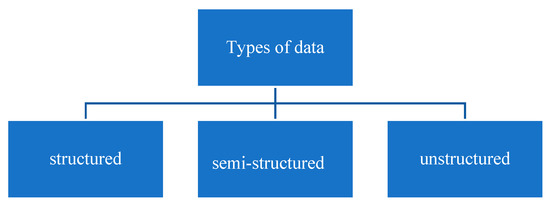
Figure 3.
Depiction of types of data.
1.2.2. Step 2: Training Dataset and Subjective Data
Two types of datasets are utilized for preparing the classifier: subjective information and unbiased information. The subjective dataset includes the notion inside the setting, while the impartial dataset does not include the sentiment or emotion of the specific situation [13]. Emotional information contains the opinion of a particular circumstance and conveys the emotion in two ways: glad or sad. An adequate measure of the negative and positive views (tweets) for two consecutive days was gathered to prepare the dataset by utilizing the classifier.
1.2.3. Step 3: Data Pre-Processing
Preprocessing is the initial phase in the supposition investigation, and it is done before semantically examining the vocabulary [14]. For instance, we can go back to the example of Twitter. Twitter is a platform where individuals from different parts of the world offer their perspectives as tweets in different languages. The information in these tweets may contain unstructured data that is boisterous, for instance, stop words, non-English words, and emphasis marks [15]. These kinds of unstructured information are exceedingly popular in tweets. In the preprocessing step, the tweet is divided based on parts of the speech (POS) tags. Information preprocessing includes evaluating URLs, sifting, expelling interrogative proclamations and stop words, barring unique characters, barring retweets, expelling hashtags on the perspective, barring emojis and pictures, expelling dialects other than English, and eliminating capitalized letters [16].
1.3. Comparison with Previous Surveys
Various approaches have been proposed for a suitable analysis of sentiment examination. Nevertheless, to the best of the authors’ knowledge, slant investigation is still in its initial stage and endures changes. A couple of efficient surveys have shaped this region well, and the existing solutions work well with the current advancements. The principal boundary is that estimation examination is a multi-faceted issue and includes various sub-problems; however, it is not a solitary errand [17]. Additionally, the existing overviews of conclusion, examination, and consideration are either centered around depicting particular specialized points or are primarily focused on a specific part of slant examination [18].
Among the studies that have been proposed recently, the one by Yue et al. [19] summed up an immensely critical research topic in the fields of SA and OM. This work is viewed as a reference book on emotion examinations, and the opinions that are extracted from it [20] focus on the multimodal SA addressed in both the supervised and unsupervised models. It has also detected the automatic sentiment from the context and tested the various machine learning (ML) approaches. Table 1 depicts the comparison of the previous surveys.

Table 1.
Comparison of the previous surveys.
2. Literature Review
This chapter presents an in-depth analysis of SA which is based on four approaches, namely, ontology-, lexicon-, machine learning-, and neural network-based approaches.
2.1. Ontology-Based Sentiment Analysis: Review
In recent developments in AI, ontologies have played an essential role in showing the relationships among class hierarchies using the concept of object-oriented programming. Ontology is defined as the precise labeling and description of the various types of relationships between an object and its properties.
There are four forms of ontology: entity, which denotes an object; the relation among things; the presence of an object in a relationship; and properties that are interrelated with the object [26]. Figure 4 shows the hierarchical structure of the general ontology for the English language. There are several reasons to build an ontology as listed below:
Figure 4.
The structure of the ontology: terminologies.
- To examine the domain-specific knowledge;
- To activate the domain knowledge for reuse;
- To provide clear domain supposition;
- To split the domain and functional expertise;
- To provide a way to share their knowledge with the software agents.
Due to the rapid increase in the number of existing websites, information extraction has become more challenging. Most search engines are keyword based or are available as full-text search engines which poses a challenge in extracting precise information. Thus, another technique for data extraction and supposition mining framework has been proposed that depends on type-2 fuzzy ontology. This framework was designed to reconstruct the consumer’s full-text data into a proper, classical format for the search engine. This methodology provides the features that are extracted using the type-2 fuzzy ontology method.
In earlier days, SA followed the traditional analysis system which had no proper or precise use for sentiment words. This system used the short-text form to share opinions or reviews in a discussion [27]. Moreover, this led to a challenge in finding the proper sentiment. Hence, to overcome these challenges, a cross-domain SA was developed. This system has enhanced the sentiment presentation through two perspectives—microscopic and macroscopic views. The fusion of these sentiments resulted in the form by considering the simplicity and the speed of the system. It also uses simple linear insertion for fusing images and texts.
where Scross media is the fusion sentiment result, Scontext is the normalized text sentiment, Simage is the normalized image sentiment, and λ is the balanced weight (when λ > 0.5, it gives better fusion results).
Scross media = λScontext + (1 − λ) Simages
The need to overcome the challenge of the ambiguities in the opinions expressed in Chinese online product reviews has led to a novel approach to identify the product aspects quickly, and it was proposed to use the opinions related to the products to build a suitable ontology [28]. The job of SentiWord is to consider the single context and the PoS presented in the statement. The SentiWord is given a score between −1 and 1, where the lowest value indicates a negative sentiment and the highest value indicates a positive one. As the SentiWord considers both the word and PoS, the statement gives a clear view of the tweet given.
Different perspectives and challenges are identified and strategies to overcome them. Sasi et al. [29] demonstrated their contribution to the analysis of the negative sentiment provided in a tweet by the consumer. To attain high customer satisfaction, they focused only on the negative opinions in the tweets related to the delivery service of the United States Postal Service. They used object properties to develop the ontology and SentiStrength to uncover the score of the statement provided in the tweet.
More past ontology-based works are presented in the Table 2 below.
Table 2.
Chronological view of ontology-based sentiment analysis.
2.2. Lexicon-Based Sentiment Analysis: A Review
One of the best examples of a lexicon is the shouts exchanged among the players in a match such as “Yeah!”, “Hoo!”, “Hut!”, “Blitz!”, “Hike!”, etc. Another set of examples is words used by lawyers in court: “I object, my lord”, “court adjourns”, “counsel”, etc. These sets of terminologies that are used among a group of people are known as lexicons. The phrases that have specific meanings are called lexemes. Different languages have different words with the same meaning; for example, water is thanni (Tamil), vellam (Malayalam), paani (Hindi), etc.
Lexicon-based SAs have two approaches—a dictionary-based approach and a corpus-based approach. The dictionary-based method contains words with semantic orientation, and the corpus-based approach has words with and without sentiments that can be used for other purposes as well [39]. Figure 5 shows the architecture of the lexicon-based SA, and it shows how the view is classified and the opinion is extracted from the new data. The data are trained by the learning model that classifies the data into three forms—positive, negative, and neutral.
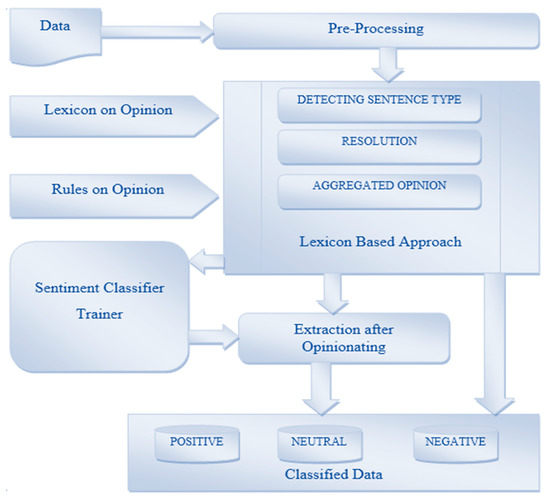
Figure 5.
Architecture of lexicon-based sentiment analysis.
Lexicon-based SA is used when the training data are inadequate. According to Thakkar et al. [40], unigrams were used in previous algorithms, but they did not provide satisfactory results. Hence, the authors proposed the n-grams method which is formed by the N number of unigrams to offer better results. For negative statements in the document, the authors proposed to use a ratio-based approach.
Another challenge to the domain are heterogeneity and linguistic problems. The domain that is specific to the sentiment can differ from content to content; however, when it comes to language, it differs from person to person [41]. To overcome these kinds of challenges, an algorithm that is domain-specific should be taken up with already existing lexicon-based domain-specific methods and with the utilization of undefined dictionary-based sentiment analysis (DBSA) and corpus-based sentiment analysis lexicons (CBSALs).
A few more past lexicon-based works are presented in Table 3 below.
Table 3.
A chronological view of lexicon-based sentiment analysis.
Lexicons are built for applications, such as online product reviews, blogs, Twitter, medical forums, etc., and various works related to them are presented.
2.3. Sentiment Analysis Based on Machine Learning: A Review
Machine learning is a model that can handle any complex work that humans cannot accomplish in real-time. In this model, humans enable machines to think and learn by themselves using the experiences they have gained. For example, when the context from feedback is extracted, the aspects and features of the review are identified. Then, the identified feature is labeled with the maximum matching class. In the past, dictionaries were significantly used to understand the views pertaining to a tweet’s specific situation during research. A noteworthy issue of lexical examination is the explicit space words that are not utilized in these lexicons, in which case, deciding the notions of these dictionaries is the best test. The current work did not require preparation for the classifier to decide the conclusion for the area’s explicit lexicons. In this examination, two words were included—incredible and poor [54]. Astounding was viewed as an exceedingly positive setting, and poor was considered to be a profoundly negative setting. The score produced from each word was observed using the given rule:
This formula helps to understand how SA is utilized, as it is human nature to know “how and what”. Since AI is the best in class, the notion assumes an indispensable job in it [55]. Previously, scholastic understudies were found to investigate the supposition of others. The Rule-Based Emission Model (RBEM) was used to recognize the extremity in sentences. Because of the exploration, the approach performed well and gave outcomes that were exceptionally ascendable, transparent, and could work effectively. It has led to the study of a new issue of unsupervised analysis of sentiment in a signed social network. Methodologically, they have suggested consolidating the signed social relations and nostalgic signs from terms into a bound together structure when feeling names are absent. Later, these were additionally analyzed on two true signed social networks—Opinions and Slashdot. The outcomes demonstrated that the proposed Signed Senti has a fundamentally preferred execution over best in class strategies [56].
It aims to provide the automatic SA that uncovers the in-depth attitude that is held towards an entity [57]. Also, the problem in SA and multimodal sentiment analysis (MSA) in terms of a different aspect of the data has been discussed, for example, through images, human–machine interactions, human–human interaction images, videos, etc. Consider the utilization of three AI approaches—for instance, naive Bayes (NB), support vector machine (SVM), and most extraordinary entropy—to separate notions into good and bad requests. They utilize the word sack to obtain results on the gathering of the supposition examination. The results exhibited in SVM would be higher in capability than NB. [58] At the same time, exactly when the dataset is lower in size for preparing and testing, the outcome would be higher while utilizing the NB classifier.
The outcomes on the Twitter dataset that was gathered demonstrated that the accuracy of the proposed showcase was 74% greater than that of the conventional directed emotion classifiers (SVM, random forest (RF), decision tree (DT), and some semi-administered calculations) [59]. Similarly, an improved NB system showed two NB varieties using lemmas (things, action words, graphic words, and modifiers), polarity lexicons, and multiword as perspective highlights.
More past works on machine learning are presented in Table 4 below.
Table 4.
A chronological view of machine-learning-based sentiment analysis.
2.4. Neural Network Models: A Review
In the neural models, unique words are utilized as the input in the parse trees which provide the synthetic data and semantic data. Hence, emotion composition is derived from the best. Recurrent neural networks and convolution neural networks are becoming more popular, and they do not require parse trees to split their features from the given sentences. Instead, recurrent neural networks and convolution neural networks (CNNs) utilize word embedding as inputs which already inscribes the semantic and synthetic data. Additionally, the architecture of the convolution neural networks and recurrent neural networks help in learning the connectivity between the words in a statement. A recursive autoencoders network (RAN) in a semi-supervised model for sentence-level SA resulted in providing a low-dimensional vector representation [68]. In a new matrix-vector recursive neural network (MVRNN), each context is also related to a matrix representation in the form of a tree [69].
The structure of a tree is derived from a parser that is used externally. It portrays a collaboration of Recurrent Neural Network (RNN) and CNN architecture for the classification of the sentiment from a short context which takes the favorable position in the coarse-grained features generated by a CNN [70].
An approach based on the linguistics LSTM for effective sentiment prediction incorporates the sentiment lexicon as a highly intensive context and negative context [71]. The LSTM includes these features while analyzing the sentiment to provide a useful view of the context. Authors have presented a traditional CNN–LSTM model which consists of two sections—local CNN and LSTM—to predict the attitude illustrated in the content [72]. Table 5 presents the overall pros and cons identified from the survey.
Table 5.
Advantages and disadvantages of existing research work on sentiment analysis.
3. Methodology
The two important methodologies used for sentiment analysis, such as the machine learning-based approach and lexicon-based approach, are discussed in the next section.
3.1. Machine Learning Approaches
As discussed in the literature review, SA can be performed through various methods. Figure 4 shows the categorization of the methods in the analysis of sentiment and aggregation of opinions.
Figure 6 mentions the different approaches that are discussed here. The methods are a probabilistic classifier, linear classifier, rule-based classifier, DT classifier, and NB classifier.
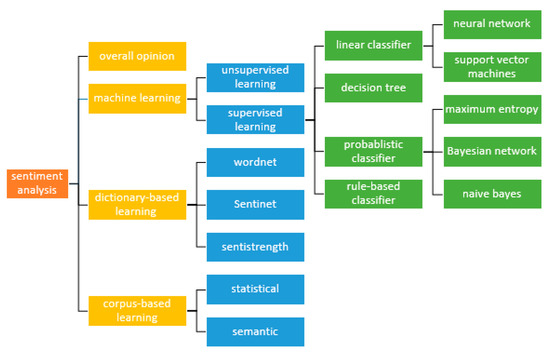
Figure 6.
Various methods of emotion AI-driven sentiment analysis.
The probabilistic classifier (PC) provides a probabilistic function to the set of input data. Further, the input function f(x) is applied with the probability and is mapped with the output function (y). Hence, the PC is denoted as follows:
where f(x) is the input function. When the conditional distributors replace the PC, it is as follows:
where the PC is changed to the conditional classifiers Pr(Z′/V′), and the given z Z′ is assigned to v V′.
Y′ = f(x)
Z′ = arg max Z Pr (Z′ = z/V′)
In a linear classifier, word T = (T1, T2, T3) is the frequency of a single word, the vector V = (V1, V2, V3) is a linear input coefficient, and the scalar S is the linear output coefficient. This classifier categorizes the margin to distinguish between the two classes [73].
In the rule-based classifier, the “if condition and then decision” approach is used to make specific rules. This rule-based classifier is also known as a multi-class classifier. Furthermore, this classifies the data into three forms—good, bad, and neither good nor bad. Besides, this unsupervised classifier mainly focuses on the prediction of emotion in the context and emoticons [74].
The DT classifier is a recursive one. For the training data, the condition based on the classification is applied, and it divides the training data such that the ones which satisfy the conditions are all of one class, and the procedure continues until all the data satisfy the condition [75].
The NB approach examines whether the feature provided with the probability has the role of the label or not. In this, every feature is independent and the specific feature is mapped with a label matched in the maximum.
P(E/A) = (P(E) × P(A/E))/P(A)
Here, P(E) is the probability of the label, and P(A) is the probability of the feature. The NB classifier is mainly required to classify features such as email IDs, URLs, words, phrases, dictionaries, parse trees, etc. The NB algorithm is solely used for the textbook, and it classifies the string and not any of the numerical data or subsets. This classifier is a class-specific unigram language model. The likelihood features are assigned the probability of every single word, and they propose the probability to each sentence as follows:
At present, for the given parameters, the positive and negative values were specified. The grade was multiplied altogether by the positive score and the negative score. The total positive score was found to be 0.0000005, and the overall negative rating was 0.0000000010 as shown in Table 6. For the given statement, a higher probability was given to the positive. Hence, the given statement is irrefutable. Figure 7 shows how the SA process was executed as well as how the classification was done for the training data using the NB classifier. The training data as classified as positive, negative or neutral. The knowledge-based method determined the record of the appearance of a word in a particular record or report.
Table 6.
Word count.
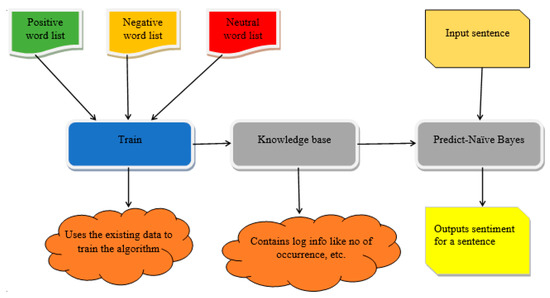
Figure 7.
Sentiment analysis using the naive Bayes classifier.
After finding the occurrence of a word, similar words are grouped together. Then, the NB approach is utilized to classify the test data and predict the sentiment to document as positive, negative or neutral [76]. The Bayesian network model used in it is a directed acyclic graph. There is a strong relationship between the feature and the label in this model. Maximum entropy deals with probability. Initially, to set-up maximum entropy modeling, the characteristics should be selected to determine the constraints. In-text classification—the use of word count—is supposed to be the feature.
where “P” refers to a function, “L” refers to label, “F” refers to features, P(L) refers to the probability of label, P(F/L) is the probability of the feature categorized as label, and P(F) refers to probability of the feature.
Further, this model is executed by the vectors. Hence, in this model, the labeled features are converted into vectors. The weight of the feature is allocated. The prediction of the label and the feature is performed to calculate the sentiment of the context. Here, the feature and the label were mapped in the form of vectors. The above representation [77] of the maximum entropy shows that if any of the words occur from the same class, the weight for that class will be higher. The primary advantage of the maximum entropy is that it utilizes the natural binary features.
The SVM algorithm classifies the data by using the hyperplane such as the positive or negative forms. In this model, no probability was applied; hence, it was not a PC. Support Vector Machine approach is exceptionally efficient in text categorization [78] and is better than PCs. The motivation behind SVM is to recognize the hyperplane which the vector symbolizes. This records vectors in single class word vectors and sentence vectors in a single year. So far, its accuracy is more than 90% which is high when compared to the NB and maximum entropy method.
Here, αj refers to a dual optimization problem and document.
j vector − αj > 0 = support vector machines. The classification part plays a major and versatile role in identifying the hyperplane and making sure which constraint falls under the set margin [79].
Random Forest approach is said to be a tree classifier. Every single class in the tree is given an information vector, and the most elevated class is taken into the point. The error rate is dictated by the connection between the two trees in the woods and the weight of individual trees in the forest. Further, to decrease the error, the trees ought to have substantial weight or quality and be free of one another. The RF takes the DT as the individual predictors that are based on the methods of randomizing outputs, boosting, and bagging. Any large number of datasets can be easily classified using RF methods with better accuracy [80].
| Algorithm 1. |
| Input: A = Total number of trees D = Training dataset F′ = Features f′ = Sub features Output: Label of bagged class 1. For each and every tree in A (i) Create a bootstrapping sample S of size D (ii) Create a tree recursively to all the internal nodes with the following steps: Step 1:- Choose the sub feature f′ randomly at feature F′ Step 2:- Best sub feature f′ has to selected Step 3:- Finally split the node 2. Test instance will be passed to trees once trees are created 3. Later, a majority of votes are provided by assigning the class labels |
The neural network model encompasses three layers: an input layer, a hidden layer, and an output layer [81]. Artificial neural networks (ANNs) are used for learning by applying a neural network of multiple layers in it. Furthermore, this is more powerful in representing the neural network, and also, it is more practical with a minuscule quantity of data and a minimum of two phases. The neural network is categorized into the recurrent neural network and the feedforward neural network. Several activation functions are to be used which include ReLu, tanh for sigmoid function, and leaky ReLu.
Sentiment Analysis in the neural network is done with the initial representation of the word into a vector and by word-level word embedding, character-level embedding, sentence-level embedding, and training the network. Numerous profound learning models that are utilized as a part of the NLP, which require the word embedding, come as information highlights. This word embedding changes over the setting into a vector of consistent, genuine numbers; e.g., word—Hai (H—0.13, a—0.15, and i—0.23). The experimentation is finished with a few calculations. Furthermore, it helps to estimate productivity and precision [82]. The convolution neural network is typically used in the picture arrangement for the examination of emotion. Likewise, it isolates the strings where every single independent setting is changed to vector [83]. Figure 8 shows the flow process of convolution layers.
| Algorithm 2. |
| Training CNN for sentiment analysis Input: f(x) = {x1, x2, …. xn} , f(y) = {y1, y2,…. yn} Step 1: Train the CNN with input f(x)and f(y) Step 2: Sentiment score of f(x) predicted Step 3: Let X be the leftover training data and Y be their sentiment Step 4: Let the CNN fine-tune with the input X and Y Step 5: Return (the average performance) Output: Sentiment of the data |
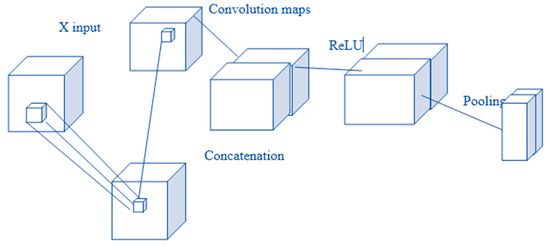
Figure 8.
Convolution neural network flow process.
The LSTM approach is a versatile type of recurrent neural network which handles the dependencies. The entire recurrent neural network follows the chain rules and is done recursively until the process achieves the optimization stage [84]. The recursive iteration in the LSTM is complicated when compared to ordinary and straightforward RNN because it has four layers that interact in a particular manner. From the cell state at the timestamp t, the LSTM decides which data that should be in the dump. This is determined by utilizing the sigmoid function (σ), which is called the “forget gate.” The capacity guarantees hit – 1 (yield from the past covered layer) and it (current data) yields a number in ‘0’ or ‘1’ where 1 means “thoroughly keep” and 0 implies “absolutely dump”.
3.2. Lexicon-Based Approaches
3.2.1. Sentiment Analysis in Gram Representation
Unigram is the representation of the word presented in the document. In addition, it is associated with the feature value of the word in the document which is referred to as term frequency (TF). Unigram is said to be a single word in the document. Every single word that is taken into account from the document presented is known as a unigram. Alternatively, every pair of words is called a bigram which is used for bigram representation from the document. Here, the feature is associated with the bigrams in the document. Further, in n-gram representation, “N” number of words in the document were considered [85].
3.2.2. Term Frequency- Inverse Document Frequency (TF-IDF) Representation
Term frequency-inverse document frequency is the representation of TF-IDF. Here, the word presented in the document is given by “total frequency (word, document) × log (inverse document frequency (word, document)”. A log is presented here for the computation of base 10, and d is the training data which are the collection of the document presented [86].
3.2.3. Dictionary-Based Approach
The new terminologies are collected manually by this approach, and then a list of synonyms and antonyms of the terms are formed. It is later matched to the list, and words with similar meanings are grouped together. This process continues whenever a new term is found [87].
3.2.4. Corpus-Based Approach
The corpus-based method is applied to a particular topic. The corpus approach has two forms: statistical approach and semantic approach. The corpus-based approach is mainly used for addressing languages. The corpus data are extracted from the corpora which has a large amount of data, and it also has the actual pattern of the language used in day-to-day life [88].
3.2.5. Statistical Approach
This approach is used to find the occurrence of words. The principal goal of this approach is to determine the extremity between positive and negative words. When positive data are high, the entire data are positive and vice versa for negative data. Cosine similarity is one of the statistical approaches utilized in determining the sentiment and the opinion that is uncovered from the context. Cosine similarity shows the similarity among two vectors which is non-zero. Cosine similarity determines the polarity, whether positive or negative [89].
4. Results and Discussions
First, the evaluation metrics that were considered for comparison between the approaches are discussed here. In order to find the effectiveness of every classifier, the following guideline was utilized to find the precision, support, review, and F-measure [90].
4.1. Evaluation Metrics
4.1.1. Prediction Accuracy
Generally, to analyze accuracy, the following rule is applied which determines how the sentiment is calculated and determined accurately. Besides, this is said to be the precision measure [91].
where LTT refers to the labeled Twitter tweets and TTT refers to the total tweets.
4.1.2. Refined Measure on Tweet Precision
The fraction of the data that are retrieved in a relevant manner is defined as follows:
where TTP refers to total positive tweets, and TTN refers to total negative tweets.
4.1.3. Recall
The fraction of the data that are retrieved in a relevant manner is defined as follows
4.1.4. F-Measure
The F-measure is used to evaluate the false rate, and the formula used to define it is as follows:
In this article, the training dataset and testing dataset were taken from Twitter. The tweets were collected based on a movie. Table 7 depicts the total dataset used for testing and training the sentiment. This particular movie data were tested with three different approaches: ontology-based SA, lexicon-based SA, and machine-learning-based SA. The results are given as follows:
Table 7.
Statistical view of dataset.
4.2. Using Ontology-Based Sentiment Analysis
In the ontology-based SA, four primary conventional approaches were tested: specific ontology-based SA, fuzzy logic-based SA, aspect-based SA, and domain-specific SA. The aspect-based SA resulted in 83% accuracy, 84% recall, and a F-measure of 50%. This shows that the exactness of prediction was high compared to the other approaches for the considered data. The results are shown in Figure 9.
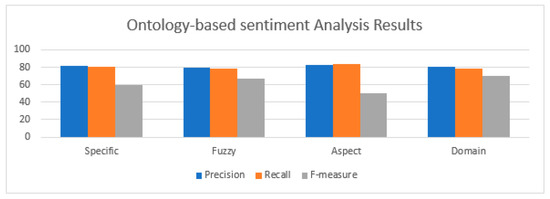
Figure 9.
Evaluation metrics of ontology-based sentiment analysis.
4.3. Using Lexicon-Based Sentiment Analysis
The four major approaches that were used to test the lexicon-based SA were term frequency approach, word count, unigram, and bigram. The precision of the word count was 91%, the recall was 88%, and the F-measure was below 10% for the considered data. The results are shown in Figure 10.
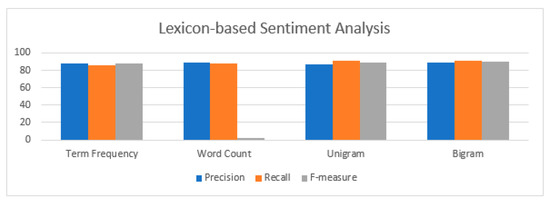
Figure 10.
Evaluation metrics on lexicon-based sentiment analysis.
4.4. Using Machine-Learning-Based Sentiment Analysis
In the machine learning approaches, the multinomial NB algorithm, RF algorithm, SVM, and XG Boosting algorithm were tested. The SVM resulted in high accuracy of 96%, recall of 66%, and F-measure of 60%. Moreover, the machine-learning-based SVM approach achieved 96% accuracy for the considered data. These results may vary when the dataset varies. The results are shown in Figure 11.
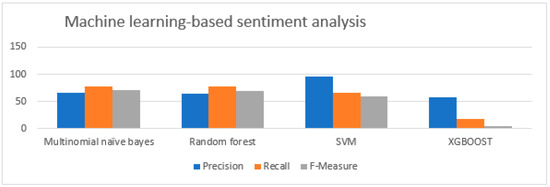
Figure 11.
Evaluation metrics of machine-learning-based sentiment analysis.
The above discussion provided quantitative results of various approaches in Sentiment Analysis. Recently, Twitter data analysis has been used the most to predict sentiment. The overall merits and demerits identified from this work is presented in Table 8.
Table 8.
Merits and demerits for lexicon, machine learning and hybrid approaches.
5. Challenges, Future Research Directions, and Open issues
Despite the several advantages of emotion AI-driven SA, there are significant challenges that have to be focused on. Resolving the below-mentioned challenges will make SA more efficient and effective, so it can be applied everywhere.
5.1. Mining Unstructured Data
In the broad range of social media, all kinds of users are present, from well-educated to uneducated users. To save time, some users have started to text in the message format; for example, to convey the message “happy with this car,” the user would text “happppppppppy vth dis  ”. This kind of text is considered to be unstructured data. Many of the SA methods preprocess this information. Hence, extracting and providing the sentiment and the emotion to these kinds of data are really challenging [92].
”. This kind of text is considered to be unstructured data. Many of the SA methods preprocess this information. Hence, extracting and providing the sentiment and the emotion to these kinds of data are really challenging [92].
”. This kind of text is considered to be unstructured data. Many of the SA methods preprocess this information. Hence, extracting and providing the sentiment and the emotion to these kinds of data are really challenging [92].5.2. Identifying Composite Media Features
Generally, this is one of the pressing issues centered around the notion of examination in the light of the fact that remarks or audits may bring attention to any issue. Table 9 depicts user data examples [93].
Table 9.
User data example.
Extracting these kinds of data, identifying the feature of the data, then determining the opinion are immense challenges in SA, because several million users use online shopping, and each has a different manner of using language to express feedback [94].
5.3. Different Words with the Same Meaning
In a user’s review, different words with the same meaning might be used. It is necessary to classify the similarity among each word, as some words are placed differently in some sentences which may cause them to sound different, even though they have the same meaning [95].
- Sentiment words that do not express a sentiment—some of the words in interrogative statements may not explicitly express any sentiment. Still, the emotion present in the statement should be identified as another challenge [96].
- Emotion identification (sarcasm)—it is difficult for the machine to identify sarcastic statements. Researchers on SA work hard to identify sarcastic comments with high accuracy, as human emotions and attitudes are often ambiguous [97].
A significant challenge faced by SA is making the machine understand intense human emotions conveyed in the context. With a rise in the usage of unstructured data, human language has become highly complicated, and it is difficult to determine the opinions, viewpoints or reviews of the customer as well as the right sentiment of the context [98]. The open issues on SA are summarized in Figure 12 as follows:
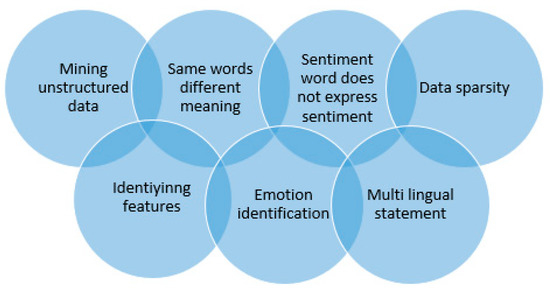
Figure 12.
Summary of open issues.
Once these challenges are addressed, the possible outcome can benefit from understanding the affinity or sentiment toward a particular phenomenon, entity or idea. Also, understanding the customers’ perspectives on a specific aspect of a product, brand or advertisement is challenging [99]. A more accurate interpretation of the sentiment is expressed in an unstructured data format that can be evaluated [100]. It further involves accessing customers’ feedback to measure customers’ satisfaction and effective e-governance and crisis management [101]. Figure 13 demonstrates the scope of future research and open issues in detail.
Figure 13.
Scope of future research and open issues.
6. Conclusions
In this paper, an overview of emotion AI-driven SA in various domains was presented. Also, this survey reviewed the merits, demerits, and scope of the different approaches that have been considered. A significant advantage of SA is that it provides the exact emotion that is underlined in the context. Traditional methodologies, such as machine-learning-based approaches, lexicon-based analysis, and ontology-based analysis, were considered for experimentation to compare performances. In the considered sample data, the aspect-based ontology approach, SVM, and term frequency achieved high accuracy and provided better SA results in each category. Future research directions as well as limitations were also highlighted for the benefit of future researchers. Even though the results showed higher accuracy for the sample data considered, these results may vary when it is applied to other applications. Deep learning approaches can also be considered for comparing the performances as part of the future work which may bring significant changes to the results.
Author Contributions
Conceptualization, P.C., D.R.V., and K.S.; Methodology, P.C., D.R.V., and K.S.; Software, P.C., V.S., and D.G.R.; Validation, C.-Y.C.; Formal Analysis, V.S., and D.G.R.; Investigation, P.C., D.R.V., and K.S.; Resources, K.S., and C.-Y.C.; Data Curation, P.C.; Writing-Original Draft Preparation, P.C., D.R.V., and K.S.; Writing-Review & Editing, V.S., C.-Y.C. and D.G.R.; Visualization, K.S.; Supervision, D.R.V.; Project Administration, C.-Y.C.; Funding Acquisition, C.-Y.C.
Funding
This research was partially funded by “Intelligent Recognition Industry Service Research Center” from The Featured Areas Research Center Program within the framework of the Higher Education Sprout Project by the Ministry of Education (MOE) in Taiwan. Grant number: N/A and the APC was funded by the aforementioned Project.
Conflicts of Interest
The authors declare that they have no conflict of interest.
Abbreviations
| ABBREVIATION | FULL FORM |
| NB | Naive Bayes |
| MNB | Multinomial naive Bayes |
| SVM | Support vector machine |
| ME | Maximum entropy |
| NN | Neural network |
| ANN | Artificial neural network |
| CNN | Convolution neural network |
| RNN | Recurrent neural network |
| LSTM | Long short-term memory |
| RF | Random forest |
| LC | Linear classifier |
| PC | Probability classifier |
| PSDEE | Polarity shift detection, elimination, and ensemble |
| TF | Term frequency |
| TF-IDF | Term frequency-inverse document frequency |
| DT | Decision tree |
| BoW | Bags of word |
| Pos | Parts of speech |
| FSC | Fuzzy semantic classifier |
| RFWC | Relative frequency word count |
| KNN | K-nearest neighbor |
| CRF | Conditional random fields |
| DL | Document level |
| SL | Sentence level |
| FL | Feature level |
References
- Khan, A.; Baharudin, B.; Khan, K. Efficient feature selection and domain relevance term weighting method for document classification. In Proceedings of the 2010 Second International Conference on the Computer Engineering and Applications (ICCEA), Bali Island, Indonesia, 19–21 March 2010; Volume 2, pp. 398–403. [Google Scholar]
- Lu, Y.; Kong, X.; Quan, X.; Liu, W.; Xu, Y. Exploring the sentiment strength of user reviews. In International Conference on Web-Age Information Management; Springer: Berlin/Heidelberg, Germany, 2010; pp. 471–482. [Google Scholar]
- Agarwal, A.; Xie, B.; Vovsha, I.; Rambow, O.; Passonneau, R. Sentiment analysis of twitter data. In Proceedings of the Workshop on Languages in Social Media; Association for Computational Linguistics: Stroudsburg, PA, USA, 2011; pp. 30–38. [Google Scholar]
- Annett, M.; Kondrak, G. A comparison of sentiment analysis techniques: Polarizing movie blogs. In Conference of the Canadian Society for Computational Studies of Intelligence; Springer: Berlin/Heidelberg, Germany, 2008; pp. 25–35. [Google Scholar]
- Liu, B. Sentiment analysis and opinion mining. Synth. Lect. Hum. Lang. Technol. 2012, 5, 1–167. [Google Scholar] [CrossRef]
- Li, X.; Peng, Q.; Sun, Z.; Chai, L.; Wang, Y. Predicting Social Emotions from Readers’ Perspective. IEEE Trans. Affect. Comput. 2017, 10, 255–264. [Google Scholar] [CrossRef]
- Liu, B.; Hu, M.; Cheng, J. Opinion observer: Analyzing and comparing opinions on the web. In Proceedings of the 14th International Conference on World Wide Web, Cardiff, UK, 25 January 2020; ACM: New York, NY, USA, 2005; pp. 342–351. [Google Scholar]
- Li, C.; Sun, A.; Weng, J.; He, Q. Tweet segmentation and its application to named entity recognition. IEEE Trans. Knowl. Data Eng. 2015, 27, 558–570. [Google Scholar] [CrossRef]
- Rout, J.K.; Choo, K.K.R.; Dash, A.K.; Bakshi, S.; Jena, S.K.; Williams, K.L. A model for sentiment and emotion analysis of unstructured social media text. Electron. Commer. Res. 2018, 18, 181–199. [Google Scholar] [CrossRef]
- Che, W.; Zhao, Y.; Guo, H.; Su, Z.; Liu, T. Sentence compression for aspect-based sentiment analysis. IEEE/ACM Trans. Audio Speech Lang. Process. (TASLP) 2015, 23, 2111–2124. [Google Scholar] [CrossRef]
- Bell, D.; Koulouri, T.; Lauria, S.; Macredie, R.D.; Sutton, J. Microblogging as a mechanism for human–robot interaction. Knowl. Based Syst. 2014, 69, 64–77. [Google Scholar] [CrossRef]
- Xia, R.; Xu, F.; Yu, J.; Qi, Y.; Cambria, E. Polarity shift detection, elimination and ensemble: A three-stage model for document-level sentiment analysis. Inf. Process. Manag. 2015, 52, 36–45. [Google Scholar] [CrossRef]
- Singh, V.K.; Piryani, R.; Uddin, A.; Waila, P. Sentiment analysis of Movie reviews and Blog posts. In Proceedings of the 2013 3rd IEEE International Advance Computing Conference (IACC), Ghaziabad, India, 22–23 February 2013; pp. 893–898. [Google Scholar]
- Mohammad, S.M.; Zhu, X.; Kiritchenko, S.; Martin, J. Sentiment, emotion, purpose, and style in electoral tweets. Inf. Process. Manag. 2015, 51, 480–499. [Google Scholar] [CrossRef]
- Aljanaki, A.; Wiering, F.; Veltkamp, R.C. Studying emotion induced by music through a crowdsourcing game. Inf. Process. Manag. 2016, 52, 115–128. [Google Scholar] [CrossRef]
- Denecke, K.; Deng, Y. Sentiment analysis in medical settings: New opportunities and challenges. Artif. Intell. Med. 2015, 64, 17–27. [Google Scholar] [CrossRef]
- Medhat, W.; Hassan, A.; Korashy, H. Sentiment analysis algorithms and applications: A survey. Ain Shams Eng. J. 2014, 5, 1093–1113. [Google Scholar] [CrossRef]
- Tubishat, M.; Idris, N.; Abushariah, M.A. Implicit aspect extraction in sentiment analysis: Review, taxonomy, oppportunities, and open challenges. Inf. Process. Manag. 2018, 54, 545–563. [Google Scholar] [CrossRef]
- Yue, L.; Chen, W.; Li, X.; Zuo, W.; Yin, M. A survey of sentiment analysis in social media. Knowl. Inf. Syst. 2019, 60, 617–663. [Google Scholar] [CrossRef]
- Soleymani, M.; Garcia, D.; Jou, B.; Schuller, B.; Chang, S.F.; Pantic, M. A survey of multimodal sentiment analysis. Image Vis. Comput. 2017, 65, 3–14. [Google Scholar] [CrossRef]
- Yue, L.; Chen, W.; Li, X.; Zuo, W.; Yin, M. Survey on target dependent sentiment analysis of micro-blogs in social media. In Proceedings of the 9th IEEE-GCC Conference and Exhibition, GCCCE, Manama, Bahrain, 8–11 May 2017; p. 1. [Google Scholar] [CrossRef]
- Rana, T.A.; Cheah, Y.N. Aspect extraction in sentiment analysis: Comparative analysis and survey. Artif. Intell. Rev. 2016, 46, 459–483. [Google Scholar] [CrossRef]
- Yadollahi, A.; Shahraki, A.G.; Zaiane, O.R. Current state of text sentiment analysis from opinion to emotion mining. ACM Comput. Surv. (CSUR) 2017, 50, 25. [Google Scholar] [CrossRef]
- Hussein, A.; Gaber, M.M.; Elyan, E.; Jayne, C. Imitation learning: A survey of learning methods. ACM Comput. Surv. (CSUR) 2017, 50, 21. [Google Scholar] [CrossRef]
- Kaur, H.; Mangat, V. A survey of sentiment analysis techniques. In Proceedings of the 2017 International Conference on the I-SMAC (IoT in Social, Mobile, Analytics and Cloud) (I-SMAC), Palladam, India, 10–11 February 2017; pp. 921–925. [Google Scholar]
- Thakor, P.; Sasi, S. Ontology-based sentiment analysis process for social media content. Procedia Comput. Sci. 2015, 53, 199–207. [Google Scholar] [CrossRef]
- Kontopoulos, E.; Berberidis, C.; Dergiades, T.; Bassiliades, N. Ontology-based sentiment analysis of twitter posts. Expert Syst. Appl. 2013, 40, 4065–4074. [Google Scholar] [CrossRef]
- Shi, W.; Wang, H.; He, S. Sentiment analysis of Chinese microblogging based on sentiment ontology: A case study of ‘7.23 Wenzhou Train Collision. Connect. Sci. 2013, 25, 161–178. [Google Scholar] [CrossRef]
- Ali, F.; Kwak, K.S.; Kim, Y.G. Opinion mining based on fuzzy domain ontology and support vector machine: A proposal to automate online review classification. Appl. Soft Comput. 2016, 47, 235–250. [Google Scholar] [CrossRef]
- Penalver-Martinez, I.; Garcia-Sanchez, F.; Valencia-Garcia, R.; Rodriguez-Garcia, M.A.; Moreno, V.; Fraga, A.; Sanchez-Cervantes, J.L. Feature-based opinion mining through ontologies. Expert Syst. Appl. 2014, 41, 5995–6008. [Google Scholar] [CrossRef]
- Ma, J.; Xu, W.; Sun, Y.H.; Turban, E.; Wang, S.; Liu, O. An ontology-based text-mining method to cluster proposals for research project selection. IEEE Trans. Syst. ManCybern. Part A Syst. Hum. 2012, 42, 784–790. [Google Scholar] [CrossRef]
- Li, Z.; Xu, W.; Zhang, L.; Lau, R.Y. An ontology-based web mining method for unemployment rate prediction. Decis. Support Syst. 2014, 66, 114–122. [Google Scholar] [CrossRef]
- Li, S.; Liu, L.; Xiong, Z. Ontology-based sentiment analysis of network public opinions. Int. J. Digit. Content Technol. Appl. 2012, 6, 371–380. [Google Scholar]
- De Kok, S.; Punt, L.; van den Puttelaar, R.; Schouten, K.; Frasincar, F. Review-aggregated aspect-based sentiment analysis with ontology features. Prog. Artif. Intell. 2018, 7, 295–306. [Google Scholar] [CrossRef]
- Le Thi, T.; Thanh, T.Q.; Thi, T.P. Ontology-Based Entity Coreference Resolution for Sentiment Analysis. In Proceedings of the Eighth Symposium on Information and Communication Technology (SoICT 2017), Nha Trang, Vietnam, 7–8 December 2017; pp. 50–56. [Google Scholar]
- Ceci, F.; Leopoldo Goncalves, A.; Weber, R. A model for sentiment analysis based on ontology and cases. IEEE Lat. Am. Trans. 2016, 14, 4560–4566. [Google Scholar] [CrossRef]
- Shojaee, S.; Murad, M.A.A.; Azman, A.B.; Sharef, N.M.; Nadali, S. Detecting deceptive reviews using lexical and syntactic features. In Proceedings of the 13th International Conference on Intelligent Systems Design and Applications (ISDA), Bangi, Malaysia, 8–10 December 2013; pp. 53–58. [Google Scholar]
- Khan, F.H.; Bashir, S.; Qamar, U. TOM: Twitter opinion mining framework using hybrid classification scheme. Decis. Support Syst. 2014, 57, 245–257. [Google Scholar] [CrossRef]
- Duwairi, R.M.; Ahmed, N.A.; Al-Rifai, S.Y. Detecting sentiment embedded in Arabic social media—A lexicon-based approach. J. Intell. Fuzzy Syst. 2015, 29, 107–117. [Google Scholar] [CrossRef]
- Asghar, M.Z.; Khan, A.; Ahmad, S.; Qasim, M.; Khan, I.A. Lexicon-enhanced sentiment analysis framework using rule-based classification scheme. PLoS ONE 2017, 12, e0171649. [Google Scholar] [CrossRef]
- Dey, A.; Jenamani, M.; Thakkar, J.J. Thakkar. Senti-N-Gram: An n-gram lexicon for sentiment analysis. Expert Syst. Appl. 2018, 103, 92–105. [Google Scholar] [CrossRef]
- Deng, S.; Sinha, A.P.; Zhao, H. Adapting sentiment lexicons to domain-specific social media texts. Decis. Support Syst. 2017, 94, 65–76. [Google Scholar] [CrossRef]
- Thompson, J.J.; Leung, B.H.; Blair, M.R.; Taboada, M. Sentiment analysis of player chat messaging in the video game StarCraft 2: Extending a lexicon-based model. Knowl. Based Syst. 2017, 137, 149–162. [Google Scholar] [CrossRef]
- Asghar, M.Z.; Khan, A.; Ahmad, S.; Khan, I.A.; Kundi, F.M. A unified framework for creating domain dependent polarity lexicons from user generated reviews. PLoS ONE 2015, 10, e0140204. [Google Scholar] [CrossRef]
- Kang, H.; Yoo, S.J.; Han, D. Senti-lexicon and improved NB algorithms for sentiment analysis of restaurant reviews. Expert Syst. Appl. 2012, 39, 6000–6010. [Google Scholar] [CrossRef]
- Zeng, L.; Li, F. A classification-based approach for implicit feature identification. In Chinese Computational Linguistics and Natural Language Processing Based on Naturally Annotated Big Data; Springer: Berlin/Heidelberg, Germany, 2013; pp. 190–202. [Google Scholar]
- Wang, H.H.; Yu, L.; Tian, S.W.; Peng, Y.F.; Pei, X.J. Bidirectional LSTM Malicious webpages detection algorithm based on convolutional neural network and independent recurrent neural network. Appl. Intell. 2019, 49, 3016–3026. [Google Scholar] [CrossRef]
- Eirinaki, M.; Pisal, S.; Singh, J. Feature-based opinion mining and ranking. J. Comput. Syst. Sci. 2012, 78, 1175–1184. [Google Scholar] [CrossRef]
- Jurado, F.; Rodriguez, P. Sentiment Analysis in monitoring software development processes: An exploratory case study on GitHub’s project issues. J. Syst. Softw. 2015, 104, 82–89. [Google Scholar] [CrossRef]
- Cheng, K.; Li, J.; Tang, J.; Liu, H. Unsupervised sentiment analysis with signed social networks. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Pujari, C.; Shetty, N.P. Comparison of Classification Techniques for Feature Oriented Sentiment Analysis of Product Review Data. In Data Engineering and Intelligent Computing; Springer: Singapore, 2018; pp. 149–158. [Google Scholar]
- Poria, S.; Cambria, E.; Howard, N.; Huang, G.B.; Hussain, A. Fusing audio, visual and textual clues for sentiment analysis from multimodal content. Neurocomputing 2016, 174, 50–59. [Google Scholar] [CrossRef]
- Valstar, M.; Gratch, J.; Schuller, B.; Ringeval, F.; Lalanne, D.; Torres Torres, M.; Scherer, S.; Stratou, G.; Cowie, R.; Pantic, M. Avec 2016: Depression, mood, and emotion recognition workshop and challenge. In Proceedings of the 6th International Workshop on Audio/Visual Emotion Challenge; ACM: New York, NY, USA, 2016; pp. 3–10. [Google Scholar]
- Moh, M.; Gajjala, A.; Gangireddy, S.C.R.; Moh, T.S. On multi-tier sentiment analysis using supervised machine learning. In Proceedings of the IEEE/WIC/ACM International Conference on Web Intelligence and Intelligent Agent Technology (WI-IAT), Singapore, 6–9 December 2015; Volume 1, pp. 341–344. [Google Scholar]
- Socher, R.; Pennington, J.; Huang, E.H.; Ng, A.Y.; Manning, C.D. Semi-supervised recursive autoencoders for predicting sentiment distributions. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Edinburgh, UK, 27–31 July 2011; Association for Computational Linguistics: Stroudsburg, PA, USA, 2011; pp. 151–161. [Google Scholar]
- Davidov, D.; Tsur, O.; Rappoport, A. Semi-supervised recognition of sarcastic sentences in twitter and amazon. In Proceedings of the Fourteenth Conference on Computational Natural Language Learning, Uppsala, Sweden, 15–16 July 2010; Association for Computational Linguistics: Stroudsburg, PA, USA, 2010; pp. 107–116. [Google Scholar]
- Liu, S.; Li, F.; Li, F.; Cheng, X.; Shen, H. Adaptive co-training SVM for sentiment classification on tweets. In Proceedings of the 22nd ACM International Conference on Information & Knowledge Management, San Francisco, CA, USA, 27 October–1 November 2013; ACM: New York, NY, USA, 2013; pp. 2079–2088. [Google Scholar]
- Ren, R.; Wu, D.D.; Liu, T. Forecasting Stock Market Movement Direction Using Sentiment Analysis and Support Vector Machine. IEEE Syst. J. 2018, 13, 760–770. [Google Scholar] [CrossRef]
- Gamallo, P.; Garcia, M. A Naive-Bayes Strategy for Sentiment Analysis on English Tweets. In Proceedings of the 8th International Workshop on Semantic Evaluation SemEval, Dulbin, Ireland, 23–24 August 2014. [Google Scholar]
- Koohzadi, M.; Charkari, N.M.; Ghaderi, F. Unsupervised representation learning based on the deep multi-view ensemble learning. Appl. Intell. 2019, 49, 1–20. [Google Scholar] [CrossRef]
- Zhang, Y.; Song, D.; Zhang, P.; Li, X.; Wang, P. A quantum-inspired sentiment representation model for twitter sentiment analysis. Appl. Intell. 2019, 49, 3093–3108. [Google Scholar] [CrossRef]
- Boiy, E.; Moens, M.F. A machine learning approach to sentiment analysis in multilingual Web texts. Inf. Retr. 2009, 12, 526–558. [Google Scholar] [CrossRef]
- Akaichi, J. Sentiment Classification at the Time of the Tunisian Uprising: Machine Learning Techniques Applied to a New Corpus for Arabic Language. In Proceedings of the 2014 European Network Intelligence Conference (ENIC), Wroclaw, Poland, 29–30 September 2014; pp. 38–45. [Google Scholar]
- Povoda, L.; Burget, R.; Dutta, M.K. Sentiment analysis based on Support Vector Machine and Big Data. In Proceedings of the 2016 39th International Conference on Telecommunications and Signal Processing (TSP), Vienna, Austria, 27–29 June 2016; pp. 543–545. [Google Scholar]
- Tripathy, A.; Agrawal, A.; Rath, S.K. Classification of sentimental reviews using machine learning techniques. Procedia Comput. Sci. 2015, 57, 821–829. [Google Scholar] [CrossRef]
- Xia, R.; Zong, C.; Li, S. Ensemble of feature sets and classification algorithms for sentiment classification. Inf. Sci. 2011, 181, 1138–1152. [Google Scholar] [CrossRef]
- Garcia-Moya, L.; Anaya-Sánchez, H.; Berlanga-Llavori, R. Retrieving product features and opinions from customer reviews. IEEE Intell. Syst. 2013, 28, 19–27. [Google Scholar] [CrossRef]
- Lai, S.; Xu, L.; Liu, K.; Zhao, J. Recurrent convolutional neural networks for text classification. AAAI 2015, 333, 2267–2273. [Google Scholar]
- Duwairi, R.M. Sentiment analysis for dialectical Arabic. In Proceedings of the 2015 6th International Conference on Information and Communication Systems (ICICS), Amman, Jordan, 7–9 April 2015; pp. 166–170. [Google Scholar]
- Chen, T.; Xu, R.; He, Y.; Wang, X. Improving sentiment analysis via sentence type classification using BiLSTM-CRF and CNN. Expert Syst. Appl. 2017, 72, 221–230. [Google Scholar] [CrossRef]
- Wang, J.; Yu, L.C.; Lai, K.R.; Zhang, X. Dimensional sentiment analysis using a regional CNN-LSTM model. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics 2, Berlin, Germany, 7–12 August 2016; pp. 225–230. [Google Scholar]
- Guggilla, C.; Miller, T.; Gurevych, I. CNN-and LSTM-based claim classification in online user comments. In Proceedings of the COLING 2016, the 26th International Conference on Computational Linguistics: Technical Papers, Osaka, Japan, 11–16 December 2016; pp. 2740–2751. [Google Scholar]
- Duwairi, R.; El-Orfali, M. A study of the effects of preprocessing strategies on sentiment analysis for Arabic text. J. Inf. Sci. 2014, 40, 501–513. [Google Scholar] [CrossRef]
- Popescu, O.; Strapparava, C. Time corpora: Epochs, opinions and changes. Knowl. Based Syst. 2013, 69, 3–13. [Google Scholar] [CrossRef]
- Neviarouskaya, A.; Prendinger, H.; Ishizuka, M. Compositionality Principle in Recognition of Fine-Grained Emotions from Text. In Proceedings of the ICWSM, San Jose, CA, USA, 17–20 May 2009. [Google Scholar]
- Fei, G.; Liu, B.; Hsu, M.; Castellanos, M.; Ghosh, R. A dictionary-based approach to identifying aspects implied by adjectives for opinion mining. In Proceedings of the COLING 2012: Posters, Mumbai, India, 8–15 December 2012; pp. 309–318. [Google Scholar]
- Cui, H.; Mittal, V.; Datar, M. Comparative experiments on sentiment classification for online product reviews. In Proceedings of the AAAI’06 Proceedings of the 21st National Conference on Artificial Intelligence, Boston, MA, USA, 16–20 July 2006; Volume 6, pp. 1265–1270. [Google Scholar]
- Oliveira, N.; Cortez, P.; Areal, N. The impact of microblogging data for stock market prediction: Using Twitter to predict returns, volatility, trading volume and survey sentiment indices. Expert Syst. Appl. 2017, 73, 125–144. [Google Scholar] [CrossRef]
- Gupte, A.; Joshi, S.; Gadgul, P.; Kadam, A.; Gupte, A. Comparative study of classification algorithms used in sentiment analysis. Int. J. Comput. Sci. Inf. Technol. 2014, 5, 6261–6264. [Google Scholar]
- Pang, B.; Lee, L. A sentimental education: Sentiment analysis using subjectivity summarization based on minimum cuts. In Proceedings of the 42nd Annual Meeting on Association for Computational Linguistics, Barcelona, Spain, 21–26 July 2004; p. 271. [Google Scholar]
- Priyanka, D.Y.; Senthilkumar, R. Sampling techniques for streaming dataset using sentiment analysis. In Proceedings of the 2016 International Conference on Recent Trends in Information Technology (ICRTIT), Chennai, India, 8–9 April 2016; pp. 1–6. [Google Scholar]
- Saura, J.R.; Herráez, B.R.; Reyes-Menendez, A. Comparing a traditional approach for financial Brand Communication Analysis with a Big Data Analytics technique. IEEE Access 2019, 7, 37100–37108. [Google Scholar] [CrossRef]
- Sánchez-Rada, J.F.; Iglesias, C.A. Onyx: A linked data approach to emotion representation. Inf. Process. Manag. 2016, 52, 99–114. [Google Scholar] [CrossRef]
- Cambria, E.; Poria, S.; Bajpai, R.; Schuller, B. SenticNet 4: A semantic resource for sentiment analysis based on conceptual primitives. In Proceedings of the COLING 2016, the 26th International Conference on Computational Linguistics: Technical Papers, Osaka, Japan, 11–16 December 2016; pp. 2666–2677. [Google Scholar]
- Balahur, A.; Perea-Ortega, J.M. Sentiment analysis system adaptation for multilingual processing: The case of tweets. Inf. Process. Manag. 2015, 51, 547–556. [Google Scholar] [CrossRef]
- Severyn, A.; Moschitti, A.; Uryupina, O.; Plank, B.; Filippova, K. Multi-lingual opinion mining on youtube. Inf. Process. Manag. 2016, 52, 46–60. [Google Scholar] [CrossRef]
- Socher, R.; Huval, B.; Manning, C.D.; Ng, A.Y. Semantic compositionality through recursive matrix-vector spaces. In Proceedings of the 2012 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning, Jeju Island, Korea, 12–14 July 2012; Association for Computational Linguistics: Stroudsburg, PA, USA, 2012; pp. 1201–1211. [Google Scholar]
- Wang, X.; Jiang, W.; Luo, Z. Combination of convolutional and recurrent neural network for sentiment analysis of short texts. In Proceedings of the COLING 2016, the 26th International Conference on Computational Linguistics: Technical Papers, Osaka, Japan, 11–16 December 2016; pp. 2428–2437. [Google Scholar]
- Lau, R.Y.; Li, C.; Liao, S.S. Social analytics: Learning fuzzy product ontologies for aspect-oriented sentiment analysis. Decis. Support Syst. 2014, 65, 80–94. [Google Scholar] [CrossRef]
- Cambria, E. Affective computing and sentiment analysis. IEEE Intell. Syst. 2016, 31, 102–107. [Google Scholar] [CrossRef]
- Cambria, E.; Schuller, B.; Xia, Y.; Havasi, C. New avenues in opinion mining and sentiment analysis. IEEE Intell. Syst. 2013, 28, 15–21. [Google Scholar] [CrossRef]
- Conroy, N.J.; Rubin, V.L.; Chen, Y. Automatic deception detection: Methods for finding fake news. In Proceedings of the 78th ASIS&T Annual Meeting: Information Science with Impact: Research in and for the Community, St. Louis, MO, USA, 6–10 November 2015; American Society for Information Science: Silver Springs, MD, USA, 2015; p. 82. [Google Scholar]
- Bracewell, D.G.; Francis, R.; Smales, C.M. The future of host cell protein (HCP) identification during process development and manufacturing linked to a risk-based management for their control. Biotechnol. Bioeng. 2015, 112, 1727–1737. [Google Scholar] [CrossRef]
- Nguyen, T.H.; Shirai, K.; Velcin, J. Sentiment analysis on social media for stock movement prediction. Expert Syst. Appl. 2015, 42, 9603–9611. [Google Scholar] [CrossRef]
- Zavattaro, S.M.; French, P.E.; Mohanty, S.D. A sentiment analysis of US local government tweets: The connection between tone and citizen involvement. Gov. Inf. Q. 2015, 32, 333–341. [Google Scholar] [CrossRef]
- Van den Broek-Altenburg, E.M.; Atherly, A.J. Using Social Media to Identify Consumers’ Sentiments towards Attributes of Health Insurance during Enrollment Season. Appl. Sci. 2019, 9, 2035. [Google Scholar] [CrossRef]
- Bologna, G.; Hayashi, Y. A rule extraction study from svm on sentiment analysis. Big Data Cogn. Comput. 2018, 2, 6. [Google Scholar] [CrossRef]
- Reyes-Menendez, A.; Saura, J.; Alvarez-Alonso, C. Understanding# WorldEnvironmentDay user opinions in Twitter: A topic-based sentiment analysis approach. Int. J. Environ. Res. Public Health 2018, 15, 2537. [Google Scholar]
- Ren, G.; Hong, T. Investigating online destination images using a topic-based sentiment analysis approach. Sustainability 2017, 9, 1765. [Google Scholar] [CrossRef]
- Wiemer, H.; Drowatzky, L.; Ihlenfeldt, S. Data Mining Methodology for Engineering Applications (DMME)—A Holistic Extension to the CRISP-DM Model. Appl. Sci. 2019, 9, 2407. [Google Scholar] [CrossRef]
- Herráez, B.; Bustamante, D.; Saura, J.R. Information classification on social networks. Content analysis of e-commerce companies on Twitter. Rev. Espac. 2017, 38, 16. [Google Scholar]
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).