Emotion AI-Driven Sentiment Analysis: A Survey, Future Research Directions, and Open Issues


 , ,
, ,  ,
,  and
and 
Abstract
1. Introduction
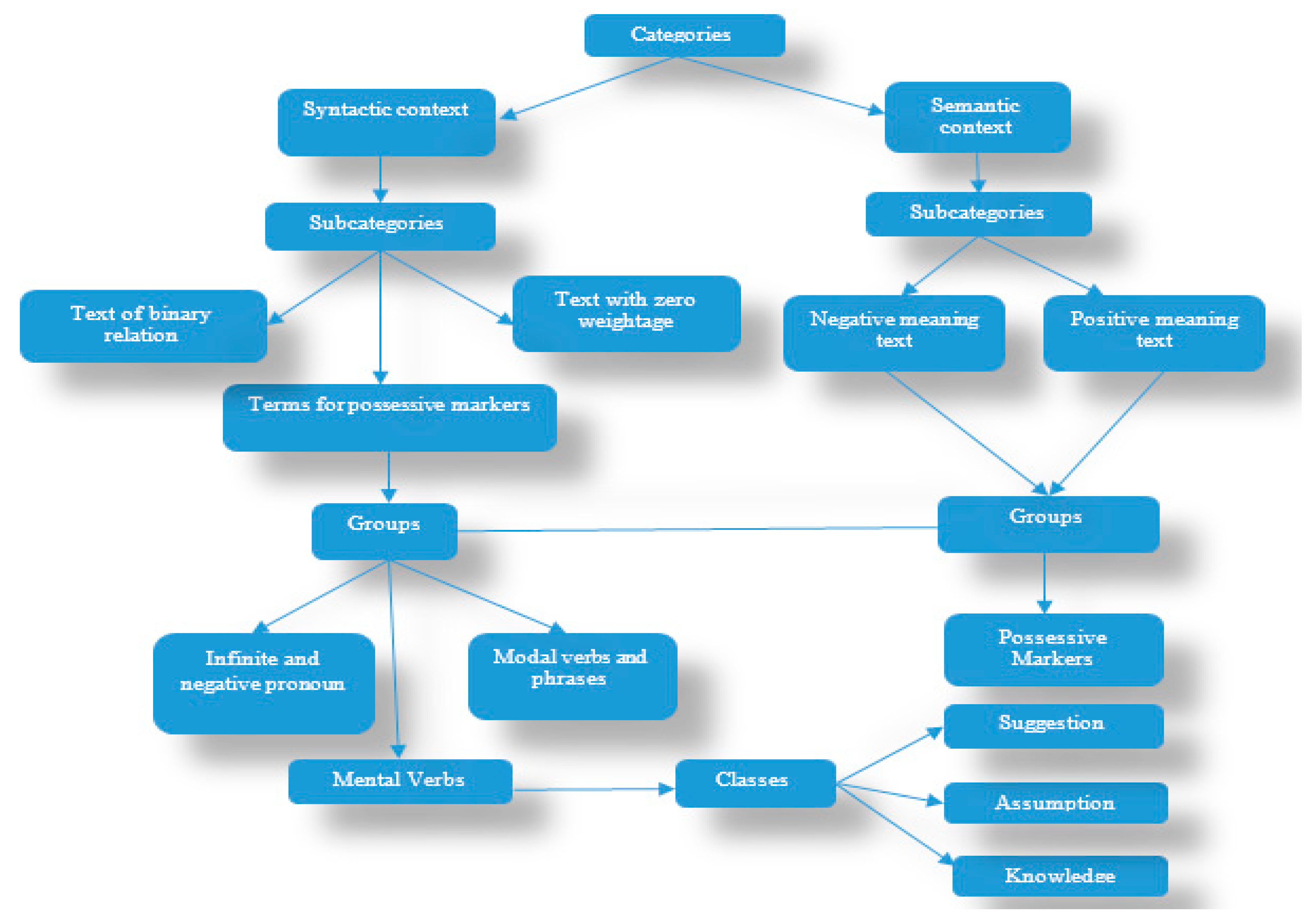
1.1. Emotion AI-Driven Sentiment Analysis: Taxonomy
1.2. Sentiment Analysis (SA) Process
1.2.1. Step 1: Data Collection
1.2.2. Step 2: Training Dataset and Subjective Data
1.2.3. Step 3: Data Pre-Processing
1.3. Comparison with Previous Surveys
2. Literature Review
2.1. Ontology-Based Sentiment Analysis: Review
- To examine the domain-specific knowledge;
- To activate the domain knowledge for reuse;
- To provide clear domain supposition;
- To split the domain and functional expertise;
- To provide a way to share their knowledge with the software agents.
2.2. Lexicon-Based Sentiment Analysis: A Review
2.3. Sentiment Analysis Based on Machine Learning: A Review
2.4. Neural Network Models: A Review
3. Methodology
3.1. Machine Learning Approaches
| Algorithm 1. |
| Input: A = Total number of trees D = Training dataset F′ = Features f′ = Sub features Output: Label of bagged class 1. For each and every tree in A (i) Create a bootstrapping sample S of size D (ii) Create a tree recursively to all the internal nodes with the following steps: Step 1:- Choose the sub feature f′ randomly at feature F′ Step 2:- Best sub feature f′ has to selected Step 3:- Finally split the node 2. Test instance will be passed to trees once trees are created 3. Later, a majority of votes are provided by assigning the class labels |
| Algorithm 2. |
| Training CNN for sentiment analysis Input: f(x) = {x1, x2, …. xn} , f(y) = {y1, y2,…. yn} Step 1: Train the CNN with input f(x)and f(y) Step 2: Sentiment score of f(x) predicted Step 3: Let X be the leftover training data and Y be their sentiment Step 4: Let the CNN fine-tune with the input X and Y Step 5: Return (the average performance) Output: Sentiment of the data |
3.2. Lexicon-Based Approaches
3.2.1. Sentiment Analysis in Gram Representation
3.2.2. Term Frequency- Inverse Document Frequency (TF-IDF) Representation
3.2.3. Dictionary-Based Approach
3.2.4. Corpus-Based Approach
3.2.5. Statistical Approach
4. Results and Discussions
4.1. Evaluation Metrics
4.1.1. Prediction Accuracy
4.1.2. Refined Measure on Tweet Precision
4.1.3. Recall
4.1.4. F-Measure
4.2. Using Ontology-Based Sentiment Analysis
4.3. Using Lexicon-Based Sentiment Analysis
4.4. Using Machine-Learning-Based Sentiment Analysis
5. Challenges, Future Research Directions, and Open issues
5.1. Mining Unstructured Data
 ”. This kind of text is considered to be unstructured data. Many of the SA methods preprocess this information. Hence, extracting and providing the sentiment and the emotion to these kinds of data are really challenging [92].
”. This kind of text is considered to be unstructured data. Many of the SA methods preprocess this information. Hence, extracting and providing the sentiment and the emotion to these kinds of data are really challenging [92].5.2. Identifying Composite Media Features
5.3. Different Words with the Same Meaning
- Sentiment words that do not express a sentiment—some of the words in interrogative statements may not explicitly express any sentiment. Still, the emotion present in the statement should be identified as another challenge [96].
- Emotion identification (sarcasm)—it is difficult for the machine to identify sarcastic statements. Researchers on SA work hard to identify sarcastic comments with high accuracy, as human emotions and attitudes are often ambiguous [97].
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| ABBREVIATION | FULL FORM |
| NB | Naive Bayes |
| MNB | Multinomial naive Bayes |
| SVM | Support vector machine |
| ME | Maximum entropy |
| NN | Neural network |
| ANN | Artificial neural network |
| CNN | Convolution neural network |
| RNN | Recurrent neural network |
| LSTM | Long short-term memory |
| RF | Random forest |
| LC | Linear classifier |
| PC | Probability classifier |
| PSDEE | Polarity shift detection, elimination, and ensemble |
| TF | Term frequency |
| TF-IDF | Term frequency-inverse document frequency |
| DT | Decision tree |
| BoW | Bags of word |
| Pos | Parts of speech |
| FSC | Fuzzy semantic classifier |
| RFWC | Relative frequency word count |
| KNN | K-nearest neighbor |
| CRF | Conditional random fields |
| DL | Document level |
| SL | Sentence level |
| FL | Feature level |
References
- Khan, A.; Baharudin, B.; Khan, K. Efficient feature selection and domain relevance term weighting method for document classification. In Proceedings of the 2010 Second International Conference on the Computer Engineering and Applications (ICCEA), Bali Island, Indonesia, 19–21 March 2010; Volume 2, pp. 398–403. [Google Scholar]
- Lu, Y.; Kong, X.; Quan, X.; Liu, W.; Xu, Y. Exploring the sentiment strength of user reviews. In International Conference on Web-Age Information Management; Springer: Berlin/Heidelberg, Germany, 2010; pp. 471–482. [Google Scholar]
- Agarwal, A.; Xie, B.; Vovsha, I.; Rambow, O.; Passonneau, R. Sentiment analysis of twitter data. In Proceedings of the Workshop on Languages in Social Media; Association for Computational Linguistics: Stroudsburg, PA, USA, 2011; pp. 30–38. [Google Scholar]
- Annett, M.; Kondrak, G. A comparison of sentiment analysis techniques: Polarizing movie blogs. In Conference of the Canadian Society for Computational Studies of Intelligence; Springer: Berlin/Heidelberg, Germany, 2008; pp. 25–35. [Google Scholar]
- Liu, B. Sentiment analysis and opinion mining. Synth. Lect. Hum. Lang. Technol. 2012, 5, 1–167. [Google Scholar] [CrossRef]
- Li, X.; Peng, Q.; Sun, Z.; Chai, L.; Wang, Y. Predicting Social Emotions from Readers’ Perspective. IEEE Trans. Affect. Comput. 2017, 10, 255–264. [Google Scholar] [CrossRef]
- Liu, B.; Hu, M.; Cheng, J. Opinion observer: Analyzing and comparing opinions on the web. In Proceedings of the 14th International Conference on World Wide Web, Cardiff, UK, 25 January 2020; ACM: New York, NY, USA, 2005; pp. 342–351. [Google Scholar]
- Li, C.; Sun, A.; Weng, J.; He, Q. Tweet segmentation and its application to named entity recognition. IEEE Trans. Knowl. Data Eng. 2015, 27, 558–570. [Google Scholar] [CrossRef]
- Rout, J.K.; Choo, K.K.R.; Dash, A.K.; Bakshi, S.; Jena, S.K.; Williams, K.L. A model for sentiment and emotion analysis of unstructured social media text. Electron. Commer. Res. 2018, 18, 181–199. [Google Scholar] [CrossRef]
- Che, W.; Zhao, Y.; Guo, H.; Su, Z.; Liu, T. Sentence compression for aspect-based sentiment analysis. IEEE/ACM Trans. Audio Speech Lang. Process. (TASLP) 2015, 23, 2111–2124. [Google Scholar] [CrossRef]
- Bell, D.; Koulouri, T.; Lauria, S.; Macredie, R.D.; Sutton, J. Microblogging as a mechanism for human–robot interaction. Knowl. Based Syst. 2014, 69, 64–77. [Google Scholar] [CrossRef]
- Xia, R.; Xu, F.; Yu, J.; Qi, Y.; Cambria, E. Polarity shift detection, elimination and ensemble: A three-stage model for document-level sentiment analysis. Inf. Process. Manag. 2015, 52, 36–45. [Google Scholar] [CrossRef]
- Singh, V.K.; Piryani, R.; Uddin, A.; Waila, P. Sentiment analysis of Movie reviews and Blog posts. In Proceedings of the 2013 3rd IEEE International Advance Computing Conference (IACC), Ghaziabad, India, 22–23 February 2013; pp. 893–898. [Google Scholar]
- Mohammad, S.M.; Zhu, X.; Kiritchenko, S.; Martin, J. Sentiment, emotion, purpose, and style in electoral tweets. Inf. Process. Manag. 2015, 51, 480–499. [Google Scholar] [CrossRef]
- Aljanaki, A.; Wiering, F.; Veltkamp, R.C. Studying emotion induced by music through a crowdsourcing game. Inf. Process. Manag. 2016, 52, 115–128. [Google Scholar] [CrossRef]
- Denecke, K.; Deng, Y. Sentiment analysis in medical settings: New opportunities and challenges. Artif. Intell. Med. 2015, 64, 17–27. [Google Scholar] [CrossRef]
- Medhat, W.; Hassan, A.; Korashy, H. Sentiment analysis algorithms and applications: A survey. Ain Shams Eng. J. 2014, 5, 1093–1113. [Google Scholar] [CrossRef]
- Tubishat, M.; Idris, N.; Abushariah, M.A. Implicit aspect extraction in sentiment analysis: Review, taxonomy, oppportunities, and open challenges. Inf. Process. Manag. 2018, 54, 545–563. [Google Scholar] [CrossRef]
- Yue, L.; Chen, W.; Li, X.; Zuo, W.; Yin, M. A survey of sentiment analysis in social media. Knowl. Inf. Syst. 2019, 60, 617–663. [Google Scholar] [CrossRef]
- Soleymani, M.; Garcia, D.; Jou, B.; Schuller, B.; Chang, S.F.; Pantic, M. A survey of multimodal sentiment analysis. Image Vis. Comput. 2017, 65, 3–14. [Google Scholar] [CrossRef]
- Yue, L.; Chen, W.; Li, X.; Zuo, W.; Yin, M. Survey on target dependent sentiment analysis of micro-blogs in social media. In Proceedings of the 9th IEEE-GCC Conference and Exhibition, GCCCE, Manama, Bahrain, 8–11 May 2017; p. 1. [Google Scholar] [CrossRef]
- Rana, T.A.; Cheah, Y.N. Aspect extraction in sentiment analysis: Comparative analysis and survey. Artif. Intell. Rev. 2016, 46, 459–483. [Google Scholar] [CrossRef]
- Yadollahi, A.; Shahraki, A.G.; Zaiane, O.R. Current state of text sentiment analysis from opinion to emotion mining. ACM Comput. Surv. (CSUR) 2017, 50, 25. [Google Scholar] [CrossRef]
- Hussein, A.; Gaber, M.M.; Elyan, E.; Jayne, C. Imitation learning: A survey of learning methods. ACM Comput. Surv. (CSUR) 2017, 50, 21. [Google Scholar] [CrossRef]
- Kaur, H.; Mangat, V. A survey of sentiment analysis techniques. In Proceedings of the 2017 International Conference on the I-SMAC (IoT in Social, Mobile, Analytics and Cloud) (I-SMAC), Palladam, India, 10–11 February 2017; pp. 921–925. [Google Scholar]
- Thakor, P.; Sasi, S. Ontology-based sentiment analysis process for social media content. Procedia Comput. Sci. 2015, 53, 199–207. [Google Scholar] [CrossRef]
- Kontopoulos, E.; Berberidis, C.; Dergiades, T.; Bassiliades, N. Ontology-based sentiment analysis of twitter posts. Expert Syst. Appl. 2013, 40, 4065–4074. [Google Scholar] [CrossRef]
- Shi, W.; Wang, H.; He, S. Sentiment analysis of Chinese microblogging based on sentiment ontology: A case study of ‘7.23 Wenzhou Train Collision. Connect. Sci. 2013, 25, 161–178. [Google Scholar] [CrossRef]
- Ali, F.; Kwak, K.S.; Kim, Y.G. Opinion mining based on fuzzy domain ontology and support vector machine: A proposal to automate online review classification. Appl. Soft Comput. 2016, 47, 235–250. [Google Scholar] [CrossRef]
- Penalver-Martinez, I.; Garcia-Sanchez, F.; Valencia-Garcia, R.; Rodriguez-Garcia, M.A.; Moreno, V.; Fraga, A.; Sanchez-Cervantes, J.L. Feature-based opinion mining through ontologies. Expert Syst. Appl. 2014, 41, 5995–6008. [Google Scholar] [CrossRef]
- Ma, J.; Xu, W.; Sun, Y.H.; Turban, E.; Wang, S.; Liu, O. An ontology-based text-mining method to cluster proposals for research project selection. IEEE Trans. Syst. ManCybern. Part A Syst. Hum. 2012, 42, 784–790. [Google Scholar] [CrossRef]
- Li, Z.; Xu, W.; Zhang, L.; Lau, R.Y. An ontology-based web mining method for unemployment rate prediction. Decis. Support Syst. 2014, 66, 114–122. [Google Scholar] [CrossRef]
- Li, S.; Liu, L.; Xiong, Z. Ontology-based sentiment analysis of network public opinions. Int. J. Digit. Content Technol. Appl. 2012, 6, 371–380. [Google Scholar]
- De Kok, S.; Punt, L.; van den Puttelaar, R.; Schouten, K.; Frasincar, F. Review-aggregated aspect-based sentiment analysis with ontology features. Prog. Artif. Intell. 2018, 7, 295–306. [Google Scholar] [CrossRef]
- Le Thi, T.; Thanh, T.Q.; Thi, T.P. Ontology-Based Entity Coreference Resolution for Sentiment Analysis. In Proceedings of the Eighth Symposium on Information and Communication Technology (SoICT 2017), Nha Trang, Vietnam, 7–8 December 2017; pp. 50–56. [Google Scholar]
- Ceci, F.; Leopoldo Goncalves, A.; Weber, R. A model for sentiment analysis based on ontology and cases. IEEE Lat. Am. Trans. 2016, 14, 4560–4566. [Google Scholar] [CrossRef]
- Shojaee, S.; Murad, M.A.A.; Azman, A.B.; Sharef, N.M.; Nadali, S. Detecting deceptive reviews using lexical and syntactic features. In Proceedings of the 13th International Conference on Intelligent Systems Design and Applications (ISDA), Bangi, Malaysia, 8–10 December 2013; pp. 53–58. [Google Scholar]
- Khan, F.H.; Bashir, S.; Qamar, U. TOM: Twitter opinion mining framework using hybrid classification scheme. Decis. Support Syst. 2014, 57, 245–257. [Google Scholar] [CrossRef]
- Duwairi, R.M.; Ahmed, N.A.; Al-Rifai, S.Y. Detecting sentiment embedded in Arabic social media—A lexicon-based approach. J. Intell. Fuzzy Syst. 2015, 29, 107–117. [Google Scholar] [CrossRef]
- Asghar, M.Z.; Khan, A.; Ahmad, S.; Qasim, M.; Khan, I.A. Lexicon-enhanced sentiment analysis framework using rule-based classification scheme. PLoS ONE 2017, 12, e0171649. [Google Scholar] [CrossRef]
- Dey, A.; Jenamani, M.; Thakkar, J.J. Thakkar. Senti-N-Gram: An n-gram lexicon for sentiment analysis. Expert Syst. Appl. 2018, 103, 92–105. [Google Scholar] [CrossRef]
- Deng, S.; Sinha, A.P.; Zhao, H. Adapting sentiment lexicons to domain-specific social media texts. Decis. Support Syst. 2017, 94, 65–76. [Google Scholar] [CrossRef]
- Thompson, J.J.; Leung, B.H.; Blair, M.R.; Taboada, M. Sentiment analysis of player chat messaging in the video game StarCraft 2: Extending a lexicon-based model. Knowl. Based Syst. 2017, 137, 149–162. [Google Scholar] [CrossRef]
- Asghar, M.Z.; Khan, A.; Ahmad, S.; Khan, I.A.; Kundi, F.M. A unified framework for creating domain dependent polarity lexicons from user generated reviews. PLoS ONE 2015, 10, e0140204. [Google Scholar] [CrossRef]
- Kang, H.; Yoo, S.J.; Han, D. Senti-lexicon and improved NB algorithms for sentiment analysis of restaurant reviews. Expert Syst. Appl. 2012, 39, 6000–6010. [Google Scholar] [CrossRef]
- Zeng, L.; Li, F. A classification-based approach for implicit feature identification. In Chinese Computational Linguistics and Natural Language Processing Based on Naturally Annotated Big Data; Springer: Berlin/Heidelberg, Germany, 2013; pp. 190–202. [Google Scholar]
- Wang, H.H.; Yu, L.; Tian, S.W.; Peng, Y.F.; Pei, X.J. Bidirectional LSTM Malicious webpages detection algorithm based on convolutional neural network and independent recurrent neural network. Appl. Intell. 2019, 49, 3016–3026. [Google Scholar] [CrossRef]
- Eirinaki, M.; Pisal, S.; Singh, J. Feature-based opinion mining and ranking. J. Comput. Syst. Sci. 2012, 78, 1175–1184. [Google Scholar] [CrossRef]
- Jurado, F.; Rodriguez, P. Sentiment Analysis in monitoring software development processes: An exploratory case study on GitHub’s project issues. J. Syst. Softw. 2015, 104, 82–89. [Google Scholar] [CrossRef]
- Cheng, K.; Li, J.; Tang, J.; Liu, H. Unsupervised sentiment analysis with signed social networks. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Pujari, C.; Shetty, N.P. Comparison of Classification Techniques for Feature Oriented Sentiment Analysis of Product Review Data. In Data Engineering and Intelligent Computing; Springer: Singapore, 2018; pp. 149–158. [Google Scholar]
- Poria, S.; Cambria, E.; Howard, N.; Huang, G.B.; Hussain, A. Fusing audio, visual and textual clues for sentiment analysis from multimodal content. Neurocomputing 2016, 174, 50–59. [Google Scholar] [CrossRef]
- Valstar, M.; Gratch, J.; Schuller, B.; Ringeval, F.; Lalanne, D.; Torres Torres, M.; Scherer, S.; Stratou, G.; Cowie, R.; Pantic, M. Avec 2016: Depression, mood, and emotion recognition workshop and challenge. In Proceedings of the 6th International Workshop on Audio/Visual Emotion Challenge; ACM: New York, NY, USA, 2016; pp. 3–10. [Google Scholar]
- Moh, M.; Gajjala, A.; Gangireddy, S.C.R.; Moh, T.S. On multi-tier sentiment analysis using supervised machine learning. In Proceedings of the IEEE/WIC/ACM International Conference on Web Intelligence and Intelligent Agent Technology (WI-IAT), Singapore, 6–9 December 2015; Volume 1, pp. 341–344. [Google Scholar]
- Socher, R.; Pennington, J.; Huang, E.H.; Ng, A.Y.; Manning, C.D. Semi-supervised recursive autoencoders for predicting sentiment distributions. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Edinburgh, UK, 27–31 July 2011; Association for Computational Linguistics: Stroudsburg, PA, USA, 2011; pp. 151–161. [Google Scholar]
- Davidov, D.; Tsur, O.; Rappoport, A. Semi-supervised recognition of sarcastic sentences in twitter and amazon. In Proceedings of the Fourteenth Conference on Computational Natural Language Learning, Uppsala, Sweden, 15–16 July 2010; Association for Computational Linguistics: Stroudsburg, PA, USA, 2010; pp. 107–116. [Google Scholar]
- Liu, S.; Li, F.; Li, F.; Cheng, X.; Shen, H. Adaptive co-training SVM for sentiment classification on tweets. In Proceedings of the 22nd ACM International Conference on Information & Knowledge Management, San Francisco, CA, USA, 27 October–1 November 2013; ACM: New York, NY, USA, 2013; pp. 2079–2088. [Google Scholar]
- Ren, R.; Wu, D.D.; Liu, T. Forecasting Stock Market Movement Direction Using Sentiment Analysis and Support Vector Machine. IEEE Syst. J. 2018, 13, 760–770. [Google Scholar] [CrossRef]
- Gamallo, P.; Garcia, M. A Naive-Bayes Strategy for Sentiment Analysis on English Tweets. In Proceedings of the 8th International Workshop on Semantic Evaluation SemEval, Dulbin, Ireland, 23–24 August 2014. [Google Scholar]
- Koohzadi, M.; Charkari, N.M.; Ghaderi, F. Unsupervised representation learning based on the deep multi-view ensemble learning. Appl. Intell. 2019, 49, 1–20. [Google Scholar] [CrossRef]
- Zhang, Y.; Song, D.; Zhang, P.; Li, X.; Wang, P. A quantum-inspired sentiment representation model for twitter sentiment analysis. Appl. Intell. 2019, 49, 3093–3108. [Google Scholar] [CrossRef]
- Boiy, E.; Moens, M.F. A machine learning approach to sentiment analysis in multilingual Web texts. Inf. Retr. 2009, 12, 526–558. [Google Scholar] [CrossRef]
- Akaichi, J. Sentiment Classification at the Time of the Tunisian Uprising: Machine Learning Techniques Applied to a New Corpus for Arabic Language. In Proceedings of the 2014 European Network Intelligence Conference (ENIC), Wroclaw, Poland, 29–30 September 2014; pp. 38–45. [Google Scholar]
- Povoda, L.; Burget, R.; Dutta, M.K. Sentiment analysis based on Support Vector Machine and Big Data. In Proceedings of the 2016 39th International Conference on Telecommunications and Signal Processing (TSP), Vienna, Austria, 27–29 June 2016; pp. 543–545. [Google Scholar]
- Tripathy, A.; Agrawal, A.; Rath, S.K. Classification of sentimental reviews using machine learning techniques. Procedia Comput. Sci. 2015, 57, 821–829. [Google Scholar] [CrossRef]
- Xia, R.; Zong, C.; Li, S. Ensemble of feature sets and classification algorithms for sentiment classification. Inf. Sci. 2011, 181, 1138–1152. [Google Scholar] [CrossRef]
- Garcia-Moya, L.; Anaya-Sánchez, H.; Berlanga-Llavori, R. Retrieving product features and opinions from customer reviews. IEEE Intell. Syst. 2013, 28, 19–27. [Google Scholar] [CrossRef]
- Lai, S.; Xu, L.; Liu, K.; Zhao, J. Recurrent convolutional neural networks for text classification. AAAI 2015, 333, 2267–2273. [Google Scholar]
- Duwairi, R.M. Sentiment analysis for dialectical Arabic. In Proceedings of the 2015 6th International Conference on Information and Communication Systems (ICICS), Amman, Jordan, 7–9 April 2015; pp. 166–170. [Google Scholar]
- Chen, T.; Xu, R.; He, Y.; Wang, X. Improving sentiment analysis via sentence type classification using BiLSTM-CRF and CNN. Expert Syst. Appl. 2017, 72, 221–230. [Google Scholar] [CrossRef]
- Wang, J.; Yu, L.C.; Lai, K.R.; Zhang, X. Dimensional sentiment analysis using a regional CNN-LSTM model. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics 2, Berlin, Germany, 7–12 August 2016; pp. 225–230. [Google Scholar]
- Guggilla, C.; Miller, T.; Gurevych, I. CNN-and LSTM-based claim classification in online user comments. In Proceedings of the COLING 2016, the 26th International Conference on Computational Linguistics: Technical Papers, Osaka, Japan, 11–16 December 2016; pp. 2740–2751. [Google Scholar]
- Duwairi, R.; El-Orfali, M. A study of the effects of preprocessing strategies on sentiment analysis for Arabic text. J. Inf. Sci. 2014, 40, 501–513. [Google Scholar] [CrossRef]
- Popescu, O.; Strapparava, C. Time corpora: Epochs, opinions and changes. Knowl. Based Syst. 2013, 69, 3–13. [Google Scholar] [CrossRef]
- Neviarouskaya, A.; Prendinger, H.; Ishizuka, M. Compositionality Principle in Recognition of Fine-Grained Emotions from Text. In Proceedings of the ICWSM, San Jose, CA, USA, 17–20 May 2009. [Google Scholar]
- Fei, G.; Liu, B.; Hsu, M.; Castellanos, M.; Ghosh, R. A dictionary-based approach to identifying aspects implied by adjectives for opinion mining. In Proceedings of the COLING 2012: Posters, Mumbai, India, 8–15 December 2012; pp. 309–318. [Google Scholar]
- Cui, H.; Mittal, V.; Datar, M. Comparative experiments on sentiment classification for online product reviews. In Proceedings of the AAAI’06 Proceedings of the 21st National Conference on Artificial Intelligence, Boston, MA, USA, 16–20 July 2006; Volume 6, pp. 1265–1270. [Google Scholar]
- Oliveira, N.; Cortez, P.; Areal, N. The impact of microblogging data for stock market prediction: Using Twitter to predict returns, volatility, trading volume and survey sentiment indices. Expert Syst. Appl. 2017, 73, 125–144. [Google Scholar] [CrossRef]
- Gupte, A.; Joshi, S.; Gadgul, P.; Kadam, A.; Gupte, A. Comparative study of classification algorithms used in sentiment analysis. Int. J. Comput. Sci. Inf. Technol. 2014, 5, 6261–6264. [Google Scholar]
- Pang, B.; Lee, L. A sentimental education: Sentiment analysis using subjectivity summarization based on minimum cuts. In Proceedings of the 42nd Annual Meeting on Association for Computational Linguistics, Barcelona, Spain, 21–26 July 2004; p. 271. [Google Scholar]
- Priyanka, D.Y.; Senthilkumar, R. Sampling techniques for streaming dataset using sentiment analysis. In Proceedings of the 2016 International Conference on Recent Trends in Information Technology (ICRTIT), Chennai, India, 8–9 April 2016; pp. 1–6. [Google Scholar]
- Saura, J.R.; Herráez, B.R.; Reyes-Menendez, A. Comparing a traditional approach for financial Brand Communication Analysis with a Big Data Analytics technique. IEEE Access 2019, 7, 37100–37108. [Google Scholar] [CrossRef]
- Sánchez-Rada, J.F.; Iglesias, C.A. Onyx: A linked data approach to emotion representation. Inf. Process. Manag. 2016, 52, 99–114. [Google Scholar] [CrossRef]
- Cambria, E.; Poria, S.; Bajpai, R.; Schuller, B. SenticNet 4: A semantic resource for sentiment analysis based on conceptual primitives. In Proceedings of the COLING 2016, the 26th International Conference on Computational Linguistics: Technical Papers, Osaka, Japan, 11–16 December 2016; pp. 2666–2677. [Google Scholar]
- Balahur, A.; Perea-Ortega, J.M. Sentiment analysis system adaptation for multilingual processing: The case of tweets. Inf. Process. Manag. 2015, 51, 547–556. [Google Scholar] [CrossRef]
- Severyn, A.; Moschitti, A.; Uryupina, O.; Plank, B.; Filippova, K. Multi-lingual opinion mining on youtube. Inf. Process. Manag. 2016, 52, 46–60. [Google Scholar] [CrossRef]
- Socher, R.; Huval, B.; Manning, C.D.; Ng, A.Y. Semantic compositionality through recursive matrix-vector spaces. In Proceedings of the 2012 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning, Jeju Island, Korea, 12–14 July 2012; Association for Computational Linguistics: Stroudsburg, PA, USA, 2012; pp. 1201–1211. [Google Scholar]
- Wang, X.; Jiang, W.; Luo, Z. Combination of convolutional and recurrent neural network for sentiment analysis of short texts. In Proceedings of the COLING 2016, the 26th International Conference on Computational Linguistics: Technical Papers, Osaka, Japan, 11–16 December 2016; pp. 2428–2437. [Google Scholar]
- Lau, R.Y.; Li, C.; Liao, S.S. Social analytics: Learning fuzzy product ontologies for aspect-oriented sentiment analysis. Decis. Support Syst. 2014, 65, 80–94. [Google Scholar] [CrossRef]
- Cambria, E. Affective computing and sentiment analysis. IEEE Intell. Syst. 2016, 31, 102–107. [Google Scholar] [CrossRef]
- Cambria, E.; Schuller, B.; Xia, Y.; Havasi, C. New avenues in opinion mining and sentiment analysis. IEEE Intell. Syst. 2013, 28, 15–21. [Google Scholar] [CrossRef]
- Conroy, N.J.; Rubin, V.L.; Chen, Y. Automatic deception detection: Methods for finding fake news. In Proceedings of the 78th ASIS&T Annual Meeting: Information Science with Impact: Research in and for the Community, St. Louis, MO, USA, 6–10 November 2015; American Society for Information Science: Silver Springs, MD, USA, 2015; p. 82. [Google Scholar]
- Bracewell, D.G.; Francis, R.; Smales, C.M. The future of host cell protein (HCP) identification during process development and manufacturing linked to a risk-based management for their control. Biotechnol. Bioeng. 2015, 112, 1727–1737. [Google Scholar] [CrossRef]
- Nguyen, T.H.; Shirai, K.; Velcin, J. Sentiment analysis on social media for stock movement prediction. Expert Syst. Appl. 2015, 42, 9603–9611. [Google Scholar] [CrossRef]
- Zavattaro, S.M.; French, P.E.; Mohanty, S.D. A sentiment analysis of US local government tweets: The connection between tone and citizen involvement. Gov. Inf. Q. 2015, 32, 333–341. [Google Scholar] [CrossRef]
- Van den Broek-Altenburg, E.M.; Atherly, A.J. Using Social Media to Identify Consumers’ Sentiments towards Attributes of Health Insurance during Enrollment Season. Appl. Sci. 2019, 9, 2035. [Google Scholar] [CrossRef]
- Bologna, G.; Hayashi, Y. A rule extraction study from svm on sentiment analysis. Big Data Cogn. Comput. 2018, 2, 6. [Google Scholar] [CrossRef]
- Reyes-Menendez, A.; Saura, J.; Alvarez-Alonso, C. Understanding# WorldEnvironmentDay user opinions in Twitter: A topic-based sentiment analysis approach. Int. J. Environ. Res. Public Health 2018, 15, 2537. [Google Scholar]
- Ren, G.; Hong, T. Investigating online destination images using a topic-based sentiment analysis approach. Sustainability 2017, 9, 1765. [Google Scholar] [CrossRef]
- Wiemer, H.; Drowatzky, L.; Ihlenfeldt, S. Data Mining Methodology for Engineering Applications (DMME)—A Holistic Extension to the CRISP-DM Model. Appl. Sci. 2019, 9, 2407. [Google Scholar] [CrossRef]
- Herráez, B.; Bustamante, D.; Saura, J.R. Information classification on social networks. Content analysis of e-commerce companies on Twitter. Rev. Espac. 2017, 38, 16. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference Number | Survey Objective | Survey Outcome |
|---|---|---|
| [21] | To survey the development of sentiment analysis on images, videos, blogs, etc. To discuss visualized sentiment analysis and speech sentiment analysis. | It focused on the methodology to be used to provide the sentiment for both speech and visualization. It discussed how the automatic sentiment analyzer could be proposed for both speech and visual data. |
| [22] | To focus on increasing precision and reducing the false rate of sentiment analysis. | The evaluation metrics were discussed, and they showed the experimental results. It explained how the supervised and unsupervised algorithms work. |
| [23] | To conduct a sentiment analysis for the communities. | It discussed fine-grained sentiment analysis and algorithm classification. |
| [24] | To depict the n-gram, unigram, and focuses on interpreting the sentiment in every single sentence. | It discussed the neural network-based approach and word embedding and elucidated how the recurrent neural network works. |
| [25] | To conduct a survey to implement Twitter sentiment analysis. | It presented the methodology of HybridSeg and discussed subjective data. |
| References Number | Problem Identified | Methodology | Dataset Used | Results | Limitation |
|---|---|---|---|---|---|
| [30] | Data sparsity problem | Specific domain ontology | Tweets | 82% | Constrained accuracy |
| [31] | To improve the accuracy | Microblog specific sentiment lexicon | Dataset from Tencent Weibo (2013) on 20 topics | 84.3% | Only for Chinese blogs |
| [32] | Binary classification problem and accuracy | Fuzzy ontology (FO) with machine learning technique (ML) | Hotel reviews | 82.70% | Increased complexity |
| [33] | Binary classification problem | Ontology at aspect extraction | Tweets | 82.9% | Not suitable for all domains |
| [34] | To increase the efficiency of the project | Ontology-based text mining method (OTMM) and Self Organizing Maps (SOM) | National Natural Science Foundation of China (NSFC), 110,000 proposals | 91.2% | Time-consuming technique |
| [35] | Polarity shift problem | Polarity Shifting Device Model | Movie reviews | 87.1% | Limited accuracy |
| [36] | Lexicon-based approach | Movie review dataset | 77.6% | Hard to refresh the word reference | |
| [37] | Sentiment compression technique before the aspect-based sentiment analysis | Chinese blog review dataset | 88.78% | Extractive compression technique failed to achieve accuracy | |
| [38] | For enhancing the prediction accuracy of the unemployment rate | Domain ontology | Unemployment Initial Claims (UICs) values between January 2004 and March 2012, US Department of Labor | 81.7% | Rate prediction was not accurate |
| Reference Number | Level of Analysis | Approach | Dataset Used | Results |
|---|---|---|---|---|
| [42] | Feature-based term weight | Term Frequency (TF) | Multi-domain dataset | 85% |
| [43] | - | Support Vector Machine | Tweets | 75.5% |
| [44] | Feature based | Polarity classifier, enhanced emoticon classifier SentiWordNet-based classifier | Tweets | 87% |
| [45] | - | Relative frequency word count | Drug, car, hotel | 80% |
| [46] | Word level | Relative frequency word count (RFWC) | Tweets | Less than 50% |
| [47] | Sentence level | Weight scheme | Tweets | 70% |
| [48] | Phrase level | OpenDover (web service) | Tweets | 75% |
| [49] | Sentence level | Semantic-based lexicon analysis | Tweets | - |
| [50] | Word level | Word emotion lexicon | Socio-political (SP) and sports | Did not add value |
| [51] | SentiWord level | Opinion works affixation | 9 various emotion/sentiment database | 94% |
| [52] | Feature based | Opinion mining and ranking adjective count algorithm | DVD players | 97.1% |
| [53] | Link based | Sentiment strength propagation approach | Hotel survey report | 72% |
| [60] | [61] | [62] | [63] | [64] | [65] | [66] | [67] | |
|---|---|---|---|---|---|---|---|---|
| Approach | Unsupervised | Supervised | Classifier approach | Classifier approach | Supervised | Unsupervised | Hybrid | Supervised |
| Features | Sentiment orientation weight | Sentiment orientation weight Multi-nomial Sentiment Analyis MSA | Word stem + n-gram | Word stem + n-grams MSA | n-gram | Semantic sentiment weight | n-grams | Word stem, SentiWord |
| Algorithm | Based lexicon | Based lexicon | SVM, Naïve Bayes (NB), KNN | SVM, NB, KNN | SVM, NB | Rule-based and lexicon-based | SVM + lexicon-based approach | SVM, NB |
| Dataset | Social network | Aljazeera | Facebook and blogs | Microblog | ||||
| Accuracy | 83% | 97% | 96% | 67% | 75% | 46% | 84.01% | 87% |
| Limitation | Negation and intensification were not considered | Manual extraction and feature score were done | Fewer features and classifiers were used | Could use more features as well as/Parts of Speech tag | More classifiers can be included to reduce the false rate | Did not add value | Negation was not considered | Usage of the dictionary-based rule to translate the word to MSA |
| Pros | Cons |
|---|---|
| • Many utilized fewer parameters. | • Some of the approaches require labeled data. |
| • Labeling data is not necessary for feature extraction. | • It does not count the absence of text. |
| • Training is done easily. | • Features are confused at times during analysis. |
| • Some of the low-featured data can be extracted easily. | • When there is more than one possible opinion, it fails to handle the situation. |
| • Opinion words are categorized into different forms. | • Many consider only adjectives. |
| • Develops new standardized data. | • Exact feature identification is complicated. |
| • Implicit statements are considered in the text during extraction. | • Unlabeled data are not analyzed properly. |
| • Some of the lexicon approaches provide less false rates. | • It does not analyze short text properly. |
| • Domain-specific data achieve high accuracy in predicting sentiments. | • Even though it ensures high accuracy, F-measure is also high. |
| • Neural net models on predicting the sentiment achieve high accuracy with a less false rate. | • Building neural net ID is highly complicated. |
| • Ontology sentiment analysis provides high accuracy when it is domain-specific. | • The false rate in the analysis is high in ontology when compared to the lexicon. |
| Word | Positive Word | Negative Word |
|---|---|---|
| She | 0.100 | 0.20000 |
| Like | 0.100 | 0.00010 |
| This | 0.010 | 0.01000 |
| Comedy | 0.050 | 0.00500 |
| Movie | 0.010 | 0.10000 |
| Dataset | Positive | Negative | Neutral | Total |
|---|---|---|---|---|
| Testing | 10,000 | 5800 | 4200 | 20,000 |
| Training | 2000 | 2000 | 2000 | 6000 |
| Types | Approaches | Merits | Demerits |
|---|---|---|---|
| Lexicon based | Dictionary-based and rule-based approach Ensemble modeling | There is more extensive-term analysis and, hence, accuracy reaches a high. | This is strictly limited to a smaller number of words in the lexicon trained; hence, it is utilized in the fixed score of opinion. |
| Machine learning | Bayesian networks Support vector machines Maximum entropy Random forest Decision tree Neural networks | It is efficient in training the model for a particular purpose. | It is only applicable when the data are labeled. This is more costly. |
| Hybrid | Lexicon + machine learning | It is done at the sentence level, so it is easy at the document level. | It is complex and too noisy. |
| User | Comment |
|---|---|
| User 1 | “the amazon delivered the paste before the delivery date,” |
| User 2 | “Paste tastes really good, and my cavity is reducing.” |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chakriswaran, P.; Vincent, D.R.; Srinivasan, K.; Sharma, V.; Chang, C.-Y.; Reina, D.G. Emotion AI-Driven Sentiment Analysis: A Survey, Future Research Directions, and Open Issues. Appl. Sci. 2019, 9, 5462. https://doi.org/10.3390/app9245462
Chakriswaran P, Vincent DR, Srinivasan K, Sharma V, Chang C-Y, Reina DG. Emotion AI-Driven Sentiment Analysis: A Survey, Future Research Directions, and Open Issues. Applied Sciences. 2019; 9(24):5462. https://doi.org/10.3390/app9245462
Chicago/Turabian StyleChakriswaran, Priya, Durai Raj Vincent, Kathiravan Srinivasan, Vishal Sharma, Chuan-Yu Chang, and Daniel Gutiérrez Reina. 2019. "Emotion AI-Driven Sentiment Analysis: A Survey, Future Research Directions, and Open Issues" Applied Sciences 9, no. 24: 5462. https://doi.org/10.3390/app9245462
APA StyleChakriswaran, P., Vincent, D. R., Srinivasan, K., Sharma, V., Chang, C.-Y., & Reina, D. G. (2019). Emotion AI-Driven Sentiment Analysis: A Survey, Future Research Directions, and Open Issues. Applied Sciences, 9(24), 5462. https://doi.org/10.3390/app9245462