3.1. The Data Description and the Forecasting Modeling for Each Income Group
Considering that tuberculosis prevalence rates are associated with income groups, we seek to make full use of the hierarchical tuberculosis prevalence rates. Thus, for each income group, we construct six different types of regression models with good adjusted R-square values. The tuberculosis prevalence rates from 2000 to 2012 are used for model construction and coefficient estimation. Linear and nonlinear regression models, such as the quadratic polynomial model, the two-term exponential model, the sum-of-sines model, and the Gaussian model, are repeatedly used for the different income groups. It is worth noting that the adjusted R-square value is regarded as the appropriate metric to evaluate the model’s goodness-of-fit. That is to say, we prefer to select regression models with adjusted R-square values as large as possible. Tuberculosis prevalence rates from 2013 to 2016 are forecasted for each income group, respectively.
In addition, for each income group, a total of six individual regression models are combined to forecast tuberculosis prevalence rates from 2013 to 2016, and the weights of the combination forecasting model are optimized by the cuckoo search algorithm. Below, the results of the individual and combination forecasting models are presented in great detail.
- (1)
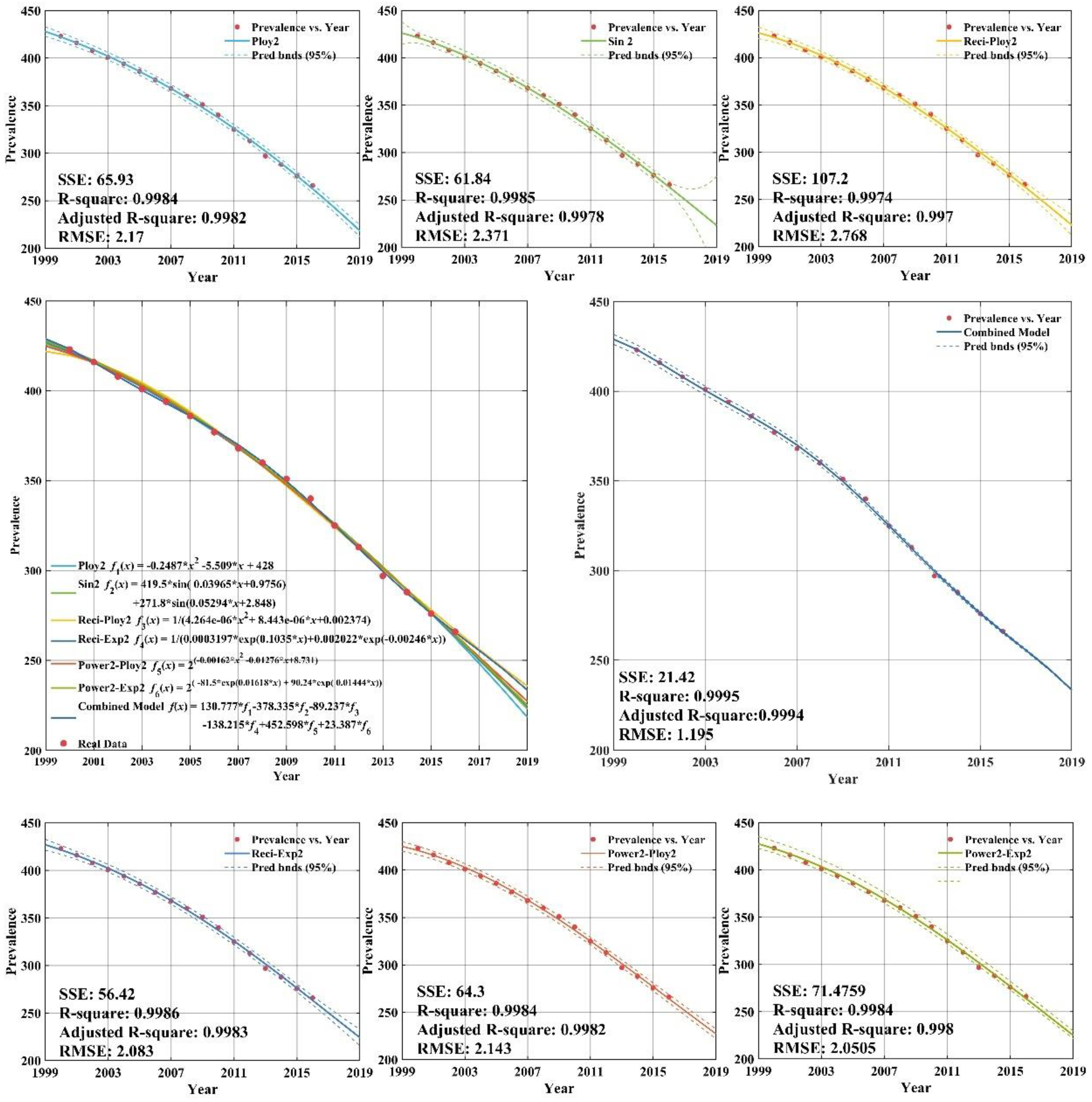
With respect to tuberculosis prevalence rates for the high income group, we first construct two regression models based on the original dataset using the quadratic polynomial model (Poly2) as well as the sum-of-two-sines model (Sin2). In addition, the original tuberculosis prevalence rates are transformed by taking reciprocals and then the quadratic polynomial model (Reci-Poly2) and the two-term exponential model (Reci-Exp2) are applied to characterize the data using a global fit. Finally, the original time series is transformed by taking base-2 logarithms and then the quadratic polynomial model (Power2-Poly2), as well as the one-term Gaussian model (Power2-Gauss1), are built.
- (2)
In regard to tuberculosis prevalence rates for upper-middle income group, the seven types of forecasting models are the quadratic polynomial model (Poly2), the single sine model (Sin1), the reciprocal transformation plus quadratic polynomial model (Reci-Poly2) or the two-term exponential model (Reci-Exp2), the base-2 logarithm transformation with the quadratic polynomial model (Power2-Poly2), or the two-term exponential model (Power2-Exp2), and the combination model (CS-Combined).
- (3)
Taking the tuberculosis prevalence rates for the lower-middle income group into account, the quadratic polynomial model (Poly2), the single sine model (Sin1), reciprocal transformation plus the quadratic polynomial model (Reci-Poly2), or the two-term exponential model (Reci-Exp2), the base-2 logarithm transformation with the quadratic polynomial model (Power2-Poly2), or the two-term exponential model (Power2-Exp2), as well as the combination model (CS-Combined) sequentially comprise a total of seven types of forecasting models.
- (4)
With regard to the tuberculosis prevalence rates for the low income group, as described above, the cubic polynomial model (Poly2), the single sine model (Sin1), the reciprocal transformation plus the quadratic polynomial model (Reci-Poly2), or the two-term exponential model (Reci-Exp2), the base-2 logarithm transformation with the quadratic polynomial model (Power2-Poly2), or the two-term exponential model (Power2-Exp2), as well as the combination model (CS-Combined), are constructed sequentially.
3.2. Analysis of the Modeling Result for Tuberculosis Prevalence Rate in Each Income Group
According to the above analysis, in this part, we further analyze the tuberculosis prevalence rate forecasting results of four different income groups. Note that the corresponding inverse transformations are implemented to obtain final forecasting values. The coefficients of each regression model are estimated by the least-squares method, and the adjusted
R-square (A-R2) of each regression model is calculated. Finally, the combination model is formed based on the six individual regression models, whose weights are optimized by the cuckoo search algorithm, which is denoted as “CS-Combined”. The reason why the aforementioned six regression models are chosen in our combined approach, is that these models have higher adjusted
R-square values than other competing models.
Appendix C plots the fit curves of all seven types of forecasting models while including details of the regression equations and adjusted
R-squares.
Combined models which integrate the results of six individual regression models are often utilized in the forecasting field. In order to obtain the optimal weight coefficients of the individual models, a novel deciding weight method based on the cuckoo search is developed to determine the optimal combination weights. The optimization is as follows.
According to the cuckoo’s process of hatching bird eggs, the CS algorithm is described as follows:
Step 1 Defines the objective function , initializes the function, and randomly generates the initial position of n nests (i = 1, 2, …, n) to set parameters such as population size, problem dimension, maximum discovery probability P, and maximum iterative times;
Step 2 Chooses the fitness function and calculates the objective function value of each bird’s nest position, and obtains the current optimal function value;
Step 3 Records the optimal function value of the previous generation, and uses the formula (5.10) to update the position and state of the other nests;
Step 4 The existing position function value is compared with the previous generation optimal function value and, if it is better, the current optimal value is changed;
Step 5 After the location update, compare the random number with P. If , randomly change , otherwise, it will not change. Finally, keep the best of a group of nest positions ;
Step 6 If the maximum number of iterations or the minimum error requirement is not reached, return to step 2, otherwise, continue to the next step;
Step 7 Output the global optimal combination weight.
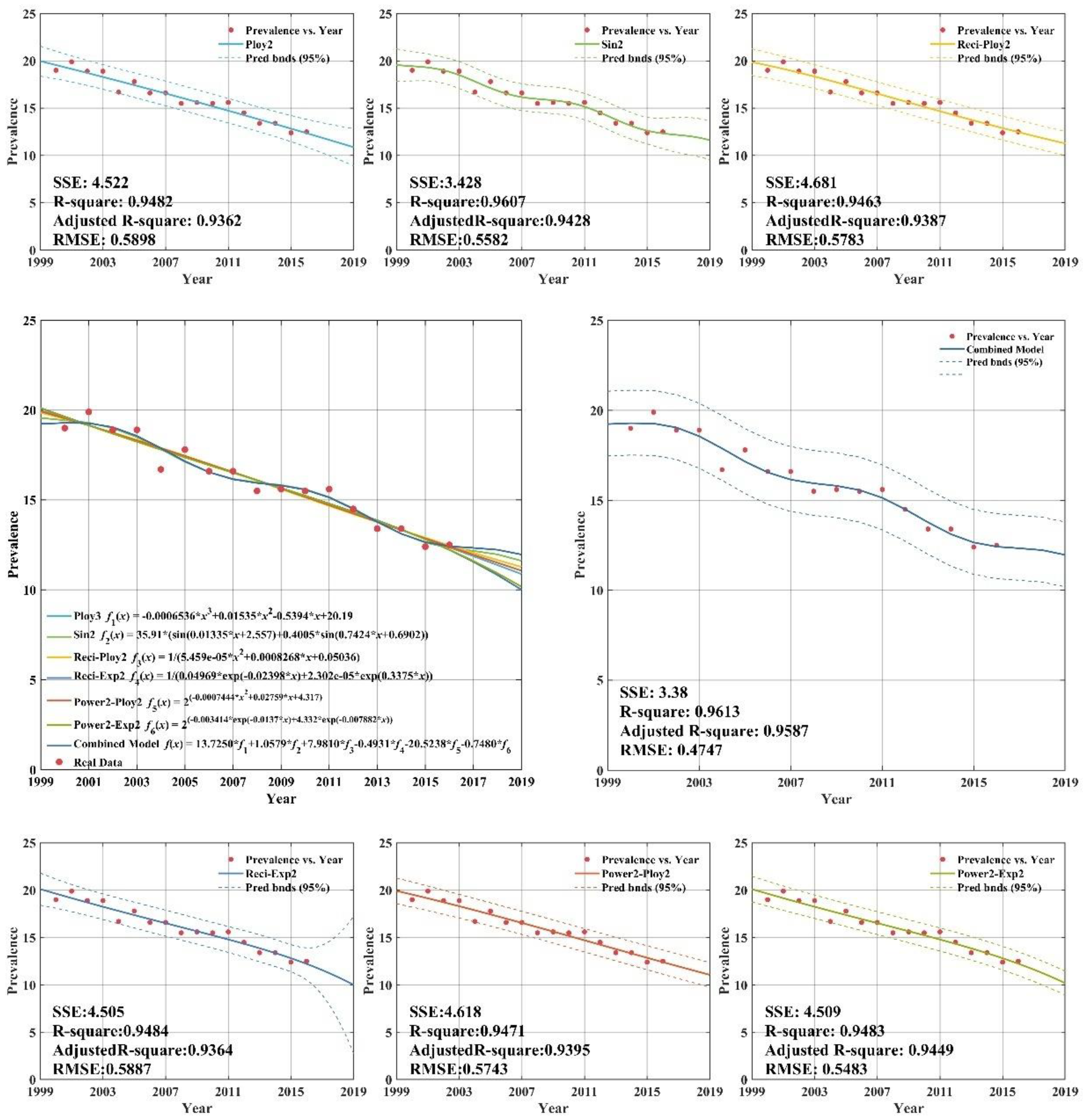
As demonstrated in
Appendix C (
Figure A1), all six individual regression models provide remarkable goodness-of-fit, with adjusted
R-squares all above 0.93. Thus, the selection of regression models is proper and effective. From
Appendix C (
Figure A1), there are clearly significant improvements for combined model forecasts compared with the results of other forecasting models for high income group. The annual high income group tuberculosis prevalence rate from 2013 to 2016 years was forecasted by CS-combined model. The forecasting results show that the SSE (sum square error), RMSE (root mean square error) are 3.38 and 0.9587, respectively. The forecasting values are close to the actual value. It is indicated that the CS-combined model has better forecasting performance, which has high popularization and application in forecasting the tuberculosis prevalence rate. It can provide a reference basis for the prevention and control measures of TB in the world.
Appendix C (
Figure A2) plots the fitting and forecasting curves and presents related regression equations and goodness-of-fit for the upper-middle income group. From
Appendix C (
Figure A2), it can be concluded that the estimated fitting equations are able to fit the dataset quite well; the adjusted
R-squares of the six regression models all being above 0.99.
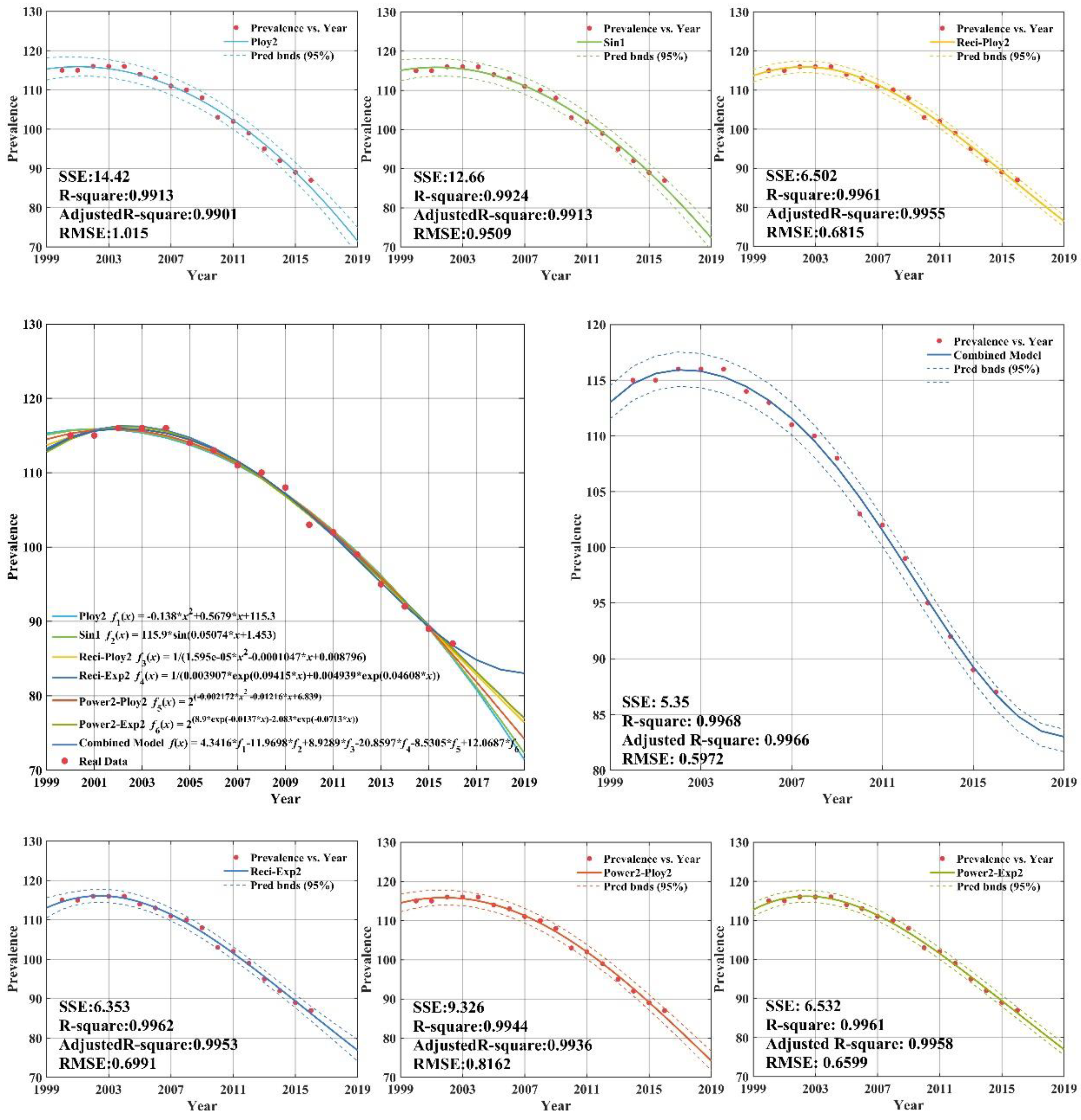
Appendix C (
Figure A2) demonstrated that the sum square error, root mean square error,
R-square, and adj
R-square of the CS-combined forecasting model established by the upper-middle income group tuberculosis prevalence rate from 2000 to 2012 were 5.35, 0.5972, 0.9968, and 0.9966, respectively. This indicates that the forecasting efficiency of the combined model is better than the other model, which can achieve higher forecasting requirements and be used for extrapolation forecasting. The forecasting can help provide reference for the formulation of tuberculosis prevalence rate control measures in upper-middle income group.
The related fitting and forecasting curves for the lower-middle income group are drawn in
Appendix C (
Figure A3), which demonstrates that all six regression models fit the dataset very well, with adjusted
R-square values greater than 0.99. As indicated in
Appendix C (
Figure A3), the forecasting results of tuberculosis prevalence rate for lower-middle income group from 2013 to 2016 was 258.3/100,000; 252.6/100,000; 246.9/100,000; and 241.2/100,000, showing a downward trend year by year. The forecasting results of CS-combined showed that sum square error is 1.957, and root mean square error is 0.6651. The CS-combined model fitting accuracy criteria (
R-square) indicated that the fitting accuracy of CS-combined model is 0.9998, and the fitting curve almost coincides with the actual tuberculosis prevalence rate curve. The fitting effect is better than the other models and can be used for forecasting the lower-middle income group tuberculosis prevalence rate.
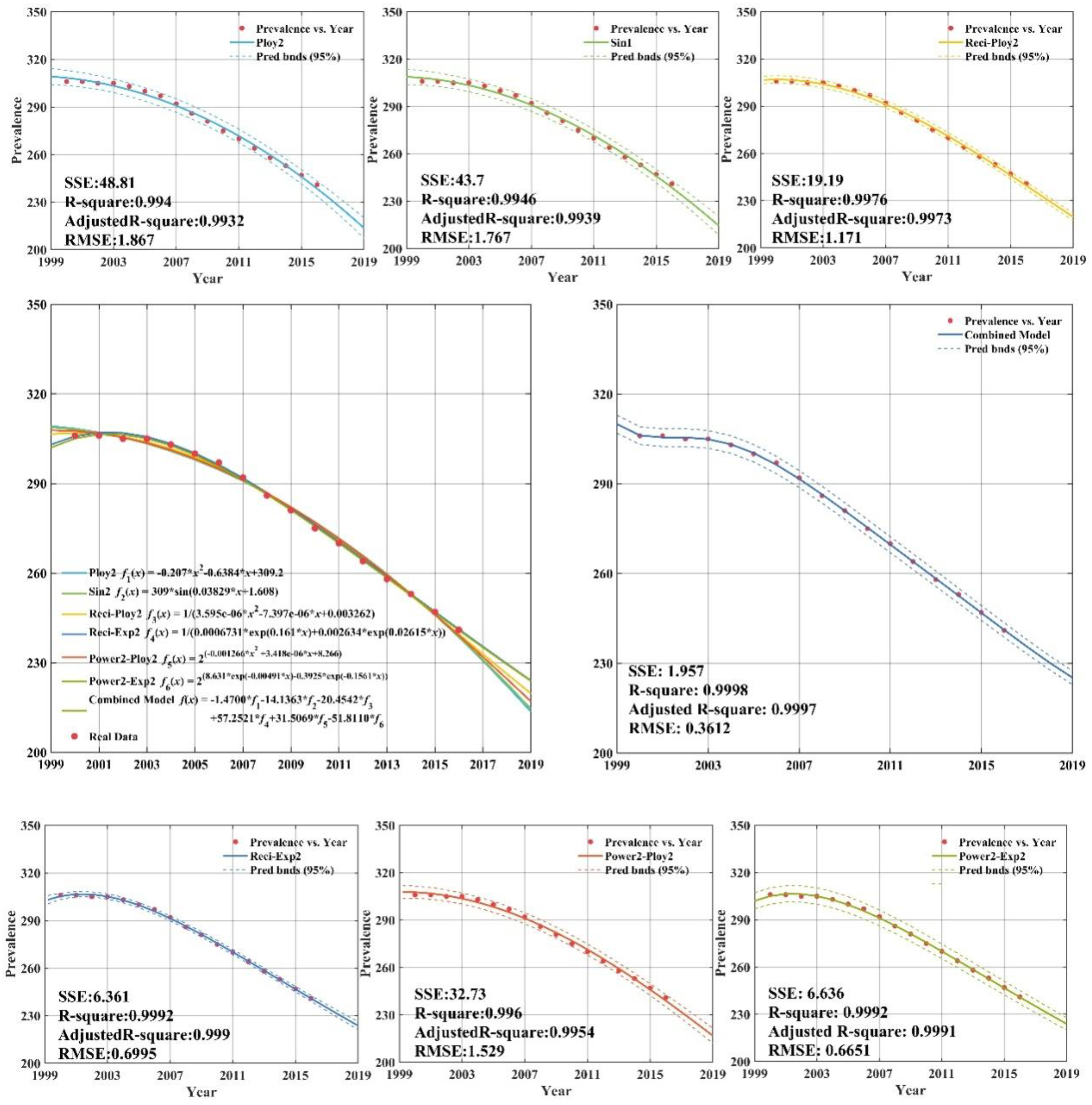
The low income group with fitting and forecasting curves is plotted in
Appendix C (
Figure A4). According to
Appendix C (
Figure A4), the individual regression models all have remarkable goodness-of-fit with adjusted
R-square values greater than 0.99.
Appendix C (
Figure A4) shows that the CS-combined model is used to fit tuberculosis prevalence rate time series for low income group during 2000–2012. The data of tuberculosis prevalence rate from 2013 to 2016 are forecasted by CS-combined model. The fitting value and forecasting value of the CS-combined model for 2000–2016 are basically the same as the actual tuberculosis prevalence rate, which is very similar to the actual value, and shows that the fitting and forecasting results are better than individual regression models.
3.3. Forecasting Results of Individual and Combined Models
In this section, forecasting results of both individual and combined methods are presented. The real values and forecasting values for the four different income groups from 2013 to 2016, generated by all seven forecasting models, are listed in
Appendix B.
From
Table 5, it can be concluded that the absolute values of the differences between the real values and the forecasting values, by means of the combined forecasting model, are no greater than four. Moreover, one-third of the twelve forecasting values derived from the proposed combination forecasting model are exactly equal to their real values. Thus, related analysis sufficiently reflects the superiority of the proposed combination forecasting model based on artificial intelligence optimization.
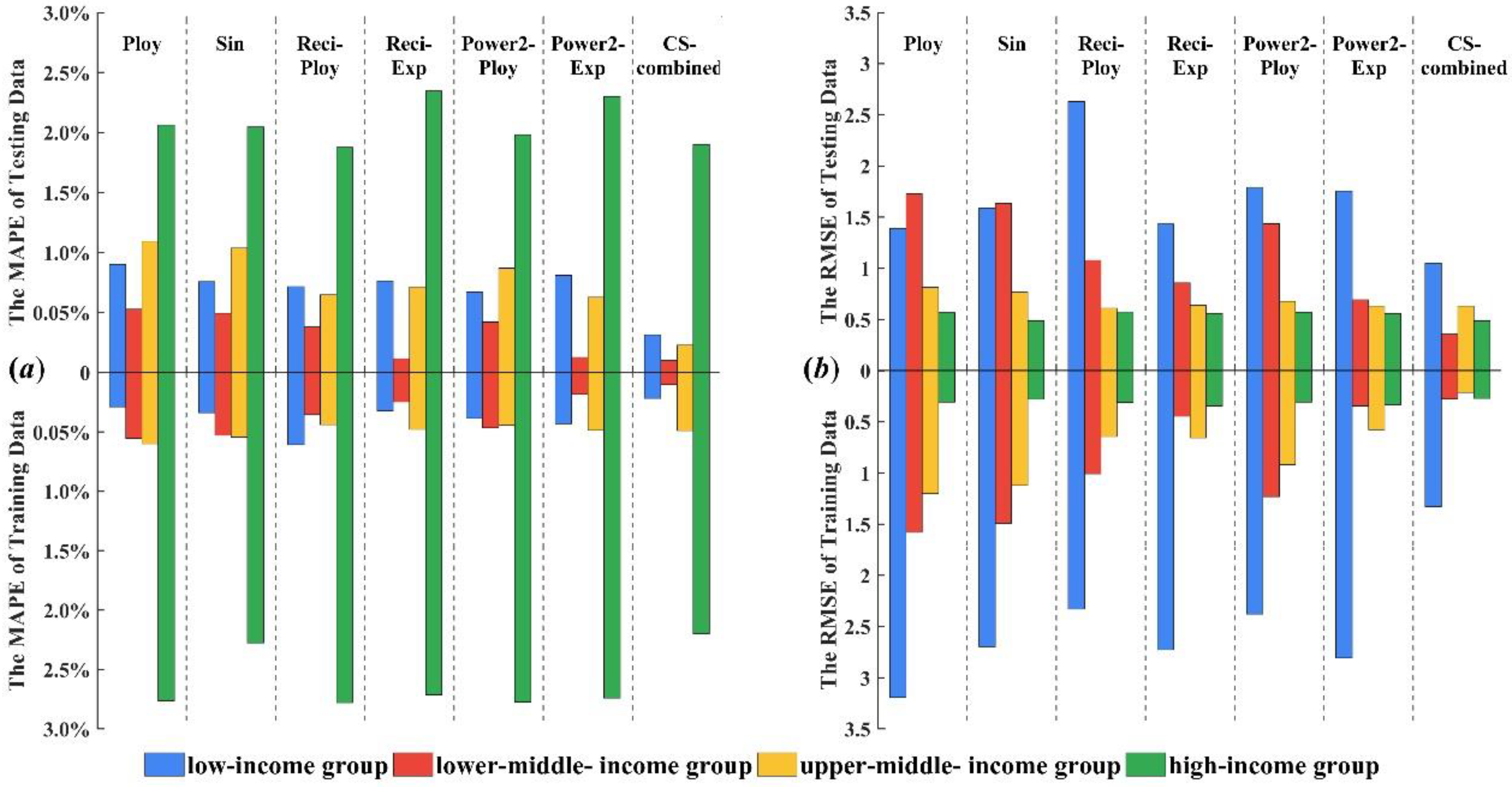
Figure 2 presents the stack bars of forecast errors, including
MAPE and
RMSE, of the seven forecasting models for the four income groups. Note that, in
Figure 2, the
MAPE value is represented as a percentage.
From
Figure 2 and
Table 5 we can see that the combined forecasting model can further improve forecast accuracy compared with individual regression models as evidenced by it always achieving the lowest forecast error. Based on the fitting results of six polynomial regression models from 2000 to 2012, the combined weight of each model is calculated according to the combined model theory. In order to get the optimal combined weight, cuckoo algorithm is used to optimize the combination weight and the forecasting results (2013–2016) of CS-combined model is calculated by the optimal combination weight.
The CS-combined model was established for the tuberculosis prevalence rate in high income population, which fitted the trend of the original tuberculosis prevalence rate. The forecasting accuracy of CS-combined model is higher than the other model and could be used for the forecasting tuberculosis epidemic trend in high income group. The forecasting results show that the incidence of tuberculosis in the high income group has been declining year by year since 2013 and the decline in 2013–2016 fluctuated between 2% and 4%. The tuberculosis prevalence rate in upper-middle income group in 2013–2016 showed a decreasing trend. For the forecasting results of upper-middle income group from 2013 to 2016, the RMSE and MAPE of CS-combined forecasting model were 0.6307 and 0.4883% respectively, which indicated that the CS-combined model has better forecasting performance and can meet higher forecasting requirements. From another point of view, the CS-combined model can be used for other diseases forecasting. For the lower-middle income group, the RMSE and MAPE of CS-combined model are 0.2113% and 0.2270%, respectively. The forecasting result of CS-combined model indicates that the tuberculosis prevalence rate from 2013 to 2016 is also declining. The forecasting results of tuberculosis prevalence rate for low income group from 2013 to 2016 showed that RMSE and MAPE were 0.3556% and 0.1028%, respectively, and the forecasting values were close to the actual values, which indicate that the CS-combined model has good forecasting performance and application in the tuberculosis prevalence rate forecasting. The forecasting results of the combined model could be used for the prevention and control of tuberculosis in low income group, and provide reference for formulating measures. The above analysis shows that global tuberculosis control strategies and measures have obtained significant achievements, which effectively curb the trend of tuberculosis prevalence rate.
Remark: The CS-combined model proposed in this paper can improve the forecasting accuracy, which combines the advantages of a variety of models and overcomes the influence of the characteristics of the tuberculosis prevalence rate time series on the forecasting results, such as fluctuating trend, small sample, randomness, and non-linearity. Therefore, the combination model in the forecasting and analysis of tuberculosis prevalence rate trend shows good forecasting performance. Therefore, infectious disease control has great significance.
3.4. Analysis of the Performance of Each Model
To further estimate and analyze the performance of the proposed combined tuberculosis prevalence rate forecasting model, the forecasting availability [
40] and the DM (Diebold–Mariano) test [
44], which evaluate the forecasting performance, are discussed in this part.
- (1)
Table 6 shows the results of the DM test. We can reject the null hypothesis and it is deemed that the difference between the prediction abilities of two models is significant. The significance level for a study is chosen before data collection, and typically set to 1%, 5%, 10% [
45,
46]. The corresponding significance level is as follows:
- (a)
If |DM| > 1.65 the null hypothesis is rejected at a 10% level, otherwise, if |DM| ≤ 1.65 we accept the null hypothesis.
- (b)
If |DM| > 1.96 the null hypothesis is rejected at a 5% level, otherwise, if |DM| ≤ 1.96 we accept the null hypothesis.
- (c)
If |DM| > 2.58 the null hypothesis is rejected at a 1% level, otherwise, if |DM| ≤ 2.58 we accept the null hypothesis.
For example, the results of low income group indicate that the combined model is different than Reci-ploy2 at the 10% significance level for training process, for the testing process, the |DM| value of Reci-ploy2 is 2.146856 at the 5% significance level, and the |DM| value of Ploy2, Sin2, Reci-exp2, Power2-ploy2, and Power2-Exp2 are 1.809601, 1.695902, 1.642031, 1.487737, and 1.524198 at the 10% significance level in tuberculosis prevalence rate forecasting. The upper limits at the different significance levels are smaller than the DM statistics in four income groups in tuberculosis prevalence rates. The combined model successfully overcomes some limitations of the individual forecasting models and effectively improves the forecasting accuracy. These results indicate that the proposed combined model is more valid and significantly superior to the other models. Thus, it is obvious that the proposed combined model is superior to the other six individual regression models. Accordingly, the proposed combined forecasting model can satisfactorily approximate the observed tuberculosis prevalence rate.
- (2)
Table 7 indicates that the first-order and second-order forecasting availabilities offered by the proposed combined model outperform six individual regression models for the four income groups in tuberculosis prevalence rate forecasting. For example, for the low income group, the first-order forecasting availabilities offered by each forecasting model are 0.998405, 0.998663, 0.99874, 0.998651, 0.998815, 0.998572, and 0.999445, respectively, while their second-order values are 0.998403, 0.998662, 0.99874, 0.99865, 0.998814, 0.998571, and 0.999445, respectively.
Remark: The results indicate that the proposed combined model is more valid and significantly superior to the other models. Accordingly, the proposed combined forecasting model can satisfactorily approximate the observed tuberculosis prevalence rate.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}





