1. Introduction
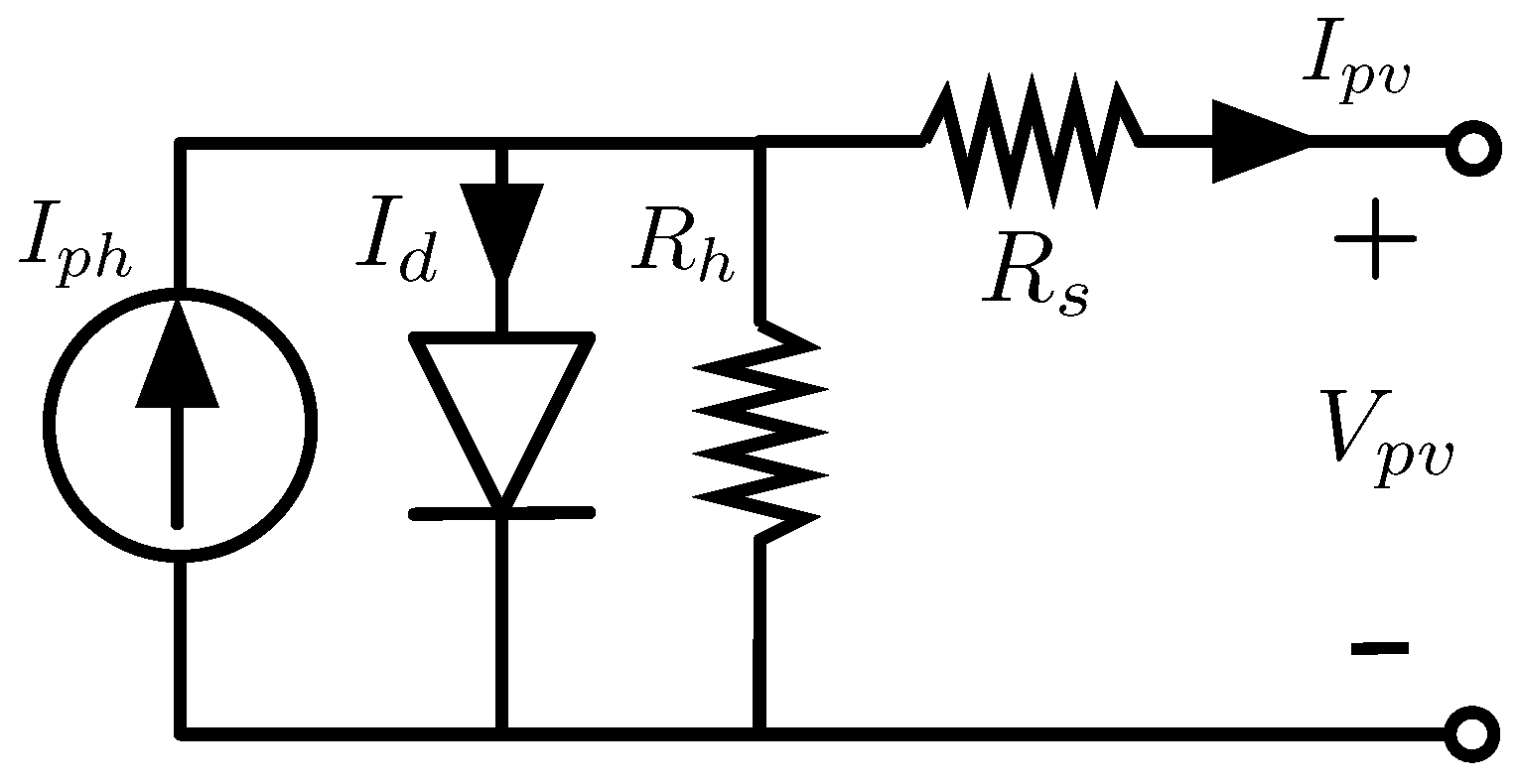
The photovoltaic (PV) single-diode model (SDM), shown in
Figure 1, is widely used for describing the electrical behavior of a photovoltaic source because it is a good trade-off between model complexity and precision. Such a model is mainly adopted to reproduce the electrical I-V curve of the PV source, and in general, it operates offline with respect to the system under investigation. The SDM is also useful in online applications such as model-based maximum power point tracking (MPPT) and monitoring/diagnosis operation [
1,
2,
3,
4].
The five parameters (
,
,
,
,
) appearing in (1), which is the equation underlying the SDM, are usually calculated by using datasheet information, or experimental data, or a combination of them. Due to the strong nonlinearity and the involved implicit relationships, the calculation of the SDM parameters is a challenging task. In particular, this calculation involves the use of iterative algorithms that have some drawbacks: they are slow and do not guarantee the convergence to the exact solution if a good initial estimate (guess solution) is not available. Therefore, iterative methods for the SDM parameter identification are not suitable to be applied on-line, for example to support MPPT [
5].
Some papers highlighted how the variation of the SDM parameters is strictly related to some degradation phenomena occurring inside the PV panel. Such degradation phenomena should be properly monitored and eventually removed to avoid significant losses in the energy production [
6,
7]. In this scenario, the adoption of online parameter identification procedures, working during the normal operation of the PV source, is very attractive. By comparing the identified values with the ones assumed as the reference and related to the proper operation of the source, the state of health of the PV panels can be detected.
Besides the aging issues, there are some common circumstances where the state of health of the PV panels changes suddenly as for hot-spot phenomena. In these cases, a prompt identification of the SDM parameters’ variations can avoid destroying the PV panels and prevent dangerous situations like triggering a fire. In mismatched PV fields, hot-spot phenomena appear frequently, so that an on-line monitoring of the state of health is highly recommended.
For all the above reasons, several technical contributions have been proposed to perform the online parameter identification of the PV SDM. For example, in [
8], a four-parameter formulation of the SDM is used to estimate the I-V curve and the maximum power point (MPP) in real time by using six pairs of voltage-current experimental points close to the MPP, whereas in [
2], a software running on a personal computer (PC), which is connected to a testbed system, is used to validate the real-time implementation of such a technique.
In [
9], the calculation of the SDM parameter is proposed based on explicit formulas. Specifically, the number of parameters of the SDM is reduced to four (one of the two resistances is neglected) on the basis of a suitable classification of PV panels according to their series to parallel ratio (SPR). In [
10], a method that allows identifying the set of five SDM parameters by explicit formulas is given; it always keeps the fifth-order model, but in extreme conditions, it can result in unrealistic negative values of one of these two resistances. Moreover, in [
11], suitable parameter translation equations, used to evaluate the SDM parameters under any environmental condition, are tested for several identification methods based on explicit formulas, and the accuracy of the translation procedure is quantitatively assessed for different case studies.
Most of the procedures described in the literature to calculate the SDM parameters require the knowledge of the short circuit current () and the open circuit voltage () in the actual environmental conditions. This information allows simplifying the parameters’ calculation since at such points, the PV voltage and current are equal to zero; thus, some equations can be simplified. On the other hand, in order to maximize the energy production, the PV system is always controlled to work as close as possible to its maximum power point. Therefore, the measurement of and is undesirable, since in such points, the PV source delivers zero power. Moreover, the power converter used to regulate the PV source is often not properly designed to work in the short circuit or open circuit points. Therefore, additional devices and complex procedures should be introduced to perform those measurements. For these reasons, all the SDM parameter identification procedures requiring the and values are mainly effective when run offline, on the basis of previously-acquired sets of measurements.
In recent years, some authors have proposed computational intelligence-based methods for the PV source model parameter identification. The proposed methods range from genetic algorithms (GAs) to differential evolution, and examples of applications to the identification of the five-parameter SDM are given in the literature [
12,
13]. In the case of GAs, the core idea is to define a population of individuals where each individual is a set of parameter values and then to select the best-fitted individuals as the base for generating a new population, by minimizing an error function. The main advantage of this approach is that it does not require the use of complex equations to evaluate the model parameters.
As well as in any other numerical approaches, although the initial values could be generated randomly, providing a good guess solution significantly helps the algorithm convergence and improves the execution time. On the other hand, an inappropriate selection of the initial values will result in unacceptable parameter values or in non-convergence of the algorithm [
14].
Computational intelligence-based algorithms usually require powerful computing platforms to exhibit a reasonable execution time; for this reason, up to now, the embedded implementation of such techniques has been critical, sometimes forcing designers to simplify the objective function or to discard the algorithm. However, powerful embedded platforms have recently been made available on the market, for example field programmable system-on-chip (FPSoC ) and microcontrollers based on 32-bit ARM processor cores, such as the STM32 family.
As for FPSoC, a technical contribution has demonstrated that it is possible to achieve a performance comparable to that of a desktop computer when running a particle swarm optimization (PSO) algorithm [
15]. As for the other platform, an STM32 microcontroller has been used for the implementation of a fixed low-order controller [
16]; however, to the best of the authors’ knowledge, no implementation of complex optimization algorithms on such a device family has been proposed, yet.
In this paper, a novel approach for the online SDM five-parameter identification, requiring only some measured points close to the MPP, is proposed. In particular, the values of
and
are properly estimated so as to avoid the loss of power deriving from their measurements. Then, the problem of the appropriate determination of the guess solution is solved by using a set of suitable explicit formulas [
10]. Finally, the exact solution is obtained by running a GA. The proposed method has been implemented on a very low-cost (EUR 20.00), high-performance board, namely the NUCLEO-F429ZI, which is based on an STM32 microcontroller by STMicroelectronics (Geneva, Switzerland) . The experimental results demonstrate the validity of the proposed approach.
2. The Optimized SDM Parameter Identification Method Based on Genetic Algorithm
The method proposed in this paper combines the GA, which is a common method for calculating the five parameters (
,
,
,
,
) [
12,
17], with some explicit equations that are also used to calculate the SDM parameters in a direct way [
10,
11], i.e., without requiring iterative algorithms. Both methods, when applied independently, require the knowledge of the current and voltage values in the MPP and the values of
and
for the actual environmental condition. In the proposed solution, the measurements of
and
are replaced by their estimated values to obtain an approximated solution for the five parameters (
,
,
,
,
). The latter is used as a guess solution in the GA algorithm and also used to constrain the GA research space in a proper way, thus allowing a fast convergence towards the optimal solution. In order to catch the right information about the I-V curvature around the MPP, some additional current and voltage values close to MPP must be measured and used in the GA fitness function to assure a precise evaluation of the SDM parameters.
2.1. Genetic Algorithm Basic Function Description
Although many advanced genetic algorithm tools are available [
18,
19,
20], a basic version of GA has been selected for implementing the proposed method. This choice has been made because the main objective of this paper is to implement the technique on a low-cost digital platform, thus suitably for the online operation. The GA code has been developed in C/C++ starting from the free-download version available in [
21] and distributed under the GNU Lesser General Public License license.
The GA starts by randomly generating the individuals of the initial population. The number of individuals (
N) is the population size. Each individual represents a solution of the problem to be solved, and the elements composing the individuals are called genes. For the SDM parameter estimation problem, each individual is composed of five genes representing the values of (
,
,
,
,
); hence, the individual is a vector of five elements. Differently from [
21], in the proposed approach, the five genes of one individual of the initial population are initialized with the guess solution, which is computed as discussed in
Section 2.4.
The GA evolves by modifying the population emulating the biological evolution; in fact, the new individuals are obtained by means of the following processes:
Selector function: the individuals that survive and reproduce are selected by evaluating the cumulative fitness function.
Crossover function: the individuals created by the Selector function can swap genes with another individual of the population (i.e., the other parent); therefore, these children inherit genes from both parents. The percentage of individuals created with this function is determined by parameter .
Mutation function: the individuals created by the Selector function can be subject to a random mutation of their genes. The percentage of individuals created with this function is determined by parameter .
Elite function: the individuals with the best fitness function in the current population are preserved in the next generation. The number of preserved individuals is specified using parameter .
The Crossover, Mutation and Elitefunctions have been implemented as shown in [
21]. On the other hand, the Selector function of [
21] has been modified so as to speed up the execution on the embedded platform as much as possible, as discussed in
Section 4.
On the basis of the values of , and , the individuals move differently in the research space from one generation to another. The GA makes the population evolve until the maximum number of generations () is reached. The individual with the best fitness in the last generation will be the optimal solution.
2.2. Genetic Algorithm Fitness Function Calculation
The GA fitness function is evaluated by accounting for the deviation from the desired goals. A first error term is the root mean square error (RMSE) of the fitted I-V curve, given M experimental test points. Since the I-V curvature changes significantly around the MPP, the M points must be selected so as to include the MPP. For each test point
, the measured current
must be compared with the current that satisfies the implicit and transcendental SDM equation (
1) for
. To this aim, the explicit version of (
1) can be obtained using the Lambert-W function:
with:
In [
10,
22], many details and useful references about the Lambert-W function can be found. The numerical calculation of the Lambert-W function has been implemented in C language as shown in [
23].
Once
is known for
i in
, the RMSE of the fitting curve can be computed as:
Moreover, to constrain the P-V curve to have its maximum in the MPP, the error on the derivative of the power in the MPP is also calculated, as shown in [
24], thus improving the convergence and precision of the genetic algorithm [
12]:
To account for both types of errors, which are independent, they must be combined in quadrature. Furthermore, since the considered genetic algorithm maximizes the objective function, the latter has been made equal to the reciprocal of the overall error:
It is worth noting that in [
12,
17], the fitness function is calculated by selecting test points from
to
; in this paper, instead, all the points are concentrated close to the MPP.
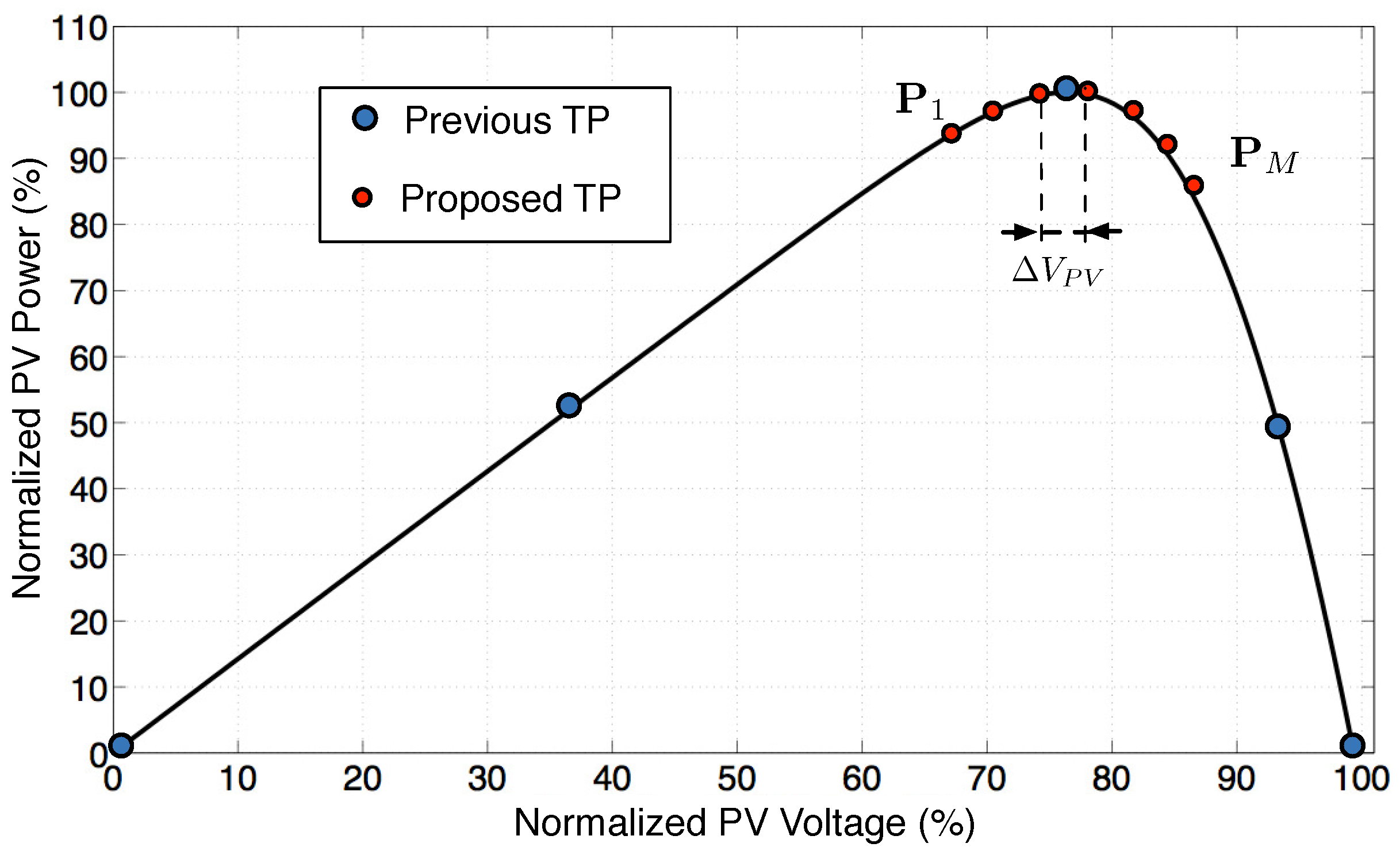
Figure 2 shows the difference and highlights that the new approach allows reducing the power loss significantly because the system is controlled to operate not too far from the MPP. It is also evident that the distribution of test points must be large enough to easily catch the I-V curvature; thus, the choice of the number and position of test points around the MPP must be made as a trade-off between power loss reduction and precision in the SDM parameters’ identification. This aspect is described in
Section 3.1, where some experimental cases are proposed.
2.3. GA Boundary Constraint Definition
In general, the genes assigned to the individuals of a GA population are constrained in ranges depending on the problem to be solved. As explained in [
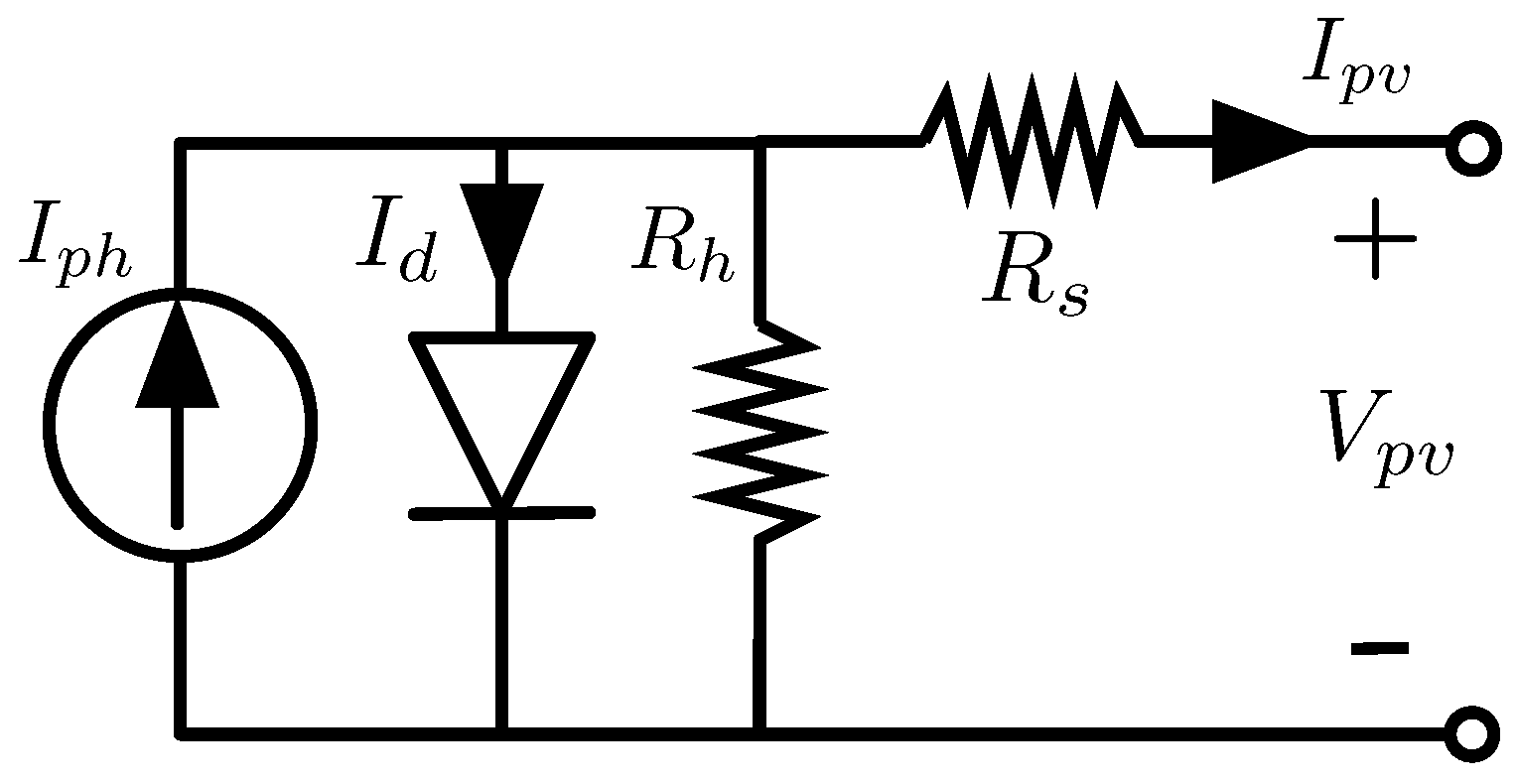
12] and related references, for each SDM parameter, the bounds have been selected by considering the physical constraints, applied to the equivalent electrical circuit of the photovoltaic source shown in
Figure 1, as well as typical values found in the literature where experimental tests have been performed to put into evidence the variations of those parameters for the different PV technologies and environmental conditions.
The obtained bounds are shown in
Table 1. It is worth noting that, if no further information is available, the GA research space is only confined by such bounds.
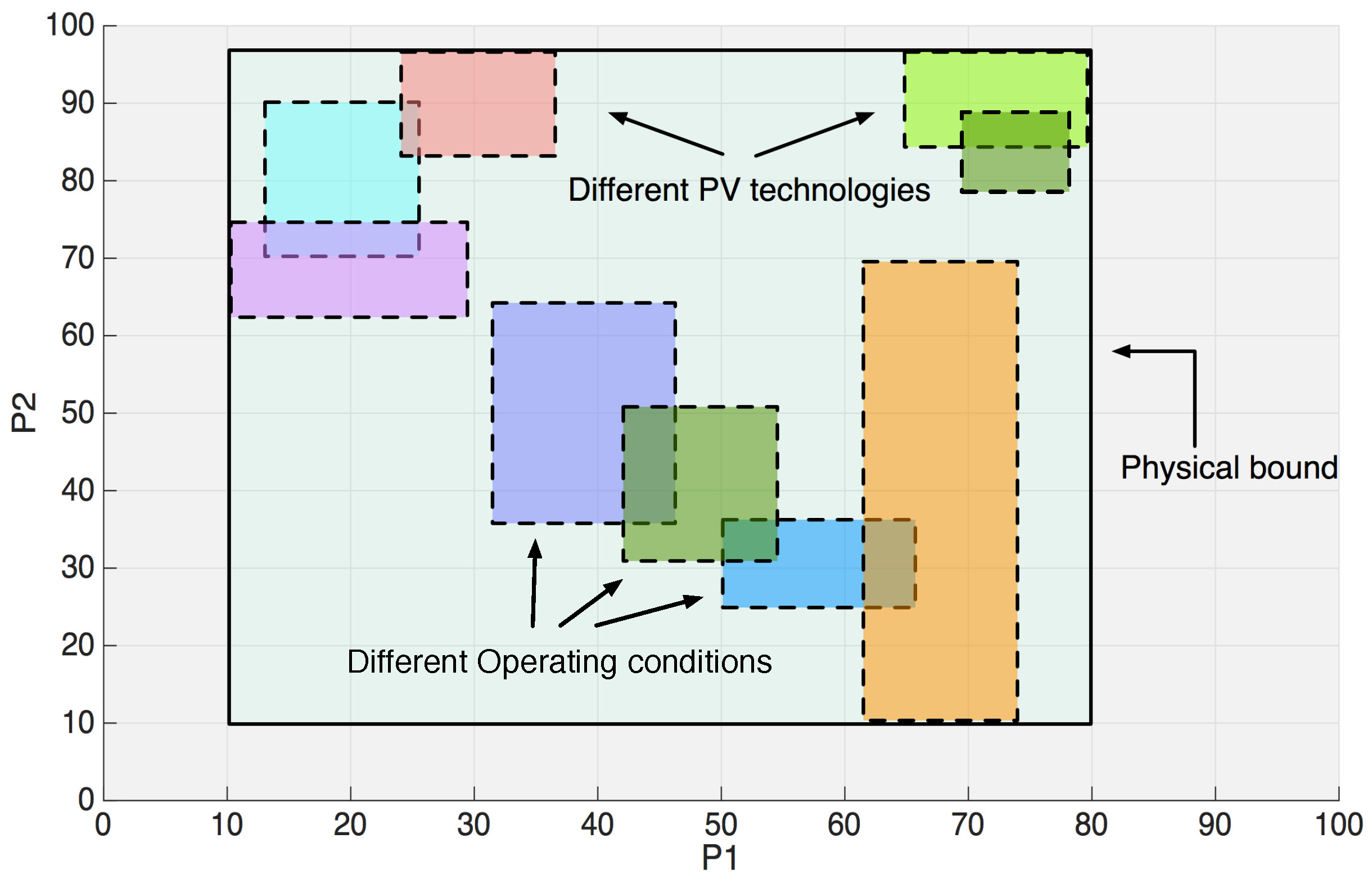
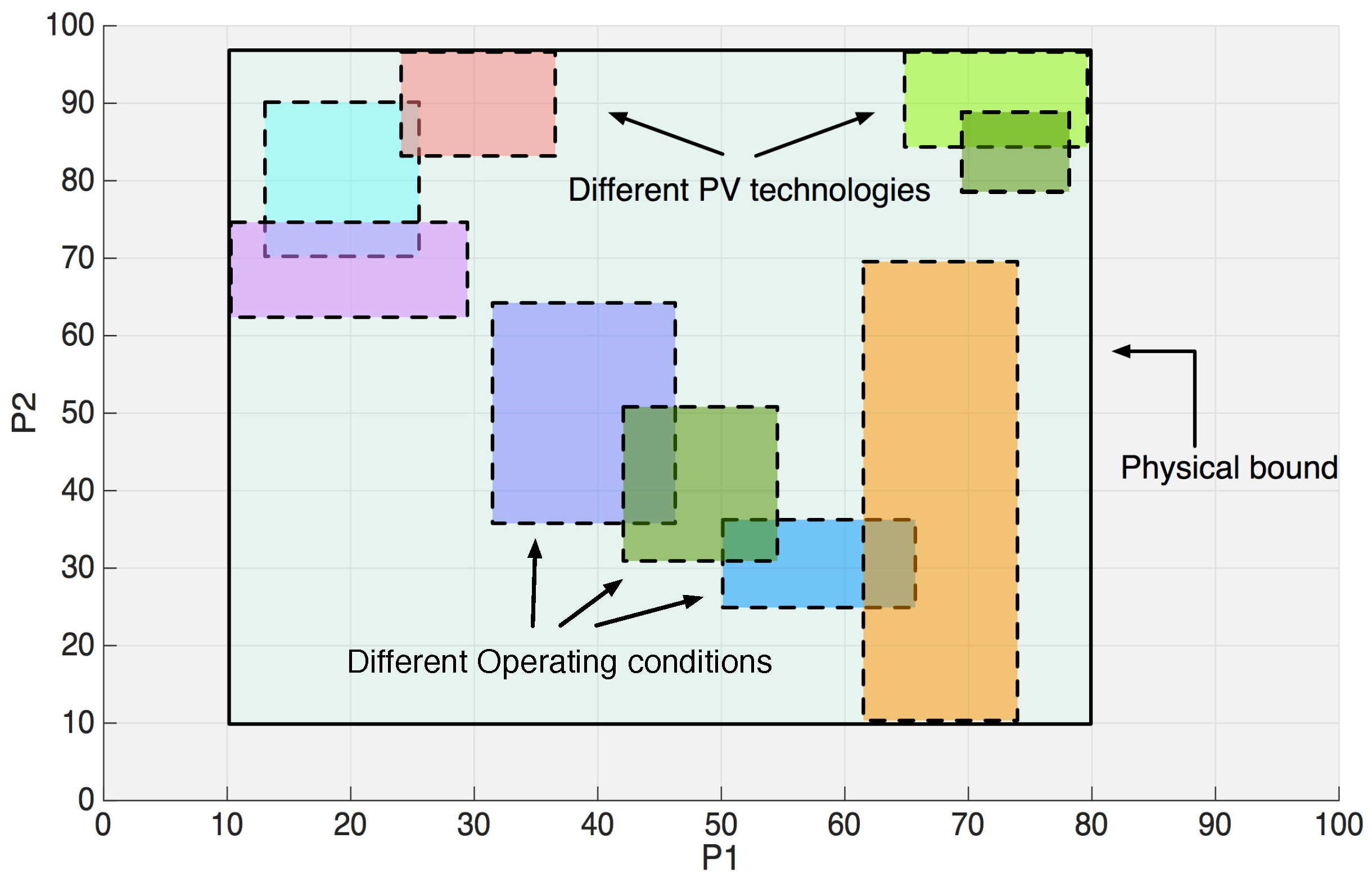
The nonlinear equation representing the I-V photovoltaic curve is strongly sensitive to the parameters’ variation; considering that the number of parameter combinations is high, it is very difficult to find the optimal solution when the research space is very large and the multimodality of the objective function increases the probability to be trapped in a local optimum. However, since the operating conditions and the PV technology significantly affect the SDM parameters, this information can be properly exploited to reduce the research domain with respect to that expressed by the physical bounds, thus improving the robustness of the GA to converge towards the global optimum and consequently to enhance the performance of the on-line SDM parameters’ identification method. This concept is qualitatively explained with the help of
Figure 3 for a bi-dimensional case (i.e., for two generic parameters
and
).
The approach used in this paper adopts a guess solution not only to initialize the genes of one individual of the population, but also to preliminarily detect the region of the physical research domain where it is highly probable to find the best solution. Then, the GA evolves by searching the optimal solution only in this region. In particular, every time the SDM parameter identification method is activated, the guess solution
is preliminarily calculated, and the new boundary conditions of the GA research space are computed as shown in
Table 2.
The real bounds for the parameters having large variations () are at least one order of magnitude higher and lower with respect to the guess solution values. In this way, a wide enough range is provided to account for any error in the guess solution, which is computed using approximated explicit equations, as discussed in the next section.
2.4. Guess Solution Calculation
The guess solution is obtained by means of the explicit equations shown in the following and is used as an approximated solution for the SDM parameters. More details are given in [
11,
25] and the related references.
where
is the thermal voltage of the PV junction,
is the material bandgap and
is the temperature coefficient. The latter quantity is computed using the following equations:
The subscript “0” stands for a reference condition, which usually corresponds to standard test conditions (STC).
The auxiliary variable
x is calculated by using the Lambert-W function again:
As the previous equations show, datasheet information concerning the operation in standard test conditions (STC) and the thermal coefficients and is needed to calculate the SDM parameters. Moreover, the values of , , and the PV cell temperature T at the current environmental condition must also be provided.
It is worth noting that
and
appear only in (
7) and (
9), respectively. In the proposed method, to avoid the measure of
and
in the actual operating conditions, the following approximation will be used for silicon-based PV panels:
The ranges of
and
have been selected as suggested in [
26,
27]. As a reference, average values for the silicon-based PV panels studied in [
5,
9,
11] are
and
. On the other hand, the dye-sensitized solar cells (DSSCs) and polymer PV modules (PPM) studied in [
28] exhibit slightly higher values:
,
for DSSCs and
,
for PPM. Hence, the ranges of
and
should be slightly increased for non-silicon PV panels.
3. Validation of the GA-Based SDM Parameter Identification Method
This section presents the results obtained by compiling and running on a desktop PC (Intel i5-3470 quad-core processor, running at 3.2 GHz) the code written in C language to implement the GA and to calculate the guess solution. The aim is to test the code, to tune the genetic algorithm parameters and to validate the approach. A further section is dedicated to the details about the embedded system implementation.
The procedure has been applied to the experimental data of a Sunowe Solar SF125x125-72-m(l) PV panel. The related datasheet parameters are given in
Table 3.
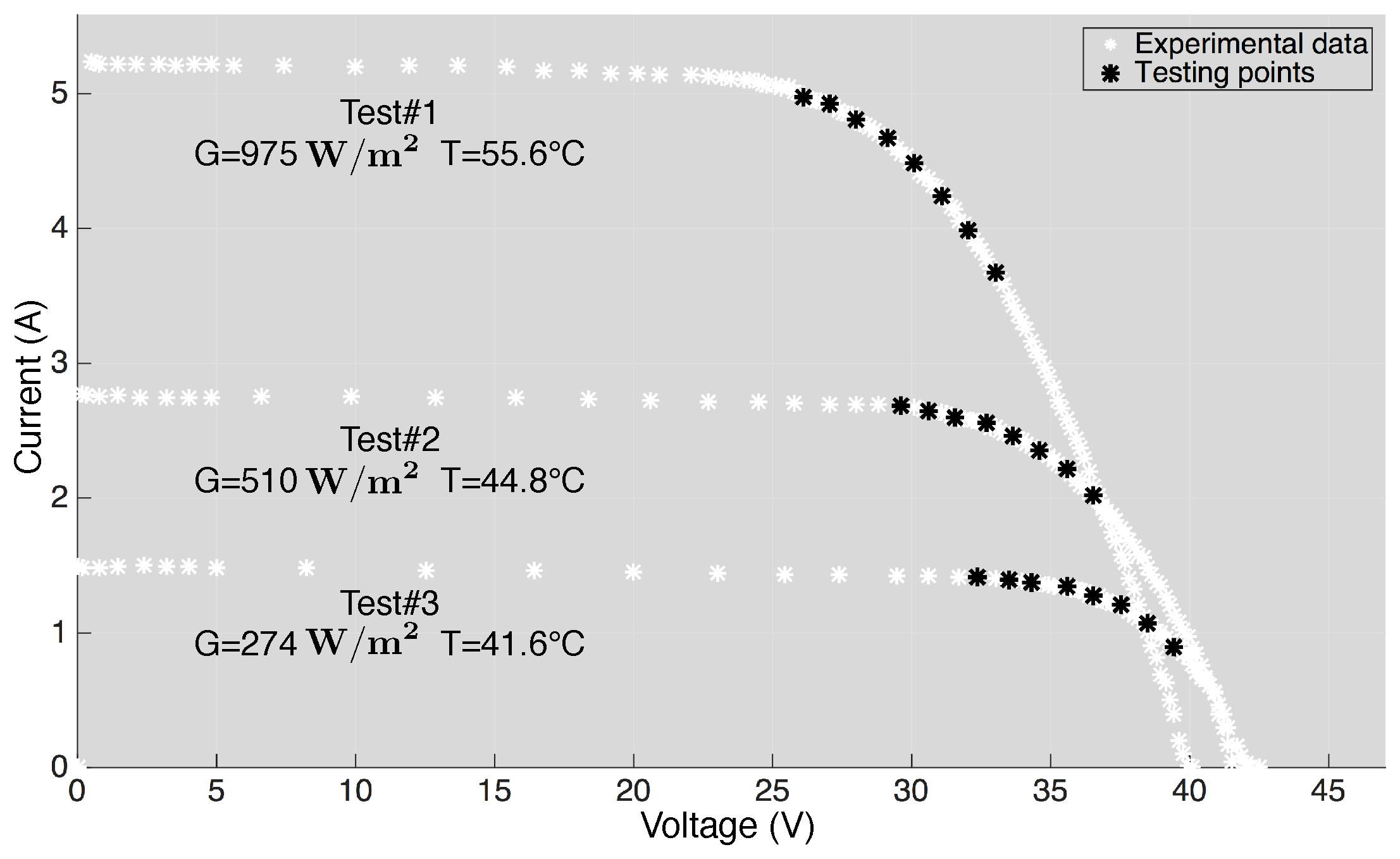
Figure 4 shows the experimental data used to test the proposed SDM parameter identification procedure. The white curves are the measured I-V curves, acquired in different irradiance and temperature conditions. The black points are the test points selected to be used by the proposed SDM parameter identification procedure. Specifically, the case related to Test #1 is discussed hereinafter, whereas the cases related to Tests #2 and #3 will be explained in
Section 4.
The module temperature (
T) is measured by a sensor placed at the backside of the PV panel. This quantity is used in the identification procedure for calculating the guess solution. In the absence of such a sensor,
T can be estimated by using the ambient temperature, as described in [
25].
The guess solution for the first experimental case has been calculated by using Equations (
7)–(
11) with
and
. The corresponding parameters are reported in
Table 4.
It is worth noting that different guess solutions can be calculated by changing the values of
and
within their respective ranges. The choice of the best guess solution can be made by evaluating the corresponding fitness with (
6). For the case of
Table 4, the fitness value is reported in the last column.
In order to appreciate the benefit of using a restricted research space for the SDM parameter identification, the genetic algorithm has been launched twice: using the physical bounds of
Table 1 and using the real boundary conditions of
Table 2, calculated on the basis of the guess solution reported in
Table 4. When the real boundary conditions are used, the guess solution is also included as an individual of the initial population; thus, a further improvement is obtained in the GA convergence.
The parameters of the GA have been set as reported in
Table 5; they have been selected on the basis of the fitness function behavior. In order to show the different behavior,
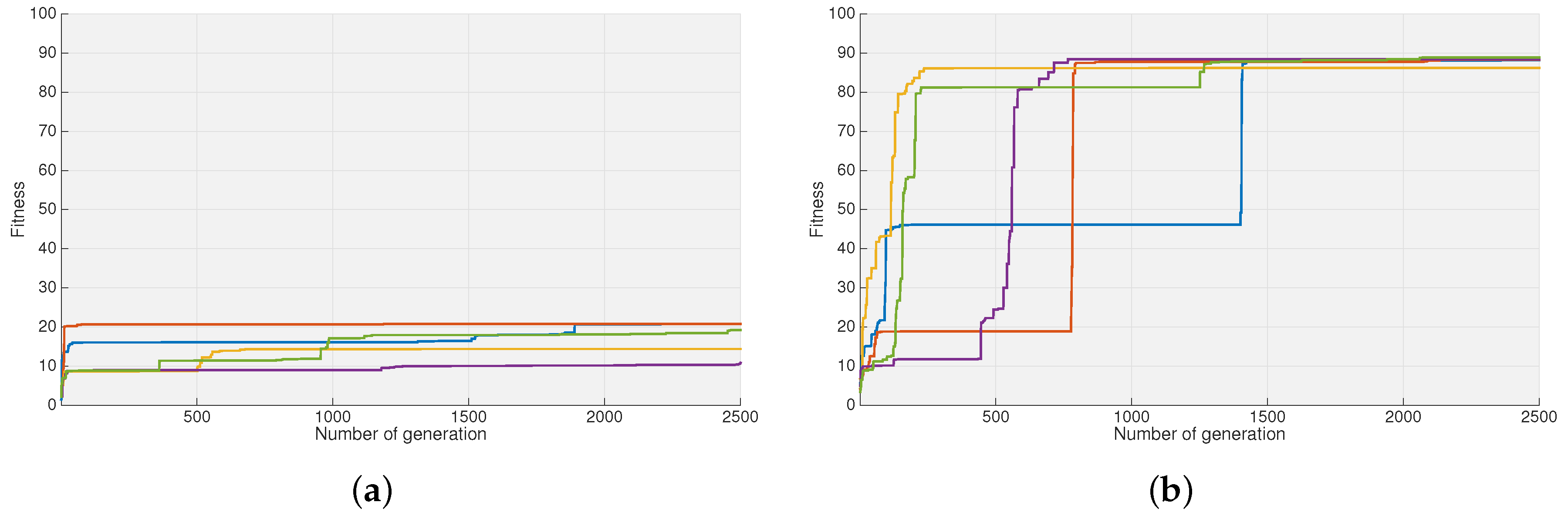
Figure 5 shows the trend of the best individual’s fitness with respect to the number of generations for the two above-mentioned scenarios: using only the physical bounds (
Figure 5a) and using the real boundary constraints and the corresponding guess solution (
Figure 5b). The figure is related to the case Test #1, but it is also representative of the other two cases. The improvement is evident in terms of the higher fitness value and faster convergence.
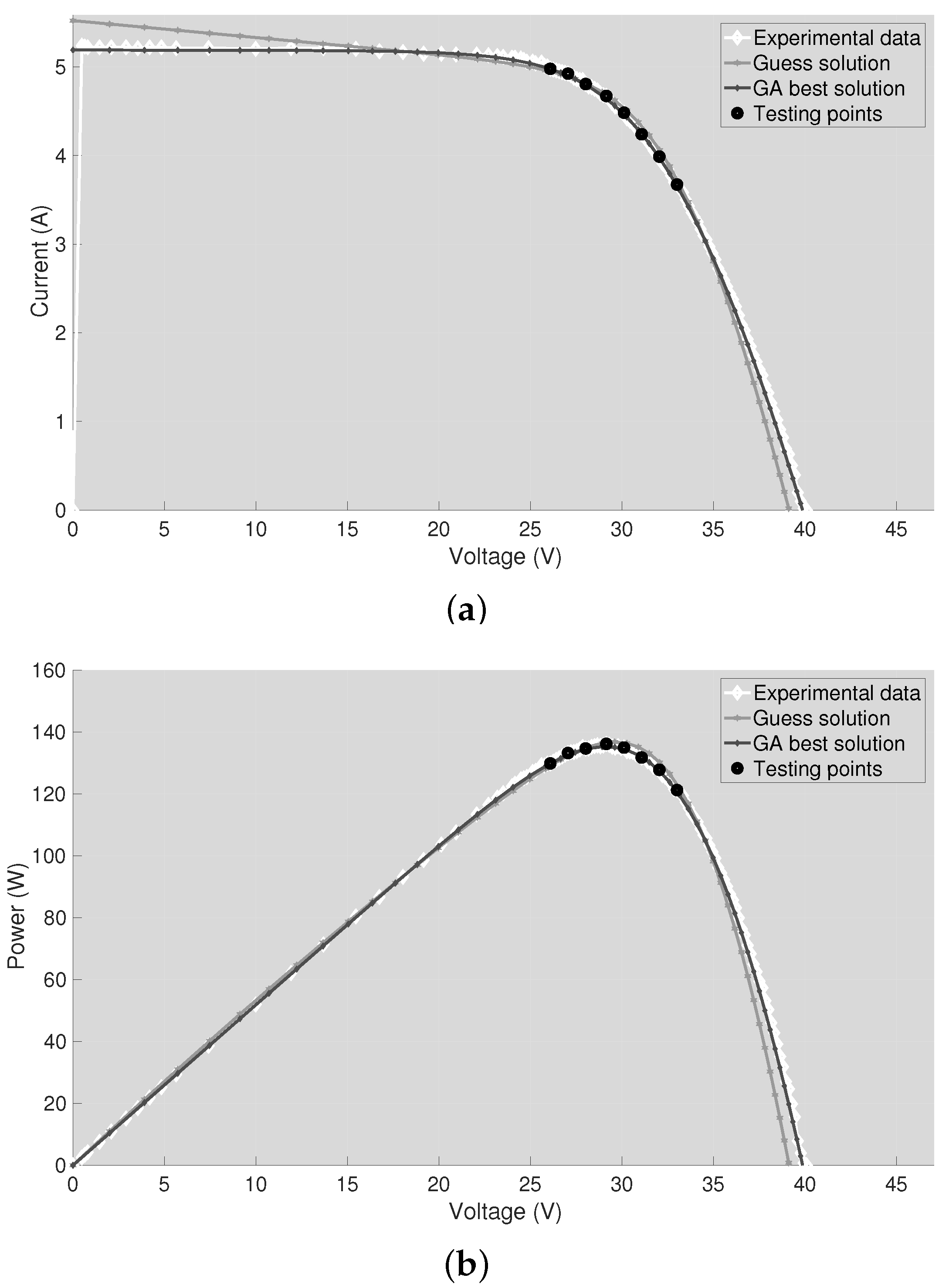
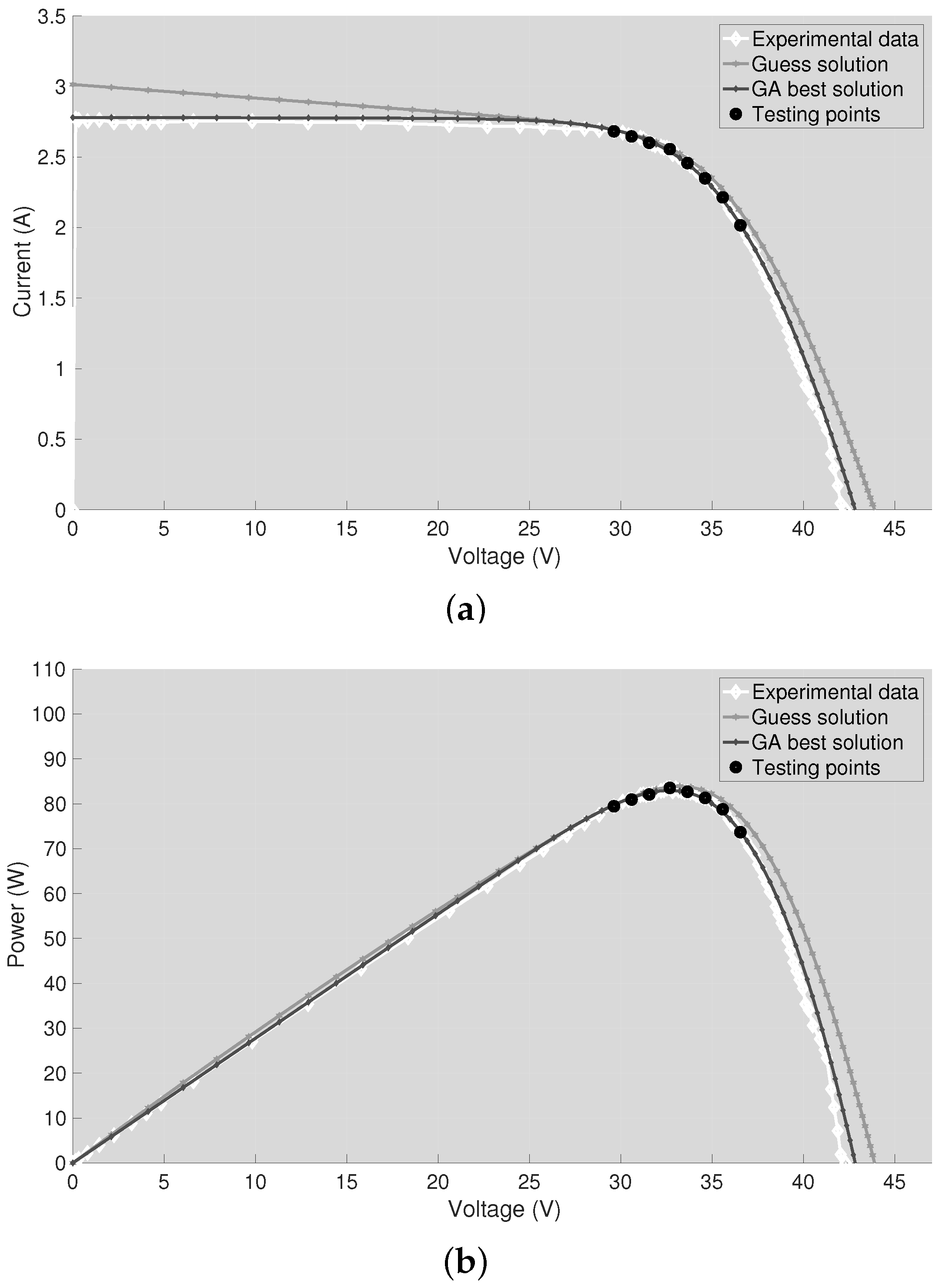
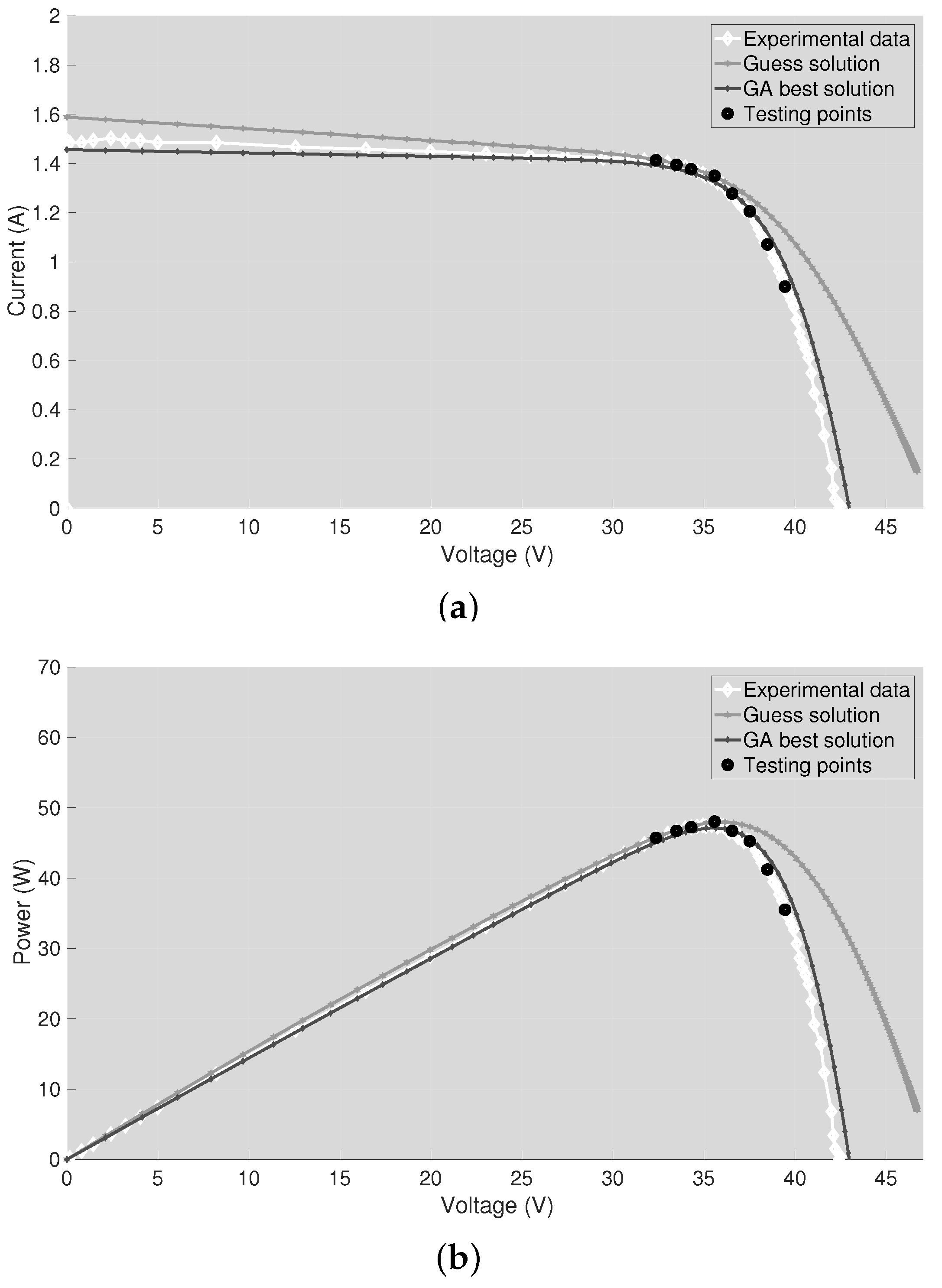
Once the GA has returned the best solution, the latter has been used to reconstruct the I-V and P-V curves of the PV panel. Then, the reconstructed curves have been compared with the ones obtained using the guess solution and with the experimental data. The plots are shown in
Figure 6, which refers to the case Test #1. As expected, the guess solution does not fit the experimental data in the regions far from the MPP since approximated values of
and
have been used. Instead, the best solution returned by the GA allows reproducing the correct I-V curvature since the information coming from the M experimental test points has been exploited.
Finally, in
Table 6, the best GA solution is compared with the guess solution:
and
are the parameters that have been affected by the main variations after the refinement of the guess solution performed by the GA.
3.1. Test Point Selection
The maximum variation of the I-V curvature occurs in proximity to the MPP, while the I-V curve is almost linear near
and
. Thus, the number and positions of the test points must be chosen as a trade-off between the minimum distance from the MPP (reduced power loss) and the right I-V curvature identification (high precision in the SDM parameter calculation). As a reference, the authors of [
7] focused on the identification of
, and they suggested selecting test points up to
of
. On the other hand, a 15% voltage reduction to the left of
is usually enough to enter the other nearly linear portion of the I-V curve. Since the PV source is usually controlled by regulating the PV voltage, it is very simple to acquire the PV voltage and current by increasing (or decreasing) the control voltage reference in a step-by-step manner, thus moving with high precision around the MPP. For the case under study, the test points are equally spaced by
. To cover the desired range, N = 8 points are enough, and 4 V is the maximum distance from the MPP.
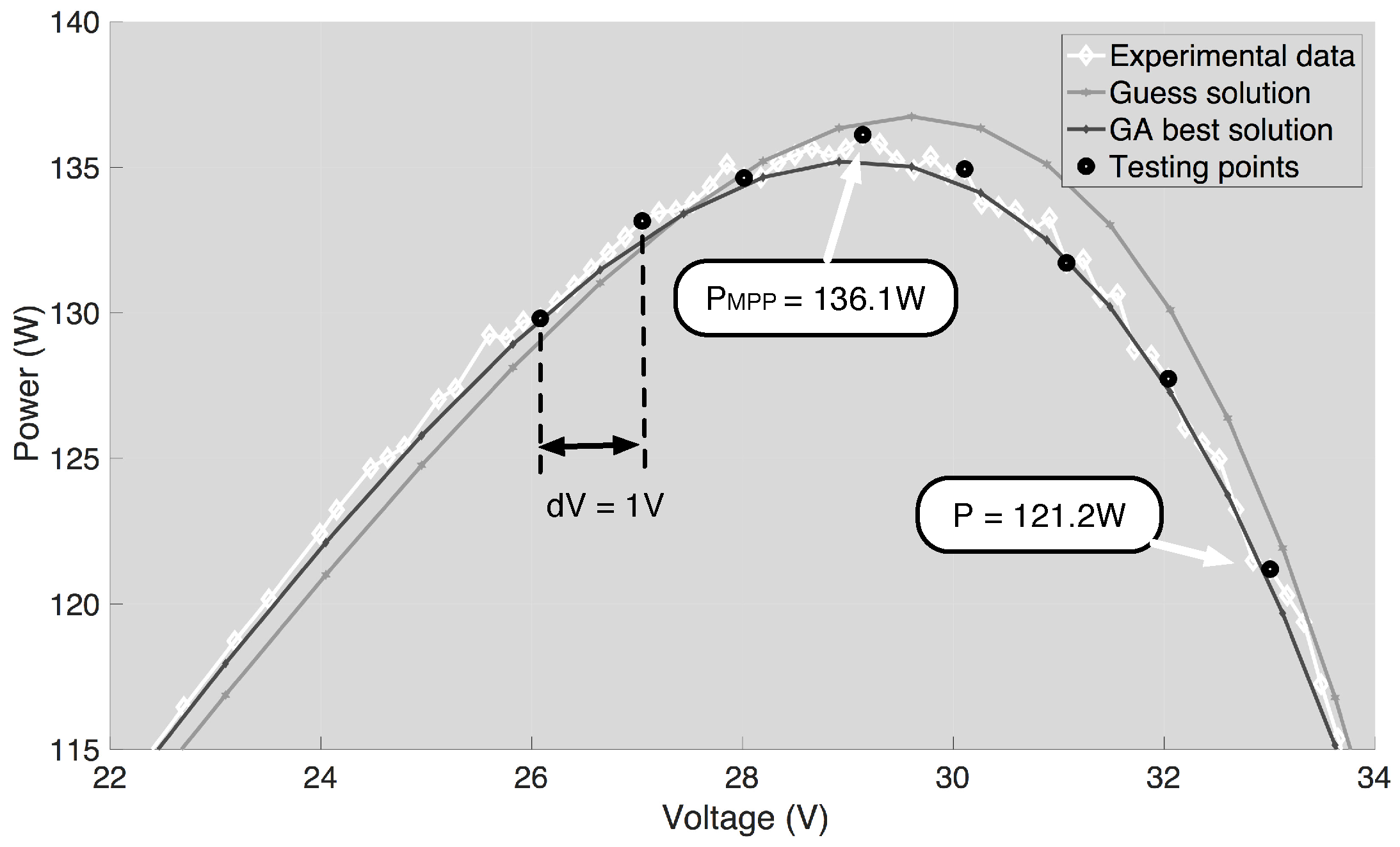
As highlighted in the previous sections, the main benefit of the proposed approach is the reduction of the power loss during the measurement of the test points. For the case under study, in the worst case, the power delivered during the acquisition of the test points is only 11% less than the one delivered in the MPP, as shown in
Figure 7.
4. Performance Evaluation of the Embedded GA-Based Method
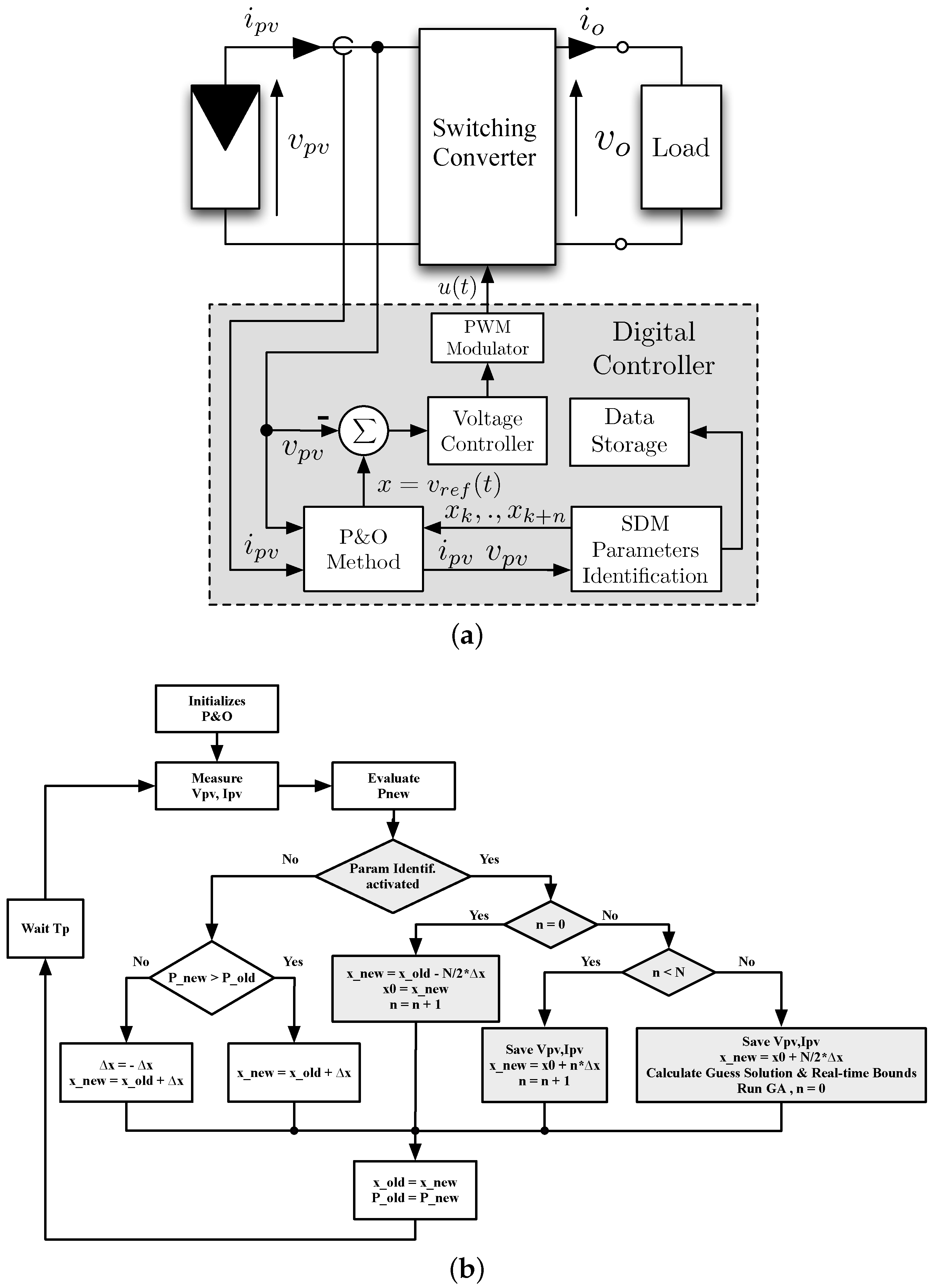
The platform chosen for the embedded implementation of the proposed GA-based parameter identification algorithm is the NUCLEO-F429ZI board by STMicroelectronics. Despite being a very low-cost board (EUR 20.00), it encompasses an STM32F429ZI microcontroller that is based on a high-performance Cortex-M4 32-bit RISC (Reduced Instruction Set Computing) core by ARM (Cambridge, United Kingdom), operating at up to 180 MHz and capable of up to 225 DMIPS. Such a microcontroller is equipped with 2 MB of Flash memory and 256 kB of SRAM. It features a rich variety of internal peripherals, among which three 12-bit, analog to digital converters (ADCs) and two expansion connectors that allow using a wide choice of specialized shields. Suitable signal conditioning circuits have been set up to extend the ADC voltage range; the obtained measurement system exhibits a 100-V voltage range and a 10-A current range. A virtual serial port over a USB connection has been used to print debug messages and statistics. The need to generate the 48-MHz clock for the USB port has imposed a maximum working frequency of 168 MHz for the microprocessor. Nonetheless, a frequency of 180 MHz can be used if the USB communication is not required.
After the validation on a desktop PC described in
Section 3, the functions written in C language to implement the GA and to calculate the guess solution have been integrated into a previously implemented digital controller for the switching converter of the PV panel.
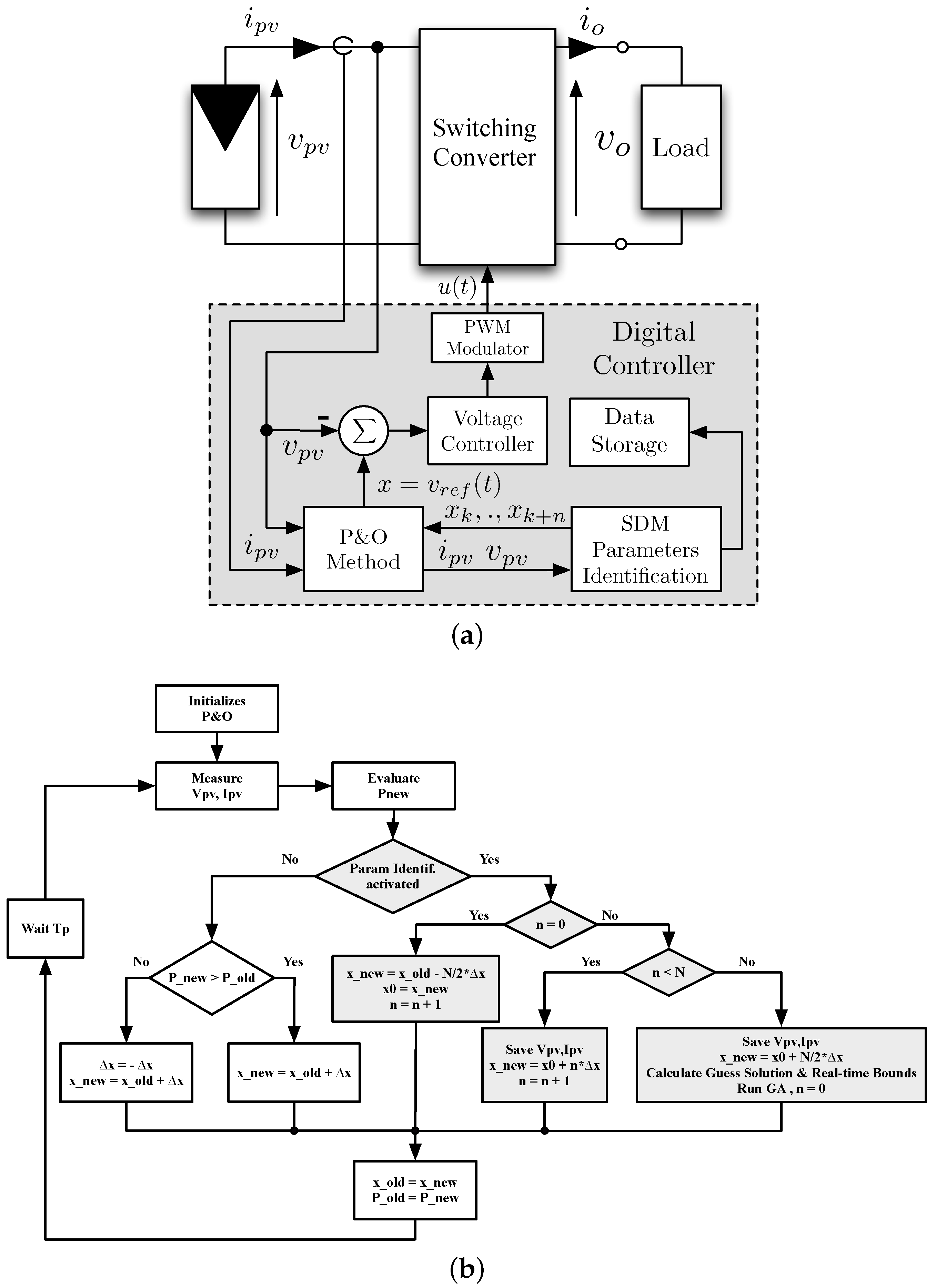
Figure 8 shows the functional scheme and the flowchart of the enhanced digital controller, which encompasses a voltage controller, a perturb and observe (P&O) MPPT algorithm and the proposed online parameter identification algorithm. With reference to
Figure 8b, the white blocks represent the typical flowchart of the perturb and observe algorithm, whereas the gray blocks allow performing the I-V scan and activating the online parameter identification procedure. In
Figure 8b, Tp is the period of the MPPT algorithm, thus it is in the order of magnitude of milliseconds. The on-line identification method can be managed by an interrupt service routine activated by an additional timer having a periodicity of hours or minutes, depending on the objective of the monitoring procedure.
The whole C project has been compiled with no relevant modifications for the STM32 microprocessor and experimentally tested. When the parameter identification procedure is triggered, for example by a timer or on demand, the MPPT algorithm is temporary disabled, and the PV operating point is driven to the left of the MPP at . Then, the I-V curve is scanned and the voltage and current values corresponding to the M operating points close to the MPP are stored in memory. Subsequently, the guess solution and the real bounds are calculated. Once the GA has been configured, it is launched, and the MPPT algorithm is reactivated. It is worth noting that the time spent calculating the best solution of the SDM parameters does not affect the control dynamics of the DC/DC converter since this task runs concurrently with the MPPT algorithm until a new request of the SDM parameter identification is triggered.
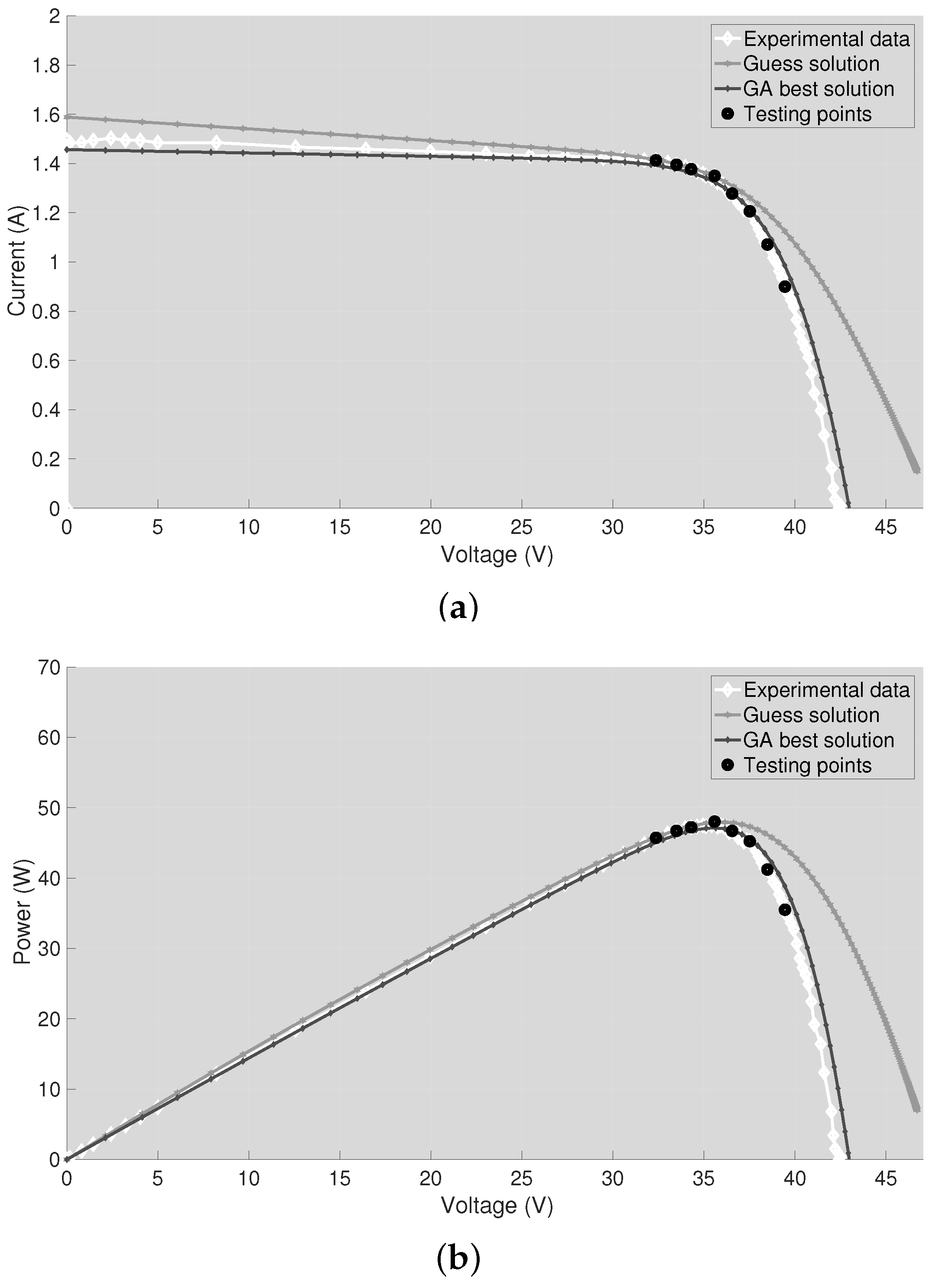
The experimental validation has been performed on the same Sunowe Solar PV panel of
Section 3 in the other two operating conditions (Tests #2 and #3). The white curves of
Figure 4 are the whole I-V curves measured offline, whereas the black points are the M test points acquired online by the embedded system.
The guess solutions and the best solutions returned by the GA for the two experimental cases are shown in
Table 7. Once again, these solutions have been used to reconstruct the I-V and P-V curves of the PV panel in the two considered operating conditions. Then, the reconstructed curves have been compared with the ones obtained using the guess solution and with the experimental data referred to each test case. The plots are shown in
Figure 9 and
Figure 10 and show that the best solutions returned by the GA allows a correct I-V curve reproduction.
As for the numerical results returned by the GA, there is no difference in comparison with the execution on the desktop PC because the C compiler for the STM32 microcontroller supports the double data type. The execution time on the microcontroller, instead, is very different from that on the desktop PC. Aiming to reduce it as much as possible, the Selector function of the GA available in [
21] has been suitably modified. In particular, to pick up the individuals that survive and reproduce, the original function used a linear search over a vector holding the values of the cumulative fitness function. The worst-case computational complexity of the linear search is
. Instead, in the proposed approach, a binary search algorithm is used, which has a worst-case computational complexity of
.
Table 8 reports the average execution time of the GA in different conditions and shows that an appreciable speed gain has been obtained. Overall, the obtained execution time of the GA using the binary search on the STM32 microcontroller is under 10 min, thus more than adequate for on-line monitoring/diagnosis applications.

 ,
, 



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}