Abstract
Emergency supplies allocation is a critical task in post-disaster response, as ineffective or delayed decisions can directly lead to increased human suffering and loss of life. In practice, emergency managers must make rapid allocation decisions over multiple periods under incomplete information and highly unpredictable demand, making robust and adaptive decision support essential. However, existing allocation approaches face several challenges: (1) Those traditional approaches rely heavily on predefined uncertainty sets or probabilistic models, and are inherently static, making them unsuitable for multi-period, dynamically allocation problems; and (2) while reinforcement learning (RL) technique is inherently suitable for dynamic decision-making, most existing RL-base approaches assume fixed demand, making them unable to cope with the non-stationary demand patterns seen in real disasters. To address these challenges, we first establish a multi-period and multi-objective emergency supplies allocation problem with demand uncertainty and then formulate it as a two-player zero-sum Markov game (TZMG). Demand uncertainty is modeled through an adversary rather than predefined uncertainty sets. We then propose RESA, a novel RL framework that uses adversarial training to learn robust allocation policies. In addition, RESA introduces a combinatorial action representation and reward clipping methods to handle high-dimensional allocations and nonlinear objectives. Building on RESA, we develop RESA_PPO by employing proximal policy optimization as its policy optimizer. Experiment results with realistic post-disaster data show that RESA_PPO achieves near-optimal performance, with an average gap of only 3.7% in terms of the objective value of the formulated problem, from the theoretical optimum derived by exact solvers. Moreover, RESA_PPO outperforms all baseline methods, including heuristic and standard RL methods, by at least 5.25% on average.
1. Introduction
Given the critical role of resource deployment in disaster response, the allocation of emergency supplies has emerged as a key research direction and an essential component of effective relief operations. Its primary objective is to develop optimal distribution strategies that effectively deliver emergency supplies to affected populations, thereby mitigating their losses and suffering. Unlike commercial logistics, which prioritizes operational costs, emergency supply allocation (ESA) emphasizes two fundamental principles: distribution efficiency and equity [1]. Hence, ESA problems are commonly formulated as multi-objective optimization problems.
In addition, multi-period planning represents another defining characteristic of ESA problems. Following a disaster, the procurement and distribution of consumable emergency supplies, such as drinking water and food, must be conducted periodically due to the dynamic changes in both demand and supply over time. Multi-period ESA [2] effectively addresses this temporal variability by enabling adaptive allocation strategies in each period. This helps to minimize the potential waste of emergency resources and then enhance the effectiveness of relief efforts.
Moreover, when a disaster strikes, the demand in influenced areas (IAs) can fluctuate rapidly due to various factors. The inherent uncertainty in demand for emergency resources makes real-time decision-making based on accurate situational data extremely challenging. Thus, developing robust allocation strategies that can withstand demand uncertainty becomes both critical and unavoidable. To tackle demand uncertainty, existing approaches primarily rely on model-based methods, such as robust optimization (RO) [2] and distributionally robust optimization (DRO) [2,3]. These methods require specifying uncertainty sets or ambiguity sets, which itself requires specifying elements such as demand distributions learned from historical data. However, such information is often unreliable in dynamic, real-world disasters, making these explicit mathematical models impractical. Moreover, these methods are fundamentally static in nature, which prevents them from producing adaptive, state-dependent policies. This limitation makes them insufficient for emergency supplies allocation, where decisions must continuously adjust to rapidly evolving conditions.
With the rapid advancement of artificial intelligence, new perspectives have emerged for addressing complex decision-making problems [4,5,6,7]. In particular, adversarial RL approaches have shown promising results in environments with uncertainty and disturbances [8,9,10,11]. Unlike traditional robust optimization methods that rely on predefined uncertainty sets, these approaches enable dynamic worst-case reasoning through interaction with adversarial agents, making them particularly suitable for emergency supplies allocation under rapidly changing and uncertain demand. Although some studies [12,13,14] explore the application of RL to address the ESA problem, they all overlook the uncertainty of demands. Deep Reinforcement Learning (DRL) has garnered considerable attention in recent years and has demonstrated remarkable success in various complex decision-making problems [15]. However, our analysis reveals that DRL still encounters significant challenges when applied to demand-uncertain ESA problems, primarily due to the inherent complexity of disaster scenarios:
Demand uncertainty in disasters. DRL inherently lacks robustness against environmental disturbances, i.e., uncertainty in demand. Therefore, the key challenge resides in developing effective training methodologies to enhance DRL’s resilience against demand fluctuations in disaster response scenarios.
Overlarge action space. In real-world disaster scenarios, the enormous number of possible emergency supply allocation combinations creates an excessively large action space for DRL agents. This dimensionality curse in the action space significantly compromises DRL’s effectiveness [16]. Therefore, the challenge lies in reducing the action space during the design of DRL agent.
Local optima and instability due to highly nonlinear objective function. The primary objective in the emergency resource allocation is to minimize victims’ suffering, which typically follows a nonlinear temporal function. This nonlinearity can lead to RL sampling extreme rewards, resulting in issues such as falling into local optima and instability during the training process of DRL agent. A fundamental challenge therefore involves developing methodological approaches to attenuate the impact of such extreme rewards during learning.
In this paper, we first introduce a multi-period ESA problem, named ESADU, which jointly optimizes effectiveness, efficiency, and equity in the context of demand uncertainty. We formulate ESADU as a two-player zero-sum Markov game involving an adversarial agent and a decision-making agent. We introduce an adversarial training method to address the game. By iteratively optimizing the policies of both agents, the method improves the robustness of the decision-making agent against demand uncertainty. Then we propose a combinatorial action representation method to address the challenge of overlarge action space by pruning the action space of ESADU and constructing a mapping from multi-dimensional actions to one-dimensional ones. Finally, we design a reward clipping method to scale the rewards to a narrower range by an adaptive threshold. This method can effectively handle extreme rewards arising from nonlinear objective functions without sacrificing useful reward information. We propose a framework by integrating the above three methods and introduce a new DRL-based approach which uses PPO as the policy optimizer of the agents in this framework, to address ESADU. We conduct extensive experiments to validate the superior performance of our approach. We list the main contributions as follows:
Adversarial formulation for ESADU. We formulate emergency supplies allocation under demand uncertainty as a two-player zero-sum Markov game, in which an adversarial agent dynamically perturbs the time-varying demand of IAs. This formulation provides an adaptive way to model non-stationary uncertainty without predefined uncertainty sets. To the best of our knowledge, this is the first work that applies such an adversarial game formulation to ESADU.
Structurally tailored RL framework. We propose a novel framework called RESA for DRL to address ESADU. RESA incorporates adversarial training to handle demand uncertainty and enhance robustness, a combinatorial action representation reduces action dimensionality, and a reward clipping method that stabilizes learning under nonlinear objectives. Together, these components address the aforementioned challenges.
We further develop RESA_PPO by using PPO as the underlying policy optimizer of RESA. Experiments with realistic post-disaster data show that RESA_PPO achieves near-optimal performance, with an average gap of only 3.7% from the optimal solutions. Moreover, it consistently leads all baseline methods, outperforming them by at least 5.25% on average. These results demonstrate the strong robustness and reliability of RESA_PPO for real-world emergency response.
The remaining paper is structured as follows. Section 2 introduces the relevant background knowledge of reinforcement learning and related work. Section 3 outlines the system and describes the problem formulation. In Section 4, we introduce our framework RESA and present the approach RESA_PPO. The evaluation is presented in Section 5, followed by the conclusion in Section 6. Table 1 provides the definitions and descriptions of notations used in the rest of the paper.

Table 1.
Summary of key notations.
2. Background and Related Work
2.1. Background
In this section, we give an introduction to reinforcement learning in Section 2.1.1. Then the description of PPO is given in Section 2.1.2.
2.1.1. Reinforcement Learning
RL is an approach that enables an agent to learn the optimal strategy through trial and error by receiving feedback from the environment. A basic RL problem can be formalized using the Markov decision process (MDP), which can be represented as a tuple . The goal of RL is to learn an optimal policy that maximizes the cumulative discounted reward
where is the discount factor.
State-value function and action-value function are typically employed to evaluate the effectiveness of a given policy. The state-value function quantifies the expected cumulative discounted reward starting from a particular state under the adopted policy , and can be defined as Equation (2).
The action-value function is employed to represent the expected cumulative discounted rewards of policy starting from state with action , which can be expressed as Equation (3).
Based on the approach for optimizing the cumulative discounted rewards, RL algorithms can be categorized into value-based and policy-based algorithms. Value-based algorithms choose actions according to the action-value function. Policy-based algorithms learn a policy to map state directly to the best action .
2.1.2. Proximal Policy Optimization Algorithm
As a classical policy-based DRL algorithm, PPO [17] has been employed as a benchmark algorithm in the field of RL. In the context of the Actor-Critic framework, PPO consists of two deep neural networks: an actor network denoted as and a critic network denoted as , where and represent the corresponding parameters of these networks. Given an input state , the actor will output the probability distribution of actions while the critic will output the value of the state . The function of can be expressed as follows:
The clipped surrogate objective function for updating can be formulated as follows:
where is the ratio between the old actor policy and the new one. and are the clip factor and the coefficient, respectively. denotes an entropy bonus to encourage exploration. is the generalized advantage estimator (GAE) which is shown as follows:
where is a tuning parameter of GAE.
The loss function for updating the parameters of the critic network can be defined as
2.2. Related Work
As a crucial aspect of emergency management, ESA has garnered considerable attention from scholars around the world. This paper focuses on employing deep reinforcement learning algorithms to tackle the challenge of ESA under demand uncertainty. Therefore, we review the related research from two perspectives: (1) ESA problems, and (2) solutions to ESA problems in Section 2.2.1 and Section 2.2.2, respectively. Finally, we discuss related work in Section 2.2.3.
2.2.1. ESA Problems
Most studies consider a single optimization objective, with efficiency being the most prevalent [18], i.e., minimizing costs [19] or minimizing travel time [20]. Different from conventional materials allocation, ESA also needs to consider effectiveness and equity to reduce casualties and property losses. Effectiveness typically denotes the assessment of the quality of allocation service, which is commonly reflected by minimizing the number of fatalities [21], maximizing demand satisfaction [22], etc. Equity serves as an objective to guarantee that no affected area is systematically disadvantaged, emphasizing fairness in the allocation of emergency supplies. Typically, equity is evaluated by minimizing the maximum or average arrival time [23] and minimizing the range of waiting times [20]. Some studies combine the above objectives and consider dual objectives, such as minimizing transportation time and allocation cost [24], maximizing demand satisfaction rate, and minimizing travel distance [25]. However, few studies consider three indicators [12,18].
Studies on the allocation of emergency supplies can also be categorized into single-period [26,27,28] and multi-period based on the planning horizon. However, single-period models fail to address adequately the impacts of dynamic changes in demands and supplies in disaster scenarios. Therefore, numerous studies choose to explore ESA problems over multiple periods [12,29,30,31,32]. Wang et al. propose a multi-period ESA model, which simultaneously considers efficiency and equity [33].
However, the above studies focus on deterministic ESA. Disasters typically feature a high degree of uncertainty and it is essential to account for this uncertainty when managing ESA [34]. The main approaches used to deal with the uncertainty are stochastic optimization [35,36], fuzzy optimization [29,37], robust optimization [38], and distributionally robust optimization [39].
2.2.2. Solutions of ESA Problems
The algorithms currently utilized for addressing ESA problems mainly fall into four categories: exact algorithms, heuristic algorithms, metaheuristic algorithms, and RL algorithms. Exact algorithms employ advanced mathematical optimization techniques to determine the best solution. Liu et al. [40] propose an exact algorithm called multiple dynamic programming to tackle the challenge of minimizing transportation time for medical supplies scheduling in public health emergencies. However, exact algorithms have limitations in generating feasible solutions for large-scale ESA problems within a reasonable amount of time.
Metaheuristic algorithms can efficiently tackle large-scale ESA problems by reducing the time complexity of problems. Most of the relevant studies utilize genetic algorithms [41], ant colony optimization algorithms [42], and particle swarm optimization [43]. However, these algorithms rely on specific rules designed for particular problems and are not inherently suitable for sequential decision-making problems such as ESA.
RL has emerged as a promising solution for ESA problems with the advancement of machine learning. RL can directly interact with simulated environments, learning from reward functions and previous actions to improve and explore strategies for decision. Fan et al. [13] model a multi-period multi-objective deterministic ESA problem as an MDP and devise a DQN-based approach to address it. Van Steenbergen et al. [44] propose two deep RL approaches to tackle the challenge of last-mile relief distribution under uncertain travel time.
2.2.3. Research Gap
We summarize related studies that are closely aligned with our research in Table 2 and yield the following conclusions.
Table 2.
Comparison of the proposed approach with existing studies.
Some studies explore the multi-period allocation of emergency supplies under uncertainties but few studies simultaneously address the objectives of effectiveness, efficiency, and equity.
Some studies consider the application of RL to ESA problems. However, few studies consider the robustness of RL-based ESA approaches under demand uncertainty.
Therefore, we focus on multi-period ESA under demand uncertainty, with efficiency, effectiveness, and equity as optimization objectives in this paper. We design a novel framework to address the challenges faced by DRL in this problem. Based on this framework, we propose a robust DRL-based approach to address the problem and validate its performance through experiments.
3. System Description and Problem Formulation
In this section, the system description is given in Section 3.1. Then we introduce the problem formulation of ESADU in Section 3.2 and model ESADU as a two-zero Markov game in Section 3.3.
3.1. System Description
The primary challenge in allocating emergency supplies is to ensure the efficiency, effectiveness, and equity of disaster response in disaster scenarios with uncertainty. This uncertainty primarily refers to the unpredictable demand in IAs because only imperfect information is available in disasters. It is necessary to make multi-period ESA decisions due to the supply and demand of emergency supplies changing over time. Therefore, we propose a multi-period and multi-objective ESA problem with demand uncertainty. The problem is configured with several IAs and a local response center (LRC) for gathering and allocating emergency supplies, as illustrated in Figure 1.
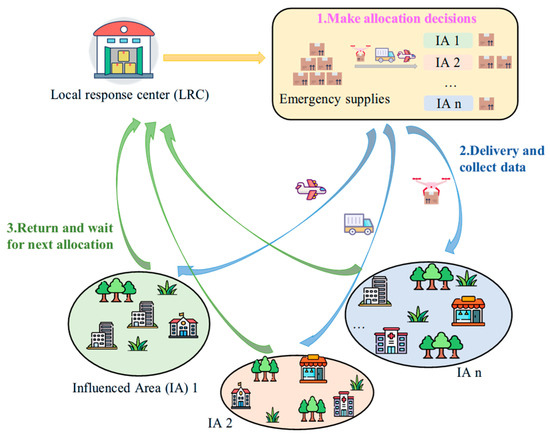
Figure 1.
System overview.
It is known that the first 72 h after the disaster are typically considered the golden rescue period for disaster relief operations [45]. Therefore, we focus on the allocation of emergency supplies within the critical 72 h period following a disaster. We divide the planning horizon into several equal-length allocation periods, whose duration is adjustable to achieve different levels of decision accuracy.
To facilitate problem modeling, we introduce the following assumptions.
- (A1)
- The LRC can only make a nominal estimate of the demand in IAs based on historical data. This assumption is reasonable because it is difficult to estimate the exact demand with imperfect information.
- (A2)
- The LRC can allocate emergency supplies equal to its capacity within a single allocation period [32]. In addition, it is reasonable to assume that these emergency supplies are insufficient to meet demands in all IAs.
- (A3)
- Emergency supplies will be dispatched simultaneously at the beginning of each allocation period and are expected to be delivered by the end of the period [13].
- (A4)
- A fixed delivery cost is incurred based on the distance when delivering one unit of emergency supplies from the LRC to an IA.
These assumptions are consistent with common practice in existing research and help keep the problem formulation clear and tractable. It is also important to clarify that the effectiveness of our method does not depend on these specific assumptions, and the method can be adapted when more detailed operational information is available.
3.2. Formulation as Mathematical Programming
According to the above description, we formulate ESADU as
The objective of ESADU consists of three components: efficiency, effectiveness, and equity. In terms of efficiency, the first part of Equation (8) signifies the delivery cost of emergency supplies. In this part, is the delivery cost of one unit of emergency supplies from the LRC to the IA and represents the number of unit emergency supplies allocated to IA in allocation period .
The second part of Equation (8) is used to evaluate the effectiveness of the allocation strategy. is the starting-state-based deprivation cost (S2DC) function [13], utilized to quantify the suffering of survivors due to the lack of emergency supplies. The S2DC can be defined as
where represents the duration of each allocation period, and parameters of deprivation are denoted by and . denotes the state of IA in allocation period , which serves as its scarcity level of emergency supplies [12].
The third component of Equation (8) is the fair punishment cost (FPC), which evaluates the equity of the allocation strategy. The assessment of equity refers to evaluating the status of residents in IAs at the end of the planning horizon. For simplicity, we represent FPC as S2DC in Equation (14), similar to the setup in [46].
The objective of ESADU is to minimize the total cost through supplies allocation across all periods. Since directly optimizing multiple objectives simultaneously is challenging, we convert the multi-objective formulation into a single-objective function using a weighted aggregation approach. and represent the weights of the three cost functions in Equation (8), which can be used to control the importance of the three objectives. Without loss of generality, we set in the following experiments, consistent with [12].
In practice, the weights can be adjusted by decision-makers based on the desired balance among the three objectives. For example, higher weights may be assigned to delivery cost when rapid delivery is critical. However, we emphasize that adjusting these weights is not the focus of our study, and the design and performance of our approach are independent of the specific weighting. This flexibility allows the model to align with different real-world operational needs while ensuring that the algorithm consistently provides robust and adaptive allocation policies under demand uncertainty.
The problem involves four constraints. Constraint Equation (9) ensures that the sum of allocated emergency supplies allocated per allocation period does not exceed the capacity of the LRC. Constraint Equation (10) represents the state transition constraint and represents the nominal value of emergency supplies demand in IA . is used to characterize the disturbance of demand in IA . It follows a specific distribution controlled by a disturbance intensity factor and the nominal demand , as depicted in constraint Equation (11). We assume that the demand of each IA is independently generated, consistent with existing studies [47,48]. Finally, constraint Equation (12) restricts the decision variable to be a non-negative integer less than .
3.3. Formulation as Two-Player Zero-Sum Markov Game
To leverage DRL for solving the ESADU, we need to model the problem as a Markov decision process (MDP). However, the presence of demand uncertainty makes policies trained under a standard MDP prone to performance degradation when real-world demand deviates from the training distribution. To address this issue, we introduce an adversary to explicitly model demand uncertainty. The adversary perturbs the demand of IAs with the objective of degrading the performance of the allocation agent, i.e., the LRC. Under this competitive setting, the original MDP naturally extends to a two-player zero-sum Markov game (TZMG) [49], enabling the allocation agent to learn robust policies against highly variable demand conditions. Our TZMG can be represented as a tuple . Here, represents the state space and denotes the state transition probability. The action space of the LRC and the adversary are denoted by and , respectively. The reward function of the LRC and the adversary are represented by and . represents the total length of the game. The essential elements of our TZMG are defined as follows.
State Space: The state of the TZMG represents the scarcity level of emergency supplies in IAs. Hence, the state in allocation period can be expressed as
where is the total number of IAs and represents the state of IA in allocation period , with a higher value indicating higher level of scarcity. Since the agent relies solely on these estimated scarcity levels rather than exact demand values, the decision-making process operates under partial observability, consistent with real disaster-response settings where true demand is typically uncertain and only indirectly inferred.
Action Space: In each allocation period, the agent and adversary need to take actions according to the current state. The action spaces of the agent and adversary are different. We first introduce the action of the decision-making agent in allocation period , which can be described as
where represents the quantity of supplies allocated to IA in allocation period . It has the value in the range according to Constraint Equation (12).
We assume that in each allocation period, the adversary can choose an IA to add a disturbance to its demand, or choose not to take action. Then the action space of the adversarial agent can be defined as
In allocation period , the adversary can choose an action from the action space. While independent disturbances are used in the current implementation [47,48], the proposed approach is not tied to this assumption. Different demand dependency structures can be incorporated by modifying the adversary’s action design.
Reward: Since the goal of the LRC is to minimize the objective function, the reward received by the decision-making agent in allocation period can be shown as
Since the goal of the adversarial agent is to minimize the reward of the LRC, its reward function can be defined as
State transition: The state of each IA is influenced by the actions of both agents. Therefore, the state transition of IA can be represented as
If , the adversarial agent will impose disturbances on IA , leaving other IAs unaffected.
4. RESA_PPO Approach
This section introduces the approach RESA_PPO that we proposed for ESADU. As RESA_PPO is based on our framework RESA, we first introduce RESA in Section 4.1. Then we give the details of RESA_PPO in Section 4.2.
4.1. RESA Framework
RESA consists of three components: an adversarial training method, a combinatorial action representation method, and a reward clipping method, with its architecture depicted in Figure 2. We provide descriptions of these three components separately in Section 4.1.1, Section 4.1.2 and Section 4.1.3. In Section 4.1.4, we summarize the contribution of RESA to addressing the challenges outlined in Section 1.
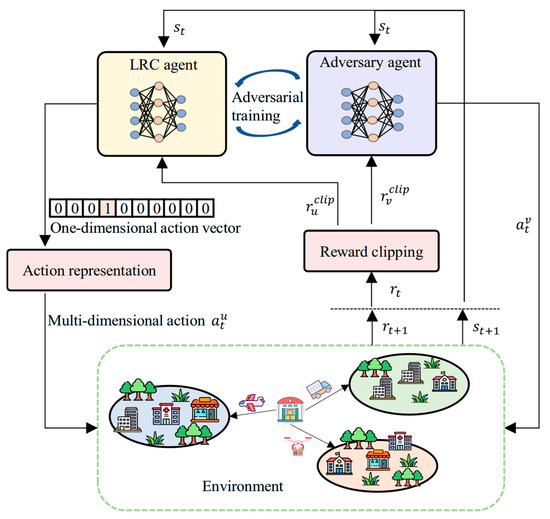
Figure 2.
Overall structure of RESA.
4.1.1. Adversarial Training Method
In our TZMG, both the LRC and the adversary observe the state in allocation period . According to the state, they take actions and , respectively. Then the state transits to according to Equation (20) and a reward is given from the environment. In our TZMG, the LRC obtains the reward while the adversary obtains an opposite reward . The goal of the LRC is to maximize its cumulative discounted reward under the adversarial disturbance. can be represented as
where and are the policy of the LRC and the adversary.
Nash equilibrium is equivalent to the minimax equilibrium [50,51] for our TZMG with optimal equilibrium reward , which can be expressed as
where and are the optimal policy of the LRC and the adversary, respectively. The Nash equilibrium determines the maximum returns that the LRC can obtain against the most formidable adversary. It is meaningful if the adversary is a learnable agent and updates its behavior based on the strategy of the LRC. Our goal is to find the optimal policy for the LRC by approximating the Nash equilibrium to cope with demand disturbances in real disaster scenarios.
To achieve this goal, we employ the adversarial training method proposed in [49]. This training method employs an alternating process to optimize the policy of the LRC and the adversary, respectively. In the first phase, the policy of the adversary is fixed, which means the policy of adding demand disturbances remains constant. We optimize the policy of the LRC for more effective supplies allocation in this context. Then in the second phase, we fix the policy of the LRC, and optimize the policy of the adversary with the aim of disrupting the policy of the LRC. By alternately executing these two processes, we ultimately converge both policies towards a Nash equilibrium.
From a game-theoretic perspective, this alternating optimization serves as a practical heuristic to solve the Minimax objective of the formulated TZMG. Conceptually, this process can be interpreted as seeking a saddle point in the joint policy space. While exact convergence is generally difficult to guarantee in high-dimensional, continuous settings, prior studies on adversarial reinforcement learning and zero-sum Markov games indicate that such alternating schemes empirically lead to stable and robust policies [52,53]. This holds under the assumptions that the neural networks have sufficient capacity to approximate value functions. As a result, the learned policy represents a robust policy capable of performing well even against a worst-case adversary.
4.1.2. Combinatorial Action Representation Method
ESADU has a high-dimensional action space, which is determined by the capacity of the LRC and the number of IAs . According to Equation (12) and Equation (16), the size of can be represented as
DRL will encounter the challenge of the explosion of the action space as or increases. Furthermore, actions represented in this manner may not always be valid. For example, there exists an action that allocates unit of emergency supplies to each IA, which violates Constraint Equation (9). It is common to introduce a penalty in the reward function to avoid these invalid actions. However, the penalty usually needs to be specially designed according to the problem, making the design of the reward function more complex. In addition, some DRL algorithms, e.g., DQN, do not support multi-dimensional action space. Hence, we propose a novel combinatorial action representation method in compliance with Constraint Equation (9), enhancing the capability of DRL algorithms in ESADU. Figure 3 provides two encoding examples with and . As shown in the figure, we employ a one-hot vector representation of length 10 to map the combinatorial action space. In this encoding, each dimension of the vector corresponds uniquely to a specific allocation scheme. For example, allocating one unit of resources to IA1 and IA2 corresponds to the fourth action, so the fourth element of the vector is 1 and the others are 0. Similarly, allocating one unit to IA1 and IA3 corresponds to the fifth action, with the fifth element set to 1. This mapping allows the LRC to select complex combinatorial actions by outputting a probability distribution over this discrete vector.
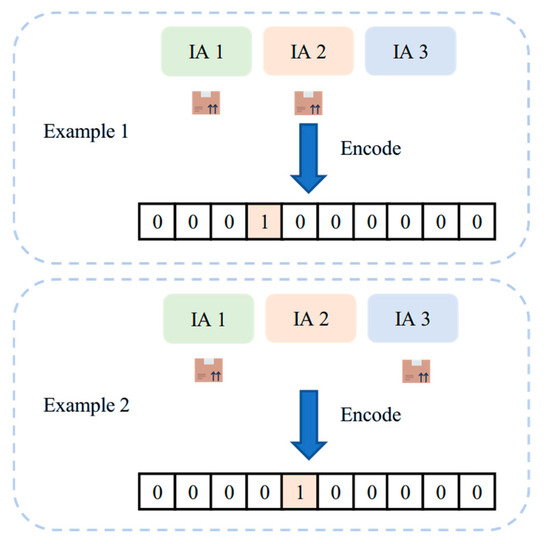
Figure 3.
Encoding examples of the combinatorial action representation method.
In summary, there are three main advantages of our action representation method. Firstly, our method has a smaller action space. To prove this conclusion, we first establish the size of the action space under our method in Theorem 1. Then we separately compare with under different and , and the results are shown in Figure 4. The correctness of this conclusion is presented in Theorem 2. Second, our method avoids a specific design to handle invalid actions, and simplifies the process of applying DRL to solve ESADU. Finally, the method establishes a mapping of multi-dimensional actions to one-dimensional. This enables the application of DRL algorithms that do not support a multi-dimensional action space.
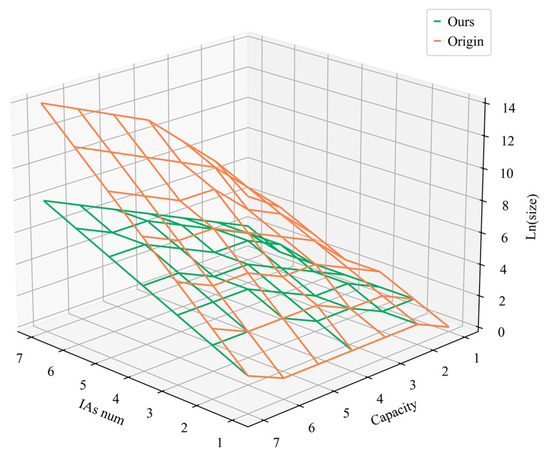
Figure 4.
Comparison of action space sizes for different action representation methods.
Theorem 1.
Consider the feasible allocation set
which satisfies the global allocation constraint. The number of feasible allocation actions is
Proof.
Define a slack variable
This yields an -dimensional non-negative integer vector satisfying the equality constraint
Conversely, any -dimensional non-negative integer vector whose components sum to defines a feasible allocation with by discarding the last component. This establishes a bijection between the set and the set . By the standard stars-and-bars argument, the latter set has cardinality
which is identical to Equation (25). □
Theorem 2.
Our proposed combinatorial action representation method reduces the size of the action space in any scenario, independent of the LRC capacity and the number of IAs .
Proof.
Firstly, we reasonably assume that there are at least two IAs in disaster scenarios, i.e., . Then we compute the ratio of and as
As , then we have
As , , our action representation method can reduce the size of the action space, and its effectiveness becomes more pronounced as and increase. □
4.1.3. Reward Clipping Method
Since DRL agent requires extensive random exploration during the training process, there is a possibility of repeatedly sampling suboptimal actions. These actions can lead to chronic shortages of emergency supplies in certain IAs. Given the highly nonlinear S2DC and FPC, these shortages will lead to extreme rewards and thus affect the stability of the training process. We propose a reward clipping method to address this challenge, which narrows the range of rewards by trimming values that exceed a predefined threshold . As the reward values are mainly controlled by state values, the reward threshold is also controlled by a state threshold .
Due to the scarcity of emergency supplies in the early stages of a disaster, the state value of each IA will continuously increase. Therefore, we attempt to determine the state threshold from the state space in allocation period . Then we consider a simple ESA method called proportional allocation method (PA). The method allocates emergency supplies to each IA in each allocation period according to a specific proportion. The proportion refers to the ratio of the final state of each IA at the end of the planning horizon in the absence of ESA. The final state of IA under this method can be expressed as
Given the highly nonlinearity of the S2DC and FPC, this method is not optimal. Therefore, we set the state threshold . Since the delivery costs are fixed in our problem, we directly use the product of the maximum unit transportation cost and the LRC capacity as the threshold for delivery costs. Next, the reward threshold can be directly computed using Equation (33), without the need for manual tuning.
Then the clipped reward function can be shown as
4.1.4. Summary
We address the challenges mentioned in Section 1 through the methods proposed in the preceding three sections. Then, we propose a new framework that incorporates these methods as components. We summarize the contributions of these components in addressing the challenges as follows:
Adversarial training method. This method tackles the challenge of demand uncertainty in disasters. By iteratively optimizing the policies of both the LRC and the adversary, this method guides the LRC policy towards a Nash equilibrium. This enhances the robustness of the LRC policy against the uncertainty of demand.
Action representation method. This method tackles the challenge of the overlarge action space. By pruning the action space of ESADU and establishing an action mapping, this method enhances the ability of the agent to tackle large-scale problems.
Reward clipping method. This method tackles the challenge of nonlinearity in the objective function. By setting an adaptive threshold to clip rewards into a narrower range, this method mitigates the impact of extreme rewards caused by S2DC and FPC during the training process of DRL agent.
4.2. RESA_PPO Workflow
Based on RESA, we propose a novel DRL-based approach called RESA_PPO to address ESADU. RESA_PPO leverages PPO as policy optimizer of RESA, i.e., the policies of the adversary and the LRC are optimized separately using PPO. PPO is selected due to its empirical stability and widespread success in sequential decision-making tasks. It is important to note that this choice is not inherent to RESA. Thus, PPO can be replaced by alternative DRL algorithms without modifying the core framework. The details of our approach are presented in Algorithm 1 and Figure 5.
| Algorithm 1 RESA_PPO | |
| Input: Environment | |
| 1: | do: |
| 2: | |
| 3: | do: |
| 4: | do: |
| 5: | LRC chooses allocation action |
| 6: | Adversary chooses an IA to add disturbance |
| 7: | Take actions, and obtain |
| 8: | according to Equation (6) |
| 9: | |
| 10: | If done, reset the environment and continue |
| 11: | with gradient |
| 12: | End for |
| 13: | End for |
| 14: | |
| 15: | do: |
| 16: | do: |
| 17: | LRC chooses allocation action |
| 18: | Adversary chooses an IA to add disturbance |
| 19: | Take actions, and obtain |
| 20: | according to Equation (6) |
| 21: | |
| 22: | If done, reset the environment and continue |
| 23: | with gradient |
| 24: | End for |
| 25: | End for |
| 26: | End for |
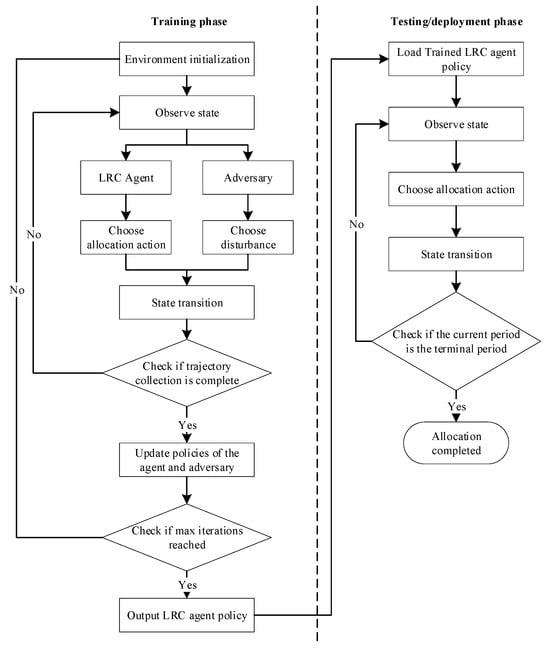
Figure 5.
Overall workflow of RESA_PPO.
We first initialize the policy parameters for both the LRC and the adversary. We set the number of iterations to . In each iteration, we perform an alternating optimization process to separately optimize the policies of the LRC and the adversary. In the first phase of each iteration, we optimize the policy parameters and of the LRC to maximize Equation (21) while holding the policy parameters and of the adversary constant. Training begins by initializing the environment and observing the initial state. At each step of an episode, the LRC agent selects an allocation action , and simultaneously, the adversary generates a disturbance action that alters the demand of one IA. These two actions jointly determine the subsequent state transition of the environment. After collecting these transition samples, we use them to update the LRC policy. We optimize the policy of the LRC for episodes, with each episode consisting of steps, and then proceed to the next phase of the iteration. In the next phase, the policy parameters and of the LRC are held constant, and the policy parameters and are optimized using the same method to minimize Equation (21). RESA_PPO repeats this alternating optimization process for iterations to obtain the optimal policy of the LRC.
Figure 5 illustrates the workflow of RESA_PPO. Once the LRC policy is trained, deployment becomes straightforward. The current state of the IAs is fed into the trained policy and the allocation action for each period is obtained directly without any further training.
It is worth noting that the computational cost of our approach is dominated by the training phase. Since training can be performed offline before a disaster occurs, the associated overhead does not affect real-time deployment. During actual disaster response, the learned policy only requires a lightweight forward pass to generate allocation decisions, resulting in fast inference and making the approach suitable for time-critical operational environments.
5. Experimental Results and Discussions
In this section, we first introduce the experimental setup and approach hyperparameters in Section 5.1. Section 5.2 provides the ablation study evaluating the effect of the reward clipping mechanism, and Section 5.3 presents the convergence analysis of our method. Finally, Section 5.4 compares the performance of our approach with other baseline methods. Section 5.5 provides a sensitivity analysis of RESA_PPO with respect to disturbance intensity, probability, and distribution.
5.1. Experiment Setting
The initial parameters of the environment are constructed using realistic data from the 2008 Wenchuan earthquake in China. It is important to emphasize that our method does not rely on earthquake-specific assumptions and can be readily extended to other disaster types such as floods, hurricanes, or typhoons. The Wenchuan earthquake is selected primarily because its publicly available records provide sufficiently detailed and reliable data for model construction and experimental evaluation. For data that are not publicly available, we use reasonable estimates derived from existing research [46] and empirical information from real emergency response operations. While these estimates may not perfectly reflect actual conditions, they capture the essential characteristics of emergency supply shortages and are adequate for evaluating the effectiveness of RESA_PPO. It is worth noting that the initial parameters of the environment will not have a substantial impact on the effectiveness of RESA_PPO. For simplicity, we set the initial state of each IA to 0, similar to [12]. The details of other parameters are given in Table 3.
Table 3.
Initial parameters of the environment.
Next, we introduce the hyperparameter settings of DRL approaches used in the experiments. In addition to PPO, we also select a classic value-based DRL approach, DQN, as policy optimizer of RESA for comparison. We determine the optimal parameters for both approaches through extensive experiments, as shown in Table 4. We implement a learning rate decay strategy in both algorithms to ensure the stability of the training process, which can be represented as
where is the learning rate of the k-th episode.
Table 4.
Hyper-parameter definition of DRL-based approaches.
5.2. Ablation Study
As discussed earlier, RESA contains two structural components designed to address the challenges of ESADU, the combinatorial action representation and the reward clipping method. The effectiveness of the action representation has been theoretically established by proving that it reduces the action-space size. Therefore, in this section, we focus on empirically evaluating the reward clipping method (clip).
To assess its impact, we compare our method with the original scheme without reward clipping (origin). Both DQN and PPO are tested with 10 different seeds on the Wenchuan earthquake scenario under deterministic demand. Figure 6 presents the corresponding learning curves, where we apply the natural logarithm of the total cost to compress the scale for clearer visualization. The results show that incorporating the reward clipping method substantially improves convergence speed, training stability, and final solution quality for both algorithms. These findings confirm that reward clipping is an essential component for enhancing the training performance of DRL approaches in ESADU. Consequently, we adopt this mechanism in all DRL-based baselines to ensure a fair and competitive comparison.
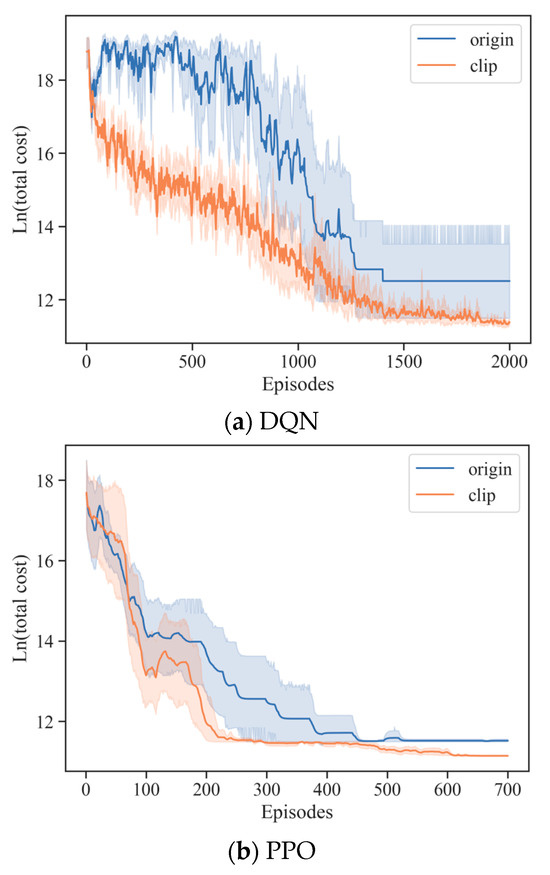
Figure 6.
Effect of the reward clipping method on convergence performance.
5.3. Convergence Analysis
In this section, we evaluate the convergence behavior of RESA_PPO. Referring to [44], we assume that follows a uniform distribution . Without loss of generality, we set and illustrate the convergence curve of RESA_PPO in Figure 7. The green region represents the training phase of the LRC, while the red region indicates the training phase of the adversary.
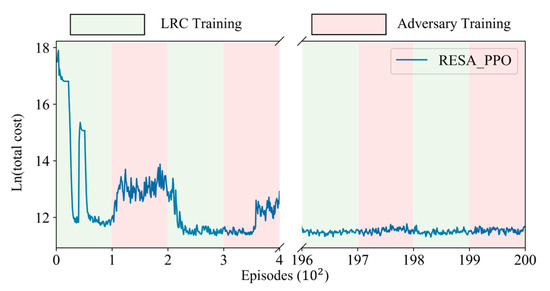
Figure 7.
Convergence curve of RESA_PPO.
It can be observed that in the early stages of iteration, the total cost rapidly decreases during the training phase of the LRC, indicating optimization of its policy . However, during the training phase of the adversary, as is fixed, the total cost starts to increase. The reason is that during the adversary training phase, the adversary optimizes its policy to degrade the performance of . The performance of RESA_PPO stabilizes in the final two iterations, which indicates that the LRC and the adversary have reached equilibrium. In practice, the number of iterations can be adjusted according to convergence trends to ensure stable policy learning.
5.4. Comparison Analysis
To evaluate the effectiveness of RESA_PPO, we compare it against several representative baselines, including an optimal benchmark, heuristic algorithms, and DRL-based methods.
Optimal Algorithm (Optimal): We first introduce a strong benchmark obtained by solving a deterministic version of the problem using Gurobi. In this setting, the complete demand sequence across all allocation periods is assumed to be fully known in advance. This allows us to compute the best possible allocation plan under perfect information, which serves as a theoretical upper bound for performance evaluation. Although this benchmark is not achievable in real-world scenarios, it provides a valuable reference for assessing how close the proposed approach can approach optimal performance.
The heuristic algorithms are as follows:
Greedy Algorithm (GA): The greedy algorithm is a classical heuristic algorithm that centers on choosing the action that maximizes the reward in the current state. We further enhance its capabilities by providing it with advanced knowledge of the actual demand in each allocation period.
Rotation Algorithm (RA): We design this heuristic algorithm that focuses on the most severely affected IAs in each allocation period. The rotation algorithm will allocate one unit of emergency supplies to each of the top affected areas with the highest state values in each allocation period.
The DRL-based methods are as follows:
DQN: DQN is a classic RL algorithm that is used to address ESA problems in [13]. In our experiments, DQN is trained without demand disturbances.
PPO: PPO is selected for comparison with RESA_PPO to validate the effectiveness of RESA in enhancing the capabilities of DRL algorithm. PPO is trained similarly to DQN.
RESA_DQN: RESA_DQN is a DQN-based approach that utilizes RESA as its underlying framework, similar to RESA_PPO.
Traditional RO and DRO methods are not included because they rely on detailed uncertainty information, such as demand distributions or ambiguity-set parameters, which is typically unavailable or unreliable in real disaster settings. Moreover, these approaches are primarily designed for static problems and cannot be readily applied to sequential, adversarial environments like ESADU. Metaheuristic algorithms are also excluded, as ESADU requires real-time sequential decisions, whereas metaheuristics are generally better suited for static scenarios. Table 5 presents a comparison between RESA_PPO and the baseline methods.
Table 5.
Comparison of RESA_PPO with baseline methods.
We first validate the performance of RESA_PPO under low disturbance intensities. Therefore, both training and testing disturbance intensities are set to 0.1, i.e., and .
During the testing process, demand disturbance is assumed to follow a uniform distribution . In each allocation period, a decision is made with a disturbance probability to determine whether to add a disturbance to demand. If so, a randomly selected IA will be added the disturbance . We conduct tests under 10 different disturbance probabilities . We repeat each test instance for 500 times to account for randomness.
Figure 8 illustrates the mean total cost obtained by RESA_PPO and baselines. Compared with GA and RA, DRL-based approaches deliver substantially better solution quality, and heuristic methods consistently underperform across all experiments. Hence, we do not present the results of the heuristic baseline separately in subsequent experiments. As the disturbance probability increases, both RESA_DQN and RESA_PPO outperform their native counterparts, demonstrating that the RESA framework effectively enhances the robustness of DRL under uncertain demand. Among all methods, RESA_PPO achieves the best performance among the learning-based and heuristic approaches and maintains high stability across all test instances. Although it does not outperform the Optimal baseline, it remains very close to this theoretical upper bound. This demonstrates that RESA_PPO can achieve near-optimal performance even in highly uncertain and dynamic environments.
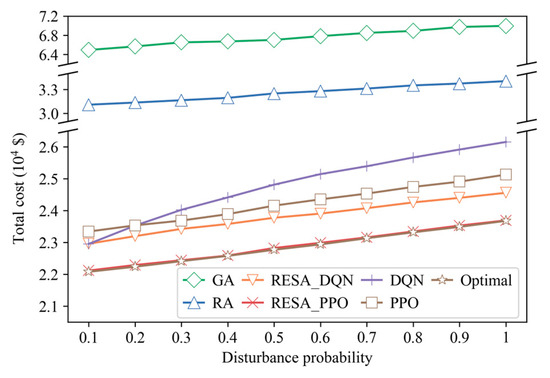
Figure 8.
Performance comparison when .
5.5. Sensitivity Analysis
Although decision-makers in real disaster scenarios may estimate a plausible demand range based on historical information, such estimates are often imprecise. One possible approach is to assume a broad demand range, but this may degrade solution quality. To address this challenge, we perform a sensitivity analysis to evaluate the robustness of RESA_PPO when the actual demand range differs from the estimated one. We simulate this by altering the testing disturbance intensity to be different from the training disturbance intensity . We conduct experiments with four testing disturbance intensities . We train RESA_PPO and RESA_DQN under two different training disturbance intensities and use the trained policies for testing. The corresponding results are presented in Table 6.
Table 6.
Results obtained by DRL-based approaches under different levels of disturbance intensity.
It can be observed that RESA_PPO with consistently outperforms all other baselines across most test instances. Specifically, it achieves at least a 5.25% reduction in total cost on average. Notably, its performance remains very close to the Optimal baseline, with an average gap of only 3.7%, and even in the worst case the gap is limited to 20.49%. This worst case occurs when the disturbance intensity during testing is sharply increased to 0.9 and the disturbance probability is set to 1.0, while the policy was trained under a much milder intensity of 0.3. Despite this substantial mismatch between the training and testing environments, RESA_PPO still maintains stable and robust performance, demonstrating strong generalization capability under significant distribution shifts. These results further show that RESA_PPO is robust to variations in both disturbance intensity and disturbance probability. Even when both factors are significantly increased, RESA_PPO continues to deliver stable performance, indicating its strong robustness to a wide range of uncertainty levels.
Then we validate the robustness of RESA_PPO in cases where the disturbance distribution differs from that during the training process. This is necessary because obtaining disturbance distribution information in real disaster scenarios is difficult. We assume that the testing disturbance distribution follows a normal distribution . For clarity, we only choose the present the results of PPO, RESA_PPO (Normal), i.e., the RESA_PPO policy trained under disturbance following a normal distribution with , and RESA_PPO (Uniform), i.e., the RESA_PPO policy trained under disturbance following a uniform distribution with . As depicted in Figure 9, the results achieved by RESA_PPO (Uniform) and RESA_PPO (Normal) remain consistent across all test instances, with both consistently outperforming PPO. Moreover, this superiority becomes even more pronounced with the increases in disturbance intensity and probability. This indicates that RESA_PPO can adapt well to changes in demand distribution, with its robust performance not relying on prior knowledge of demand distribution. This demonstrates great potential for application in real-world scenarios.
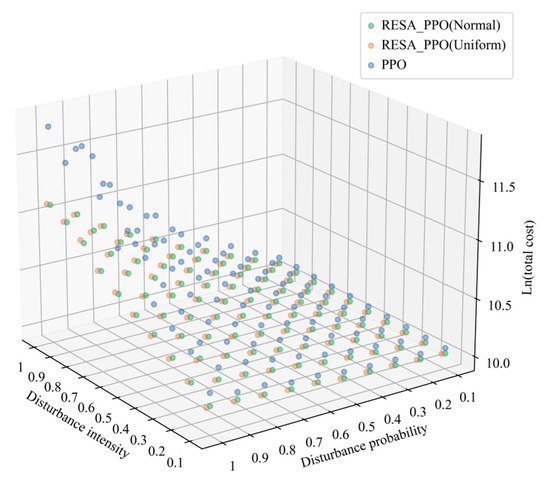
Figure 9.
Performance comparison when testing disturbance distribution changes to a normal distribution.
6. Conclusions and Future Work
In this paper, we introduce a multi-objective and multi-period ESA problem with demand uncertainty and formulate it as a two-player zero-sum Markov game. Then, we propose a novel framework RESA to help DRL address this problem. We adopt an adversarial training method in RESA to help the LRC learn a policy robust to demand disturbances. To address the challenges of overlarge action space and nonlinear of the problem, we also design a combinatorial action representation method and a reward clipping method in RESA. Finally, we propose a novel DRL-based approach, RESA_PPO to address the problem. We conducted experiments based on the actual disaster scenario of the 2008 Wenchuan earthquake in China. The experimental results indicate the robustness of RESA_PPO in various test instances. Its strong performance under demand uncertainty demonstrates the practical value of transitioning from static, deterministic planning to dynamic, robustness-oriented policies. In addition, the workflow of offline training and online deployment offers a practical means to support real-time decision-making in time-sensitive post-disaster operations.
Since our study focuses on demand uncertainty, extending it to incorporate additional sources of uncertainty would enhance the applicability of the approach. Second, while the approach is inherently conservative due to its worst-case design, future work could explore ways to balance robustness with efficiency. Third, relaxing the assumptions made in this study would allow us to further demonstrate the practicality of RESA_PPO in real-world scenarios. In particular, relaxing the current independent-demand assumption to capture spatially correlated demand patterns, such as geographically adjacent IAs experiencing similar demand fluctuations, would constitute an important and practical extension. Finally, applying RESA_PPO to a broader range of disaster scenarios, such as floods and hurricanes, would further validate its generality and practical value.
Author Contributions
Conceptualization, W.W. and J.F.; methodology, W.W.,W.Z. and X.C.; data curation and system experimental, W.W., J.F., W.Z., Y.C., Y.Y. (Yang Yang), X.Z., Y.Y. (Yingying Yao) and X.C.; writing—original draft preparation, W.W.; writing—review and editing, W.Z. and X.C. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by National Natural Science Foundation of China (NSFC) (U2468206) and also funded by Foundation Project of Institute of Computing Technology, China Academy of Railway Sciences Corporation Limited (DZYF24-35).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The original contributions presented in the study are included in the article. Further inquiries can be directed to the corresponding author.
Conflicts of Interest
Authors Weimeng Wang, Weiqiao Zhu, Yujing Cai, Yang Yang and Xuanming Zhang were employed by the company Institute of Computing Technologies, China Academy of Railway Sciences Corporation Limited. The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
References
- Gralla, E.; Goentzel, J.; Fine, C. Assessing trade-offs among multiple objectives for humanitarian aid delivery using expert preferences. Prod. Oper. Manag. 2014, 23, 978–989. [Google Scholar] [CrossRef]
- Yin, Y.; Wang, J.; Chu, F.; Wang, D. Distributionally robust multi-period humanitarian relief network design integrating facility location, supply inventory and allocation, and evacuation planning. Int. J. Prod. Res. 2024, 62, 45–70. [Google Scholar] [CrossRef]
- Liang, Z.; Wang, X.; Xu, S.; Chen, W. Application of Distributionally Robust Optimization Markov Decision-Making Under Uncertainty in Scheduling of Multi-category Emergency Medical Materials. Int. J. Comput. Intell. Syst. 2025, 18, 50. [Google Scholar] [CrossRef]
- Jia, Y.; Xie, J.; Jivaganesh, S.; Li, H.; Wu, X.; Zhang, M. Seeing sound, hearing sight: Uncovering modality bias and conflict of ai models in sound localization. arXiv 2025, arXiv:2505.11217. [Google Scholar] [CrossRef]
- Xiao, L.; Mao, R.; Zhao, S.; Lin, Q.; Jia, Y.; He, L.; Cambria, E. Exploring Cognitive and Aesthetic Causality for Multimodal Aspect-Based Sentiment Analysis; IEEE Transactions on Affective Computing: Los Alamitos, CA, USA, 2025. [Google Scholar]
- Wu, X.; Jia, Y.; Xiao, L.; Zhao, S.; Chiang, F.; Cambria, E. From query to explanation: Uni-rag for multi-modal retrieval-augmented learning in stem. arXiv 2025, arXiv:2507.03868. [Google Scholar]
- Jia, Y.; Wu, X.; Zhang, Q.; Qin, Y.; Xiao, L.; Zhao, S. Towards robust evaluation of stem education: Leveraging mllms in project-based learning. arXiv 2025, arXiv:2505.17050. [Google Scholar]
- Plaksin, A.; Kalev, V. Zero-sum positional differential games as a framework for robust reinforcement learning: Deep Q-learning approach. arXiv 2024, arXiv:2405.02044. [Google Scholar]
- Dong, J.; Hsu, H.L.; Gao, Q.; Tarokh, V.; Pajic, M. Robust reinforcement learning through efficient adversarial herding. arXiv 2023, arXiv:2306.07408. [Google Scholar] [CrossRef]
- Wang, Z.; Xuan, J.; Shi, T.; Li, Y.F. Multi-label domain adversarial reinforcement learning for unsupervised compound fault recognition. Reliab. Eng. Syst. Saf. 2025, 254, 110638. [Google Scholar] [CrossRef]
- Bi, C.; Liu, D.; Zhu, L.; Li, S.; Wu, X.; Lu, C. Short-term voltage stability emergency control strategy pre-formulation for massive operating scenarios via adversarial reinforcement learning. Appl. Energy 2025, 389, 125751. [Google Scholar] [CrossRef]
- Yu, L.; Zhang, C.; Jiang, J.; Yang, H.; Shang, H. Reinforcement learning approach for resource allocation in humanitarian logistics. Expert Syst. Appl. 2021, 173, 114663. [Google Scholar] [CrossRef]
- Fan, J.; Chang, X.; Mišić, J.; Mišić, V.B.; Kang, H. DHL: Deep reinforcement learning-based approach for emergency supply distribution in humanitarian logistics. Peer–Peer Netw. Appl. 2022, 15, 2376–2389. [Google Scholar] [CrossRef]
- Hao, Q.; Xu, F.; Chen, L.; Hui, P.; Li, Y. Hierarchical reinforcement learning for scarce medical resource allocation with imperfect information. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, New York, NY, USA, 14 August 2021; pp. 2955–2963. [Google Scholar]
- Shakya, A.K.; Pillai, G.; Chakrabarty, S. Reinforcement learning algorithms: A brief survey. Expert Syst. Appl. 2021, 2023, 120495. [Google Scholar] [CrossRef]
- Zhang, S.; Jia, R.; Pan, H.; Cao, Y. A safe reinforcement learning-based charging strategy for electric vehicles in residential microgrid. Appl. Energy 2023, 348, 121490. [Google Scholar] [CrossRef]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal policy optimization algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar] [CrossRef]
- Wang, S.L.; Sun, B.Q. Model of multi-period emergency material allocation for large-scale sudden natural disasters in humanitarian logistics: Efficiency, effectiveness and equity. Int. J. Disaster Risk Reduct. 2023, 85, 103530. [Google Scholar] [CrossRef]
- Barbarosoğlu, G.; Özdamar, L.; Cevik, A. An interactive approach for hierarchical analysis of helicopter logistics in disaster relief operations. Eur. J. Oper. Res. 2002, 140, 118–133. [Google Scholar] [CrossRef]
- Yang, M.; Allen, T.T.; Fry, M.J.; Kelton, W.D. The call for equity: Simulation optimization models to minimize the range of waiting times. IIE Trans. 2013, 45, 781–795. [Google Scholar] [CrossRef]
- Fiedrich, F.; Gehbauer, F.; Rickers, U. Optimized resource allocation for emergency response after earthquake disasters. Saf. Sci. 2000, 35, 41–57. [Google Scholar] [CrossRef]
- De Angelis, V.; Mecoli, M.; Nikoi, C.; Storchi, G. Multiperiod integrated routing and scheduling of World Food Programme cargo planes in Angola. Comput. Oper. Res. 2007, 34, 1601–1615. [Google Scholar] [CrossRef]
- Campbell, A.M.; Vandenbussche, D.; Hermann, W. Routing for relief efforts. Transp. Sci. 2008, 42, 127–145. [Google Scholar] [CrossRef]
- Li, C.; Han, P.; Zhou, M.; Gu, M. Design of multimodal hub-and-spoke transportation network for emergency relief under COVID-19 pandemic: A meta-heuristic approach. Appl. Soft Comput. 2023, 133, 109925. [Google Scholar] [CrossRef]
- Hu, B.; Jiang, G.; Yao, X.; Chen, W.; Yue, T.; Zhao, Q.; Wen, Z. Allocation of emergency medical resources for epidemic diseases considering the heterogeneity of epidemic areas. Front. Public Health 2023, 11, 992197. [Google Scholar] [CrossRef] [PubMed]
- Sheu, J.B.; Chen, Y.H.; Lan, L.W. A novel model for quick response to disaster relief distribution. In Proceedings of the Eastern Asia Society for Transportation Studies, Bangkok, Thailand, 21–24 September 2005; Volume 5, pp. 2454–2462. [Google Scholar]
- Zhang, J.H.; Li, J.; Liu, Z.P. Multiple-resource and multiple-depot emergency response problem considering secondary disasters. Expert Syst. Appl. 2012, 39, 11066–11071. [Google Scholar] [CrossRef]
- Zhang, D.; Zhang, Y.; Li, S.; Li, S. A novel min–max robust model for post-disaster relief kit assembly and distribution. Expert Syst. Appl. 2023, 214, 119198. [Google Scholar] [CrossRef]
- Wan, M.; Ye, C.; Peng, D. Multi-period dynamic multi-objective emergency material distribution model under uncertain demand. Eng. Appl. Artif. Intell. 2023, 117, 105530. [Google Scholar] [CrossRef]
- Wang, Y. Multiperiod optimal allocation of emergency resources in support of cross-regional disaster sustainable rescue. Int. J. Disaster Risk Sci. 2021, 12, 394–409. [Google Scholar] [CrossRef]
- Wang, Y.; Sun, B. Multiperiod optimal emergency material allocation considering road network damage and risk under uncertain conditions. Oper. Res. 2022, 22, 2173–2208. [Google Scholar] [CrossRef]
- Yang, Y.; Yin, Y.; Wang, D.; Ignatius, J.; Cheng, T.C.E.; Dhamotharan, L. Distributionally robust multi-period location-allocation with multiple resources and capacity levels in humanitarian logistics. Eur. J. Oper. Res. 2023, 305, 1042–1062. [Google Scholar] [CrossRef]
- Wang, Y.; Lyu, M.; Sun, B. Emergency resource allocation considering the heterogeneity of affected areas during the COVID-19 pandemic in China. Humanit. Soc. Sci. Commun. 2024, 11, 225. [Google Scholar] [CrossRef]
- Liberatore, F.; Pizarro, C.; de Blas, C.S.; Ortuño, M.T.; Vitoriano, B. Uncertainty in humanitarian logistics for disaster management. A review. Decis. Aid Models Disaster Manag. Emergencies 2013, 7, 45–74. [Google Scholar]
- Wang, B.; Deng, W.; Tan, Z.; Zhang, B.; Chen, F. A two-stage stochastic optimization for disaster rescue resource distribution considering multiple disasters. Eng. Optim. 2024, 56, 1–17. [Google Scholar] [CrossRef]
- Meng, L.; Wang, X.; He, J.; Han, C.; Hu, S. A two-stage chance constrained stochastic programming model for emergency supply distribution considering dynamic uncertainty. Transp. Res. Part E Logist. Transp. Rev. 2023, 179, 103296. [Google Scholar] [CrossRef]
- Cao, C.; Liu, Y.; Tang, O.; Gao, X. A fuzzy bi-level optimization model for multi-period post-disaster relief distribution in sustainable humanitarian supply chains. Int. J. Prod. Econ. 2021, 235, 108081. [Google Scholar] [CrossRef]
- Sun, H.; Wang, Y.; Xue, Y. A bi-objective robust optimization model for disaster response planning under uncertainties. Comput. Ind. Eng. 2021, 155, 107213. [Google Scholar] [CrossRef]
- Wang, W.; Yang, K.; Yang, L.; Gao, Z. Distributionally robust chance-constrained programming for multi-period emergency resource allocation and vehicle routing in disaster response operations. Omega 2023, 120, 102915. [Google Scholar] [CrossRef]
- Liu, J.; Bai, J.; Wu, D. Medical supplies scheduling in major public health emergencies. Transp. Res. Part E Logist. Transp. Rev. 2021, 154, 102464. [Google Scholar] [CrossRef] [PubMed]
- Aliakbari, A.; Rashidi Komijan, A.; Tavakkoli-Moghaddam, R.; Najafi, E. A new robust optimization model for relief logistics planning under uncertainty: A real-case study. Soft Comput. 2022, 26, 3883–3901. [Google Scholar] [CrossRef]
- Ferrer, J.M.; Ortuño, M.T.; Tirado, G. A new ant colony-based methodology for disaster relief. Mathematics 2020, 8, 518. [Google Scholar] [CrossRef]
- Han, Y.; Han, P.; Yuan, B.; Zhang, Z.; Liu, L.; Panneerselvam, J. Design and Application of Vague Set Theory and Adaptive Grid Particle Swarm Optimization Algorithm in Resource Scheduling Optimization. J. Grid Comput. 2023, 21, 24. [Google Scholar] [CrossRef]
- Van Steenbergen, R.; Mes, M.; Van Heeswijk, W. Reinforcement learning for humanitarian relief distribution with trucks and UAVs under travel time uncertainty. Transp. Res. Part C Emerg. Technol. 2023, 157, 104401. [Google Scholar] [CrossRef]
- Faraci, G.; Rizzo, S.A.; Schembra, G. Green Edge Intelligence for Smart Management of a FANET in Disaster-Recovery Scenarios. IEEE Trans. Veh. Technol. 2023, 72, 3819–3831. [Google Scholar] [CrossRef]
- Yu, L.; Zhang, C.; Yang, H.; Miao, L. Novel methods for resource allocation in humanitarian logistics considering human suffering. Comput. Ind. Eng. 2018, 119, 1–20. [Google Scholar] [CrossRef]
- Zhang, X.; Chen, D. Prepositioning network design for humanitarian relief purposes under correlated demand uncertainty. Comput. Ind. Eng. 2023, 182, 109365. [Google Scholar] [CrossRef]
- Fu, F.; Liu, Q.; Yu, G. Robustifying the resource-constrained project scheduling against uncertain durations. Expert Syst. Appl. 2024, 238, 122002. [Google Scholar] [CrossRef]
- Pinto, L.; Davidson, J.; Sukthankar, R.; Gupta, A. Robust adversarial reinforcement learning. In International Conference on Machine Learning; PMLR: Cambridge, MA, USA, 2017; pp. 2817–2826. [Google Scholar]
- Patek, S.D. Stochastic and Shortest Path Games: Theory and Algorithms. Ph.D. Dissertation, Massachusetts Institute of Technology, Cambridge, MA, USA, 1997. [Google Scholar]
- Zhu, Y.; Zhao, D. Online minimax Q network learning for two-player zero-sum Markov games. IEEE Trans. Neural Netw. Learn. Syst. 2020, 33, 1228–1241. [Google Scholar] [CrossRef]
- Cai, Y.; Luo, H.; Wei, C.Y.; Zheng, W. Uncoupled and convergent learning in two-player zero-sum markov games. In 2023 Workshop The Many Facets of Preference-Based Learning; ICML: Seoul, Republic of Korea, 2023. [Google Scholar]
- Reddi, A.; Tölle, M.; Peters, J.; Chalvatzaki, G.; D’Eramo, C. Robust adversarial reinforcement learning via bounded rationality curricula. arXiv 2023, arXiv:2311.01642. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2026 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license.