Abstract
The integration of artificial intelligence into remote patient monitoring (RPM) offers significant benefits for proactive and continuous healthcare, but also raises critical concerns regarding privacy, integrity, and robustness. Federated Learning (FL) provides a decentralized approach to model training that preserves data locality, yet most existing solutions address only isolated security aspects and lack contextual adaptability for clinical use. This paper presents MedGuard-FL, a context-aware FL framework tailored to e-healthcare environments. Spanning device, edge, and cloud layers, it integrates encryption, adaptive differential privacy, anomaly detection, and Byzantine-resilient aggregation. At its core, a policy engine dynamically adjusts privacy and robustness parameters based on the patient’s status and the system’s risk. Evaluations on real-world clinical datasets show MedGuard-FL maintains high model accuracy while neutralizing various adversarial attacks (e.g., label-flip, poisoning, backdoor, membership inference), all with manageable latency. Compared to static defenses, it offers improved trade-offs between privacy, utility, and responsiveness. Additional edge-level privacy analyses confirm its resilience, with attack effectiveness near random. By embedding clinical risk awareness into adaptive defense mechanisms, MedGuard-FL lays a foundation for secure, real-time federated intelligence in RPM.
1. Introduction
Growing prevalence of chronic ailments such as diabetes, hypertension, and heart failure places a significant burden on existing healthcare infrastructure [1]. Remote Patient Monitoring (RPM) helps mitigate this burden by collecting real-time physiological data through home devices and wearables, enabling timely clinical decisions [2]. However, deploying RPM at scale poses major challenges: Sensitive data must remain private, devices are resource-constrained, and clinical alerts must be issued with minimal delay. Centralized learning exposes raw data to GDPR (General Data Protection Regulation) and HIPAA risks (Health Insurance Portability and Accountability Act) [3,4]. Federated Learning (FL) offers a privacy-preserving alternative by keeping patient data local [5]. Still, maintaining FL models’ privacy and reliability is challenging in RPM settings. Wearable and home-sensor data are highly heterogeneous, often noisy, and non-IID, making the global model more sensitive to inference and poisoning attacks. These systems must also operate under strict latency and resource constraints, which limit the use of heavyweight protections and create a persistent trade-off among privacy, robustness, and timely clinical response. The difficulty increases when attacks or strict timing constraints are involved. In this work, we try to answer the following question: how do we design a federated RPM framework that maintains confidentiality, secures against attacks, and adheres to clinical real-time needs?
We address these needs (Figure 1) by introducing MedGuard-FL, a cross-layer adaptive Federated Learning framework designed expressly for the realities of remote patient monitoring. Unlike existing FL systems that treat all clients uniformly, MedGuard-FL introduces a cross-layer, patient-aware security design that adapts protection levels to each individual’s clinical conditions. The framework integrates three complementary mechanisms per-patient Differential Privacy [6] to safeguard sensitive signals at the device and edge, edge-side lightweight anomaly screening [7] to detect abnormal inputs before they propagate, and robust aggregation [8] to limit the influence of compromised nodes during global model updates. A central innovation of our approach is a policy engine that interprets patient risk and moment-to-moment clinical status to determine the appropriate strength of each defence. By tying security behaviour to patient context, MedGuard-FL provides stronger confidentiality and resilience while maintaining the low latency required for real-time monitoring.

Figure 1.
Federated RPM privacy–robustness–latency tradeoff.
As a complementary measure of integrity robustness, we incorporate a lightweight, edge-only membership-inference (MIA) verification check to ensure confidentiality in our edge-deployed model. We instantiate three typical MIA families—loss-based (Yeom) [9], confidence/entropy-based (ML-Leaks) [10], and shadow-model—under black-box and limited white-box vantage [11,12] at the edge. A detailed analysis of privacy threats and membership-inference risks at the edge and server will be presented in Section 5, while full privacy probing across layers [12,13,14] is left for future work.
The structure of the paper is as follows. Section 2 outlines the landscape of threats and surveys existing countermeasures. Section 3 overviews relevant work on Federated Learning for healthcare and positions our work. Section 4 outlines MedGuard-FL’s architecture, including its policy engine, adaptive security module, and countermeasures for given threats. Section 5 outlines experiment setup and reports results under baseline, secure, and adversarial conditions. Section 6 provides a comparative discussion, contrasting MedGuard-FL with state-of-the-art defenses and highlighting how tri-dimensional adaptation (privacy, robustness, and clinical awareness) yields improved resilience and operational performance. Section 7 concludes with key findings and future work directions.
2. Background
Healthcare applications increasingly rely on machine learning to process data from clinical equipment and wearable sensors. Federated Learning (FL) is gaining traction as a privacy-preserving alternative to centralized learning, since it keeps raw data on-device and reduces regulatory risks under GDPR and HIPAA. For this reason, FL is appealing in RPM settings, where the data is sensitive, and clinicians expect rapid responses. However, FL is still vulnerable to several types of attacks. Privacy-focused attacks such as membership inference [11], model inversion [15], property inference [16] and model extraction [17] aim to extract sensitive information or replicate model behavior from outputs or gradients. Model extraction attacks [17] target the confidentiality of the model itself, allowing adversaries to reconstruct the decision function or copy the model for unauthorized use. Integrity-focused attacks—including poisoning [18], label-flipping [18], and backdoor injection [19] manipulate training data or updates to alter model behavior. Sybil attacks [20] further amplify malicious influence by injecting fake clients.
To address these vulnerabilities (Figure 2), two classes of countermeasures emerged: preventive and detective. Preventive mechanisms include Differential Privacy (DP), which limits information leakage at the cost of some accuracy, and cryptographic methods such as Secure Multiparty Computation [21] and Homomorphic Encryption [22], which provide strong confidentiality but impose heavy latency unsuitable for RPM [23]. Blockchain-based schemes [24] offer auditability but face scalability and storage overheads. Detective methods include edge-side anomaly detection [25] and robust server aggregation [26], though both rely on careful tuning and assumptions on the proportion of honest clients. Related work has also explored adaptive anomaly detection outside the Federated Learning setting, including semi-supervised deep reinforcement learning approaches for abnormal network traffic detection [27]. While effective in network security contexts, such methods do not address federated training, privacy constraints, or the real-time clinical requirements central to remote patient monitoring.
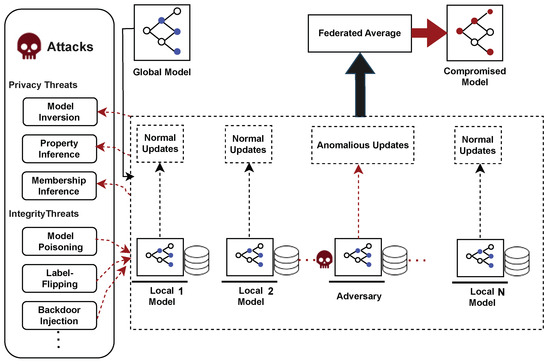
Figure 2.
Federated learning threats landscape.
As shown in Table 1, each defence addresses only part of the threat landscape. Heavy cryptographic tools conflict with RPM latency constraints, while single-facet defences address only part of the problem. These limitations argue for a multi-layer, context-aware security framework tailored to healthcare that dynamically adapts protection levels based on patient risk, system conditions, and real-time clinical urgency. The next section reviews related work in this area and highlights the limitations of current approaches to addressing the dual challenges of privacy and integrity under real-time healthcare constraints.

Table 1.
Countermeasures against FL threats.
3. Literature Review
Federated Learning (FL) has gained traction in healthcare, yet most studies focus on a single aspect of security. Privacy and robustness are often treated separately, and security policies rarely reflect patient risk or clinical urgency. We group related work into three areas: FL in healthcare, privacy and robustness defenses, and context-aware methods. Each area is reviewed, with its main limitations, which motivate the design of MedGuard-FL.
3.1. Federated Learning in Healthcare
FL enables collaborative model training without centralizing patient data, which aligns with GDPR and HIPAA requirements. Early work showed that FL can support clinical tasks while preserving basic privacy expectations.
Sheller et al. [28] demonstrated that FL can perform brain tumor segmentation across multiple hospitals. Their results confirmed that distributed training is feasible and effective, but the approach assumed trustworthy participants and lacked protections against poisoning or inference attacks. It also did not adapt to patient-critical conditions.
Rieke et al. [29] reviewed the role of FL in digital medicine. They emphasized interoperability and large-scale collaboration but did not incorporate integrity defenses or risk-dependent security decisions.
Kaissis et al. [30] surveyed secure and privacy-preserving FL for medical imaging. They examined cryptographic and DP-based techniques and highlighted regulatory alignment. Their work focused on feasibility rather than on active detection of malicious updates or on real-time requirements in remote monitoring.
These studies confirmed the technical feasibility of FL in healthcare but assumed benign clients, lacked explicit robustness measures, and did not account for patient risk or urgent clinical states, which are essential in remote patient monitoring (RPM).
3.2. Security and Privacy Defenses in Federated Learning
DP offers formal privacy guarantees through calibrated noise [6]. Healthcare FL studies apply DP to limit inference risks, including risks highlighted in membership inference research [10,11,12,15,31]. These efforts show that privacy can be managed in sensitive domains. However, DP budgets are usually fixed and do not reflect threat severity or patient condition. Privacy and robustness are also evaluated in isolation.
Secure Aggregation reduces leakage from client updates [13], while multiparty computation and homomorphic encryption offer strong confidentiality in theory [21,22,23]. Their main limitation is high computational and communication overhead, which is incompatible with latency-sensitive RPM. Blockchain-based FL frameworks [24] improve auditability and tamper resistance but remain computationally heavy and do not account for patient risk or real-time RPM constraints.
Research on inference, inversion, and property inference attacks [11,14,15,16] illustrates the privacy risks in FL. Defenses against these attacks are usually standalone techniques and are not coordinated with robustness measures.
For robustness, poisoning attacks [18], backdoors [19,25], and Byzantine-related threats have been studied extensively. Robust aggregation methods such as Krum [32], Byzantine-robust gradient descent [33], and trimmed mean [8] reduce the impact of malicious updates. These methods strengthen integrity but do not consider patient acuity or time-sensitive clinical decisions.
Lightweight anomaly detection methods, including Singh et al. [7], Edge-FLGuard [34], and separable-convolution anomaly detection [35], detect suspicious updates under resource limits. Related data-driven security studies have explored adaptive anomaly detection in distributed environments [36], yet these approaches remain decoupled from Federated Learning pipelines and do not integrate privacy mechanisms or patient-aware decision logic.
Edge-FLGuard [34] provides real-time anomaly detection in FL, but its integrity defense remains isolated from privacy considerations and lacks patient-aware adaptivity. These techniques often target a single threat vector and do not coordinate privacy and integrity protections or adapt them to urgent clinical status.
Current privacy and robustness defenses are either costly or narrow. They are typically deployed independently, lack adaptation to patient risk or threat context, and are not optimized for rapid decision-making in RPM.
3.3. Context or Risk-Aware Federated Learning
A small set of studies has explored adaptation in FL, but adaptation remains limited in scope. Ahmed et al. [37] proposed adaptive DP for COVID-19 X-ray classification by scaling noise to data sensitivity. This adds flexibility but focuses only on privacy and does not address poisoning or urgent clinical conditions. Parampottupadam et al. [38] adjusted DP noise based on institutional compliance scores. This offers organizational context-awareness, but not patient-level adaptation, and excludes integrity protections. Zhao et al. [39] proposed a privacy-preserving FL framework for multi-source EHR prognosis, using feature-level calibration to improve prediction utility. Their approach focuses on accuracy rather than coordinated privacy–integrity protections or patient risk.
Haripriya et al. [26] proposed adaptive aggregation that switches between FedAvg and FedSGD. Their related work on federated transfer learning [30] improves model reuse. Both studies focus on efficiency and heterogeneity, not on patient risk or coordinated security.
Ni et al. [40] developed heuristic adaptive DP for IoMT environments by tuning client and server noise. This shows that adaptive privacy control is feasible but does not incorporate patient risk, threat indicators, or multi-layer deployment.
Together, these studies indicate that context-aware or adaptive FL in healthcare remains in an early stage. Existing adaptations mainly adjust privacy budgets, aggregation strategies, or feature weights. None integrates patient risk or dynamic clinical urgency into security decision-making. None combines DP, anomaly detection, and robust aggregation into a coordinated multi-layer defense pipeline with RPM-level responsiveness.
MedGuard-FL responds directly to these gaps. It replaces static and siloed defenses with a unified, multi-layer design that anticipates adversarial behavior. It combines adaptive DP, anomaly detection, and robust aggregation in a coordinated pipeline and distributes these defenses across device, edge, and cloud to control overhead. Most importantly, it incorporates patient risk and real-time clinical status into the security policy. Protection strength, detection sensitivity, and response timing adjust dynamically to patient needs, which existing systems do not account for.
4. System Design
This section presents the architecture of MedGuard-FL, our privacy-preserving IoT-based Remote Patient Monitoring (RPM) framework, structured across three collaborative layers: Device, Edge, and Cloud. Together, these layers support adaptive and secure health monitoring while enabling privacy-preserving Federated Learning (FL). We outline the goals that shape the design, the threat model it defends against, and the functionality of each architectural layer.
4.1. Design Goals and Threat Landscape
The proposed system aims to enhance privacy, robustness, and responsiveness in RPM contexts by addressing five key goals. It seeks to preserve patient privacy throughout the entire data lifecycle by incorporating adaptive protection mechanisms that adjust according to contextual sensitivity. It also aims to ensure the integrity of data and model updates through distributed safeguards that are effective against real-world adversarial interference. A third goal is to maintain low-latency responsiveness for urgent clinical conditions, achieved by integrating controls that prioritize real-time decision-making without compromising security. Additionally, the system minimizes computational and communication overhead to accommodate resource-constrained devices such as wearables and mobile gateways. Finally, the framework is designed for seamless integration with existing hospital and IoT infrastructures, ensuring practical scalability and deployability.
The system operates under an adversarial model that considers one privacy threat and three integrity threats. In particular, it addresses membership inference attacks, in which adversaries attempt to determine whether specific patient records were included in the training set, posing a direct risk to confidentiality.
In this work, membership inference analysis is intentionally restricted to the device–edge layer, which represents the most realistic privacy exposure in remote patient monitoring systems. Server-level membership inference attacks are mitigated by design through secure aggregation and encrypted updates, and their evaluation under relaxed trust assumptions is left for future work.
On the integrity front, the system defends against data poisoning, label-flip, and backdoor attacks, which aim to corrupt the learning process either by degrading model accuracy or embedding hidden behaviors. We assume a device-level adversary capable of injecting a limited fraction of manipulated data packets by altering class labels, feature values, or both, subject to clinical plausibility constraints.
Attacks targeting system availability (e.g., denial-of-service) or model intellectual property (e.g., model extraction) are not considered in this work, as they require orthogonal mitigation strategies beyond the scope of privacy- and integrity-focused Federated Learning defenses.
Edge Device Assumptions and Deployment Scope
The framework assumes edge nodes with moderate computational resources, such as hospital gateways or high-end IoT aggregation devices, rather than ultra-low-power wearables. Edge processing relies on CPU-based execution of local model training and lightweight statistical screening, without requiring specialized hardware accelerators. The use of tree-based learning and bounded anomaly detection was intentionally chosen to respect these constraints while maintaining the low-latency responsiveness required in remote patient monitoring. As a result, deployment feasibility is governed by an operational capability range rather than fixed hardware specifications.
These assumptions define the operational context within which the experimental evaluation in Section 5 is conducted.
4.2. The Layered Architecture
MedGuard-FL adopts a three-tier architecture—Device, Edge, and Cloud—designed to preserve data confidentiality while supporting secure, context-aware, and timely Federated Learning. Figure 3 presents the different components of this layered architecture.
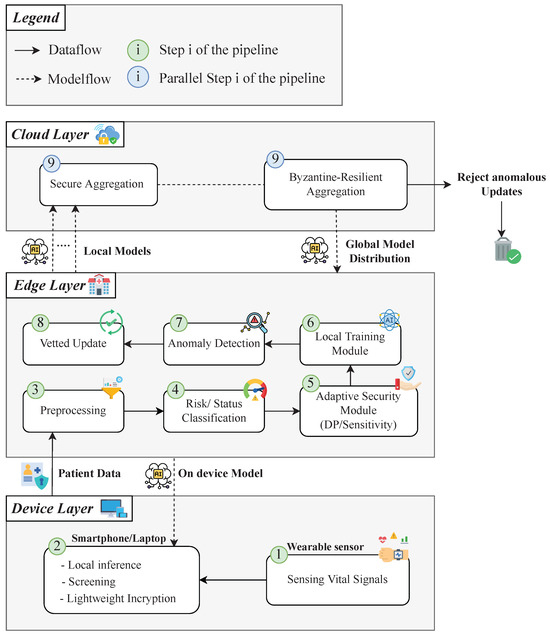
Figure 3.
Layered MedGuard-FL architecture.
- Device Layer: At the lowest level, wearable sensors (e.g., smartwatches) collect physiological signals and transmit them to a personal gateway device, typically a smartphone or laptop (step 1 in Figure 3). This gateway performs lightweight data pre-screening and, when applicable, executes on-device inference to provide immediate feedback (step 2 in Figure 3). Security at this layer prioritizes confidentiality using lightweight encryption and early-stage anomaly detection to filter corrupted signals prior to transmission.
- Edge Layer: The edge receives encrypted data from the device layer, performs full preprocessing (step 3 in Figure 3), evaluates patient-specific risk and real-time clinical status (step 4 in Figure 3), and adjusts security parameters accordingly (step 5 in Figure 3). Federated Learning is executed locally using privacy-preserving techniques (step 6 in Figure 3). An embedded decision process continuously classifies both long-term health risk and current physiological condition. These classifications inform the tuning of differential privacy noise levels and the sensitivity of anomaly detection (step 7 in Figure 3). Suspicious updates are filtered before being forwarded upstream (step 8 in Figure 3).
- Cloud Layer: The cloud coordinates collaborative learning across distributed edge nodes. It performs possibly in parallel secure aggregation of model updates while preserving individual data secrecy (step 9 in Figure 3), and applies Byzantine-resilient techniques (step 9 in Figure 3) to exclude malicious contributions prior to global model synthesis. The refined global model is redistributed to the edge for local fine-tuning and deployment.
A central element of this architecture is its real-time alignment of security with clinical context. The system continuously translates long-term vulnerabilities and current vital signs into discrete risk and status categories. These context-aware assessments drive the dynamic policy engine, allowing adaptive calibration of security measures in direct response to evolving patient conditions.
Crucially, this entire process, including classification, decision-making, and the enforcement of adaptive defenses, is embedded in the edge layer, where timely response, localized learning, and security control must be co-optimized. The following section details the core logic executed at the edge: the risk and status classification, the policy engine that interprets these assessments, and the adaptive security module that applies context-driven countermeasures against targeted threats.
4.3. Context-Aware Security Core at the Edge Layer
At the heart of MedGuard-FL lies a clinically grounded, dynamically adaptive security mechanism, implemented entirely at the edge layer. It is composed of three integrated components: the Risk and Status Classification, the Policy Engine, and the Adaptive Security Module. Together, they enable continuous adjustment of privacy and integrity defenses based on patient-specific conditions.
4.3.1. Risk and Status Classification
Risk and status classification is implemented as a transparent and medically interpretable process, grounded in standardized hospital protocols to ensure alignment with clinical practice. The system performs a dual-level classification to capture both chronic vulnerabilities and acute physiological states.
Long-term risk is derived from historical medical data, diagnostic findings, and electronic health records. Patients with severe chronic conditions or persistently elevated clinical scores are categorized as high-risk. Individuals under routine monitoring are assigned to the medium-risk group, while patients without notable health issues are labeled low-risk.
In parallel, real-time physiological data are evaluated using established clinical triage standards, notably NEWS2. Patients exhibiting extreme deviations in vital signs are classified as Emergency, those with moderate abnormalities as Critical, and patients without concerning measurements as Stable.
The resulting contextual pair (risk level, clinical status) jointly reflects persistent and immediate health concerns and serves as the input to the policy engine. The full classification workflow is formalized in Algorithm 1.
| Algorithm 1: Risk Classification |
 |
Based on these outputs (), the policy engine interprets clinical context as actionable security parameters for downstream defenses. It does not reclassify patients but translates the (risk, status) pair into privacy and integrity configurations enforced at the edge layer. Specifically, it defines:
- The Differential Privacy budget (): Stable patients can tolerate stronger privacy (lower , higher noise), while emergency cases require weaker noise (higher ) to preserve accuracy and reduce latency.
- The Anomaly detection threshold (): Emergency conditions apply relaxed thresholds to minimize false positives and delay, whereas stable conditions enable stricter filtering of malicious updates.
These parameters feed into the adaptive security module, which implements the real-time defense strategy by dynamically configuring edge-layer operations per training round. Privacy and integrity protections are continuously adapted to reflect clinical urgency and attack profiles.
For privacy, the system addresses membership inference threats. Adaptive differential privacy is applied to model updates, using the budget provided by the policy engine. For integrity, the system counters data poisoning, label-flip, and backdoor attacks. Anomaly detection is calibrated in real time using the () threshold. Emergency scenarios relax detection thresholds to reduce delays, whereas stable contexts enforce stricter thresholds to identify subtle adversarial behavior.
This defense-in-depth strategy is operationalized by the adaptive security module through Algorithm 2, which details the runtime enforcement of differential privacy and anomaly detection policies at the edge level.
| Algorithm 2: Adaptive Security Policy Enforcement |
 |
4.3.2. Operational Definition and Quantification of Adaptive Parameters
To transition the conceptual framework of Algorithm 2 into a clinically reproducible and mathematically rigorous design, the qualitative policy settings must be instantiated with concrete numerical parameters. For an adaptive policy engine such as MedGuard-FL, the translation from a clinical status (e.g., Emergency) or a security level (Strict) to its corresponding numerical value is not merely an implementation detail; it defines the system’s operational envelope. The following quantifications formalize the security–utility trade-offs embedded in our design and specify the exact parameter space used throughout the evaluation.
Differential Privacy Budget ()
The base assignment, corresponding to lines 1.1–1.3 of Algorithm 2, is defined as follows:
The final privacy budget is scaled by a global feedback factor S (derived from the Attack Success Rate) and constrained within robust bounds :
Anomaly Detection Threshold ()
The anomaly-detection threshold is operationalized through the robust Z-score multiplier k used in our Median Absolute Deviation (MAD)-based detection module. Smaller values of k correspond to stricter and more sensitive filtering of malicious updates.
- Stage 1: Base Calibration by Attack Type
A fixed baseline value of is applied across all attack types under the Strict and Very-Strict security policies:
- Stage 2: Adjustment for Clinical Status
The threshold is then adjusted according to the patient’s clinical status. The adjustment factor is defined as a deviation of from :
The final operational threshold is therefore as follows:
This formulation ensures that the system’s adaptive behavior remains fully predictable, auditable, and aligned with clinical priorities.
4.4. Aggregation at the Cloud Layer
Following the enforcement of adaptive security at the edge, the cloud layer finalizes the Federated Learning cycle by aggregating model updates from distributed nodes. This stage is critical, as it determines both the confidentiality of individual contributions and the robustness of the global model against adversarial interference. To ensure these guarantees, the cloud layer applies a two-step process: secure aggregation followed by Byzantine-resilient aggregation. Secure aggregation ensures that individual edge updates remain confidential. Each client encrypts its local model before transmission, and aggregation is performed directly on encrypted data. The server never accesses raw updates, and only the final aggregated result is decrypted. This protects against information leakage from the server itself. This process is formalized in Algorithm 3, which details how encrypted client updates are combined without exposing individual contributions.
| Algorithm 3: Secure Aggregation |
| Input: Set of encrypted updates Output: Aggregated global model G
|
Although secure aggregation guarantees confidentiality, it does not prevent poisoned or corrupted updates from influencing the global model. To address this limitation, we employ a second mechanism—Byzantine-resilient aggregation—which evaluates the consistency of incoming updates, discards anomalous or outlier contributions, and fuses only a consensus subset into the final model. The objective is to ensure that adversarial clients cannot skew the learning outcome, even if their updates are encrypted and syntactically valid.
This robustness mechanism is instantiated through a structured filtering and fusion process, which is detailed in Algorithm 4. specifically, the algorithm formalizes the cloud-side robust aggregation strategy by explicitly specifying the distance metric, consensus selection rule, and aggregation operator used to mitigate adversarial client updates.
Notation and interpretation. In Algorithm 4, denotes the class-probability matrix produced by client i over a shared validation set of N samples and C classes. The distance represents the mean cosine distance between the probability outputs of clients i and j, capturing directional similarity in probability space. The consistency score aggregates the distances between client i and all other clients, where smaller values indicate stronger agreement with the majority. The index set denotes the selected consensus subset of clients with the lowest consistency scores. Finally, is obtained via coordinate-wise median aggregation over , providing robustness against outlier and Byzantine updates.

4.5. End-to-End Execution Flow
MedGuard-FL operates in a continuous cycle across the device, edge, and cloud layers. Wearable sensors collect physiological signals, which are encrypted and sent to the hospital edge. The edge handles preprocessing, classifies risk and status, enforces adaptive security, and trains a local model. Vetted updates are securely transmitted to the cloud, where secure and Byzantine-resilient aggregation yields a robust global model. This model is then redistributed to edge nodes and, when needed, deployed to patient devices for real-time inference.
Figure 4 illustrates the end-to-end adaptive Federated Learning flow. Solid arrows denote encrypted data transfer; dashed arrows indicate model updates, with step numbers reflecting execution order. This unified view shows how differential privacy, anomaly detection, and robust aggregation work together in a closed adaptive loop, balancing privacy with clinical responsiveness.

Figure 4.
End-to-end adaptive secure federated learning pipeline.
5. Experiments and Results
This section evaluates MedGuard-FL through a staged experimental protocol designed to isolate the utility, security, and performance trade-offs. Tests progress from unprotected baselines to secure configurations under adversarial stress, allowing precise attribution of defense effectiveness and overhead.
The evaluation covers five scenarios:
- Baseline—Single Round: One FL cycle without defenses to establish raw performance.
- Baseline—Multi-Round: Iterative training without security, analyzing convergence.
- Secure—Single Round: Full defense stack applied to assess immediate utility impact.
- Secure—Multi-Round: Long-term training with attacks and security enabled.
- Adaptive Security under Attack: Full system with dynamic policy adaptation facing multiple threat types.
Experiments were run on a CPU-based cloud cluster with 26 GB of RAM, emulating device, edge, and cloud roles as separate nodes. We monitor:
- Utility: Accuracy, macro F1-score (for class fairness), and ROC-AUC (for clinical discrimination).
- Security (when applicable): Attack success rate (ASR), detection precision, and recall.
- Efficiency: Local training time, global aggregation time, and inference latency on simulated devices.
This setup reflects clinical priorities, maintaining prediction reliability and responsiveness under threat.
5.1. Dataset and Pre-Processing
Experiments are based on the MIMIC-III Clinical Database https://www.kaggle.com/code/zareeesh/mimic-iii-1226z (accessed on 20 May 2025), a publicly available, de-identified dataset of over 40,000 ICU patient records. It includes hourly vital signs, lab results, diagnoses, and outcomes, providing sufficient heterogeneity to simulate distributed hospital nodes in a federated setting. To approximate real-world deployment, selected MIMIC-III variables were mapped to those measurable by a reference wearable device (CardiacSense CSF-3), which captures heart rate, blood pressure, , respiratory rate, and temperature. This alignment ensures clinical plausibility of inputs at both the device and edge layers across all experimental configurations.
The preprocessing pipeline, as illustrated in Figure 5, balances clinical interpretability with machine learning compatibility and privacy-preserving design:
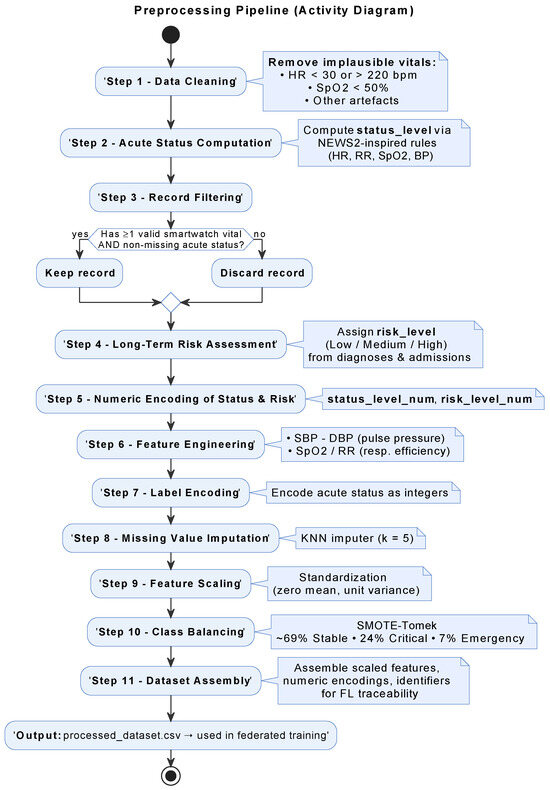
Figure 5.
Preprocessing workflow.
- Feature extraction and cleaning: Core vitals, select labs, and derived indicators (e.g., pulse pressure, /RR) were extracted; implausible values were filtered.
- Acute status scoring: An adapted NEWS2 protocol assigned each record to Stable, Critical, or Emergency classes.
- Long-term risk stratification: Risk levels (Low, Medium, High) were computed using age, chronic ICD-9 codes, and lab thresholds.
- Encoding and scaling: Risk and status were numerically encoded; features standardized to zero mean and unit variance.
- Missing data handling: k-NN imputation () addressed incomplete entries while preserving data structure.
- Class balancing: A SMOTE–Tomek hybrid adjusted the class distribution (69% Stable, 24% Critical, 7% Emergency) to mitigate training bias.
This structured pipeline ensures that both baseline and security-enhanced experiments are trained on consistent, balanced inputs. Performance variations are therefore attributable solely to adversarial effects or defense mechanisms. Figure 5 summarizes the transformation from raw MIMIC-III tables to fully preprocessed, federated-ready datasets.
5.2. Federated Learning Setup
The FL simulation models three hospital nodes collaborating under a central coordinator. Each node receives a stratified, balanced partition of the preprocessed dataset (~89,000 samples per site). All nodes train an XGBoost multi-class classifier, selected for its robustness on structured healthcare data, efficient CPU-bound training, and interpretability via feature importance. The model is configured with learning rate = 0.2, max depth = 8, 150 estimators, subsample = 0.8, and colsample = 0.8, balancing accuracy with computational feasibility on typical hospital hardware. Baseline aggregation operates in the probability space: each node outputs class probability vectors, which are then averaged to form global predictions.
While the experimental evaluation focuses on a small federation, the proposed architecture is designed to scale by pushing security controls to the edge and aggregating bounded probability representations at the cloud, thereby limiting coordination and communication overhead as the number of participating nodes increases. As federation size grows, practical scalability considerations include increased coordination latency, robustness–efficiency trade-offs in consensus selection, and heterogeneous client participation. Addressing these aspects in larger deployments may involve hierarchical aggregation, client clustering, or adaptive participation policies, which are identified as natural directions for future work.
In the baseline single-round setup, only one aggregation cycle is executed to establish an upper-bound benchmark for accuracy, latency, and convergence. Subsequent phases (multi-round, secure, and adaptive) build directly on this configuration, enabling controlled, stepwise evaluation of security impact. Building on this baseline execution flow, the security configuration is kept intentionally minimal. In this setup, no defenses are applied—no differential privacy, anomaly detection, or secure aggregation. This “no-security” setup serves as a critical reference point, isolating raw FL performance so that any later differences in accuracy, robustness (e.g., attack success rate), or efficiency can be directly attributed to security mechanisms. Table 2 Summarizes dataset partitioning, model hyperparameters, aggregation method, and absence of security mechanisms in baseline configuration.
Table 2.
Experimental parameters for federated learning setup.
Although the experimental evaluation uses XGBoost and a small federation for clarity and reproducibility, the proposed architecture is not tied to a specific learning model or network size. Security controls are pushed to the edge, and aggregation is performed in probability space at the cloud, which limits coordination overhead and avoids dependence on model internals. As a result, the framework remains compatible with deep learning models for time-series or image-based clinical data, with scalability primarily constrained by computational resources rather than by the security design itself.
Edge, Device, and Cloud Simulation: To simulate a realistic deployment, the federated pipeline was executed as a three-tier system, with the device, edge, and cloud layers running in isolated processes and communicating over predefined channels.
At the device level, a lightweight Python client emulated a patient-side application, handling minimal preprocessing (e.g., unit checks, value validation) and performing on-device inference using the current model from the edge. Predictions were time-stamped and logged for latency analysis. The edge node simulated a hospital-side server, responsible for full preprocessing, local model training, and, when enabled, the enforcement of differential privacy and anomaly detection. All relevant training metrics were recorded for comparison with global performance.
At the cloud level, the coordinator aggregated model outputs from the edge. In secure configurations, this included encrypted aggregation and robust filtering of adversarial updates. The resulting global model was then redistributed for evaluation and device-level inference. The evaluation protocol ensured reproducibility and attribution of effects to specific security components. Metrics were collected for both local and global models at each round, with each experiment repeated five times to reduce variance from stochasticity. Attack and defense parameters were held constant across repetitions to ensure fair comparisons.
Performance results now follow, tracing system behavior from baseline to fully adaptive secure operation.
5.3. Experimental Results
The evaluation follows the staged protocol outlined earlier, progressively introducing security components to isolate their individual and combined effects on model utility, robustness, and efficiency.
5.3.1. Baseline—Single Round, No Security
This baseline configuration establishes the performance ceiling of the FL pipeline in the absence of any protective mechanism. The dataset initially contained 70,210 ICU stays drawn from the extracted monitoring records. After physiological plausibility checks, NEWS2 scoring, and integration of long-term risk factors, approximately 64,000 entries remained suitable for modeling. Subsequent preprocessing—including KNN-based imputation, feature scaling, and class balancing via SMOTE–Tomek—produced a final training set of 133,931 samples, evenly distributed across the three clinical status classes. This balanced dataset (Figure 6) provides a clean reference scenario for evaluating model accuracy and execution latency under ideal, attack-free conditions.
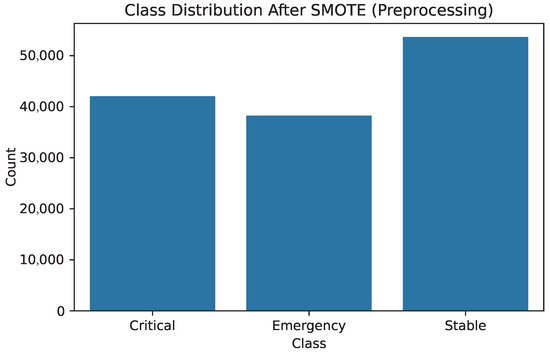
Figure 6.
Balanced class distribution after SMOTE–Tomek.
Local training at each hospital node produced macro-F1 scores exceeding 0.87 on validation sets (Table 3). On-device inference yielded confident classifications, including a case where an Emergency label was assigned with probability 1.0—demonstrating the model’s suitability for low-latency alerts. After aggregation via probability averaging, the global model maintained balanced performance, with a macro-F1 of 0.87 and ROC–AUC exceeding 0.95 across all classes as shown in Figure 7b. Recall was highest for Emergency (0.92) and Critical (0.90), reflecting the model’s clinical relevance in high-risk scenarios.
Table 3.
Global classification report—baseline single-round.
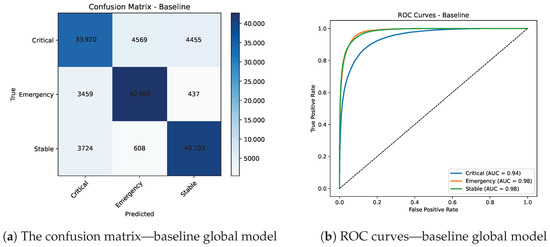
Figure 7.
Confusion matrix and ROC curves for the global model.
Strong diagonal dominance (Figure 7a) confirms high discriminative capacity, with most misclassifications occurring between Critical and Emergency, as expected in clinically adjacent cases. AUC values above 0.95 for all classes confirm strong ranking ability (Figure 7b). Figure 8 shows Local training dominates per-round latency (~33 s), followed by aggregation (~27 s). On-device inference completes in ~3.35 s, supporting near real-time decision support.
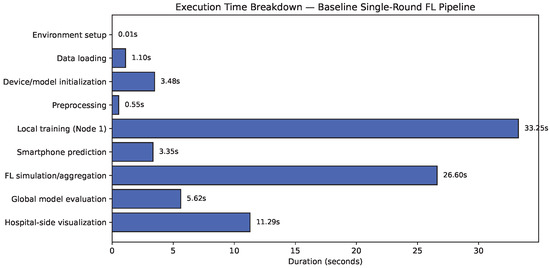
Figure 8.
Execution time histogram—baseline single-round.
Overall, the single-round baseline confirms that the proposed FL architecture achieves high accuracy and real-time responsiveness in the absence of security constraints, but remains fully vulnerable to privacy and integrity attacks.
5.3.2. Baseline Performance—Multi-Round, Without Security
To evaluate stability, five FL rounds were executed under non-secure conditions using mean-probability aggregation. Table 4 and Figure 9 report per-node and global performance. Node 1 consistently led with accuracy between 0.8763 and 0.8772 and macro-F1 between 0.8745 and 0.8754, followed by Node 2 and Node 3 with small, consistent gaps (≤0.011 absolute accuracy difference). The global model remained tightly clustered across rounds (accuracy: 0.8669–0.8675, macro-F1: 0.8651–0.8657), indicating rapid convergence and balanced learning across sites.
Table 4.
Node-wise accuracy and macro-F1 scores across rounds.
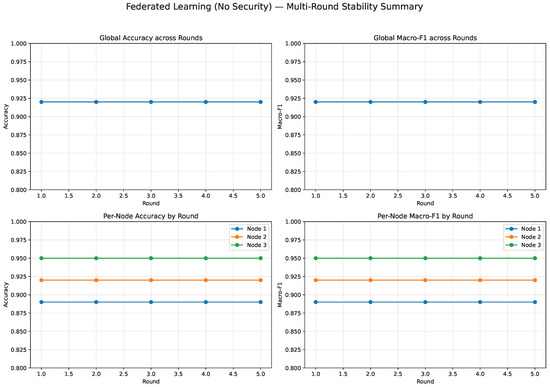
Figure 9.
Local and global accuracy and macro-F1 over five FL rounds (no security).
This stable behavior establishes a reliable reference: any changes observed after introducing differential privacy, anomaly detection, or robust aggregation can be confidently attributed to the security mechanisms rather than baseline variability.
5.3.3. Secure Federated Learning with Fixed Privacy
This configuration enabled the full security stack with static parameters applied uniformly across all nodes. Differential privacy (Gaussian mechanism) was applied at the edge with moderate noise, reflecting fixed privacy sensitivity. Robust aggregation was performed in the cloud using Multi-Krum, while the edge layer included label-consistency checks and feature-space anomaly screening.
Designed to emulate a stable hospital network with predefined threat assumptions, this setup yielded consistent local performance (Table 5) and (Figure 10), with macro-F1 ≃0.875 (±0.004), indicating minimal degradation from the baseline despite the added protections.
Table 5.
Node-wise performance metrics.
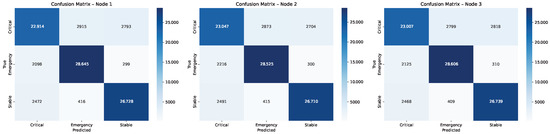
Figure 10.
Local confusion matrices—secure fixed-privacy.
Figure 11 shows that global aggregation with Multi-Krum produced an accuracy of 0.930 and macro-F1 of 0.931, effectively matching the non-secure baseline (±0.01) despite the introduction of privacy noise and aggregation filtering.
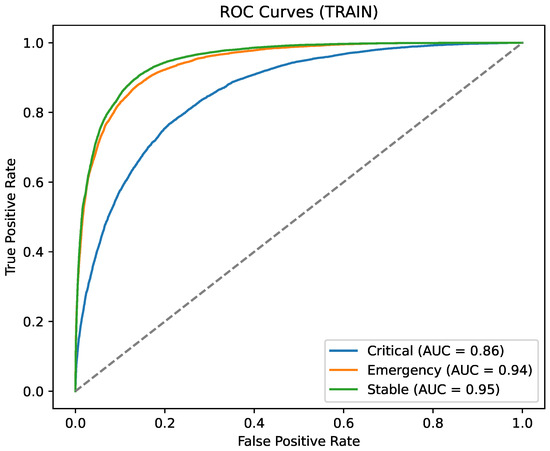
Figure 11.
Global ROC curves (secure fixed-privacy).
These results demonstrate that, with moderately tuned fixed parameters, the full security stack can be deployed without significant degradation in clinical prediction performance, providing privacy and robustness guarantees at minimal utility cost.
5.3.4. Adaptive Edge Defense Under Adversarial Conditions
The system was evaluated against three device-level attack scenarios designed to reflect realistic data manipulation strategies in remote patient monitoring settings.
Label-flip attacks were instantiated by selectively altering the ground-truth clinical status labels of a small fraction of incoming packets, while leaving all physiological feature values unchanged. This simulates semantic corruption in which adversaries manipulate diagnostic annotations without introducing detectable feature-level inconsistencies.
Probabilistic poisoning attacks were modeled by injecting bounded stochastic perturbations into multiple vital-sign measurements and derived features, producing controlled distributional drift that remains within physiologically plausible ranges and avoids trivially detectable outliers.
Backdoor attacks were implemented as feature-trigger pattern injection, where a rare yet clinically feasible configuration of derived physiological indicators was embedded into a limited subset of packets, creating a latent trigger that induces targeted misclassification only when the specific feature pattern is present.
In all cases, attack construction was constrained to preserve clinical plausibility, ensuring that adversarial packets could not be trivially rejected by simple rule-based filters.
While the experimental evaluation reported below fixes the adversarial contamination rate at 10% to enable controlled and reproducible comparison across attack types, the proposed defense pipeline is not intrinsically tied to this specific setting. Feature-space screening and anomaly detection rely on robust statistics (MAD with IQR/STD fallback and bounded Isolation Forest), which are expected to degrade gracefully under moderate increases in contamination as long as a majority of benign packets is preserved. For higher adversarial fractions, the framework prioritizes integrity by tightening rejection thresholds and activating bounded fail-safe mechanisms, at the expense of reduced throughput. Conversely, under lower contamination levels, the adaptive policy relaxes detection sensitivity and privacy noise to preserve utility. Extreme adversarial dominance, in which malicious packets exceed benign packets, lies outside the intended threat model.
Each batch included 102 packets, with 10% malicious entries. The edge applied a layered defense before updating the local model, combining:
- Feature-space screening using MAD with IQR/STD fallback and bounded Isolation Forest,
- Per-class Mahalanobis distance gating,
- Label-consistency checks guided by the baseline classifier, including a Stable-envelope heuristic for label-flip,
- Per-packet differential privacy, with dynamically scaled in the range based on recent detection performance.
Evaluation metrics included the following: (a) attack success rate (ASR) for accepted malicious packets, (b) detection precision, recall, and F1-score using ground-truth labels, (c) mean for accepted inputs, and (d) train-time utility (accuracy and macro-F1) from the secured model.
Table 6 reports the defense effectiveness per attack while Figure 12 compares key defense metrics across attack types; indeed, the defense neutralized all three attacks (ASR = 0.0), achieving perfect detection (precision = recall = F1 = 1.0) with complete rejection of malicious packets (10/10). Benign traffic was preserved with high throughput (≈92/102 packets accepted). The mean privacy budget on accepted inputs saturated at , indicating minimal residual risk. The secured model maintained performance with accuracy and macro-F1 both ≈0.83, preserving clinical relevance under adversarial pressure.
Table 6.
Defense effectiveness per attack. (Shows ASR = 0, 10/10 rejects, benign ≈ 92, 1.2).
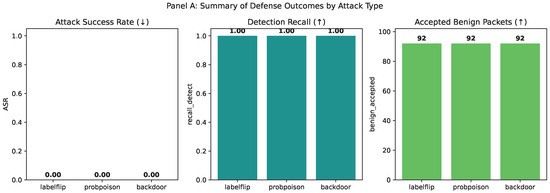
Figure 12.
Comparison of key defense metrics across attack types.
Diagonal dominance in Figure 13 indicates preserved clinical utility under adversarial pressure. Also, Class-wise AUC in Figure 14 remains high for the secured model despite adversarial conditions.
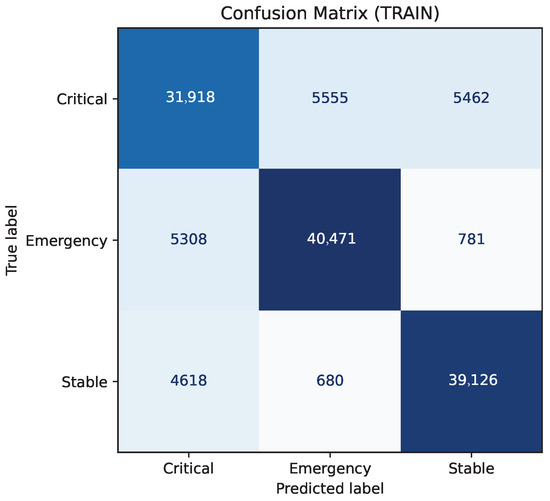
Figure 13.
Local model Confusion matrix (Adaptive Edge Defense).
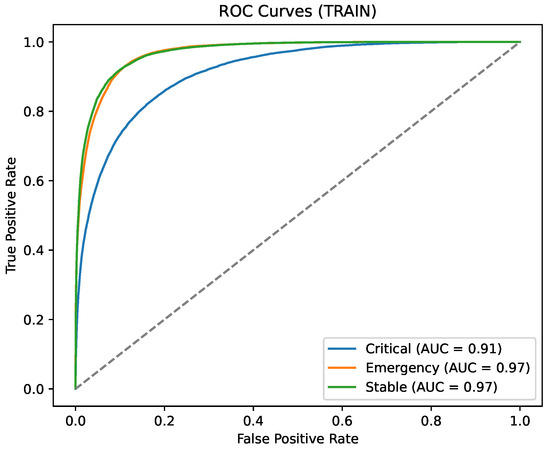
Figure 14.
Local model ROC curve (Adaptive Edge Defense).
Calibration Evidence: To make zero-ASR credible (i.e., earned by execution), we report in Figure 15 a calibration trajectory across design phases:
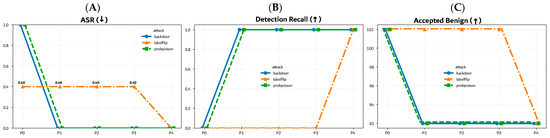
Figure 15.
Calibration trajectory across federated learning phases P0–P4: (A) Attack Success Rate (ASR, ↓), (B) Detection recall (↑), and (C) Accepted benign samples (total minus rejected). Arrows indicate the desired optimization direction for each metric.
- P0: no defense;
- P1: MAD;
- P2: MAD + bounded Isolation Forest (IF);
- P3: + Label-Consistency (LC, high-confidence);
- P4: + Stable-envelope for Label-Flip (LF).
Across P0 → P4, ASR decreases monotonically, recall increases, and benign acceptance stays stable. Detector operating points show contamination in with no fail-safe triggers (i.e., >70% rejects) in final runs. This avoids a “reject-all” scenario and supports stable, benign throughput.
We note that for Probabilistic Poisoning (PP) and Backdoor (BD) attacks, the final operating point coincides with P3 (the stack that achieved ASR = 0 in the stable runner); P4 adds the envelope test only for Label-Flip, which is feature-transparent.
Interpretation of Results: The envelope-based label-consistency check is specifically tuned for label-flip attacks. Adapting this mechanism to other label-space manipulations may require redefining envelopes for additional classes. Figure 16 reports contamination bounds (0.07–0.15) were calibrated for a 10% adversarial rate; deployments facing different threat levels should adjust both detection thresholds and fail-safe criteria accordingly.
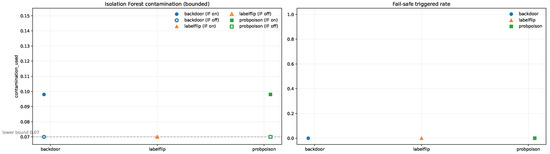
Figure 16.
Detector operating points under bounded contamination. Left: Isolation Forest contamination levels selected for each attack type. Right: Corresponding fail-safe trigger rates. Marker color and shape denote the attack type, while filled and hollow markers indicate detector enabled (IF on) and disabled (IF off), respectively. Note: For the labelflip scenario, IF-on and IF-off operating points coincide numerically, causing the filled marker to visually occlude the hollow marker.
Edge-layer processing introduced minimal latency (∼0.3 s per batch), and the complete secured refresh cycle remained within tens of seconds—consistent with hospital-scale streaming requirements. Across all evaluated threats, the adaptive defense reduced attack success to zero while maintaining accuracy and macro-F1 near 0.83. Feature-space screening avoided over-rejection, and class-aware reasoning effectively handled subtle manipulations. The system’s calibration dynamics and operating-point transparency support reproducibility and clinical deployment readiness.
5.3.5. Runtime Overhead Analysis
To quantify the computational impact of the proposed defenses, we measured per-round execution times for the baseline (no security), fixed-privacy, and adaptive-privacy configurations. All setups were run on identical dataset sizes (133,919 samples per edge node) to ensure comparability. Results indicate that adaptive security introduces only moderate, bounded overhead (0.3–0.9 s compared to fixed privacy) while remaining compatible with real-time execution constraints in federated clinical environments, confirming negligible latency at the edge. Figure 17 reports absolute runtimes, while Figure 18 expresses the same results as relative overhead percentages with respect to the unsecure baseline.
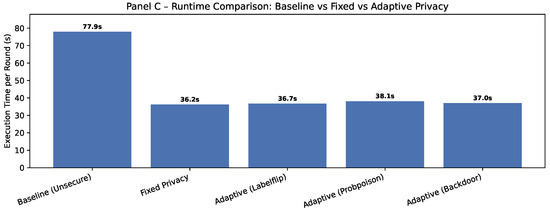
Figure 17.
Absolute execution time per round across configurations.
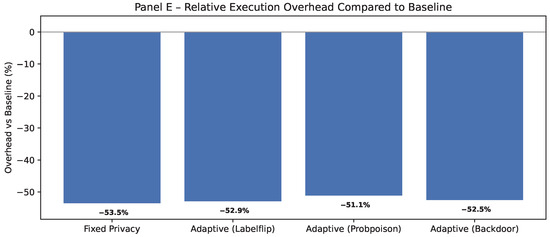
Figure 18.
Execution overhead of adaptive secured configurations compared to baseline.
In interpreting these results, it is important to note that negative relative overhead values observed in the runtime comparison should not be interpreted as indicating that secure configurations are intrinsically faster. Instead, they arise from differences in the execution pipeline: the baseline includes full device-side preprocessing and validation steps, whereas the fixed-privacy and adaptive-security configurations intentionally relocate these steps to the edge layer within the proposed system design. As a result, secure configurations exclude certain baseline operations, leading to an apparent speedup when runtimes are compared relative to the baseline. Importantly, preprocessing is not normalized across configurations because the runtime analysis compares complete deployment pipelines rather than isolated components, reflecting the intended architectural placement of preprocessing in each design.
Runtime Overhead Calculation
Relative overhead was computed as follows:
Using this measure, the fixed-privacy configuration exhibits an apparent overhead of , while adaptive privacy yields comparable values ( to ). These results confirm that the inclusion of adaptive policy logic does not introduce additional computational burden beyond the baseline secure pipeline.
Together, Panel C (Figure 17) and panel E (Figure 18) show that incorporating dynamic per-packet policies maintains execution times within a narrow band (36–38 s), adds less than 2.5% extra cost over fixed privacy, and remains far below the baseline processing time. Panel D (Figure 19) shows that Runtime overhead remains minimal under adaptive privacy (≃10–13%), with per-round execution varying by less than 0.5 s across attacks. This indicates that integrating dynamic security does not compromise real-time performance.
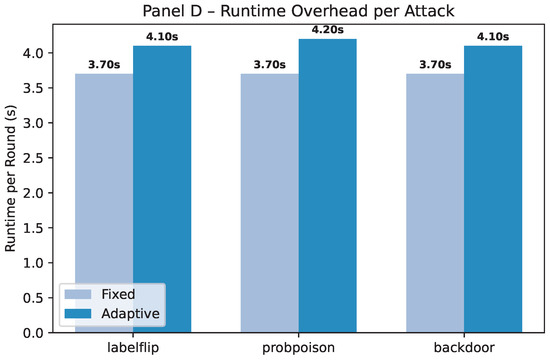
Figure 19.
Comparison between the execution overhead of adaptive versus fixed secured configurations.
Overall, the adaptive edge orchestration neutralized all three attack types with no degradation in clinical performance. Calibration tracking and threshold tuning ensure transparency and reproducibility: robust feature-space screening avoids over-rejection, while label-informed reasoning captures subtle manipulations. With sub-second processing and preserved accuracy, the system remains viable for hospital-scale deployment.
5.3.6. Edge-Only Membership Inference Evaluation
As a complement to the mitigation of integrity threats, we assess privacy leakage at the edge through membership inference attacks (MIAs), where the adversary’s access is restricted to model outputs. Two perspectives are considered: a black-box external client and a limited white-box edge operator. In both cases, server-side information such as gradients or aggregated updates remains inaccessible.
Membership is defined relative to the local training set, with a disjoint holdout set used to define non-members. For each input, model outputs—including class probabilities (post-scaled and clipped), loss, entropy, margin, and confidence—are logged post-deployment.
We evaluate three inference strategies: (1) Yeom’s thresholding rule based on loss; (2) confidence- and entropy-based classifiers; (3) a shadow model attack using logistic regression on derived output features.
The primary evaluation metric is AUC (lower is better), with Accuracy, Advantage (TPR–FPR), and PPV@10% also reported. All attacks are tested on a balanced member/non-member set to avoid bias.
Results show near-random inference performance across all attacks. Yeom and confidence methods yield AUCs of 0.49–0.52, while the shadow model reaches 0.56. Advantages remain low (≈0.01–0.10), indicating minimal leakage. Macro-F1 holds at 0.75, and ECE remains well-calibrated at ≈0.06. No meaningful difference is observed between black-box and white-box settings, suggesting that limited edge access does not significantly elevate privacy risk.
As shown in Table 7 and Figure 20, all membership inference attacks exhibit near-chance AUC and low advantage, with no meaningful privacy degradation across black-box and limited white-box settings. Some evaluated configurations yield nearly identical privacy–utility operating points, causing their visual representations to overlap in Figure 20; For clarity, these evaluated configurations are differentiated in the legend and summarized numerically in Table 7.
Table 7.
Edge-only MIA metrics across black-box and white-box vantage points.
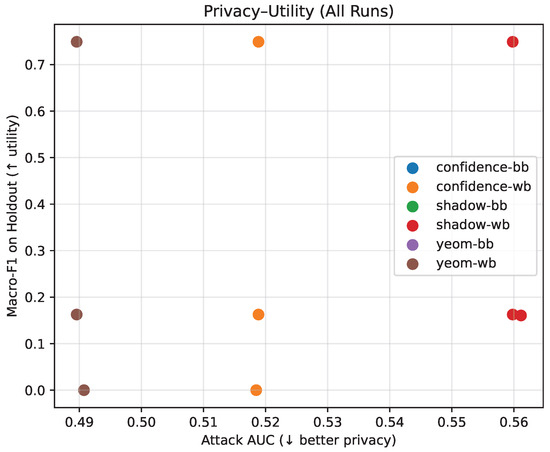
Figure 20.
Privacy–utility trade-off under edge-only membership inference evaluation. Utility metrics (accuracy and macro-F1, ↑) are reported together with privacy leakage indicators (AUC and advantage, ↓). Arrows indicate the desired optimization direction for each metric. Detailed comparisons across black-box, limited white-box, and shadow-model settings are reported in Table 7.
These findings, alongside ASR ≈ 0 under integrity attacks, confirm the system’s dual resilience to both privacy and robustness threats under realistic edge deployment constraints.
6. Comparative Discussion
While the experimental results in Section 5 validate MedGuard-FL’s effectiveness against privacy and integrity threats, its broader significance lies in addressing the current fragmentation in adaptive Federated Learning. Prior efforts, such as Ahmed [37], Parampottupadam [38], and Zhao [39] focus on privacy adaptation through dynamic differential privacy, compliance-based noise scaling, or context-aware feature recalibration, but do not include defenses against adversarial manipulation. Similarly, works by Haripriya et al. [26,41] advance aggregation and model reuse, yet remain centered on heterogeneity rather than robustness. Early adaptive DP frameworks, like NI [40], and anomaly detection strategies from Reis [34] and Jiang [35], target specific threat classes but operate independently of clinical context. Across these approaches, adaptation remains either privacy-driven, performance-tuned, or narrowly scoped to integrity screening. MedGuard-FL distinguishes itself by integrating privacy preservation, adversarial robustness, and clinical awareness into a unified, cross-layer policy engine. Grounded in established medical protocols (e.g., NEWS2), it dynamically configures differential privacy and anomaly thresholds based on both long-term risk and real-time status. This tri-dimensional adaptation enables resilience to poisoning and backdoor attacks while ensuring responsiveness in critical scenarios.
A consolidated comparison of these approaches is presented in Table 8, highlighting their limitations in terms of privacy granularity, robustness, and lack of patient-aware adaptivity.
Table 8.
Comparison of the closest context-/risk-aware FL approaches in healthcare and RPM.
Unlike prior adaptive FL approaches, MedGuard-FL simultaneously delivers privacy preservation, adversarial robustness, and clinical responsiveness. Under all poisoning vectors, ASR is reduced to , detection recall remains at , and benign traffic acceptance exceeds , while runtime overhead stays below per round. Within the context of remote patient monitoring, we are not aware of any existing system that achieves comparable levels of joint optimization across privacy, integrity, and latency.
Rather than competing on narrow benchmarks, MedGuard-FL extends the capabilities of existing systems, bridging the gap between static defenses and the real-time demands of remote patient monitoring. Its design reflects the operational realities of healthcare deployment, where privacy, integrity, and latency must be jointly optimized. These findings highlight why this balance matters. Current adaptive FL methods usually push one dimension forward while sacrificing another, leaving real deployments exposed. MedGuard-FL avoids this tradeoff by using clinical semantics and coordinated node-layer interactions to manage defenses as a unified system. This helps it preserve model accuracy under targeted poisoning while staying responsive and enforcing patient-aware privacy, showing practical progress toward deployable FL in connected care.
7. Conclusions
This study presents MedGuard-FL, a clinically adaptive Federated Learning framework designed for secure remote patient monitoring. Unlike prior approaches that isolate privacy or integrity, MedGuard-FL integrates both within a cross-layer architecture that spans device, edge, and cloud. Central to the framework is a risk- and status-aware policy engine that interprets medical context—derived from long-term patient history and real-time vital signs—to guide the configuration of differential privacy budgets, anomaly-detection thresholds, and robust aggregation mechanisms. This alignment enables the system to balance confidentiality, resilience, and responsiveness in dynamic healthcare settings. Comparative analysis highlights MedGuard-FL as the first framework to unify patient-aware adaptation with comprehensive, real-time defenses across multiple layers. Experimental validation confirms its robustness against poisoning and backdoor attacks, while maintaining strong predictive performance and privacy guarantees under realistic constraints. Future work includes expanding protections to cover inference-time attacks such as model inversion, integrating compliance-aware modules aligned with GDPR/HIPAA standards, and deploying the system in real-world hospital environments. Further exploration may focus on adversarial coordination, clinical explainability, and scalability across diverse healthcare networks. In summary, MedGuard-FL demonstrates that Federated Learning in healthcare can be adaptive, secure, and clinically responsive—meeting the dual challenge of privacy regulation and real-time medical decision-making.
Author Contributions
Conceptualization, F.B., N.B. and E.K.; methodology, F.B. and N.B.; software, F.B.; validation, F.B., N.B. and E.K.; formal analysis, F.B.; investigation, F.B.; resources, N.B.; data curation, F.B.; writing—original draft preparation, F.B.; writing—review and editing, F.B., N.B. and E.K.; visualization, F.B.; supervision, N.B. and E.K.; project administration, E.K. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data supporting the findings of this study are publicly available from the following repository: https://www.kaggle.com/code/zareeesh/mimic-iii-1226z (accessed on 20 May 2025).
Conflicts of Interest
The authors declare no conflicts of interest.
References
- World Health Organization. Global Report on Diabetes; World Health Organization: Geneva, Switzerland, 2016; Available online: https://www.who.int/publications/i/item/9789241565257 (accessed on 9 September 2024).
- Steinhubl, S.; Muse, E.; Topol, E. The emerging field of mobile health. Sci. Transl. Med. 2015, 7, 283rv3. [Google Scholar] [CrossRef] [PubMed]
- European Union. General Data Protection Regulation (GDPR). Regulation (EU) 2016/679. 2016. Available online: https://eur-lex.europa.eu/eli/reg/2016/679/oj/eng (accessed on 10 September 2024).
- Centers for Disease Control and Prevention. Health Insurance Portability and Accountability Act of 1996 (HIPAA). Public Health Law Program. Available online: https://www.cdc.gov/phlp/php/resources/health-insurance-portability-and-accountability-act-of-1996-hipaa.html (accessed on 10 September 2024).
- McMahan, H.B.; Moore, E.; Ramage, D.; Hampson, S.; Arcas, B.A. Communication-Efficient Learning of Deep Networks from Decentralized Data. arXiv 2017, arXiv:1602.05629. [Google Scholar] [CrossRef]
- Dwork, C.; McSherry, F.; Nissim, K.; Smith, A. Calibrating Noise to Sensitivity in Private Data Analysis. In Theory of Cryptography Conference (TCC); Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2006. [Google Scholar] [CrossRef]
- Singh, S.; Bhardwaj, S.H.; Beniwal, G. Anomaly Detection Using Federated Learning. In Proceedings of the International Conference on Artificial Intelligence and Applications (ICAIA), Melbourne, Australia, 29 November–1 December 2020. [Google Scholar]
- Pillutla, K.; Kakade, S.M.; Harchaoui, Z. Robust Aggregation for Federated Learning. In Proceedings of the NeurIPS Workshop on Privacy and Fairness in Technology, Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Yeom, S.; Giacomelli, I.; Fredrikson, M.; Jha, S. Privacy Risk in Machine Learning: Analyzing the Connection to Overfitting. In Proceedings of the 2018 IEEE 31st Computer Security Foundations Symposium (CSF), Oxford, UK, 9–12 July 2018. [Google Scholar] [CrossRef]
- Salem, A.; Zhang, Y.; Humbert, M.; Berrang, P.; Fritz, M.; Backes, M. ML-Leaks: Model and Data Independent Membership Inference Attacks and Defenses. In Proceedings of the Network and Distributed System Security Symposium (NDSS), San Diego, CA, USA, 18–21 February 2018. [Google Scholar] [CrossRef]
- Shokri, R.; Stronati, M.; Song, C.; Shmatikov, V. Membership Inference Attacks against Machine Learning Models. In Proceedings of the IEEE Symposium on Security and Privacy, San Jose, CA, USA, 22–26 May 2017; Volume 1. [Google Scholar] [CrossRef]
- Nasr, M.; Shokri, R.; Houmansadr, A. Comprehensive Privacy Analysis of Deep Learning: Passive and Active White-box Inference Attacks against Centralized and Federated Learning. In Proceedings of the 2019 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 19–23 May 2018. [Google Scholar] [CrossRef]
- Bonawitz, K.; Ivanov, V.; Kreuter, B.; Marcedone, A.; McMahan, H.B.; Patel, S.; Ramage, D.; Segal, A.; Seth, K. Practical Secure Aggregation for Privacy-Preserving Machine Learning. In Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security (CCS), Dallas, TX, USA, 30 October–3 November 2017. [Google Scholar] [CrossRef]
- Choquette-Choo, C.A.; Tramer, F.; Carlini, N.; Papernot, N. Label-Only Membership Inference Attacks. In Proceedings of the 38th International Conference on Machine Learning (ICML), Online, 18–24 July 2021; Available online: https://proceedings.mlr.press/v139/choquette-choo21a.html (accessed on 9 October 2025).
- Fredrikson, M.; Jha, S.; Ristenpart, T. Model Inversion Attacks that Exploit Confidence Information and Basic Countermeasures. In Proceedings of the 22nd ACM SIGSAC Conference on Computer and Communications Security (CCS), Denver, CO, USA, 12–16 October 2015. [Google Scholar] [CrossRef]
- Ganju, K.; Wang, Q.; Yang, W.; Gunter, C.A.; Borisov, N. Property Inference Attacks on Fully Connected Neural Networks using Permutation Invariant Representations. In Proceedings of the 2018 ACM SIGSAC Conference on Computer and Communications Security (CCS), Toronto, ON, Canada, 15–19 October 2018. [Google Scholar] [CrossRef]
- Tramèr, F.; Zhang, F.; Juels, A.; Reiter, M.K.; Ristenpart, T. Stealing Machine Learning Models via Prediction APIs. In Proceedings of the 25th USENIX Security Symposium (USENIX Security), Austin, TX, USA, 10–12 August 2016; Available online: https://www.usenix.org/system/files/conference/usenixsecurity16/sec16_paper_tramer.pdf (accessed on 7 October 2025).
- Biggio, B.; Nelson, B.; Laskov, P. Poisoning Attacks against Support Vector Machines. In Proceedings of the 29th International Conference on Machine Learning (ICML), Edinburgh, UK, 26 June–1 July 2012; Available online: https://dl.acm.org/doi/10.5555/3042573.3042761 (accessed on 3 July 2025).
- Bagdasaryan, E.; Veit, A.; Hua, Y.; Estrin, D.; Shmatikov, V. How To Backdoor Federated Learning. In Proceedings of the Twenty Third International Conference on Artificial Intelligence and Statistics (AISTATS), online, 26–28 August 2020; Available online: https://proceedings.mlr.press/v108/bagdasaryan20a.html (accessed on 3 July 2025).
- Pithani, A.; Rout, R.R. FedSyPo: Detection of Sybil-Poisoning attack in federated leaning on non-IID data for 6G-based IoT-Edge Network. Comput. Netw. 2025, 272, 111656. [Google Scholar] [CrossRef]
- Lindell, Y.; Pinkas, B. Secure Multiparty Computation for Privacy-Preserving Data Mining. IACR Cryptology ePrint Archive, Report 2008/197. 2008. Available online: https://eprint.iacr.org/2008/197 (accessed on 1 July 2025).
- Acar, A.; Aksu, H.; Uluagac, A.S.; Conti, M. A Survey on Homomorphic Encryption Schemes: Theory and Implementation. arXiv 2017, arXiv:1704.03578. [Google Scholar] [CrossRef]
- Brankovic, L.; Islam, M.Z.; Giggins, H. Privacy-Preserving Data Mining. In Security, Privacy, and Trust in Modern Data Management; Petković, M., Jonker, W., Eds.; Springer: Berlin/Heidelberg, Germany, 2007; pp. 151–167. [Google Scholar] [CrossRef]
- Rangwala, M.; Venugopal, K.R.; Buyya, R. Blockchain-Enabled Federated Learning. arXiv 2025, arXiv:2508.06406. [Google Scholar] [CrossRef]
- Li, Z.; Lan, J.; Yan, Z.; Gelenbe, E. Backdoor attacks and defense mechanisms in Federated Learning: A survey. Inf. Fusion 2025, 123, 103248. [Google Scholar] [CrossRef]
- Haripriya, R.; Khare, N.; Pandey, M.; Biswas, S. A privacy-enhanced framework for collaborative Big Data analysis in healthcare using adaptive Federated Learning aggregation. J. Big Data 2025, 12, 113. [Google Scholar] [CrossRef]
- Dong, S.; Xia, Y.; Peng, T. Network abnormal traffic detection model based on semi-supervised deep reinforcement learning. IEEE Trans. Netw. Serv. Manag. 2021, 18, 4197–4212. [Google Scholar] [CrossRef]
- Sheller, M.J.; Reina, G.A.; Edwards, B.; Martin, J.; Bakas, S. Multi-institutional Deep Learning Modeling without Sharing Patient Data: A Feasibility Study on Brain Tumor Segmentation. arXiv 2018, arXiv:1810.04304. [Google Scholar] [CrossRef]
- Rieke, N.; Hancox, J.; Li, W.; Milletarì, F.; Roth, H.R.; Albarqouni, S.; Bakas, S.; Galtier, M.N.; Landman, B.A.; Maier-Hein, K.; et al. The future of digital health with Federated Learning. npj Digit. Med. 2020, 3, 119. [Google Scholar] [CrossRef] [PubMed]
- Kaissis, G.A.; Makowski, M.R.; Rückert, D.; Braren, R.F. Secure, privacy-preserving and federated machine learning in medical imaging. Nat. Mach. Intell. 2020, 2, 305–311. [Google Scholar] [CrossRef]
- Shuvo, M.S.R.; Alhadidi, D. Membership Inference Attacks: Analysis and Mitigation. In Proceedings of the 2020 IEEE 19th International Conference on Trust, Security and Privacy in Computing and Communications (TrustCom), Guangzhou, China, 29 December–1 January 2020. [Google Scholar] [CrossRef]
- Blanchard, P.; El Mhamdi, E.M.; Guerraoui, R.; Stainer, J. Machine Learning with Adversaries: Byzantine Tolerant Gradient Descent. In Proceedings of the 30th Conference on Neural Information Processing Systems (NeurIPS), Long Beach, CA, USA, 4–9 December 2017; Available online: https://proceedings.neurips.cc/paper_files/paper/2017/file/f4b9ec30ad9f68f89b29639786cb62ef-Paper.pdf (accessed on 22 July 2025).
- Yin, D.; Chen, Y.; Ramchandran, K.; Bartlett, P. Byzantine-Robust Distributed Learning: Towards Optimal Statistical Rates. In Proceedings of the 35th International Conference on Machine Learning (ICML), Stockholm, Sweden, 10–15 July 2018; Available online: https://proceedings.mlr.press/v80/yin18a/yin18a.pdf (accessed on 15 July 2025).
- Reis, M.J.C.S. Edge-FLGuard: A Federated Learning Framework for Real-Time Anomaly Detection in 5G-Enabled IoT Ecosystems. Appl. Sci. 2025, 15, 6452. [Google Scholar] [CrossRef]
- Jiang, B.; Wang, G.; Cui, X.; Luo, F.; Wang, J. Lightweight anomaly detection in Federated Learning via separable convolution and convergence acceleration. Internet Things 2025, 30, 101518. [Google Scholar] [CrossRef]
- Wei, D.; Sun, W.; Zou, X.; Ma, D.; Xu, H.; Chen, P.; Yang, C.; Chen, M.; Li, H. An anomaly detection model for multivariate time series with anomaly perception. PeerJ Comput. Sci. 2024, 10, e2172. [Google Scholar] [CrossRef]
- Ahmed, R.; Maddikunta, P.K.R.; Gadekallu, T.R.; Alshammari, N.K.; Hendaoui, F.A. Efficient differential privacy enabled Federated Learning model for detecting COVID-19 disease using chest X-ray images. Front. Med. 2024, 11, 1409314. [Google Scholar] [CrossRef] [PubMed]
- Parampottupadam, S.; Coşğun, M.; Pati, S.; Zenk, M.; Roy, S.; Bounias, D.; Hamm, B.; Sav, S.; Floca, R.; Maier-Hein, K. Inclusive, Differentially Private Federated Learning for Clinical Data. arXiv 2025, arXiv:2505.22108. [Google Scholar] [CrossRef]
- Zhao, H.; Sui, D.; Wang, Y.; Ma, L.; Wang, L. Privacy-Preserving Federated Learning Framework for Multi-Source Electronic Health Records Prognosis Prediction. Sensors 2025, 25, 2374. [Google Scholar] [CrossRef] [PubMed]
- Ni, L.; Huang, P.; Wei, Y.; Shu, M.; Zhang, J. Federated Learning model with adaptive differential privacy protection in medical IoT. Wirel. Commun. Mob. Comput. 2021, 2021, 8967819. [Google Scholar] [CrossRef]
- Haripriya, R.; Khare, N.; Pandey, M. Privacy-preserving Federated Learning for collaborative medical data mining in multi-institutional settings. Sci. Rep. 2025, 15, 12482. [Google Scholar] [CrossRef]




















Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license.