Abstract
Unit commitment (UC) is a critical challenge in power system optimization, typically formulated as a high-dimensional mixed-integer linear programming (MILP) problem with non-deterministic polynomial-time hard (NP-hard) complexity. While the branch-and-bound (B&B) algorithm can determine optimal solutions, its computational cost increases exponentially with the number of units, which limits the practical application of UC. Machine learning (ML) has recently emerged as a promising tool for addressing UC, but its effectiveness relies on substantial training samples. Moreover, ML models suffer significant performance degradation when the number of units changes, a phenomenon known as the task mismatch problem. This paper introduces a novel method for Branching Acceleration for UC, aiming to reduce the computational complexity of the B&B algorithm while achieving near-optimal solutions. The method leverages invariant branching tree-related features and UC domain-specific features, employing imitation learning to develop an enhanced pruning policy for more precise node pruning. Numerical studies on both standard and practical testing systems demonstrate that the method significantly accelerates computation with few training samples and negligible accuracy loss. Furthermore, it exhibits robust generalization capability for handling task mismatches and can be seamlessly integrated with other B&B acceleration techniques, providing a practical and efficient solution for UC problems.
1. Introduction
1.1. Background and Motivation
Unit commitment (UC) serves as a crucial component in power system operations and electricity market clearing problems. It is crucial to obtain high-quality solutions within stringent time constraints [1,2]. However, UC is inherently a non-deterministic polynomial-time hard (NP-hard) problem, as it is formulated as a mixed-integer linear programming (MILP) problem involving numerous binary and continuous variables as well as equality and inequality constraints. This has led to longstanding challenges in solving UC problems in terms of computational performance and solution quality, and there is an urgent need for breakthrough approaches [3,4,5,6].
The global optimal solution to the UC problem is typically obtained using the branch-and-bound (B&B) algorithm. Nevertheless, it suffers from slow solution speeds, and its computational complexity grows exponentially with the number of units, rendering it impractical for real-time applications [7,8,9].
In recent years, machine learning (ML) has undergone rapid development, attracting considerable attention in the field of mathematical optimization. As an advanced computational tool, ML demonstrates a remarkable ability to uncover hidden data patterns, trends, and correlations across similar problem domains [10,11]. This capability establishes ML as a disruptive approach for addressing the trade-off between computational complexity and performance in MILP challenges. It has spurred significant interest among researchers in the field of power systems in utilizing ML techniques to tackle UC optimization problems [12,13,14].
1.2. Literature Survey
Existing research on applying ML methods to solve UC problems can be broadly classified into two main categories: “direct” ML methods and “indirect” ML methods [15].
The “direct” ML methods refer to end-to-end learning approaches, where ML models are trained to generate solutions directly from input examples. Reference [16] proposes a multiagent fuzzy reinforcement learning model, where generator sets are treated as participants in a reinforcement learning scenario to solve UC problems. However, this model may face limitations when applied to large-scale systems. In [17], regression trees and random forests are used to predict the difference between the MILP solution and the linear programming (LP) relaxed solution for the UC problem. The LP relaxed solution is then adjusted based on this prediction. Nevertheless, this method may face challenges when the difference between the two solutions is large. Reference [18] clusters the historical data of the IEEE 118-bus system into multiple patterns and trains a gated recurrent unit (GRU) to predict the solutions for new instances. In [19], K-nearest neighbor (KNN), random forest, and support vector machines (SVM) were used to predict the on/off status of units in the 39-bus system. A difficulty is that the methods often struggle to maintain prediction accuracy when applied to scenarios outside their training data.
In practical research, exploring the direct relationship between load and solutions to UC problems is often challenging. As a result, “direct” ML methods frequently struggle to deliver high-quality solutions. In this context, “indirect” ML methods have gained significant attention, as they can improve solution efficiency by providing supplementary decision-making information to the UC algorithm or integrating directly with it. Reference [20] proposes a joint branch selection policy that groups discrete variables to construct separate predictors for each group. For large-scale problems, where many possible branch choices exist, this method is ineffective. Reference [21] employs graph convolutional neural networks to learn the full strong branching strategy for B&B decisions, thereby reducing the solution time for the UC problem. However, the method exhibits insufficient prediction accuracy and achieves only a limited reduction in the number of branch nodes. In [22], the unconstrained problem is solved first, followed by the addition of violated constraints, which are then learned using KNN. This approach has limited applicability, and it is not easy to design representative scenarios. Reference [23] proposes an integrated framework that combines data-driven and variable aggregation approaches. ML techniques are used to predict the difficulty of solving UC instances, determining whether heuristics should be applied to accelerate the MILP solver. While this approach enhances problem-solving efficiency, it may compromise solution quality. Reference [24] learns the on/off status of units in the Polish system under different scenarios, reducing the number of binary variables by fixing the on/off status of some units. However, this approach cannot predict instances beyond the existing scenarios.
Existing research has demonstrated the significant potential of ML technology in solving UC problems, but several intractable challenges remain. Beyond the fact that computational efficiency and solution quality are not ideal, two prominent shortcomings persist. On the one hand, a large number of training problem instances are required. For a specific system, thousands or even hundreds of thousands of training examples may be needed, resulting in prohibitive sample acquisition and training costs, which are impractical in real-world applications. On the other hand, existing methods frequently demonstrate limited generalization capability, as they are typically tailored to specific systems. Changes in the number of units can lead to significant performance degradation or even render these methods inapplicable—commonly known as the task mismatch issue.
Among existing studies, integrating ML techniques with the B&B algorithm has shown great promise for solving MILP problems [25]. In particular, imitation learning offers valuable ideas for addressing the aforementioned challenges in UC problems. This method was first introduced in [26] and accelerates the B&B algorithm by simulating expert decision-making. However, to ensure decision feasibility, the method requires maintaining a large search space for each instance, which results in high computational complexity. Reference [27] integrates reinforcement learning with imitation learning to enhance the efficiency of the B&B algorithm. Although this approach is theoretically applicable to all combinatorial optimization problems, its practical performance still requires further validation, and it may not be effective in handling instances with unknown distributions and scales. Reference [28] employs imitation learning for wireless network resource allocation, using the support vector machine to enhance the efficiency of the B&B algorithm with only a few hundred training samples. However, the solution quality is suboptimal, and the acceleration effect is constrained by decision feasibility. These studies, while promising, reveal limitations in search space management, generalization capability, and solution quality, which hinder the direct application of such approaches to complex UC problems.
1.3. Contribution and Organization
To address the challenges outlined above, this paper introduces an innovative ML-based method termed Branching Acceleration for UC. This method enhances the efficiency of solving UC problems by improving the B&B algorithm, providing an approximate optimal solution. The main contributions of this study are summarized as follows:
- Branching acceleration for UC transforms the B&B algorithm into a sequential decision problem, employing imitation learning to learn the optimal pruning policy for the B&B tree, thereby enhancing the original policy. This improvement enables the method to effectively prune uncertain, non-optimal nodes, significantly accelerating the B&B algorithm in solving UC problems. It is worth mentioning that by setting the threshold to iteratively expand the search space, the method ensures feasibility while reducing the average search space.
- To further improve the performance of branching acceleration for UC, this study carefully designs the training process and input features of the ML model. Numerical studies demonstrate that the method achieves near-optimal performance with only a few training UC problem instances and low computational complexity, while exhibiting excellent generalization capability under task mismatches. Furthermore, the studies investigate the impact of various threshold settings during the testing phase. Appropriate threshold settings can effectively improve the method’s performance while balancing its various performance metrics.
- In contrast to the idea of discarding the original policy of the B&B algorithm in existing related research. Branching acceleration for UC is independent of the B&B algorithm’s stages. It can be seamlessly combined with B&B improvement methods, leveraging the strengths of each to enhance overall performance.
The rest of this paper is organized as follows: Section 2 presents the formulation of the UC problem, followed by an introduction to the B&B algorithm in Section 3. The key method of this paper, branching acceleration for UC, is proposed in Section 4. Section 5 discusses the numerical studies conducted on various testing systems. Finally, this work is concluded in Section 6.
2. Formulation of Unit Commitment Problem
In this section, we introduce the formulation of the UC problem. The UC cost minimization problem in power systems is a typical MILP problem that involves binary variables (e.g., units’ on/off status and startup/shutdown operations), continuous variables (e.g., unit output power), and constraints associated with both units and loads. The formulation provided here builds upon the approach in [29], aiming to optimize the objective function while ensuring compliance with the following specific constraints.
2.1. Objective Function
The objective of a UC problem is to minimize the total cost of all generating units:
where and are the total number of time periods and the total number of units, respectively; , and are the generation cost, startup cost, and shutdown cost of the unit , respectively; is the output power of the unit at the period ; and are the unit startup and shutdown control 0-1 variables, respectively. denote that the unit performs startup/shutdown operations at the period .
2.2. Constraints
This subsection describes the constraints that must be satisfied in minimizing the total cost of a UC problem.
- System power balance constraints:
- 2.
- Generation capacity constraints:
- 3.
- Ramp-up/down rate constraints:
- 4.
- Dependency of binary variables:
When the changes, the correct values of and can be ensured. For example, when and , and are forced to be set to 1 and 0, respectively.
- 5.
- Minimum up/down time constraints:
- 6.
- Hydropower plant generation capacity constraints:
- 7.
- Hydropower plant daily generation constraints:
3. Branch-and-Bound Algorithm
This section provides a detailed introduction to the B&B algorithm. As one of the fundamental algorithms for obtaining global optimal solutions to MILP problems [30], the B&B algorithm is extensively applied to the UC problem in power systems. Its key concept involves constructing a search tree to systematically enumerate feasible solutions that could potentially be the global optimum. Through branching and pruning operations, the upper bound (current optimal feasible solution) and lower bound (current optimal linear relaxed solution) of the problem are dynamically updated. The global optimal solution is identified when the gap between these bounds is less than the predefined value. The search process of the B&B algorithm consists of three main components, which are
- Branch selection policy: By assessing the significance of discrete candidate variables, branches are generated to further partition the feasible region, thereby reducing the number of generated nodes.
- Node selection policy: Determine the exploration order of unexplored nodes to guide the B&B algorithm in identifying the node corresponding to the global optimal solution.
- Pruning policy: Deciding whether a node should be further explored can effectively minimize the size of the search tree.
To aid in understanding the algorithm, this paper first defines some symbols. Each node of the B&B search tree contains an MILP relaxed problem (linear programming problem). Let be the -th node and be the relaxed problem at that node. The number of variables in the problem variable is denoted as , and the ordinal numbers of all the discrete variables are stored in . The original problem variable feasible domain is relaxed to and is the -th problem variable. It follows that the objective function of the original problem and the objective function of the relaxed problem are and , respectively. Let the optimal solution and objective function values of the relaxed problem at node be and , respectively,
In this paper, we use to denote the value of the -th variable in , , and set as the best integer solution found during the iterative solving process of the B&B search tree.
The B&B algorithm maintains an unexplored node relaxed problem list , and this list only contains the root node relaxed problem at the beginning. In each iteration, the node selection policy is first used to pop a relaxed problem from to solve it and obtain its and . Then, the pruning policy decides the following action of the node based on the obtained and . If the policy decides to prune, the node does not need to be branched, and the algorithm proceeds to the next iteration. Otherwise, the node is preserved, and the branch selection policy evaluates the importance of the discrete variables in the original problem. If the most important discrete variable is indexed as , the feasible domain of will be divided into two parts for branching as follows
where and represent the feasible domains of the two new nodes and , respectively, after the branching of the node . and are the values of the -th variable of the node to be rounded upward and downward, respectively, which are set to 1 and 0 in this paper. On this basis, relaxed problems and at nodes and are formed as follows
In the end, and are placed in . This completes one iteration of the B&B algorithm. The process is repeated until there are no node problems remaining in , at which point the global optimal solution to the original problem can be obtained.
In this paper, the branch selection policy of the B&B algorithm randomly selects the discrete variable that deviates the most from its integer value. The node selection policy employs a breadth-first exploration policy. The pruning policy prunes a node only if one of the following conditions is met:
- Prune by bound: The solution of the is a non-integer solution but greater than or equal to . Since and ( is the feasible domain of all the children node of ), the value of is a lower bound on the solution of and the optimal solution of its children cannot be the global optimal solution to the original problem.
- Prune by infeasibility: The relaxed problem is infeasible, i.e., unsolvable. It is considered as .
- Prune by integrality: , is an integer, we have already found an optimal solution to . Therefore, there is no longer a need to search for the children of .
We develop the B&B algorithm for the problem, as presented in Algorithm 1.
| Algorithm 1 The branch-and-bound (B&B) algorithm |
| 1. , node number , upper bound ; 2. , ; 3. while do 4. ; 5. Pop the node relaxed problem from ; 6. ; 7. if , is an integer then 8. ; 9. else 10. if then 11. Select the non-integer variable to round up and down; 12. Cutting feasible region ; 13. Two children nodes of ; 14. end if 15. end if 16. end while |
The computation time of the B&B algorithm is directly proportional to the size of the search tree, which grows exponentially with the number of discrete variables. This characteristic is particularly pronounced in UC problems, where the extensive search space makes it challenging for the B&B algorithm to achieve satisfactory solutions within a reasonable timeframe. Therefore, the ability to effectively reduce the size of the search tree is critical to the feasibility of the B&B algorithm in UC problem practical applications.
4. Branching Acceleration for Unit Commitment
This section begins by introducing the key idea of branching acceleration for UC, which leverages an enhanced pruning policy based on imitation learning to improve the B&B algorithm. Next, a specific feature design is carried out according to the characteristics of the UC problem. Finally, the method framework is presented in detail, encompassing the design of classifiers as well as the training and testing phase.
4.1. Enhanced Pruning Policy Based on Imitation Learning
The tree search process of the B&B algorithm can be regarded as a sequential decision problem, which consists of the state space , the action space , and the policy space [31]. The specific decision-making process can be briefly described as follows. For the node , the decision-making agent uses its policy to provide the optimal action based on the observed state , i.e., . The action will have an impact on the next state of the problem.
Theoretically, if the features and labels of all nodes are known, strategies for such finite-dimensional sequential decision problems can be determined through supervised learning. However, in the UC problem, the large number of binary variables results in an excessively large training dataset and an overwhelming number of input features, significantly increasing the complexity of training and rendering this approach highly inefficient. If only some of these nodes are selected for training, and the model’s performance cannot be guaranteed, it may lead to unsatisfactory results. To address the challenge, this paper adopts the data aggregation algorithm, dynamically collecting features and labels to reduce training complexity while ensuring performance [32]. This algorithm shifts the approach from supervised learning to the realm of imitation learning.
The key idea of imitation learning is that learners can improve their performance by imitating the behavior of experts. Unlike supervised learning, which needs to prepare all features and labels before training, imitation learning collects features and labels for the learning object during the learning process, allowing for the correction of errors from the previous policy. This dynamic data collection method reduces the size of the training dataset and improves the training performance and efficiency.
From Section 3, the computation time of the B&B algorithm is determined by the number of nodes explored in its search tree. Among the three policies, the pruning policy plays the most direct and effective role in controlling the number of nodes explored. The B&B algorithm adopts a conservative pruning policy to ensure global optimality by exhaustively checking and comparing all potential solutions. However, this policy results in a significant portion of the computation time being wasted on examining non-optimal nodes. Consequently, enhancing the original pruning policy can effectively reduce the algorithm’s computational time and improve its efficiency.
In this paper, we presented an enhanced pruning policy based on imitation learning. This policy utilizes imitation learning to learn the optimal pruning policy of the B&B algorithm. By integrating an additional policy model into the original pruning policy, it effectively prunes undetermined non-optimal nodes, substantially reducing the search tree size. Specifically, a neural network is employed as the classifier for the enhanced pruning policy. The learned policy takes the features of node () as input and outputs the probabilities of different actions, thereby determining the action to be taken, . Using a neural network as the classifier not only facilitates the application of the threshold iteration algorithm to ensure test feasibility but also dynamically balances computational performance with complexity. The specific design of the neural network is elaborated in Section 4.3.1.
The objective of the enhanced pruning policy is to identify the global optimal solution with a minimal number of nodes, retaining only nodes on the search path to the optimal solution (i.e., the feasible domain contains only the optimal solution). These retained nodes are termed optimal nodes () are shown as red-bordered nodes in Figure 1. The are labeled as class preserve, while all other nodes are labeled as class prune.
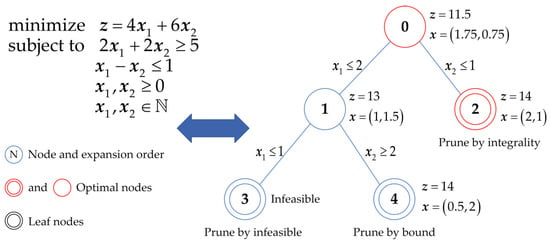
Figure 1.
Example graph of optimal nodes for the B&B algorithm.
4.2. Feature Design
The design of input features for neural networks plays a critical role in the quality of the enhanced pruning policy model. It directly impacts the method’s performance, necessitating meticulous tailoring to the specific application domain. In this study, the input features are composed of data from the B&B search tree structure (branching tree-related features) and the UC problem (UC domain-specific features).
4.2.1. Branching Tree-Related Features
These features exclusively include information from the B&B search tree, the solution to the relaxed problem, and its objective value. Being universal to all MILP problems, these features provide branching acceleration for UC with a solid foundation for generalization capability. Specifically, they can be categorized into the following three types:
- Node features: The action taken by the algorithmic policy is closely related to the state of the current node . Therefore, key information about the node is essential for effective decision-making, such as its depth in the B&B search tree and the objective value of the relaxed problem, i.e., .
- Branching features: The action also depends on the branching variable that generated the current node , determined during the variable selection step of its father node. These features include the value of the branching variable at the current node, i.e., , and the value at the root node, i.e., .
- Tree features: Information from the B&B tree search process is critical. This includes the solution to the relaxed problem at the root node, i.e., , the current local upper bound , and the number of solutions identified so far.
Most of the above features exhibit significant variation across different UC problems. Firstly, there is considerable variation in the objective values; therefore, all objective values as input features in the B&B search tree should be normalized by . Secondly, the search depth of nodes and the number of solutions found vary greatly depending on the number of units, necessitating normalization to mitigate the impact of this scale factor.
4.2.2. UC Domain-Specific Features
For the MILP problem, branching tree-related features are universal; however, relying solely on these features is insufficient for learning an effective policy [33]. Therefore, incorporating UC domain-specific features is critical for enhancing the performance of the policy model.
In power system dispatch, the UC problem is typically formulated as an optimization task aimed at minimizing total generation cost—ensuring economic operation by accurately determining each unit’s operational status and output levels to meet load demand at minimal cost. Drawing on UC domain knowledge and the need for generalization across systems with varying unit counts, we selected the following key features:
- Daily load features: Maximum and minimum daily loads capture crucial load information to establish overall power output limits, thereby affecting unit operation.
- Unit cost features: Operating costs directly influence generation expenses. Within the B&B tree, the generation cost and startup/shutdown costs associated with the current branching variable determine a unit’s potential operating state.
These features are essential for the design and optimization of the policy model, significantly enhancing its performance. Moreover, normalizing these features further improves the model’s generalization capability.
4.3. The Branching Acceleration for UC Framework
This subsection provides a concise overview of the branching acceleration for UC framework, covering the design of the neural network classifier as well as the training and testing phases. The computational process is illustrated in Figure 2.
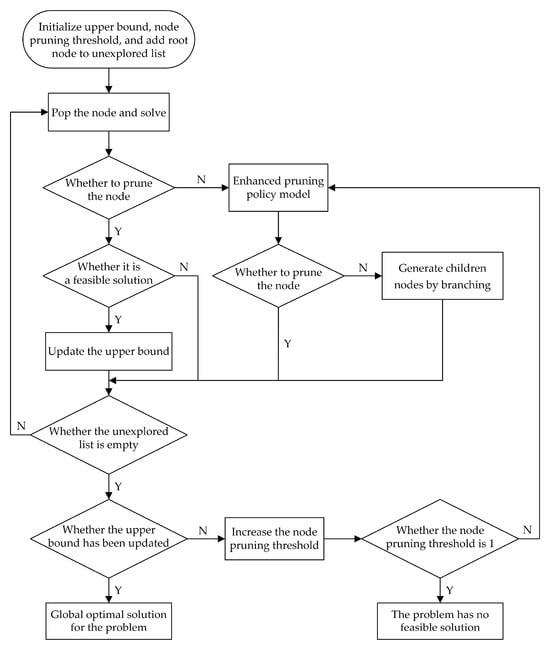
Figure 2.
Computational process of branching acceleration for UC.
4.3.1. Neural Network as Classifier
This study employs the multi-layer perceptron (MLP), a type of neural network, as the binary classifier for the enhanced pruning policy. The input consists of 10 features introduced from Section 4.2, excluding the solution of the relaxed problem at the root node. The output comprises the action probabilities for preserving (optimal node, ) and pruning (non-optimal node, ).
In each layer of the -layer MLP, the inputs are processed by multiplying them with a learned weight matrix, adding a bias term, and then applying a nonlinear activation function element-wise. Specifically, the inputs for the -th layer are computed as follows,
where is the weight matrix for the -th layer; is the bias vector for the -th layer; denotes the output of the -th layer , and are the input features. is the rectified linear unit function, i.e., .
The output of the last layer indicates the probability of each class:
where denotes the -th component of the vector .
In the training phase, the loss function is the weighted cross entropy:
where is the class label; specifically, corresponds to the class prune, while denotes otherwise; represents the weight assigned to each class, which is manually adjusted.
In the process of label acquisition, we observed a significant imbalance between the number of optimal nodes and non-optimal nodes, with the former being much smaller. To address this imbalance, we assigned a higher weight to the samples of optimal nodes. The weight for non-optimal nodes was set to . Specifically,
where and are the set of non-optimal nodes and the set of all nodes in the training dataset, respectively; is the number of nodes in the set.
4.3.2. Training Phase
This study employs a data aggregation algorithm to iteratively update the training dataset for the enhanced pruning policy. During the iterative training, after solving any UC problem (training sample), the policy model will be promptly updated to correct erroneous decisions. This training method effectively reduces the size of the training dataset and the number of training samples required, not only improving training efficiency but also enhancing the practical application value of branching acceleration for UC. The detailed training process is outlined in Algorithm 2.
| Algorithm 2 The training process of branching acceleration for unit commitment (UC) |
| 1. , feature dataset , action dataset , upper bound , training iteration , initial policy ; 2. while do 3. ; 4. while do 5. if then 6. Algorithm 1 is used to solve the -th UC problem; 7. Update the optimal solution and identify optimal nodes ; 8. Label as class preserve and all other nodes as class prune; 9. Store the input features of all nodes to ; 10. ; 11. Determine the correctness of the node action in add the input features of error action nodes and optimal nodes to ; 12. Update the policy model ; 13. ; 14. if then 15. ; 16. ; 17. end if 18. else 19. Go to step 10; 20. end if 21. end while 22. end while |
For the first training iteration, an arbitrary randomized policy is used to solve the first UC problem. In the -th training iteration, we apply the enhanced pruning policy to solve the -th UC problem (a total of UC problems as training samples, with a maximum of training iterations). Firstly, the collected node features are input into the policy to obtain the corresponding decision actions (preserve or prune). Secondly, based on pre-collected labels, the node features with incorrect decision actions are added to the training dataset . During the B&B tree search process, incorrect pruning has more severe consequences than incorrect branching. The optimal node represents the desired search path, and we expect that the enhanced pruning policy does not miss any of these nodes. Ideally, during the testing phase, the policy should preserve only the optimal nodes. Therefore, the features of all optimal nodes are added to .
Finally, the policy is updated to to solve the next UC problem. It is important to note that the frequency of updating the model in iterative training can be adjusted based on the specific characteristics of the problem. The update frequency of the training dataset remains unchanged.
4.3.3. Testing Phase
In the testing phase, branching acceleration for UC is used to efficiently solve UC problems (testing samples). The method employs the enhanced pruning policy to make additional pruning decisions for each node that the original pruning policy has not pruned. The testing process is presented in detail in Algorithm 3.
| Algorithm 3 The testing process of branching acceleration for UC |
| 1. , node number , testing iteration , upper bound , initial threshold ; 2. , ; 3. while do 4. ; 5. if then 6. , increasing the ; 7. end if 8. while do 9. ; 10. Pop the node relaxed problem from and solve it , , ; 11. if , is an integer then 12. ; 13. else 14. if then 15. ; 16. if then 17. ; 18. else 19. , two children nodes of ; 20. end if 21. end if 22. end if 23. end while 24. end while |
For the B&B search tree, an overly conservative pruning policy may preserve too many nodes, leading to increased computational costs, while an overly aggressive pruning policy risks failing to yield a feasible solution. Therefore, this paper aims to dynamically control the search space during the testing phase to strike the optimal balance between performance and computational cost.
Fortunately, neural network classifiers can achieve this ideal process by setting a threshold . The output is a two-dimensional vector, where the values represent the probabilities of preserving and pruning the current node, respectively. These probability values are compared against the threshold to determine the policy action (preserve or prune). For instance, if , the node is pruned; otherwise, it is preserved. A pruning policy with higher thresholds tends to preserve more nodes, achieving better performance but expanding the search space. If the testing phase fails to produce feasible solutions, iteratively increasing the threshold has proven highly effective in numerical studies.
5. Numerical Studies
This section evaluates the performance of branching acceleration for UC in solving the power system UC cost minimization problem. The numerical studies are conducted on both standard testing systems (with unit parameters detailed in Table A1, Appendix A) and practical testing systems from a provincial region in China. All experiments are performed on a computer with a 2.90 GHz Intel (R) Core (TM) i7-10700 CPU and 16 GB of RAM (Intel, Santa Clara, CA, USA). The models and methods are implemented in MATLAB 2021b, and linear programming solutions are obtained using the commercial solver Mosek 10.1.
5.1. Dataset Setup and Performance Evaluation Metrics
In this subsection, we outline the dataset setup and the method’s performance evaluation metrics. Additionally, we present the size of the UC problem across various systems and the computational metrics of the B&B algorithm.
The unit parameters for the standard testing systems are based on [34] and real-world provincial UC data in China. For UC problems involving a larger number of units, the 12-unit configuration is duplicated. The net load data for standard testing systems are sourced from annual load data in Ireland, available publicly in [35]. Although the unit parameters derived from [34] have been adaptively adjusted to better reflect real-world conditions, they remain overly idealized. In particular, there are significant disparities among different unit types, whereas units within the same type display highly similar parameters.
To better validate the superiority and universality of the proposed method, numerical studies were also performed on practical test systems. For these systems, both unit parameters and load data are derived from real-world data in a provincial region of China. A specific number of thermal power plants (15 in total) are randomly selected, with the units within the same plant being identical. Any one of these units may serve as a representative for its corresponding plant. Additionally, all hydropower units (141 in total) are included to form various practical testing systems. It is important to note that the unit count refers exclusively to thermal power units. This study does not consider the on/off status of hydropower units, and standard testing systems do not include such units.
During the training and testing phases, the net loads of the various systems are scaled appropriately by total unit generation capacities. The load sampling interval is set to 15 min, dividing a single day into 96 periods. Table 1 presents the sizes of the UC problem, measured by the number of binary and continuous variables, for different systems.

Table 1.
Sizes of the UC problem.
In the training phase, for the enhanced pruning policy model, the hidden units of the neural network are set to . The model is trained for ten iterations, with input features as described in Section 4.2. The output corresponds to the probabilities of preserving and pruning nodes.
In the testing phase, the performance of the method is evaluated using four metrics: the average node count, average calculation time, speedup, and optimality gap. The average node count refers to the total number of nodes explored to solve all tested UC problems, divided by the number of problems. The average calculation time indicates the total computation time for solving all tested UC problems, divided by the number of problems. The speedup metric quantifies the relative improvement in the computation speed of the particular algorithm compared to the B&B algorithm (e.g., 2× means the particular algorithm solves the UC problem twice as fast as the B&B algorithm). This metric is determined by the total number of nodes explored by both algorithms during the UC problem resolution, covering all nodes explored during the iterative testing process. The optimality gap indicates the difference between the objective function value computed by the particular algorithm and the optimal solution provided by the B&B algorithm, representing the accuracy loss.
In this study, the method’s performance is evaluated during the testing phase using 50 daily load profiles (testing samples), each representing a UC problem. All metrics are averaged across the 50 testing daily load profiles. While searching the B&B tree for each testing daily load profile, the learned enhanced pruning policies are applied to each generated node. The average node count in the B&B tree typically increases exponentially with the number of units. As a result, 50 testing daily load profiles may contain thousands, or even tens of thousands, of testing nodes, providing a sufficient basis for performance evaluation. The average node count and the average computation time for solving the UC problem with the B&B algorithm across different systems are shown in Table 2.
Table 2.
Computational metric for the B&B algorithm.
In addition, this study employs the iterative algorithm to ensure the feasibility of the test. The first testing iteration threshold is set to 0.4, and subsequent thresholds are determined based on the to find the optimal search path for the method’s decision-making process. The parameter represents the threshold adjustment step, while is the number of testing iterations. To provide a more intuitive demonstration of the method’s superiority, is set to 0.03 by default. The effects of different settings will be analyzed in detail in Section 5.4.
5.2. Performance of Branching Acceleration for UC
Obtaining training samples is often difficult and costly, particularly in UC problems, where acquiring a substantial amount of real-world data is hard. Therefore, the number of training samples required to effectively learn a sufficiently robust enhanced pruning policy serves as a critical indicator of the method’s quality.
In this subsection, a 24-unit standard testing system and a 10-unit practical testing system are first used as examples to evaluate the performance of branching acceleration for UC with a minimal number of training daily load profiles (training samples). The corresponding results are presented in Table 3 and Table 4. Subsequently, 30 daily load profiles are utilized to train the enhanced pruning policy models for systems with varying numbers of units. These models are then tested to verify the effectiveness of branching acceleration for UC, with the results summarized in Table 5.
Table 3.
Performance of branching acceleration for UC with different numbers of training daily load profiles in the 24-unit standard testing system.
Table 4.
Performance of branching acceleration for UC with different numbers of training daily load profiles in the 10-unit practical testing system.
Table 5.
Performance of branching acceleration for UC with 30 training daily load profiles.
As demonstrated in Table 3 and Table 4, branching acceleration for UC exhibits remarkable performance with just 20, 25, or 30 training daily load profiles. In the practical testing system, the method achieves a speedup of over 15 times compared to the B&B algorithm, with an accuracy loss of less than 0.05%. In the standard testing system, although the method’s best performance is slightly reduced, it still delivers a speedup of over 10 times, maintaining an accuracy loss of less than 0.08%.
As shown in Table 5, the test results demonstrate that the proposed method substantially accelerates the B&B algorithm while incurring minimal accuracy loss in solving the UC problem. Except for the 12-unit standard testing system and the 5-unit practical testing system (further analyzed in Section 5.3), branching acceleration for UC consistently achieves a speedup of over nine times, with an accuracy loss of less than 0.08%.
Compared to existing studies that often require thousands or even hundreds of thousands of training samples, the numerical studies in this subsection highlight that branching acceleration for UC achieves excellent performance with a minimal number of training samples. A smaller training dataset offers advantages such as lower computational complexity and reduced training time but results in relatively lower method performance. As the number of training samples increases, the method’s performance steadily improves, albeit at the expense of higher label acquisition and training costs. In real-world applications, perfect method performance is not always necessary. An appropriate number of training samples can be chosen based on specific objectives to save costs rather than unthinkingly obsessing over using as many training samples as possible.
5.3. Generalization Capability Analysis of the Enhanced Pruning Policy
The generalization capability of ML models is a key factor that determines their practical value and impact, making it a critical area of focus in ML research. To evaluate the generalization capability of the enhanced pruning policy model proposed in this paper, including the generalization capability for scenarios involving systems with larger or smaller numbers of units. This subsection evaluates policy models trained on the 24-unit standard testing system and the 10-unit practical testing system under varying systems. The number of training daily load profiles is 30, and the number of testing daily load profiles is 50. The results are presented in Table 6.
Table 6.
Generalization capability of the enhanced pruning policy.
As shown in Table 6, the proposed policy models exhibit excellent generalization capability in scenarios with larger or smaller numbers of units. While the performance shows a slight decline compared to re-trained policy models in Table 5, the results remain highly satisfactory. Based on the data in Table 6 and the analysis provided in Section 5.2, the following conclusions can be drawn:
- When testing the enhanced pruning policy model for performance and generalization capability on the 12-unit standard testing system and the 5-unit practical testing system, it becomes evident that the acceleration effect is somewhat less pronounced compared to other systems. This discrepancy occurs because the B&B algorithm generates a relatively small number of search tree nodes, leaving less space for pruning acceleration. As a result, in these cases, the speedup metric does not fully capture the excellent acceleration effect of branching acceleration for UC.
- The performance and generalization capability evaluations of the 5-unit practical testing system reveal suboptimal results for the optimality gap metric. This can be attributed to the fact that systems with smaller total unit generator capacities and corresponding loads tend to have lower costs and greater cost volatility. Even a minor cost difference is reflected in a more significant optimality gap metric.
5.4. Effect of Threshold Settings on Performance
The standard testing system is characterized by a noticeable gap between the parameters of different types of units and highly similar parameters within the same type of units. This allows the method in this study to perform well at low thresholds (below 0.5), often making further testing iterations unnecessary. To investigate the effect of the threshold adjustment step on branching acceleration for UC, the speedup and optimality gap metrics for the 10-unit practical testing system policy model are tested under varying unit numbers and threshold adjustment steps . The number of training daily load profiles is 30, and the number of testing daily load profiles is 50. The results are presented in Table 7 and Table 8.
Table 7.
Speedup of the 10-unit practical testing system policy model under varying unit numbers and threshold adjustment steps .
Table 8.
Optimality gap of the 10-unit practical testing system policy model under varying unit numbers and threshold adjustment steps .
Based on the analysis of the data presented in the tables, the following conclusions can be drawn:
- In most situations, a difference in the threshold adjustment step will have opposite effects on the speedup and optimality gap metrics. Specifically, as the threshold increases, the speedup metric decreases, while the optimality gap metric exhibits an inverse correlation. This occurs because a higher threshold (not the threshold adjustment step) causes the enhanced pruning policy to search the B&B tree more carefully. As the number of search nodes increases, both the quality of the solutions and the likelihood of finding the optimal solution improve.
- In certain cases, the optimality gap and speedup metrics did not show opposing trends in response to varying threshold adjustment steps. This occurs due to an inappropriate threshold adjustment step setting (particularly when set to 0.01), which increases the number of testing iterations required to find a solution. During the iterative search process, a large number of unnecessary nodes are generated when no solution can be found, leading to poor acceleration performance of the method.
Taking into account the data presented in the table in this subsection, is set to 0.03, and for all testing iterations except the first, the threshold is set to to balance the performance metrics in this study. It should be noted that branching acceleration for UC can achieve superior performance across all testing systems by appropriately tuning the threshold adjustment step parameter, .
5.5. Application with the Branch-and-Cut Algorithm
Branching acceleration for UC proposed in this paper is independent of branch selection, node selection, and bound-tightening policies in the B&B algorithm. As a result, it can be applied with various B&B improvement methods, such as the branch-and-cut (B&C) algorithm, to further enhance the overall performance.
B&C is one of the most effective algorithms for solving MILP problems [36]. It combines the B&B algorithm with the cutting plane method, playing a crucial role in improving the solution efficiency for MILP problems. The key characteristic of the B&C algorithm is its dynamic incorporation of cutting planes, particularly at the root node of the B&B search tree, to achieve a better approximation of the integer programming problem. While the cutting plane method increases the constraint size of the MILP model compared to using the B&B algorithm alone, it effectively reduces the feasible domain and the number of nodes explored, which typically results in a significant improvement in overall performance. For these reasons, the B&C algorithm is widely used in practical applications.
In this subsection, branching acceleration for UC is combined with the B&C algorithm, which utilizes strengthened lift-and-project cuts as the cutting planes [37]. Compared with the testing process of branching acceleration for UC (Algorithm 3) described in Section 4, the combined method only adds a certain number of cutting planes at the root node of the B&B tree. The maximum number of cutting planes is set to 10. Note that this study focuses solely on evaluating the effectiveness of combining branching acceleration for UC with other B&B improvement methods. Therefore, the impact of the B&C algorithm on the solution time for the UC problem is not considered. The results are shown in Table 9.
Table 9.
Performance comparison of each algorithm with 50 testing daily load profiles.
The results demonstrate that branching acceleration for UC can be effectively combined with other B&B improvement methods (e.g., the B&C algorithm) to further enhance the overall performance, leveraging their respective strengths for optimal synergy.
6. Conclusions
In this paper, we proposed branching acceleration for UC based on ML techniques to enhance the B&B algorithm through imitation learning and neural networks. This method addresses the UC cost minimization problem, which is typically formulated as a high-dimensional MILP problem in power systems. The effectiveness of the method is validated on both standard testing systems and practical testing systems from a provincial region in China. We have the following significant findings from numerical studies:
- Branching acceleration for UC requires only a few dozen training instances to significantly reduce the computational complexity of the B&B algorithm with negligible accuracy loss, dramatically lowering data acquisition and training costs compared to existing methods that typically demand thousands or even hundreds of thousands of training samples.
- The enhanced pruning policy model exhibits outstanding generalization capability, effectively addressing the task mismatch challenge caused by dynamic changes in unit count—an issue that most existing methods struggle to overcome.
- The iterative algorithm ensures feasibility while mitigating the excessive search space issues common in other B&B improvements.
- Adjusting the iteration threshold further optimizes the method’s performance and allows it to meet the specific requirements of different UC problems in terms of computational efficiency and accuracy loss.
- Branching acceleration for UC is relatively independent of the B&B algorithm’s stages, enabling seamless integration with other B&B improvement methods to further enhance overall performance.
These findings significantly enhance the practical value and applicability of branching acceleration for UC in real-world scenarios. This research is expected to make a meaningful contribution to advancing ML technology in the power systems domain. Future work may explore its application to various testing systems with a larger number of units, its combination with more advanced methods, or the development of specialized neural networks to enhance method performance—promising areas for further investigation.
Author Contributions
Conceptualization, C.Z. and Z.Q.; methodology, C.Z. and Z.Q.; software, C.Z.; validation, C.Z., Z.Q. and Y.S.; formal analysis, C.Z. and Z.Q.; investigation, C.Z.; resources, C.Z. and Z.Q.; data curation, C.Z., Z.Q. and Y.S.; writing—original draft preparation, C.Z.; writing—review and editing, C.Z. and Z.Q.; visualization, C.Z.; supervision, Z.Q.; project administration, Z.Q.; funding acquisition, Z.Q. All authors have read and agreed to the published version of the manuscript.
Funding
This work is supported by the National Natural Science Foundation of China, grant number 52367003.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Partial data analyzed in this study are included in the article. Other data analyzed during the current study are not publicly available due to privacy issues but are available from the corresponding author upon reasonable request.
Conflicts of Interest
Author Yan Sun was employed by the company Guangxi Power Grid Co., Ltd. The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| UC | Unit commitment |
| MILP | Mixed-integer linear programming |
| NP-hard | Non-deterministic polynomial-time hard |
| ML | Machine learning |
| B&B | Branch-and-bound |
| GRU | Gated recurrent unit |
| KNN | K-nearest neighbor |
| SVM | Support vector machines |
| MLP | Multi-layer perceptron |
| B&C | Branch-and-cut |
Appendix A
Table A1.
Standard testing system unit parameters [30].
Table A1.
Standard testing system unit parameters [30].
| Unit ID | Type | (MW) | (MW) | (MW/15 min) | (minutes) | (€) | (€/MW) |
|---|---|---|---|---|---|---|---|
| 1 | Base | 400 | 200 | 30 | 36 | 15,000 | 5 |
| 2 | Base | 400 | 200 | 32 | 34 | 15,000 | 5.25 |
| 3 | Base | 400 | 200 | 34 | 32 | 15,000 | 5.5 |
| 4 | Medium | 300 | 100 | 26 | 20 | 12,000 | 12.5 |
| 5 | Medium | 300 | 100 | 30 | 19 | 12,000 | 12.75 |
| 6 | Medium | 300 | 100 | 34 | 18 | 12,000 | 13 |
| 7 | Medium | 300 | 100 | 38 | 17 | 12,000 | 13.25 |
| 8 | Peak | 250 | 0 | 31 | 1 | 7500 | 80 |
| 9 | Peak | 250 | 0 | 32 | 1 | 7500 | 81 |
| 10 | Peak | 250 | 0 | 33 | 1 | 7500 | 82 |
| 11 | Peak | 250 | 0 | 34 | 1 | 7500 | 83 |
| 12 | Peak | 250 | 0 | 35 | 1 | 7500 | 84 |
References
- Shahidehpour, M.; Yamin, H.; Li, Z. Market Overview in Electric Power Systems. In Market Operations in Electric Power Systems; Wiley-IEEE Press Publishing: New York, NY, USA, 2002; pp. 1–20. [Google Scholar]
- Ostrowski, J.; Anjos, M.F.; Vannelli, A. Tight Mixed Integer Linear Programming Formulations for the Unit Commitment Problem. IEEE Trans. Power Syst. 2012, 27, 39–46. [Google Scholar] [CrossRef]
- Yan, B.; Luh, P.B.; Zheng, T.; Schiro, D.A.; Bragin, M.A.; Zhao, F.; Zhao, J.; Lelic, I. A Systematic Formulation Tightening Approach for Unit Commitment Problems. IEEE Trans. Power Syst. 2020, 35, 782–794. [Google Scholar] [CrossRef]
- Wu, J.; Luh, P.B.; Chen, Y.; Yan, B.; Bragin, M.A. Synergistic Integration of Machine Learning and Mathematical Optimization for Unit Commitment. IEEE Trans. Power Syst. 2024, 39, 391–401. [Google Scholar] [CrossRef]
- Qu, M.; Ding, T.; Sun, Y.; Mu, C.; Pan, K.; Shahidehpour, M. Convex Hull Model for a Single-Unit Commitment Problem With Pumped Hydro Storage Unit. IEEE Trans. Power Syst. 2023, 38, 4867–4880. [Google Scholar] [CrossRef]
- Lin, W.-M.; Yang, C.-Y.; Tsai, M.-T.; Wang, Y.-H. Unit Commitment with Ancillary Services in a Day-Ahead Power Market. Appl. Sci. 2021, 11, 5454. [Google Scholar] [CrossRef]
- Chen, Y.; Pan, F.; Holzer, J.; Rothberg, E.; Ma, Y.; Veeramany, A. A High Performance Computing Based Market Economics Driven Neighborhood Search and Polishing Algorithm for Security Constrained Unit Commitment. IEEE Trans. Power Syst. 2021, 36, 292–302. [Google Scholar] [CrossRef]
- Quarm, E.; Madani, R. Scalable Security-Constrained Unit Commitment Under Uncertainty via Cone Programming Relaxation. IEEE Trans. Power Syst. 2021, 36, 4733–4744. [Google Scholar] [CrossRef]
- Nair, V.; Bartunov, S.; Gimeno, F.; Glehn, I.V.; Lichocki, P.; Lobov, I.; O’Donoghue, B.; Sonnerat, N.; Tjandraatmadja, C.; Wang, P.; et al. Solving Mixed Integer Programs Using Neural Networks. arXiv 2020, arXiv:2012.13349. [Google Scholar]
- Shen, Y.; Shi, Y.; Zhang, J.; Letaief, K.B. LORM: Learning to Optimize for Resource Management in Wireless Networks With Few Training Samples. IEEE Trans. Wireless Commun. 2020, 19, 665–679. [Google Scholar] [CrossRef]
- Sang, L.; Xu, Y.; Sun, H. Ensemble Provably Robust Learn-to-Optimize Approach for Security-Constrained Unit Commitment. IEEE Trans. Power Syst. 2023, 38, 5073–5087. [Google Scholar] [CrossRef]
- Zhang, Z.; Zhang, D.; Qiu, R.C. Deep reinforcement learning for power system applications: An overview. CSEE J. Power Energy Syst. 2020, 6, 213–225. [Google Scholar] [CrossRef]
- Gao, Q.; Yang, Z.; Li, W.; Yu, J.; Lu, Y. Online Learning of Stable Integer Variables in Unit Commitment Using Internal Information. IEEE Trans. Power Syst. 2023, 38, 2947–2950. [Google Scholar] [CrossRef]
- Yan, J.; Li, Y.; Yao, J.; Yang, S.; Li, F.; Zhu, K. Look-Ahead Unit Commitment With Adaptive Horizon Based on Deep Reinforcement Learning. IEEE Trans. Power Syst. 2024, 39, 3673–3684. [Google Scholar] [CrossRef]
- Bengio, Y.; Lodi, A.; Prouvost, A. Machine learning for combinatorial optimization: A methodological tour d’horizon. Eur. J. Oper. Res. 2021, 290, 405–421. [Google Scholar] [CrossRef]
- Navin, N.K.; Sharma, R. A fuzzy reinforcement learning approach to thermal unit commitment problem. Neural Comput. Appl. 2019, 31, 737–750. [Google Scholar] [CrossRef]
- Lin, X.; Hou, Z.J.; Ren, H.; Pan, F. Approximate Mixed-Integer Programming Solution with Machine Learning Technique and Linear Programming Relaxation. In Proceedings of the 2019 3rd International Conference on Smart Grid and Smart Cities (ICSGSC), Berkeley, CA, USA, 25–28 June 2019; pp. 101–107. [Google Scholar] [CrossRef]
- Yang, N.; Yang, C.; Xing, C.; Ye, D.; Jia, J.; Chen, D.; Shen, X.; Huang, Y.; Zhang, L.; Zhu, B. Deep learning-based SCUC decision-making: An intelligent data-driven approach with self-learning capabilities. IET Gener. Transm. Distrib. 2022, 16, 629–640. [Google Scholar] [CrossRef]
- Iqbal, T.; Banna, H.U.; Feliachi, A.; Choudhry, M. Solving Security Constrained Unit Commitment Problem Using Inductive Learning. In Proceedings of the 2022 IEEE Kansas Power and Energy Conference (KPEC), Manhattan, KS, USA, 25–26 April 2022; pp. 1–4. [Google Scholar] [CrossRef]
- Lodi, A.; Zarpellon, G. On learning and branching: A survey. Top 2017, 25, 207–236. [Google Scholar] [CrossRef]
- Sun, Y.; Wu, J.; Zhang, G.; Zhang, L.; Li, R. An ultra-fast optimization algorithm for unit commitment based on neural branching. Energy Rep. 2023, 9, 1112–1120. [Google Scholar] [CrossRef]
- Jiménez-Cordero, A.; Morales, J.M.; Pineda, S. Warm-starting constraint generation for mixed-integer optimization: A Machine Learning approach. Knowl.-Based Syst. 2022, 253, 109570. [Google Scholar] [CrossRef]
- Yang, Y.; Wu, L. Machine learning approaches to the unit commitment problem: Current trends, emerging challenges, and new strategies. Electr. J. 2021, 34, 106889. [Google Scholar] [CrossRef]
- Zhou, Y.; Zhai, Q.; Wu, L.; Shahidehpour, M. A Data-driven Variable Reduction Approach for Transmission-constrained Unit Commitment of Large-scale Systems. J. Mod. Power Syst. Clean Energy 2023, 11, 254–266. [Google Scholar] [CrossRef]
- Scavuzzo, L.; Aardal, K.; Lodi, A.; Yorke-Smith, N. Machine learning augmented branch and bound for mixed integer linear programming. Math. Program. 2024, 1–44. [Google Scholar] [CrossRef]
- He, H.; Daumé, H., III; Eisner, J.M. Learning to Search in Branch and Bound Algorithms. In Proceedings of the Advances in Neural Information Processing Systems, Cambridge, MA, USA, 8 December 2014; pp. 3293–3301. [Google Scholar]
- Wang, Q. Empowering branch-and-bound algorithms via reinforcement and imitation learning for enhanced search. Appl. Soft Comput. 2025, 170, 112690. [Google Scholar] [CrossRef]
- Lee, M.; Yu, G.; Li, G.Y. Learning to Branch: Accelerating Resource Allocation in Wireless Networks. IEEE Trans. Veh. Technol. 2022, 69, 958–970. [Google Scholar] [CrossRef]
- Gao, Q.; Yang, Z.; Yin, W.; Li, W.; Yu, J. Internally Induced Branch-and-Cut Acceleration for Unit Commitment Based on Improvement of Upper Bound. IEEE Trans. Power Syst. 2022, 37, 2455–2458. [Google Scholar] [CrossRef]
- Conforti, M.; Cornuéjols, G.; Zambelli, G. Integer Programming Models. In Integer Programming; Springer International Publishing: Cham, Switzerland, 2014; pp. 45–84. [Google Scholar]
- Silver, D.; Huang, A.; Maddison, C.J.; Guez, A.; Sifre, L.; van den Driessche, G.; Schrittwieser, J.; Antonoglou, I.; Panneershelvam, V.; Lanctot, M.; et al. Mastering the game of Go with deep neural networks and tree search. Nature 2016, 529, 484–489. [Google Scholar] [CrossRef]
- Ross, S.; Gordon, G.J.; Bagnell, J.A. A Reduction of Imitation Learning and Structured Prediction to No-Regret Online Learning. In Proceedings of the International Conference on Artificial Intelligence and Statistics, Fort Lauderdale, FL, USA, 11–13 April 2011; pp. 627–635. [Google Scholar] [CrossRef]
- Balcan, M.-F.; Dick, T.; Sandholm, T.; Vitercik, E. Learning to Branch. In Proceedings of the 35th International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 344–353. [Google Scholar] [CrossRef]
- Pineda, S.; Fernández-Blanco, R.; Morales, J. Time-Adaptive Unit Commitment. IEEE Trans. Power Syst. 2019, 34, 3869–3878. [Google Scholar] [CrossRef]
- Real Time System Information. Available online: https://www.eirgrid.ie/grid/real-time-system-information (accessed on 30 July 2024).
- Sun, X.; Luh, P.B.; Bragin, M.A.; Chen, Y.; Wan, J.; Wang, F. A Novel Decomposition and Coordination Approach for Large Day-Ahead Unit Commitment with Combined Cycle Units. IEEE Trans. Power Syst. 2018, 33, 5297–5308. [Google Scholar] [CrossRef]
- Cornuéjols, G. Valid inequalities for mixed integer linear programs. Math. Program. 2008, 112, 3–44. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).