Abstract
Large language models (LLMs), consisting of billions and trillions of parameters, have demonstrated exceptional ability in natural language understanding (NLU) and natural language generation (NLG) tasks. Increases in their numbers of parameters and model sizes have resulted in better performance and accuracy. However, models with such enormous numbers of parameters incur significant computational costs and resources, making them challenging to fine tune and adapt to a specific downstream task. Several parameter-efficient fine-tuning (PEFT) techniques have been proposed to address this issue. This study demonstrates the improvement obtained over the base LLaMA3-8B model using two prominent PEFT techniques: LoRA and QLoRA. We use the sequence classification task of sentiment analysis to conduct the experiments. Additionally, we analyze the effects of hyperparameter adjustments (r and ) on the model’s performance. We examine the tradeoff between efficiency and memory savings obtained using the quantized LoRA (QLoRA) technique. We also investigate and compare the performance changes of LoRA and QLoRA techniques obtained after adapting to attention layers (query, key, value, and project) to all the linear layers during fine tuning. We report the findings of our work along with limitations and future directions.
1. Introduction
Transformer-based language models, which use self-attention mechanisms [1], have revolutionized natural language processing (NLP). Such language models are pretrained on an enormous amount of data using a self-supervised technique. The datasets used during pretraining are generic and do not necessarily cater to a particular domain or task. The objectives used during pretraining are usually masked, prefixed, or left-to-right language models. Such objectives help the LLMs to understand natural language’s intrinsic nature and complexities. Such pretrained models are called base models, such as in [2,3,4,5,6,7]. When direct access to these LLMs is not possible or limited, techniques such as chain of thoughts (CoT) [8] and in-context learning (ICL) [9,10] are used to interact with these pretrained base models through an API.
The ICL input prompt includes a few examples (input–target pairs), enabling a model to perform the downstream task. Therefore, the performance of the ICL technique depends solely on the capabilities a model learns during pretraining. Also, as ICL does not use gradient-based training, it can perform various tasks without additional preprocessing. However, whenever a prediction is made, the ICL processes all the training examples given, resulting in a substantial computational cost. Furthermore, using such base models directly in the target task causes the ICL to produce poor results compared to those produced with fine tuning. Finally, the order examples and the wording and formatting of the prompts in the ICL can also have unpredictable impacts on the model’s performance. Fine tuning overcomes these issues. Further training of these foundation models in the target dataset improves their performance, allowing them to adapt much better to the target domain, vocabulary, and task.
Unlike pretraining, which uses a self-supervised approach, the fine-tuning model uses a supervised technique that requires a labeled dataset of the downstream task. Additionally, data from a generic domain are used for pretraining, whereas data from specific distributions are used for fine tuning or transfer learning. A fine-tuning technique improves the performance of base models in a specific downstream task. This helps to tailor and adapt to the language models to align with the target domain data. For instance, even if the base language model was not explicitly trained in the token or sequence classification domains, it can be fine tuned to adapt to and perform classification tasks, such as sentiment analysis, name entity recognition, and part-of-speech tagging. Fine tuning enables the model to learn and acquire domain-specific knowledge and vocabulary. It can add desirable behaviors and remove undesirable ones, improving the model’s performance in the target task.
1.1. Motivation
Fine tuning involves adjusting the weights (model parameters) using a much smaller dataset, a set relevant to the specific domain. Although the dataset is comparatively smaller, fine tuning updates all the parameters across all the layers. Because large language models are enormous, updating all the weights becomes expensive and computationally intensive, and the model size grows. This requires a non-trivial amount of GPU memory, and, hence, the fine-tuning process incurs significant overhead. For example, consider the LLaMA3-8B model, Large Language Model Meta AI with 8 billion parameters [11]. During backpropagation, it learns the matrix, which contains information on how much the original weight matrix (W) needs to be updated to minimize the loss function during training. The matrix will have the same number of parameters (8 billion) as the original W matrix. As a result, computing the matrix becomes memory intensive and computationally expensive.
Also, as an entirely new model is required for every task, fine tuning becomes parameter inefficient [12]. Furthermore, fine-tuning LLMs also results in high CO2 emissions (carbon footprints) [13]. With an increasing focus on environmental sustainability, using LLMs effectively and efficiently has become paramount. Several parametric-efficient fine-tuning (PEFT) methods have been proposed. These methods freeze the pretrained weights and train only a low number of additional parameters, called adapters. Such PEFT techniques allow the reuse of pretrained LLMs with reduced energy consumption, leaving behind minimal computational, resource, and carbon footprints. Additionally, they are helpful in scenarios where larger models must be fine tuned on devices with comparatively smaller GPU memories because of budget constraints and resource limitations. PEFT techniques, such as LoRA [14] and QLoRA [15], have been proposed that address these issues by significantly reducing the GPU memory requirements needed during fine tuning. These techniques present a promising alternative to the ICL and fine tuning. They adapt to and store only a low number of task-specific parameters, considerably boosting operational efficiency when deployed.
1.2. Background
A neural network contains many dense layers that perform matrix multiplications. The weight matrices in these layers typically have full-rank matrices, which capture the knowledge representation from the given datasets. Such full-rank matrices do not have linearly dependent rows or columns so that no redundancy can be eliminated. On the other hand, low-rank matrices have redundant rows or columns. Such low intrinsic dimensions [16] imply that the data can still be effectively represented or approximated using a lower-dimensional space while retaining most of their essential information.
The authors of [17] demonstrated how the pretrained language models have a low intrinsic dimension. The paper [17] pointed out how pretraining implicitly minimizes the intrinsic dimension, and, therefore, the pretrained LLMs are still effective with low-rank intrinsic dimensions during fine tuning, when they are adapted to a specific domain or task. That is, a low-dimensional reparameterization exists that allows the model to learn as effectively, when fine tuned, as the full parameter space. Therefore, once pretrained, there is no need to update all the weights to capture the information during adaptation; instead, the information can be captured using smaller matrices. As a result, fine tuning will result in low-rank perturbations (updates) to the base model’s weight matrix during adaptation. The weight change during model adaptation has a low intrinsic rank.
1.2.1. LoRA
The Low-Rank Adaptation (LoRA) technique [14] decomposes the weight-change matrix, , into a lower-rank representation. It injects several trainable matrices (parameters) into each model layer while freezing the original pretrained parameters. As a result, it can approximate the full-supervised fine tuning in a more parameter-efficient manner. It involves freezing a pretrained weight matrix, , and training only low-rank perturbations () to selected weight matrices (A and B), as shown in Equations (1) and (2).
where represents the pretrained weight matrix. is frozen during training and does not receive gradient updates, while A and B contain trainable parameters. The decomposition of the matrix means representing the matrix using two smaller matrices, A and B, such that A has the same number of rows as , and B has the same number of columns as . accumulates gradient updates during adaptation. As shown in Equation (2), the weight-change matrix () for the newly adapted task can be decomposed into a lower-dimensional space without losing too much information.
The user chooses which to adapt (‘target modules’) and the rank, . By doing so, only parameters are trained instead of (d × k), which reduces the memory and number of FLOPS required for computing the gradient. For example, if has 20,000 rows and 30,000 columns, it stores 600,000,000 parameters. But, if we choose A and B with , then A has twenty thousand rows and eight columns, and B has eight rows and thirty thousand columns; that is, 20,000 × 8 + 8 × 30,000 = 400,000 parameters, which is about 1500× fewer than 600,000,000.
The hyperparameter r represents several matrix-A columns and matrix-B rows. It is used to specify the rank of low-rank matrices (A and B) used for adaptation. A lower value of r results in fewer parameters to learn during adaptation, leading to faster training and reduced computational cost. The value of r, therefore, controls how many parameters will be trained during fine tuning. We analyze the effects of r on the model’s performance in Section 5.
and are multiplied by the same input (x), and their respective output vectors are summed coordinate-wise. Additionally, is used as a scaling factor for . The forward pass of the LoRA is represented by Equation (3).
We perform experiments where the target modules (layers to be adapted during fine tuning) are set at the attention layers comprising , and matrices or all-linear layers. , and represent the self-attention module’s query, key, value, and output projection matrices.
Another hyperparameter is , a scaling factor that can adjust the magnitude of the combined result, consisting of the original model output plus the low-rank adaptation. Using , it becomes possible to balance the pretrained model’s knowledge and the new task-specific adaptation. A higher value would emphasize low-rank matrices (AB) more, whereas a lower value would reduce their influences, making the model rely more on the original parameters (W). In other words, adjusting helps to strike a balance and prevent underfitting and/or overfitting by regularizing the model. We analyze the effects of on the model’s performance in Section 5.
As LoRA injects low-rank matrices, the need to calculate the gradients and maintain the optimizer states for most parameters is eliminated. Instead, only the low-rank matrices are optimized, making LoRA memory and computing efficient. These injected trainable parameters are often termed as adapters. Furthermore, LoRA also makes it easier to switch the model to another downstream task. The original pretrained matrix, , can be recovered by subtracting AB and adding a different with very little memory overhead. During stochastic gradient descent, gradients are passed through the fixed pretrained model weights to the adapter, which is updated to optimize the loss function. Overall, LoRA reduces memory requirements by freezing the pretrained weights and using or updating only a small set of trainable parameters.
1.2.2. QLoRA
The Quantized Low-Rank Adapters (QLoRA) technique [15] is an efficient fine-tuning approach that can reduce memory usage to an extent so that a model having as many as 65 B parameters can be stored on a single GPU with 48 GB memory and still preserve the full 16-bit fine-tuning task performance. Quantization is the process of discretizing or approximating an input from a representation that holds more information to a representation with less information. It often means converting a data type with more bits to one with fewer bits, such as from 32-bit floats to 8-bit integers. QLoRA quantizes the pretrained weights to 4-bit precision, reducing memory usage during backpropagation/fine tuning. It then adds a small set of learnable low-rank adapter weights tuned by backpropagating gradients through the quantized weights.
QLoRA backpropagates gradients to low-rank adapters (LoRAs) through a frozen pretrained 4-bit quantized language model. Whenever a QLoRA weight tensor is used, it is dequantized to BFloat16, and then the matrix is multiplied by 16 bits.
Therefore, to work around the common GPU memory bottleneck issue encountered in full fine tuning and, to some extent, in LoRA, QLoRA becomes a feasible alternative to train the model. It offers 33% GPU memory savings but at the cost of a 39% increase in the runtime. In QLoRA, the quantization and dequantization steps of the pretrained model weights incur additional processing times. QLoRA presents or offers a memory and time tradeoff that might be worthwhile if constrained by the GPU memory. Overall, the benefits obtained using LoRA and QLoRA PEFT techniques enabled us to perform an in-depth study of the classification task performance of the LLaMA3-8B model, which would have been impossible using regular or full fine tuning because of the memory bottleneck. Figure 1 illustrates and compares these three techniques.
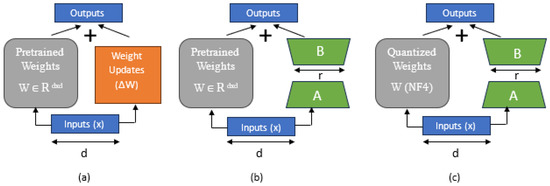
Figure 1.
Comparison of (a) fine tuning, (b) LoRA, and (c) QLoRA.
1.3. Contributions
The contributions of our research article are manifold, as follows:
- 1.
- The article analyzes the improvement obtained over the base LLaMA3-8B model using two PEFT techniques—LoRA and QLoRA;
- 2.
- It also explores the effects of hyperparameter adjustments (r and ) on the model’s performance to find the optimal values of r and for the classification task;
- 3.
- The paper examines the tradeoff between efficiency and memory savings obtained using the quantized technique over LoRA;
- 4.
- It also investigates and compares the change in the performance obtained after the adaptation of the attention layers (query, key, value, and project) versus all the linear layers during fine tuning at LoRA and QLoRA settings;
- 5.
- Finally, the article experiments with the usage of the decoder-based Llama-3-8B model for classification tasks, such as sentiment analysis.
The outline of this paper is as follows: Section 2 elucidates on the strategy, dataset, and hardware used to conduct the study. Section 3 illustrates the results of different experiments conducted by adjusting the hyper-parameters and adaptation settings, along with the scope of our work. Section 4 on related work explains different fine tuning techniques used for efficient parameter fine tuning, which update only a low fraction of the model parameters. We conclude our study in Section 5.
2. Methodology
2.1. Model and Task
To conduct the experiments, we used the LLaMA3 model with 8 billion parameters (LLaMA3-8B). It is an auto-regressive language model, a pretrained generative text model. Its context length is 8 K, and the token count is over 15 trillion. It uses grouped-query attention (GQA) to improve the inference scalability. We used a sentiment-analysis-based sequence classification task to evaluate the performances of the base, LoRA, and QLoRA-enabled versions of the LLaMA3-8B model. LoRA and QLoRA allow the training of this enormous 8 B parameter-sized model on a single A100 GPU.
We implemented the experiments, using the Llama-3-8B checkpoint in the HuggingFace library. We used the AutoModelForSequenceClassification class to automatically instantiate and load the Llama-3-8B model (LlamaForSequenceClassification) for sequence classification. As a result, it uses a five-class classification head. The Llama-3 model is not primarily meant for sequence classification. Therefore, when loading the Llama for this task, we obtain a warning message that the model should be fine tuned (trained on a downstream task) first before being used for predictions and inferences.
In QLoRA, the parameters are stored in a 4-bit format. In the forward pass, logits and losses are computed. In the backward pass, the gradients of the loss concerning the trainable parameters are computed. Cross-entropy was used to compute the loss. After each batch, the model parameters are updated, and the gradients are reset. In LoRA and QLoRA, the gradients of only the injected parameters are computed, and, therefore, only the low-rank matrices are updated.
2.2. Dataset and Setup
For the experiment, we considered and compared several datasets (Twitter, Amazon Reviews, IMDB, Yelp, and SST) that are used for classification tasks, such as sentiment analysis. After a careful review, the Yelp dataset was deemed as more appropriate for our experiment. It had not two but five sentiment labels, which effectively represent the real-world classification challenges. Additionally, the Yelp dataset was of better quality and required fewer cleaning and preprocessing steps than the others. We used the Yelp dataset that was available from the HuggingFace library [18]. The dataset consists of five sentiment labels, ranging from 1 to 5, where 5 implies a positive sentiment and 1 indicates a strongly negative sentiment. For a feasibility purpose, we considered a subset of this dataset. Our training dataset comprises 50 K samples, with 10 K samples from each category. The validation dataset comprised 10 K samples, with 2 K samples from each sentiment class. We used the same subset and sample of records for all the experiments conducted in this work. The metrics used to evaluate this dataset are the accuracy, F1-score, precision, and recall.
We ran all the experiments only for one epoch, with a batch size of 8, using the ADAM optimizer, a dropout of 0.05, and a learning rate of 1 × 10−4. The max length of the sequence was set at 128, with padding and truncation enabled. We used TrainingArgs and the Trainer Library from Hugging Faces to conduct the experiments. Additionally, for QLoRA, we set load_in_4bit to True and bnb_4bit_quant_type to “nf4” (a 4-bit NormalFloat).
2.3. Hardware, Time, and Memory
All the experiments were conducted on a single A100 GPU with 40 GB of memory (Nvidia, Santa Clara, CA, USA). As shown in Table 1, the time taken for all the LoRA experiments at the all-layer and attention-layer settings was approximately 30 min. LoRA reduces the number of trainable parameters significantly and the GPU memory requirement by 3× times. In contrast, the time required for all the quantized QLoRA experiments was around 5 h, approximately 10× times longer than that for the LoRA. However, in QLoRA, the parameters are quantized and stored in 4-bit memory settings, which makes them more storage efficient and requires less memory. Because of the quantization in QLoRA, dequantization is needed during matrix multiplication, requiring additional computation time.

Table 1.
Training times and memory consumed for LoRA and QLoRA models.
2.4. Selection of Hyperparameters
Two of the goals of our work are to use the LLAMA3 model to demonstrate how LoRA and QLoRA perform better than the base model and to find the optimal values for hyperparameters r and . To perform this empirical experimentation, we chose a set of values to find the combinations of r and that perform better in the classification task. In this empirical testing, we adjusted the r values from 1 to 512 by keeping alpha constant. The value of r is doubled in each successive iteration of the experiment. Similarly, for , to find its ideal performing value, we adjusted the values of from 1 to 64 by keeping r constant. The value of alpha is doubled in the consecutive iteration of the experiment. As discussed in the Experiments and Results section, these experiments help to capture the impacts of the changes in the r and values on the accuracy metrics for the LoRA and QLoRA techniques.
2.5. Computational Efficiency During Inference and Training
We explore the memory requirements required for the training (fine tuning) and inference of the LLAMA3-8B model and its LoRA and QLoRA counterparts. This is crucial for the efficient utilization and deployment of these models, as it impacts the choice of hardware and the overall cost. Training the model requires much more memory than just loading it into the GPU. This is because there are many components involved during training that require the use of GPU memory. The main components during training in GPU memory are model weights, optimizer states, gradients, and forward activations, which are saved for gradient computation. Also, the amount of space required by parameters depends on the data type used. For 32-bit floating points (fp32s), 4 bytes are needed. BF16 requires 2 bytes, int8 requires 1 byte, and int4 type requires 0.5 bytes. Normally, the less storage required by a parameter type, the lower the performance tends to be. However, although lower precision (such as int4) may result in some loss of accuracy, it can significantly reduce memory requirements and increase the inference speed. Below, we look at the memory estimation required by the LLAMA3-8B base model during fine tuning and inferences.
2.5.1. Memory Estimation for Inferences
There are no optimizer states and gradients for inferences. Other factors influence memory usage, but the main component of the memory usage during inferences is the parameters. So, for the LLAMA3-8B model, the estimated memory requirements during inferences are the memory, equal to the number of parameters multiplied by the size of the data type. For instance, it will be 29.80 GB for 32-bit precision, 14.90 GB for BF16 precision, and 7.45 GB for int8 precision. Although lower precision (e.g., INT4) may result in some loss of accuracy, it can significantly reduce memory requirements and increase the inference speed. Table 2 shows the approximate amounts of memory needed for different configurations. Note that inferences require additional memory beyond that for just the parameters.
Table 2.
Memory requirements for different data types during fine tuning and inferences.
2.5.2. Memory Estimation for Training
Usually, the amount of memory needed for fine tuning is approximately four times the required amount of memory for inferences with the same parameter count and type. For example, training the LLAMA-8B model with 32-bit float precision required approximately 119.2 GB (29.80 GB × 4). During training or fine tuning, the memory requirement is based on the gradients and optimizer states. The amount of memory required for gradients is the same as the amount of memory needed for the number of parameters (29.80 GB for fp32). Furthermore, the amount of memory needed for the optimizer states depends on the type of the optimizer used. For instance, the amount of memory required for the AdamW optimizer is twice the amount of memory required by the number of parameters (29.80 GB × 2). Because AdamW maintains two states, it requires 8 bytes per parameter. The amount of memory required for the SGD optimizer is equal to the amount of memory required by the number of parameters (29.80 GB). Table 2 outlines the approximate memory requirements for fine-tuning Llama3-8B models using different data types.
2.6. Comparative Analysis of LoRA and QLoRA Techniques
2.6.1. LoRA
LoRA decomposes a large weight matrix into two smaller low-rank matrices (called update matrices) to make fine tuning more efficient. These new matrices can be trained to adapt to the new data while keeping the overall number of changes low. The original weight matrix remains frozen and has not received any further adjustments. The original and adapted weights are combined to produce the final results. Also, LoRA does not add inference latency when adapter weights are merged with the base model. The number of parameters in LoRA is determined by the rank and shape of the original weights. In practice, trainable parameters vary as low as 0.1–1% of all the parameters. As the number of parameters needing fine tuning decreases, the sizes of the gradients and optimizer states attached to them decrease accordingly. Thus, the overall size of the loaded model reduces.
We leveraged LoRA for efficient parameter updates, as it reduces memory requirements by adding small trainable rank decomposition matrices to existing weights. This enables task-specific adaptations without modifying all the model parameters. In our experiments, we adapt LLAMA3 for downstream classification tasks using LoRA and QLoRA. The hyperparameter r sets the ranks of LoRA matrices, balancing the model’s performance with memory use. The hyperparameter acts as a scaling factor to avoid overfitting. During inferences, LoRA involves running the original model with the entire parameter volume once (without needing gradients and optimizer states). So, as shown in Table 3, the memory requirement for inferences using LoRA is the same as the memory required by the number of parameters. Using low-rank adaptation (LoRA), Llama3 is loaded into the GPU memory as quantized 8-bit weights. However, during fine tuning using LoRA, a smaller model is trained that achieves nearly the same performance as that of the original model. Parameter types cannot be int8 or int4 to ensure model convergence during training. Generally, float fp32 is used, and for slightly lower performance, BF16 is an option.
Table 3.
Memory requirements for LoRA and QLoRA during fine tuning and inferences (r = 8).
Full-parameter fine tuning took hours, but as shown in Table 1, fine tuning with LoRA completed in less than 30 min. LoRA also makes the process more efficient than QLoRA, as it reduces the fine-tuning time by 10× times. This is because LoRA has fewer trainable parameters, which translate to fewer derivative calculations, and less memory is required to store and update weights. Also, when deployed, LoRA merges the trainable matrices (learned weights) with frozen (main) weights, introducing no inference latency compared to the fine-tuned model or adapter layers. The most significant benefit comes from reductions in memory and storage usages, which allowed us to train the model using a single GPU and avoid I/O bottlenecks. Another benefit is that it enables switching between tasks while deployed at a much lower cost by only swapping the LoRA weights as opposed to all the parameters.
2.6.2. QLoRA
QLoRA stands for quantized model weights with low-rank adaptation. Fine tuning using QLoRA is more memory efficient than LoRA. As shown in Table 3, the pretrained model in QLoRA is loaded into the GPU as 4-bit NormalFloat (NF4) data, which is a novel high-precision technique to quantize a pretrained model to 4-bit data.
NF4 is optimal for normally distributed weights and yields better empirical results than 4-bit integers and 4-bit floats. QLoRA backpropagates gradients through the frozen 4-bit quantized pretrained language model to LoRA, where a small set of learnable low-rank adapter weights is then added. QLoRA takes LoRA a step further by quantizing the LoRA adapters’ weights (smaller matrices) to a lower precision level (e.g., 4-bit instead of 8-bit). This further reduces the memory footprint and storage requirements.
QLoRA is the better choice because of its even greater memory efficiency, but LoRA may be preferable because of its slightly faster training times. LoRA focuses on reducing the number of parameters that need to be fine tuned. At the same time, QLoRA takes it a step further by combining low-rank adaptation with quantization to lower memory requirements. Together, these methods make fine-tuning large models more accessible. QLoRA generally takes more time than LoRA during fine tuning because of the additional computational overhead involved in the quantization process, where model weights are converted to lower precision (like 4-bit) levels to reduce memory usage significantly.
As shown in Table 3, the LLAMA3-8B model using QLoRA’s NF4 data type requires only 3.857 GB of memory during fine tuning, where the memory requirement for loading the model itself took around 3.73 GB of space. Additionally, the space occupied by trainable parameters comes to 0.0097 GB, followed by 0.078 GB for gradient and 0.039 GB for optimizer states. As shown in Table 4, we used different values of r while conducting the experiments. We list the trainable parameters associated with each value of r for the LLaMA3 model, which has 8 billion parameters. The number of trainable parameters remains the same at LoRA and QLoRA settings.
Table 4.
LLaMA3-8B’s trainable parameters.
2.7. Strategy
Our research aimed to find the optimal values of r and for classification tasks. To find the optimal value of r, we considered 10 different values and for r, where the value of was kept constant ( = 2 × r). We changed the value of while keeping the learning rate and r constant to analyze the effect of . As stated in a LoRA paper [14], tuning is roughly the same as tuning the learning rate. Therefore, to find the optimal value, we kept the values of the learning rate = 1 × 10−4 and constant and changed the value from r to . Also, as per article [19], the knowledge in large language models can be stored in the attention and the feedforward network (FFN) layers. Knowledge with similar semantics, such as language and city, is stored in the same attention heads of the different attention layers. In contrast, knowledge with distinct semantics is stored in different attention heads. As stated in [20], one of the primary functions of FFN layers is to store the knowledge acquired during the model’s pretraining phase. To find the effects of the attention and FFN layers adapted during fine tuning on the accuracy, we perform experiments by adapting (1) all-linear layers and (2) attention layers and then comparing their performances. We report our observations and findings in the next section. As shown in Figure 2, neurons from both the attention and FFN layers are essential, as they contribute to the knowledge prediction in the deep layers.
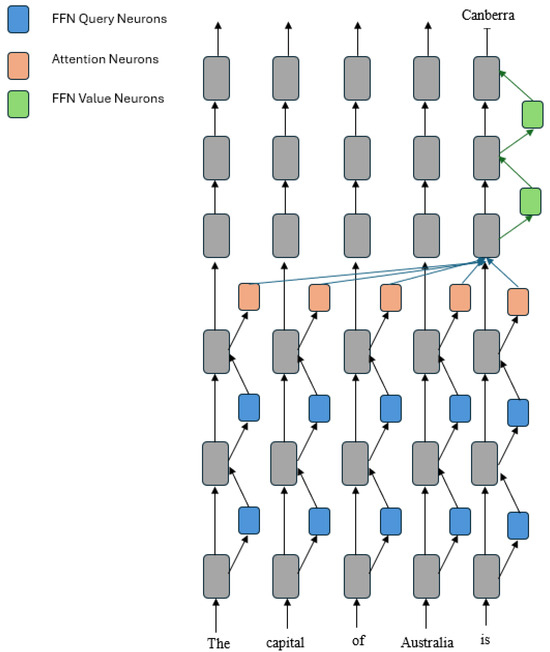
Figure 2.
Neurons in FFN and attention layers.
3. Experiments and Results
Before fine tuning the LLaMA3-8B model, we perform sentiment analysis’s classification task using the base model in a subset of the Yelp dataset. The base (non-fine-tuned) model results are shown in Table 5.
Table 5.
LLaMA3-8B base model’s performance.
For fine tuning, we conduct our experiments mainly at two settings: (1) At the first setting, all the linear layers of the LoRA and QLoRA models are adapted; (2) at the second setting, only the attention layers of the LoRA and QLoRA models are adapted. We plan to explore other combinations and possibilities in future experiments.
Next, we investigate and test whether a lower value of r results in poor adaptation (underfitting). A lower value of r implies fewer parameters, which can reduce the low-rank matrix’s capacity to capture task-specific information. Similarly, we test whether a higher value of r (more trainable parameters) results in the model being overfitted in the downstream task.
3.1. Constant r
In our initial study, we kept r constant and analyzed the impact of varying the value of on the model’s performance. An increase in increases the scaling factor (), which gives more importance to the trained injected parameters over the pretrained frozen parameters. The results of this analysis are shown in Figure 3 and Figure 4.
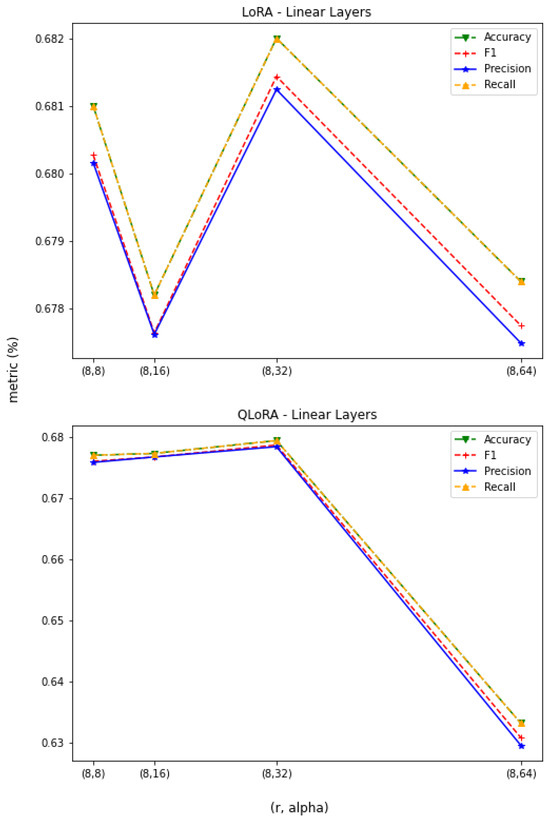
Figure 3.
LLaMA3—linear layer adaptation, .
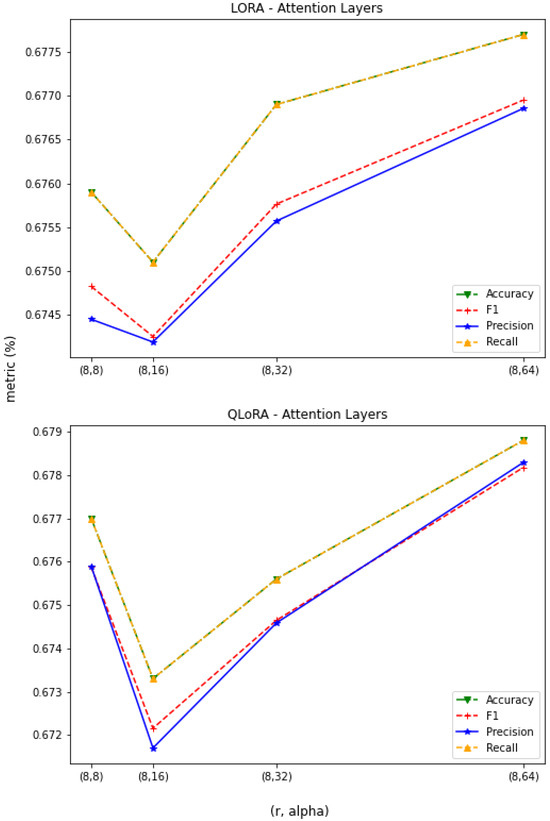
Figure 4.
LLaMA3—attention layer adaptation, ().
If all the linear layers are adapted in LoRA and QLoRA, the performance decreases after exceeds 32, whereas if only the attention layers are adapted in LoRA and QLoRA, the performance steadily increases as the value of exceeds 16. So, an increase in the value of can have a degrading effect when all the layers are adapted, but it performs better only when the attention layers are adapted.
The experiment also demonstrates how QLoRA, for , delivers the same performance as LoRA when all the linear layers are adapted. Similarly, for , QLoRA delivers the same performance as that of LoRA when only the attention layers are adapted. LoRA’s and QLoRA’s performances peak at 68% (at ) when all the linear layers are adapted. They perform equally well (at ) when only the attention layers are adapted. According to this analysis, we recommend using QLoRA with a higher value of for attention layers and a lower value of (≤32) if all the linear layers are to be adapted.
These results in Figure 3 and Figure 4 consistently show that the performance of the 4-bit QLoRA with the NF4 data type matches the 16-bit LoRA’s fine-tuning performance in the classification task of the sentiment analysis. In other words, QLoRA can replicate the 16-bit LoRA’s fine-tuning performance with a 4-bit base model.
3.2. Constant
In this experimental setup, we keep constant at and analyze the impact of varying the value of the hyperparameter r on the model’s performance. An increase in the value of r implies the injection of more trainable parameters. Additionally, as we have kept the value of constant, an increase in the value of r decreases the scaling factor (), resulting in more consideration of pretrained weights and less focus on trained or adapted parameters. As shown in Figure 5, for the all-linear layer adaptation, the performances of the LoRA and QLoRA models remain pretty steady as long as the value of r is ≤. However, the performance of LoRA degrades as the value of r exceeds 64. Similarly, the performance degrades as the value of r exceeds 128, , at the QLoRA setting. When the value of r jumps from 64 to 256 and then to 512, the performances of all the metrics significantly drop. Therefore, we recommend using a model with a low number of trainable parameters (at and ), as these yield the optimal results for both LoRA and QLoRA techniques, as compared to higher values of .
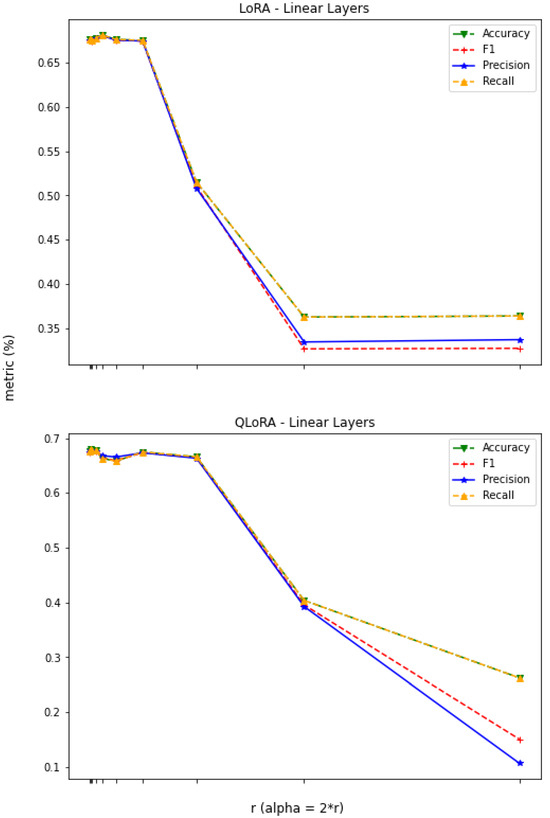
Figure 5.
LLaMA3—linear layer adaptation, and .
In the case of the attention-layer adaptation, as shown in Figure 6, both the LoRA and QLoRA models maintain steady performances as long as the value of r is ≤. However, the performances dip significantly when r exceeds 256. Also, after comparing Figure 5 and Figure 6, it can be observed that the performances that LoRA and QLoRA achieved by adapting to all-linear layers are also attainable by adjusting only the attention layers (for ).
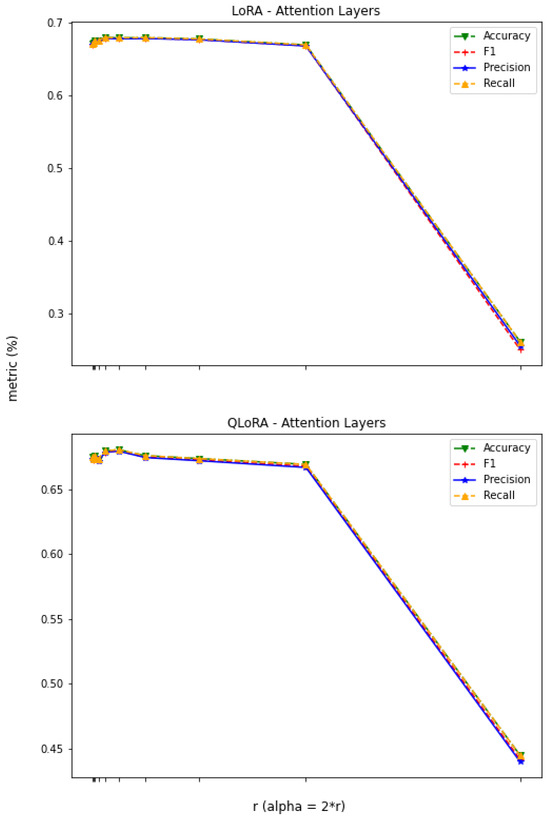
Figure 6.
LLaMA3—attention-layer adaptation, and .
According to this analysis, we recommend using QLoRA with a lower value of . In both experiments (1 and 2), LoRA and QLoRA significantly improved the performance of the LLaMA3-8B base model. Additionally, both experiments demonstrated how LoRA’s performance is attainable using QLoRA and with lower GPU memory requirements but at the expense of more time required to train the model. Additionally, instead of adapting to all the linear layers, QLoRA can attain the same performance by adjusting only the attention layers, which require far fewer trainable parameters.
3.3. LoRA vs. QLoRA Performance
We compare the performances of LoRA when it adapted to all the layers or the attention layers to the performances of QLoRA at similar configuration settings. The value of is set at , where r starts at one and doubles in consecutive iterations. As shown in Figure 7, for , the performances of LoRA and QLoRA are higher when they adapt to all the linear layers rather than only to the attention layers.
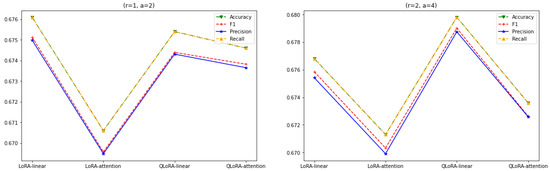
Figure 7.
LoRA and QLoRA with linear and attention layers and .
Similarly, for , the performances of LoRA and QLoRA are greater when they adapt to all the linear layers rather than only the attention-layer adaptation. This signifies that the adaptation of all-linear layers for LoRA and QLoRA performs better for lower values of r than their attention-layer adaptation counterparts.
In Figure 8, it can be observed that the performance of the QLoRA, when all the linear layers are adapted, is consistent for both and . Meanwhile, the performance of the LoRA (for both adaptations) increases as the value of r goes up from 4 to 8. Also, if we consider both Figure 7 and Figure 8, the performance of the LoRA has increased with an increase in the value of r, whereas the performance of the QLoRA has pretty much remained steady or is unaffected by the change in r.
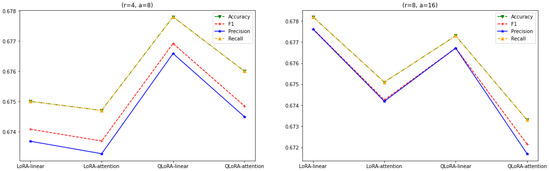
Figure 8.
LoRA and QLoRA with linear and attention layers and .
As seen in Figure 9, the performance of the LoRA starts remaining steady with an increase in the value of r, . Also, QLoRA’s performance for all-linear-layer adaptation starts degrading as r exceeds the value of 8. Also, QLoRA with attention-layer adaptation performs better than QLoRA with all-layer adaptation as the r value exceeds 8, .
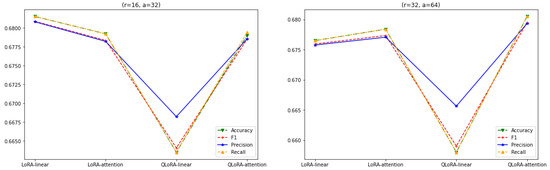
Figure 9.
LoRA and QLoRA with linear and attention layers and .
As shown in Figure 10, the performance of the LoRA when all the linear layers are adapted keeps dropping significantly as the value of r is increased to 64 and 128, . Compared to the results obtained for and , QLoRA’s performance starts improving as the r value exceeds 32, , for both linear and attention-layer adaptations.
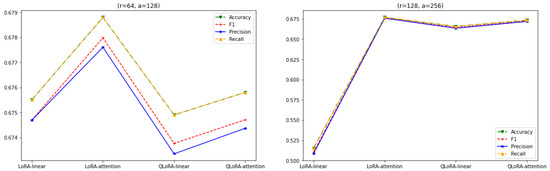
Figure 10.
LoRA and QLoRA with linear and attention layers and .
Furthermore, in Figure 11, the performances of the LoRA for both adaptations (linear and attention layers) keep declining with an increase in value of r. This also holds true for QLoRA, where the performance degrades for both adaptations as r exceeds 128, .
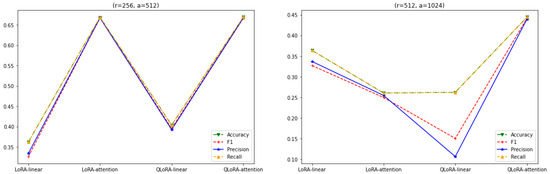
Figure 11.
LoRA and QLoRA with linear and attention layers and .
Overall, based on the above experiments, the performances of LoRA and QLoRA with all-linear-layer adaptation remain steady at around 67%. Also, LoRA and QLoRA with all-layer adaptations perform slightly better than their attention-layer adaptation counterparts for a value of . Furthermore, QLoRA with attention-layer adaptation performs comparatively better than its LoRA counterpart for an value. As shown in Figure 7, Figure 8, Figure 9, Figure 10 and Figure 11, the performances of LoRA and QLoRA with attention-layer adaptations remain consistent at around 67% as long as the value of r is ≤.
3.4. Scope
We limit our study to adapting weights either for all the linear layers or only the attention layers for downstream tasks, both for simplicity and parameter-efficiency purposes. Because of the immense resource costs, we leave the empirical investigation of adapting to the MLP layers, LayerNorm layers, and biases to a future work. In all the scenarios considered in this study, the value of was always greater than r. In future work, we plan to investigate the effect on the model’s performance when the value of is kept lower than r. Furthermore, we trained the model only for one epoch with one seed because of budget constraints. Our future work will scale our experiments to consider at least five epochs and multiple seeds. Also, we limited our study to adapting either the attention-layer weights or all the linear weights only. In future work, we plan to explore the effects of individual weight matrices (, , and ) and their combinations on the model’s performance. Additionally, we will be focusing on performing comparative analyses with other modern PEFT methods, such as AdaLoRA. We will consider different datasets used for PEFT evaluation in order to capture the diversity in the data, context, and domain.
4. Related Work
4.1. PEFTs
Because of the enormous number of parameters in LLMs, the traditional fine-tuning approach has been time consuming, resource intensive, and environmentally unfriendly. Additionally, a separate copy is required to perform fine tuning for each downstream task because during fine tuning, all the parameters are updated [12]. Such fine tuning demands excessive storage space and powerful GPUs or TPU clusters, which are expensive and mainly inaccessible to everyone. To address this issue, researchers have developed several techniques, over the years, that require only a subset of parameters and yet yield performances comparable to those of fully fine-tuned models. These methods, called parameter-efficient fine-tuning techniques (PEFTs), require significantly reduced storage, memory, and computation resources.
As a result, it becomes feasible to train large models and run inferences, even on a single device.
Several PEFT methods have been proposed, such as soft prompting, adapters, matrix decomposition, and reparameterization. PEFT techniques offer an alternative paradigm in which only a small set of parameters is trained to enable a model to perform a new task. The main goal of all these techniques is to reduce the number of trainable parameters, making the models more accessible and easy to train without incurring additional computation and storage costs. Furthermore, unlike in fine tuning, the pretrained model parameters are frozen in all the PEFT methods so that a single model can serve multiple downstream tasks. Next, we discuss some of the most prominent PEFT alternatives to the conventional LLM fine-tuning mechanism.
4.2. Reparameterization Methods
LoRA uses the reparameterization technique and distributes the learnable parameters across all the layers in the network. LoRA constrains the fine tuning to a low-rank subspace of the original parameter space, where the rank, r, is chosen to be much lower than the dimension of the weight matrix. Additionally, is the merge ratio that balances the retention of the pretrained model’s information and its adaptation to the target domain concepts. However, LoRA ignores the importance of weight matrices, which can vary significantly across modules and layers. For example, giving the critical weight matrices more trainable parameters can boost the model’s performance.
Methods such as LoRA, adapters, and prefix tuning, where the trainable parameters are evenly distributed across all the layers (weight matrices), might yield suboptimal performance. Unlike in LoRA, in AdaLoRA [21], layers with less importance are assigned fewer parameters, whereas more parameters are allocated to important weight matrices and layers. Adding more parameters to less important weight matrices can result in marginal gains or harm the performance. AdaLoRA adaptively allocates the parameter budget (the total number of trainable parameters) among weight matrices according to their importance score.
IA3 [22] uses learned vectors to scale the activations, helping to achieve a more substantial performance while introducing and updating relatively (up to 10,000×) fewer new parameters. IA3 adds three learned vectors, and , to rescale (multiplication in elements) the keys and values in the attention mechanisms and the inner activations in position-based feedforward networks.
Methods based on matrix factorization (such as LoRA) suffer from the low-rank constraint. The weight updates are confined within this space, which can impact the fine tuning of the model’s performance. To solve this problem, LoHa [23] approximates the large weight matrix with more low-rank matrices and combines them with the Hadamard product. It reparameterizes the weight parameters of the layers using low-rank weights followed by the Hadamard product. One of the advantages of LoHa is that the maximum rank of the resulting matrix is higher () than that of the resulting matrix in LoRA and, therefore, the matrix has a far higher capacity. Therefore, decomposing the weight update using the Hadamard product further improves the fine-tuning capability given the same number of trainable parameters.
Although LoRA blocks are parameter efficient, they suffer from two significant problems: First, the sizes of LoRA blocks are fixed and cannot be modified after training. Therefore, if LoRA blocks need to be retrained from scratch, their rank must be changed.
Second, optimizing the hyperparameters, , and rank, r, demands exhaustive research and effort. Ref. [24] introduces a dynamic low-rank adaptation (DyLoRA) technique to solve these two problems together. The DyLoRA method trains LoRA blocks for a range of ranks instead of a single rank. It sorts the representation learned by the adapter module at different ranks during training. The results show that DyLoRA can train dynamic search-free models at least four to seven times (depending on the task) faster than LoRA without significantly compromising the performance. DyLoRA can select the rank without requiring multiple retraining sessions, making LoRA dynamic at inference time. As a result, by avoiding searching for the most optimal ranks, DyLoRA can still achieve a performance comparable to that of LoRA.
DoRA [25] introduces a unique weight decomposition technique, which decomposes the pretrained weight into magnitude and direction components. After model training, these decomposed magnitude and direction components can be merged into the pretrained weight, ensuring no extra inference overhead. It employs LoRA for directional updates to efficiently minimize the number of trainable parameters during fine tuning. Employing DoRA enhances LoRA’s learning capacity and training stability while avoiding additional inference overhead. When fine tuned using LLaMA, LLaVA, and VL-BART, DoRA outperforms LoRA in various downstream tasks, such as common sense reasoning and visual instruction tuning.
GLoRA [26] enhances the low-rank adaptation approach with a more generalized prompt module to optimize pretrained model weights and adjust intermediate activations. Employing a generalized prompt module design per layer offers enhanced capability and flexibility in fine tuning across diverse tasks and datasets. It learns the individual adapters of each layer and facilitates efficient parameter adaptation by employing a scalable, modular, and layer-wise structure search. Its structural reparameterization ensures inference efficiency without incurring any additional cost. GLoRA [26] shows considerable enhancements in the language domain compared to the original LoRA using the LLaMA-1 and LLaMA-2 models. By adopting a generalized low-rank adaptation and reparameterization framework, GLoRA significantly reduces the number of parameters and computation resources required for fine tuning. This makes it a more resource-efficient and practical method for real-world applications.
KronA [27] and COMPACTER [28] use Kronecker product decomposition, which is another factorization method. KronA [27] replaces low-rank decomposition in LoRA with Kronecker product decomposition for efficient model fine tuning. This results in improved accuracy without increasing the inference latency. COMPACTER [28] inserts task-specific weight matrices into a pretrained model’s weights. These weights are generated by adding Kronecker products between shared “slow” weights and “fast” rank-one matrices specific to each COMPACTER layer. Ref. [28] shows that despite learning 2127.66 × fewer parameters compared to full fine tuning, it achieves better or comparable performance at full-data settings while outperforming it at data-limited settings. A unique advantage of Kronecker products is their multiplicative ranks, which help to overcome the limitations of low-rank assumptions.
4.3. Adapter Tuning
Ref. [12] proposes transfer using an adapter-tuning strategy. Unlike low-rank methods, which use a lower number of learnable parameters randomly projected in a low-dimensional subspace, adapter methods inject new layers into the original pretrained model. The original parameters are kept frozen, while the adapter layers, which are randomly initialized, are trained. Adapter modules are comparatively smaller than the original network and yield compact and extensible models, adding only a few trainable parameters per task. In [12], it was observed that some adapters had more influence on the network than others.
P-adapters, also called prompt adapters [29], inject lightweight models between the embedding layer and the first attention layer of LLMs. They take LLM embeddings as input and output continuous prompts to query the LLM. The LLM is frozen (embeddings included) while the parameters of the P-adapter are trained. The adapter also helps to mitigate the variability among the prompts’ phrasings and typographic errors.
4.4. Prompt-Based Methods
Prompts can provide examples of tasks the model should learn or describe using instructions. In a way, prompting prepends extra information about the task, which helps the model to understand the downstream task. Next, we discuss some prominent prompt-based techniques.
4.4.1. Prompt Tuning
In prompt tuning [30], a small trainable model is used, which encodes the prompt text to generate task-specific tokens. These tokens have their parameters and are added to the input embeddings. The parameters of these inserted prompt tokens are tunable or trainable and are updated and optimized through backpropagation. After completing the prompt-tuning process, the parameters of the prompt tokens are used during inferences. The prompt-tuning approach saves significant storage space by training and storing only task-specific prompt parameters, which are less than 0.01% of the total number of model parameters.
4.4.2. Prefix Tuning
Prefix tuning [31] was developed using the GPT model for NLG tasks. It is similar to prompt tuning, which adds or prepends task-specific vectors to the inputs. The task-specific prefix-related parameters are trainable and optimized during backpropagation, whereas the pretrained model parameters remain frozen. Prefix tuning uses a separate feedforward network (FNN) to optimize the task-specific parameters associated with the prefix. However, unlike in prompt tuning, where the prompt-related parameter is added only to the input embeddings, in prefix tuning, the prefix-related parameters are inserted into all the model layers. Despite having 1000× fewer parameters, prefix tuning maintained a performance comparable to those of fine-tuned models at low- and full-data settings.
For example, the Llama adapter [32] used a lightweight adapter to efficiently fine tune the LLaMA model into an instruction-following model. It adopts a set of learnable adaption prompts as a prefix and prepends or appends them to the input instruction tokens at higher transformer layers. These prompts learn to adaptively inject new instructions (conditions) into the frozen LLaMA. All the pretrained 7 B parameters were frozen, and only 1.2 M learnable parameters were injected. It took less than an hour to fine tune the model on 8× A100 GPUs using a 52 K self-instruct dataset, resulting in superior efficiency compared to that of the 7 B parameter Alpaca.
4.4.3. P-Tuning
P-tuning [33] is another soft prompt variation developed for NLU tasks. It also adds learnable parameters optimized using backpropagation to find better prompts. It differs from prefix tuning in a couple of aspects. First, prompt tokens are not restricted to the beginning of the input sequence but can be placed anywhere. Second, the prompt parameters are only added to the input embeddings instead of being added to all the layers. Lastly, they also introduce anchor tokens that capture the characteristics of a component in the input sequence and help to improve the overall performance.
All the above ‘Prompt tuning, Prefix tuning, and P-tuning’ techniques concatenate learned continuous embeddings with the model’s input or activations to induce the model to perform a task. Because of the reduction in the number of trainable parameters, these techniques become efficient and cost effective. Overall, the performances of the state-of-the-art PEFT methods discussed in this section can match the performance of fine tuning all the model’s parameters while updating only a tiny fraction (e.g., 0.01%) of the model parameters.
5. Conclusions
This article demonstrates the results of using a decoder-based Llama-3 model in a classification task. The experiments in this study also showed the benefits of using PEFT techniques, such as LoRA and QLoRA, in a sentiment analysis task. The results obtained using the LoRA technique ensure that the low-rank adaptation matrix successfully emphasizes the crucial features for the downstream task that were learned but not highlighted in the pretraining phase. Furthermore, a LoRA paper [14] used encoder models, such as RoBERTa, DeBERTa, GPT-2, and GPT-3, to demonstrate the efficacy of the LoRA technique. This paper complements the original work by demonstrating the effectiveness of the LoRA technique when incorporated into a decoder model (Llama-3). Additionally, we observed the differences in performances of both the LoRA and QLoRA techniques when all the linear layers were adapted versus when only the attention layers were considered.
This experiment also demonstrated how adjusting the hyperparameter values can give QLoRA, which requires less GPU memory, a similar performance gain as that of LoRA. This study also noted the effects of the hyperparameters on the metrics and recommended the optimal values of and r for LoRA and QLoRA in classification tasks at different adaption (all-linear and attention-layer) settings. A higher value of resulted in underfitting for all-linear-layer adaptations but was good when only attention layers were adapted.
Additionally, according to the analyses, a higher value of ‘r’ is not recommended for all-linear and attention-layer adaption settings, as it results in poor adaptation. In other words, an increase in the value of r did not cover a more meaningful subspace, so a low-rank adaptation matrix was adequate. To conclude, according to these analyses, we recommend QLoRA with a value of r > 8 for attention-layer adaptation and QLoRA or LoRA for all-linear-layer adaptation with .
Author Contributions
Conceptualization, R.P.; Methodology, R.P.; Validation, P.K.; Formal analysis, P.K.; Resources, V.G.; Data curation, P.K.; Writing—original draft, R.P.; Writing—review & editing, V.G.; Supervision, V.G. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data presented in this study are openly available in huggingface library at https://huggingface.co/datasets/Yelp/yelp_review_full/tree/main/yelp_review_full.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. Advances in Neural Information Processing Systems. 2017. Available online: https://proceedings.neurips.cc/paper/2017/hash/3f5ee243547dee91fbd053c1c4a845aa-Abstract.html (accessed on 15 February 2025).
- Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.; Li, W.; Liu, P.J. Exploring the limits of transfer learning with a unified text-to-text transformer. J. Mach. Learn. Res. 2020, 21, 5485–5551. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language models are few-shot learners. Adv. Neural Inf. Process. Syst. 2020, 33, 1877–1901. [Google Scholar]
- Achiam, J.; Adler, S.; Agarwal, S.; Ahmad, L.; Akkaya, I.; Aleman, F.L.; Almeida, D.; Altenschmidt, J.; Altman, S.; Anadkat, S.; et al. Gpt-4 technical report. arXiv 2023, arXiv:2303.08774. [Google Scholar]
- Touvron, H.; Lavril, T.; Izacard, G.; Martinet, X.; Lachaux, M.A.; Lacroix, T.; Rozière, B.; Goyal, N.; Hambro, E.; Azhar, F.; et al. Llama: Open and efficient foundation language models. arXiv 2023, arXiv:2302.13971. [Google Scholar]
- Zhang, S.; Roller, S.; Goyal, N.; Artetxe, M.; Chen, M.; Chen, S.; Dewan, C.; Diab, M.; Li, X.; Lin, X.V.; et al. Opt: Open pre-trained transformer language models. arXiv 2022, arXiv:2205.01068. [Google Scholar]
- Wei, J.; Wang, X.; Schuurmans, D.; Bosma, M.; Xia, F.; Chi, E.; Le, Q.V.; Zhou, D. Chain-of-thought prompting elicits reasoning in large language models. Adv. Neural Inf. Process. Syst. 2022, 35, 24824–24837. [Google Scholar]
- Dong, Q.; Li, L.; Dai, D.; Zheng, C.; Wu, Z.; Chang, B.; Sun, X.; Xu, J.; Sui, Z. A survey on in-context learning. arXiv 2022, arXiv:2301.00234. [Google Scholar]
- Wang, T.; Roberts, A.; Hesslow, D.; Le Scao, T.; Chung, H.W.; Beltagy, I.; Launay, J.; Raffel, C. What language model architecture and pretraining objective works best for zero-shot generalization? In Proceedings of the International Conference on Machine Learning, PMLR, Online, 28–30 March 2022; pp. 22964–22984. [Google Scholar]
- Introducing Meta Llama 3: The Most Capable Openly Available LLM to Date. Available online: https://huggingface.co/meta-llama/Meta-Llama-3-8B (accessed on 15 November 2024).
- Houlsby, N.; Giurgiu, A.; Jastrzebski, S.; Morrone, B.; De Laroussilhe, Q.; Gesmundo, A.; Attariyan, M.; Gelly, S. Parameter-efficient transfer learning for NLP. In Proceedings of the International Conference on Machine Learning, PMLR, Long Beach, CA, USA, 10–15 June 2019; pp. 2790–2799. [Google Scholar]
- Patterson, D.; Gonzalez, J.; Le, Q.; Liang, C.; Munguia, L.M.; Rothchild, D.; So, D.; Texier, M.; Dean, J. Carbon emissions and large neural network training. arXiv 2021, arXiv:2104.10350. [Google Scholar]
- Hu, E.J.; Shen, Y.; Wallis, P.; Allen-Zhu, Z.; Li, Y.; Wang, S.; Wang, L.; Chen, W. Lora: Low-rank adaptation of large language models. arXiv 2021, arXiv:2106.09685. [Google Scholar]
- Dettmers, T.; Pagnoni, A.; Holtzman, A.; Zettlemoyer, L. Qlora: Efficient finetuning of quantized llms. Adv. Neural Inf. Process. Syst. 2023, 36, 10088–10115. [Google Scholar]
- Li, C.; Farkhoor, H.; Liu, R.; Yosinski, J. Measuring the intrinsic dimension of objective landscapes. arXiv 2018, arXiv:1804.08838. [Google Scholar]
- Aghajanyan, A.; Zettlemoyer, L.; Gupta, S. Intrinsic dimensionality explains the effectiveness of language model fine-tuning. arXiv 2020, arXiv:2012.13255. [Google Scholar]
- Zhang, X.; Zhao, J.; LeCun, Y. Character-level Convolutional Networks for Text Classification, Advances in Neural Information Processing Systems, 28, NIPS 2015. Available online: https://proceedings.neurips.cc/paper/2015/hash/250cf8b51c773f3f8dc8b4be867a9a02-Abstract.html (accessed on 15 February 2025).
- Yu, Z.; Ananiadou, S. Neuron-level knowledge attribution in large language models. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, Miami, FL, USA, 12–16 November 2024; pp. 3267–3280. [Google Scholar]
- Zheng, Z.; Wang, Y.; Huang, Y.; Song, S.; Yang, M.; Tang, B.; Xiong, F.; Li, Z. Attention heads of large language models: A survey. arXiv 2024, arXiv:2409.03752. [Google Scholar] [CrossRef]
- Zhang, Q.; Chen, M.; Bukharin, A.; He, P.; Cheng, Y.; Chen, W.; Zhao, T. AdaLoRA: Adaptive budget allocation for parameter-efficient fine-tuning. arXiv 2023, arXiv:2303.10512. [Google Scholar]
- Liu, H.; Tam, D.; Muqeeth, M.; Mohta, J.; Huang, T.; Bansal, M.; Raffel, C.A. Few-shot parameter-efficient fine-tuning is better and cheaper than in-context learning. Adv. Neural Inf. Process. Syst. 2022, 35, 1950–1965. [Google Scholar]
- Hyeon-Woo, N.; Ye-Bin, M.; Oh, T.H. Fedpara: Low-rank hadamard product for communication-efficient federated learning. arXiv 2021, arXiv:2108.06098. [Google Scholar]
- Valipour, M.; Rezagholizadeh, M.; Kobyzev, I.; Ghodsi, A. Dylora: Parameter efficient tuning of pre-trained models using dynamic search-free low-rank adaptation. arXiv 2022, arXiv:2210.07558. [Google Scholar]
- Liu, S.Y.; Wang, C.Y.; Yin, H.; Molchanov, P.; Wang, Y.C.F.; Cheng, K.T.; Chen, M.H. Dora: Weight-decomposed low-rank adaptation. arXiv 2024, arXiv:2402.09353. [Google Scholar]
- Chavan, A.; Liu, Z.; Gupta, D.; Xing, E.; Shen, Z. One-for-all: Generalized lora for parameter-efficient fine-tuning. arXiv 2023, arXiv:2306.07967. [Google Scholar]
- Edalati, A.; Tahaei, M.; Kobyzev, I.; Nia, V.P.; Clark, J.J.; Rezagholizadeh, M. Krona: Parameter efficient tuning with kronecker adapter. arXiv 2022, arXiv:2212.10650. [Google Scholar]
- Mahabadi, R.K.; Henderson, J.; Ruder, S. Compacter: Efficient low-rank hypercomplex adapter layers. Adv. Neural Inf. Process. Syst. 2021, 34, 1022–1035. [Google Scholar]
- Newman, B.; Choubey, P.K.; Rajani, N. P-adapters: Robustly extracting factual information from language models with diverse prompts. arXiv 2021, arXiv:2110.07280. [Google Scholar]
- Lester, B.; Al-Rfou, R.; Constant, N. The power of scale for parameter-efficient prompt tuning. arXiv 2021, arXiv:2104.08691. [Google Scholar]
- Li, X.L.; Liang, P. Prefix-tuning: Optimizing continuous prompts for generation. arXiv 2021, arXiv:2101.00190. [Google Scholar]
- Zhang, R.; Han, J.; Liu, C.; Gao, P.; Zhou, A.; Hu, X.; Yan, S.; Lu, P.; Li, H.; Qiao, Y. Llama-adapter: Efficient fine-tuning of language models with zero-init attention. arXiv 2023, arXiv:2303.16199. [Google Scholar]
- Liu, X.; Zheng, Y.; Du, Z.; Ding, M.; Qian, Y.; Yang, Z.; Tang, J. GPT Understands, Too. AI Open 2024, 5, 208–215. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).