Abstract
Deep hashing has gained widespread attention in cross-modal retrieval due to its low cost and efficient retrieval advantages. However, existing cross-modal hashing methods either focus solely on exploring relationships between data points—which inevitably leads to intra-class dispersion—or emphasize the relationships between data points and categories while neglecting the preservation of inter-class structural relationships, resulting in suboptimal hash codes. To address this issue, this paper proposes a Deep Class-Guided Hashing (DCGH) method, which approaches model learning from the category level. It ensures that data of the same category are clustered around the same class center while maintaining the structural relationships between class centers. Extensive comparative experiments conducted on three benchmark datasets demonstrate that the DCGH method achieves comparable or even superior performance compared to existing cross-modal retrieval methods.
1. Introduction
Cross-modal retrieval has shown great potential in handling large-scale multimedia retrieval tasks, primarily due to the use of Approximate Nearest Neighbor (ANN) search [1,2,3]. The primary challenge, however, lies in effectively bridging the semantic gap between modalities to accurately capture their semantic relationships. As the scale of the data increases, these methods often experience a serious decline in efficiency, primarily due to the growing computational complexity. In this context, hashing techniques offer a promising and efficient solution for cross-modal ANN search, as they embed high-dimensional data points into a compact binary subspace, with similarity across modalities being measured via fast XOR operations. Recently, rapid advancements in deep learning have sparked increased interest in deep hashing approaches [4,5,6,7,8,9,10,11,12], which have been shown to outperform traditional shallow models in terms of semantic representation capabilities [13,14,15,16,17,18].
As prominent learning strategies for deep hashing, pairwise loss and triplet loss based on Data-to-Data Metric Learning effectively preserve inter-class structural relationships by pulling similar instances closer together while pushing dissimilar instances further apart. However, these approaches predominantly focus on the relative distances between samples without imposing global constraints on the intra-class distribution, which leads to intra-class dispersion. This limitation is further exacerbated by the hashing quantization process, which significantly undermines the model’s ability to capture fine-grained semantic representations. To address this issue, some recent strategies have emerged that are based on Data-to-Class Metric Learning, such as center loss [12,19] and proxy loss [4,20,21,22]. Center loss penalizes the distance between each sample and its corresponding class center, effectively clustering intra-class samples and promoting a more compact intra-class distribution. However, in multi-label scenarios, learning a stable center vector for each class remains challenging. Proxy loss-based methods mitigate this issue by introducing a proxy vector for each single-label category and learning the hash representation by minimizing the distance between samples and their corresponding proxies while maximizing the distance between samples and proxies from other categories. Notably, proxy-based hashing methods demonstrate remarkable generalization capabilities, particularly in handling unseen categories, as they shift the learning focus from modeling the relationships between samples to learning the relationships between samples and proxy vectors. Despite their advantages, however, as illustrated in Figure 1, these approaches also suffer from a significant drawback: they struggle to preserve the inter-class similarity structure.
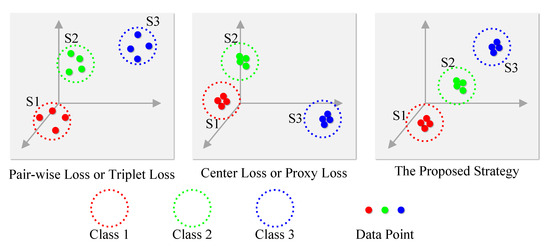
Figure 1.
Illustration of hash codes learned using different learning strategies.
To simultaneously preserve intra-class and inter-class similarity structures, an intuitive approach is to combine with . However, constructing an optimal solution that leverages the advantages of both objectives presents significant challenges. Firstly, the semantic bias issue inevitably arises when considering the similarity relationships not only among data points themselves but also between data points and class proxies. This issue becomes particularly pronounced in scenarios where there are imbalances in the number of data points across different classes. Taking Figure 2 as an example, class is related to proxy points , , and , and class is related to proxy points and . The pentagrams (★★★★) represent proxies for each category. When considering both types of relationships, all the data points are prone to semantic bias—they will be predominantly attracted to proxy if a significantly larger proportion of them are related to proxy compared to other proxies. Unfortunately, ensuring class balance in real-world applications is challenging, which makes semantic bias a significant obstacle to the practical deployment of this approach.
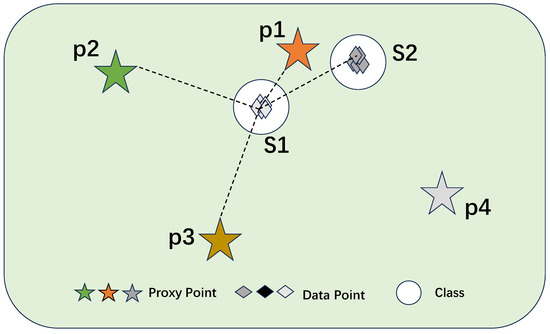
Figure 2.
An example of a semantic bias issue and an intra-class dispersion issue.
Worse still, despite preserving inter-class similarity relationships effectively, directly combining and will cause an intra-class dispersion issue again. Considering the relationships between data point A and other data points, as well as the relationships between data point A and relevant category proxies, the connections of data point A with other data points are far more numerous than its connections with relevant category proxies. Data-to-Data Metric Learning still plays a dominant role, inevitably leading to intra-class dispersion. This limitation, in turn, undermines the preservation of the intra-class similarity structure.
To answer the above questions, we proposed a novel Deep Class-Guided Hashing (DCGH) method for multi-label cross-modal retrieval. We have introduced a variance constraint to ensure that the distances between each data point and its corresponding proxy are as consistent as possible, preventing semantic bias. Regarding the issue of intra-class dispersion, considering that in multi-label datasets, the number of irrelevant pairs in pairwise loss is much smaller than the number of relevant pairs and that positive sample pairs have a stronger constraint and are more likely to cause intra-class dispersion compared to negative sample pairs, we assign different small weights to the positive and negative sample constraints of pairwise loss. This allows for the aggregation of similar data points to be primarily guided by proxy loss, thereby addressing the issue of intra-class dispersion.
To sum up, the main contributions of this article are threefold:
- General advancements: Starting from the perspective of intra-class aggregation and inter-class structural relationship maintenance, this paper proposes a combination of proxy loss and pairwise loss;
- Innovative methodologies: In further considering the issues arising from the combination of proxy loss and pairwise loss, the DCGH method is proposed;
- Comprehensive experiments: Extensive experiments on three benchmark datasets demonstrate that the proposed DCGH algorithm outperforms other baseline methods in cross-modal hashing retrieval.
The remainder of this paper is organized as follows. Section 2 introduces representative supervised cross-modal hashing methods and unsupervised cross-modal hashing methods. Section 3 introduces the proposed method in detail. The experimental results and analysis are provided in Section 4, and Section 5 summarizes the conclusions and future work.
2. Related Works
In this section, we review the related studies from two aspects: supervised cross-modal hashing in Section 2.1 and unsupervised cross-modal hashing in Section 2.2.
2.1. Supervised Hashing Methods
Supervised hashing methods primarily leverage label information to learn hashing functions, achieving satisfactory semantic discrimination of binary codes. Existing methods either consider the similarity relationships between data points based on pairwise loss or triplet loss or learn the hashing functions by considering the relationship between data and public anchor points through center loss or proxy loss. We will briefly introduce previous work from these two perspectives.
2.1.1. Data-to-Data Metric Learning
Pairwise loss and triplet loss both learn the hashing function by leveraging the relative relationships between data points.
Pairwise loss-based methods.
DCMH was the first to integrate hash code learning and feature learning into the same framework for each modality, enabling end-to-end learning [23]. In order to explore the inherent similarity structure between pairwise data points, the GCH method introduces graph convolutional networks to capture structural semantic information [24]. SSAH incorporates adversarial learning in a self-supervised manner into cross-modal hashing learning, employing two adversarial networks to jointly learn high-dimensional features specific to each modality and using information obtained from the label network to supervise the learning process [25]. As multi-label cross-modal hashing methods gain significant attention, the MESDCH approach, which employs a multi-label semantic similarity module, is used to maintain pairwise similarity relationships within multi-label data [26]. However, optimizing binary hash codes during model training is challenging. In response to this, scholars from home and abroad have proposed a selection mechanism for the DCHMT method to more effectively optimize the hash codes [27]. HHF further explores the incompatible conflict between metric learning and quantization learning in the optimization process, setting different thresholds according to different hash bit lengths and the number of categories to reduce this conflict [28]. To address the issues of solution space compression and loss function oscillation, SCH categorizes sample pairs into fully semantically similar, partially semantically similar, and semantically negative pairs based on their similarity. It imposes different constraints on each category to ensure the entire Hamming space is utilized, and it sets upper and lower bounds on the similarity between samples to prevent loss function oscillation [29].
Triplet loss-based methods.
TDH introduces intra-modal and inter-modal triplets, proposing a triplet-based deep hashing framework to establish semantic relationships between heterogeneous data from different modalities [30]. Additionally, the Deep Adversarial Discrete Hashing framework has developed a weighted cosine triplet loss to explore the similarity relationships between data under multi-label settings [31].
2.1.2. Data-to-Class Metric Learning
Center loss-based methods.
To address the issue of intra-class dispersion, EGDH employs a label network that encodes non-redundant multi-label annotations into hash codes to form a common classifier, guiding the hash feature learning network to construct features that are easily classified by the classifier and close to their semantic hash code anchors [5]. SCCGDH utilizes the label information of the data to learn a specific class center for each label, keeping data points close to their corresponding class centers to maintain intra-class aggregation [19].
Proxy loss-based methods.
DCPH first introduced the concept of proxy hash, mapping label or category information to proxy hash codes, which are then used to guide the training of modality-specific hash networks [20]. Considering that the generation of previous proxies did not take into account the distribution of the data, DAPH integrates data features and labels into a framework to learn category proxies and then uses the obtained category proxies to guide the training of modality-specific hash networks [21]. DSPH employs Transformer as the feature extraction architecture and points out that proxy hashing methods have an issue with ambiguous relationships between negative samples, adding a negative sample constraint to proxy loss to address this issue [4]. How to independently preserve each hash bit and learn zero-mean threshold hash functions has always been a very challenging issue in cross-modal hashing [32]. Moreover, due to the variability of balance conditions across batches, the current binary balance mechanism is not well-suited for batch processing in training methods. To address these issues, DNPH introduces a uniform distribution constraint into proxy loss to ensure that the distribution of hash codes follows a discrete uniform distribution; to maintain modality-specific semantic information, it adds a prediction layer for each modality network using cross-entropy loss [22]. DHaPH further considers the potential semantic hierarchical relationships between multi-modal samples, introduces learnable shared hierarchical proxies in hyperbolic space, and proposes a hierarchical perception proxy loss algorithm that effectively mines potential semantic hierarchical information without requiring any hierarchical prior knowledge [33].
2.2. Unsupervised Hashing Methods
Under the condition of lacking supervisory information, deep cross-modal hashing technology has shown excellent performance in cross-modal retrieval tasks. DBRC [34] introduces a deep learning framework designed for binary reconstruction, which aims to model the relationships between different modalities and learn the corresponding hash codes. UDCMH [35] uses an alternating optimization strategy to solve discrete optimization problems and dynamically assigns weights to different modalities during the optimization process. DJSRH [36] reconstructs a structure that captures the joint semantics to learn hash codes, explicitly incorporating the original neighborhood information derived from the multi-modal data. AGCH [37] aggregates structural information and applies various similarity measurement methods to construct a comprehensive similarity matrix. JDSH [38] creates a joint-modal similarity matrix and designs a sampling and weighting mechanism to generate more discriminative hash codes. CIRH [39] designs a multi-modal collaborative graph to build heterogeneous multi-modal correlations and performs semantic aggregation on graph networks to generate a multi-modal complementary representation.
3. Methodology
This section introduces the proposed method. We begin with a formal problem formulation. Subsequently, an overview of the DCGH framework is provided, followed by a detailed discussion of its individual components.
3.1. Problem Formulation
Notations. Without loss of generality, sets are denoted by math script uppercase letters (e.g., ). Scalers or constants are signed by uppercase letters (e.g., C). Matrices are represented in uppercase bold letters (e.g., ), and the -th element of is denoted by . Vectors are denoted by lowercase bold letters (e.g., ), and the i-th element of is represented by . A transpose of a matrix or a vector is denoted by a superscript, T (e.g., ). Functions are denoted by calligraphy uppercase letters (e.g., ). The frequently used mathematical notations are summarized in Table 1 for readability.

Table 1.
A summary of frequently-used notations and symbols.
Problem Definition. This work focuses on two common modalities: image (denoted by x) and text (denoted by y). Given a dataset, , where represents the i-th sample, and represent the i-th image and text, respectively. is the multi-label vector for , where C is the number of categories. The goal of cross-modal hashing is to learn two hashing functions, and , to generate binary codes and , ensuring that the Hamming distance between similar samples is smaller and the distance between dissimilar ones is larger. Since binary optimization is a typical NP-hard problem, the continuous relaxation strategy is employed to obtain the binary-like codes.
3.2. Overview of DCGH Framework
As illustrated in Figure 3, the proposed DCGH framework, in general, consists of two modules: the feature learning module and the hash learning module.
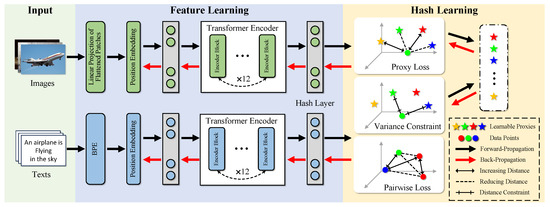
Figure 3.
An overview of our proposed DCGH framework, including two parts: (1) Feature Learning: Two feature extractors with different Transformer Encoders are designed to extract the representative semantic features from image modalities and text modalities, respectively. (2) Hash Learning: Ingeniously combining proxy loss and pairwise loss while exploring relationships between points and between points and classes, preventing semantic bias, variance constraints are introduced to ensure the consistency of the relationship between data and relevant proxy points.
Feature learning module. Inspired by [4,27], we introduce feature extraction based on a Transformer encoder into cross-modal retrieval to obtain representative semantic features from both the image and text modalities. Specifically, the image Transformer encoder has the same structure as the VIT encoder [40], which is composed of stacked 12-encoder blocks. Each encoder block has the same structure, including Layer Normalization (LN), Multi-Head Self-Attention (MSA), and MLP blocks. The number of MSA is 12. For the image semantic feature , represents the image semantic encoder and represents the parameters of the image semantic encoder. The text Transformer encoder consists of 12 encoder blocks, each with 8 MSA. For the text semantic feature , represents the text semantic encoder, and is the parameter of the text semantic encoder.
3.3. Hash Learning
In order to generate hash codes that maintain intra-class aggregation while preserving inter-class structural relationships, a comprehensive objective function composed of proxy loss, pairwise loss, and variance constraint has been designed to optimize the parameters of our proposed DCGH framework. In the following sections, we will detail each component of the DCGH architecture.
3.3.1. Proxy Loss
Proxy-based methods can achieve satisfactory performance in single-label cross-modal retrieval, but when considering multi-label cross-modal retrieval, proxy-based methods have been proven to produce poor performance with limited hash bits because they fail to deeply express multi-label correlations and neglect the preservation of inter-class structural relationships [20]. However, since only the relationships between data and proxy points need to be considered, the learned hash codes can maintain intra-class aggregation well. Therefore, we first learn hash codes for intra-class aggregation through proxy loss.
For proxy loss [4], a learnable proxy is first generated for each label category. The hash representation is learned by bringing samples closer to their relevant proxies and pulling away irrelevant data-proxy pairs. For , represents the learnable proxies for each label category, where is a K-bits vector. When the samples and the proxy are relevant, we can calculate the cosine distance between the binary-like hash codes and relevant proxies by using , and for proxies that are not related to the samples, the distance between binary-like hash codes and irrelevant proxies is pushed away by using .
Hence, the proxy loss of image could be calculated as shown in Equation (2).
where I is an indicator function. The denominators represent the number of relevant data-proxy pairs and irrelevant data-proxy pairs, respectively, aiming for normalization [4]. Similarly, the proxy loss of text, , can be calculated as shown in Equation (3).
The total multi-modal proxy loss is calculated, as shown in Equation (4).
3.3.2. Pairwise Loss
In order to maintain inter-class structural relationships, we further explore the relationships between data. That is, to bring similar data closer together and to push away dissimilar data. For this, we provide a similarity matrix, S, which is defined as follows:
where is the norm, and is the transpose of the vector (or matrix). The range of is [0, 1]. If > 0, then (or ), and (or ) is called an relevant pair. If = 0, then they are considered irrelevant pairs. To pull relevant pairs closer, we can calculate the cosine distance between relevant data pairs using ; inspired by [29], we relax the constraints on irrelevant data pairs. The distance between irrelevant data pairs is pushed away using .
Hence, the relevant loss, , can be calculated using Equation (7).
Similarly, irrelevant loss, , is calculated using Equation (8).
To address the issue of intra-class dispersion arising from pairwise loss, we assign a small weight to pairwise loss, allowing the aggregation of similar data points to be primarily guided by proxy loss, thereby resolving the issue of intra-class dispersion. Considering the fact that in multi-label datasets, the number of irrelevant pairs in pairwise loss is significantly smaller than the number of relevant pairs and that positive sample pairs have a stronger constraint and are more likely to lead to intra-class dispersion compared to negative sample pairs, we assign different small weights to the positive and negative sample constraints of pairwise loss. Therefore, the overall pairwise loss, , is given by the following formula:
where and are the small weight hyperparameters for positive and negative sample constraints, respectively.
3.3.3. Variance Constraint
As shown in Figure 2, when considering both the relationships between points and proxies and between points and points, if there are more data points related to proxy P1 than to other proxies, the data points will tend to lean towards proxy P1. However, data points should maintain a consistent relationship with each of their relevant proxies. Therefore, we use variance constraints to maintain a consistent distance relationship between the data and their relevant proxy points. For image data, , represents their label, and we use to denote the index set of its corresponding relevant proxies, where . Then, the variance constraint for it can be given by the following formula:
where represents the number of elements in the set, . Hence, the overall constraint of the image, , and the text, , can be calculated using Equation (11).
The total variance constraint loss, , is calculated, as shown in Equation (12).
3.4. Optimization
The training algorithm is a critical component of our proposed DCGH framework and is presented in Algorithm 1. The DCGH model is optimized by standard backpropagation algorithms and mini-batch gradient descent methods. The algorithm for generating the hash code is shown in Algorithm 2. For a query sample, use the well-trained DCGH model to generate binary-like hash codes and then use the sign function to generate the final binary hash codes.
Specifically, when given the query data, (), the compact hash code can be generated by Equation (14).
| Algorithm 1 Learning algorithm for DCGH |
| Input: Training dataset ; Binary codes length K; Hyperparameters: , . |
| Output: Network Parameters: , . |
|
| Algorithm 2 Learning hash codes for DCGH |
| Input: Query samples , Parameters for DCGH. |
| Output: Binary hash code for . |
|
4. Experiments
In this section, we will present and analyze the experimental results of the proposed method alongside those of several state-of-the-art competitors. Firstly, the details of the experimental setting are introduced in Section 4.1. We then proceed to discuss performance comparison, ablation studies, sensitivity to parameters, training and encoding time, and visualization in Section 4.2, Section 4.3, Section 4.4, Section 4.5 and Section 4.6, respectively.
4.1. Experimental Setting
Datasets. Our experiments were conducted on three commonly used benchmark datasets, i.e., MIRFLICKR-25K [41], NUS-WIDE [42], and MS COCO [43]. A brief introduction to them is listed here:
- MIRFLICKR-25K: This is a small-scale cross-modal multi-label dataset collected from the Flickr website. It includes 24,581 image-text pairs corresponding to 24 classes, in which each sample pair belongs to at least one category.
- NUS-WIDE: This dataset contains 269,648 image-text pairs, and each of them belongs to at least 1 of the 81 categories. To enhance the dataset’s practicality and compatibility with other research methods, we conducted a selection process, removing categories with fewer samples and choosing 21 common categories. This subset contains 195,834 image-text pairs, with each pair belonging to at least one of the categories.
- MS COCO: This dataset is a highly popular large-scale dataset in computer vision research. Comprising 82,785 training images and 40,504 validation images, each image is accompanied by corresponding textual descriptions and labels. It covers 80 different categories. In our study, the training and validation sets were combined, with each sample containing both image and text modalities, and each sample belongs to at least one category.
The statistics of these three datasets are reported in Table 2.
Table 2.
Statistics of MIRFLICKR-25K, NUS-WIDE, and MS COCO.
Implementation details. In our experiments, we implemented a unified sampling strategy across the three datasets. Initially, we randomly selected 5000 image-text pairs from a dataset as the query set, with the remainder serving as the database set. During the model training phase, we randomly chose 10,000 image-text pairs as the training set. To ensure consistency and fairness in the experiments, we performed the same preprocessing operations on the images and text for all datasets: the image sizes were adjusted to 224 × 224, and the text was represented through BPE [44] encoding.
To ease reading, we report the detailed configuration of each of the components in the proposed DCGH framework in Table 3.
Table 3.
Configuration of the proposed architecture.
Experimental environment. We implemented our DCGH via Pytorch, with a GPU leveraging NVIDIA RTX 3090. For the network configuration, the two Transformer encoders of DCGH, ViT [40] and GPT-2 [45], were initialized using pre-trained CLIP (ViT-B/32) [46]. Our model employs an adaptive moment estimation (Adam) optimizer to update the network parameters until convergence [47]. The learning rate of two backbone Transformer encoders, ViT and GPT-2, was set as 0.00001, while the learning rate of the hash learning module in DCGH was set to 0.001. The two hyperparameters, and , were set to 0.05 and 0.8, respectively. The batch size was 128.
Baseline methods. In our experiments, we selected 14 state-of-the-art deep cross-modal hashing methods for comparison, which contain Deep Cross-Modal Hashing [23], Self-Supervised Adversarial Hashing [25], Cross-Modal Hamming Hash [48], Adversary Guided Asymmetric Hashing [49], Deep Adversarial Discrete Hashing [31], Self-Constraining Attention Hashing Network [9], Multi-label Enhancement Self-supervised Deep Cross-modal Hashing [26], Differentiable Cross-modal Hashing via Multi-modal Transformers [27], Modality-Invariant Asymmetric Networks [50], Data-Aware Proxy Hashing [21], Deep Semantic-aware Proxy Hashing [4], Deep Neighborhood-aware Proxy Hashing [22], Deep Hierarchy-aware Proxy Hashing [33], and Semantic Channel Hash [29]. Due to some methods not being open source, we directly cite the results from the published papers.
Evaluation protocols. In our experiments, we employed five commonly used evaluation metrics to assess the performance of cross-modal similarity searches, which include mean Average Precision (mAP), Normalized Discounted Cumulative Gain using the top 1000 returned samples (NDCG@1000), Precision with a Hamming radius of 2 (P@H ≤ 2) curve, Precision-Recall (PR) curve, and Precision@Top N curve. The mAP is calculated as the average of the AP across all query samples. The PR curve represents the variation curve between recall and precision. Top-N Precision curve illustrates the proportion of truly relevant data among the top N results returned by the system. NDCG@1000 is a comprehensive metric that assesses the ranking performance of the top 1000 retrieval results. Precision with a Hamming radius of 2 describes the precision of the samples retrieved within the specified Hamming radius. The experimental results from the aforementioned evaluation metrics demonstrate that the DCGH method achieves excellent performance in cross-modal similarity searches.
4.2. Performance Comparison
We validated the performance of DCGH by comparing it with state-of-the-art deep cross-modal hashing methods on image-text retrieval tasks across three public datasets. The mAP results are shown in Table 4, where “Img2Txt” indicates image-to-text retrieval, and “Txt2Img” indicates text-to-image retrieval. In most cases, DCGH outperforms other baseline methods, achieving satisfactory performance. On the MIRFLICKR-25K dataset, compared to the baseline methods, the SCH method performs the best. In the image-to-text retrieval task, the SCH method is, on average, 0.37% higher than the method in the present study, and in the text-to-image retrieval task, the SCH method is, on average, 0.9% higher than the method in the present study. However, on the NUS-WIDE and MS COCO datasets, as the amount of data increases, the issue of intra-class dispersion leads to unsatisfactory performance for the SCH method. In contrast, our DCGH method considers both intra-class aggregation and inter-class structural relationships, and it essentially achieves the best performance compared to other baseline methods. This confirms the effectiveness of our method. The performance of this method in the multi-label retrieval scenario was evaluated using the NDCG@1000 evaluation metric.
Table 4.
Comparison with baselines in terms of mAP on MIRFLICKR-25K, NUS-WIDE, and MS COCO. The best results are in bold font.
The results of NDCG@1000 can be found in Table 5. From Table 5, it can be observed that our method and the DNPH method have comparable scores, with each having its own advantages and disadvantages. The DNPH method, which introduces a uniform distribution constraint on the basis of proxy loss, achieves the optimal NDCG@1000 scores for the image-text retrieval tasks at 16 bits and 32 bits on three public datasets in most cases. However, at 64 bits, as the length of the hash code increases, the discrete space becomes sparser, and DCGH can obtain higher-quality ranking results compared to DNPH.
Table 5.
Comparison with baselines in terms of NDCG@1000 on MIRFLICKR-25K, NUS-WIDE, and MS COCO; the best results are shown in bold.
To further evaluate the performance of our method, Figure 4, Figure 5 and Figure 6 show the PR curves on the MIRFLICKR-25K, NUS-WIDE, and MS COCO datasets at 16 bits and 32 bits, and Figure 7 shows the results of TopN-precision curves on the MIRFLICKR-25K, NUS-WIDE, and MS COCO datasets regarding 32 bits. The mAP@H ≤ 2 results for different hash code lengths on the MIRFLICKR-25K, NUS-WIDE, and MS COCO datasets are shown in Figure 8, where Figure 8a–c display the mAP@H ≤ 2 results for the image retrieval text task. Figure 8d–f show the mAP@H ≤ 2 results for the text retrieval image task. Compared with the state-of-the-art methods in the baseline, our method achieves comparable or even better results.
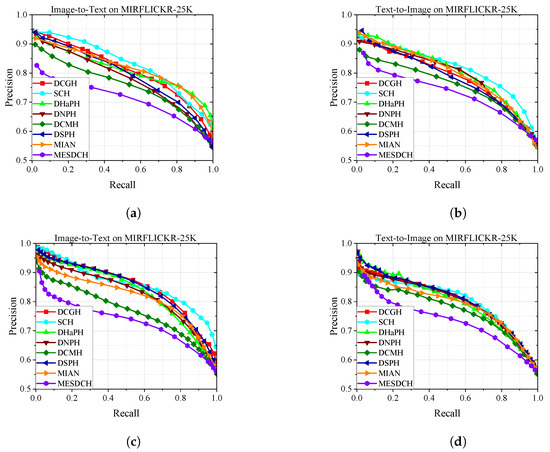
Figure 4.
Results of Precision-Recall curves on MIRFLICKR-25K. (a) PR@16 bits. (b) PR@16 bits. (c) PR@32 bits. (d) PR@32 bits.
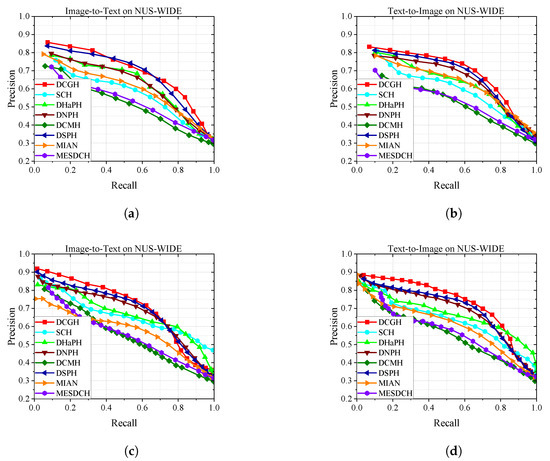
Figure 5.
Results of Precision-Recall curves on NUS-WIDE. (a) PR@16 bits. (b) PR@16 bits. (c) PR@32 bits. (d) PR@32 bits.
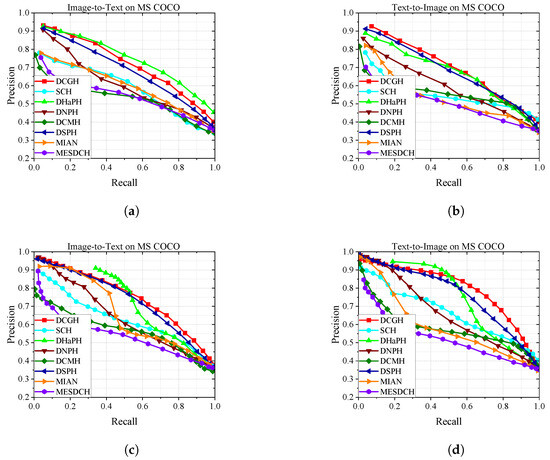
Figure 6.
Results of Precision-Recall curves on MS COCO. (a) PR@16 bits. (b) PR@16 bits. (c) PR@32 bits. (d) PR@32 bits.
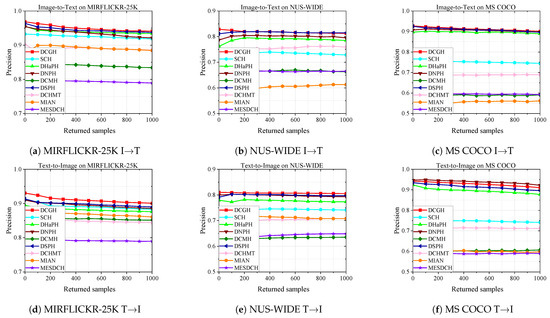
Figure 7.
Results of TopN-precision curves on the MIRFLICKR-25K, NUS-WIDE, and MS COCO datasets for 32 bits.
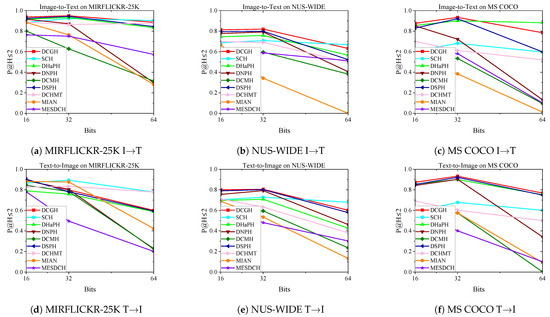
Figure 8.
The mAP@H≤2 results for different code lengths on the MIRFLICKR-25K, NUS-WIDE, and MS COCO datasets.
4.3. Ablation Studies
To validate the effectiveness of the DCGH method, we implemented three variations to calculate the mAP values for the tasks of the image retrieval of text and the text retrieval of images. In detail, (1) DCGH-P-V: uses only proxy loss, , to train the model. (2) DCGH-X-V: uses only pairwise loss, , to train the model. Since proxy loss was not considered, and were set to 1. (3) DCGH-V: variance constraint, , was not used.
The ablation experiment results are shown in Table 6. Comparing the results of DCGH-P-V and DCGH-X-V on three benchmark datasets reveals that DCGH-P-V, which only uses proxy loss, generally performs better on large datasets like NUS-WIDE and MS COCO than DCGH-X-V, which only uses pairwise loss. As the amount of data increases, the issue of intra-class dispersion caused by pairwise loss can significantly affect the effectiveness of the hash codes. Comparing the performance of DCGH-V with DCGH-P-V and DCGH-X-V across the three datasets shows that DCGH-V, which combines proxy loss and pairwise loss to consider both intra-class aggregation and inter-class structural relationship preservation, significantly outperforms DCGH-P-V and DCGH-X-V, which only use one type of loss each. This confirms the rationality of our combination approach. By comparing the results of DCGH and DCGH-V on the three benchmark datasets, it is evident that introducing a variance constraint to prevent semantic bias leads to better results, confirming the effectiveness of the variance constraint. By comparing three variables, the effectiveness of each component of the DCGH method was verified. By combining proxy loss, pairwise loss, and variance constraints, DCGH is able to learn excellent hash codes.
Table 6.
mAP results of DCGH and its variants on MIRFLICKR-25K, NUS-WIDE, and MS COCO. The best results are shown in bold.
4.4. Sensitivity to Hyperparameters
We also investigated the sensitivity of the parameters and . We set their ranges to {0.001, 0.01, 0.05, 0.1, 0.5, 0.8, 1}, and the results are reported in Figure 9. From Figure 9a,d, it can be observed that the trend of alpha and beta on the MIRFLICKR-25K dataset is quite intuitive, with the best performance occurring at alpha and beta values of 0.05 and 0.8, respectively. Figure 9b,c show that on large-scale datasets, as the value of alpha increases, meaning the constraint between positive samples becomes stronger, proxy loss can no longer dominate the training of the hashing network, leading to intra-class dispersion and a significant drop in mAP scores. Figure 9f indicates that due to the more relaxed constraint on negative samples, the increase in beta has a smaller impact on the hashing network. From Figure 9e, we also find an interesting phenomenon that the value of beta has almost no effect on the mAP scores on the NUS-WIDE dataset, which we believe may be due to the overwhelming size of the NUS-WIDE dataset with only 21 categories, and the proportion of unrelated samples is too small. This also demonstrates the ingenuity of our approach to set separate weight parameters for positive and negative sample constraints in pairwise loss.
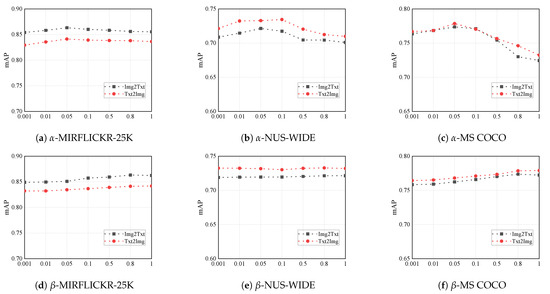
Figure 9.
Parameter sensitivity of and on the MIRFLICKR-25K, NUS-WIDE, and MS COCO datasets. The code length is 64.
4.5. Training and Encoding Time
To investigate the efficiency of the model, we compared the training time and encoding time of the DCGH algorithm with other Transformer-based cross-modal hashing algorithms on the MIRFLICKR-25K dataset using 32-bit binary codes, with the results shown in Figure 10. During the optimization of the DCGH model, a proxy loss algorithm was proposed, which has a time complexity of , and C is the number of categories. Additionally, the time complexities for the pairwise loss and variance constraint were and , respectively. Here, represents the ratio of the number of related data-proxy pairs to the total number of data-proxy pairs, with being less than 1. Therefore, the total time complexity of our algorithm is , which is approximately equal to . As shown in Figure 10a, compared with several other state-of-the-art methods, our training time is average, and since the training process of these methods is offline, the training time does not affect the performance of the method. As shown in the comparison of encoding time in Figure 10b, the encoding time of all methods is within the millisecond range, indicating that our method achieves comfortable encoding time.
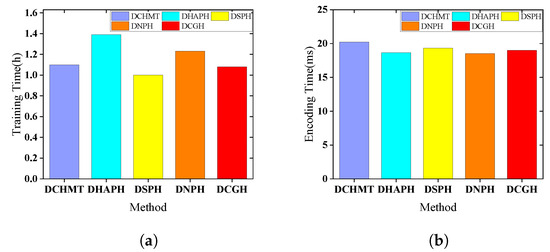
Figure 10.
Training time and Encoding time of DCGH on MIRFLICKR-25K. (a) Training time. (b) Encoding time.
4.6. Visualization
To explore the ability of our model to bridge the semantic gap between different modalities, we used the T-sne [51] technique to project discrete hash codes into a two-dimensional space on three public datasets. As shown in Figure 11, different colored points represent data from different modalities. As we can see, the data from the text modality and the image modality are aligned very well.
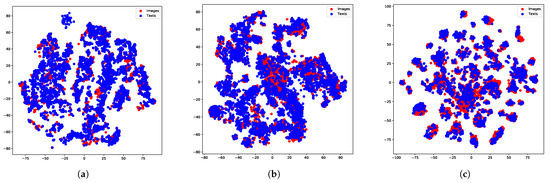
Figure 11.
T-sne visualization of the hash codes of image and text modalities on the MIRFLICKR-25K, NUS-WIDE, and MS COCO datasets. The code length is 64. (a) MIRFLICKR-25K. (b) NUS-WIDE. (c) MS COCO.
To explore the quality of the hash codes and the intra-class aggregation, we selected samples from seven different single-label categories in the NUS-WIDE dataset and performed T-sne visualization on 16-bit hash codes using the DCHMT, SCH, and DCGH methods. The results are shown in Figure 12; the different colored dots represent different single-label category data. Through comparison and analysis, we can see that our method can obtain higher quality and more intra-class aggregated binary hash codes due to the joint training of the model with proxy loss, pairwise loss, and variance constraint terms.
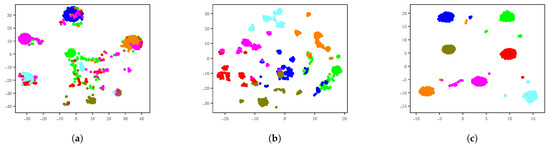
Figure 12.
T-sne result of DCHMT, SCH, and DCGH on NUS-WIDE for 16 bits. (a) DCHMT. (b) SCH. (c) DCGH.
5. Conclusions
This paper proposes a cross-modal retrieval method based on Deep Class-Guided Hashing (DCGH), which simultaneously considers the intra-class aggregation and inter-class structural relationship preservation of hash codes, thereby generating superior hash codes. Recently, quantum computing has garnered significant attention due to its parallelism and exponential acceleration potential. For example, quantum parallelism could enable rapid gradient computation to reduce model training time [52], and quantum mechanics-based hash algorithms could enhance information security in cross-modal retrieval [53]. However, current quantum computers face limitations in qubit count, making it challenging to directly process large-scale cross-modal data. In the future, we plan to explore the integration of quantum computing with the DCGH framework, such as leveraging quantum computing to accelerate the training process of deep neural networks and designing robust hash functions resilient to quantum hardware noise.
Author Contributions
Conceptualization, H.C.; methodology, H.C.; software, X.Z.; validation, H.C., Z.Z. and X.Z.; formal analysis, H.C.; investigation, H.C.; resources, X.Z.; data curation, Z.Z.; writing—original draft preparation, H.C.; writing—review and editing, X.Z.; visualization, H.C.; supervision, Y.L.; project administration, X.Z.; funding acquisition, X.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The public datasets used in this paper can be accessed through the following links: MIRFLICKR-25K: https://press.liacs.nl/mirflickr/mirdownload.html, accessed on 19 December 2024; NUS-WIDE: https://pan.baidu.com/s/1BzEho9BvpWX93sMA4A_o-A?pwd=swq3, accessed on 19 December 2024; MS COCO: https://cocodataset.org, accessed on 19 December 2024.
Acknowledgments
The authors would like to express their gratitude to the technical staff at the Hunan Agricultural University, Teaching Building 13, Lab 511 and 503 for their invaluable support throughout the experiments. We also acknowledge the contributions of Lei Zhu for providing insightful comments on the manuscript.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Li, F.; Wang, B.; Zhu, L.; Li, J.; Zhang, Z.; Chang, X. Cross-Domain Transfer Hashing for Efficient Cross-Modal Retrieval. IEEE Trans. Circuits Syst. Video Technol. 2024, 34, 9664–9677. [Google Scholar] [CrossRef]
- Wang, Y.; Dong, F.; Wang, K.; Nie, X.; Chen, Z. Weighted cross-modal hashing with label enhancement. Knowl. Based Syst. 2024, 293, 111657. [Google Scholar] [CrossRef]
- Zhang, C.; Song, J.; Zhu, X.; Zhu, L.; Zhang, S. HCMSL: Hybrid Cross-modal Similarity Learning for Cross-modal Retrieval. ACM Trans. Multim. Comput. Commun. Appl. 2021, 17, 2:1–2:22. [Google Scholar] [CrossRef]
- Huo, Y.; Qin, Q.; Dai, J.; Wang, L.; Zhang, W.; Huang, L.; Wang, C. Deep semantic-aware proxy hashing for multi-label cross-modal retrieval. IEEE Trans. Circuits Syst. Video Technol. 2023, 34, 576–589. [Google Scholar] [CrossRef]
- Shi, Y.; You, X.; Zheng, F.; Wang, S.; Peng, Q. Equally-Guided Discriminative Hashing for Cross-modal Retrieval. In Proceedings of the International Joint Conference on Artificial Intelligence (IJCAI), Macao, China, 10–16 August 2019; pp. 4767–4773. [Google Scholar]
- Qin, Q.; Huo, Y.; Huang, L.; Dai, J.; Zhang, H.; Zhang, W. Deep Neighborhood-preserving Hashing with Quadratic Spherical Mutual Information for Cross-modal Retrieval. IEEE Trans. Multimed. 2024, 26, 6361–6374. [Google Scholar] [CrossRef]
- Wu, Q.; Zhang, Z.; Liu, Y.; Zhang, J.; Nie, L. Contrastive Multi-Bit Collaborative Learning for Deep Cross-Modal Hashing. IEEE Trans. Knowl. Data Eng. 2024, 36, 5835–5848. [Google Scholar] [CrossRef]
- Song, G.; Huang, K.; Su, H.; Song, F.; Yang, M. Deep Ranking Distribution Preserving Hashing for Robust Multi-Label Cross-modal Retrieval. IEEE Trans. Multimed. 2024, 26, 7027–7042. [Google Scholar] [CrossRef]
- Wang, X.; Zou, X.; Bakker, E.M.; Wu, S. Self-constraining and attention-based hashing network for bit-scalable cross-modal retrieval. Neurocomputing 2020, 400, 255–271. [Google Scholar] [CrossRef]
- Liu, Y.; Wu, Q.; Zhang, Z.; Zhang, J.; Lu, G. Multi-Granularity Interactive Transformer Hashing for Cross-modal Retrieval. In Proceedings of the 31st ACM International Conference on Multimedia, Ottawa, ON, Canada, 29 October–3 November 2023; pp. 893–902. [Google Scholar]
- Song, G.; Su, H.; Huang, K.; Song, F.; Yang, M. Deep self-enhancement hashing for robust multi-label cross-modal retrieval. Pattern Recognit. 2024, 147, 110079. [Google Scholar] [CrossRef]
- Gao, Z.; Wang, J.; Yu, G.; Yan, Z.; Domeniconi, C.; Zhang, J. Long-tail cross modal hashing. In Proceedings of the AAAI Conference on Artificial Intelligence, Washington, DC, USA, 7–14 February 2023; Volume 37, pp. 7642–7650. [Google Scholar]
- Lin, Z.; Ding, G.; Hu, M.; Wang, J. Semantics-preserving hashing for cross-view retrieval. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3864–3872. [Google Scholar]
- Ding, G.; Guo, Y.; Zhou, J. Collective matrix factorization hashing for multimodal data. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 2075–2082. [Google Scholar]
- Hotelling, H. Relations Between Two Sets of Variates. Biometrika 1936, 28, 321–377. [Google Scholar] [CrossRef]
- Wang, D.; Gao, X.; Wang, X.; He, L. Semantic topic multimodal hashing for cross-media retrieval. In Proceedings of the Twenty-Fourth International Joint Conference on Artificial Intelligence, Buenos Aires, Argentina, 25–31 July 2015; pp. 3890–3896. [Google Scholar]
- Zhang, D.; Li, W.J. Large-scale supervised multimodal hashing with semantic correlation maximization. In Proceedings of the AAAI Conference on Artificial Intelligence, Québec City, QC, Canada, 27–31 July 2014; pp. 2177–2183. [Google Scholar]
- Norouzi, M.; Fleet, D.J. Minimal loss hashing for compact binary codes. In Proceedings of the 28th International Conference on International Conference on Machine Learning, Bellevue, WA, USA, 28 June–2 July 2011; pp. 353–360. [Google Scholar]
- Shu, Z.; Bai, Y.; Zhang, D.; Yu, J.; Yu, Z.; Wu, X.J. Specific class center guided deep hashing for cross-modal retrieval. Inf. Sci. 2022, 609, 304–318. [Google Scholar] [CrossRef]
- Tu, R.C.; Mao, X.L.; Tu, R.X.; Bian, B.; Cai, C.; Wang, H.; Wei, W.; Huang, H. Deep cross-modal proxy hashing. IEEE Trans. Knowl. Data Eng. 2022, 35, 6798–6810. [Google Scholar] [CrossRef]
- Tu, R.C.; Mao, X.L.; Ji, W.; Wei, W.; Huang, H. Data-aware proxy hashing for cross-modal retrieval. In Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval, Taipei, Taiwan, 23–27 July 2023; pp. 686–696. [Google Scholar]
- Huo, Y.; Qibing, Q.; Dai, J.; Zhang, W.; Huang, L.; Wang, C. Deep Neighborhood-aware Proxy Hashing with Uniform Distribution Constraint for Cross-modal Retrieval. Acm Trans. Multimed. Comput. Commun. Appl. 2024, 20, 169. [Google Scholar] [CrossRef]
- Jiang, Q.Y.; Li, W.J. Deep cross-modal hashing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3232–3240. [Google Scholar]
- Xu, R.; Li, C.; Yan, J.; Deng, C.; Liu, X. Graph Convolutional Network Hashing for Cross-Modal Retrieval. In Proceedings of the International Joint Conference on Artificial Intelligence (IJCAI), Macao, China, 10–16 August 2019; Volume 2019, pp. 982–988. [Google Scholar]
- Li, C.; Deng, C.; Li, N.; Liu, W.; Gao, X.; Tao, D. Self-supervised adversarial hashing networks for cross-modal retrieval. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4242–4251. [Google Scholar]
- Zou, X.; Wu, S.; Bakker, E.M.; Wang, X. Multi-label enhancement based self-supervised deep cross-modal hashing. Neurocomputing 2022, 467, 138–162. [Google Scholar] [CrossRef]
- Tu, J.; Liu, X.; Lin, Z.; Hong, R.; Wang, M. Differentiable cross-modal hashing via multimodal transformers. In Proceedings of the 30th ACM International Conference on Multimedia, Lisboa, Portugal, 10–14 October 2022; pp. 453–461. [Google Scholar]
- Xu, C.; Chai, Z.; Xu, Z.; Li, H.; Zuo, Q.; Yang, L.; Yuan, C. HHF: Hashing-guided hinge function for deep hashing retrieval. IEEE Trans. Multimed. 2022, 25, 7428–7440. [Google Scholar] [CrossRef]
- Hu, Z.; Cheung, Y.m.; Li, M.; Lan, W. Cross-Modal Hashing Method with Properties of Hamming Space: A New Perspective. IEEE Trans. Pattern Anal. Mach. Intell. 2024, 46, 7636–7650. [Google Scholar] [CrossRef]
- Deng, C.; Chen, Z.; Liu, X.; Gao, X.; Tao, D. Triplet-based deep hashing network for cross-modal retrieval. IEEE Trans. Image Process. 2018, 27, 3893–3903. [Google Scholar] [CrossRef]
- Bai, C.; Zeng, C.; Ma, Q.; Zhang, J.; Chen, S. Deep adversarial discrete hashing for cross-modal retrieval. In Proceedings of the 2020 International Conference on Multimedia Retrieval, Dublin, Ireland, 8–11 June 2020; pp. 525–531. [Google Scholar]
- Zhang, Q.; Hu, L.; Cao, L.; Shi, C.; Wang, S.; Liu, D.D. A probabilistic code balance constraint with compactness and informativeness enhancement for deep supervised hashing. In Proceedings of the 31st International Joint Conference on Artificial Intelligence, IJCAI 2022, Vienna, Austria, 23–29 July 2022; pp. 1651–1657. [Google Scholar]
- Huo, Y.; Qin, Q.; Zhang, W.; Huang, L.; Nie, J. Deep Hierarchy-aware Proxy Hashing with Self-paced Learning for Cross-modal Retrieval. IEEE Trans. Knowl. Data Eng. 2024, 36, 5926–5939. [Google Scholar] [CrossRef]
- Li, X.; Hu, D.; Nie, F. Deep binary reconstruction for cross-modal hashing. In Proceedings of the 25th ACM international conference on Multimedia, Mountain View, CA, USA, 23–27 October 2017; pp. 1398–1406. [Google Scholar]
- Wu, G.; Lin, Z.; Han, J.; Liu, L.; Ding, G.; Zhang, B.; Shen, J. Unsupervised Deep Hashing via Binary Latent Factor Models for Large-scale Cross-modal Retrieval. In Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence, Stockholm, Sweden, 13–19 July 2018; The AAAI Press: Washington, DC, USA, 2018; pp. 2854–2860. [Google Scholar]
- Su, S.; Zhong, Z.; Zhang, C. Deep joint-semantics reconstructing hashing for large-scale unsupervised cross-modal retrieval. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 3027–3035. [Google Scholar]
- Zhang, P.F.; Li, Y.; Huang, Z.; Xu, X.S. Aggregation-based graph convolutional hashing for unsupervised cross-modal retrieval. IEEE Trans. Multimed. 2021, 24, 466–479. [Google Scholar] [CrossRef]
- Liu, S.; Qian, S.; Guan, Y.; Zhan, J.; Ying, L. Joint-modal distribution-based similarity hashing for large-scale unsupervised deep cross-modal retrieval. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual, China, 25–30 July 2020; pp. 1379–1388. [Google Scholar]
- Zhu, L.; Wu, X.; Li, J.; Zhang, Z.; Guan, W.; Shen, H.T. Work together: Correlation-identity reconstruction hashing for unsupervised cross-modal retrieval. IEEE Trans. Knowl. Data Eng. 2022, 35, 8838–8851. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. In Proceedings of the International Conference on Learning Representations, Vienna, Austria, 4 May 2021; pp. 1–22. [Google Scholar]
- Huiskes, M.J.; Lew, M.S. The mir flickr retrieval evaluation. In Proceedings of the 1st ACM International Conference on Multimedia Information Retrieval, Vancouver, BC, Canada, 30–31 October 2008; pp. 39–43. [Google Scholar]
- Chua, T.S.; Tang, J.; Hong, R.; Li, H.; Luo, Z.; Zheng, Y. Nus-wide: A real-world web image database from national university of Singapore. In Proceedings of the ACM International Conference on Image and Video Retrieval, Fira, Greece, 8–10 July 2009; pp. 1–9. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Proceedings, Part V 13. Springer: Cham, Switzerland, 2014; pp. 740–755. [Google Scholar]
- Sennrich, R.; Haddow, B.; Birch, A. Neural Machine Translation of Rare Words with Subword Units. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, Berlin, Germany, 7–12 August 2016; Volume 1: Long Papers, pp. 1715–1725. [Google Scholar]
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language models are unsupervised multitask learners. OpenAI Blog 2019, 1, 9. [Google Scholar]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning transferable visual models from natural language supervision. In Proceedings of the International Conference on Machine Learning, Virtual, 18–24 July 2021; pp. 8748–8763. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015. Conference Track Proceedings, 2015. [Google Scholar]
- Cao, Y.; Liu, B.; Long, M.; Wang, J. Cross-modal hamming hashing. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8 September 2018; pp. 202–218. [Google Scholar]
- Gu, W.; Gu, X.; Gu, J.; Li, B.; Xiong, Z.; Wang, W. Adversary guided asymmetric hashing for cross-modal retrieval. In Proceedings of the 2019 on International Conference on Multimedia Retrieval, Ottawa, ON, Canada, 10–13 June 2019; pp. 159–167. [Google Scholar]
- Zhang, Z.; Luo, H.; Zhu, L.; Lu, G.; Shen, H.T. Modality-invariant asymmetric networks for cross-modal hashing. IEEE Trans. Knowl. Data Eng. 2022, 35, 5091–5104. [Google Scholar] [CrossRef]
- Van der Maaten, L.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Biamonte, J.; Wittek, P.; Pancotti, N.; Rebentrost, P.; Wiebe, N.; Lloyd, S. Quantum machine learning. Nature 2017, 549, 195–202. [Google Scholar] [CrossRef]
- Asfaw, A.; Blais, A.; Brown, K.R.; Candelaria, J.; Cantwell, C.; Carr, L.D.; Combes, J.; Debroy, D.M.; Donohue, J.M.; Economou, S.E.; et al. Building a quantum engineering undergraduate program. IEEE Trans. Educ. 2022, 65, 220–242. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).