1. Introduction
Endometriosis (EMS) is a chronic, invaliding, inflammatory gynecological condition affecting about 10% of women of reproductive age [
1]. EMS is characterized by lesions of endometrial-like tissue outside the uterus involving the pelvic peritoneum and ovaries. In addition, distant foci are sometimes observed [
2]. Unfortunately, little is known about EMS etiology. Although non-malignant, EMS shares similar features with cancer, such as the development of local and distant foci, resistance to apoptosis, and invasion of other tissues with subsequent damage to the target organs. Moreover, patients with EMS (particularly ovarian EMS) show a high risk (about 3 to 10 times) of developing epithelial ovarian cancer (EOC). Epidemiologic, morphological, and molecular studies showed that EMS lesions can progress to ovarian cancer (OC). In fact, patients with EMS (particularly deep infiltrating EMS and ovarian endometriomas) show an increased risk of up to 19 times higher of developing OC The most frequently associated histotypes are represented by clear cell OC (CCC) and endometrioid subtypes.
In advanced stages, OC is the most lethal female gynecological cancer, with median survival rates varying between approximatively 2–7 years based on surgical and chemotherapy outcomes. Some of the most important factors contributing to its late diagnosis are the lack of effective screening tools, as well as the lack of symptoms. OC rapidly spreads over the entire peritoneal surface (carcinosis), thus involving all abdominal organs.
EOC diagnosis and clinical staging are mainly based on imaging exams (CT, ultrasound, PET-CT, and MRI); however, their sensitivity and specificity are suboptimal. Moreover, qualitative imaging often fails to identify different types of lesions (i.e., cancer, borderline, and EMS) in the same patients.
Of note, the reliability of diagnosis, staging, and prognostic evaluation strongly depends on individual training and clinical experience. The typical chronic inflammatory process of EMS involves many factors, such as hormones, cytokines, glycoproteins, and angiogenic factors, which are related to the pathogenesis of the disease. Some of these factors may be expected to perform as EMS biomarkers, together with a variety of other blood markers that have also been investigated during the past decades. In EAOC studies, based on the biomarker hypothesis, changes in levels of analytes, proteins, miRNAs, genes, or other markers could be related to disease stage and patient prognosis. A consistent and biologically relevant categorization can guide clinical management, particularly the choice of targeted therapies and patients’ stratification in clinical trials.
A promising new branch of cancer research is the use of artificial intelligence (AI) and radiomics to recognize patterns in microscopic images and identify novel biomarkers to improve the current diagnostic accuracy and risk assessment of cancer patients.
Several approaches have been proposed in the literature, mainly using the machine learning (ML) model applied to extract the radiomics feature, convolutional neural network (CNN) directly on clinical images or hybrid models (e.g., combining CNN and ML methods).
The most used ML algorithms are Random Forest (RF) [
3], Gradient Boosting (GB) [
4], and Support Vector Machine (SVM) [
5]. Each algorithm has distinct characteristics and mathematical foundations that determine its suitability for specific tasks. RF is a majority-voting ensemble method where multiple classifiers contribute to the final decision by evaluating the margin between the correct class and the alternatives. GB optimizes learning by minimizing a loss function through gradient descent. It follows an iterative process in which a weak learner, typically a decision tree, is sequentially improved to enhance performance. SVM is a supervised classifier that finds the optimal hyperplane to separate two classes by maximizing the margin between their closest data points, known as support vectors [
5]. For non-linearly separable data, SVM employs kernel functions to map inputs into a higher-dimensional space, enabling separation [
5]. In particular, the SVM algorithm is the most used one reported in the literature [
5,
6,
7,
8], in combination with deep learning approaches, due to its complexity (which allows one to obtain more precise results and makes it suitable to be used on small datasets); on the other hand, it is time-consuming since it requests a lot of computational resources [
9].
CNNs are deep networks designed for spatially structured data such as images [
10]. They consist of convolutional layers that apply filters to extract hierarchical features, followed by pooling layers to reduce dimensionality and enhance translational invariance. The final layers are typically fully connected for classification [
10]. Different CNN architectures are employed for bi-dimensional image classification (i.e., tumoral vs. non-tumoral tissue). Transfer learning is widely used in medical imaging to address the challenges posed by small datasets. The most employed CNN architectures are ResNet and VGG-based models [
9], which leverage residual blocks to enhance training stability and improve parameter updates in early layers.
The hybrid approach combines CNN with an ML model and extracts features from clinical images by removing the CNN’s final layers and using the extracted features to train the ML model, bypassing the CNN’s classification stage.
A further strategy to improve model performance relies on ensemble strategies, such as the majority voting approach [
11]. This approach enhances robustness while reducing overfitting, leveraging the diversity among different underlying input models [
12]. In this way, generalization is improved by mitigating individual model biases and limitations [
13].
Both CNN and ML models rely on meticulous data processing, balancing, and validation strategies. Data are typically split into training, validation, and test sets, often following a 70:20:10 [
14] ratio, ensuring comprehensive model development, hyperparameter tuning, and unbiased evaluation. Addressing data imbalance is critical, as skewed class distributions can degrade predictive accuracy. Solutions such as oversampling, undersampling, or synthetic data generation (e.g., SMOTE) help restore class balance [
15]. In CNNs, data augmentation—applying geometric transformations, random cropping, or noise injection—enhances data diversity and mitigates overfitting. Cross-validation [
16], e.g., 5-fold, remains a robust standard for performance estimation, optimizing generalizability. These strategies collectively underpin the reliability of ML and CNN models, which are essential for clinical decision-making applications.
To date, no methods have been proposed to distinguish between women with EAOC, NEOC, or OC and benign tissues using pre-operative contrast-enhanced CT (CE-CT) images [
17], which are widely used in clinical practice. Currently, a definitive diagnosis requires post-surgical evaluation by a pathologist, limiting personalized surgical approaches due to the absence of pre-surgical biomarkers for the early detection of EAOC.
This study addressed this gap by developing several hybrid AI approaches to differentiate EAOC from NEOC or tumoral vs. non-tumoral lesions using pre-operative CE-CT images. A key novelty lies in the implementation of advanced data processing and balancing strategies, along with a robust model comparison framework leveraging multiple metrics to enhance reliability and predictive performance. Furthermore, the co-creation approach, involving collaboration between clinicians and AI developers, may enhance the model’s usability in clinical settings.
2. Materials and Methods
2.1. Study Design
Patients were enrolled in the Division of Oncologic Gynecology, IRCCS Azienda Ospedaliero-Universitaria di Bologna, between 1 November 2021 and 31 December 2023.
Inclusion criteria were (i) patients with definitive histological diagnosis of OC; (ii) definitive histological diagnosis of EAOC defined as the presence of concomitant EMS and OC in the same patients with/without the presence of atypical endometriosis/borderline lesions; (iii) patients diagnosed with EMS who underwent surgical resection as part of their treatment; (iv) patients with germline mutation of BRCA who underwent prophylactic surgery; (v) high-quality CT-scan available for analysis; (vi) patients treated with primary debulking surgery at our center; (vii) age > 18 years; (viii) written informed consent.
Exclusion criteria included: (i) patients not deemed suitable for surgery; (ii) history of prior pelvic radiotherapy and/or chemotherapy; (iii) patients undergoing neoadjuvant chemotherapy; (iv) non-epithelial OCs and diagnosis of other tumors; (v) recurrent OC.
Figure 1 illustrates the study design, encompassing imaging, data processing, model development, and performance evaluation using various machine learning algorithms and metrics.
2.2. Images and Segmentation
The imaging acquisition parameters used were as follows: mA range: 80–701; kV range: 100–140; helical technique: helix; slice thickness range: 0.625–3 mm; low-osmolality non-ionic iodinated contrast agent administered IV dose: 90–140 mL. CT examinations were performed on the following machines: Siemens SOMATOM Definition Edge, Siemens SOMATOM Definition AS, GE Discovery CT 750HD, GE Lightspeed VCT, GE Revolution Evo, GE Optima CT 660, Philips ingenuity CT 128, Philips Incisive CT, Philips Brilliance 16-slice, and Fujifilm FCT Speedia.
Volumes of interest (VOIs), i.e., right and left ovaries, were segmented on the venous phase of the CE-CT image by an expert radiologist using a semi-automatic approach. It relies on manual segmentation in one of the representative axial slices (generally including the central slice in the cranio-caudal position) and the autopilot function of the MIM software (v. 7.1.4, MIM Software Inc. Cleveland, OH, USA), which helps to guide the segmentation operation in the other slices based on the previous delineations.
2.3. VOI Classification
Final histopathological results were used to label each VOI as EAOC, NEOC, non-tumoral (i.e., ovary without cancer), with EMS or BRCA mutation.
In this study, we used all available data to distinguish between two endpoints, i.e., EAOC versus NEOC or any type of ovarian cancer (i.e., EAOC or NEOC) versus non-tumoral ovaries (i.e., benign EMS or healthy ovaries from patients with mutated BRCA).
Of note, borderline VOIs were excluded.
2.4. Image Pre-Processing and Python Pipeline
CE-CT images were exported from the MIM software in DICOM format for the VOI delineation and exported to Python (version 3.9.13) for the pre-processing operations necessary to arrange the data in a suitable format for the four pre-trained CNNs available in Python [
18]. The database was divided with balanced output for each classification investigated (i.e., EAOC vs. NEOC or OC vs. control) in 70% training, 20% testing, and 10% validation. The training dataset was augmented by rotating each CE-CT scan of 30, 45, 90, 325 degrees with respect to the cranio-caudal (CC) axis and axial slices were obtained in each VOI.
To guarantee the convergence of CNN models, greyscale images were rescaled by dividing each pixel by 255, which was the maximum permitted value in each pixel.
Each delineated VOI available on the augmented CE-CT dataset was resized to a 224 × 224 × 128 or to a 299 × 299 × 128 matrix. Each axial slice with a 224 × 224 matrix was used as input in three pre-trained CNNs (i.e., VGG19 [
19], ResNet50 [
20], and DenseNet121 [
21]), while the axial slice with a 299 × 299 matrix was used as input for the Xception CNN [
18]. All CNNs were pre-trained with the same dataset,
ImageNet [
22].
Each axial slice was associated with a binary classification according to the endpoint investigated.
In our dataset, the EROC vs. NEOC class distribution was as follows: 59 samples for the positive class and 95 samples for the negative class, with a 1:1.6 ratio indicating moderated unbalancing. Furthermore, the EROC + NEOC vs. non-tumoral class distribution was as follows: 154 samples for the positive class and 84 samples for the negative class, with a ratio of 1.8:1, indicating moderated unbalancing.
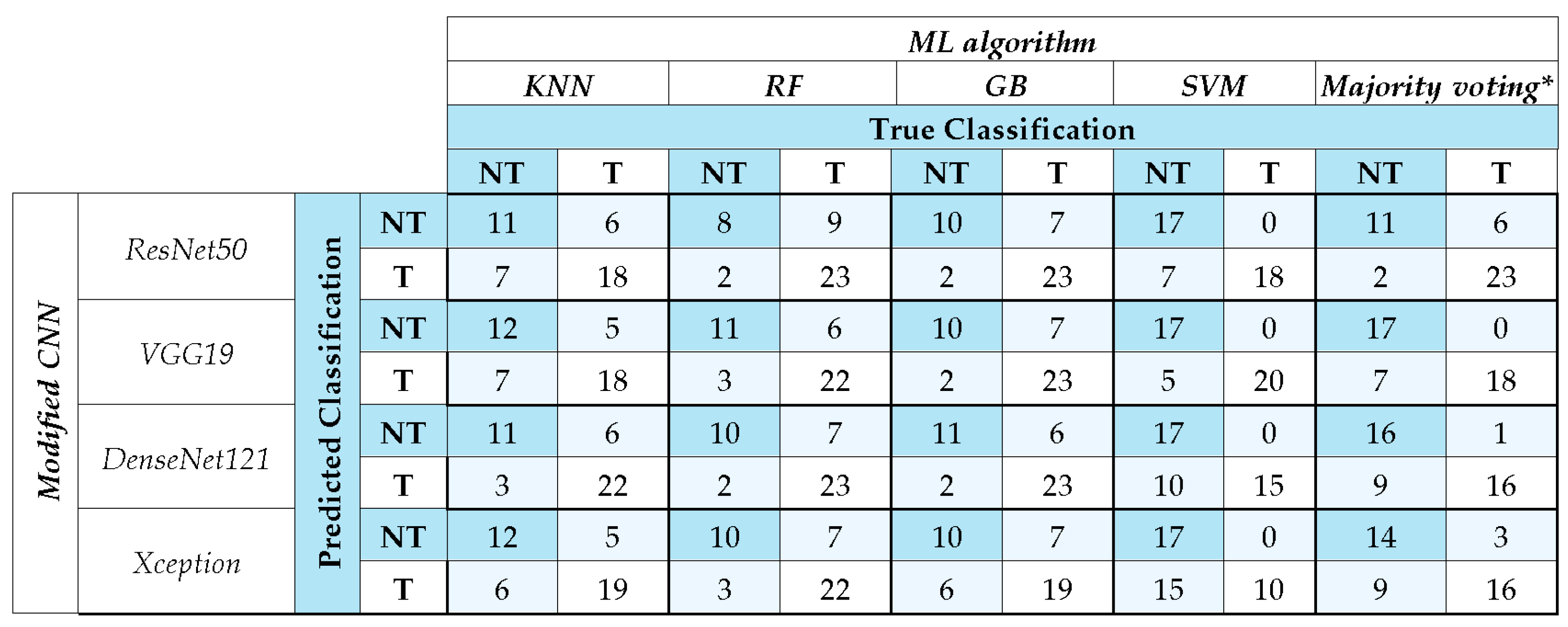
To address the potential class imbalance, we used an undersampling option during the training phase of each CNN algorithm for class balancing. Furthermore, in addition to accuracy, AUC, and F1-score, we evaluated the confusion matrix for the EAOC vs. NEOC class and tumoral (EAOC or NEOC) vs. non-tumoral class to assess the model performance.
The selected CNNs were trained using a massive dataset to distinguish between 1000 different types of objects [
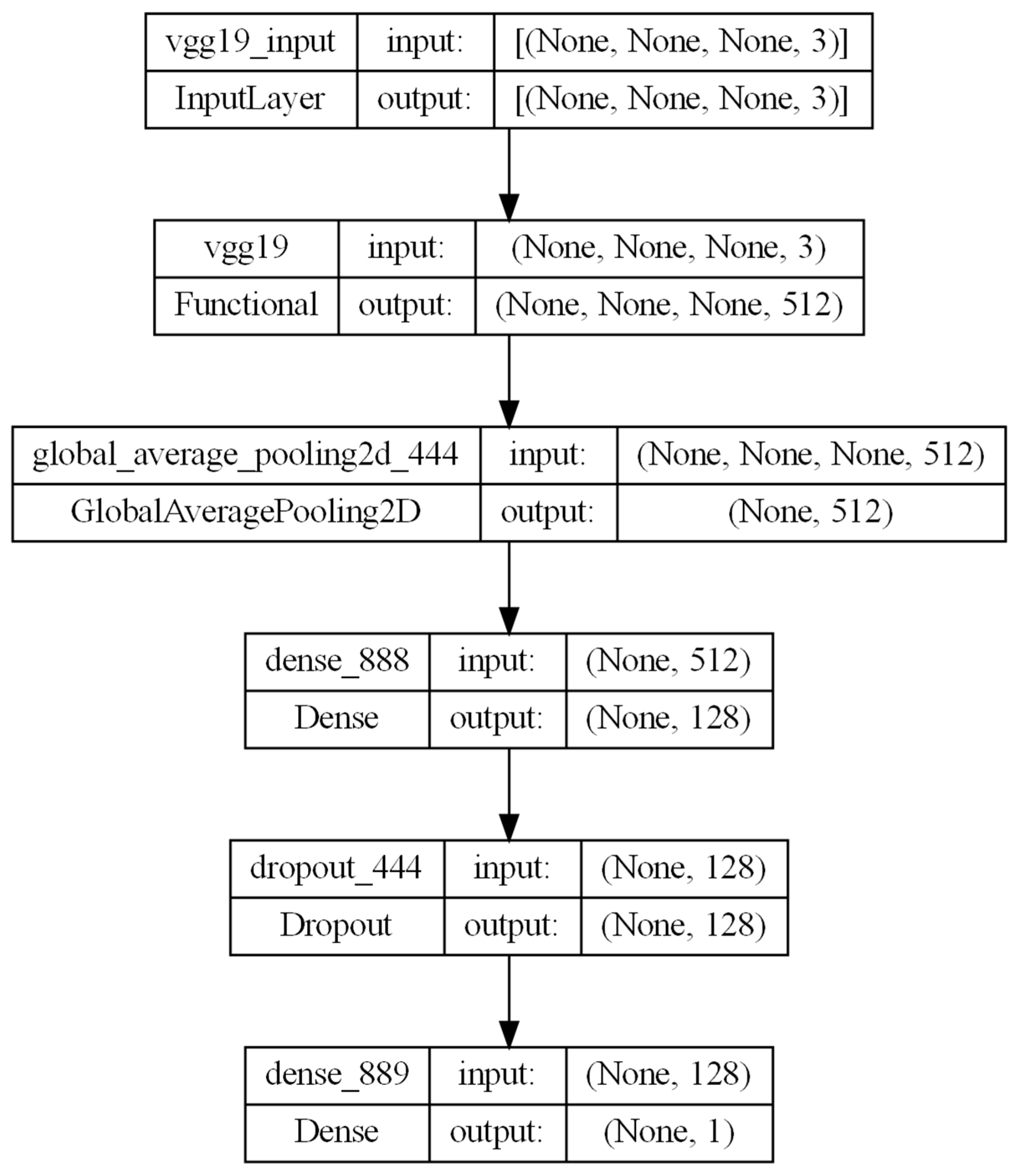
22]. We modified the last four layers to allow for a binary classification while freezing all the other layers to preserve the network’s complexity for image classification. The implemented architecture leverages a pre-trained CNN (e.g., VGG19) as a feature extractor, followed by a GlobalAveragePooling2D layer to reduce spatial dimensions. It includes a Dense layer with 128 neurons, a Dropout layer with L1 penalization to prevent overfitting, and a final Dense layer with one neuron having a sigmoid activation function for binary classification. Each CNN was trained for 100 epochs, with a patience of 50 epochs.
The modified architecture combines transfer learning and task-specific layers for robust image classification; see
Figure 2 as an example for the VGG-19 CNN.
Since the CNNs were not able to classify the whole VOI, we customized the CNN architecture to analyze each slice of the VOI. The CNN-predicted results were used as input for the ML algorithms, which were our final meta-classifier to produce a final single classification of the whole VOI.
Finally, three different ML algorithms, available in
keras, i.e., K-Nearest Neighbor (KNN), Random Forest (RF), and Gradient Boosting (GB) classifier were used to predict the two classifications. Each ML model was trained using a 5-fold cross-validation, both in fine-tuning and actual training. A grid search approach was used to identify the best combination of hyper-parameters. Since each algorithm has its peculiar kind of hyper-parameters, which can be modified, we had to change the type of hyper-parameters to look for the best set for the ML algorithm: the number of neighbors, weights, and kind of distance for KNN algorithm; the number of estimators, maximum depth and features, and minimum of samples split and leaves for RF; the number of estimators, learning rate, maximum depth and features for GB. The best combination of these hyper-parameters is reported in
Table S2 in the Supplementary Material for each ML algorithm.
Overall, we investigated 12 models combining four CNNs as base learners, four ML algorithms as meta-learners, and an ensemble approach (i.e., a voting system based on KNN, RF, and GB). For both learners, a fine-tuning phase to optimize their hyperparameters was run before the actual training and test phases.
Moreover, we compared results obtained with this approach with more solid approaches in the literature for classification tasks, such as the SVM ML algorithm or the majority voting approach [
11]. The SVM ML algorithm was developed by following the same approaches previously reported for the other ML models and used as a reference for subsequent comparisons of hybrid approaches.
Finally, an ensemble voting approach was developed by combining the three ML algorithms, i.e., KNN, RF, and GB classifiers. Each model was trained independently on the same dataset, and their predictions were aggregated using a majority voting strategy; the class predicted by most models determined the final classification.
2.5. Performance Metrics
To assess the overall performance of the combined CNN and ML models, we utilized multiple evaluation metrics, including accuracy, the area under the receiver operating characteristic curve (AUC-ROC), and the F1-score. We then compared the results of the CNN and ML algorithms (KNN, RF, and GB) with those obtained using SVM, as well as with a majority voting strategy applied to each of the hybrid algorithms (KNN, RF, and GB). Additionally, we conducted a DeLong test to assess statistically significant differences among the models and analyzed confusion matrices to gain deeper insight into their classification performance, considering the class imbalance in the test dataset.
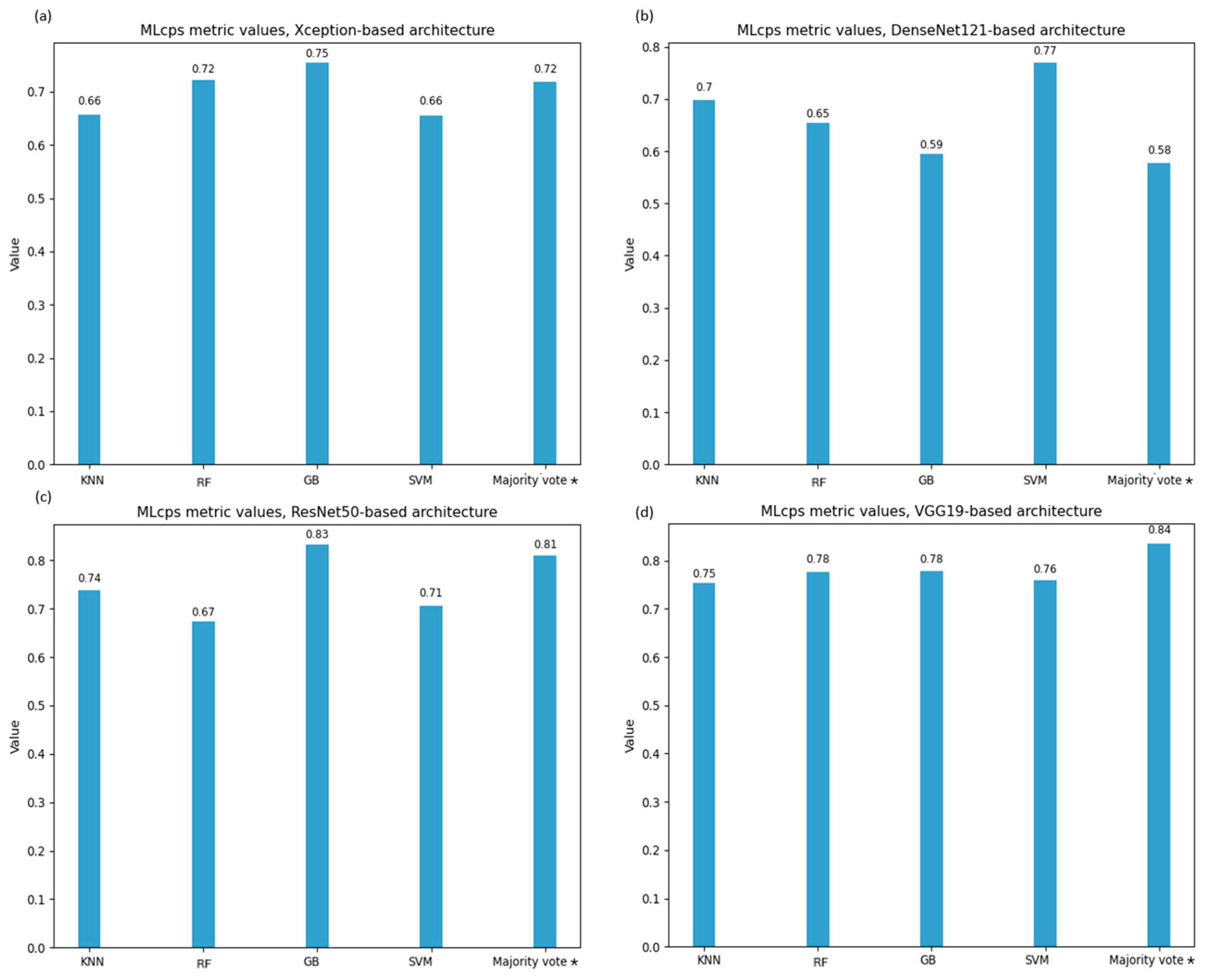
To identify the optimal CNN-ML model combination, we selected the ML cumulative performance score (MLcps) as the evaluation metric [
23]. Recognizing the critical importance of accurate prediction using clinical imaging, we adjusted the MLcps weighting scheme to favor models with higher specificity and sensitivity. Specifically, the MLcps was computed using the following normalized weights: 0.1 for AUC-ROC, 0.4 for sensitivity, 0.3 for specificity, and 0.2 for the F1-score.
4. Discussion
Ovary cancer, particularly when arising from endometriosis, represents a rare but clinically significant entity requiring tailored therapeutic strategies due to differing disease outcomes.
While MRI remains the gold standard for preoperative evaluation, its limited availability—due to long acquisition times and the restricted number of scanners—often necessitates the use of CE-CT as a more accessible alternative. Although CE-CT generally offers a lower image quality compared to MRI, AI-driven analysis can extract clinically relevant information that may not be visible to the human eye. This study demonstrates that despite MRI’s superiority in qualitative assessment, CE-CT can provide significant quantitative data through advanced image processing techniques, enhancing its diagnostic value and broadening its applicability in centers where MRI access is limited. Moreover, to mitigate the variability introduced by scanners from different vendors, our institution implements regular quality assurance programs, including protocol harmonization and optimization conducted by medical physicists, ensuring standardized imaging conditions for a more reliable AI-driven analysis.
This is the first prospective study demonstrating that CE-CT can provide significant quantitative information, moving beyond traditional qualitative assessment. By leveraging advanced image analysis, we enhanced the predictive value of CE-CT, offering crucial insights to support gynecological surgeons in optimizing surgical planning. This novel approach paves the way to a more personalized surgical strategy, with the potential for widespread adoption across numerous centers, ultimately improving patient outcomes in this challenging disease subset.
However, the number of cases of rare diseases such as gynecological cancer is also generally limited in oncological HUB centers such as the IRCCS AOUBo. Given this limitation, our study adopts transfer learning [
23] and data augmentation to overcome data scarcity [
24,
25,
26]. These techniques enhance model performance, facilitating early detection and differentiation of ovarian cancers while reducing computational costs [
10]. By leveraging pre-trained CNNs and stacking approaches, we improve classification accuracy despite the dataset size constraint.
Traditional CNN architectures extract features from 2D medical images, such as MRI and ultrasound, to develop diagnostic models. Previous studies have applied U-Net-based segmentation to small CT datasets, including one limited to a cohort of 20 patients with ovarian cancer [
27]. In contrast, our approach leverages a significantly larger, prospectively collected CE-CT dataset with a pathology-confirmed diagnosis at the level of each ovary. By integrating data augmentation and a hybrid AI strategy, we enhance the differentiation of NEOC from non-cancerous tissues and EAOC from NEOC, addressing key diagnostic challenges.
This study implemented several AI-based approaches using four pre-trained CNNs as base-learners combined with four ML algorithms as meta-learners to distinguish EAOC from EOC and tumoral from non-tumoral ovaries, alongside a voting system based on KNN, RF, and GB. The CNN architectures were selected for their accessibility via the Keras package (Python) and their proven performance in transfer learning for classification tasks. The CNN architecture was modified by freezing layers and substituting the final four to optimize binary classification, with fine-tuning focused on the last layers (L1 penalization and dropout rate). The ML models were chosen for their minimal assumptions, such as KNN’s reliance on local data similarity [
28], RF’s robustness to outliers [
3], GB’s error reduction through boosting [
4], and SVM’s ability to handle small, complex datasets. Multiple performance metrics were used to evaluate the hybrid models, with twenty stacking models fine-tuned for binary classification. The developed hybrid models were ranked in terms of MLcps, and a statistical test (e.g., Delong test) was used to check whether models were equivalent or not.
To our knowledge, this is the first study to classify EAOC versus NEOC and the most extensive study distinguishing EAOC vs. NEOC, assessed using histological analyses, and tumoral versus non-tumoral ovaries using CE-CT images. Another significant innovation in this study is the introduction of the MLcps weighted metric as a key performance metric, which emphasizes sensitivity and specificity. This is the first time such a metric has been used to assess a transfer learning approach in ovarian cancer classification tasks, providing a more targeted way to evaluate performance. The use of this metric helps to prioritize critical factors for medical diagnoses, setting this study apart from previous research that lacked such a tailored evaluation approach. All the investigated endpoints were confirmed by the definitive pathology.
Out of the developed models, the ResNet50 model coupled with Gradient Boosting resulted in the highest F1-score of 0.82 and AUC value [95% CI] of 0.88 [0.76, 0.98] in distinguishing EAOC and NEOC. VGG19 exhibited performance comparable to ResNet50, with both surpassing DenseNet121 and Xception. The error analysis carried out using confusion matrices highlights these differences in classification more prominently. ResNet50 and VGG19 coupled with GB and majority voting achieved the highest correct classifications, reinforcing their robustness. SVM exhibited stable performance across models, particularly excelling with VGG19. Conversely, KNN consistently underperformed, highlighting its limitations in this classification task. Majority voting improved overall accuracy, suggesting the advantage of ensemble strategies in mitigating individual model biases.
This performance difference can likely be attributed to variations in network depth and architectural design. Specifically, VGG19, with 19 layers, relies on a simple sequential architecture of convolutional layers, while ResNet50 features 50 layers and leverages residual connections to combat vanishing gradients and improve feature learning in deeper networks. In contrast, DenseNet121 (121 layers) utilizes dense connectivity to encourage feature reuse, and Xception employs depth-wise separable convolutions for computational efficiency, which might trade off some of the features learning capacity. These design differences impact the networks’ ability to learn and generalize effectively [
29]. The performance of CNN coupled with SVM reached a similar one to the other ML approaches for distinguishing EAOC vs. NEOC except for Xception + SVM. The voting system based on KNN, RF, and GB achieved a similar performance.
A similar behavior was observed for tumoral vs. non-tumoral classification. Out of the twenty models, the AUC ranged from 0.70 [0.56, 0.84] (ResNet50 + KNN) to 0.97 [0.92, 1.00] (VGG19 + SVM), while F1-score ranged from 0.78 (ResNet50 + KNN) to 0.88 (VGG19 + SVM), sensitivity from 0.72 (ResNet50 + KNN) to 0.92 (VGG19 + SVM), and specificity from 0.59 (DenseNet121 + RF) to 0.80 (VGG19 + SVM). In this endpoint, CNN combined with SVM performed excellently in distinguishing tumoral from non-tumoral ovaries, while the voting system (KNN, RF, GB) showed comparable performance across metrics and MLcps. GB achieved high MLcps scores, confirming its efficiency, while RF performed similarly to previous studies [
30,
31]. As expected, KNN showed the lowest performance [
32]. GB and RF were further validated by comparison with SVM and majority voting, which outperformed individual models. SVM excelled in handling high-dimensional, imbalanced datasets [
5] while majority voting improved accuracy and generalization by reducing model bias [
11]. Analysis error through confusion matrices showed that ResNet50 and VGG19 coupled with GB and majority voting achieved the highest correct classifications, confirming their reliability. SVM also performed well, particularly with VGG19, while KNN showed weaker results. Majority voting consistently improved classification accuracy, reinforcing the advantage of ensemble methods in reducing individual model biases and enhancing robustness in medical imaging tasks. Overall, the differences among models are likely due to the adopted architecture affecting the overall performance, for tumoral vs. non-tumoral classification, too.
This discrimination is an endpoint generally investigated using magnetic resonance imaging (MRI) performed with multiple types of sequences [
17]. Using this imaging modality, Wang et al. [
33] classified with homemade CNN 545 ovarian lesions as benign or malignant, using a dataset confirmed by either pathology or imaging follow-up, reporting an AUC of 0.91 ± 0.05 and an F1-score of 0.87 ± 0.06. A similar approach was implemented by Saida et al. [
34] to distinguish malignant and benignant ovaries, defined based on the consensus of the two radiologists, with AUC values ranging from 0.83 to 0.89, accuracy ranging from 0.81 to 0.87, sensitivity from 0.77 to 0.85, and specificity from 0.77 to 0.92. Moreover, Mingxiang et al. [
35] used the T2-weighted MRI to distinguish between type I and type II NEOCs with a cohort of 437 cancer patients with an AUC [95% IC] of 0.86 [0.786, 0.946]. Similar results on CT images were reported by Kodipalli A. et al. [
27] on 20 patients (i.e., 2560 benign and 2370 malignant slices) with the U-Net approach (based on VGG16 and ResNet152 combined with RF and Gradient Boosting) to segment and classify lesions in the ovarian district with the F1-score ranging from 0.819 to 0.918. Of note, we used a larger dataset of 119 CE-CT images (i.e., 10,752 benign and 19,712 malignant slices) analyzed with both ResNet50 and VGG19 associated with a GB algorithm, resulting in an F1-score of 0.880. These results seem promising considering that CE-CT is expected to have a lower image quality when compared to multiple sequences of MRI when used for diagnostic purposes by expert radiologists, thus suggesting that AI-based approaches can reveal details not visible by human eyes.
Moreover, the accessibility of MRI is often limited by long acquisition times and the limited number of scanners relative to CT modality. For this reason, several attempts to use alternative imaging, including ultrasound (US), have been explored. Martinez-Mas et al. [
36] used a pure ML approach on a dataset comprising 187 ovarian US images (112 benign, 75 malignant), obtaining an AUC of 0.877 with an SVM algorithm.
Regarding data quality, while CE-CT generally offers a lower image quality than MRI, AI-driven CT analysis presents a compelling alternative due to the widespread availability and rapid acquisition of CT scans. This advantage makes CT-based AI models particularly valuable in clinical settings where MRI access is restricted, broadening their potential impact on ovarian cancer diagnostics. Our dataset was generated in a prospective study founded by the Italian Ministry of Health (ENDO-2021-12371926), thus guaranteeing the possibility to use harmonized protocols for CE-CT acquisition. On the contrary, most of the above-mentioned studies refer to retrospective datasets.
Regarding automatic segmentation, significant efforts have been made to extend its application from ultrasound (US) imaging to various types of medical images [
37,
38]. Different segmentation techniques have been implemented for CT acquisitions; they are mainly divided into methods based on texture features and methods based on gray-level features, including amplitude segmentation based on histogram features, edge-based ones, and region-based ones [
39]. In this context, AI-based algorithms can be seen as tools to further optimize these basic techniques. Nevertheless, although several AI-based tools for the automatic segmentation of organs have been developed and proven to reduce variability among young and experienced physicians [
40], to the best of our knowledge, no software for automatic ovary segmentation is currently available for CT images. This is because the ovarian tissue has similar Hounsfield Unit (HU) values to those surrounding tissues. Moreover, ovaries are challenging to detect even for radiologists without experience in the gynecological field. For this reason, obtaining a large database of contoured ovaries—essential for the training, testing, and validation of robust AI-based models—is particularly difficult. Thus, the possibility of using fully automatic segmentation can be considered a possible further improvement of our predictive models.
A further limitation of our approach is the lack of standardized guidelines for selecting weights in MLcps generation. While all metrics showed similar behavior, no single metric alone could define the optimal model, highlighting the challenge of performance evaluation across test datasets.


 ,
, 






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}