
Automated Dataset-Creation and Evaluation Pipeline for NER in Russian Literary Heritage



Abstract
1. Introduction
- Persons—The texts include numerous references to individuals, and the identification of these entities facilitates the reconstruction of Pushkin’s social network during the creation of his literary works.
- Locations—These entities encompass both real and fictional places. The recognition of real locations enables an analysis of the geographical context of Pushkin’s creative activities and correspondence, while fictional locations provide insights into the settings described in his literary compositions.
- Dates—Identifying dates in texts concerning Pushkin’s works contributes to the development of a chronology of his creative process, which is essential for enriching his biography.
- Organizations—Throughout his life, Pushkin interacted with numerous organizations, including educational institutions, publishing houses, censorship committees, and others. Recognizing mentions of these organizations in texts broadens our understanding of his life and creative journey.
- Works by A.S. Pushkin—Texts about Pushkin’s works often reference other literary compositions, both by Pushkin himself and by other authors. This category is particularly challenging to identify due to the frequent use of multiple and varying titles for the same work.
- Presenting the pipeline for collecting, processing, and annotating the dataset.
- Providing a comprehensive, high-quality, proofreader-annotated dataset for Russian NER.
- Evaluation of the dataset with our NER model to benchmark the performance and illustrate the dataset.
2. Related Work
2.1. Domain-Specific NER Dataset Creation
2.2. Language-Specific NER Dataset Creation
2.3. Automating NER Dataset Creation
3. Dataset
3.1. Data Collection
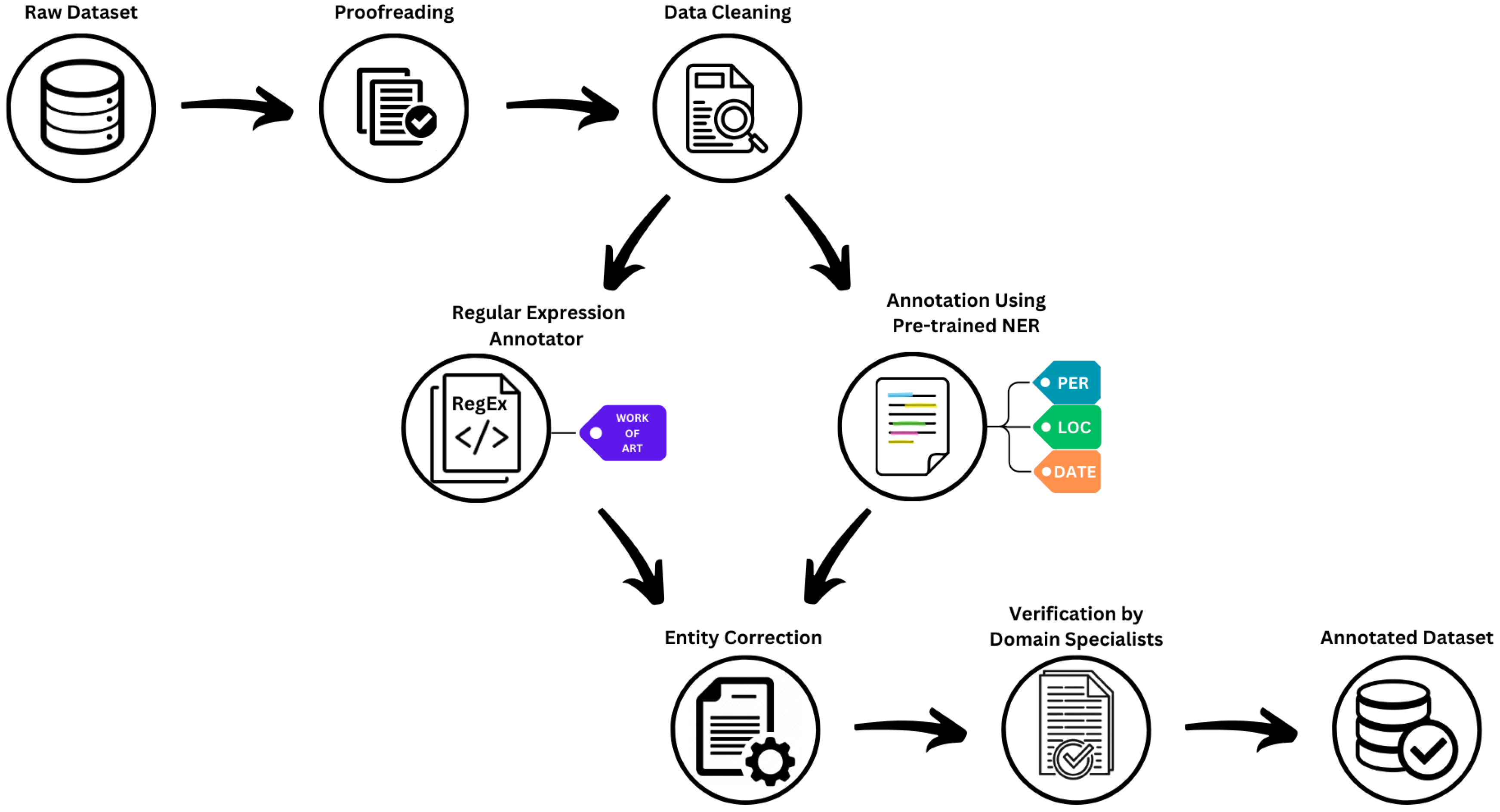
3.2. Dataset Annotation
- Proofreading: the raw dataset was proofread by specialists in order to split each document in the dataset into meaningful paragraphs and to validate the standardization of the text’s structure.
- Data cleaning: This stage aims to process the proofread data in order to clean unnecessary punctuations and prepare the data in the correct format to be annotated by NER models.
- Annotating: This part contains two stages simultaneously—using DeepPavlov [35] to annotate (PER, ORG, DATE) entities and using a regular expression annotator to annotate the work-of-art entities. We built our regex annotator because DeepPavlov struggled with extracting WOA entities from the literature texts.
- Entity correction: This stage aims to automatically check the validation of the annotated entities by previous stages and verify the spans that define each recognized entity.
- Verification: In this stage, the annotated dataset was checked by specialists again to verify the correction of each entity and add any entities that were not recognized by the automated process.
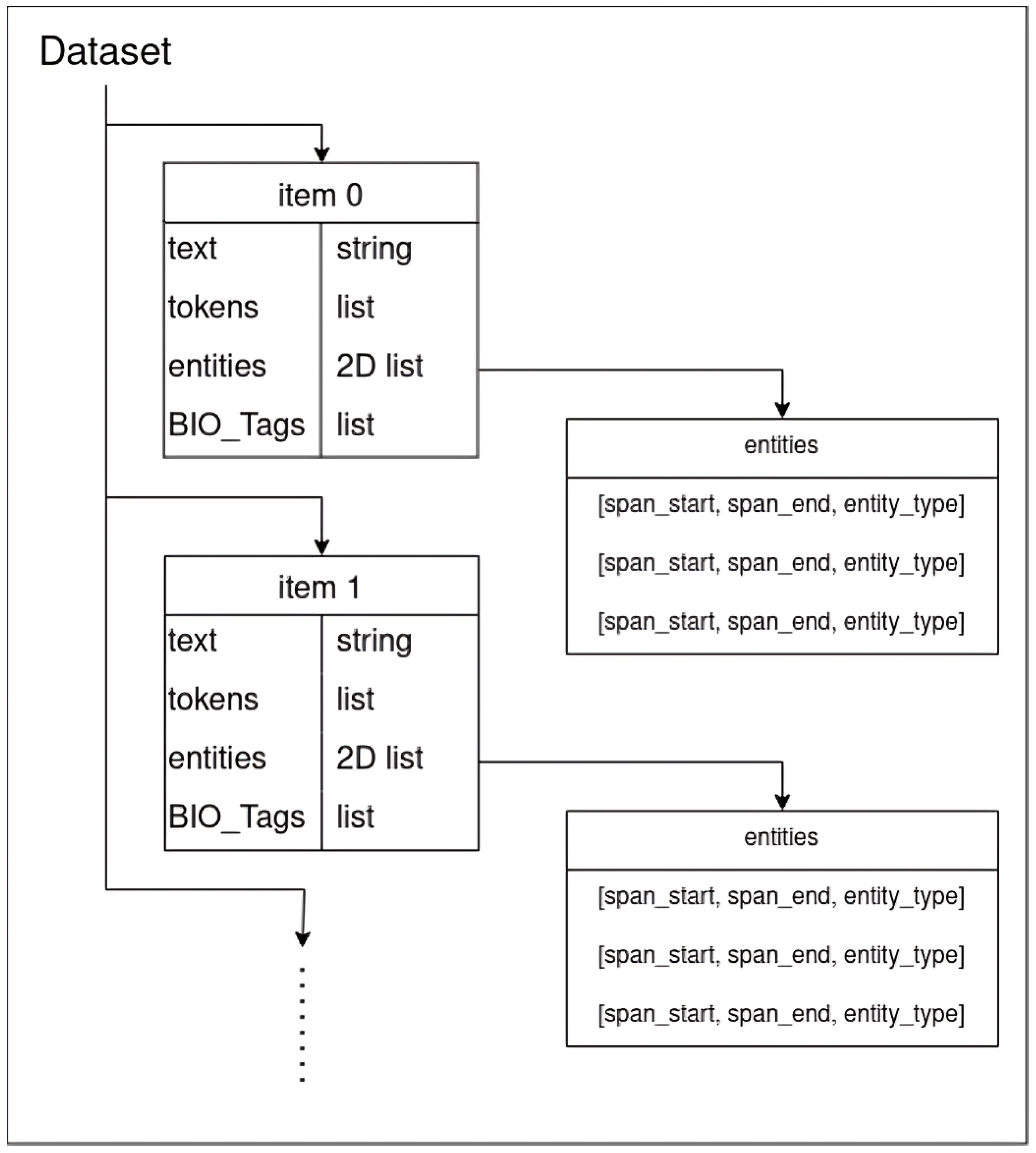
3.3. Data Description
3.4. Data Analysis
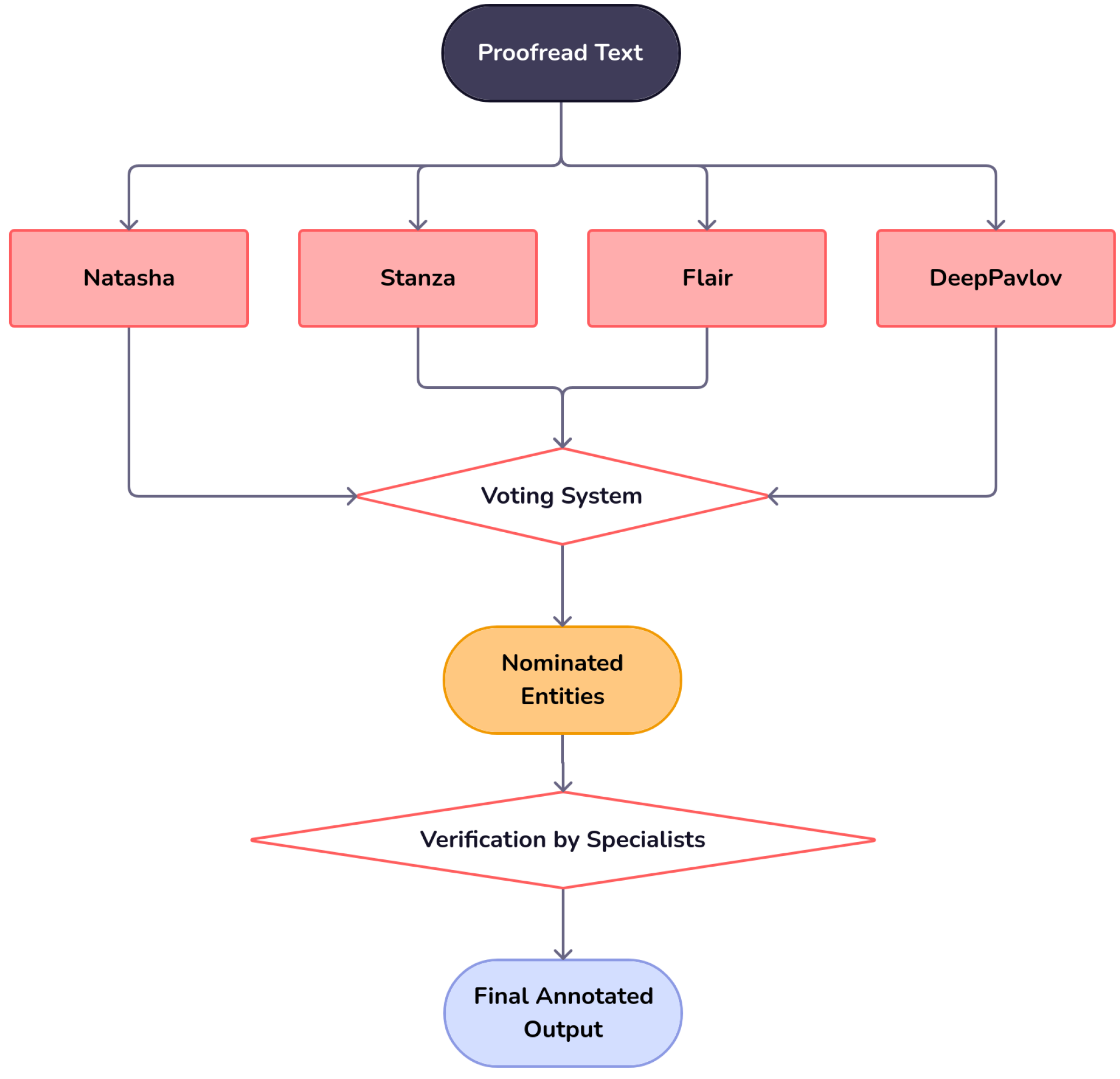
4. Automated Pipeline Description for Dataset Creation and Evaluation
- : Set of models used in the system where ;
- : Set of coefficients referring to the importance of each model for the voting system, where ;
- : Set of recognized entities of type k, where ;
- : Set of entities recognized by model , and from type k;
- T: The threshold for electing entities in the voting system.
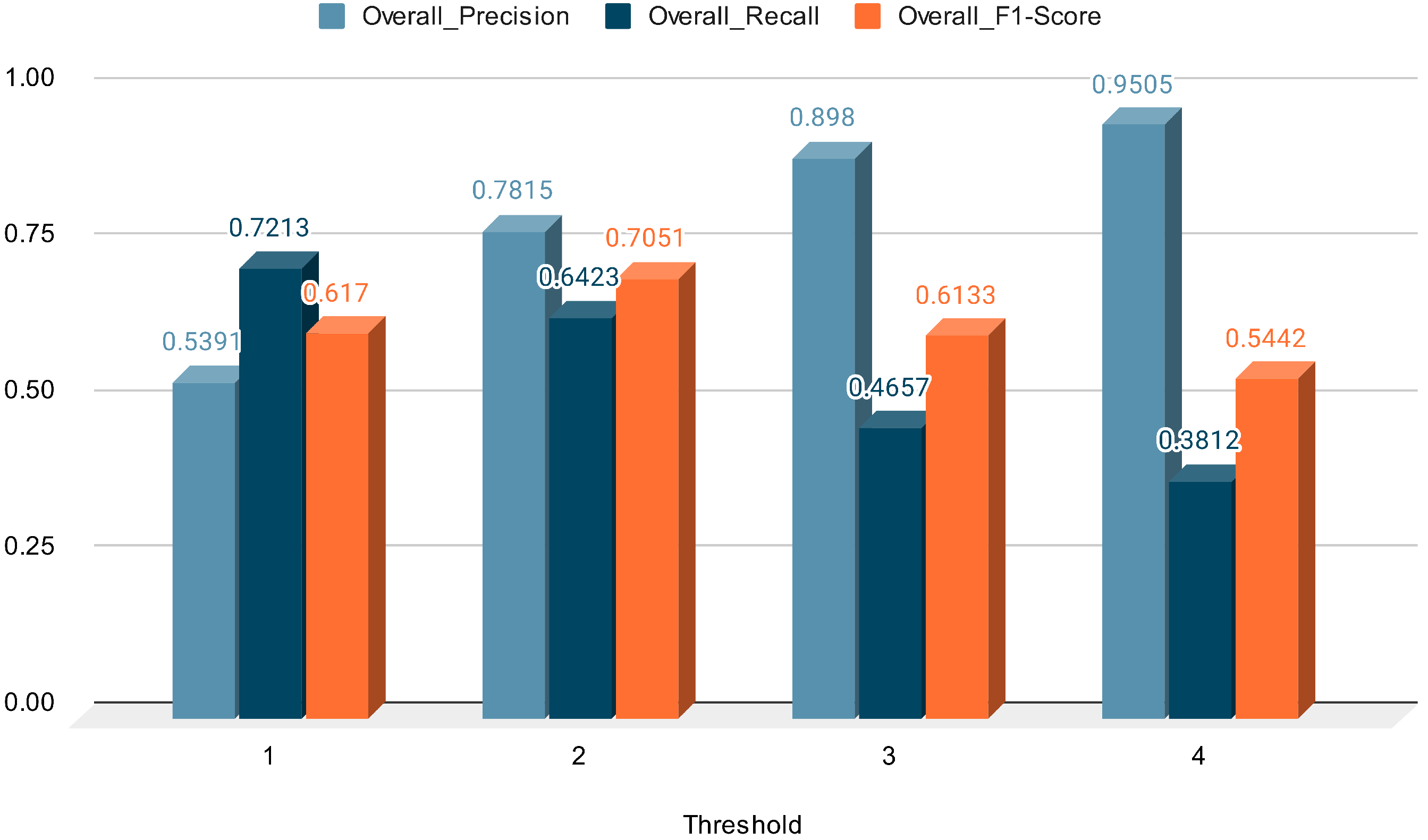
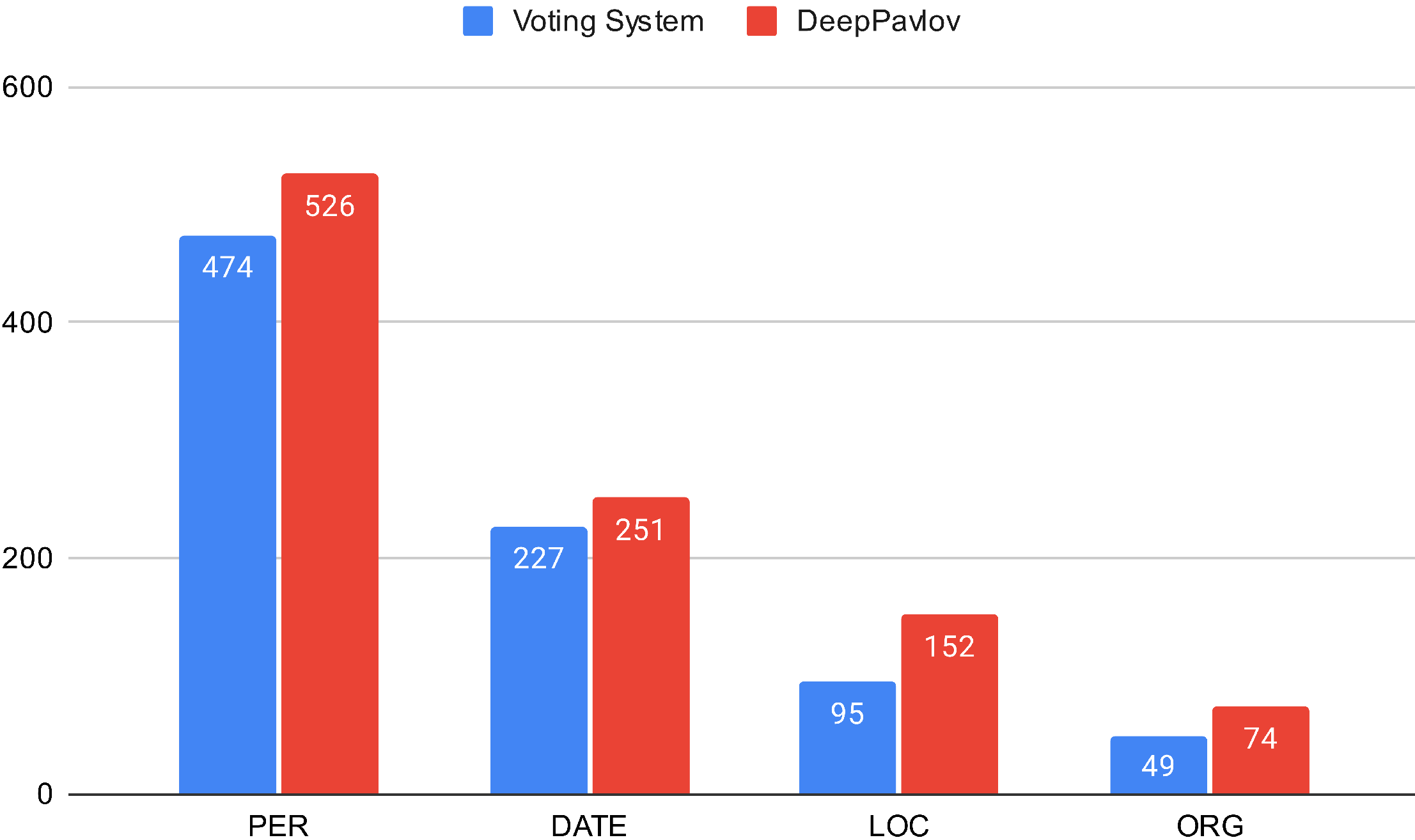
5. Dataset Evaluation
6. Discussion
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Goyal, A.; Gupta, V.; Kumar, M. Recent named entity recognition and classification techniques: A systematic review. Comput. Sci. Rev. 2018, 29, 21–43. [Google Scholar] [CrossRef]
- Mansouri, A.; Affendey, L.; Mamat, A. Named Entity Recognition Approaches. Int. J. Comp. Sci. Netw. Sec. 2008, 8, 339–344. [Google Scholar]
- Wang, Y.; Tong, H.; Zhu, Z.; Li, Y. Nested named entity recognition: A survey. ACM Trans. Knowl. Discov. Data (TKDD) 2022, 16, 1–29. [Google Scholar] [CrossRef]
- Brandsen, A.; Verberne, S.; Wansleeben, M.; Lambers, K. Creating a dataset for named entity recognition in the archaeology domain. In Proceedings of the Twelfth Language Resources and Evaluation Conference, Marseille, France, 11–16 May 2020; pp. 4573–4577. [Google Scholar]
- Frei, J.; Kramer, F. Annotated dataset creation through large language models for non-english medical NLP. J. Biomed. Inform. 2023, 145, 104478. [Google Scholar] [CrossRef] [PubMed]
- Shaheen, Z.; Wohlgenannt, G.; Zaity, B.; Mouromtsev, D.I.; Pak, V. Russian Natural Language Generation: Creation of a Language Modelling Dataset and Evaluation with Modern Neural Architectures. arXiv 2020, arXiv:2005.02470. [Google Scholar]
- Rahimi, A.; Li, Y.; Cohn, T. Massively Multilingual Transfer for NER. In Proceedings of the Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019. [Google Scholar]
- Matos, E.; Rodrigues, M.; Teixeira, A. Towards the automatic creation of NER systems for new domains. In Proceedings of the 16th International Conference on Computational Processing of Portuguese, Santiago de Compostela, Spain, 14–15 March 2024; pp. 218–227. [Google Scholar]
- Sboev, A.; Sboeva, S.; Moloshnikov, I.; Gryaznov, A.; Rybka, R.; Naumov, A.; Selivanov, A.; Rylkov, G.; Ilyin, V. Analysis of the full-size russian corpus of Internet drug reviews with complex ner labeling using deep learning neural networks and language models. Appl. Sci. 2022, 12, 491. [Google Scholar] [CrossRef]
- Shaheen, Z.; Mouromtsev, D.I.; Postny, I. RuLegalNER: A new dataset for Russian legal named entities recognition. Sci. Tech. J. Inf. Technol. Mech. Opt. 2023, 23, 854–857. [Google Scholar] [CrossRef]
- Zhang, Y.; Xiao, G. Named Entity Recognition Datasets: A Classification Framework. Int. J. Comput. Intell. Syst. 2024, 17, 71. [Google Scholar] [CrossRef]
- Sang, E.T.K.; Meulder, F.D. Introduction to the CoNLL-2003 Shared Task: Language-Independent Named Entity Recognition. In Proceedings of the Conference on Computational Natural Language Learning, Edmonton, AB, Canada, 31 May–1 June 2003. [Google Scholar]
- Weischedel, R.; Pradhan, S.; Ramshaw, L.; Palmer, M.; Xue, N.; Marcus, M.; Taylor, A.; Greenberg, C.; Hovy, E.; Belvin, R.; et al. Ontonotes Release 4.0; LDC2011T03; Linguistic Data Consortium: Philadelphia, PA, USA, 2011; Volume 17. [Google Scholar]
- Ringland, N.; Dai, X.; Hachey, B.; Karimi, S.; Paris, C.; Curran, J.R. NNE: A Dataset for Nested Named Entity Recognition in English Newswire. In Proceedings of the Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019. [Google Scholar]
- Ivanova, R.; Kirrane, S.; van Erp, M. Comparing Annotated Datasets for Named Entity Recognition in English Literature. In Proceedings of the International Conference on Language Resources and Evaluation, Marseille, France, 20–25 June 2022. [Google Scholar]
- Shah, A.; Vithani, R.; Gullapalli, A.; Chava, S. FiNER-ORD: Financial Named Entity Recognition Open Research Dataset. arXiv 2023, arXiv:2302.11157. [Google Scholar]
- Leitner, E.; Rehm, G.; Moreno-Schneider, J. A Dataset of German Legal Documents for Named Entity Recognition. arXiv 2020, arXiv:2003.13016. [Google Scholar]
- Osenova, P.; Simov, K.; Marinova, I.; Berbatova, M. The Bulgarian Event Corpus: Overview and Initial NER Experiments. In Proceedings of the Thirteenth Language Resources and Evaluation Conference, Marseille, France, 20–25 June 2022; pp. 3491–3499. [Google Scholar]
- Todorovic, B.S.; Krstev, C.; Stanković, R.; Nešić, M.I. Serbian NER&Beyond: The Archaic and the Modern Intertwinned. In Proceedings of the Recent Advances in Natural Language Processing, Online, 6–7 September 2021. [Google Scholar]
- Yu, B.; Hu, Y.; Mang, Q.; Hu, W.; He, P. Automated Testing and Improvement of Named Entity Recognition Systems. In Proceedings of the 31st ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering, San Francisco, CA, USA, 3–9 December 2023; pp. 883–894. [Google Scholar]
- Naraki, Y.; Yamaki, R.; Ikeda, Y.; Horie, T.; Naganuma, H. Augmenting NER Datasets with LLMs: Towards Automated and Refined Annotation. arXiv 2024, arXiv:2404.01334. [Google Scholar]
- Frei, J.; Kramer, F. German medical named entity recognition model and dataset creation using machine translation and word alignment: Algorithm development and validation. JMIR Form. Res. 2023, 7, e39077. [Google Scholar] [CrossRef] [PubMed]
- Gopalakrishnan, A.; Soman, K. Enhancing Named Entity Recognition in Low-Resource Languages: The Crucial Role of Data Sampling in Malayalam. In Proceedings of the 2024 11th International Conference on Computing for Sustainable Global Development (INDIACom), New Delhi, India, 28 February–March 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 1543–1547. [Google Scholar]
- Gareev, R.; Tkachenko, M.; Solovyev, V.; Simanovsky, A.; Ivanov, V. Introducing Baselines for Russian Named Entity Recognition. In Proceedings of the Computational Linguistics and Intelligent Text Processing, Samos, Greece, 24–30 March 2013; Springer: Berlin/Heidelberg, Germany, 2013; Volume 7816, pp. 329–342. [Google Scholar] [CrossRef]
- Starostin, A.S.; Bocharov, V.V.; Alexeeva, S.V.; Bodrova, A.A.; Chuchunkov, A.S.; Dzhumaev, S.S.; Efimenko, I.V.; Granovsky, D.V.; Khoroshevsky, V.F.; Krylova, I.V.; et al. FactRuEval 2016: Evaluation of Named Entity Recognition and Fact Extraction Systems for Russian. 2016. Available online: https://dspace.spbu.ru/bitstream/11701/8554/1/2016_Dialogue_Alexeeva_als_FactRuEval.pdf (accessed on 27 January 2025).
- Loukachevitch, N.; Artemova, E.; Batura, T.; Braslavski, P.; Ivanov, V.; Manandhar, S.; Pugachev, A.; Rozhkov, I.; Shelmanov, A.; Tutubalina, E.; et al. NEREL: A Russian information extraction dataset with rich annotation for nested entities, relations, and wikidata entity links. Lang. Resour. Eval. 2024, 58, 547–583. [Google Scholar] [CrossRef]
- Tedeschi, S.; Maiorca, V.; Campolungo, N.; Cecconi, F.; Navigli, R. WikiNEuRal: Combined neural and knowledge-based silver data creation for multilingual NER. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2021, Online Event, 1–6 August 2021; pp. 2521–2533. [Google Scholar]
- Heng, Y.; Deng, C.; Li, Y.; Yu, Y.; Li, Y.; Zhang, R.; Zhang, C. ProgGen: Generating Named Entity Recognition Datasets Step-by-step with Self-Reflexive Large Language Models. arXiv 2024, arXiv:2403.11103. [Google Scholar]
- Piskorski, J.; Babych, B.; Kancheva, Z.; Kanishcheva, O.; Lebedeva, M.; Marcińczuk, M.; Nakov, P.; Osenova, P.; Pivovarova, L.; Pollak, S.; et al. Slav-NER: The 3rd cross-lingual challenge on recognition, normalization, classification, and linking of named entities across Slavic languages. In Proceedings of the 8th Workshop on Balto-Slavic Natural Language Processing, Online, 20 April 2021; The Association for Computational Linguistics: Kiyv, Ukraine, 2021. [Google Scholar]
- Papantoniou, K.; Efthymiou, V.; Plexousakis, D. Automating Benchmark Generation for Named Entity Recognition and Entity Linking. In Proceedings of the European Semantic Web Conference, Hersonissos, Greece, 28 May–1 June 2023; Springer: Cham, Switzerland, 2023; pp. 143–148. [Google Scholar]
- Jain, N.; Sierra-Múnera, A.; Ehmueller, J.; Krestel, R. Generation of training data for named entity recognition of artworks. Semant. Web 2022, 14, 239–260. [Google Scholar] [CrossRef]
- Bhadauria, D.; Sierra-Múnera, A.; Krestel, R. The Effects of Data Quality on Named Entity Recognition. In Proceedings of the Ninth Workshop on Noisy and User-generated Text (W-NUT 2024), San Ġiljan, Malta, 19–21 March 2024; pp. 79–88. [Google Scholar]
- Tejani, A.S.; Ng, Y.S.; Xi, Y.; Fielding, J.R.; Browning, T.G.; Rayan, J.C. Performance of multiple pretrained BERT models to automate and accelerate data annotation for large datasets. Radiol. Artif. Intell. 2022, 4, e220007. [Google Scholar] [CrossRef] [PubMed]
- Gokceoglu, G.; Cavusoglu, D.; Akbas, E.; Dolcerocca, Ö.N. A multi-level multi-label text classification dataset of 19th century Ottoman and Russian literary and critical texts. arXiv 2024, arXiv:2407.15136. [Google Scholar]
- Burtsev, M.; Seliverstov, A.; Airapetyan, R.; Arkhipov, M.; Baymurzina, D.; Bushkov, N.; Gureenkova, O.; Khakhulin, T.; Kuratov, Y.; Kuznetsov, D.; et al. DeepPavlov: Open-Source Library for Dialogue Systems. In Proceedings of the ACL 2018, System Demonstrations, Melbourne, Australia, 15–20 July 2018; Association for Computational Linguistics: Melbourne, Australia, 2018; Volume 7. [Google Scholar] [CrossRef]
- Honnibal, M.; Montani, I.; Van Landeghem, S.; Boyd, A. spaCy: Industrial-Strength Natural Language Processing in Python. 2020. Available online: https://zenodo.org/records/10009823 (accessed on 27 January 2025).
- Kukushkin, A. Natasha. Version 1.6.0. 2023. Available online: https://github.com/natasha/natasha (accessed on 14 February 2025).
- Qi, P.; Zhang, Y.; Zhang, Y.; Bolton, J.; Manning, C.D. Stanza: A Python Natural Language Processing Toolkit for Many Human Languages. arXiv 2020, arXiv:2003.07082. [Google Scholar]
- Schweter, S.; Akbik, A. FLERT: Document-Level Features for Named Entity Recognition. arXiv 2020, arXiv:2011.06993. [Google Scholar]
- Kassab, K.; Teslya, N. An Approach to a Linked Corpus Creation for a Literary Heritage Based on the Extraction of Entities from Texts. Appl. Sci. 2024, 14, 585. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Language | Source | Entity Types | Annotation Method | Availability | Notable Features |
|---|---|---|---|---|---|---|
| CoNLL03 [12] | English, German | Newswires | PER LOC ORG MISC | Manual | Public | Widely used benchmark for English NER. |
| OntoNotes [13] | English, Chinese, Arabic | Newswires, conversations, etc. | Expanded types, including nested | Manual | Public | Rich annotation schema for multiple tasks. |
| NNE [14] | English | Newswires | Nested entities | Manual | Public | Supports nested NER with a detailed annotation scheme. |
| Russian NER [24] | Russian | Yandex News | PER, ORG | Manual (IOB tagging) | Restricted (academic use) | Focused on business news; copyright restrictions limit use. |
| FactRuEval [25] | Russian | Newswire, analytical essays | PER, ORG, LOC | Semi-automated | Public | Created for competition tasks; supports evaluation and development. |
| NEREL [26] | Russian | Wikinews | 29 entity types, 49 relation types | Semi-automated | Public | Large corpus annotated for both NER and relation extraction; Creative Commons licensed. |
| WikiNEuRal_RU [27] | English, French, Spanish, German, Italian, Russian, Portuguese, Dutch, Polish | Wikipedia | PER, LOC, ORG, MISC | Automated (LLMs, pre-trained) | Public | Multilingual dataset with significant size and coverage; scalable. |
| Proposed Dataset | Russian | Literature | PER, LOC, ORG, DATE, WOA | Semi-automated with voting system | Public | Balances manual accuracy and efficiency; reduces biases in entity annotations. |
| Number of Samples | Total Length | Total Tokens | Average Length per Sample | Average Tokens per Sample |
|---|---|---|---|---|
| 1567 | 1,064,459 | 201,613 | 679.297 | 128.662 |
| Entity Type | Total Number of Entities | Total Tokens | Average Tokens per Entity |
|---|---|---|---|
| WOA | 3206 | 16,184 | 5.048 |
| PER | 7851 | 11,653 | 1.484 |
| DATE | 2539 | 6196 | 2.440 |
| LOC | 890 | 1007 | 1.131 |
| ORG | 221 | 443 | 2.004 |
| Model | Entity Types |
|---|---|
| Natasha | PER, ORG, LOC |
| Stanza | PER, ORG, LOC |
| Flair | PER, ORG, LOC, DATE |
| DeepPavlov | PER, ORG, LOC, DATE |
| Model | Entity | Precision | Recall | F1-Score |
|---|---|---|---|---|
| Natasha | Overall | 0.6403 | 0.4524 | 0.5402 |
| PER | 0.7541 | 0.7964 | 0.7747 | |
| LOC | 0.4815 | 0.6582 | 0.5561 | |
| ORG | 0.1364 | 0.3889 | 0.2019 | |
| Stanza | Overall | 0.5691 | 0.4958 | 0.5299 |
| PER | 0.7230 | 0.8899 | 0.7978 | |
| LOC | 0.5196 | 0.6709 | 0.5856 | |
| ORG | 0.2414 | 0.1296 | 0.1687 | |
| Flair | Overall | 0.4808 | 0.6845 | 0.5648 |
| PER | 0.8145 | 0.8719 | 0.8423 | |
| LOC | 0.7536 | 0.6582 | 0.7027 | |
| ORG | 0.3836 | 0.5185 | 0.4409 | |
| DATE | 0.6359 | 0.7874 | 0.7036 | |
| DeepPavlov | Overall | 0.6708 | 0.6519 | 0.6482 |
| PER | 0.7996 | 0.8295 | 0.8143 | |
| LOC | 0.5176 | 0.5570 | 0.5366 | |
| ORG | 0.3485 | 0.4259 | 0.3833 | |
| DATE | 0.7069 | 0.8642 | 0.7777 |
| Entity | Precision | Recall | F1-Score |
|---|---|---|---|
| Overall | 0.9505 | 0.3812 | 0.5442 |
| PER | 0.9499 | 0.6957 | 0.8032 |
| DATE | 0.8157 | 0.7146 | 0.7618 |
| LOC | 0.9565 | 0.4177 | 0.5815 |
| ORG | 1.0000 | 0.0926 | 0.1695 |
| Model | Entity | Precision | Recall | F1-Score |
|---|---|---|---|---|
| Our Model | Ents | 0.9020 | 0.8885 | 0.8952 |
| PER | 0.9357 | 0.9004 | 0.9177 | |
| DATE | 0.9077 | 0.8909 | 0.8992 | |
| LOC | 0.8478 | 0.7358 | 0.7878 | |
| ORG | 0.6949 | 0.7592 | 0.7256 | |
| WOA | 0.8577 | 0.9083 | 0.8823 | |
| DeepPavlov | Ents | 0.6196 | 0.6497 | 0.6343 |
| PER | 0.7982 | 0.8281 | 0.8129 | |
| DATE | 0.7053 | 0.8622 | 0.7759 | |
| LOC | 0.5207 | 0.5570 | 0.5382 | |
| ORG | 0.3485 | 0.4259 | 0.3833 | |
| WOA | 0.1239 | 0.1126 | 0.1179 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kassab, K.; Teslya, N.; Vozhik, E. Automated Dataset-Creation and Evaluation Pipeline for NER in Russian Literary Heritage. Appl. Sci. 2025, 15, 2072. https://doi.org/10.3390/app15042072
Kassab K, Teslya N, Vozhik E. Automated Dataset-Creation and Evaluation Pipeline for NER in Russian Literary Heritage. Applied Sciences. 2025; 15(4):2072. https://doi.org/10.3390/app15042072
Chicago/Turabian StyleKassab, Kenan, Nikolay Teslya, and Ekaterina Vozhik. 2025. "Automated Dataset-Creation and Evaluation Pipeline for NER in Russian Literary Heritage" Applied Sciences 15, no. 4: 2072. https://doi.org/10.3390/app15042072
APA StyleKassab, K., Teslya, N., & Vozhik, E. (2025). Automated Dataset-Creation and Evaluation Pipeline for NER in Russian Literary Heritage. Applied Sciences, 15(4), 2072. https://doi.org/10.3390/app15042072