2.3. Data Preprocessing
The preprocessing steps of the meteorological data were crucial to ensure the quality and reliability of the dataset used in this study. To address missing values, a full row imputation method was employed, where rows containing missing values were removed to maintain data consistency. This approach was deemed suitable given the high frequency of data collection, ensuring that sufficient data points remained for analysis.
Outliers were detected and handled using a domain-specific range-based method. Given the high variability of climatic data, employing common statistical methods (e.g., interquartile range or z-scores) could risk removing valuable information that contributes to the model’s learning process. Instead, our approach focused on eliminating data points outside plausible physical ranges, as determined by historical and domain knowledge. In our case, solar irradiance values below 0 W/m2 or above 1000 W/m2 were removed, as such extremes are not physically possible. Similarly, wind speeds below 0 m/s or above 30 m/s were excluded, as these values are inconsistent with historical observations in the region. Air temperature values below 0 °C or above 40 °C were also discarded, as such conditions have never been recorded in the study area.
This range-based filtering minimized the influence of extreme and implausible values on model training while preserving the essential variability within the dataset.
2.4. Resampling and Data Filtering
The dataset was then resampled at 10 min, 20 min, 30 min, and 1 h intervals using the mean values of each interval to seek to smooth the time series and remove randomness from the data. The resampling operation is depicted in Equation (
1).
where
N represents the number of samples in the intervals of 5 min, 10 min, 30 min, or 1 h, respectively,
V the variable to resample, and
the time instants in each interval.
Table 3 shows that the 10 min resampling series is very similar to the original series (5 min), presenting noise due to the random nature of the data in the study area. However, we consider that the series loses little information compared to the 20 min, 30 min, and even 1 h series (See
Figure 2). However, we would make the model work more inaccurately due to the randomness still present. We thus decided to analyze 3 resampling intervals of 10 min, 30 min, and 1 h.
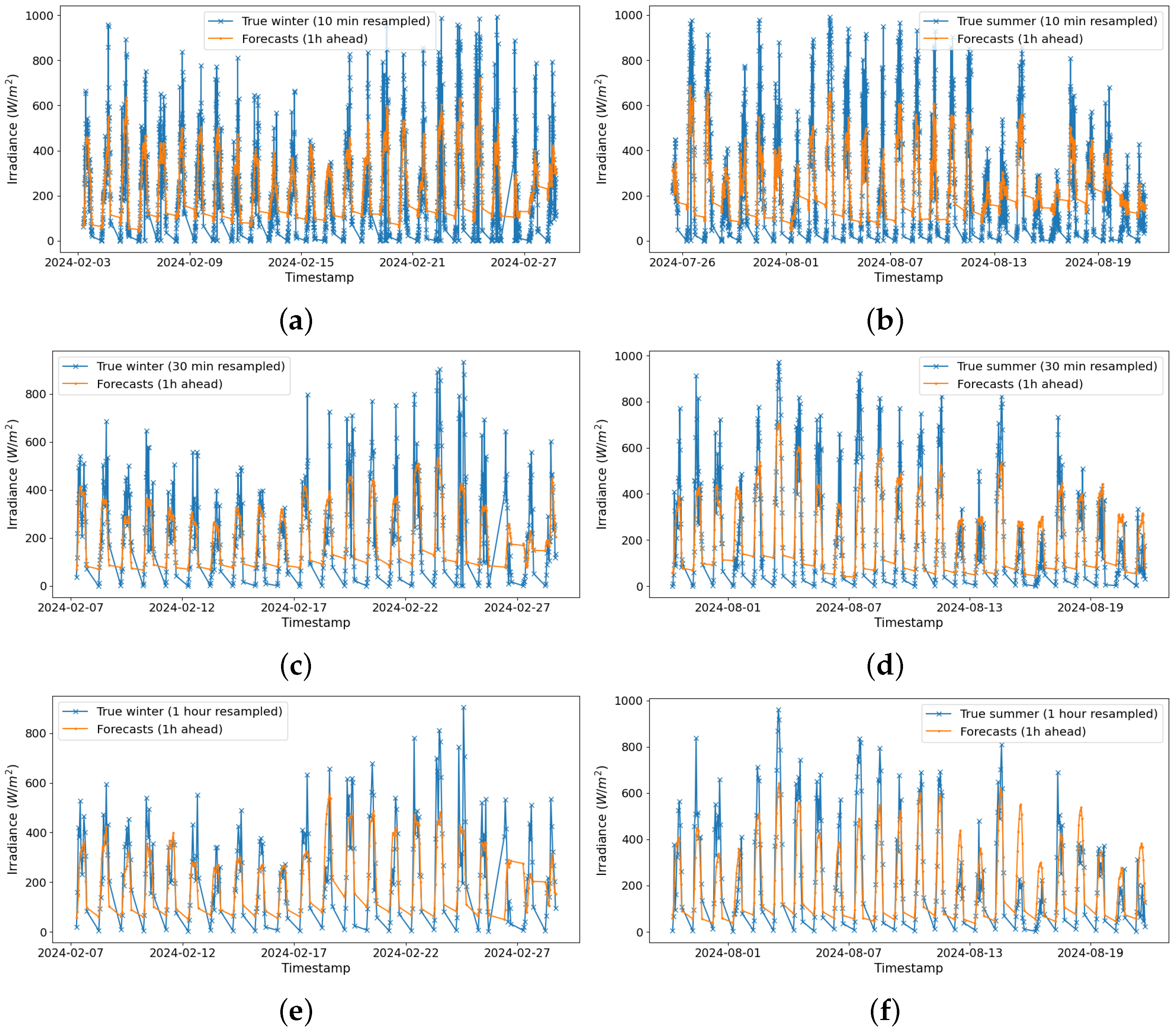
Since the analysis focuses on solar irradiance, the data were filtered out of the time range in which solar irradiance is recorded, i.e., from 6:00 to a maximum of 18:00. Finally, the processed dataset comprised 30,528 records, representing observations for the entire year.
2.8. Complete Ensemble Empirical Mode Decomposition with Adaptive Noise (CEEMDAN)
CEEMDAN was created as an improved version of the EEMD method. EEMD is a noise-assisted signal decomposition technique that solves the problem of modal mixing in EMD by introducing white Gaussian noise to the original signal, allowing the complex signals to be decomposed into high-frequency intrinsic modal functions (IMF) and a low-frequency part called residual (
R) over several iterations [
46]. However, the white Gaussian noise added to the EEMD must be repeatedly averaged to be removed, which consumes considerable time. In addition, the reconstructed signal, which includes residual noise, can produce a variable number of IMFs. Therefore, we use the CEEMDAN method to overcome these problems.
The CEEMDAN process is described as follows:
White noise
w with a standard deviation
is added to the original signal
, which can be expressed by Equation (
8).
where
i represents the number of realizations.
The EMD decomposition step is performed on the signal after each realization, and then the first IMF
is calculated by averaging the decomposition components (see Equation (
9)).
The residual of the first stage is given as
. Then, the signal
can be further decomposed by EMD to calculate the second IMF mode, which can be formulated as in Equation (
10).
where
represents the second IMF mode obtained by the EMD algorithm.
In the next stage, the residual
and the component
can be calculated using Equation (
11).
where
represents the
-th IMF mode obtained by the CEEMDAN algorithm.
Repeat steps 3 and 4 until the residual
meets the stopping criterion of Equation (
12).
where
T represents the length of the sequence
,
is the sequence after the
n-th decomposition, and the empirical value of
is set to 0.2.
Finally, the original signal
can be decomposed as Equation (
13).
where
is the final residual.
In selecting the parameters in
Table 4, consideration was given between decomposition accuracy and computational efficiency. First, 100 realizations (trials) were selected so that the intrinsic mode functions (IMFs) would capture the original signal features without adding excess noise. Then,
was used to control the magnitude of the added noise, with the noise_scale set to 0.5 to maintain an appropriate signal-to-noise ratio. The number of siftings (num_siftings) was set to 100 to ensure that each IMF was extracted with maximum accuracy.
CEEMDAN helps to analyze solar irradiance data due to the complex and variable nature of these signals, especially in regions with high climatic variability. Under these conditions, solar irradiance signals exhibit rapid fluctuations and seasonal variations, which can be difficult for the model to learn directly. CEEMDAN can effectively separate high-frequency components, such as noise and rapid fluctuations, from low-frequency trends, such as seasonal and long-term variations, by decomposing the data into different IMFs, allowing the model to learn these patterns more efficiently, increasing its robustness and accuracy.
In
Figure 4, the original solar irradiance (10 min resampled) time series is presented at the top (labeled “True”), followed by the different IMFs labeled 1 through 14. Each IMF can represent a different frequency component of the original signal:
IMF 1 to IMF 4: These may be capturing high-frequency variations, which may be associated with rapid and noisy fluctuations in solar irradiance.
IMF 5 to IMF 8: These may be representing mid-frequency components, which could be related to more significant periodic changes throughout the day.
IMF 9 to IMF 14: These may be capturing low frequency variations, which correspond to longer trends and seasonal changes in solar irradiance.
CEEMDAN was used in this research because it allowed the original signal (solar irradiance) to be decomposed into components that the model could quickly understand, facilitating the identification of specific patterns in the time series. This is useful for improving our forecasting model as it deals more effectively with rapid variations and long-term trends in the solar irradiance data.
To enable real-time forecasting, CEEMDAN can be applied using a sliding window approach on recent historical data (e.g., one year) to ensure the inclusion of new information while maintaining computational efficiency, minimizing IMF variations, and preserving the method’s robustness in high variability environments.
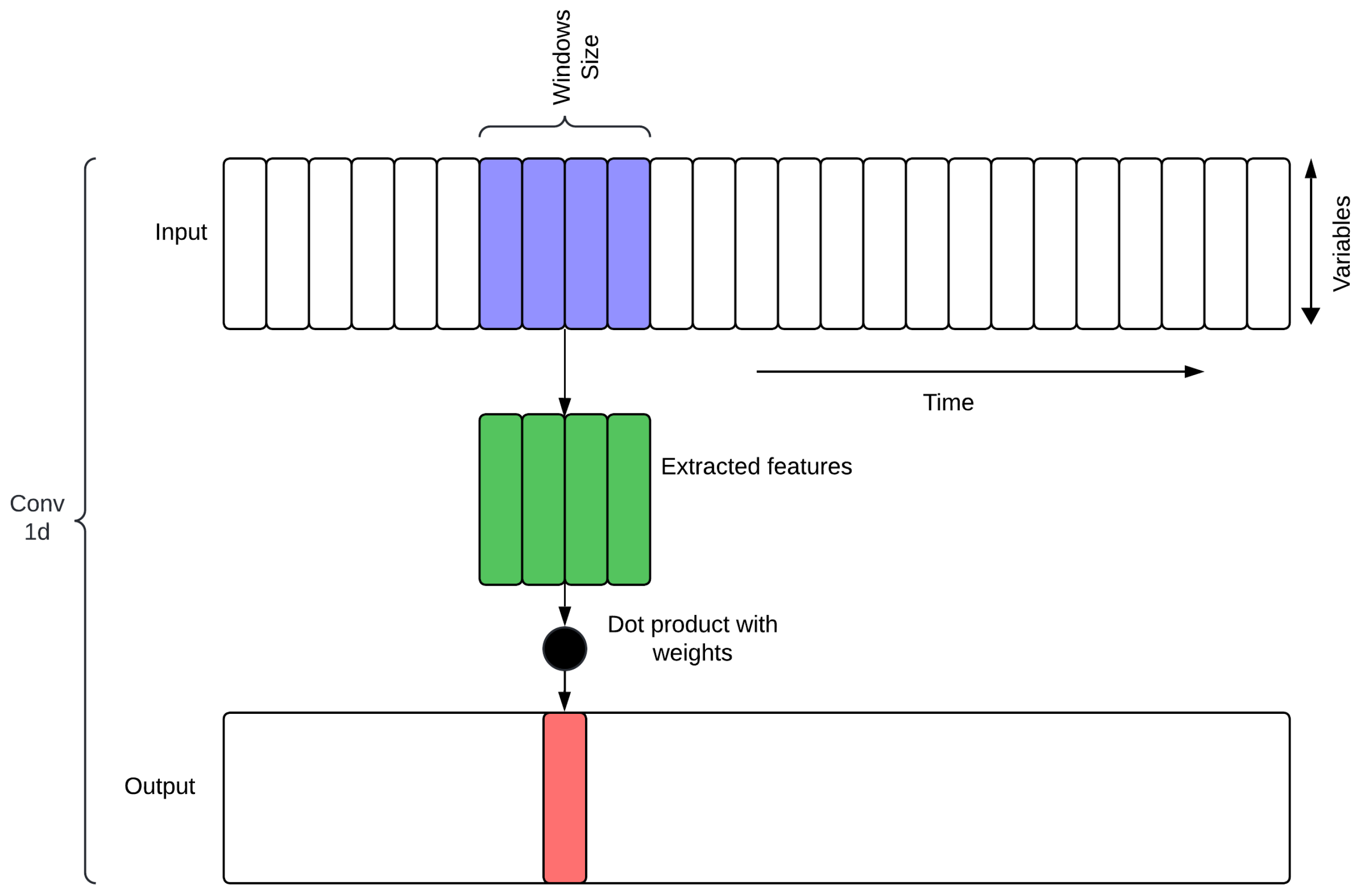
2.9. Convolutional Neural Networks (CNN)
CNNs are specialized deep learning models that process data within a grid structure. While time series data have a one-dimensional grid topology, image data typically have a two-dimensional grid of pixels. CNNs use convolutions in at least one of their layers, a specific type of linear operation that replaces the generic matrix multiplication used in other neural networks. Over time, various CNN architectures have emerged, such as multichannel and multi-head, although the basic structure remains essentially the same [
47].
CNN models are versatile and capable of handling multiple input data formats, including 1D, 2D, and nD, where data typically consists of 1 to n channels [
48]. This study employed a 1D input data format within the proposed hybrid model (see
Figure 5). For this purpose, the time series data were treated as a one-dimensional grid, where each variable is represented as a distinct channel, allowing the CNN to learn the spatial relationships between variables while preserving the temporal sequence. The sliding window size should ensure that the model effectively captures the temporal features encountered. Therefore, our CNN has three convolutional layers, kernel sizes of 3, and stride of 1, which were optimized to balance computational efficiency and the ability to learn hierarchical patterns. This enables the CNN to extract meaningful features that are passed on to downstream components in the hybrid encoder-decoder model, improving the overall predictive accuracy of the model.
The application of CNNs in this research follows that in the cited literature, which the authors have used to extract and identify patterns in meteorological variables to improve solar irradiance forecasting. We intend to take advantage of the ability of CNNs to automatically learn hierarchical features from raw input data, such that the model could effectively capture complex temporal dependencies and spatial correlations within the data. The integration of CNNs into the hybrid model can complement other components by providing complex feature extraction, improving the overall predictive accuracy of solar irradiance forecasts.
2.10. Long Short-Term Memory (LSTM)
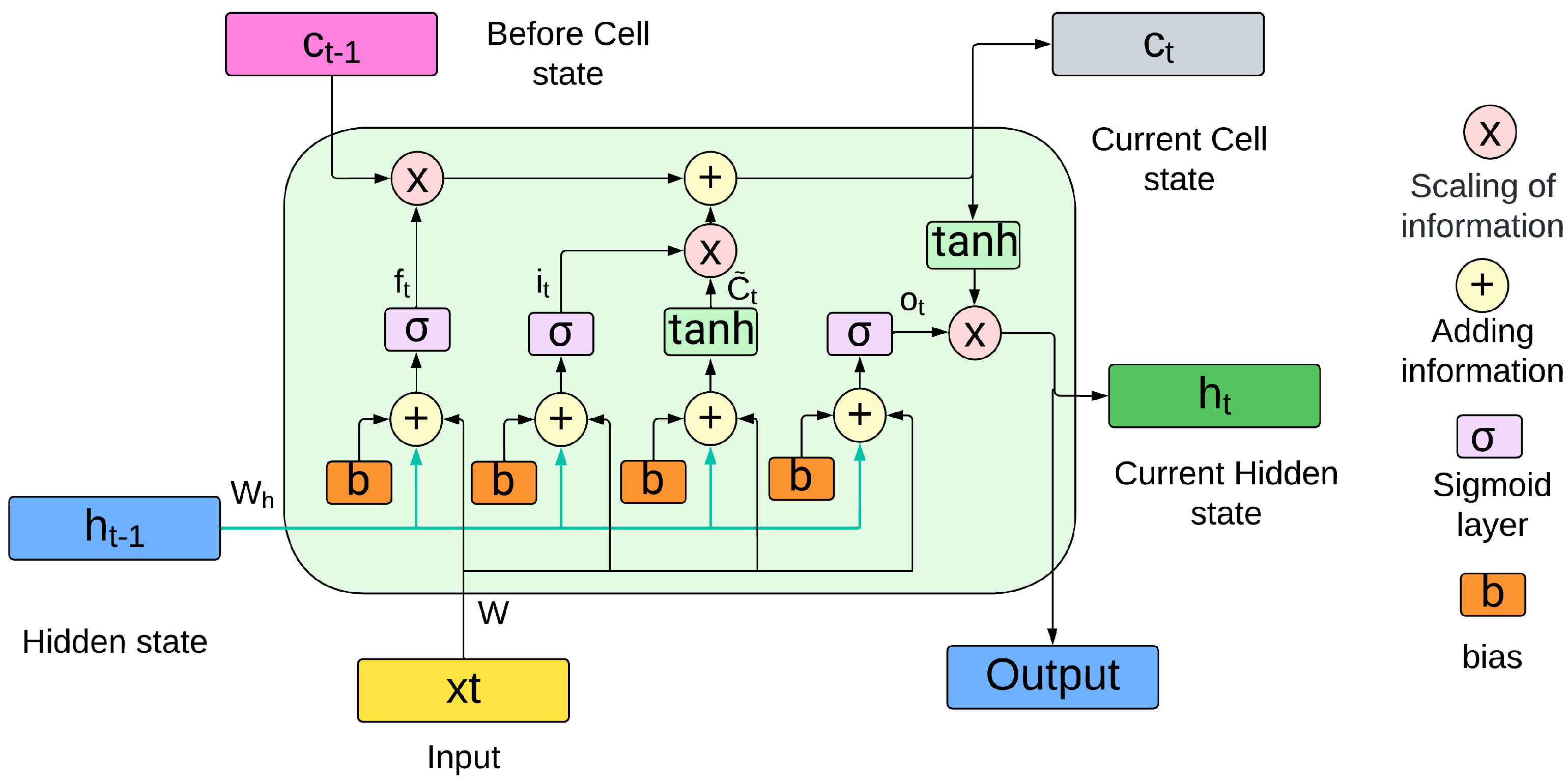
The LSTMs depicted in
Figure 6 are a variant of recurrent neural networks (RNNs). RNNs can process sequential data and maintain information over time, but basic RNNs need help with problems such as vanishing and gradient bursting, which complicate their ability to capture long-term dependencies [
49,
50]. Therefore, LSTMs were developed, which incorporate forget, input, and output gates, and an internal memory unit called the cell state. The forget gate is responsible for removing irrelevant information, the input gate updates the cell state with new information, and the output gate filters the current state to transmit the most important information. LSTMs has been shown in several papers to be highly effective for accurate forecasting in a variety of applications, including renewable energy.
The forget gate is calculated by the sigmoid function applied to the linear combination of the previous hidden state
and the current input
, as shown in Equation (
14).
Next, the input gate is determined in a similar manner, as shown in Equation (
15).
The new candidate information for the memory cell is calculated using the hyperbolic tangent function (tanh), as shown in Equation (
16).
The state of cell
is updated by combining the old information, modulated by the forgetting gate, with the new candidate information, weighted by the input gate, as described in Equation (
17).
The output gate, which determines the part of the cell that should be passed to the next hidden state, is defined by Equation (
18).
Finally, the new hidden state
is calculated by applying the function tanh to the cell state and multiplying by the gate output, as presented in Equation (
19).
where,
,
,
, and
are the weights associated with each gate, while
,
,
, and
are the corresponding biases. The
function represents the sigmoid activation that regulates the flow of information in the gates, while tanh is used to generate the new memory units
due to its ability to capture nonlinear relationships efficiently.
2.11. Multi-Head Attention Mechanism (ATT)
The ATT (see
Figure 7) first presented by [
51] was a new advance in DL architectures, especially in the transformer model. This mechanism has been used in several applications to improve learning capability [
52]. This mechanism uses three main matrices: the query matrix
Q, which represents the encoded temporal features to which attention is paid; the key matrix
K, which represents the encoded features available for comparison; and the value matrix
V, which contains the features used to compute the attention result. These matrices simultaneously focus on different parts of the input sequence, thus capturing a wide range of contextual information.
Mathematically, the ATT is defined as Equations (
20) and (
21).
where,
Q,
K, and
V represent the query, key, and value matrices, respectively. The projection matrices
,
, and
correspond to each attention head
i, and
is the output projection matrix. The function Attention is defined as the scaled scalar product attention (see Equation (
22)).
where
denotes the dimensionality of the keys. The softmax function ensures that the attention weights are positive and their sum equals one, thus facilitating the effective weighting of values according to their relevance to queries.
We use this mechanism to improve the ability of our hybrid model to capture long-term dependencies and complex relationships in climate data. To this end, the ATT can identify hidden patterns and time-varying correlations. This results in more accurate and robust forecasts, especially for dynamic and seasonal features.
2.12. Positional Encoding and Embedding
Positional encoding is a technique that allows our hybrid model to incorporate temporal position information from the input sequences. This is useful to capture the sequentiality of time series data, which can be easily lost in ATT. On the other hand, the embedding layer maps the original input features, which represent variables such as irradiance, temperature and wind speed in a higher dimensional space, allowing the model to capture complex patterns and interactions between variables.
The embedding operation can be expressed as Equation (
23).
where
represents the input feature vector,
is the embedding matrix, and
is the bias term.
Consequently, we add positional encoding so that we can add unique information about the time steps in the input sequence, with each position in the input sequence thus having a distinct time position. The positional encoding vector
of each time step is represented using sinusoidal functions (see Equations (
24) and (
25)).
where
is the position of the time step in the sequence,
i represents the dimension, and
is the dimensionality of the embedding space. Including of positional encoding allows the temporal structure of the data to be maintained, which is essential for the model to understand the temporal positions of the data in time-dependent problems, e.g., solar irradiance prediction.
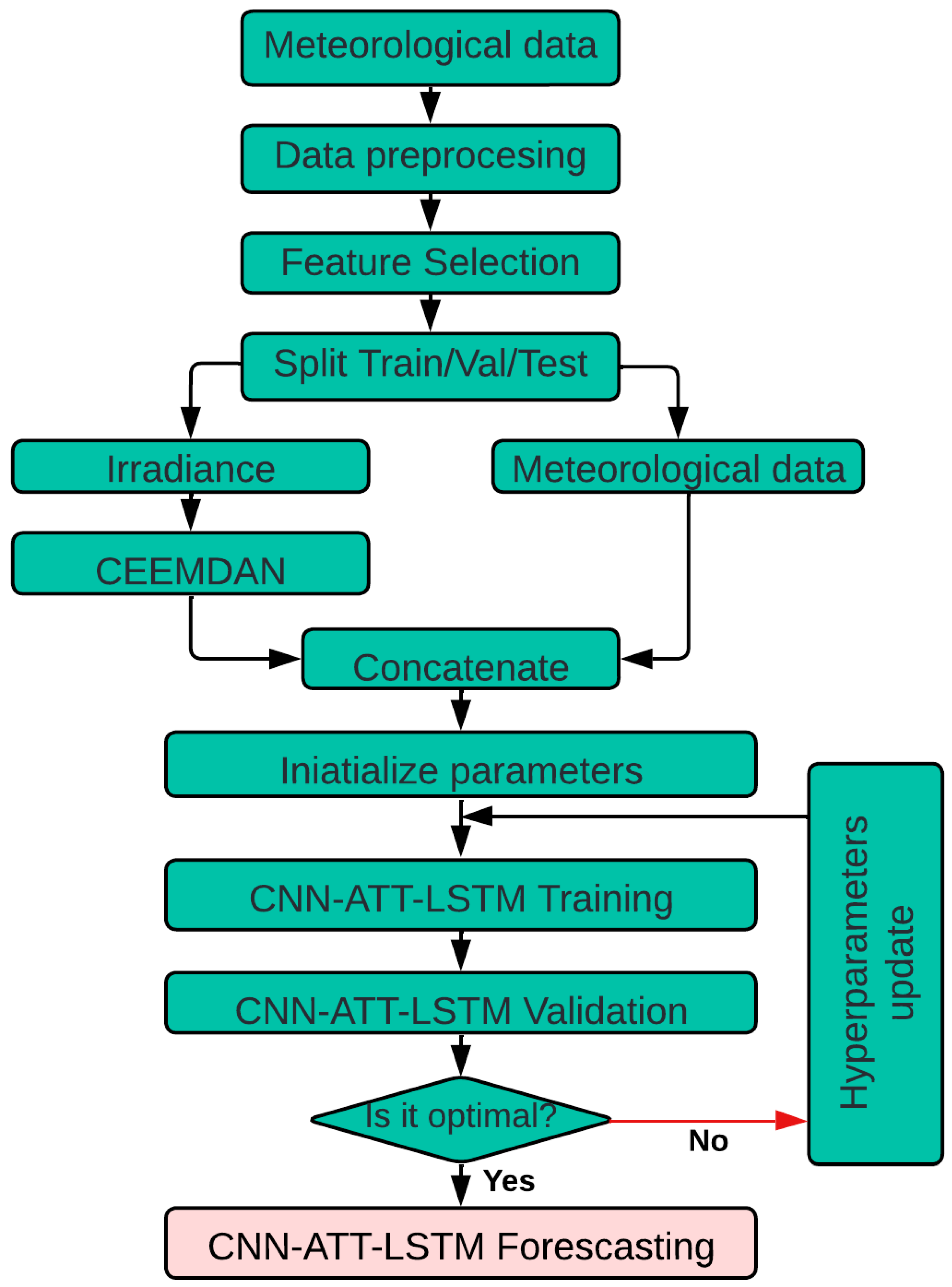
2.13. CEEMDAN-CNN-ATT-LSTM Model
Figure 8 presents a hybrid achitecture for solar radiance forecasting that combines CNNs, LSTM networks, and an ATT for solar irradiance forecasting. This combination leverages the strengths of each component: CNNs for spatial feature extraction, LSTMs to capture short-term temporal dependencies, and an ATT to extract long-term patterns from the input sequence.
Our proposed CEEMDAN-CNN-ATT-LSTM model employs a carefully designed architecture with specific hyperparameters to optimize its performance. The CNN encoder consists of three sequential 1D convolutional layers. The first convolutional layer has 256 filters, the second 128 filters, and the third 256 filters, each with a kernel size of 3 and a padding of 1 to preserve the input size. Batch normalization is introduced after each convolutional layer to stabilize and speed up training. In addition, dropout regularization with a specific probability is applied after each layer to avoid overfitting. After the last convolutional layer, a ReLU activation function is applied to introduce nonlinearity. The goal of this setup is to extract spatial features from the input data while maintaining local temporal dependencies.
The LSTM component includes two stacked LSTM layers with 256 hidden units each. A dropout regularization with a rate of 0.2 is applied between the layers to mitigate overfitting and improve generalization. The outputs of the LSTM layers are normalized using layer normalization to stabilize the training.
For ATT, eight attention heads were employed, each with a projection dimension of 64. This design allows the model to focus on different parts of the input sequence simultaneously, effectively capturing both short- and long-term dependencies. Positional coding is added to maintain temporal order within the input sequence, ensuring that the model correctly interprets the sequential nature of the data.
The final dense layer consists of 128 units, followed by a single output unit with a sigmoid trigger function to produce normalized forecasting. This ensures that the output is limited to a range suitable for forecasting solar irradiance.
The model input is the sequence of irradiance data preprocessed using the CEEMDAN decomposition. In addition to irradiance, variables such as temperature and air humidity are included. Mathematically, the input x is a tensor , where q is the sequence length (number of time points) and n is the number of features (in this case, 19 features). The input shape is .
Three cascaded 1D convolutional layers are applied in the encoder, each using filters to extract local features from the input sequence. Each convolutional layer’s input
x consists of the irradiance and other meteorological variables for each time step. The convolution operation is expressed in Equation (
26).
where
is the output of the
l-th convolutional layer,
are the weights (with
k being the kernel size,
n the input feature dimension, and
m the output feature dimension),
are the biases, and ∗ denotes the convolution operation. The ReLU activation function introduces non-linearity to the output, allowing the model to learn complex patterns in the data.
Following each convolutional layer, average pooling is applied to reduce the dimensionality of the feature maps and prevent overfitting. This operation is defined in Equation (
27).
where
is the pooled output from the
l-th layer, and
is the pooling window size. After pooling, batch normalization is applied to standardize the outputs, as shown in Equation (
28).
where
and
are the mean and variance of the output from the
l-th layer, and
is a small constant for numerical stability.
The features extracted by the CNN are then passed through two LSTM layers. The input to each LSTM layer consists of the normalized outputs from the previous stage, which are data sequences representing features over time. The LSTM operation is given in Equation (
29).
where LayerNorm represents layer normalization, and Dropout is used to prevent overfitting. The hidden units in this LSTM layer are set to 256. The LSTM layer captures the temporal dependencies in the data, with
being the output at time step
t.
ATT is then applied to the outputs of the two LSTM layers and the positional encoding (see Equation (
30)). The attention layer calculates the importance of each time step in the sequence, helping the model focus on the most relevant features for predicting solar irradiance. This is expressed in Equation (
31).
Residual connections are then employed (see Equation (
32)) to add the original input back to the output of the attention mechanism:
This technique helps to maintain the original input information, enhancing the stability and performance of the model.
Before applying the ATT in the decoder, the target history (i.e., historical irradiance data) is embedded to map the input features into a higher-dimensional space that can capture more complex patterns. The embedding operation is described in Equation (
33).
where
represents the sequence of past irradiance values, and Embedding is the operation that transforms these values into a higher-dimensional space
, where
d is the embedding dimension.
To incorporate temporal information into the sequence, positional encoding is added to the embedded target history. This process is shown in Equation (
34).
The positional encoding allows the model to differentiate between the positions of time steps in the sequence, which is crucial for tasks involving sequential data.
A multi-head attention mechanism is then applied to the outputs of the encoder and the positional encoded target history. This is expressed in Equation (
35).
Then, residual connections are employed to add the original input back to the output of the ATT (See Equation (
36)).
The features extracted are then passed through two LSTM layers. The LSTM operation is given in Equation (
37).
The output from the LSTM is flattened into a one-dimensional vector, as shown in Equation (
38).
This vector is then passed through a fully connected layer to produce the final prediction (See Equation (
39)).
where
and
are the weights and biases of the fully connected layer, and
is the predicted solar irradiance value. The output is then passed through a sigmoid function to constrain the predictions (See Equation (
40))
where
represents the sigmoid activation applied to the predicted value to ensure non-negative output.
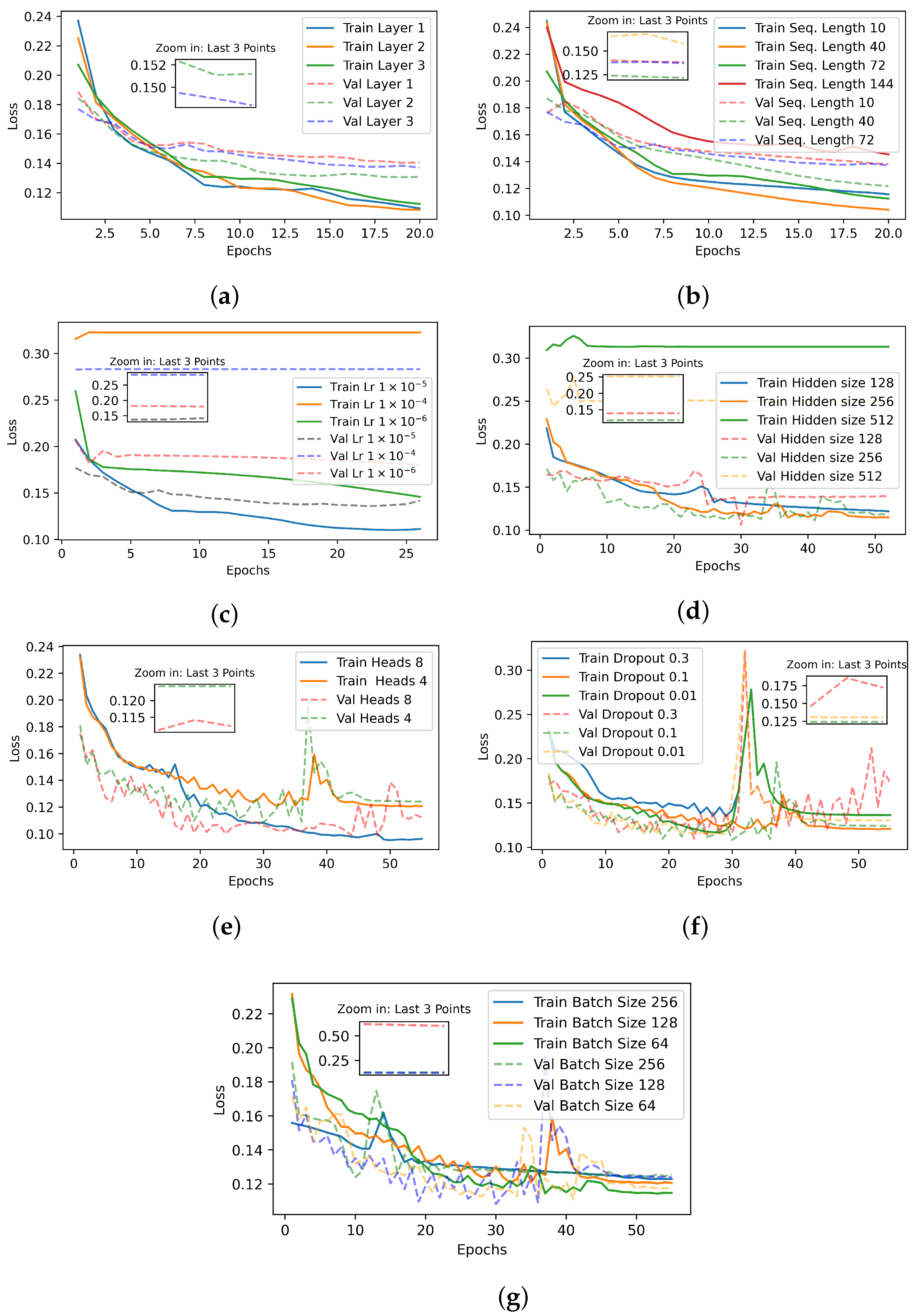
Algorithms 1 and 2 describe the training and forecasting process of the hybrid model developed for this task. In the first phase, the model is iteratively trained on a dataset, adjusting its parameters to minimize a loss function represented as
. During each epoch, the model is evaluated on a validation set to ensure that it learns from the training data and generalizes well to new data. The prediction phase, which follows training, uses the optimized model to generate predictions on test data.
| Algorithm 1: Training and Prediction with CNN-LSTM-MultiHeadAttention Model |
- 1:
Input: Time series data , where T is the time series length, v is the number of variables, and is the history of irradiance. - 2:
Step 1: CEEMDAN Decomposition of Irradiance - 3:
Initialize CEEMDAN parameters: trials, noise level, siftings - 4:
Apply CEEMDAN to decompose the irradiance data into Intrinsic Mode Functions (IMFs) and a residue - 5:
Append IMFs and residue to the feature set - 6:
Initialize: - 7:
Load configuration parameters: hidden layers , batch size , epochs e, patience p - 8:
Initialize model - 9:
Apply weight initialization and move model to device - 10:
Define loss criterion - 11:
Define optimizer and scheduler - 12:
Initialize variables: best_val_loss = ∞, patience_counter = 0 - 13:
Load , , and irradiance history h - 14:
Create DataLoader iterators for training, validation, and test data with batch size - 15:
for each epoch e do - 16:
Training Phase: - 17:
Set model to training mode - 18:
Initialize training loss to zero - 19:
for each batch in do - 20:
Zero the parameter gradients - 21:
- 22:
Compute loss - 23:
Add L1 regularization - 24:
Perform backpropagation - 25:
Clip gradients and update model parameters - 26:
Accumulate training loss - 27:
end for - 28:
Compute average training loss - 29:
Validation Phase: - 30:
Set model to evaluation mode - 31:
Initialize validation loss to zero - 32:
for each batch in do - 33:
Disable gradient computation - 34:
- 35:
Compute loss - 36:
Accumulate validation loss - 37:
end for - 38:
Compute average validation loss - 39:
Early Stopping: - 40:
if best_val_loss then - 41:
Update best_val_loss - 42:
Save model parameters and reset patience_counter - 43:
else - 44:
Increment patience_counter - 45:
end if - 46:
if patience_counter then - 47:
Break training loop early - 48:
end if - 49:
end for
|
| Algorithm 2: Prediction with CNN-LSTM-MultiHeadAttention Model |
- 1:
Test the model using - 2:
Set model to evaluation mode - 3:
Initialize test loss to zero - 4:
Initialize lists for predictions, actual values, and dates - 5:
for each batch in do - 6:
Disable gradient computation - 7:
- 8:
Compute test loss - 9:
Accumulate test loss - 10:
Store predictions and actual values for future analysis - 11:
end for - 12:
Compute average test loss - 13:
Post-processing: - 14:
Apply EWMA smoothing to the test loss - 15:
Apply sliding window anomaly detection to identify possible faults - 16:
Compute evaluation metrics: RMSE, MAE, R2, MAPE - 17:
Save predictions, actual values, and metrics for reporting - 18:
Output: - 19:
Final model performance metrics and saved model for deployment or further analysis
|
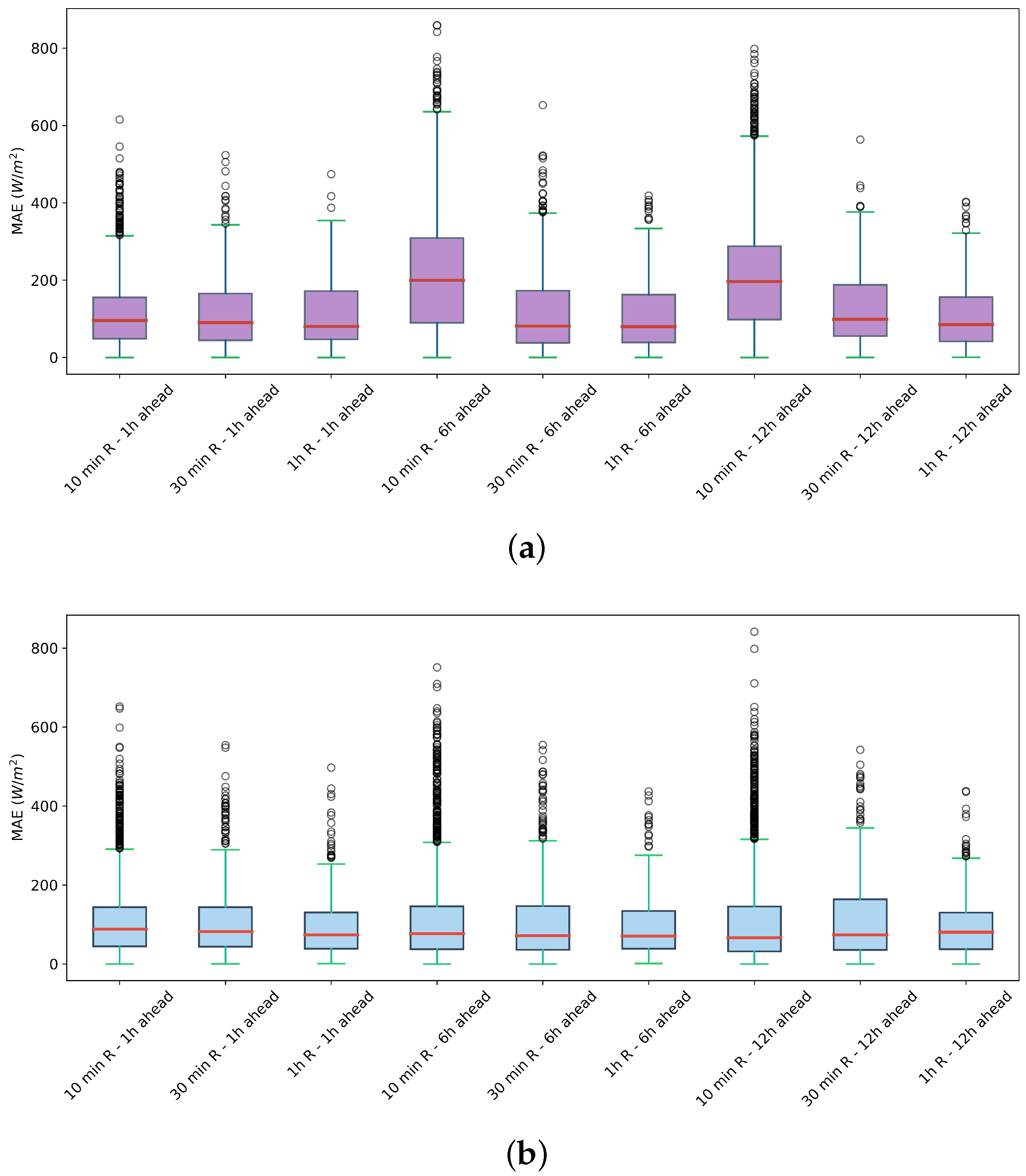
2.16. Model Evaluation Metrics
We use different common error metrics in forecasting models to evaluate the proposed model. These metrics include the root mean square error (RMSE), the mean absolute error (MAE), the mean absolute percentage error (MAPE), and the coefficient of determination (
). In Equations (
41)–(
44) we define these metrics.
Root mean square error (RMSE): RMSE calculates the square root of the mean of the squared differences between the predicted values (
) and the actual values (
). It is highly sensitive to large errors, as these are squared before averaging. A lower RMSE indicates higher predictive accuracy, and a value of zero would represent a perfect model. RMSE is calculated as in Equation (
41).
Mean absolute error (MAE): MAE is defined as in Equation (
42). This metric calculates the mean of the absolute differences between predicted and actual values. In contrast to RMSE, MAE does not penalize large errors so heavily and so it is a good option when a metric that treats all errors equally is required. A lower MAE indicates better model performance.
Mean absolute percentage error (MAPE): MAPE is the mean of the absolute percentage errors between the forecast and actual values. A lower MAPE indicates that the forecast is closer to the observed values. However, one disadvantage of MAPE is that when actual values tend toward zero, they typically become extremely large, leading to disproportionately large values. Its calculation is based on Equation (
43).
Coefficient of determination (
):
, defined in Equation (
44), measures the proportion of the variance in the dependent variable that is predictable from the independent variables. A value
close to 1 indicates that the model accurately predicts the target variable. In contrast, a value
close to 0 indicates that the model does no better than the mean of the target values.
In Equations (
41)–(
44),
represents the actual values,
represents the predicted values,
n is the number of samples, and
is the mean value of
.
To conclude this section, the experiments were conducted using the Python programming language (version 3.11.11) in the PyTorch library (version 2.5.1+cu121) within a Google Colab environment. The environment comprised an Intel(R) Xeon(R) CPU @ 2.20 GHz (Intel, Santa Clara, CA, USA), 51.00 GB of RAM, a Tesla K80 accelerator (Tesla, Austin, TX, USA), and 12 GB of GDDR5 VRAM.



 ,
, 




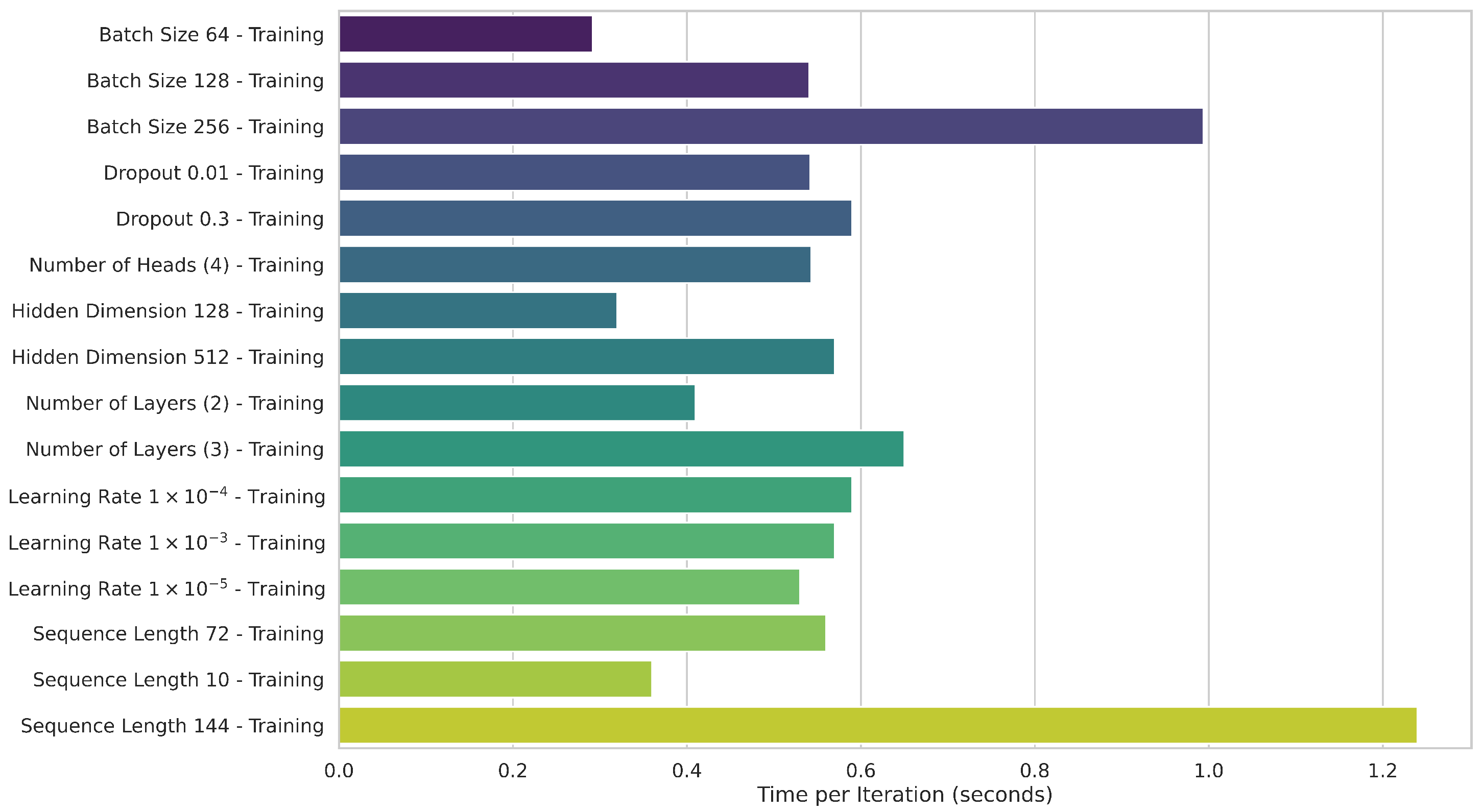



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}