
Face and Voice Recognition-Based Emotion Analysis System (EAS) to Minimize Heterogeneity in the Metaverse

Abstract
1. Introduction
2. Related Works
2.1. Neural Network Models for Facial Emotion Analysis
2.2. Neural Network Models for Voice Emotion Analysis
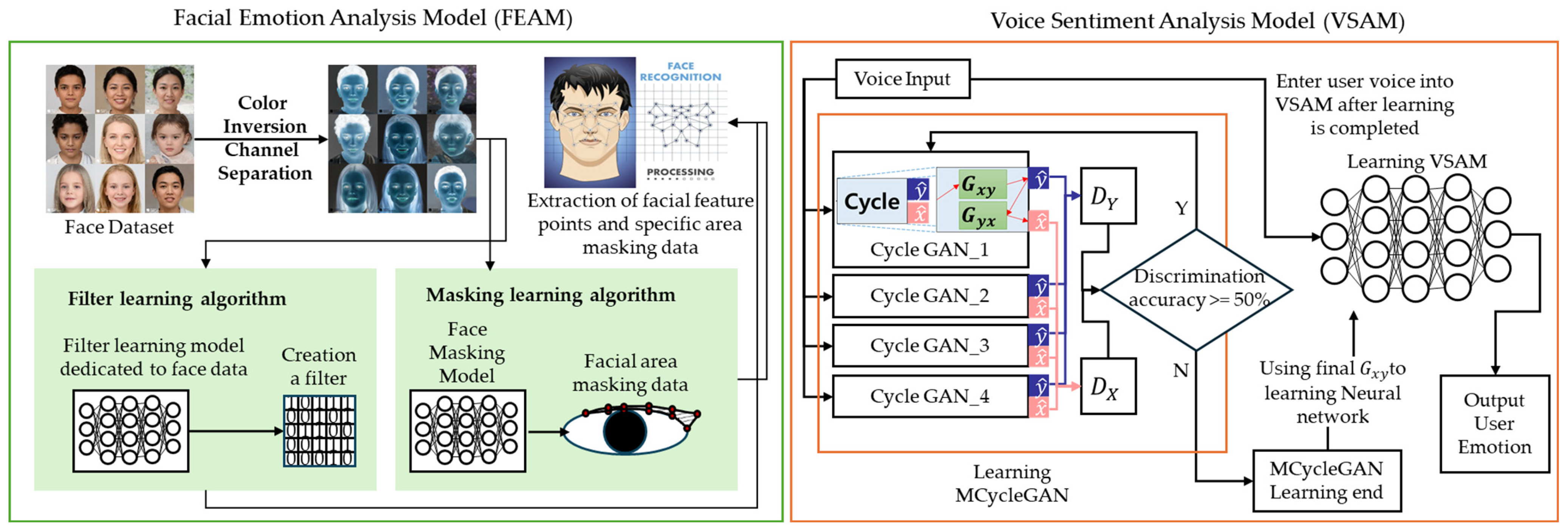
3. Design of the EAS
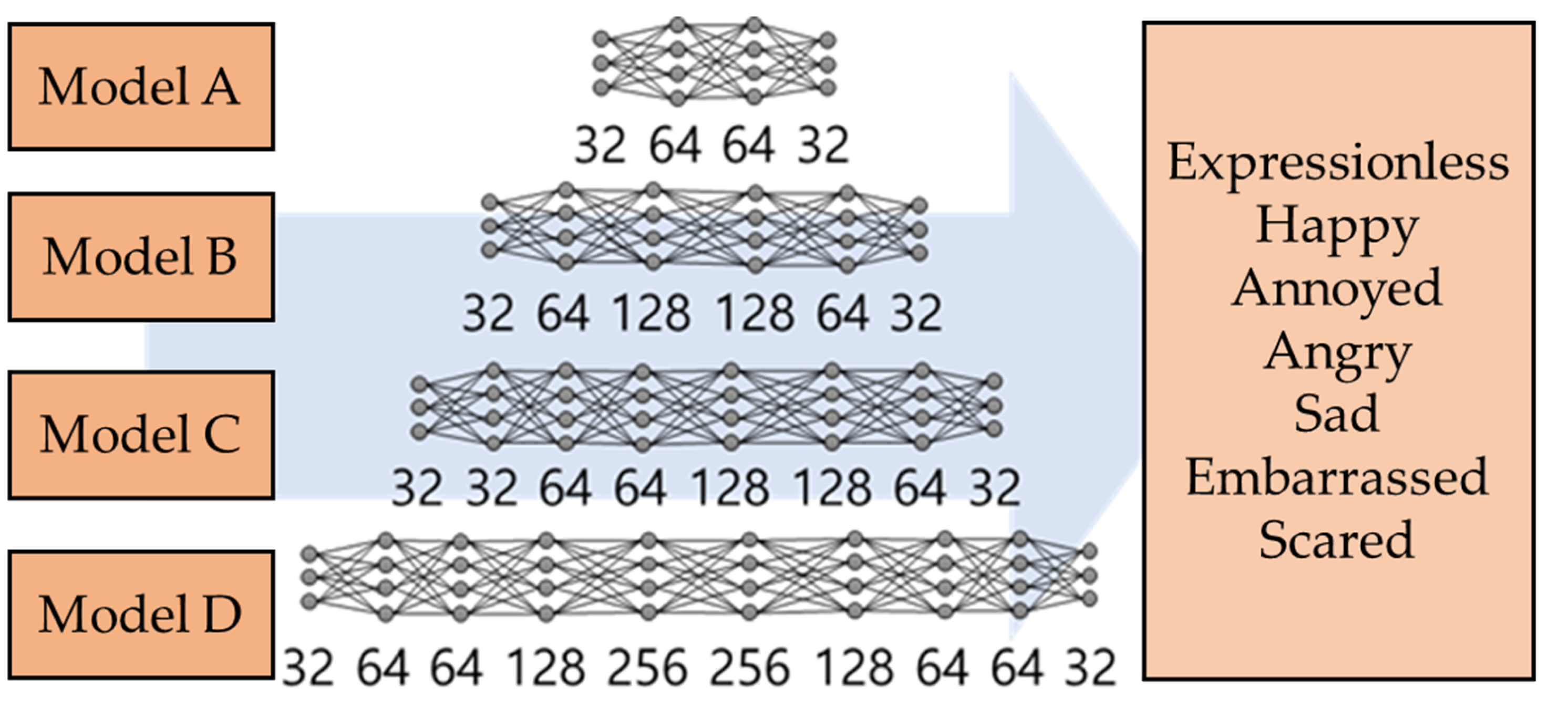
3.1. Constructing an Emotion Recognition Model Through Facial Expressions
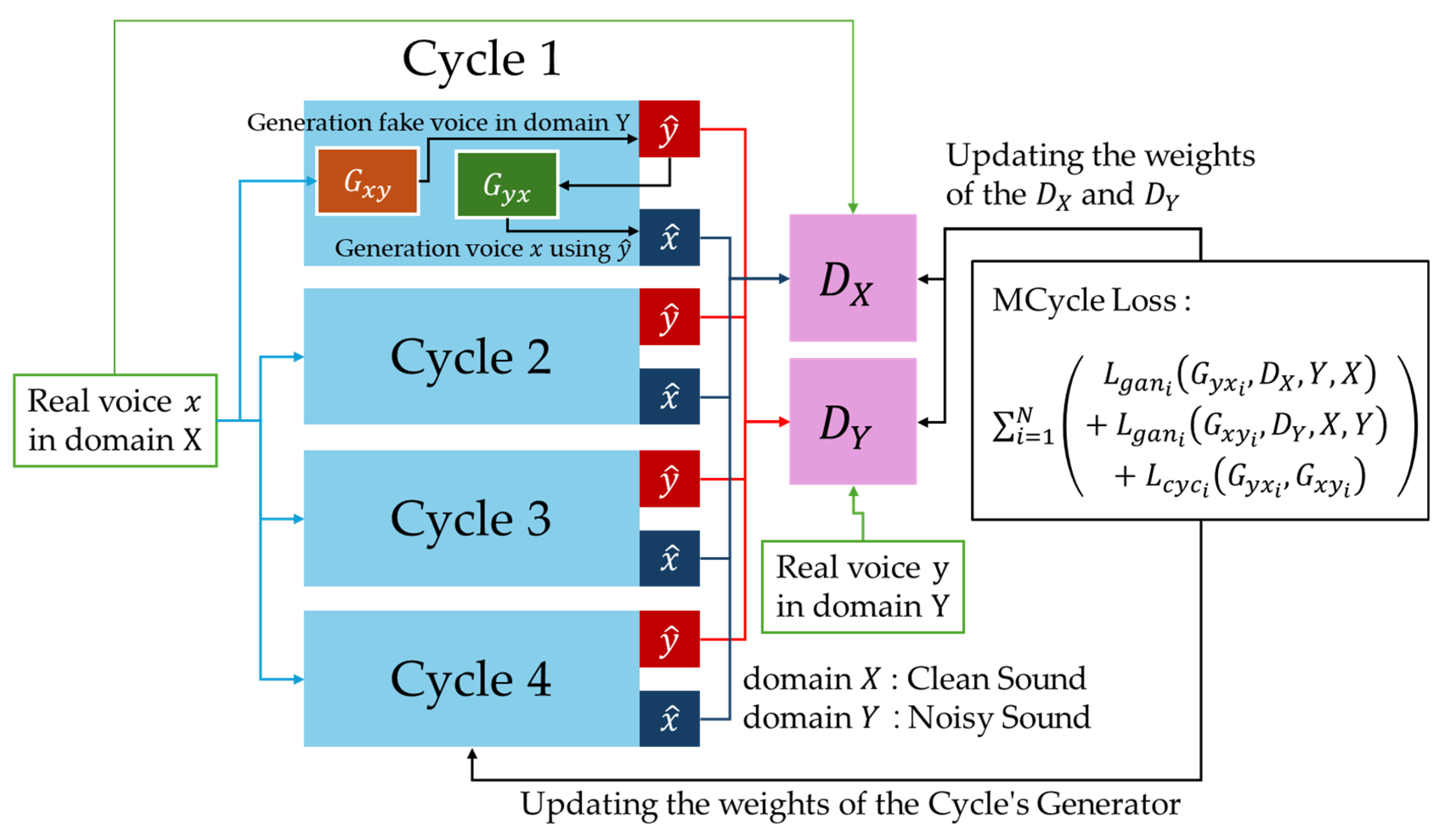
3.2. MCycle GAN
3.3. Detailed Structure of the MCycle GAN
3.4. Constructing an Metaverse Emotion Recognition Model
4. Simulation
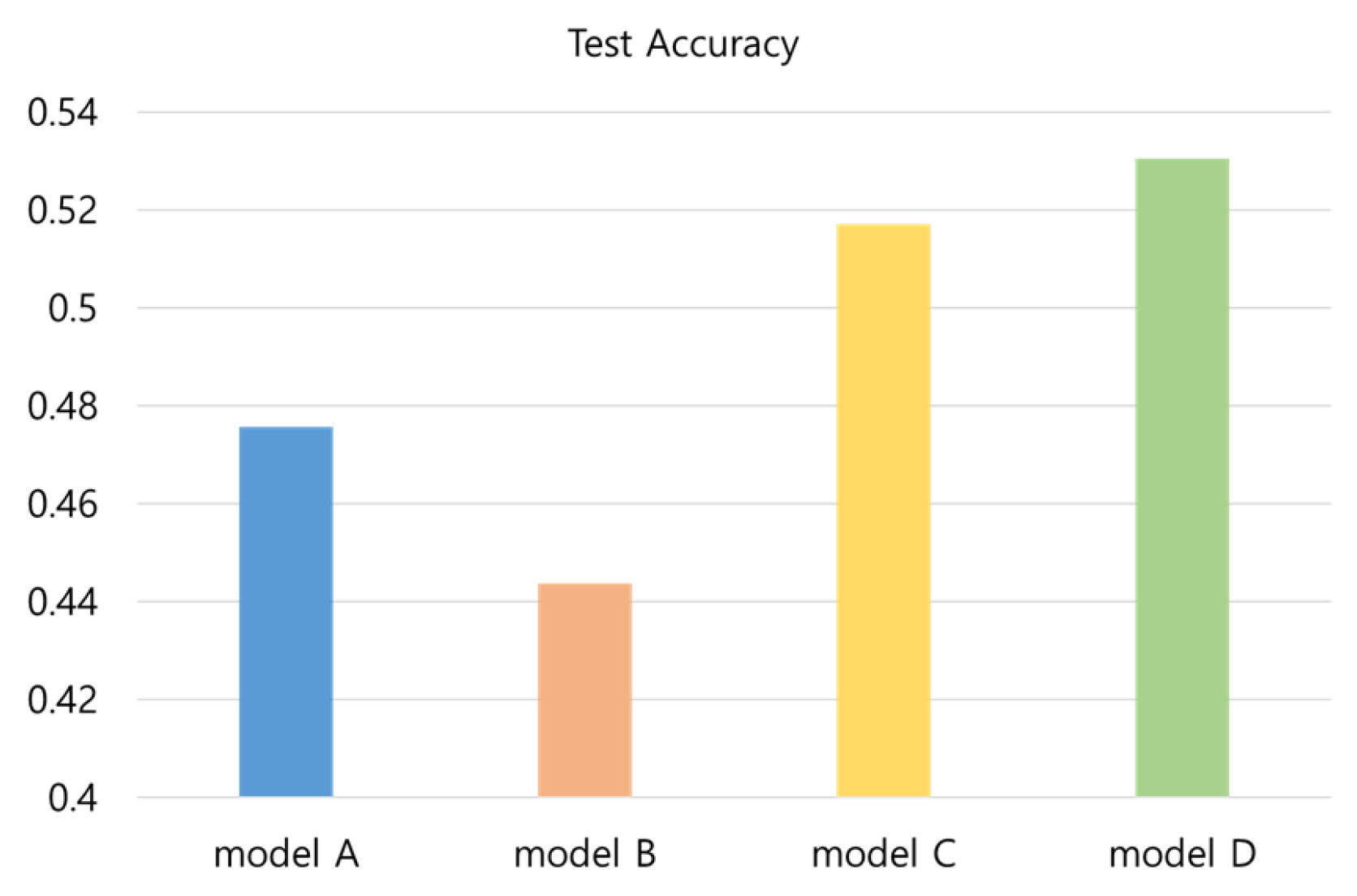
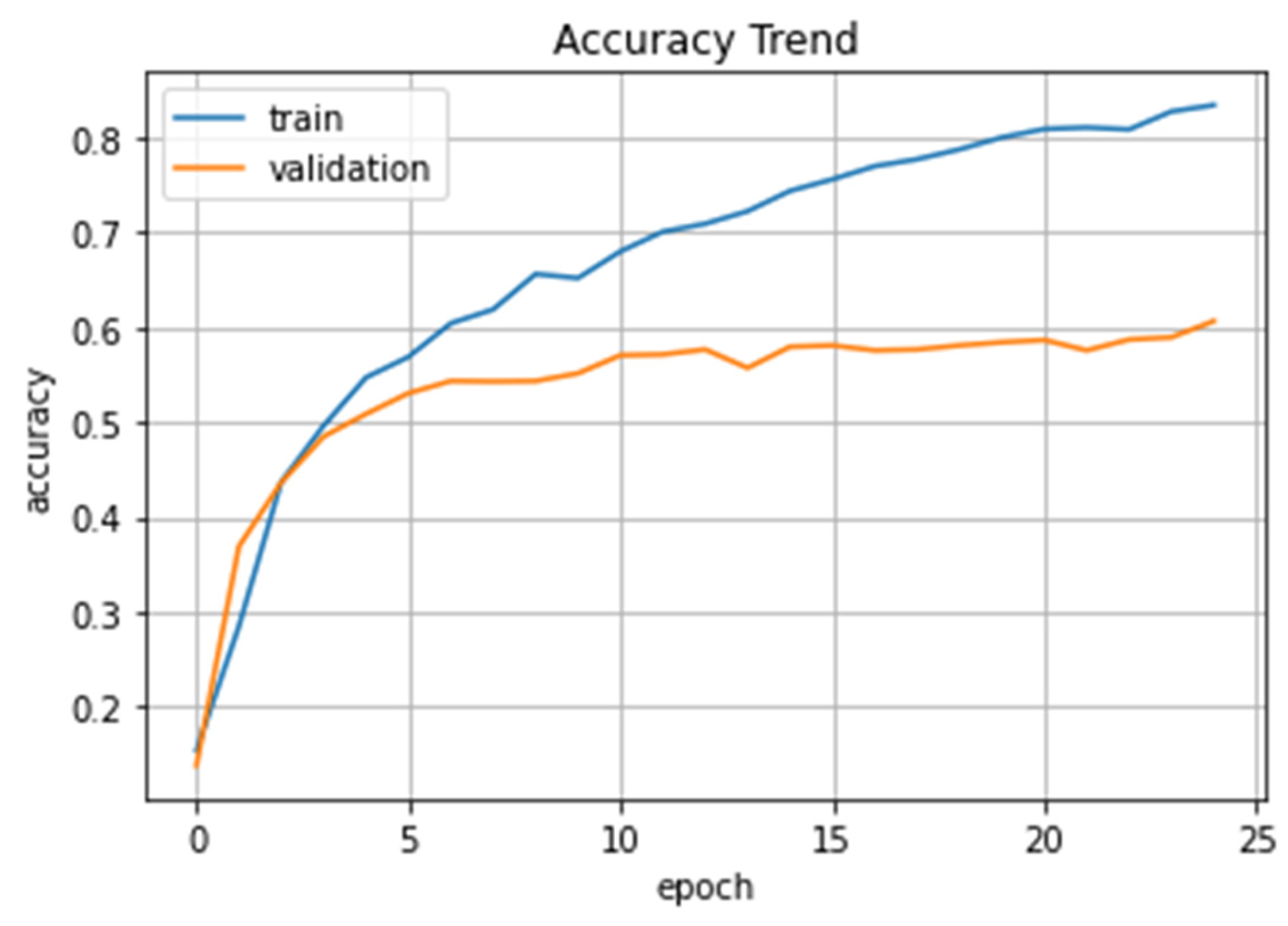
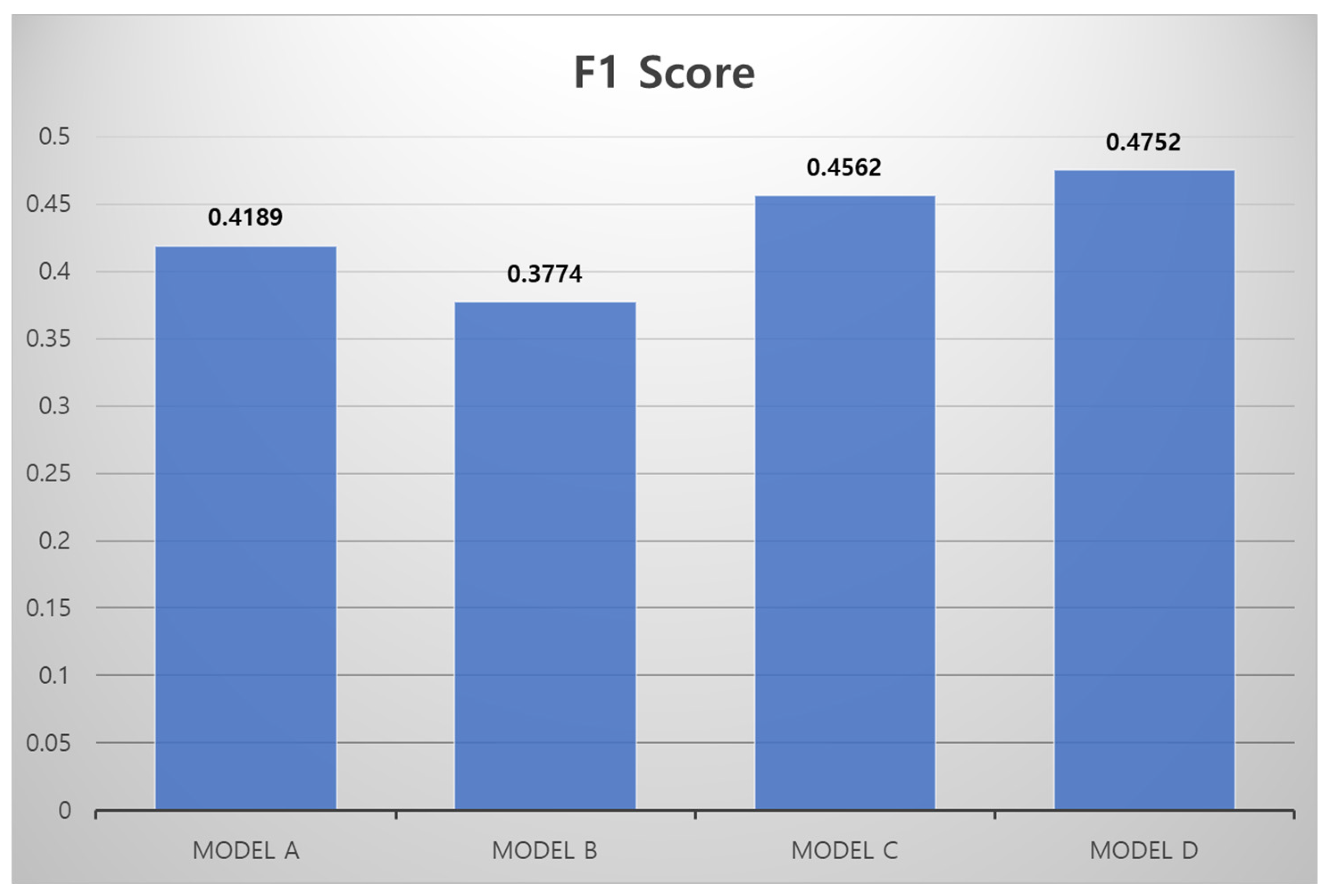
4.1. Simulation of the FEAM
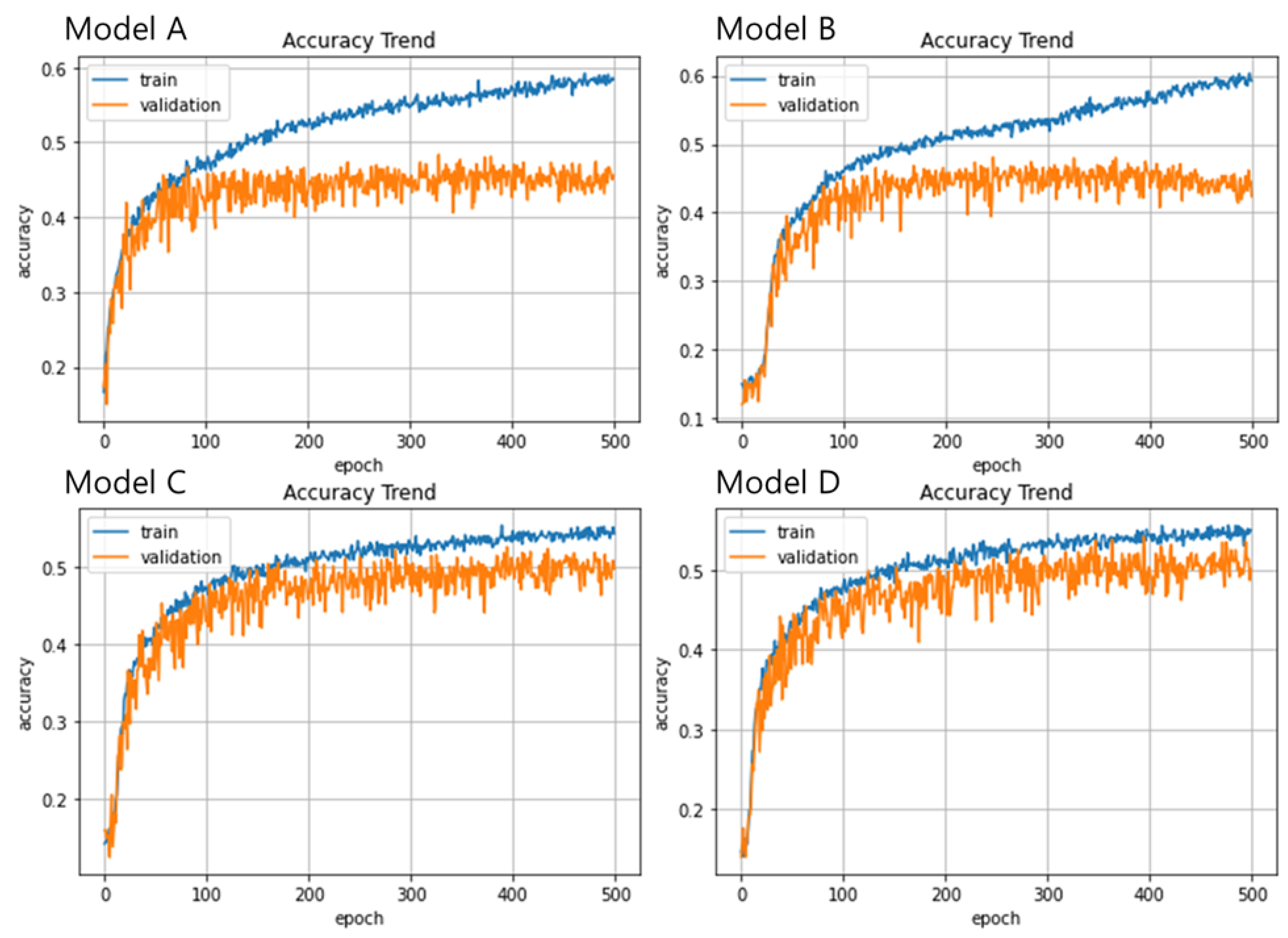
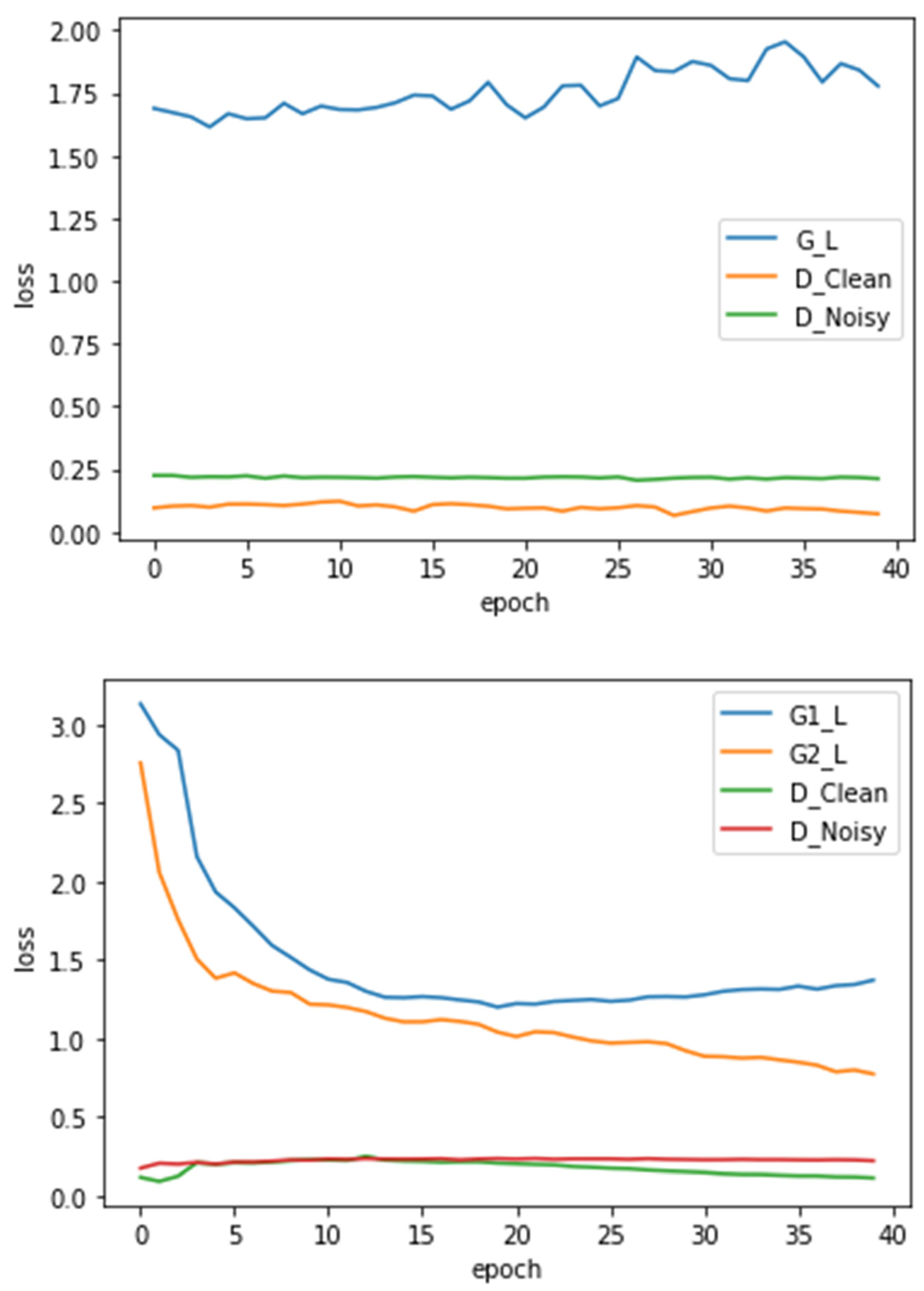
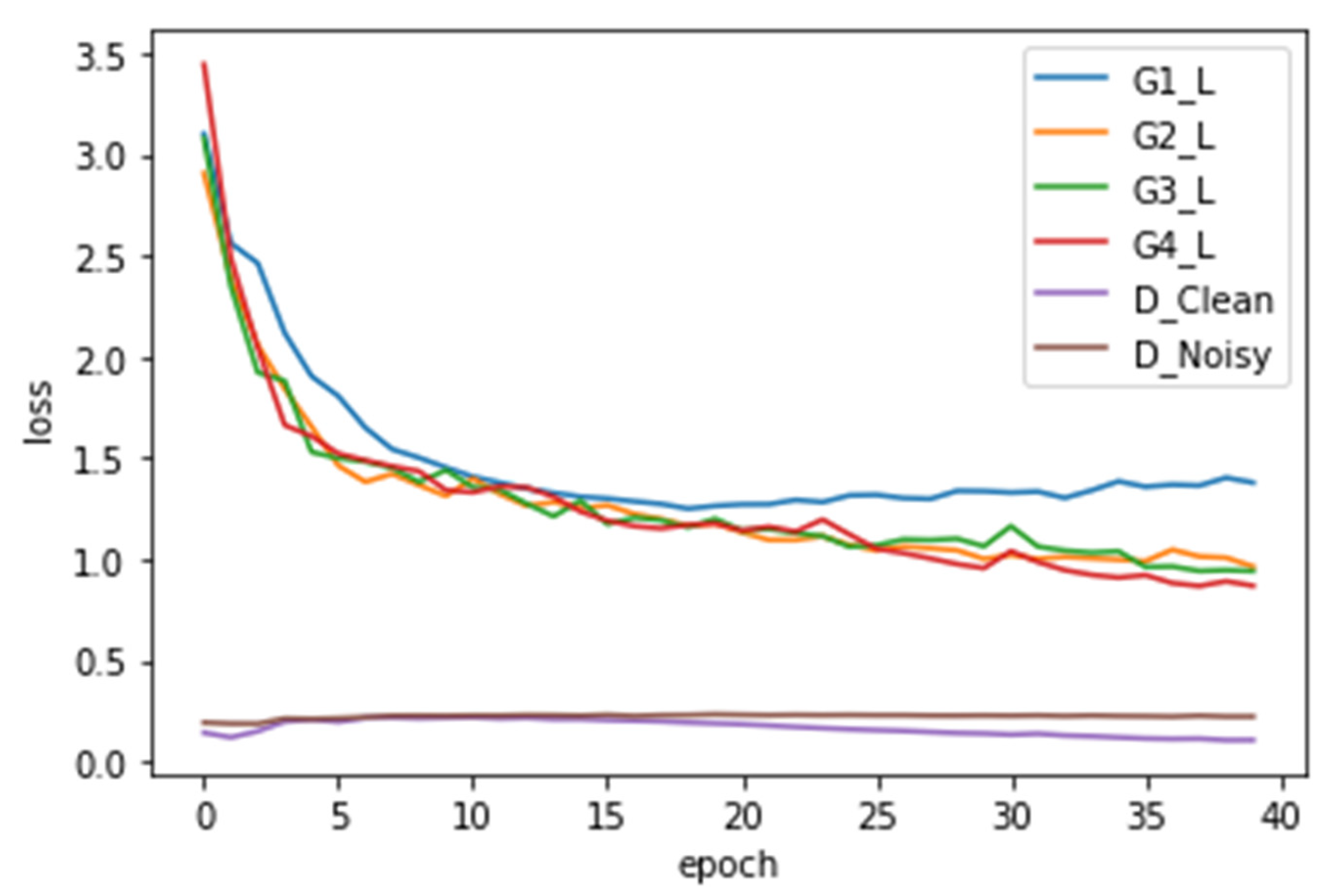
4.2. Simulation of the MERM
- Error Compared to the Original Data: This metric is calculated by inputting 10 samples of data generated by the generator, which incorporates noise into the original data, and predicting the data. The evaluation measures the sum of squared differences between the predicted data and the original data. A lower value indicates that the model outputs data more like the original data.
- Training Time: This metric represents the time required for the model to complete training for 40 epochs. A shorter training time indicates a faster model.
- Discriminator’s Loss Function: This value reflects the discriminator’s ability to detect the generator’s forgery. A lower value indicates that the discriminator effectively identifies forged data. Conversely, a higher value suggests that the generator is more successful at deceiving the discriminator or that the discriminator has been enhanced. The evaluation involves using the generator to predict 50 test samples and calculating the discriminator’s loss function value.
5. Conclusions
- Facial Emotion Analysis Model (FEAM): This model receives facial expressions as input and classifies them into seven emotions using facial landmarks.
- Voice Sentiment Analysis Model (VSAM): This model extracts voices from noisy environments using McycleGAN to accurately identify emotions from the user’s voice.
- Comprehensive Sentiment Analysis Module (CSAM): This module receives the results from FEAM and VSAM and accurately analyzes the current emotions of the user.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Bae, J.H.; Wang, B.H.; Lim, J.S. Study for Classification of Facial Expression using Distance Features of Facial Landmarks. J. IKEEE 2021, 25, 613–618. [Google Scholar]
- An, Y.-E.; Lee, J.-M.; Kim, M.-G.; Pan, S.-B. Classification of Facial Expressions Using Landmark-based Ensemble Network. J. Digit. Contents Soc. 2022, 23, 117–122. [Google Scholar] [CrossRef]
- Gu, J.; Kang, H.C. Facial Landmark Detection by Stacked Hourglass Network with Transposed Convolutional Layer. J. Korea Multimed. Soc. 2021, 24, 1020–1025. [Google Scholar]
- Kim, D.Y.; Chang, J.Y. Integral Regression Network for Facial Landmark Detection. J. Broadcast Eng. 2019, 24, 564–572. [Google Scholar]
- Sohn, M.-K.; Lee, S.-H.; Kim, H. Analysis and implementation of a deep learning system for face and its landmark detection on mobile applications. In Proceedings of the Symposium of the Korean Institute of Communications and Information Sciences, Seoul, Republic of Korea, 16–18 June 2021; pp. 920–921. [Google Scholar]
- Yoon, K.-S.; Lee, S. Music player using emotion classification of facial expressions. In Proceedings of the Korean Society of Computer Information Conference; Korean Society of Computer Information: Seoul, Republic of Korea, 2019; Volume 27, pp. 243–246. [Google Scholar]
- Choi, I.-K.; Song, H.; Lee, S.; Yoo, J. Facial Expression Classification Using Deep Convolutional Neural Network. J. Broadcast Eng. 2017, 22, 162–172. [Google Scholar]
- Choi, W.; Kim, T.; Bae, H.; Kim, J. Comparison of Emotion Prediction Performance of CNN Architectures; Korean Institute of Information Scientists and Engineers: Daejeon, Republic of Korea, 2019; pp. 1029–1031. [Google Scholar]
- Salimov, S.; Yoo, J.H. A Design of Small Scale Deep CNN Model for Facial Expression Recognition using the Low Resolution Image. J. Korea Inst. Electron. Commun. Sci. 2021, 16, 75–80. [Google Scholar]
- Park, J.H. A Noise Filtering Scheme with Machine Learning for Audio Content Recognition. 2019.02. Available online: https://repository.hanyang.ac.kr/handle/20.500.11754/100017 (accessed on 9 January 2024).
- Lee, H.-Y. A Study on a Non-Voice Section Detection Model among Speech Signals using CNN Algorithm. J. Converg. Inf. Technol. 2021, 11, 33–39. [Google Scholar]
- Lim, K.-H. GAN with Dual Discriminator for Non-stationary Noise Cancellation. In Proceedings of the Symposium of the Korean Institute of Information Scientists and Engineers, Republic of Korea, 18 December 2019. [Google Scholar]
- Pascual, S.; Serra, J.; Bonafonte, A. Time-domain Speech Enhancement Using Generative Adversarial Networks. Speech Commun. 2019, 114, 10–21. [Google Scholar] [CrossRef]
- Michelsanti, D.; Tan, Z.H. Conditional generative adversarial networks for speech enhancement and noise-robust speaker verification. arXiv 2017, arXiv:1709.01703. [Google Scholar]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Lai, W.H.; Wang, S.L.; Xu, Z.Y. CycleGAN-Based Singing/Humming to Instrument Conversion Technique. Electronics 2022, 11, 1724. [Google Scholar] [CrossRef]
- Mao, X.; Li, Q.; Xie, H.; Lau, R.Y.; Wang, Z.; Paul Smolley, S. Least squares generative adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv 2015, arXiv:1511.06434. [Google Scholar]
- Yamamoto, S.; Yoshitomi, Y.; Tabuse, M.; Kushida, K.; Asada, T. Recognition of a baby’s emotional cry towards robotics baby caregiver. Int. J. Adv. Robot. Syst. 2013, 10, 86. [Google Scholar] [CrossRef]
- Hwang, I.-K.; Song, H.-B. AI-based Infant State Recognition Using Crying Sound. J. Korean Inst. Inf. Technol. 2019, 17, 13–21. [Google Scholar]
- Composite Images for Korean Emotion Recognition. Available online: https://www.aihub.or.kr/aihubdata/data/view.do?currMenu=115&topMenu=100&aihubDataSe=realm&dataSetSn=82 (accessed on 2 April 2024).
- Conversational Speech Dataset for Sentiment Classification. Available online: https://aihub.or.kr/aihubdata/data/view.do?currMenu=115&topMenu=100&dataSetSn=263 (accessed on 2 April 2024).
- ESC-50: Dataset for Environmental Sound Classification, Noisy Sound Data Set. Available online: https://github.com/karolpiczak/ESC-50 (accessed on 2 April 2024).


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Cycle GAN | MCycle GAN(2) | MCycle GAN(4) | |
|---|---|---|---|
| Error | 17,150 | 14,781 | 15,312 |
| Training time (s) | 2037 | 3838 | 7590 |
| Discriminator loss function | 11.2139 | 0.2813 | 0.2409 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Son, S.; Jeong, Y. Face and Voice Recognition-Based Emotion Analysis System (EAS) to Minimize Heterogeneity in the Metaverse. Appl. Sci. 2025, 15, 845. https://doi.org/10.3390/app15020845
Son S, Jeong Y. Face and Voice Recognition-Based Emotion Analysis System (EAS) to Minimize Heterogeneity in the Metaverse. Applied Sciences. 2025; 15(2):845. https://doi.org/10.3390/app15020845
Chicago/Turabian StyleSon, Surak, and Yina Jeong. 2025. "Face and Voice Recognition-Based Emotion Analysis System (EAS) to Minimize Heterogeneity in the Metaverse" Applied Sciences 15, no. 2: 845. https://doi.org/10.3390/app15020845
APA StyleSon, S., & Jeong, Y. (2025). Face and Voice Recognition-Based Emotion Analysis System (EAS) to Minimize Heterogeneity in the Metaverse. Applied Sciences, 15(2), 845. https://doi.org/10.3390/app15020845