
PGN: Progressively Guided Network with Pixel-Wise Attention for Underwater Image Enhancement



Abstract
1. Introduction
- A Progressively Guided Network (PGN) for underwater image enhancement is proposed, which can progressively deepen the network’s understanding of image structures and details through a multiple-stage supervision strategy.
- A Pixel-Wise Attention Module (PAM) is proposed. The PAM extracts features from clear images and serves as a guide to further enhance feature representation at each stage.
- Experiments on publicly available datasets and real-world underwater images show that our method outperforms state-of-the-art methods in terms of both visual quality and quantitative metrics.
2. Related Works
2.1. Traditional Methods
2.2. Deep Learning-Based Methods
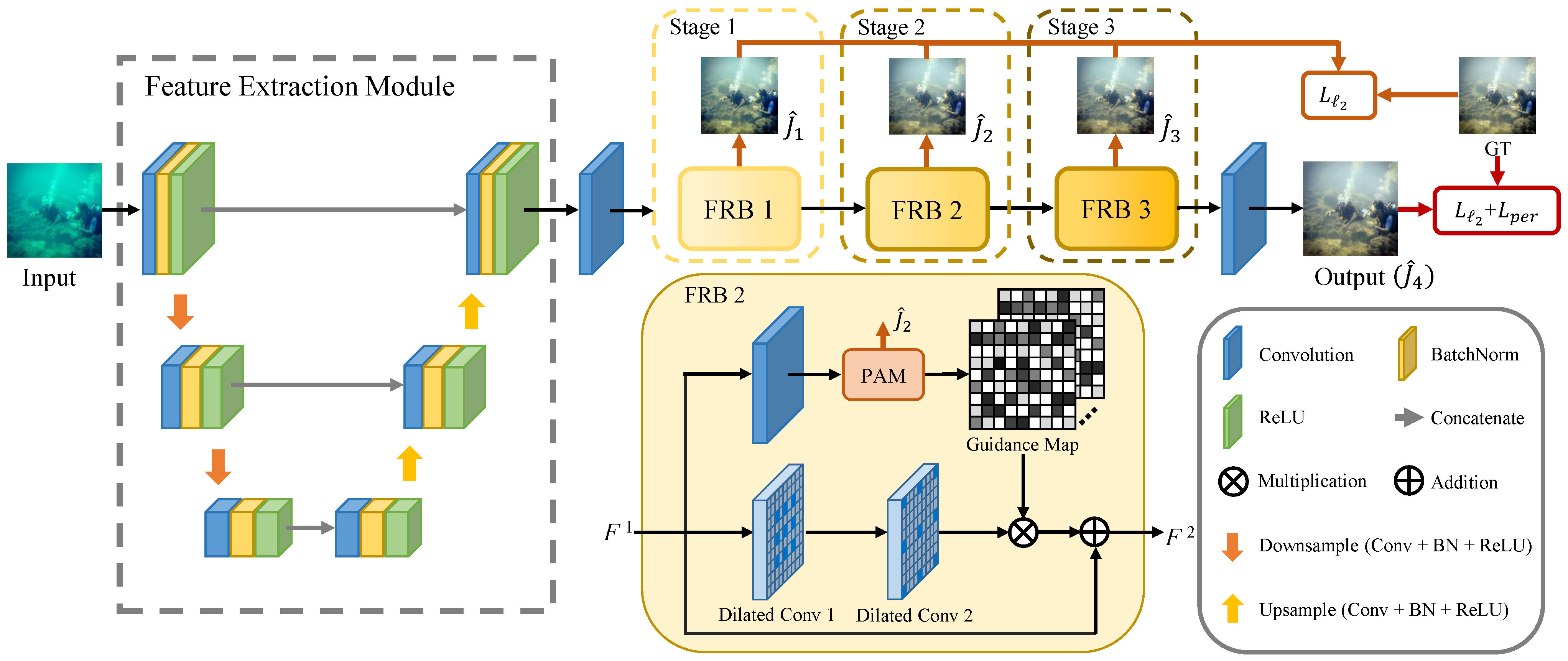
3. The Proposed Method
3.1. Feature Representation Block
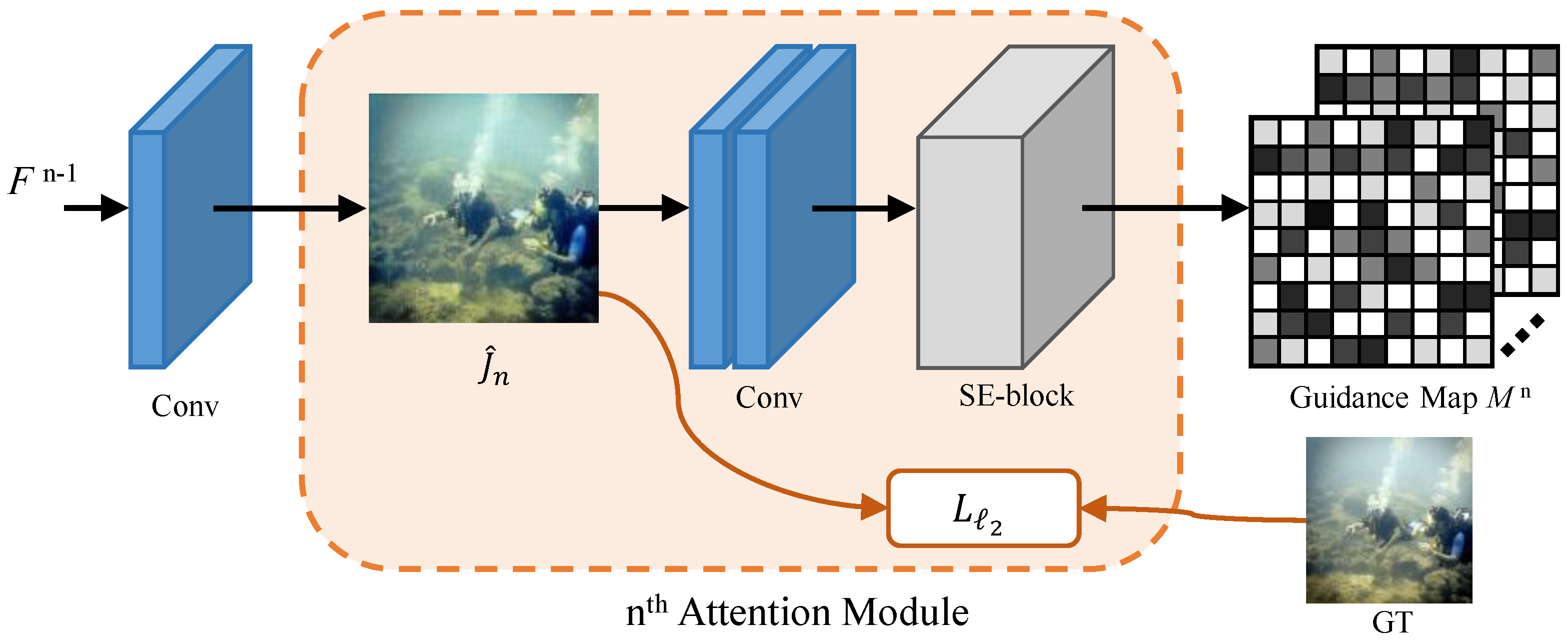
3.2. Pixel-Wise Attention Module
3.3. Training
4. Experiments
4.1. Experiment Settings
4.1.1. Datasets
4.1.2. Training Settings
4.1.3. Evaluation Metrics
4.1.4. Compared Methods
4.2. Quantitative Comparisons
4.3. Visual Comparisons
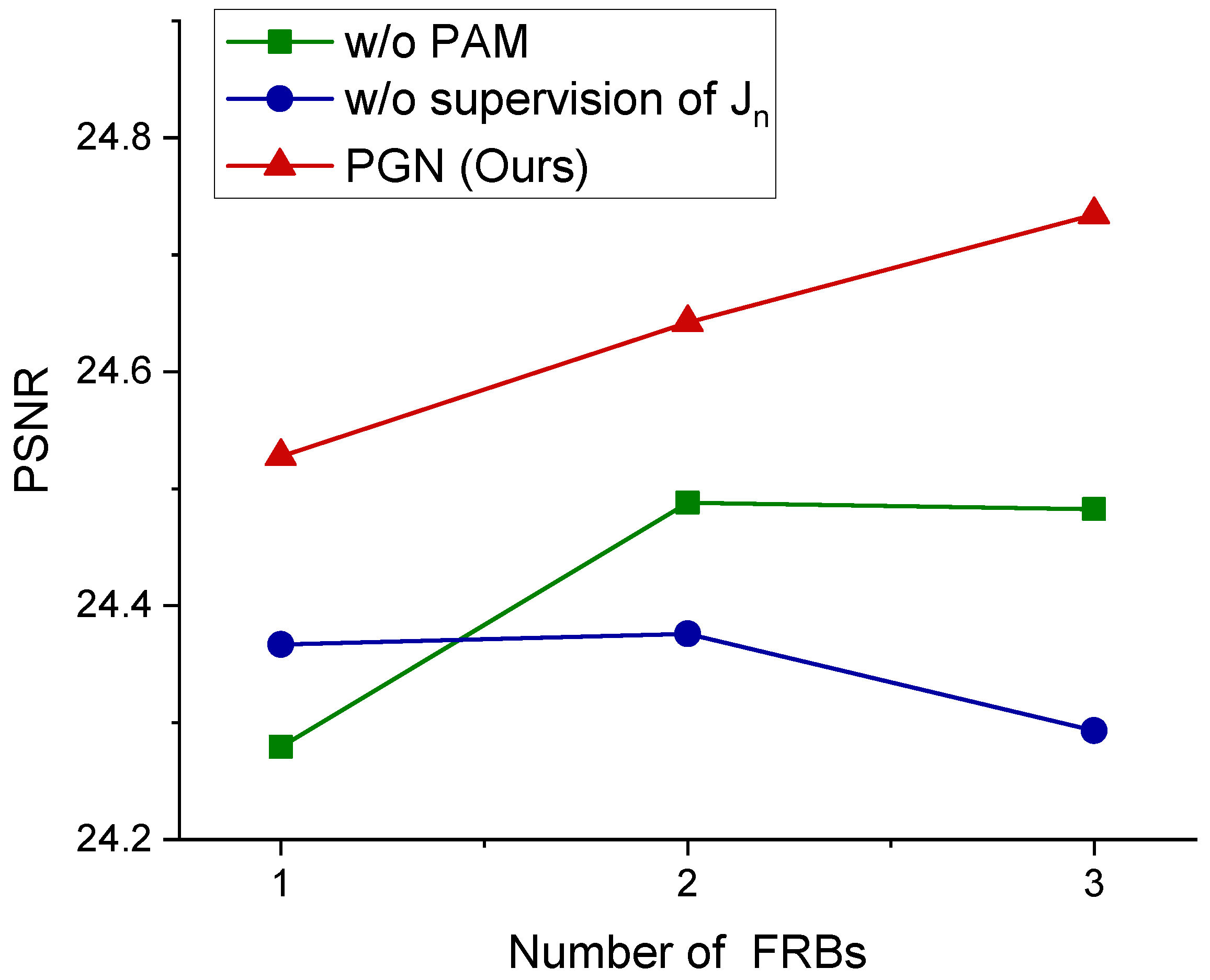
4.4. Ablation Study
4.4.1. Pixel-Wise Attention Module
4.4.2. Feature Representation Block
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ren, W.; Luo, J.; Jiang, W.; Qu, L.; Han, Z.; Tian, J.; Liu, H. Learning Self- and Cross-Triplet Context Clues for Human-Object Interaction Detection. IEEE Trans. Circuits Syst. Video Technol. 2024, 34, 9760–9773. [Google Scholar] [CrossRef]
- Wang, Y.; Ma, X.; Wang, J.; Hou, S.; Dai, J.; Gu, D.; Wang, H. Robust AUV Visual Loop-Closure Detection Based on Variational Autoencoder Network. IEEE Trans. Ind. Inform. 2022, 18, 8829–8838. [Google Scholar] [CrossRef]
- Yuan, X.; Li, W.; Chen, G.; Yin, X.; Li, X.; Liu, J.; Zhao, J.; Zhao, J. Visual and Intelligent Identification Methods for Defects in Underwater Structure Using Alternating Current Field Measurement Technique. IEEE Trans. Ind. Inform. 2022, 18, 3853–3862. [Google Scholar] [CrossRef]
- Wang, Q.; Huang, Z.; Fan, H.; Fu, S.; Tang, Y. Unsupervised person re-identification based on adaptive information supplementation and foreground enhancement. IET Image Process. 2024, 18, 4680–4694. [Google Scholar] [CrossRef]
- Huang, D.; Wang, Y.; Song, W.; Sequeira, J.; Mavromatis, S. Shallow-Water Image Enhancement Using Relative Global Histogram Stretching Based on Adaptive Parameter Acquisition. In Proceedings of the MultiMedia Modeling, Bangkok, Thailand, 5–7 February 2018; pp. 453–465. [Google Scholar]
- Zhang, W.; Zhuang, P.; Sun, H.H.; Li, G.; Kwong, S.; Li, C. Underwater Image Enhancement via Minimal Color Loss and Locally Adaptive Contrast Enhancement. IEEE Trans. Image Process. 2022, 31, 3997–4010. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Guo, J.; Gao, H.; Yue, H. UIEC∧2-Net: CNN-based Underwater Image Enhancement using Two Color Space. Signal Process. Image Commun. 2021, 96, 116250. [Google Scholar] [CrossRef]
- Li, C.; Anwar, S.; Hou, J.; Cong, R.; Guo, C.; Ren, W. Underwater Image Enhancement via Medium Transmission-Guided Multi-Color Space Embedding. IEEE Trans. Image Process. 2021, 30, 4985–5000. [Google Scholar] [CrossRef]
- Lin, Y.; Shen, L.; Wang, Z.; Wang, K.; Zhang, X. Attenuation Coefficient Guided Two-Stage Network for Underwater Image Restoration. IEEE Signal Process. Lett. 2021, 28, 199–203. [Google Scholar] [CrossRef]
- Islam, M.J.; Xia, Y.; Sattar, J. Fast Underwater Image Enhancement for Improved Visual Perception. IEEE Robot. Autom. Lett. 2020, 5, 3227–3234. [Google Scholar] [CrossRef]
- Li, J.; Skinner, K.A.; Eustice, R.M.; Johnson-Roberson, M. WaterGAN: Unsupervised Generative Network to Enable Real-time Color Correction of Monocular Underwater Images. IEEE Robot. Autom. Lett. 2018, 3, 387–394. [Google Scholar] [CrossRef]
- Wang, K.; Hu, Y.; Chen, J.; Wu, X.; Zhao, X.; Li, Y. Underwater Image Restoration based on a Parallel Convolutional Neural Network. Remote Sens. 2019, 11, 1591. [Google Scholar] [CrossRef]
- Chen, R.; Cai, Z.; Yuan, J. UIESC: An Underwater Image Enhancement Framework via Self-Attention and Contrastive Learning. IEEE Trans. Ind. Inform. 2023, 19, 11701–11711. [Google Scholar] [CrossRef]
- Li, C.; Anwar, S.; Porikli, F. Underwater Scene Prior Inspired Deep Underwater Image and Video Enhancement. Pattern Recognit. 2020, 98, 107038. [Google Scholar] [CrossRef]
- Li, C.; Guo, C.; Ren, W.; Cong, R.; Hou, J.; Kwong, S.; Tao, D. An Underwater Image Enhancement Benchmark Dataset and Beyond. IEEE Trans. Image Process. 2020, 29, 4376–4389. [Google Scholar] [CrossRef] [PubMed]
- Fabbri, C.; Islam, M.J.; Sattar, J. Enhancing Underwater Imagery using Generative Adversarial Networks. In Proceedings of the IEEE International Conference on Robotics and Automation, Brisbane, Australia, 21–25 May 2018; pp. 7159–7165. [Google Scholar] [CrossRef]
- Liu, P.; Wang, G.; Qi, H.; Zhang, C.; Zheng, H.; Yu, Z. Underwater Image Enhancement with a Deep Residual Framework. IEEE Access 2019, 7, 94614–94629. [Google Scholar] [CrossRef]
- Ancuti, C.O.; Ancuti, C.; De Vleeschouwer, C.; Bekaert, P. Color Balance and Fusion for Underwater Image Enhancement. IEEE Trans. Image Process. 2018, 27, 379–393. [Google Scholar] [CrossRef] [PubMed]
- Peng, Y.T.; Cosman, P.C. Underwater Image Restoration Based on Image Blurriness and Light Absorption. IEEE Trans. Image Process. 2017, 26, 1579–1594. [Google Scholar] [CrossRef] [PubMed]
- Song, W.; Wang, Y.; Huang, D.; Tjondronegoro, D. A Rapid Scene Depth Estimation Model Based on Underwater Light Attenuation Prior for Underwater Image Restoration. In Proceedings of the Advances in Multimedia Information Processing, Hefei, China, 21–22 September 2018; pp. 678–688. [Google Scholar]
- Akkaynak, D.; Treibitz, T. Sea-Thru: A Method for Removing Water From Underwater Images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 1682–1691. [Google Scholar]
- Liang, Z.; Ding, X.; Wang, Y.; Yan, X.; Fu, X. GUDCP: Generalization of Underwater Dark Channel Prior for Underwater Image Restoration. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 4879–4884. [Google Scholar] [CrossRef]
- McGlamery, B.L. A Computer Model For Underwater Camera Systems. In Proceedings of the Ocean Optics VI, Monterrey, CA, USA, 23 October 1980; Volume 0208, pp. 221–231. [Google Scholar] [CrossRef]
- Jaffe, J. Computer modeling and the design of optimal underwater imaging systems. IEEE J. Ocean. Eng. 1990, 15, 101–111. [Google Scholar] [CrossRef]
- He, K.; Sun, J.; Tang, X. Single Image Haze Removal using Dark Channel Prior. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 2341–2353. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Liu, H.; Chau, L.P. Single Underwater Image Restoration Using Adaptive Attenuation-Curve Prior. IEEE Trans. Circuits Syst. I Regul. Pap. 2018, 65, 992–1002. [Google Scholar] [CrossRef]
- Kim, J.; Lee, J.K.; Lee, K.M. Accurate Image Super-Resolution Using Very Deep Convolutional Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 1646–1654. [Google Scholar] [CrossRef]
- Yang, H.H.; Huang, K.C.; Chen, W.T. LAFFNet: A Lightweight Adaptive Feature Fusion Network for Underwater Image Enhancement. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021; pp. 685–692. [Google Scholar]
- Wu, J.; Liu, X.; Qin, N.; Lu, Q.; Zhu, X. Two-Stage Progressive Underwater Image Enhancement. IEEE Trans. Instrum. Meas. 2024, 73, 1–18. [Google Scholar] [CrossRef]
- Liu, J.; Liu, Z.; Wei, Y.; Ouyang, W. Recovery for underwater image degradation with multi-stage progressive enhancement. Opt. Express 2022, 30, 11704–11725. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar] [CrossRef]
- Li, H.; Li, J.; Wang, W. A Fusion Adversarial Underwater Image Enhancement Network with a Public Test Dataset. arXiv 2019, arXiv:1906.06819. [Google Scholar]
- Liu, R.; Jiang, Z.; Yang, S.; Fan, X. Twin Adversarial Contrastive Learning for Underwater Image Enhancement and Beyond. IEEE Trans. Image Process. 2022, 31, 4922–4936. [Google Scholar] [CrossRef] [PubMed]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| IBLA | RGHS | ULAP | FGAN | Water-Net | Ucolor | MLLE | PGN | ||
|---|---|---|---|---|---|---|---|---|---|
| [19] | [5] | [20] | [10] | [15] | [8] | [6] | |||
| EUVP Dark | PSNR ↑ | 16.66 | 15.91 | 17.37 | 21.17 | 20.80 | 20.56 | 14.28 | 21.77 |
| SSIM ↑ | 0.773 | 0.789 | 0.771 | 0.881 | 0.864 | 0.857 | 0.588 | 0.889 | |
| UISM ↑ | 7.152 | 7.141 | 7.216 | 7.179 | 7.203 | 7.207 | 7.599 | 7.234 | |
| MUSIQ ↑ | 51.72 | 53.05 | 50.81 | 51.76 | 51.23 | 54.60 | 54.15 | 54.83 | |
| COSINE ↑ | 0.786 | 0.801 | 0.784 | 0.901 | 0.897 | 0.883 | 0.654 | 0.927 | |
| EUVP Imagenet | PSNR ↑ | 16.09 | 16.51 | 18.39 | 22.21 | 22.50 | 23.12 | 15.44 | 24.98 |
| SSIM ↑ | 0.634 | 0.714 | 0.707 | 0.767 | 0.817 | 0.783 | 0.584 | 0.839 | |
| UISM ↑ | 6.784 | 6.779 | 6.935 | 6.961 | 6.952 | 6.930 | 7.44 | 7.12 | |
| MUSIQ ↑ | 44.48 | 45.11 | 43.73 | 46.11 | 45.29 | 46.98 | 48.10 | 47.15 | |
| COSINE ↑ | 0.689 | 0.759 | 0.776 | 0.786 | 0.837 | 0.819 | 0.612 | 0.846 | |
| EUVP Scenes | PSNR ↑ | 19.65 | 18.43 | 19.93 | 25.48 | 22.65 | 26.21 | 14.98 | 27.40 |
| SSIM ↑ | 0.723 | 0.751 | 0.747 | 0.830 | 0.820 | 0.865 | 0.631 | 0.890 | |
| UISM ↑ | 6.499 | 6.613 | 6.575 | 7.161 | 7.141 | 7.222 | 7.410 | 7.198 | |
| MUSIQ ↑ | 35.56 | 35.13 | 35.64 | 44.85 | 44.24 | 45.69 | 42.56 | 45.89 | |
| COSINE ↑ | 0.785 | 0.806 | 0.812 | 0.856 | 0.842 | 0.917 | 0.685 | 0.933 | |
| UGAN | PSNR ↑ | 15.80 | 16.30 | 18.02 | 22.40 | 22.12 | 23.58 | 15.90 | 24.98 |
| SSIM ↑ | 0.627 | 0.708 | 0.699 | 0.759 | 0.806 | 0.793 | 0.596 | 0.839 | |
| UISM ↑ | 6.999 | 7.052 | 7.067 | 6.959 | 6.936 | 6.914 | 7.339 | 7.145 | |
| MUSIQ ↑ | 43.34 | 44.32 | 42.65 | 45.14 | 44.61 | 46.17 | 46.96 | 46.26 | |
| COSINE ↑ | 0.685 | 0.721 | 0.714 | 0.788 | 0.826 | 0.813 | 0.641 | 0.857 |
| IBLA | RGHS | ULAP | FGAN | Water-Net | Ucolor | MLLE | TACL | PGN | ||
|---|---|---|---|---|---|---|---|---|---|---|
| [19] | [5] | [20] | [10] | [15] | [8] | [6] | [33] | |||
| UIEB | PSNR ↑ | 15.31 | 19.72 | 16.33 | 19.82 | 23.82 | 22.28 | 18.22 | 23.22 | 24.73 |
| SSIM ↑ | 0.647 | 0.839 | 0.758 | 0.835 | 0.889 | 0.904 | 0.727 | 0.854 | 0.922 | |
| UISM ↑ | 6.565 | 7.048 | 6.943 | 7.133 | 7.181 | 7.191 | 7.468 | 7.203 | 7.215 | |
| MUSIQ ↑ | 45.40 | 46.14 | 45.21 | 42.57 | 44.22 | 46.61 | 52.1 | 45.08 | 47.13 | |
| COSINE ↑ | 0.741 | 0.853 | 0.789 | 0.865 | 0.912 | 0.927 | 0.791 | 0.886 | 0.952 | |
| C60 | UISM ↑ | 2.16 | 2.56 | 6.71 | 7.14 | 2.61 | 2.48 | 3.12 | 2.95 | 7.40 |
| MUSIQ ↑ | 40.31 | 39.65 | 43.18 | 40.37 | 40.23 | 40.07 | 40.34 | 38.63 | 46.61 | |
| U45 | UISM ↑ | 7.04 | 7.36 | 6.98 | 7.14 | 7.19 | 7.24 | 7.47 | 7.24 | 7.54 |
| MUSIQ ↑ | 45.58 | 46.14 | 45.88 | 43.45 | 45.97 | 47.28 | 51.67 | 43.89 | 48.23 |
| Model | PSNR | SSIM | MUSIQ |
|---|---|---|---|
| w/o PAM | 24.4826 | 0.9208 | 47.1192 |
| w/o Supervision of | 24.2930 | 0.9165 | 46.9278 |
| w/o Dilated Convs | 24.3673 | 0.9189 | 46.6050 |
| PGN (Ours) | 24.7345 | 0.9216 | 47.1285 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jia, H.; Wang, Q.; Fu, B.; Zheng, Z.; Tang, Y. PGN: Progressively Guided Network with Pixel-Wise Attention for Underwater Image Enhancement. Appl. Sci. 2025, 15, 641. https://doi.org/10.3390/app15020641
Jia H, Wang Q, Fu B, Zheng Z, Tang Y. PGN: Progressively Guided Network with Pixel-Wise Attention for Underwater Image Enhancement. Applied Sciences. 2025; 15(2):641. https://doi.org/10.3390/app15020641
Chicago/Turabian StyleJia, Huidi, Qiang Wang, Bo Fu, Zhimin Zheng, and Yandong Tang. 2025. "PGN: Progressively Guided Network with Pixel-Wise Attention for Underwater Image Enhancement" Applied Sciences 15, no. 2: 641. https://doi.org/10.3390/app15020641
APA StyleJia, H., Wang, Q., Fu, B., Zheng, Z., & Tang, Y. (2025). PGN: Progressively Guided Network with Pixel-Wise Attention for Underwater Image Enhancement. Applied Sciences, 15(2), 641. https://doi.org/10.3390/app15020641