Abstract
Rail transit dispatch speech plays a critical role in ensuring the safety of urban rail operations. To enable automated and accurate compliance assessment of dispatch speech, this study proposes an improved deep learning model to address the limitations of conventional approaches in terms of accuracy and robustness. Building upon the baseline Whisper model, two key enhancements are introduced: (1) low-rank adaptation (LoRA) fine-tuning to better adapt the model to the specific acoustic and linguistic characteristics of rail transit dispatch speech, and (2) a novel entity-aware attention mechanism that incorporates named entity recognition (NER) embeddings into the decoder. This mechanism enables attention computation between words belonging to the same entity category across different commands and recitations, which helps highlight keywords critical for compliance assessment and achieve precise inter-sentence element alignment. Experimental results on real-world test sets demonstrate that the proposed model improves recognition accuracy by 30.5% compared to the baseline model. In terms of robustness, we evaluate the relative performance retention under severe noise conditions. While Zero-shot, Full Fine-tuning, and LoRA-only models achieve robustness scores of 72.2%, 72.4%, and 72.1%, respectively, and the NER-only variant reaches 88.1%, our proposed approach further improves to 89.6%. These results validate the model’s significant robustness and its potential to provide efficient and reliable technical support for ensuring the normative use of dispatch speech in urban rail transit operations.
1. Introduction
In recent years, China’s rail transit industry has expanded rapidly, with a steady increase in the number of operating trains. In practice, dispatch communications are often affected by channel interference, congestion, and high workload, leading to occasional non-compliance with standardized recitation protocols—including misused instructions, omissions, or errors—which introduce human-induced safety risks [1]. Concurrently, the “transportation powerhouse” initiative under China’s 14th Five-Year Plan emphasizes digital and intelligent transformation in railways. Although technologies such as face recognition have been applied to improve efficiency in stations, the use of intelligent methods to enhance the safety of dispatch communications remains underdeveloped [2].
Advances in deep learning have greatly improved speech recognition and natural language processing (NLP) [3]. The field has shifted from rule-based [4] and statistical methods (e.g., n-grams [5]) to data-driven paradigms. The introduction of the Transformer architecture [6] and the “pre-training–fine-tuning” paradigm enabled models like BERT [7] and GPT [8] to learn general linguistic knowledge from large-scale corpora, achieving strong performance in text and speech tasks. Self-supervised approaches such as wav2vec 2.0 [9] improved robustness in low-resource speech settings, while knowledge-enhanced models like ERNIE [10] integrated external knowledge for better semantic understanding.
Nevertheless, despite the scaling of model parameters, challenges in domain adaptation, fine-grained semantic alignment, and sensitivity to specialized terminology persist—especially in high-stakes domains like rail dispatch. Here, communication requires not only syntactic correctness but also strict conformity to operational entities (e.g., train numbers, locations, commands). Recent studies suggest that combining parameter-efficient tuning and knowledge-aware architectural adjustments may improve robustness in domain-specific speech recognition [11,12,13]. Techniques such as structured attention [11], entity perception modules [12], and rule-guided pre-training [13] underscore the value of explicit entity-level modeling for safety-critical applications.
Building on this perspective, this paper proposes an integrated framework that combines LoRA-based parameter-efficient adaptation with explicit entity-type embeddings incorporated into the Transformer decoder architecture. This methodological combination enables the model to capture domain-critical entity information more effectively while maintaining computational efficiency during fine-tuning. We demonstrate the effectiveness of this approach in the context of rail transit scheduling, where accuracy and robustness are essential for compliance verification of dispatch speech. More importantly, the contribution of this study lies not only in advancing rail communication safety but also in establishing a broadly applicable strategy for enhancing specialized speech recognition tasks across other high-stakes domains such as aviation, medical reporting, and emergency services.
2. Data Preparation and Processing
The voice data of rail transit dispatching is characterized by high professionalism, strong standardization and low fault tolerance, and for its processing process the dual characteristics of voice signals and text semantics need to be considered. In this section, the core steps and technical challenges of data preparation are systematically elaborated from multimodal data acquisition and domain terminology annotation to enhancement strategy design based on real dispatching voice call recordings.
Anonymized call recordings are obtained from urban rail transit dispatch centers, covering scenarios such as daily dispatching, emergencies, equipment failures, etc., with a total duration of about 25 h and a sampling rate of 16 kHz.
In this study, four core categories of named entities are identified and defined for the rail transportation scheduling domain, as summarized in Table 1.

Table 1.
Classification of structured entities.
Speech annotation: labeling acoustic boundaries of key terms in speech for training entity-aware speech recognition models (Table 2).
Table 2.
Example of labeling.
Text labeling: entity labeling of transcribed text using BIOES format and cross-modal offsets are labeled with the speech layer (Table 2).
The core function of the BIOES annotation scheme is to provide named entity recognition models with more precise and richer entity boundary information compared to the traditional BIO scheme. By explicitly encoding the entity’s beginning (B-), end (E-), single-word (S-), and inside (I-) positions, it significantly enhances the model’s ability to identify entity boundaries and has been shown to improve performance on various datasets. Its core value lies in “decoupling” the features of single-word entities from the starting words of multi-word entities, which allows the model to learn and distinguish between these two cases in a more granular way.
Enhancement and generation of data based on real data is based on the thesaurus randomly replacing non-key fields such as train number and station name to generate new samples with unchanged semantics but diverse entity combinations (Figure 1). Background noise such as train whistle and radio interference is added to simulate speech degradation scenarios in real dispatching environments (Figure 2), resulting in a total duration of 75 h after data augmentation.

Figure 1.
Term replacement pseudo-code.

Figure 2.
Acoustic enhancement pseudo-code.
Dataset Partitioning Strategy
To ensure rigorous and reproducible model evaluation, this study employs a strict data partitioning strategy. Based on a speech dataset totaling 75 h after data augmentation, we randomly partitioned it into training, validation, and test sets at a 7:2:1 ratio. The training set is used for model parameter learning; the validation set is used for hyperparameter tuning and early stopping to prevent overfitting; the test set is used for the final evaluation of the model’s generalization performance. During partitioning, we ensured that data from the same call record or the same dispatcher appeared in only one set to avoid data leakage and guarantee the reliability of the evaluation results. This partitioning strategy enables a comprehensive and objective assessment of the model’s speech recognition and compliance judgment capabilities on unseen data.
3. Whisper Model Improvement
To meet the high-precision requirements of speech compliance assessment for rail transit dispatching, this section addresses the key deficiencies of general speech recognition models in professional scenarios by introducing domain-adaptive architectural improvements and multi-task learning strategies based on OpenAI’s Whisper model. It also elaborates on the model optimization methods and technical implementation details.
The core innovation of this study lies in proposing a collaborative learning framework that integrates parameter-efficient fine-tuning with a knowledge-enhanced architecture. By deeply combining an explicit entity-type embedding mechanism with a LoRA-adapted Transformer decoder, we have developed a speech recognition solution with industry-adaptive capabilities. Practical applications in railway communication scenarios demonstrate that: (1) This architectural combination significantly improves entity-level recognition accuracy for speech containing professional terminology, achieving notable gains over baseline models; (2) Parameter-efficient fine-tuning effectively injects domain knowledge while maintaining model lightweighting and enhancing robustness; (3) The proposed technical approach exhibits strong generalizability and can be extended to other speech recognition tasks involving specialized terminology, dialects, or domain-specific rules. This methodological innovation not only validates the effectiveness of collaborative architectures in vertical domain speech tasks but also provides novel solutions for domain adaptation in resource-constrained scenarios.
Detailed implementations of the Whisper model architecture, LoRA fine-tuning mechanism, and named entity recognition embedding techniques will be elaborated in the respective subsequent chapters. For a quick reference to the key mathematical symbols and abbreviations used throughout this paper, please refer to the Nomenclature table provided in Appendix A (Table A2).
3.1. Whisper Model Architecture and Features
Whisper is an end-to-end speech recognition model proposed by OpenAI that supports multilingual automatic speech recognition (ASR), speech translation, and language identification tasks [14]. The core of its design lies in a unified multi-task framework and the use of large-scale pre-training data, which enables it to perform well in diverse speech-to-text scenarios. As summarized in Appendix A (Table A1), Whisper significantly outperforms or is comparable to current mainstream models such as wav2vec and XLS-R [15] on a variety of publicly available corpora, including LibriSpeech [16], Common Voice [17], CHiME-6 [18], TED-LIUM 3 [19], and the multilingual MLS [20]. Its strong performance across these general-purpose benchmarks provides a reliable foundation for its fine-tuning in domain-specific tasks, such as the railway communication scenario explored in this study. Although it only temporarily lags behind VoxPopuli [21], Whisper maintains a leading position in long-form audio transcription tasks with consistently low word error rates, as illustrated in Table 3, fully demonstrating its combined modeling advantages in handling noise interference, multi-speaker variability, and long temporal context dependencies.
Table 3.
Comparison of long audio transcription tasks (WER).
Beyond Whisper, wav2vec, and XLS-R, a number of domain-adapted ASR frameworks have been proposed in recent years. Traditional toolkits such as Kaldi and ESPnet provide flexible recipes for domain adaptation through feature-space maximum likelihood linear regression (fMLLR), speaker adaptation, and transfer learning pipelines. While these methods remain effective in controlled benchmarks, they typically require substantial expert knowledge for feature engineering and extensive computational resources for full re-training, which limits their scalability in dynamic domain-specific settings such as railway dispatch communications. Similarly, DeepSpeech and its successors focus on end-to-end optimization but have demonstrated limited robustness when confronted with noisy, code-switching, or terminology-rich speech. More recently, SpeechBrain and other modular frameworks have explored multi-task adaptation strategies, but they often treat domain adaptation as a generic fine-tuning problem without explicitly leveraging domain semantics.
In contrast, large pre-trained models such as ERNIE-SAT or HuBERT highlight the importance of integrating semantic information into acoustic modeling, yet their adaptation remains primarily data-driven and tends to underperform when labeled in-domain data is scarce. Compared with these approaches, our method introduces LoRA-based lightweight parameter tuning combined with NER-driven semantic injection, which not only reduces adaptation cost but also explicitly incorporates domain-specific entities (e.g., train IDs, dispatch commands) into the recognition process. This dual-level adaptation ensures that the system not only maintains Whisper’s general robustness to noise and long-form audio but also achieves higher precision in domain-specific terminology recognition, addressing a key shortcoming of prior domain-adapted ASR systems.
Whisper is a Transformer-based encoder–decoder model (Figure 3) designed for multilingual speech processing. Audio inputs are resampled to 16 kHz, and 80-channel log-Mel spectrograms are extracted using 25 ms frames with a 10 ms step. These features are globally normalized to the range [−1, 1].
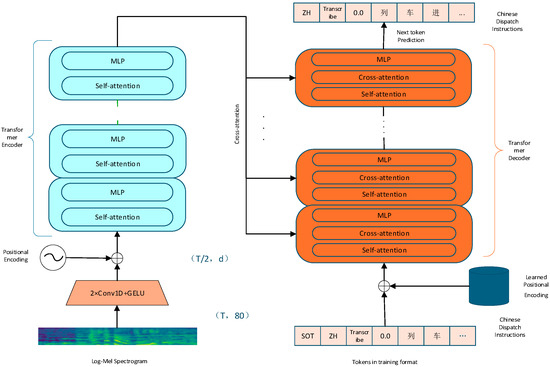
Figure 3.
Whisper model architecture diagram.
The encoder begins with two convolutional layers: the first uses a kernel of size 3 and stride 1, while the second uses stride 2 for frame reduction, both followed by GELU activation. Sinusoidal positional embeddings are added to the resulting representation before it enters the Transformer encoder. The encoder consists of a stack of identical layers, each comprising a self-attention mechanism and a feed-forward network with pre-activation layer normalization.
The decoder autoregressively generates token sequences. Token embeddings are combined with decoder-side positional encodings and processed through multiple decoder layers. Each layer includes self-attention over previous tokens, cross-attention over the encoder outputs, and a feed-forward sub-layer, all with pre-normalization. The final output is projected to the vocabulary space via a linear layer followed by softmax.
Trained on 680 k hours of multilingual data, Whisper generalizes well to open-domain speech tasks—including transcription, translation, and language identification—and exhibits strong robustness to noise and long audio. Nevertheless, its zero-shot performance remains limited in highly specialized domains, such as rail communication, where accurate recognition of structured entity sequences and compliance with operational jargon are critical. For full architectural details, readers are referred to the original Whisper paper [14].
3.2. Efficient Fine-Tuning Based on LoRA
In general-purpose language processing tasks, the Whisper speech-recognition model has matured to deliver high accuracy. However, as illustrated in Figure 4, which schematically shows the model’s limitations, in specialized domains such as railway dispatch communications—where train-borne interlock control systems are used—it still shows limitations in recognizing domain-specific pronunciations of digits and letters. In the railway-dispatch context, standardized conventions govern how certain digits are spoken [22]: for example, “0,” “1,” “2,” and “7” are pronounced as “dòng,” “yāo,” “liǎng,” and “guǎi,”, respectively; however, when the first or the first two digits of a train number are “0,” they should uniformly be spoken as “líng.” Likewise, letters in passenger-train service identifiers—namely “G,” “C,” “D,” “Z,” “T,” “K,” “L,” “Y,” and “F”—are conventionally pronounced “gāo,” “chéng,” “dòng,” “zhí,” “tè,” “kuài,” “lín,” “yóu,” and “fǎn.” Without domain adaptation, the Whisper model frequently fails to recognize and output these industry-standard pronunciations correctly. Therefore, it is necessary to fine-tune and optimize the model specifically for the phonetic rules of railway dispatch communication.
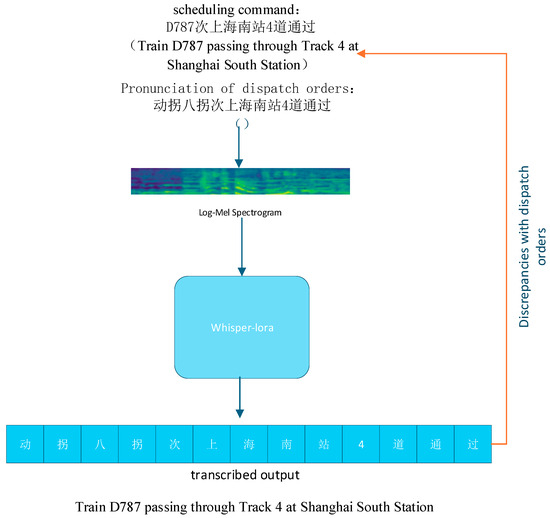
Figure 4.
Schematic of Whisper limitations.
LoRA (Low-Rank Adaptation) is a parameter-efficient fine-tuning method [23] that enables domain adaptation using a small number of trainable parameters. It works by freezing the original weights of the pre-trained model and incorporating an adapter module based on low-rank decomposition alongside the existing weight matrices. The core formulation is as follows:
where . d is the rank and and are low-rank matrices. The overall architecture and placement of the LoRA adapter relative to the original weight matrix are illustrated in Figure 5.
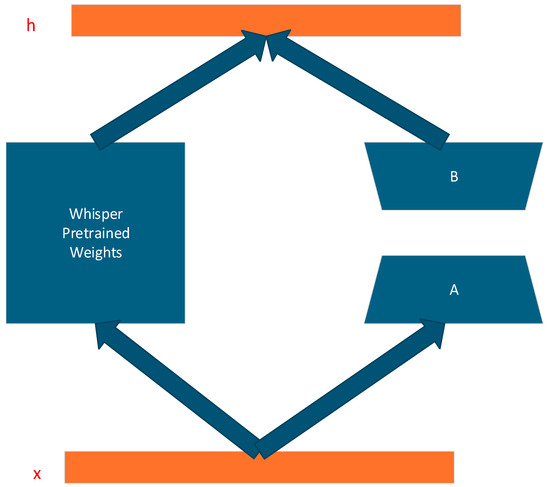
Figure 5.
Schematic diagram of LoRA.
In this study, we use the Low-Rank Adaptation (LoRA) method to fine-tune the Whisper model to improve its performance in the railroad dispatch speech recognition task. The hyperparameters used in our LoRA implementation were carefully selected to balance adaptation capacity and parameter efficiency: a rank (r) of 16, an alpha (α) value of 32, and application to the query and value projection matrices (q_proj, v_proj) within the self-attention modules of the Whisper model. Additionally, a dropout rate of 0.1 and a learning rate of 0.001 were used during training.
Compared with the traditional full-parameter fine-tuning method, LoRA significantly reduces the number of parameters and computational resources required for training, and at the same time reduces the risk of overfitting, which is especially suitable for scenarios with limited resources or requiring multi-task scaling. In this study, LoRA is applied to fine-tune the Whisper model to effectively capture not only the proprietary phonetic features and pronunciation specifications in the railroad dispatch context (e.g., the digits “0,” “1,” “2,” and “7” are pronounced as “dòng,” “yāo,” “liǎng,” and “guǎi,” and the letters “G,” “C,” “D,” “Z,” “T,” “K,” “L,” “Y,” and “F”—are conventionally pronounced “gāo,” “chéng,” “dòng,” “zhí,” “tè,” “kuài,” “lín,” “yóu,” and “fǎn.”), also retains the original model’s strong ability in general-purpose speech recognition tasks, reflecting the model’s balance between generality and specialization. The effect of this fine-tuning is illustrated in Figure 6, showing that the model achieves higher accuracy on domain-specific speech while preserving general recognition performance.
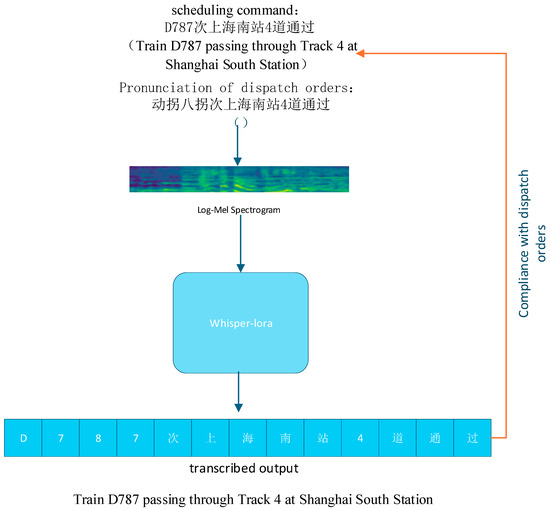
Figure 6.
The effect after fine-tuning.
3.3. Named Entity Information Embedding
Traditional speech recognition models (e.g., Whisper) rely heavily on global acoustic-text alignment and lack fine-grained modeling of domain-critical entities [24] (e.g., train numbers and operating instructions in rail scheduling). This limitation results in a significantly higher error rate when recognizing specialized terminology compared with general-purpose vocabulary.
To address this, we introduce a Named Entity Recognition (NER) embedding module into the Whisper decoder. This module provides explicit, token-level semantic guidance by integrating domain-specific entity information. The overall architecture of the improved model is illustrated in Figure 7.
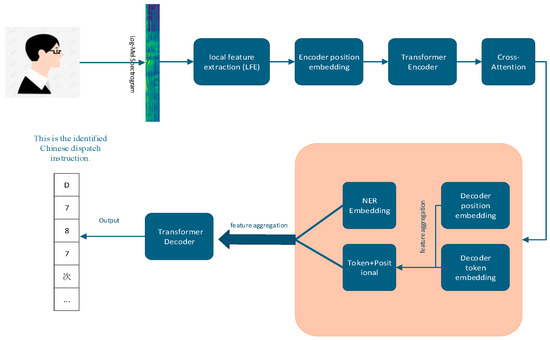
Figure 7.
Improved model architecture.
The named entity label for each token is obtained using a Lexicon-Based Convolutional Neural Network (LR-CNN) [25]. This model architecture was selected for its proven effectiveness in incorporating external lexical knowledge into the neural encoding process, a critical advantage for processing domain-specific texts like rail communication transcripts. The LR-CNN model integrates pre-defined domain lexicons into a convolutional neural network, allowing it to better capture entity boundaries and mitigate segmentation errors that are common in Chinese NER. The specific model used was first pre-trained on a large-scale general Chinese corpus to learn robust linguistic representations and was subsequently fine-tuned on our annotated rail communication transcripts to adapt to the specialized domain vocabulary. This combined approach leverages broad linguistic knowledge and domain-specific lexicon to accurately identify entity boundaries and assign word-level NER tags following the BIO scheme. Since Whisper employs subword tokenization, each word-level entity label is subsequently propagated to all its constituent subword tokens. Tokens not belonging to any entity are assigned the “O” (Outside) label.
Each NER label is mapped to a trainable embedding vector . The embedding layer consists of four vectors, each corresponding to one of the predefined entity types (e.g., train number, location, instruction, time). These vectors are initialized randomly from a uniform distribution, consistent with the initialization range of the pre-trained Whisper embeddings, to ensure stable training.
The dimension d of is set to be identical to that of the token embedding and the positional embedding (i.e., d = 512 for Whisper-medium). This dimensional homogeneity allows for direct, element-wise summation, forming the enhanced decoder input embedding:
This operation seamlessly integrates token-level semantic, positional, and entity-aware information into a unified representation.
After obtaining the named entity labels, the rail transit dispatch speech is divided into four distinct sub-parts according to the entity type, as illustrated in Figure 8. These structured segments are then fed into the model as additional information, allowing it to focus on and verify one type of named entity at a time, thereby obtaining more precise named entity interaction features. This process explicitly informs the model which core elements to prioritize during recognition.
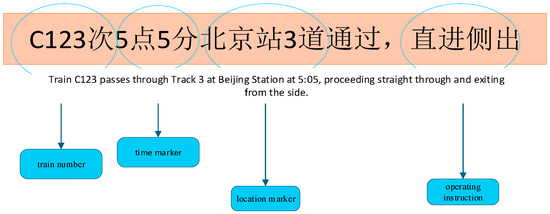
Figure 8.
NER division of scheduling instructions.
The labeling scheme for named entity recognition used in this study is summarized in Table 4, which provides an example of the token-to-entity alignment. The compact numeric representation (e.g., [11111222233333004444]) is used for illustrative readability only; the model utilizes the high-dimensional, trainable embedding vectors described above.
Table 4.
NER Embedding Labeling.
By integrating NER embeddings and structured entity processing, the model gains the ability to prioritize and verify critical domain-specific entities explicitly, leading to significantly improved accuracy and robustness in structured speech recognition tasks.
4. Experiments and Analysis of Results
4.1. Experimental Setup
To verify the effectiveness of the improved Whisper model based on NER Embedding and LoRA fine-tuning proposed in this paper in the task of checking the speech normality of rail transit dispatching, we conducted experiments on a real collected dispatching speech dataset. The dataset contains daily dispatching, emergency and equipment failure scenarios with a total duration of about 15 h. The data preprocessing procedure includes acoustic feature extraction (Log-Mel spectrum), speech transcription, data generation and enhancement, and named entity labeling based on BIOES format. The experiments were conducted on an Ubuntu 18.04 system using the Pytorch framework and accelerated with the help of RTX4090 GPU.
4.2. Comparison of Models and Evaluation Metrics
In this study, we conduct a comprehensive comparison of the following model configurations to ensure a rigorous and interpretable experimental evaluation:
Baseline A (Zero-Shot): The off-the-shelf Whisper-medium model from Hugging Face, applied directly to the rail transit dispatch speech test set without any fine-tuning. This serves as a reference for the model’s zero-shot generalization capability.
Baseline B (Full Fine-Tuning): The Whisper-medium model fine-tuned in a conventional manner, i.e., with full parameter updates on the domain-specific rail transit dispatch dataset, without incorporating any additional structural modifications or entity processing modules. This represents the standard supervised fine-tuning baseline.
Ablation 1 (LoRA Only): The Whisper-medium model fine-tuned using Low-Rank Adaptation (LoRA), a parameter-efficient tuning method, without integrating the NER embedding module. This setup isolates the contribution of efficient domain adaptation via LoRA.
Ablation 2 (NER Only): The Whisper-medium model enhanced with the proposed NER embedding layer, which incorporates named entity information into the decoder input, but trained using conventional full-parameter fine-tuning. This allows us to evaluate the isolated effect of the structural modification for entity awareness.
Proposed Model: The complete proposed framework, comprising Whisper-medium augmented with both the NER embedding module and fine-tuned using the LoRA technique, integrating entity guidance and parameter-efficient domain adaptation.
Evaluation metrics include:
Recognition Accuracy: Both the overall transcription correctness and the accuracy of recognizing key named entities (e.g., train numbers, operation commands, spatio-temporal identifiers).
Robustness Metrics: Stability and consistency of model outputs under noisy and degraded speech conditions.
Response Time: The average inference time per audio sample under identical hardware configurations.
This structured experimental setup enables a clear and quantifiable assessment of the individual and synergistic contributions of both LoRA-based fine-tuning and the NER embedding enhancement.
4.3. Overall Recognition Accuracy Improvement
Figure 9 presents a comprehensive comparison of Character Error Rate (CER) performance across five modeling approaches under no-noise conditions. The results demonstrate that the proposed model (LoRA + NER) achieves the lowest CER of 9.3%, significantly outperforming all other methods and approaching the 10% CER threshold commonly considered indicative of high-quality speech recognition systems.
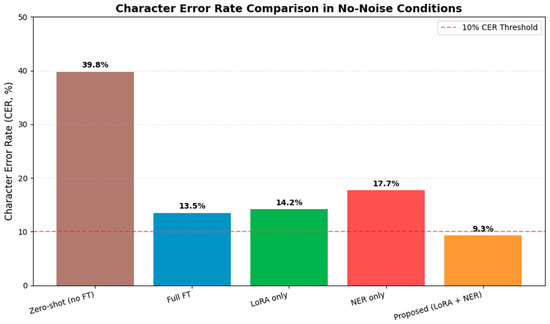
Figure 9.
Character Error Rate Comparison in No-Noise Conditions.
The proposed approach reduces CER by 30.5 percentage points compared to the zero-shot baseline (39.8% CER) and by 4.2–8.4 points compared to the individual component methods. Both Full FT (13.5% CER) and LoRA-only (14.2% CER) configurations show comparable performance, suggesting that parameter-efficient fine-tuning provides similar accuracy gains to full parameter optimization in ideal acoustic conditions. The NER-only approach achieves a moderate CER of 17.7%, indicating that while structural enhancements contribute to error reduction, they are most effective when combined with parameter optimization techniques.
These findings complement the robustness analysis by establishing that the proposed method not only maintains stability under noisy conditions but also achieves superior accuracy in clean environments. The 9.3% CER represents a significant advancement toward production-ready performance for safety-critical applications where minimal error rates are essential. The synergistic combination of NER embeddings and LoRA fine-tuning proves effective in addressing both accuracy and robustness requirements, providing a comprehensive solution for real-world deployment scenarios where environmental conditions may vary substantially.
4.4. Named Entity Recognition Effective
Figure 10 presents a comprehensive comparison of entity recognition accuracy across five distinct modeling approaches for rail transit dispatch speech. The results demonstrate that the proposed model, which synergistically combines NER embeddings with LoRA fine-tuning, achieves superior performance across all entity categories (train number, operation instruction, time marker, and location marker) compared to both baseline and ablation models.
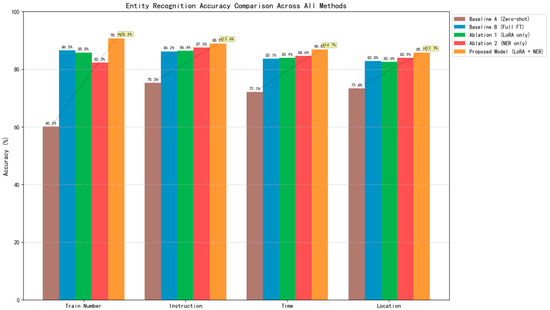
Figure 10.
Entity Recognition Accuracy Comparison Across All Methods.
The proposed model attains the highest accuracy in all categories, notably achieving 90.7% for train numbers, which represents a significant improvement of approximately 30 percentage points over the zero-shot baseline. It also achieves the best scores for operation instructions (88.9%), time markers (86.8%), and location markers (85.7%). While the NER-only ablation configuration shows competitive performance in instruction recognition (87.5%), it is still outperformed by the complete proposed framework.
The performance progression from baseline models through ablation studies to the final proposed architecture clearly illustrates the complementary benefits of integrating parameter-efficient fine-tuning (LoRA) with semantic-aware structural enhancements (NER embeddings). This combination effectively addresses the dual challenges of domain adaptation and precise entity boundary detection in safety-critical rail communication environments.
4.5. Analysis of Changes in Attention Mechanisms
Visualization of the attention distributions in the Transformer decoder (Figure 11 and Figure 12) demonstrates the impact of introducing NER embeddings. Compared with the LoRA-only model (Figure 12), the LoRA + NER model (Figure 11) assigns higher attention weights to critical named entities such as train numbers, station names, and track identifiers. This indicates that the additional NER embeddings enable the model to capture task-relevant semantic units more effectively, thereby enhancing the focus of the attention mechanism. The comparison between Figure 11 and Figure 12 provides visual evidence that the LoRA + NER method strengthens entity-level alignment in the attention process. By concentrating attention on semantically salient entities, the influence of irrelevant context is mitigated, leading to reduced recognition errors. This refined attention distribution improves entity discrimination and enhances robustness and generalization across diverse utterances, ultimately resulting in superior recognition performance.
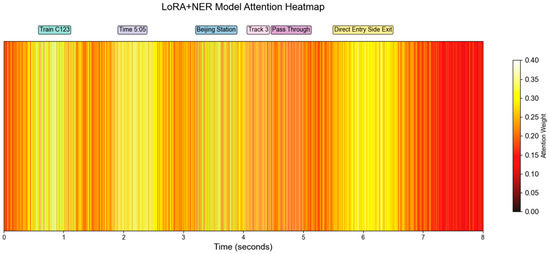
Figure 11.
LoRA + NER Model Attention Heatmap.
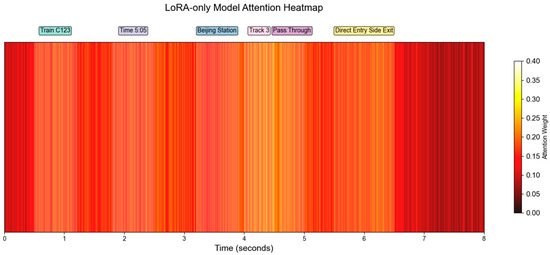
Figure 12.
LoRA-only Model Attention Heatmap.
4.6. Robustness Experiments
Figure 13 presents a comprehensive comparison of model robustness under various noise degradation conditions, evaluating five distinct approaches: zero-shot baseline, full fine-tuning, LoRA-only fine-tuning, NER-enhanced only, and the proposed combined method (LoRA + NER). The results demonstrate that the proposed model maintains superior normative consistency across all noise levels, achieving 90.7% under clean conditions and retaining 81.3% even under strong noise—the highest among all compared methods.
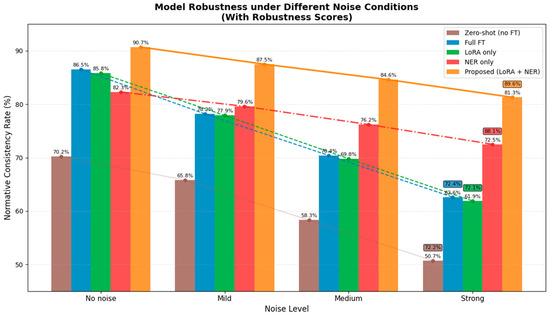
Figure 13.
Model Robustness under Different Noise Conditions.
The proposed approach shows remarkable robustness, with only 9.4 percentage points performance degradation from no-noise to strong-noise conditions, significantly outperforming traditional full fine-tuning (23.9 points degradation) and LoRA-only methods (23.9 points degradation). Notably, while the NER-enhanced model demonstrates the best noise resilience with only 9.8 points of degradation, it suffers from lower baseline performance in clean environments (82.3%).
The integration of NER embeddings with LoRA-based fine-tuning proves particularly effective, combining the strengths of both techniques: the NER component provides structural robustness against acoustic degradation while LoRA fine-tuning enhances overall accuracy. This synergistic combination achieves an average performance improvement of +18.1 percentage points across all noise levels compared to the zero-shot baseline, with particularly impressive gains of +20.6 points under strong noise conditions. These results validate the proposed method’s capability to maintain reliable performance in variable real-world environments where background noise and channel interference are prevalent.
4.7. Response Time
Figure 14 presents the inference latency measurements across the five modeling approaches, revealing a remarkably efficient performance profile for the proposed method. The zero-shot baseline establishes the reference at 1.81 s, with both Full FT (1.83 s, +1.1%) and LoRA-only (1.82 s, +0.6%) approaches demonstrating minimal overhead—confirming the parameter-efficient nature of these fine-tuning techniques. The NER-only approach shows a moderate increase to 1.95 s (+7.7%), reflecting the additional computational requirements of entity recognition components. Most significantly, the proposed combined method (LoRA + NER) achieves an inference time of 1.97 s, representing only a 0.16 s (+8.8%) increase over the baseline despite incorporating both enhancement strategies.
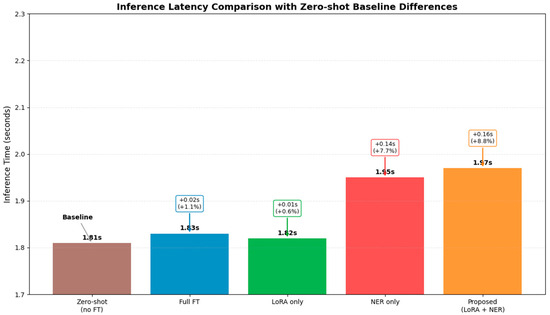
Figure 14.
Inference Latency Comparison with Zero-shot Baseline Differences.
5. Analysis and Discussion
5.1. Conclusion Analysis
This experiment shows that:
Domain Knowledge Explicit Advantage: By incorporating named entity information into the decoder input in the form of NER Embedding, it enables the model to explicitly focus on key information during the generation process. Formula:
The fusion of three kinds of embedded information is intuitively demonstrated to effectively improve the recognition performance of domain terms.
Attention distribution and recitation checking: The results of the attention weight visualization show that the improved model has a more concentrated weight distribution at the location of key named entities, which verifies that after the fusion of multimodal information, the model is better able to identify and recite key entities in the interactive feature extraction phase, and improves the accuracy of the compliance assessment.
Robustness Improvement: Experimental results under the condition of adding background noise and actual degradation show that the improved model is more tolerant to noise interference and exhibits better generalization ability and robustness, which is of great significance for the task of checking the speech normality of real rail transit dispatching.
High efficiency of LoRA fine-tuning: With LoRA technology, only low-rank adapters are introduced while freezing the main parameters, which significantly reduces the cost of fine-tuning, and effectively captures the domain-specific speech features while maintaining the speech recognition capability of the original model, realizing the effect that is difficult to achieve with full-parameter fine-tuning.
In summary, the improvement strategy proposed in this paper achieves significant results in the task of checking speech normality in rail transit dispatching. Through experimental validation, the improved model outperforms the baseline model in terms of overall recognition accuracy, key named entity recognition, attention mechanism focusing, and noise robustness. Beyond this specific domain, the findings highlight a more generalizable methodological contribution: architecturally integrating explicit entity-type embeddings into a LoRA-tuned Transformer decoder is an effective and efficient strategy for enhancing specialized speech recognition systems. This conclusion suggests that making domain knowledge explicit and adopting parameter-efficient fine-tuning strategies can serve as a widely applicable paradigm for improving the performance of speech recognition in other high-stakes fields such as aviation, medical reporting, and emergency communication.
5.2. Qualitative Error Analysis
While quantitative metrics demonstrate significant improvement, a qualitative analysis of the proposed model’s errors provides crucial insights into its remaining limitations and guides future refinement. Our manual inspection of erroneous transcripts revealed several persistent challenges, among which the influence of regional Chinese dialects stands out as a particularly significant hurdle.
The most pronounced source of errors stems from the variation in regional accents and dialects across the vast Chinese rail network. While the model is trained primarily on standard Mandarin, dispatchers and crew often speak with strong local accents or mix dialectal terms into their communications. For instance, a pronunciation of “杭州” (Hángzhōu) with a southern Wu-influenced accent might be misrecognized as a different entity entirely. Similarly, the frequent confusion between certain station names (e.g., “虹桥hongqiao” vs. “红桥hongqiao”) is severely exacerbated by specific dialectal phonetics, where the initial consonants h- and f- are often merged or altered. This indicates that our current data augmentation strategy, which focuses on ambient noise and entity substitution, fails to capture the profound phonological shifts introduced by dialects.
Beyond dialects, other challenges persist. The model can struggle with overlapping and interrupted speech, common in busy dispatch environments, sometimes omitting truncated segments or generating incomplete entities. Furthermore, while entity replacement augmentation broadens coverage, handling truly novel or out-of-vocabulary (OOV) entity combinations not seen during training remains a challenge, revealing limitations in compositional generalization.
This error profile underscores that our model, though robust to many acoustic degradations, is highly sensitive to linguistic variation. The primary failure modes are not purely acoustic but often stem from a complex interplay between challenging audio conditions and the rich phonological diversity of spoken Chinese. This critically directs future work towards explicitly incorporating dialectal variability into the training process, perhaps through multi-accent training data or targeted adversarial training techniques, to build truly nationwide robust speech recognition systems.
5.3. Theoretical Implications
Our work extends beyond an engineering solution and offers meaningful theoretical implications for integrating symbolic knowledge into sub-symbolic neural architectures.
Traditionally, a tension exists between end-to-end, data-driven deep learning systems and knowledge-driven, rule-based systems. The former excel at pattern recognition but often lack explicit reasoning and struggle with data scarcity, while the latter are interpretable and data-efficient but brittle. Our approach, which injects discrete, symbolic NER-type embeddings into the Transformer’s continuous representation space, represents a hybrid paradigm that seeks to leverage the strengths of both.
The effectiveness of this strategy, as visualized by the more focused attention mechanism in Figure 11, can be theorized as follows: The NER embeddings act as semantic anchors that bias the model’s internal computations. By pre-allocating dedicated capacity in the embedding space to specific entity types, the model does not need to rediscover these semantic concepts purely from audio-text pairs. This provides a strong prior that guides the acoustic-to-text translation process, reducing the entropy of the target output space. The LoRA modules then efficiently adapt the pre-trained acoustic and linguistic knowledge of Whisper to the domain, while the NER embeddings ensure this adaptation is structurally aligned with the domain’s key semantic units.
This synergy demonstrates that explicit symbolic guidance can complement and enhance data-driven learning, especially in low-resource, high-stakes domains. It provides a practical blueprint for “informed learning,” where domain knowledge is not just used for post-processing but is intrinsically baked into the model’s architecture, leading to more robust, interpretable, and data-efficient learning dynamics. This bridges a critical gap, showing that we can move beyond purely statistical learning towards models that incorporate human-understandable knowledge structures.
5.4. Practical Implications and Future Work
Despite the promising results achieved by the proposed model, this study is subject to several limitations that warrant further discussion. Primarily, the model is trained and evaluated on a dataset comprising approximately 75 h of audio after augmentation, which originates from a specific set of dispatch centers. While the use of a powerful pre-trained model (Whisper) and parameter-efficient fine-tuning (LoRA) mitigates the risk of overfitting to some extent, the relatively limited scale and scope of the dataset inevitably raise concerns regarding potential dataset bias and the model’s generalizability.
The data augmentation techniques employed, such as entity replacement and background noise addition, though effective, cannot fully capture the extensive diversity of real-world operational environments. Consequently, the model’s performance may vary when deployed across different rail lines characterized by distinct regional accents, communication protocols, acoustic backgrounds, or radio equipment characteristics. The strong performance demonstrated herein, therefore, should be interpreted within the context of the data it was trained on, and its generalizability to the entire national rail network remains an open question that necessitates further validation.
To address these limitations in future work, we intend to collaborate with railway operators to compile a larger and more geographically diverse dataset encompassing speech from multiple dispatch centers across China’s vast rail network. This will enable a more rigorous assessment of the model’s robustness and generalizability. Furthermore, we plan to explore domain generalization techniques and investigate the feasibility of few-shot or continual learning paradigms to allow the model to adapt efficiently to new operational environments with minimal additional data.
Beyond the limitations of the current dataset, our research opens several pathways for practical deployment and future investigation. The integration of NER embeddings with LoRA fine-tuning presents a promising solution for domain-specific ASR, yet its real-world application necessitates addressing critical engineering challenges.
Practical Implications for Deployment:
The primary practical consideration for deploying our system in a real-time dispatch environment is computational efficiency and latency. Although the proposed method introduces only a modest increase in inference time (as detailed in Section 4.7), achieving sub-second latency on resource-constrained edge devices (e.g., onboard computers or portable terminals) remains a significant hurdle. Future engineering efforts must focus on further model optimization, potentially through quantization, pruning, or knowledge distillation, to meet the stringent requirements of real-time communication without compromising accuracy.
Furthermore, the system must be adaptable to dynamic operational contexts. Rail transportation procedures evolve, and emergency situations arise that are not present in the training data. A purely static model would quickly become obsolete. Therefore, a practical deployment framework must incorporate mechanisms for continuous learning or rapid fine-tuning with minimal new data, allowing the model to adapt to new terminology, procedures, and unforeseen scenarios without catastrophic forgetting of previously acquired knowledge.
Future Research Directions:
To translate this research from a laboratory prototype to a field-ready system, we outline the following future work:
Real-time Optimization and Edge Deployment: We will investigate the deployment of our model on edge computing platforms prevalent in rail infrastructure. This involves benchmarking performance against latency thresholds and developing optimized versions suitable for hardware with limited computational resources.
Robustness in Dynamic and Emergent Scenarios: We plan to develop and test continual learning protocols for our architecture. This will enable the model to incrementally learn from new commands and emergency protocols post-deployment, ensuring long-term viability and adaptability to changing operational needs.
Generalization Across Domains: While our current focus is rail transportation, the methodological synergy of parameter-efficient tuning and knowledge infusion is broadly applicable. We will explore the transferability of this approach to other safety-critical, jargon-heavy domains such as air traffic control, maritime communication, and industrial maintenance, where similar challenges of accuracy and robustness exist.
Human-AI Collaboration Framework: Finally, we recognize that full automation may not be feasible or desirable in all scenarios. Future work will explore interactive systems where the model acts as a high-accuracy assistant to human dispatchers, providing real-time transcriptions and entity validation while flagging low-confidence predictions for human review. This human-in-the-loop approach could significantly enhance reliability and safety during the transition to more automated systems.
By addressing these practical challenges and research directions, we aim to bridge the gap between the strong experimental results demonstrated in this study and the demanding requirements of real-world, mission-critical speech recognition systems.
Author Contributions
Conceptualization, Q.Z. and J.Z.; methodology, J.Z.; software, L.C.; validation, Q.Z. and L.C.; formal analysis, J.Z.; investigation, Q.Z.; resources, J.Z.; data curation, Q.Z.; writing—original draft preparation, Q.Z.; writing—review and editing, J.Z. All authors have read and agreed to the published version of the manuscript.
Funding
The financial support from Shanghai Municipal Education Commission of Artificial Intelligence Empowering Paradigm Shift in Scientific Research to Drive Disciplinary Advancement (AIZX-3) and Shanghai “Belt and Road” China-Laos Railway Engineering International Joint Laboratory (21210750300) are sincerely acknowledged.
Data Availability Statement
All the data in this article can be obtained by contacting the corresponding author.
Conflicts of Interest
The authors declare no conflicts of interest.
Appendix A
Table A1.
Comparison of Whisper with other models (Word Error Rate, WER).
Table A1.
Comparison of Whisper with other models (Word Error Rate, WER).
| Datasets | wav2vec | XLS-R | Whisper | Relative Improvements |
|---|---|---|---|---|
| LibriSpeech | 2.7% | - | 2.5% | 7.4% |
| Common Voice | 29.9% | - | 9.0% | 69.9% |
| CHiME-6 | 65.8% | - | 25.5% | 61.2% |
| TED-LIUM 3 | 10.5% | - | 4.0% | 61.9% |
| MLS | - | 10.9% | 7.3% | 33.0% |
| VoxPopuli | - | 10.6% | 13.6% | −28.3% |
Table A2.
Nomenclature.
Table A2.
Nomenclature.
| Symbol | Description |
|---|---|
| Weighting matrix after adaptation | |
| Original weight matrix of the pre-trained model | |
| Weight Incremental Updates | |
| Low-rank decomposed matrix | |
| The rank of LoRA | |
| α | LoRA scaling parameter (alpha) |
| Dimension of the Original Weight Matrix | |
| Token input at time step | |
| The named entity label corresponding to time step | |
| Time step | |
| Named Entity Embedding. An embedding vector generated based on the named entity label at time step | |
| Word embedding. The embedding vector of the word corresponding to time step | |
| Position embedding. The position encoding vector at time step | |
| Enhanced decoder input embeddings. Obtained by element-wise summation of word embeddings, position embeddings, and named entity embeddings. | |
| Weighting matrix after adaptation |
References
- Dai, C.; Liu, J.; Li, X.; Zhang, Y. Human factor analysis methods for accidents in railway locomotive system. Railw. Transp. Econ. 2025, 47, 1–10. [Google Scholar]
- Zhang, L.; Yang, X.; Fu, Y.; Sun, X.; Gan, M. Research status and prospects of intelligent logistics technology in railway freight systems. Railw. Transp. Econ. 2025, 47, 11–19. [Google Scholar] [CrossRef]
- Dong, S.; Wang, P.; Abbas, K. A survey on deep learning and its applications. Comput. Sci. Rev. 2021, 40, 100379. [Google Scholar] [CrossRef]
- Cambria, E.; White, B. Jumping NLP curves: A review of natural language processing research. IEEE Comput. Intell. Mag. 2014, 9, 48–57. [Google Scholar] [CrossRef]
- Kang, R.; Zhang, H.; Hao, W.; Cheng, K.; Zhang, G. Learning Chinese word embeddings with words and subcharacter n-grams. IEEE Access 2019, 7, 42987–42992. [Google Scholar] [CrossRef]
- Xian, Y.; Akata, Z.; Sharma, G.; Schiele, B.; Vedaldi, A. Multimodal learning with transformers: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 12113–12132. [Google Scholar] [CrossRef]
- Acheampong, F.A.; Nunoo-Mensah, H.; Chen, W.Y. Transformer models for text-based emotion detection: A review of BERT-based approaches. Artif. Intell. Rev. 2021, 54, 5789–5829. [Google Scholar] [CrossRef]
- Yenduri, G.; Ramalingam, M.; Selvi, G.C.; Supriya, Y.; Srivastava, G.; Maddikunta, P.K.R.; Deepti, R.G.; Jhaveri, R.H.; Prabadevi, B.; Wang, W.; et al. GPT (Generative Pre-Trained Transformer)—A comprehensive review on enabling technologies, potential applications, emerging challenges, and future directions. IEEE Access 2024, 12, 54608–54649. [Google Scholar] [CrossRef]
- Baevski, A.; Zhou, H.; Mohamed, A.; Auli, M. wav2vec 2.0: A framework for self-supervised learning of speech representations. Adv. Neural Inf. Process. Syst. 2020, 33, 12449–12460. Available online: https://arxiv.org/abs/2006.11477 (accessed on 2 January 2025).
- Zhang, Z.; Han, X.; Liu, Z.; Jiang, X.; Sun, M.; Liu, Q. ERNIE: Enhanced Language Representation with Informative Entities. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics (ACL), Florence, Italy, 28 July–2 August 2019; pp. 1441–1451. Available online: https://aclanthology.org/P19-1139/ (accessed on 5 January 2025).
- Lu, Y.; Zhang, J.; Zeng, J.; Li, J.; Liu, Y.; Zong, C. Attention analysis and calibration for transformer in natural language generation. IEEE/ACM Trans. Audio Speech Lang. Process. 2022, 30, 1927–1938. [Google Scholar] [CrossRef]
- Zhang, Y.; Li, J.; Xin, Y.; Zhao, X.; Liu, Y. A model for Chinese named entity recognition based on global pointer and adversarial learning. Chin. J. Electron. 2023, 32, 854–867. [Google Scholar] [CrossRef]
- Wang, H.; Li, J.; Wu, H.; Hovy, E. Pre-trained language models and their applications. Engineering 2022, 25, 51–65. [Google Scholar] [CrossRef]
- Radford, A.; Kim, J.W.; Xu, T.; Brockman, G.; McLeavey, C.; Sutskever, I. Robust Speech Recognition via Large-Scale Weak Supervision. In Proceedings of the 40th International Conference on Machine Learning (ICML), Honolulu, HI, USA, 23–29 July 2023; pp. 28492–28518. Available online: https://proceedings.mlr.press/v202/radford23a.html (accessed on 1 September 2025).
- Babu, A.; Wang, C.; Tjandra, A.; Lakhotia, K.; Xu, Q.; Goyal, N.; Singh, K.; Platen, P.; Saraf, Y.; Pino, J.; et al. XLS-R: Self-Supervised Cross-Lingual Speech Representation Learning at Scale. In Proceedings of the Interspeech 2022, Incheon, Republic of Korea, 18–22 September 2022; pp. 3465–3469. Available online: https://arxiv.org/abs/2111.09296 (accessed on 5 January 2025).
- Debnath, D.; Becerra-Martinez, H.; Hines, A. Well Said: An Analysis of the Speech Characteristics in the LibriSpeech Corpus. In Proceedings of the 34th Irish Signals and Systems Conference (ISSC), Letterkenny, Ireland, 15–16 June 2023; pp. 1–6. [Google Scholar] [CrossRef]
- Ardila, R.; Branson, M.; Davis, K.; Kohler, M.; Meyer, J.; Henretty, M.; Morais, R.; Saunders, L.; Tyers, F.; Weber, G. Common Voice: A Massively-Multilingual Speech Corpus. In Proceedings of the 12th Language Resources and Evaluation Conference (LREC), Marseille, France, 11–16 May 2020; pp. 4218–4222. Available online: https://aclanthology.org/2020.lrec-1.520/ (accessed on 21 January 2025).
- Watanabe, S.; Mandel, M.; Barker, J.; Vincent, E.; Arora, A.; Chang, X.; Khudanpur, S.; Manohar, V.; Povey, D.; Raj, D.; et al. CHiME-6 Challenge: Tackling Multispeaker Speech Recognition for Unsegmented Recordings; CHiME-6 Workshop: Inria, France, 2020; pp. 1–7. Available online: https://arxiv.org/abs/2004.09249 (accessed on 21 January 2025).
- Hernandez, F.; Nguyen, V.; Ghannay, S.; Tomashenko, N.; Estève, Y. TED-LIUM 3: Twice as much data and corpus repartition for experiments on speaker adaptation. In Speech and Computer (SPECOM 2018); Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2018; Volume 11096, pp. 198–208. [Google Scholar] [CrossRef]
- Pratap, V.; Xu, Q.; Sriram, A.; Synnaeve, G.; Collobert, R. MLS: A Large-Scale Multilingual Dataset for Speech Research. In Proceedings of the Interspeech 2020, Shanghai, China, 25–29 October 2020; pp. 2826–2830. [Google Scholar] [CrossRef]
- Wang, C.; Riviere, M.; Lee, A.; Wu, A.; Talnikar, C.; Haziza, D.; Williamson, M.; Pino, J.; Dupoux, E. VoxPopuli: A Large-Scale Multilingual Speech Corpus for Representation Learning, Semi-Supervised Learning and Interpretation. In Proceedings of the Interspeech 2021, Brno, Czech Republic, 30 August–3 September 2021; pp. 3530–3534. [Google Scholar]
- TB/T 30003-2020; Railway Vehicle-Machine Joint Control Operation. National Railway Administration of China: Beijing, China, 2020.
- Zhang, L.; Wei, W.; Shi, Q.; Shen, C.; Van Den Hengel, A.; Zhang, Y. Accurate tensor completion via adaptive low-rank representation. IEEE Trans. Neural Netw. Learn. Syst. 2020, 31, 4170–4184. [Google Scholar] [CrossRef] [PubMed]
- Guo, Y.; Wen, X.; Jiao, Y.; Zhao, Y. A research on named entity recognition integrating multiple features and semi-supervised learning. Mod. Electron. Technol. 2024, 47, 1–9. Available online: http://kns.cnki.net/kcms/detail/61.1224.TN.20241015.1602.002.html (accessed on 2 May 2025).
- Gui, T.; Ma, R.; Zhang, Q.; Zhao, L.; Jiang, Y.G.; Huang, X. CNN-Based Chinese NER with Lexicon Rethinking. Proc. IJCAI 2019, 2019, 4982–4988. Available online: https://www.ijcai.org/proceedings/2019/0692.pdf (accessed on 10 May 2025).
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).