Abstract
Precise oriented object detection of corn provides critical support for automated agricultural tasks such as harvesting, spraying, and precision management. In this work, we address this challenge by leveraging oriented object detection in combination with depth information to estimate corn poses. To enhance detection accuracy while maintaining computational efficiency, we construct a precise annotated oriented corn detection dataset and propose YOLOv11OC, an improved detector. YOLOv11OC integrates three key components: Angle-aware Attention Module for angle encoding and orientation perception, Cross-Layer Fusion Network for multi-scale feature fusion, and GSConv Inception Network for efficient multi-scale representation. Together, these modules enable accurate oriented detection while reducing model complexity. Experimental results show that YOLOv11OC achieves 97.6% mAP@0.75, exceeding YOLOv11 by 3.2%, and improves mAP50:95 by 5.0%. Furthermore, when combined with depth maps, the system achieves 92.5% pose estimation accuracy, demonstrating its potential to advance intelligent and automated cultivation and spraying.
1. Introduction
With the rapid advancement of smart agriculture [1], achieving real-time and accurate detection and pose estimation of corn—one of the world’s most important staple crops [2]—has become a critical task. Such capabilities are essential for supporting downstream applications, including growth status monitoring [3] and intelligent harvesting [4]. In particular, when combined with depth maps, oriented object detection provides an effective means to accomplish reliable pose estimation. Traditional corn detection approaches typically rely on horizontal bounding box (HBB) annotations. However, due to the naturally inclined posture of corn, objects often appear tilted in images. Consequently, HBB-based methods fail to tightly enclose the object regions, frequently introducing redundant background information that adversely affects subsequent tasks such as tracking, segmentation, and localization. To overcome this limitation, oriented object detection has been introduced, where object boundaries are represented more accurately by annotating the four vertices of an oriented bounding box (OBB) [5]. A comparison between HBB and OBB is illustrated in Figure 1. If this detection is based on RGB data, only oriented detection of corn can be achieved. However, by combining depth data and the precise bounding box of corn, the pose of corn can be estimated. A comparison with pose estimation using stereo images is under discussion.

Figure 1.
The comparison between OBB and HBB.
Research on oriented object detection [6] and pose estimation [7] in agriculture has received increasing attention, but existing works remain limited in several aspects: many rely on outdated detection frameworks, lack integration of 3D information, and seldom conduct research on corn specifically. For instance, Song [8] employed R-CNN for detecting oriented corn tassels, while Zhou [9] proposed a YOLOv8-OBB model to detect Zizania. Liu [10] applied YOLOv3 to identify broken corn kernels during mechanical harvesting. In other fields, Wang [11] utilized a diffusion model for oriented object detection in aerial images, while Su [12] proposed MOCA-Net to detect oriented objects in remote sensing images.
Regarding pose estimation, existing methods often suffer from large and complex network architectures. For example, Mola [13] proposed an apple detection and 3D modeling method using an RGB-D camera, where RGB and depth information were fused to generate point clouds for dimension estimation. Du [14] developed a technique for tomato 3D pose estimation in clustered scenes by identifying key points and processing point clouds to extract centroid and calyx positions. More recently, Gao [15] introduced a stereo-based 3D object detection method for estimating the pose of corn, where joint bounding boxes were predicted and fed into a deep learning model to infer 3D bounding boxes and poses. Existing approaches often rely on complex data modalities, such as point clouds or stereo imagery, which necessitate the use of more sophisticated neural architectures. In contrast, the present work is grounded solely in an object detection framework. In other fields, oriented detection based on unmanned aerial vehicle data [16] is a hot direction. Zhang [17] utilized point cloud to estimate the pose of industrial parts, Ausserlechner [18] proposed ZS6D to utilize vision transformers for zero-shot 6D object Pose.
For more precise pose estimation, this study introduces a corn pose estimation framework with two major contributions. First, during the annotation stage, orientation labels are designed to capture the natural growth poses of corn, thereby constructing a precisely oriented corn detection dataset that incorporates depth information for pose estimation. Second, at the algorithmic level, this work introduces a lightweight yet precise oriented detection model, YOLOv11 Oriented Corn (YOLOv11OC), specifically tailored for corn.
Recent advances in deep learning-based detection frameworks [19], including Faster R-CNN [20], the YOLO series [21], and Vision Transformers [22], have shown remarkable success in general object detection tasks. Among them, the YOLO series has become widely adopted due to its generality and ease of deployment. In this work, the latest YOLOv11 is adopted as the baseline for oriented corn detection. To further improve detection precision, we integrate three modules: the Angle-aware Attention Module (AAM) for angle feature encoding and fusion, the GSConV Inception Network (GSIN) for efficient multi-scale feature extraction with reduced model complexity, and the Cross-Layer Fusion Network (CLFN) to enhance multi-scale object detection through cross-layer feature fusion.
This study presents a corn pose estimation approach based on RGB-D data and OBB detection, specifically designed to overcome the limitations of accuracy in existing corn OBB detection methods. The main contributions of this paper are summarized as follows:
- (1)
- This work constructs a precise OBB detection dataset for corn. Unlike conventional HBB annotations, the proposed OBB labels are precise and effectively reduce redundant background regions. Furthermore, by combining OBB annotations with depth maps, the pose of corn can be accurately estimated.
- (2)
- This work proposes a lightweight oriented detection framework YOLOv11OC based on YOLOv11. To achieve both efficiency and accuracy, the framework integrates the GSConV Inception Network to reduce parameter complexity and the Cross-Layer Fusion Network to strengthen multi-scale feature fusion capability.
- (3)
- This work designs the Angle-aware Attention Module, which encodes orientation information as an attention mechanism, thereby enhancing the model’s ability to perceive and regress object angles more accurately.
2. Materials and Methods
This section provides the collection, annotation, and augmentation process of oriented corn and describes the pose estimation method and the proposed YOLOv11OC method, overall network architecture, and the design of the AAM Module, GSIN module, and the CLFN module.
2.1. Oriented Corn Detection Dataset
2.1.1. Data Collection and Annotation
This work constructs an oriented corn detection dataset. Data collection was conducted in the experimental fields of Yangzhou University, Jiangsu Province (32.3972° N, 119.4125° E; 12 MASL), from June to August 2025. The corn used for data collection was at a near-mature growth stage, approximately three months old. To address the challenges of strong outdoor illumination and to provide depth information for future research, a ZED2i stereo depth camera (Stereolabs Inc., San Francisco, CA, USA) was employed for image and depth data acquisition, as illustrated in Figure 2. ZED2i camera is a state-of-the-art stereo vision camera designed for robust 3D perception in outdoor and industrial environments. The camera calibration details are designed by the built-in functions to provide the internal parameters.

Figure 2.
The experimental field and equipment used in this study.
The dataset consists of approximately 1000 field-captured raw images, each containing between one and four corn instances. OBB annotations in this study were carefully labeled manually using the X-AnyLabeling tool [23]. Specifically, a four-point annotation scheme was employed, where each corner of the bounding box was represented by its coordinates. Unlike traditional horizontal bounding boxes, these annotations were carefully aligned with the natural orientation of corn in the field, thereby providing tighter and more accurate object representations. In particular, the following points are ensured: (1) The top point of the corn was constrained to coincide with the midpoint of the upper edge of the bounding box. (2) The bottom point was aligned with the midpoint of the lower edge. (3) The left and right edges were adjusted to closely conform to the lateral boundaries of the corn ear, ensuring that the annotated bounding boxes not only captured the spatial extent of the object but also preserved its growth orientation in a natural field setting.
For oriented object detection, the training annotations were stored in a quadrilateral format, where each object was represented by its four corner coordinates. Specifically, each annotation is defined as
where denote the pixel coordinates of the four vertices of the oriented bounding box in a clockwise order, and c represents the object category label.
This format eliminates the need for an explicit angle parameter by directly encoding the orientation of the object through the quadrilateral geometry. During preprocessing, the coordinates are normalized with respect to the image width and height to ensure scale invariance. An example of the annotation is expressed as
where the first value corresponds to the class index, followed by the normalized coordinates of the four corners.
2.1.2. Data Augmentation
To enhance the generalization capability of the model and mitigate performance degradation under varying environmental conditions, a series of data augmentation techniques was employed during both training and testing phases. Augmentations were applied randomly during training. As summarized in Table 1, the adopted methods include mosaic augmentation [24], horizontal flipping, scaling (with a factor of 0.75), and color space conversion [25]. First, a color conversion was applied to 80% of the raw data. Then, Mosaic, Flip, and Scale operations were performed with a probability of 0.5 on the color-converted data. After augmentation, approximately 4000 samples were generated for training.

Table 1.
Table of probabilities for data augmentation.
To reduce the luminance disparity between overexposed and underexposed regions in images and thereby improve the model’s robustness under varying illumination conditions, this study adopts a data augmentation strategy based on brightness adjustment in the HSV color space. Specifically, the original RGB image is first converted into the HSV space, where the hue (H), saturation (S), and value (V) channels are separated. The H and S channels are preserved, while the V channel is adjusted using a nonlinear gamma correction defined as in Equation (1):
where denotes the adjusted value channel, V is the original value channel, and is the gamma coefficient controlling the degree of luminance compression. A value of brightens dark regions, whereas suppresses highlights. Finally, the modified V channel is recombined with the original H and S channels, and the result is converted back to the RGB space for model training. This approach balances luminance variations without altering the original chromatic information.
Figure 3 provides examples of both augmented and raw images.

Figure 3.
Comparison of both augmented and raw images.
After data augmentation, the final dataset consists of approximately 4000 images, which are partitioned into training and testing subsets with a 9:1 ratio. Furthermore, to evaluate the effectiveness of pose estimation, a subset of 100 carefully selected samples was utilized to perform pose estimation experiments.
2.2. Pose Estimation Method
2.2.1. Pose Definitions
In this study, corn is approximated as a cylindrical object, and its pose is characterized by five parameters: length, width, 3D center coordinates, yaw angle, and pitch angle, as shown in Figure 4.
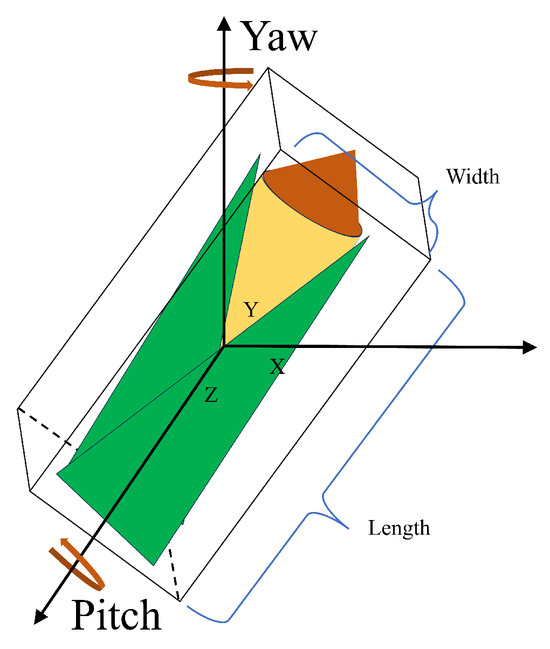
Figure 4.
The pose definitions of the corn.
2.2.2. The Process of Pose Estimation of Corn
The process of this work is shown in Figure 5. The precise oriented bounding boxes of corn detection are detected by a deep learning model; its corresponding depth map and camera intrinsic parameters are utilized to compute the pose and dimensions. Specifically, the 3D coordinates are extracted for several key points: the two endpoints of the bottom edge, the midpoints of the bottom and top edges, and the bounding box center. For the bottom-edge endpoints, the depth value is approximated using the depth of the bounding box center. Based on these 3D coordinates, the corn’s physical dimensions (length and width), yaw angle, and pitch angle can be derived. The detailed calculation process is as follows:

Figure 5.
The process of pose estimation in this work.
2.2.3. Dimension Estimation
Length: The length is defined as twice the Euclidean distance between the midpoint of the bottom edge and the center of the OBB.
Width: The width is obtained as the Euclidean distance between the two endpoints of the bottom edge. To maintain consistency in depth, the depth values of the endpoints are assigned to be equal to that of the OBB center.
2.2.4. Angle Estimation
Yaw angle: The orientation angle is calculated by projecting the vector from the midpoint of the bottom edge to the OBB center onto the plane. The angle between this projected vector and the X-axis represents the object’s horizontal orientation.
Pitch angle: The pitch angle is defined as the inclination of the object’s principal axis relative to the plane. It is derived from the vector connecting the midpoint of the bottom edge and the OBB center, reflecting the upward or downward tilt of the object in 3D space.
2.2.5. 3D Center Coordinates
3D center coordinates: The 3D center coordinates of each corn are computed by projecting the depth value at the OBB center into 3D space using the camera’s intrinsics.
2.3. Oriented Object Detection Model
In this section, YOLOv11 was introduced first as the baseline model for oriented object detection. While YOLOv11 provides strong detection capabilities, it is not specifically optimized for handling orientation information in agricultural scenarios. To address these limitations, YOLOv11OC was proposed, an enhanced framework that incorporates an orientation-aware module and feature fusion strategies to achieve more precise and robust detection of corn in the field.
2.3.1. Standard YOLOv11 Model
The standard YOLOv11 has been chosen as the baseline model in order to satisfy the detection criteria of precision agriculture, taking into account the robustness and accuracy. The head layer, neck layer, and backbone network make up the YOLOv11 architecture. These backbone network properties are combined at each scale via the neck layer. While YOLOv11 models of various sizes (n, s, m, and l) have similar architecture, their channel depths and the number of convolution modules differ; the head layer uses three feature maps that are obtained to forecast objects of different sizes. The structure of the standard YOLOv11 (YOLOv11n) is shown in Figure 6.
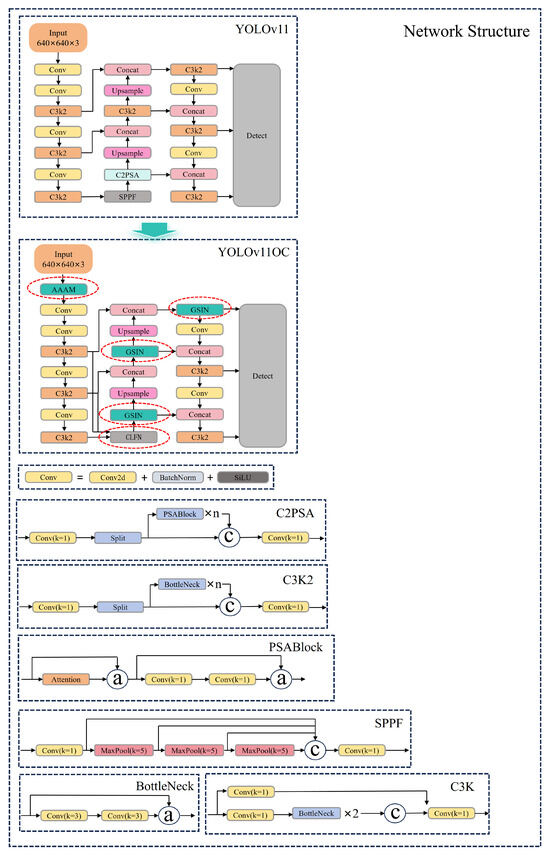
Figure 6.
The structure of proposed YOLOv11OC. The red dotted circles represent the location of our proposals.
2.3.2. YOLOv11OC Model
This work focuses on enhancing the detection performance of the oriented corn by introducing key structural improvements to the YOLOv11 architecture. YOLOv11OC is proposed in this work, which incorporates three novel components: AAM in the stem to enhance angle awareness; GSIN to replace the original ELAN-H module for more efficient multi-scale detection with fewer parameters; and CLFN in the neck to improve the fusion from different layers. The architecture of YOLOv11OC is illustrated in Figure 6.
Angle-Aware Attention Module
AAM is introduced to enhance the model’s ability to perceive and encode angle feature [26]. This module dynamically generates feature maps with attention weights derived from the object’s orientation. Specifically, the primary orientation angle of the object is computed from the coordinates of its first corner points and represented as a directional vector in sine–cosine form. This direction vector is then mapped into the channel space using a lightweight embedding network with channel attention [27]. Additionally, a spatial attention mechanism [28] is integrated to emphasize orientation-related spatial features. The AAM can significantly improve the model’s sensitivity to objects’ angle information, making it particularly effective for oriented bounding box regression tasks. This contributes to enhanced accuracy and robustness in oriented corn detection. The structure of AAM and its components is illustrated in Figure 7.
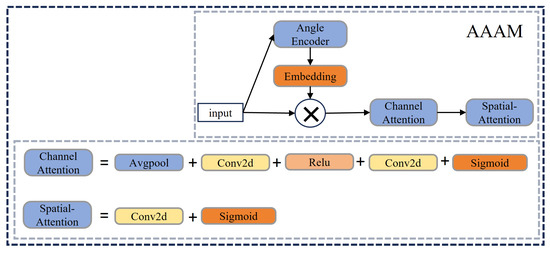
Figure 7.
The structure of proposed AAM.
AAM encodes the orientation angle (derived from the four annotated corner points) into a continuous directional vector as shown in Equation (2):
The directional vector is then projected into a high-dimensional channel-wise attention embedding via a lightweight multi-layer perceptron as shown in Equation (3):
where denotes the MLP used to learn the projection.
The generated angle-aware weight tensor is broadcasted and applied to the input feature map through element-wise multiplication as shown in Equation (4):
where ⊙ denotes channel-wise multiplication.
By incorporating orientation information into the attention mechanism, this module allows the network to better extract feature from the object’s direction, thereby improving the accuracy of oriented bounding box regression.
GSConv Inception Network
The GSIN module is constructed by integrating the inception [29] network with the GSConv architecture, adopting a multi-kernel convolutional fusion strategy to effectively aggregate semantic information across multiple dimensions. Specifically, it employs four parallel convolutional branches with distinct receptive fields to capture objects at multiple scales. The outputs of these branches are concatenated and subsequently processed through GSConv [30] and CBS layers.
By replacing the original ELAN-H module in the neck, GSIN not only reduces the overall parameter count but also enhances the network’s capability to extract and fuse the multi-scale feature. The structure of GSIN and its components is illustrated in Figure 8. This design achieves improved obtaining multi-scale feature extraction while preserving a compact and efficient architecture.
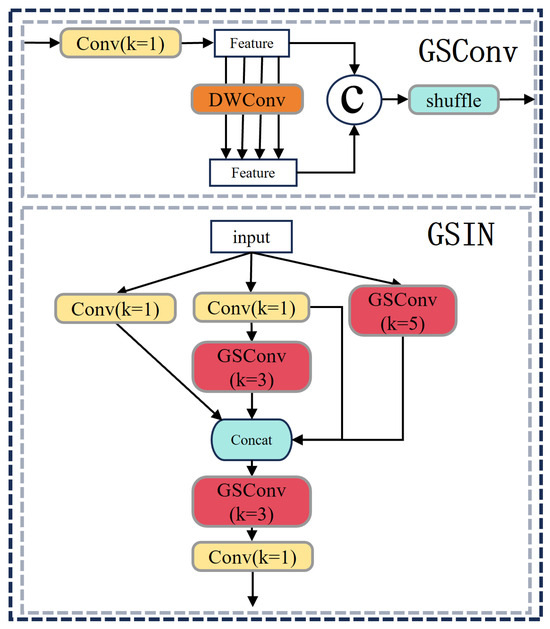
Figure 8.
The structure of proposed GSIN.
Cross-Layer Fusion Network
The CLFN is proposed as an improved multi-scale feature fusion [31] structure to enhance the accuracy of detecting multi-scale objects. Built upon the original YOLOv11 architecture, CLFN introduces cross-layer feature fusion that strengthens the integration of features from different layers. To maintain computational efficiency when processing high-dimensional feature maps after fusion, depthwise separable convolutions [32] are employed, ensuring parameter control without compromising detection accuracy as shown in Figure 9.
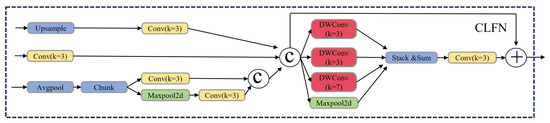
Figure 9.
The structure of proposed CLFN.
2.4. Experimental Setting
Table 2 lists the hardware and software setups used for model testing and training in this study. With a batch size of nine, the training epochs are set at 1000. The Adam optimizer with a momentum of 0.9 is used to carry out the optimization. Every 400 rounds, the learning rate is modified from the starting setting of 0.001.
Table 2.
Software and hardware configuration.
2.5. Training Loss
In our oriented object detection framework, the total loss function is defined as a weighted combination of classification loss, bounding box regression loss, and distribution focal loss as shown in Equation (5):
where are hyperparameters controlling the contribution of each component.
2.6. Model Evaluation Indicators
The performance of oriented object detection was measured in this study using precision , recall , and mean average precision mAP. In particular, P stands for the percentage of accurate positive predictions, as indicated by Equation (6), and R for the percentage of accurate forecasts relative to the total number of positive samples, as indicated by Equation (7). In Equation (8), stands for average precision. The mean value of under various thresholds is represented by the mAP, as seen in Equation (9). The threshold has a step size of 0.05 and is set between 0.5 and 0.95.
where refers to true positive, refers to false positive, refers to false negative. The accuracy of the pose estimates is gauged by the . The formula for computation in Equation (10) is
where refers to the ground truth value from manual calculation.
3. Results
3.1. Performance Comparison of YOLOv11 Variants
To evaluate the performance of the YOLOv11 framework under different computational budgets, four scaled versions (YOLOv11-n, s, m, and l) were compared; these models differ in width and depth multipliers. Table 3 summarizes their performance on the oriented corn detection dataset.
Table 3.
Performance comparison of YOLOv11 variants.
The results indicate that YOLOv11n achieves comparable performance to larger models with significantly fewer parameters and higher inference speed, making it suitable for this work on resource-constrained devices for agricultural task.
3.2. Ablation Study on Proposed Modules
The experiments further evaluate the individual and combined effects of the proposed modules: AAM, CLFN, and GSIN. All ablation experiments are conducted on YOLOv11-n to highlight improvements under lightweight settings.
From Table 4, it is evident that AAM provides the most substantial accuracy gain due to its ability to encode orientation information into the attention mechanism. Meanwhile, GSIN and CLFN enhance multi-scale object detection and cross-layers’ feature fusion while also helping reduce parameters size. Their combination yields the best balance between performance and efficiency.
Table 4.
Ablation study on YOLOv11n with proposed modules.
3.3. Comparison of YOLOv11OC and YOLOv11
3.3.1. Comparison of Training Loss
Figure 10 presents the training loss curves of YOLOv11OC and the baseline YOLOv11. Both models demonstrate similar convergence trends, indicating that the proposed architectural modifications do not hinder the optimization process and maintain comparable training stability and learning dynamics. While the difference in training loss values appears small, this does not directly translate to a negligible difference in overall performance results.
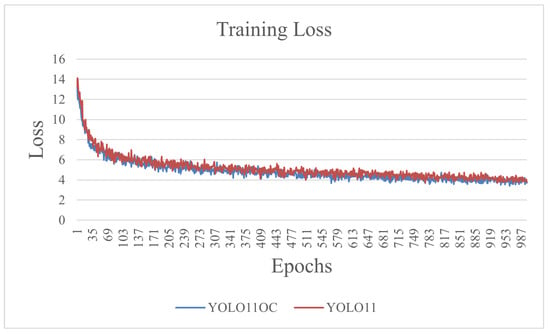
Figure 10.
Comparison of YOLOv11OC and YOLOv11 in training loss.
3.3.2. Comparison of Detected Results
As shown Figure 11, YOLOv11OC achieves higher confidence scores than YOLOv11 in oriented corn detection. In addition, the detection results of YOLOv11OC exhibit a closer alignment with the actual corn boundaries, while YOLOv11 tends to generate looser bounding boxes. This improvement indicates that YOLOv11OC not only enhances detection reliability but also provides more precise bounding boxes of the objects. Consequently, the refined detection outputs contribute to improved accuracy in subsequent pose estimation tasks.

Figure 11.
Comparison of YOLOv11OC and YOLOv11 in detected results. The IoU threshold is set as 0.75.
For example, in the first sample, YOLOv11OC yields an average confidence score of 0.93, outperforming YOLOv11, which achieves 0.88. In addition, the bounding box generated by YOLOv11OC more accurately aligns with the corn edges, thereby minimizing redundant background information.
3.3.3. Comparison of mAP
As illustrated in Table 5, the mAP values of YOLOv11OC and YOLOv11 remain comparable when the IoU threshold is set below 0.8, with differences less than 2%, suggesting that both models can reliably detect oriented objects under a low IoU threshold. However, as the IoU threshold increases beyond 0.8, the performance gap becomes more pronounced. Specifically, YOLOv11OC maintains a higher mAP, with differences reaching up to 8% at an IoU threshold of 0.95. This trend indicates that YOLOv11OC has a stronger capability for accurate oriented object localization, which is likely attributable to its orientation-aware and cross-layer fusion mechanisms that enhance feature representation. In contrast, YOLOv11 is more prone to slight localization deviations, which are penalized more heavily under high IoU evaluation criteria, leading to a sharper decline in mAP.
Table 5.
mAP comparison of YOLOv11OC and YOLOv11 at different IoU thresholds.
To ensure that the observed improvements are not due to random variation, we conducted multiple independent runs and reported the mean performance with error bars representing the standard deviation (0.03–0.05%). The maximum fluctuation observed across runs was about 0.2%. Statistical significance tests confirmed that the improvements of YOLOv11OC over YOLOv11 are significant (p < 0.01).
3.4. Presentation of Results
Figure 12 illustrates the workflow of the proposed method, where OBBs are first detected and subsequently combined with the depth map to estimate the pose. This process enables the estimation of corn length, width, yaw and pitch angles.

Figure 12.
The process of detecting the OBB and pose estimation of corn.
3.5. Pose Estimation Accuracy
As illustrated in Table 6, the proposed approach attains an accuracy of about 92.5% in estimating corn pose relative to the manually calculated ground truth, thereby validating its robustness and reliability under field conditions.
Table 6.
Accuracy (%) of pose estimation in pose estimation experiments.
4. Discussion
4.1. Main Work
Precision agriculture and smart farming have emerged as transformative paradigms for enhancing crop yield, optimizing resource utilization, and enabling intelligent field management. A central challenge in these domains lies in the precise 3D perception of crops. In the context of corn cultivation, high-precision pose estimation of individual corn is crucial for improving the efficiency of automated planting systems and advancing overall management practices.
Building upon RGB-D data and camera intrinsic parameters, accurate pose estimation can be achieved through precise OBB detection. Unlike conventional HBB, OBBs provide a more faithful representation of object geometry by aligning with the natural orientation of the object. In agricultural scenarios, this orientation-aware representation enables finer delineation of plant boundaries and more reliable spatial alignment. Nevertheless, OBB detection introduces unique challenges, particularly the difficulty of robust angle regression and the increased complexity of annotation preprocessing. Addressing these challenges constitutes the primary focus of this work.
To this end, YOLOv11OC was proposed, an enhanced framework designed specifically for oriented corn detection. This model incorporates three key components to improve YOLOv11’s representational capacity and regression accuracy: the AAM, CLFN, and GSIN. Experimental results confirm that the integration of these modules significantly strengthens orientation-aware object detection. Specifically, the AAM improves the model’s ability to perceive and encode angular information by deriving orientation vectors from OBB corner coordinates. Through dynamic modulation of both spatial and channel attention, AAM achieves more stable angle regression and markedly enhances sensitivity to variations in object orientation.
The CLFN mitigates the loss of low-dimensional features that typically occur in traditional FPN structures by introducing a cross-layer fusion mechanism. This design enables more effective integration of semantic information from both low-level and high-level feature maps, thereby enhancing the detection of multi-scale objects. Complementarily, the GSIN employs a multi-kernel convolution fusion strategy in combination with GSConV to maintain a lightweight yet powerful architecture. This module effectively extracts and fuses multi-scale features, compensating for the limitations of single-scale convolution, and is particularly effective in detecting small or edge-blurred objects.
The complementary strengths of these three modules—angle encoding, cross-layer feature fusion, and lightweight multi-scale feature extraction—enable YOLOv11OC to achieve robust and precise OBB detection. This improvement not only advances the accuracy of oriented corn detection but also provides a solid foundation for pose estimation.
On the basis of precise OBB detection, this work further integrates depth maps to estimate the pose of corn. By computing the 3D coordinates of key points—including the midpoints of the bounding box edges, the corner endpoints, and the OBB center—using depth values in conjunction with camera intrinsic parameters, the length, width, yaw, and pitch angles of each corn instance can be derived. To the best of our knowledge, this is the first study to introduce precise OBB detection as a basis for crop pose estimation. This approach establishes a technical foundation for phenotypic analysis and lays the groundwork for future applications in intelligent harvesting and automated crop management.
4.2. Comparison with Previous Studies
4.2.1. Comparison with Previous Studies of OBB Detection
Table 7 compares the proposed YOLOv11OC and previous studies. This work is based on the latest detection model YOLOv11. The proposed YOLOv11OC achieved the best mAP and was the first work for detecting oriented corn.
Table 7.
Comparison of YOLOv11OC algorithm with previous agricultural studies.
4.2.2. Comparison with Previous Studies of Pose Estimation
Table 8 presents a comparison between this work and previous studies. To the best of our knowledge, this is the first attempt in the field of smart agriculture to employ OBB detection with RGB-D data for estimating the pose and shape of corn under occlusion. The proposed method achieves a detection speed of up to 10 ms per corn instance. In terms of efficiency, it outperforms the approaches of Chen [33] and Gené-Mola [13], which rely on 3D modeling for shape estimation. Furthermore, in both speed and methodological simplicity, it demonstrates superiority over Guo [34], who employed point cloud segmentation.
Table 8.
Comparison of pose estimation with previous agricultural studies.
Compared with our previous work [15], as shown in Table 8, the proposed approach places stricter requirements on the accuracy of annotation and depth acquisition. However, its pose estimation, based on physically interpretable calculations, provides a stronger explanatory foundation. Overall, under conditions of limited data volume and relatively small variability, the proposed method proves to be more suitable and effective than prior approaches.
4.3. Limitations
Experiments show that at the commonly used IoU threshold of 0.5, YOLOv11 and YOLOv11OC exhibit comparable detection accuracy, suggesting that the performance gains of the proposed method are not highly pronounced under standard evaluation settings. This observation underscores the need to construct more challenging datasets containing a higher proportion of small objects, densely packed targets, or severe occlusion, which would better demonstrate the advantages of oriented detection frameworks. From a deep learning model perspective, future work could focus on integrating global context modeling mechanisms, such as Transformer-based architectures, to further improve detection robustness under complex scenarios.
Moreover, the present study was conducted using data collected from a single area, season, and growth stage, under relatively stable environmental conditions. While this provides a controlled evaluation setting, it may limit the generalizability of the results, as lighting variations, environmental diversity, and different corn varieties were not considered. Future work should therefore include broader data collection campaigns covering multiple environments, seasons, and corn cultivars, to comprehensively validate the robustness and adaptability of the proposed method.
Furthermore, pose estimation based on OBB detection imposes stringent requirements on both model precision and dataset annotation quality. Reliable results demand high-quality, fine-grained annotations, which are labor-intensive and time-consuming. A promising direction for future research is to leverage auxiliary approaches, such as semantic segmentation, to enable automated, precise labeling. This would reduce annotation effort and further enhance pose estimation performance in agricultural applications.
4.4. Implementation for Precision Agriculture
The proposed system shows promise for deployment in precision agriculture. With 97.6% mAP@0.75 and 94% pose estimation accuracy, it can meet the precision requirements of automated harvesting, where small pose errors are acceptable. Its inference speed of about 10 ms further supports real-time operation on harvesting vehicles.
However, the current dataset mainly covers corn near maturity and a single variety, limiting generalization. Future work will expand testing across different growth stages and varieties, and integrate the system with harvesting platforms to verify its practical applicability.
5. Conclusions
This study focused on precise OBB detection for corn pose estimation. To this end, we proposed YOLOv11OC, which integrates three novel modules: AAM for stable and accurate orientation perception, CLFN for enhanced multi-scale feature fusion, and GSIN for lightweight yet effective feature extraction and multi-scale detection.
Experimental results demonstrate that the proposed framework significantly improves oriented detection performance. The YOLOv11n variant achieves competitive accuracy with the smallest parameter size, underscoring its potential for deployment on resource-constrained agricultural platforms. Ablation studies further confirm that AAM yields the most notable performance gain, while CLFN and GSIN both improve accuracy and contribute to parameter reduction. Moreover, results show that while YOLOv11 and YOLOv11OC perform similarly at lower IoU thresholds, the performance gap increases at higher thresholds, reflecting the superior localization precision of YOLOv11OC.
Overall, YOLOv11OC achieves a strong balance between detection precision, efficiency, and robustness. Leveraging these advantages, the proposed framework enables accurate and reliable corn pose estimation, supporting key agricultural applications such as automated harvesting, growth monitoring, and pesticide spraying. With 97.6% mAP@0.75 and 94% pose estimation accuracy, the proposed method satisfies the precision requirements of automated harvesting while maintaining real-time inference speed suitable for on-vehicle deployment. Nonetheless, the current dataset primarily covers corn near maturity and a single variety, which may limit generalization. Future work will extend evaluation across diverse growth stages and varieties, and integrate the system into harvesting machinery to validate its field applicability.
By bridging precise oriented detection with practical agricultural needs, this work contributes to advancing automation, efficiency, and sustainability in smart agriculture.
Author Contributions
Conceptualization, Y.G., H.T., and Y.W.; Methodology, Y.G., B.L., and Z.L.; Software, Y.G., Z.L., H.T., and Y.W.; Validation, Y.G.; Formal analysis, Y.G.; Data curation, T.L., H.T., and Y.W.; Investigation, Y.G. and T.L.; Writing—original draft, Y.G. and T.L.; Writing—review and editing, Y.G., Z.L., H.T., and Y.W.; Visualization, Y.G. and T.L.; Supervision, B.L., Z.L., and L.Z.; Formal analysis, B.L. and Y.G.; Project administration, B.L. and L.Z.; Resources, B.L. and L.Z.; Funding acquisition, L.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by JST SPRING, Japan Grant Number JPMJSP2154.
Data Availability Statement
The datasets analyzed during the current study are available from the corresponding author upon reasonable request.
Conflicts of Interest
The authors declare no conflicts of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| YOLOv11 Oriented Corn | YOLOv11OC |
| Oriented bounding boxes | OBB |
| Horizontal Bounding Box | HBB |
| Angle-aware Attention Module | AAM |
| Cross-Layer Fusion Network | CLFN |
| GSConV Inception Network | GSIN |
References
- Çakmakçı, R.; Salık, M.A.; Çakmakçı, S. Assessment and principles of environmentally sustainable food and agriculture systems. Agriculture 2023, 13, 1073. [Google Scholar] [CrossRef]
- García-Lara, S.; Serna-Saldivar, S.O. Corn history and culture. Corn 2019, 1–18. [Google Scholar] [CrossRef]
- Zhao, B.; Zhang, Y.; Duan, A.; Liu, Z.; Xiao, J.; Liu, Z.; Qin, A.; Ning, D.; Li, S.; Ata-Ul-Karim, S.T. Estimating the growth indices and nitrogen status based on color digital image analysis during early growth period of winter wheat. Front. Plant Sci. 2021, 12, 619522. [Google Scholar] [CrossRef]
- Zhou, H.; Wang, X.; Au, W.; Kang, H.; Chen, C. Intelligent robots for fruit harvesting: Recent developments and future challenges. Precis. Agric. 2022, 23, 1856–1907. [Google Scholar] [CrossRef]
- Xia, G.S.; Bai, X.; Ding, J.; Zhu, Z.; Belongie, S.; Luo, J.; Datcu, M.; Pelillo, M.; Zhang, L. DOTA: A large-scale dataset for object detection in aerial images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 3974–3983. [Google Scholar]
- Wang, K.; Wang, Z.; Li, Z.; Su, A.; Teng, X.; Pan, E.; Liu, M.; Yu, Q. Oriented object detection in optical remote sensing images using deep learning: A survey: K. Wang et al. Artif. Intell. Rev. 2025, 58, 350. [Google Scholar] [CrossRef]
- Yuanwei, C.; Zaman, M.H.M.; Ibrahim, M.F. A review on six degrees of freedom (6D) pose estimation for robotic applications. IEEE Access 2024, 12, 161002–161017. [Google Scholar] [CrossRef]
- Song, C.; Zhang, F.; Li, J.; Zhang, J. Precise maize detasseling base on oriented object detection for tassels. Comput. Electron. Agric. 2022, 202, 107382. [Google Scholar] [CrossRef]
- Zhou, S.; Zhong, M.; Chai, X.; Zhang, N.; Zhang, Y.; Sun, Q.; Sun, T. Framework of rod-like crops sorting based on multi-object oriented detection and analysis. Comput. Electron. Agric. 2024, 216, 108516. [Google Scholar] [CrossRef]
- Liu, Z.; Wang, S. Broken Corn Detection Based on an Adjusted YOLO With Focal Loss. IEEE Access 2019, 7, 68281–68289. [Google Scholar] [CrossRef]
- Wang, L.; Jia, J.; Dai, H. OrientedDiffDet: Diffusion Model for Oriented Object Detection in Aerial Images. Appl. Sci. 2024, 14, 2000. [Google Scholar] [CrossRef]
- Su, H.; You, Y.; Liu, S. Multi-Oriented Enhancement Branch and Context-Aware Module for Few-Shot Oriented Object Detection in Remote Sensing Images. Remote Sens. 2023, 15, 3544. [Google Scholar] [CrossRef]
- Gené-Mola, J.; Sanz-Cortiella, R.; Rosell-Polo, J.R.; Escola, A.; Gregorio, E. In-field apple size estimation using photogrammetry-derived 3D point clouds: Comparison of 4 different methods considering fruit occlusions. Comput. Electron. Agric. 2021, 188, 106343. [Google Scholar] [CrossRef]
- Du, X.; Meng, Z.; Ma, Z.; Lu, W.; Cheng, H. Tomato 3D pose detection algorithm based on keypoint detection and point cloud processing. Comput. Electron. Agric. 2023, 212, 108056. [Google Scholar] [CrossRef]
- Gao, Y.; Li, Z.; Hong, Q.; Li, B.; Zhang, L. Corn pose estimation using 3D object detection and stereo images. Comput. Electron. Agric. 2025, 231, 110016. [Google Scholar] [CrossRef]
- Han, Y.; Liu, H.; Wang, Y.; Liu, C. A comprehensive review for typical applications based upon unmanned aerial vehicle platform. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 9654–9666. [Google Scholar] [CrossRef]
- Zhang, Q.; Xue, C.; Qin, J.; Duan, J.; Zhou, Y. 6D Pose Estimation of Industrial Parts Based on Point Cloud Geometric Information Prediction for Robotic Grasping. Entropy 2024, 26, 1022. [Google Scholar] [CrossRef]
- Ausserlechner, P.; Haberger, D.; Thalhammer, S.; Weibel, J.B.; Vincze, M. ZS6D: Zero-shot 6D Object Pose Estimation using Vision Transformers. In Proceedings of the 2024 IEEE International Conference on Robotics and Automation (ICRA), Yokohama, Japan, 13–17 May 2024; pp. 463–469. [Google Scholar] [CrossRef]
- Zaidi, S.S.A.; Ansari, M.S.; Aslam, A.; Kanwal, N.; Asghar, M.; Lee, B. A survey of modern deep learning based object detection models. Digit. Signal Process. 2022, 126, 103514. [Google Scholar] [CrossRef]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. Yolox: Exceeding yolo series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar] [CrossRef]
- Khan, S.; Naseer, M.; Hayat, M.; Zamir, S.W.; Khan, F.S.; Shah, M. Transformers in vision: A survey. ACM Comput. Surv. (CSUR) 2022, 54, 1–41. [Google Scholar] [CrossRef]
- Wang, W. Advanced Auto Labeling Solution with Added Features. 2023. Available online: https://github.com/CVHub520/X-AnyLabeling (accessed on 1 May 2025).
- Hao, W.; Zhili, S. Improved mosaic: Algorithms for more complex images. In Journal of Physics: Conference Series; IOP Publishing: Bristol, UK, 2020; Volume 1684, p. 012094. [Google Scholar]
- Lee, D.J.; Archibald, J.K.; Chang, Y.C.; Greco, C.R. Robust color space conversion and color distribution analysis techniques for date maturity evaluation. J. Food Eng. 2008, 88, 364–372. [Google Scholar] [CrossRef]
- Li, Z.; Hou, B.; Ma, S.; Wu, Z.; Guo, X.; Ren, B.; Jiao, L. Masked angle-aware autoencoder for remote sensing images. In Proceedings of the European Conference on Computer Vision, Milan, Italy, 29 September–4 October 2024; Springer: Berlin/Heidelberg, Germany, 2024; pp. 260–278. [Google Scholar]
- Bastidas, A.A.; Tang, H. Channel attention networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Zhu, X.; Cheng, D.; Zhang, Z.; Lin, S.; Dai, J. An empirical study of spatial attention mechanisms in deep networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6688–6697. [Google Scholar]
- Yu, W.; Zhou, P.; Yan, S.; Wang, X. Inceptionnext: When inception meets convnext. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 5672–5683. [Google Scholar]
- Li, H.; Li, J.; Wei, H.; Liu, Z.; Zhan, Z.; Ren, Q. Slim-neck by GSConv: A lightweight-design for real-time detector architectures. J. Real-Time Image Process. 2024, 21, 62. [Google Scholar] [CrossRef]
- Qu, Z.; Gao, L.y.; Wang, S.y.; Yin, H.n.; Yi, T.m. An improved YOLOv5 method for large objects detection with multi-scale feature cross-layer fusion network. Image Vis. Comput. 2022, 125, 104518. [Google Scholar] [CrossRef]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Chen, H.; Liu, S.; Wang, C.; Wang, C.; Gong, K.; Li, Y.; Lan, Y. Point cloud completion of plant leaves under occlusion conditions based on deep learning. Plant Phenomics 2023, 5, 0117. [Google Scholar] [CrossRef] [PubMed]
- Guo, R.; Xie, J.; Zhu, J.; Cheng, R.; Zhang, Y.; Zhang, X.; Gong, X.; Zhang, R.; Wang, H.; Meng, F. Improved 3D point cloud segmentation for accurate phenotypic analysis of cabbage plants using deep learning and clustering algorithms. Comput. Electron. Agric. 2023, 211, 108014. [Google Scholar] [CrossRef]
- Magistri, F.; Marks, E.; Nagulavancha, S.; Vizzo, I.; Läebe, T.; Behley, J.; Halstead, M.; McCool, C.; Stachniss, C. Contrastive 3D shape completion and reconstruction for agricultural robots using RGB-D frames. IEEE Robot. Autom. Lett. 2022, 7, 10120–10127. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).