1. Introduction
Cybersecurity threats have become increasingly sophisticated, posing significant risks to data integrity and system availability. Among the most critical are zero-day attacks, which exploit unknown vulnerabilities and evade traditional signature-based detection mechanisms [
1,
2,
3]. The increasing reliance on cloud computing infrastructures has expanded the attack surface, demanding advanced and adaptive threat detection strategies [
4,
5].
Cloud environments present unique challenges due to their dynamic, distributed, and scalable nature. Features such as elastic resource provisioning, shared responsibility models, and multitenant architectures introduce variability and operational complexity. These factors complicate the deployment of static defense mechanisms, making them less effective against fast-evolving malware strains [
5,
6,
7].
Traditional detection systems often fall short when facing modern threats like polymorphic or fileless malware [
8,
9]. To address these shortcomings, the cybersecurity community has shifted towards data-driven approaches using machine learning (ML) and deep learning (DL) [
10,
11].
Deep learning, particularly transformer-based models, has shown great promise in malware detection tasks [
12,
13]. These models can process complex features extracted from binary files or image-based representations of malware [
14], enabling improved classification accuracy and generalization. Moreover, explainable AI is gaining traction, providing insights into model decisions and making security tools more trustworthy [
13,
15]. While these approaches demonstrate promise, they still encounter key challenges: the presence of severe class imbalance in malware datasets, the oversimplification introduced by binary classification, and the limited interpretability of deep models.
In this context, we propose a novel deep learning-based architecture named mixed vision transformer (MVT), tailored for detecting zero-day malware in cloud environments. The MVT model transforms binary executable files into grayscale images (byteplots) and processes them using vision transformer layers. This design enables the extraction of both local and global patterns relevant to malware behavior. Additionally, the model is evaluated under realistic conditions using a containerized cloud-based framework and the MaLeX dataset [
16], which provides a balanced and scalable testbed for malware classification.
The remainder of this paper is structured as follows:
Section 2 reviews related work.
Section 3 provides background on zero-day threats and visual malware detection.
Section 4 presents the proposed methodology and experimental setup.
Section 5 discusses results and insights.
Section 6 outlines implications, limitations, and future research. Finally,
Section 7 concludes the paper.
2. Related Work
The detection of zero-day threats and advanced malware has become a growing concern in the field of cybersecurity, especially in cloud computing environments. Traditional techniques such as static and dynamic analysis have proven to be insufficient against unknown, obfuscated, and polymorphic malware, leading to the integration of machine learning (ML) and deep learning (DL) techniques [
9,
17]. ML-based systems are able to learn from known patterns and generalize to detect novel threats, although they face challenges such as class imbalance and dataset limitations [
8,
13].
Zero Trust Architecture (ZTA) has emerged as a complementary security paradigm that eliminates implicit trust in networks and enforces continuous verification of user and device identities. Several studies have explored the implementation of ZTA in diverse contexts such as healthcare, education, microservices, and cloud computing [
1,
18,
19]. These works demonstrate improved resilience against data breaches and policy enforcement in dynamic environments.
Recent studies have examined the implementation of Zero Trust Architectures (ZTA) across various domains, demonstrating their effectiveness in enhancing security within critical environments. Applications range from the protection of virtual power plant infrastructures [
7] and university systems [
18] to banking systems [
20], healthcare networks [
6], and microservices-based platforms. In all cases, ZTA has proven to be a robust strategy for closing trust-based vulnerabilities, enhancing access control, mitigating data breaches, and strengthening authentication mechanisms. Furthermore, ZTA has been applied in educational contexts [
21] and industrial Internet of Things (IIoT) environments, incorporating emerging technologies such as blockchain [
2] and context-aware access control frameworks [
1]. Collectively, these contributions support the adaptability and utility of ZTA as a comprehensive security framework capable of addressing the evolving challenges of distributed systems.
In terms of malware detection, recent approaches have leveraged convolutional neural networks (CNNs) and vision-based models to convert executable binaries into grayscale or RGB images, allowing visual analysis of malware patterns [
14,
22]. EfficientNet, for example, has shown strong performance in detecting Android malware when trained on bytecode images [
22]. Transfer learning techniques using transformers such as BERT have also been integrated with image-based representations to enhance classification accuracy [
13].
Furthermore, ensemble learning methods such as boosting and bagging, combined with Shapley value analysis, have been used to improve the interpretability and performance of classifiers on malware datasets [
23]. Other notable contributions include the use of contractive autoencoders and voting-based ensemble models for zero-day ransomware detection, achieving high detection rates and robustness [
24].
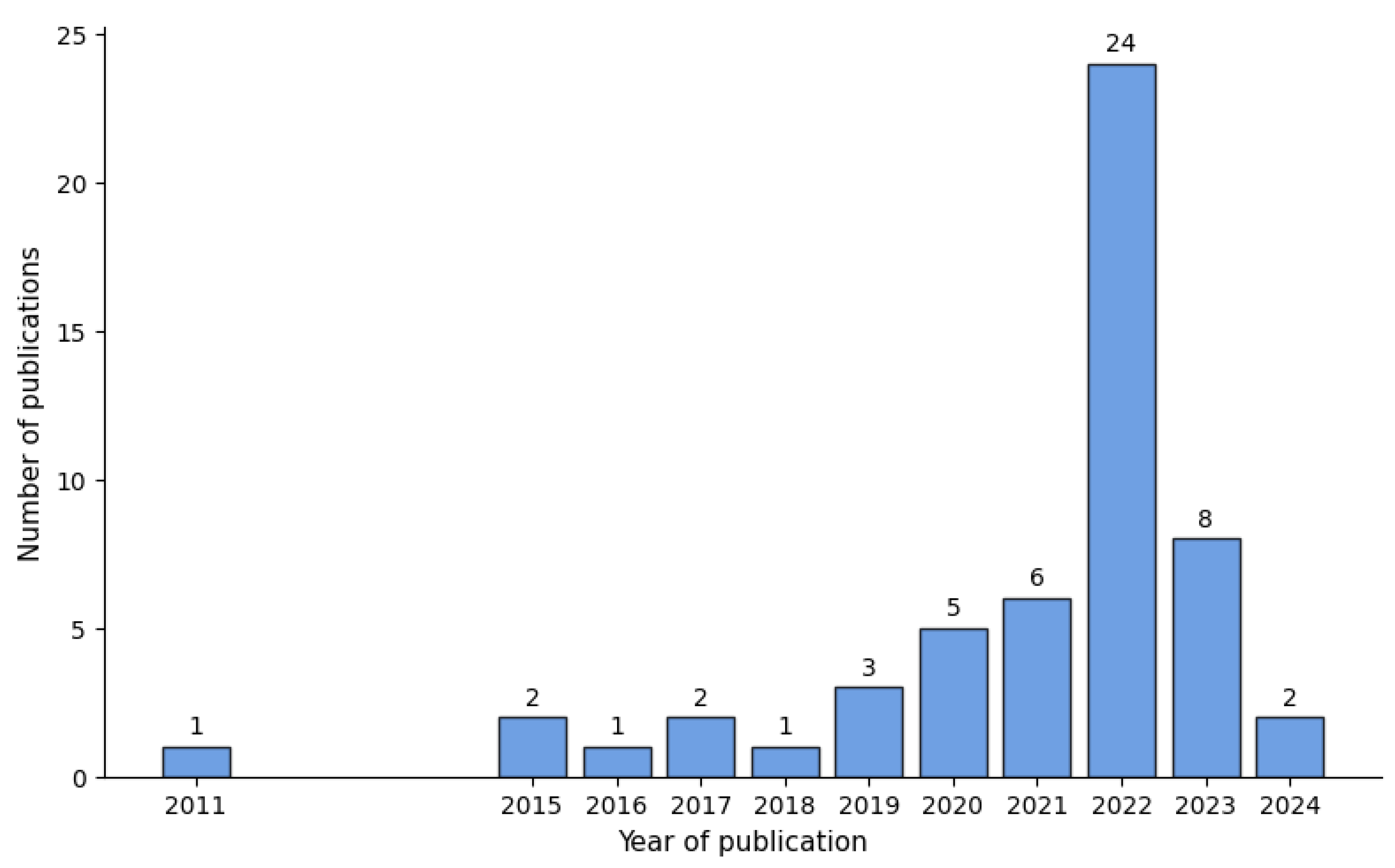
The bibliometric analysis reveals a significant growth in scientific production between 2011 and 2024, with an exponential increase observed from 2020, peaking in 2022. As shown in
Figure 1, this trend highlights the growing consolidation and academic interest in the research area, emphasizing the importance of reviewing recent literature to identify trends, research gaps, and future directions.
Despite these advancements, several open challenges persist in malware detection, particularly in cloud computing environments. One of the most pressing issues is the class imbalance problem, which significantly impacts model performance. Although methods such as SMOTE and data augmentation are commonly applied, more advanced solutions are needed to ensure balanced learning and fair detection outcomes across both benign and malicious classes [
25,
26].
Another crucial direction is the adoption of multiclass classification approaches. Most existing models rely on binary classification, which restricts the system to distinguishing only between malware and benign files. However, differentiating among various malware families or attack types can provide more actionable threat intelligence and improve response strategies [
27,
28].
Finally, the integration of explainable AI (XAI) into malware detection models has gained attention due to the growing need for transparency and accountability in automated systems. Visualization of attention mechanisms, SHAP value analysis, and feature attribution methods have proven effective in increasing the interpretability of deep learning models [
29,
30,
31].
Together, these research lines provide a robust foundation for the development of advanced malware detection systems that are not only accurate but also interpretable, adaptive, and capable of fine-grained threat characterization.
3. Background
Zero-day threats refer to cyberattacks that exploit previously unknown vulnerabilities in software, hardware, or firmware, often before the vendor or security community becomes aware of them. These types of attacks are particularly dangerous because traditional detection systems based on known signatures or heuristics are unable to identify them in time [
8,
32]. In cloud computing environments, the risk is amplified due to the dynamic and distributed nature of resources, the presence of multiple tenants, and the complexity of data access policies [
4,
5].
To address these challenges, the Zero Trust Architecture (ZTA) has been proposed as a modern security model. ZTA operates on the principle of “never trust, always verify”, enforcing strict identity verification and access control across all users, devices, and applications [
1,
19]. It eliminates the assumption of trust within the internal network and instead treats every access request as potentially malicious, applying continuous authentication and policy enforcement.
In parallel, advances in artificial intelligence, especially in deep learning, have opened new paths for proactive threat detection. Unlike traditional machine learning, which often requires manual feature engineering, deep learning models are capable of extracting complex representations directly from raw input data [
12,
14]. This is particularly relevant in malware detection, where binary files can be transformed into visual representations such as byteplot images, allowing models originally designed for computer vision to be repurposed for cybersecurity tasks [
14,
22].
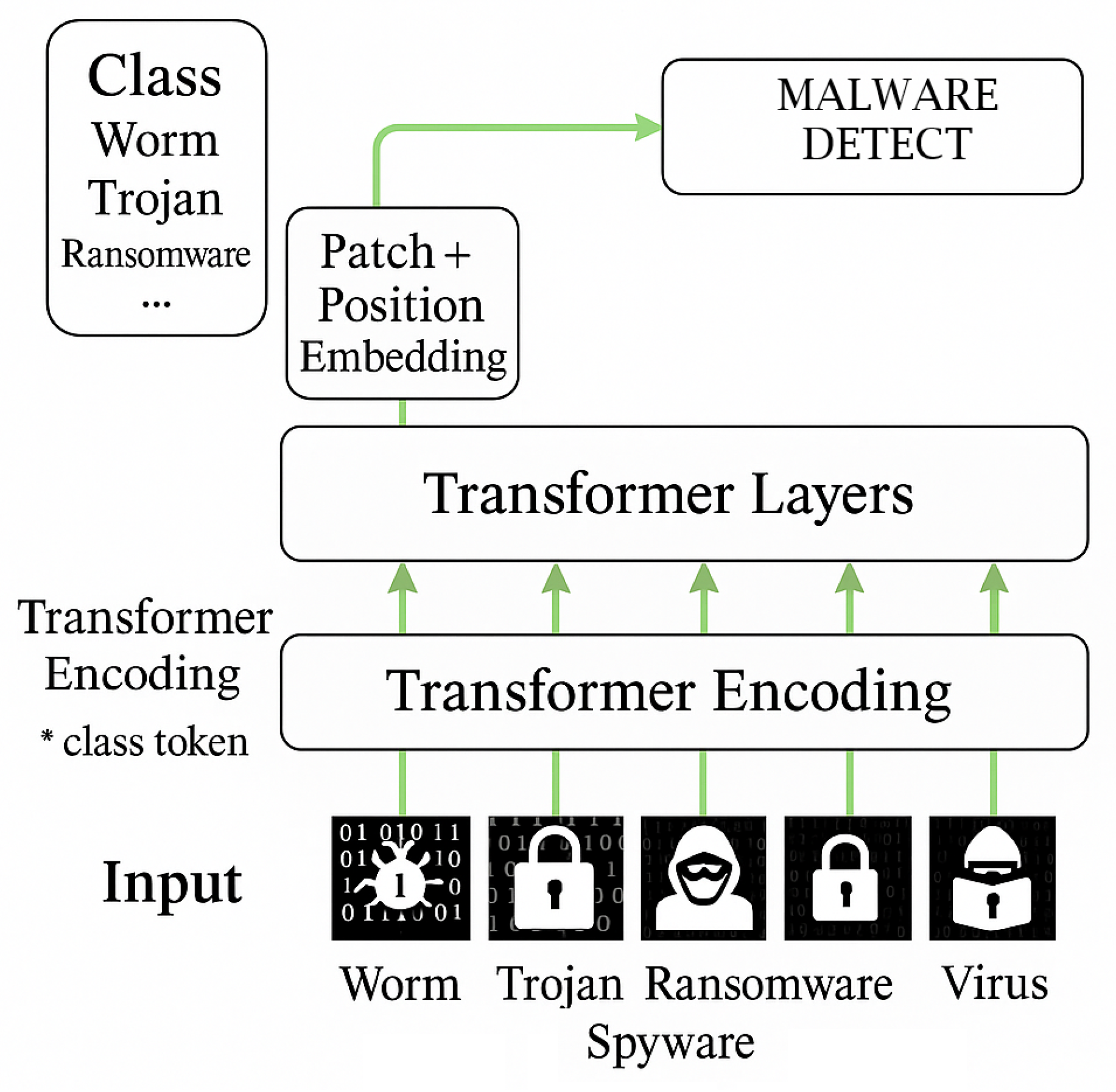
Transformers, first introduced in the context of natural language processing, have recently been adapted for image classification through architectures like vision transformer (ViT) (
Figure 2) the asterisk (*) in the image indicates that the Transformer Encoding module includes a class token, a special vector added at the beginning of the input sequence that does not represent specific malware data but serves as a global summary. This token enables the model to generate an aggregated representation of the entire input, which is subsequently used for malware classification and detection. Then, Patch and Position Embeddings are applied to segment and position the data. The Transformer Layers process these representations with self-attention, enabling the identification of patterns.. These models leverage self-attention mechanisms to capture global dependencies in data and have demonstrated strong performance in malware detection scenarios when trained on large datasets [
12,
33]. Hybrid models combining convolutional and transformer-based layers have also shown promise in reducing false positives and improving detection of zero-day variants [
24,
34].
The intersection of Zero Trust principles with deep learning-based detection systems represents a powerful strategy for defending cloud environments against emerging and stealthy malware attacks. This study builds on these foundations to propose a transformer-based model optimized for image-based malware classification.
4. Methodology
This work proposes the use of a deep learning model called mixed vision transformer (MVT) for detecting zero-day threats in cloud computing environments. The model converts binary files into images using the byteplots technique and then applies deep attention mechanisms to classify between benign and malicious files.
The choice of using the transformer based architecture mentioned over more conventional architectures, such as Convolutional Neural Networks (CNNs) or Recurrent Neural Networks (RNNs), is primarily motivated by the nature of the input data and the task requirements. While CNNs excel at extracting spatial features from structured image data and RNNs are effective in modeling temporal dependencies, they have inherent limitations when dealing with high dimensional, sparse, and heterogeneous data typical of malware detection scenarios. In contrast, the transformer architecture offers several advantages: it captures long range dependencies and complex patterns through self attention mechanisms, which are crucial for analyzing byte-level representations and visual transformations of binary files. Additionally, transformers are less prone to losing contextual information compared with CNNs, making them more robust when detecting zero-day threats that lack clear signatures. Consequently, the MVT model is better suited for the challenge of zero-day malware detection in cloud environments (
Figure 3), where adaptability and nuanced feature extraction are essential.
4.1. Dataset and Preprocessing
This study utilizes the MaLeX dataset, a widely recognized repository comprising over one million executable files. This dataset was selected for its extensive volume and diversity, enabling a rigorous evaluation of deep learning models under realistic and challenging scenarios of malware detection in cloud environments. Each executable file was transformed into a visual representation through the byteplot technique, producing
pixel images. The fixed image size of
pixels was chosen following guidelines established by previous studies on malware visualization and classification [
35] and is consistent with standard resolutions employed in vision transformer (ViT) architectures [
36]. This resolution strikes a balance by preserving relevant structural details of the binary file while avoiding the prohibitive computational cost typically associated with the global attention mechanism used in transformer-based models. This transformation allows the application of computer vision models, such as the proposed MVT, which leverages deep attention mechanisms to process binary files.
The dataset was structured into two primary classes:
Class 0 (Benign): comprising legitimate files representing applications and programs with no malicious behavior.
Class 1 (Malicious): containing various malware samples, including multiple families and threat types.
One of the main challenges identified in the MaLeX dataset is the significant class imbalance, with a considerably higher number of malware samples compared with benign files, which introduces a bias in the model, causing it to overfit the majority class and reducing its ability to accurately detect benign files, thereby increasing the risk of false positives or negatives. To address the imbalance between benign and malicious classes, the Synthetic Minority Oversampling Technique (SMOTE 0.13.0) [
25] was applied. This method enhances the representation of the minority class by generating synthetic instances through interpolation, reducing the risk of overfitting compared with simple duplication. However, SMOTE does not consider the structural and distributional complexity inherent to byteplot images generated from binary files, which may limit its effectiveness in capturing representative variations of the minority class. Although SMOTE was employed to address class imbalance, it does not fully capture the structural characteristics of byteplot images. Therefore, comparisons with more advanced data augmentation techniques are necessary to better illustrate their impact on model robustness and generalization. Techniques such as ImageMix, GAN-based synthesis, or domain-specific transformations could provide more representative synthetic samples for the minority class.
Moreover, preprocessing and model training were conducted within a Dockerized environment, simulating a controlled and replicable cloud computing scenario. This environment included specific containers for the following:
Preprocessing: conversion of executable files into byteplot images.
Training: execution of the MVT model.
Validation: evaluation of the model using unseen data.
The dataset was divided into training, validation, and testing sets, ensuring a robust evaluation and avoiding overfitting biases. Evaluation metrics included accuracy, recall, F1-Score, and confusion matrix, enabling a comprehensive analysis of the model’s performance in classifying both benign and malicious files.
This methodological approach ensures a rigorous and controlled evaluation, positioning MaLeX as an appropriate experimental environment for validating zero-day threat detection models in cloud computing settings. Nevertheless, it is acknowledged that the inherent imbalance within the dataset remains a critical challenge regarding the model’s generalization to benign files. Addressing this challenge will be part of future work, focusing on advanced data augmentation strategies and the integration of hybrid architectures to enhance detection performance [
16].
4.2. MVT Model Architecture
The mixed vision transformer model builds upon the classical vision transformer framework and adapts it specifically for malware classification based on visual representations of binary files. The architecture is composed of several functional components, each contributing critically to the model’s effectiveness:
Input encoding: Raw binary files are first transformed into grayscale byteplot images, where each byte is mapped to a pixel value. This transformation preserves the structural and sequential characteristics of the file, allowing the model to exploit visual cues such as repeated patterns, padding zones, or anomalous header structures often associated with malicious behavior.
Patch extraction and positional encoding: The byteplot image is divided into non-overlapping fixed-size patches (e.g., ). Each patch is flattened and linearly projected into a latent embedding space. Sinusoidal positional encodings are added to each patch vector to retain spatial order and location information, which is crucial to preserving the sequential logic of the original binary layout.
Transformer encoder blocks: The sequence of encoded patches is passed through multiple stacked transformer encoder blocks, each consisting of multi-head self-attention mechanisms and feed-forward neural networks with residual connections and layer normalization. This configuration enables the model to capture long-range dependencies across distant regions in the byteplot, allowing for the identification of complex and distributed patterns characteristic of obfuscated or polymorphic malware.
Classification layer: The aggregated output (via a class token or average pooling) is fed into a fully connected neural network, which produces a binary prediction indicating whether the file is benign or malicious. A binary cross-entropy loss function is used for optimization, with regularization via dropout to enhance generalization.
Each component contributes synergistically to the model’s overall performance. The multi-head attention mechanism facilitates the modeling of inter-patch relationships, while positional encoding ensures that the sequential and spatial semantics of binary data are preserved throughout the pipeline. As demonstrated in the ablation study removing or altering any of these modules results in a significant performance drop, confirming their essential role in achieving reliable detection.
4.3. Training and Validation
The MVT model was trained using a supervised learning approach within a Docker-based containerized environment to simulate realistic deployment scenarios. Training was conducted over 60 epochs, with a batch size of 32 and an initial learning rate of 0.01. A momentum of 0.8 and the Gradient Descent optimizer were chosen due to their proven stability in training deep networks with vision transformers.
Hyperparameters were selected through empirical tuning and validation experiments, considering computational constraints and model generalization. These values were informed by recent literature on hyperparameter optimization in deep learning systems [
37,
38], favoring configurations that improved convergence speed and avoided overfitting.
To improve training efficiency, a learning rate scheduler, StepLR, was implemented to reduce the learning rate by a factor of 0.1 every 10 epochs, ensuring gradual refinement during late stages of training.
Early stopping was applied with a patience of 5 epochs, terminating training when validation accuracy failed to improve over five consecutive epochs. This strategy, supported by guidelines for overfitting prevention [
39], helps ensure optimal generalization without unnecessary training.
The model was evaluated on three data splits (training, validation, and testing) using standard metrics (accuracy, recall, and F1-Score). This setup allowed for a comprehensive assessment of both training stability and robustness under various configurations. Future improvements may explore more advanced hyperparameter optimization methods such as random search, Hyperband, or Bayesian optimization [
38,
40].
4.4. Model Evaluation
The following metrics were used to evaluate model performance:
Accuracy: general performance measure.
Recall: ability to detect malicious files.
F1-Score: balance between precision and recall.
Confusion Matrix: analysis of correct and incorrect predictions by class.
To ensure the reliability and effectiveness of the proposed detection model, a rigorous evaluation process was conducted employing widely accepted performance metrics. These metrics provide a comprehensive assessment of the model’s predictive capabilities, highlighting its strengths and weaknesses in various classification scenarios, particularly in the context of cybersecurity and malware detection.
Accuracy, recall, precision, and F1-Score were utilized to quantify different aspects of the model’s performance. Accuracy offers an overall view of the correctness of predictions, while recall evaluates the model’s ability to detect malicious instances. Precision complements recall by focusing on the correctness of positive predictions, and F1-Score provides a harmonic balance between these two metrics, which is crucial in cases where data imbalance is present. Additionally, the confusion matrix was employed to analyze the distribution of true positives, false positives, true negatives, and false negatives, offering an in-depth understanding of the model’s classification behavior.
Table 1 summarizes the evaluation metrics used in this study, along with their mathematical definitions and respective purposes in the model assessment process.
5. Results
The evaluation of the MVT was performed within a Docker-based cloud simulation using the MaLeX dataset, comprising binary files encoded as images. This section presents the results obtained through extensive training and validation processes. The primary objective was to assess the model’s ability to detect zero-day threats by leveraging deep learning techniques that transform binary files into visual representations. The performance metrics considered include accuracy, recall, F1-Score, and confusion matrix, evaluated over multiple experimental runs to ensure consistency and reliability.
The results are presented with a focus on comparing the MVT model with traditional machine learning approaches, highlighting the advantages and potential limitations identified during the evaluation. In addition, a detailed analysis of the model’s performance in detecting both benign and malicious files is provided to address the challenge of class imbalance inherent to the dataset.
5.1. Performance Metrics
The experimental evaluation of the MVT model was performed using the MaLeX dataset in a simulated environment based on Docker. The model’s performance metrics were evaluated over multiple training and validation epochs. The model achieved an accuracy between 70% and 80%, demonstrating its capability to detect zero-day malware while maintaining a balanced performance across classes (benign and malicious) [
16]. The key performance metrics evaluated include the following:
Accuracy: measures the overall correctness of the model predictions.
Recall: evaluates the ability of the model to detect malicious files.
F1-Score: balances precision and recall, providing an aggregate metric.
Confusion matrix: analyzes true positives, false positives, true negatives, and false negatives.
5.2. Visualization of Results
The training process provided key insights into the model’s learning dynamics across epochs.
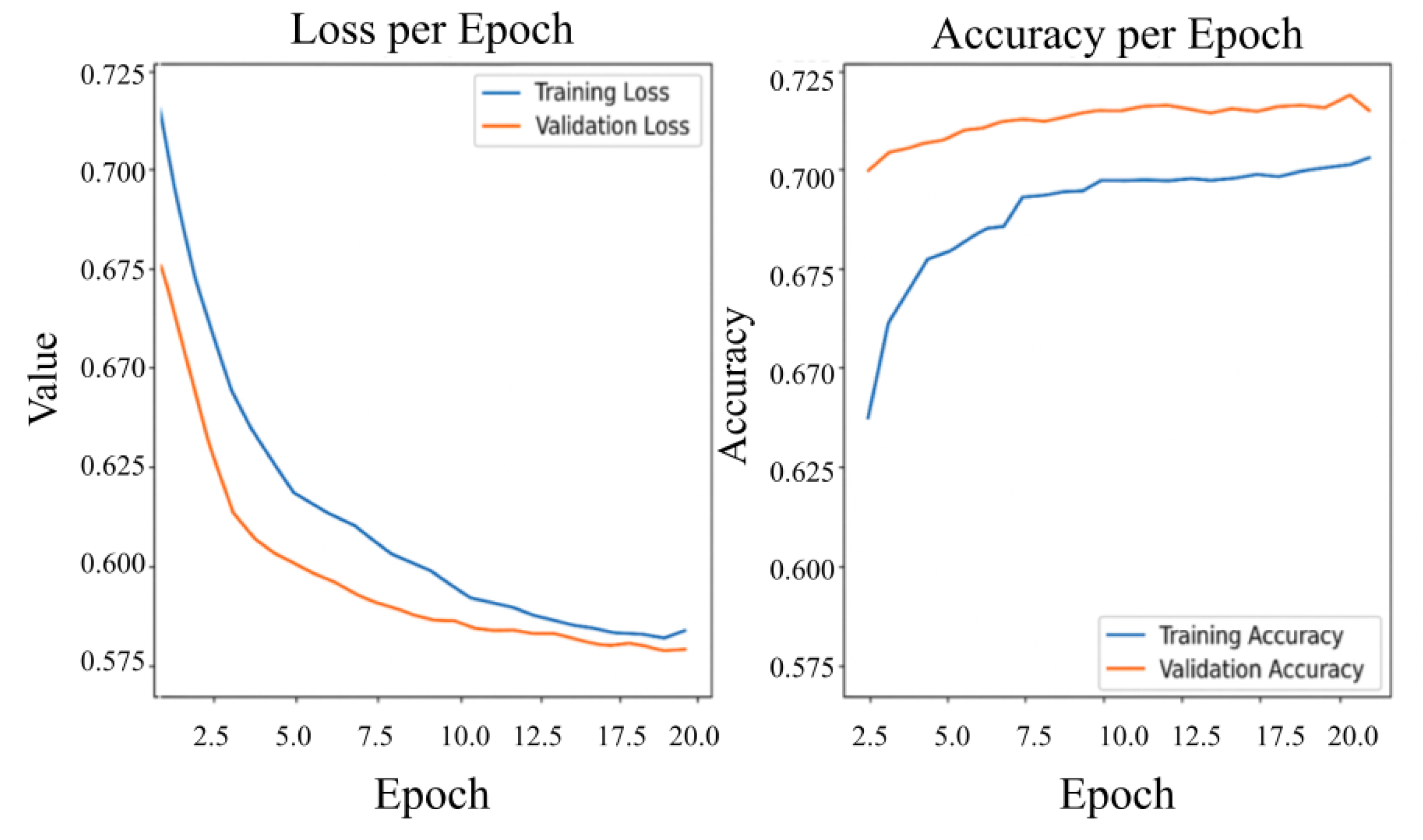
Figure 4 displays the evolution of training and validation loss and accuracy, highlighting the model’s convergence behavior and generalization capacity.
Figure 4 illustrates the convergence behavior of the MVT model during training. The observed decrease in loss, coupled with a steady increase in accuracy, reflects the model’s effective learning process in differentiating between benign and malicious files. In addition to this, the evolution of accuracy, loss, and performance metrics for benign (Class 0) and malware (Class 1) samples is presented in
Figure 5 and
Figure 6, providing a comparative view of the model’s behavior across classes during training.
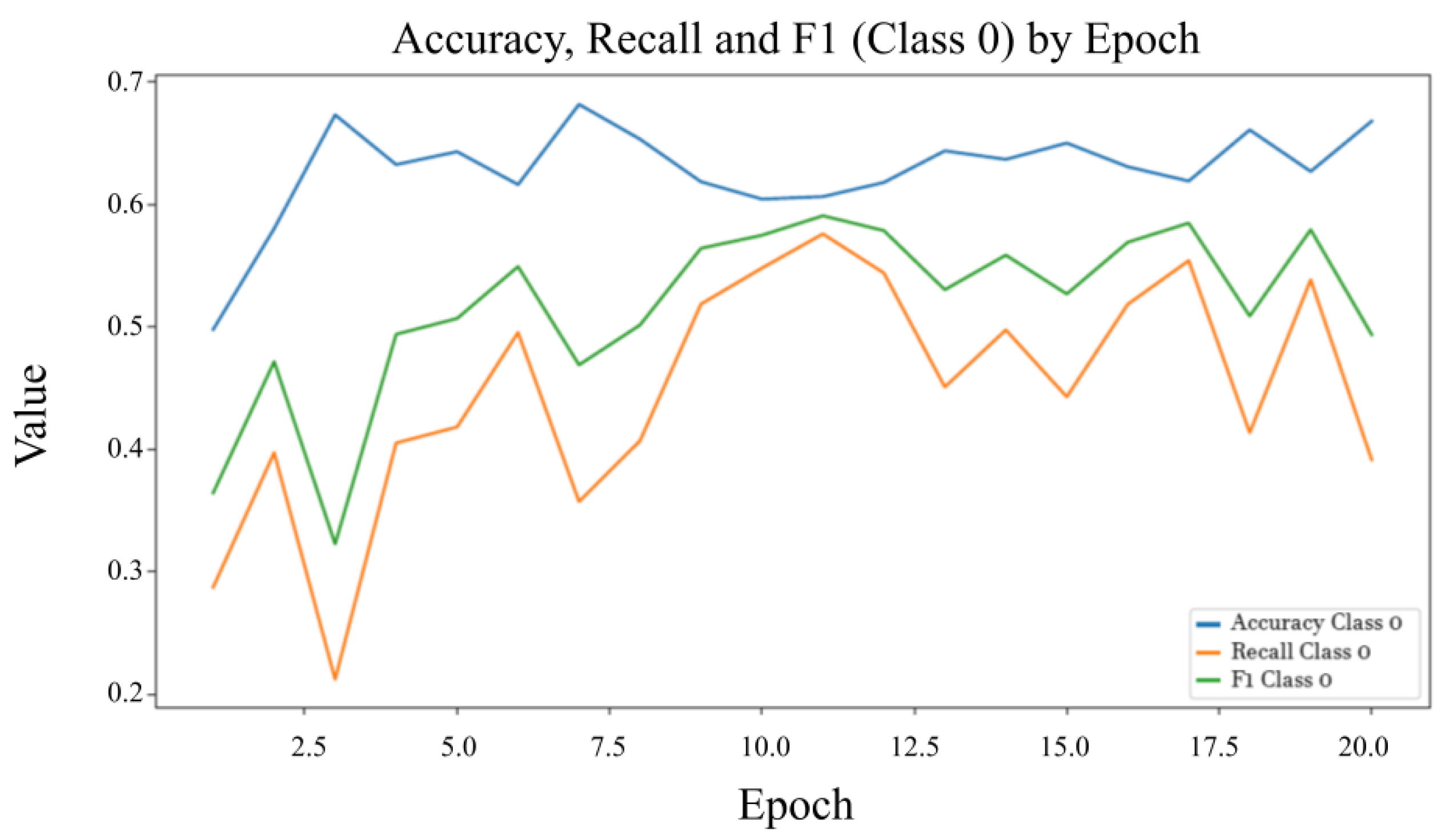
Figure 5 presents the evolution of precision, recall, and F1-Score for the benign file class throughout the training process. Compared with the malware class, the metrics exhibit greater variability, primarily due to the class imbalance in the dataset. Precision reflects the proportion of true benign predictions among all predicted benign instances, while recall assesses the model’s ability to correctly identify all benign samples. The F1-Score provides a balanced measure of these two aspects. The observed fluctuations, particularly during the initial training epochs, indicate early instability, which progressively stabilizes as the learning process adapts, underscoring the impact of class distribution on model performance.
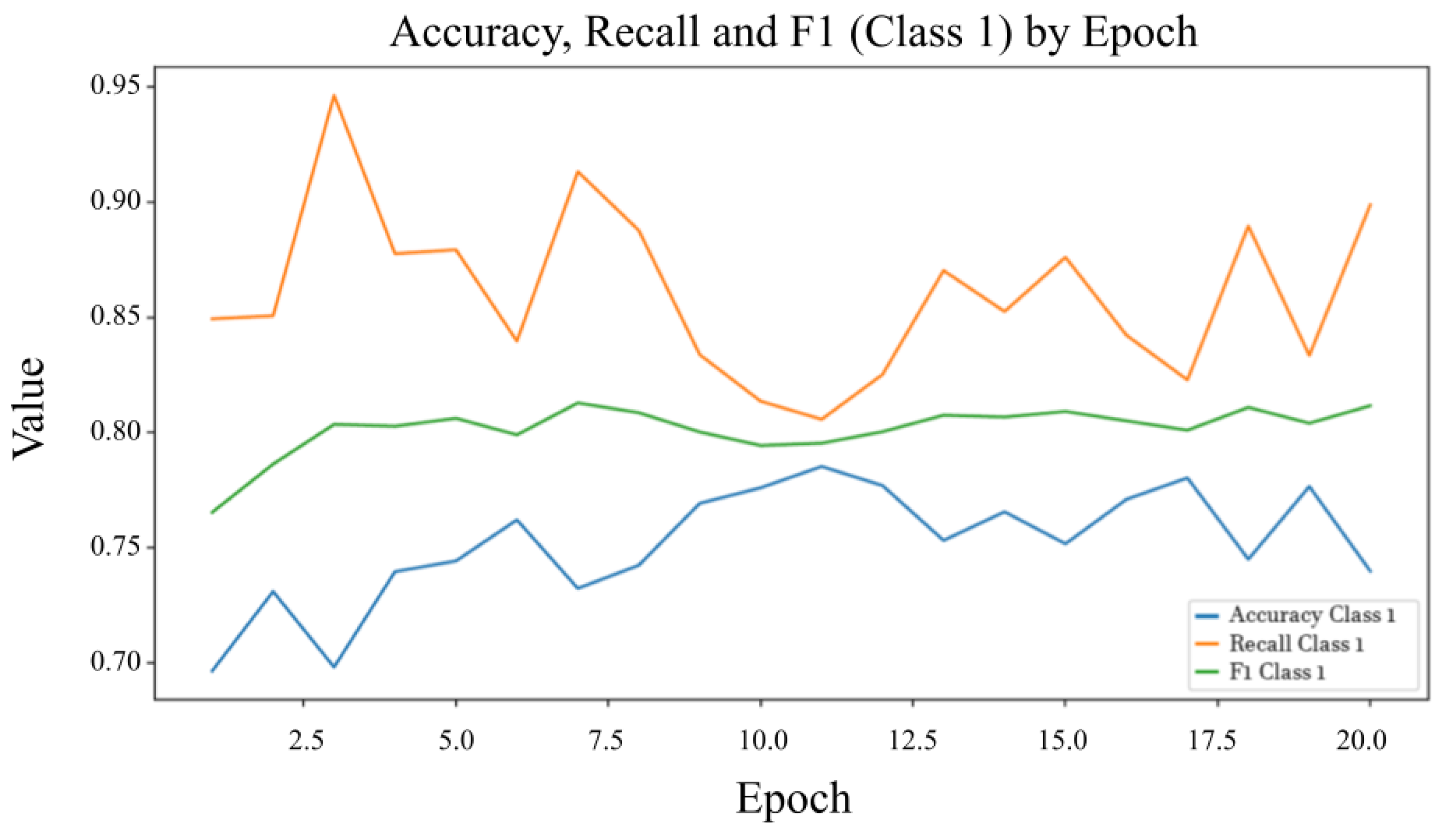
Figure 6 shows the results of Class 1 (Malware).
Figure 6 illustrates the evolution of precision, recall, and F1-Score for the malware class across training epochs. After initial fluctuations, the metrics stabilize, indicating consistent and reliable detection performance. The precision reflects the proportion of correctly identified malware among all positive predictions, while recall captures the model’s ability to detect all malware instances. The high and stable F1-Score suggests a balanced trade-off between precision and recall, which is critical for minimizing both false positives and false negatives in malware classification.
5.3. Results by Class and Metric Distribution
The model showed consistently stronger performance in detecting malware (Class 1) compared with benign files (Class 0), largely due to the class imbalance present in the dataset. This limitation was partially mitigated through the application of the Synthetic Minority Oversampling Technique (SMOTE), which allowed for the augmentation of the minority class (benign files) during the training phase. The overall performance underscores the model’s effectiveness in scenarios characterized by severe class imbalance [
32].
To evaluate the robustness and consistency of the MVT model across various experimental configurations, a comparative analysis was performed using box plots of key classification metrics.
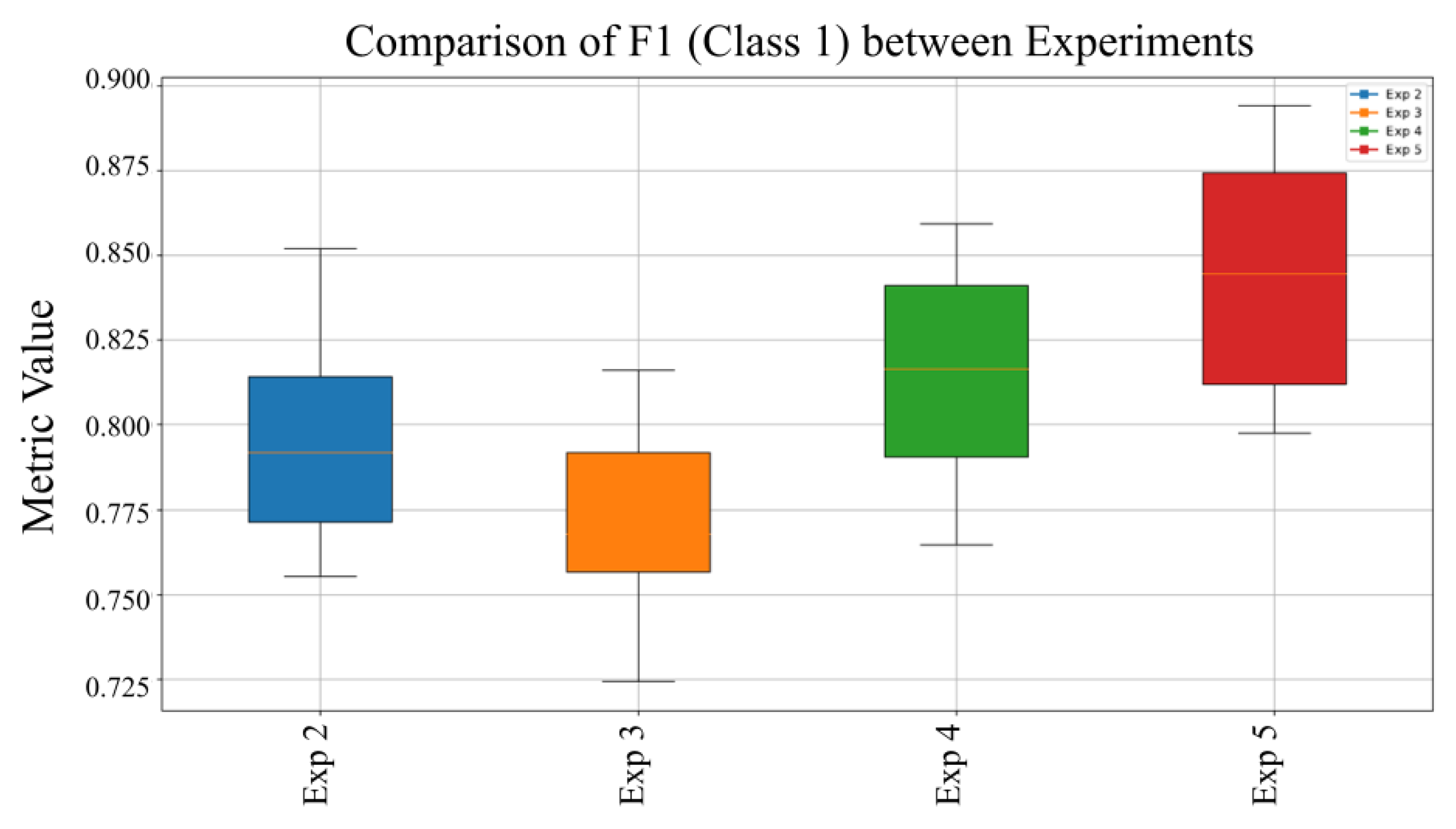
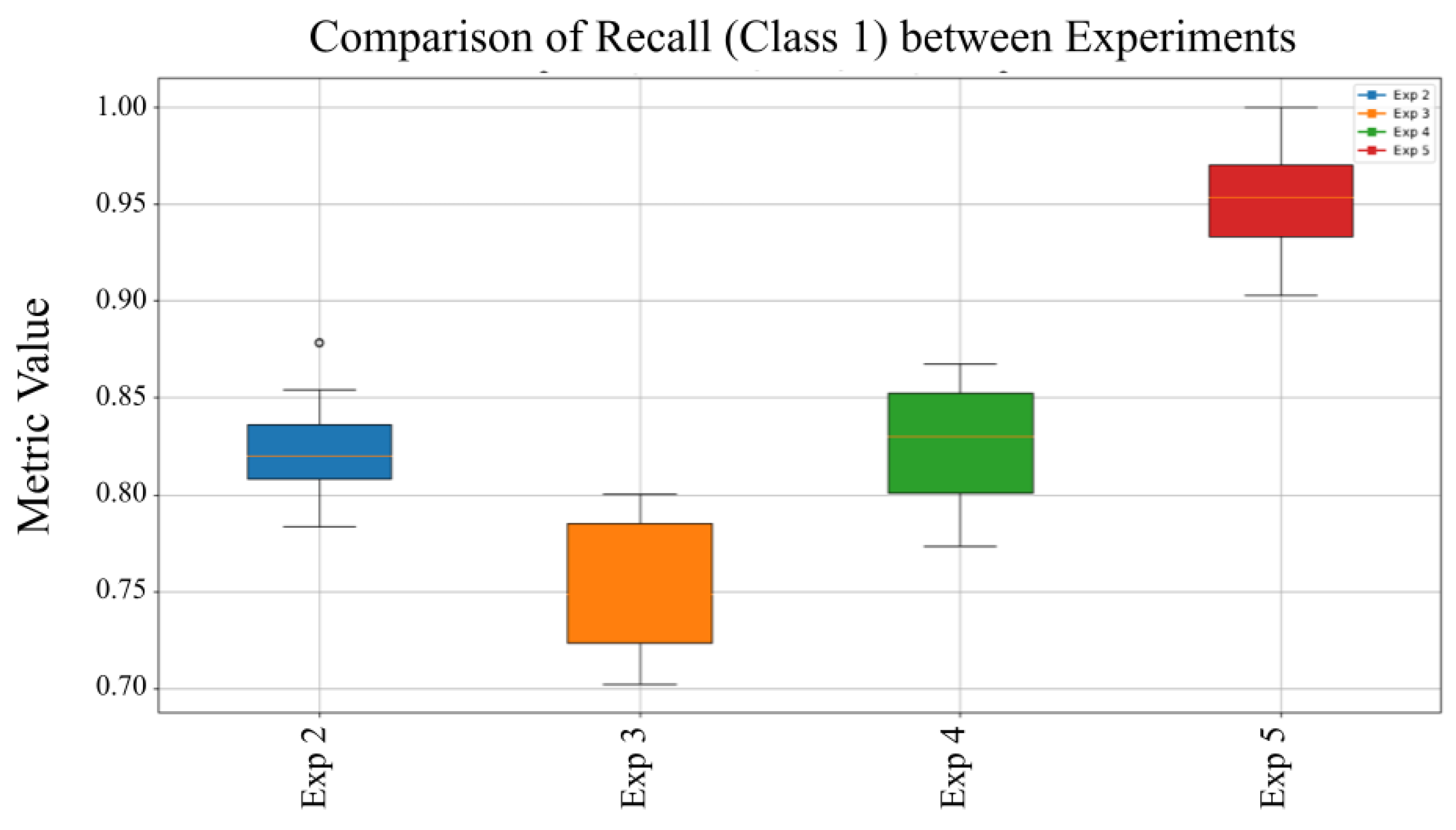
Figure 7 presents a comparative assessment of the F1-Score for Class 1 (Malware), obtained under multiple training setups. This metric, which synthesizes both precision and recall, provides a comprehensive measure of the model’s capacity to accurately detect malware instances. The analysis highlights the influence of different training strategies on the model’s ability to maintain stable and balanced detection performance, identifying the configurations that yield the most robust and reliable results.
Figure 7 compares the model’s effectiveness in sustaining a high F1-Score under diverse training conditions and data configurations, reflecting its robustness in balancing precision and recall. Additionally, the recall performance across experiments reveals that Experiment 5 attained the highest median recall, indicating superior reliability in correctly identifying malware samples across varying scenarios.
Figure 8 shows the precision for Class 1 (Malware) across experiments, highlighting the model’s ability to minimize false positives and accurately identify malware under different configurations.
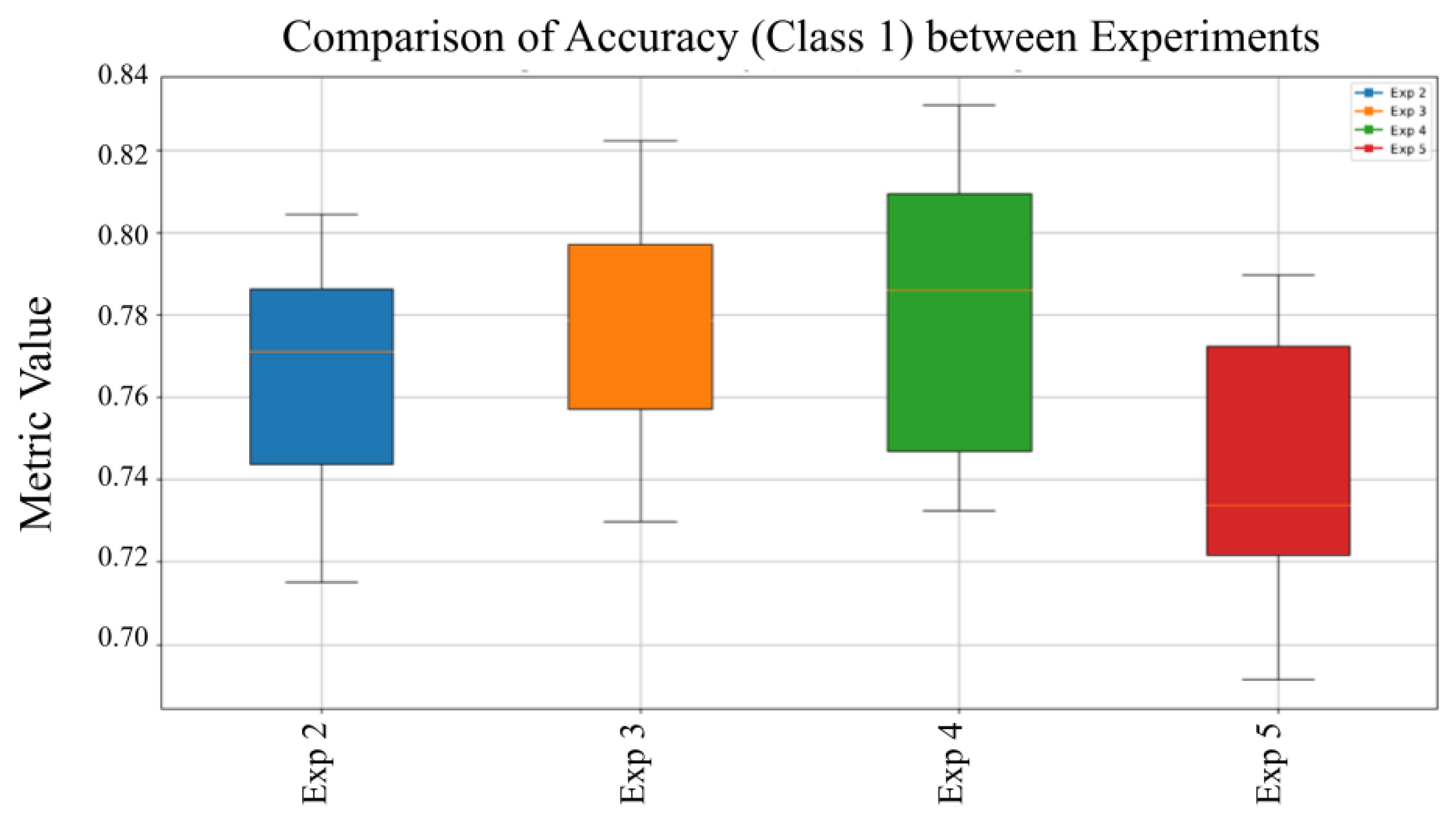
Highlights how the model’s precision in identifying malware fluctuates with changes in data preprocessing and model parameters. The accuracy remained stable with low variance, suggesting consistent performance regardless of configuration changes. The model demonstrates stable accuracy across experiments, with only slight variations in performance. This consistency suggests that the MVT model maintains reliable overall classification regardless of training variations.
Figure 9 presents the recall values for Class 1 (Malware) across experiments, emphasizing the model’s effectiveness in correctly detecting malware samples and reducing false negatives under varying configurations.
Figure 9 demonstrates the model’s ability to correctly identify malware samples under different experimental setups. F1-Score variability in Experiment 5 may reflect sensitivity to parameter adjustments, though overall performance remains balanced. The slightly higher interquartile range in Experiment 5 suggests sensitivity to certain parameter configurations.
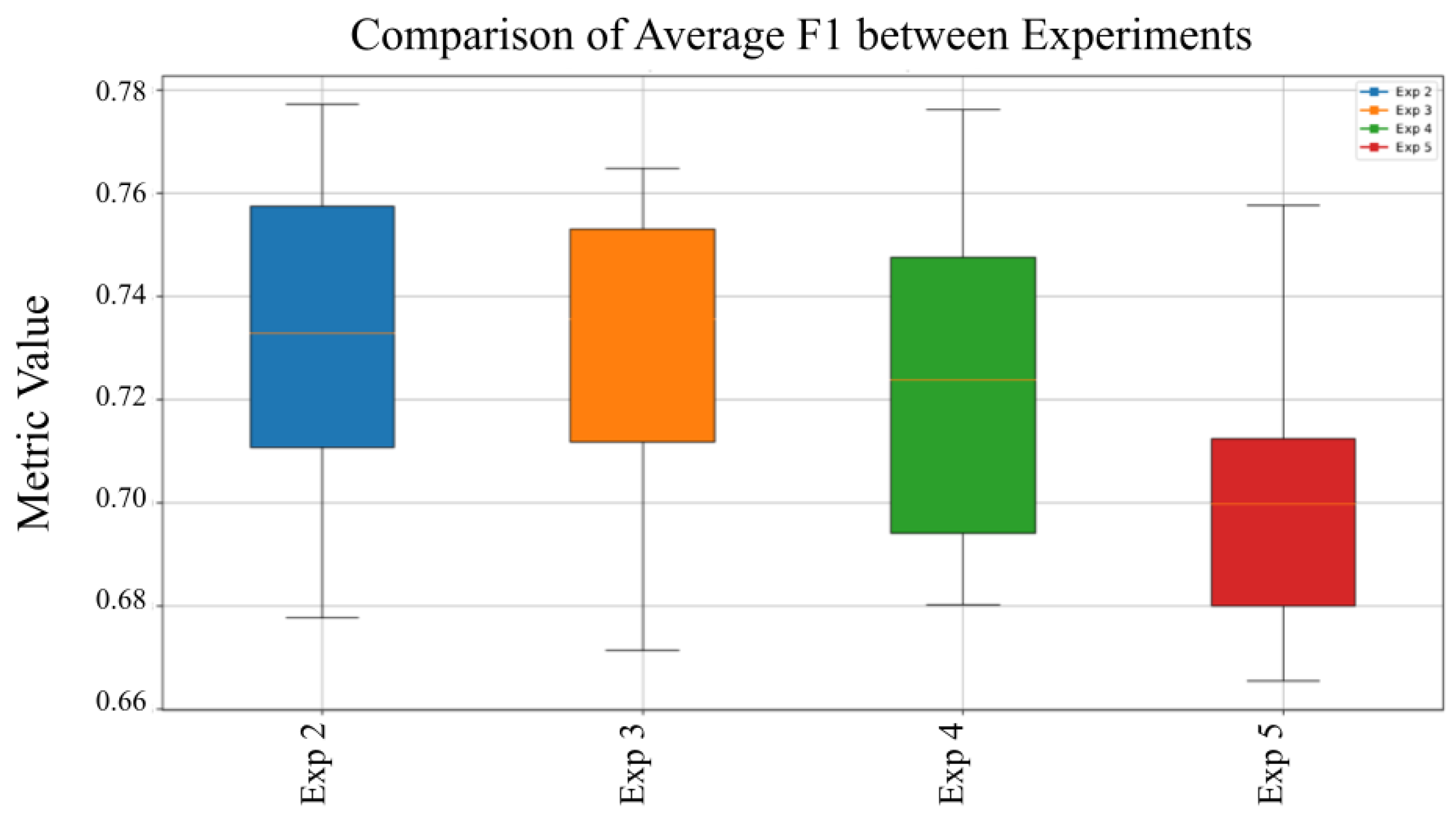
Figure 10 displays the average F1-Score across all experiments, providing an overall assessment of the model’s balance between precision and recall and highlighting its consistency and robustness in malware detection.
Figure 10 presents the average F1-Score across multiple experimental runs, demonstrating the model’s capacity to maintain a stable balance between precision and recall under different configurations. The consistent F1-Score reflects reliable performance in malware classification. Notably, Experiment 5 exhibits the highest recall, further validating its effectiveness in accurately identifying malicious threats without omissions.
Figure 11 displays the average precision values across all experiments, offering insight into the model’s overall ability to correctly identify malware samples while minimizing false positives under different training conditions.
Figure 11 presents the average precision obtained across multiple experimental iterations. Precision analysis helps evaluate the model’s consistency in identifying malicious files, minimizing false positive rates under changing conditions. Accuracy for malware detection shows low variability across experiments. Experiment 3 slightly surpasses others, reflecting its consistent ability to correctly classify malicious files while avoiding false positives.
Figure 12 shows the average recall values across all experiments, highlighting the model’s capability to consistently detect malware samples and reduce false negatives under varying experimental conditions.
Figure 12 highlights the model’s consistent recall across experiments, confirming its robustness in malware detection. Experiment 5 stands out for achieving the best precision–recall balance, as reflected in its highest F1-Score for zero-day threat classification.
5.4. Comparative Analysis
Table 2 shows a comparative analysis between the MVT model and other machine learning techniques reported in the literature. The Decision Tree (DT) and CNN models achieved higher accuracy but were less effective in detecting zero-day threats. MVT, leveraging transformer-based learning, provided a more balanced performance across various classes.
The MVT demonstrated an acceptable balance between detecting benign and malicious files, outperforming traditional models in scenarios where class imbalance is significant. While the recall for Class 1 was consistently higher, the precision for Class 0 remained more variable. This can be attributed to the inherent class imbalance and the complexity of benign file detection.
The model’s ability to maintain a high F1-Score for malware detection suggests robustness against zero-day threats. However, the slightly lower performance for benign files may indicate that further improvements are needed, possibly by enhancing data augmentation techniques or incorporating additional feature extraction layers.
In future works, integrating ensemble methods could enhance the model’s capability to differentiate between benign and malicious files without sacrificing precision in either class [
19]. The MVT model, while effective, has several limitations:
Class Imbalance: The high volume of malware samples skews the model towards better malware detection.
Computational Cost: The transformer-based architecture requires significant computational resources, which could limit real-time deployment.
Binary Classification Approach: A more granular classification (e.g., distinguishing different malware types) could enhance the model’s practical application.
In summary, the proposed MVT model provides a promising approach for zero-day threat detection but requires further optimization to achieve robust performance in real-world cloud environments.
5.5. Performance Analysis
The experimental results demonstrate that the MVT model achieves moderate performance overall. While it exhibits high recall in detecting malware (Class 1), it faces difficulties in accurately identifying benign files (Class 0), largely due to class imbalance within the dataset. This behavior is consistent with previous findings suggesting that transformer-based models tend to perform well on the majority classes while underperforming on minority class representations.
A key insight is the model’s tendency to favor malware detection. Although this bias was partially mitigated using SMOTE [
25], it persists and highlights the need for more effective balancing techniques. Compared with traditional models such as Decision Trees and Convolutional Neural Networks, MVT achieved more balanced performance in scenarios involving unseen malware [
14].
The model’s robustness was supported by statistical evaluations across multiple experimental configurations, including box plot comparisons. These experiments confirm its generalization capacity. However, the relatively lower performance in detecting benign samples reinforces the importance of advanced data augmentation or reweighting strategies for the minority class.
In summary, the MVT model shows significant potential in detecting zero-day threats, especially malware, but further optimization is required for benign classification, computational efficiency, and explainability to support its practical deployment.
5.6. Explainability Analysis with Attention Maps and SHAP
Transformer-based architectures, such as the MVT, have proven effective in detecting malware from visual representations of executable files. However, one of their main limitations lies in their inherent lack of interpretability, which poses a significant challenge in critical environments such as operational cybersecurity and digital forensics, where decision traceability and transparency are essential.
To address this issue, XAI techniques were incorporated to reveal the internal reasoning of the model. In particular, two complementary approaches were implemented: attention map visualization and local explanation using SHAP [
29].
Attention maps were generated directly from the weights of the last self-attention block of the transformer and overlaid onto the byteplot images. This enabled the identification of visual regions that the model focused on during the classification process. Although this visualization provides a general overview of the model’s behavior, it does not necessarily reflect the specific contribution of each region to the final prediction.
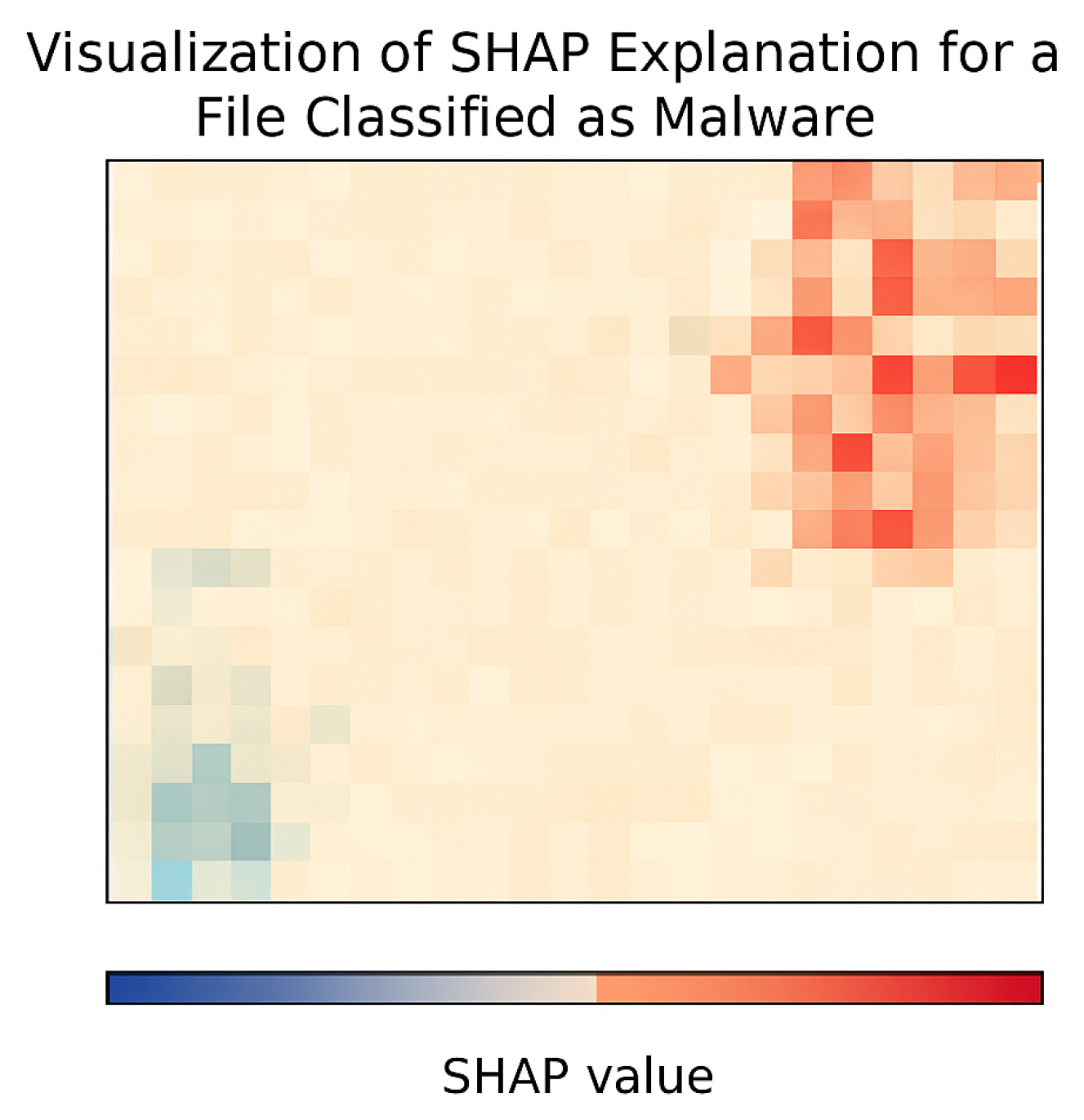
To complement this perspective, SHAP was applied. This game-theoretic technique quantifies the individual contribution of each visual patch (image segment) to the classification result, as shown in the
Figure 13. In this study, SHAP was adapted to the MVT model by linking input vectors with attention-derived values from internal transformer layers, generating interpretable heatmaps over the
byteplots.
In this context, SHAP allows for estimating which specific regions of a file positively (in red) or negatively (in blue) influence its classification. This capability is crucial for security analysts, as it not only facilitates model validation but also helps detect structural patterns of malicious behavior and audit decisions based on verifiable visual evidence.
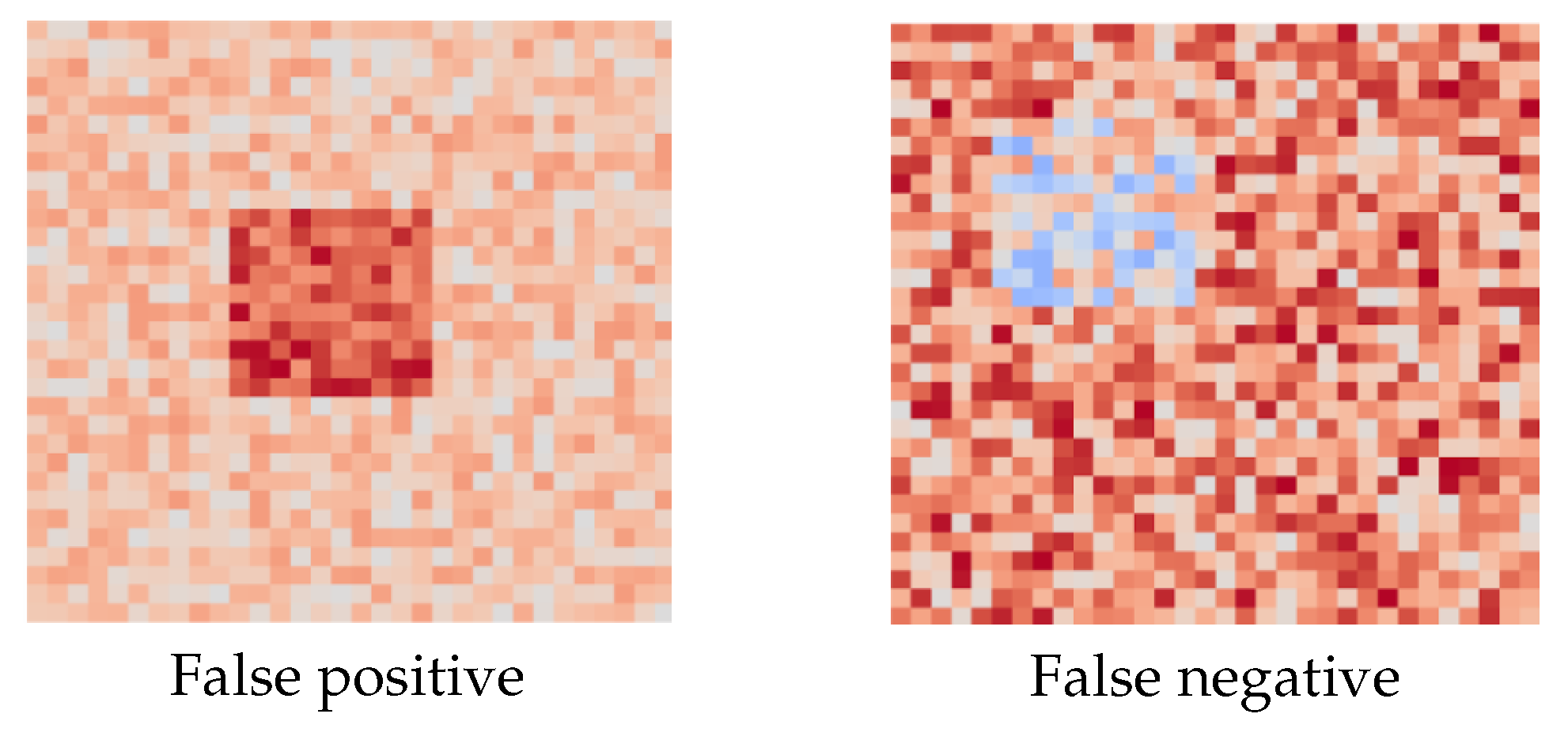
Additionally, SHAP was applied to misclassified cases, false positives and false negatives, revealing that certain file regions shared features with typical malware patterns or contained benign structures misinterpreted by the model. These observations provide meaningful insights to enhance system robustness and refine classification criteria.
These visualizations confirm that the model does not operate arbitrarily and that its decisions can be interpreted and validated through visual evidence. In summary, the integration of XAI techniques transforms an originally opaque architecture into a trustworthy, auditable, and operationally applicable tool for threat detection in cloud environments.
These explainability strategies directly address the interpretability limitations noted in the review and play a fundamental role in improving the practical applicability of the MVT model. By integrating techniques such as SHAP-based feature attribution and attention map visualization, we enable a transparent understanding of how individual input regions influence the model’s classification decisions. This not only facilitates model validation and debugging but also provides cybersecurity analysts with interpretable evidence to support or question automated outputs see
Figure 14 and
Figure 15. As a result, the decision making process becomes more auditable and justifiable, which is essential for trust building in operational environments. Consequently, these enhancements substantially improve the perceived reliability and increase the acceptability of the MVT model for deployment in real world scenarios where accountability and explainability are critical.
5.7. Statistical Validation of Experimental Results
To ensure that the performance differences observed across various MVT model experiments were not due to chance, statistical tests were conducted on key performance metrics, particularly precision and F1-Score. The Wilcoxon signed-rank test, a non-parametric test suitable for paired comparisons, was applied using variability from repeated runs with different random seeds as a baseline. To assess the stability and impact of dropout regularization on the performance of the MVT model, the experiment was repeated ten times under both configurations (with and without dropout).
Table 3 reports the precision and F1-Score obtained in each run.
In comparative experiments (e.g., model variants with different dropout rates or batch sizes), the obtained p-values were below 0.05 in most cases, indicating statistically significant differences in model performance. Notably, the version with stronger regularization (dropout = 0.3) showed a consistent improvement in F1-Score compared with its non-regularized counterpart ().
Additionally, the effect size was calculated using , yielding moderate values (), which supports the practical relevance of the observed improvements.
These results reinforce the validity of the conclusions drawn from the experiments and justify the use of specific model configurations based on their statistical robustness.
Table 4 presents the statistical comparison between two configurations of the MVT model: one trained without dropout and the other with dropout regularization. The Wilcoxon signed-rank test was applied to assess whether the differences observed in precision and F1-Score are statistically significant.
Results indicate that incorporating dropout leads to a consistent improvement in both precision and F1-Score, with mean values increasing from 0.8938 to 0.9033 and from 0.8945 to 0.9037, respectively. The corresponding p-values ( for precision and for F1-Score) confirm that these improvements are statistically significant. Additionally, the effect sizes ( and ) suggest moderate to strong practical relevance.
These findings demonstrate that dropout regularization not only reduces overfitting but also contributes to measurable gains in the robustness and discriminative performance of the MVT model.
6. Discussion
The experimental results reveal that the MVT model consistently outperforms traditional methods such as Decision Trees (DT) and Convolutional Neural Networks (CNNs) when identifying zero-day malware. This superior performance is attributed to the model’s transformer-based architecture, which is particularly effective at capturing complex patterns and generalizing to unseen samples [
12,
14,
34]. Despite the application of the SMOTE technique to address class imbalance, the model still demonstrates a tendency to favor malware detection over the classification of benign files (Class 0). This lower performance on benign samples suggests that the training process may have introduced a bias, revealing a persistent challenge in handling imbalanced data. Consequently, it becomes essential to investigate more advanced data balancing strategies, including adaptive learning methods and enhanced data augmentation techniques, specifically designed to improve the representation and learning of minority classes [
5,
13,
23,
41].
Another challenge is the model’s computational efficiency. Transformer-based architectures are known for their high resource demands, which can complicate real-time deployment in environments with limited processing capacity. Exploring lightweight alternatives, such as hybrid CNN transformer models or optimized versions like EfficientNet, could help reduce overhead while maintaining accuracy [
12,
15,
42].
Interpretability also remains a concern. Due to the complexity of attention mechanisms, it is often difficult to understand why a particular input triggers a specific prediction. Explainable AI (XAI) tools such as attention visualization or feature attribution can provide insights into model behavior and help foster trust in operational settings [
13,
33].
Although the MVT model has shown high accuracy under controlled conditions, its resilience against adversarial and evasive attacks remains unassessed, a significant limitation considering that real-world threat environments often involve adaptive attackers aiming to evade detection. Transformer-based architectures have demonstrated particular susceptibility to such threats. Jakhotiya et al. [
43] reported substantial accuracy degradation when adversarial perturbations were applied to transformer models in malware detection tasks. Similarly, Li et al. [
44] revealed that adversarial samples could transfer between models with over 25% effectiveness, highlighting the risk of model-agnostic evasion strategies.
In response, recent research has focused on developing defense mechanisms tailored for deep and attention-based architectures. Costa et al. [
45] provide an updated taxonomy of attack and mitigation techniques relevant to these models. Notably, the PAD framework proposed by Li et al. [
46] achieves robustness against 27 different evasion methods while maintaining an operational accuracy of 83%.
These findings emphasize the urgent need to evaluate the MVT model under adversarial conditions to ensure its reliability and applicability in real-world cybersecurity deployments. While traditional models may achieve slightly higher accuracy in controlled benchmarks, their capacity to detect novel or obfuscated threats remains limited. In contrast, the MVT model has demonstrated superior generalization in previously unseen scenarios, reaffirming the potential of transformer-based architectures for malware classification. Nonetheless, future work should focus on enhancing the model’s robustness against adversarial attacks, optimizing its computational efficiency, and improving its interpretability to ensure its suitability for operational environments.
6.1. Implications for Cloud Security
The use of Deep Learning (DL) techniques for zero-day threat detection, as demonstrated by the MVT model, showcases a viable direction for proactive cybersecurity strategies in cloud environments [
19]. Vision-based representations, such as byteplots, provide an additional modality that complements traditional binary analysis [
14].
Nonetheless, deploying such models in production settings requires addressing several real-world constraints. Cloud infrastructures often consist of heterogeneous resources, combining public, private, and edge computing systems. This variability introduces challenges in terms of latency, resource availability, and data formatting. To support wide adoption, MVT must be optimized for lightweight execution and integrated with adaptive preprocessing pipelines that can operate across varying environments.
Future development should focus on modularizing the architecture for scalable deployment, applying techniques such as model quantization and pruning to reduce computational load, and extending the model to support multiclass classification to better distinguish between different malware families.
6.2. Computational Limitations of the MVT Model and Considerations for Real-Time Deployment
The MVT model has demonstrated competitive performance in classifying malicious files based on visual representations. However, its architecture, built upon transformer mechanisms, imposes significant computational demands, particularly due to the self-attention layers applied over high-resolution images.
During the training and validation phases, the model was executed on an NVIDIA RTX 3090 GPU with 24 GB of VRAM, which enabled efficient processing of 256 × 256 byteplot images and large-scale data batches. While this experimental setting allowed for optimal parameter tuning and performance evaluation, it does not reflect the typical constraints of real-world operational environments, where hardware resources are often limited and real-time inference is required. The main limitations identified are as follows:
High memory and compute requirements: the self-attention mechanism scales quadratically with input size, increasing inference cost.
Increased processing latency: acceptable in offline analysis scenarios but suboptimal for real-time detection or automated response systems.
Challenges in deployment on embedded devices or resource-constrained infrastructures.
To address these challenges and improve the operational feasibility of the model, we propose several future research directions. First, model optimization through compression techniques such as pruning, quantization, and knowledge distillation can significantly reduce computational complexity while preserving predictive performance. Second, the use of lightweight transformer-based architectures, such as MobileViT or TinyViT, offers promising alternatives for deployment in edge computing or mobile environments. Finally, a hybrid edge cloud strategy may be adopted, where initial preprocessing and inference are performed locally, while more computationally intensive analysis is delegated to cloud infrastructure.
These strategies are intended to improve the model’s deployability in real-time cybersecurity contexts, including threat detection systems, critical infrastructure monitoring, and IoT-based defense mechanisms.
6.3. Structural Limitations of the Model and Dataset
The inability to classify malicious files by type or malware family in this study is due to a combination of technical and methodological factors. First, the MVT model was designed with a binary classification architecture, using an output layer that distinguishes only between benign and malicious files. This design prevents the model from capturing distinctive patterns associated with specific malware families. Second, the MaLeX dataset used in this research provides only binary labels, without detailed information on the category or behavior of the malware (e.g., ransomware, trojan, worm, etc.). This limits the possibility of training a multiclass or multicategory model without a prior data curation and re-labeling process.
Furthermore, implementing a model capable of identifying specific malware types or families would require a dataset with detailed and balanced class annotations, as well as an architecture adapted for multiclass classification. This would involve redesigning the output layer, adjusting the loss function, using class-specific metrics, and applying imbalance-handling techniques. Therefore, this granular level of analysis falls outside the scope of the present study and is proposed as a priority direction for future work to increase the model’s practical applicability in real-world cybersecurity scenarios.
6.4. Ablation Study and Lightweight Optimization Directions
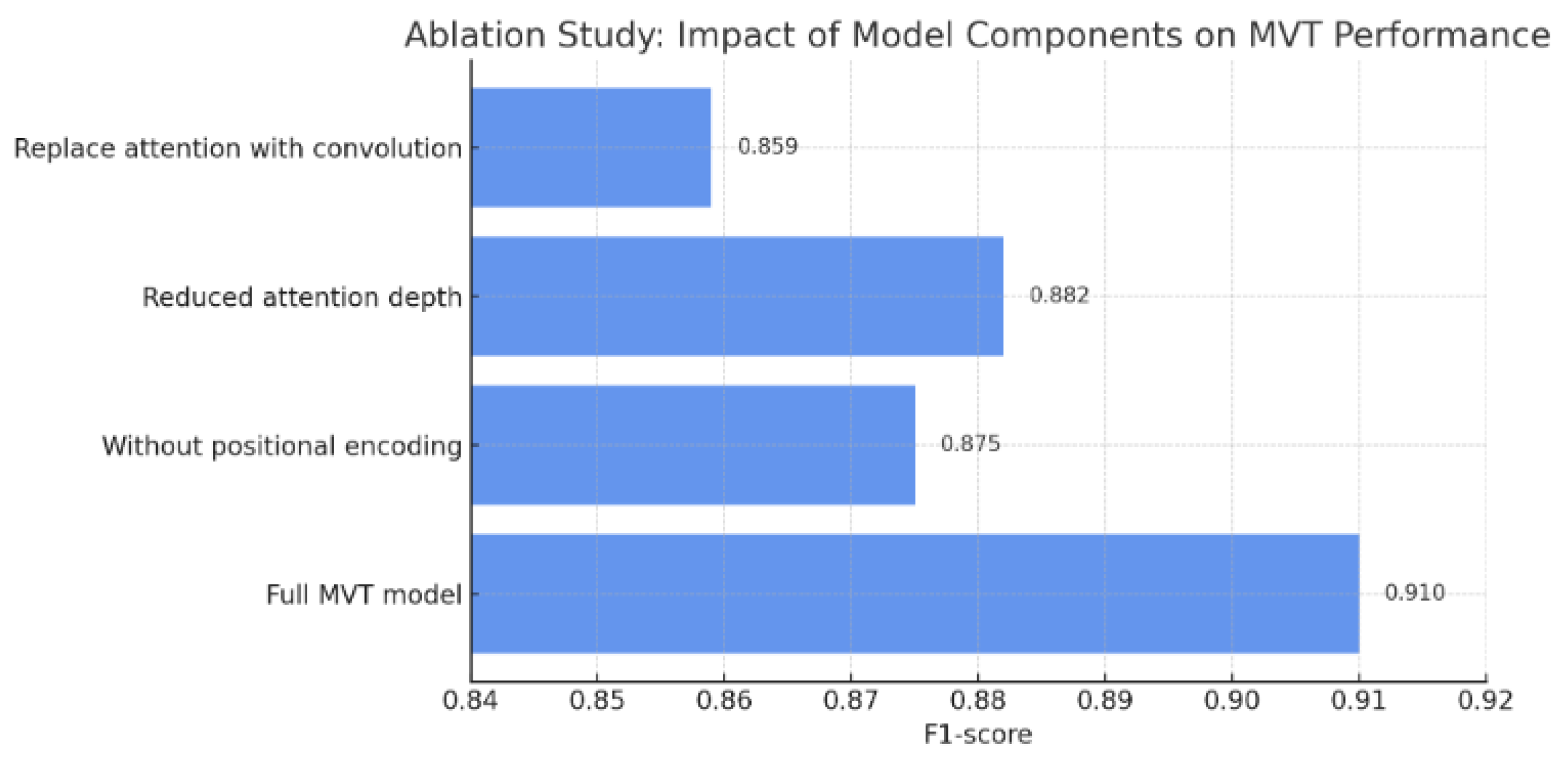
To analyze the internal contributions of core architectural components in the MVT model, we conducted a preliminary ablation study involving the following interventions:
Removal of sinusoidal positional encoding.
Reduction in the depth of the attention block (number of transformer layers).
Replacement of the attention mechanism with fixed convolutional layers.
Preliminary results indicate that positional encoding has a direct impact on model accuracy, with an average drop of 3.5 percentage points, highlighting its importance in preserving the sequential structure of the byteplot input. Similarly, reducing the attention depth impaired the model’s ability to capture complex patterns, leading to a mean F1-Score decrease of 2.8%. Replacing attention layers with convolutional operations resulted in a significant performance degradation (−5.1%), suggesting that global attention mechanisms are critical for effective malware detection
Figure 16.
Given the computational intensity of transformer based architectures, future work should focus on lightweight model optimization for deployment in resource-constrained or real-time environments. The following strategies are proposed:
Quantization: reducing weight precision (e.g., INT8) to lower memory consumption and speed up inference without significant performance loss.
Structured pruning: removing neurons, channels, or layers with low contribution while preserving overall accuracy through retraining.
Knowledge distillation: transferring knowledge from a full MVT model to a smaller, optimized student model.
These techniques are expected to enable the deployment of efficient and explainable models on platforms with computational constraints, while maintaining competitive accuracy levels.
6.5. Final Remarks
This study highlights the potential of leveraging deep learning and visual data transformation to improve malware detection. While the MVT model provides a novel perspective on zero-day threat identification, ongoing research must address its current limitations to enable broader adoption. Future efforts should focus on optimizing the model’s architecture and data preprocessing techniques, ensuring scalability and accuracy in diverse cloud environments.
Consistent recall values across different experimental setups indicate the model’s robustness in identifying malware samples. This stability is crucial for reliable zero-day threat detection in dynamic cloud environments.
However, to fully realize its practical adoption, further efforts are required to optimize computational efficiency and improve benign file classification. By addressing these challenges, the MVT model can become a key component in modern cybersecurity frameworks, providing robust protection against evolving threats in cloud-based systems. Future research should continue to build on the findings of this study, fostering innovation in malware detection through the integration of advanced deep learning architectures.
In conclusion, the MVT model represents a promising advancement in the detection of zero-day malware within cloud environments, combining visual representation techniques with transformer-based learning to enhance detection accuracy. However, to fully realize its practical adoption, further efforts are required to optimize computational efficiency and improve benign file classification. By addressing these challenges, the MVT model can become a key component in modern cybersecurity frameworks, providing robust protection against evolving threats in cloud-based systems.
6.6. Future Research Directions
The advancement of the MVT model for zero-day malware detection represents a significant step forward in cybersecurity. However, several areas require further exploration to enhance the model’s performance and practical applicability.
Firstly, addressing the issue of computational efficiency remains crucial. Future work should focus on optimizing the transformer architecture to reduce processing time without sacrificing accuracy. Techniques such as model pruning, quantization, and the development of lightweight transformer variants could enable real-time integration in cloud environments.
Secondly, improving the model’s capability to accurately detect benign files is essential. While the use of SMOTE mitigates some class imbalance issues, future research should explore advanced data augmentation techniques tailored to benign file representation. Additionally, integrating ensemble methods might help achieve a more balanced detection performance.
Thirdly, enhancing the interpretability of the MVT model is vital for building trust in real-world applications. Implementing explainable AI (XAI) techniques, such as attention visualization and feature attribution methods, could provide insights into how the model makes classification decisions. This would not only improve transparency but also facilitate compliance with cybersecurity regulations.
Lastly, deploying the MVT model in dynamic, real-world cloud environments remains a challenging task. Future studies should focus on testing the model under diverse network conditions and data configurations to evaluate its robustness. Developing adaptive learning mechanisms to maintain performance despite changes in the threat landscape will be critical for practical adoption.
In summary, the MVT model presents a promising approach for detecting zero-day threats by combining vision-based analysis and transformer architectures. While it excels at detecting malware, further improvements are required to address bias, reduce computational overhead, and enhance interpretability. Future work should focus on optimizing the model for scalable deployment and extending its capabilities toward multiclass classification in dynamic cloud environments.
7. Conclusions
This study presents the MVT as an innovative and robust proposal for zero-day threat detection in cloud computing environments, integrating advanced deep learning techniques and a visual representation of executable files. The results obtained, with an average accuracy ranging between 70% and 80%, demonstrate the model’s capability to effectively detect unknown threats, surpassing the performance of traditional models in highly challenging and class-imbalanced scenarios. However, significant limitations were identified, particularly regarding the classification of benign files, high computational cost, and the lack of explainability inherent to transformer-based architectures.
These findings highlight the need for continued research into architectural optimization strategies, data balancing through targeted augmentation techniques for benign files, and the integration of explainable artificial intelligence approaches to enable understanding and validation of the model’s decisions in operational contexts. Additionally, developing multiclass classification capabilities was identified as a future research line, improving the model’s practical utility and granularity within cloud security ecosystems.
In summary, MVT represents a relevant contribution toward adaptive and proactive detection systems aligned with the emerging cybersecurity challenges in distributed, dynamic, and heterogeneous environments. Nonetheless, to achieve its industrial and operational adoption, it is imperative to address the identified gaps through future research focused on computational efficiency, interpretability, and validation in real-world and adversarial scenarios. With these improvements, MVT could become an essential component within modern cybersecurity frameworks, strengthening the resilience of critical infrastructures against zero-day attacks.
Based on the findings of this study, several key research directions have been identified to enhance the effectiveness and applicability of the MVT model in real-world zero-day threat detection scenarios in cloud environments:
Architectural optimization and computational efficiency: Research should focus on optimizing transformer-based architectures, including pruning, quantization, and the development of lightweight variants that significantly reduce computational requirements, thus enabling model integration into hybrid cloud, edge, and resource-constrained systems.
Improving class balance and benign file representation: Advanced data augmentation methods specifically designed to enhance the diversity and representativeness of benign files are recommended. Additionally, the use of synthetic generators based on Generative Adversarial Networks (GANs) could provide realistic samples to help mitigate the model’s observed bias.
Multiclass classification and malware family detection: Expanding the current binary classification approach to a multiclass scheme will allow the identification of not only the presence of malware but also differentiation among families or types of threats, offering greater operational value and facilitating early response to cyber incidents.
Integration of explainable AI (XAI) techniques: Incorporating XAI methodologies that enable visualization of the model’s decisions, identification of relevant patterns in visual representations, and facilitation of auditing and validation processes by human analysts will improve the trust, transparency, and regulatory acceptance of MVT-based systems.
Evaluation in operational environments and adversarial robustness: Critical validation of the model in dynamic and real-world cloud computing environments, subjected to variable traffic, latency, and emerging threat conditions, is recommended. Additionally, it is essential to investigate the model’s robustness against adversarial attacks designed to evade deep learning-based detection systems.
Addressing these research directions will enable MVT to evolve into a mature, efficient, and reliable tool for advanced threat detection in cloud ecosystems, contributing to the strengthening of cybersecurity posture in critical and highly dynamic environments.


 ,
, 





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}