1. Introduction
With the exponential growth of multicore architectures in modern servers, optimizing concurrency control (CC) has become a critical challenge for online transaction processing (OLTP) systems. As the demand for higher throughput and lower latency intensifies, efficiently scaling transaction processing across cores is essential for latency-sensitive applications such as financial trading, e-commerce, and distributed databases. However, the performance of these protocols degrades rapidly on workloads with high contention [
1], where hot data items are frequently accessed and modified by many concurrent transactions. Existing approaches to addressing high-contention workloads can be broadly classified into two main paradigms:
1. Partition-based execution. Partitioning techniques aim to colocate contention transactions within the same partition to minimize cross-partition communication and CC overhead. By assigning transactions to fixed threads or cores, partition-based strategies reduce inter-partition contention and facilitate execution with minimal coordination, making explicit CC mechanisms unnecessary in ideal deployment scenarios. However, they inherently limit intra-transaction concurrency and lack flexibility in the presence of dynamic or skewed workloads. Moreover, many real-world workloads are not naturally partitionable [
2,
3], which further constrains their applicability.
2. Fine-grained CC. Although hot data may constitute only a small portion of a transaction’s execution time, traditional CC schemes like two-phase locking (2PL) [
4] and optimistic concurrency control (OCC) [
5] operate at the transaction level, either holding locks or aborting entire transactions, leaving much of the potential concurrency unexploited. To overcome this problem, techniques such as transaction chopping [
6,
7], IC3 [
8], and runtime pipelining [
9] decompose transactions into smaller pieces or operations. These techniques enable the early exposure of intermediate results, but they require careful scheduling to prevent deadlocks and cyclic dependencies. For example, if one transaction accesses Table A before B and another accesses them in reverse order, IC3 merges these operations into a single execution unit to avoid cycles—sacrificing parallelism for safety. In real-world OLTP applications, transaction dependencies become increasingly complex due to high-frequency access to hot items and fluctuating client request patterns [
10]. Existing methods face fundamental challenges in balancing transaction dependencies and concurrency, which urges the design of
dynamic,
dependency-aware scheduling frameworks.
Deep reinforcement learning (DRL) has shown great promise in solving complex combinatorial optimization problems such as graph routing and job scheduling [
11,
12,
13]. However, its application to contention-aware scheduling in OLTP systems remains relatively unexplored.
In this paper, we propose Dynamic Contention Scheduling (DCoS), a DRL-based framework designed to enhance transaction concurrency by adaptively resolving both inter-transaction and intra-transaction contentions. Rather than developing a new high-performance concurrency control scheme, we improve the effectiveness of transaction processing through dependency-aware scheduling, with the capability to adapt to varying levels of contention. We implement a flexible contention identification mechanism based on hot data, enabling DCoS to dynamically switch between lightweight execution for low-contention workloads and DRL-based fine-grained scheduling for high-contention scenarios. Specifically, DCoS introduces a two-stage transaction processing architecture:
Transactions are first dynamically partitioned. Transactions without cross-partition contention are executed independently and in parallel across cores.
Transactions with potential cross-partition contentions are further decomposed into fine-grained operations. A DRL agent is then used to learn contention-aware execution orders, optimizing core utilization and minimizing aborts under dynamic workloads.
Our contributions are summarized as follows:
We formulate complex-dependency transaction scheduling as a Markov Decision Process (MDP), enabling adaptive execution through learned scheduling policies.
We propose an Adaptive Placement Graph structure to jointly encode intra-transaction and inter-transaction dependencies, as well as partition-to-core mappings.
We develop a scalable, architecture-agnostic DRL executor with efficient feature embeddings, capable of generalizing across diverse concurrency scenarios and processing environments.
We conduct an extensive experimental evaluation to demonstrate the effectiveness of the proposed approach, showing consistent improvements over both existing transaction-scheduling strategies and state-of-the-art CC methods without scheduling.
2. Related Work
2.1. Transaction Partitioning
Transaction partitioning has been introduced to address scalability and performance bottlenecks in multicore database systems, particularly under high-concurrency workloads. By dividing transactions based on data access patterns, partitioning minimizes inter-core synchronization and coordination overhead, thereby improving throughput and simplifying CC within the system. Static transaction-partitioning methods include range-based partitioning, which divides data based on value ranges (e.g., timestamps or IDs), and hash-based partitioning, which distributes data evenly across cores using hash functions.
As data distributions and access frequencies evolve, dynamic partitioning adjusts real-time data allocation to balance load and optimize performance. Horticulture [
2] develops an analytical cost model that allows for the rapid estimation of relative coordination costs and skews associated with a specific workload and candidate database design. Horticulture facilitates an informed exploration of the vast solution space through large neighborhood search techniques. Schism [
3] partitions the co-access graph among data items and uses these partitions to infer the static partition predicates. Clay [
14] is an elasticity algorithm that balances load and minimizes distributed transactions simultaneously, by creating dynamic blocks on-the-fly while monitoring the workload. Prasaad et al. [
15] propose a transaction-processing protocol for high-contention workloads, which identifies hot records in the database during runtime, clusters transactions that access them together, and executes them without CC protocol. The effectiveness of transaction partitioning is highly dependent on workload distribution. Imbalanced partitioning schemes can lead to over-provisioned partitions with unnecessary resource allocation, or suffer from load imbalances, resulting in underutilized compute resources.
2.2. Concurrency Control
Conventional CC approaches enforce serializability through strict access ordering mechanisms:
2PL [
4]: Enforces exclusive write locks until a transaction completes. Conflicting reads must wait for locks to be released, leading to sequential bottlenecks.
OCC [
5]: Delays the visibility of writes until a validation phase, resulting in write-set propagation delays for dependent transactions.
Multi-Version CC (MVCC) [
16]: Utilizes timestamp-based version control, restricting reads to committed versions available before the transaction start time.
2.2.1. Transaction Decomposition
For two transactions with inter-transaction dependencies, all three above approaches require one transaction critical path to wait for the other to complete. To address these limitations, transaction decomposition-based methods have been proposed [
6,
7,
8,
9]. Transaction decomposition minimizes contention and reduces the duration of locks on commonly accessed data items by analyzing programs to divide a transaction into independent sub-transactions, which enables controlled access to uncommitted writes through dependency tracking. IC3 [
8] integrates a static analysis of transaction workloads with runtime techniques that manage and enforce dependencies among concurrent transactions, ensuring serializability while permitting parallel execution of certain conflicting transactions. Callas [
9] partitions a transaction into groups, then employs different CC protocols for groups to execute independently.
2.2.2. Transaction Dependency Management
Mitigating transaction contention and optimizing CC synchronization overhead are critical challenges in high-performance transaction processing systems. Effective management of inter-transaction dependency and intra-transaction dependency can significantly improve system throughput and reduce latency.
Inter-transaction dependency: Calvin [
17] maintains dependency information between transaction groups, ensuring that dependent transactions only proceed after the completion of prerequisite transactions. Ding et al. [
18] propose a thread-aware policy to reorder transactions efficiently in a multi-threaded OLTP architecture based on OCC. AlNiCo [
19] utilizes SmartNICs to route transaction requests to CPU cores, reducing contention with low latency intelligently.
Intra-transaction dependency: Polyjuice [
18] leverages RL model to explore a policy space of fine-grained actions for individual operations. Bamboo [
20] introduces a CC protocol that extends traditional 2PL by dynamically assigning timestamps, allowing locks on hot data items to be retired early while preserving serializability. Chiller [
21] modifies lock order to reduce lock hold times for hot records.
2.3. Transaction Assignment
Most transaction-processing systems employ a thread-to-transaction assignment strategy, limiting their ability to utilize intra-transaction parallelism effectively. To address this limitation, several studies have explored techniques to harness such parallelism [
8,
22,
23,
24,
25]. QueCC [
25] adopts a queue-to-thread assignment strategy, dynamically parallelizing operations through two phases of priority-based planning. Similarly, LADS [
24] separates contention resolution and transaction execution into two stages, enabling the decentralized and dynamic partitioning of dependency graphs into load-balanced subgraphs at the record level. Traditional thread-to-queue assignment methods struggle to adapt to fluctuating transaction priorities and varying access patterns. When high-priority transactions encounter unresolved contention, static queue-based architectures experience prolonged tail latency, leading to system inefficiencies. DCoS proposes a novel execution model which adapts to dynamic workloads to reduce the latency of transaction processing.
3. Preliminaries
In this section, we establish the formal foundations of transaction processing and then introduce key concepts for reinforcement learning.
3.1. Formalism of Transaction Processing
Definition 1 (Transaction). A transaction constitutes a finite sequence of database operations executing as an atomic unit. Each operation represents either a or action on data item .
Operations within the same transaction can exhibit two types of dependencies, which arise based on the transaction’s logical structure. We categorize these as intra-transaction dependency, which are further divided into (1) data dependency and (2) commit dependency.
Definition 2 (
Intra-Transaction Dependency)
. For operations and within transaction , the partial order satisfies: Intra-transaction data dependency exists when relies on data computed by . Formally, is said to be data-dependent on if it requires a value produced by .
Intra-transaction commit dependency ensures transaction atomicity when certain operations may be subject to logic-induced aborts. Logic-induced aborts result from violating integrity constraints defined by applications, which are captured by the set of constraints . Intuitively, if an operation is associated with at least one constraint that may not be satisfied after the execution of the operation, then it is abortable.
Another type of dependency exists between operations of different transactions, which the execution model induces.
Definition 3 (
Inter-Transaction Dependency)
. For distinct transactions , a dependency exists iff: This general dependency can be classified into two specific cases:
Write–read dependency: If , then ’s commit must precede ’s execution to prevent cascading aborts.
Write–write dependency: If , then and require mutual exclusion on d, meaning they must be serialized to avoid data inconsistency. Unlike write–read dependency, this type of contention does not enforce a strict execution order.
Transaction contention. Transaction contention primarily arises from inter-transaction dependencies, where multiple transactions contend for shared data. A transaction is considered conflict-free with another transaction if there are no contentions between them. The nature of these contentions is determined by the isolation level enforced by the CC protocol. For example:
Under serializability, contention occurs when two transactions access the same data item, and at least one modifies it.
Under snapshot isolation, contention occurs if two transactions attempt to write the same data item.
Effectively managing transaction contentions is essential for maintaining database integrity, ensuring correctness, and optimizing performance in a concurrent environment.
3.2. Reinforcement Learning
Reinforcement learning is a practical approach for adaptive decision making in dynamic environments. In this framework, an agent iteratively refines its actions based on feedback from the system state. This learning paradigm is typically modeled as a Markov Decision Process, represented by the tuple .
The agent interacts with the environment at discrete time steps. At each step t, the agent observes a state from the state space and selects an action from the action space . After executing the action, the environment provides a reward , and the agent transitions to a new state according to the transition probability distribution .
The process of selecting actions is guided by a policy
, which specifies the probability of choosing an action
a in a given state
s. The objective of the learning-based optimization process is to derive an optimal policy
that maximizes the expected cumulative reward:
where
is the discount factor that controls the importance of future rewards.
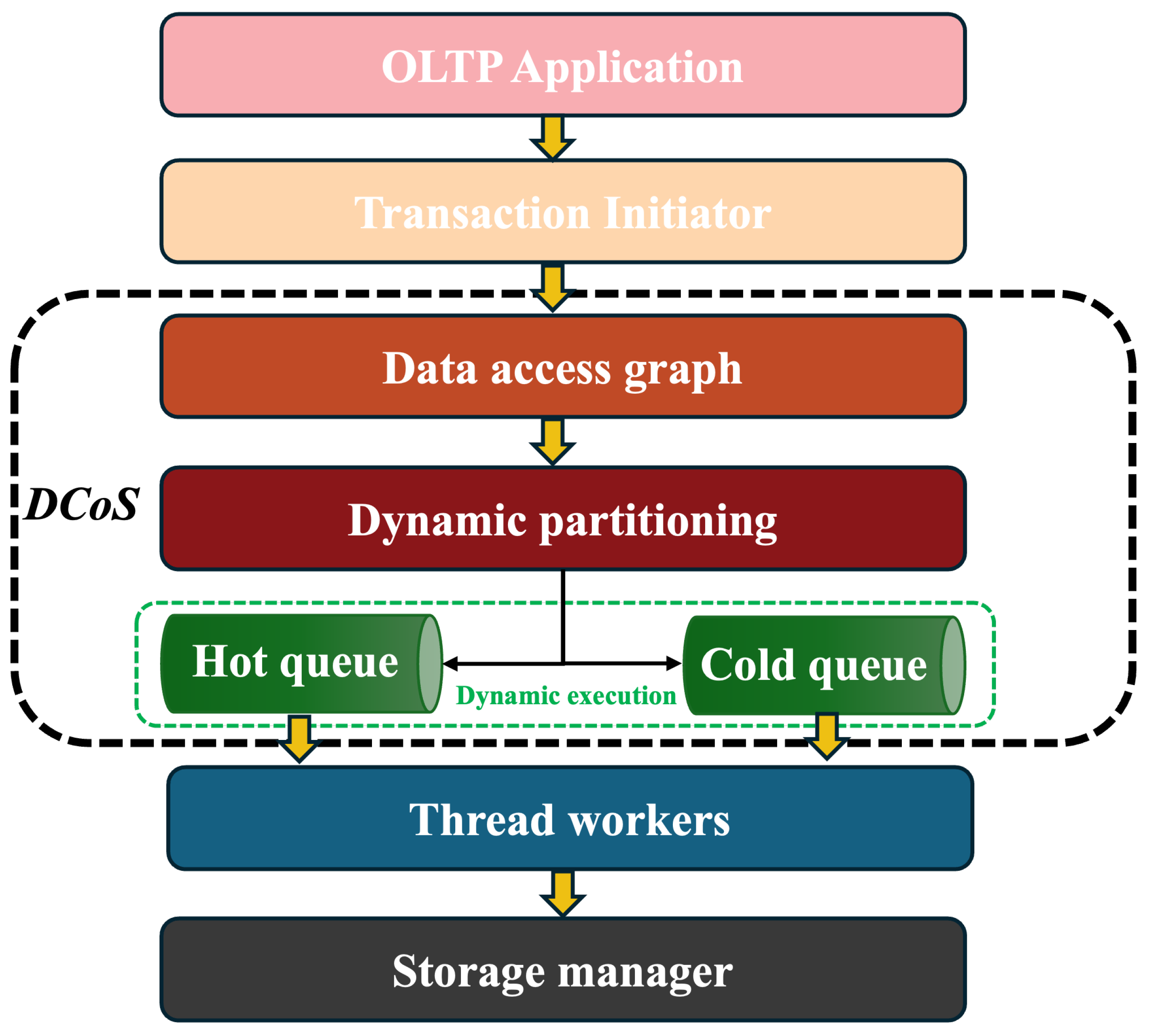
4. Design of DCoS
DCoS adopts a one-shot transaction-processing model, in which a transaction begins execution only after all its inputs are ready. Many modern in-memory systems employ similar models, including H-Store [
26], Calvin [
17], and Silo [
27], which leverage pre-declared access patterns to enable efficient scheduling and deterministic execution in some cases. DCoS adopts two coordinated phases to optimize transaction processing.
Figure 1 shows the workflow of DCoS.
(
Section 4.1) Conflict-free partitioning phase: Transactions are partitioned based on high-contention data items.
(
Section 4.2) Dynamic execution phase: The CC granularity of the transactions is determined dynamically according to data access patterns.
4.1. Conflict-Free Partitioning Phase
Given a transaction batch , DCoS applies a partitioning function to minimize concurrency control to divide it into:
p conflict-free clusters ;
A residual set , where , and serves as the residual threshold parameter.
The transaction-partitioning problem is generally NP-hard, and extensive research has been conducted in this domain [
3,
15,
24]. We adopt the dynamic partitioning algorithm following [
15], and DCoS is also compatible with other partitioning functions.
DCoS follows a proactive framework that leverages the knowledge of the complete database scheme and the complete set of stored procedures in OLTP applications. DCoS analyzes the contention among transactions based on their read–write sets by creating the data access graph from the read–write set of transactions. Specifically, the partitioning phase consists of three key processes:
1. Identifying hot data items. Hot data items are probabilistically detected by randomly sampling transactions for trials. The data items accessed by these sampled transactions are merged into a designated hot cluster, ensuring that only transactions are processed and hot clusters are formed in this step.
2. Expanding the hot cluster with cold items. For the remaining transactions, if at most one of their accessed data items belongs to an existing hot cluster, the data set of the entire transaction is merged into that cluster. However, if a transaction accesses data items spanning multiple hot clusters, it is skipped to prevent cross-cluster conflicts.
3. Optimizing the volume of the residual set. The system continuously monitors the residual growth ratio . If the residual volume exceeds the threshold , a hot cluster merging process is triggered to balance the trade-off between reducing CC synchronization overhead and maintaining thread concurrency efficiency.
4.2. Dynamic Execution Phase
4.2.1. Execution Model
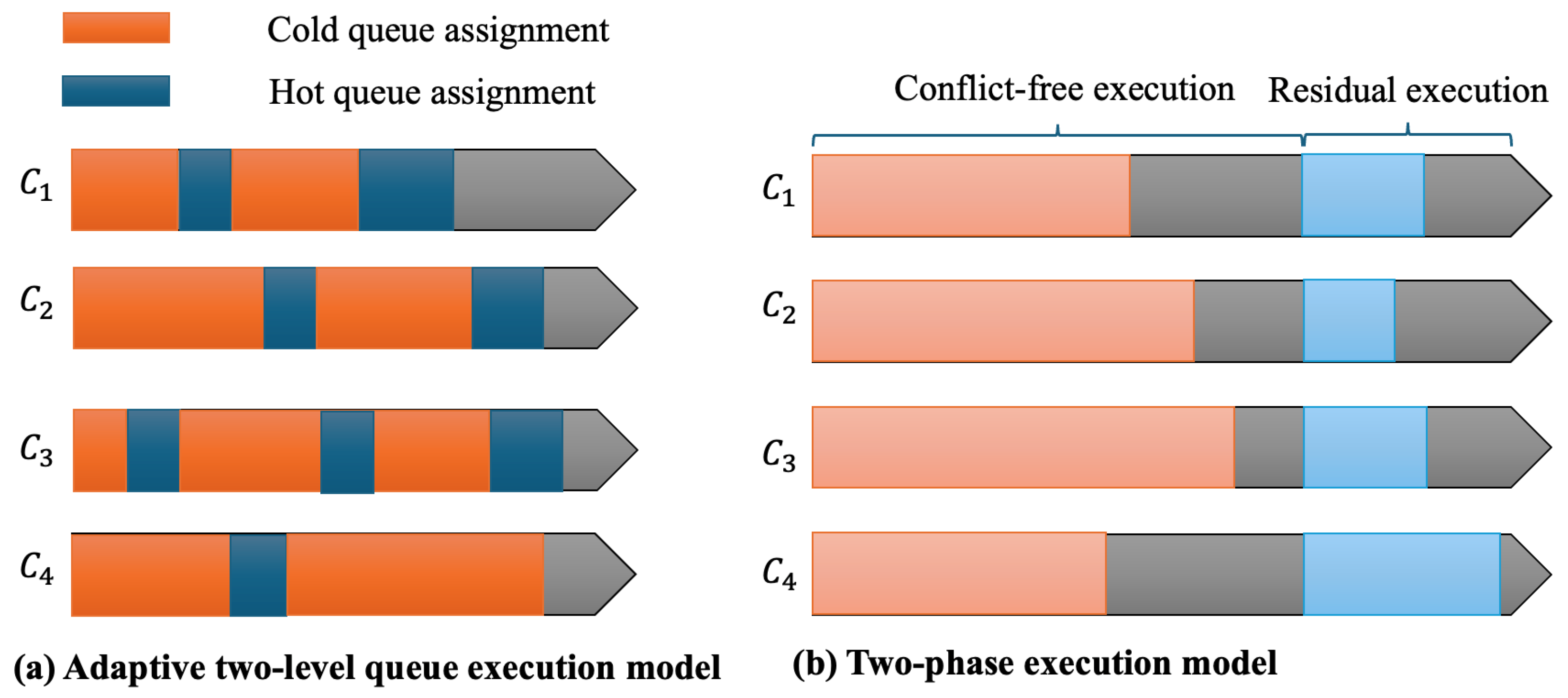
Existing solutions [
15,
28] employ a two-phase execution method, as shown in
Figure 2b. In the first phase, conflict-free clusters are executed serially without requiring any CC protocol on
m available cores
. We consider the situation in which each core is assigned to a single thread and use thread worker and core assignment interchangeably in the following paper. In the second phase, residual transactions involving cross-partition data items are executed using conventional CC protocols across all cores. However, this approach has inherent limitations: transactions in the residual set limit the entire transaction processing latency due to cross-partition dependencies (see
Section 4.2.2 for details). The system can manage conflicts more effectively and improve concurrency control by decomposing transactions into smaller pieces based on their contention data set.
DCoS solution. Given the varying workloads and processing times of conflict-free clusters, particularly for residual transactions, DCoS introduces a fine-grained scheduling approach for cross-partition transactions. Firstly, transactions accessing multiple high-contention data items (i.e., cross-partition transactions) are decomposed into transactions pieces leveraging runtime pipelining (RP) [
9]. RP organizes these pieces based on data dependencies and assigns each group a rank. Depends on whether access hot data item in different partition, the transaction pieces can be further divided into
contention-intensive transaction pieces and
non-contentious transaction pieces. Among the same group, existing RP-based methods mainly merge these accesses into a single execution unit to avoid deadlocks, which limits the level of parallelism that can be potentially exploited. We employ fine-grained scheduling with a DRL-based executor to explore more concurrency among the same group (see
Section 4.2.3 for details).
Then DCoS employs an
adaptive two-level queue execution model as shown in
Figure 2a.
Hot queue: Designed to handle contention-intensive transaction pieces requiring fine-grained scheduling at the operation level. A DRL-based executor is employed to maximize concurrency within these contention-intensive transaction pieces.
Cold queue: Designed to handle transactions (or transaction pieces) that do not involve cross-partition data. Utilize a coarse-grained scheduling approach (e.g., conventional methods such as round-robin allocation), where entire transactions (pieces) are assigned to threads.
The adaptive two-level queue execution model adheres to the following scheduling principles:
Principle 1: Concurrent execution and scheduling. DCoS executes cold-queue transactions with hot-queue transactions scheduling concurrently. The fine-grained scheduling process dynamically adapts to execution progress according to thread state.
Principle 2: Priority-based scheduling. Transactions in the hot queue are assigned higher execution priority, while cold-queue transactions are assigned lower priority. If no hot transactions can proceed due to dependency constraints, the thread first fetches from the cold queue. Instead of forcing hot-queue transactions to wait idly, the system dynamically schedules transactions in the cold queue to execute first.
Principle 3: Dependent enforcing. Hot-queue transactions are often dependent on cold-queue transactions. Since cold-queue transactions access low-contention data but may still hold locks on critical data items, hot-queue transactions that require those items must wait until the locks are released. In addition, execution dependencies between transaction pieces within the same transaction are enforced via the lock mechanism defined in the RP framework [
9]. Specifically, a later transaction piece cannot acquire the locks until all earlier pieces have released theirs.
Compared with the two-phase execution model, the two-level queue execution model dynamically adjusts execution order based on dependencies and thread status with the following objectives:
Reduced lock contention: Hot transactions experience fewer conflicts through fine-grained scheduling to reduce the probability of aborts.
Higher resource utilization: Cores remain active by executing transactions in the cold queue when hot transactions wait for a lock.
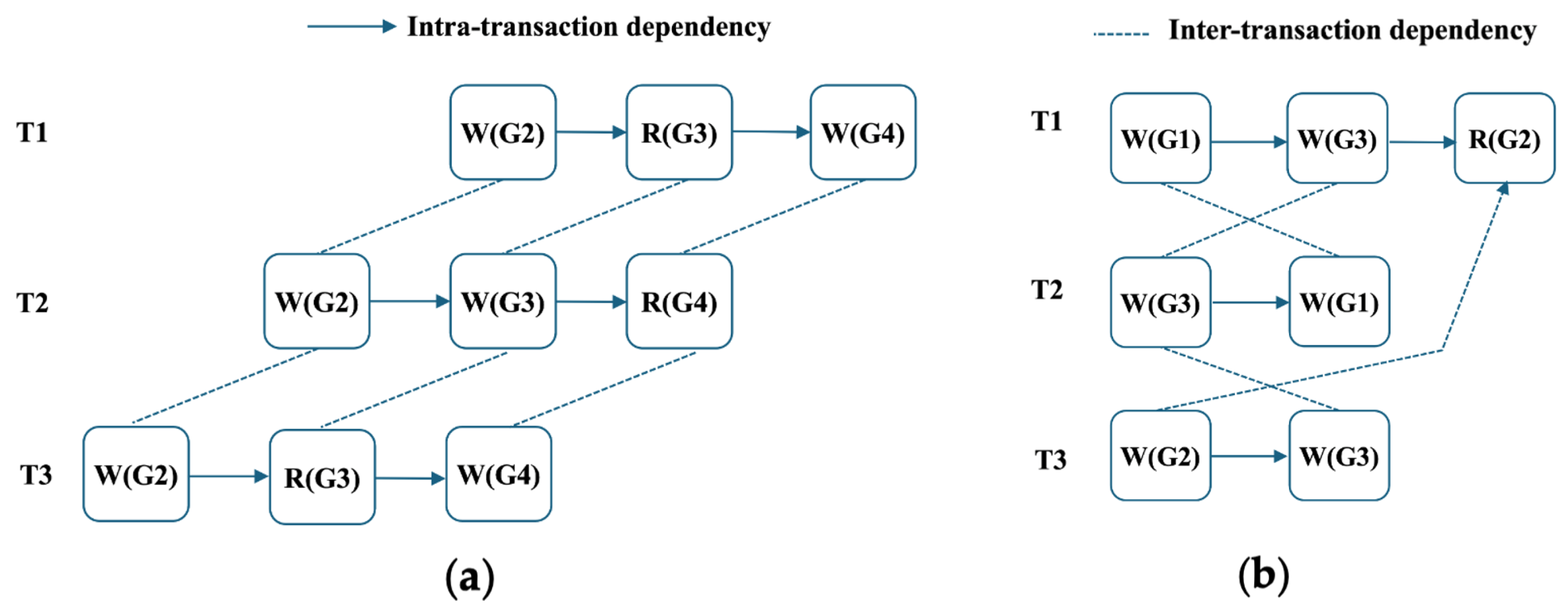
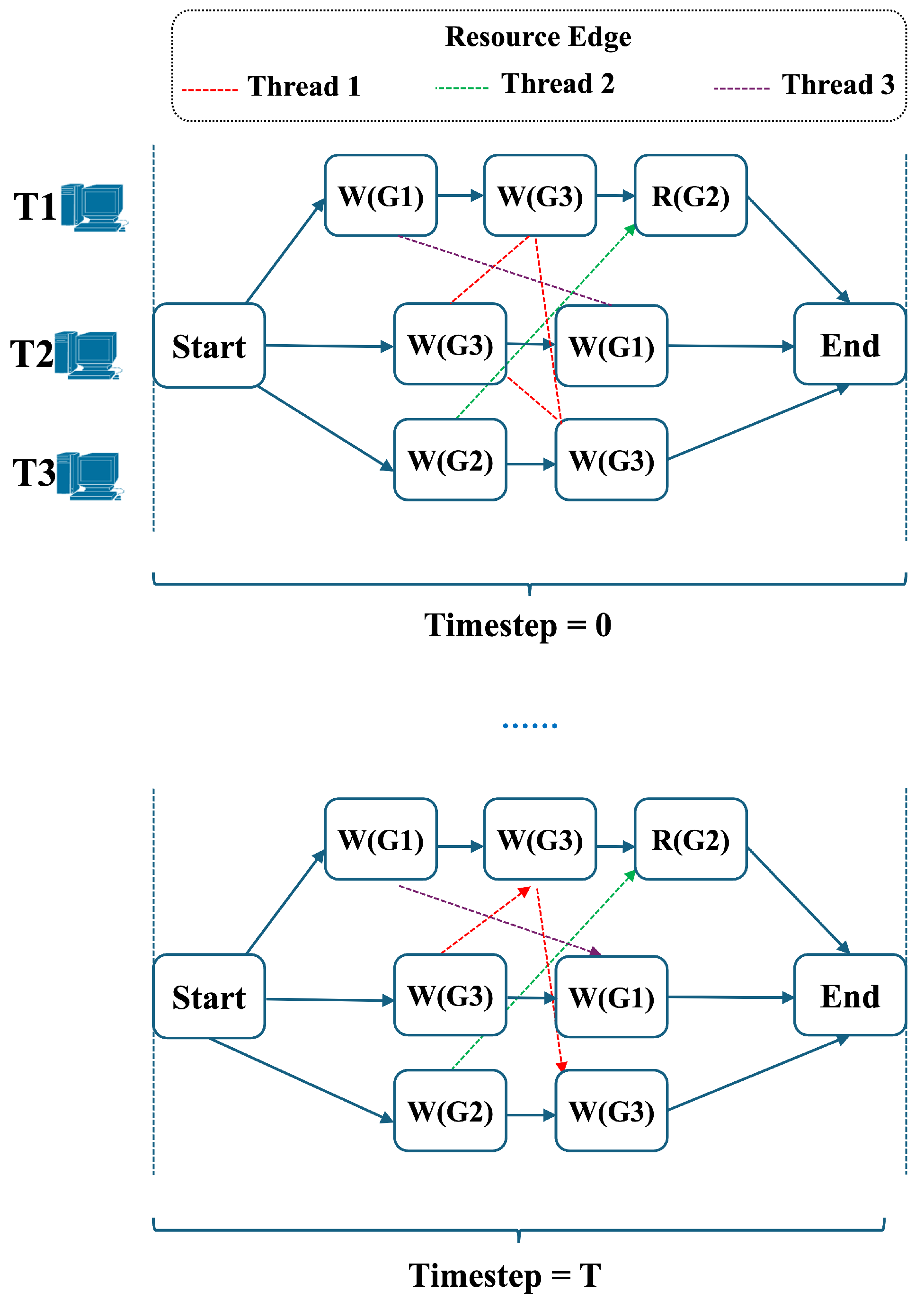
4.2.2. Contention Transaction Patterns
Before introducing the fine-grained scheduling design, we first analyze the fundamental dependency patterns within the residual set
using two representative examples, as illustrated in
Figure 3.
denotes a write operation, and
represents a read operation.
Example 1 (
Direct dependency)
. Figure 3a illustrates a direct dependency scenario in which transactions , , and access shared data items , , and with overlapping write operations. To ensure serializability under such contention, transaction execution can be coordinated by assigning different start times based on dependency order. For instance, by applying proactive delayed data access [28], ’s write to can be scheduled first, followed by , and finally , respecting a write sequence to avoid conflicts. Example 2 (
Transitive dependency)
. In real-world workloads, more complex dependency chains frequently arise, as shown in Figure 3b. Here, transitive dependencies exist among , , and . Unlike direct dependencies, simply adjusting the execution order of transactions cannot resolve the scheduling problem. An inappropriate sequence may still result in transaction aborts, which imposes a more sophisticated scheduling solution. 4.2.3. Fine-Grained Scheduling
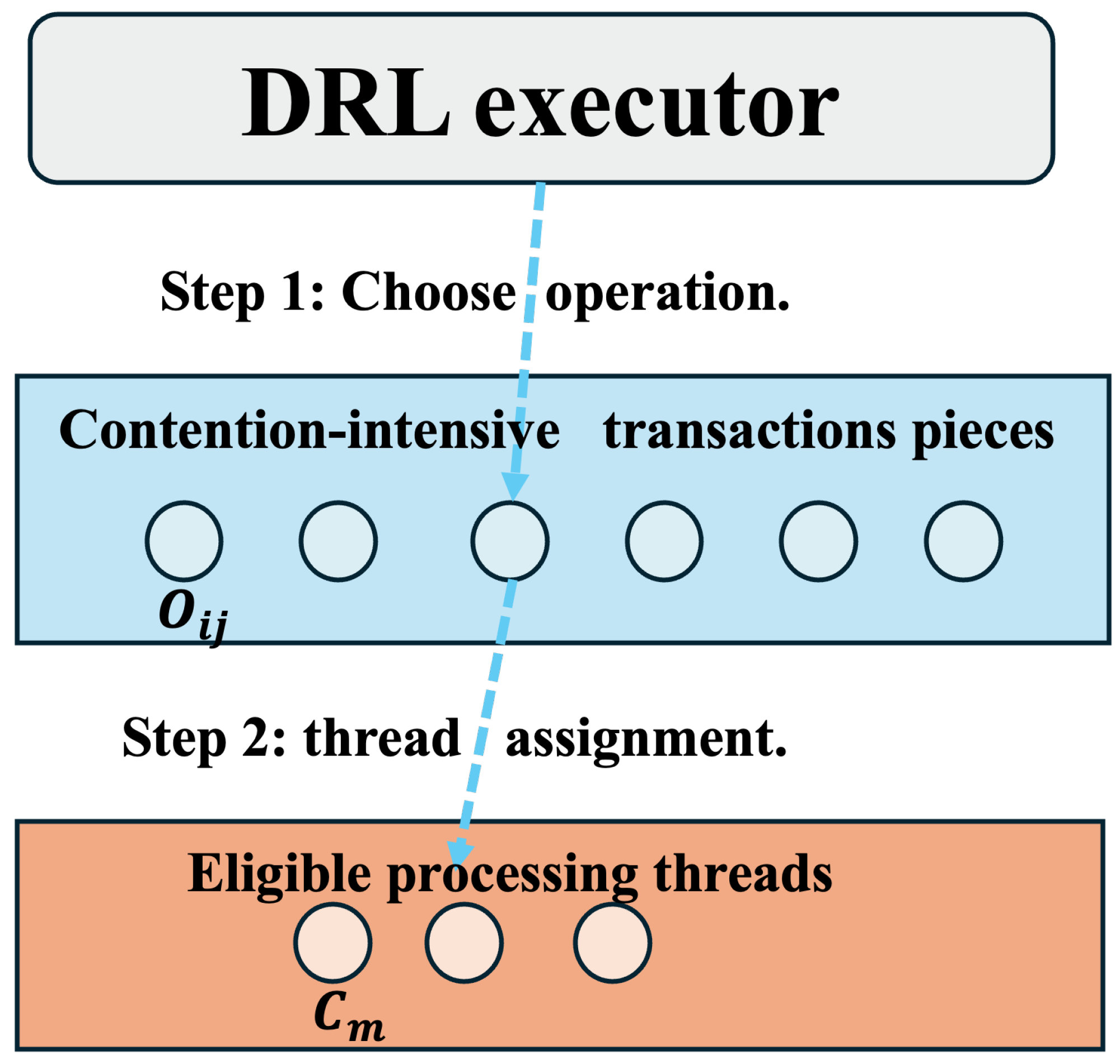
To effectively schedule contention-intensive transactions, we design a DRL-based executor to determine the access sequence on hot data items (i.e., operation sequence) and their corresponding thread assignment, as shown in
Figure 4. The scheduling process satisfies the following constraints:
Minimizing cross-partition coordination: Scheduling operations while respecting inter-transaction and intra-transaction dependency constraints to reduce synchronization overhead.
Optimizing core utilization: Ensuring proper core assignment to prevent resource underutilization and avoid excessive load concentration on specific cores.
Problem formulation. Given a residual transaction set consisting of variable-length operation sequences () over a data subset , the executor schedules these transactions across m available processing threads, . We assume , as DCoS processes residual transactions concurrently within a single period across available cores. If residual transactions exceed the available cores (), transactions are grouped and scheduled across multiple periods.
Residual transaction processing follows the same mapping function as conflict-free transaction processing to ensure the serial execution of operations on the same data. Let
represent the partitioning function that assigns transactions to
p disjoint subsets. Additionally, a one-to-many mapping
allocates these partitions to thread groups. Consequently, the mapping of operations to threads is formally defined as follows:
where
represents an operation from transaction
.
The makespan refers to the maximum completion time across all threads, i.e., the time by which the last thread completes its assigned operations. The objective of the scheduler is to minimize the total makespan required to process
. Specifically, the overall makespan is given by:
where
denotes the makespan of the
i-th thread. By optimizing the operations sequence and operations to threads, the scheduler aims to achieve balanced workload distribution while reducing contention and synchronization overhead.
5. Drl-Based Executor
DCoS implements a DRL agent to act as the executor and solve the scheduling problem above. We propose the Adaptive Placement Graph (APG) as the input to the scheduling process, providing a structured way to represent both intra-transaction and inter-transaction dependencies.
Graph structure. The APG is defined as:
where
and
are the dummy starting and ending of scheduling sequence. The set
consists of intra-transaction dependency edges, capturing the execution order of operations within a single transaction. The set
represents resource edges, which link pairs of operations requiring the same thread worker for execution, as dictated by
. Resource edges consist of a mix of directed and undirected arcs:
Undirected arcs: Represent intra-transaction dependency, indicating that two operations contend for the same resource without enforcing a strict execution order.
Directed arcs: Represent write–read dependency, ensuring that a write operation must be committed before a dependent read operation is executed.
Figure 5 illustrates how DCoS schedules contention-intensive transactions in Example 2. By updating the resource edges (from undirected to directed), DCoS can generate a scheduling solution that optimizes the processing of transactions across available threads, ensuring minimal makespan while respecting the dependencies between transactions.
Moreover, DCoS leverages historical workload traces containing transaction-processing metadata (e.g., procedure parameters, execution timestamps, query parameters). Using this data, DCoS estimates per-thread operation processing times set based on current thread-worker state .
5.1. MDP Formulation
The scheduling process comprises consecutive decision steps. We formalize the MDP defined by a tuple as follows:
States . The global state at timestep t consists of a APG state and a thread-worker state :
APG State:
and
denote scheduled/unscheduled set of resource edges. For each
,
, representing operation state, where
is a binary indicator (1 for scheduled operation, 0 otherwise),
is scheduled time or the estimated minimum completion time defined as:
Action . The hierarchical action space contains:
Reward . The incremental reward at step
t is:
The objective is to minimize makespan
by maximizing cumulative rewards
.
APG Transition . At timestep t, after the agent acts with updating one directed arc, a new APG is generated with a new global state with .
5.2. Network Architecture
We employ distinct networks, for operation selection policy and for thread-worker assignment policy, to guide the transaction-scheduling process. We use a distinct embedding layer for two policies as follows.
Graph embedding. We adopt a
L-layer graph isomorphism network (GIN) [
29], a variant of graph neural network (GNN), to compute structural embeddings for
. A GNN is a neural network architecture that operates on graph-structured data by iteratively aggregating feature information from a node’s neighbors. In our case, the embedding of each operation is updated at iteration
as follows:
where
denotes the set of operations that have intra-transaction dependencies with
, and
u is one such operation.
represents the learnable parameters of layer
l, and
is a trainable scalar that controls the relative weight of self-information and neighbor information during aggregation.
After
L iterations, we obtain a global representation of the APG using an average pooling function that aggregates the embeddings of all operations into a vector:
We adopt a fully connected layer to encode the thread-worker state by computing the embedding vector of each thread worker and the pooling vector .
Arc transformation. APG is a mixed graph containing undirected arcs and directed arcs. For operations with no inter-transactions dependency that has undirected edges, we replace each undirected arc with two directed arcs in opposite directions. We ignore undirected disjunctive arcs in the initial state to reduce computational complexity [
30], with
to avoid APG too dense to be efficiently processed by GIN. With the transaction scheduling process,
becomes larger since more directed arcs will be added.
Action selection. We implement MLP layers as action decoders based on state embeddings. First, we compute the action score of operation selection action
and thread-worker assignment action
:
For operations that are already scheduled or violate precedence constraints, or thread workers that are incompatible with the selected operation. We set their score to
. Finally, we normalize the scores using the softmax function, a standard transformation that converts real-valued inputs into a probability distribution. This enables the computation of selection probabilities and supports a sampling-based strategy for action prediction.
5.3. Training Algorithm
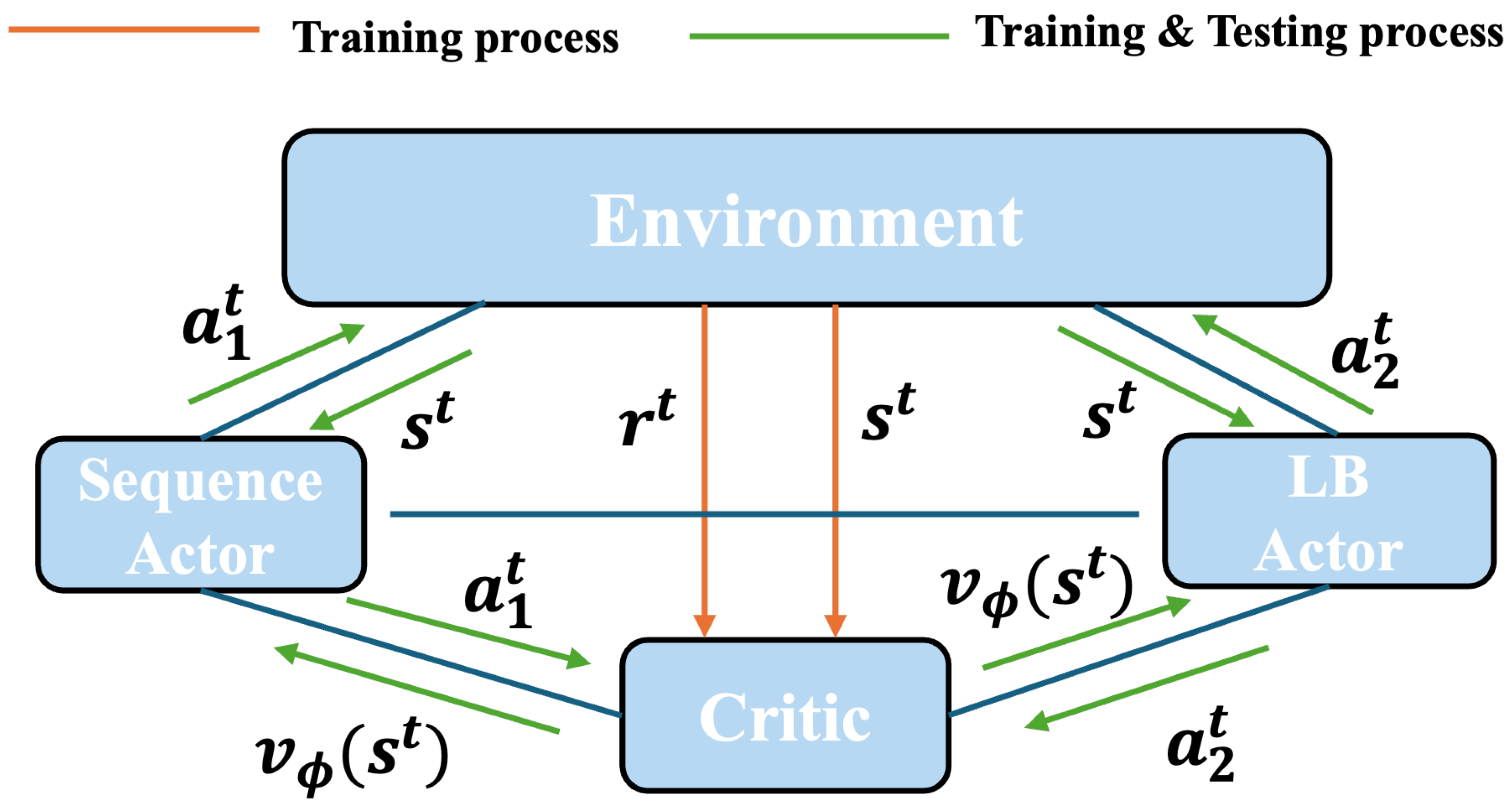
To train the policy network, we employ the Proximal Policy Optimization (PPO) algorithm [
31] with a Sequence Actor for operation selection policy, a Load-Balancing (LB) Actor for thread-worker assignment policy, and a global critic, as shown in
Figure 6. Actors running in the environment collect training experience tuples, and then the two sub-policies
and
are updated via the collected samples.
Objectives of actor network. We implement identical objective computation mechanisms for both actor networks. The overall objective function combines the clipped surrogate objective and entropy regularization:
where
denotes the parameters of both actor networks. Here,
represents the clipped surrogate objective,
is the entropy regularization term, and
indicates the probability ratio between the updated and old policies. The hyperparameters
,
, and
control the clipping range and objective weighting.
Objective of critic network. Both actors share a common critic network with state-value function
. The advantage function estimator is calculated as follows:
where
serves as a variance-reduced advantage estimator. The critic network is optimized by minimizing the mean squared error (MSE) between predicted and actual returns:
6. Deployment of DCoS
DCoS functions as an intelligent scheduling layer within the transaction processing pipeline. It builds upon a correctness enforcement layer that guarantees serializability through partitioning methods and runtime pipelining (RP).
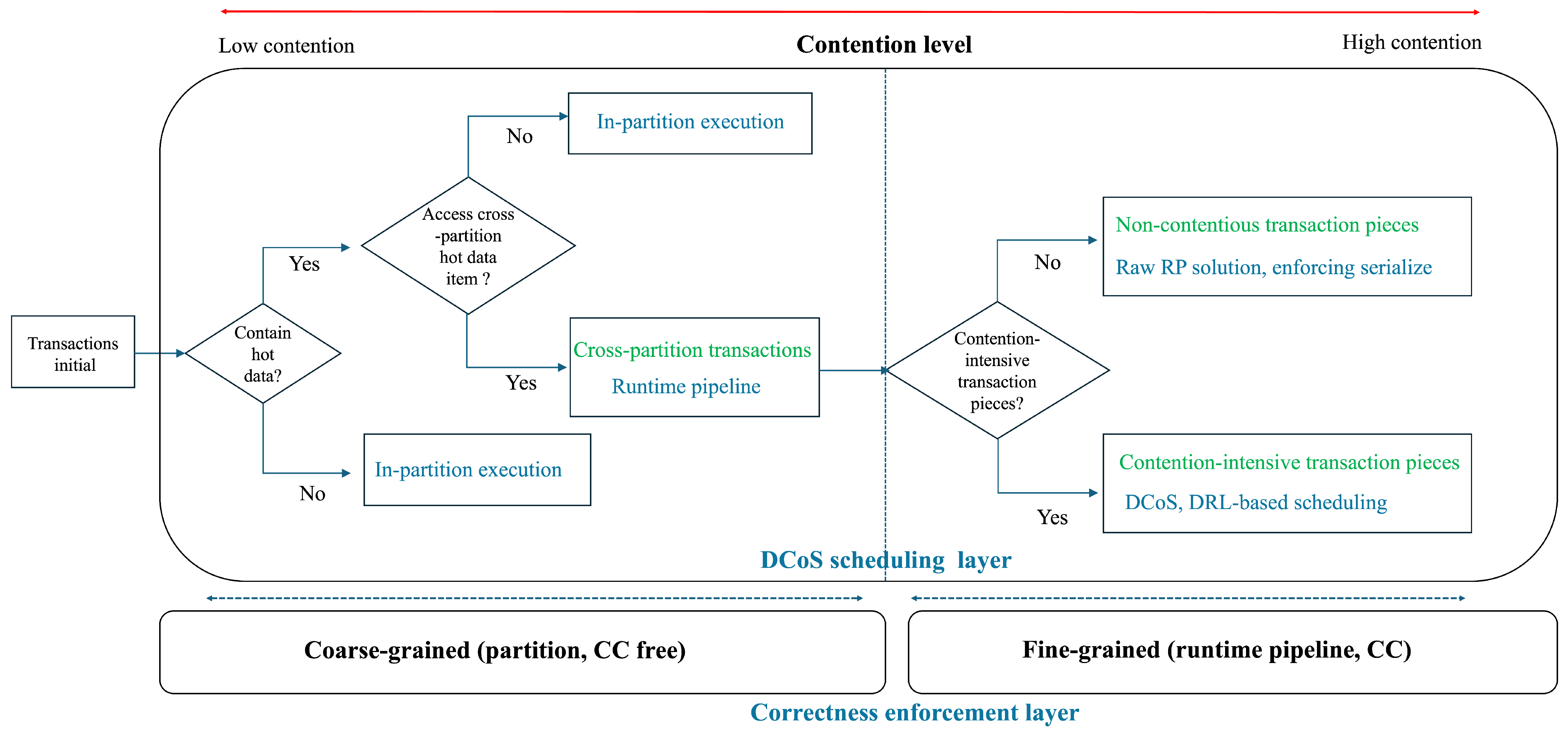
Figure 7 depicts the hierarchical interaction among partitioning, CC protocols, and scheduling methods. DCoS has the following characteristics:
Adaptive execution under varying contention levels. In low-contention scenarios, coarse-grained execution is sufficient. Transactions that do not access hot data and are free from contention can be executed entirely within a single partition. This approach eliminates coordination overhead and avoids the complexity associated with fine-grained control mechanisms. When contention is detected, typically through cross-partition accesses to hot data items, DCoS responds by activating a fine-grained scheduler based on DRL. The scheduler reorders and interleaves contention-intensive transaction pieces in a way that minimizes conflicts and improves concurrency.
Complementarity with existing CC protocols. DCoS is designed to serve as a complement to existing correctness mechanisms. Rather than replacing CC protocols that optimize lock acquisition order or validation timing, DCoS enhances them by operating at the scheduling layer. DCoS focuses on improving execution order to reduce conflicts and transaction aborts. DCoS assumes the presence of a base CC protocol, such as RP, to enforce correctness, while it adaptively applies fine-grained scheduling only when it is beneficial.
Limitations and Practical Considerations
DCoS introduces several practical considerations:
Assumption of known access patterns. DCoS relies on a one-shot transaction processing model where access patterns are known ahead of execution, which may limit its applicability in dynamic or ad hoc workloads with unpredictable access patterns.
Accuracy in hot data and contention detection. The integration of a DRL-based scheduler requires offline training. The effective activation of fine-grained scheduling depends on the accurate identification of hot data items and contention-intensive transaction pieces.
A promising direction for future work is the tighter integration of DCoS-style scheduling with enhanced CC mechanisms, enabling adaptive selection of scheduling strategies tailored to workload characteristics. Furthermore, exploring lightweight online learning and transfer learning techniques [
32] could reduce training overhead and improve scheduler adaptability, broadening DCoS’s applicability across diverse OLTP environments.
7. Experimental Results
In this section, we comprehensively evaluate DCoS by comparing it with existing systems. Specifically, we focus on the following aspects:
(
Section 7.2) First, we assess the effectiveness of the DCoS executor for handling high-contention workloads.
(
Section 7.3 and
Section 7.4) Then, we evaluate DCoS against state-of-the-art CCs for handling various workloads.
(
Section 7.5) Finally, we analyze the overhead introduced by DCoS in high-contention scenarios to provide insights into the trade-offs involved in employing DRL-based scheduling.
7.1. Experimental Setup
We implement a prototype of DCoS within the DBx1000 [
33] transaction-processing engine and integrate a partitioning algorithm following [
15]. Our experiments are conducted on two machines equipped with two 16-core AMD 7302 processors and an NVIDIA 24GB Ampere A30 GPU. One machine initializes the OLTP application, while the other serves as the transaction-processing engine.
Hyperparameters. The embedding network of the executor consists of two layers, each containing two hidden layers with a hidden dimension of 128 neurons. Following common practice in DRL tasks [
31], we set the coefficients for clipping, policy loss, value function, and entropy to 0.2, 2, 1, and 0.01, respectively. During training, we use the widely adopted Adam optimizer [
34] with a learning rate of
, which is a standard choice in policy gradient algorithms.
Metrics. We measure the performance of the transaction-processing system using the following metrics:
Makespan: The total execution time of a transaction batch, highlighting the effectiveness of scheduling under contention.
Throughput: The number of transactions committed per second, reflecting overall system efficiency.
7.2. Microbenchmark Evaluation
In this section, we evaluate the effectiveness of the DCoS DRL-based scheduler by comparing it against three state-of-the-art scheduling methods:
We design a workload generator to evaluate the performance of DCoS under high-contention with varying workload skew. We sample a set of hot data items from the database and then test a set of transactions that will operate on these hot data items. With the increase of concurrent contention-intensive transactions, the contention rate also increases. We manage workload variance by adjusting the number of cold items, while the processing time for hot transactions, denoted as , can vary with the cold item distribution. Specifically, we define three workload states among cores based on average transaction-processing time: for low workload variance, for medium workload variance, and for high workload variance.
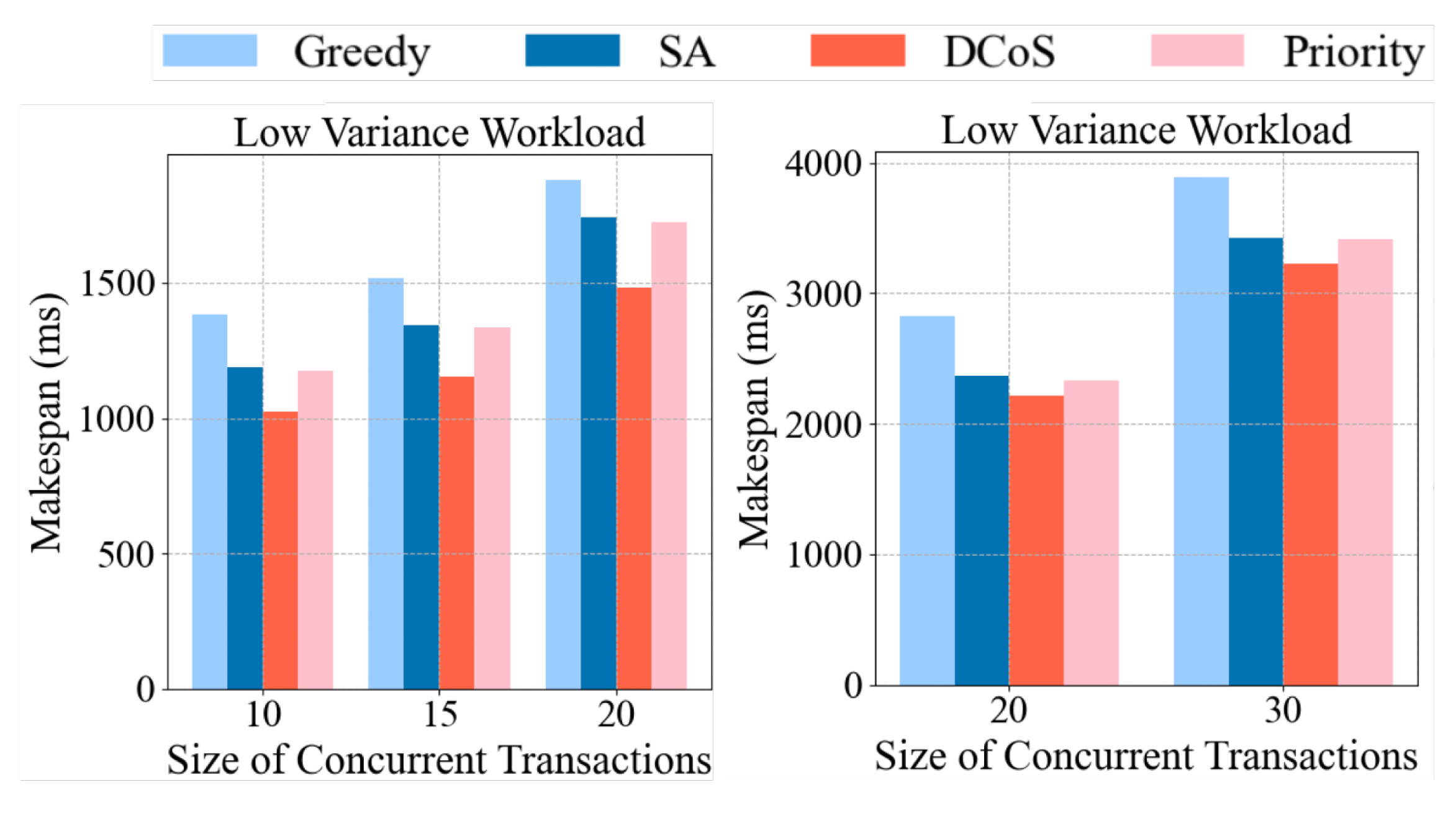
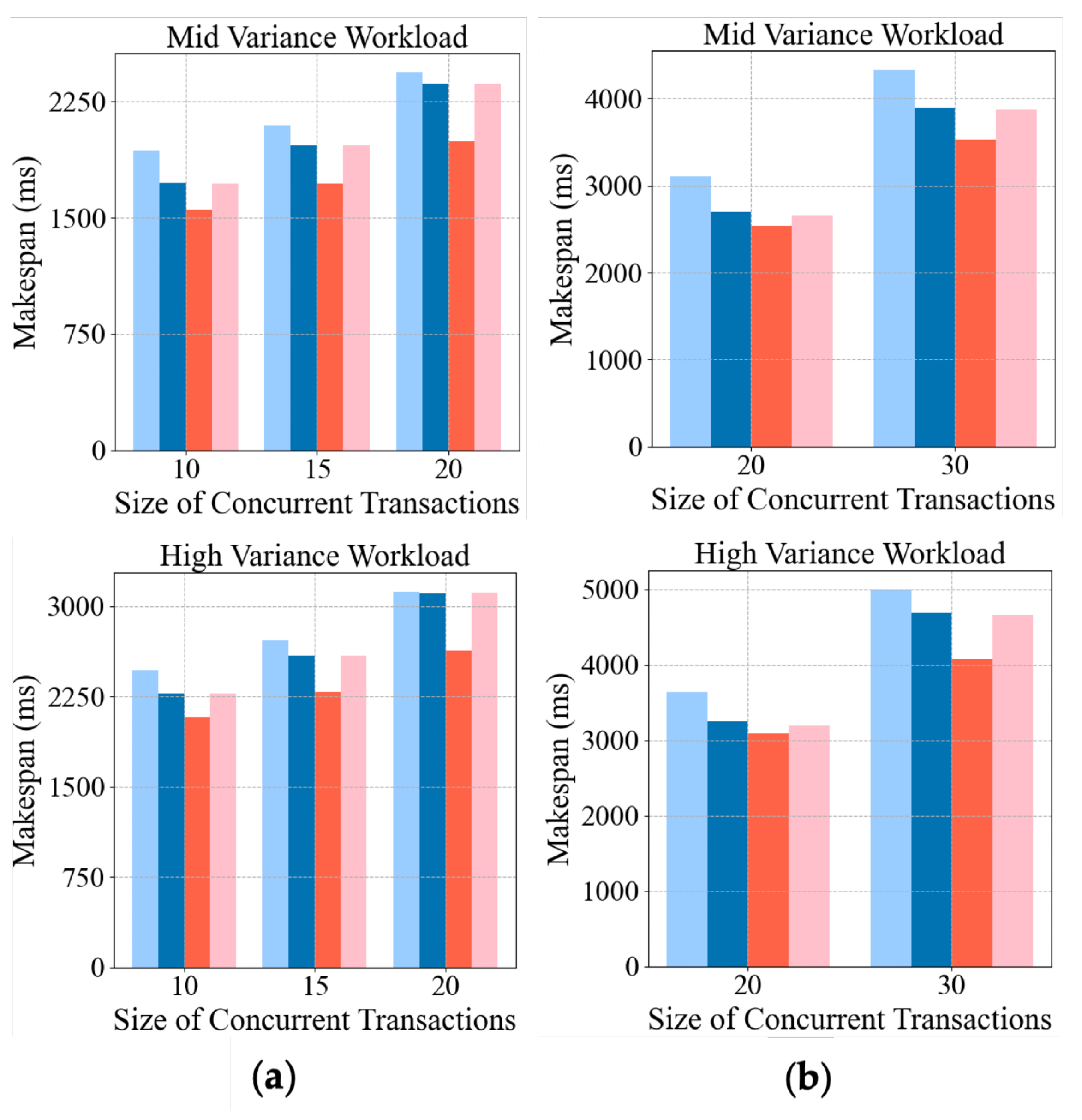
Varying contention levels. We set the available thread workers to 5 and the number of concurrent contention-intensive transactions (10, 15, 20) to simulate increasing contention rates. The DCoS model was trained for 1000 episodes until convergence was reached, ensuring stable policy learning. We generated 500 distinct transaction workload sets not encountered during training for testing. The mean value of the results is used for comparison; we collect the makespan of processing the batch of hot items as shown in
Figure 8a. DCoS consistently outperforms other algorithms across all scenarios, particularly under high workload variance and large concurrent transactions. Compared to the best-performing SA, DCoS demonstrates a makespan reduction of 8.8% to 12.8% under low workload variance and 14% to 15.5% under high workload variance as the number of concurrent transactions increases. The Greedy algorithm shows performance decreases in handling increased concurrency, which aligns with the inherent weakness of greedy approaches, which make locally optimal but globally suboptimal decisions. The priority algorithm performs comparably to SA under moderate conditions; however, with workload variance increases, the performance among SA, Greedy, and Priority is affected due to their lack of adaptability to dynamic adjustments, which limits their effectiveness.
Generalization. To evaluate cross-scale generalization, we conduct transfer learning experiments where DCoS trained on small-scale configurations (five thread workers, 20 concurrent contention-intensive transactions) is directly deployed in large-scale environments (ten thread workers, 20–30 concurrent high-contention transactions). This zero-shot adaptation test eliminates parameter fine-tuning to isolate model generalization capacity. The evaluation protocol maintains 10 worker threads while scaling contention-intensive transactions to represent 100–150% of the original training workloads.
Figure 8b shows the testing results, we observe a similar trend to small-scale transactions, with DCoS demonstrating a 12.57% makespan reduction compared to the best-performing SA. Since we implement embedding layers to enable DCoS to generalize effectively to different sizes of concurrent transaction sets and thread workers, even without additional training, this allows DCoS to adapt to various transaction workload scenarios.
7.3. TPC-C Benchmark Evaluation
DBx1000 features a pluggable lock manager that supports multiple CC schemes, enabling a direct comparison of DCoS against various baseline approaches within the same system. Specifically, we implement and evaluate the following three methods:
To ensure an industry-standard evaluation, we conduct comprehensive experiments using the TPC-C benchmark [
35] with enhanced contention control analysis. We maintain a balanced transaction mix of 50% New-Order and 50% Payment transactions to model real-world order-processing workloads closely. These two transactions comprise the vast majority of the benchmark and have been used previously to evaluate high-contention workloads to stress concurrency control. Our evaluation framework extends the classical TPC-C benchmark by varying two key factors: (i) the number of warehouses while maintaining a constant thread count, and (ii) the number of worker threads while keeping the warehouse count.
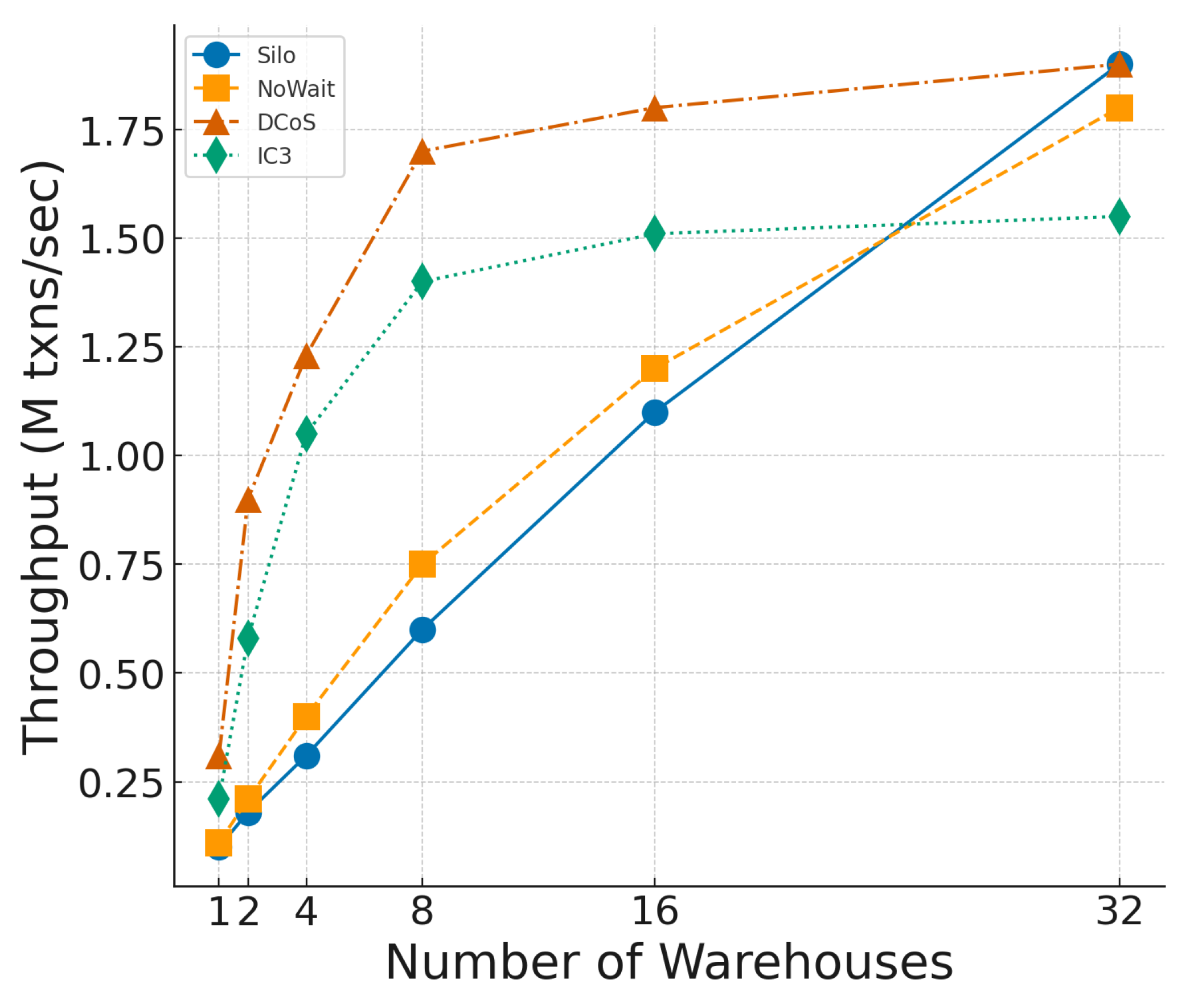
We fix the number of worker threads at 32 and vary the number of warehouses from 1 (high contention) to 32 (low contention). As shown in
Figure 9, DCoS achieves the highest throughput across all warehouse configurations, significantly outperforming others, especially under high contention. At one warehouse, DCoS is three times higher than Silo and
times higher than IC3. These results highlight the effectiveness of DCoS in mitigating contention bottlenecks and maintaining robust performance under varying workloads, since it can avoid unnecessary waiting through intelligent scheduling based on runtime information. At the same time, IC3 only leverages the static information.
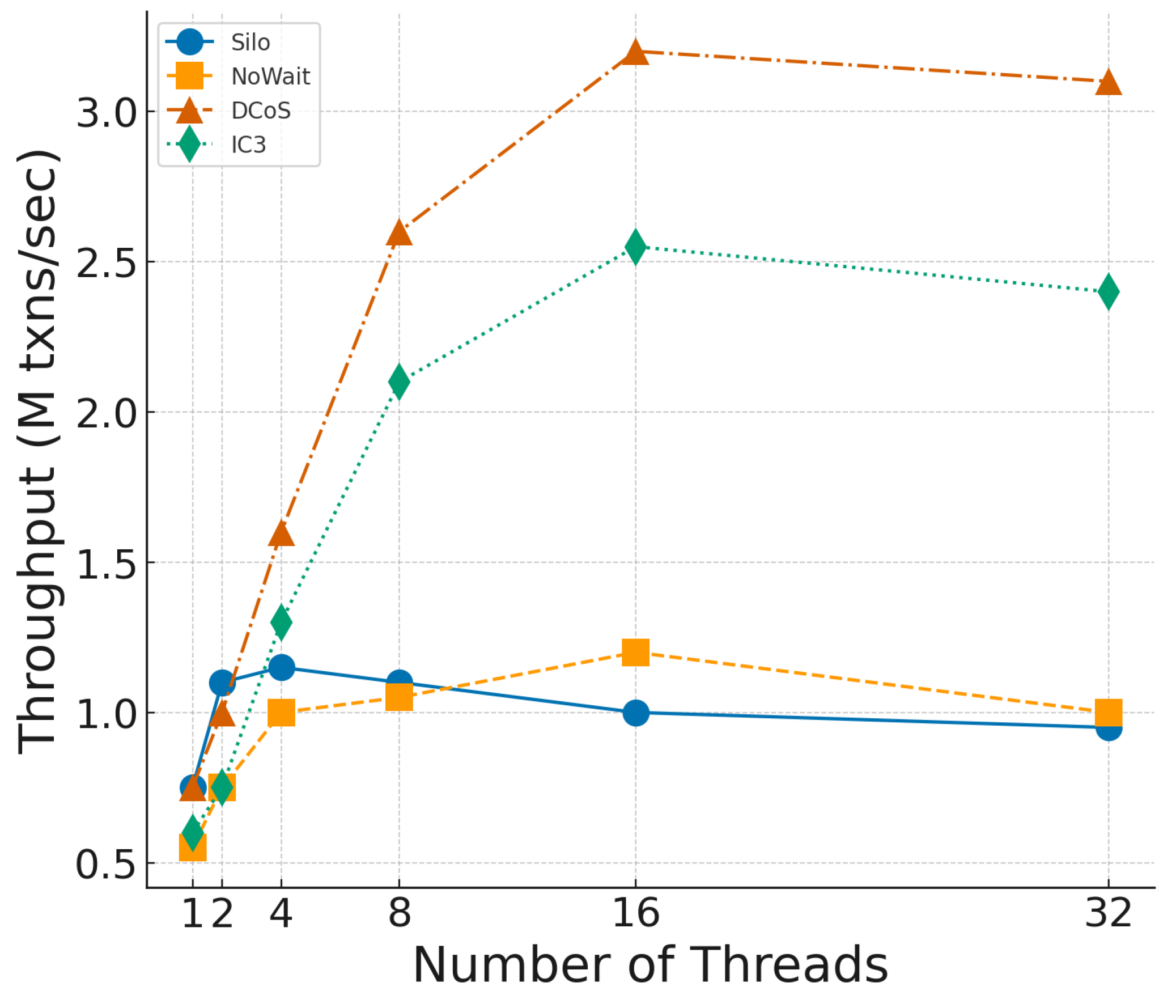
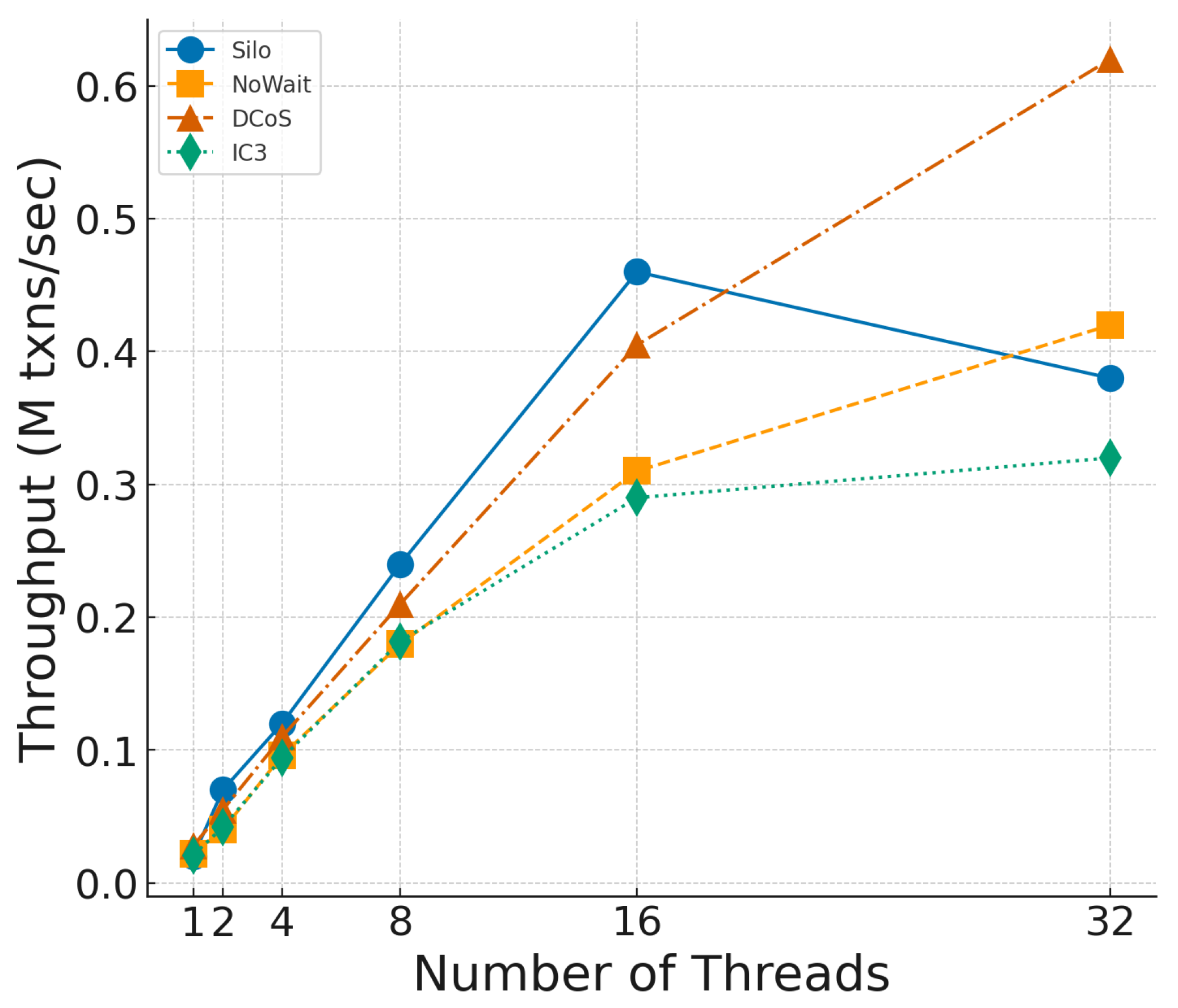
To assess system scalability, we vary the number of worker threads from 1 to 32 while keeping the warehouse count fixed at 1, as shown in
Figure 10. The performance advantage of DCoS becomes more pronounced as the number of threads increases. At 16 threads, DCoS reaches 3.2 M txns/s, surpassing IC3 by 25% and significantly outperforming NoWait and Silo.
7.4. TPC-E Benchmark Evaluation
To evaluate how well DCoS adapts to a more complex contention scenario, we conduct experiments using the TPC-E benchmark [
36]. This benchmark simulates transaction workloads with varying data access patterns. We control contention by changing the frequency of updates to the SECURITY table, using a Zipfian distribution for these updates. We adjust the skew parameter
from 0 to 4. Higher values of
indicate more significant data access skew and increased contention.
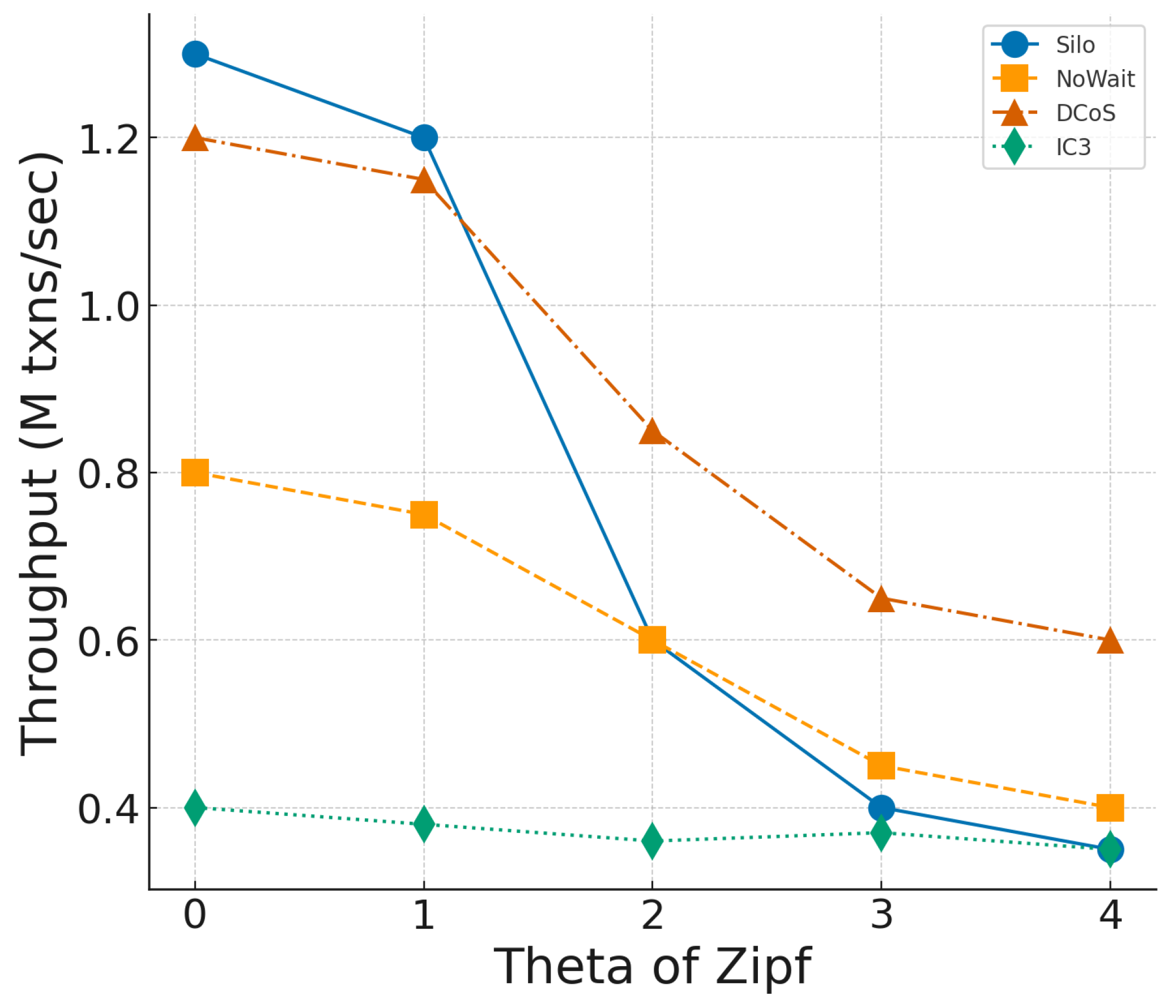
As shown in
Figure 11, throughput decreases for all methods as
increases, reflecting the impact of contention due to skewed data access. DCoS maintains the highest throughput across all skew levels. At
, DCoS achieves 1.2 M txns/s, slightly behind Silo (1.3 M txns/s), since DCoS adopts a dependency analysis, but at
, DCoS still maintains 0.6 M txns/s, whereas Silo drops to 0.35 M txns/s. Silo performs best under low-skew scenarios but degrades significantly as contention increases. NoWait and IC3 consistently underperform, struggling to handle skewed workloads efficiently. These findings highlight that DCoS is more resilient to data skew than traditional CC methods, as it dynamically adapts to runtime contention.
To analyze the combined effect of parallelism and contention, we vary the number of worker threads while maintaining a Zipfian skew of
. The results, shown in
Figure 12, indicate that DCoS significantly outperforms Silo and NoWait beyond 16 threads. At 32 threads, DCoS achieves a throughput that is
times higher than Silo,
times higher than NoWait, and
times higher than IC3.
In summary, the findings from TPC-C and TPC-E demonstrate that DCoS is particularly effective at managing data skew, sustaining high throughput even in scenarios of extreme contention. These results highlight the significance of runtime-adaptive scheduling strategies employed in DCoS for optimizing transaction throughput in OLTP systems.
7.5. Overhead Analysis
To evaluate the runtime overhead of the DRL-based scheduling executor, we analyze the overhead in
Section 7.4, where
represents a highly skewed, high-contention scenario. Our overhead analysis focuses on high-contention workloads, where both the benefits and costs of DCoS are most evident.
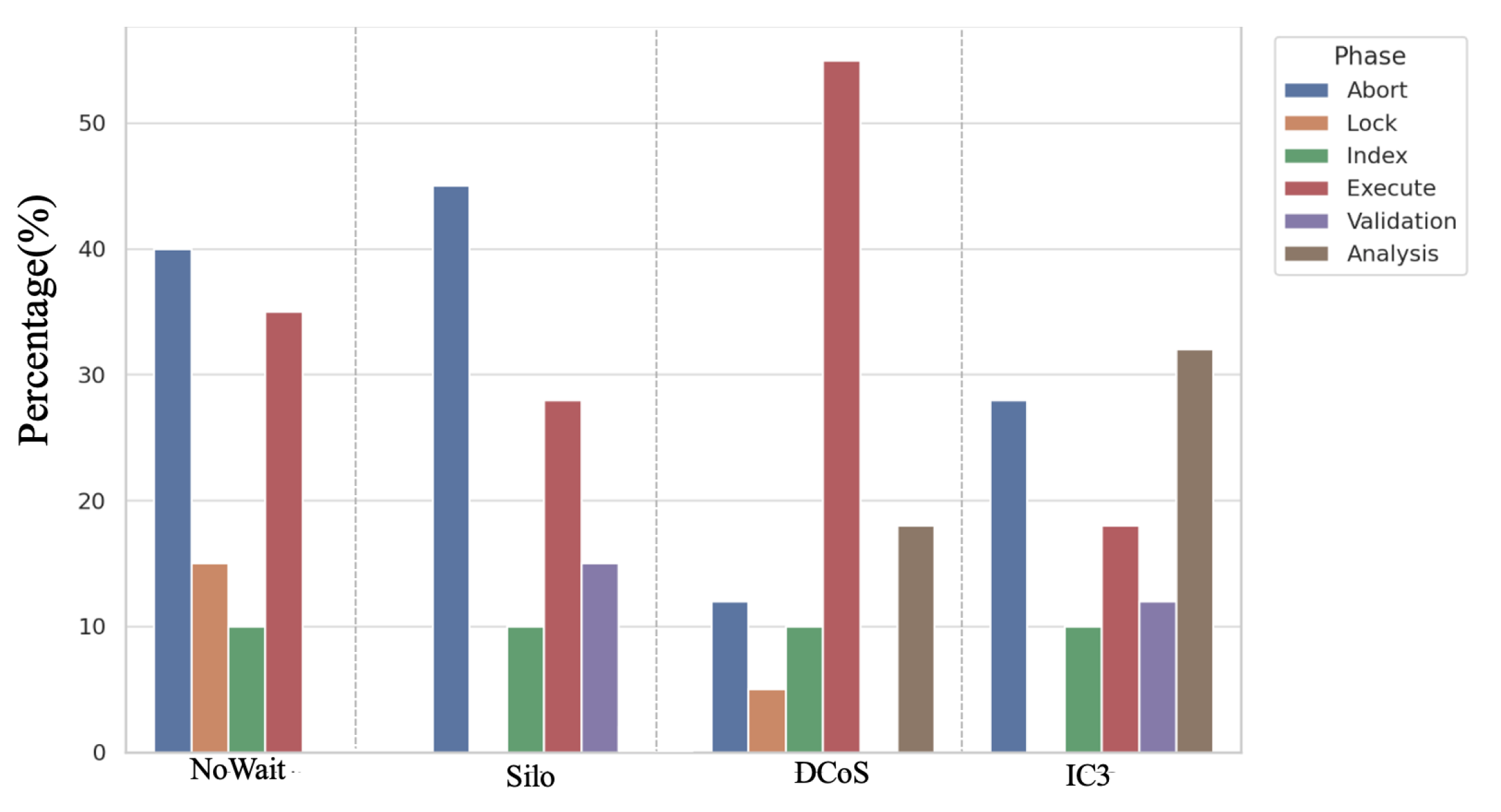
Figure 13 presents the execution profile across different phases of transaction processing. Note that for IC3, which uses an active waiting mechanism under high contention, we include its associated costs within the analysis phase for comparison. DCoS spends the largest percentage of execution time in the execute phase. Although DCoS introduces an additional analysis phase responsible for hot data item identification and DRL-based scheduling decisions, the abort-related overhead stays below 20%, which is significantly lower than the abort-related overhead observed in NoWait (40%) and Silo (45%). We also observe that IC3, which fully decomposes transactions, incurs even higher analysis overhead while achieving lower execution efficiency. This comparison illustrates that DCoS strikes a more favorable balance between coordination cost and execution throughput.
8. Conclusions
In this paper, we propose DCoS, a transaction-scheduling method based on DRL. DCoS is compatible with existing partitioning methods that divide transactions into conflict-free sets, and adopts a fine-grained scheduling architecture to enable efficient concurrency for high-contention transaction sets. DCoS addresses the transaction-scheduling problem by updating the undirected arcs in the novel APG structure. Our experimental results demonstrate that DCoS improves the system throughput compared to state-of-the-art scheduling approaches across diverse workload scenarios and maintains robust generalization capabilities when exposed to unseen transaction workload patterns. The fine-grained scheduling mechanism is selectively applied in high-contention scenarios, thereby avoiding unnecessary overhead in low-contention settings. Future work involves extending DCoS to distributed settings and examining its compatibility with emerging CC schemes across varying deployment architectures.
Author Contributions
Conceptualization, S.C.; methodology, C.S.; software, S.C.; validation, C.W.; formal analysis, C.S.; investigation, S.C.; resources, S.C.; data curation, C.S.; writing—original draft preparation, C.S.; writing—review and editing, C.W.; visualization, S.C.; supervision, C.W.; project administration, C.S.; funding acquisition, C.W. All authors have read and agreed to the published version of the manuscript.
Funding
This work is supported by the National Key R&D Program of China (2024YFB2906500) and Key R&D Program of Zhejiang (2024SSYS0001).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The TPC-C and TPC-E benchmark are available in the references; the self-constructed microbenchmarks will be made available on request.
Conflicts of Interest
The authors declare no conflicts of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| DCoS | Dynamic Contention Scheduling |
| CC | Concurrency control |
| OLTP | Online transaction processing |
| 2PL | Two-phase blocking |
| OCC | Optimistic concurrency control |
| MDP | Markov decision process |
| MVCC | Multi-version concurrency control |
| RP | Runtime pipelining |
| GIN | Graph isomorphism network |
| DRL | Deep reinforcement learning |
References
- Yu, X.; Bezerra, G.; Pavlo, A.; Devadas, S.; Stonebraker, M. Staring into the Abyss: An Evaluation of Concurrency Control with One Thousand Cores; MIT Labraries: Cambridge, MA, USA, 2014. [Google Scholar]
- Pavlo, A.; Curino, C.; Zdonik, S. Skew-aware automatic database partitioning in shared-nothing, parallel OLTP systems. In Proceedings of the 2012 ACM SIGMOD International Conference on Management of Data, Scottsdale, AZ, USA, 20–24 May 2012; pp. 61–72. [Google Scholar]
- Curino, C.; Jones, E.P.C.; Zhang, Y.; Madden, S.R. Schism: A Workload-Driven Approach to Database Replication and Partitioning; MIT Labraries: Cambridge, MA, USA, 2010. [Google Scholar]
- Gray, J.; Reuter, A. Transaction Processing: Concepts and Techniques; Elsevier: Amsterdam, The Netherlands, 1992. [Google Scholar]
- Kung, H.T.; Robinson, J.T. On optimistic methods for concurrency control. ACM Trans. Database Syst. (TODS) 1981, 6, 213–226. [Google Scholar] [CrossRef]
- Shasha, D.; Llirbat, F.; Simon, E.; Valduriez, P. Transaction chopping: Algorithms and performance studies. ACM Trans. Database Syst. (TODS) 1995, 20, 325–363. [Google Scholar] [CrossRef]
- Zhang, Y.; Power, R.; Zhou, S.; Sovran, Y.; Aguilera, M.K.; Li, J. Transaction chains: Achieving serializability with low latency in geo-distributed storage systems. In Proceedings of the Twenty-Fourth ACM Symposium on Operating Systems Principles, Farmington, PA, USA, 3–6 November 2013; pp. 276–291. [Google Scholar]
- Wang, Z.; Mu, S.; Cui, Y.; Yi, H.; Chen, H.; Li, J. Scaling multicore databases via constrained parallel execution. In Proceedings of the 2016 International Conference on Management of Data, San Francisco, CA, USA, 26 June–1 July 2016; pp. 1643–1658. [Google Scholar]
- Xie, C.; Su, C.; Littley, C.; Alvisi, L.; Kapritsos, M.; Wang, Y. High-performance ACID via modular concurrency control. In Proceedings of the 25th Symposium on Operating Systems Principles, Monterey, CA, USA, 5–7 October 2015; pp. 279–294. [Google Scholar]
- Zhou, N.; Zhou, X.; Zhang, X.; Du, X.; Wang, S. Reordering transaction execution to boost high-frequency trading applications. Data Sci. Eng. 2017, 2, 301–315. [Google Scholar] [CrossRef]
- Liu, W.x.; Cai, J.; Chen, Q.C.; Wang, Y. DRL-R: Deep reinforcement learning approach for intelligent routing in software-defined data-center networks. J. Netw. Comput. Appl. 2021, 177, 102865. [Google Scholar] [CrossRef]
- Yang, L.; Wei, Y.; Yu, F.R.; Han, Z. Joint routing and scheduling optimization in time-sensitive networks using graph-convolutional-network-based deep reinforcement learning. IEEE Internet Things J. 2022, 9, 23981–23994. [Google Scholar] [CrossRef]
- Zhao, L.; Fan, J.; Zhang, C.; Shen, W.; Zhuang, J. A DRL-based reactive scheduling policy for flexible job shops with random job arrivals. IEEE Trans. Autom. Sci. Eng. 2023, 21, 2912–2923. [Google Scholar] [CrossRef]
- Serafini, M.; Taft, R.; Elmore, A.J.; Pavlo, A.; Aboulnaga, A.; Stonebraker, M. Clay: Fine-grained adaptive partitioning for general database schemas. Proc. VLDB Endow. 2016, 10, 445–456. [Google Scholar] [CrossRef]
- Prasaad, G.; Cheung, A.; Suciu, D. Handling highly contended OLTP workloads using fast dynamic partitioning. In Proceedings of the 2020 ACM SIGMOD International Conference on Management of Data, Portland, OR, USA, 14–19 June 2020; pp. 527–542. [Google Scholar]
- Bernstein, P.A.; Goodman, N. Multiversion concurrency control—Theory and algorithms. ACM Trans. Database Syst. (TODS) 1983, 8, 465–483. [Google Scholar] [CrossRef]
- Thomson, A.; Diamond, T.; Weng, S.C.; Ren, K.; Shao, P.; Abadi, D.J. Calvin: Fast distributed transactions for partitioned database systems. In Proceedings of the 2012 ACM SIGMOD International Conference on Management of Data, Scottsdale, Arizona, 20–24 May 2012; pp. 1–12. [Google Scholar]
- Ding, B.; Kot, L.; Gehrke, J. Improving optimistic concurrency control through transaction batching and operation reordering. Proc. VLDB Endow. 2018, 12, 169–182. [Google Scholar] [CrossRef]
- Li, J.; Lu, Y.; Wang, Q.; Lin, J.; Yang, Z.; Shu, J. {AlNiCo}:{SmartNIC-accelerated} contention-aware request scheduling for transaction processing. In Proceedings of the 2022 USENIX Annual Technical Conference (USENIX ATC 22), Carlsbad, CA, USA, 11–13 July 2022; pp. 951–966. [Google Scholar]
- Guo, Z.; Wu, K.; Yan, C.; Yu, X. Releasing locks as early as you can: Reducing contention of hotspots by violating two-phase locking. In Proceedings of the 2021 International Conference on Management of Data, Xi’an, China, 20–25 June 2021; pp. 658–670. [Google Scholar]
- Zamanian, E.; Shun, J.; Binnig, C.; Kraska, T. Chiller: Contention-centric transaction execution and data partitioning for modern networks. In Proceedings of the 2020 ACM SIGMOD International Conference on Management of Data, Portland, OR, USA, 14–19 June 2020; pp. 511–526. [Google Scholar]
- Pandis, I.; Johnson, R.; Hardavellas, N.; Ailamaki, A. Data-oriented transaction execution. Proc. VLDB Endow. 2010, 3, 928–939. [Google Scholar] [CrossRef]
- Qadah, T.; Gupta, S.; Sadoghi, M. Q-Store: Distributed, Multi-partition Transactions via Queue-oriented Execution and Communication. In Proceedings of the EDBT 23rd International Conference on Extending Database Technology, Copenhagen, Denmark, 30 March–2 April 2020; pp. 73–84. [Google Scholar]
- Yao, C.; Agrawal, D.; Chen, G.; Lin, Q.; Ooi, B.C.; Wong, W.F.; Zhang, M. Exploiting single-threaded model in multi-core in-memory systems. IEEE Trans. Knowl. Data Eng. 2016, 28, 2635–2650. [Google Scholar] [CrossRef]
- Qadah, T.M.; Sadoghi, M. Quecc: A queue-oriented, control-free concurrency architecture. In Proceedings of the 19th International Middleware Conference, Rennes, France, 10–14 December 2018; pp. 13–25. [Google Scholar]
- Kallman, R.; Kimura, H.; Natkins, J.; Pavlo, A.; Rasin, A.; Zdonik, S.; Jones, E.P.; Madden, S.; Stonebraker, M.; Zhang, Y.; et al. H-store: A high-performance, distributed main memory transaction processing system. Proc. VLDB Endow. 2008, 1, 1496–1499. [Google Scholar] [CrossRef]
- Tu, S.; Zheng, W.; Kohler, E.; Liskov, B.; Madden, S. Speedy transactions in multicore in-memory databases. In Proceedings of the Twenty-Fourth ACM Symposium on Operating Systems Principles, Farmington, PA, USA, 3–6 November 2013; pp. 18–32. [Google Scholar]
- Cao, Y.; Fan, W.; Ou, W.; Xie, R.; Zhao, W. Transaction Scheduling: From Conflicts to Runtime Conflicts. Proc. ACM Manag. Data 2023, 1, 26. [Google Scholar] [CrossRef]
- Xu, K.; Hu, W.; Leskovec, J.; Jegelka, S. How powerful are graph neural networks? arXiv 2018, arXiv:1810.00826. [Google Scholar]
- Zhang, C.; Song, W.; Cao, Z.; Zhang, J.; Tan, P.S.; Chi, X. Learning to dispatch for job shop scheduling via deep reinforcement learning. Adv. Neural Inf. Process. Syst. 2020, 33, 1621–1632. [Google Scholar]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal policy optimization algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar]
- Zhuang, F.; Qi, Z.; Duan, K.; Xi, D.; Zhu, Y.; Zhu, H.; Xiong, H.; He, Q. A comprehensive survey on transfer learning. Proc. IEEE 2020, 109, 43–76. [Google Scholar] [CrossRef]
- DBx1000. Available online: https://github.com/yxymit/DBx1000 (accessed on 31 May 2025).
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Transaction Processing Performance Council. TPC-C Standards Specification; Technical Report; Transaction Processing Performance Council: San Francisco, CA, USA, 2010. [Google Scholar]
- Transaction Processing Performance Council. TPC-E Standards Specification; Technical Report; Transaction Processing Performance Council: San Francisco, CA, USA, 2015. [Google Scholar]
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}