
Optimizing an LSTM Self-Attention Architecture for Portuguese Sentiment Analysis Using a Genetic Algorithm

 ,
,  ,
,  ,
,  ,
,  and
and 
Abstract
Featured Application
Abstract
1. Introduction
- (1)
- Is it possible to develop high-accuracy SA models for the Portuguese language without relying on LLMs?
- (2)
- Can an LSTM-based model’s architecture with self-attention mechanisms be optimized with a metaheuristic algorithm to provide a performance improvement over a retrained baseline model in NLP, specifically BERT tailored for Portuguese text?
2. Materials and Methods
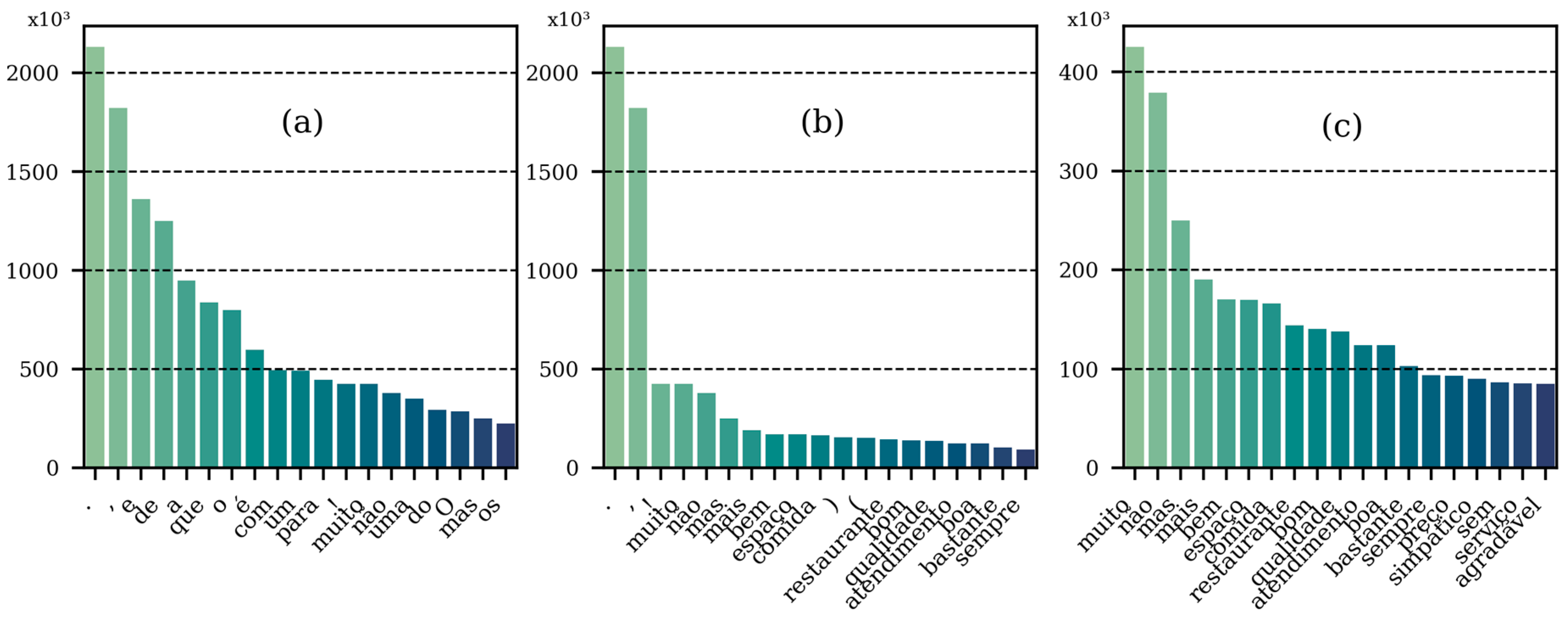
2.1. Dataset
2.2. Evaluaton
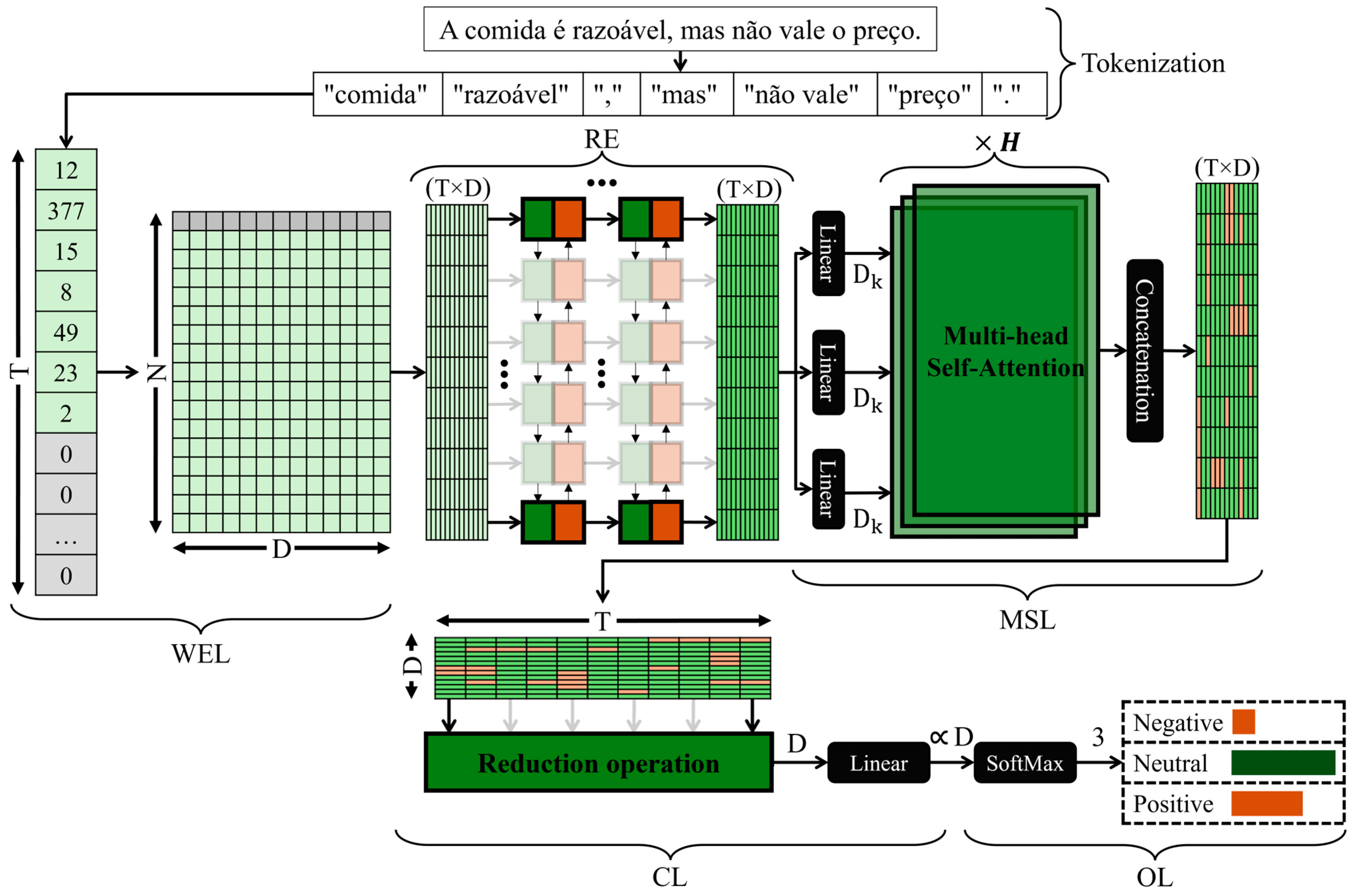
2.3. Model Architecture
- Word embedding layer (WEL): the input matrix has the dimension , where is the vocabulary size and is the number of intended features. This is the interface that transforms the tokenized text into a primary vector representation. The input layer receives a tensor of dimension , which is the pre-defined maximum number of tokens, where each position, or timestep, is an integer that represents a unique token from the vocabulary. Internally, each integer is converted into a one-hot encoding representation and multiplied by the embedding matrix. The vocabulary size was determined heuristically using a quick search algorithm, where a baseline model was trained multiple times, testing values from 5000 to 30,000 tokens. The performance parameter was the ROC-AUC. The resultant vocabulary size was = 11,560.The features for each dimension are learned using Word2Vec, an unsupervised neural network algorithm used to extract contextual relationships between adjacent tokens by considering a window of four tokens to each side of the target token, five training epochs, and an initial learning rate of 0.03 to learn features. Additionally, position embedding is included to identify the position of each token in the input sequence. This is required since the self-attention mechanism does not operate sequentially over tokens. These features are pre-trained and are fine-tuned during the globally supervised training.
- Recurrent encoder (RE): stacked bidirectional LSTM layers are employed to extract sequential and contextualized information, with recurrent units each. Additionally, each LSTM layer features a dropout value (in percentage) to avoid overfitting. Unidirectional LSTM layers are also considered for further optimization. Adding multiple layers possibly allows for a more complex model that could learn more intricate relations between the input and output data. For this reason, testing multiple stacked layers is valuable to consider during optimization.
- Multi-head self-attention layer (MSL): This layer emphasizes the most relevant tokens from the input. It is relevant to determine the best position to apply the self-attention mechanism—before, after, or before and after the recurrent encoder. The multi-head self-attention layer is parametrized with attention heads and an internal projection of , given bywith an activation function to introduce non-linearities during the computation of the weights. The recurrent encoder and the multi-head self-attention layer constitute the encoder block.
- Classification layer (CL): Once the context vector is produced by the previous layers, an operation is performed to extract and reduce the information that will be passed to the output layer, followed by an ANN with a number of parameters as a function of and an activation function.
- Output layer (OL): The decoded representation enters a linear layer with three neurons, one for each class. This layer employs a SoftMax activation function to convert the output of the real values into a probability distribution, where the position of the higher value indicates whether the input text is negative, neutral, or positive.
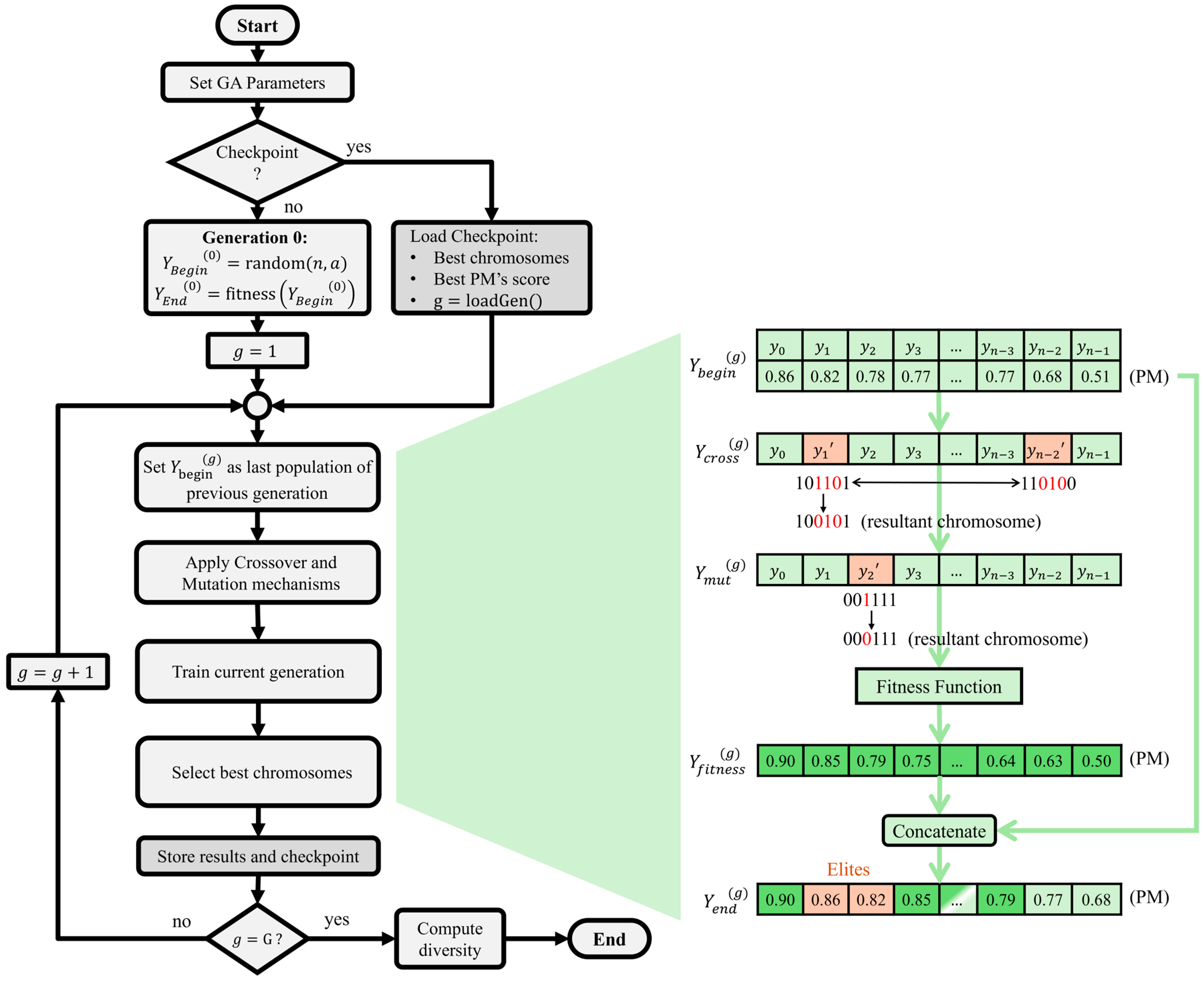
2.4. Genetic Algorithm
- Segment crossover operation, with a probability of , after tournaments between two parents. The crossover combines the genetic information of two parents, combining a section of one chromosome into another from the same population. This is an easy-to-implement solution at the cost of less diverse populations. The pseudocode is displayed below.
Crossover Input: selected_population
crossover_rateOutput: crossovered_population Repeat “size of selected_population” times:
If Apply crossover(crossover_rate)?
parent1 = select_random_chromosome()
parent2 = select_random_chromosome()
assert parent1 != parent2
point1, point2 = select_random_bits_in_chromosome()
new_child <-- parent1
new_child[point1:point2] <-- parent2[point1:point2]
Else
parent = select_random_chromosome()
new_child <-- parent
End If
Add_to_population(crossovered_population, new_child) - Bit flipping mutation operation, with a probability of , with a decreasing mutation rate along the generations. The mutations maintain genetic diversity from one population to the next one.
Mutation Input: crossovered_population
mutation_rate
current_genOutput: mutated_population
new_mutation_rateFor each chromosome in crossovered_population
For each bit in chromosome
If Apply mutation(new_mutation_rate)
New_chromosome[bit] = NOT(chromosome[bit])
Else
New_chromosome[bit] = chromosome[bit]
End If
Add_to_population(mutated_population, New_chromosome) - Rank selection between parents and children, based on the PM, always maintaining the most fitted chromosomes from to the next generation (elitism), while keeping constant. The convergence rate of the GA depends upon the selection pressure, and employing elitism reduces the chances of premature convergence.
Rank selection Input: parents_population
children_populationOutput: selected_population Note: parents_population and children_population are sorted by score (AUC)
1. Group Parents and Children (leaving empty locations for Elite chromosomes).
2. Sort group of Parents and Children (best ones are first).
3. Select Elite members and place them in the top of the new population.
4. Sort the selected_population by score (best ones are first).
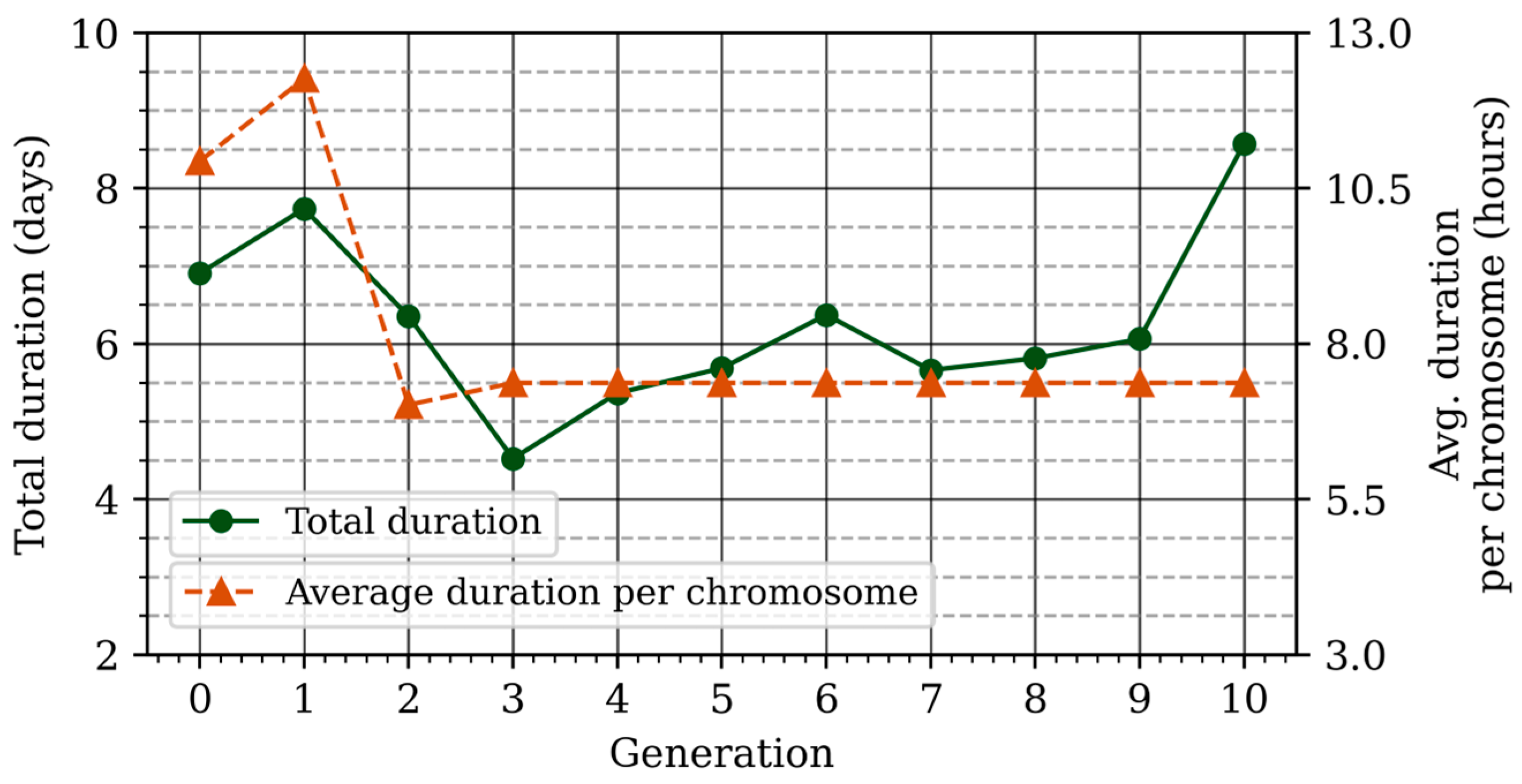
2.4.1. Training
2.4.2. Parametrization
2.4.3. Search Space
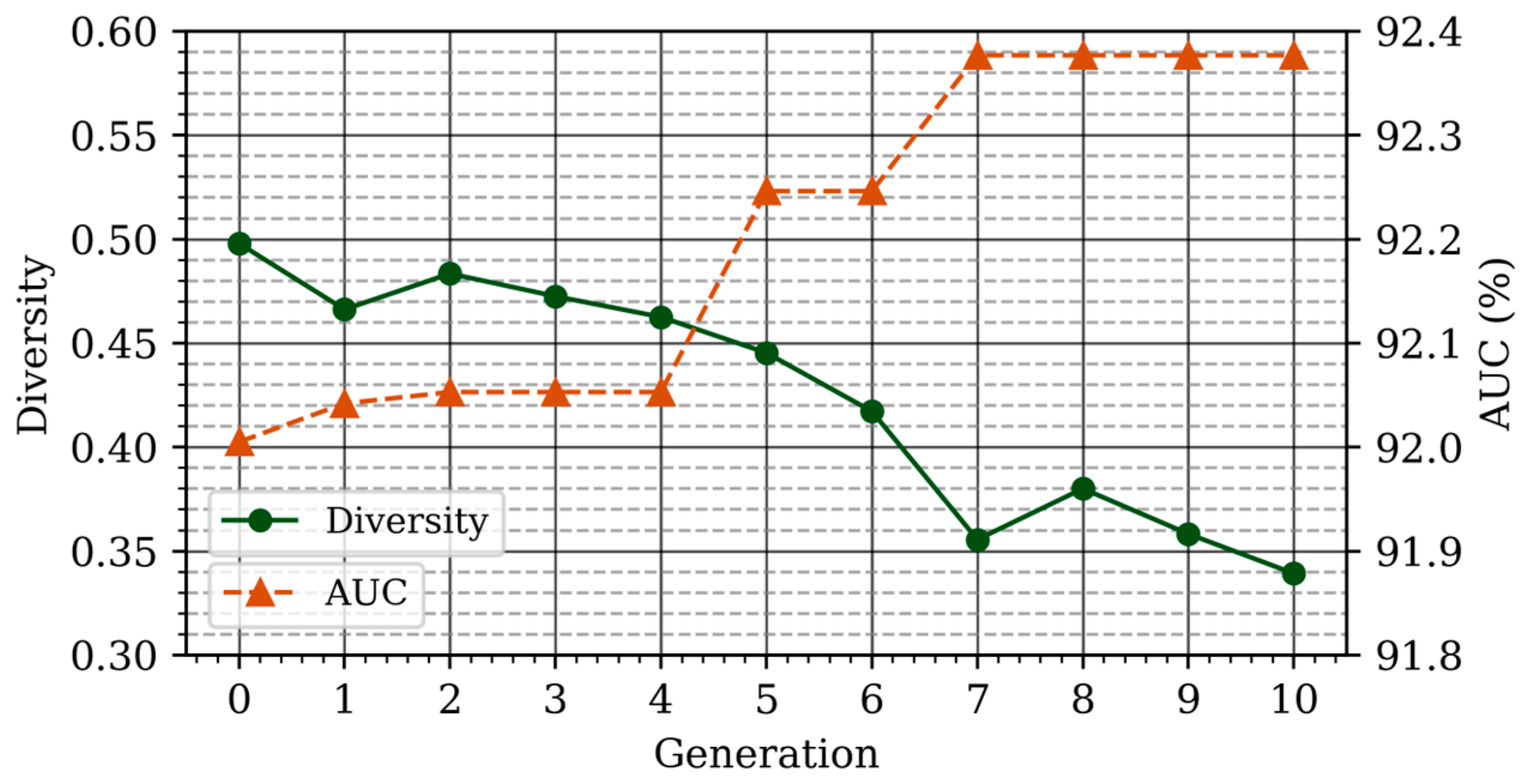
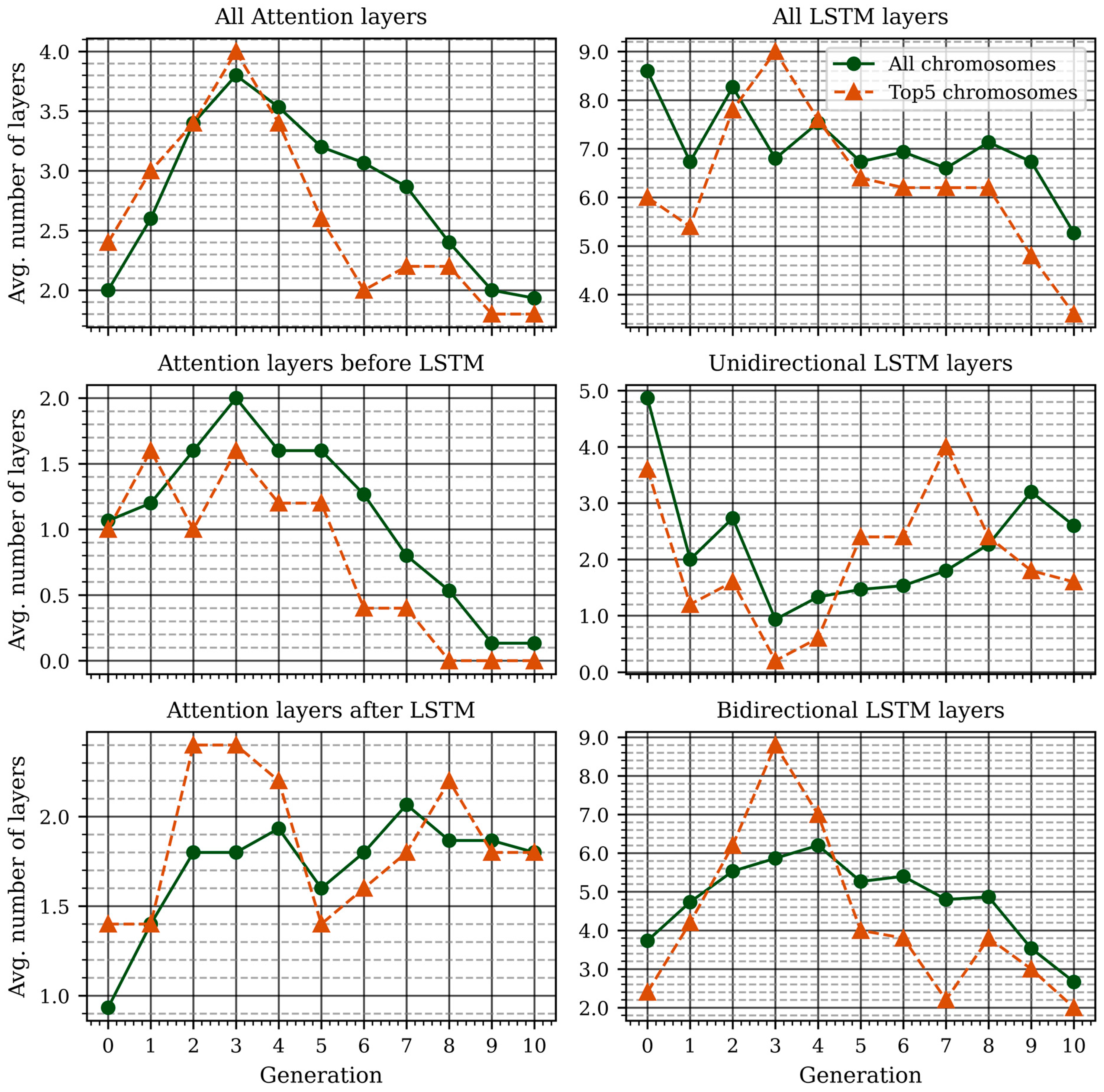
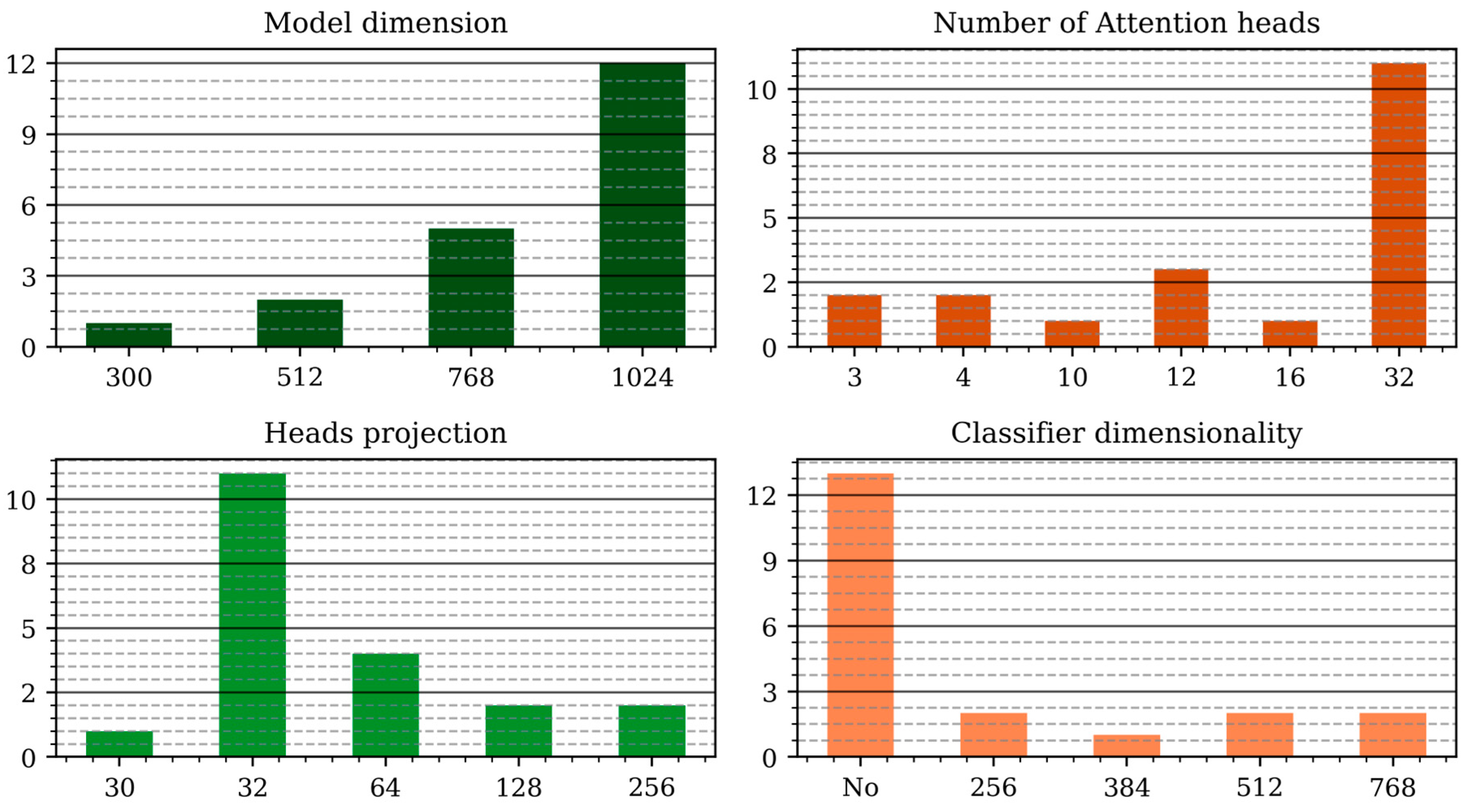
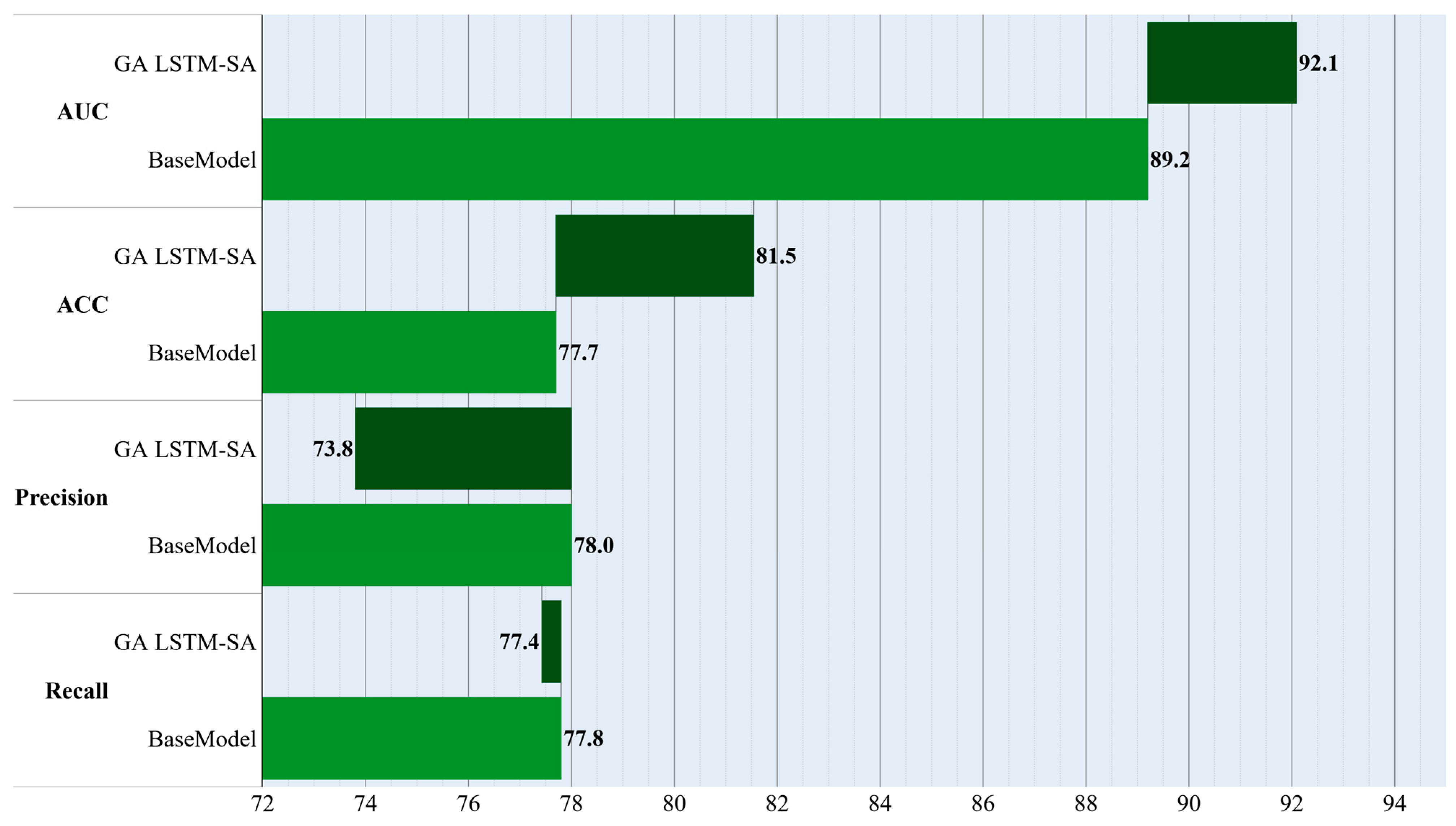
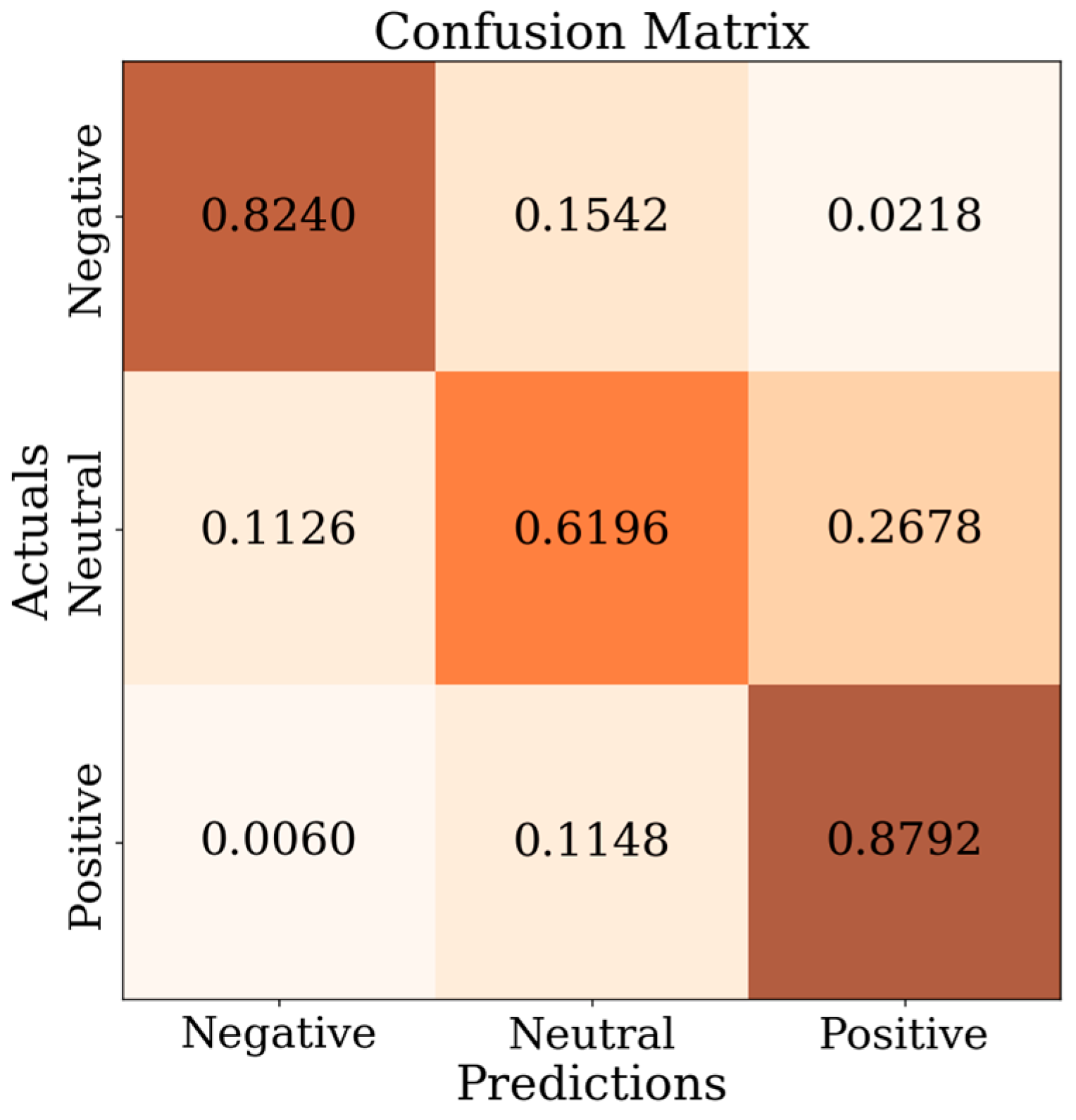
3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| ANN | Artificial Neural Network |
| AUC | Area Under the Curve |
| BoW | Bag-of-Words |
| BERT | Bidirectional Encoder Representations from Transformers |
| CL | Classification Layer |
| CNN | Convolutional Neural Network |
| CSL | Cost-Sensitive Learning |
| DL | Deep Learning |
| FFCV | Five-Fold Cross-Validation |
| FFNN | Feed Forward Neural Network |
| GA | Genetic Algorithm |
| GPU | Graphics Processing Units |
| LAT | Layer-wise Attention Tracing |
| LLM | Large Language Model |
| LR | Logistic Regressions |
| LSTM | Long Short-Term Memory |
| MDPI | Multidisciplinary Digital Publishing Institute |
| ML | Machine Learning |
| MSL | Multi-Head Self-Attention Layer |
| NB | Naïve Bayes |
| NLP | Natural Language Processing |
| OL | Output Layer |
| OOV | Out-of-Vocabulary |
| PM | Performance Metric |
| RE | Recurrent Encoder |
| ROC | Receiver Operating Characteristic |
| SA | Sentiment Analysis |
| SVM | Support Vector Machines |
| TFCV | Two-Fold Cross-Validation |
| TL | Transfer Learning |
| TLM | Transformer Language Model |
| WEL | Word Embedding Layer |
References
- Zhang, L.; Wang, S.; Liu, B. Deep Learning for Sentiment Analysis: A Survey. WIREs Data Min. Knowl. Discov. 2018, 8, e1253. [Google Scholar] [CrossRef]
- Young, T.; Hazarika, D.; Poria, S.; Cambria, E. Recent Trends in Deep Learning Based Natural Language Processing [Review Article]. IEEE Comput. Intell. Mag. 2018, 13, 55–75. [Google Scholar] [CrossRef]
- Khurana, D.; Koli, A.; Khatter, K.; Singh, S. Natural Language Processing: State of The Art, Current Trends and Challenges. Multimed. Tools Appl. 2022, 82, 3713–3744. [Google Scholar] [CrossRef] [PubMed]
- Touvron, H.; Lavril, T.; Izacard, G.; Martinet, X.; Lachaux, M.A.; Lacroix, T.; Rozière, B.; Goyal, N.; Hambro, E.; Azhar, F.; et al. LLaMA: Open and Efficient Foundation Language Models. arXiv 2023. [Google Scholar] [CrossRef]
- Languages Most Frequently Used for Web Content as of January 2024, by Share of Websites. Available online: https://www.statista.com/statistics/262946/most-common-languages-on-the-internet/ (accessed on 19 June 2024).
- Ferrone, L.; Zanzotto, F.M. Symbolic, Distributed and Distributional Representations for Natural Language Processing in the Era of Deep Learning: A Survey. Front. Robot. AI 2020, 6, 153. [Google Scholar] [CrossRef]
- Otter, D.; Medina, J.; Kalita, J. A Survey of the Usages of Deep Learning for Natural Language Processing. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 604–624. [Google Scholar] [CrossRef]
- Mao, Y.; Liu, Q.; Zhang, Y. Sentiment analysis methods, applications, and challenges: A systematic literature review. J. King Saud Univ. Comput. Inf. Sci. 2024, 36, 102048. [Google Scholar] [CrossRef]
- Pereira, D.A. A Survey of Sentiment Analysis in the Portuguese Language. Artif. Intell. Rev. 2021, 54, 1087–1115. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Long and Short Papers), Minneapolis, MN, USA, 2–7 June 2019; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; pp. 4171–4186. [Google Scholar] [CrossRef]
- Wankhade, M.; Rao, A.; Kulkarni, C. A survey on sentiment analysis methods, applications, and challenges. Artif. Intell. Rev. 2022, 55, 5731–5780. [Google Scholar] [CrossRef]
- Rehman, A.U.; Malik, A.K.; Raza, B.; Ali, W. A Hybrid CNN-LSTM Model for Improving Accuracy of Movie Reviews Sentiment Analysis. Multimed. Tools Appl. 2019, 78, 26597–26613. [Google Scholar] [CrossRef]
- Souza, F.; Nogueira, R.; Lotufo, R. BERTimbau: Pretrained BERT Models for Brazilian Portuguese. In Intelligent Systems; Cerri, R., Prati, R.C., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2020; Volume 12319, pp. 403–417. [Google Scholar] [CrossRef]
- Rodrigues, J.; Gomes, L.; Silva, J.; Branco, A.; Santos, R.; Cardoso, H.L.; Osório, T. Advancing Neural Encoding of Portuguese with Transformer Albertina PT-*. arXiv 2023. [Google Scholar] [CrossRef]
- Souza, E.; Vitório, D.; Castro, D.; Oliveira, A.L.I.; Gusmão, C. Characterizing Opinion Mining: A Systematic Mapping Study of the Portuguese Language. In Proceedings of Computational Processing of the Portuguese Language, Processings of the 12th International Conference, PROPOR 2016, Tomar, Portugal, 13–15 July 2016; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2016; Volume 9727, pp. 122–127. [Google Scholar] [CrossRef]
- Souza, F.D.; Baptista de Oliveira e Souza Filho, J. Sentiment Analysis on Brazilian Portuguese User Reviews. In Proceedings of the 2021 IEEE Latin American Conference on Computational Intelligence (LA-CCI), Temuco, Chile, 2–4 November 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Brum, H.B.; Nunes, M.d.G.V. Building a Sentiment Corpus of Tweets in Brazilian Portuguese. In Proceedings of the Eleventh International Conference on Language Resources and Evaluation (LREC 2018), Miyazaki, Japan, 7–12 May 2018; European Language Resources Association (ELRA): Paris, France, 2017; pp. 4167–4172. [Google Scholar] [CrossRef]
- Gomes, F.B.; Coello, J.M.A.; Kintschner, F.E. Studying the Effects of Text Preprocessing and Ensemble Methods on Sentiment Analysis of Brazilian Portuguese Tweets. In Statistical Language and Speech Processing, Proceedings of the 6th International Conference, SLSP 2018, Mons, Belgium, 15–16 October 2018; Lecture Notes in Computer Science; Springer Nature Switzerland: Cham, Switzerland, 2018; pp. 167–177. [Google Scholar] [CrossRef]
- dos Santos, F.L.; Ladeira, M. The Role of Text Pre-processing in Opinion Mining on a Social Media Language Dataset. In Proceedings of the 2014 Brazilian Conference on Intelligent Systems, Sao Paulo, Brazil, 18–22 October 2014; pp. 50–54. [Google Scholar] [CrossRef]
- Souza, F.D.; Baptista de Oliveira e Souza Filho, J. Embedding Generation for Text Classification of Brazilian Portuguese User Reviews: From Bag-of-Words to Transformers. Neural Comput. Appl. 2022, 35, 9393–9406. [Google Scholar] [CrossRef]
- Repositório de Word Embeddings do NILC. Available online: http://www.nilc.icmc.usp.br/embeddings (accessed on 30 June 2023).
- Vianna, D.; Carneiro, F.; Carvalho, J.; Plastino, A.; Paes, A. Sentiment analysis in Portuguese tweets: An evaluation of diverse word representation models. Lang Resour. Eval. 2024, 58, 223–272. [Google Scholar] [CrossRef]
- Cardoso, M.H.; Maria Da Rocha Fernandes, A.; Marin, G.; Quietinho Leithardt, V.R.; Crocker, P. Comparison between Different Approaches to Sentiment Analysis in the Context of the Portuguese Language. In Proceedings of the 16th Iberian Conference on Information Systems and Technologies (CISTI), Chaves, Portugal, 23–26 June 2021; pp. 1–6. [Google Scholar] [CrossRef]
- de Oliveira, D.N.; de, C. Merschmann, L.H. Joint Evaluation of Preprocessing Tasks with Classifiers for Sentiment Analysis in Brazilian Portuguese Language. Multimed. Tools Appl. 2021, 80, 15391–15412. [Google Scholar] [CrossRef]
- Adán-Coello, J.M.; Neto, A.D.C. Sentiment Analysis of Tweets in Brazilian Portuguese with Convolutional Neural Networks. Int. J. Innov. Educ. Res. 2019, 7, 29–41. [Google Scholar] [CrossRef]
- Britto, L.F.S.; Pessoa, L.A.S.; Agostinho, S.C.C. Cross-Domain Sentiment Analysis in Portuguese using BERT. In Proceedings of the Anais do XIX Encontro Nacional de Inteligência Artificial e Computacional (ENIAC 2022), Campinas, Brazil, 28 November–1 December 2022; Sociedade Brasileira de Computação-SBC: Porto Alegre, Brazil, 2022; pp. 61–72. [Google Scholar] [CrossRef]
- Branco, A.; Parada, D.; Silva, M.; Mendonça, F.; Mostafa, S.S.; Morgado-Dias, F. Sentiment Analysis in Portuguese Restaurant Reviews: Application of Transformer Models in Edge Computing. Electronics 2024, 13, 589. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. arXiv 2017. [Google Scholar] [CrossRef]
- Xia, H.; Ding, C.; Liu, Y. Sentiment Analysis Model Based on Self-Attention and Character-Level Embedding. IEEE Access 2020, 8, 184614–184620. [Google Scholar] [CrossRef]
- Wu, Z.; Nguyen, T.-S.; Ong, D. Structured Self-Attention Weights Encode Semantics in Sentiment Analysis. In Proceedings of the Third BlackboxNLP Workshop on Analyzing and Interpreting Neural Networks for NLP, Online, 20 November 2020; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 255–264. [Google Scholar] [CrossRef]
- Katoch, S.; Chauhan, S.S.; Kumar, V. A review on genetic algorithm: Past, present, and future. Multimed. Tools Appl. 2021, 80, 8091–8126. [Google Scholar] [CrossRef]
- De Olival, D.; Branco, A.; Silva, M.; Mendonça, F.; Mostafa, S.S.; Morgado-Dias, F. PT-EN Zomato Dataset. Mendeley Data 2024. [Google Scholar] [CrossRef]
- Yadollahi, A.; Shahraki, A.; Zaïane, O. Current State of Text Sentiment Analysis from Opinion to Emotion Mining. ACM Comput. Surv. 2017, 50, 1–33. [Google Scholar] [CrossRef]
- AL-Smadi, M.; Hammad, M.M.; Al-Zboon, S.A.; AL-Tawalbeh, S.; Cambria, E. Gated Recurrent Unit with Multilingual Universal Sentence Encoder for Arabic Aspect-Based Sentiment Analysis. Knowl.-Based Syst. 2023, 261, 107540. [Google Scholar] [CrossRef]
- Bergstra, J.; Bengio, Y. Random Search for Hyper-Parameter Optimization. J. Mach. Learn. Res. 2012, 13, 281–305. [Google Scholar] [CrossRef]
- Liashchynskyi, P.B.; Liashchynskyi, P. Grid Search, Random Search, Genetic Algorithm: A Big Comparison for NAS. arXiv 2019, arXiv:1912.06059v1. [Google Scholar]
- Mendonça, F.; Mostafa, S.S.; Freitas, D.; Morgado-Dias, F.; Ravelo-García, A.G. Multiple Time Series Fusion Based on LSTM: An Application to CAP A Phase Classification Using EEG. Int. J. Environ. Res. Public Health 2022, 19, 10892. [Google Scholar] [CrossRef]
- Zhou, P.; Qi, Z.; Zheng, S.; Xu, J.; Bao, H.; Xu, B. Text Classification Improved by Integrating Bidirectional LSTM with Two-dimensional Max Pooling. In Proceedings of the COLING 2016, the 26th International Conference on Computational Linguistics: Technical Papers, Osaka, Japan, 11–16 December 2016; ACL: Stroudsburg, PA, USA, 2016; pp. 3485–3495. Available online: http://dblp.uni-trier.de/db/conf/coling/coling2016.html#ZhouQZXBX16 (accessed on 12 January 2025).

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Mean Length | Median Length | Vocabulary Size (1 g) |
|---|---|---|---|
| Olist | 7 | 6 | 3272 |
| Buscape | 25 | 17 | 13,470 |
| B2W | 14 | 10 | 12,758 |
| UTLCApps | 21 | 10 | 28,283 |
| UTLCMovies | 15 | 7 | 69,711 |
| Used dataset (Zomato Portugal) | 73 | 52 | 52,388 |
| Labels | 1 * | 1.5 * | 2 * | 2.5 * | 3 * | 3.5 * | 4 * | 4.5 * | 5 * |
|---|---|---|---|---|---|---|---|---|---|
| Star rating (%) | 4.3 | 0.7 | 3.5 | 2.0 | 10.6 | 10.2 | 29.7 | 12.5 | 26.6 |
| Polarity (%) | 8.47 | 22.76 | 68.77 | ||||||
| Imbalance ratio | 1:8 | 1:3 | 1:1 | ||||||
| Class | Negative | Neutral | Positive | ||||||
| Hyperparameter | Locus | Definition | |
|---|---|---|---|
| Direction of LSTM layers | 0 | 0: Unidirectional | 1: Bidirectional |
| Number of stacked LSTM layers | 1–2 | 00: 1 10: 3 | 01: 2 11: 4 |
| Position of self-attention layer | 3–4 | 00: No 10: After | 01: Before 11: Both |
| Model dimension | 5–6 | 00: 300 10: 768 | 01: 512 11: 1024 |
| Heads dimension | 7–8 | 00: 32 10: 128 | 01: 64 11: 256 |
| Dropout percentage | 9–11 | 000: 5 100: 25 001: 10 101: 30 | 010: 15 110: 35 011: 20 111: 40 |
| Operation before classification layer | 12–13 | 00: FFNN 10: LSTM | 01: Pooling 11: BiLSTM |
| Classification layer shape factor | 14–15 | 00: 0.0 10: 1.0 | 01: 0.5 11: 1.5 |
| Activation function | 16–17 | 00: ReLU 10: Leaky-ReLU | 01: Tanh 11: eLU |
| Encoder replications | 18–19 | 00: 0 10: 2 | 01: 1 11: 3 |
| Tokenizer | 20 | 0: Blankspace | 1: WordPiece |
| Reference | Model | Accuracy | F1-Score |
|---|---|---|---|
| Brum and Nunes, 2017 [17] | NB | 64.6 | 59.9 |
| Gomes et al., 2018 [18] | LR | 81.3 | 79.6 |
| Adán-Coello and Neto, 2019 [25] | Self-AT-LSTM | 66.5 | 67.6 |
| Britto et al., 2022 [26] | BERTimbau | 78.8 | 66.8 |
| Branco et al., 2024 [27] | BERTimbau with AdaBoost | 84.0 | 77.7 |
| This study | LSTM-SA | 81.5 | 75.4 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Parada, D.; Branco, A.; Silva, M.; Mendonça, F.; Mostafa, S.; Morgado-Dias, F. Optimizing an LSTM Self-Attention Architecture for Portuguese Sentiment Analysis Using a Genetic Algorithm. Appl. Sci. 2025, 15, 6336. https://doi.org/10.3390/app15116336
Parada D, Branco A, Silva M, Mendonça F, Mostafa S, Morgado-Dias F. Optimizing an LSTM Self-Attention Architecture for Portuguese Sentiment Analysis Using a Genetic Algorithm. Applied Sciences. 2025; 15(11):6336. https://doi.org/10.3390/app15116336
Chicago/Turabian StyleParada, Daniel, Alexandre Branco, Marcos Silva, Fábio Mendonça, Sheikh Mostafa, and Fernando Morgado-Dias. 2025. "Optimizing an LSTM Self-Attention Architecture for Portuguese Sentiment Analysis Using a Genetic Algorithm" Applied Sciences 15, no. 11: 6336. https://doi.org/10.3390/app15116336
APA StyleParada, D., Branco, A., Silva, M., Mendonça, F., Mostafa, S., & Morgado-Dias, F. (2025). Optimizing an LSTM Self-Attention Architecture for Portuguese Sentiment Analysis Using a Genetic Algorithm. Applied Sciences, 15(11), 6336. https://doi.org/10.3390/app15116336