1. Introduction
Recognition of the combustion state of the flame in the cement rotary kilns refers to the process of analyzing and identifying real-time images of the flame during the clinker calcination process, ensuring the smooth progress of cement production through the recognition, detection, and control of the combustion state. A flame combustion state recognition method based on a rotary kiln can provide many advantages in the cement production process. Such a method is conducive to real-time monitoring of the firing process, ensuring that workers detect abnormal conditions and take necessary measures to ensure the safety and stability of the production process. Analyzing the color, shape, and other characteristics of the flame is beneficial for detecting and evaluating the quality of cement and taking measures to improve the quality of cement production. Flame combustion images help understand the combustion efficiency, and adjusting the supply of oxygen and raw materials based on image analysis can improve production efficiency, reduce production costs, and decrease carbon emissions. However, due to complex factors such as high temperature, high pressure, and high levels of smoke inside the rotary kiln, workers’ inaccurate recognition of the combustion state can affect the effective control of the calcination process. Existing machine learning-based flame combustion state recognition methods have low accuracy and poor generalization ability due to the influence of the complex environment inside the furnace. Furthermore, deep learning-based flame combustion state recognition methods face difficulties in modeling due to low data volume and severely uneven sample distributions. Therefore, this paper proposes a new method for recognizing the combustion state of cement rotary kilns that can accurately and quickly identify the flame combustion state, even with a small and unevenly distributed data volume.
2. Related Worked
Detection and recognition methods for the clinker calcination process are mainly divided into four categories: manual observation methods, contact detection methods, infrared detection methods, and flame image processing and recognition detection methods. Manual observation methods are easily influenced by workers’ experience and lead to incorrect judgments in complex furnace environments. Contact detection methods and infrared measurement methods cannot meet the requirements of long-term continuous and real-time detection in environments with high temperature, high levels of smoke, and strong physical and chemical reactions. Most contact detection equipment requires regular maintenance and updates, consuming considerable material and human resources. Flame image processing and recognition detection methods have made great progress in recent years and cane mainly be divided into two mainstream methods: machine learning recognition methods based on manual feature extraction and deep learning recognition methods based on automatic feature extraction.
Feature-based machine learning recognition methods mainly consist of two steps: feature extraction and state prediction. The purpose of feature extraction is to convert high-dimensional data into low-dimensional feature data, which serve as input for machine learning. Wang et al. [
1] proposed a method for identifying the combustion conditions of rotary kilns based on the extraction of texture features of flame images using the Gray-Level Co-occurrence Matrix (GLCM) and the KPCA-GLVQ recognition method. Zhou et al. [
2] established a fuzzy support vector machine model to predict the end point of converter blowing based on flame spectral features and furnace flame characteristics. Liu et al. [
3] proposed a quaternion directional statistical algorithm to extract color texture features of images, then analyzed the features using K-nearest neighbor regression and a Generalized Regression Neural Network (GRNN). Zhao et al. [
4] extracted and analyzed the features of furnace flame chroma, boundary, and texture, using them as inputs. They established a model of the relationship between furnace flame images and blowing data using a least squares support vector machine network model and used the particle swarm optimization algorithm to establish the optimal prediction model, achieving good prediction results. Li et al. [
5] proposed a method to describe the dynamic deformation characteristics of flames and determine the end point of steel making based on dynamic information on flame boundaries.
Flame combustion exhibits various characteristics, and the choice of which features to extract as inputs for machine learning is influenced by scholars’ “expert experience”. Different choices of features have a significant impacts on the recognition results, and such methods are difficult to generalize. Because different factories have different production scenarios, the characteristics of flame combustion vary. Moreover, the complex and changing environment inside the furnace makes it difficult for methods based on single-feature extraction to be stable. In recent years, many scholars have chosen deep learning methods that can automatically extract various features of flames for research. Yang et al. [
6] proposed a novel neural network architecture that can effectively capture the spatiotemporal changes of image sequences by using a series of flame image sequences to predict the combustion state. This method can quickly and effectively predict the combustion state of rotary kilns. Sun et al. [
7] proposed an improved method for determining the end point of converter blowing based on DenseNet, effectively improving the accuracy of converter end-point determination. Hu et al. [
8] improved the attention loss function of the network based on DenseNet, proposed the EL-DenseNet combustion state recognition method, and further improved the recognition accuracy. Gu et al. [
9] proposed a new recognition model, which first preprocesses the furnace flame video sequence, then uses a Convolutional Recurrent Neural Network (CRNN) to further learn the spatiotemporal features of the flame to obtain the recognition results. Wang et al. [
10] used the bidirectional recurrent multi-scale convolutional deep neural network algorithm to take into account the characteristics of the frequency-domain structure and the time-domain dynamic sequence. It was applied to the deep learning of BOF flame spectral information.
Deep learning requires a large amount of balanced data with different sample numbers to support model training. However, abnormal burning conditions are rare in the field, and it is very difficult to collect a large amount of data with uniform distribution. Therefore, scholars have proposed the use of image generation models to expand training data to address this issue. Qiu et al. [
11] established a VAE model to reconstruct a large amount of generated data by using flame images collected from coal-fired boilers as input and processed through an encoder and decoder. Recently, the image generation method based on Denoising Diffusion Probabilistic Models (DDPMs) has made great progress [
12], and its potential in expanding image datasets has been increasingly recognized by scholars. Many scholars have begun to use this method to address the problem of uneven distribution of image sample data. Lee and Yun [
13] proposed a DDPM to generate images similar to datasets including several different types of microstructures (such as polycrystalline alloys, carbonates, ceramics, copolymers, fiber composites, etc.). Khader et al. [
14] proposed the generation magnetic resonance images (MRIs) and computed tomography (CT) images using a DDPM and demonstrated that the generated images can be used to train image segmentation models. Yilmaz et al. [
15] proposed a method for generating microscope image data that can effectively generate fully annotated microscope image datasets by establishing a DDPM and training the model. This helps reduce the reliance on manual annotation when training deep learning-based segmentation methods, enabling the segmentation of different datasets without the need for manual annotation. Khanna et al. [
16] improved an original network based on a DDPM to address the spatiotemporal characteristics of remote sensing data and proposed the DiffusionSat model for the generation satellite remote sensing images. Asya et al. [
17] proposed the GradPaint method to generate a coordinated image by calculating a custom loss to measure its consistency with the masked input image. Existing diffusion-based inpainting methods are limited to single-modal guidance and require task-specific training, hindering their cross-modal scalability. To solve this problem, Yang et al. [
18] proposed the Uni-paint generation model. Uni-paint is based on pre-trained stable diffusion and does not require task-specific training on a specific dataset, achieving a few-shot generalization capability on custom images.
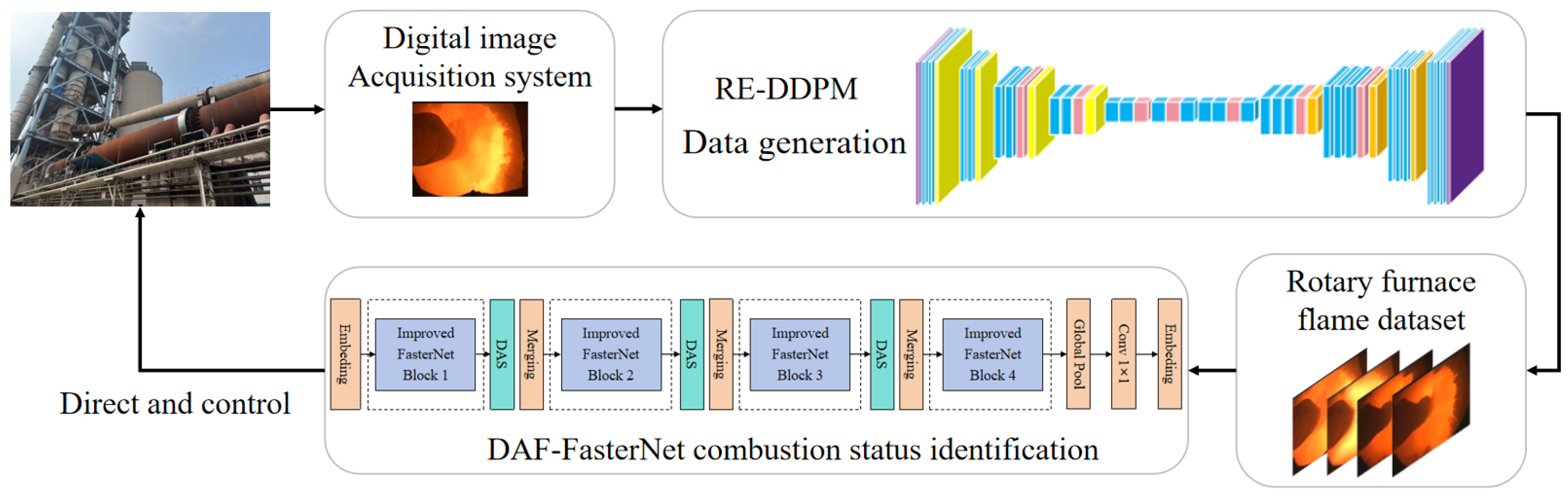
This article proposes a flame combustion image generation method based on RE-DDPM to address the problems of insufficient data and severely uneven sample distribution. In this paper, the RE-DDPM method is used to generate a large number of images that are extremely similar to real data based on a small number of live burning strip images, solving the problem of insufficient training samples for deep learning. Experiments show that following the use of the method proposed in this paper to expand the data, the generated data are more similar to the real data, and the recognition accuracy of the model can be improved. Secondly, to address the problem of low accuracy in combustion state recognition, a combustion state recognition method based on DAF-FasterNet is proposed. This article improves upon the original FasterNet network [
19] to significantly improve recognition accuracy while ensuring recognition speed. Extensive experiments show that the combustion state recognition method proposed in this paper has advantages in terms of both speed and accuracy.
The main contributions of this research can be summarized as follows:
A new model for recognizing the combustion state of cement rotary kilns is proposed. This model first addresses the problem of a small dataset and uneven sample distribution through RE-DDPM. Then, it achieves precise and fast recognition of the combustion state through DAF-FasterNet.
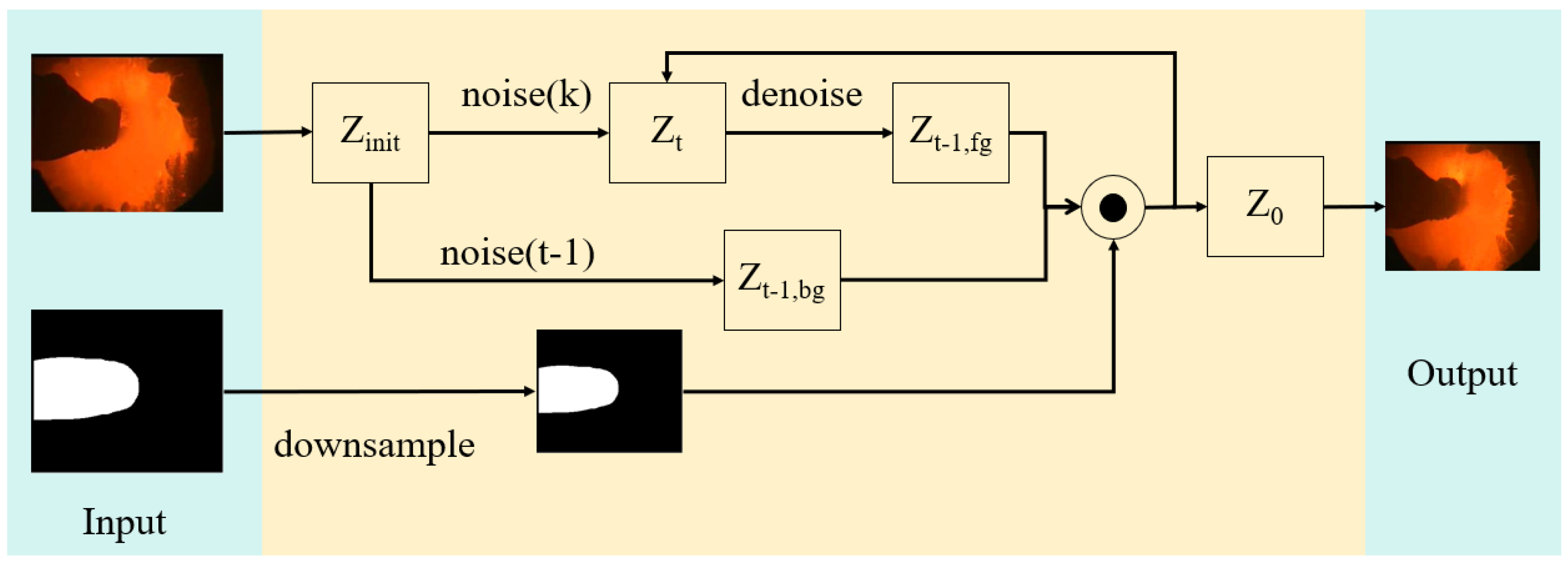
This paper proposes a new image generation method, RE-DDPM. During training, a mask operation is applied to a part of the original image, and the mask is also included as input, achieving local redrawing of the image. This makes the generated data more consistent with real scenes. The proposed local redrawing method outperforms traditional redrawing methods.
This paper proposes a new method for recognizing the combustion state of flames, DAF-FasterNet. By improving the activation function in FasterNet to FReLU, the activation function gains the ability to capture spatial layouts, improving the model’s recognition accuracy. Additionally, a lightweight attention DAS is introduced, making the model pay more attention to the combustion characteristics of flames. This not only ensures the lightweight nature of the model but also further improves recognition accuracy.
5. Experiments
To validate the effectiveness and superiority of the cement rotary kiln flame combustion state recognition method proposed in this paper, a large number of experiments were conducted. The experiments reported in this paper were conducted under the following conditions: operating system: Windows 10; CUDA: 11.0; GPU: RTX 3080; CPU: i7-12700KF; framework: PyTorch 2.0.1.
The image generation model was trained on each dataset for 500 epochs, and the batch size was set to 16. For the first 200 epochs, a learning rate of was used, followed by a learning rate of for the next 300 epochs. We choose the Adam optimizer ( = 0.9, = 0.999) to train the L1 loss function. We trained the FasterNet recognition model for 300 epochs, the batch size was set to 32, the learning rate was set to , and the AdamW optimizer was used.
5.1. Evaluation Metrics
The evaluation metrics proposed in this paper consist of two parts: image generation evaluation metrics and neural network evaluation metrics. They are used to demonstrate the superiority of the RE-DDPM and DAF-FasterNet proposed in this paper.
5.1.1. Flame Image Generation Evaluation Metrics
We use Structural Similarity (SSIM) as one of the evaluation criteria for image generation quality [
33].
where
and
represent the mean pixel intensities of images
X and
Y, respectively;
and
represent the pixel-intensity variances of
X and
Y, respectively;
represents the covariance of images
X and
Y; and
and
are two variables for stable division.
The Frechet Inception Distance (FID) score is a metric that calculates the distance between the feature vectors of real and generated images [
34]. A lower score indicates that the two sets of images are more similar or that their statistics are more similar. The FID score is 0.0 in the best case scenario, indicating identical images.
where
and
represent the feature means of the real and generated images and
and
represent the covariance matrices of the actual feature vectors and the generated feature vectors.
The Learned Perceptual Image Patch Similarity LPIPS can also evaluate the distortion of generated images. LPIPS essentially calculates the similarity between activations of two image patches in a predefined network. LPIPS can be defined as follows:
where
and
are the height and width of the input features in layer
l of the predefined network, respectively.
is the weight of each feature in layer
l.
and
represent the normalized features of pixel
in layer
l. ⊙ multiplies the feature vector at each pixel by the feature weight.
5.1.2. Flame Combustion State Recognition Evaluation Metrics
For the requirements of the cement rotary kiln production scene, high accuracy (ACC) is one of the most important requirements. The formula for calculating accuracy is shown in Equation (
18):
where
represents true positives;
represents true negatives; and
P and
N are the total numbers of positives and negatives, respectively.
Due to the limitations of computing equipment in production scenarios, the computational load of the model (FLOPs) also needs to be considered. Large models are difficult to deploy in practice, so it is necessary to reduce model complexity while ensuring recognition accuracy. Additionally, high latency is unacceptable in real production, as it can lead to significant economic losses and potential production safety hazards.
In summary, accuracy and parameter count and latency are used as the basis for evaluating neural network recognition methods.
5.2. Data Preparation
The flame image monitoring device (CCD camera and cooling system) was installed in the cement rotary kiln of a cement plant, as shown in
Figure 10. A color CCD camera (resolution: 1920 × 1080; refresh rate: 30 FPS) was used to collect the burning data, and the subsequent detection of the burning state was carried out. A cooling system was used to reduce the temperature of the camera’s operating environment to ensure the normal operation of the equipment. The resolution of the collected image is 1920 × 1080, which is sufficient to reflect the detailed distribution characteristics, texture characteristics, and color characteristics of the flame.
The data collected on site were manually annotated by experts, classifying the combustion state in the combustion zone into three categories: normal sintering, under-sintering, and over-sintering. The on-site images of each condition are shown in
Figure 11. The distribution of data samples collected by the monitoring device is shown in
Table 1.
The data in the table indicate a severe imbalance in sample distribution, and the data volume is completely insufficient to support deep learning training. Therefore, it is necessary to expand the data samples to achieve a balanced sample distribution to meet the needs of deep learning training.
Due to the high-temperature environment inside the furnace, some images have significant noise and require denoising processing. In this study, a Gaussian filter was used for denoising. Through analysis of the sample data, it was found that the contribution of the furnace wall edges to the classification is very small. Therefore, the images were cropped around the discharge port to 1080 × 1080. This not only reduces network training time but also reduces the interference of some unimportant factors.
5.3. Experimental Results
To verify the feasibility of the method, optimize the data generation part, and improve the detection method, we conducted experiments on the flame combustion state model of a cement rotary kiln based on RE-DDPM and DAF-FasterNet. The initial DDPM and FasterNet model were evaluated, and the performance after improvement for these two parts was studied. Additionally, we conducted a large number of comparative and ablation experiments, comparing the results obtained with the proposed methods. The research results include SSIM, FID, and LPIPS for the image generation part and ACC, FLOPs, and latency for the detection part.
5.3.1. Flame Image Generation
We compared our proposed method with other neural networks (GAN, VAE, and original DDPM).
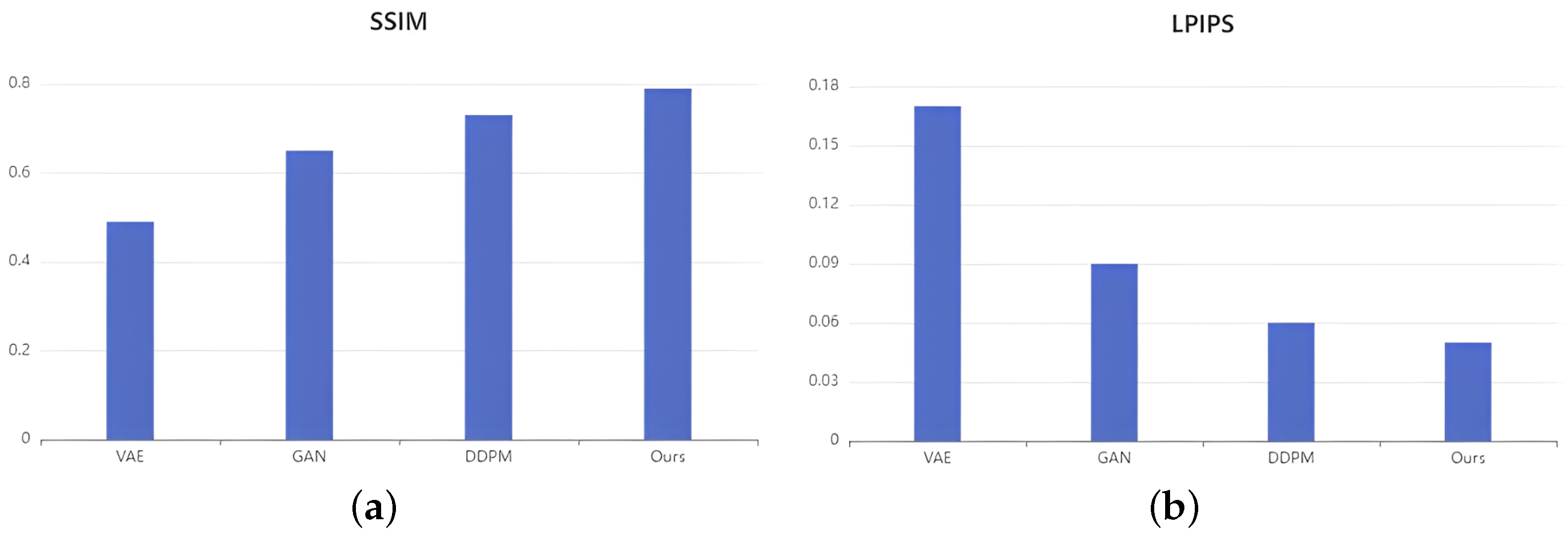
Figure 12 shows the performance of each model. In terms of SSIM, DDPM outperforms GAN and VAE, and our method, RE-DDPM, outperforms the original DDPM. In terms of LPIPS, our method achieved the lowest score, indicating that the images generated by our method are more in line with human perception.
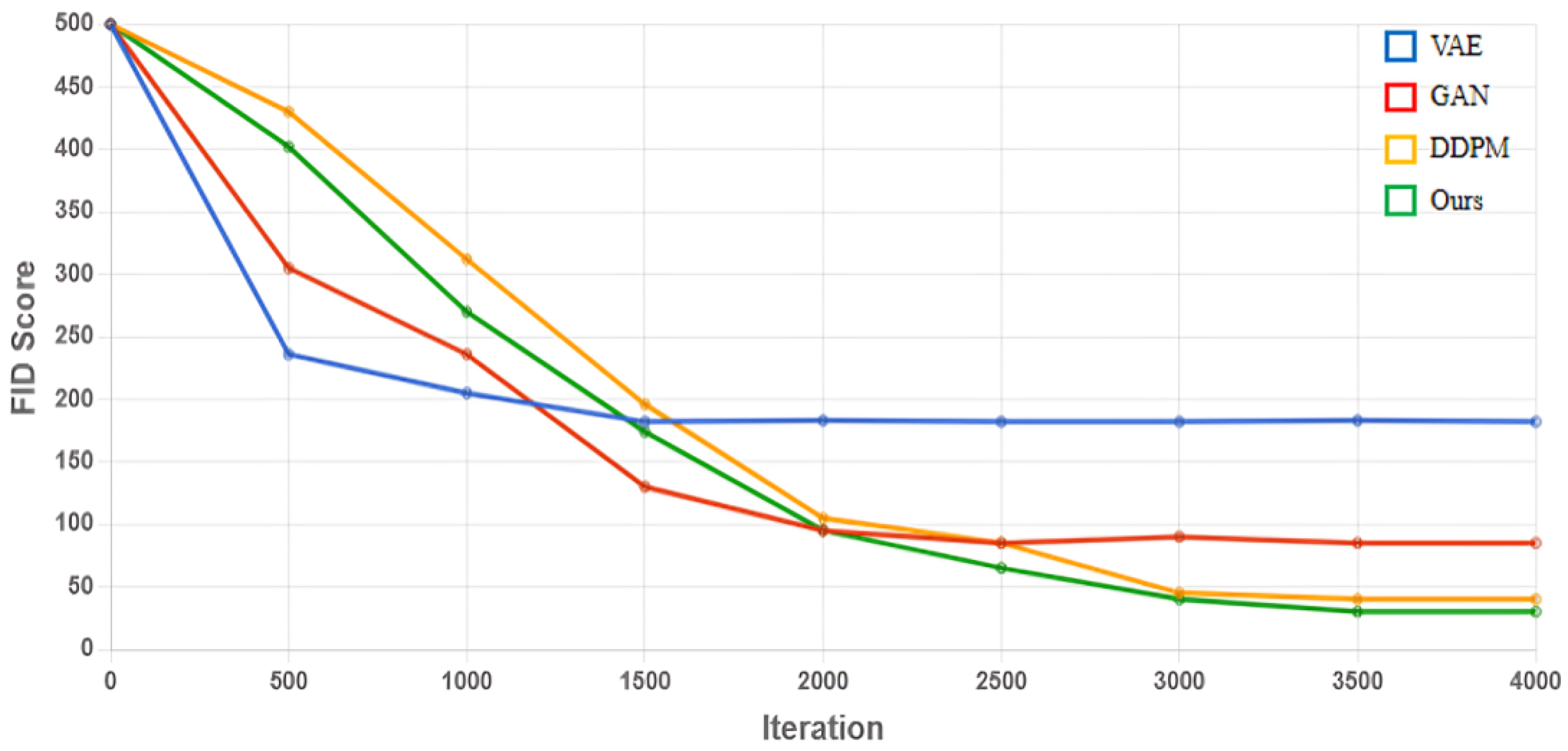
Figure 13 shows the FID scores for certain iterations, with the FID scores gradually decreasing with an increasing number of iterations. A lower FID score indicates more similarity, as the FID score between two identical datasets is almost zero.
Although the DDPM shows promise in data augmentation, the sampling speed is still much slower compared to GAN and VAE. A GAN consists of a discriminator and a generator. The generator is responsible for generating images, while the discriminator is used to judge the authenticity of the generated images. A trained GAN model can directly generate target images in one step. However, unlike aa GAN, a DDPM recovers images from noise in the form of a Markov chain in the reverse denoising process. This means that the more iterations we set, the longer it takes to generate images. Nevertheless, the images generated by a DDPM still achieve satisfactory results. Furthermore, due to improvements in network attention and the use of local redrawing methods in our method, the images generated by the model are more realistic, and the training speed of the network is also improved.
Figure 14 shows images generated by different models. The images generated by VAE are too blurry to display the rich details of flame images. Compared to the DDPM, VAE’s loss function typically includes a reconstruction loss, which measures the difference between the images generated by the decoder and the original input images. This reconstruction loss helps the model learn the data distribution but may result in generated images lacking detail and clarity, especially for complex structures or high-resolution images. Additionally, VAE assumes that the latent space is continuous, meaning that similar latent vectors generate similar images. This continuity may cause the model to converge to some blurry intermediate representations when generating images rather than producing clear images. The images generated by a GAN differ significantly from the real images in the distribution of flame texture features. The original DDPM achieves satisfactory results in terms of clarity and diversity, but there are significant differences in flame texture details compared to real images. For example, in the images of normal sintering generated by the original DDPM, there are large areas of bright flames, which severely deviate from the actual distribution of flames in real images and may cause the recognition network to identify them as over-sintering, reducing recognition accuracy. The images generated by our RE-DDPM are closer to real images.
Traditional local redrawing focuses on the global generation of the redrawn region and does not consider the data distribution relationship between the redrawn region and other regions. This can cause a noticeable discontinuity at the boundary between the two regions, as shown in
Figure 15. When RE-DDPM performs local redraw, it considers the distribution of flame characteristics between the redrawn region and other regions. Our proposed redrawing method can maintain the consistency around the furnace wall while achieving high similarity and diversity in the redrawn flame region. The generated images appear more realistic and natural at the boundary between the redrawn region and other regions.
We also conducted ablation experiments on the improvement of the attention module in the U-Net network, with evaluation metrics including SSIM, LPIPS, and FID, to demonstrate that our improvements, indeed, enhance the generation effect. While adding more self-attention distributions may increase the computational cost of model training and slow down the training speed, it allows the network to extract more effective features, resulting in generated images with richer textures that better match the on-site images. The original U-Net’s attention mechanism is distributed in 16 × 16 layers. We improved it to 32 × 32, 16 × 16, and 8 × 8 layers. The specific performance is shown in
Table 2.
Using the image generation method we proposed, we expanded the original collected dataset. The normal combustion data were reduced to 1000 images, while the over-sintered images were increased to 1000 images and the under-sintered images were also increased to 1000 images. We partitioned the dataset such that 80% was used as the training set, 10% as the test set, and 10% as the validation set.The sample distribution of the expanded dataset is shown in
Table 3.
In order to verify the effectiveness of the proposed image generation method in augmenting the dataset, experiments were conducted on the original data, DDPM-augmented data, and RE-DDPM-augmented data. The experimental results demonstrate the effectiveness of the proposed method.The experimental results are shown in
Table 4.
5.3.2. Combustion State Recognition
To validate the accuracy and speed optimization of the method in the detection of combustion states in cement rotary kilns, we first conducted comparative experiments on different backbones to verify the superiority of the proposed method. The specific experimental results are shown in
Table 5. Although FasterNet does not have a significant advantage in Params and FLOPs, it achieves excellent scores in latency, being 35.4 ms faster than the most widely used ResNet. Furthermore, compared to other lightweight networks such as MobileNet and ShuffleNet, FasterNet still achieves better results. MobileNet, ShuffleNet, GhostNet, and other networks use depthwise convolution (DWConv) and/or group convolution (GConv) to extract spatial features. However, in the process of reducing FLOPs, operators often suffer from the side effects of increased memory access. Additionally, these networks are often accompanied by additional data operations such as concatenation, shuffling, and pooling, which are often important for small models in terms of runtime. Our method improves the structure and receptive field of the network based on FasterNet. We upgraded the single-layer PConv to a double-layer and improved the receptive field from 3 × 3 to 9 × 9. Experimental results show that while there is no significant increase in parameters or computational complexity, the recognition accuracy is improved.
After improvement, FasterNet can achieve an accuracy of 93.7% in recognition accuracy, but it still cannot meet the requirements of actual production. One reason is the lack of an attention mechanism in the original network. To address the issue of low recognition accuracy, we propose the introduction of a lightweight attention mechanism, DAS, to improve the network. This improvement not only ensures that the model is lightweight but also improves the recognition accuracy. The experimental results are shown in
Table 6. The proposed improvement method increases the parameters by only 0.13 M and the FLOPs by only 0.01 G compared to the original network while improving the accuracy by 2.7%. We also compared it with other common attention mechanisms, such as SENet, BAM, and CBAM, demonstrating the significant superiority of the proposed improvement method.
To validate the effectiveness of our improvement of the activation function in FasterNet, we replaced all ReLU activation functions in the network with FReLU visual activation functions and conducted experiments. The experimental results are shown in
Table 7. Additionally, we compared it with other activation functions, such as ReLU, PReLU, and Swish, demonstrating that the improvement proposed in this paper has a significant advantage in accuracy.



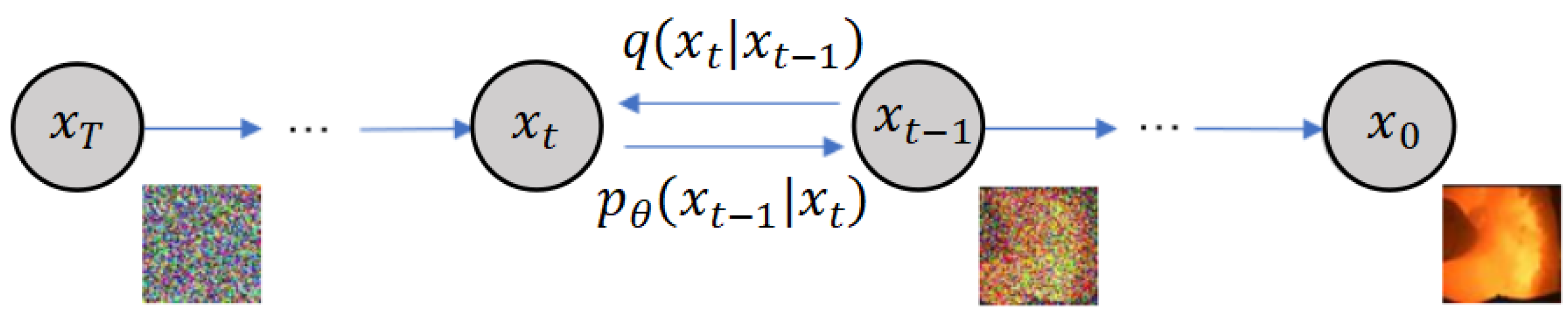










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}