


An Application Programming Interface (API) Sensitive Data Identification Method Based on the Federated Large Language Model

Abstract
1. Introduction
- Enhanced accuracy and generalization for API sensitive data identification: Compared to existing open-source large language models, the dedicated large language model for API sensitive data identification, APILLM, possesses powerful contextual understanding and feature extraction capabilities, significantly improving the accuracy and generalization of API sensitive data identification.
- A solution is provided for the issue of computational resource depletion in the integrated application of federated learning and large models. A parameter-efficient LoRA fine-tuning method is proposed, and a continual learning approach is introduced to prevent crucial knowledge in the global model from being forgotten during local model training, thereby solving the issue of computational resource exhaustion in the combined application of federated learning and large models.
- A solution is provided for the issue of API privacy data protection. Through federated learning, this paper effectively addresses the issue of potentially exposing user privacy from each data source and compromising information security when multiple data sources jointly train a large language model (LLM).
2. Related Works
2.1. API Sensitive Data Identification
- Rule-Based Algorithms: Rule-based methods utilize predefined patterns and rules to match sensitive data. For instance, regular expressions can be employed to detect common sensitive information such as social security numbers, credit card numbers, email addresses, etc. These patterns can be manually defined or automatically generated. The advantages lie in their simplicity, directness, and ease of implementation, as well as their strong interpretability with clear and concise rules. However, they suffer from difficulties in maintenance and updating, and lack flexibility in dealing with unknown patterns and highly variable data.
- Machine Learning Algorithms: Machine learning algorithms identify sensitive data by training models. These models can automatically recognize and classify sensitive information within data. In supervised learning, classifiers are trained using labeled training data, with common algorithms including Support Vector Machines (SVMs), Random Forest, and K-Nearest Neighbor (KNN), primarily used for identifying sensitive information in structured data. In unsupervised learning, sensitive data are identified by discovering patterns and anomalies within the data, with algorithms such as clustering (e.g., K-Means) and Isolation Forest commonly employed for detecting anomalies and sensitive information in unlabeled data.
- Hybrid Methods: Hybrid methods combine the strengths of multiple technologies and algorithms to improve the accuracy and efficiency of sensitive data identification. For example, a hybrid approach might integrate rule-based methods with machine learning methods, initially screening data with rules and then refining the classification with machine learning models.
- Privacy-Enhancing Technologies: Privacy-enhancing technologies enable sensitive data identification while ensuring data privacy. For instance, federated learning allows devices to collaboratively train models without sharing raw data, thereby protecting data privacy. This paper focuses on implementing API sensitive data identification through the fusion of federated learning and large language models.
2.2. Federated Learning
2.3. Large Language Models
3. Method Design
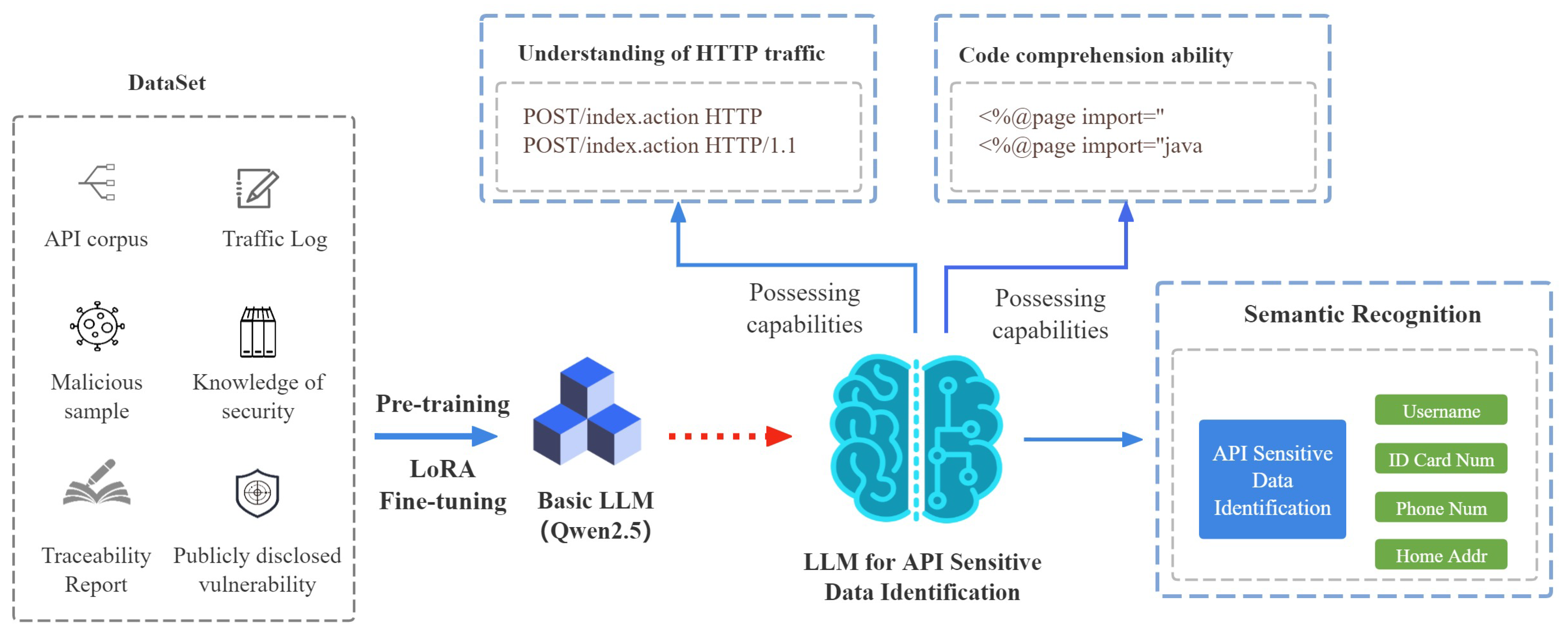
3.1. Method Overview
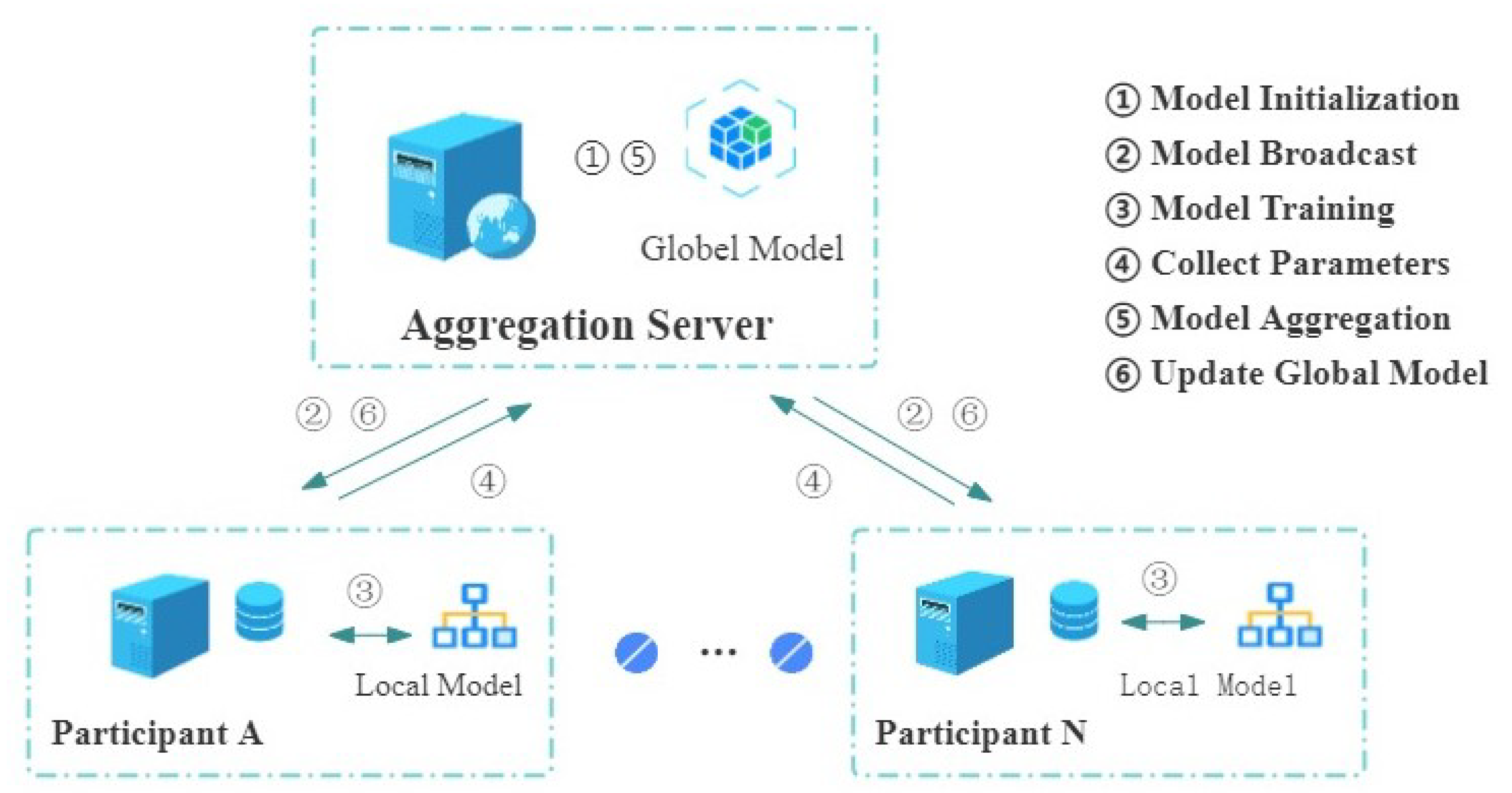
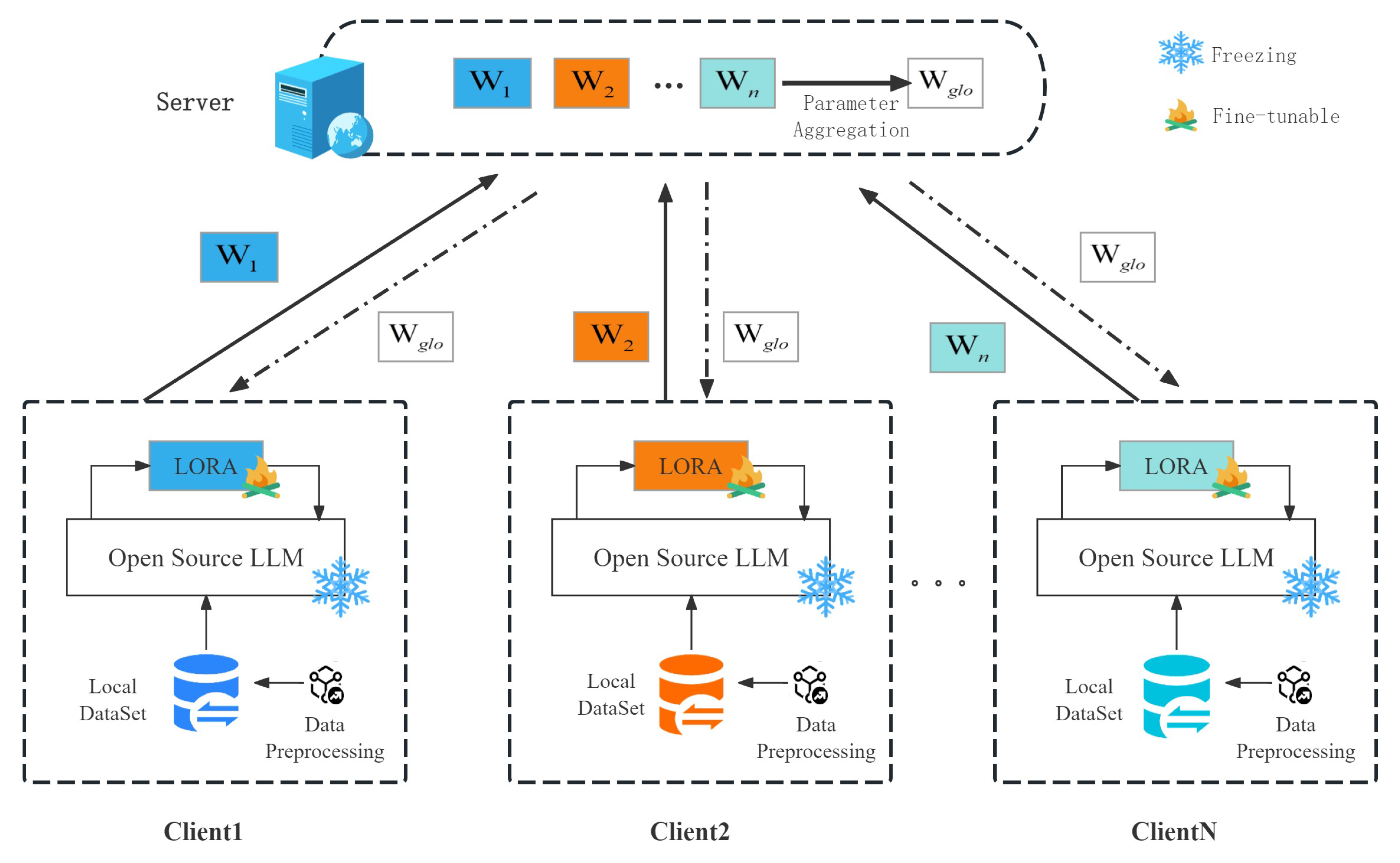
3.2. Network Architecture
3.3. Data Preprocessing
3.4. Instruction Tuning
| Algorithm 1 Federated Learning-based LoRA Client Training Process |
| Input: Global model parameters wglo, Local Dataset Di Output: Local model update ∆ wi 1: While Server returns update do 2: Receive global model parameters from Server . 3: For number of iterations k = 1, …, K do: 4: Train model using local data Di. 5: Train local model update ∆ using LORA. 6: end for 7: . 8: //Encrypt the local updates , where is the encryption operator. 9: Send encrypted updates ∆ to Server. 10: End While |
| Algorithm 2 The parameter aggregation process on the LORA server based on FL |
| Input: Pre—trained model parameters wpro, number of clients N Output: Global model parameters wglo 1: 2: While not converged do 3: For each client i in 1 to N do 4: Send the global model parameters to client 5: End For 6: For each client i in 1 to N do 7: Receive the encrypted update ∆ from client 8: 9: . 10: 11: 12: end for 13: . 14: End While |
| Algorithm 3 Security Aggregation Process for LoRA Servers Based on FL |
| Input: {∆ w1, ∆ w2,…, ∆ wn} Output: Global model parameters wglo 1: 2: 3: For client to N do 4: If TrustScore(i) > threshold then 5: . 6: 7: end if 8: End For 9: If > 0 then 10: 11: End if 12: return |
4. Experiments and Analysis
4.1. Experimental Environment
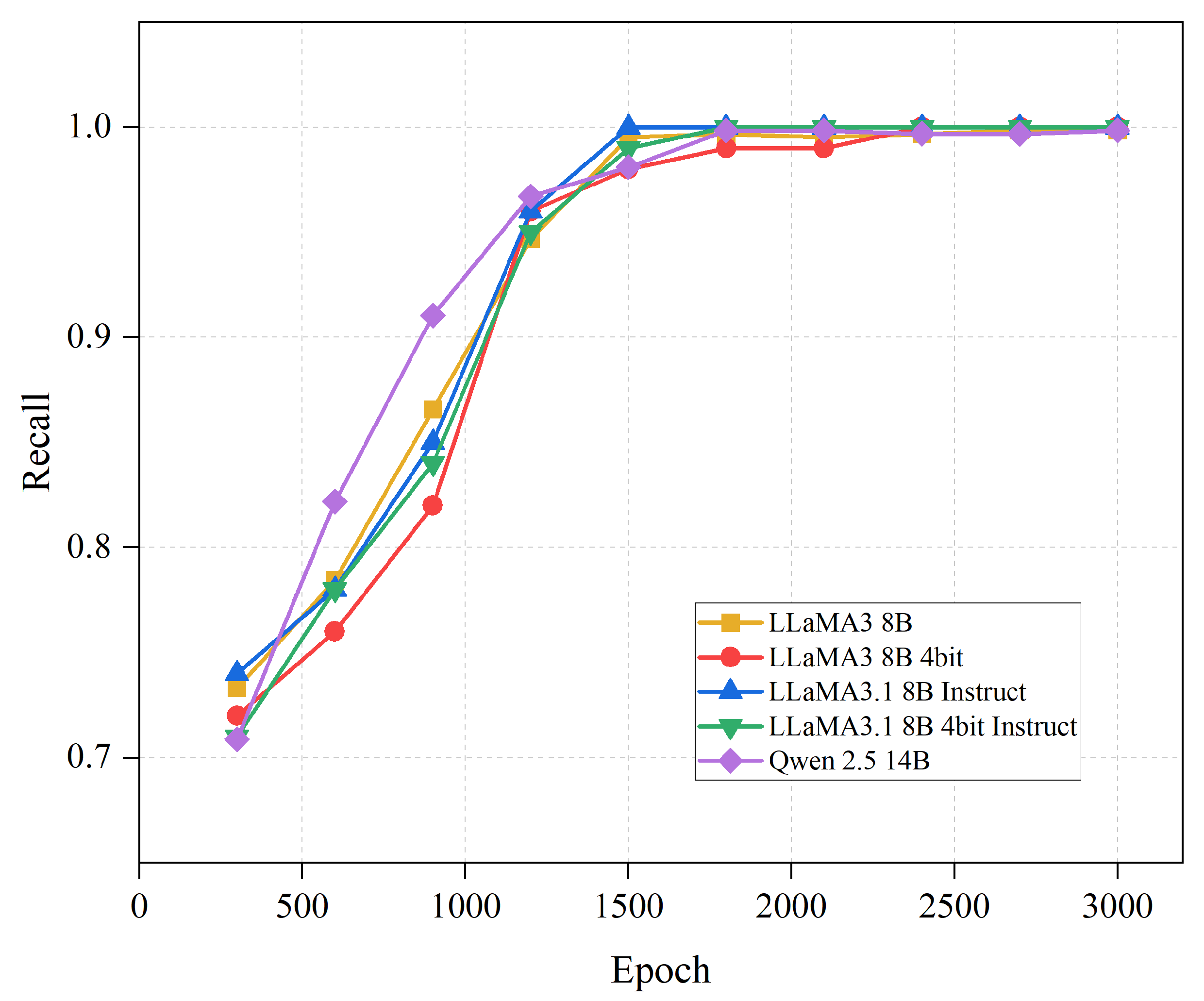
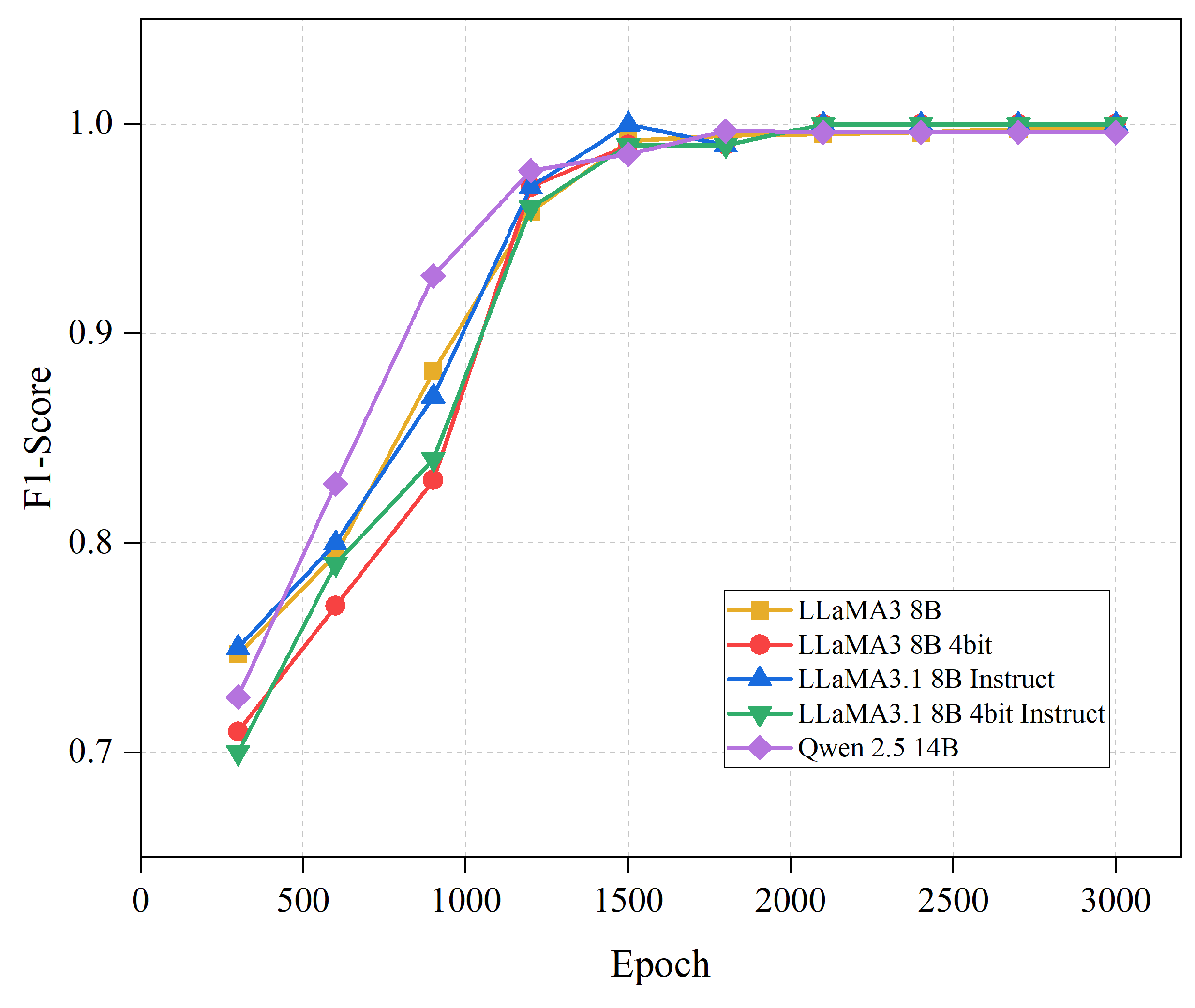
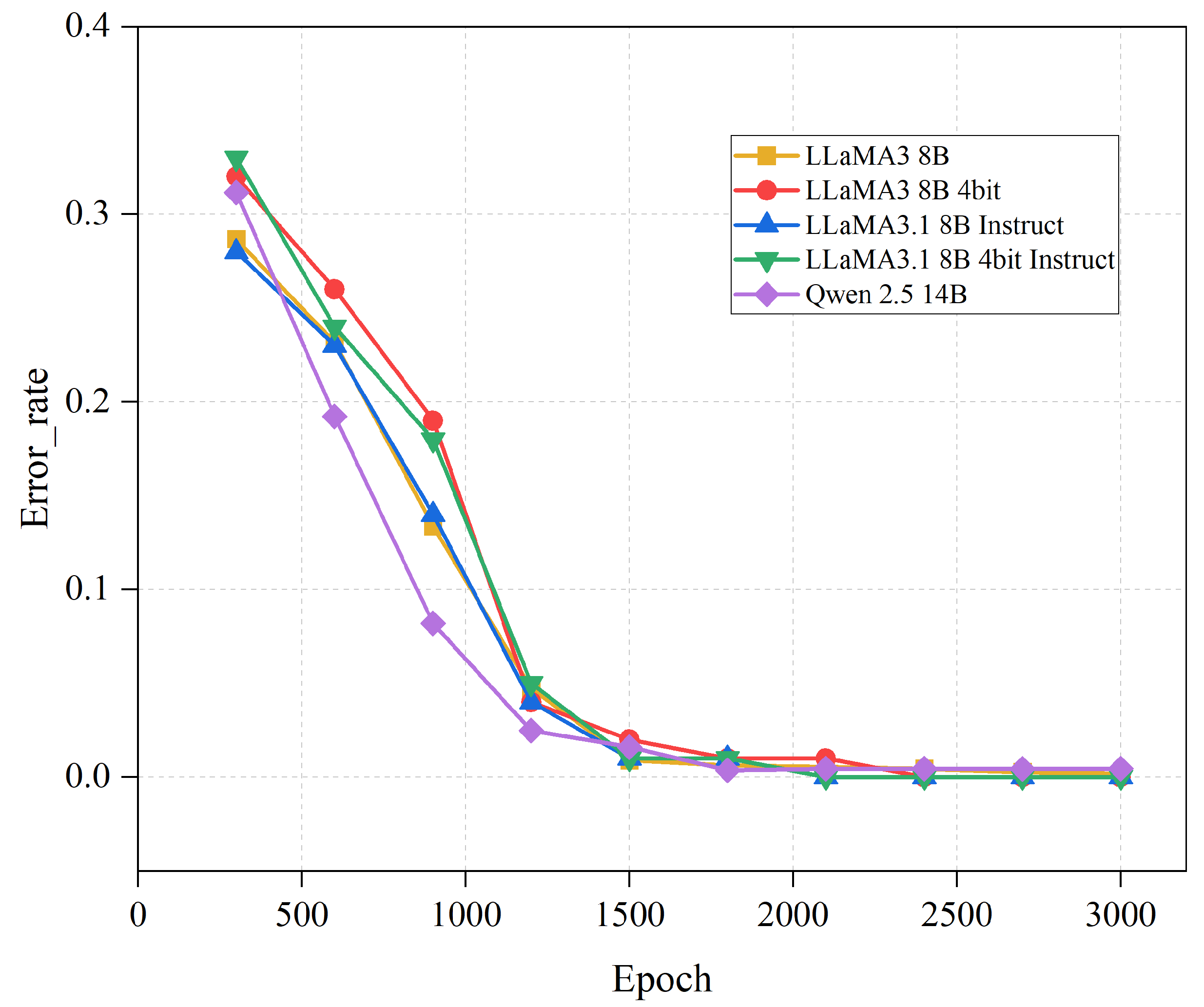
4.2. Experiment on the Impact of Training Epochs on Model Performance
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- 2023 API Security Status Report. Available online: https://www.traceable.ai/2023-state-of-api-security (accessed on 5 August 2024).
- Salt Labs. API Predictions for 2024. Available online: https://salt.security/blog/api-predictions-for-2024 (accessed on 5 August 2024).
- Cheh, C.; Chen, B.B. Analyzing OpenAPI Specifications for Security Design Issues. In Proceedings of the 2021 IEEE Secure Development Conference (SecDev), Atlanta, GA, USA, 18–20 October 2021; Volume 10, pp. 15–22. [Google Scholar]
- Faruk, M.J.H.; Patinga, A.J.; Migiro, L.; Shahriar, H.; Sneha, S. Leveraging Healthcare API to transform Interoperability: API Security and Privacy. In Proceedings of the 2022 IEEE 46th Annual Computers, Software, and Applicationis Conference (COMPSAC 2022), Los Alamitos, CA, USA, 27 June–1 July 2022; pp. 444–445. [Google Scholar]
- Sun, R.H.; Wang, Q.X.; Guo, L. Research Towards Key Issues of API Security. Cyber Secur. 2022, 1506, 179–192. [Google Scholar]
- Vörös, T.; Bergeron, S.P.; Berlin, K. Web content filtering through knowledge distillation of large language models. In Proceedings of the 22nd IEEE/WIC International Conference on Web Intelli-gence and Intelligent Agent Technology (WI-IAT), Venice, Italy, 26–29 October 2023; pp. 357–361. [Google Scholar]
- Kumar, D.; Abuhashem, Y.A.; Durumeric, Z. Watch your language: Large language models and content moderation. In Proceedings of the Eighteenth International AAAI Conference on Web and Social Media, Buffalo, NY, USA, 3–6 June 2024; AAAI Press: Washington, DC, USA, 2024; Volume 18, pp. 865–878. [Google Scholar]
- Qin, Y.; Liang, S.; Ye, Y.; Zhu, K.; Yan, L.; Lu, Y.; Lin, Y.; Cong, X.; Tang, X.; Qian, B.; et al. Toolllm: Facilitating large language models to master 16000+ real-world apis. arXiv 2023, arXiv:2307.16789. [Google Scholar]
- Brisimi, T.S.; Chen, R.; Mela, T.; Olshevsky, A.; Paschalidis, I.C.; Shi, W. Federated learning of predictive models from federated Elec-tronic Health Records. Int. J. Med. Inform. 2018, 112, 59–67. [Google Scholar] [CrossRef] [PubMed]
- Kumar, R.; Khan, A.A.; Kumar, J.; Golilarz, N.A.; Zhang, S.; Ting, Y.; Zheng, C.; Wang, W. Blockchain-federated-learning and deep learning models for COVID-19 detection using CT Imaging. IEEE Sens. J. 2021, 21, 16301–16314. [Google Scholar] [CrossRef] [PubMed]
- Shi, D.; Tong, Y.; Zhou, Z.; Song, B.; Lv, W.; Yang, Q. Learning to assign: Towards fair task assignment in large-scale ride hailing. In Proceedings of the 27th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD), Singapore, 14–18 August 2021. [Google Scholar]
- Mcmahan, H.B.; Moore, E.; Ramage, D.; Hampson, S.; y Arcas, B.A. Communication-efficient learning of deep networks from decentralized data. In Proceedings of the 20th International Conference on Artificial Intelligence and Statistics, Fort Lauderdale, FL, USA, 20–22 April 2017; pp. 1273–1282. [Google Scholar]
- Yue, L.N.; Liu, Q.; Du, Y.C.; Gao, W.B.; Liu, Y.; Ya, F.Z. FedJudge: Federated Legal Large Language Model. arXiv 2024, arXiv:2309.08173v3. [Google Scholar]
- Xing, P.W.; Lu, S.T.; Yu, H. Federated Neuro-Symbolic Learning. arXiv 2024, arXiv:2308.15324. [Google Scholar]
- Jiang, J.G.; Liu, X.Y.; Fan, C.Y. Low-Parameter Federated Learning with Large Language Models. arXiv 2023, arXiv:2307.13896. [Google Scholar]
- OpenAI ChatGPT. Available online: https://openai.com/chatgpt (accessed on 5 August 2024).
- Touvron, H.; Lavril, T.; Izacard, G.; Martinet, X.; Lachaux, M.A.; Lacroix, T.; Rozière, B.; Goyal, N.; Hambro, E.; Azhar, F.; et al. Llama: Open and efficient foundation language models. arXiv 2023, arXiv:2302.13971. [Google Scholar]
- Jiang, A.Q.; Sablayrolles, A.; Roux, A.; Mensch, A.; Savary, B.; Bamford, C.; Chaplot, D.S.; Casas, D.d.; Hanna, E.B.; Bressand, F.; et al. Mixtral of experts. arXiv 2024, arXiv:2401.04088. [Google Scholar]
- Anil, R.; Borgeaud, S.; Alayrac, J.; Yu, J.; Soricut, R.; Schalkwyk, J.; Dai, A.M.; Hauth, A.; Millican, K.; Silver, D.; et al. Gemini: A family of highly capable multimodal models. arXiv 2023, arXiv:2312.11805. [Google Scholar]
- Kaur, R.; Gabrijelcic, D.; Klobucar, T. Artificial intelligence for cybersecurity: Literature review and future research directions. Inf. Fusion 2023, 97, 101804. [Google Scholar] [CrossRef]
- Kumar, S.; Gupta, U.; Singh, A.K.; Kishore Singh, A.K. Artificial intelligence: Revolutionizing cyber security in the digital era. J. Comput. Mech. Manag. 2023, 2, 31–42. [Google Scholar] [CrossRef]
- Mijwil, M.; Aljanabi, M. Towards artificial intelligence-based cybersecurity: The practices and chatgpt generated ways to combat cybercrime. Iraqi J. Comput. Sci. Math. 2023, 4, 65–70. [Google Scholar]
- da Silva, G.D.J.C.; Westphall, C.B. A survey of large language models in cybersecurity. arXiv 2024, arXiv:2402.16968. [Google Scholar]
- Motlagh, F.N.; Hajizadeh, M.; Majd, M.; Najafi, P.; Cheng, F.; Meinel, C. Large language models in cybersecurity: State-of-the-art. arXiv 2024, arXiv:2402.00891. [Google Scholar]
- Web API Dataset. Available online: https://github.com/gaozhirui233/openData (accessed on 18 October 2024).
- Dettmers, T.; Pagnoni, A.; Holtzman, A.; Zettlemoyer, L. QLORA: Efficient finetuning of quantized LLMs. In Proceedings of the 37th Conference on Neural Information Processing Systems (NeurIPS), New Orleans, LA, USA, 10–16 December 2023. [Google Scholar]
- Chavan, A.; Liu, Z.; Gupta, D.; Xing, E.; Shen, Z. One-for-All: Generalized LoRA for parameter-efficient fine-tuning. arXiv 2023, arXiv:2306.07967. [Google Scholar]
- Zhang, Q.; Chen, M.; Bukharin, A.; Karampatziakis, N.; He, P.; Cheng, Y.; Chen, W.; Zhao, T. AdaLoRA: Adaptive budget allocation for parame-ter-efficient fine-tuning. arXiv 2023, arXiv:2303.10512. [Google Scholar]
- Hu, E.J.; Shen, Y.; Wallis, P.; Allen-Zhu, Z.; Li, Y.; Wang, S.; Wang, L.; Chen, W. Lora: Low-rank adaptation of large language models. arXiv 2021, arXiv:2106.09685v2. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Curran Associates, Inc.: Red Hook, NY, USA, 2017; pp. 6000–6010. [Google Scholar]
- Gong, R.H.; Fan, Y.Q.; Wei, X.Y.; Bai, S.H.; Zhang, Y.C.; Zhang, X.G. Methodologies for the Implementation of Large Language Models in the Era of AI: Costs, Efficiency, and Effectiveness. China Artif. Intell. 2023, 3, 52–61. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature/Model | ChatGPT 4 | LLaMA3.1 8B | Qwen2.5 14B |
|---|---|---|---|
| Model Size | 9 billion parameters | 8 billion parameters | 14 billion parameters |
| Training Data | Bilingual focus | Multi-domain datasets | Large-scale multi-domain datasets |
| Computational Power | High | High | Very high |
| Energy Consumption | High | High | Very high |
| Application Scenarios | Chinese NLP, bilingual tasks | Various NLP tasks | Wide-range NLP tasks |
| Language Understanding | Extremely strong | High | Very strong |
| Generative Ability | Extremely strong | High | Extremely strong |
| Conversational Ability | Very strong | High | Very strong |
| Robustness | Extremely high | High | Very high |
| Training Time | Very long | Long | Very long |
| Scalability | Good | Good | Moderate to good |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, J.; Chen, L.; Fang, S.; Wu, C. An Application Programming Interface (API) Sensitive Data Identification Method Based on the Federated Large Language Model. Appl. Sci. 2024, 14, 10162. https://doi.org/10.3390/app142210162
Wu J, Chen L, Fang S, Wu C. An Application Programming Interface (API) Sensitive Data Identification Method Based on the Federated Large Language Model. Applied Sciences. 2024; 14(22):10162. https://doi.org/10.3390/app142210162
Chicago/Turabian StyleWu, Jianping, Lifeng Chen, Siyuan Fang, and Chunming Wu. 2024. "An Application Programming Interface (API) Sensitive Data Identification Method Based on the Federated Large Language Model" Applied Sciences 14, no. 22: 10162. https://doi.org/10.3390/app142210162
APA StyleWu, J., Chen, L., Fang, S., & Wu, C. (2024). An Application Programming Interface (API) Sensitive Data Identification Method Based on the Federated Large Language Model. Applied Sciences, 14(22), 10162. https://doi.org/10.3390/app142210162