
MDSA: A Dynamic and Greedy Approach to Solve the Minimum Dominating Set Problem



Abstract
1. Introduction
- Inspired by the Malatya centrality algorithm, this concept was applied to the MDS problem and is the first study in the literature using it.
- A greedy search strategy application that applies the same steps in each run, produces the same result, and provides robust, efficient, and effective solutions.
- Optimization in terms of time and resource complexity thanks to a dynamic search strategy that updates the graph at each step.
- It is easily applicable to large graphs since it is designed to have polynomial time and resource complexities.
- Increasing its preference rate in application areas since it produces optimum or nearly optimum solutions for the MDS problem.
- It is suitable for a wide range of application scenarios since it has the ability to find minimum dominant sets for all memory allocated graph structures.
2. Related Works
3. The Dominating Set Problem
- For each variable , create a node .
- For each clause , create a node .
- If a variable appears positively in a clause , add an edge between and . If the negation appears in , also add an edge between and .
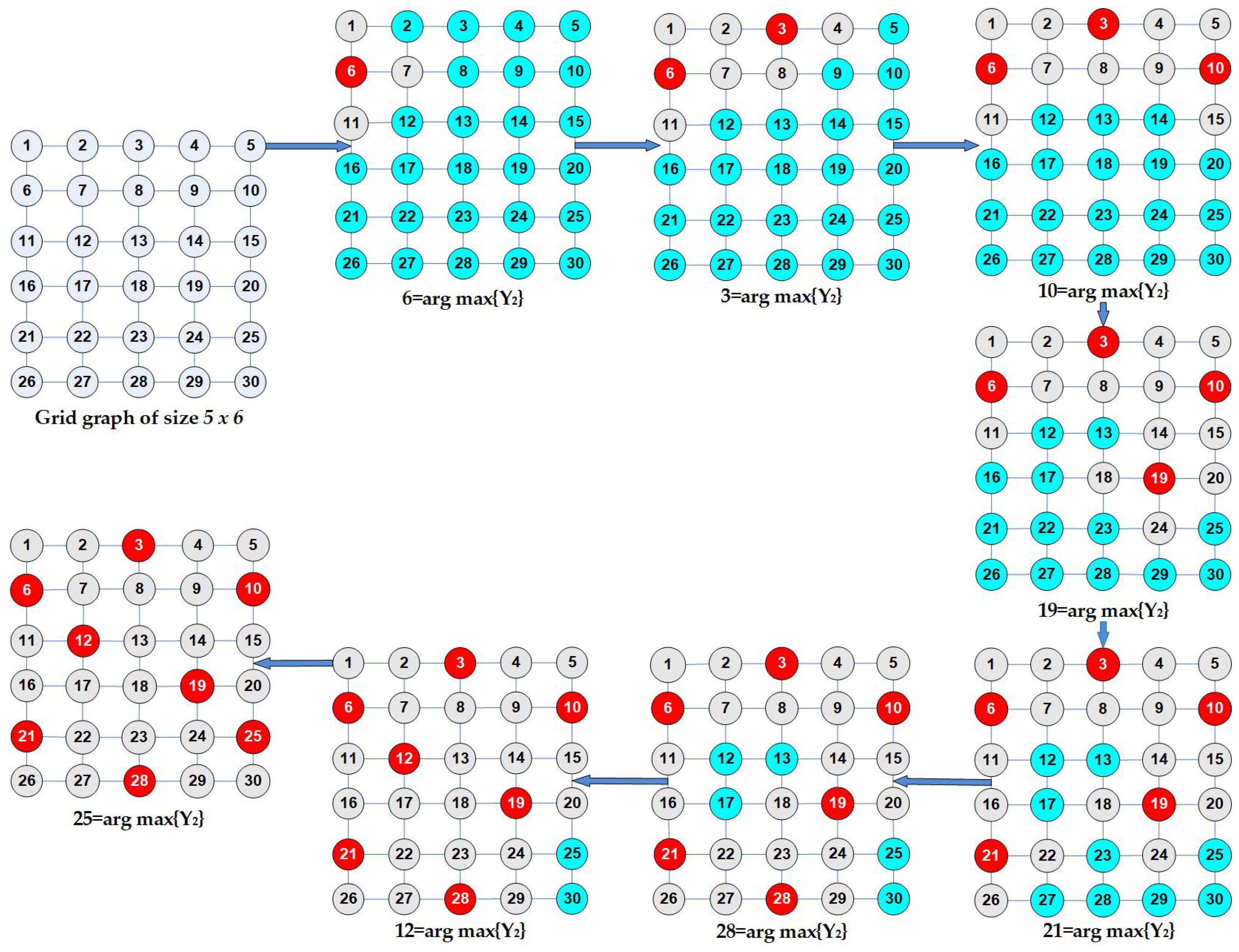
4. Malatya Dominating Set Algorithm (MDSA)
- The previous version contains the initial Malatya centrality value equation as follows:
- In the previous version, the selected nodes and their neighbors are removed from the given graph. In the current version, only the selected node is removed from the graph; however, the neighbors of the selected node are not removed, except for those with active degrees equal to 2.
- The previous version finds an independent dominating set and does not aim to find the optimal solution. In contrast, the current version finds the dominating set/minimum dominating set.
- Extensive experiments and competitive method comparisons were not performed in previous work. However, in this study, extensive experiments and comparisons were made on large and small datasets.
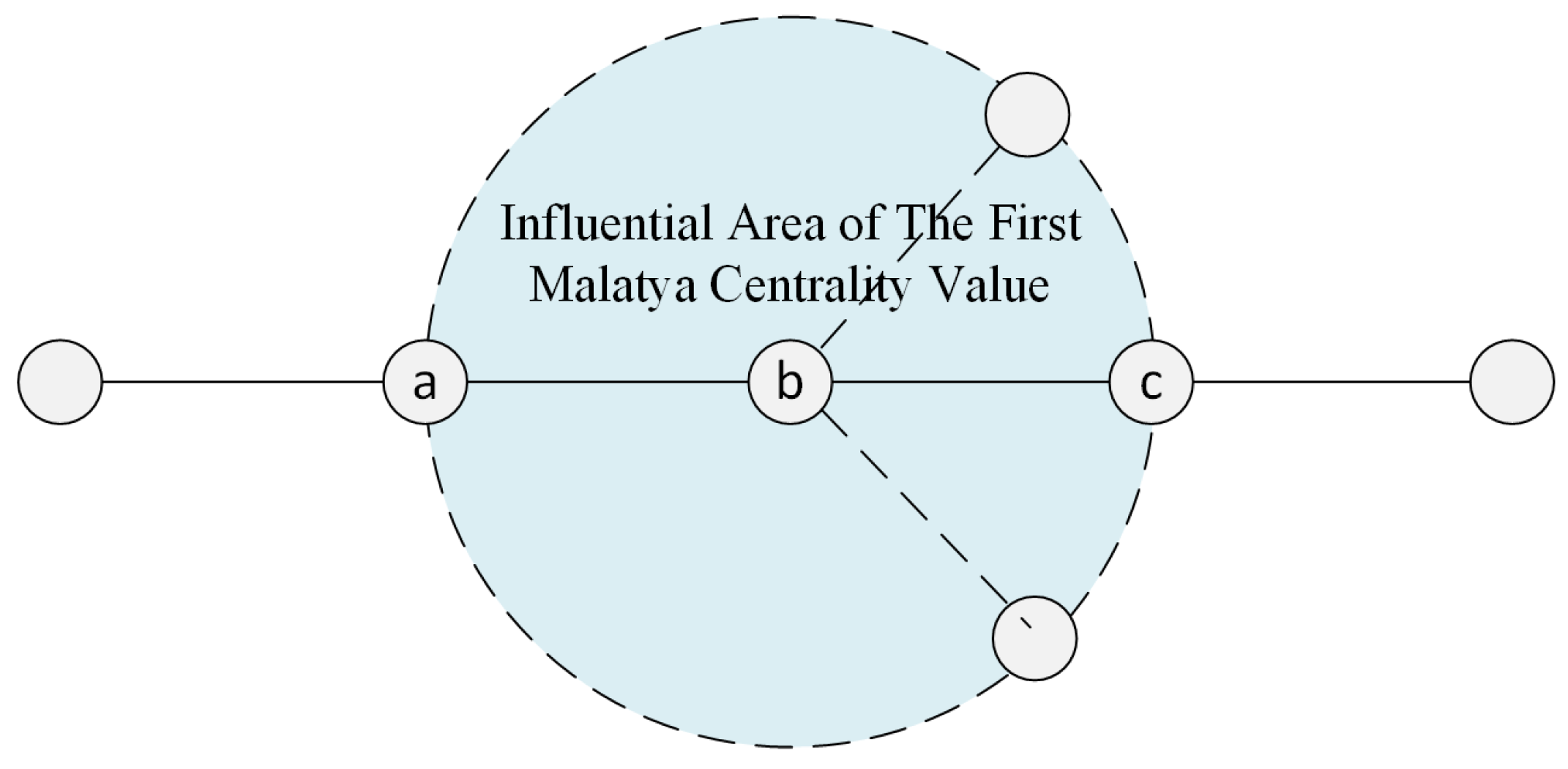
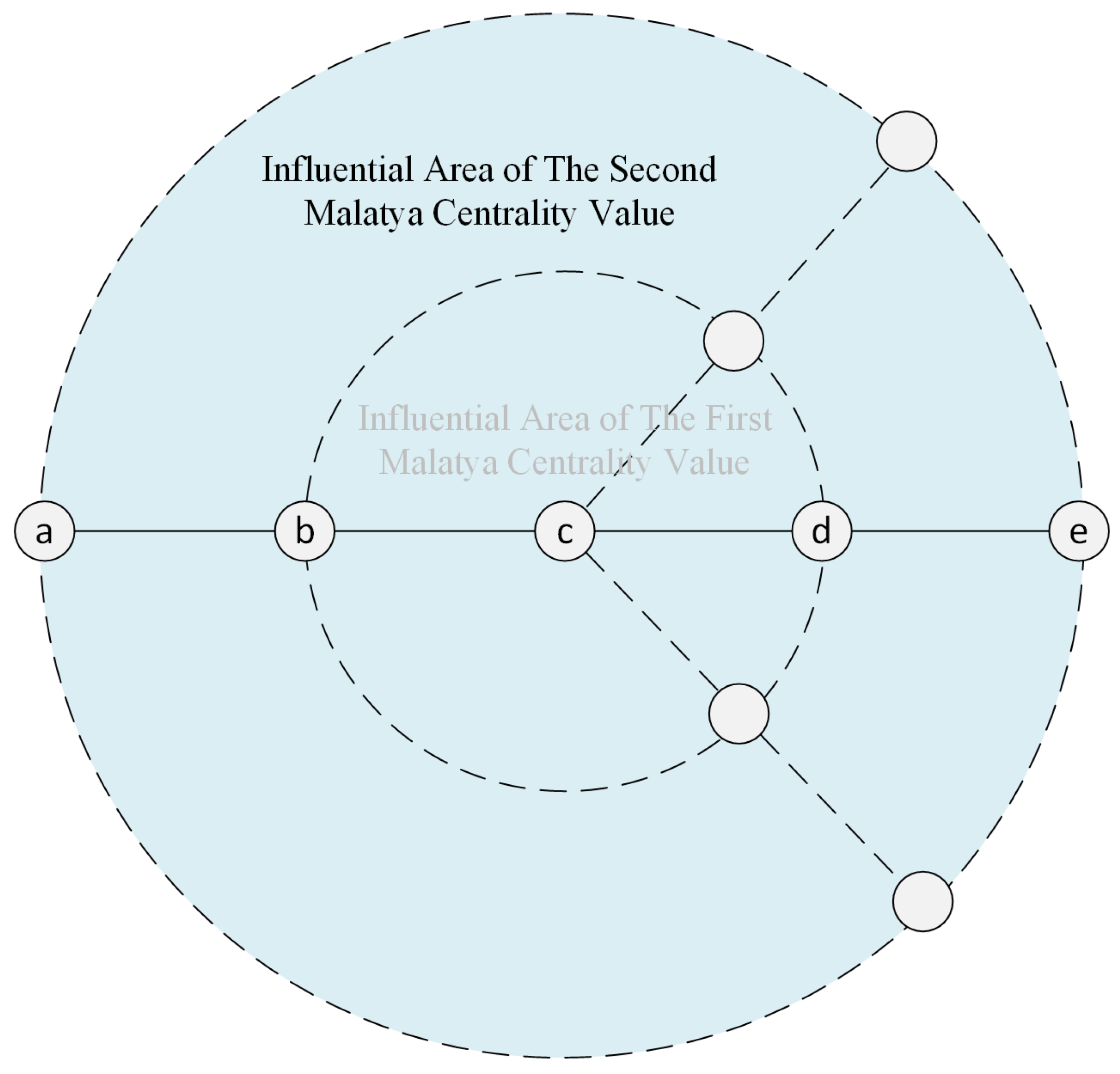
4.1. The First Malatya Centrality Value
| Algorithm 1. The First Malatya Centrality Algorithm. |
| function FirstMalatyaCentrality (A, D, DA) output: MC1//The first Malatya centrality values input: A, //Adjacency matrix D, //Degree vector DA //Active degree vector 1 for i ← 1…n //(A is of sizes n × n) 2 L ← Neighbors(i) 3 for j in L 4 MC1(i) = MC1(i) + D(i)/D(j) 5 end 6 end 7 MC1 = MC1*DA //vector inner product 8 for i ← 1,…,n 9 if D(i) ≠ 0 10 MC1(i) = MC1(i)/D(i) 11 end 12 end 13 return MC1 |
4.2. The Second Malatya Centrality Value
| Algorithm 2. The Second Malatya Centrality Algorithm |
| function SecondMalatyaCentrality (A, D, DA, MC1, MC2) output: MC2 //The second Malatya centrality values input: A, //Adjacency matrix 1 for i ← 1…n //(A is of sizes n × n) 2 L ← Neighbors(i) 3 for j in L 4 MC1(i) = MC1(i) + D(i)/D(j) 5 end 6 end 7 MC1 = MC1*DA 8 for i ← 1, …, n 9 if D(i) ≠ 0 10 MC1(i) = MC1(i)/D(i) 11 end 12 end 13 return MC1 |
4.3. The Main Algorithm
| Algorithm 3. The Dominating Set Algorithm |
| function DominatingSet (A) output: VD ← ∅ input: A, //Adjacency matrix 1 n ← sizeof(A) //n is the size of graph (G = (V,E), |V| = n) 2 MC1 ← 0, MC2 ← 0 3 NodeColor ← 0 //Grey node = 1, White nod e = 0 4 D ← ∅ //Degree vector 5 DA ← ∅ //Active degree vector 6 NodeColor(G) ← white 7 while Termination ≠ False 8 MC1 ← FirstMalatyaCentrality (A, D, DA, MC1) 9 MC2 ← SecondMalatyaCentrality (A, D, DA, MC1, MC2) 10 NodeColor ← NodeSelection (A, D, DA, NodeColor, MC2) 11 Termination ← Terminate (A, NodeColor) 12 End 13 return VD 14 function NodeSelection (A, D, DA, NodeColor, MC2, VD) 15 SN ← Max (MC2) //Select the node with the maximum MC2 value (white node has priority) 16 NodeColor (SN) ← red 17 NodeColor (Neighbors of SN) ← grey 18 return NodeColor 19 function Terminate (A, NodeColor) 20 n ← sizeof (A) 21 Termination ← false; 22 for i ← 1, …, n 23 if NodeColor (i) is white 24 Termination ← true 25 end 26 end 27 return Termination |
- First Way: Adjacency matrix method.Space: The adjacency matrix of given graph is used and the proposed algorithm is an iterative algorithm not a recursive algorithm. Consequently, the space complexity is , where and d is the average degree. Thus, the space complexity of Algorithm 1 is .Time: Assume that and its adjacency matrix is of size . To compute the first round values, an adjacency matrix of is used, and it requires time complexity, since the adjacency matrix has size and the average degree is d. That is why the time complexity of Algorithm 1 is .
- Second Way: Linked list method using neighbors list.Space: The neighbors of any node are stored as a linked list data structure. Assume that the averaged degree in graph is . If , the space complexity of Algorithm 1 is .Time: If linked list data structures are used to represent the given graph, the space requirement for storing graph is . The time complexity of each node to compute is maximum . There are nodes, and so, the time complexity of Algorithm 1 is . □
5. Experimental Results
- Random Generated Graph: The algorithm identified a dominating set of 15 nodes out of 70 nodes with 133 edges, completing the task in 0.051 s.
- dsjc500.1: For this graph with 500 nodes and 12,458 edges, MDSA found a dominating set of 23 nodes, executing in 0.091 s.
- latin_square: With 900 nodes and 307,350 edges, MDSA found a dominating set of 2 nodes, taking 0.107 s.
- flat1000_50_0: This graph contains 1000 nodes and 245,000 edges. MDSA identified a dominating set of 6 nodes in 0.175 s.
- dsjc250.5: For this graph with 250 nodes and 31,336 edges, MDSA found a dominating set of 5 nodes, executing it in 0.041 s.
- r1000.5: This graph has 1000 nodes and 238,267 edges. MDSA identified a dominating set of 5 nodes in 0.095 s.
- dsjc1000.1: For this graph containing 1000 nodes and 49,629 edges, MDSA found a dominating set of 27 nodes, executing it in 0.219 s.
- C2000.5: For this graph with 2000 nodes and 999,836 edges, MDSA identified a dominating set of 7 nodes, completing in 0.745 s.
- flat1000_60_0: This dataset has 1000 nodes and 245,830 edges, with MDSA finding a dominating set of 7 nodes in 0.204 s.
- flat1000_76_0: With 1000 nodes and 246,708 edges, MDSA found a dominating set of 6 nodes, executing it in 0.125 s.
6. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Fomin, F.V.; Kratsch, D.; Woeginger, G.J. Exact (Exponential) algorithms for the dominating set problem. Lect. Notes Comput. Sci. 2004, 3353, 245–256. [Google Scholar] [CrossRef]
- Campan, A.; Truta, T.; Beckerich, M. Fast Dominating Set Algorithms for Social Networks. In Proceedings of the Midwest Artificial Intelligence and Cognitive Science Conference, Greensboro, NC, USA, 25–26 April 2015; pp. 55–62. [Google Scholar]
- Leskovec, J.; Huttenlocher, D.; Kleinberg, J. Signed Networks in Social Media. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Atlanta, GA, USA, 10–15 April 2010. [Google Scholar]
- Raei, H.; Yazdani, N.; Asadpour, M. A new algorithm for positive influence dominating set in social networks. In Proceedings of the 2012 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining, Istanbul, Turkey, 26–29 August 2012; pp. 253–257. [Google Scholar] [CrossRef]
- Li, Y.; Thai, M.T.; Wang, F.; Yi, C.W.; Wan, P.J.; Du, D.Z. On greedy construction of connected dominating sets in wireless networks. Wirel. Commun. Mob. Comput. 2005, 5, 927–932. [Google Scholar] [CrossRef]
- Lee, C.K.M.; Ip, C.M.; Park, T.; Chung, S.Y. A Bluetooth Location-based Indoor Positioning System for Asset Tracking in Warehouse. In Proceedings of the IEEE International Conference on Industrial Engineering and Engineering Management, IEEE Computer Society, Macao, China, 15–18 December 2019; pp. 1408–1412. [Google Scholar]
- Zhao, D.; Xiao, G.; Wang, Z.; Wang, L.; Xu, L. Minimum Dominating Set of Multiplex Networks: Definition, Application, and Identification. IEEE Trans. Syst. Man, Cybern. Syst. 2021, 51, 7823–7837. [Google Scholar] [CrossRef]
- Girvan, M.; Newman, M.E.J. Community structure in social and biological networks. Proc. Natl. Acad. Sci. USA 2002, 99, 7821–7826. [Google Scholar] [CrossRef]
- Wang, N.; Dai, J.; Li, D.; Li, M. An approximation algorithm for connected dominating set in wireless ad hoc network. In Proceedings of the IET International Conference on Information Science and Control Engineering 2012 (ICISCE 2012), Shenzhen, China, 7–9 December 2012. [Google Scholar] [CrossRef]
- Xu, X.; Tang, Z.; Sun, W.; Chen, X.; Li, Y.; Xia, G.; Bi, W.; Zong, Z. An Algorithm for the Minimum Dominating Set Problem Based on a New Energy Function Algorithm for MDSP. In Proceedings of the SICE Annual Conference 2004, Sapporo, Japan, 4–6 August 2004; p. 80. [Google Scholar] [CrossRef]
- Shen, C.; Li, T. Multi-Document Summarization via the Minimum Dominating Set. In Proceedings of the 23rd International Conference on Computational Linguistics, (COLING ’10), Association for Computational Linguistics USA, Beijing, China, 23–27 August 2010; pp. 984–992. [Google Scholar]
- Truta, T.M.; Campan, A.; Beckerich, M. Efficient Approximation Algorithms for Minimum Dominating Sets in Social Networks. Int. J. Serv. Sci. Manag. Eng. Technol. 2018, 9, 1–32. [Google Scholar] [CrossRef]
- Cao, H.; Wu, W.; Chen, Y. A navigation route based minimum dominating set algorithm in VANETs. In Proceedings of the 2014 International Conference on Smart Computing (SMARTCOMP 2014), Hong Kong, China, 3–5 November 2014; pp. 71–76. [Google Scholar] [CrossRef]
- Balasundaram, B.; Butenko, S. Graph Domination, Coloring and Cliques in Telecommunications. In Handbook of Optimization in Telecommunication; Springer: Boston, MA, USA, 2006; pp. 865–890. [Google Scholar] [CrossRef]
- Ho, C.K.; Singh, Y.P.; Ewe, H.T. An Enhanced Ant Colony Optimization Metaheuristic for the Minimum Dominating Set Problem. Appl. Artif. Intell. 2006, 20, 881–903. [Google Scholar] [CrossRef]
- Jovanovic, R.; Tuba, M. Ant colony optimization algorithm with pheromone correction strategy for the minimum connected dominating set problem. Comput. Sci. Inf. Syst. 2013, 10, 133–149. [Google Scholar] [CrossRef]
- Chalupa, D. An order-based algorithm for minimum dominating set with application in graph mining. Inf. Sci. 2018, 426, 101–116. [Google Scholar] [CrossRef]
- Cappelle, M.R.; Gomes, G.C.M.; Dos Santos, V.F. Parameterized algorithms for locating-dominating sets. Procedia Comput. Sci. 2021, 195, 68–76. [Google Scholar] [CrossRef]
- Alofairi, A.A.; Ismail, R.; Mabrouk, E.; Saeed, F.; Elsemman, I.E. Quality Evaluation Measures of Genetic Algorithm and Integer Linear Programming for Minimum Dominating Set Problem. J. Theor. Appl. Inf. Technol. 2021, 28, 764–775. [Google Scholar]
- Grandoni, F. A note on the complexity of minimum dominating set. J. Discret. Algorithms 2006, 4, 209–214. [Google Scholar] [CrossRef]
- Purohit, G.N.; Sharma, U. Constructing Minimum Connected Dominating Set: Algorithmic Approach. Int. J. Appl. Graph Theory Wirel. Ad Hoc Netw. Sens. 2010, 2, 59–66. [Google Scholar] [CrossRef]
- Karci, A. New Algorithms for Minimum Dominating Set in Any Graphs. J. Comput. Sci. 2020, 7, 81–88. [Google Scholar]
- Karci, A.; Yakut, S.; Öztemiz, F. A New Approach Based on Centrality Value in Solving the Minimum Vertex Cover Problem: Malatya Centrality Algorithm. Comput. Sci. 2022, 7, 81–88. [Google Scholar] [CrossRef]
- Chalupa, D.; Blum, C. Mining k-reachable sets in real-world networks using domination in shortcut graphs. J. Comput. Sci. 2017, 22, 1–14. [Google Scholar] [CrossRef]
- Wang, Y.; Cai, S.; Chen, J.; Yin, M. A Fast Local Search Algorithm for Minimum Weight Dominating Set Problem on Massive Graphs. In Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence, Stockholm, Sweden, 13–19 July 2018. [Google Scholar]
- Fan, Y.; Lai, Y.; Li, C.; Li, N.; Ma, Z.; Zhou, J.; Latecki, L.J.; Su, K. Efficient Local Search for Minimum Dominating Sets in Large Graphs. Lect. Notes Comput. Sci. 2019, 11447, 211–228. [Google Scholar] [CrossRef]
- Cai, S.; Hou, W.; Wang, Y.; Luo, C.; Lin, Q. Two-goal Local Search and Inference Rules for Minimum Dominating Set. In Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence, Yokohama, Japan, 7–15 January 2021. [Google Scholar]
- Zhong, H.; Tang, Y.; Zhang, Q.; Lin, R.; Li, W. A unified greedy approximation for several dominating set problems. Theor. Comput. Sci. 2023, 973, 114069. [Google Scholar] [CrossRef]
- Sun, R.; Wu, J.; Jin, C.; Wang, Y.; Zhou, W.; Yin, M. An efficient local search algorithm for minimum positive influence dominating set problem. Comput. Oper. Res. 2023, 154, 106197. [Google Scholar] [CrossRef]
- Nakanishi, M. A note on vertices contained in the minimum dominating set of a graph with minimum degree three. Theor. Comput. Sci. 2023, 956, 113831. [Google Scholar] [CrossRef]
- Casado, A.; Bermudo, S.; López-Sánchez, A.D.; Sánchez-Oro, J. An iterated greedy algorithm for finding the minimum dominating set in graphs. Math. Comput. Simul. 2023, 207, 41–58. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhang, Z.; Du, D.Z. Construction of minimum edge-fault tolerant connected dominating set in a general graph. J. Comb. Optim. 2023, 45, 63. [Google Scholar] [CrossRef]
- Chen, J.; Cai, S.; Wang, Y.; Xu, W.; Ji, J.; Yin, M. Improved local search for the minimum weight dominating set problem in massive graphs by using a deep optimization mechanism. Artif. Intell. 2023, 314, 103819. [Google Scholar] [CrossRef]
- Akbay, M.A.; López Serrano, A.; Blum, C. A Self-Adaptive Variant of CMSA: Application to the Minimum Positive Influence Dominating Set Problem. Int. J. Comput. Intell. Syst. 2022, 15, 44. [Google Scholar] [CrossRef]
- Chakraborty, D.; Das, S.; Mukherjee, J. On dominating set of some subclasses of string graphs. Comput. Geom. 2022, 107, 101884. [Google Scholar] [CrossRef]
- Rehm, H.; Kassouf-Short, R.; Rombach, P. Generating Dominating Sets Using Locally-Defined Centrality Measures. arXiv 2023, arXiv:2305.08218. [Google Scholar]
- Gu, J. Local Search for Satisfiability (SAT) Problem. IEEE Trans. Syst. Man Cybern. 1993, 23, 1108–1129. [Google Scholar] [CrossRef]
- Science, A.; Yakut, S.; Öztemiz, F.; Karcı, A. A New Approach Based on Centrality Value in Solving the Maximum Independent Set Problem: Malatya Centrality Algorithm. Comput. Sci. 2023, 8, 16–23. [Google Scholar] [CrossRef]
- Yakut, S.; Öztemiz, F.; Karci, A. A new robust approach to solve minimum vertex cover problem: Malatya vertex-cover algorithm. J. Supercomput. 2023, 79, 19746–19769. [Google Scholar] [CrossRef]
- Science, A.; Karcı, Ş.; Okumuş, F.; Karci, A. Calculating the Centrality Values According to the Strengths of Entities Relative to their Neighbours and Designing a New Algorithm for the Solution of the Minimal Dominating Set Problem. Comput. Sci. 2023, 8, 50–56. [Google Scholar] [CrossRef]
- Johnson, D.S.; Aragon, C.R.; McGeoch, L.A.; Schevon, C. Optimization by Simulated Annealing: An Experimental Evaluation; Part II, Graph Coloring and Number Partitioning. Oper. Res. 1991, 39, 378–406. [Google Scholar] [CrossRef]
- Johnson, D.; Trick, M. Cliques, Coloring, and Satisfiability: Second DIMACS Implementation Challenge, October 11–13, 1993, 26th ed.; American Mathematical Society: Ann Arbor, MI, USA, 1996. [Google Scholar]
- Sewell, E.C. An improved algorithm for exact graph coloring. In DIMACS Series in Computer Mathematics and Theoretical Computer Science; American Mathematical Society: Ann Arbor, MI, USA, 1996; pp. 359–373. [Google Scholar]
- Wang, Y.; Cai, S.; Yin, M. Local Search for Minimum Weight Dominating Set with Two-Level Configuration Checking and Frequency Based Scoring Function (Extended Abstract). In Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence (IJCAI-17), Melbourne, Australia, 19–25 August 2017. [Google Scholar]
- Rossi, R.A.; Ahmed, N.K. The Network Data Repository with Interactive Graph Analytics and Visualization. In Proceedings of the AAAI, Austin, TX, USA, 15–30 January 2015. [Google Scholar]
- Leskovec, J.; Adamic, L.A.; Huberman, B.A. The dynamics of viral marketing. ACM Trans. Web 2007, 1, 5-es. [Google Scholar] [CrossRef]
- Leskovec, J.; Kleinberg, J.; Faloutsos, C. Graphs over time: Densification laws, shrinking diameters and possible explanations. In Proceedings of the Eleventh ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Chicago, IL, USA, 21–24 August 2005; pp. 177–187. [Google Scholar] [CrossRef]
- Leskovec, J.; Lang, K.J.; Dasgupta, A.; Mahoney, M.W. Community Structure in Large Networks: Natural Cluster Sizes and the Absence of Large Well-Defined Clusters. Internet Math. 2009, 6, 29–123. [Google Scholar] [CrossRef]
- Richardson, M.; Agrawal, R.; Domingos, P. Trust Management for the Semantic Web. Lect. Notes Comput. Sci. 2003, 2870, 351–368. [Google Scholar] [CrossRef]
- Albert, R.; Jeong, H.; Barabási, A.L. Diameter of the World-Wide Web. Nature 1999, 401, 130–131. [Google Scholar] [CrossRef]
- Newman, M.E.J. The structure of scientific collaboration networks. Proc. Natl. Acad. Sci. USA 2001, 98, 404–409. [Google Scholar] [CrossRef]
- Pizzuti, C. A multiobjective genetic algorithm to find communities in complex networks. IEEE Trans. Evol. Comput. 2012, 16, 418–430. [Google Scholar] [CrossRef]
- Newman, M.E.J. Finding community structure in networks using the eigenvectors of matrices. Phys. Rev. E Stat. Nonlinear Soft Matter Phys. 2006, 74, 036104. [Google Scholar] [CrossRef]
- Knuth, D.E. The Stanford GraphBase: A Platform for Combinatorial Computing; ACM Press: New York, NY, USA, 1993. [Google Scholar]
- Zachary, W.W. An Information Flow Model for Conflict and Fission in Small Groups. J. Anthropol. Res. 1977, 33, 452–473. [Google Scholar] [CrossRef]
- Watts, D.J.; Strogatz, S.H. Collective dynamics of ‘small-world’ networks. Nature 1998, 393, 440–442. [Google Scholar] [CrossRef]
- Lusseau, D.; Schneider, K.; Boisseau, O.J.; Haase, P.; Slooten, E.; Dawson, S.M. The bottlenose dolphin community of doubtful sound features a large proportion of long-lasting associations: Can geographic isolation explain this unique trait? Behav. Ecol. Sociobiol. 2003, 54, 396–405. [Google Scholar] [CrossRef]
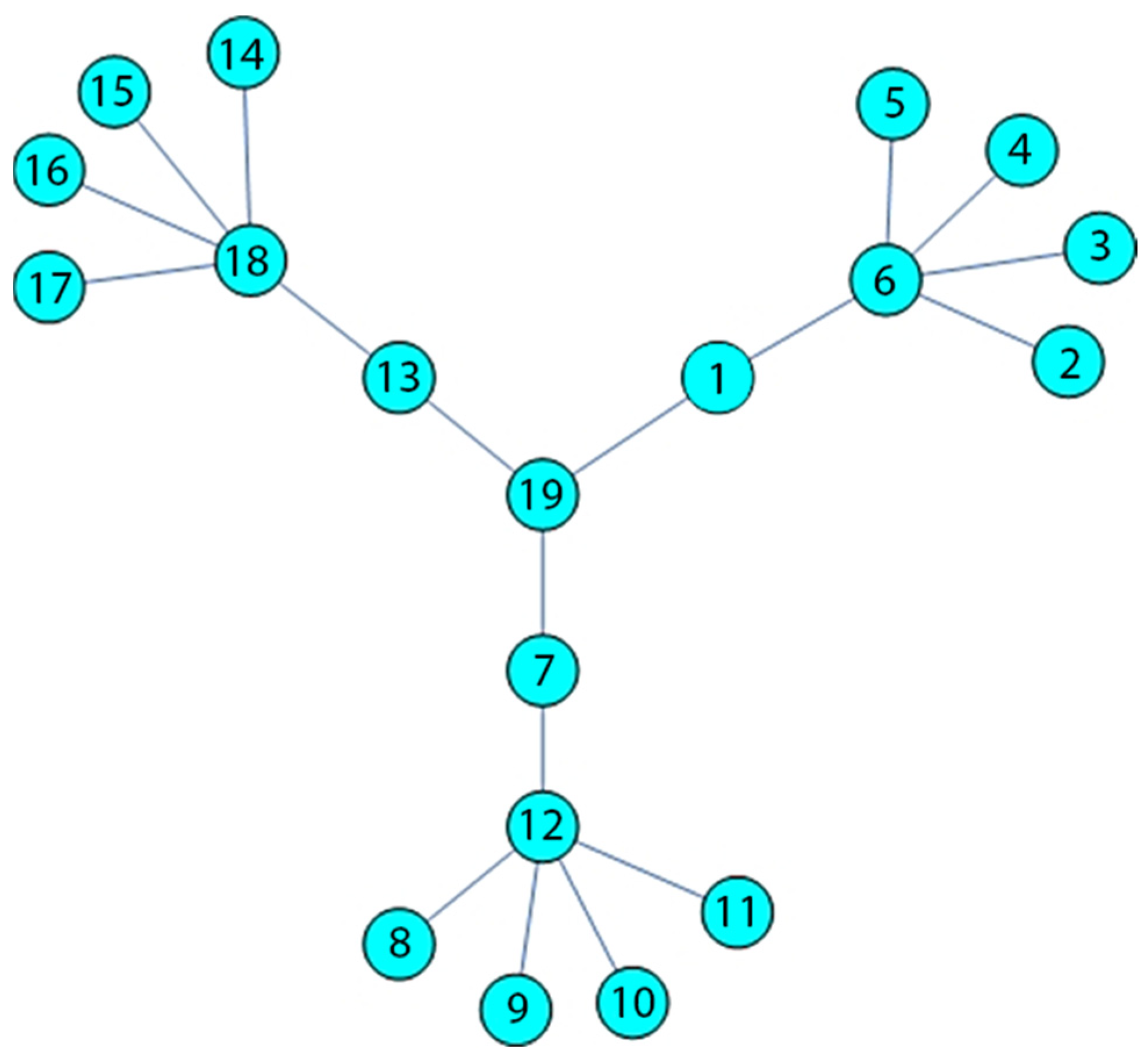
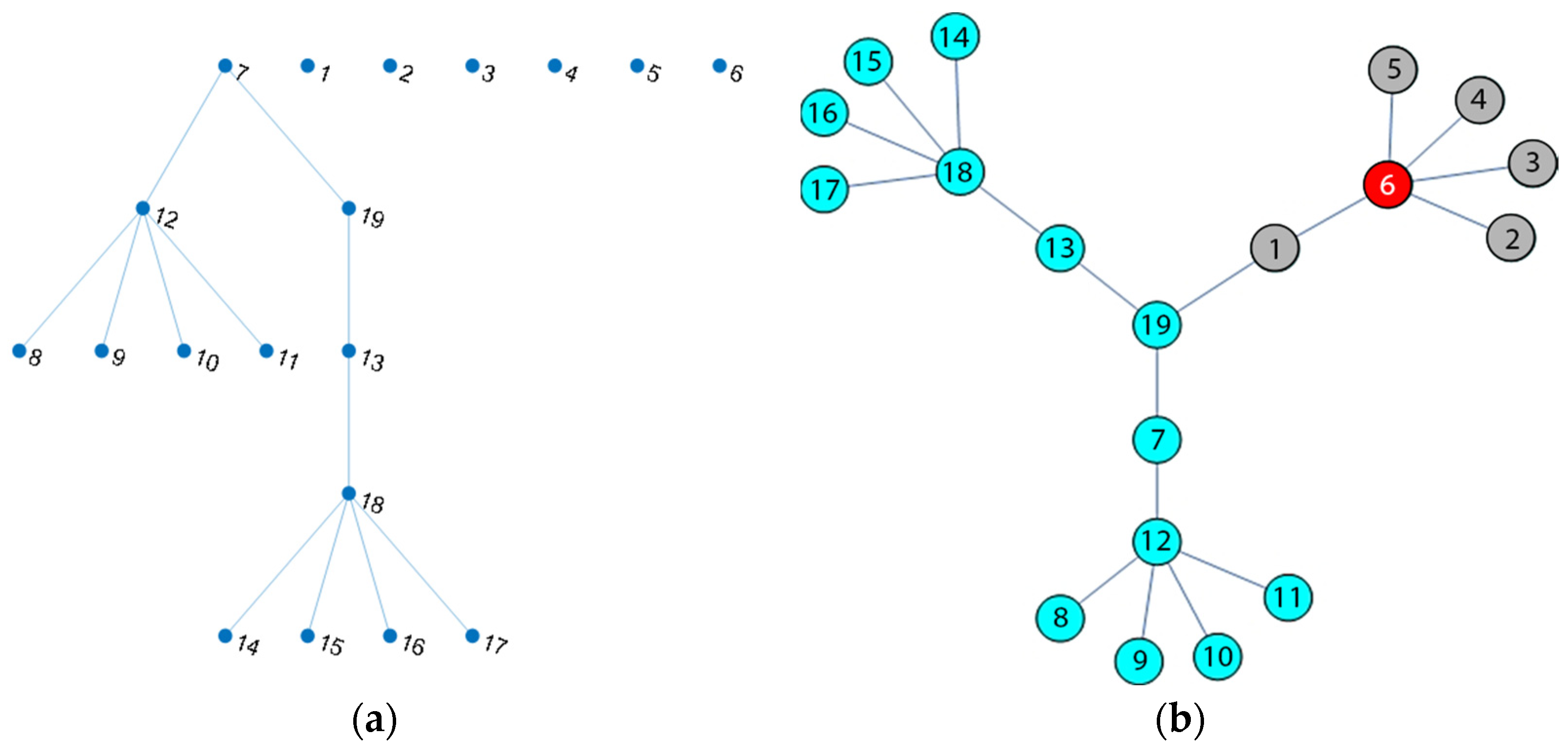


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Node # | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| Ψ1 | 1.33 | 3.25 | 2.75 | 3.25 | 1.33 | 3.25 | 4.67 | 4.33 | 4.67 | 3.25 | 2.75 | 4.33 | 4 | 4.33 | 2.75 |
| Ψ2 | 0.41 | 1.44 | 0.77 | 1.44 | 0.41 | 1.44 | 1.26 | 1.13 | 1.26 | 1.44 | 0.83 | 1.15 | 0.94 | 1.15 | 0.83 |
| Node # | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 |
| Ψ1 | 2.75 | 4.33 | 4 | 4.33 | 2.75 | 3.25 | 4.67 | 4.33 | 4.67 | 3.25 | 1.33 | 3.25 | 2.75 | 3.25 | 1.33 |
| Ψ2 | 0.83 | 1.15 | 0.94 | 1.15 | 0.83 | 1.44 | 1.26 | 1.13 | 1.26 | 1.44 | 0.41 | 1.44 | 0.78 | 1.44 | 0.41 |
| Node # | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| Ψ1 | 0 | 0.67 | 3.25 | 3.25 | 1.33 | 0 | 3 | 3.50 | 4.67 | 3.25 | 1.17 | 2.67 | 4 | 4.33 | 2.75 |
| Ψ2 | 0 | 0.11 | 2.27 | 1.38 | 0.41 | 0 | 2.16 | 0.73 | 1.32 | 1.44 | 0.49 | 0.56 | 1.14 | 1.15 | 0.83 |
| Node # | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 |
| Ψ1 | 2.17 | 4.33 | 4 | 4.33 | 2.75 | 3.25 | 4.67 | 4.33 | 4.67 | 3.25 | 1.33 | 3.25 | 2.75 | 3.25 | 1.33 |
| Ψ2 | 0.67 | 1.41 | 0.94 | 1.15 | 0.83 | 1.55 | 1.26 | 1.13 | 1.26 | 1.44 | 0.41 | 1.44 | 0.78 | 1.44 | 0.41 |
| Node # | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| Ψ1 | 0 | 0 | 0 | 1.50 | 0.83 | 0 | 0 | 1 | 3.17 | 3.25 | 1.33 | 2 | 4 | 4.33 | 2.75 |
| Ψ2 | 0 | 0 | 0 | 1.14 | 0.20 | 0 | 0 | 0.28 | 0.87 | 2.04 | 0.64 | 0.54 | 1.48 | 1.26 | 0.83 |
| Node # | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 |
| Ψ1 | 2.17 | 4.67 | 4 | 4.33 | 2.75 | 3.25 | 4.67 | 4.33 | 4.67 | 3.25 | 1.33 | 3.25 | 2.75 | 3.25 | 1.33 |
| Ψ2 | 0.61 | 1.66 | 0.93 | 1.15 | 0.83 | 1.55 | 1.24 | 1.13 | 1.26 | 1.44 | 0.41 | 1.44 | 0.78 | 1.44 | 0.41 |
| Node # | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| Ψ1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1.33 | 2.17 | 2.75 | 2.17 | 1.33 |
| Ψ2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.62 | 0.64 | 1.06 | 0.64 | 0.62 |
| Node # | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 |
| Ψ1 | 2.17 | 4.67 | 4.33 | 4.67 | 2.17 | 3.25 | 4.67 | 4.33 | 4.67 | 3.25 | 1.33 | 3.25 | 2.75 | 3.25 | 1.33 |
| Ψ2 | 0.61 | 1.60 | 1.11 | 1.60 | 0.61 | 1.55 | 1.24 | 1.11 | 1.24 | 1.55 | 0.41 | 1.44 | 0.78 | 1.44 | 0.41 |
| Node # | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| Ψ1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1.33 | 2.50 | 0.67 | 0 | 0 |
| Ψ2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.58 | 1.40 | 0.12 | 0 | 0 |
| Node # | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 |
| Ψ1 | 2.17 | 3.75 | 3 | 0 | 0 | 3.25 | 4.67 | 2.50 | 3.25 | 0.83 | 1.33 | 3.25 | 2.75 | 2.33 | 1.67 |
| Ψ2 | 0.64 | 1.00 | 2.17 | 0 | 0 | 1.55 | 1.50 | 0.38 | 2.20 | 0.19 | 0.41 | 1.44 | 1.04 | 0.66 | 1.36 |
| Node # | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| Ψ1 | 1.07 | 0.2 | 0.2 | 0.2 | 0.2 | 22.5 | 1.07 | 0.2 | 0.2 | 0.2 |
| Ψ2 | 0.14 | 0.009 | 0.009 | 0.009 | 0.009 | 94.22 | 0.14 | 0.009 | 0.009 | 0.009 |
| Node # | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | |
| Ψ1 | 0.2 | 22.5 | 1.07 | 0.2 | 0.2 | 0.2 | 0.2 | 22.5 | 4.5 | |
| Ψ2 | 0.009 | 94.22 | 0.14 | 0.009 | 0.009 | 0.009 | 0.009 | 94.22 | 4.22 |
| Node # | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| Ψ1 | 0 | 0 | 0 | 0 | 0 | 0 | 1.4 | 0.2 | 0.2 | 0.2 |
| Ψ2 | 0 | 0 | 0 | 0 | 0 | 0 | 0.38 | 0.009 | 0.009 | 0.009 |
| Node # | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | |
| Ψ1 | 0.2 | 22.5 | 1.4 | 0.2 | 0.2 | 0.2 | 0.2 | 0.2 | 22.5 | |
| Ψ2 | 0.009 | 93.21 | 0.38 | 0.009 | 0.009 | 0.009 | 0.009 | 93.21 | 1.43 |
| Dataset | Number of Nodes | Number of Edges | Dominating Set | Time (S) |
|---|---|---|---|---|
| Random generated graph | 70 | 133 | VD = {1, 7, 10, 16, 23, 26, 32, 36, 37, 39, 44, 47, 52, 56, 65, 67} | 0.051 |
| dsjc250.5 [41] | 250 | 31,336 | VD = {1, 62, 87, 118, 189} | 0.041 |
| dsjc500.1 [41] | 500 | 12,458 | VD = {32, 40, 55, 56, 70, 101, 150, 160, 164, 201, 204, 205, 211, 247, 256, 295, 312, 332, 337, 349, 390, 405, 494} | 0.091 |
| latin_square [42] | 900 | 307,350 | VD = {1, 721} | 0.107 |
| flat1000_50_0 [42] | 1000 | 245,000 | VD = {266, 326, 357, 672, 704, 969} | 0.175 |
| r1000.5 [43] | 1000 | 238,267 | VD = {13, 241, 374, 483, 602} | 0.095 |
| dsjc1000.1 [41] | 1000 | 49,629 | VD = {12, 22, 65, 120, 166, 184, 207, 253, 317, 382, 387, 394, 523, 531, 565, 618, 627, 638, 651, 676, 741, 768, 793, 813, 855, 870, 950} | 0.219 |
| C2000.5 [42] | 2000 | 999,836 | VD = {17, 545, 552, 636, 826, 1023, 1324} | 0.745 |
| flat1000_60_0 [42] | 1000 | 245,830 | VD = {41, 60, 475, 747, 748, 966} | 0.204 |
| flat1000_76_0 [42] | 1000 | 246,708 | VD = {171, 467, 508, 531, 550, 595} | 0.125 |
| Dataset | CC2FS [44] | FastMWDS [25] | RLS0 [17] | ScBppw [26] | FastDS [27] | Our Work |
|---|---|---|---|---|---|---|
| frb40-19-1 [45] | 14 | 14 | 14 | 15 | 14 | 2 |
| frb40-19-2 [45] | 14 | 14 | 15 | 16 | 14 | 2 |
| frb40-19-3 [45] | 14 | 14 | 15 | 16 | 14 | 2 |
| frb40-19-4 [45] | 14 | 14 | 15 | 15 | 14 | 2 |
| frb40-19-5 [45] | 14 | 14 | 15 | 15 | 14 | 2 |
| frb45-21-1 [45] | 16 | 16 | 16 | 17 | 16 | 2 |
| frb45-21-2 [45] | 16 | 16 | 17 | 18 | 16 | 2 |
| frb45-21-3 [45] | 16 | 16 | 17 | 17 | 16 | 2 |
| frb45-21-4 [45] | 16 | 16 | 17 | 17 | 16 | 2 |
| frb45-21-5 [45] | 16 | 16 | 17 | 18 | 16 | 2 |
| frb50-23-1 [45] | 18 | 18 | 19 | 19 | 18 | 2 |
| frb50-23-2 [45] | 18 | 18 | 19 | 19 | 18 | 2 |
| frb50-23-3 [45] | 18 | 18 | 19 | 20 | 18 | 2 |
| frb50-23-4 [45] | 18 | 18 | 20 | 19 | 18 | 2 |
| frb50-23-5 [45] | 18 | 18 | 19 | 19 | 18 | 2 |
| frb53-24-1 [45] | 19 | 19 | 20 | 21 | 19 | 2 |
| frb53-24-2 [45] | 19 | 19 | 20 | 21 | 19 | 2 |
| frb53-24-3 [45] | 19 | 19 | 20 | 20 | 19 | 2 |
| frb53-24-4 [45] | 18 | 19 | 19 | 19 | 18 | 2 |
| frb53-24-5 [45] | 19 | 19 | 20 | 20 | 19 | 2 |
| frb56-25-1 [45] | 20 | 20 | 21 | 21 | 20 | 2 |
| frb56-25-2 [45] | 20 | 20 | 21 | 21 | 20 | 2 |
| frb56-25-3 [45] | 20 | 20 | 22 | 21 | 20 | 2 |
| frb56-25-4 [45] | 20 | 20 | 22 | 22 | 20 | 2 |
| frb56-25-5 [45] | 20 | 20 | 21 | 21 | 20 | 2 |
| frb59-26-1 [45] | 21 | 21 | 22 | 22 | 20 | 2 |
| frb59-26-2 [45] | 21 | 21 | 22 | 22 | 21 | 2 |
| frb59-26-3 [45] | 21 | 21 | 22 | 23 | 21 | 2 |
| frb59-26-4 [45] | 21 | 21 | 23 | 23 | 21 | 2 |
| frb59-26-5 [45] | 21 | 21 | 24 | 23 | 21 | 2 |
| frb100-40 [45] | 37 | 38 | 40 | 39 | 36 | 2 |
| Average Run Time | 96.68 s | 101.44 s | - | 95.62 s | 0.761 s |
| Dataset | FastMWDS [25] | RLS0 [17] | ScBppw [26] | FastDS [27] | Our Work |
|---|---|---|---|---|---|
| Amazon0302 [46] | 35,616 | 38,735 | 36,199 | 35,593 | 37,806 |
| Amazon0312 [46] | 45,531 | 49,326 | 45,914 | 45,490 | 47,424 |
| Amazon0505 [46] | 47,362 | 51,281 | 47,734 | 47,310 | 49,207 |
| Amazon0601 [46] | 42,319 | 45,952 | 42,717 | 42,289 | 44,274 |
| Cit-HepPh [47] | 3078 | 3192 | 3087 | 3078 | 3223 |
| Cit-HepTh [47] | 2935 | 2985 | 2944 | 2936 | 3023 |
| Email-EuAll [46] | 18,181 | 18,181 | 18,181 | 18,181 | 18,179 |
| p2p-Gnutela04 [47] | 2227 | 2227 | 2227 | 2227 | 2239 |
| p2p-Gnutela24 [47] | 5418 | 5418 | 5418 | 5418 | 5418 |
| p2p-Gnutela25 [47] | 4519 | 4519 | 4519 | 4519 | 4519 |
| p2p-Gnutela30 [47] | 7169 | 7169 | 7169 | 7169 | 7169 |
| p2p-Gnutela31 [47] | 12,582 | 12,593 | 12,582 | 12,582 | 12,582 |
| soc-Slashdot0811 [48] | 14,312 | 14,333 | 14,312 | 14,312 | 14,323 |
| soc-Slashdot0902 [48] | 15,305 | 15,334 | 15,305 | 15,305 | 15,351 |
| soc-Epinions1 [49] | 15,734 | 15,742 | 15,734 | 15,734 | 15,751 |
| web-BerkStan [48] | 28,434 | 30,119 | 28,615 | 28,432 | 28,972 |
| web-Google [48] | 79,700 | 81,106 | 79,756 | 79,699 | 80,334 |
| web-NotDame [50] | 23,733 | 23,950 | 23,746 | 23,735 | 23,800 |
| web-Stanford [48] | 13,198 | 14,099 | 13,298 | 13,199 | 13,433 |
| Wiki-Vote [3] | 1116 | 1116 | 1116 | 1116 | 1116 |
| cond-mat-2005 [51] | 6508 | 6509 | 6531 | 6508 | 5748 |
| Dataset | Our Work | Greedy [24] | CBC [24] | RLSo [17] | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Dmin | NR | ET(sn) | Dmin | NR | ET(sn) | Dmin | NR | ET(sn) | Dmin | NR | ET(sn) | |
| polbooks [52] | 14 | 1 | 0.052 | 14 | 1000 | ≈36,000 | 13 | 10 | ≈36,000 | 13 | 20 | ≈600 |
| adjnoun [53] | 19 | 1 | 0.06 | 18 | 1000 | ≈36,000 | 18 | 10 | ≈36,000 | 18 | 20 | ≈600 |
| football [8] | 15 | 1 | 0.051 | 13 | 1000 | ≈36,000 | 12 | 10 | ≈36,000 | 12 | 20 | ≈600 |
| lesmis [54] | 10 | 1 | 0.061 | 10 | 1000 | ≈36,000 | 10 | 10 | ≈36,000 | 10 | 20 | ≈600 |
| netscience [53] | 349 | 1 | 0.963 | 477 | 1000 | ≈36,000 | 477 | 10 | ≈36,000 | 477 | 20 | ≈600 |
| zachary [55] | 4 | 1 | 0.04 | 4 | 1000 | ≈36,000 | 4 | 10 | ≈36,000 | 4 | 20 | ≈600 |
| celegansneural [56] | 17 | 1 | 0.053 | 17 | 1000 | ≈36,000 | 16 | 10 | ≈36,000 | 16 | 20 | ≈600 |
| dolphins [57] | 14 | 1 | 0.035 | 15 | 1000 | ≈36,000 | 14 | 10 | ≈36,000 | 14 | 20 | ≈600 |
| hep-th [51] | 2234 | 1 | 197 | 2633 | 1000 | ≈36,000 | 2613 | 10 | ≈36,000 | 2613 | 10 | ≈3600 |
| astro-ph [51] | 2140 | 1 | 695 | 3011 | 1000 | ≈36,000 | 2930 | 10 | ≈36,000 | 2930 | 10 | ≈3600 |
| cond-mat-2003 [51] | 4744 | 1 | 4207 | 5489 | 1000 | ≈36,000 | 5379 | 10 | ≈36,000 | 5379 | 10 | ≈3600 |
| power-US-grid [56] | 1481 | 1 | 33 | 1545 | 1000 | ≈36,000 | 1481 | 10 | ≈36,000 | 1481 | 20 | ≈600 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Okumuş, F.; Karcı, Ş. MDSA: A Dynamic and Greedy Approach to Solve the Minimum Dominating Set Problem. Appl. Sci. 2024, 14, 9251. https://doi.org/10.3390/app14209251
Okumuş F, Karcı Ş. MDSA: A Dynamic and Greedy Approach to Solve the Minimum Dominating Set Problem. Applied Sciences. 2024; 14(20):9251. https://doi.org/10.3390/app14209251
Chicago/Turabian StyleOkumuş, Fatih, and Şeyda Karcı. 2024. "MDSA: A Dynamic and Greedy Approach to Solve the Minimum Dominating Set Problem" Applied Sciences 14, no. 20: 9251. https://doi.org/10.3390/app14209251
APA StyleOkumuş, F., & Karcı, Ş. (2024). MDSA: A Dynamic and Greedy Approach to Solve the Minimum Dominating Set Problem. Applied Sciences, 14(20), 9251. https://doi.org/10.3390/app14209251