Abstract
Within the phenomenology of particle physics, the theoretical model of 4-zero textures is validated using a chi-square criterion that compares experimental data with the computational results of the model. Traditionally, analytical methods that often imply simplifications, combined with computational analysis, have been used to validate texture models. In this paper, we propose a new meta-heuristic variant of the differential evolution algorithm that incorporates aspects of the particle swarm optimization algorithm called “HE-DEPSO” to obtain chi-squared values that are less than a bound value, which exhaustive and traditional algorithms cannot obtain. The results show that the proposed algorithm can optimize the chi-square function according to the required criteria. We compare simulated data with experimental data in the allowed search region, thereby validating the 4-zero texture model.
1. Introduction
Broadly speaking, physics can be classified into three areas: the theoretical part, which, through mathematical formalism, explains and understands the physical phenomena; the experimental part, which groups disciplines related to the acquisition of data, the methods of data acquisition, and the design and performance of experiments; and finally, the aspect that links these two, known as phenomenology, which deals with (1) validating theoretical models, (2) investigating how to measure their parameters, (3) investigating how to distinguish one model from another, and (4) studying the experimental consequences of these models. This paper addresses a phenomenological approach by providing a solution to the validation of a theoretical model of physics, more specifically, from particle physics, to unveil the mechanisms of fermion mass generation and to reproduce the elements of the (Cabibbo–Kobayashi–Maskawa unitary matrix), which describes the mixing of different types of quark during weak interactions by encapsulating the probabilities of transitions between these quark types (see, for example, pertinent introductory reviews [1,2,3]), known as the mixing matrix.
The beginning of these models goes back to the first years of the 1970s, shortly after the establishment of the standard model (SM) of particle physics. Since then, different approaches have been developed in the context of theoretical and phenomenological models, which can be broadly classified as follows: Radiative mechanisms, where fermion masses come from contributions of processes generated by new particles added to SM [4,5]; Textures, where the mass matrix has zeros in some entries [6,7,8]; Symmetries between families, where a mathematical group symmetry is added to the theory [9,10]; and Seesaw mechanisms, an elegant way of generating small masses for neutrinos [11,12,13]. These approaches are phenomenological interrelated; for example, when we add an extra group symmetry to the theory it is common to arrive at texture structure to mass matrices [14,15], and in linear and inverse Seesaw models a texture structure is used to obtain the neutrino masses [16].
The texture formalism was born by considering that certain entries of the mass matrix are zero, such that we can compute analytically the matrix that diagonalizes it and hence the matrix . In 1977, Harald Fritzsch created this formalism by using 6-zero hermetic textures as a viable model [17]; in 2005, with experimental data from that year, he found that 4-zero hermetic textures were viable to generate the quark masses and the mixing matrix [18]. The analytical approach is very complex, so certain considerations are made to simplify the model. However, the results obtained are not accurate, which is why numerical approaches have recently been used to obtain more accurate solutions. Given the precision of the current experimental data, it is worthwhile assessing the feasibility of these texture models with early studies on the 4-zero mass matrix [19], further exploring their potential to align with experimental data.
There are numerical works on 4-zero texture models; however, the detailed numerical descriptions of the techniques and algorithms used are not described by their authors [20]. The numerical analysis of texture models requires a criterion that establishes when the theoretical part of the model agrees with the experimental part [21]. That is, to validate the model, a function (which we will call ) is built, and permissible values of the free parameters X of the model must be found, such that this function takes the minimum value possible greater than 0 but less than 1. In other words, it is necessary to optimize said function under a certain threshold. For the particular case of the function obtained from the texture formalism, the difficulty comes from the cumbersome algebraic manipulation of the expressions involved, which complicate and entangle the application of classic optimization techniques; thus, alternative optimization techniques are required.
To the best of the authors’ knowledge, the works where bio-inspired optimization algorithms have been used within particle physics are as follows: in experimental contexts, where particle swarm optimization algorithms (PSOs), as well as genetic algorithms (GAs), have been implemented within the hyperparameter optimization of machine-learning (ML) models used in the analysis of data obtained in high-energy physics experiments [22]; in the optimization of the design of particle accelerators, where the differential evolution (DE) algorithm is quite effective [23,24]; and in phenomenology, where genetic algorithms have been used to discriminate models from supersymmetric theories [25].
As can be seen, the incursion of bio-inspired optimization algorithms in particle physics has been very limited, even when the results are favorable. For this reason, further application of these techniques and algorithms in this type of particle physics area, especially in texture formalism, is of great interest.
The DE algorithm is one of the evolutionary algorithms that has stood out the most in recent times due to its simplicity, power, and efficiency [26,27]; however, like other evolutionary algorithms, it is likely to suffer premature convergence and stagnation in local minima [26,28]. The strategies implemented to solve these problems can be classified as follows [29]:
- Change the mutation strategy. The mutation phase of the DE algorithm is important since it allows the integration of new individuals into the existing population, thus influencing its performance. Algorithms such as CoDE [30] have introduced new mutation strategies and implemented different mutation strategies, respectively, in order to improve the efficiency of the DE algorithm.
- Change the parameter control. The DE algorithm is sensitive to the configuration of its main parameters: the scale factor F and the crossover probability [26,31]. Self-adaptive control of these parameters has been shown to improve the performance of the DE algorithm significantly. In this sense, the SHADE [32] and SaDE [33] algorithms represent two fairly well-known variants.
- Incorporation of population mechanisms. The way in which the population is handled in the DE algorithm can improve its performance. Techniques such as genotypic topology [34], opposition-based initialization [35], and external population archives, as seen in JADE [36], have shown positive effects.
- Hybridization with other optimization algorithms. One way to improve the performance of the DE algorithm is to take advantage of the operators’ strengths from other algorithms and incorporate them into the structure of the DE algorithm through a hybridization process [27,37]. Hybridization with other computational intelligence algorithms, such as artificial neural networks (ANNs), ant colony optimization (ACO), and particle swarm optimization (PSO), has marked a trend within the last decade [27,38].
The self-adaptive differential evolution algorithm based on particle swarm optimization (DEPSO) [39] is a recent variant of the DE algorithm that integrates the PSO mutation strategy within its structure. DEPSO employs a probabilistic selection technique to choose between two mutation strategies: a new mutation strategy with an elite file called DE/e-rand/1, a modification of the DE/rand/1 strategy, and the mutation strategy of the PSO algorithm. This probabilistic selection technique enables DEPSO to improve the balance between exploitation and exploration, resulting in significantly better performance compared to both DE and PSO on various single-objective optimization problems.
This paper proposes a new variant of the DEPSO algorithm called historical elite differential evolution based on particle swarm optimization (HE-DEPSO) to improve optimization performance in solving complex single-objective problems, with a specific focus on addressing the problem of optimizing the criteria for the 4-zero texture model of high energy physics. The proposed variant aims to explore the areas of opportunity encountered to enhance DEPSO, specifically introducing a new mutation strategy named DE/current-to-EHE/1, which utilizes information from the elite individuals of the population and incorporates historical data from the evolutionary process to improve the balance between exploration and exploitation by leveraging information from elite individuals and historical data, particularly during the early stages of the evolutionary process. Additionally, HE-DEPSO employs the self-adaptive parameter control mechanism from the SHADE algorithm to reduce the sensitivity of the algorithm’s parameters. To test the HE-DEPSO algorithm’s performance, it was compared against other optimization algorithms, including DE, PSO, CoDE, SHADE, and DEPSO, using the CEC 2017 single-objective benchmark function set. The HE-DEPSO algorithm outperformed the other algorithms in terms of solution quality. Finally, the validation of the 4-zero texture model was conducted, optimizing the function and, at the same time, comparing the performance of our proposal against DE, PSO, CoDE, SHADE, and DEPSO algorithms for this particular application. The results are encouraging and expand the use of bio-inspired methods in high-energy physics by integrating a metaheuristic approach.
The remainder of the paper is structured as follows: Section 2 contains the definition of the problem to be solved, including the definition of the criterion; Section 3 reviews the versions of the PSO and DEPSO algorithms used here. Section 4 explains our proposal, the HE-DEPSO algorithm; Section 5 subjects our algorithm to benchmark tests, while Section 6 presents the validation problem of the 4-zero texture model. Finally, in Section 7, the conclusions are presented.
2. Problem Definition
Within the scope of the SM, the masses of the quarks come from hermetic matrices known as mass matrices (one for u-type quarks and another for d-type quarks) [40,41,42], as the absolute values of their eigenvalues and the matrix as the product of the matrix that diagonalizes the u-type quarks and the matrix that diagonalizes the d-type quarks; however, due to the mathematical formalism used, the mass matrices remain entirely unknown and, consequently, the masses of the quarks and the mixing matrix cannot be theoretically predicted. The experiment provides us with the numerical value of these quantities.
The mixing matrix can be written in a general way as:
and is a unitary matrix containing information about the probability of transition between u-type quarks (left-hand index) and d-type quarks (right-hand index), through the weak interaction [43]. That is, quantifies the transition probability between the quark u and the quark s through the interaction with the boson . Over many years and different collaborations, the magnitudes of the elements of the mixing matrix have been experimentally measured with an accuracy up to , and it is well known that four quantities (three angles and one phase) are needed to have a parametrization that adequately describes the matrix [3,44]. In this work, we choose the Chau–Keng parametrization [3], and the three corresponding angles , , and are obtained by choosing the three magnitudes of the elements , , and , and the phase is obtained from the Jarslog invariant (J) through the following relations:
where . Hence, we choose , , , and J as independent quantities.
Within the SM context, the mixing matrix, , is defined by [3]:
where is the matrix that diagonalizes the mass matrix of the u-type quarks and is the matrix that diagonalizes the d-type quarks. It is here where the texture formalism is born, which consists of proposing structures with zeros in some entries of the mass matrix in such a way that we can find the matrices that diagonalize it and be able to calculate analytically the mixing matrix and validate the chosen texture structure.
Without loss of generality, the mass matrices and are considered hermitian so that the general mass structure has the form:
where the index q runs over the labels . The elements , , and are real, while , , and are complex and are usually written in their polar form , where is the magnitude and is its angular phase ().
A matrix of the type 4-zero texture [18] is formed from the above matrix by taking the entries , , and equal to zero. Thus, we arrive at the following matrix structure:
In references [6,18], it is shown that this matrix can be diagonalized by a unitary matrix as follows:
where denotes a diagonal matrix and denotes each of the three eigenvalues of . The matrices and are given by:
and
Taking and , the relations between and the physical masses of the quarks are:
where is the u quark mass, is the c quark mass, is the t quark mass, is the d quark mass, is the s quark mass, and is the b quark mass, and its experimental value is presented in Appendix A. In this work, the same 4-zero texture structure is considered for the u-quark mass matrix and the d-type quark mass matrix (a parallel mass structure). The q-index takes two values, and .
From Equation (9), it is noticed that the elements of the matrix depend on the free parameters and ; the first parameter takes values of and and tells us that the eigenvalue of the mass matrix is negative, when the first eigenvalue is negative and the second eigenvalue is positive, and when the first eigenvalue is positive and the second eigenvalue is negative. The combinations of signs of the and parameters define the different cases of study to be considered (see Table 1). The second pair of free parameters are and , whose values are restricted to the intervals and to ensure that the elements of the and matrices are real.

Table 1.
Cases of study.
From the above, the mixing matrix , predicted by the 4-zero texture model, is given by:
in an explicit form:
where the phases and are defined as:
These are considered to be measured in radians with principal argument , and the indices i and j correspond, respectively, to the indices and .
The magnitude of the elements of the mixing matrix is given by:
At this point, it is essential to emphasize that analytical expressions are obtained for the elements of the mixing matrix predicted by the 4-zero texture formalism; with this information, it is possible to construct a more complete theory of the standard model where the origin of the mixing matrix is explained.
It only remains to validate the theoretical model of textures with 4 zeros, that is, to find the range of the free parameters , , , and that agree with the experimental values of the matrix , and for this, we define a function and use a chi-square criterion [45,46] established by:
where and
The super-indexes “” are given by Equation (15) and the quantities without super-index are the experimental data with uncertainty (see Equations (A1) and (A2)).
Although, at first sight, the mathematically constructed function turns out to have a simple structure and the amount of free parameters is small, the difficulty of finding the numerical range of the same ones that fulfill the condition given in Equation (16) comes from the cumbersome composition of functions that constitute it. In order to have a notion of the topographic relief of this function, different projections of the function in different planes are shown in Figure 1. Figure 1a shows the projection onto the planes and (held fixed values for and ); that is, the dependence of the function on the variables and is shown (right graph) and the corresponding contour lines are illustrated (left graph). Similarly, Figure 1b corresponds to the projection of the function onto and (setting and ). Analogously in the graphical displays, we show the behavior of the function in the planes and (Figure 1c), in the planes and (Figure 1d), in the planes and (Figure 1e), and in the and planes (Figure 1f).
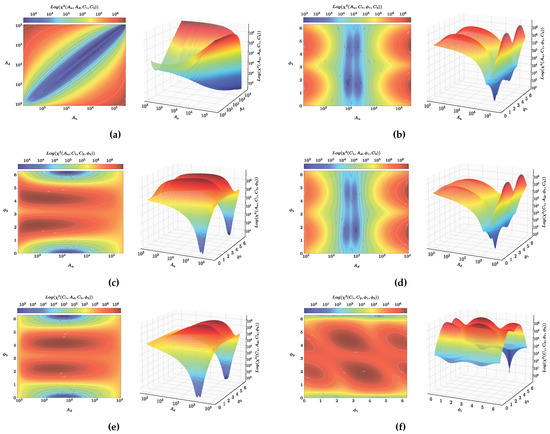
Figure 1.
function projections over variables , , , . (a) Dependence of the function on the variables and (right graph). From the contour lines (left-hand graph), we note that the region that minimizes lies around a straight line at . (b) Dependence of the function with respect to the variables and (right-hand graph) and corresponding contour lines (left-hand graph). We note a periodicity of the maxima of the function with respect to the variable . (c) Dependence of the function with respect to the variables and (right-hand graph) and corresponding contour lines (left-hand graph). We note a periodicity of the maxima and the minima of the function with respect to the variable . (d) Dependence of the function with respect to the variables and (right-hand graph) and corresponding contour lines (left-hand graph). We note a periodicity of the maxima of the function with respect to the variable . (e) Dependence of the function with respect to the variables and (right-hand graph) and corresponding contour lines (left-hand graph). We note a periodicity of the maxima and the minima of the function with respect to the variable . (f) Dependence of the function on the variables and (right-hand graph) and corresponding contour lines (left-hand graph).
The following color code has been established; regions towards the intense red color mean larger values of , while regions towards the intense blue color correspond to smaller values of . We point out that the function to optimize is defined on (17) with variables , , , bounded on the boundaries , , , , and as can be observed from the graphs (Figure 1), the topography that it is intended to optimize is rugged. With this, one sees the opportunity to explore the use of alternative optimization techniques such as bio-inspired algorithms.
3. Review of PSO, DE, and DEPSO
3.1. Particle Swarm Optimization
The particle swarm optimization (PSO) algorithm [47] is one of the most popular swarm intelligence-based algorithms. It models the behavior of groups of individuals, such as flocks, to solve complex optimization problems in D-dimensional space. The algorithm performs a search for the global optimum using a swarm of particles. For the i-th particle of the swarm (), its position and velocity at iteration t are represented by and , respectively. At each iteration, the position and velocity of each particle is updated, taking into account the information of the best solution found by the swarm and the best solution found individually, , by each particle. In the standard version of the PSO algorithm, the way in which the updating of the position and velocity of each particle is performed is carried out according to the following expressions [48]:
where and are the social and cognitive coefficients, respectively, which commonly take the values . and are two randomly selected values within the interval . is known as the inertia parameter and it aims to provide a better balance between global and local search. The inertia parameter is updated at each iteration as follows:
where t refers to the current iteration, is the maximum number of iterations, and and are the minimum and maximum values of the inertia factor, which are generally set to values and .
3.2. Differential Evolution
The DE algorithm proposed by Storn and Price [49,50] is one of the most representative evolutionary algorithms, which, due to its ease of implementation, effectiveness, and robustness, has been widely used in the solution of several complex optimization problems [51,52]. This algorithm makes use of a population P constituted from individuals or parameter vectors:
where t refers to the current iteration and each individual has D dimensions. At the beginning of the execution of this algorithm, the population is initialized randomly within the search space of the problem.
The DE algorithm consists mainly of three operators: mutation, crossover, and selection. These operators allow the algorithm to perform the search for the global optimum. Mutation, crossover, and selection are applied consecutively to each individual of the population in each of the t iterations until a certain stopping criterion is satisfied. Within the mutation, in each iteration and for each individual, a mutated vector is generated by means of the information of the current population and the application of a mutation scheme. In the standard version of the DE algorithm, the mutated vector is generated following the DE/rand/1 mutation scheme, described as follows:
where the indices , and are randomly selected within the range such that they are different from each other and different from the index i. is the scaling factor and is one of the parameters of the algorithm. The value of parameter F is typically within the interval .
The next stage within the DE algorithm consists of the crossover, in which a test vector is generated; that is, once the mutated vector is generated for the individual , the information crossover between the vector and the vector is performed. This crossover operation is performed consistently following the binomial crossover:
where is a number uniformly selected within the interval and is an index corresponding to a variable that is uniformly selected in the interval . Here, is known as the crossover probability, and like F, it is another parameter of the algorithm.
Once the corresponding test vector is generated for the individual , a selection procedure is carried out from which the population for iteration is constructed. The standard way to perform this selection procedure consists of comparing the fit value of the test vector against the fit value of the individual , always keeping the individual with the best fit value. This procedure is performed as follows:
3.2.1. Improvements on DE Parameters Control
One of the components that influence the performance of the DE algorithm is the control of the F and parameters [32,53]. The standard version of the DE algorithm uses fixed values for these two parameters; however, the selection of these parameters can be done deterministically (following a certain rule that modifies these values after a certain number of iterations), adaptively (according to the feedback of the search process), and in a self-adaptive way (by means of the evolution information provided by the individuals of the population) [37]. One of the most representative variants concerning the improvement of the control of the parameters F and of the DE algorithm is proposed in the SHADE algorithm [32].
Precisely, in each iteration of the SHADE algorithm, the parameters F and , which are associated with test vectors with a better fit than their parent vector, are stored in two sets: and , respectively. Two archives or memories, and with a defined time H, and whose contents and are initialized with a value of , serve to generate the parameters and of the i-th individual at each iteration t. The way to generate the values of these parameters requires the uniform selection of an index, , and is carried out according to the following expressions:
where is the element selected from to generate the value of , while is the element selected from to generate the value of ; represents a normal distribution with mean and standard deviation , while represents a Cauchy distribution with parameter position and scale factor . When generating the value of the parameter , it must be verified that it is within the range ; otherwise, if then is truncated to 0 and if then is truncated to 1. For the parameter , if then is truncated to 1, otherwise, if then is regenerated until .
At the end of each iteration, the contents of the and memories are updated as follows:
where is the Lehmer weighted mean defined by the means of Equation (29), and S refers to or .
In Equations (27) and (28), determines the position in memory to be updated. At iteration t, the k-th element in memory is updated. At the beginning of the optimization process, and is incremented each time a new element is added to memory. If , k is assigned equal to 1.
Due to the good performance obtained by the SHADE algorithm when solving optimization problems using this strategy, this paper takes advantage of the adaptive control of the parameters provided by the SHADE algorithm.
3.2.2. DEPSO Algorithm
The self-adaptive differential evolution algorithm based on particle swarm optimization (DEPSO) [39] is a recent method, which incorporates characteristics of the PSO algorithm within the structure of the DE algorithm for solving numerical optimization problems. In this algorithm, the top of the best particles in the current iteration is used to form an elite sub-swarm , while the rest are used to form a non-elite sub-swarm .
The DEPSO algorithm follows a scheme similar to the standard version of the DE algorithm, i.e., it uses mutation, crossover, and selection operators within the evolutionary process of the algorithm. Within the mutation, a mutation strategy is implemented that, in a self-adaptive way, selects between two mutation schemes to generate in each iteration a mutated vector for the i-th particle , as follows:
where is a random number selected uniformly within the interval and represents the probability of selecting between one of the two mutation schemes. In Equation (32), the case in which represents the form in which a novel mutation scheme denoted DE/e-rand/1 generates a mutated vector . In this scheme, two optimal solutions of the elite sub-swarm and and one solution of the non-elite sub-swarm are required, and a scaling factor is used, which acts at the level of each particle. The remaining case represents the way in which the mutation scheme of the standard PSO algorithm is used to generate a mutated vector .
The selection probability of Equation (32) changes adaptively within the evolution of the algorithm, as follows:
where is the maximum number of iterations and t is the current iteration. is a positive constant.
Within the crossover operator, a test vector is generated by combining the information of the current particle and the mutated vector , following the binomial crossover (see Equation (23)). The selection of the surviving particle to the next iteration is carried out by the competition between the current particle and the test vector ; the one with the best fit value according to the objective function is selected to remain within the next iteration.
When a particle remains stagnant over a maximum number of iterations (e.g., 5), the values of its corresponding scale factor and crossover probability are reset in order to increase diversity. The way in which the values of these parameters are reset is as follows:
where and are the scaling factor and the crossover probability, respectively, of the particle at iteration t. and are the lower and upper bounds respectively of the scaling factor. and are the lower and upper bounds, respectively, of the crossover probability and is a random number selected within the interval . is a stagnation counter for each particle and is the maximum number of iterations with stagnation.
To avoid stagnation, the DEPSO algorithm randomly updates a sub-dimension of individuals within the non-elite population , in which , to reset them as follows:
where is a random number selected within the interval , is a probability fixed value, and and are the lower and upper limits, respectively, of the variable j.
In general, the DEPSO algorithm manages to be superior to other variants of the DE algorithm in different optimization problems. The performance of this algorithm is due to the fact that it maintains a good balance between exploration and exploitation, thanks to the use of the self-adaptive mutation strategy, in which the “DE/e-rand/1” scheme has better exploration abilities, while the mutation scheme of the PSO algorithm achieves better convergence abilities. With this strategy, the population manages to maintain a good diversity in the first stages of the evolutionary process and a faster convergence towards the last stages of the process.
4. Proposed HE-DEPSO Algorithm
Despite the development of several advanced versions of the DE algorithm in recent years, its performance still needs to improve in optimization problems with multiple local minima. To address these issues, the design of effective mutation operators and parameter control are two key aspects to improve the performance of the DE algorithm. In the proposed HE-DEPSO algorithm, an adaptive hybrid mutation operator is developed, which takes the self-adaptive mutation strategy from the DEPSO algorithm [39] as a basis and incorporates the parameter control mechanism from the SHADE algorithm [32]. This adaptive hybrid mutation operator introduces a new mutation strategy called “DE/current-to-EHE/1”, which utilizes the historical information of the elite individuals in the population to enhance the optimization of the function.
4.1. Adaptive Hybrid Mutation Operator
In order to achieve a better balance between exploration and exploitation, the mutation operator of the HE-DEPSO algorithm adopts a dual mechanism in which it adaptively selects between two mutation strategies. First, a new mutation strategy called “DE/current-to-EHE/1” is presented, which is oriented to improve the balance between exploration and exploitation abilities within the early stages of the evolutionary process. On the other hand, to improve the exploitation capacity within the more advanced stages of the evolutionary process, the mutation scheme of the PSO algorithm (Equation (32)) is incorporated in a similar way to the self-adaptive mutation strategy of the DEPSO algorithm (Equation (18)).
Unlike the “DE/e-rand/1” scheme used within the self-adaptive mutation strategy of the DEPSO algorithm, in which only the information of the individuals of the current iteration is used, the “DE/current-to-EHE/1” strategy uses the historical information of the elite and obsolete individuals of the evolutionary process to improve the exploration capability of the algorithm. This strategy is described below.
4.1.1. DE/Current-to-EHE/1 Mutation Strategy
Within evolutionary algorithms, the best individuals in the population, also known as elite individuals, retain valuable evolutionary information to guide the population to promising regions [39,54,55,56]. However, many of the proposals made use of the information from the elite individuals of the current iteration, completely forgetting the information from the previous elite individuals. This absence of information within subsequent iterations may limit the ability of new individuals to explore the search space. Because of this, historical evolution information is used to improve the ability to explore new individuals.
Before applying the mutation operator, all individuals in the current population are sorted in ascending order based on their fitness values. After reordering the population, two partitions of individuals are created. The first partition, denoted by , consists of the top best individuals or elite individuals. The second partition, denoted by NEt, groups all non-elite individuals, i.e., . It is important to note that Et∪ NEt = .
Unlike other mutation strategies [36,39,57], in which only elite individuals corresponding to the current iteration are used, this strategy makes use of the evolution history by incorporating two external archives of size . The first archive, denoted by HE, stores at each iteration the elite individuals belonging to the Et partition. If the size of the archive HE is greater than then its size is readjusted. The second archive used, denoted by HL, stores the obsolete individuals (individuals discarded within the selection process) and is updated at each iteration. Similar to the HE archive, if the size of the HL file is larger than then its size is reset. With the information of the individuals belonging to Et and HE, a group of candidates can be formed using Et∪ HE to mutate individuals in the population. On the other hand, the individuals of NEt and HL make up a group of individuals NEt∪ HL, whose information contributes to the exploration of the search space. The way in which a mutated vector is generated by the “DE/current-to-EHE/1” strategy is as follows:
where is the i-th individual at iteration t, is a randomly selected individual from among the individuals in the group Et∪ HE, is an individual randomly selected from within the current population , is an individual randomly selected from the individuals comprising the group NEt∪ HL, and is the scaling factor corresponding to the i-th individual.
Following Equation (37), it is possible to observe that the “DE/current-to-EHE/1” strategy can help the HE-DEPSO algorithm to maintain a good exploration capability and direct the mutated individuals to promising regions without leading to stagnation in local minima. This can be explained as follows:
- The use of a randomly selected individual within the group Et ∪ HE, i.e., , helps to guide mutated individuals to more promising regions. However, due to the presence of the historical information of the elite individuals (HE), the mutated individuals are prevented from being directed towards the best regions found, thus allowing the maintenance of good diversity in the population and increasing the chances of targeting optimal regions.
- The participation of two individuals, and , randomly selected from and HL, respectively, promotes the diversity of mutated individuals. Consequently, the search diversity of the HE-DEPSO algorithm is considerably improved, which is beneficial for escaping from possible local minima.
At the beginning of the execution of the HE-DEPSO algorithm, the archives HE and HL are defined as empty. Through the evolutionary process, they store the elite and obsolete individuals, respectively. When analyzing the effect of the parameter , which determines the percentage of individuals within the participation of Et, it was found that values close to promote the participation of a more significant number of elite individuals, causing a greater diversity in the population. However, this diversity increase may affect the HE-DEPSO algorithm’s convergence capability. On the other hand, values close to may restrict the number of elite individuals to be considered, which improves the convergence of the algorithm but may cause stagnation at local minima. Due to the above, within the HE-DEPSO algorithm we choose to update in each iteration the value of following a linear decrement, given as follows:
where t refers to the current iteration, is the maximum number of iterations, and and are the minimum and maximum values of the interval assigned for the percentage of individuals within the partition Et. In this work, we have chosen to use the values and . In this way, the sensitivity of the parameter is reduced and, at the same time, a good balance between exploitation and exploration is maintained.
4.1.2. Selection of Mutation Strategy for Adaptive Hybrid Mutation Operator
The adaptive hybrid mutation operator implemented in the HE-DEPSO algorithm uses two mutation strategies that aim to improve the exploration and exploitation abilities of the HE-DEPSO algorithm at different stages of the evolutionary process. Concretely, for each individual in the population, this operator generates a mutated vector as follows:
where is a random number selected uniformly within the interval and represents the probability of selecting between the “DE/current-to-EHE/1” mutation strategy and the adopted mutation strategy of the PSO algorithm (Equation (18)).
The probability of selection is updated at each iteration according to Equation (33), taking a value of . Figure 2 shows the mutation strategy selection curve followed by the adaptive hybrid mutation operator of the HE-DEPSO algorithm. The probability selection curve described by Equation (33) with a value of , for a maximum number of iterations , is illustrated in red in Figure 2a. On the other hand, Figure 2b shows, as an example, a possible distribution of occurrences among which is selected the mutation strategy “DE/current-to-EHE/1” (squares in blue color) or the adopted strategy of the PSO algorithm (circles in magenta color). According to these graphs, it can be observed that, within the first stages of evolution of the HE-DEPSO algorithm, the probability of selection tends towards values close to 1, which increases the probability that the mutation strategy “DE/current-to-EHE/1” is selected, and the balance between exploration and exploitation provided by this strategy is taken advantage of. On the other hand, towards the advanced stages of the algorithm evolution, the mutation strategy adopted from the PSO algorithm is selected more frequently; this implies that, during the advanced stages, there is a higher probability that the HE-DEPSO algorithm increases its exploitation ability due to more frequent use of the information of the best positions of each individual, as well as the information of the position of the best individual in the population.
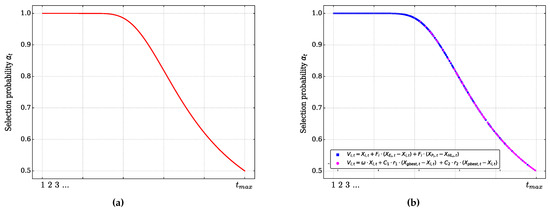
Figure 2.
Strategy selection curve; (a) Selection probability , (b) Distribution of strategy selection.
4.2. The Complete HE-DEPSO Algorithm
The HE-DEPSO algorithm follows the usual structure of the DE algorithm in general, in which we have the stages of mutation, crossover, and selection. After generating a mutated vector for the i-th individual of the population, as described in the previous section, we proceed to generate a test vector for the individual using the binomial crossover (Equation (23)). In order to reduce the sensitivity of the F and parameter controls, the HE-DEPSO algorithm takes advantage of the individual-level adaptive parameter control of the SHADE algorithm to generate the parameter configuration of F and for each individual. Finally, in the selection stage, the individuals that would make up the population for the next iteration are identified; this is done according to Equation (24). Based on the above description, the pseudocode of the complete HE-DEPSO is reported in Algorithm 1.
| Algorithm 1: The pseudocode of HE-DEPSO |
 |
4.3. Complexity Analysis of the HE-DEPSO Algorithm
The logical operations of HE-DEPSO are simple, so its computational complexity is low. The analysis uses the big- notation. The initialization of the NP individuals has a complexity of . The evaluation of the cost function is , and the sorting of individuals has a complexity of . Updating the values of each individual depends on mutation and crossover operations, each with a complexity of , so the update of the individuals is given by . Thus, the total complexity of HE-DEPSO is . This complexity is similar to the computational cost of recent DE variants (CoDE, SHADE, and DEPSO) proposed for global optimization; therefore, HE-DEPSO has similar execution times to these variations [30,32,39].
5. Experimental Results and Analysis
This section verifies the performance of the proposed HE-DEPSO algorithm in solving different optimization problems. First, the set of test problems used is presented, then the algorithms selected to carry out comparisons are presented, as well as the configuration of their parameters. Then, the performance of the HE-DEPSO algorithm is compared against the selected algorithms within the test problem set. Finally, a discussion of the results obtained is presented.
5.1. Benchmark Functions
In order to validate the performance of the HE-DEPSO algorithm in solving different optimization problems, the set of single-objective test functions with boundary constraints CEC 2017 [58] was used. This set consists of 29 test functions whose global optimum is known. We have two unimodal functions and , seven simple multimodal functions , ten hybrid functions , and ten composite functions . In all these optimization problems, we seek to find the global minimum () within the search space bounded in each dimension by the interval . Information about this set of test functions is briefly presented in Table 2.
Table 2.
Details of benchmark functions used in the experiments.
5.2. Algorithms and Parameter Settings
In this subsection, HE-DEPSO is compared with five algorithms, including the PSO and DE algorithms, as well as three representative and advanced variants of the DE algorithm, named CoDE [30], SHADE [32], and DEPSO [39]. Among these algorithms, CoDE and DEPSO incorporate modifications mainly within the mutation operator of the DE algorithm, while SHADE modifies the control of the F and parameters. The performance comparison of the HE-DEPSO algorithm with the previously mentioned algorithms was performed in two dimensions, and , on the CEC 2017 test function set.
In order to ensure a fair comparison, the parameter settings in common to all algorithms were assigned identically: the maximum number of iterations, , was set to 1000, the population size, , to 100, and 31 independent runs were performed. The configuration of each algorithm’s parameters followed the values suggested by their respective authors, as presented in Table 3. The proposed HE-DEPSO algorithm was implemented in Python version 3.11, and all algorithms were executed on the same computer with 8 GB of RAM and a six-core 3.6 GHz processor.
Table 3.
Parameter settings of all algorithms.
5.3. Comparison with DE, PSO, and Three State-of-the-Art DE Variants
In order to evaluate the performance of the HE-DEPSO algorithm, its optimization results and convergence properties are compared and analyzed with respect to those obtained by the algorithms DE, PSO, CoDE, SHADE, and DEPSO, on the set of CEC 2017 test functions.
Table 4 and Table 5 report the statistical results for each algorithm at and , respectively. The error measure of the solution , where is the known solution of the problem and is the best solution found in each iteration of each algorithm, was used to obtain these results. These tables show the mean and standard deviation (Std) of the solution error measure for each function and algorithm over the 31 independent runs and the ranking achieved based on the mean value obtained. The best results are highlighted in bold.
Table 4.
Comparison of results between HE-DEPSO, DE, PSO, and three advanced variants of the DE algorithm on the set of CEC 2017 test functions with .
Table 5.
Comparison of results between HE-DEPSO, DE, PSO, and three advanced variants of the DE algorithm on the CEC 2017 test function set with .
A non-parametric Wilcoxon rank sum test, with a confidentiality level of , was performed to identify statistically significant differences between the results obtained by the HE-DEPSO algorithm and the results obtained by the other algorithms. In these tables, the statistical significance related to the performance of the HE-DEPSO algorithm is represented by the symbols “+”, “≈”, and “−”, which indicate that the performance of the HE-DEPSO algorithm is “better/similar/worse” than the algorithm to which it is compared. The row “W/T/L” counts the total number of “+”, “≈”, and “−”, respectively.
5.3.1. Optimization Results
According to the results reported in Table 4, for the proposed HE-DEPSO algorithm obtains the global optimal solution for functions , , and . For the unimodal function , DEPSO and SHADE obtain the global optimal solution. On the other hand, SHADE, CoDE, and DE obtain the global optimal solution in the simple multimodal function . For functions , , , , , and , the HE-DEPSO algorithm achieves the best result among all algorithms. DEPSO is the best in the functions , , , and . SHADE obtains the best results on function , while CoDE obtains the best results on functions , , and . The PSO does not show superior results in any function. The results of this table indicate that, for these tests, the proposed HE-DEPSO algorithm obtains the best ranking according to the mean value among all the algorithms. On the other hand, the results of the Wilcoxon rank sum test show that HE-DEPSO is superior to DEPSO, SHADE, CoDE, DE, and PSO in 17, 20, 24, 25, and 29 functions out of a total of 29 test functions, respectively.
For , the statistical results presented in Table 5 show that the HE-DEPSO algorithm achieves the best results on the functions , , , , , and . On the other hand, DEPSO, SHADE, CoDE, and DE achieve the best results in the function. DEPSO is the best in the functions , , , , and , while SHADE is shown to be the best in the function in comparison to the rest of the algorithms. With these results, it is possible to identify that HE-DEPSO obtains the best ranking among all the algorithms for these tests. According to the Wilcoxon rank sum test results, among the 29 test functions, HE-DEPSO has 19, 20, 26, 26, 25, and 27 items that are better than DEPSO, SHADE, CoDE, DE, and PSO, respectively.
5.3.2. Convergence Properties
The convergence properties can be summarized into four types, which are represented by the graphs presented in Figure 3 and Figure 4.
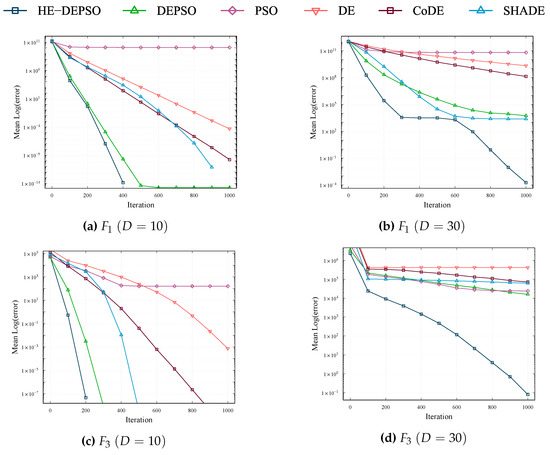

Figure 3.
Convergence curves for the functions , , , and , with and 30. The horizontal and vertical axis represent the iterations and the mean error values for the 31 independent repetitions.
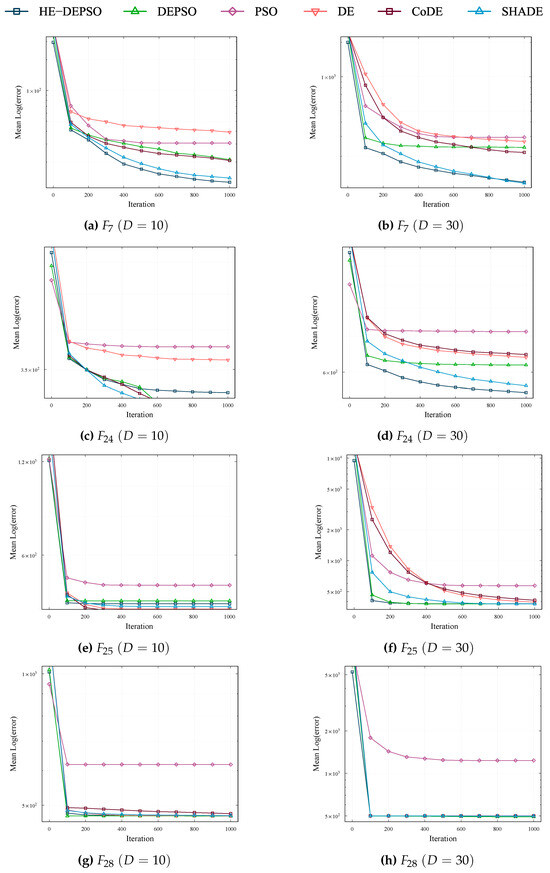
Figure 4.
Convergence curves for the functions , , and , with and 30. The horizontal and vertical axis represent the iterations and the mean error values for the 31 independent repetitions.
- The convergence properties of the functions , , and can be identified within the same class; this can be observed with the help of Figure 3a–d. In this type, the HE-DEPSO algorithm shows faster convergence than the other algorithms at , while at it obtains a better mean error value.
- In Figure 3e–h, the convergence curves of functions and are presented, which are similar to the corresponding ones for functions , , , and . All algorithms have different degrees of evolutionary stagnation or exhibit slow evolution for these functions.
- The convergence curves of the functions , , , and are similar to the curves of the functions and (see Figure 4a–d) obtained for the HE-DEPSO algorithm. In this type, HE-DEPSO presents a fast convergence at the beginning and, subsequently, it keeps evolving downward.
- The evolutionary process presented in the convergence curves of the functions and follows the same trend as the convergence curves of the functions and , as can be seen in Figure 4e–h. Here, most of the algorithms present stagnation in an accelerated way, although some of them manage to keep evolving downward.
The experiments performed above prove the superiority of the proposed HE-DEPSO algorithm in solving different optimization problems. The reasons why the HE-DEPSO algorithm obtains such superior performance can be summarized as follows:
- The adaptive hybrid mutation operator implemented in HE-DEPSO is based on the self-adaptive mutation strategy of the DEPSO algorithm, which has proven to be helpful in tackling several complex optimization problems. On the other hand, the collaborative work between the “DE/current-to-EHE/1” mutation strategy with historical information of the elite individuals and the PSO algorithm strategy generates a good balance between exploration and exploitation at different stages of the evolutionary process.
- The self-adaptive control of the F and parameters adopted from the SHADE algorithm allows the mitigation of parameter sensitivity. In this way, the crossover probability and the scale factor are dynamically adjusted during the evolutionary process at the level of each individual, which can make the proposed algorithm suitable for a wider variety of optimization problems.
6. Four-Zero Texture Model Validation
In order to verify the physical feasibility of the 4-zero texture model, it is essential to find sets of numerical values for the parameters , , , and that minimize the function to a value of less than one (see Equation (16)), and also that the numerical values for all predicted for the 4-zero texture model (evaluated in these sets of values) are in agreement with the experimental data. Firstly, an analysis of the HE-DEPSO algorithm’s behavior when optimizing the function will be conducted. The study will assess the algorithm’s optimization, convergence, and stability properties, providing insights into its performance when dealing with the optimization problem.
6.1. HE-DEPSO Performance in Optimization
The given optimization problem seeks to minimize the function given by Equation (17). The search space is constrained by the possible signs of the parameters and , as shown in Table 1. The phases and can take values between 0 and . The ranges of parameters and depend on the signs of and . Specifically considering case of study 1, can take values in the interval , while can take values in the interval .
6.1.1. Experiment Configuration
Through an experiment, an evaluation of the performance of the HE-DEPSO algorithm in the optimization of the function will be carried out in order to determine its ability to find the global minimum. This study will be carried out in the search space defined in case 1 previously mentioned. The performance of HE-DEPSO will be compared with the PSO and DE algorithms, as well as with advanced variants of the DE algorithm, such as CoDE, SHADE, and DEPSO. To ensure a fair comparison, standard parameters have been set for all algorithms ( and ) and 31 independent runs have been performed. The settings of the other parameters of each algorithm have been made following the indications in Table 3.
6.1.2. Experiment Results
To evaluate the effectiveness of the proposed HE-DEPSO algorithm, comparisons and analysis of its optimization results were performed with the DE, PSO, and three advanced variants of DE algorithms applied to the function. Using an approach similar to that described in Section 5, Table 6 presents the statistical data for each algorithm evaluated.
Table 6.
Comparison of results between HE-DEPSO, DE, PSO, and three advanced variants of the DE algorithm on the function .
According to the data presented in Table 6, the HE-DEPSO algorithm excels in obtaining the best results in optimizing the function, outperforming DEPSO. Although DEPSO comes close to the results of HE-DEPSO, its accuracy is not matched. On the other hand, the DE algorithm also demonstrated acceptable accuracy, although it was lower than that achieved by HE-DEPSO and DEPSO. In contrast, the SHADE, CoDE, and PSO algorithms obtained the lowest results compared to the others. In terms of average ranking, HE-DEPSO is positioned as the leader among all the analyzed algorithms. Furthermore, the results of the Wilcoxon test confirm the superiority of HE-DEPSO over DEPSO, SHADE, CoDE, DE, and PSO in the optimization of the function.
Figure 5 presents the curves obtained over 31 independent runs by the HE-DEPSO, DEPSO, SHADE, CoDE, DE, and PSO algorithms. It is observed that the HE-DEPSO algorithm exhibits excellent convergence behavior, consistently outperforming SHADE, CoDE, DE, and PSO and achieving a lower mean error value. Although DEPSO converges faster starting from the 300 iteration, the performance of HE-DEPSO stands out for its consistency and exploration capability, which could explain its more extended convergence compared to DEPSO.

Figure 5.
Convergence curves of the error measure in the solution for the function. The horizontal and vertical axis represent the iterations and the mean error values for the 31 independent iterations.
In Figure 6, box and whisker plots show the results of the HE-DEPSO, DEPSO, SHADE, CoDE, DE, and PSO algorithms, based on the best overall fits of 31 independent runs to the chi-square function. These graphs illustrate the distribution of these values into quartiles, with the median highlighted by a red horizontal line within a blue box. The box boundaries correspond to the upper (Q3) and lower (Q1) quartiles. Lines extending from the box indicate the maximum and minimum values, excluding outliers represented by the “+” symbol in blue. The green circles represent the mean of the overall best fits of the 31 independent runs.
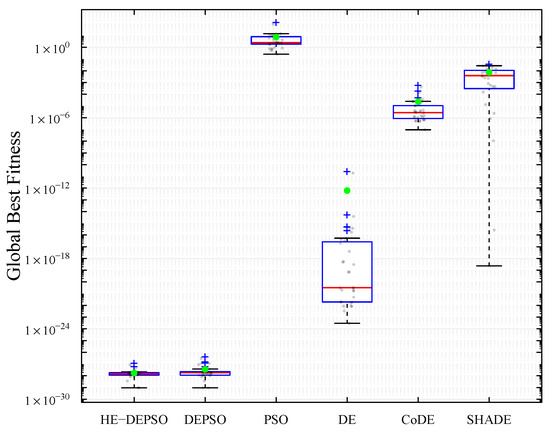
Figure 6.
Box and whisker plots of the best global fit values obtained by HE-DEPSO and the DEPSO, SHADE, CoDE, DE, and PSO algorithms in the 31 independent repetitions in the function. The horizontal axis shows the algorithms to be compared, and the vertical axis shows the global fit values.
According to the box and whisker plots, the HE-DEPSO algorithm demonstrated superior performance compared with the other evaluated algorithms regarding stability and solution quality, based on 31 independent runs. The distribution of the best global fitness values achieved by HE-DEPSO presents a higher concentration around a lower optimum, reflected in a lower average than the other algorithms. Consequently, the HE-DEPSO offers a more robust and stable performance.
6.2. Valid Regions for Parameters , and
In this subsection, we present the results obtained after applying the HE-DEPSO algorithm to search for valid regions of the , , , and parameters. This process was carried out using the most recent experimental values of the matrix elements, the quark masses, and the Jarlskog invariant (see Appendix A).
Figure 7 and Figure 8 present the allowed regions for the parameters , , , and , scaled as , and , respectively, in the first case study of Table 1. These regions are classified by the solutions found using the HE-DEPSO algorithm and are represented by black, blue, and orange dots, which correspond to different levels of precision of the function. The orange region, the smallest, indicates the region of highest precision, where experimental data agree best with theoretical predictions. These solutions were found by iteratively executing the algorithm until a total of 5000 solutions were collected at each of the precisions (, , and ).
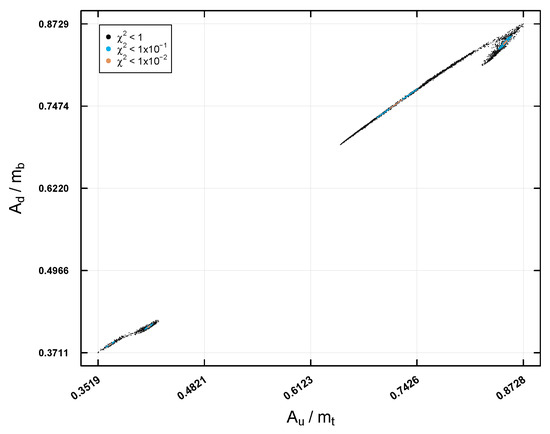
Figure 7.
Allowed regions for and constrained based on current experimental data with different levels of precision: (black dots), (blue dots), and (orange dots).
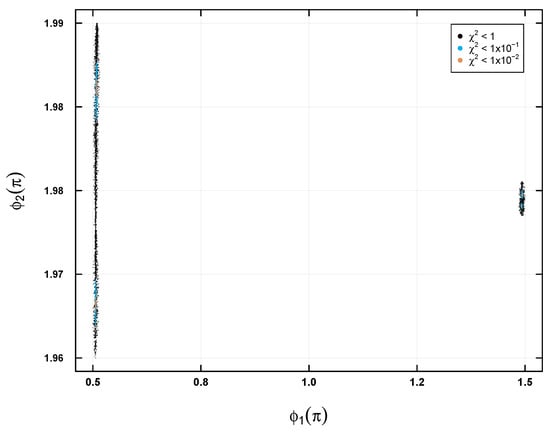
Figure 8.
Allowed regions for and constrained based on current experimental data with different levels of precision: (black dost), (blue dots), and (orange dots).
It is worth noting that, for the rest of the case studies (see Table 1), the found regions for the parameters , , , and were similar.
6.3. Predictions for the Elements
The second part of model validation is as follows: With the data obtained from the valid regions for the four free parameters of the 4-zero texture model, , , , and , found with the help of HE-DEPSO, we can evaluate the feasibility of the model according to the latest experimental values of the matrix and the Jarlskog invariant. This can be achieved by checking the model’s predictive power when predicting the remaining elements of the matrix that were not used within the fit, i.e., , , , , , and . Using Equations (2)–(5), the Chau–Keng parametrization [3], and the solutions found, we can calculate the numerical predictions for those elements. These predictions are then presented using scatter plots. Each graph includes the experimental central value of each element with its associated experimental error value. The points that fall within the region delimited by the experimental values are considered good predictions, while those outside the region are considered poor predictions.
In Figure 9, the predictions for the elements and in the first case study are presented. The black, blue, and orange points indicate a precision of , , and , respectively. For , the experimental central value is indicated with a solid red vertical line on the corresponding axis, while its experimental error () is shown with two red dashed vertical lines on either side of the central value. In the case of , the experimental central value is represented with a solid blue horizontal line on the axis, and its experimental error () is indicated with two blue dashed horizontal lines on either side of the central value. The predictions for the two elements show that the data with a precision of can be outside the experimental error region, suggesting a poor prediction. On the other hand, the predictions with and remain within this region, indicating accurate predictions. This pattern is repeated in the rest of the analyzed case studies.
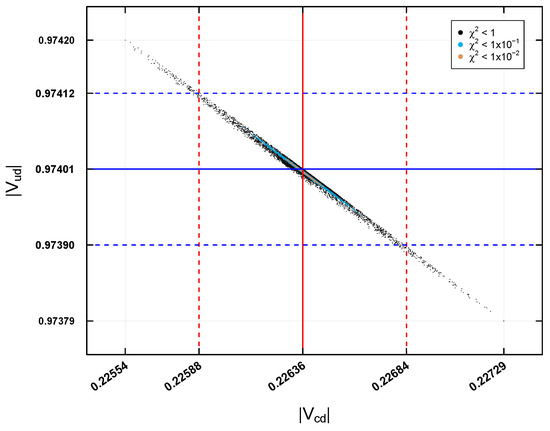
Figure 9.
Predictions for and for and .
The predictions for the elements and are shown in Figure 10 for the first case study. The experimental central value of is represented by a solid red vertical line at the center of the axis at , while its experimental error of is indicated by red dashed vertical lines on either side. The experimental central value of is shown by a solid blue horizontal line at the center of the axis at , and its experimental error of is represented by blue dashed horizontal lines on either side. According to the predictions shown in Figure 10, the data obtained with do not represent good predictions, as they are outside the experimental errors. On the other hand, the predictions with and remain within the error region, indicating that they are good predictions. This pattern is repeated in the four case studies.
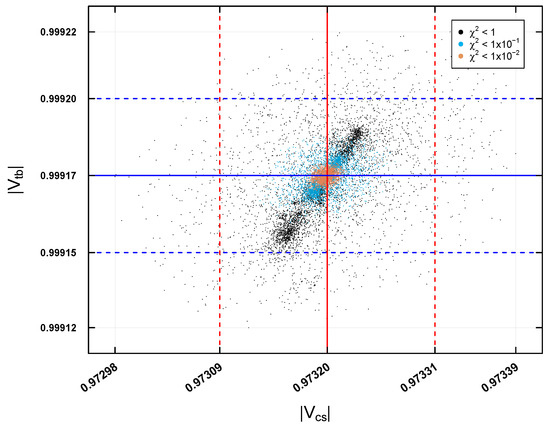
Figure 10.
Predictions for and for and .
Finally, in Figure 11, the predictions for the elements and are shown in the four case studies. For , the experimental central value is represented by a solid vertical line at , and its experimental error with two red dashed vertical lines at . For , the experimental central value is shown with a solid blue horizontal line at , and its experimental error with two blue dashed horizontal lines at . The predictions for these two elements indicate that the data obtained with precisions of and may be outside the experimental errors, so they are not good predictions. In contrast, the prediction with remains within the errors, being a good prediction. These characteristics are observed in the four case studies.
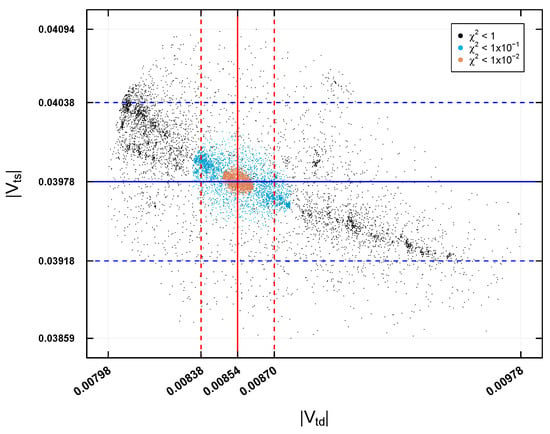
Figure 11.
Predictions for and for and .
When analyzing the predictions of the elements of the matrix (, , , , , and ), it was observed that only the solutions of the HE-DEPSO algorithm, with an accuracy of , fit within the limits of experimental error. These solutions are considered valid and capable of reproducing the matrix in all case studies and elements. Thus, it can be established that the 4-zero texture model is physically viable. It would be interesting, however, to explore the implications of this information obtained within the texture formalism.
7. Conclusions
This paper explored the feasibility of the 4-zero texture model using the most recent experimental values. To gather data that can inform decisions on the model’s viability, we employed a chi-square fit to compare the theoretical expressions of the model with the experimental values of well-measured physical observables. We developed a single-objective optimization model by defining a function to identify the allowed regions for the free parameters of the 4-zero texture model that are consistent with the experimental data. To address the challenge of optimizing the function within the chi-square fit, we proposed a new DEPSO algorithm variant, HE-DEPSO.
The proposed algorithm has demonstrated its ability to efficiently optimize different functions, particularly those from the CEC 2017 single-objective benchmark functions set. The convergence properties of HE-DEPSO show a good balance between solution precision and convergence speed in most cases. Regarding optimizing the function, our findings indicate that HE-DEPSO and DEPSO are more than adequate for solving the optimization problem, with HE-DEPSO providing the best solution quality and consistency. At the same time, DEPSO maintains a faster convergence rate. This part of the investigation also highlights the difficulty that some algorithms can face when optimizing the function, such as algorithms like SHADE and CoDE, despite exhibiting good performance on the CEC 2017 test set. We can also conclude that optimization algorithms such as SHADE, CoDE, and DE would be worth considering for optimization problems in high-energy physics. Finally, with the use of the HE-DEPSO algorithm we show that the 4-zero texture model is compatible with current experimental data, and thus we can affirm that this model is physically feasible. Importantly, our proposed approach, with the help of HE-DEPSO, allows a more accurate exploration of the full parameter space of the elements of the 4-zero texture quark mass matrix, an aspect that is often overlooked in analytical approaches. While aligning with the latest experimental data, this approach could enhance the structural features of 4-zero quark mass matrices. It may serve as a valuable starting point for future model building.
Future work will focus on enhancing the convergence speed of the HE-DEPSO algorithm and evaluating its effectiveness across diverse problem domains, exploring its ability to tackle more complex optimization challenges. An extended comparative analysis against other bio-inspired algorithms or other advanced DE variants could also be conducted. Furthermore, this research could be expanded by analyzing additional texture models like 2- and 5-zero texture models and determining their validity based on current experimental data. Additionally, the use of this method could have potential applications in any phenomenological fermion mass model SM extension, for example, nearest-neighbor textures [59], neutrino mass models [60], and discrete flavor symmetries models [14,15].
Author Contributions
Conceptualization, P.M.-R. and R.N.-P.; methodology, P.L.-E., P.M.-R. and R.N.-P.; software, E.M.-G.; validation, E.M.-G. and P.L.-E.; formal analysis, P.L.-E. and P.M.-R.; investigation, E.M.-G. and P.L.-E.; resources, P.M.-R. and P.L.-E.; writing—original draft preparation, E.M.-G., P.M.-R. and R.N.-P.; writing—review and editing, P.M.-R. and J.C.S.-T.-M.; visualization, P.M.-R. and J.C.S.-T.-M.; supervision, P.M.-R. and J.C.S.-T.-M.; funding acquisition, J.C.S.-T.-M. All authors have read and agreed to the published version of the manuscript.
Funding
This study was supported by the Autonomous University of Hidalgo (UAEH) and the National Council for Humanities, Science, and Technology (CONAHCYT) with project number F003-320109.
Data Availability Statement
The chi-Square function code is available on Github: https://github.com/EmX-Mtz/Chi-Square_Function, accessed on 5 August 2024.
Acknowledgments
The first author acknowledges the National Council for Humanities, Science, and Technology (CONAHCYT) for the financial support received in pursuing graduate studies, which has been essential for the completion of this research.
Conflicts of Interest
The authors declare no conflicts of interest.
Appendix A
In this work, the following experimental values for the elements of the , the Jarlskog invariant, and the masses of the quarks (at the scale of ) are considered [61]:
References
- Battaglia, M.; Buras, A.J.; Gambino, P.; Stocchi, A.; Abbaneo, D.; Ali, A.; Amaral, P.; Andreev, V.; Artuso, M.; Barberio, E.; et al. The CKM Matrix and the Unitarity Triangle. In Proceedings of the First Workshop on the CKM Unitarity Triangle, CERN, Geneva, Switzerland, 13–16 February 2002. [Google Scholar] [CrossRef]
- Fleischer, R. Flavor physics and CP violation. In Proceedings of the European School on High-Energy Physics, Tsakhkadzor, Armenia, 24 August–6 September 2003; pp. 81–150. [Google Scholar]
- Branco, G.C.; Lavoura, L.; Silva, J.P. CP Violation; Clarendon Press: Oxford, UK, 1999; Volume 103. [Google Scholar]
- Altarelli, G.; Feruglio, F. Neutrino masses and mixings: A theoretical perspective. Phys. Rept. 1999, 320, 295–318. [Google Scholar] [CrossRef][Green Version]
- Altarelli, G.; Feruglio, F. Models of neutrino masses and mixings. New J. Phys. 2004, 6, 106. [Google Scholar] [CrossRef]
- Fritzsch, H.; Xing, Z.Z. Mass and flavor mixing schemes of quarks and leptons. Prog. Part. Nucl. Phys. 2000, 45, 1–81. [Google Scholar] [CrossRef]
- Xing, Z.Z. Flavor structures of charged fermions and massive neutrinos. Phys. Rept. 2020, 854, 1–147. [Google Scholar] [CrossRef]
- Gupta, M.; Ahuja, G. Flavor mixings and textures of the fermion mass matrices. Int. J. Mod. Phys. A 2012, 27, 1230033. [Google Scholar] [CrossRef]
- Froggatt, C.D.; Nielsen, H.B. Hierarchy of Quark Masses, Cabibbo Angles and CP Violation. Nucl. Phys. B 1979, 147, 277–298. [Google Scholar] [CrossRef]
- King, S.F.; Luhn, C. Neutrino Mass and Mixing with Discrete Symmetry. Rept. Prog. Phys. 2013, 76, 056201. [Google Scholar] [CrossRef]
- Borzumati, F.; Nomura, Y. Low scale seesaw mechanisms for light neutrinos. Phys. Rev. D 2001, 64, 053005. [Google Scholar] [CrossRef]
- Lindner, M.; Ohlsson, T.; Seidl, G. Seesaw mechanisms for Dirac and Majorana neutrino masses. Phys. Rev. D 2002, 65, 053014. [Google Scholar] [CrossRef]
- Flieger, W.; Gluza, J. General neutrino mass spectrum and mixing properties in seesaw mechanisms. Chin. Phys. C 2021, 45, 023106. [Google Scholar] [CrossRef]
- Aranda, A.; Bonilla, C.; Rojas, A.D. Neutrino masses generation in a Z4 model. Phys. Rev. D 2012, 85, 036004. [Google Scholar] [CrossRef]
- Ahn, Y.H.; Kang, S.K. Non-zero θ13 and CP violation in a model with A4 flavor symmetry. Phys. Rev. D 2012, 86, 093003. [Google Scholar] [CrossRef]
- Sinha, R.; Samanta, R.; Ghosal, A. Maximal Zero Textures in Linear and Inverse Seesaw. Phys. Lett. B 2016, 759, 206–213. [Google Scholar] [CrossRef][Green Version]
- Fritzsch, H. Calculating the Cabibbo angle. Phys. Lett. B 1977, 70, 436–440. [Google Scholar] [CrossRef]
- Fritzsch, H.; Xing, Z.Z. Four zero texture of Hermitian quark mass matrices and current experimental tests. Phys. Lett. B 2003, 555, 63–70. [Google Scholar] [CrossRef]
- Kang, K.; Kang, S.K. New class of quark mass matrix and calculability of the flavor mixing matrix. Phys. Rev. D 1997, 56, 1511–1514. [Google Scholar] [CrossRef]
- Xing, Z.-Z.; Zhao, Z.-H. On the four-zero texture of quark mass matrices and its stability. Nucl. Phys. B 2015, 897, 302–325. [Google Scholar] [CrossRef]
- Gómez-Ávila, S.; López-Lozano, L.; Miranda-Romagnoli, P.; Noriega-Papaqui, R.; Lagos-Eulogio, P. 2-zeroes texture and the Universal Texture Constraint. arXiv 2021, arXiv:2105.01554. [Google Scholar]
- Tani, L.; Rand, D.; Veelken, C.; Kadastik, M. Evolutionary algorithms for hyperparameter optimization in machine learning for application in high energy physics. Eur. Phys. J. C 2021, 81, 170. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhou, D. Application of differential evolution algorithm in future collider optimization. In Proceedings of the 7th International Particle Accelerator Conference (IPAC’16), Busan, Republic of Korea, 8–13 May 2016; pp. 1025–1027. [Google Scholar]
- Wu, J.; Zhang, Y.; Qin, Q.; Wang, Y.; Yu, C.; Zhou, D. Dynamic aperture optimization with diffusion map analysis at CEPC using differential evolution algorithm. Nucl. Instruments Methods Phys. Res. Sect. A Accel. Spectrometers Detect. Assoc. Equip. 2020, 959, 163517. [Google Scholar] [CrossRef]
- Allanach, B.C.; Grellscheid, D.; Quevedo, F. Genetic algorithms and experimental discrimination of SUSY models. J. High Energy Phys. 2004, 2004, 069. [Google Scholar] [CrossRef]
- Bilal; Pant, M.; Zaheer, H.; Garcia-Hernandez, L.; Abraham, A. Differential Evolution: A review of more than two decades of research. Eng. Appl. Artif. Intell. 2020, 90, 103479. [Google Scholar] [CrossRef]
- Ahmad, M.F.; Isa, N.A.M.; Lim, W.H.; Ang, K.M. Differential evolution: A recent review based on state-of-the-art works. Alex. Eng. J. 2022, 61, 3831–3872. [Google Scholar] [CrossRef]
- Pan, J.S.; Liu, N.; Chu, S.C. A Hybrid Differential Evolution Algorithm and Its Application in Unmanned Combat Aerial Vehicle Path Planning. IEEE Access 2020, 8, 17691–17712. [Google Scholar] [CrossRef]
- Opara, K.R.; Arabas, J. Differential Evolution: A survey of theoretical analyses. Swarm Evol. Comput. 2019, 44, 546–558. [Google Scholar] [CrossRef]
- Wang, Y.; Cai, Z.; Zhang, Q. Differential Evolution With Composite Trial Vector Generation Strategies and Control Parameters. IEEE Trans. Evol. Comput. 2011, 15, 55–66. [Google Scholar] [CrossRef]
- Peñuñuri, F.; Cab, C.; Carvente, O.; Zambrano-Arjona, M.; Tapia, J. A study of the Classical Differential Evolution control parameters. Swarm Evol. Comput. 2016, 26, 86–96. [Google Scholar] [CrossRef]
- Tanabe, R.; Fukunaga, A. Success-history based parameter adaptation for Differential Evolution. In Proceedings of the 2013 IEEE Congress on Evolutionary Computation, Cancun, Mexico, 20–23 June 2013; pp. 71–78. [Google Scholar] [CrossRef]
- Qin, A.K.; Huang, V.L.; Suganthan, P.N. Differential Evolution Algorithm with Strategy Adaptation for Global Numerical Optimization. IEEE Trans. Evol. Comput. 2009, 13, 398–417. [Google Scholar] [CrossRef]
- Das, S.; Abraham, A.; Chakraborty, U.K.; Konar, A. Differential Evolution Using a Neighborhood-Based Mutation Operator. IEEE Trans. Evol. Comput. 2009, 13, 526–553. [Google Scholar] [CrossRef]
- Rahnamayan, S.; Tizhoosh, H.R.; Salama, M.M. Opposition-based differential evolution. IEEE Trans. Evol. Comput. 2008, 12, 64–79. [Google Scholar] [CrossRef]
- Zhang, J.; Sanderson, A. JADE: Adaptive Differential Evolution with Optional External Archive. Evol. Comput. IEEE Trans. 2009, 13, 945–958. [Google Scholar] [CrossRef]
- Chakraborty, S.; Saha, A.K.; Sharma, S.; Sahoo, S.K.; Pal, G. Comparative Performance Analysis of Differential Evolution Variants on Engineering Design Problems. J. Bionic Eng. 2022, 19, 1140–1160. [Google Scholar] [CrossRef] [PubMed]
- Lagos-Eulogio, P.; Miranda-Romagnoli, P.; Seck-Tuoh-Mora, J.C.; Hernández-Romero, N. Improvement in Sizing Constrained Analog IC via Ts-CPD Algorithm. Computation 2023, 11, 230. [Google Scholar] [CrossRef]
- Wang, S.; Li, Y.; Yang, H. Self-adaptive mutation differential evolution algorithm based on particle swarm optimization. Appl. Soft Comput. 2019, 81, 105496. [Google Scholar] [CrossRef]
- Novaes, S.F. Standard model: An Introduction. In Proceedings of the 10th Jorge Andre Swieca Summer School: Particle and Fields, São Paulo, Brazil, 6–12 February 1999; pp. 5–102. [Google Scholar]
- Langacker, P. Introduction to the Standard Model and Electroweak Physics. In Proceedings of the Theoretical Advanced Study Institute in Elementary Particle Physics: The Dawn of the LHC Era, Boulder, CO, USA, 1 January 2010; pp. 3–48. [Google Scholar] [CrossRef]
- Isidori, G.; Nir, Y.; Perez, G. Flavor Physics Constraints for Physics Beyond the Standard Model. Ann. Rev. Nucl. Part. Sci. 2010, 60, 355. [Google Scholar] [CrossRef]
- Antonelli, M.; Asner, D.M.; Bauer, D.; Becher, T.; Beneke, M.; Bevan, A.J.; Blanke, M.; Bloise, C.; Bona, M.; Bondar, A.; et al. Flavor Physics in the Quark Sector. Phys. Rept. 2010, 494, 197–414. [Google Scholar] [CrossRef]
- Eidelman, S. Review of particle physics. Particle Data Group. Phys. Lett. B 2004, 592, 1. [Google Scholar] [CrossRef]
- Félix-Beltrán, O.; González-Canales, F.; Hernández-Sánchez, J.; Moretti, S.; Noriega-Papaqui, R.; Rosado, A. Analysis of the quark sector in the 2HDM with a four-zero Yukawa texture using the most recent data on the CKM matrix. Phys. Lett. B 2015, 742, 347–352. [Google Scholar] [CrossRef]
- Barranco, J.; Delepine, D.; Lopez-Lozano, L. Neutrino mass determination from a four-zero texture mass matrix. Phys. Rev. D 2012, 86, 053012. [Google Scholar] [CrossRef]
- Eberhart, R.C.; Kennedy, J. A new optimizer using particle swarm theory. In Proceedings of the MHS’95, Proceedings of the Sixth International Symposium on Micro Machine and Human Science, Nagoya, Japan, 4–6 October 1995; pp. 39–43. [Google Scholar]
- Shi, Y.; Eberhart, R. A modified particle swarm optimizer. In Proceedings of the 1998 IEEE International Conference on Evolutionary Computation Proceedings, IEEE World Congress on Computational Intelligence (Cat. No. 98TH8360), Anchorage, Alaska, 4–9 May 1998; pp. 69–73. [Google Scholar] [CrossRef]
- Storn, R.; Price, K. Differential Evolution: A Simple and Efficient Adaptive Scheme for Global Optimization Over Continuous Spaces. J. Glob. Optim. 1995, 23. Available online: https://cse.engineering.nyu.edu/~mleung/CS909/s04/Storn95-012.pdf (accessed on 1 July 2024).
- Storn, R.; Price, K. Differential Evolution—A Simple and Efficient Heuristic for Global Optimization over Continuous Spaces. J. Glob. Optim. 1997, 11, 341–359. [Google Scholar] [CrossRef]
- Sánchez Vargas, O.; De León Aldaco, S.E.; Aguayo Alquicira, J.; Vela Valdés, L.G.; Mina Antonio, J.D. Differential Evolution Applied to a Multilevel Inverter—A Case Study. Appl. Sci. 2022, 12, 9910. [Google Scholar] [CrossRef]
- Batool, R.; Bibi, N.; Muhammad, N.; Alhazmi, S. Detection of Primary User Emulation Attack Using the Differential Evolution Algorithm in Cognitive Radio Networks. Appl. Sci. 2023, 13, 571. [Google Scholar] [CrossRef]
- Elsayed, S.M.; Sarker, R.A.; Ray, T. Differential evolution with automatic parameter configuration for solving the CEC2013 competition on Real-Parameter Optimization. In Proceedings of the 2013 IEEE Congress on Evolutionary Computation, Cancun, Mexico, 20–23 June 2013; pp. 1932–1937. [Google Scholar] [CrossRef]
- Zhong, X.; Cheng, P. An elite-guided hierarchical differential evolution algorithm. Appl. Intell. 2021, 51, 4962–4983. [Google Scholar] [CrossRef]
- Yang, Q.; Guo, X.; Gao, X.D.; Xu, D.D.; Lu, Z.Y. Differential Elite Learning Particle Swarm Optimization for Global Numerical Optimization. Mathematics 2022, 10, 1261. [Google Scholar] [CrossRef]
- Huang, Y.; Yu, Y.; Guo, J.; Wu, Y. Self-adaptive Artificial Bee Colony with a Candidate Strategy Pool. Appl. Sci. 2023, 13, 10445. [Google Scholar] [CrossRef]
- Wang, S.; Li, Y.; Yang, H.; Liu, H. Self-adaptive differential evolution algorithm with improved mutation strategy. Soft Comput. 2017, 22, 3433–3447. [Google Scholar] [CrossRef]
- Kumar, A.; Price, K.V.; Mohamed, A.W.; Hadi, A.A.; Suganthan, P.N. Problem Definitions and Evaluation Criteria for the CEC 2017 Special Session and Competition on Single Objective Bound Constrained Numerical Optimization; Technical Report; Nanyang Technological University: Singapore, 2016; pp. 1–34. [Google Scholar]
- Branco, G.C.; Emmanuel-Costa, D.; Simoes, C. Nearest-Neighbour Interaction from an Abelian Symmetry and Deviations from Hermiticity. Phys. Lett. B 2010, 690, 62–67. [Google Scholar] [CrossRef]
- Centelles Chuliá, S.; Herrero-Brocal, A.; Vicente, A. The Type-I Seesaw family. J. High Energy Phys. 2024, 2024, 60. [Google Scholar] [CrossRef]
- Fritzsch, H.; Xing, Z.Z.; Zhang, D. Correlations between quark mass and flavor mixing hierarchies. Nucl. Phys. B 2022, 974, 115634. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).