
Efficient Implementation of Multilayer Perceptrons: Reducing Execution Time and Memory Consumption

 ,
,  , , and
, , and 
Abstract
1. Introduction
2. Materials and Methods
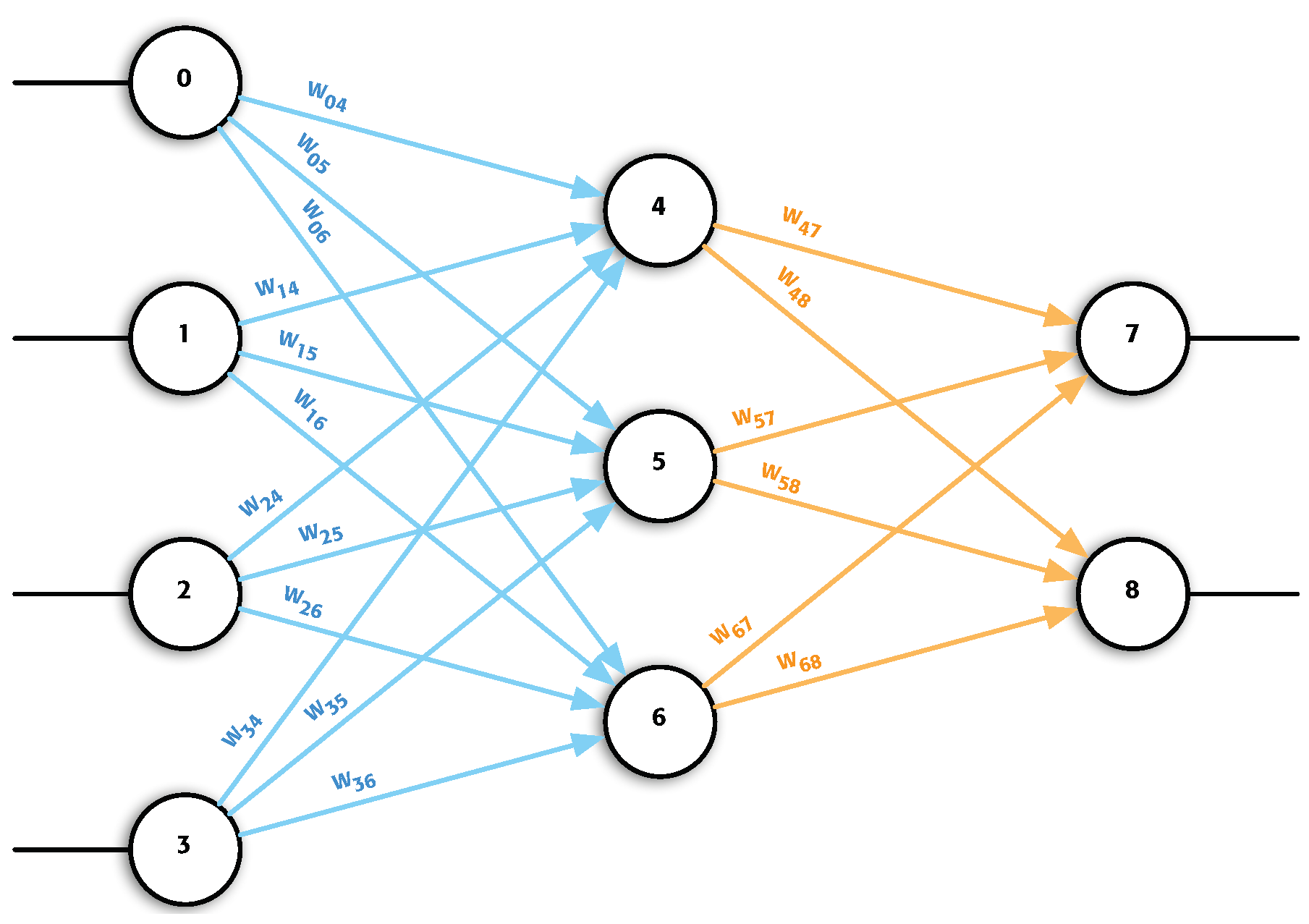
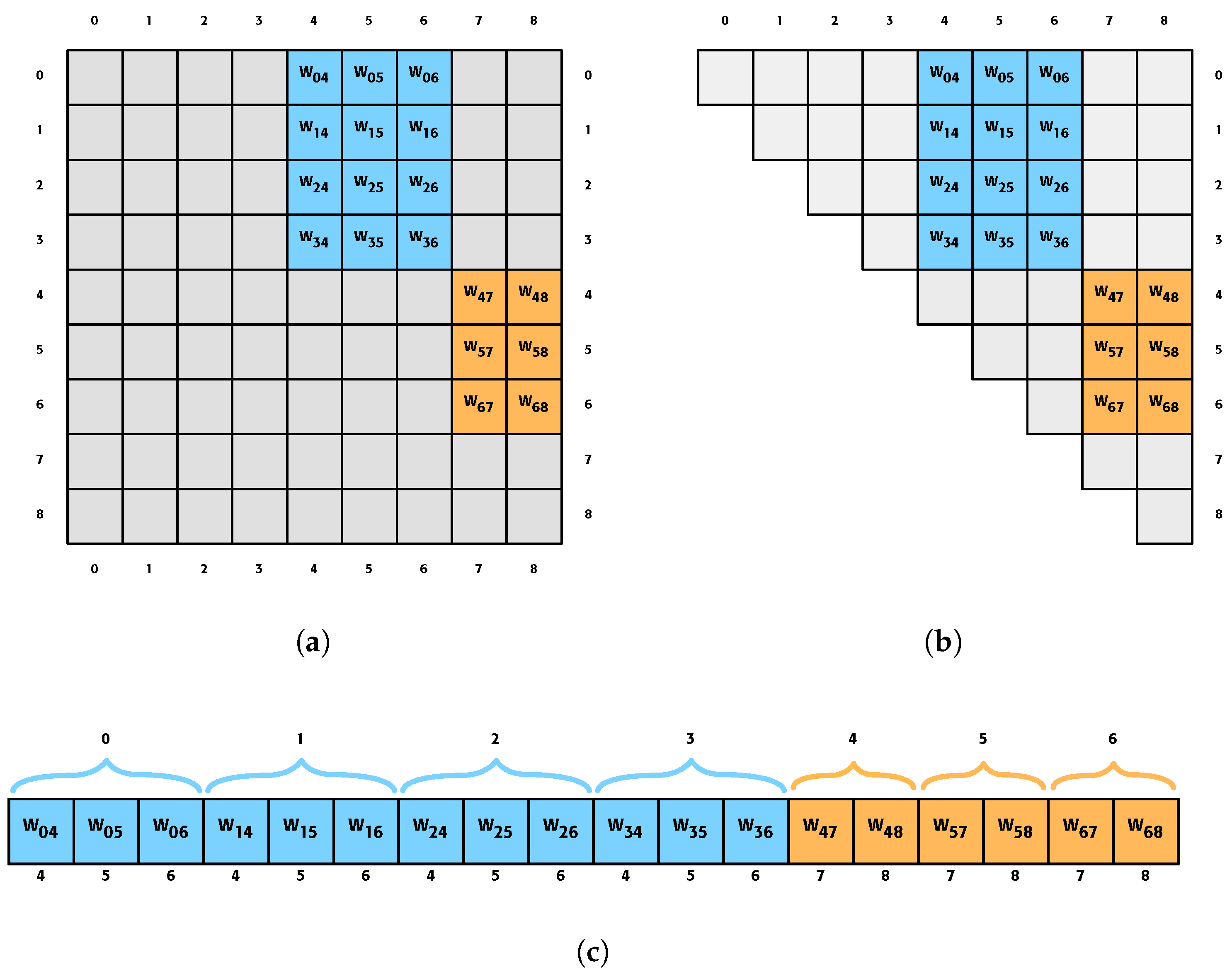
2.1. Proposed Approach
2.2. Implementation
2.2.1. Required Variables
- num_layer: Number of layers in the network (including input, output and hidden layers).
- num_neurons: Number of neurons in the network.
- Layer (array): The i position indicates the number of processing elements in the i layer.
- Position (array): This indicates which layer the processing element i belongs to.
- Index (array): This indicates the position that the processing element occupies within the layer.
- num_weights: Number of weights that the network has.
- Weight (array): Value of the network connections.
- Stride (array): The i position indicates where the outgoing weights of the i neuron start.
2.2.2. Length of Arrays
- Layer: The size of this array is given by the value of num_layer, that is, the number of layers.
- Index and position: The size of this array is given by the value of num_neurons, that is, the number of neurons in the network.
- Stride: The size of this array is given by the number of neurons that have outgoing connections, i.e., all the neurons except the output layer.
- Weight: The size of this array is determined by the number of outgoing connections that can exist, which is determined by the num_weight variable:
2.2.3. Pseudocode
| Listing 1. Pseudocode of the proposed solution. |
| POSITION = getArrayInt (NUM_NEURONS); INDEX = getArrayInt (NUM_NEURONS); for (l = i = 0; i < NUM_LAYERS; i++) { for (j = 0; j < LAYER[i]; j++, l++) { POSITION[l] = i; INDEX[l] = j; } } TMP = NUM_NEURONS − LAYER[NUM_LAYERS − 1]; STRIDE = getArrayInt (TMP); STRIDE[0] = 0; for (i = 1; i < TMP; i++) { STRIDE[i] = STRIDE[i − 1] + LAYER[POSITION[i − 1] + 1]; } NUM_WEIGHTS = 0; for (i = 0; i < NUM_LAYERS − 1; i++) { NUM_WEIGHT += LAYER[i] ∗ LAYER[i + 1]; } |
| Listing 2. Pseudocode to obtain the output network. |
| first_pe = in_pe = 0; for (l = 1; l < NUM_LAYERS; l++) { first_pe += LAYER[l − 1]; for (in = 0; in < LAYER[l − 1]; in++, in_pe++) { pe = first_pe; for (out = 0; out < LAYER[l]; out++, pe++) { NET[pe] += NET[pe] ∗ WEIGHT[out+STRIDE[in_pe]]; } } for (tmp = first_pe; tmp < pe; tmp++) { NET[tmp] = ACTIVATION[tmp](NET[TMP]); } } |
3. Results
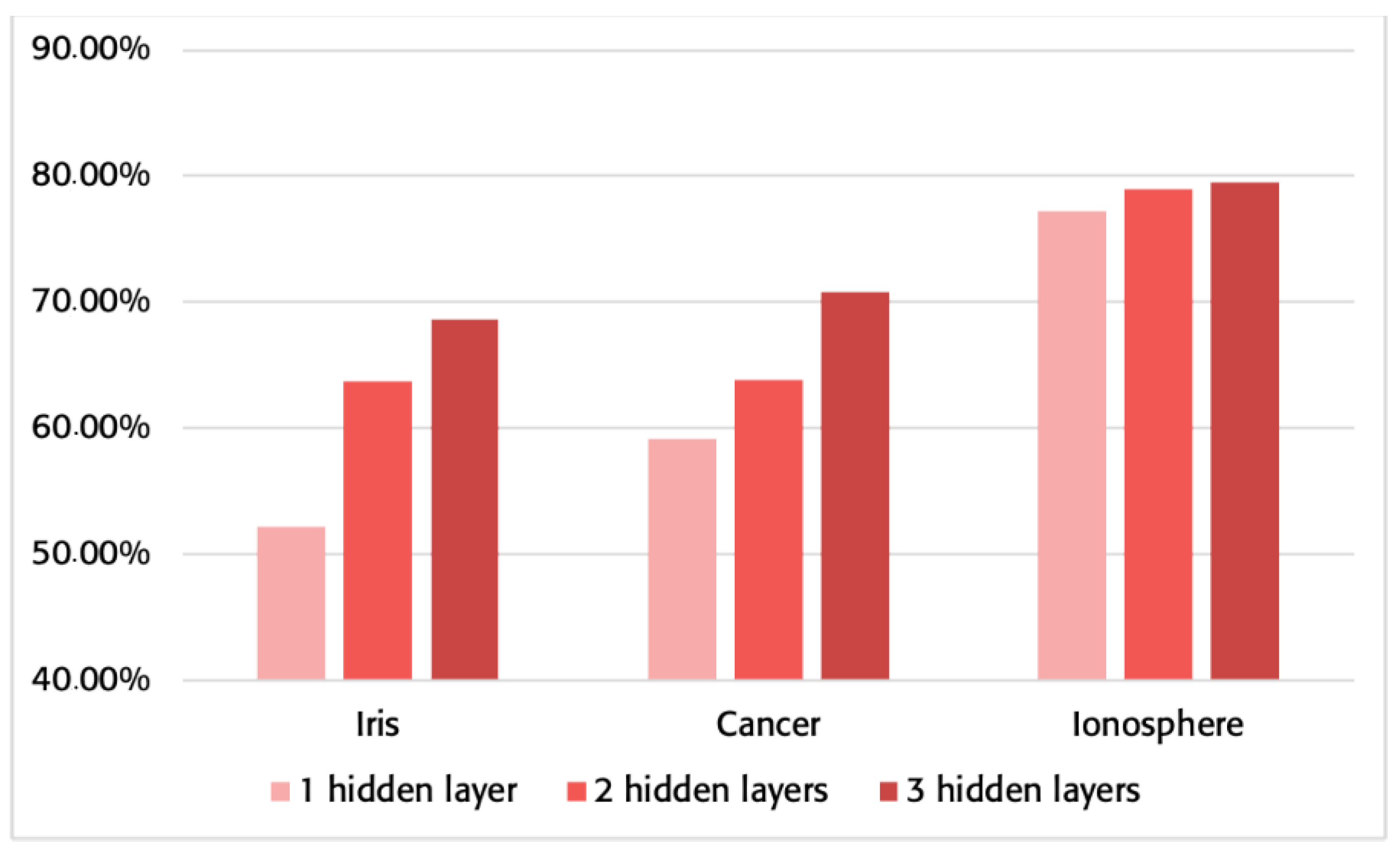
3.1. Memory Consumption
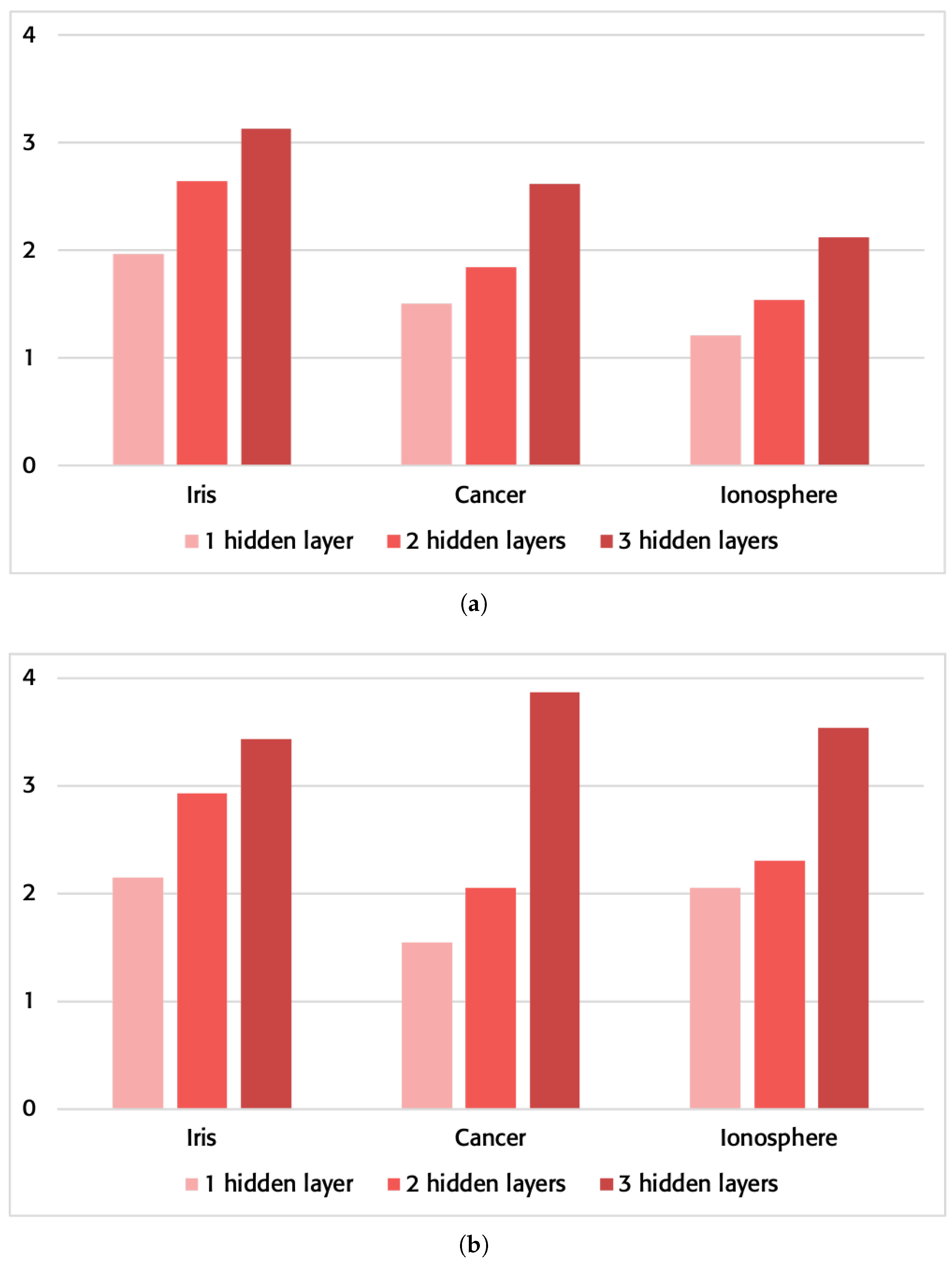
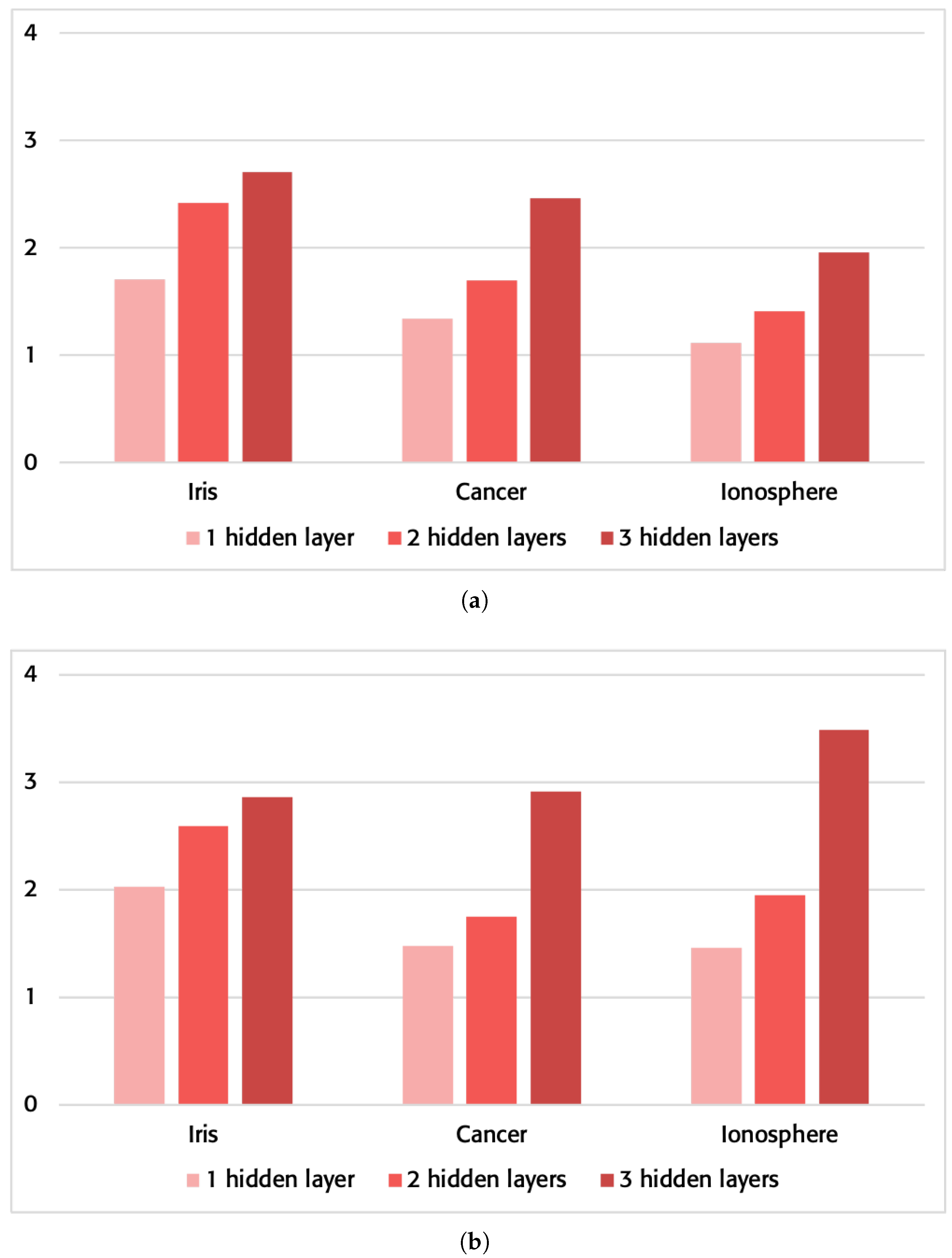
3.2. Operation Time
3.2.1. Personal Computer
3.2.2. Computer Server
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| ANN | Artificial neural network |
| MLP | Multilayer perceptron |
| PEs | Process elements |
References
- Misra, J.; Saha, I. Artificial neural networks in hardware: A survey of two decades of progress. Neurocomputing 2010, 74, 239–255. [Google Scholar] [CrossRef]
- Abiodun, O.I.; Jantan, A.; Omolara, A.E.; Dada, K.V.; Mohamed, N.A.; Arshad, H. State-of-the-art in artificial neural network applications: A survey. Heliyon 2018, 4, e00938. [Google Scholar] [CrossRef] [PubMed]
- Gardner, M.W.; Dorling, S. Artificial neural networks (the multilayer perceptron)—A review of applications in the atmospheric sciences. Atmos. Environ. 1998, 32, 2627–2636. [Google Scholar] [CrossRef]
- Hecht-Nielsen, R. Theory of the backpropagation neural network. In Neural Networks for Perception; Elsevier: Amsterdam, The Netherlands, 1992; pp. 65–93. [Google Scholar]
- Popescu, M.C.; Balas, V.E.; Perescu-Popescu, L.; Mastorakis, N. Multilayer perceptron and neural networks. WSEAS Trans. Circuits Syst. 2009, 8, 579–588. [Google Scholar]
- Yan, D.; Wu, T.; Liu, Y.; Gao, Y. An efficient sparse-dense matrix multiplication on a multicore system. In Proceedings of the 2017 IEEE 17th International Conference on Communication Technology (ICCT), Chengdu, China, 27–30 October 2017; pp. 1880–1883. [Google Scholar]
- Amdahl, G.M. Computer architecture and amdahl’s law. Computer 2013, 46, 38–46. [Google Scholar] [CrossRef]
- Brunel, N.; Hakim, V.; Isope, P.; Nadal, J.P.; Barbour, B. Optimal information storage and the distribution of synaptic weights: Perceptron versus Purkinje cell. Neuron 2004, 43, 745–757. [Google Scholar] [PubMed]
- Nishtala, R.; Vuduc, R.W.; Demmel, J.W.; Yelick, K.A. When cache blocking of sparse matrix vector multiply works and why. Appl. Algebra Eng. Commun. Comput. 2007, 18, 297–311. [Google Scholar] [CrossRef]
- Blanco Heras, D.; Blanco Pérez, V.; Carlos Cabaleiro Domínguez, J.; Fernández Rivera, F. Modeling and improving locality for irregular problems: Sparse matrix-Vector product on cache memories as a case study. In Proceedings of the High-Performance Computing and Networking; Sloot, P., Bubak, M., Hoekstra, A., Hertzberger, B., Eds.; Springer: Berlin/Heidelberg, Germany, 1999; pp. 201–210. [Google Scholar]
- Buluc, A.; Gilbert, J.R. Challenges and advances in parallel sparse matrix-matrix multiplication. In Proceedings of the 2008 37th International Conference on Parallel Processing, Portland, OR, USA, 9–12 September 2008; pp. 503–510. [Google Scholar]
- Vincent, K.; Tauskela, J.; Thivierge, J.P. Extracting functionally feedforward networks from a population of spiking neurons. Front. Comput. Neurosci. 2012, 6, 86. [Google Scholar] [CrossRef] [PubMed]
- Bilski, J.; Rutkowski, L. Numerically robust learning algorithms for feed forward neural networks. In Neural Networks and Soft Computing; Springer: Zakopane, Poland, 2003; pp. 149–154. [Google Scholar]
- Caruana, R.; Niculescu-Mizil, A. Data Mining in Metric Space: An Empirical Analysis of Supervised Learning Performance Criteria. In Proceedings of the KDD’04: 10th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 22–25 August 2004; pp. 69–78. [Google Scholar] [CrossRef]
- Fisher, R. UCI Machine Learning Repository Iris Data Set. 1936. Available online: https://archive.ics.uci.edu/ml/datasets/Iris (accessed on 19 January 2022).
- Zwitter, M.; Soklic, M. UCI Machine Learning Repository Breast Cancer Data Set. 1988. Available online: https://archive.ics.uci.edu/ml/datasets/breast+cancer (accessed on 19 January 2022).
- Sigillito, V. UCI Machine Learning Repository Ionosphere Data Set. 1989. Available online: https://archive.ics.uci.edu/ml/datasets/Ionosphere (accessed on 19 January 2022).
- Porto-Pazos, A.B.; Veiguela, N.; Mesejo, P.; Navarrete, M.; Alvarellos, A.; Ibáñez, O.; Pazos, A.; Araque, A. Artificial astrocytes improve neural network performance. PLoS ONE 2011, 6, e19109. [Google Scholar] [CrossRef] [PubMed]
- Haneda, M.; Knijnenburg, P.M.W.; Wijshoff, H.A.G. Optimizing general purpose compiler optimization. In Proceedings of the CF’05: 2ND Conference on Computing Frontiers, New York, NY, USA, 4–6 May 2005. [Google Scholar] [CrossRef]
- Dong, S.; Olivo, O.; Zhang, L.; Khurshid, S. Studying the influence of standard compiler optimizations on symbolic execution. In Proceedings of the 2015 IEEE 26th International Symposium on Software Reliability Engineering (ISSRE), Washington, DC, USA, 2–5 November 2015. [Google Scholar] [CrossRef]
- Intel Core i5 7360U Processor 4M Cache up to 3.60 Ghz Product Specifications. Available online: https://ark.intel.com/content/www/us/en/ark/products/97535/intel-core-i57360u-processor-4m-cache-up-to-3-60-ghz.html (accessed on 23 January 2022).
- CESGA—Centro de Supercomputación de Galicia. Available online: https://www.cesga.es/ (accessed on 19 January 2022).
- Intel Xeon Processor E5 2680 v3 30 M Cache 2.50 Ghz Product Specifications. Available online: https://ark.intel.com/content/www/us/en/ark/products/81908/intel-xeon-processor-e52680-v3-30m-cache-2-50-ghz.html (accessed on 23 January 2022).
- Tan, S.Z.K.; Du, R.; Perucho, J.A.U.; Chopra, S.S.; Vardhanabhuti, V.; Lim, L.W. Dropout in Neural Networks Simulates the Paradoxical Effects of Deep Brain Stimulation on Memory. Front. Aging Neurosci. 2020, 12, 273. [Google Scholar] [CrossRef] [PubMed]
- Madakam, S.; Ramaswamy, R.; Tripathi, S. Internet of Things (IoT): A Literature Review. J. Comput. Commun. 2015, 3, 164–173. [Google Scholar] [CrossRef]
- Raman Kumar, S.P. Applications in Ubiquitous Computing; Springer: Cham, Switzerland, 2021. [Google Scholar]
- Arduino Board Mega 2560. Available online: https://www.arduino.cc/en/Main/ArduinoBoardMega2560 (accessed on 23 January 2022).


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Approach | Cells | Saving |
|---|---|---|
| Matrix | 81 | - |
| Superior triangular matrix | 45 | 44.4% |
| Proposed approach | 18 | 77.7% |
| Dataset | One Hidden Layer | Two Hidden Layers | Three Hidden Layers |
|---|---|---|---|
| Iris | 4, 5, 3 | 4, 5, 7, 3 | 4, 4, 5, 5, 3 |
| Cancer | 9, 7, 1 | 9, 7, 3, 1 | 9, 12, 8, 4, 1 |
| Ionosphere | 34, 9, 1 | 34, 9, 4, 1 | 34, 12, 8, 4, 1 |
| Dataset | Network Topology | Traditional Approach | Proposed Approach | Memory Saving |
|---|---|---|---|---|
| Iris | 4, 5, 3 | 644 B | 308 B | 52.17% |
| 4, 5, 7, 3 | 1544 B | 560 B | 63.73% | |
| 4, 4, 5, 5, 3 | 1876 B | 588 B | 68.66% | |
| Cancer | 9, 7, 1 | 1244 B | 508 B | 59.16% |
| 9, 7, 3, 1 | 1704 B | 616 B | 63.85% | |
| 9, 12, 8, 4, 1 | 4788 B | 1400 B | 70.76% | |
| Ionosphere | 34, 9, 1 | 7940 B | 1812 B | 77.18% |
| 34, 9, 4, 1 | 9432 B | 1988 B | 78.92% | |
| 34, 12, 8, 4, 1 | 14188 B | 2900 B | 79.56% |
| No Optimization Flags | Using Optimization Flags | ||||||
|---|---|---|---|---|---|---|---|
|
Network Topology |
Traditional Approach |
Proposed Approach | Speed Up |
Traditional Approach |
Proposed Approach | Speed Up | |
| Iris | 4, 5, 3 | 0.4108 s | 0.2084 s | 1.9712x | 0.1295 s | 0.0604 s | 2.1440x ↑ |
| 4, 5, 7, 3 | 1.1077 s | 0.4185 s | 2.6468x | 0.3152 s | 0.1075 s | 2.9320x ↑ | |
| 4, 4, 5, 5, 3 | 1.3989 s | 0.4470 s | 3.1295x | 0.3942 s | 0.1147 s | 3.4367x ↑ | |
| Cancer | 9, 7, 1 | 0.5568 s | 0.3690 s | 1.5089x | 0.1459 s | 0.0942 s | 1.5488x ↑ |
| 9, 7, 3, 1 | 0.8677 s | 0.4695 s | 1.8481x | 0.2295 s | 0.1117 s | 2.0546x ↑ | |
| 9, 12, 8, 4, 1 | 2.9614 s | 1.1292 s | 2.6225x | 0.8527 s | 0.2204 s | 3.8688x ↑ | |
| Iono… | 34, 9, 1 | 1.6810 s | 1.3907 s | 1.2087x | 0.5276 s | 0.2569 s | 2.0537x ↑ |
| 34, 9, 4, 1 | 2.3799 s | 1.5479 s | 1.5375x | 0.6511 s | 0.2823 s | 2.3064x ↑ | |
| 34, 12, 8, 4, 1 | 4.9259 s | 2.3174 s | 2.1256x | 1.4572 s | 0.4120 s | 3.5368x ↑ | |
| No Optimization Flags | Using Optimization Flags | ||||||
|---|---|---|---|---|---|---|---|
|
Network Topology |
Traditional Approach |
Proposed Approach | Speed Up |
Traditional Approach |
Proposed Approach | Speed Up | |
| Iris | 4, 5, 3 | 0.3791 s | 0.2221 s | 1.7068x | 0.1301 s | 0.0641 s | 2.0296x ↑ |
| 4, 5, 7, 3 | 1.0686 s | 0.4412 s | 2.4220x | 0.3036 s | 0.1171 s | 2.5926x ↑ | |
| 4, 4, 5, 5, 3 | 1.2403 s | 0.4587 s | 2.7039x | 0.3659 s | 0.1280 s | 2.8585x ↑ | |
| Cancer | 9, 7, 1 | 0.5180 s | 0.3852 s | 1.3447x | 0.1389 s | 0.0941 s | 1.4760x ↑ |
| 9, 7, 3, 1 | 0.8367 s | 0.4926 s | 1.6985x | 0.2103 s | 0.1203 s | 1.7481x ↑ | |
| 9, 12, 8, 4, 1 | 2.9419 s | 1.1932 s | 2.4655x | 0.7555 s | 0.2593 s | 2.9136x ↑ | |
| Iono… | 34, 9, 1 | 1.6926 s | 1.5160 s | 1.1164x | 0.3911 s | 0.2678 s | 1.4604x ↑ |
| 34, 9, 4, 1 | 2.3677 s | 1.6797 s | 1.4095x | 0.5905 s | 0.3029 s | 1.9494x ↑ | |
| 34, 12, 8, 4, 1 | 4.9747 s | 2.5451 s | 1.9546x | 1.6443 s | 0.4714 s | 3.4881x ↑ | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cedron, F.; Alvarez-Gonzalez, S.; Ribas-Rodriguez, A.; Rodriguez-Yañez, S.; Porto-Pazos, A.B. Efficient Implementation of Multilayer Perceptrons: Reducing Execution Time and Memory Consumption. Appl. Sci. 2024, 14, 8020. https://doi.org/10.3390/app14178020
Cedron F, Alvarez-Gonzalez S, Ribas-Rodriguez A, Rodriguez-Yañez S, Porto-Pazos AB. Efficient Implementation of Multilayer Perceptrons: Reducing Execution Time and Memory Consumption. Applied Sciences. 2024; 14(17):8020. https://doi.org/10.3390/app14178020
Chicago/Turabian StyleCedron, Francisco, Sara Alvarez-Gonzalez, Ana Ribas-Rodriguez, Santiago Rodriguez-Yañez, and Ana Belen Porto-Pazos. 2024. "Efficient Implementation of Multilayer Perceptrons: Reducing Execution Time and Memory Consumption" Applied Sciences 14, no. 17: 8020. https://doi.org/10.3390/app14178020
APA StyleCedron, F., Alvarez-Gonzalez, S., Ribas-Rodriguez, A., Rodriguez-Yañez, S., & Porto-Pazos, A. B. (2024). Efficient Implementation of Multilayer Perceptrons: Reducing Execution Time and Memory Consumption. Applied Sciences, 14(17), 8020. https://doi.org/10.3390/app14178020