
Multitask Learning-Based Affective Prediction for Videos of Films and TV Scenes


Abstract
1. Introduction
- A modified multitask learning model with gating network architecture (multi-headed attention and factor correlation-based progressive layered extraction (MHAF-PLE)) is proposed for fine-grained affective prediction. The additional label of the presence of characters in the picture becomes an auxiliary task to improve the prediction effect of the model.
- The static information of film and TV scene video keyframes is appended to the video dynamic information to obtain more complete visual information. Using multi-headed self-attention, features with rich information can be given higher weights, which is proved to have a better affective representation ability.
- A mixed loss function based on factor association constraints is proposed, giving the same weight to sentiments with strong relevance and combining the change in weights and losses.
2. Related Work
2.1. Affective Analysis Model
2.2. Visual Emotional Features
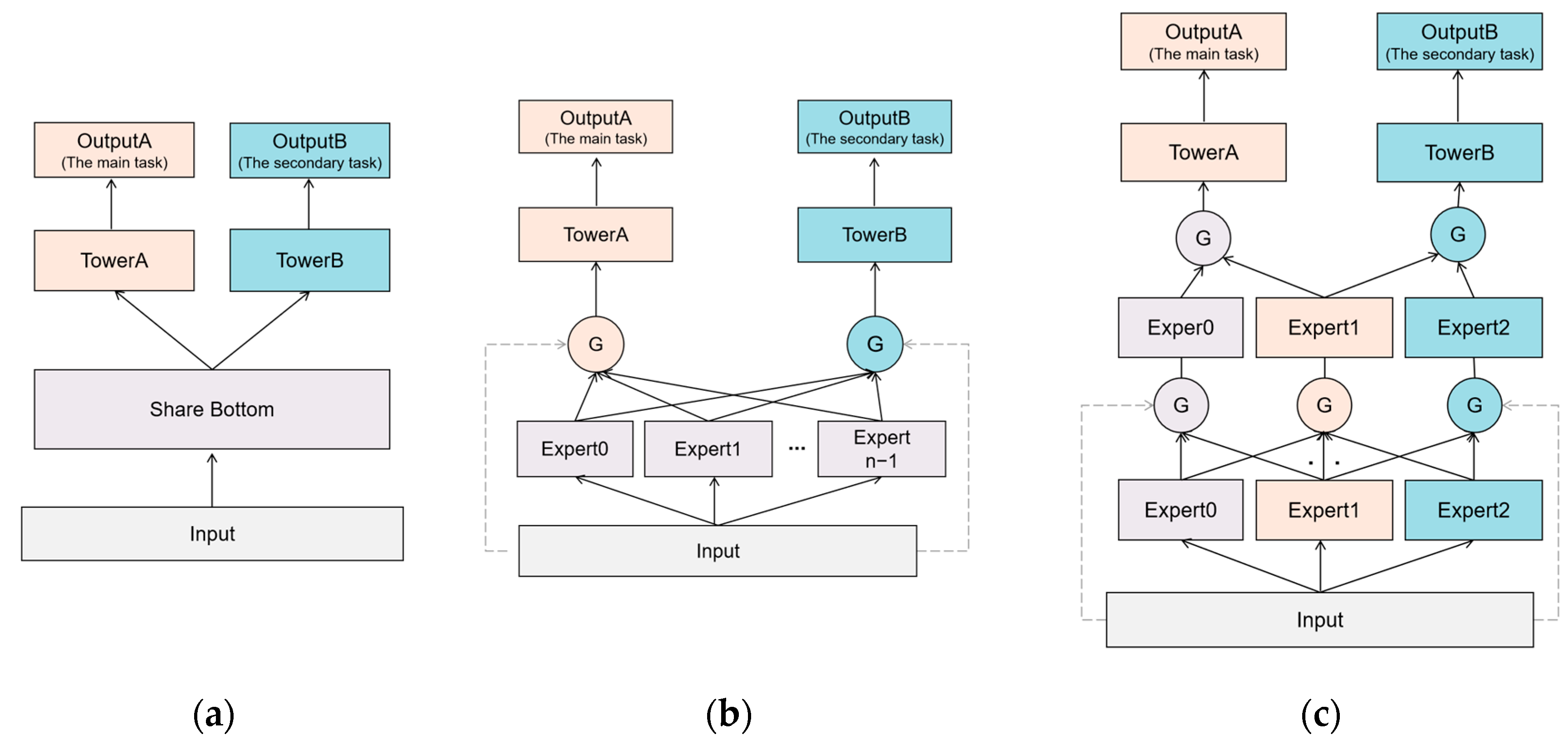
2.3. Multitask Learning
3. Method
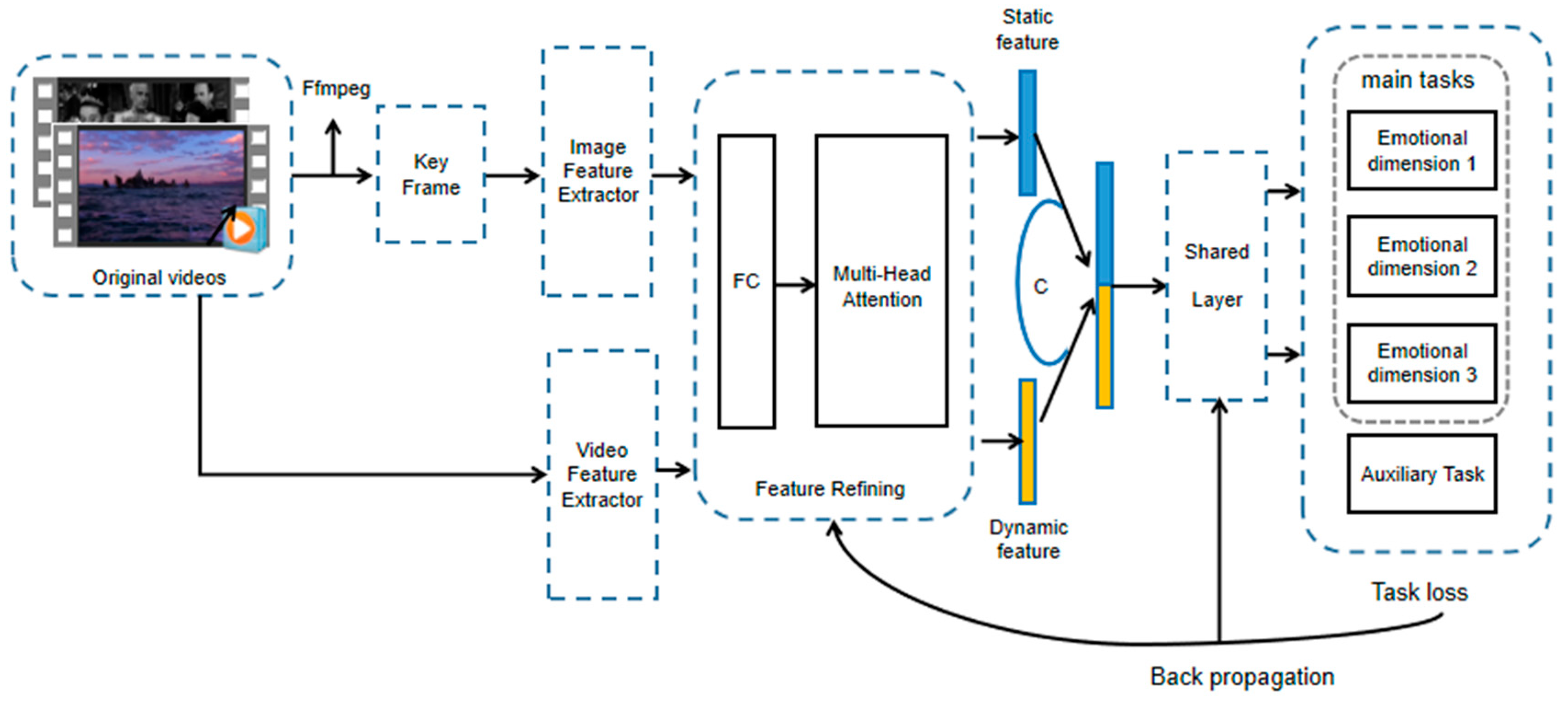
3.1. Proposed Framework
3.2. Feature Extraction
3.2.1. Video Dynamic Feature Extraction
3.2.2. Video Static Feature Extraction
3.3. Feature Refining
3.4. Loss Function
3.4.1. Factor Analysis
3.4.2. Joint Loss Function
4. Experimental Results
4.1. Dataset
4.2. Implementation
4.3. Results
4.3.1. Algorithm Prediction Results Based on Different Feature Selection Methods
4.3.2. Algorithm Prediction Results Based on Different Task Selection Methods
4.3.3. Algorithm Prediction Results Based on Different Loss Functions
4.3.4. Comparison with Other Algorithms
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhao, S.; Yao, X.; Yang, J.; Jia, G.; Ding, G.; Chua, T.S.; Schuller, B.W.; Keutzer, K. Affective image content analysis: Two decades review and new perspectives. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 6729–6751. [Google Scholar] [CrossRef] [PubMed]
- Poria, S.; Cambria, E.; Bajpai, R.; Hussain, A. A review of affective computing: From unimodal analysis to multimodal fusion. Inf. Fusion 2017, 37, 98–125. [Google Scholar] [CrossRef]
- Yang, J.; Yu, Y.; Niu, D.; Guo, W.; Xu, Y. ConFEDE: Contrastive Feature Decomposition for Multimodal Sentiment Analysis. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics, Toronto, ON, Canada, 9–14 July 2023; pp. 7617–7630. [Google Scholar] [CrossRef]
- Liu, C.; Zhao, S.; Luo, Y.; Liu, G. TransIEA: Transformer-Baseartd Image Emotion Analysis. In Proceedings of the 2022 7th International Conference on Computer and Communication Systems (ICCCS), Wuhan, China, 22–25 April 2022; pp. 310–313. [Google Scholar] [CrossRef]
- Yan, M.; Lou, X.; Chan, C.A.; Wang, Y.; Jiang, W. A Semantic and Emotion-based Dual Latent Variable Generation Model for a Dialogue System. CAAI Trans. Intell. Technol. 2023, 8, 319–330. [Google Scholar] [CrossRef]
- Al-Saadawi, H.F.T.; Das, R. TER-CA-WGNN: Trimodel Emotion Recognition Using Cumulative Attribute-Weighted Graph Neural Network. Appl. Sci. 2024, 14, 2252. [Google Scholar] [CrossRef]
- Karuthakannan, U.K.D.; Velusamy, G. TGSL-Dependent Feature Selection for Boosting the Visual Sentiment Classification. Symmetry 2021, 13, 1464. [Google Scholar] [CrossRef]
- Chaudhari, A.; Bhatt, C.; Krishna, A.; Mazzeo, P.L. ViTFER: Facial Emotion Recognition with Vision Transformers. Appl. Syst. Innov. 2022, 5, 80. [Google Scholar] [CrossRef]
- Zisad, S.N.; Chowdhury, E.; Hossain, M.S.; Islam, R.U.; Andersson, K. An Integrated Deep Learning and Belief Rule-Based Expert System for Visual Sentiment Analysis under Uncertainty. Algorithms 2021, 14, 213. [Google Scholar] [CrossRef]
- Yu, Y.; Lin, H.; Meng, J.; Zhao, Z. Visual and Textual Sentiment Analysis of a Microblog Using Deep Convolutional Neural Networks. Algorithms 2016, 9, 41. [Google Scholar] [CrossRef]
- Vandenhende, S.; Georgoulis, S.; Proesmans, M.; Dai, D.; Gool, L.V. Revisiting Multi-Task Learning in the Deep Learning Era. arXiv 2020, arXiv:2004.13379v1. [Google Scholar]
- Pons, G.; Masip, D. Multi-task, multi-label and multi-domain learning with residual convolutional networks for emotion recognition. arXiv 2018, arXiv:1802.06664. [Google Scholar]
- Zhao, S.; Yao, H.; Gao, Y.; Ji, R.; Ding, G. Continuous probability distribution prediction of image emotions via multitask shared sparse regression. IEEE Trans. Multimed. 2016, 19, 632–645. [Google Scholar] [CrossRef]
- Shen, J.; Zheng, J.; Wang, X. MMTrans-MT: A Framework for Multimodal Emotion Recognition Using Multitask Learning. In Proceedings of the 13th International Conference on Advanced Computational Intelligence (ICACI), Wanzhou, China, 14–16 May 2021; pp. 52–59. [Google Scholar] [CrossRef]
- Ekman, P.; Friesen, W.V. Constants across cultures in the face and emotion. J. Pers. Soc. Psychol. 1971, 17, 124–129. [Google Scholar] [CrossRef] [PubMed]
- Maninis, K.K.; Radosavovic, I.; Kokkinos, I. Attentive single-tasking of multiple tasks. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, Long Beach, CA, USA, 15–21 June 2019; pp. 1851–1860. [Google Scholar] [CrossRef]
- Guo, J.; Li, W.; Guan, J.; Gao, H.; Liu, B.; Gong, L. SIM: An improved few-shot image classification model with multi-task learning. J. Electron. Imaging 2022, 31, 033044. [Google Scholar] [CrossRef]
- Bertasius, G.; Wang, H.; Torresani, L. Is space-time attention all you need for video understanding? ICML 2021, 2, 4. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Plutchik, R. A general psychoevolutionary theory of emotion. In Theories of Emotion; Plutchik, R., Kellerman, H., Eds.; Academic Press: Cambridge, MA, USA, 1980; pp. 3–33. [Google Scholar] [CrossRef]
- Mehrabian, A.; O’Reilly, E. Analysis of personality measures in terms of basic dimensions of temperament. J. Pers. Soc. Psychol. 1980, 38, 492–503. [Google Scholar] [CrossRef]
- Haralick, R.M.; Shanmugam, K.; Dinstein, I.H. Textural features for image classification. IEEE Trans. Syst. Man. Cybern. 1973, SMC-3, 610–621. [Google Scholar] [CrossRef]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Losson, O.; Porebski, A.; Vandenbroucke, N.; Macaire, L. Color texture analysis using CFA chromatic co-occurrence matrices. Comput. Vis. Image Underst. 2013, 117, 747–763. [Google Scholar] [CrossRef]
- Machajdik, J.; Hanbury, A. Affective image classification using features inspired by psychology and art theory. In Proceedings of the 18th ACM international conference on Multimedia, Firenze, Italy, 25–29 October 2010; pp. 83–92. [Google Scholar] [CrossRef]
- Lu, X.; Suryanarayan, P.; Adams, R.B., Jr.; Li, J.; Newman, M.G.; Wang, J.Z. On shape and the computability of emotions. In Proceedings of the 20th ACM International Conference on Multimedia, Nara, Japan, 29 October–2 November 2012; pp. 229–238. [Google Scholar] [CrossRef]
- Borth, D.; Chen, T.; Ji, R.; Chang, S.F. Sentibank: Large-scale ontology and classifiers for detecting sentiment and emotions in visual content. In Proceedings of the 21st ACM International Conference on Multimedia, Barcelona, Spain, 21–25 October 2013; pp. 459–460. [Google Scholar] [CrossRef]
- Fayyaz, M.; Saffar, M.H.; Sabokrou, M.; Fathy, M.; Klette, R.; Huang, F. STFCN: Spatio-temporal FCN for semantic video segmentation. arXiv 2016, arXiv:1608.05971. [Google Scholar]
- Caruana, R. Multitask learning. Mach. Learn. 1997, 28, 41–75. [Google Scholar] [CrossRef]
- Bi, Y.; Xue, B.; Zhang, M. Multitask feature learning as multiobjective optimization: A new genetic programming approach to image classification. IEEE Trans. Cybern. 2022, 53, 3007–3020. [Google Scholar] [CrossRef] [PubMed]
- Hou, Y.; Lai, Y.; Chen, C.; Che, W.; Liu, T. Learning to bridge metric spaces: Few-shot joint learning of intent detection and slot filling. arXiv 2021, arXiv:2106.07343. [Google Scholar]
- Liu, S.; Shi, Q.; Zhang, L. Few-shot hyperspectral image classification with unknown classes using multitask deep learning. IEEE Trans. Geosci. Remote Sens. 2020, 59, 5085–5102. [Google Scholar] [CrossRef]
- Zhang, L.; Yang, Q.; Liu, X.; Guan, H. Rethinking hard-parameter sharing in multi-domain learning. In Proceedings of the 2022 IEEE International Conference on Multimedia and Expo (ICME), Taipei, Taiwan, 18–22 July 2022; pp. 01–06. [Google Scholar] [CrossRef]
- Jacobs, R.A.; Jordan, M.I.; Nowlan, S.J.; Hinton, G.E. Adaptive mixtures of local experts. Neural Comput. 1991, 3, 79–87. [Google Scholar] [CrossRef] [PubMed]
- Ma, J.; Zhao, Z.; Yi, X.; Chen, J.; Hong, L.; Chi, E.H. Modeling task relationships in multi-task learning with multi-gate mixture-of-experts. In Proceedings of the 24th ACM SIGKDD International Conference On Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; pp. 1930–1939. [Google Scholar] [CrossRef]
- Tang, H.; Liu, J.; Zhao, M.; Gong, X. Progressive layered extraction (ple): A novel multi-task learning (mtl) model for personalized recommendations. In Proceedings of the 14th ACM Conference on Recommender Systems, Virtual Event, Brazil, 22–26 September 2020; pp. 269–278. [Google Scholar] [CrossRef]
- Wang, Y.; Lam, H.T.; Wong, Y.; Liu, Z.; Zhao, X.; Wang, Y.; Chen, B.; Guo, H.; Tang, R. Multi-task deep recommender systems: A survey. arXiv 2023, arXiv:2302.03525. [Google Scholar]
- Pang, N.; Guo, S.; Yan, M.; Chan, C.A. A Short Video Classification Framework Based on Cross-Modal Fusion. Sensors 2023, 23, 8425. [Google Scholar] [CrossRef] [PubMed]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE conference on computer vision and pattern recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning transferable visual models from natural language supervision. In Proceedings of the 38th International Conference on Machine Learning, Virtual Event, 18–24 July 2021; pp. 8748–8763. [Google Scholar]
- Maurício, J.; Domingues, I.; Bernardino, J. Comparing Vision Transformers and Convolutional Neural Networks for Image Classification: A Literature Review. Appl. Sci. 2023, 13, 5521. [Google Scholar] [CrossRef]
- Wang, J.; Liu, H.; Ying, H.; Qiu, C.; Li, J.; Anwar, M.S. Attention-based neural network for end-to-end music separation. CAAI Trans. Intell. Technol. 2023, 8, 355–363. [Google Scholar] [CrossRef]
- Yan, M.; Xiong, R.; Wang, Y.; Li, C. Edge Computing Task Offloading Optimization for a UAV-assisted Internet of Vehicles via Deep Reinforcement Learning. IEEE Trans. Veh. Technol. 2023, 73, 5647–5658. [Google Scholar] [CrossRef]
- Gu, Q.; Wang, Z.; Zhang, H.; Sui, S.; Wang, R. Aspect-Level Sentiment Analysis Based on Syntax-Aware and Graph Convolutional Networks. Appl. Sci. 2024, 14, 729. [Google Scholar] [CrossRef]
- Ma, J.; Cheng, J.; Chen, Y.; Li, K.; Zhang, F.; Shang, Z. Multi-Head Self-Attention-Enhanced Prototype Network with Contrastive–Center Loss for Few-Shot Relation Extraction. Appl. Sci. 2024, 14, 103. [Google Scholar] [CrossRef]
- Zhang, R.; Xue, C.; Qi, Q.; Lin, L.; Zhang, J.; Zhang, L. Bimodal Fusion Network with Multi-Head Attention for Multimodal Sentiment Analysis. Appl. Sci. 2023, 13, 1915. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 6000–6010. [Google Scholar]
- Guo, J.H.; Xu, N.N. Evaluation and cluster analysis of universities’ transformation ability of scientific and technological achievements in China. J. Intell. 2016, 35, 155–168. [Google Scholar]
- Liu, S.; Johns, E.; Davison, A.J. End-to-end multi-task learning with attention. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 1871–1880. [Google Scholar] [CrossRef]
- Kendall, A.; Gal, Y.; Cipolla, R. Multi-task learning using uncertainty to weigh losses for scene geometry and semantics. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7482–7491. [Google Scholar]
- Yang, Z.; Zhong, W.; Lv, Q.; Chen, C.Y.C. Multitask deep learning with dynamic task balancing for quantum mechanical properties prediction. Phys. Chem. Chem. Phys. 2022, 24, 5383–5393. [Google Scholar] [CrossRef] [PubMed]
- Zhibin, S.; Yahong, Q.; Yu, G.; Hui, R. Research on emotion space of film and television scene images based on subjective perception. J. China Univ. Posts Telecommun. 2019, 26, 75–81. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | MAE of Affective Prediciton |
|---|---|
| MviT | 0.1898 |
| C3D | 0.2484 |
| TimeSformer | 0.1637 |
| Model | MAE of Affective Prediction |
|---|---|
| Vgg16 | 0.1057 |
| GoogLeNet | 0.0950 |
| ViT | 0.1432 |
| CLIP | 0.0885 |
| Component | Factor 1 | Factor 2 | Factor 3 |
|---|---|---|---|
| Warm | 0.913 | −0.298 | 0.100 |
| Hopeful | 0.798 | −0.352 | 0.275 |
| Happy | 0.872 | −0.335 | 0.005 |
| Romantic | 0.65 | −0.241 | 0.48 |
| Relaxed | 0.839 | −0.449 | 0.126 |
| Fresh | 0.711 | −0.357 | 0.359 |
| Cozy | 0.908 | −0.299 | 0.015 |
| Sunny | 0.872 | −0.326 | 0.151 |
| Magnificent | −0.054 | −0.239 | 0.849 |
| Dreamy | 0.432 | −0.235 | 0.791 |
| Lonely | −0.397 | 0.795 | −0.085 |
| Sentimental | −0.269 | 0.897 | −0.235 |
| Disappointed | −0.259 | 0.904 | −0.232 |
| Depressed | −0.349 | 0.893 | −0.209 |
| Oppressive | −0.511 | 0.739 | −0.21 |
| Anxious | −0.427 | 0.827 | −0.247 |
| Indicator | |||
| Eigenvalue | 10.863 | 1.826 | 1.208 |
| Variance (%) | 67.897 | 11.414 | 7.551 |
| Cumulative (%) | 67.863 | 79.311 | 86.862 |
| Warm | Magnificent | Depressed | Happy |
| Relaxed | Anxious | Dreamy | Hopeful |
| Sentimental | Sunny | Romantic | Oppressive |
| Fresh | Cozy | Disappointed | Lonely |
| TimeSformer + CLIP | ||||
|---|---|---|---|---|
| First Frame | Frame | |||
| Component | TimeSformer | TimeSformer + Clip | First + Last | First + Middle + Last |
| Warm | 0.0522 | 0.0248 | 0.0270 | 0.0254 |
| Hopeful | 0.1754 | 0.0713 | 0.0606 | 0.0621 |
| Happy | 0.1936 | 0.0715 | 0.0548 | 0.0565 |
| Romantic | 0.1613 | 0.0545 | 0.0507 | 0.0529 |
| Relaxed | 0.2080 | 0.0793 | 0.0571 | 0.0597 |
| Fresh | 0.1646 | 0.0577 | 0.0581 | 0.0593 |
| Cozy | 0.1877 | 0.0581 | 0.0514 | 0.0527 |
| Sunny | 0.1901 | 0.0694 | 0.0589 | 0.0602 |
| Magnificent | 0.1331 | 0.0508 | 0.0472 | 0.0481 |
| Dreamy | 0.1613 | 0.0526 | 0.0472 | 0.0513 |
| Lonely | 0.1887 | 0.0707 | 0.0643 | 0.0661 |
| Sentimental | 0.1556 | 0.0661 | 0.0643 | 0.0650 |
| Disappointed | 0.1536 | 0.0676 | 0.0546 | 0.0551 |
| Depressed | 0.1518 | 0.0670 | 0.0519 | 0.0523 |
| Oppressive | 0.1686 | 0.0737 | 0.0506 | 0.0643 |
| Anxious | 0.1731 | 0.0651 | 0.0580 | 0.0612 |
| Average (MAE) | 0.1637 | 0.0694 | 0.0542 | 0.0558 |
| Classification (%) | 76% | 97% | 98% | 97% |
| Number | Task |
|---|---|
| 1 | Positive emotion (warm) predictions + character classification + emotional polarity classification |
| 2 | Positive emotion (warm) prediction + negative emotion (disappointed) prediction + character classification |
| 3 | Positive emotion (warm and magnificent) prediction + negative emotion prediction (disappointed and depressed) + character classification |
| 4 | Positive emotion (warm, magnificent, and sunny) prediction + negative emotion prediction (disappointed and depressed) + character classification |
| Task Number | |||||
|---|---|---|---|---|---|
| Predict Result | 1 | 2 | 3 | 4 | Proposed Task |
| Warm | 0.0370 | 0.0270 | 0.0258 | 0.2500 | 0.0248 |
| Sunny | / | / | 0.0781 | 0.0725 | 0.0694 |
| Magnificent | / | / | 0.0600 | 0.0536 | 0.0508 |
| Disappointed | / | 0.0892 | 0.0754 | 0.0720 | 0.0676 |
| Depressed | / | / | / | 0.7567 | 0.6700 |
| Character Classification | 69% | 71% | 71% | 75% | 97% |
| Emotional polarity classification | 65% | / | / | / | / |
| Emotion Task | Weight Consistency | FA | FA + Loss Weight | FA + Loss Weight + Amplification Factor |
|---|---|---|---|---|
| Warm | 0.0240 | 0.0210 | 0.0210 | 0.0185 |
| Hopeful | 0.0545 | 0.0488 | 0.0455 | 0.0465 |
| Happy | 0.0518 | 0.0452 | 0.0447 | 0.0394 |
| Romantic | 0.0489 | 0.0482 | 0.0488 | 0.0504 |
| Relaxed | 0.0586 | 0.0508 | 0.0475 | 0.0465 |
| Fresh | 0.0519 | 0.0521 | 0.0510 | 0.0501 |
| Cozy | 0.0447 | 0.0567 | 0.0587 | 0.0444 |
| Sunny | 0.0525 | 0.0545 | 0.0538 | 0.0523 |
| Magnificent | 0.0505 | 0.0585 | 0.0529 | 0.0498 |
| Dreamy | 0.0541 | 0.0507 | 0.0472 | 0.0456 |
| Lonely | 0.0479 | 0.0430 | 0.0427 | 0.0433 |
| Sentimental | 0.0452 | 0.0369 | 0.0343 | 0.0328 |
| Disappointed | 0.0542 | 0.0423 | 0.0419 | 0.0418 |
| Depressed | 0.0433 | 0.0429 | 0.0381 | 0.0352 |
| Oppressive | 0.0464 | 0.0614 | 0.0589 | 0.0586 |
| Anxious | 0.0686 | 0.0469 | 0.0451 | 0.0371 |
| Average | 0.0500 | 0.0474 | 0.0457 | 0.0432 |
| k | MAE of Affective Prediciton |
|---|---|
| 1 | 0.0432 |
| 3 | 0.0389 |
| 4 | 0.0388 |
| 5 | 0.0361 |
| 6 | 0.0387 |
| 7 | 0.0403 |
| 8 | 0.0412 |
| 9 | 0.0432 |
| Task | Share-Bottom | PLE | RF. [12] | MMTrans-MT [14] | MHAF-PLE (Ours) |
|---|---|---|---|---|---|
| Warm | 0.2498 | 0.1761 | 0.1619 | 0.2069 | 0.0185 |
| Hopeful | 0.2329 | 0.1870 | 0.1888 | 0.2027 | 0.0465 |
| Happy | 0.2787 | 0.1880 | 0.2252 | 0.2243 | 0.0394 |
| Romantic | 0.2217 | 0.1724 | 0.1868 | 0.1870 | 0.0504 |
| Relaxed | 0.2695 | 0.2315 | 0.1856 | 0.2295 | 0.0465 |
| Fresh | 0.2555 | 0.1733 | 0.2289 | 0.1945 | 0.0501 |
| Cozy | 0.2603 | 0.1810 | 0.1936 | 0.2123 | 0.0444 |
| Sunny | 0.2503 | 0.1891 | 0.1830 | 0.2163 | 0.0523 |
| Magnificent | 0.1341 | 0.1025 | 0.1697 | 0.1601 | 0.0498 |
| Dreamy | 0.1836 | 0.1510 | 0.2062 | 0.1852 | 0.0456 |
| Lonely | 0.2636 | 0.2178 | 0.2126 | 0.1907 | 0.0433 |
| Sentimental | 0.1784 | 0.1578 | 0.2027 | 0.1831 | 0.0328 |
| Disappointed | 0.1780 | 0.1637 | 0.1928 | 0.1698 | 0.0418 |
| Depressed | 0.1900 | 0.1757 | 0.1905 | 0.1933 | 0.0352 |
| Oppressive | 0.2159 | 0.2245 | 0.2147 | 0.1905 | 0.0586 |
| Anxious | 0.2101 | 0.1801 | 0.2038 | 0.2047 | 0.0371 |
| Average | 0.2232 | 0.1794 | 0.1966 | 0.1970 | 0.0432 |
| Character classification | 80% | 79% | 55% | 59% | 98% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Su, Z.; Lin, S.; Zhang, L.; Feng, Y.; Jiang, W. Multitask Learning-Based Affective Prediction for Videos of Films and TV Scenes. Appl. Sci. 2024, 14, 4391. https://doi.org/10.3390/app14114391
Su Z, Lin S, Zhang L, Feng Y, Jiang W. Multitask Learning-Based Affective Prediction for Videos of Films and TV Scenes. Applied Sciences. 2024; 14(11):4391. https://doi.org/10.3390/app14114391
Chicago/Turabian StyleSu, Zhibin, Shige Lin, Luyue Zhang, Yiming Feng, and Wei Jiang. 2024. "Multitask Learning-Based Affective Prediction for Videos of Films and TV Scenes" Applied Sciences 14, no. 11: 4391. https://doi.org/10.3390/app14114391
APA StyleSu, Z., Lin, S., Zhang, L., Feng, Y., & Jiang, W. (2024). Multitask Learning-Based Affective Prediction for Videos of Films and TV Scenes. Applied Sciences, 14(11), 4391. https://doi.org/10.3390/app14114391