
TTDAT: Two-Step Training Dual Attention Transformer for Malware Classification Based on API Call Sequences


Abstract
:1. Introduction
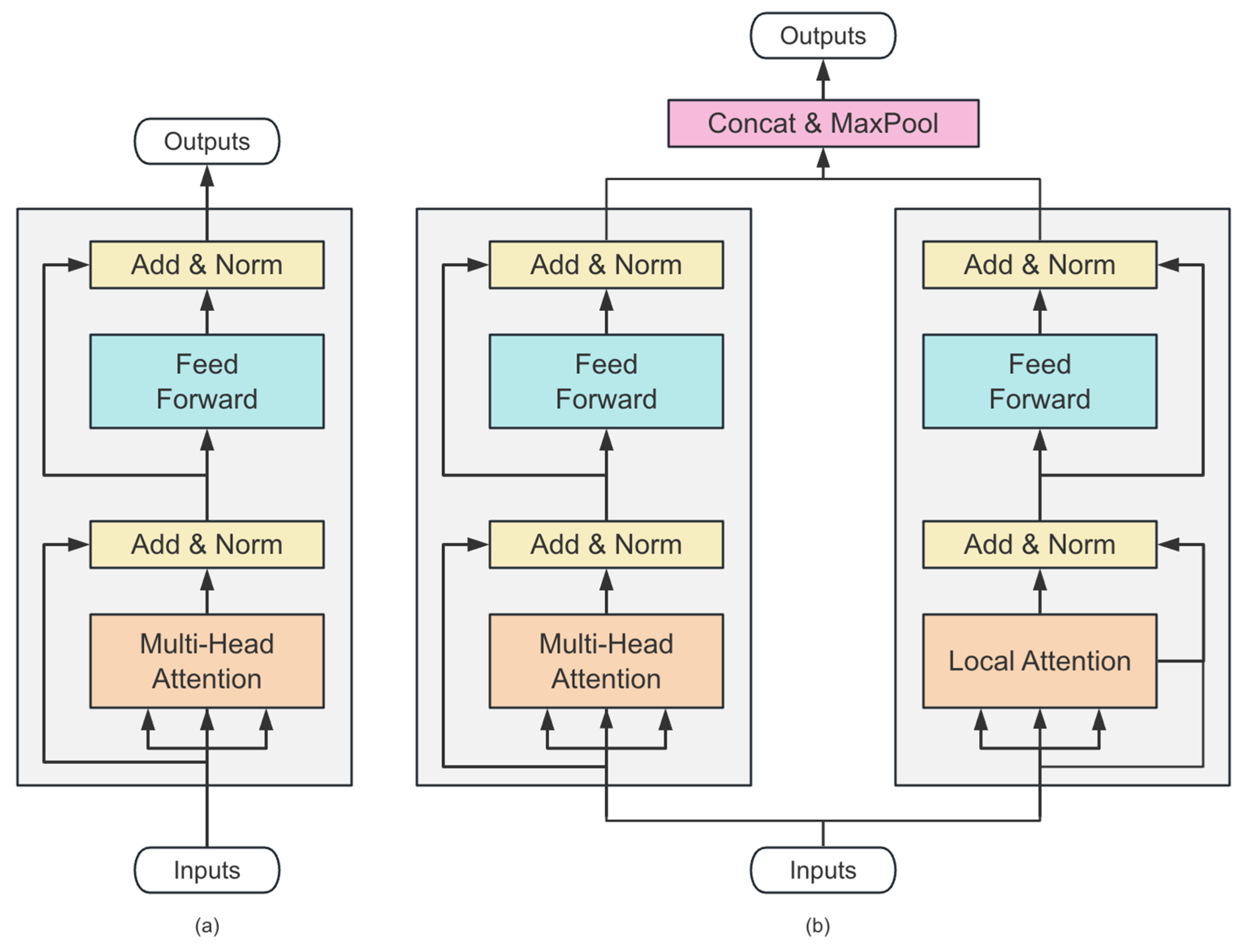
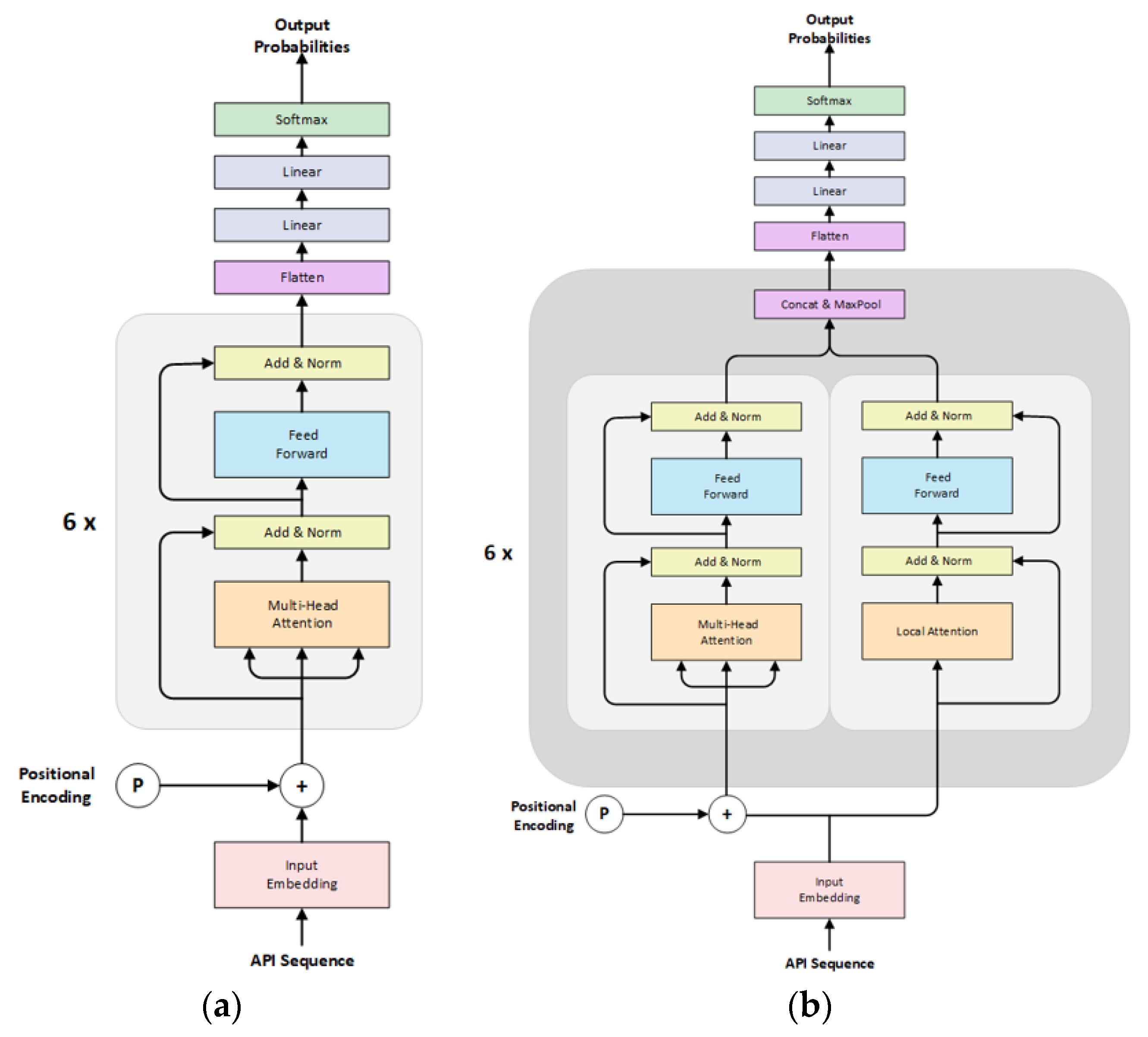
- We present a tiny local attention mechanism as a complementary component to the multi-head attention in the Transformer, and a new encoder is proposed to model the short-term relationship between API call sequences;
- We provide a two-step training method for accuracy facilitation. Unlike adding some cumbersome components to the model that require large computational resources, a novel training method is computationally free during the inference time;
- Massive experimental results show that the proposed method outperforms the state-of-the-art malware classifiers in two datasets, and we carry out an ablation study to demonstrate the effectiveness of our module and two-step training strategy.
2. Related Work
2.1. Deep Learning-Based or API-Call-Related Malware Classification
2.2. Transformer Models and Local Attention
2.3. Training Strategies
2.4. Related-Work Summary and Comparison
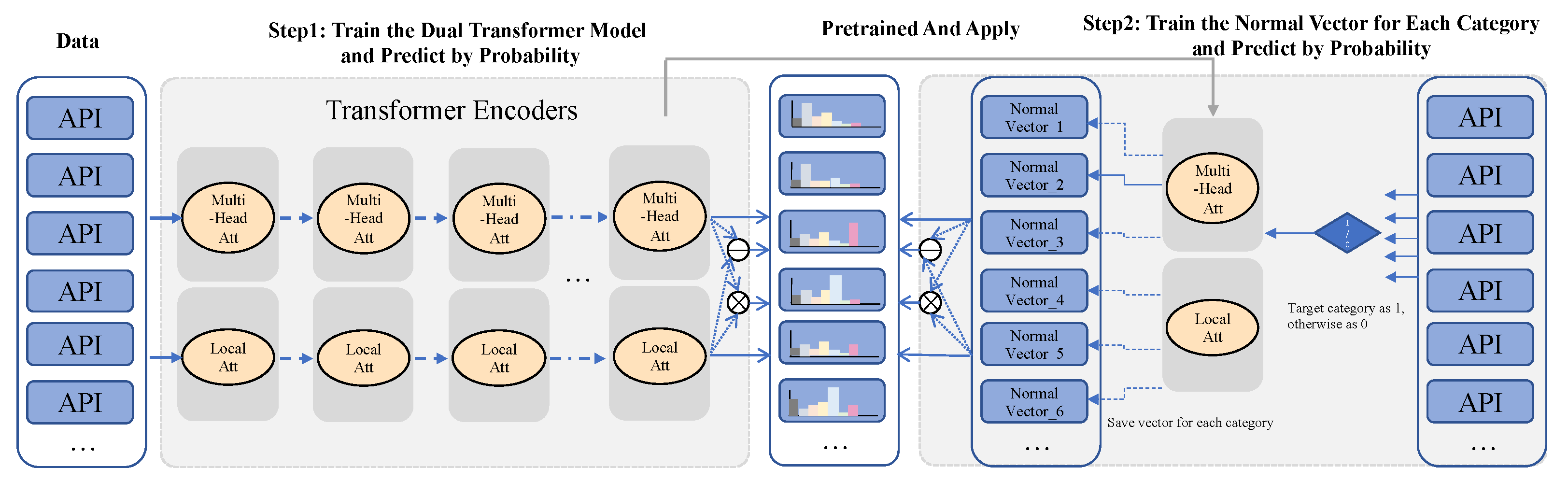
3. Methodology
3.1. Overview and Design Principles
3.2. Dual Attention Transformer Encoder
3.3. Two-Step Training
3.3.1. Training Step #1
| Algorithm 1 Siamese network inference |
| Input: The API call sequence of the malware needed to be classified. Output: The label of . Init: : All the classes of malware, : The trained model function predict (): ← [] for in do: ← average ([.predict(, ) for ← RandSelect (, )]) end for return end function |
3.3.2. Training Step #2
| Algorithm 2 Normal Vector optimization |
| Input: The malware category which needs to generate the Normal Vector. Output: The generated Normal Vector . Init: : the training set in this work, for training sample , denotes its API call sequence, and is the corresponding label, : The trained model whose parameters are fixed except for NormalVector layer. function generateNormalVector(): ← [] ← [] for in do: () If , then else end if end for return end function |
| Algorithm 3 Feature extraction and classification |
| Input: The API call sequence of the malware needed to be classified. Output: The category of . Init: : All the classes of malware, : The trained model function getNormalVector(): if not exist in NormalVectorSet then NormalVectorSet[] ← generatorNormalVector() return NormalVectorSet[] end function function predict (): ← [] for in do: ← .predict(, getNormalVector()) end for return end function |
4. Experiments and Discussion
4.1. Dataset and Implementation Details
4.2. Comparison with Previous Methods
4.3. Ablation Studies
4.3.1. Ablation Study on Local Attention Mechanism
4.3.2. Ablation Study on Training Step #1
4.3.3. Ablation Study on Training Step #2
4.3.4. Two-Step Inference
4.4. Findings and Limitations
- (1)
- Our proposed method can achieve an accuracy of 0.9606, but most classical methods cannot exceed 0.90. In addition, this paper is validated on two datasets, and although the performance of all the models on the second dataset is generally degraded, the method in this paper still outperforms the others, which suggests that the method in this paper is very effective and capable of achieving the latest SOTA results;
- (2)
- We compare two works based on the Transformer architecture. Overall, the performances of the three methods are nice, which illustrates the effect of natural language modeling, especially the latest Transformer architecture, on the processing capability of API sequential calls. We further designed the fusion of local attention mechanisms based on the local feature relationships between API calls, which can enhance the feature-capturing ability even further. And this can also be compared more carefully in ablation experiments. By exploring the DAT encoder, we can find that the local attention module can indeed achieve better results than the original Transformer encoder;
- (3)
- Our ablation analysis for Step 1 also further verifies that the introduction of the Siamese Network can improve the performance to a certain extent, with an improvement in accuracy from 0.837 to 0.87. In the second step, we use the Normal Vector to simplify the process of malware classification and obtain a more generalizable category representation vector that can further improve the accuracy of the model, with an increase in the average accuracy from 0.87 to 0.92. This suggests that, compared to randomly selected samples, the Normal Vector obtained in the second training step is better at capturing malware category features;
- (4)
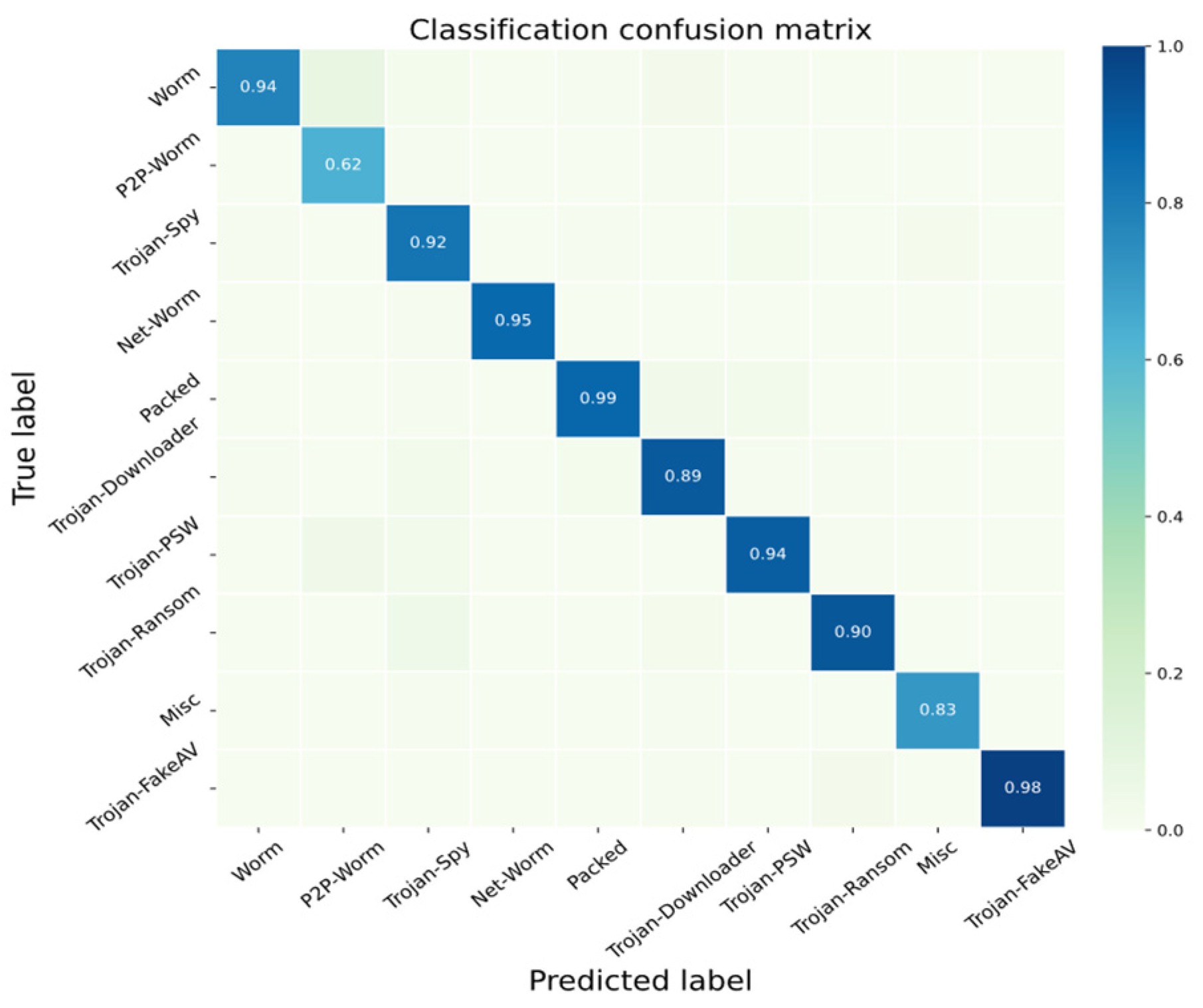
- Finally, we made a further attempt to adapt to the hierarchical relationship between the samples by performing a two-step inference, trying to classify the parent category first and then the subcategories. Experiments show that this strategy is effective and can improve the accuracy from 0.92 to 0.96, which utilizes the richer data in the parent category to improve the stability of the Normal Vectors of the subcategories with limited data and to alleviate the problem of data scarcity for specific malware types (e.g., P2P worms).
- (1)
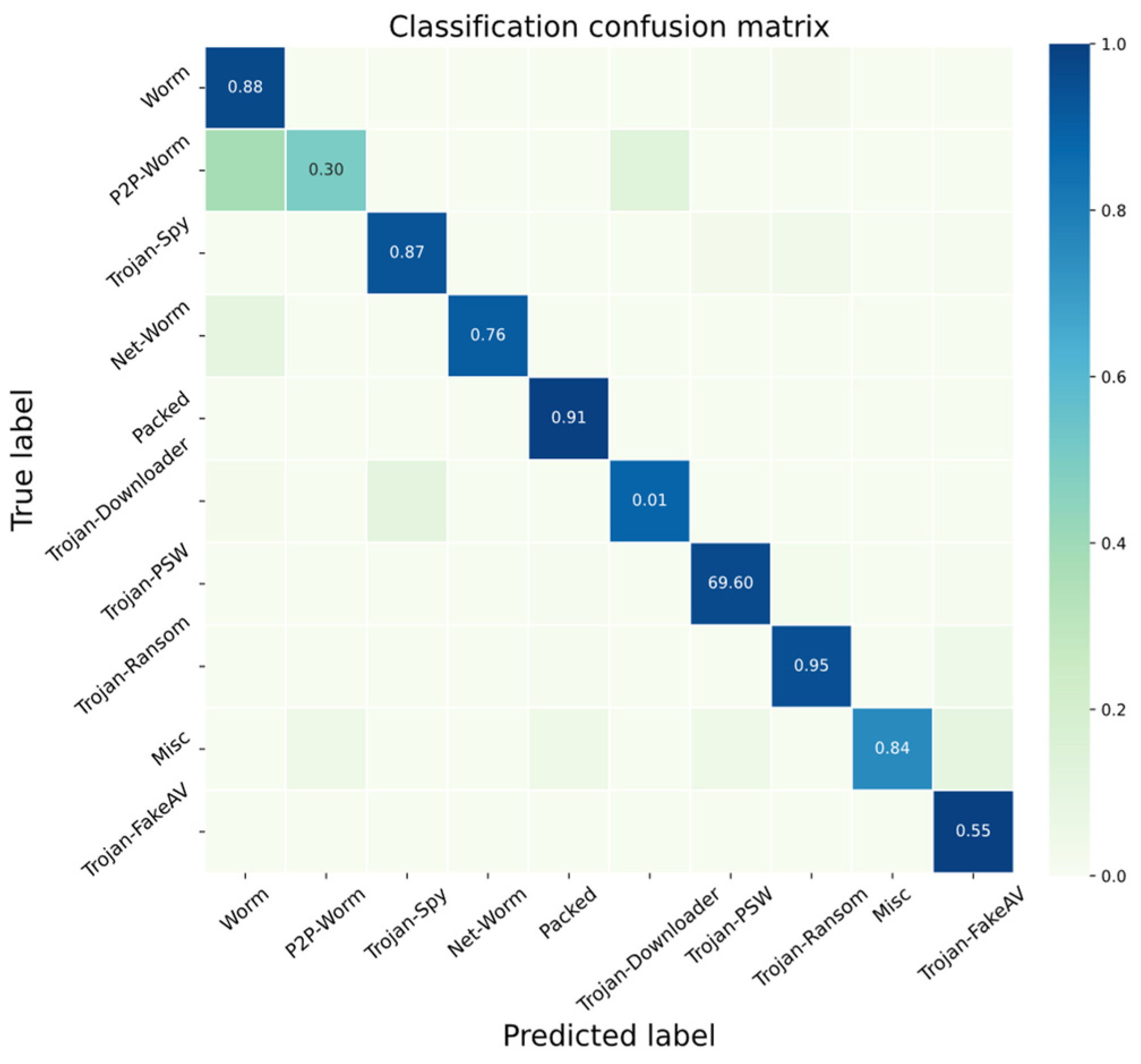
- The challenge of data scarcity: Despite the efforts to address the data scarcity issue through the training steps, in multiple comparison experiments, relatively high variance in F1-scores can be found across different categories, e.g., P2P Worms and Misc, which still exhibit low F1-scores. The performance of the model is limited by the availability of representative data, and the strategy to deal with rare data needs to be further explored;
- (2)
- Generalization of new samples: The model’s ability to generalize to new, unseen samples is not explicitly discussed currently. Evaluating its performance on brand new malware samples, especially those that do not exist in the training data, is crucial to assessing real-world applicability;
- (3)
- Interpretability Issues: the interpretability of the model is not adequately discussed, and understanding how decisions are made, especially in security-related applications, is important for building trust in the model’s predictions.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Aboaoja, F.A.; Zainal, A.; Ghaleb, F.A.; Al-rimy, B.A.S.; Eisa, T.A.E.; Elnour, A.A.H. Malware Detection Issues, Challenges, and Future Directions: A Survey. Appl. Sci. 2022, 12, 8482. [Google Scholar] [CrossRef]
- Begovic, K.; Al-Ali, A.; Malluhi, Q. Cryptographic Ransomware Encryption Detection: Survey. Comput. Security 2023, 132, 103349. [Google Scholar] [CrossRef]
- Molloy, C.; Banks, J.; Ding, H.S.; Charland, P.; Walenstein, A.; Li, L. Adversarial Variational Modality Reconstruction and Regularization for Zero-Day Malware Variants Similarity Detection. In Proceedings of the 2022 IEEE International Conference on Data Mining (ICDM), Orlando, FL, USA, 28 November–1 December 2022; pp. 1131–1136. [Google Scholar]
- Ling, X.; Wu, L.; Zhang, J.; Qu, Z.; Deng, W.; Chen, X.; Qian, Y.; Wu, C.; Ji, S.; Luo, T. Adversarial Attacks against Windows PE Malware Detection: A Survey of the State-of-the-Art. Comput. Secur. 2023, 128, 103134. [Google Scholar] [CrossRef]
- Gržinić, T.; González, E.B. Methods for Automatic Malware Analysis and Classification: A Survey. Int. J. Inf. Comput. Secur. 2022, 17, 179–203. [Google Scholar] [CrossRef]
- Aslan, Ö.A.; Samet, R. A Comprehensive Review on Malware Detection Approaches. IEEE Access 2020, 8, 6249–6271. [Google Scholar] [CrossRef]
- Muzaffar, A.; Hassen, H.R.; Lones, M.A.; Zantout, H. An In-Depth Review of Machine Learning Based Android Malware Detection. Comput. Secur. 2022, 121, 102833. [Google Scholar] [CrossRef]
- Firdausi, I.; Erwin, A.; Nugroho, A.S. Analysis of Machine Learning Techniques Used in Behavior-Based Malware Detection. In Proceedings of the 2010 Second International Conference on Advances in Computing, Control, and Telecommunication Technologies, Jakarta, Indonesia, 2–3 December 2010; pp. 201–203. [Google Scholar]
- Fuyong, Z.; Tiezhu, Z. Malware Detection and Classification Based on N-Grams Attribute Similarity. In Proceedings of the 2017 IEEE International Conference on Computational Science and Engineering (CSE) and IEEE International Conference on Embedded and Ubiquitous Computing (EUC), Guangzhou, China, 21–24 July 2017; Volume 1, pp. 793–796. [Google Scholar]
- Taheri, L.; Kadir, A.F.A.; Lashkari, A.H. Extensible Android Malware Detection and Family Classification Using Network-Flows and API-Calls. In Proceedings of the 2019 International Carnahan Conference on Security Technology (ICCST), Chennai, India, 1–3 October 2019; pp. 1–8. [Google Scholar]
- Mu, T.; Chen, H.; Du, J.; Xu, A. An Android Malware Detection Method Using Deep Learning Based on Api Calls. In Proceedings of the 2019 IEEE 3rd Advanced Information Management, Communicates, Electronic and Automation Control Conference (IMCEC), Chongqing, China, 11–13 October 2019; pp. 2001–2004. [Google Scholar]
- Tran, T.K.; Sato, H.; Kubo, M. Image-Based Unknown Malware Classification with Few-Shot Learning Models. In Proceedings of the 2019 Seventh International Symposium on Computing and Networking Workshops (CANDARW), Nagasaki, Japan, 26–29 November 2019; pp. 401–407. [Google Scholar]
- Makandar, A.; Patrot, A. Malware Class Recognition Using Image Processing Techniques. In Proceedings of the 2017 International Conference on Data Management, Analytics and Innovation (ICDMAI), Pune, India, 24–26 February 2017; pp. 76–80. [Google Scholar]
- Tran, T.K.; Sato, H. NLP-Based Approaches for Malware Classification from API Sequences. In Proceedings of the 2017 21st Asia Pacific Symposium on Intelligent and Evolutionary Systems (IES), Hanoi, Vietnam, 15–17 November 2017; pp. 101–105. [Google Scholar]
- Nagano, Y.; Uda, R. Static Analysis with Paragraph Vector for Malware Detection. In Proceedings of the 11th International Conference on Ubiquitous Information Management and Communication, Beppu, Japan, 5–7 January 2017; pp. 1–7. [Google Scholar]
- Schofield, M.; Alicioglu, G.; Binaco, R.; Turner, P.; Thatcher, C.; Lam, A.; Sun, B. Convolutional Neural Network for Malware Classification Based on API Call Sequence. In Proceedings of the 8th International Conference on Artificial Intelligence and Applications (AIAP 2021), Zurich, Switzerland, 23–24 January 2021; pp. 23–24. [Google Scholar]
- Ravi, C.; Manoharan, R. Malware Detection Using Windows Api Sequence and Machine Learning. Int. J. Comput. Appl. 2012, 43, 12–16. [Google Scholar] [CrossRef]
- Nakazato, J.; Song, J.; Eto, M.; Inoue, D.; Nakao, K. A Novel Malware Clustering Method Using Frequency of Function Call Traces in Parallel Threads. IEICE Trans. Inf. Syst. 2011, 94, 2150–2158. [Google Scholar] [CrossRef]
- Kolosnjaji, B.; Zarras, A.; Webster, G.; Eckert, C. Deep Learning for Classification of Malware System Call Sequences. In Proceedings of the AI 2016: Advances in Artificial Intelligence: 29th Australasian Joint Conference, Hobart, TAS, Australia, 5–8 December 2016; Proceedings 29. Springer: Berlin/Heidelberg, Germany, 2016; pp. 137–149. [Google Scholar]
- Li, C.; Zheng, J. API Call-Based Malware Classification Using Recurrent Neural Networks. J. Cyber Secur. Mobil. 2021, 10, 617–640. [Google Scholar] [CrossRef]
- Li, C.; Lv, Q.; Li, N.; Wang, Y.; Sun, D.; Qiao, Y. A Novel Deep Framework for Dynamic Malware Detection Based on API Sequence Intrinsic Features. Comput. Secur. 2022, 116, 102686. [Google Scholar] [CrossRef]
- Li, C.; Cheng, Z.; Zhu, H.; Wang, L.; Lv, Q.; Wang, Y.; Li, N.; Sun, D. DMalNet: Dynamic Malware Analysis Based on API Feature Engineering and Graph Learning. Comput. Secur. 2022, 122, 102872. [Google Scholar] [CrossRef]
- Daeef, A.Y.; Al-Naji, A.; Chahl, J. Features Engineering for Malware Family Classification Based API Call. Computers 2022, 11, 160. [Google Scholar] [CrossRef]
- Deore, M.; Kulkarni, U. Mdfrcnn: Malware Detection Using Faster Region Proposals Convolution Neural Network. Int. J. Interact. Multimedia Artif. Intell. 2022, 7, 146–162. [Google Scholar] [CrossRef]
- Cho, K.; Van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning Phrase Representations Using RNN Encoder-Decoder for Statistical Machine Translation. arXiv 2014, arXiv:1406.1078. [Google Scholar]
- Staudemeyer, R.C.; Morris, E.R. Understanding LSTM—A Tutorial into Long Short-Term Memory Recurrent Neural Networks. arXiv 2019, arXiv:1909.09586. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar]
- Zeyer, A.; Bahar, P.; Irie, K.; Schlüter, R.; Ney, H. A Comparison of Transformer and Lstm Encoder Decoder Models for Asr. In Proceedings of the 2019 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), Singapore, 14–18 December 2019; pp. 8–15. [Google Scholar]
- Rahali, A.; Akhloufi, M.A. MalBERT: Malware Detection Using Bidirectional Encoder Representations from Transformers. In Proceedings of the 2021 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Melbourne, Australia, 17–20 October 2021; pp. 3226–3231. [Google Scholar]
- Yang, X.; Yang, D.; Li, Y. A Hybrid Attention Network for Malware Detection Based on Multi-Feature Aligned and Fusion. Electronics 2023, 12, 713. [Google Scholar] [CrossRef]
- Ma, Q.; Yu, L.; Tian, S.; Chen, E.; Ng, W.W. Global-Local Mutual Attention Model for Text Classification. IEEE/ACM Trans. Audio Speech Lang. Process. 2019, 27, 2127–2139. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. Yolov4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- DeVries, T.; Taylor, G.W. Improved Regularization of Convolutional Neural Networks with Cutout. arXiv 2017, arXiv:1708.04552. [Google Scholar]
- Sung, K.-K.; Poggio, T. Example-Based Learning for View-Based Human Face Detection. IEEE Trans. Pattern Anal. Mach. Intell. 1998, 20, 39–51. [Google Scholar] [CrossRef]
- Shrivastava, A.; Gupta, A.; Girshick, R. Training Region-Based Object Detectors with Online Hard Example Mining. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 761–769. [Google Scholar]
- Yu, J.; Jiang, Y.; Wang, Z.; Cao, Z.; Huang, T. Unitbox: An Advanced Object Detection Network. In Proceedings of the 24th ACM International Conference on Multimedia, Amsterdam, The Netherlands, 15–19 October 2016; pp. 516–520. [Google Scholar]
- Hwang, J.; Kim, J.; Lee, S.; Kim, K. Two-Stage Ransomware Detection Using Dynamic Analysis and Machine Learning Techniques. Wirel. Pers. Commun. 2020, 112, 2597–2609. [Google Scholar] [CrossRef]
- Baek, S.; Jeon, J.; Jeong, B.; Jeong, Y.-S. Two-Stage Hybrid Malware Detection Using Deep Learning. Hum. Centric Comput. Inf. Sci. 2021, 11, 10–22967. [Google Scholar]
- Ebad, S.A. Exploring How to Apply Secure Software Design Principles. IEEE Access 2022, 10, 128983–128993. [Google Scholar] [CrossRef]
- Koch, G.; Zemel, R.; Salakhutdinov, R. Siamese Neural Networks for One-Shot Image Recognition. In ICML Deep Learning Workshop; University of Toronto: Lille, France, 2015; Volume 2. [Google Scholar]
- Snell, J.; Swersky, K.; Zemel, R. Prototypical Networks for Few-Shot Learning. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar]
- Ki, Y.; Kim, E.; Kim, H.K. A Novel Approach to Detect Malware Based on API Call Sequence Analysis. Int. J. Distrib. Sens. Netw. 2015, 11, 659101. [Google Scholar] [CrossRef]
- Gupta, S.; Sharma, H.; Kaur, S. Malware Characterization Using Windows API Call Sequences. In Proceedings of the Security, Privacy, and Applied Cryptography Engineering: 6th International Conference, SPACE 2016, Hyderabad, India, 14–18 December 2016; Proceedings 6. Springer: Berlin/Heidelberg, Germany, 2016; pp. 271–280. [Google Scholar]
- Nataraj, L.; Yegneswaran, V.; Porras, P.; Zhang, J. A Comparative Assessment of Malware Classification Using Binary Texture Analysis and Dynamic Analysis. In Proceedings of the 4th ACM Workshop on Security and Artificial Intelligence, Chicago, IL, USA, 21 October 2011; pp. 21–30. [Google Scholar]
- Kim, H.-J. Image-Based Malware Classification Using Convolutional Neural Network. In Advances in Computer Science and Ubiquitous Computing: CSA-CUTE 17; Springer: Berlin/Heidelberg, Germany, 2018; pp. 1352–1357. [Google Scholar]
- Agarap, A.F. Towards Building an Intelligent Anti-Malware System: A Deep Learning Approach Using Support Vector Machine (SVM) for Malware Classification. arXiv 2017, arXiv:1801.00318. [Google Scholar]
- Qiao, Y.; Yang, Y.; He, J.; Tang, C.; Liu, Z. CBM: Free, Automatic Malware Analysis Framework Using API Call Sequences. In Knowledge Engineering and Management, Proceedings of the Seventh International Conference on Intelligent Systems and Knowledge Engineering, Beijing, China, 15–17 December 2012 (ISKE 2012); Springer: Berlin/Heidelberg, Germany, 2014; pp. 225–236. [Google Scholar]
- Demirkıran, F.; Çayır, A.; Ünal, U.; Dağ, H. An Ensemble of Pre-Trained Transformer Models for Imbalanced Multiclass Malware Classification. Comput. Secur. 2022, 121, 102846. [Google Scholar] [CrossRef]
- Pektaş, A.; Acarman, T. Malware Classification Based on API Calls and Behaviour Analysis. IET Inf. Secur. 2018, 12, 107–117. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Research Paper | Features | Feature Vector and Models |
|---|---|---|
| Nagano et al. (2017) [15] | DLL Imports, Assembly Code, and Hex Dumps | PV-DBOW + SVM, KNN |
| Tran et al. (2017) [14] | API Call Sequences | N-gram, Doc2Vec, TF-IDF + SVM, KNN, MLP and RF |
| Hwang et al. (2020) [37] | API Call Sequences | Markov Chain + RF |
| C Li et al. (2021) [20] | API Call Sequences | RNN |
| Schofield et al. (2021) [16] | API Call Sequences | N-gram. TF-IDF + CNN |
| Rahali et al. (2021) [29] | API Call Sequences | Transformer |
| Baek et al. (2021) [38] | Process Memory, API Category, API Calls | Bi-LSTM, EfficientNet-B3 |
| Li et al. (2022) [21] | API Call Sequences | Embedding Layer + Bi-LSTM |
| Li et al. (2022) [22] | API Call Sequences | Similarity Encoding + GNN |
| Daeef et al. (2022) [23] | API Call Sequences | Frequence Encoding + RF, LSTM |
| Deore et al. (2022) [24] | Hex Features, Disassembled File Features | Similarity Statistical + F-RCNN |
| Yang et al. (2023) [30] | Binary File, Assembly File | Stacked CNN + Regular Attention + Cross Attention |
| Category | Subcategory | Ratio (%) |
|---|---|---|
| Backdoor | 3.37 | |
| Worm | Worm | 3.32 |
| Email-Worm | 0.55 | |
| Net-Worm | 0.79 | |
| P2P-Worm | 0.30 | |
| Packed | 5.57 | |
| PUP | Adware | 13.63 |
| Downloader | 2.94 | |
| WebToolbar | 1.22 | |
| Trojan | Trojan (Generic) | 29.3 |
| Trojan-Banker | 0.14 | |
| Trojan-Clicker | 0.12 | |
| Trojan-Downloader | 2.29 | |
| Trojan-Dropper | 1.91 | |
| Trojan-FakeAV | 18.8 | |
| Trojan-GameThief | 0.63 | |
| Trojan-PSW | 3.79 | |
| Trojan-Ransom | 2.58 | |
| Trojan-Spy | 3.12 | |
| Misc. | 5.52 |
| Category | Subcategory | Ratio (%) |
|---|---|---|
| Backdoor | 27.30 | |
| Worm | Email-Worm | 1.71 |
| Net-Worm | 1.00 | |
| Trojan | Trojan (Generic) | 29.3 |
| Trojan-Banker | 1.61 | |
| Trojan-Clicker | 1.90 | |
| Trojan-Downloader | 18.46 | |
| Trojan-Dropper | 7.18 | |
| Trojan-GameThief | 18.11 | |
| Trojan-PSW | 8.47 | |
| Trojan-Proxy | 1.23 | |
| Trojan-Spy | 8.40 | |
| Virus | 1.77 | |
| Exploit | 1.07 | |
| Rootkit | 0.50 | |
| HackTool | 1.28 |
| Methods | Features | Samples | Families | Accuracy |
|---|---|---|---|---|
| Malware Image + GIST [44] | File content | 63,002 | 531 | 0.7280 |
| Malware Image + CNN [45] | File content | 10,868 | 9 | 0.9176 |
| Malware Image + GRU-SVM [46] | File content | 9339 | 25 | 0.8492 |
| BBIS + CARL [47] | API calls | 3131 | 28 | 0.8840 (F1) |
| NLP(TF-IDF) + SVM [14] | API calls | 23,080 | 10 | 0.8654 |
| Category Vector + CNN [16] | API calls | 23,080 | 10 | 0.8797 |
| Frequence Vector + RF [23] | API calls | 23,080 | 10 | 0.8005 |
| Embedding + RNN [20] | API calls | 23,080 | 10 | 0.8690 |
| Encoder (Embedding + CNN) + Bi_LSTM [21] | API calls | 23,080 | 10 | 0.9021 |
| Random Transformer Forest [48] | API calls | 23,080 | 10 | 0.9330 |
| Ours | API calls | 23,080 | 10 | 0.9606 |
| Methods | Features | Samples | Families | Accuracy |
|---|---|---|---|---|
| Category Vector + CNN [16] | API calls | 33,240 | 16 | 0.7782 |
| Frequence Vector + RF [23] | API calls | 33,240 | 16 | 0.6685 |
| Embedding + RNN [20] | API calls | 33,240 | 16 | 0.8690 |
| Voting Experts + Confidence Weighted [49] | API calls, Actions | 33,240 | 16 | 0.8570 |
| Encoder (Embedding + CNN) + Bi_LSTM [21] | API calls | 33,240 | 16 | 0.8051 |
| Random Transformer Forest [48] | API calls | 33,240 | 16 | 0.8703 |
| Ours | API calls | 33,240 | 10 | 0.8859 |
| Encoder | Accuracy |
|---|---|
| Transformer encoder | 0.7719 ± 0.0049 |
| DAT encoder with | 0.8073 ± 0.0047 |
| DAT encoder with | 0.8368 ± 0.0038 |
| DAT encoder with | 0.8191 ± 0.0067 |
| DAT encoder with | 0.8075 ± 0.0084 |
| DAT encoder with | 0.8079 ± 0.0045 |
| DAT encoder with | 0.8032 ± 0.0030 |
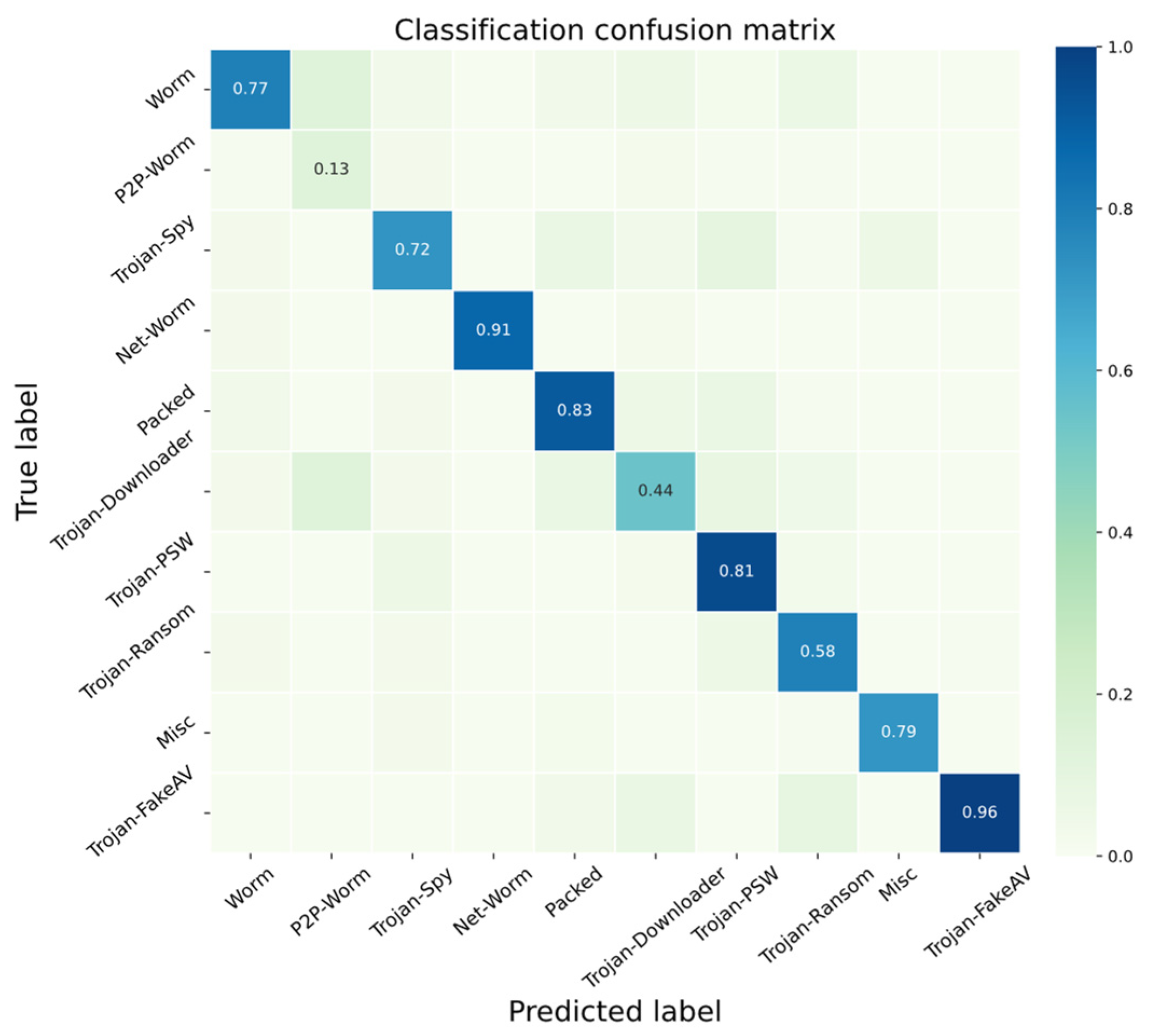
| Category | F1-Score | Support | Overall Accuracy |
|---|---|---|---|
| Worm | 0.78 | 81 | 0.8368 |
| P2P-Worm | 0.12 | 8 | |
| Trojan-Spy | 0.72 | 81 | |
| Net-Worm | 0.92 | 20 | |
| Packed | 0.84 | 145 | |
| Trojan-Downloader | 0.45 | 57 | |
| Trojan-PSW | 0.82 | 99 | |
| Trojan-Ransom | 0.58 | 67 | |
| Misc | 0.80 | 20 | |
| Trojan-FakeAV | 0.96 | 487 |
| Category | F1-Score | Overall Accuracy |
|---|---|---|
| Worm | 0.81 | 0.8700 |
| P2P-Worm | 0.20 | |
| Trojan-Spy | 0.79 | |
| Net-Worm | 0.84 | |
| Packed | 0.89 | |
| Trojan-Downloader | 0.55 | |
| Trojan-PSW | 0.93 | |
| Trojan-Ransom | 0.72 | |
| Misc | 0.47 | |
| Trojan-FakeAV | 0.98 |
| Category | F1-Score | Overall Accuracy |
|---|---|---|
| Worm | 0.89 | 0.92 |
| P2P-Worm | 0.29 | |
| Trojan-Spy | 0.88 | |
| Net-Worm | 0.78 | |
| Packed | 0.93 | |
| Trojan-Downloader | 0.71 | |
| Trojan-PSW | 0.96 | |
| Trojan-Ransom | 0.85 | |
| Misc | 0.55 | |
| Trojan-FakeAV | 0.99 |
| Category | F1-Score | Overall Accuracy |
|---|---|---|
| Worm | 0.95 | 0.96 |
| P2P-Worm | 0.62 | |
| Trojan-Spy | 0.93 | |
| Net-Worm | 0.95 | |
| Packed | 0.99 | |
| Trojan-Downloader | 0.90 | |
| Trojan-PSW | 0.95 | |
| Trojan-Ransom | 0.91 | |
| Misc | 0.83 | |
| Trojan-FakeAV | 0.99 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, P.; Lin, T.; Wu, D.; Zhu, J.; Wang, J. TTDAT: Two-Step Training Dual Attention Transformer for Malware Classification Based on API Call Sequences. Appl. Sci. 2024, 14, 92. https://doi.org/10.3390/app14010092
Wang P, Lin T, Wu D, Zhu J, Wang J. TTDAT: Two-Step Training Dual Attention Transformer for Malware Classification Based on API Call Sequences. Applied Sciences. 2024; 14(1):92. https://doi.org/10.3390/app14010092
Chicago/Turabian StyleWang, Peng, Tongcan Lin, Di Wu, Jiacheng Zhu, and Junfeng Wang. 2024. "TTDAT: Two-Step Training Dual Attention Transformer for Malware Classification Based on API Call Sequences" Applied Sciences 14, no. 1: 92. https://doi.org/10.3390/app14010092
APA StyleWang, P., Lin, T., Wu, D., Zhu, J., & Wang, J. (2024). TTDAT: Two-Step Training Dual Attention Transformer for Malware Classification Based on API Call Sequences. Applied Sciences, 14(1), 92. https://doi.org/10.3390/app14010092