Abstract
Achieving automatic question-and-answering for agricultural scenarios based on machine reading comprehension can facilitate production staff to query information and process data efficiently. Nevertheless, when studying agricultural question-and-answer classification, there are barriers, such as small-scale corpus, narrow content range of corpus, or the need for manual annotation. In the context of such production needs, this paper proposed a text classification model based on text-relational chains and applied it to machine reading comprehension and open-ended question-and-answer tasks in agricultural scenarios. This paper modified the BERT network based on semi-supervised and contrastive learning to enhance the model’s performance. By incorporating the text-relational chains with the BERT network, the Chains-BERT model is constructed. Our efficient mode method outperformed other methods on the CAIL2018 dataset. Ultimately, we developed an automatic question-and-answering application to embed the contrastive-learning information aggregation model in this paper. The accuracy of the proposed model exceeded that of several contrasting mainstream models in many open-source datasets. In agricultural scenarios, the model has achieved state-of-the-art levels and is the best in efficiency.
1. Introduction
As the process of informatization in agriculture continues to advance, increasingly more intelligent applications and services have emerged, such as fruit-picking robots, automatic plant disease detection applications [1,2,3], remote sensing field image processing [4], etc. The way to answer the questions of agricultural workers in production has gradually shifted from offline consultation to online. Machine reading comprehension (MRC) is a text-based question-and-answer task (Text-QA), and is a promising research direction in the field of artificial intelligence and natural language processing. It enables computers to help humans find the desired answers in a large amount of text, providing efficient and convenient services to users, thus reducing the cost of people’s access to information. Based on machine reading comprehension to realize automatic question-answering of agricultural scenes, it can improve the processing efficiency of data and facilitate the subsequent research related to the question-answering (QA) system, which is of great significance to the informatization of the agricultural field.
Currently, machine learning is widely used in various fields. Making machines accomplish reading comprehension and question-answering is currently a rather hot topic at the forefront of the artificial intelligence community, mainly involving deep learning, natural language processing, and information retrieval. Previous researchers have optimized different aspects of machine reading comprehension techniques to achieve breakthroughs. Lifu Huang et al. [5] introduced COSMOS QA, a large-scale dataset containing 35,600 reading comprehension questions that require common sense. The dataset is expressed in a multiple-choice format. It focuses on various collections of people’s everyday narratives. They experimented with several state-of-the-art neural architectures and proposed a new architecture that can improve the competing baselines. Finally, the baseline performance of COSMOS QA was established. An Yang et al. [6] investigated the potential of using external knowledge bases (KBs) to further improve the BERT model of MRC. They introduced a self-adaptive KT-NET structure to select the desired knowledge from KBs, then fused it with BERT to achieve contextual and knowledge-aware prediction. The KT-NET provided consistent and significant improvements over BERT, outperforming competing benchmarks on the ReCoRD and squadron 1.1 benchmarks. Zhuosheng Zhang et al. [7] applied syntax to instruct the text modeling by blending syntactic constraints into the attention mechanism. They introduced syntactic dependency of interest into the self-attention network to establish an SDOI-SAN with syntax-guided self-attention. This design can possess better linguistically motivated word representations. Ample experiments demonstrated that the proposed SG-Net facilitates powerful performance.
These high-performance machine reading comprehension techniques have also been used in all kinds of domains to meet different needs. Shuyang Gao et al. [8] suggested using MEC in state tracking from datasets and model architectures. This innovation solved the challenge that existing methods require conversation data with state information and have limited ability to generalize to unknown domains. Ryota Tanaka et al. [9] introduced a new visual machine reading comprehension dataset called VisualMRC. In this dataset, the machine will read and understand the given text in the image to answer the question in natural language. VisualMRC focuses more on developing natural language comprehension and generation capabilities. Experiments show that VisualMRC outperforms the basic sequence-to-sequence model and the state-of-the-art VQA model.
However, there are problems, such as a small corpus, a narrow range of corpus contents, or the need for manual annotation, in the study of agricultural question classification. Agricultural practitioners prefer the web to the traditional way of consulting experts on agricultural production techniques. At the same time, web data are complex and confusing, making it challenging to get the appropriate results. In the context of such production requirements, it is crucial to construct a model for machine reading comprehension and automatic question-answering scenarios applicable to agricultural production. In this paper, we proposed a text classification model based on text-relational chains and applied it to machine reading comprehension and open-ended QA tasks in agricultural scenarios. In order to improve the model effect, we modified the BERT network and developed an application to embed the presented model. The main contributions of this paper are as follows:
- Proposed a text model based on textual relational chains.
- Modified the BERT network based on semi-supervised and contrastive techniques.
- Applied extensive experimental validation on open-source datasets.
- Developed an application for the model so that it can be applied in agricultural scenarios.
The subsequent parts of this article are organized as follows: Section 2 introduces the development, tasks, and methods of machine reading comprehension. Section 3 analyzes the datasets employed in this paper and presents applied and suggested methods. Section 4 displays the experiment platform and evaluation metrics. Section 5 gives experimental outcomes and discusses these results. Section 6 summarizes the whole work and provides ideas for future works.
2. Related Works
Machine reading comprehension (MRC) is a classical task in natural language processing (NLP). It requires the machine to fully understand the linguistic meaning of co-text and then answer the question. MRC is of great practical significance. From the industrial side, MRC is the core technology of many products. In a search engine, for example, a machine can read a document and answer a user’s query. In intelligent customer service, machines can answer questions from users. Academically, MRC measures how well a machine understands natural language. All in all, MRC is an auspicious task.
2.1. Machine Reading Comprehension Development
Early MRC systems can be traced back to the 1970s when Lehnert proposed the famous QUALM system [10]. However, due to its scale and field limitations, it has not been widely used. In the 1980s and 1990s, research on MRC fell into disuse. In 1999, Hirschman et al. presented a dataset of 60 stories [11], which brought renewed attention to MRC. At that time, approaches to MRC were limited to rule-based approaches [12,13]. Although these methods have strong interpretability, they cannot understand the semantic information of the text and primarily rely on the rules and features designed by experts, so they do not achieve good results.
From 2013 to 2018, researchers began formalizing MRC as a supervised learning task and using manual annotation methods to construct datasets. In 2013, MCTest [14] was released as a multiple-choice reading comprehension dataset, which was of high quality, whereas it was to small to train neural models. In 2015, CNN/Daily Mail [15] and CBT [16] were released. These two datasets are generated automatically from different domains and are much larger than previous datasets. In 2016, SQuAD [17] was launched as the first large-scale dataset with questions and answers written by humans. Then, in the same year, other datasets with high quality were constructed [18]. Within the next three years, various datasets from different domains sprung up [19,20,21,22,23], making training an end-to-end MRC model possible.
Since 2018, there has been tremendous change in solving MRC tasks. Along with the release of larger datasets, neural MRC, built by fully developed deep-learning techniques, shows its great superiority over traditional rule-based and machine-learning-based MRC and has gradually become the mainstream in the research community. Neural MRC methods based on deep learning can capture the semantic information of text to a certain extent, such as Math-LSTM [24], BiDAF [25], and QANet [26]. These models go far beyond traditional approaches. In recent years, with the advent of large-scale pre-trained language models such as BERT [27], MRC has made remarkable progress and even surpassed human performance on some datasets.
2.2. MRC Tasks
Machine reading comprehension is a primary task of the question-answering system. It provides relevant context to each question to infer the answer. Machine reading comprehension aims to extract the correct answer from a given context and even generate more complex answers based on the context. Analogous to the process of human reading comprehension, at present, machine reading comprehension can be divided into four types: cloze, multiple choice, span extraction, and free answer. In the following sections, each type of task is described in turn.
2.2.1. Cloze Tests
The cloze MRC usually takes a paragraph of text and removes a word or sentence from the text. The contents omitted from the text are usually nouns or entities, and the machine needs to pick the correct answer from the candidate words or sentences to fill the gap after fully understanding the context. This test method was proposed by linguists in 1953 [28]. The cloze MRC not only examines the machine’s language modeling ability but also the profound reasoning ability. A typical case of cloze-type MRC is shown in Figure 1.

Figure 1.
Cloze-type MRC [29].
2.2.2. Multiple Choice
There are three core components in a multiple-choice MRC task: document, question, and candidate. The document is usually a given text containing several sentences. For each question, multiple candidates are provided, and usually, only one option is the correct answer. After reading a given document, the system is asked to choose the correct answer from a list of candidates for the question given. A typical example of a multiple-choice MRC is shown in Figure 2.

Figure 2.
Multiple-choice MRC [14].
2.2.3. Span Extraction
Unlike the above two types of reading comprehension, this type of MRC has no candidate answer after a given question and needs to extract a piece of continuous text from the document as the answer. Specifically, given the context and the question, the machine needs to find a start position and an end position based on the question, with the text segment between the start position and the end position as the answer. In recent years, span extraction has become the most widely studied reading comprehension task. A typical example of span-extraction MRC is shown in Figure 3.

Figure 3.
Span-extraction MRC [17]. Color fonts represent the answers of questions.
2.2.4. Free Answering
The above three types of MRC tasks are limited to a single context, which is unusual in real life. Freestyle question answering requires the machine to be able to reason and summarize the answer in multiple contexts for a given question. Therefore, the free-answer task is the most complex of the four tasks and is more suitable for realistic application scenarios. The free answer usually contains only the context and the question, and the machine needs to generate the answer to the question based on the context, which can be either a span in the context or text that does not appear in the context. A typical case of free-response MRC is shown in Figure 4.

Figure 4.
Free-answer MRC [20].
2.3. Open Evaluation Datasets
Datasets are an essential driver to accelerate the development of the field of MRC. Some of these datasets, such as CNN & Daily Mail [15], SQuAD [17], and MSMARCO [18], can be seen as milestones in MRC, facilitating the emergence of the latest technologies. In this section, we present several representative datasets for each MRC task, as detailed in Table 1.

Table 1.
Public datasets for machine reading comprehension.
3. Materials and Methods
3.1. Dataset Analysis
The dataset used in this paper was collected from the Agricultural Information Database of China Agricultural University and the Shandong Farm Manager App database. The dataset contains a total of 145,318 agricultural scenes, including topics such as animal husbandry, plant protection, and fine agriculture. The annotation of the database was accomplished by undergraduate and graduate students with relevant expertise from the College of Information and Electrical Engineering, College of Agronomy and Biotechnology, College of Plant Protection, and College of Biological Science of China Agricultural University.
3.2. Methods
In this paper, we proposed a contrastive learning approach based on text matching, which achieved higher accuracy while consuming the same amount of computing power as traditional methods.
3.2.1. Text Model Based on the Textual Relation Chain
In this paper, we proposed a method for the relation chain of different texts. Specifically, we considered labels as a sequence and constructed a chain relationship between labels based on this sequence. It is like the context in a sentence, as shown in Figure 5.
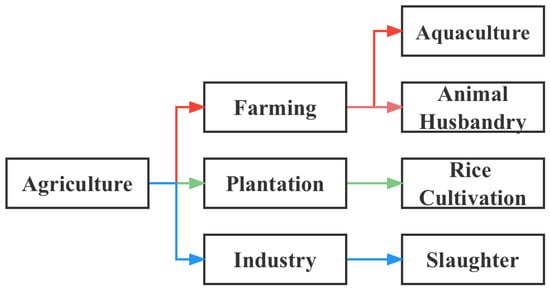
Figure 5.
Textual relation chain.
In order to make this text structure based on chained representations processable by BERT networks, we then adapted the training process of BERT networks.
The model was first trained to learn the generic text representation by MLM (Mask Language Model) and NSP (Next Sentence Prediction) using a large-scale unlabeled corpus. Then the model parameters were fine-tuned on a specific downstream task dataset. In this training paradigm, the model parameters are no longer randomly initialized but have been integrated with generic knowledge. BERT has Base (12-layer Transformer as the encoder) and Large versions (24-layer Transformer as the encoder) according to the size of the model parameters, and cased (case sensitive) and uncased (case insensitive) versions according to whether they are case-sensitive or not, as shown in Figure 6.
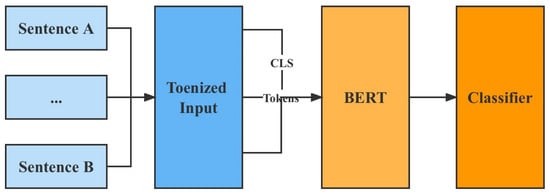
Figure 6.
Training process of the BERT network.
3.2.2. Optimization for BERT
To improve the accuracy of the model, this paper used the original BERT model as the fixed feature providing model and the BERT model to be fine-tuned as the representation model to be trained . The pairing of the representation vector obtained by pooling the output of the same sentence at each Transformer layer of , and its representation vector at the CLS label obtained after , was used as a positive example. In contrast, the pairing between the representation vectors obtained from different sentences was used as a negative example for contrastive learning, as shown in Figure 7.

Figure 7.
The structure of the BERT sentence encoder.
In the word embedding session, we added words that did not appear more than two times in BERT’s original word list to the word embedding by random initialization. In the encoding model of labels, we also used BERT to encode the text of labels or their descriptions. Then we add chain information to the encoding of labels. Finally, we encoded the label sequences by a Bi-LSTM. The overall flow of the model is shown in Figure 8.
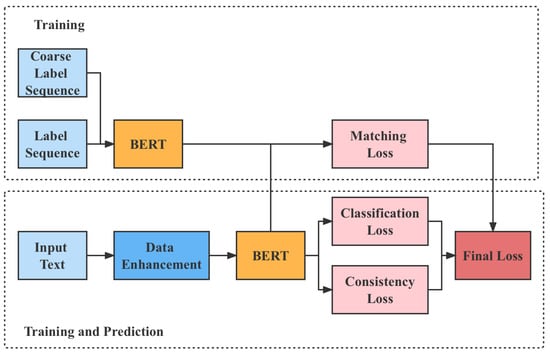
Figure 8.
The structure of the classification model.
3.2.3. Semi-Supervised
As unsupervised learning, semi-supervised learning aims to learn a generic feature representation for downstream tasks. In the classification task, we cannot determine the class of unlabeled samples. However, based on common sense, we can assume that the following basic assumptions hold for most tasks:
- Smoothness assumption: If two samples, and , are similar, their corresponding output representations, and , should also be close to each other. Conversely, if the two samples, and , are different, their corresponding output representations, and , should also be far apart.
- Clustering hypothesis and low-density hypothesis: The sample data should be clustered into clusters, and each cluster of samples corresponds to a subclass. In other words, similar samples are always densely clustered in one area, and the boundary line of classification is always located at the place where the sample density is low. Therefore, it can be assumed that if two samples, and , are very similar, they are of the same kind, and the classification boundary will not be located between them.
- The stream shape assumption: The input control consists of multiple low-dimensional stream shapes, all samples are located in a stream shape, and the data points located on the same stream shape have the same classification labels.
In this paper, we use two semi-supervised learning methods:
- Agent labeling-based semi-supervised learning method.Proxy labels are high-confidence labels derived from the classification of the model itself, which are mixed into the labeled samples to provide additional information to assist in the subsequent training steps. However, these proxy labels are usually noisy and not fully accurate.Further, semi-supervised learning methods based on agent labels can be subdivided into self-supervised learning methods and multi-view learning methods. The self-supervised learning method first uses the labeled data to train the model, then uses the trained model to classify the unlabeled samples, removes the part of the classification confidence above a certain threshold, adds it to the labeled samples, then retrains the model and repeats this step until all the unlabeled samples have been added to the labeled samples.The multi-view learning approach involves training several models with different parameters, each with a higher confidence level of unlabeled samples classified by other models in addition to the labeled dataset. The classical methods are the Co-training and Tri-training.Co-training divides the labeled dataset into two and trains the two classification models separately. Each classification model adds its own unlabeled samples with confidence higher than a certain threshold to the training set of the other classification model and then repeats the training until all unlabeled samples have been added to both training sets.Tri-training is performed by taking three training sets from the originally labeled samples with put-back sampling, and training three models separately, and then each model adds the unlabeled samples judged by the other two models to its own training set, and then repeats the training until all the unlabeled samples have been added to the three training sets.
- Consistency-based semi-supervised learning method.The consistency-based semi-supervised learning method mainly utilizes the clustering assumption/low-density assumption, i.e., two extremely similar samples belong to the same class, regardless of the possibility that the classification boundary may cross the high-density region between them. Thus, for sample x, a certain perturbation can be made to produce , and it is assumed that x and must belong to the same classification.We assume that a slight perturbation does not change the classification of a sample, so for the same sample x, and are obtained by applying different dropouts and random data augmentation, respectively, by the model operation, and the results of the two operations are and with a certain weight added to the final loss function, as shown in Equation (1),where w is the weight of the consistency loss, is the unlabeled dataset, is the labeled training set, f is the classification model, H is the classification loss function, and refers to the mean square error.
3.2.4. Contrastive Learning and Information Aggregation Method
This section discusses the incorporation of contrastive learning and information aggregation method, as shown in Figure 9.
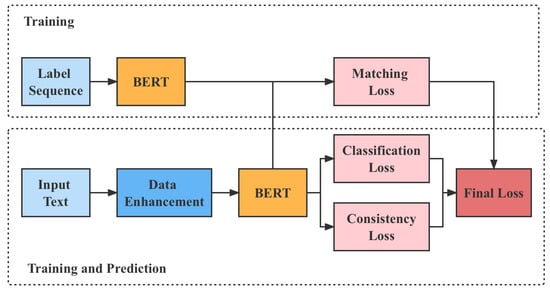
Figure 9.
Structure of information improved by contrastive learning.
By adjusting the hyperparameters, this section will be discussed in Section 4.3; it is proven that the two methods are compatible and can be superimposed on each other. The superimposed methods achieve better results than the two methods alone on CAIL2018. Moreover, the combined method achieves the best results, as shown in Table 2.
Table 2.
Superimposed experiments based on CAIL2018.
4. Experiments
4.1. Platform
The test device is a desktop computer with a Core i9-10900k CPU and Nvidia RTX3080 GPU. In the training process, the experiments were run on Ubuntu 20.14, using the Python programming language, and the model implementation was based on the PyTorch framework.
4.2. Evaluation Index
For different MRC tasks, there are different assessment indicators. For cloze and multiple-choice, the most common evaluation index is accuracy. For fragment extraction, the model’s performance is evaluated by calculating the exact matching (EM) and values. The widely used evaluation metrics are micro-F1 and macro-F1 because the answers of the free answer are not limited to the context. In this section, we describe these evaluation metrics in detail.
4.2.1. Accuracy and F1 Score
Accuracy based on correct answers is often used in cloze tests and multiple choice evaluations. Given a problem set with m problems if the model accurately predicts the answers to n questions.
Exact matching () is a variant of accuracy often used in span-extraction MRC. Specifically, an exact match indicates whether the predicted answer exactly matches the standard answer. The value is 1 if the predicted answer matches the standard answer and 0 otherwise.
value is a critical evaluation index in the classification task. In MRC, is often used in span extraction tasks; it can be calculated using Equation (2).
Suppose S is the model’s predicted answer and T is the standard answer. shows the text length of the predicted answers, and shows the length of the accurate answers. shows the length S overlapped with T. For Equation (2), the calculation of the and are shown in Equations (3) and (4).
Compared to the value, the value is used to measure the degree of textual overlap between the model’s predicted answer and the standard answer. The value of all QA pairs in the dataset is averaged, which is the value of the whole dataset.
4.2.2. Micro-F1 and Macro-F1
The micro-F1 is the micro value. Considering the multi-label classification as n binary classifications, there are n confusion matrices. Then we can calculate the (True Positive), (False Positive), and (False Negative) of n categories. Thus we can sum up these metrics to get the overall , , and , so as to find the overall Precision and Recall and then find the micro-F1 value. The calculation process is shown in Equations 5-6.
Therefore, the value calculated based on the above and is the , as shown in Equation (7).
In contrast, macro-F1 is precisely the arithmetic average of calculated by first finding the of all classes and then calculating it directly. The procedure is shown in Equations (8)–(10).
Therefore, in the case of multiple classifications, it is necessary to decide depending on the number of different classes in the dataset:
- Typically, if the amount of data in the dataset is unbalanced for each class and all classes are equally important, then using macro-F1 will work; because macro-F1 is calculated by class and then takes the average F1 as the final value. In comparison, micro-F1 will approximate the F1 of the category with the largest amount of data under extremely unbalanced data, which is not a good measure of the overall effect of the model.
- If we need to focus on weak categories in an unbalanced dataset, weighted-F1 should be utilized, which is a weighted average of macro-F1, and the weight is the weight of category numbers to the overall number.
4.3. Hyperparameters Analysis and Two Mode
In this section, we will discuss how we set up the hyperparameters in our model. Specifically, this includes the number of batch sizes, the number of hidden layers, and other parameters. For the batch size, the larger the number, the better the model is trained in theory, so we set it to the maximum value, i.e., 64, as far as the graphics memory of the card can support, and we also performed experiments to verify, as shown in Table 3. For the setting of hidden layers and other parameters, we refer to the work in [33].
Table 3.
Verification experiments on batch size from the MCTest dataset.
In addition, for some scenarios, such as control scenarios, where real-time is more important, we have stripped the information integration branch and named it efficient mode, while the corresponding mode with all functions is called performance mode.
5. Results and Discussion
5.1. Results
From Table 4, we can see that our efficient mode method outperforms other methods on the CoLA dataset, and the operational efficiency is much higher than that of the other methods. It is close to that of the improved multi-label text classification method using BERT as the text encoder.
Table 4.
Comparisons for different methods based on the CoLA dataset.
As shown in Table 5, the MCTest dataset has a shallow level of labels, and the problem more closely resembles a traditional multi-label text classification problem.
Table 5.
Comparisons for different methods based on the MCTest dataset.
5.2. Discussion
5.2.1. Ablation Experiments for Contrast Learning
This paper conducted ablation experiments on the RCv1 dataset to verify the situation without the two contrastive learning text-matching auxiliary loss functions.
As shown in Table 6, both auxiliary loss functions for contrastive learning text matching enable the model to better use the relationships between labels and the text description information of the labels themselves, which plays a vital role in the text classification task.
Table 6.
Ablation experiments based on contrastive learning.
5.2.2. Agricultural QA Scenario Test
In order to solve the problem of low accuracy of the question-answering system in the agricultural scenario, we applied the proposed information aggregation model to machine reading comprehension datasets for testing and received the following results in Table 7.
Table 7.
Testing results by applying the proposed model to agricultural datasets.
From Table 7, we can see that our model’s and metrics outperform the original BERT model. Such model performance indicates that the proposed method can achieve automatic problems in agricultural scenarios. Figure 10 shows the application after deploying our model to the wechat platform.
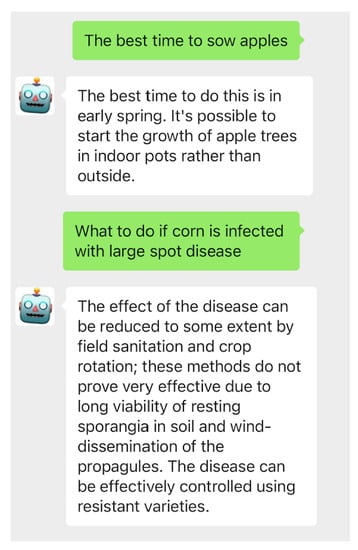
Figure 10.
Screenshot of automatic question-and-answering in agricultural scenarios based on the wechat platform.
5.2.3. Future Work
First, the current text classification methods still essentially treat categories as mere labels and model each category by the samples in the category, even with semantic matching, as an auxiliary loss function. Therefore, they require a certain amount of the training set in the domain and cannot be directly transferred to a text classification task at other levels without a training set. In real-life text classification tasks, the application scenarios are very diverse, and it is not possible to manually label the data for each specific application scenario in a short period of time, given the high cost of manual labeling. This requires a model with good migration capability, which can be applied to another domain at a low cost by training in one domain, and this will be the next research direction of the authors.
6. Conclusions
Machine realizing machine reading comprehension and question-and-answering are hot topics in the current artificial intelligence field. Applying question-and-answering in agriculture can facilitate data management and practical query use. Therefore, this paper presented a text model based on a textual relation chain to achieve high-performance automatic question-and-answering in agricultural scenarios. In order to improve the effectiveness of the model, we modified the BERT network: the semi-supervision and contrastive techniques were introduced into BERT, and a large number of test experiments and ablation experiments were undertaken based on many datasets. The main contributions of this paper are as follows:
- We proposed a text model based on the chain of textual relations.
- We modified the BERT grid based on semi-supervised and contrastive techniques.
- We used extensive experimental validation on open-source datasets.
- We designed a low-computing-power model for edge-computing scenarios and finally deployed it using an information aggregation method based on contrastive learning.
- We developed applications for the model to be used in agricultural scenarios. The application is capable of providing detailed instructions for planting after being questioned. For example, it can answer the appropriate time to plant vegetables or fruit. In addition, the automatic question-and-answering system will deliver proper treatment for a specific plant disease.
The accuracy of the proposed model can outperform the mainstream models on many datasets. Our method based on contrastive learning reached 86.5 micro-F1, 68.8 macro-F1, and 4.9 classification samples per second on the CAIL2018 dataset. Moreover, it also achieved 84.9 micro-F1, 50.1 macro-F1, and 5.1 classification samples per second on the CoLA dataset. The efficient mode is the best in terms of efficiency. The information aggregation method based on contrastive learning has achieved a state-of-the-art level in the agricultural scenario dataset. Further research will be conducted based on this method to improve the classification effect of agricultural questions.
Author Contributions
Y.H.: Writing—original draft, Writing—review editing, Visualization, Methodology; J.L.: Writing—original draft; Validation; C.L.: Funding acquisition, Project administration, Writing—review editing. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by Natural Science Fund Project in Shandong grant number ZR202102220347.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Acknowledgments
The authors would like to acknowledge the support from Zongrui Li, Ran Ye and Xinai Lu.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Zhang, Y.; Wa, S.; Sun, P.; Wang, Y. Pear Defect Detection Method Based on ResNet and DCGAN. Information 2021, 12, 397. [Google Scholar] [CrossRef]
- Zhang, Y.; Wa, S.; Liu, Y.; Zhou, X.; Sun, P.; Ma, Q. High-Accuracy Detection of Maize Leaf Diseases CNN Based on Multi-Pathway Activation Function Module. Remote Sens. 2021, 13, 4218. [Google Scholar] [CrossRef]
- Zhang, Y.; Wa, S.; Zhang, L.; Lv, C. Automatic Plant Disease Detection Based on Tranvolution Detection Network with GAN Modules Using Leaf Images. Front. Plant Sci. 2022, 13, 875693. [Google Scholar] [CrossRef]
- Lin, X.; Wa, S.; Zhang, Y.; Ma, Q. A Dilated Segmentation Network with the Morphological Correction Method in Farming Area Image Series. Remote Sens. 2022, 14, 1771. [Google Scholar] [CrossRef]
- Huang, L.; Bras, R.L.; Bhagavatula, C.; Choi, Y. Cosmos QA: Machine reading comprehension with contextual commonsense reasoning. arXiv 2019, arXiv:1909.00277. [Google Scholar]
- Yang, A.; Wang, Q.; Liu, J.; Liu, K.; Lyu, Y.; Wu, H.; She, Q.; Li, S. Enhancing pre-trained language representations with rich knowledge for machine reading comprehension. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 2346–2357. [Google Scholar]
- Zhang, Z.; Wu, Y.; Zhou, J.; Duan, S.; Zhao, H.; Wang, R. SG-Net: Syntax-guided machine reading comprehension. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 9636–9643. [Google Scholar]
- Gao, S.; Agarwal, S.; Chung, T.; Jin, D.; Hakkani-Tur, D. From machine reading comprehension to dialogue state tracking: Bridging the gap. arXiv 2020, arXiv:2004.05827. [Google Scholar]
- Tanaka, R.; Nishida, K.; Yoshida, S. Visualmrc: Machine reading comprehension on document images. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021; Volume 35, pp. 13878–13888. [Google Scholar]
- Lehnert, W.G. The Process of Question Answering; Yale University: New Haven, CT, USA, 1977. [Google Scholar]
- Hirschman, L.; Light, M.; Breck, E.; Burger, J.D. Deep read: A reading comprehension system. In Proceedings of the 37th annual meeting of the Association for Computational Linguistics, Stroudsburg, PA, USA, 20–26 June 1999; pp. 325–332. [Google Scholar]
- Riloff, E.; Thelen, M. A rule-based question answering system for reading comprehension tests. In Proceedings of the ANLP-NAACL 2000 Workshop: Reading Comprehension Tests as Evaluation for Computer-Based Language Understanding Systems, Seattle, WA, USA, 4 May 2000. [Google Scholar]
- Poon, H.; Christensen, J.; Domingos, P.; Etzioni, O.; Hoffmann, R.; Kiddon, C.; Lin, T.; Ling, X.; Ritter, A.; Schoenmackers, S.; et al. Machine reading at the university of washington. In Proceedings of the NAACL HLT 2010 First International Workshop on Formalisms and Methodology for Learning by Reading, Los Angeles, CA, USA, 6 June 2010; pp. 87–95. [Google Scholar]
- Richardson, M.; Burges, C.J.; Renshaw, E. Mctest: A challenge dataset for the open-domain machine comprehension of text. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, Seattle, WA, USA, 18–21 October 2013; pp. 193–203. [Google Scholar]
- Hermann, K.M.; Kocisky, T.; Grefenstette, E.; Espeholt, L.; Kay, W.; Suleyman, M.; Blunsom, P. Teaching machines to read and comprehend. Adv. Neural Inf. Process. Syst. 2015, arXiv:1506.0334028. [Google Scholar]
- Hill, F.; Bordes, A.; Chopra, S.; Weston, J. The goldilocks principle: Reading children’s books with explicit memory representations. arXiv 2015, arXiv:1511.02301. [Google Scholar]
- Rajpurkar, P.; Zhang, J.; Lopyrev, K.; Liang, P. Squad: 100,000+ questions for machine comprehension of text. arXiv 2016, arXiv:1606.05250. [Google Scholar]
- Nguyen, T.; Rosenberg, M.; Song, X.; Gao, J.; Tiwary, S.; Majumder, R.; Deng, L. MS MARCO: A human generated machine reading comprehension dataset. In Proceedings of the CoCo@ NIPs, Barcelona, Spain, 9 December 2016. [Google Scholar]
- Trischler, A.; Wang, T.; Yuan, X.; Harris, J.; Sordoni, A.; Bachman, P.; Suleman, K. Newsqa: A machine comprehension dataset. arXiv 2016, arXiv:1611.09830. [Google Scholar]
- Kočiskỳ, T.; Schwarz, J.; Blunsom, P.; Dyer, C.; Hermann, K.M.; Melis, G.; Grefenstette, E. The narrativeqa reading comprehension challenge. Trans. Assoc. Comput. Linguist. 2018, 6, 317–328. [Google Scholar] [CrossRef]
- Joshi, M.; Choi, E.; Weld, D.S.; Zettlemoyer, L. Triviaqa: A large scale distantly supervised challenge dataset for reading comprehension. arXiv 2017, arXiv:1705.03551. [Google Scholar]
- Lai, G.; Xie, Q.; Liu, H.; Yang, Y.; Hovy, E. Race: Large-scale reading comprehension dataset from examinations. arXiv 2017, arXiv:1704.04683. [Google Scholar]
- Xie, Q.; Lai, G.; Dai, Z.; Hovy, E. Large-scale cloze test dataset designed by teachers. arXiv 2017, arXiv:1711.03225. [Google Scholar]
- Wang, S.; Jiang, J. Machine comprehension using match-lstm and answer pointer. arXiv 2016, arXiv:1608.07905. [Google Scholar]
- Seo, M.; Kembhavi, A.; Farhadi, A.; Hajishirzi, H. Bidirectional attention flow for machine comprehension. arXiv 2016, arXiv:1611.01603. [Google Scholar]
- Lyu, A.W.; Dohan, D.; Luong, M.T.; Zhao, R.; Chen, K.; Norouzi, M.; Le, Q.V. Qanet: Combining local convolution with global self-attention for reading comprehension. arXiv 2018, arXiv:1804.09541. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Taylor, W.L. “Cloze procedure”: A new tool for measuring readability. J. Q. 1953, 30, 415–433. [Google Scholar] [CrossRef]
- Paperno, D.; Kruszewski, G.; Lazaridou, A.; Pham, Q.N.; Bernardi, R.; Pezzelle, S.; Baroni, M.; Boleda, G.; Fernández, R. The LAMBADA dataset: Word prediction requiring a broad discourse context. arXiv 2016, arXiv:1606.06031. [Google Scholar]
- Šuster, S.; Daelemans, W. Clicr: A dataset of clinical case reports for machine reading comprehension. arXiv 2018, arXiv:1803.09720. [Google Scholar]
- Dunn, M.; Sagun, L.; Higgins, M.; Guney, V.U.; Cirik, V.; Cho, K. Searchqa: A new q&a dataset augmented with context from a search engine. arXiv 2017, arXiv:1704.05179. [Google Scholar]
- He, W.; Liu, K.; Liu, J.; Lyu, Y.; Zhao, S.; Xiao, X.; Liu, Y.; Wang, Y.; Wu, H.; She, Q.; et al. Dureader: A chinese machine reading comprehension dataset from real-world applications. arXiv 2017, arXiv:1711.05073. [Google Scholar]
- Sahoo, S.P.; Ari, S.; Mahapatra, K.; Mohanty, S.P. HAR-Depth: A Novel Framework for Human Action Recognition Using Sequential Learning and Depth Estimated History Images. IEEE Trans. Emerg. Top. Comput. Intell. 2021, 5, 813–825. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).