
Automatic Extraction of Flooding Control Knowledge from Rich Literature Texts Using Deep Learning


Abstract
:1. Introduction
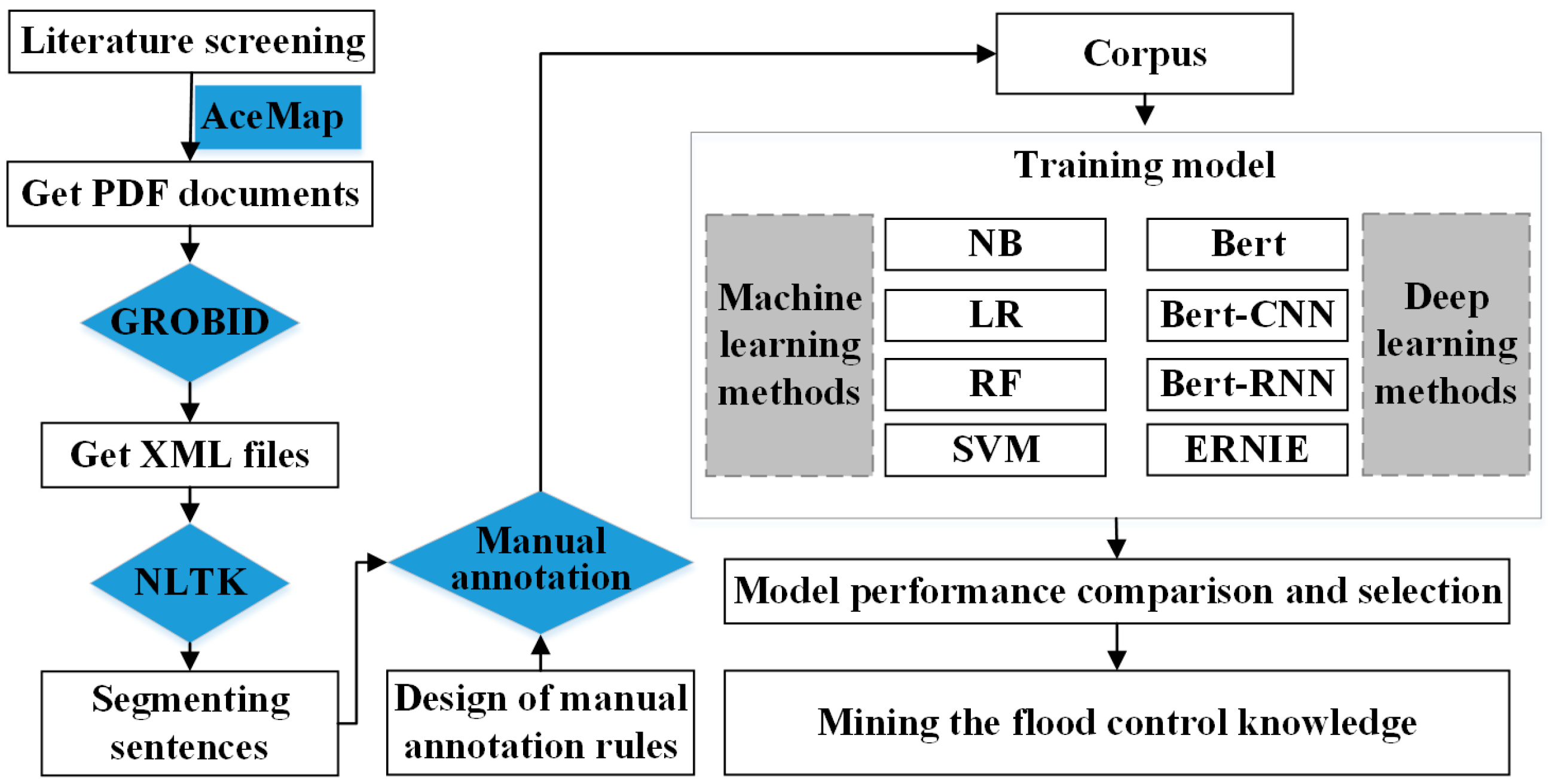
2. Materials and Methods
2.1. Data Acquisition
2.2. Research Methods
2.2.1. PDF Parsing and Text Preprocessing
2.2.2. Manual Annotation Rules for Sentence Classification
2.2.3. Sentence Classification Method
- (1)
- Machine learning methods
- (2)
- Artificial neural network-based deep learning methods
3. Results
3.1. Comparative Analysis of Sentences Classification Models
3.2. Yearwise Distribution Analysis of Research Method Sentences
4. Discussion
4.1. Comparison of Machine Learning and Deep Learning Methods
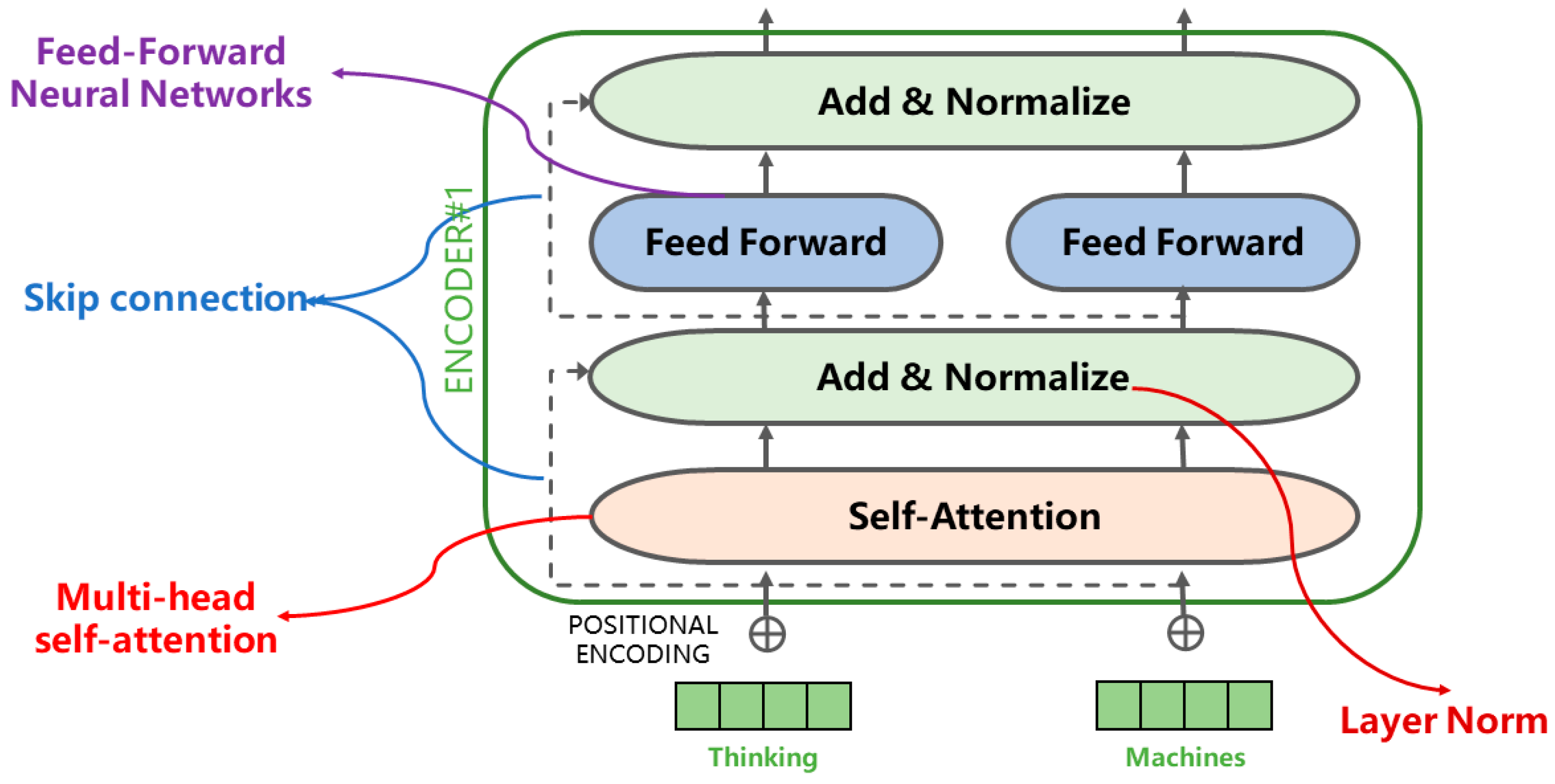
4.2. Analyzing the Deep Learning Method from the Perspective of Principle
4.3. Analysis of the Distribution of Research Method Sentences in Flood Disaster Text
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhang, M.; Wang, J. Global flood disaster research graph analysis based on literature mining. Appl. Sci. 2022, 12, 3066. [Google Scholar] [CrossRef]
- Li, Y. Construction and Application of Natural Disaster Emergency Knowledge Graph-Taking Flood Disaster as an Example. Ph.D. Thesis, Wuhan University, Wuhan, China, 2021. [Google Scholar]
- Jiang, T. A comparative study of term extraction schemes in academic literature. J. Inf. Resour. Manag. 2021, 111, 112–122. [Google Scholar]
- Bornmann, L.; Mutz, R. Growth rates of modern science: A bibliometric analysis based on the number of publications and cited references. J. Assoc. Inf. Sci. Technol. 2015, 66, 2215–2222. [Google Scholar] [CrossRef]
- Li, X.; Wang, Z.; Lu, Q. An extraction method for papers via integration of rules with SVM. Comput. Technol. Dev. 2017, 27, 24–29. [Google Scholar]
- Wiebe, J.; Bruce, R.; O’Hara, T. Development and use of a gold standard data set for subjectivity classifications. In Proceedings of the 37th Annual Meeting of the Association for Computational Linguistics (ACL-99); Association for Computational Linguistics: Stroudsburg, PA, USA, 2000. [Google Scholar] [CrossRef]
- Cui, H.; Huang, C. Rule-based implementation of English sentence classification. Informatiz. Constr. 2015, 11, 180–181. [Google Scholar]
- Hua, X.; Xu, F.; Wang, Z.; Li, P. Fine-grained classification method for abstract sentence of scientific paper. Comput. Eng. 2012, 38, 138–140. [Google Scholar]
- Hayes, P.J.; Andersen, P.M.; Nirenburg, I.B.; Schmandt, L.M. TCS: A shell for content-based text categorization. In Proceedings of the Sixth Conference on Artificial Intelligence for Applications, Santa Monica, CA, USA, 5–9 May 1990; pp. 320–326. [Google Scholar]
- Asghar, M.Z.; Khan, A.; Bibi, A.; Kundi, F.M.; Ahmad, H. Sentence-Level Emotion Detection Framework Using Rule-Based Classification. Cogn. Comput. 2017, 9, 1–27. [Google Scholar] [CrossRef]
- Tan, L.; Phang, W.; Chin, K.O.; Patricia, A. Rule-based sentiment analysis for financial news. In Proceedings of the 2015 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Kowloon Tong, Hong Kong, 9–12 October 2015. [Google Scholar]
- Widyantoro, D.H.; Amin, I. Citation sentence identification and classification for related work summarization. In Proceedings of the International Conference on Advanced Computer Science & Information Systems, Jakarta, Indonesia, 18–19 October 2014. [Google Scholar]
- Liakata, M.; Saha, S.; Dobnik, S.; Batchelor, C.; Rebholz, D. Automatic recognition of conceptualization zones in scientific articles and two life science applications. Bioinformatics 2012, 28, 991–1000. [Google Scholar] [CrossRef]
- Hirohata, K.; Okazaki, N.; Ananiadou, S.; Ishizuka, M. Identifying sections in scientific abstracts using conditional random fields. In Proceedings of the Third International Joint Conference on Natural Language Processing, Hyderabad, India, 7–12 January 2008; pp. 381–388. [Google Scholar]
- Shirsat, V.S.; Jagdale, R.S.; Deshmukh, S.N. Sentence level sentiment identification and calculation from news articles using machine learning techniques. In Proceedings of the ICCASP 2018, Lonere, India, 26–27 January 2018. [Google Scholar]
- Chung, J.; Gulcehre, C.; Cho, K.H.; Bengio, Y. Empirical evaluation of gated recurrent neural networks in sequence modeling. arXiv 2014, arXiv:1412.3555. [Google Scholar]
- Kim, Y. Convolutional neural networks for sentence classification. arXiv 2014, arXiv:1408.5882. [Google Scholar]
- Socher, R.; Perelygin, A.; Wu, J.; Chuang, J.; Manning, C.D.; Ng, A.Y.; Potts, C. Recursive deep models for semantic compositionality over a sentiment treebank. Empirical Methods in Natural Language Processing. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, Seattle, WA, USA, 18–21 October 2013. [Google Scholar]
- Anke, L.E.; Schockaert, S. Syntactically aware neural architectures for definition extraction. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, New Orleans, LA, USA, 1–6 June 2018; pp. 378–385. [Google Scholar]
- Li, X.; Zhang, Z.; Liu, H. Automatic recognition of concept definition sentences based on Bert model. Inf. Sci. 2022, 40, 160–166. [Google Scholar]
- Wang, Z.; Li, C.; Huang, M.; Liu, S. Research on Intelligent Classification Method of Seismic Information Text Based on BERT-BiLSTM Optimization Algorithm. In Proceedings of the 2022 IEEE 2nd International Conference on Computer Communication and Artificial Intelligence (CCAI), Beijing, China, 6–8 May 2022; pp. 55–59. [Google Scholar] [CrossRef]
- Jindal, A.; Gnaneshwar, D.; Sawhney, R.; Shah, R.R. Leveraging BERT with mixup for sentence classification (Student Abstract). In Proceedings of the Processing National Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020. [Google Scholar]
- Zheng, S.; Yang, M. A New Method of Improving BERT for Text Classification. In Proceedings of the 9th International Conference, IScIDE 2019, Nanjing, China, 17–20 October 2019. [Google Scholar]
- Zong, H.; Yang, J.; Zhang, Z.; Li, Z.; Zhang, X. Semantic categorization of Chinese eligibility criteria in clinical trials using machine learning methods. BMC Med. Inform. Decis. Mak. 2021, 21, 128. [Google Scholar] [CrossRef]
- Xu, H.; Zhou, J.; Jiang, T.; Lu, J.; Zhang, Z.; Hu, W. Chinese telephone fraud text recognition based on word embedding and hybrid neural work. Comput. Technol. Dev. 2022, 32, 37–42. [Google Scholar]
- Xia, Z. Research on Chinese Short Text Classification Based on Pre-Trained Language Model; Chongqing University of Technology: Chongqing, China, 2021. [Google Scholar]
- Wang, X.; Li, S.; Yang, Z.; Lin, H.; Wang, J. Chinese knowledge base question answering system based on pre-trained language model. J. Shanxi Univ. Nat. Sci. Ed. 2020, 43, 955–962. [Google Scholar]
- Wang, J.; Kun, B.; Yang, F.; Yuan, Y.; Wei, H. Disaster risk reduction knowledge service: A paradigm shift from disaster data towards knowledge services. Pure Appl. Geo-Phys. 2019, 177, 135–148. [Google Scholar] [CrossRef]
- Wang, J.; Han, X.; Bu, K.; Zhang, M.; Wang, X.; Yuan, Y. Knowledge service system on disaster risk reduction and its application in social media analysis. J. Glob. Chang. Data Discov. 2020, 4, 25–32. [Google Scholar] [CrossRef]
- Zhang, Q.; Zhou, L.; Tang, J.; Fu, L.; Wang, X. Internet of everything: Interconnection, mining and visualization of academic data. Chin. J. Internet Things 2018, 2, 56–60. [Google Scholar]
- Zhang, Y.; Jia, Y.; Fu, L.; Wang, X. AceMap academic map and AceKG academic knowledge graph for academic data visualization. J. Shanghai Jiaotong Univ. 2018, 52, 1357–1362. [Google Scholar]
- Zhou, Y. Research on PDF Structure Analysis Technology of Academic Papers; Hunan University: Changsha, China, 2020. [Google Scholar]
- Bogdan. What’s So Hard about PDF Text Extraction? Available online: https://filingdb.com/b/pdf-text-extraction (accessed on 14 July 2020).
- Xue, H. Information Recognition and Extraction from Chinese Periodical Papers Based on Conditional Random Fields; Chinese Academy of Agricultural Sciences: Beijing, China, 2019. [Google Scholar]
- Zhang, Y.; Zhang, C. Methodological and automatic sentence extraction from academic article’s full-text. J. China Soc. Sci. Tech. Inf. 2020, 39, 640–650. [Google Scholar]
- Zhang, Z.; Wang, Y.; Wang, R. Constructing the corpus of method in the information science domain. Sci. Inf. Res. 2020, 2, 30–45. [Google Scholar]
- Hadipour, V.; Vafaie, F.; Deilami, K. Coastal flooding risk assessment using a GIS-based spatial multi-criteria decision analysis approach. Water 2020, 12, 2379. [Google Scholar] [CrossRef]
- Akbari, R.; Hessami-Kermani, M.R.; Shojaee, S. Flood routing: Improving outflow using a new non-linear muskingum model with four variable parameters coupled with PSO-GA algorithm. Water Resour. Manag. 2020, 34, 3291–3316. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Song, M.; Liu, Y. Application and optimization of Bert in sentiment classification of Weibo short text. J. Chin. Comput. Syst. 2021, 42, 714–718. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Nomponkrang, T.; Sanrach, C. The comparison of algorithms for Thai-sentence classification. Int. J. Inf. Educ. Technol. 2016, 6, 801–808. [Google Scholar] [CrossRef]
- He, C.; Chen, S.; Huang, S.; Zhang, J.; Song, X. Using convolutional neural network with BERT for intent determination. In Proceedings of the 2019 International Conference on Asian Language Processing (IALP), Shanghai, China, 15–17 November 2019. [Google Scholar]
- Luo, P.; Wang, Y.; Wang, J. Automatic discipline classification for scientific papers based on a deep pre-training language model. J. China Soc. Sci. Tech. Inf. 2020, 39, 14. [Google Scholar]
- Zhang, J. Give Up Fantasy and Embrace Transformer: Comparison of Three Feature Extractors (CNN/RNN/TF) for Natural Language Processing. Available online: https://zhuanlan.zhihu.com/p/54743941 (accessed on 8 October 2022).
- Tang, G.; Müller, M.; Rios, A.; Sennrich, R. Why self-attention? A targeted evaluation of neural machine translation architectures. arXiv 2018, arXiv:1808.08946. [Google Scholar]
- Li, Q.; Peng, H.; Li, J.; Xia, C.; Yang, R.; Sun, L.; Yu, P.S.; He, L. A survey on text classification: From shallow to deep Learning. arXiv 2020, arXiv:2008.00364. [Google Scholar]
- Alec, R.; Karthik, N.; Tim, S.; Ilya, S. Improving Language Understanding by Generative Pre-Training. Available online: https://s3-us-west-2.amazonaws.com/openai-assets/research-covers/language-unsupervised/language_understanding_paper.pdf (accessed on 8 October 2022).
- Domhan, T. How much attention do you need? A granular analysis of neural machine translation architectures. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, Melbourne, NSW, Australia, 15–20 July 2018; Volume 1. [Google Scholar]
- Yan, Q. Overview of global catastrophes in 2003. Insur. Stud. 2004, 6, 4. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method Type | Research Methods | References | Methods Evaluation |
|---|---|---|---|
| Rule-based methods | Heuristic rules | Hua et al. [8] | The rule-based method has a high accuracy rate, but a low recall rate, and needs to formulate matching rules in advance. |
| TCL rule base | Hayes et al. [9] | ||
| Rules for the detection and classification of emotion signals | Asghar et al. [10] | ||
| Sentiment composition rules | Tan et al. [11] | ||
| Machine learning methods | Naïve Bayes, complement Naïve Bayes and Decision Tree | Widyantoro et al. [12] | Machine learning methods require more time for feature extraction, and the quality of the feature selection also affects model performance. |
| logistic regression model | Zhang et al. [1] | ||
| SVM and CRF | Liakata et al. [13] | ||
| CRF | Hirohata et al. [14] | ||
| SVMs and NB | Shirsat et al. [15] | ||
| Artificial neural network-based deep learning methods | LSTM and GRU | Chung et al. [16] | Artificial neural network-based deep learning methods have addressed the feature selection problem [17,18,19]. It can automatically obtain feature expression, replace the artificial feature engineering in machine learning methods, and it also has better performance. |
| BERT model | Li et al. [20] | ||
| BERT-BiLSTM | Wang et al. [21] | ||
| BERT, CNN, LSTM | Jindal et al. [22] | ||
| BERT-CNN model, char-CNN, fast Text, DRNN and Bert | Zheng et al. [23] | ||
| LR, NB, KNN, SVM, CNN, RNN, FastText, BERT and ERNIE. | Zong et al. [24] | ||
| Word2vec, ELMo and Bert | Xu et al. [25] | ||
| CNN, BiLSTM, RCNN, BiGRU, BERT, ALBERT | Xia [26] | ||
| Bert, XLNet, RoBERTa, and ERNIE | Wang et al. [27] |
| Dataset | Total Number of Sentences | Number of Non-Research Method Sentences | Number of Usage Method Sentences | Number of Quotation Method Sentences |
|---|---|---|---|---|
| Training set | 4922 | 3123 | 1318 | 481 |
| Validation set | 593 | 383 | 161 | 49 |
| Test set | 684 | 473 | 160 | 51 |
| Model | Acc | F1@0 | F1@1 | F1@2 | Macro_F1 | Weighted_F1 | Loss | Time |
|---|---|---|---|---|---|---|---|---|
| NB | 71.94 | – | – | – | – | – | – | 1 s |
| LR | 73.82 | – | – | – | – | – | – | 1 s |
| RF | 71.40 | – | – | – | – | – | – | 1 s |
| SVM | 76.05 | – | – | – | – | – | – | 5 s |
| Bert | 77.34 | 60.00 | 54.69 | 85.68 | 66.79 | 77.37 | 0.62 | 3:17:43 |
| Bert-CNN | 79.82 | 64.81 | 56.47 | 86.97 | 69.42 | 79.51 | 0.57 | 2:45:29 |
| Bert-RNN | 73.25 | 61.21 | 53.16 | 81.36 | 65.25 | 74.55 | 0.61 | 5:24:18 |
| ERNIE | 81.29 | 67.67 | 64.37 | 87.58 | 73.21 | 81.19 | 0.58 | 2:41:54 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, M.; Wang, J. Automatic Extraction of Flooding Control Knowledge from Rich Literature Texts Using Deep Learning. Appl. Sci. 2023, 13, 2115. https://doi.org/10.3390/app13042115
Zhang M, Wang J. Automatic Extraction of Flooding Control Knowledge from Rich Literature Texts Using Deep Learning. Applied Sciences. 2023; 13(4):2115. https://doi.org/10.3390/app13042115
Chicago/Turabian StyleZhang, Min, and Juanle Wang. 2023. "Automatic Extraction of Flooding Control Knowledge from Rich Literature Texts Using Deep Learning" Applied Sciences 13, no. 4: 2115. https://doi.org/10.3390/app13042115
APA StyleZhang, M., & Wang, J. (2023). Automatic Extraction of Flooding Control Knowledge from Rich Literature Texts Using Deep Learning. Applied Sciences, 13(4), 2115. https://doi.org/10.3390/app13042115