Abstract
Over the last decade, many methods have been developed to address the domain dependency problem of sentiment classification under domain shift. This problem is exacerbated in Arabic by its feature sparsity induced by morphological complexity and dialect variability. However, only a few studies have proposed sentiment domain adaptation methods for Arabic, with inconsistent comparisons resulting from different datasets and settings, making it difficult to identify the most effective approaches. This is the first comparative study of the most effective domain adaptation methods for Arabic sentiment classification. We replicate the existing methods proposed for Arabic and compare their effectiveness on the standard dataset settings. To further examine the extent to which adaptation performance differs between Modern Standard Arabic (MSA) and Dialectal Arabic (DA), we employ two public multi-domain sentiment datasets. We also test two well-established methods that have been thoroughly utilized in English-related studies and examine if they maintain the same levels of performance when applied to Arabic. Our findings indicate that adaptation performanace on MSA is better than on DA for all traditional approaches. However, implementing adaptation on top of transformer-based language models shows superior performance on DA. Finally, methods that have proven to excel in English suffer from low performance when applied to Arabic and exhibit negative transfer in most cases.
1. Introduction
The task of sentiment classification in natural language processing (NLP) involves determining whether a sentiment is positive or negative [1]. Its uses have spread across a wide range of domains, from politics and sports to business and health care. However, a sentiment classifier that has been trained to perform well in one domain may perform worse when applied to another, since sentiment classification is a domain-specific problem [2]. Even with the significant advances made in recent supervised deep learning models, these models still need a large number of labeled samples for training to attain excellent outcomes. Additionally, it is costly and time-consuming to handle domain dependency by annotating samples for every new domain. The use of domain adaptation is valuable for situations in which there are many labeled samples in a field that has been extensively investigated (i.e., a source domain) but none in the field of interest (i.e., the target domain). In such a case, domain adaptation trains a model that is sufficiently resistant to feature mismatch using both the source-labeled and target-unlabeled samples. Feature mismatch denotes differences between the probability distributions of the source and target feature spaces [3]. In other words, people convey their feelings in various ways across domains using different words [4]. As illustrated by Figure 1, the word “delicious” conveys a positive view in the restaurants domain but not in the products domain.
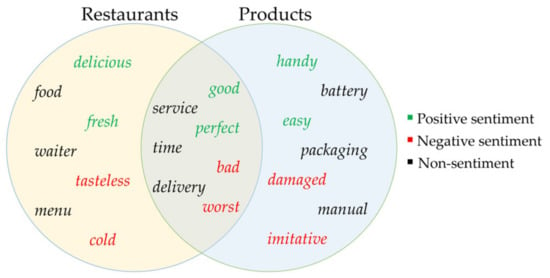
Figure 1.
Examples of different words from two different domains.
Machine learning assumes that training and test sets are drawn from the same underlying distribution. Therefore, a classifier trained on product reviews, for instance, will experience a drop in performance when applied to restaurant reviews due to what is called a domain shift or feature mismatch [5]. By using labeled product reviews and available restaurant reviews (unlabeled), adaptation methods can attempt to train a satisfactory classifier for the restaurants domain. Formally, given that DS = {XS, P(XS)} and DT = {XT, P(XT)} are source and target domains, respectively; XS and XT are the source and target feature spaces, respectively; P(XS) and P(XT) are probability distributions over XS and XT such that P(XS) ≠ P(XT); TS = {YS, PS(YS|XS)} and TT = {YT, PT(YTlXT)} are the source and target tasks, respectively; YS and YT are the source and target label spaces, respectively, such that YS = YT; PS(YS|XS) is the source conditional probability distribution; and SL and TUL are sufficiently labeled data in DS and unlabeled data in DT, respectively. Unsupervised domain adaptation then uses SL and TUL to learn PT(YTlXT), the conditional probability distribution of the target domain. Throughout this study, we use the term “domain adaptation” rather than “unsupervised domain adaptation.” Figure 2 describes the underlying idea behind domain adaptation.
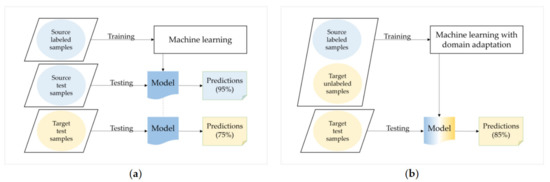
Figure 2.
The underlying idea of domain adaptation: (a) a model that performs well in the source domain but worse when tested in the target domain (e.g., a decline in accuracy from 95% to 75%); (b) domain adaptation attempts to train a satisfactory model for the target domain by adding unlabeled target samples to the process (e.g., an improvement in accuracy from 75% to 85%).
Over the last decade, many domain adaptation methods have been developed to address the domain dependency problem of sentiment classification and other NLP tasks. The current state of domain adaptation for NLP, including its approaches, applications, and challenges, have recently been surveyed [5]. However, there is a scarcity of research on domain adaptation for Arabic texts in general and on sentiment domain adaptation in particular [6]. Unfortunately, the few studies [6,7] that have employed domain adaptation for Arabic sentiment classification are hampered by inconsistent comparisons due to them using different datasets and settings. In contrast, all existing studies on English used the well-known Amazon multi-domain dataset [8] in a unified manner (i.e., binary classes, balanced samples and equal size of each domain), which helped provide a broader understanding and accelerate the accumulation of knowledge. Moreover, it is noteworthy that the domain dependency problem is expected to be more severe in Arabic. Aside from the scarcity of Arabic resources, this can be linked to the sparsity of features created by the language’s morphological richness, which in turn has a negative impact even on in-domain classification accuracy [9]. However, it remains uncertain how different domain adaptation techniques perform in Arabic when compared with their reported performance in English. This gap calls for further experiments and research.
The main objective of the present study is to address the lack of a comparative empirical investigation on domain adaptation techniques for Arabic sentiment classification. We aim to provide a clear understanding of the most effective methods for adapting sentiment classification in Arabic texts by comparing them directly in the same dataset. In addition, we seek to explore the difference in adaptation performance when applied to different types of Arabic texts, namely Modern Standard Arabic (MSA) and Dialectal Arabic (DA), and also when applied to different languages, namely Arabic and English. We achieve these objectives through the following contributions:
- We employ two public multi-domain sentiment datasets (i.e., MSA and DA) in a unified configuration, following previous research in sentiment domain adaptation in English (i.e., binary classification, balanced dataset and equal domain size), allowing for a consistent comparison of methods and assisting future research;
- We replicate the existing domain adaptation methods for Arabic and compare their performance on both MSA and DA;
- We test two of the best-known domain adaptation methods and assess their performance on Arabic, compared with their reported performance on English.
In the present study, we begin by providing a summary of the literature on domain adaptation, outlining the main approaches and listing some examples. Next, we conduct a comparison of two domain adaptation methods for Arabic, namely domain adversarial network with representation learning (DARL) [6] and AraBERT-based adversarial-learned loss for domain adaptation (AraBERT-ALDA) [7], as well as the two well-known adaptation algorithms, domain-adversarial training of neural networks (DANN) [10] and the marginalized stacked denoising autoencoders (mSDA) [11]. We test the effectiveness of these approaches on the large Arabic multi-domain (LAMD) [12] and multi-Domain Arabic resources for sentiment analysis (MARSA) [13] datasets.
The rest of the paper is organized as follows: Section 2 provides background on domain adaptation for sentiment classification and the Arabic language; Section 3 describes the methodology (i.e., the datasets, preprocessing, methods compared, experimental setup, and evaluation metrics); Section 4 presents the experiments conducted and their results; Section 5 further discusses the results obtained; finally, we conclude the paper and highlight gaps and future directions in Section 6.
2. Literature Review
Domain adaptation has been widely used in fields such as computer vision and NLP to take advantage of the remarkable progress that has been made in supervised learning, while simultaneously overcoming the problem of limited labeled data in some domains. In NLP, domain adaptation facilitates a range of tasks, including sentiment classification, part-of-speech (POS) tagging and parsing [5]. Although most proposed adaptation methods are task-independent, some are sentiment-specific. Domain adaptation generally follows either feature-based or instance-based adaptation or a combination of the two.
Feature-based approaches address feature mismatch by attempting to learn a shared feature space between the source and the target domain [14]. Alternatively, some target features can be added to the source domain through feature augmentation. A common concept implemented in these methods is the pivot, which refers to any shared features of the task in both domains [4]. Methodologies in this line include projection learning, feature expansion, and deep learning. Initial forms of projection learning were structural correspondence learning (SCL) [4] and spectral feature alignment [15], which aimed to bridge the differences in distribution between source and target features by learning a domain-invariant shared space. To accomplish the same goal, feature expansion augments source features with borrowed features from the target domain. One method of feature expansion has been implemented using joint sentiment/topic [16] by augmenting polarity-bearing topics extracted from the target domain into the source domain’s feature space [17]. Another method used the sentiment sensitive thesaurus [18], which selects adjectives, adverbs and nouns labeled with their corresponding labels. Their relations to all lexical terms are then assigned using pointwise mutual information to extend each source document with the top related terms. Additionally, a recently applied feature expansion method uses core/periphery decomposition on a weighted graph structure [19]. Under the feature-based deep learning approach, there are autoencoder-based methods and pivot-based methods [5]. Denoising autoencoders (DA) apply representation learning by training networks consisting of an encoder and a decoder to minimize the reconstruction loss after corrupting the original text with noise, typically by scrambling or masking words [20]. Stacked denoising autoencoders (SDA) use multiple DAs to create an invariant feature space with higher-level representation [21]. Though effective, SDA suffers from high computational costs and a limited ability to work with higher-dimensional data. This problem was later addressed through mSDA [11], which considers domain-independent features during reconstructions. Interestingly, the first pivot-based deep learning method combined autoencoders and SCL [22], where non-pivot features were encoded into low-dimensional representations to learn how to predict and reconstruct pivot features. Later, pivot-based language modeling [23] combined SCL with a language model (LM) to predict the presence of pivots instead of following words, leading to context-aware representations. Without needing a pivot selection step, a hierarchical attention transfer network [24] can automatically distinguish between pivots and non-pivots through two hierarchical attention networks, in which a classifier is trained on the shared hidden representations.
Instance-based approaches work on the instance level to reduce domain discrepancy, rather than directly on features. These approaches are domain (or instance) selection, self-labeling and deep learning. The selection methods assign a weight to each source (or instance) based on its similarity to the target domain in such a way that the distance between the source and target domains is minimized [25]. Sometimes, such an approach is used as preparation for the adaptation process [26]. Examples of the weighting and selection approach include positive and unlabeled learning [27] and principal component analysis-based sample selection [28]. In the self-labeling approach, source-labeled data are used to train a model, which is then applied to iteratively predict target pseudo-labels [29]. Moving the training data gradually from the source to the target domain is the idea underlying self-labeling methods. In the first work to employ self-labeling for domain adaptation, expectation-maximization was used to adjust a naive Bayes classifier [30]. The classical self-labeling algorithms of self-training [31], co-training [32] and tri-training [33] were used in later investigations. To increase the duration and spatial complexity of the initial tri-training strategy, a recent study proposed multi-task tri-training [34]. Other, more recent efforts [35,36] have integrated instance-based self-labeling and feature-based representational learning techniques. Traditional graph-based, semi-supervised algorithms, such as RANK [37] and label propagation [38], also provide a method for self-labeling to transfer sentiment between domains. When it comes to learning representations, instance-based deep learning techniques are similar to feature-based ones. However, they vary in that they use domain-adversarial loss rather than autoencoders to reduce domain discrepancies [5]. DANN [10], the earliest and most popular domain-adversarial technique, learns a representation by maximizing the domain classifier’s loss while minimizing that of the source sentiment classifier. By using two memory networks for sentiment and domain, the adversarial memory network [39] combines DANN and the pivot-based approach. Recently, finetuning pretrained LMs on source-labeled samples has been a straightforward adaptation approach [5]. Although it reveals robust cross-domain performance and sometimes surpasses conventional domain adaptation methods, it still suffers from various degrees of performance decline. Thus, a later work proposed adversarial adaptation with distillation (AAD) [40] as a special adversarial domain adaptation method for pretrained LMs. After finetuning a BERT model on the source samples, AAD uses the weights obtained to initialize another BERT model for the target domain and apply both adversarial learning and knowledge distillation. The study found that knowledge distillation (i.e., transferring knowledge from large models to smaller ones) functions as a type of regularization that eases model overfitting on the source samples. Moreover, a new line of approach has emerged that leverages contrastive learning (CL), a type of self-supervised representation learning based on data augmentation. Domain confused contrastive learning (DCCL) [41], for example, utilizes adversarial attack with perturbations to create domain-confused samples from the source and target domains. Next, CL brings the original samples from both domains closer to their domain-confused counterparts; in other words, DCCL gradually pulls samples to the domain decision boundary and hence reduces domain discrepancy. Using a different strategy, contrastive transformer-based domain adaptation [42] trains an adaptor to derive domain-shared features by minimizing the distance between domains and a CL-based discriminator to maintain the domain-specific features.
Domain adaptation for Arabic sentiment classification began with the first work, DARL [6], which combines adversarial learning and the denoising reconstruction paradigm. The results on the ArSentD-LEV multi-domain dataset [43] demonstrated that combining reconstruction loss with adversarial training improved performance somewhat in some circumstances. However, a basic support vector machine (SVM) classifier produced competitive results in some experiments. Furthermore, the paper was the first to put DANN to the test on an Arabic dataset. While DANN outperformed a simple SVM in one-third of the experiments when it was first presented [10], it outperformed it in just one-quarter of those conducted on the ArSentD-LEV dataset. Nonetheless, both the benefits and losses of adaptation were greater and more diverse in Arabic experiments. The authors ascribed the poor performance to imbalanced data as well as to deep neural networks’ failure to learn improved representation from limited data. Moreover, readers should be informed that the ArSentD-LEV dataset was used in its five-point classes (i.e., highly positive, positive, neutral, negative and highly negative), whereas the English Amazon dataset was used in a binary classification. In this paper, we employ a different dataset with standard conditions to discover the real adaptive behavior of methods on Arabic. Another study [7] applied the ALDA [44] on top of the pretrained AraBERT language model [45]. ALDA was initially developed by combining two types of methods, namely domain-adversarial learning to align source and target distributions and self-training to learn discriminative target features. To learn high-level representations, the authors utilized contextualized word embedding. The study employed two datasets for the cross-domain experiments: the ArSentD-LEV multi-domain dataset again, but with binary classes, and three different datasets combined as three domains, namely book reviews, hotel reviews and tweets. Based on the overall results, AraBERT-ALDA beat DANN and DARL.
It is worth mentioning that Arabic is the official language of 28 countries and the fourth most-used language on the Internet, with around 237 million users (https://www.internetworldstats.com/stats7.htm, accessed on 1 November 2022). There are three types of Arabic: Classical Arabic, MSA and DA [46]. Classical Arabic is the old Arabic language and the same as the language found in the holy Quran, in which most words and phrases are no longer commonly used. MSA is the unified formal Arabic among Arabic speakers and is used in Arabic schools and official news channels. DA is the language used in daily conversations, and it varies among countries and even within a single country. In contrast to MSA, DA does not adhere to strict grammtical rules, and it sometimes use words from other languages. Among dialects, many words are pronounced differently or are even unique to a single dialect. The variety of DA imposes a special challenge for Arabic NLP, in addition to other complexities caused by resource scarcity and the morphological richness of the Arabic language [47]. All these difficulties are expected to be exacerbated in domain shift scenarios, affecting even the most effective domain adaptation methods. Thus, the current study also investigates how domain adaptation methods behave when tested on both MSA and DA in standard sentiment domain adaptation settings.
3. Materials and Methods
This section describes the datasets, preprocessing steps and domain adaptation models that we used for our comparative study, as well as the experimental setup and the evaluation metrics.
3.1. Datasets
The dataset used for cross-domain experiments in the two earlier studies was small with imbalanced samples [43]. Furthermore, it was employed in the first work with its original five points [6], but it was transformed into a binary-class dataset in the second study [7], making it difficult to compare and analyze the results consistently. In our investigation, we followed the same settings as in all sentiment domain adaptation studies on English, namely a balanced binary classification dataset with 1000 positive and 1000 negative examples for each domain (80% training and 20% testing). We employed both MSA and DA datasets as follows:
- MSA dataset: The large, public Arabic multi-domain (LAMD) dataset [12] for sentiment analysis includes 33 K annotated reviews collected from several websites covering hotels, restaurants, products and movies. Due to size restrictions, the movies domain was excluded, while the products domain required a little oversampling to balance its samples;
- DA dataset: The public multi-domain Arabic resources for sentiment analysis (MARSA) [13] dataset consists of 61,353 manually labeled tweets collected from trending hashtags in the Kingdom of Saudi Arabia (KSA) across four domains: political, social, sports and technology. We excluded the technology domain because of its size limitation. MARSA covers one country-level Arabic dialect (i.e., the Saudi dialect), which itself consists of different local subdialects that are not specified in the dataset.
Each dataset has two attributes: text and polarity. More details and statistics are summarized in Table 1.

Table 1.
A summary of the datasets used in the comparative study.
3.2. Preprocessing
We applied preprocessing steps that are widely used in Arabic sentiment classification as follows:
- Normalization: to unify different forms of some letters, we replaced آ (i), أ (>) and إ (<) with ا (a) and replaced ة (p) with ه (h), where the symbols correspond to Buckwalter Arabic transliterations;
- Elongation removal: we removed repeated letters (used in social media to show strong feelings) and kept a maximum of two letters;
- Stop-words removal: we removed stop-words listed in both NLTK and Arabic stop-words libraries (we tested both options of removing or keeping stop-words and chose the best option);
- Cleaning: we removed numbers, URLs, punctuation, diacritics and non-Arabic letters.
These steps were needed for TF/IDF text representation only. For AraBERT-based experiments, we kept the original texts and used the preprocessing method of AraBERT.
3.3. Domain Adaptation Methods
To assess the performance of domain adaptation models on Arabic language, we considered DANN [10] and mSDA [11] from the models reviewed in Section 2 due to their excellence and common usage by other researchers. In addition, DARL [6] and AraBERT-ALDA [7] were considered, since they are current models that have so far been proposed and tested for Arabic sentiment classification. These methods were briefly described in Section 2, and more details can be found in the original papers. To fairly assess AraBERT-ALDA, we reported the results of DANN on top of AraBERT (AraBERT-DANN) in addition to the straightforward adaptation by simply finetuning AraBERT.
3.4. Experimental Setup
We tested the six domain adaptation models mentioned above on both MSA and DA datasets. In addition, we reported the results of the in-domain SVM classifier (i.e., trained and tested in the target domain), as well as those of an SVM classifier without adaptation as a baseline (i.e., trained in the source domain and tested in the target domain). SVM, DANN, mSDA and DARL were tested using TF/IDF of unigrams and bigrams, while AraBERT-ALDA and AraBERT-DANN were tested on top of AraBERT.
The following are some implementation details for each algorithm used in our experiments:
- DANN [10]: we followed the original implementation, where the size of the hidden layer was 50, the learning rate was 10−3 and the adaptation parameter equaled one;
- mSDA [11]: we trained a linear SVM classifier using a representation learned by mSDA with five layers and a corruption probability of 50%;
- DARL [6]: to achieve the DARL goal of combining adversarial training and denoising reconstruction, we used both mSDA and DANN (with 10−4 learning rate);
- AraBERT [45]: we trained AraBERT for five epochs with the Adam optimizer and a learning rate of 2 × 10−5 using the Transformers library of HuggingFace;
- AraBERT-ALDA [7]: we used the same implementation provided by the authors;
- AraBERT-DANN: we used an implementation provided in [7].
All experiments were conducted using Google Collab, with GPU for transformer-based experiments.
3.5. Evaluation Metrics
In a domain adaptation setting, source data form the labeled training set, where target data is separated into two sets. Commonly, 80% of the target data form an unlabeled training set, and the remaining 20% are used for testing (unseen during training). In line with most existing studies, adaptation performance was evaluated as the sentiment classification accuracy on the target. Testing accuracy was reported for each source–target pair, after which the accuracies were compared with the baselines (no adaptation). The accuracies of all source–target pairs were then averaged to attain a summarized accuracy score for each tested method.
In addition, to assess the performance of a method on MSA compared with DA, as well as its obtained results on Arabic compared with its reported results on English, we calculated the average transfer loss. A transfer loss using two metrics was proposed in a prior study [21]. The first was a transfer error e(S,T), which refers to the classification errors of a classifier trained on a source S and tested on a target T. The second was a baseline in-domain error eb(T,T), which refers to the errors of a classifier trained and tested on T. In turn, the transfer loss between S and T was computed as follows:
t(S,T) = e(S,T) − eb(T,T).
4. Results
In general, a total of 96 experiments were conducted. Table 2 and Table 3 summarize the results obtained from all the experiments on MSA and DA, respectively. The outcomes of in-domain and no adaptation across all source–target pairs demonstrated a decline in performance caused by domain shifts, where the average accuracy became worse with DA (a drop from 83% to 65%) than with MSA (a drop from 85% to 78%). One possible explanation for this is that reviews are usually longer than tweets, resulting in a higher probability of domain overlap. The nature of dialects, on the other hand, had a significant impact, since individuals freely express their opinions in their personal and local tone without regard for linguistic standards, as discussed in Section 5. Moreover, all the models trained on TF/IDF representation showed varying degrees of negative transfers in some experiments (shown by the underlined accuracy results in Table 2 and Table 3), where the obtained results for adaptation were lower than not performing adaptation at all. By contrast, AraBERT finetuning as well as other methods implemented on top of AraBERT successfully improved the results of the baseline (no adaptation) in all experiments. Interestingly, simply finetuning AraBERT yielded results that were competitive with AraBERT-ALDA and AraBERT-DANN, which illustrates the adaptable nature of pretrained LMs.
Table 2.
The classification accuracy results of in-domain, no adaptation baseline and domain adaptation methods on MSA (LAMD dataset).
Table 3.
The classification accuracy results of in-domain, no adaptation baseline and domain adaptation methods on DA (MARSA dataset).
Experiments on the MSA dataset: Starting with experiments on TF/IDF features, mSDA outperformed other methods in most experiments, followed by DARL in two experiments. On the other hand, DANN failed to outperform baseline results, showing a negative transfer in all experiments. Nevertheless, when applied on top of AraBERT, both ALDA and DANN successfully adapted the classification to target domains. However, AraBERT finetuning achieved the highest average accuracy across all experiments.
Experiments on the DA dataset: Again, DANN exhibited negative transfer in all experiments on TF/IDF features. In contrast, mSDA improved all baseline results and hence achieved the best average accuracy using TF/IDF features, followed by DALR. For AraBERT-based experiments, finetuning, ALDA and DANN all succeeded in improving baseline results in all experiments and achieved average accuracy that was even better than the average in-domain accuracy, with precedence of simple finetuning over DANN and ALDA.
5. Discussion
This section discusses the results obtained by the two sets of experiments on MSA and DA, as well as the obtained results of DANN and mSDA compared with their reported results on the English Amazon dataset.
5.1. MSA vs. DA
The two sets of experiments on MSA and DA shared a few similar observations. First, DANN suffered a negative transfer when applied on TF/IDF features, but it achieved far better results for accuracy when applied on top of AraBERT. Second, all AraBERT-based experiments were successfully improved over the baseline accuracy results, and simply finetuning AraBERT showed the best average accuracy. Third, mSDA outperformed all other methods on TF/IDF representation. In contrast, a distinguishable observation between the two sets of experiments is that mSDA totally succeeded in avoiding negative transfer in the experiments on DA, but not on MSA, where it showed many negative transfer cases.
Moving to another evaluation metric, Figure 3 illustrates the average transfer loss of each method in the two sets of experiments calculated using Equation (1). The results generally show that the adaptation performance on MSA was better than on DA (i.e., lower average transfer loss), except for AraBERT, AraBERT-ALDA and AraBERT-DANN, which performed even better than the in-domain SVM classifier on DA, as illustrated by the negative values of average transfer loss. In line with the accuracy results, finetuning AraBERT is the only method that avoided the transfer loss in both datasets.
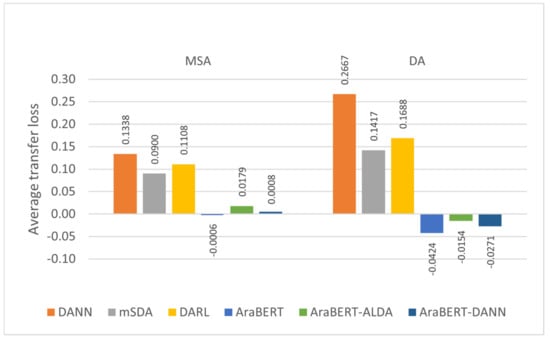
Figure 3.
Average transfer loss of each method on MSA and DA datasets.
Although different types of text were used in the two datasets (i.e., reviews vs. tweets), this was expected, due to the extra challenges imposed by DA. Regardless of the domains, DA involves a wide range of dialects spoken across the Arab world. People tend to express their opinions and feelings in their local dialects. In contrast to MSA, no rules or standards can be set for DA, making them subject to change over time, during which pronunciation changes, new words are coined or borrowed and the meaning of old terms may shift or invert. As a result, more divergence and feature mismatches are expected. This demonstrates the need for additional effort when working on domain adaptation for DA sentiment classification. However, the adaptation results of transformer-based LMs in handling DA were promising, which should encourage the creation of larger LMs that cover more dialects.
5.2. Arabic vs. English
To assess the behavior of DANN and mSDA on Arabic texts compared with English texts, we used the reported in-domain [18] and adaptation [10] results to calculate the average transfer loss of each method, as shown in Figure 4. Although these methods worked well in English (low transfer loss) [10,11], they seemed to suffer when handling the challenges of the Arabic language. As shown in Figure 4, the transfer loss of each method was doubled when tested in Arabic. However, DANN showed more degradation than mSDA. While domain dependency is a problem for any cross-domain sentiment classification task, the impact is typically even worse for Arabic, due to the challenges of dialect variety (as discussed in the previous section), resource scarcity and morphological richness. The problem of resource scarcity is noteworthy, since it prevents progress being made at the same pace as for other resource-rich languages. Given the diversity of Arabic dialects compared with the unified English language, existing resources are barely sufficient to reach an acceptable performance for DA, since the Arabic resources are distributed among various dialects. Even with all the current Arabic resources, there is still an urgent need to acquire a large amount of new labeled data from a specific dialect to achieve good performance in that dialect. This highlights the importance of exploiting transfer learning and domain adaptation to overcome this limitation. The last dimension of Arabic complexity is its morphological richness. A single word can express different meanings depending on its suffixes or prefixes. Leaving words in their original form increases the number of features and therefore leads to sparseness [19]. This makes it difficult to find sufficient common features for adaptation. At the same time, words may lose their meaning after stemming (i.e., reducing words to their roots), which in turn affects task performance. A balance between semantic loss and feature sparsity that is widely recommended for Arabic involves the application of light stemming [47]. However, data scarcity and the variety of dialects again introduce obstacles when seeking to build powerful morphological analyzers.
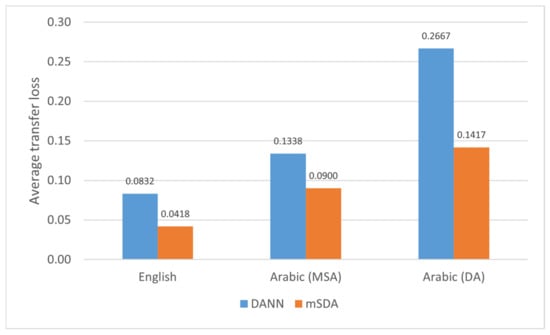
Figure 4.
Average transfer loss of DANN and mSDA on Arabic and English datasets.
6. Conclusions
This paper is the first step towards direct comparison of existing domain adaptation methods in the literature on Arabic sentiment classification to get a clear understanding of the most effective methods. The findings are limited to the methods covered in this study, and the aim is to investigate more approaches in future work to reach more comprehensive conclusions. Among the methods tested, we found AraBERT finetuning to be the best performing method on Arabic, beating even the methods specially designed for domain adaptation. In general, our experiments show the effectiveness of using pretrained LM, which is demonstrated by the gap in performance between TF/IDF-DANN and AraBERT-DANN. In addition to accuracy, we utilized transfer loss as a metric to compare overall performance on MSA vs. DA and on Arabic vs. English. The results showed a drop in performance of the methods that perform well on English, which can be attributed to the complexity of Arabic morphology and other issues related to the scarcity and quality of the available resources. Moreover, we found that all methods with TF/IDF representation performed better on MSA, which means that dialects impose additional challenges for domain adaptation on Arabic. These gaps encourage future research in two directions: Arabic resources and domain adaptation methods. A considerable amount of work must be undertaken to collect more DA datasets and create larger Arabic LMs to overcome the challenges associated with the Arabic language. The best adaptations achieved in our experiments were those utilizing AraBERT LM, although they were still much smaller than other LMs trained on other languages. Thus, training more Arabic LMs on vast amounts of data with a diverse set of Arabic dialects has the potential to further enhance domain adaption outcomes as well as other NLP tasks. Furthermore, we call for future research to develop novel Arabic-specific domain adaptation methods that take feature sparsity and dialect variability into account.
Author Contributions
Conceptualization, Y.A., N.A.-T. and A.A.; data curation, Y.A.; formal analysis, Y.A.; funding acquisition, A.A.; methodology, Y.A. and N.A.-T.; software, Y.A.; supervision, N.A.-T. and A.A.; validation, Y.A.; writing—original draft, Y.A.; writing—review and editing, N.A.-T. and A.A. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Deanship of Scientific Research, King Saud University.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Publicly available datasets were analyzed in this study. The datasets can be found in [12,13].
Acknowledgments
The authors are grateful to the Deanship of Scientific Research, King Saud University for funding through Vice Deanship of Scientific Research Chairs.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Pang, B.; Lee, L.; Vaithyanathan, S. Thumbs up? Sentiment Classification using Machine Learning Techniques. Proc. ACL Conf. EMNLP 2002, 10, 79–86. [Google Scholar]
- Liu, B. Sentiment analysis and opinion mining. Synth. Lect. Hum. Lang. Technol. 2012, 5, 1–167. [Google Scholar]
- Ben-David, S.; Blitzer, J.; Crammer, K.; Kulesza, A.; Pereira, F.; Vaughan, J.W. A theory of learning from different domains. Mach. Learn. 2010, 79, 151–175. [Google Scholar] [CrossRef]
- Blitzer, J.; McDonald, R.; Pereira, F. Domain Adaptation with Structural Correspondence Learning. In Proceedings of the 2006 Conference on Empirical Methods in Natural Language Processing (EMNLP 2006), Sydney, Australia, 22–23 July 2006; pp. 120–128. [Google Scholar]
- Ramponi, A.; Plank, B. Neural Unsupervised Domain Adaptation in NLP—A Survey. In Proceedings of the 28th International Conference on Computational Linguistics, COLING, Barcelona, Spain, 8–13 December 2020; pp. 6838–6855. [Google Scholar]
- Khaddaj, A.; Hajj, H. Improved Generalization of Arabic Text Classifiers. In Proceedings of the Fourth Arabic Natural Language Processing Workshop, Florence, Italy, 1 August 2019; pp. 167–174. [Google Scholar]
- el Mekki, A.; el Mahdaouy, A.; Berrada, I.; Khoumsi, A. Domain Adaptation for Arabic Cross-Domain and Cross-Dialect Sentiment Analysis from Contextualized Word Embedding. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Online, 6–11 June 2021; pp. 2824–2837. [Google Scholar]
- Blitzer, J.; Dredze, M.; Pereira, F. Biographies, Bollywood, Boom-Boxes and Blenders: Domain Adaptation for Sentiment Classification. In Proceedings of the 45th Annual Meeting of the Association of Computational Linguistics, Prague, Czech, 23–30 June 2007; pp. 440–447. [Google Scholar]
- Ponomareva, N.; Thelwall, M. Biographies or Blenders: Which Resource is Best for Cross-Domain Sentiment Analysis? In Proceedings of the International Conference on Intelligent Text Processing and Computational Linguistics, New Delhi, India, 11–17 March 2012; pp. 488–499. [Google Scholar]
- Ganin, Y.; Ustinova, E.; Ajakan, H.; Germain, P.; Larochelle, H.; Laviolette, F.; Marchand, M.; Lempitsky, V. Domain-Adversarial Training of Neural Networks. J. Mach. Learn. Res. 2016, 17, 2030–2096. [Google Scholar]
- Chen, M.; Xu, Z.; Weinberger, K.Q.; Sha, F. Marginalized Denoising Autoencoders for Domain Adaptation. In Proceedings of the 29th International Conference on Machine Learning, Edinburgh, UK, 26 June–1 July 2012; pp. 1627–1634. [Google Scholar]
- ElSahar, H.; El-Beltagy, S.R. Building Large Arabic Multi-domain Resources for Sentiment Analysis. In Proceedings of the International Conference on Intelligent Text Processing and Computational Linguistics, Cairo, Egypt, 14–20 April 2015; pp. 23–34. [Google Scholar]
- Alowisheq, A.; Al-Twairesh, N.; Altuwaijri, M.; Almoammar, A.; Alsuwailem, A.; Albuhairi, T.; Alahaideb, W.; Alhumoud, S. MARSA: Multi-Domain Arabic Resources for Sentiment Analysis. IEEE Access 2021, 9, 142718–142728. [Google Scholar] [CrossRef]
- Cui, X.; Al-Bazzaz, N.; Bollegala, D.; Coenen, F. A comparative study of pivot selection strategies for unsupervised cross-domain sentiment classification. Knowl. Eng. Rev. 2018, 33, 1–12. [Google Scholar] [CrossRef]
- Pan, S.J.; Ni, X.; Sun, J.T.; Yang, Q.; Chen, Z. Cross-domain sentiment classification via spectral feature alignment. In Proceedings of the 19th International Conference on World Wide Web, Raleigh, NC, USA, 26–30 April 2010; pp. 751–760. [Google Scholar]
- Lin, C.; He, Y. Joint Sentiment/Topic Model for Sentiment Analysis. In Proceedings of the 18th ACM conference on Information and knowledge management, Hong Kong, China, 2–6 November 2009; pp. 375–384. [Google Scholar]
- He, Y.; Lin, C.; Alani, H. Automatically Extracting Polarity-Bearing Topics for Cross-Domain Sentiment Classification. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics, Portland, OR, USA, 19–24 June 2011; Volume 1, pp. 123–131. [Google Scholar]
- Bollegala, D.; Weir, D.; Carroll, J. Cross-Domain Sentiment Classification Using a Sentiment Sensitive Thesaurus. IEEE Trans. Knowl. Data Eng. 2012, 25, 1719–1731. [Google Scholar] [CrossRef]
- Cui, X.; Kojaku, S.; Masuda, N.; Bollegala, D. Solving Feature Sparseness in Text Classification using Core-Periphery Decomposition. In Proceedings of the Seventh Joint Conference on Lexical and Computational Semantics, New Orleans, LA, USA, 5–6 June 2018; pp. 255–264. [Google Scholar]
- Vincent, P.; Larochelle, H. Extracting and composing robust features with denoising autoencoders. In Proceedings of the 25th International Conference on Machine Learning, Helsinki, Finland, 5–9 July 2008; pp. 1096–1103. [Google Scholar]
- Glorot, X.; Bordes, A.; Bengio, Y. Domain Adaptation for Large-Scale Sentiment Classification: A Deep Learning Approach. In Proceedings of the 28th International Conference on International Conference on Machine Learning, Bellevue, WA, USA, 28 June–2 July 2011; pp. 513–520. [Google Scholar]
- Ziser, Y.; Reichart, R. Neural Structural Correspondence Learning for Domain Adaptation. In Proceedings of the International Conference on Computational Natural Language Learning, Vancouver, BC, Canada, 3–4 August 2017; pp. 400–410. [Google Scholar]
- Ziser, Y.; Reichart, R. Pivot Based Language Modeling for Improved Neural Domain Adaptation. In Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, New Orleans, LA, USA, 1–6 June 2018; pp. 1241–1251. [Google Scholar]
- Li, Z.; Wei, Y.; Zhang, Y.; Yang, Q. Hierarchical Attention Transfer Network for Cross-domain Sentiment Classification Hierarchical Attention Transfer Network for Cross-Domain Sentiment Classification. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; pp. 5852–5859. [Google Scholar]
- Jiang, J.; Zhai, C. Instance Weighting for Domain Adaptation in NLP. In Proceedings of the 45th Annual Meeting of the Association of Computational Linguistics, Prague, Czech Republic, 23–30 June 2007; pp. 264–271. [Google Scholar]
- Remus, R. Domain adaptation using domain similarity- and domain complexity-based instance selection for cross-domain sentiment analysis. In Proceedings of the IEEE 12th International Conference on Data Mining Workshops, Brussels, Belgium, 10 December 2012; pp. 717–723. [Google Scholar]
- Xia, R.; Hu, X.; Lu, J.; Yang, J.; Zong, C. Instance Selection and Instance Weighting for Cross- Domain Sentiment Classification via PU Learning. In Proceedings of the Twenty-Third International Joint Conference on Artificial Intelligence, Beijing, China, 3–9 August 2013; pp. 2176–2182. [Google Scholar]
- Xia, R.; Zong, C.; Hu, X.; Cambria, E. Feature ensemble plus sample selection: Domain adaptation for sentiment classification. In Proceedings of the 24th International Joint Conference on Artificial Intelligence, Buenos Aires, Argentina, 25 July 2015; pp. 4229–4233. [Google Scholar]
- Ruder, S. Neural Transfer Learning for Natural Language Processing. Ph.D. Thesis, National University of Ireland, Galway, Ireland, 2019. [Google Scholar]
- Tan, S.; Cheng, X.; Wang, Y.; Xu, H. Adapting naive bayes to domain adaptation for sentiment analysis. In Proceedings of the European Conference on Information Retrieval, Toulouse, France, 6–9 April 2009; pp. 337–349. [Google Scholar]
- NYu; Kübler, S. Filling the Gap: Semi-Supervised Learning for Opinion Detection Across Domains. In Proceedings of the Fifteenth Conference on Computational Natural Language Learning, Portland, OR, USA, 23–24 June 2011; pp. 200–209. [Google Scholar]
- Chen, M.; Weinberger, K.Q.; Blitzer, J.C. Co-training for domain adaptation. In Proceedings of the 24th International Conference on Neural Information Processing Systems, Madrid, Spain, 11–15 July 2011; pp. 2456–2464. [Google Scholar]
- Saito, K.; Ushiku, Y.; Harada, T. Asymmetric tri-training for unsupervised domain adaptation. In Proceedings of the 34th International Conference on Machine Learning, Sydney, NSW, Australia, 6–11 August 2017; Volume 6, pp. 4573–4585. [Google Scholar]
- Ruder, S.; Plank, B. Strong Baselines for Neural Semi-supervised Learning under Domain Shift. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, Melbourne, Australia, 15–20 July 2018; pp. 1044–1054. [Google Scholar]
- He, R.; Lee, W.S.; Ng, H.T.; Dahlmeier, D. Adaptive semi-supervised learning for cross-domain sentiment classification. In Proceedings of the 2018 Conference on EMNLP, Brussels, Belgium, 31 October–4 November 2018; pp. 3467–3476. [Google Scholar]
- Cui, X.; Bollegala, D. Self-Adaptation for Unsupervised Domain Adaptation. In Proceedings of the International Conference on Recent Advances in Natural Language Processing, Varna, Bulgaria, 2–4 September 2019; pp. 213–222. [Google Scholar]
- Wu, Q.; Tan, S.; Cheng, X. Graph Ranking for Sentiment Transfer. In Proceedings of the ACL-IJCNLP Conference, Singapore, 4 August 2009; pp. 317–320. [Google Scholar]
- Zhu, X.; Ghahramani, Z. Learning from Labeled and Unlabeled Data with Label Propagation; Rep. No. CMU-CALD-02–107; Carnegie Mellon University: Pittsburgh, PA, USA, 2002. [Google Scholar]
- Li, Z.; Zhang, Y.; Wei, Y.; Wu, Y.; Yang, Q. End-to-End Adversarial Memory Network for Cross-domain Sentiment Classification. In Proceedings of the 26th International Joint Conference on Artificial Intelligence, Melbourne, Australia, 19–25 August 2017; pp. 2237–2243. [Google Scholar]
- Ryu, M.; Lee, G.; Lee, K. Knowledge distillation for BERT unsupervised domain adaptation. Knowl. Inf. Syst. 2022, 64, 3113–3128. [Google Scholar] [CrossRef]
- Long, Q.; Luo, T.; Wang, W.; Pan, S.J. Domain Confused Contrastive Learning for Unsupervised Domain Adaptation. In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Seattle, WA, USA, 10–15 July 2022; pp. 2982–2995. [Google Scholar]
- Fu, Y.; Liu, Y. Contrastive transformer based domain adaptation for multi-source cross-domain sentiment classification. Knowl. Based Syst. 2022, 245, 108649. [Google Scholar]
- Baly, R.; Khaddaj, A.; Hajj, H.; El-Hajj, W.; Shaban, K.B. ArSentD-LEV: A multi-topic corpus for target-based sentiment analysis in arabic levantine tweets. In Proceedings of the 3rd Workshop on Open-Source Arabic Corpora and Processing Tools, Miyazaki, Japan, 8 May 2018; p. 37. [Google Scholar]
- Chen, M.; Zhao, S.; Liu, H.; Cai, D. Adversarial-Learned Loss for Domain Adaptation. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 3521–3528. [Google Scholar]
- Antoun, W.; Baly, F.; Hajj, H. AraBERT: Transformer-based Model for Arabic Language Understanding. In Proceedings of the 4th Workshop on Open-Source Arabic Corpora and Processing Tools, Marseille, France, 12 May 2020; pp. 9–15. [Google Scholar]
- Habash, N. Introduction to Arabic Natural Language Processing. Synth. Lect. Hum. Lang. Technol. 2010, 3, 1–187. [Google Scholar]
- Oueslati, O.; Cambria, E.; Ben HajHmida, M.; Ounelli, H. A review of sentiment analysis research in Arabic language. Future Gener. Comput. Syst. 2020, 112, 408–430. [Google Scholar]




Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).