

Vision-Language Models for Zero-Shot Classification of Remote Sensing Images





Abstract
1. Introduction
2. Related Work
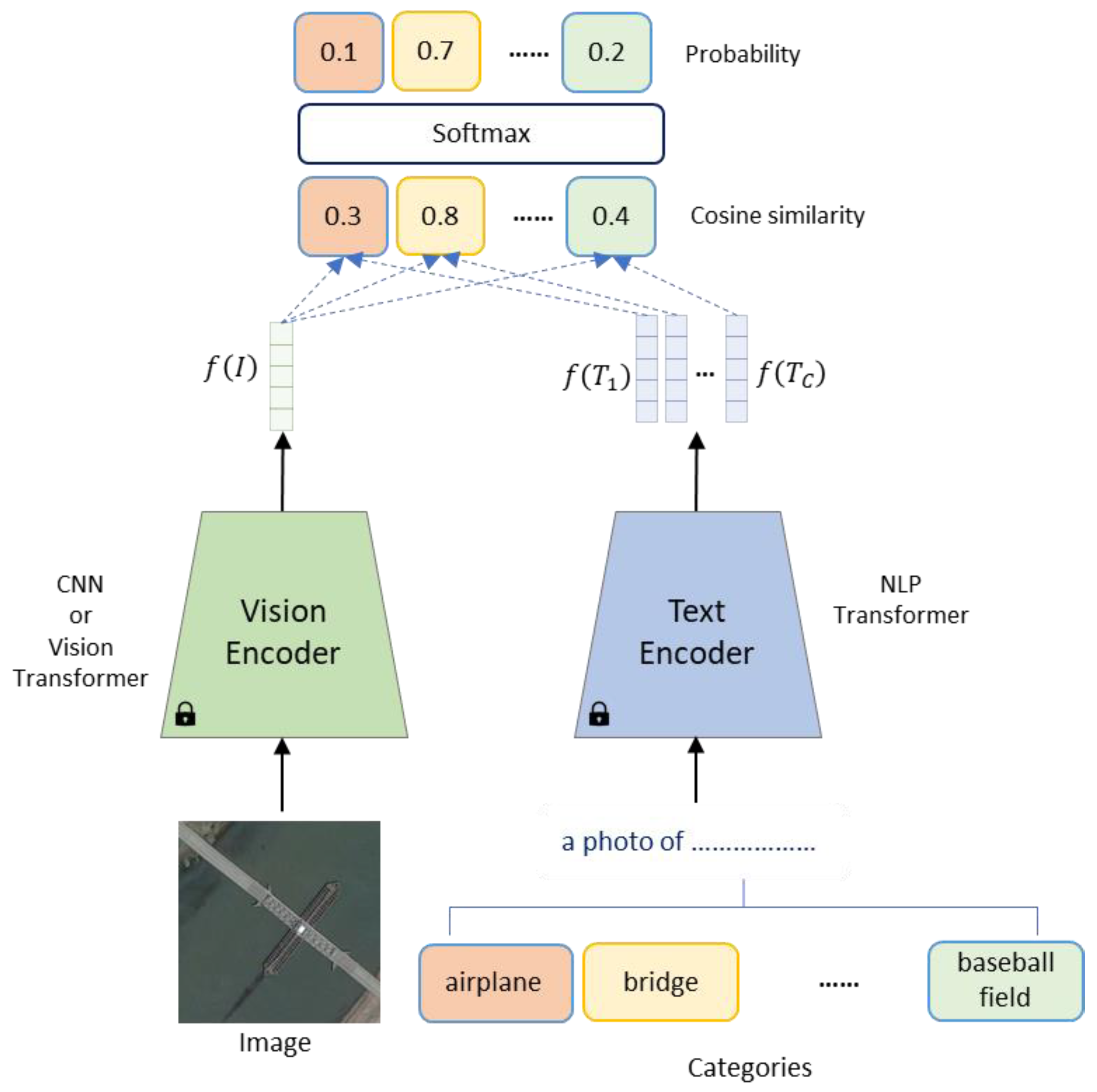
3. RS Zero-Shot Classification
4. Experimental Results
4.1. Dataset Description and Experiments Setup
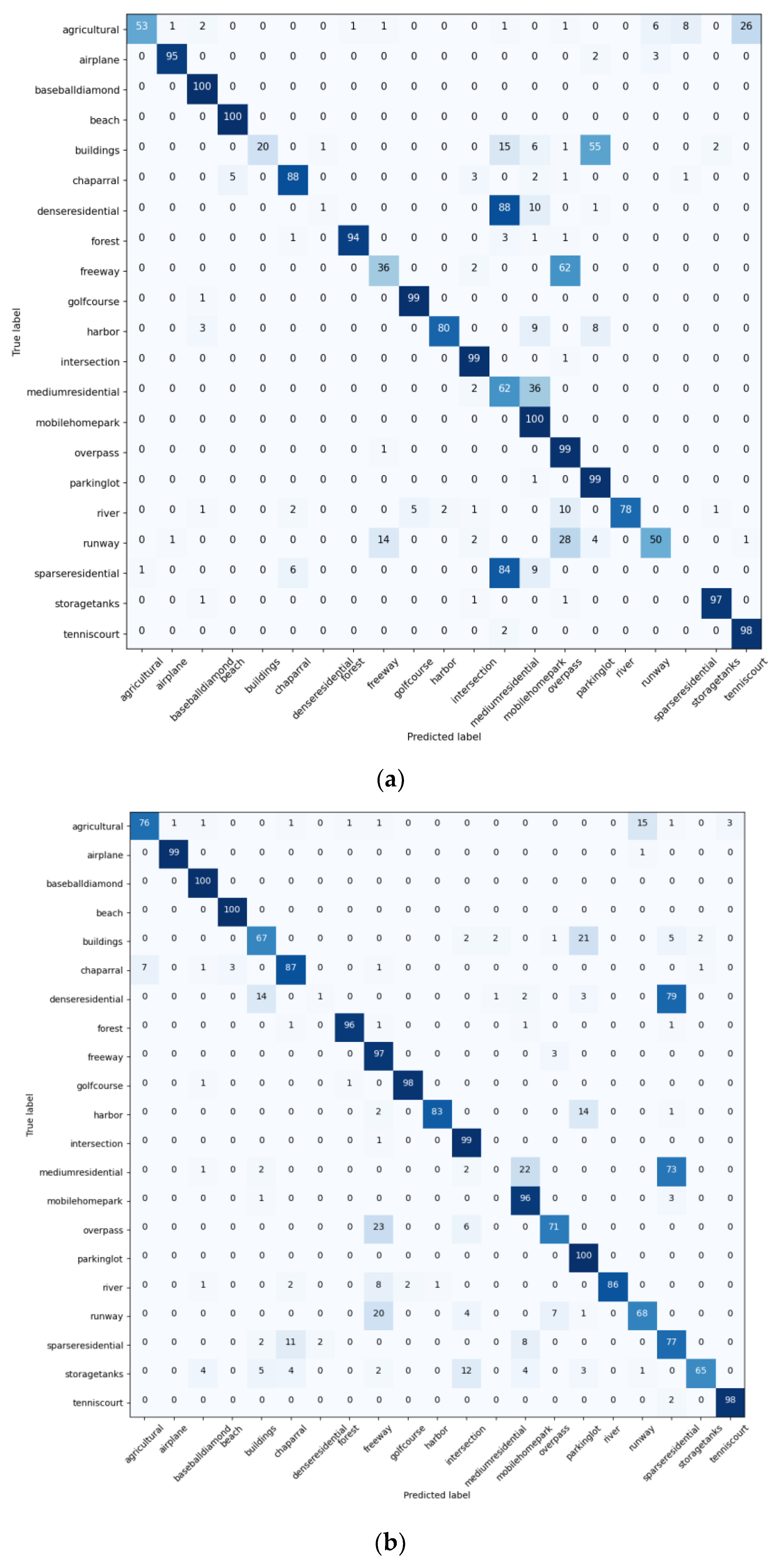
4.2. Results
4.3. Comparison to Existing Solutions
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Correction Statement
References
- Othman, E.; Bazi, Y.; Melgani, F.; Alhichri, H.; Alajlan, N.; Zuair, M. Domain Adaptation Network for Cross-Scene Classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 4441–4456. [Google Scholar] [CrossRef]
- Li, Z.; Zhang, D.; Wang, Y.; Lin, D.; Zhang, J. Generative Adversarial Networks for Zero-Shot Remote Sensing Scene Classification. Appl. Sci. 2022, 12, 3760. [Google Scholar] [CrossRef]
- Rahhal, M.M.A.; Bazi, Y.; Alsharif, N.A.; Bashmal, L.; Alajlan, N.; Melgani, F. Multilanguage Transformer for Improved Text to Remote Sensing Image Retrieval. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 9115–9126. [Google Scholar] [CrossRef]
- Bazi, Y.; Rahhal, M.M.A.; Mekhalfi, M.L.; Zuair, M.A.A.; Melgani, F. Bi-Modal Transformer-Based Approach for Visual Question Answering in Remote Sensing Imagery. IEEE Trans. Geosci. Remote Sens. 2022, 60, 4708011. [Google Scholar] [CrossRef]
- Al Rahhal, M.M.; Bazi, Y.; Alsaleh, S.O.; Al-Razgan, M.; Mekhalfi, M.L.; Al Zuair, M.; Alajlan, N. Open-Ended Remote Sensing Visual Question Answering with Transformers. Int. J. Remote Sens. 2022, 43, 6809–6823. [Google Scholar] [CrossRef]
- Rahman, S.; Khan, S.; Porikli, F. A Unified Approach for Conventional Zero-Shot, Generalized Zero-Shot, and Few-Shot Learning. IEEE Trans. Image Process. 2018, 27, 5652–5667. [Google Scholar] [CrossRef] [PubMed]
- Alajaji, D.A.; Alhichri, H. Few Shot Scene Classification in Remote Sensing Using Meta-Agnostic Machine. In Proceedings of the 2020 6th Conference on Data Science and Machine Learning Applications (CDMA), Riyadh, Saudi Arabia, 4–5 March 2020; pp. 77–80. [Google Scholar]
- Li, Y.; Kong, D.; Zhang, Y.; Tan, Y.; Chen, L. Robust Deep Alignment Network with Remote Sensing Knowledge Graph for Zero-Shot and Generalized Zero-Shot Remote Sensing Image Scene Classification. ISPRS J. Photogramm. Remote Sens. 2021, 179, 145–158. [Google Scholar] [CrossRef]
- Li, X.; Wen, C.; Hu, Y.; Zhou, N. RS-CLIP: Zero Shot Remote Sensing Scene Classification via Contrastive Vision-Language Supervision. Int. J. Appl. Earth Obs. Geoinf. 2023, 124, 103497. [Google Scholar] [CrossRef]
- Sun, X.; Wang, B.; Wang, Z.; Li, H.; Li, H.; Fu, K. Research Progress on Few-Shot Learning for Remote Sensing Image Interpretation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 2387–2402. [Google Scholar] [CrossRef]
- Yuan, Z.; Huang, W. Multi-Attention DeepEMD for Few-Shot Learning in Remote Sensing. In Proceedings of the 2020 IEEE 9th Joint International Information Technology and Artificial Intelligence Conference (ITAIC), Chongqing, China, 11–13 December 2020; Volume 9, pp. 1097–1102. [Google Scholar]
- Xu, Y.; Huang, B.; Luo, X.; Bradbury, K.; Malof, J.M. SIMPL: Generating Synthetic Overhead Imagery to Address Custom Zero-Shot and Few-Shot Detection Problems. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 4386–4396. [Google Scholar] [CrossRef]
- Wang, C.; Peng, G.; De Baets, B. A Distance-Constrained Semantic Autoencoder for Zero-Shot Remote Sensing Scene Classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 12545–12556. [Google Scholar] [CrossRef]
- Quan, J.; Wu, C.; Wang, H.; Wang, Z. Structural Alignment Based Zero-Shot Classification for Remote Sensing Scenes. In Proceedings of the 2018 IEEE International Conference on Electronics and Communication Engineering (ICECE), Xi’an, China, 10–12 December 2018; pp. 17–21. [Google Scholar]
- Li, A.; Lu, Z.; Wang, L.; Xiang, T.; Wen, J.-R. Zero-Shot Scene Classification for High Spatial Resolution Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2017, 55, 4157–4167. [Google Scholar] [CrossRef]
- Sumbul, G.; Cinbis, R.G.; Aksoy, S. Fine-Grained Object Recognition and Zero-Shot Learning in Remote Sensing Imagery. IEEE Trans. Geosci. Remote Sens. 2018, 56, 770–779. [Google Scholar] [CrossRef]
- Yang, Y.; Newsam, S. Bag-of-Visual-Words and Spatial Extensions for Land-Use Classification. In Proceedings of the 18th SIGSPATIAL International Conference on Advances in Geographic Information Systems, San Jose, CA, USA, 2–5 November 2010; Association for Computing Machinery: New York, NY, USA, 2010; pp. 270–279. [Google Scholar]
- Xia, G.; Hu, J.; Hu, F.; Shi, B.; Bai, X.; Zhong, Y.; Zhang, L.; Lu, X. AID: A Benchmark Data Set for Performance Evaluation of Aerial Scene Classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3965–3981. [Google Scholar] [CrossRef]
- Cheng, G.; Han, J.; Lu, X. Remote Sensing Image Scene Classification: Benchmark and State of the Art. Proc. IEEE 2017, 105, 1865–1883. [Google Scholar] [CrossRef]
- Zhang, Z.; Saligrama, V. Zero-Shot Learning via Semantic Similarity Embedding. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 4166–4174. [Google Scholar]
- Li, Y.; Wang, D.; Hu, H.; Lin, Y.; Zhuang, Y. Zero-Shot Recognition Using Dual Visual-Semantic Mapping Paths. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 3279–3287. [Google Scholar]
- Kodirov, E.; Xiang, T.; Gong, S. Semantic Autoencoder for Zero-Shot Learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 3174–3183. [Google Scholar]
- Wu, H.; Yan, Y.; Chen, S.; Huang, X.; Wu, Q.; Ng, M.K. Joint Visual and Semantic Optimization for Zero-Shot Learning. Knowl.-Based Syst. 2021, 215, 106773. [Google Scholar] [CrossRef]
- Xian, Y.; Lorenz, T.; Schiele, B.; Akata, Z. Feature Generating Networks for Zero-Shot Learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 5542–5551. [Google Scholar]
- Felix, R.; Kumar, B.G.V.; Reid, I.; Carneiro, G. Multi-Modal Cycle-Consistent Generalized Zero-Shot Learning. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 21–37. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Prompt 1 | class_name |
| Prompt 2 | a photo of + class_name |
| Prompt 3 | a remote sensing image of + class_name |
| Prompt 4 | a top view image of + class_name |
| Prompt 5 | a satellite image of + class_name |
| Prompt 6 | a scene of + class_name |
| (A) | ||
| Dataset | #Classes | #Images |
| Merced | 21 | 2100 |
| AID | 30 | 10,000 |
| NWPU-RESISC45 | 45 | 31,500 |
| (B) | ||
| Dataset | #Classes | |
| Merced | agricultural, airplane, baseballdiamond, beach, buildings, chaparral, denseresidential, forest, freeway, golf course, harbor, intersection, mediumresidential, mobilehomepark, overpass, parkinglot, river, runway, sparseresidential, storagetanks, tenniscourt | |
| AID | airport, bare land, baseball field, beach, bridge, center pivot, church, commercial area, dense residential, desert, farmland, forest, industrial area, meadow, medium residential, mountain, park, parking lot, playground, pond, port, railway station, resort, river, school, sparse residential, square, stadium, storage tanks, viaduct | |
| NWPU-RESISC45 | airplane, airport, baseball diamond, basketball court, beach, bridge, chaparral, church, circular farmland, cloud, commercial area, dense residential, desert, forest, freeway, golf course, ground track field, harbor, industrial area, intersection, island, lake, meadow, medium residential, mobile home park, mountain, overpass, palace, parking lot, railway, railway station, rectangular farmland, river, roundabout, runway, sea ice, ship, snowberg, sparse residential, stadium, storage tank, tennis court, terrace, thermal power station, and wetland. | |
| Model Type | Model Name | #Parameters (Millions) |
|---|---|---|
| CLIP | RN50-quickgelu | 102.54 M |
| RN101-quickgelu | 120.22 M | |
| RN50x64 | 623.67 M | |
| ViT-B-32 | 151.81 M | |
| ViT-B-16 | 150.15 M | |
| ViT-L-14 | 428.15 M | |
| Open-CLIP | Convnext_base_w | 179.92 M |
| Convnext_large_d | 352.30 M | |
| ViT-L-14’ | 428.15 M | |
| ViT-B-16’ | 150.15 M | |
| ViT-B-32’ | 151.81 M | |
| ViT-H-14’ | 986.64 M | |
| xlm-roberta-large | 1.19 B |
| (A) | ||||||||
| Model | Prompt 1 | Prompt 2 | Prompt 3 | Prompt 4 | Prompt 5 | Prompt 6 | Average | |
| Clip | RN50-quickgelu | 48 | 46 | 49 | 46 | 48 | 51 | 48.00 |
| RN101-quickgelu | 55 | 50 | 56 | 54 | 53 | 59 | 54.50 | |
| RN50x64 | 64 | 64 | 68 | 68 | 74 | 65 | 67.17 | |
| ViT-B-32 | 58 | 56 | 60 | 56 | 59 | 60 | 58.17 | |
| ViT-B-16 | 62 | 62 | 64 | 60 | 62 | 65 | 62.50 | |
| ViT-L-14 | 70 | 68 | 73 | 69 | 71 | 77 | 71.33 | |
| Open-Clip | convnext_base_w | 54 | 53 | 60 | 58 | 60 | 60 | 57.50 |
| convnext_large_d | 62 | 67 | 69 | 64 | 70 | 71 | 67.17 | |
| ViT-L-14’ | 60 | 58 | 65 | 62 | 63 | 62 | 61.67 | |
| ViT-B-16’ | 52 | 54 | 54 | 56 | 60 | 51 | 54.50 | |
| ViT-B-32’ | 45 | 54 | 48 | 51 | 56 | 47 | 50.17 | |
| ViT-H-14’ | 67 | 65 | 76 | 72 | 73 | 79 | 72.00 | |
| xlm-roberta-large | 79 | 81 | 76 | 78 | 75 | 73 | 77.00 | |
| Average | 58.08 | 58.08 | 61.83 | 59.67 | 62.42 | 62.25 | ||
| (B) | ||||||||
| Model | Prompt 1 | Prompt 2 | Prompt 3 | Prompt 4 | Prompt 5 | Prompt 6 | Average | |
| Clip | RN50-quickgelu | 42 | 43 | 46 | 47 | 46 | 48 | 45.33 |
| RN101-quickgelu | 50 | 48 | 54 | 52 | 54 | 54 | 52.00 | |
| RN50x64 | 59 | 59 | 65 | 62 | 69 | 60 | 62.33 | |
| ViT-B-32 | 49 | 50 | 57 | 55 | 54 | 55 | 53.33 | |
| ViT-B-16 | 54 | 55 | 64 | 59 | 61 | 63 | 59.33 | |
| ViT-L-14 | 59 | 56 | 63 | 61 | 63 | 61 | 60.50 | |
| Open-Clip | convnext_base_w | 55 | 58 | 61 | 59 | 61 | 61 | 59.17 |
| convnext_large_d | 55 | 61 | 61 | 59 | 66 | 61 | 60.50 | |
| ViT-L-14’ | 51 | 56 | 59 | 58 | 60 | 55 | 56.50 | |
| ViT-B-16’ | 49 | 56 | 50 | 54 | 59 | 51 | 53.17 | |
| ViT-B-32’ | 36 | 47 | 46 | 50 | 51 | 45 | 45.83 | |
| ViT-H-14’ | 56 | 59 | 63 | 56 | 67 | 66 | 61.17 | |
| xlm-roberta-large | 66 | 69 | 67 | 69 | 70 | 69 | 68.33 | |
| Average | 51.25 | 54.00 | 57.42 | 56.00 | 59.25 | 56.67 | ||
| (C) | ||||||||
| Model | Prompt 1 | Prompt 2 | Prompt 3 | Prompt 4 | Prompt 5 | Prompt 6 | Average | |
| Clip | RN50-quickgelu | 33 | 35 | 42 | 43 | 45 | 42 | 40.00 |
| RN101-quickgelu | 41 | 48 | 54 | 53 | 50 | 53 | 49.83 | |
| RN50x64 | 57 | 57 | 60 | 62 | 64 | 61 | 60.17 | |
| ViT-B-32 | 45 | 46 | 57 | 53 | 51 | 55 | 51.17 | |
| ViT-B-16 | 44 | 51 | 61 | 58 | 58 | 60 | 55.33 | |
| ViT-L-14 | 59 | 59 | 65 | 63 | 64 | 67 | 62.83 | |
| Open-Clip | convnext_base_w | 55 | 57 | 60 | 59 | 62 | 60 | 58.83 |
| convnext_large_d | 60 | 60 | 65 | 62 | 68 | 64 | 63.17 | |
| ViT-L-14’ | 58 | 59 | 64 | 65 | 66 | 61 | 62.17 | |
| ViT-B-16’ | 57 | 57 | 57 | 59 | 58 | 55 | 57.17 | |
| ViT-B-32’ | 48 | 48 | 48 | 51 | 51 | 47 | 48.83 | |
| ViT-H-14’ | 62 | 60 | 71 | 64 | 72 | 72 | 66.83 | |
| xlm-roberta-large | 59 | 62 | 63 | 63 | 66 | 62 | 62.50 | |
| Average | 52.15 | 53.77 | 59.00 | 58.08 | 59.62 | 58.38 | ||
| (A) | |||||
| Method | 16/5 | 13/8 | 10/11 | 7/14 | 0/21 |
| SSE [20] | 35.59 ± 5.90 | 23.42 ± 3.81 | 17.07 ± 3.56 | 10.82 ± 2.10 | ----- |
| DMaP [21] | 48.92 ± 8.71 | 30.91 ± 4.77 | 22.99 ± 4.81 | 17.3 ± 3.04 | ----- |
| SAE [22] | 49.5 ± 8.42 | 32.71 ± 6.49 | 24.04 ± 4.36 | 18.63 ± 2.76 | ----- |
| ZSL-LP [15] | 49.01 ± 8.85 | 31.26 ± 5.09 | 23.28 ± 4.13 | 17.55 ± 2.9 | ----- |
| VSOP [23] | 46.48 ± 7.83 | 29.81 ± 4.56 | 21.97 ± 4.11 | 16.14 ± 2.59 | ----- |
| f-CLSWGAN [24] | 56.97 ± 11.06 | 36.47 ± 6.28 | 27.89 ± 4.99 | 19.34 ± 3.96 | ----- |
| CYCLEWGAN [25] | 58.36 ± 10.04 | 36.81 ± 5.53 | 28.37 ± 4.53 | 21.15 ± 3.51 | ----- |
| DSAE [13] | 58.63 ± 11.23 | 37.5 ± 7.79 | 25.59 ± 5.24 | 20.18 ± 3.07 | ----- |
| CSPWGAN [13] | 62.66 ± 10.79 | 46.19 ± 5.52 | 35.17 ± 4.93 | 26.17 ± 3.87 | ----- |
| VLMs | |||||
| xlm-roberta-large (Open-CLIP) | 91.50 ± 7.57 | 86.2 ± 6.28 | 83.8 ± 6.07 | 79.55 + 5.55 | 75% |
| ViT-H-14 (Open-CLIP) | 91.10 ± 7.47 | 86.65 ± 5.12 | 85.05 + 5.54 | 81.22 + 5.44 | 73% |
| RN50-quickgelu (CLIP) | 78.50 ± 10.20 | 73.40 ± 6.39 | 77.4 + 12.23 | 73.95 + 11.09 | 48% |
| ViT-B-32 (CLIP) | 79.30 ± 8.93 | 73.40 + 6.39 | 75.53 + 11.62 | 71.77 + 11.35 | 59% |
| (B) | |||||
| Method | 25/5 | 20/10 | 15/15 | 10/20 | 0/30 |
| SSE [20] | 46.11 ± 7.21 | 30.28 ± 4.90 | 19.94 ± 2.43 | 12.73 ± 1.27 | ----- |
| DMaP [21] | 43.40 ± 7.29 | 28.29 ± 4.78 | 19.38 ± 2.62 | 11.56 ± 1.29 | ----- |
| SAE [22] | 47.34 ± 8.42 | 32.12 ± 4.45 | 23.73 ± 3.28 | 13.77 ± 1.17 | ----- |
| ZSLLP [15] | 46.77 ± 7.65 | 30.82 ± 4.90 | 21.78 ± 3.37 | 12.97 ± 1.06 | ----- |
| VSOP [23] | 48.56 ± 7.90 | 32.95 ± 5.52 | 24.84 ± 3.04 | 14.03 ± 2.47 | ----- |
| f-CLSWGAN [24] | 50.68 ± 11.25 | 33.89 ± 5.72 | 24.95 ± 2.96 | 17.26 ± 3.06 | ----- |
| CYCLEWGAN [25] | 52.37 ± 10.47 | 35.94 ± 5.46 | 25.28 ± 2.66 | 17.89 ± 2.86 | ----- |
| DSAE [13] | 53.49 ± 8.58 | 35.32 ± 5.17 | 25.92 ± 3.92 | 17.65 ± 2.52 | ----- |
| CSPWGAN [13] | 55.86 ± 10.60 | 37.93 ± 5.26 | 26.97 ± 2.53 | 19.43 ± 3.02 | ----- |
| VLMs | |||||
| xlm-roberta-large (Open-CLIP) | 88.10 + 5.53 | 80.40 + 6.74 | 79.00 + 5.15 | 74.90 + 2.58 | 70% |
| ViT-H-14 (Open-CLIP) | 88.40 + 8.30 | 79.9 + 0+7.07 | 76.55 + 5.91 | 72.90 + 3.36 | 73% |
| RN50-quickgelu (CLIP) | 82.03 + 13.89 | 74.0 + 10.07 | 69.73 + 11.07 | 66.20 + 10.10 | 46% |
| ViT-B-32 (CLIP) | 81.00 + 13.49 | 73.40 + 10.36 | 67.67 + 10.50 | 64.30 + 9.51 | 54% |
| (C) | |||||
| Method | 35/10 | 30/15 | 25/20 | 20/25 | 0/45 |
| SSE [20] | 33.36 ± 3.58 | 23.30 ± 2.48 | 16.88 ± 2.29 | 12.94 ± 1.46 | ----- |
| DMaP [21] | 49.53 ± 6.31 | 38.07 ± 4.83 | 28.15 ± 3.86 | 23.95 ± 2.60 | ----- |
| SAE [22] | 44.81 ± 4.73 | 35.07 ± 3.91 | 24.65 ± 3.71 | 20.77 ± 2.02 | ----- |
| ZSLLP [15] | 47.00 ± 6.64 | 36.45 ± 4.58 | 26.71 ± 3.43 | 22.90 ± 2.47 | ----- |
| VSOP [23] | 45.32 ± 5.71 | 36.09 ± 4.63 | 25.44 ± 3.13 | 22.18 ± 2.00 | ----- |
| f-CLSWGAN [24] | 45.35 ± 6.37 | 38.97 ± 4.93 | 30.06 ± 2.96 | 24.31 ± 2.57 | ----- |
| CYCLEWGAN [25] | 46.87 ± 5.99 | 39.85 ± 4.71 | 31.17 ± 2.66 | 25.06 ± 2.74 | ----- |
| DSAE [13] | 44.68 ± 6.14 | 40.31 ± 4.89 | 31.91 ± 3.07 | 24.89 ± 2.44 | ----- |
| CSPWGAN [13] | 51.52 ± 6.91 | 41.94 ± 4.61 | 31.85 ± 3.32 | 25.20 ± 2.17 | ----- |
| VLMs | |||||
| xlm-roberta-large (Open-CLIP) | 85.30 + 5.21 | 81.70 + 2.86 | 76.60 + 2.57 | 73.40 + 3.49 | 66% |
| ViT-H-14 (Open-CLIP) | 87.10 + 4.94 | 84.30 + 3.93 | 79.95 + 4.05 | 76.95 + 4.82 | 72% |
| RN50-quickgelu (CLIP) | 80.40 + 10.99 | 77.53 + 10.60 | 72.50 + 11.23 | 69.00 + 12.20 | 45% |
| ViT-B-32 (CLIP) | 79.82 + 9.85 | 76.75 + 9.50 | 71.52 + 10.01 | 68.32 + 10.84 | 51% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Al Rahhal, M.M.; Bazi, Y.; Elgibreen, H.; Zuair, M. Vision-Language Models for Zero-Shot Classification of Remote Sensing Images. Appl. Sci. 2023, 13, 12462. https://doi.org/10.3390/app132212462
Al Rahhal MM, Bazi Y, Elgibreen H, Zuair M. Vision-Language Models for Zero-Shot Classification of Remote Sensing Images. Applied Sciences. 2023; 13(22):12462. https://doi.org/10.3390/app132212462
Chicago/Turabian StyleAl Rahhal, Mohamad Mahmoud, Yakoub Bazi, Hebah Elgibreen, and Mansour Zuair. 2023. "Vision-Language Models for Zero-Shot Classification of Remote Sensing Images" Applied Sciences 13, no. 22: 12462. https://doi.org/10.3390/app132212462
APA StyleAl Rahhal, M. M., Bazi, Y., Elgibreen, H., & Zuair, M. (2023). Vision-Language Models for Zero-Shot Classification of Remote Sensing Images. Applied Sciences, 13(22), 12462. https://doi.org/10.3390/app132212462