Abstract
The automatic extraction of key entities in mechanics problems is an important means to automatically solve mechanics problems. Nevertheless, for standard Chinese, compared with the open domain, mechanics problems have a large number of specialized terms and composite entities, which leads to a low recognition capability. Although recent research demonstrates that external information and pre-trained language models can improve the performance of Chinese Named Entity Recognition (CNER), few efforts have been made to combine the two to explore high-performance algorithms for extracting mechanics entities. Therefore, this article proposes a Multi-Meta Information Embedding Enhanced Bidirectional Encoder Representation from Transformers (MMIEE-BERT) for recognizing entities in mechanics problems. The proposed method integrates lexical information and radical information into BERT layers directly by employing an information adapter layer (IAL). Firstly, according to the characteristics of Chinese, a Multi-Meta Information Embedding (MMIE) including character embedding, lexical embedding, and radical embedding is proposed to enhance Chinese sentence representation. Secondly, an information adapter layer (IAL) is proposed to fuse the above three embeddings into the lower layers of the BERT. Thirdly, a Bidirectional Long Short-Term Memory (BiLSTM) network and a Conditional Random Field (CRF) model are applied to semantically encode the output of MMIEE-BERT and obtain each character’s label. Finally, extensive experiments were carried out on the dataset built by our team and widely used datasets. The results demonstrate that the proposed method has more advantages than the existing models in the entity recognition of mechanics problems, and the precision, recall, and F1 score were improved. The proposed method is expected to provide an automatic means for extracting key information from mechanics problems.
1. Introduction
With the rapid development of artificial intelligence (AI), the research on intelligent tutoring algorithms (ITAs) has also made great progress [1,2,3]. The most important link in developing ITA for mechanics problems is problem understanding [4]. The purpose of problem understanding is to convert input problems into structured given conditions through natural language processing (NLP). Nevertheless, as mechanics problems usually involve a large number of complex relations (nested relations and overlapping relations), existing methods utilize named entity recognition (NER) to accomplish the problem understanding task [4,5].
NER is the basis for developing NLP applications [6], such as information extraction (IE) [7,8,9], knowledge extraction (KE) [10,11], question answering (QA) [12,13], and intelligent tutoring systems (ITSs) [3,4]. The main task of NER is to extract entities in unstructured text and classify the elements into predefined categories such as name, organization, location, and string value. Recognizing named entities for mechanics problems can acquire the basic information and given conditions of the input problem, which provide support for automatically finding the answer. Therefore, it is of great significance to accurately extract named entities for mechanics problems.
From the perspective of application scenarios, our purpose was to identify the key entities of input mechanics problems. For instance, the green characters are the key entities of the example provided in Figure 1. However, developing an efficient model for this task faces some challenges. In contrast to English, Chinese sentences have no boundaries for word segmentation [14]. Therefore, early Chinese named entity recognition (CNER) methods only took characters as input [15]. Since lexical boundaries are usually the same as entity boundaries, scholars have paid increasing attention to developing algorithms utilizing lexical information [16]. With continuous exploration, many innovational methods have been proposed. These methods can be divided into three categories. The first approach is the pipeline model. This type of method performs Chinese word segmentation (CWS) first and then takes these segmented sequences as the input. However, these methods ignore the influence of word segmentation, which easily causes error propagation and reduces the recognition performance. The second approach is the multi-task model. Inspired by multi-task learning, this type of method usually trains CWS and CNER jointly. However, these methods make fully mining the learning ability of the model difficult, and the generalization ability is usually poor. The last approach is the character representation enhancing model. This type of method usually enhances the character representation with lexical information before feeding it into the main model. Compared with the aforementioned two methods, the third approach can obtain better performance. The current state-of-the-art CNER algorithm was based on the third approach. The model proposed in this article also belongs to this approach.

Figure 1.
An example of named entity recognition for mechanical problems. Text in green represents the entities.
In addition to the lexical segmentation problem, there are three challenges in identifying entities from mechanics problems. Firstly, as provided in Figure 1, the target text contains much terminology, and only some of these terms are target entities. For instance, as provided in Figure 1, “速度 (speed)”, “匀减速直线运动 (uniform deceleration linear motion)”, and “运动 (motion)” are terminology. Nonetheless, only “匀减速直线运动 (uniform deceleration linear motion)” is the target entity. Although large-scale language models, such as bidirectional encoder representation from transformers (BERT), can enhance the character representation, they tend to ignore the fact that learning character terminology information directly can bring further improvement. The boundary information, semantic information, and contextual information of lexicons are a benefit to distinguishing target entities accurately. For example, as character “运 (transport)” is contained in “运动 (motion)” and “匀减速直线运动 (uniform deceleration linear motion)”, we call both terms matched words of “运 (transport)” in this article. Learning the abovementioned information can help the first “运 (transport)” predict the tag of “O” and help the second “运 (transport)” predict the tag of “I-MOT” (an inside character of a motion entity) rather than “B-MOT” (the beginning character of a motion entity) and “O”.
Secondly, there are many composite entities composed of numbers and characters, such as “20 米每秒 (20 meters per second)” and “10 米每秒 (10 meters per second)”. In this situation, the input character need to fully learn the contextual information of adjacent characters or terms to predict correct labels. For instance, the target entity “20 米每秒 (20 meters per second)” consists of the number “20” and the terminology “米每秒 (meters per second)”. By learning the nearest contextual character information and contextual lexical information, an “I-VEL” (an inside character of a velocity entity) tag can be predicted for “米 (meter)” rather than “B-VEL”(the beginning character of a velocity entity).
Thirdly, identifying entities from mechanics problems is a typical vertical field problem. Chinese characters are pictographs that evolved from pictures; thus, the structure can reflect the relevant information of the character. In Chinese, characters are usually formed by radicals, called a glyph structure. As characters consisting of the same radicals usually have similar meanings, the glyph structure can enrich the character representation further. For instance, the characters formed by “鸟 (bird)” usually indicate meanings related to birds, such as “鸡 (chicken)”, “鸭 (duck)”, and “鹰 (eagle)”. The characters formed by “月 (moon)” usually indicate meanings related to the body, such as “腰 (waist)”, “肾 (renal)”, and “肩 (shoulder)”. It has been demonstrated that the cosine distance of Chinese characters with the same radical or a similar structure is smaller [17]. Therefore, radical information can enhance the semantic information of Chinese characters. Additionally, in the medicine and medical fields, the glyph structure has been used as an important means to improve model performance. However, current research on mechanics tends to ignore this beneficial approach.
From the perspective of implementation, recent research has demonstrated that the benefits external information and a pre-trained language model bring to CNER cannot be ignored. Many scholars have noticed this and have combined the two to develop new methods. Nevertheless, there are still two defects, including the inability to use multivariate information and insufficient information learning. Firstly, most current works have concatenated the external information with the output of the pre-trained language model, and this leads to the inadequate learning of external information. In this article, we call this type of approach the model-level fusion method. Secondly, although a few methods enable the pre-trained language model to learn external information, they tend to only use external lexical information while ignoring radical information.
For Chinese, the main difference between vertical and generic domains is that vertical domains contain a large number of terms and the radicals of these terms. Therefore, we proposed a novel CNER method for the mechanics domain based on the characteristics of Chinese. Firstly, to improve the overall performance of the proposed model, we used the pre-trained language model BERT. Secondly, we used Multi-Meta Information Embedding (MMIE) and fully integrated it into BERT. The motivation was that this could help BERT to learn the multi-meta information while leveraging it. Specifically, we proposed an information adapter layer (IAL). The multi-meta embedding could be integrated into the underlying transformer of BERT through IAL directly, so that BERT could learn the multi-meta information. In this article, we call this approach the sub-model-level fusion method. In summary, the specific contributions of this article are listed as follows:
- A Multi-Meta Information Embedding method was proposed to enrich the representation of Chinese sentences.
- A sub-model-level fusion method was proposed to fuse the external information embedding into the bottom transformer of BERT, which could promote the pre-trained model to learn the external information embedding.
- An information adapter layer was proposed to fine-tune the model while leveraging the external information embedding.
The rest of this article is organized as follows. In Section 2, we introduce the related works. In Section 3, we introduce the the proposed method, including the Multi-Meta Information Embedding, the information adapter layer, the encoding layer, and the decoding layer. In Section 4, extensive experiments are presented. In Section 5, three case studies are discussed. Finally, Section 6 concludes this article.
2. Related Works
Recent research has demonstrated that external information and a pre-trained language model can improve the performance of a CNER algorithm. These algorithms can be divided into three categories: external information-based algorithms, pre-trained language model-based algorithms, and hybrid algorithms.
External information-based algorithms aim to enhance character representation by adding external information (such as lexical information). Zhang et al. [18] were the first to develop this type of method. They proposed Lattice LSTM, which encodes and matches words of the input sentence. However, each character of Lattice LSTM can only obtain the lexical information ending with that character, and there is no continuous memory for the previous lexical information. Moreover, Tang et al. [19] proposed the word-character graph convolution network (WCGCN). This algorithm enhances the lexical information using a graph convolution network (GCN). Additionally, Song et al. [20] proposed a multi-information-based algorithm. They used a bidirectional gated recurrent unit (Bi-GRU)-conditional random field (CRF) to fuse character embedding, lexical embedding, and radical embedding. Further research was reported in [21,22,23,24,25]. However, these methods do not leverage a pre-trained language model, which could significantly improve the recognition performance.
Pre-trained language model-based algorithms aim to enhance character representation using a pre-trained model (such as BERT). Research [26,27] has proved that using the character features from BERT outperforms static embedding-based CNER algorithms. These methods usually use fine-tuning to connect the pre-trained language model with traditional CNER models, such as BERT-BiLSTM-CRF and BERT-BiGRU-CRF. A defect of these methods is that they do not consider the effect of external information on the recognition performance, which is more obvious in the vertical field.
Hybrid algorithms aim to integrate external information and a pre-trained language model [17,28,29,30]. Ma et al. [30] proposed a model-level fusion method, named SoftLexicon. This algorithm takes the output of BERT as an enhanced character representation, directly concatenates it with the lexical embedding, and then inputs them into a fusion layer for CNER. Additionally, Li et al. [28] proposed the flat-lattice transformer (FLAT) to integrate lexical information and character embedding. Similarly, FLAT also uses model-level fusion when leveraging BERT. Although these methods simultaneously utilize external information and a pre-trained language model, they only use the model-level integration of the two, which does not allow the pre-trained language model to fully learn the external information and easily leads to overfitting.
With the development of deep learning, the CNER algorithm has become more and more mature in the open domain. However, for the vertical domain, the data sources are diverse, and the data structure is different. Compared with the open domain, the entities of the vertical domain are complex and difficult to identify. Guo et al. [31] proposed a CNER method combining a convolutional neural network (CNN) [32], BiLSTM, and an attention mechanism (AM) to recognize agricultural pest- and disease-related named entities. Chen et al. [33] proposed a hybrid neural network model based on MC-BERT, namely MC-BERT + BiLSTM + CNN + MHA + CRF, to recognize entities in Chinese electronic medical records. He et al. [34] proposed a CNER method that combines knowledge graph embedding with a self-attention mechanism to recognize entities in Chinese marine texts. Liu et al. [26] applied BERT-BiLSTM-CRF to the recognition of named entities in the field of history and culture. However, these research works simply applied the open-domain algorithms to the vertical domain, and few works have taken into account the characteristics of professional entities.
In summary, there are two challenges in developing an efficient CNER algorithm for the mechanics domain. The first is how to use the domain information, and the second is how to integrate the external information and pre-trained model. Therefore, this article proposes a novel CNER algorithm for recognizing mechanics entities, namely Multi-Meta Information Embedding Enhanced BERT (MMIEE-BERT). In contrast to the above methods, MMIEE-BERT uses terminology from the mechanics domain and its corresponding roots as the external information. Then, to fully integrate external information with the pre-trained model, a sub-model-level fusion method is proposed to integrate the external information into the pre-trained model BERT. The proposed method integrates external information into the underlying transformer of BERT, so that the top transformers of BERT can fully learn this information.
3. The Proposed Model
To better utilize the Multi-Meta Information Embedding (MMIE), including character embedding, lexical embedding, and radical embedding, we designed a novel structure based on BERT. As provided in Figure 2, the main architecture of the proposed method can be divided into three components, namely the embedding layer, encoding layer, and decoding layer. Compared to existing algorithms, the proposed model has two main differences at the embedding stage. Firstly, the proposed method transforms the sentence (character sequence) into a character–lexeme–radical pair sequence as the input. Secondly, an information adapter layer (IAL) is proposed between the transformer layers, which aims at integrating the character embedding, lexical embedding, and radical embedding into BERT. The details of each component, including the proposed MMIEE-BERT, encoding layer, and decoding layer, are described below.
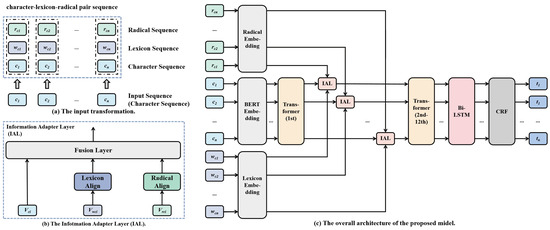
Figure 2.
The overall architecture of the proposed model, where (a) is the input transformation, (b) is the architecture of the proposed information adapter layer, and (c) is the main architecture of the whole model. In the picture, denotes the i-th character of the input sentence, denotes the lexical set of , denotes the radical set of , denotes the i-th output of the fist transformer, denotes the embedding vector of , denotes the embedding vector of , and denotes the predictive tag of .
3.1. Multi-Meta Information Embedding
As mentioned above, there is much terminology in mechanics problems. Moreover, Chinese characters are pictographs that evolved from pictures. Making full use of this information can improve the performance of a CNER model for the mechanics domain. In this article, we propose Multi-Meta Information Embedding (MMIE), including character embedding, lexical embedding, and radical embedding, to enrich the representation of a Chinese sentence. All these embeddings were designed based on simple principles, which do not need complex conversion.
3.1.1. Character Embedding
As there is no obvious lexical boundary in Chinese sentences, each character of the input sentence is mapped onto a character embedding. We chose the BERT embedding layer [35] to convert the characters into a character embedding.
As provided in Figure 3, each character embedding consists of three parts, token embedding, segment embedding, and position embedding. For instance, the character embedding of can be written as
where denotes the character embedding of , denotes the token embedding of , denotes the segment embedding of , and denotes the position embedding of .
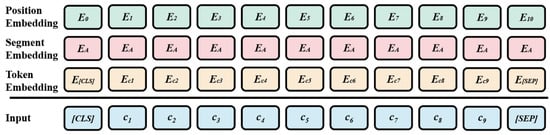
Figure 3.
The embedding layer of BERT.
3.1.2. Lexical Embedding
Character-based CNER models are prone to errors when identifying entity boundaries. Existing research has mitigated this problem by adding lexical information into character based models. Chinese lexemes consist of one or more Chinese characters. As provided in Table 1, there are three relationships between a lexeme and the characters that make it up.

Table 1.
Three relationships between words and characters, including beginning, inside, and end.
The main goal of leveraging lexical information in character-based CNER models is to integrate lexical embedding into character embedding. This study obtained the lexical embedding through the following three steps: firstly, mapping the character sequence into the lexicon group sequence according to the relationship between lexemes and characters; secondly, converting the words in the lexicon group into the embedding; thirdly, concatenating the vector of each word to acquire the final lexical embedding. We stipulated that: if the relationship between the word d and the character c meets any of the relationships defined in Table 1, then d belongs to the lexicon group corresponding to the character c. Taking the truncated sentence “匀加速直线运动 (uniformly accelerated linear motion)”, for example, the mapped lexeme set contains six words: “匀加速 (uniform acceleration)”, “匀加速直线运动 (uniformly accelerated linear motion)”, “加速 (acceleration)”, “直线 (straight line)”, “直线运动 (linear motion)”, and “运动 (motion)”. Based on the mapping rule, the character lexical mapping is provided in Figure 4.
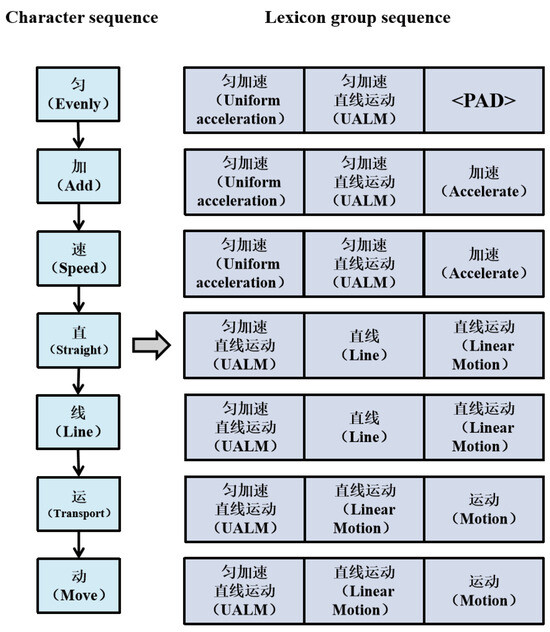
Figure 4.
Character lexical mapping of “匀加速直线运动 (uniformly accelerated linear motion)”, including six words, namely “匀加速 (uniform acceleration)”, “匀加速直线运动 (uniformly accelerated linear motion)”, “加速 (acceleration)”, “直线 (straight line)”, “直线运动 (linear motion)”, and “运动 (motion)”. “<PAD>” denotes a padding value.
To align the number of words contained in the lexical group corresponding to each character, <PAD> was employed to fill the lexical group when the number of words in the lexical group was less than the maximum number of matching words. Finally, the transformed lexical group sequence could be expressed as , where denotes the lexical group corresponding to , and denotes the i-h word in .
3.1.3. Radical Embedding
In contrast to Latin characters, Chinese characters are hieroglyphic characters, which evolved from pictorial characters. Thus, the form and meaning of Chinese characters are inextricably linked, which is helpful for CNER. For example, “力 (force)” always represents force-related words, such as “动 (move)” and “劳 (labor)”. “舟 (boat)” usually represents boat-related words, such as “航 (sail)” and “舰 (warship)”, “辶 (chuo)”, which originated from “(chuo)”, mainly represents walking-related words, such as “速 (speed)” and “运 (transport)”. As the terminology of the mechanics domain usually contains “运 (transport)”, “动 (move)”, and “速 (speed)”, in terms such as “匀速直线运动 (uniform linear motion)”, “加速度 (acceleration)”, and “振动 (vibration)”, this information is of benefit to CNER in the mechanics domain.
Generally, there are two ways to decompose Chinese characters into radicals, component construction and head–tail construction. Component construction refers to querying Chinese characters by decomposing all word roots. Head–tail construction refers to querying Chinese characters by disassembling the head radical and tail radical. As provided in Figure 5, the character “度 (degree)” can be decomposed into “广 (wide)”, “又 (also)”, and “廿 (nian)” by component construction, as well as “广 (wide)” and “又 (also)” by head–tail construction. In this article, we chose head–tail construction as the radical-level feature, and an example is provided in Figure 6.
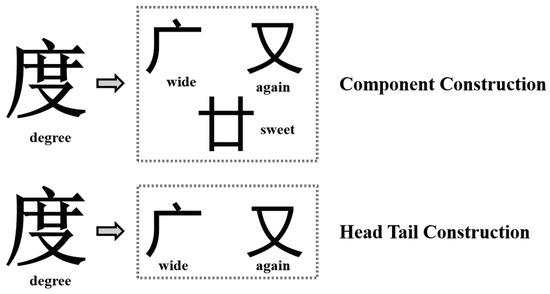
Figure 5.
The ways of decomposing Chinese characters into radicals, including component construction and head–tail construction.
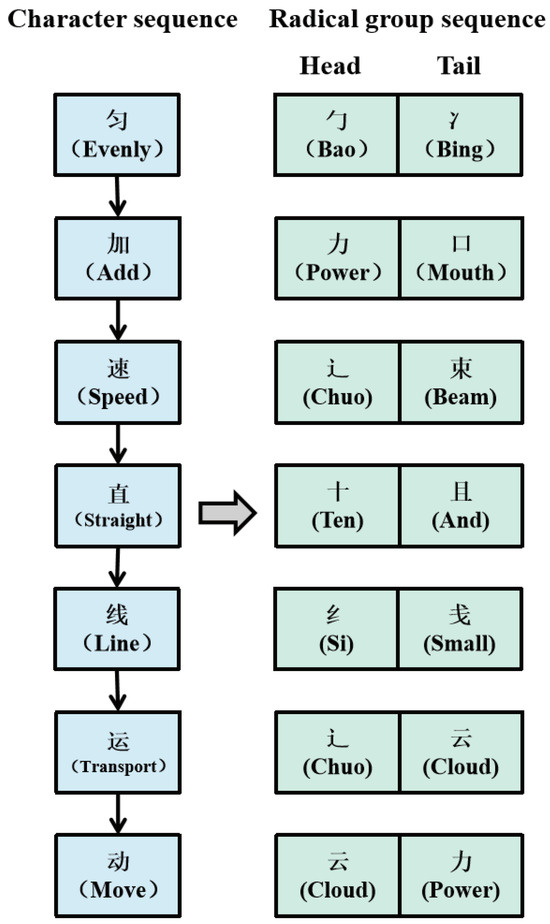
Figure 6.
Characterradical mapping of “匀加速直线运动 (uniformly accelerated linear motion)”, including head radical and tail radical.
By using the head–tail radical feature, the transformed radical group sequence could be expressed as , where denotes the radical group corresponding to , denotes the head radical of , and denotes the tail radical of .
3.2. The Information Adapter Layer
Only few of the existing methods use a pre-trained language model when leveraging external information. As provided in Figure 7, these works usually include model-level fusion models. These methods have the following defects:
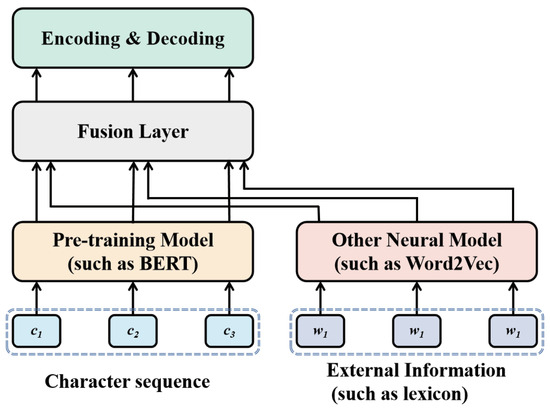
Figure 7.
The existing methods of integrating external features (such as lexicons) and BERT in CNER.
- The pre-trained model cannot fully learn external information.
- Other neural models, such as Word2Vec [36], are usually used to learn external information, which makes the overall model complex and increases the training cost.
- Due to the use of other neural models, it is easier to cause overfitting on small datasets.
To achieve a more green and economic migration of the NLP pre-trained model, present research has proposed many methods to optimize fine-tuning, such as adapter fine-tuning [37] and mask fine-tuning [35]. This study, based on the idea of adapter fine-tuning, proposes an information adapter layer to fine-tune the pre-trained model while fusing the external information.
Denoting by an input sentence containing n characters, S can be converted to after matching it with a pre-defined lexicon set and radical set, where denotes the i-th character of S, and denotes the lexicon group and the radical group corresponding to , respectively. As provided in Figure 2b, the proposed IAL only needs two alignment layers and a fusion layer to integrate external embedding and character embedding.
3.2.1. The Lexicon Alignment Layer
As the BERT model was applied to acquire the character embedding, the dimensions of the character embedding were fixed. To align the lexicon embedding with the character embedding, we performed a dimension transformation on the lexical embedding. However, the number of words in the corresponding lexicon groups of different sentences may be different. Therefore, we applied the following operation to eliminate the influence of different word matching numbers on training. Firstly, dimension reduction was performed on the lexicon group vector. Then, we transposed the reduced lexicon vector and multiplied it. Finally, the product obtained in the previous step was raised to the same dimensions as the character embedding. The propagation formula could be written as
where denotes the lexicon group vector after dimension reduction; is a -dimensional trainable parameter matrix; is a pre-defined dimension; is the dimension of the lexical lookup table; denotes the lexicon group vector after eliminating the number of matched words; denotes the lexicon group embedding after dimension upgrading; is a -dimensional trainable parameter matrix; denotes the dimension of character embedding, that is, the dimension of the BERT embedding layer; denotes the aligned lexicon group embedding; denotes the activation function (the function was applied in this study); is the -dimensional trainable parameter matrix; and is the corresponding bias.
3.2.2. The Radical Alignment Layer
As with lexical embedding, radical embedding required dimension alignment before integrating it with character embedding. Nevertheless, as head–tail construction was chosen as the radical-level feature, each character in the input sentence was mapped onto two radicals, so the radical alignment did not include dimension reduction and transposition. The propagation formula of radical alignment can be written as
where denotes the radical group embedding vector after dimension upgrading; is a -dimensional trainable parameter matrix; is the dimension of the radical embedding vector; denotes the aligned radical group embedding; denotes the activation function; is the -dimensional trainable parameter matrix; and is the corresponding bias.
3.2.3. The Fusion Layer
The fusion layer aimed to integrate the character embedding, lexical embedding, and radical embedding. The input of the fusion layer was the output of the first transformer of BERT, the output of the lexical alignment layer, and the output of the radical alignment layer. We added these three vectors directly and set three trainable parameters to dynamically scale the feature. The fusion formula can be expressed as
where denotes the final character embedding of , that is, the i-th input character vector input into second transformer of BERT; denotes the i-th output vector of the first transformer of BERT; denotes the aligned lexical embedding of ; denotes the aligned radical embedding of ; and , , and are trainable weights. Via the fusion layer, we acquired a new vector, which could be seen as the representation of the input sequence integrating the domain lexical information and radical information. In this way, other transformer layers of BERT could fully learn this information.
3.3. The Encoding Layer
An encoding layer is applied to learn the sequence feature of the output of MMIEE-BERT, usually using a CNN, long short-term memory (LSTM [38]), or a transformer encoder. This study used LSTM as the encoding model. LSTM was proposed to solve the gradient disappearance problem of traditional RNNs (recurrent neural networks). LSTM consists of three gates: a forget gate, input gate, and output gate. The basic structure of LSTM is provided in Figure 8.
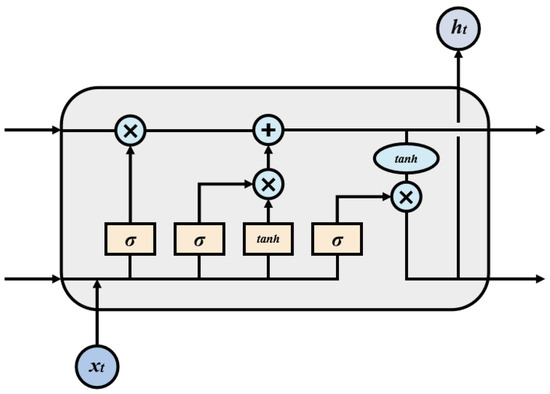
Figure 8.
The structure of an LSTM unit, where × in crcle denotes element-level multiplication.
The input of the forget gate is the hidden state of previous time and the input vector of current time . The corresponding output is . The propagation formula can be written as
where , , and are trainable parameters. The input of the input gate is the hidden state of previous time and the input vector of current time . The corresponding outputs are and . The propagation formula is
where , , , , , and are trainable parameters. The memory unit of LSTM is updated through the output of the forget gate and input gate. The update formula is
The input of the output gate is the hidden state of previous time , the input vector of current time , and the memory unit state of current time . The outputs are and the hidden state . The calculation formula is
However, LSTM can only model the input vector in a single direction. Therefore, this study used BiLSTM to learn the sequence information. A BiLSTM layer consists of a forward LSTM and a reverse LSTM. The forward LSTM is used to learn the future features, and the reverse LSTM is used to learn the historical features. As two LSTM units are used, the output of BiLSTM at time t is obtained by concatenating the output of the forward LSTM with the output of the reverse LSTM, which can be written as
where denotes the output of BiLSTM, denotes the output of the forward LSTM, and denotes the output of the reverse LSTM.
3.4. The Decoding Layer
Although BiLSTM can learn the sequence feature of the input vector and select the tag with the highest probability as the output, it cannot obtain the dependency between the labels, which may lead to the connection of two identical tags. CRF has a transfer feature, which can consider the order of output labels, so CRF [39] was applied as the decoding layer for the output of BiLSTM.
For a sequence , denoting by the corresponding label of X, then the score can be defined as
where denote the scores transferred from label to label , and denotes the transfer score matrix of the output of BiLSTM. Additionally, the function was applied to calculate the maximum probability of sequence label y, which can be written as
where denotes all possible label sequences of input sequence X. Finally, this study employed the Viterbi algorithm at the decoding stage, and the final optimal sequence with the highest predicted total score is
where denotes the final output tag sequence.
4. Experiments
4.1. Dataset Construction for Mechanics Domain
4.1.1. Data Collection
We collected the experimental data from the Internet (https://zujuan.xkw.com/ (accessed on 28 August 2023), https://zujuan.21cnjy.com/ (accessed on 28 August 2023)), and a total of 6822 mechanics problems were collected. Additionally, the data were divided into a training set, validation set, and test set with a ratio of 8:1:1. The properties of the dataset are provided in Table 2.
Table 2.
The properties of the experimental dataset, including the training set, validation set, and test set. Character number denotes the total number of characters in the set; entity number denotes the total number of entities in the set; problem number denotes the total number of problems in the set, that is, the capacity of the data; and average number denotes the average number of characters per problem in the set.
4.1.2. Entity Classification
The basis of constructing a mechanics ITS is to acquire the research object and given conditions from the input problem. The given conditions can be divided into velocity, acceleration, force, time, etc. Finally, we manually divided the entities into 15 categories, and the labels and meanings are provided in Table 3.
Table 3.
Entity classification of the dataset.
4.1.3. Tagging Schema and Entity Distribution
We chose the BIO tagging schema for our experiment to reduce the number of labels. In this schema, B denotes the starting character of the entity, I denotes the other characters of the entity (excluding the starting character), and O denotes a non-entity character. An example of this tagging schema is provided in Table 4. Table 5 reports the number distribution of each type of entity in the experimental data.
Table 4.
The tagging of truncated sentence “物体由静止开始做匀加速直线运动 (the object starts to move in a uniformly accelerated linear motion from static)” using the BIO tagging schema.
Table 5.
Distribution of the number of entity categories.
From Table 5, we can see that the dataset we collected was unbalanced. There were two reasons for this. Firstly, the key entities involved in each mechanics problem were different. Specifically, linear motion problems contained more entities like velocity, time, and acceleration, but fewer entities like force, power, and energy. On the other hand, the power-energy problems contained more power entities and energy entities. Furthermore, the number of each type of problem contained in the dataset was different. Force analysis problems and power-energy problems are usually more complex and given in the form of pictures and texts. Thus, in the plain text form, the number of these two types of problem was significantly lower than the number of linear motion problems.
4.2. Parameter Setting
We used the BERT base model, which was composed of 12 layers of transformers, and adopted fine-tuning for training. The lexicon was collected from Baidu (https://baike.baidu.com/ (accessed on 28 August 2023)), and 128,458 words were obtained. Additionally, all words in the lexicon were composed of multiple characters. That is, if and only if a sub-sequence of a sentence completely covered a word, the word was considered to be contained in the sentence. The radical set was obtained from the online Xinhua Dictionary (https://tool.httpcn.com/Zi/ (accessed on 28 August 2023)), and a total of 21,312 radicals were collected. Finally, the lexical embedding and radical embedding were all randomly initialized. The experiments were conducted using PyTorch, and the specific parameters are provided in Table 6.
Table 6.
Parameter setting of the proposed model.
4.3. Evaluation Metrics
The evaluation metrics of named entity recognition include precision (P), recall (R), and F1 score (F1). The calculation formulas are
where denotes the number of true-positive classes; denotes the number of false-positive classes; denotes the number of true-negative classes; and denotes the number of false-negative classes. As the dataset we collected was unbalanced, we used both the micro-averaged metrics and macro-averaged metrics as evaluation metrics for our experiments.
4.4. Experimental Results and Analysis
This sub-section reports the experimental results and analysis of our experiments, including a comparison experiment, a generalization analysis, and an ablation experiment.
4.4.1. Comparison with Baseline Models
To evaluate the performance of the proposed method, we tested and analyzed the existing algorithms. In this study, we chose six open-source algorithms as baseline models: BiLSTM-CRF, Lattice LSTM [18], BERT-BiLSTM-CRF [26], BERT-FLAT [28], BERT-MECT [17], and LE-BERT [29]. Among them, BiLSTM-CRF is a widely used sequence labeling algorithm. Lattice LSTM fuses lexical information and character information on the basis of BiLSTM-CRF. BERT-BiLSTM-CRF uses the pre-trained model BERT to enhance the character representation of the input sentence. BERT-FLAT utilizes lexical information on the basis of BERT-BiLSTM-CRF. Additionally, it uses model-level fusion to integrate the lexical information and pre-trained model. BERT-MECT uses radical information based on FLAT to further enhance the character representation. It also uses a model-level fusion approach. LE-BERT has BERT learn the lexical information to accomplish CNER. In contrast to the above methods, LE-BERT is a sub-model-level fusion method. The proposed method integrated external information with the pre-trained model using sub-model-level fusion. Finally, the character embedding of all models without BERT was generated by random initialization. For each model, we ran the experiment five times to acquire stable experimental results. The averages and standard deviations of the evaluation metrics are reported in Table 7.
Table 7.
Recognition performance of the proposed algorithm and baseline algorithms, including micro-averaged metrics and macro-averaged metrics, where the bold denote the high score.
Several observations can be drawn from Table 7. Firstly, the BiLSTM-CRF method performed poorly in recognition. The reason was that it did not use external information or a pre-trained language model to enhance the character representation. Secondly, we can see that adding lexical information to character-based models can improve the performance in recognizing mechanics entities. Compared with BiLSTM-CRF, the micro-averaged F1 score of Lattice LSTM was improved by 1.34 percentage points. Thirdly, the F1 score of BERT-BiLSTM-CRF was significantly improved after using the pre-trained language model BERT on the basis of Bi-LSTM-CRF. This demonstrates that BERT is very helpful in recognizing named entities in the field of mechanics. Fourth, comparing the recognition of Lattice LSTM and BERT-BiLSTM-CRF, we found that the pre-trained language model BERT could improve the recognition ability of the model more than lexical information. Fifth, the comparison results of BERT-BiLSTM-CRF, BERT-FLAT, and BERT-MECT demonstrate that the integration of BERT and lexical information through model-level fusion achieved a higher F1 value than using BERT alone. Sixth, the comparison results of BERT-FLAT, BERT-MECT, and LE-BERT demonstrate that sub-model-level fusion has more advantages than model-level fusion in extracting mechanics entities. Finally, the recognition performance of the proposed MMIEEE-BERT model was the best, achieving a 91.57% F1 score. This was 0.93 percentage points higher than the F1 score of LE-BERT and 1.24 percentage points higher than the F1 score of BERT-MECT. This demonstrates that our model made a significant improvement in recognizing mechanics entities by integrating multi-embedding information into the underlying transformer of BERT through the information fusion layer.
4.4.2. Performance for Different Classes of Entities
The recognition results of the different models for different types of entity are reported in Table 8, from which the following points can be observed. Firstly, the proposed MMIEE-BERT model performed well in recognizing several entities, such as “OBJ”, “VEL”, “ACC”, “TIM”, “FOR”, and “STA”, and performed relatively poorly in recognizing entities such as “MUL”, “FRC”, “POW”, and “ENE”. The reason for this could be that the number of these entities was small and the expression of these entities was complex, including the combination of words and numbers. Secondly, comparing the results of the models without BERT to the BERT-based models, it can be found that the recognition performance of the BERT-based models was clearly improved for several entities, including time (TIM), multiple (MUL), friction coefficient (FRC), action (ACT), power (POW), energy (ENE), position (POS), mass (MAS), and state (STA). Except for the three entities of time (TIM), mass (MAS), and state (STA), the other entities accounted for a relatively small proportion in the dataset, which indicates that the BERT models have certain advantages for imbalanced datasets.
Table 8.
F1 scores of different models for various entities.
Thirdly, it is worth noting that LE-BERT and MMIEEE-BERT had better performance on balanced data than the other models. We suggest that the reason for this was that the other models adopted model-level fusion methods, which reduced the adaptability of BERT to balanced data, while the above two methods adopted sub-model-level fusion, which had less impact on BERT. In summary, the use of BERT had a significant effect on the collected data, which was mainly reflected in the recognition of multiples (MUL), friction coefficient (FRC), action (ACT), and position (POS). Moreover, while improving the recognition performance of the above entities, the model had a good recognition effect for other entities.
Fourth, it is worth noting that, LE-BERT and MMIEEE-BERT had better performance on unbalanced data than the other models. We suggest that the reason for this was that the other models adopted model-level fusion methods, which reduced the adaptability of BERT to balanced data, while the above two methods adopted sub-model-level fusion, which had less impact on BERT. In a summary, the use of BERT had a significant effect on the collected data, which was mainly reflected in the recognition of multiples (MUL), friction coefficient (FRC), action (ACT), and position (POS). Moreover, while improving the recognition performance of the above entities, the model had a good recognition effect for other entities.
4.4.3. Generalization Analysis
To further evaluate the generalization ability of the proposed method, we conducted experiments on three other datasets, namely Chinese Resume, Yidu-S4K, and MSRA. Among them, the Chinese Resume dataset contains eight types of entity, i.e., CONT, EDU, LOC, NAME, ORG, PRO, RACE, and TITLE. The Yidu-S4K dataset contains six categories of entity, i.e., Disease and Diagnosis, Check, Inspection, Surgery, Medicine, and Anatomical Site. The MSRA dataset contains three types of entity, i.e., ORG, LOC, and PER. The statistics of these datasets are provided in Table 9.
Table 9.
Statistics of the three datasets.
We used the lexicon set and radical set mentioned in Section 4.2 to conduct experiments comparing the proposed method and the baseline algorithms. As with the above experiments, all character embedding, lexical embedding, and radical embedding was randomly initialized. Additionally, we did not use bichar embedding. The experimental results are reported in Table 10. From the results of the generalization experiments, we could make the following observations. Firstly, the BERT-based models performed better than the models without BERT on each dataset, indicating that the use of large-scale language models such as BERT can improve the recognition ability of models, and the generalization ability did not worsen. Secondly, the proposed MMIEE-BERT method still achieved the highest F1 score on each dataset. The model’s F1 scores on the three datasets were 96.74%, 76.98%, and 96.35%, which were 0.09, 0.14, and 0.09 percentage points higher than the best baseline model scores, respectively. This indicates that the proposed method still had good generalization ability and could also be applied to entity recognition in the general domain or other vertical domains.
Table 10.
Comparison of recognition effect of each model on different datasets. In the table, P denotes precision, R denotes recall, and F denotes F1 score.
4.4.4. Ablation Experiment
In this section, we present the two ablation experiments conducted using MMIEE-BERT to evaluate the influence of different structures and components on the model’s capability, i.e., the influence of input features (IF experiment) and the influence of different embedding layers and encoding layers (EE experiment).
To evaluate the influence of input features on the proposed model, an IF experiment was conducted. Specifically, the four groups of experiments presented in Figure 9 were constructed. For Experiment 1 (Base), BERT, lexical embedding, and radical embedding were deleted on the basis of MMIEEE-BERT. For Experiment 2 (w/o LR), both lexical features and radical features were deleted on the basis of MMIEEE-BERT. For Experiment 3 (w/o R), radical features were deleted on the basis of MMIEEE-BERT. For Experiment 4 (w/o L), lexical features were deleted on the basis of MMIEEE-BERT. The main results of the ablation experiments are reported in Table 11.
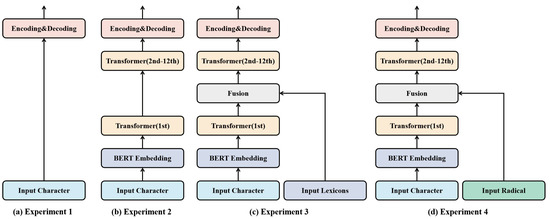
Figure 9.
Architecture of four sets of comparison experiment models. The encoding model and decoding model employed BiLSTM and CRF, respectively.
Table 11.
Statistical results of ablation experiments.
From the experimental results, we found that the combination of BERT, lexical information, and radical information produced the most significant improvement in recognition performance. Among them, the use of BERT alone caused the most obvious improvement in model performance, greater than the improvement brought by the use of lexical embedding or radical embedding alone. Additionally, compared with radical information, lexical information brought a greater improvement in the model’s performance. In summary, each feature proposed in this article could improve the recognition performance.
The EE experiment mainly evaluated the influence of different encoding layers and embedding layers on recognition performance. For the embedding layer, we chose BERT-Base, BERT-Lexicon-ML (BERT-L-M), BERT-Radical-ML (BERT-R-M), BERT-Lexical-Radical-ML (BERT-LR-M), and MMIIEE-BERT. Among them, BERT-Base is the basic BERT model, BERT-L-M has an embedding layer that fuses the BERT model with lexical information in the model-level manner, BERT-R-M has an embedding layer that fuses the BERT model with radical information in the model-level manner, and BERT-Lexical-Radical-ML fuses the BERT model with lexical information and radical information in the model-level manner. As the IF ablation experiment verified that the proposed MMIIEE-BERT model had the best performance among the sub-model-level fusion methods, the BERT-Lexicon model and BERT-Radical model with sub-model fusion were not selected in the EE experiment. For the encoding layer, BiGRU, transformer encoder, and BiLSTM were selected to conduct comparative experiments. The experimental results are reported in Table 12.
Table 12.
Statistical results of encoding layer and embedding layer comparison experiments.
The following observations could be made from Table 12. Firstly, when the same encoding layer was used, the recognition performance when employing the proposed MMIEEE-BERT model as the embedding layer was the best, followed by BERT-LR-M, BERT-L-M, BERT-R-M, and BERT-Base. This demonstrated that the pre-trained language model, lexical information, and radical information helped improve the performance in identifying key entities in mechanics problems. Additionally, the sub-model-level fusion model proposed in this article has more advantages than the other methods. Secondly, by comparing the experimental results for the last six lines, we found that BiLSTM was more suitable than BiGRU and transformer encoder as the encoding model for MMIEE-BERT. Finally, regardless of the model chosen as the encoding layer, the performance of the MMIEEE-BERT-based model was better than that of other embedding layer-based models. This indicated that the proposed MMIEEE-BERT model has strong generality. Combined with the above generalization ability analysis experiments, this demonstrates that the MMIEEE-BERT model proposed in this article can also be applied to other fields.
4.4.5. Efficiency Analysis
To evaluate the computational efficiency of MMIEE-BERT, we performed an inference experiment comparing the proposed method and the baselines. Specifically, we computed the inference time of each model on the four datasets. Then, we computed the relative inference speed, and the results are reported in Table 13. From the table, we can observe that when decoding with the same batch size (=1), the MMIEE-BERT method was more efficient than Lattice, LSTM, BERT-FLAT, and BERT MECT, performing up to 2.13 times faster than Lattice LSTM. Moreover, compared with BiLSTM-CRF, the inference speed of the BERT-based models was relative slow, because the deep layers limited the inference speed. Finally the MMIEE-BERT method was still faster than the other BERT-based structures. In summary, the proposed MMIEE-BERT model showed advantages over the other methods in terms of inference efficiency.
Table 13.
Relative inference speed (the higher the better) of the proposed model and baselines on different datasets.
5. Case Studies
To illustrate the performance of the proposed method, in this section we present three case studies on the tagged sequence generated by our model, LE-BERT, BERT-FLAT, and BERT-MECT. These three cases belong to different categories of long text data. The first case is a mechanics problem that does not contain force entities and power entities, the second is a case that contains force entities but no power entities, and the last case comprises problems that contain power entities.
5.1. Case 1: An Example of Newton’s Law of Motion
The first case is a problem concerning Newton’s law of motion. The description of this problem is: “甲, 乙两汽车沿同平直公路同向全速行驶中, 甲车在前, 乙车在后, 行驶速度均为 m/s. 当两车快要到十字路口时, 甲车司机看到红灯亮起,于是紧急刹车, 乙车司机看到甲车刹车后也紧急刹车 (乙车司机的反应时间忽略不计). 已知甲车, 乙车紧急刹车时的加速度大小分别为 m/s, m/s, 求: (1) 乙车刹车后经多长时间速度与甲车相等; (2) 为保证两车在紧急刹车过程中不相撞, 甲乙两车刹车前的距离 x 至少是多少”. (“Car A and car B two cars along the same straight road in the same direction full speed, car A in front, car B in the back, the speed is m/s. When the two cars are about to reach the intersection, the driver of car A saw the red light, and then the emergency brake, the driver of car B saw the car A brake after the emergency brake (the reaction time of the driver of car B is ignored), known car A, car B emergency braking acceleration is m/s, m/s, respectively, to find: (1) after how long the speed of car B is equal to the speed of car A; (2) to ensure that the two cars in the emergency braking process does not collide, the distance x before the two cars is at least what.”)
Table 14 reports the recognition results of the four models for case 1. It is worth noting that the target entity in case 1 contains two “刹车 (brakes)”, where the first “brake” corresponds to research object 1, “甲车 (car A)”, and the other corresponds to research object 2, “乙车 (car B)”. The three models other than MMIEEE-BERT produced errors in the recognition of these two entities. Additionally, the three baselines of LE-BERT, BERT-MECT, and BERT-FLAT failed to identify “6 m/s” as an acceleration entity.
Table 14.
The recognition performance of the four models for case 1. ✓ denotes that the model correctly identified the entity, and × denotes that the model failed to identify the entity.
5.2. Case 2: An Example of Force Analysis
The second case is a problem concerning force analysis. The description of this problem is: “据报载, 我国自行设计生产运行速度可达 m/s 的磁悬浮飞机. 假设“飞机”的总质量 , 沿水平轨道以 m/m 的加速度从静止做匀加速起动至最大速度, 忽略一切阻力的影响 ( m/s) 求: (1) “飞机”所需的动力 F; (2) “飞机”起动至最大速度所需的时间 t”. (“It is reported that a magnetic levitation aircraft with a speed of m/s has been designed and produced by our country. Assuming that the total mass of the “aircraft” is , and it accelerates uniformly from rest to maximum speed along a horizontal track with an acceleration of m/s, ignoring the influence of all resistances, ( m/s). Find: (1) the force required by the “aircraft” F (2) the time required by the “aircraft” to reach maximum speed t.”)
Table 15 reports the recognition results of the four models for case 2. It can be observed that LE-BERT produced deviations in the recognition of “1 m/s” and “匀加速起动 (uniform acceleration start)”. Specifically, the model failed to identify “1 m/s” as an acceleration entity and failed to identify “匀加速起动 (uniform acceleration start)” as a state entity. BERT-MECT failed to identify “水平 (horizontal)” and “匀加速起动 (uniform acceleration start)”. Finally, BERT-FLAT incorrectly identified the category of “10 m/s” and also failed to identify “匀加速起动 (uniform acceleration start)” as an entity.
Table 15.
The recognition performance of the four models for case 2. ✓ denotes that the model correctly identified the entity, and × denotes that the model failed to identify the entity.
5.3. Case 3: An Example of Power and Energy
The third case is a problem concerning power and energy. The description of this problem is: “哈尔滨第24 届世界大学生冬运会某滑雪道为曲线轨道, 滑雪道长 m, 竖直高度 m. 运动员从该滑道顶端由静止开始滑下, 经 s 到达滑雪道底端时速度 m/s, 人和滑雪板的总质量 kg, 取 m/s, 求人和滑雪板 (1) 到达底端时的动能; (2) 在滑动过程中重力做功的功率; (3) 在滑动过程中克服阻力做的功”. (“The length of a curve track of the 24th World University Winter Games in Harbin is m, and the vertical height is m. The athlete starts to slide down from the top of the track from a static position, and reaches the bottom of the track at a speed of m/s after s. The total mass of the person and the skis is kg. m/s. The following parameters of the person and the skis are given: (1) the kinetic energy when reaching the bottom; (2) the power of the work done by gravity in the sliding process; (3) the work done by overcoming the resistance in the sliding process.”)
Table 16 reports the recognition results of the four models for case 3. It can be seen that the three models other than MMIEEE-BERT failed to recognize the entity ” m”, which was considered to be caused by the fact that the entity was too complex. Furthermore, LE-BERT correctly recognized all other entities in this case, while BERT-MECT and BERT-FLAT failed to recognize the entity “人和滑雪板 (the person and the skis)”. Finally, BERT-FLAT incorrectly recognized “40 m/s” as acceleration.
Table 16.
The recognition performance of the four models for case 3. ✓ denotes that the model correctly identified the entity, and × denotes that the model failed to identify the entity.
Through the three case studies, it was found that for mechanics problems containing multiple research objects, the model usually displayed recognition bias for the object information of the target entities. In addition, some key entities of non-technical terms were also easily misrecognized, such as “平直 (flat)” and “上 (up)”. Finally, the model was also prone to mistakes in the recognition of complex entities containing operators and the category recognition of velocity entities and acceleration entities.
6. Conclusions
In this article, a novel NER model integrating external information was proposed for mechanics problems. It effectively improved recognition performance. The proposed model combined the pre-trained language model BERT, lexical information, and radical information and directly integrated lexical embedding and radical embedding into the underlying transformer layer in BERT using an information adapter layer. Additionally, extensive experiments were carried out on the collected data. The experimental results demonstrated that the proposed method could effectively recognize entities in mechanics problems. Compared with model-level fusion, the proposed sub-model-level fusion model could learn lexical information and radical information more sufficient;y. This method is expected to provide an automatic means for extracting key information from mechanics problems. However, the testing of the proposed method was based on small-scale datasets, which has certain limitations. In the future, an attention mechanism will be introduced to improve the performance of the model.
Author Contributions
J.Z. (Jiarong Zhang) wrote the program and drafted the manuscript. J.Y. and Z.L. conceived of the study, and participated in its design and coor-dination and helped to draft the manuscript. J.Z. (Jing Zhang) and A.L. collected and annotated the experimental data. All authors have read and agreed to the published version of the manuscript.
Funding
This study was funded by funds from Huzhou Natural Science Foundation under grant 2023YZ14.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Code and data for this work is available from the corresponding authors upon request.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Yan, W.; Liu, X.; Shi, S. Deep Neural Solver for Math Word Problems. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, (EMNLP) 2017, Copenhagen, Denmark, 7–11 September 2017; Association for Computational Linguistics: Stroudsburg, PA, USA, 2017; pp. 845–854. [Google Scholar]
- Zhang, J.; Wang, L.; Lee, K.W.; Yi, B.; Lim, E.P. Graph-to-Tree Learning for Solving Math Word Problems. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, (ACL) 2020, Washington, DC, USA, 5–10 July 2020. [Google Scholar]
- He, B.; Yu, X.; Jian, P.; Zhang, T. A relation based algorithm for solving direct current circuit problems. Appl. Intell. 2020, 50, 2293–2309. [Google Scholar] [CrossRef]
- Zhang, J.; Yuan, J.; Guo, H. Integrating deep learning with first order logic for solving kinematic problems. Appl. Intell. 2022, 52, 11808–11826. [Google Scholar] [CrossRef]
- Zhang, J.; Yuan, J.; Xu, J. An Artificial Intelligence Technology Based Algorithm for Solving Mechanics Problems. IEEE Access 2022, 10, 92971–92985. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Named Entity Recognition for Chinese Social Media with Jointly Trained Embeddings. In Proceedings of the Advances in Neural Information Processing Systems; Curran Associates, Inc.: Red Hook, NY, USA, 2017; pp. 5998–6008. [Google Scholar]
- Wang, W.; Pan, S. Integrating Deep Learning with Logic Fusion for Information Extraction. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 9225–9232. [Google Scholar] [CrossRef]
- Zhang, N.; Ye, H.; Deng, S.; Tan, C.; Chen, M.; Huang, S.; Huang, F.; Chen, H. Contrastive Information Extraction With Generative Transformer. IEEE/ACM Trans. Audio Speech Lang. Process. 2021, 29, 3077–3088. [Google Scholar] [CrossRef]
- Lai, T.; Cheng, L.; Wang, D.; Ye, H.; Zhang, W. RMAN: Relational multi-head attention neural network for joint extraction of entities and relations. Appl. Intell. 2021, 52, 3132–3142. [Google Scholar] [CrossRef]
- Che, H.; Feng, T.; Zhang, J.; Wei, C.; Li, D. Automatic knowledge extraction from Chinese natural language documents. J. Comput. Res. Dev. 2013, 60, 477–480. [Google Scholar]
- Alani, H.; Kim, S.; Millard, D.; Weal, M.; Hall, W.; Lewis, P.; Shadbolt, N. Automatic ontology-based knowledge extraction from Web documents. IEEE Intell. Syst. 2003, 18, 14–21. [Google Scholar] [CrossRef]
- Do, P.; Phan, T. Developing a BERT based triple classification model using knowledge graph embedding for question answering system. Appl. Intell. 2021, 52, 636–651. [Google Scholar] [CrossRef]
- Chen, X.; Yang, Z.; Liang, N.; Li, Z.; Sun, W. Co-attention fusion based deep neural network for Chinese medical answer selection. Appl. Intell. 2021, 51, 6633–6646. [Google Scholar] [CrossRef]
- Duan, H.; Yan, Z. A Study on Features of the CRFs-based Chinese Named Entity Recognition. Int. J. Adv. Intell. Paradig. 2011, 3, 287–294. [Google Scholar]
- Liu, Z.; Wang, X.; Chen, Q.; Tang, B. Chinese Clinical Entity Recognition via Attention-Based CNN-LSTM-CRF. In Proceedings of the 2018 IEEE International Conference on Healthcare Informatics Workshop (ICHI-W), New York, NY, USA, 4–7 June 2018; pp. 68–69. [Google Scholar] [CrossRef]
- Peng, N.; Dredze, M. Improving Named Entity Recognition for Chinese Social Media with Word Segmentation Representation Learning. arXiv 2017, arXiv:1603.00786. [Google Scholar]
- Wu, S.; Song, X.; Feng, Z. MECT: Multi-Metadata Embedding based Cross-Transformer for Chinese Named Entity Recognition. arXiv 2021, arXiv:2107.05418. [Google Scholar]
- Zhang, Y.; Yang, J. Chinese NER Using Lattice LSTM. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Melbourne, Australia, 15–20 July 2018; pp. 1554–1564. [Google Scholar] [CrossRef]
- Tang, Z.; Wan, B.; Yang, L. Word-Character Graph Convolution Network for Chinese Named Entity Recognition. IEEE/ACM Trans. Audio Speech Lang. Process. 2020, 28, 1520–1532. [Google Scholar] [CrossRef]
- Song, C.; Xiong, Y.; Huang, W.; Ma, L. Joint Self-Attention and Multi-Embeddings for Chinese Named Entity Recognition. In Proceedings of the 2020 6th International Conference on Big Data Computing and Communications (BIGCOM), Deqing, China, 24–25 July 2020; pp. 76–80. [Google Scholar] [CrossRef]
- Xu, C.; Wang, F.; Han, J.; Li, C. Exploiting Multiple Embeddings for Chinese Named Entity Recognition. In Proceedings of the 28th ACM International Conference on Information and Knowledge Management, CIKM 2019, Beijing, China, 3–7 November 2019. [Google Scholar] [CrossRef]
- Meng, Y.; Wu, W.; Wang, F.; Li, X.; Nie, P.; Yin, F.; Li, M.; Han, Q.; Sun, X.; Li, J. Glyce: Glyph-vectors for Chinese Character Representations. arXiv 2019, arXiv:1901.10125. [Google Scholar]
- Zhu, Y.; Wang, G.; Karlsson, B.F. CAN-NER: Convolutional Attention Network for Chinese Named Entity Recognition. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT, Minneapolis, MN, USA, 2–7 June 2019; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; pp. 3384–3393. [Google Scholar]
- Gui, T.; Zou, Y.; Peng, M.; Fu, J.; Wei, Z.; Huang, X. A Lexicon-Based Graph Neural Network for Chinese NER. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 1039–1049. [Google Scholar] [CrossRef]
- Dong, C.; Zhang, J.; Zong, C.; Hattori, M.; Di, H. Character-Based LSTM-CRF with Radical-Level Features for Chinese Named Entity Recognition. In Proceedings of the Natural Language Understanding and Intelligent Applications, Kunming, China, 2–6 December 2016; Springer International Publishing: Berlin/Heidelberg, Germany, 2016; pp. 239–250. [Google Scholar]
- Liu, S.; Yang, H.; Li, J.; Kolmani, S. Chinese Named Entity Recognition Method in History and Culture Field Based on BERT. Int. J. Comput. Intell. Syst. 2021, 14, 1–10. [Google Scholar] [CrossRef]
- Chang, Y.; Kong, L.; Jia, K.; Meng, Q. Chinese named entity recognition method based on BERT. In Proceedings of the 2021 IEEE International Conference on Data Science and Computer Application (ICDSCA), Dalian, China, 29–31 October 2021. [Google Scholar]
- Li, X.; Yan, H.; Qiu, X.; Huang, X. FLAT: Chinese NER Using Flat-Lattice Transformer. arXiv 2020, arXiv:2004.11795. [Google Scholar]
- Liu, W.; Fu, X.; Zhang, Y.; Xiao, W. Lexicon Enhanced Chinese Sequence Labeling Using BERT Adapter. arXiv 2021, arXiv:2105.07148. [Google Scholar]
- Ma, R.; Peng, M.; Zhang, Q.; Huang, X. Simplify the Usage of Lexicon in Chinese NER. arXiv 2019, arXiv:1908.05969. [Google Scholar] [CrossRef]
- Guo, X.; Zhou, H.; Su, J.; Hao, X.; Li, L. Chinese agricultural diseases and pests named entity recognition with multi-scale local context features and self-attention mechanism. Comput. Electron. Agric. 2020, 179, 105830. [Google Scholar] [CrossRef]
- Gui, T.; Ma, R.; Zhao, L.; Jiang, Y.G.; Huang, X. CNN-Based Chinese NER with Lexicon Rethinking. In Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence, Macao, China, 10–16 August 2019; pp. 4982–4988. [Google Scholar] [CrossRef]
- Chen, P.; Zhang, M.; Yu, X.; Li, S. Named entity recognition of Chinese electronic medical records based on a hybrid neural network and medical MC-BERT. BMC Med. Inform. Decis. Mak. 2022, 22, 315. [Google Scholar] [CrossRef]
- He, S.; Sun, D.; Wang, Z. Named entity recognition for Chinese marine text with knowledge-based self-attention. Multimed. Tools Appl. 2021, 81, 19135–19149. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Kai, C.; Corrado, G.; Dean, J. Distributed Representations of Words and Phrases and their Compositionality. Adv. Neural Inf. Process. Syst. 2013, 26, 1–9. [Google Scholar]
- Pfeiffer, J.; Rücklé, A.; Poth, C.; Kamath, A.; Vuli, I.; Ruder, S.; Cho, K.; Gurevych, I. AdapterHub: A Framework for Adapting Transformers. arXiv 2020, arXiv:2007.07779. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Lafferty, J.; Mccallum, A.; Pereira, F. Conditional Random Fields: Probabilistic Models for Segmenting and Labeling Sequence Data; Penn: Philadelphia, PA, USA, 2001; pp. 282–289. [Google Scholar]
- Kingma, D.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).