
Optimized Implementation of Argon2 Utilizing the Graphics Processing Unit

Abstract
:1. Introduction
Contributions
2. Related Work
2.1. Password Hash Algorithm
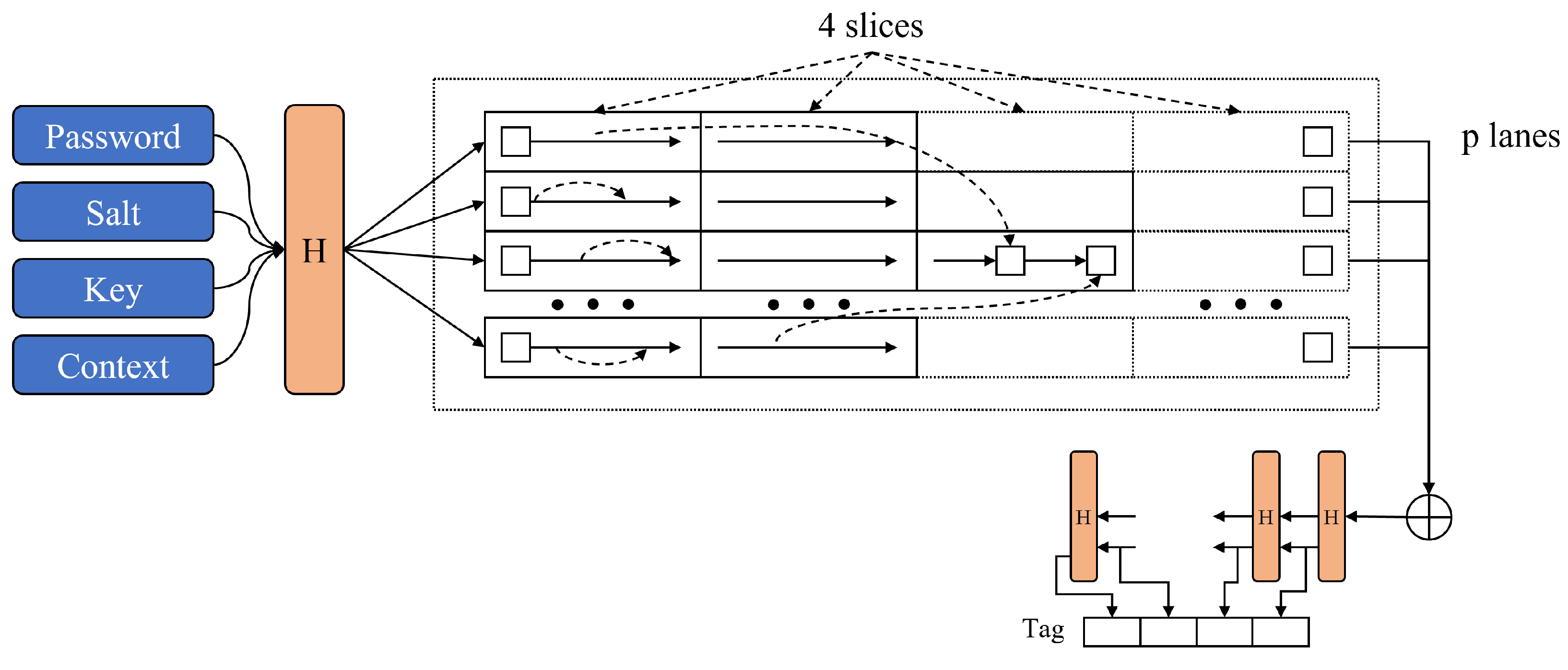
2.2. Argon2
- Argon2d maximizes data dependence to fortify resistance against parallel hardware such as GPUs. However, this variant can be sensitive to side-channel attacks.
- Argon2i, conversely, is designed to resist side-channel attacks, but may sacrifice some resistance against parallel hardware.
- Argon2id combines the two aforementioned approaches, operating like Argon2i in the early stages and like Argon2d in the subsequent stages. This hybrid aims to amalgamate the advantages of both and is currently the most broadly recommended variant.
- Initialization: The algorithm first creates an initial block using input values received from the user such as password, salt, and optionally provided secret data (associated data). This initial block fills a sequence of blocks using memory.
- Block Filling: The algorithm then populates these memory blocks up to the set memory amount. Each block’s computation depends on previous blocks, making this stage data-dependent. Argon2d and Argon2i take distinct approaches during this block-filling process.
- Final Block Creation: After filling all blocks, the algorithm selects one block as the final block.
- Hash Generation: Finally, the algorithm passes this final block to a hash function to generate the final password hash.
- Password: The user’s password. This is used to generate the encrypted hash value.
- Salt: A randomly generated value. The salt is added to each user’s password to enhance the encryption process. This ensures that users with the same password do not have the same hash value.
- Time Cost: A parameter that adjusts the amount of time consumed during the encryption process. A higher time cost increases the security by requiring more time for encryption but it may result in a slower processing speed.
- Memory Cost: A parameter that adjusts the amount of memory used for encryption. A higher memory cost requires more memory for encryption, increasing the computational cost for an attacker trying to crack the password.
- Parallelism Degree: A parameter that determines the number of threads or tasks processed concurrently. A higher parallelism degree allows for more simultaneous processing, resulting in faster encryption.
2.3. Blake2b Hash Function
- Initialization: Blake2b is used to generate the initial block.
- Block Filling: Blake2b is used in the computation of each block, based on previous blocks.
- Final Hash Generation: The final block is passed to the Blake2b hash function to generate the final password hash.
2.4. Graphics Processing Units
- Global memory is the largest memory on the GPU and is commonly used for storing and accessing data. However, it is the slowest memory due to its off-chip location.
- Local memory is used to temporarily store register values when the number of registers used by a thread exceeds the available capacity. Excessive usage of local memory can impact performance as it relies on global memory.
- Texture memory is read-only memory designed for efficient data visualization. It allows for optimized texture access patterns.
- Constant memory is read-only memory that can be initialized before executing the kernel function. It utilizes a separate constant cache within global memory, resulting in faster access when multiple threads access the same address.
- Shared memory is memory shared among threads within a block. Although it provides a smaller memory space, it offers fast access speed. Shared memory employs a banking mechanism, allowing 32 threads executed in warp units to access it simultaneously, minimizing latency.
3. Implementation
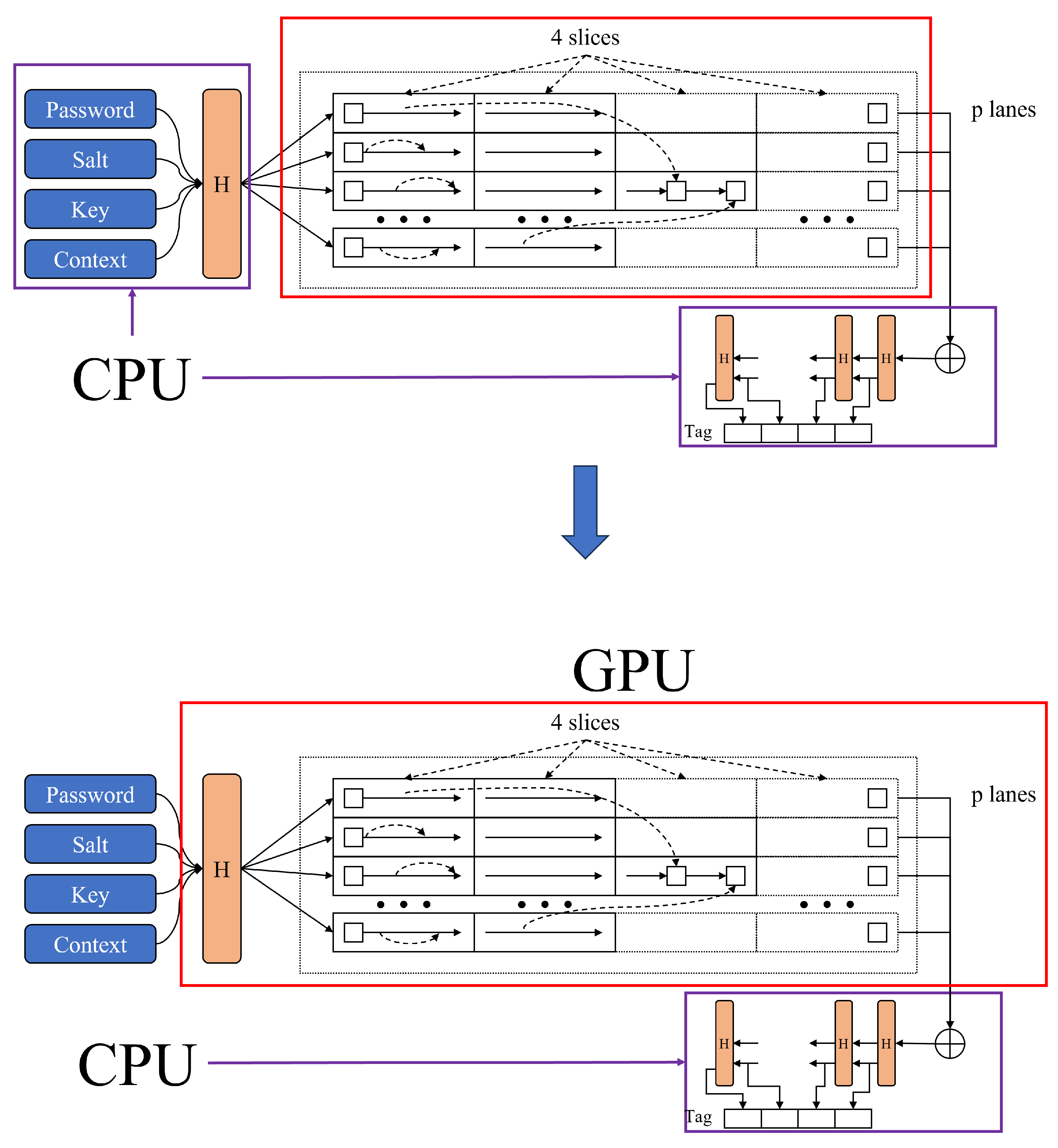
3.1. Previous Implementation [16]
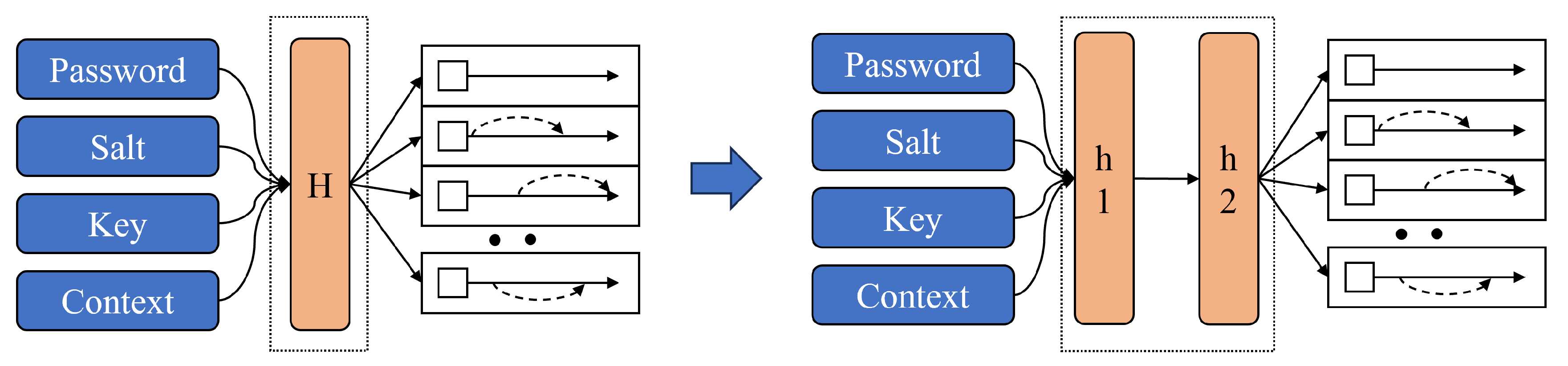
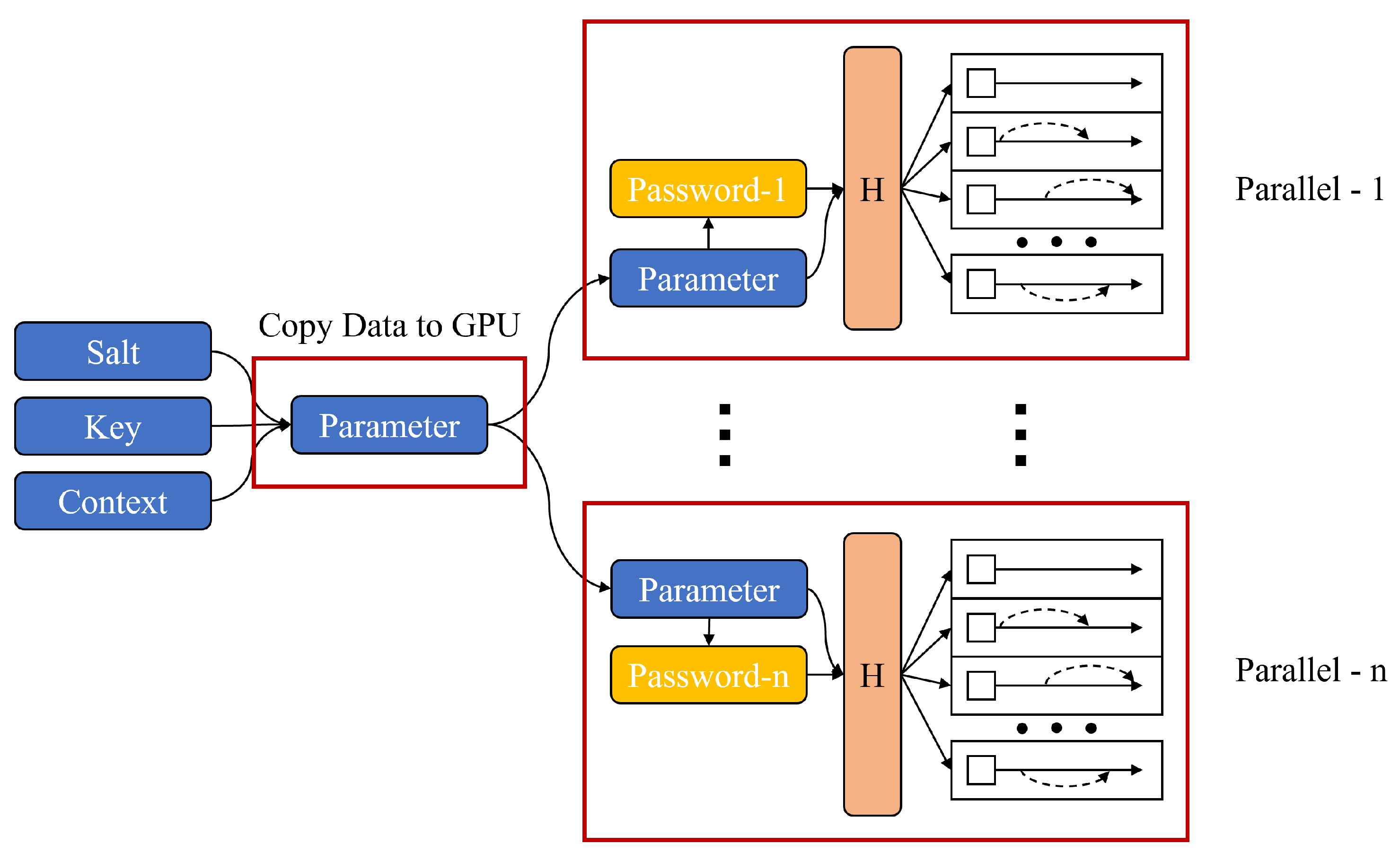
3.2. Our Implementation
3.2.1. Advantages from the Perspective of Memory
3.2.2. Advantages from the Perspective of Cracking
4. Evaluation
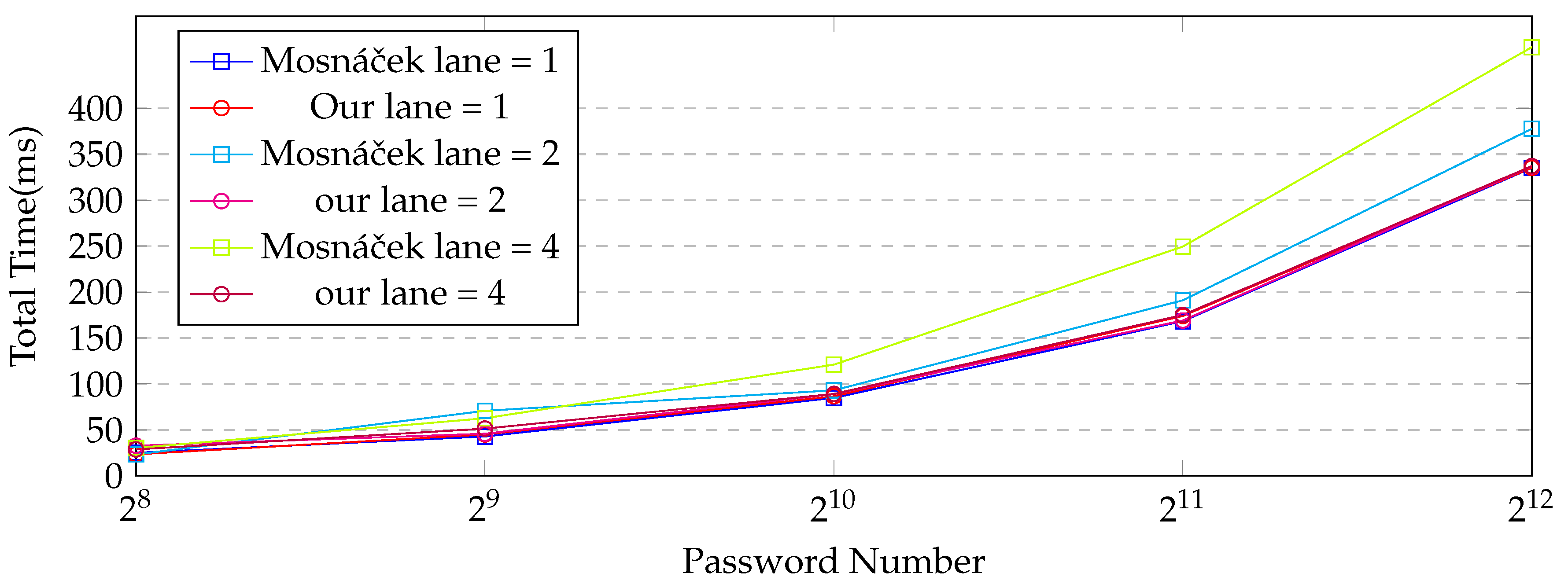
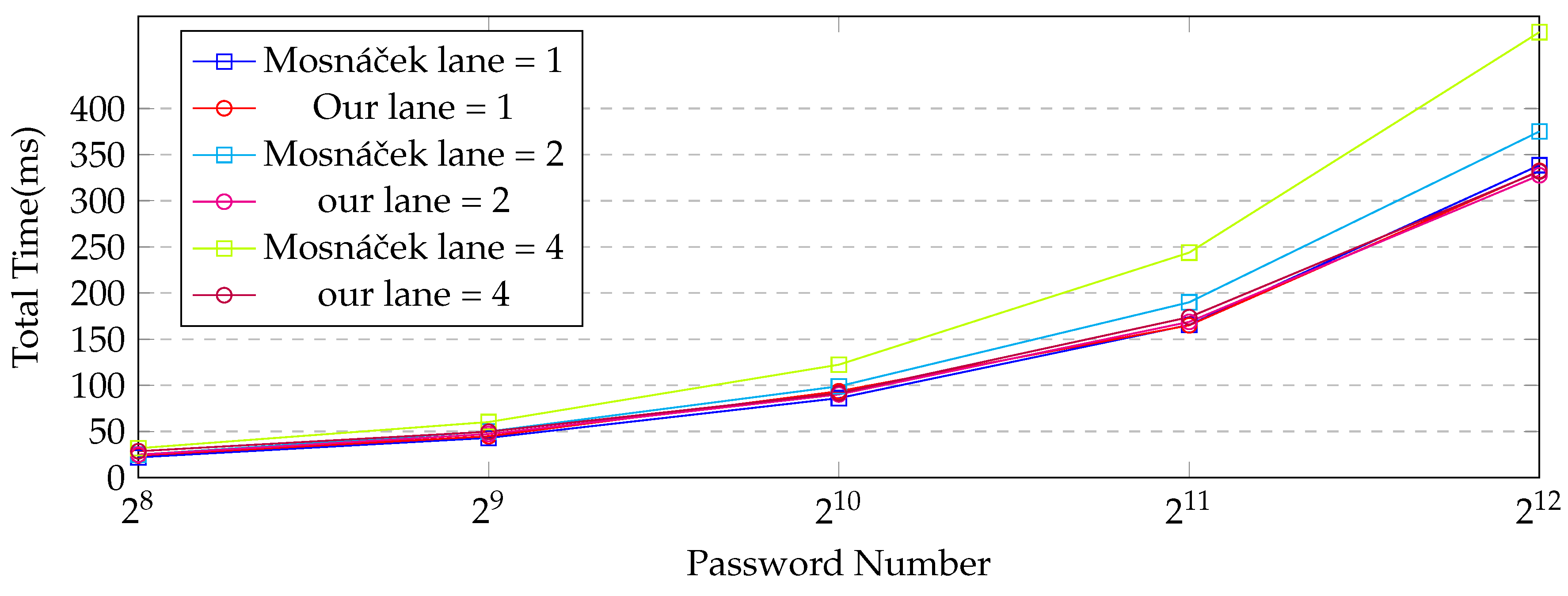
4.1. Comparison with Reference Code
4.2. Comparison with Existing CPU–GPU Implementation
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Lin, C.H.; Liu, J.C.; Chen, J.I.Z.; Chu, T.P. On the Performance of Cracking Hash Function SHA-1 Using Cloud and GPU Computing. Wirel. Pers. Commun. 2019, 109, 491–504. [Google Scholar] [CrossRef]
- Alkhwaja, I.; Albugami, M.; Alkhwaja, A.; Alghamdi, M.; Abahussain, H.; Alfawaz, F.; Almurayh, A.; Min-Allah, N. Password Cracking with Brute Force Algorithm and Dictionary Attack Using Parallel Programming. Appl. Sci. 2023, 13, 5979. [Google Scholar] [CrossRef]
- Hranickỳ, R.; Zobal, L.; Ryšavỳ, O.; Kolář, D. Distributed password cracking with BOINC and hashcat. Digit. Investig. 2019, 30, 161–172. [Google Scholar] [CrossRef]
- Hatzivasilis, G.; Papaefstathiou, I.; Manifavas, C. Password hashing competition-survey and benchmark. Cryptol. ePrint Arch. 2015. Available online: https://eprint.iacr.org/2015/265 (accessed on 8 July 2023).
- Wetzels, J. Open sesame: The password hashing competition and Argon2. arXiv 2016, arXiv:1602.03097. [Google Scholar]
- Biryukov, A.; Dinu, D.; Khovratovich, D. Argon2: New generation of memory-hard functions for password hashing and other applications. In Proceedings of the 2016 IEEE European Symposium on Security and Privacy (EuroS&P), Saarbrucken, Germany, 21–24 March 2016; pp. 292–302. [Google Scholar]
- Kumar, H.; Kumar, S.; Joseph, R.; Kumar, D.; Singh, S.K.S.; Kumar, A.; Kumar, P. Rainbow table to crack password using MD5 hashing algorithm. In Proceedings of the 2013 IEEE Conference on Information & Communication Technologies, Thuckalay, India, 11–12 April 2013; pp. 433–439. [Google Scholar]
- Provos, N.; Mazieres, D. Bcrypt Algorithm; USENIX: Berkeley, CA, USA, 1999; Available online: https://www.usenix.org/legacy/events/usenix99/provos/provos_html/node5.html (accessed on 8 July 2023).
- Percival, C.; Simon, J. The Scrypt Password-Based Key Derivation Function. No.rfc7914. 2016. Available online: https://www.rfc-editor.org/rfc/rfc7914?trk=public_post_comment-text (accessed on 11 July 2023).
- Moriarty, K.; Kaliski, B.; Rusch, A. Pkcs# 5: Password-Based Cryptography Specification Version 2.1. RFC 8018. 2017. Available online: https://www.rfc-editor.org/info/rfc8018 (accessed on 16 July 2023). [CrossRef]
- Ertaul, L.; Kaur, M.; Gudise, V.A.K.R. Implementation and performance analysis of pbkdf2, bcrypt, scrypt algorithms. International Conference on Wireless Networks (ICWN). 2016, p. 66. Available online: http://mcs.csueastbay.edu/~lertaul/PBKDFBCRYPTCAMREADYICWN16.pdf (accessed on 21 July 2023).
- Owens, J.D.; Houston, M.; Luebke, D.; Green, S.; Stone, J.E.; Phillips, J.C. GPU computing. Proc. IEEE 2008, 96, 879–899. [Google Scholar] [CrossRef]
- Choi, H.; Seo, S.C. Fast implementation of SHA-3 in GPU environment. IEEE Access 2021, 9, 144574–144586. [Google Scholar] [CrossRef]
- Iwai, K.; Nishikawa, N.; Kurokawa, T. Acceleration of AES encryption on CUDA GPU. Int. J. Netw. Comput. 2012, 2, 131–145. [Google Scholar] [CrossRef]
- CUDA C Programming Guide V6.0. Available online: https://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html (accessed on 11 July 2022).
- GPU Is Unfriendly for WebDollar-argon2-gpu for WebDollar. Available online: https://github.com/WebDollar/argon2-gpu (accessed on 1 July 2023).
- Chen, L.; Agrawal, G. Optimizing mapreduce for gpus with effective shared memory usage. In Proceedings of the 21st International Symposium on High-Performance Parallel and Distributed Computing, Minneapolis, MN, USA, 27 June–1 July 2022; pp. 199–210. [Google Scholar]
- Fang, M.; Fang, J.; Zhang, W.; Zhou, H.; Liao, J.; Wang, Y. Benchmarking the GPU memory at the warp level. Parallel Comput. 2018, 71, 23–41. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | |||
|---|---|---|---|
| Argon2i | Argon2d | Argon2id | |
| Only CPU | 0.93 | 0.9 | 0.91 |
| CPU + GPU | 0.147 | 0.144 | 0.16 |
| PWD Num | Writing (ms) | Computation (ms) | Reading (ms) | Total (ms) | Time Per Num |
|---|---|---|---|---|---|
| 4096 | 150.07/155.42 | 26.23/28.92 | 137.63/141.01 | 313.93/325.35 | 0.077/0.079 |
| 2048 | 77.25/77.97 | 13.82/14.93 | 73.51/71.27 | 164.59/164.17 | 0.080/0.080 |
| 1024 | 41.84/41.06 | 7.82/8.95 | 37.23/37.41 | 86.90/87.43 | 0.085/0.085 |
| 512 | 21.14/21.06 | 3.76/4.76 | 18.00/18.01 | 42.89/43.83 | 0.084/0.086 |
| 256 | 10.00/11.46 | 2.42/3.51 | 9.28/9.84 | 21.69/24.81 | 0.085/0.097 |
| 128 | 5.09/5.97 | 2.05/3.05 | 4.78/4.93 | 11.91/13.95 | 0.093/0.109 |
| 64 | 2.93/3.33 | 1.81/2.83 | 2.13/2.59 | 6.87/8.75 | 0.107/0.137 |
| 32 | 1.91/1.52 | 1.80/2.83 | 1.41/1.31 | 5.13/5.65 | 0.160/0.177 |
| PWD Num | Writing (ms) | Computation (ms) | Reading (ms) | Total (ms) | Time/Num |
|---|---|---|---|---|---|
| 4096 | 211.09/161.54 | 26.67/30.44 | 138.05/136.60 | 375.80/328.58 | 0.092/0.080 |
| 2048 | 101.06/91.92 | 13.58/15.69 | 77.03/70.27 | 191.68/177.88 | 0.094/0.087 |
| 1024 | 53.12/43.84 | 7.13/9.50 | 36.84/37.60 | 97.09/90.94 | 0.095/0.089 |
| 512 | 25.47/20.67 | 3.93/5.91 | 18.14/18.35 | 47.53/44.92 | 0.093/0.088 |
| 256 | 13.75/11.63 | 1.93/3.89 | 10.16/8.75 | 25.84/24.28 | 0.101/0.095 |
| 128 | 6.65/7.14 | 1.30/3.19 | 4.40/4.74 | 12.35/15.08 | 0.096/0.118 |
| 64 | 3.12/4.36 | 1.10/3.00 | 2.32/2.49 | 6.53/9.86 | 0.102/0.154 |
| 32 | 1.62/3.15 | 0.98/2.82 | 1.20/1.21 | 3.79/7.18 | 0.119/0.224 |
| PWD Num | Writing (ms) | Computation (ms) | Reading (ms) | Total (ms) | Time/Num |
|---|---|---|---|---|---|
| 4096 | 298.81/162.53 | 25.93/33.71 | 138.04/141.54 | 462.78/337.78 | 0.113/0.082 |
| 2048 | 153.27/83.51 | 13.21/17.31 | 75.02/68.66 | 241.51/169.47 | 0.118/0.083 |
| 1024 | 78.58/44.58 | 6.75/11.29 | 36.58/36.70 | 121.90/92.57 | 0.119/0.090 |
| 512 | 38.23/25.01 | 3.60/7.40 | 19.29/18.56 | 61.12/50.98 | 0.119/0.100 |
| 256 | 19.97/12.51 | 2.00/5.70 | 9.18/9.44 | 31.15/27.66 | 0.122/0.108 |
| 128 | 9.58/8.68 | 1.06/4.73 | 4.90/4.76 | 15.54/18.16 | 0.121/0.142 |
| 64 | 4.70/6.27 | 0.75/4.43 | 2.17/2.63 | 7.62/13.32 | 0.12/0.208 |
| 32 | 2.48/4.84 | 0.65/4.20 | 1.29/1.23 | 4.42/10.27 | 0.14/0.321 |
| PWD Num | Writing (ms) | Computation (ms) | Reading (ms) | Total (ms) | Time/Num |
|---|---|---|---|---|---|
| 4096 | 167.53/151.47 | 26.03/28.96 | 141.57/154.89 | 335.12/335.32 | 0.082/0.082 |
| 2048 | 81.93/87.62 | 13.81/14.87 | 72.61/71.53 | 168.35/174.02 | 0.082/0.085 |
| 1024 | 40.27/41.94 | 7.71/8.65 | 36.87/36.02 | 84.85/86.62 | 0.083/0.085 |
| 512 | 20.48/21.27 | 3.77/4.78 | 18.57/18.99 | 42.82/45.05 | 0.084/0.088 |
| 256 | 10.17/10.92 | 2.42/3.50 | 12.54/9.01 | 25.14/23.43 | 0.098/0.092 |
| 128 | 5.40/5.89 | 2.02/3.04 | 4.92/4.39 | 12.34/13.32 | 0.096/0.104 |
| 64 | 2.72/3.48 | 1.78/2.80 | 2.46/2.51 | 6.96/8.79 | 0.109/0.137 |
| 32 | 1.65/1.59 | 1.75/2.79 | 1.31/1.14 | 4.71/5.52 | 0.147/0.173 |
| PWD Num | Writing (ms) | Computation (ms) | Reading (ms) | Total (ms) | Time/Num |
|---|---|---|---|---|---|
| 4096 | 205.18/163.22 | 26.77/30.74 | 145.71/142.95 | 377.66/336.91 | 0.092/0.082 |
| 2048 | 100.84/81.77 | 13.64/16.43 | 76.58/70.86 | 191.06/169.06 | 0.093/0.083 |
| 1024 | 49.97/43.09 | 7.18/9.43 | 35.96/36.48 | 93.11/88.10 | 0.091/0.087 |
| 512 | 39.50/21.94 | 4.07/5.92 | 27.25/18.02 | 70.82/45.88 | 0.138/0.090 |
| 256 | 12.59/15.20 | 1.93/3.88 | 8.79/13.72 | 23.31/32.81 | 0.091/0.128 |
| 128 | 6.49/6.91 | 1.31/3.20 | 5.07/4.93 | 12.86/15.04 | 0.100/0.117 |
| 64 | 3.41/4.52 | 1.10/3.00 | 2.25/2.71 | 6.76/10.23 | 0.106/0.160 |
| 32 | 1.70/3.17 | 0.99/2.84 | 1.03/1.27 | 3.71/7.28 | 0.116/0.227 |
| PWD Num | Writing (ms) | Computation (ms) | Reading (ms) | Total (ms) | Time/Num |
|---|---|---|---|---|---|
| 4096 | 297.37/165.81 | 26.28/33.94 | 142.90/137.33 | 466.54/337.08 | 0.114/0.082 |
| 2048 | 159.57/87.44 | 13.38/19.07 | 76.57/68.57 | 249.52/175.08 | 0.122/0.085 |
| 1024 | 77.49/42.23 | 6.86/11.13 | 36.69/35.80 | 121.04/89.17 | 0.118/0.087 |
| 512 | 39.12/24.85 | 3.62/7.44 | 19.95/19.12 | 62.69/51.42 | 0.122/0.100 |
| 256 | 18.84/14.32 | 2.02/5.75 | 9.44/8.69 | 30.30/28.76 | 0.118/0.112 |
| 128 | 9.44/8.27 | 1.05/4.78 | 4.63/4.87 | 15.11/17.91 | 0.118/0.140 |
| 64 | 4.86/5.90 | 748.20/4.43 | 2.28/2.16 | 755.35/12.49 | 11.80/0.195 |
| 32 | 2.54/5.12 | 639.10/4.17 | 1.22/1.16 | 642.86/10.45 | 20.09/0.326 |
| PWD Num | Writing (ms) | Computation (ms) | Reading (ms) | Total (ms) | Time/Num |
|---|---|---|---|---|---|
| 4096 | 172.82/160.34 | 25.98/28.92 | 139.74/143.14 | 338.54/332.40 | 0.083/0.081 |
| 2048 | 80.73/79.39 | 13.47/14.87 | 71.25/70.80 | 165.46/165.06 | 0.081/0.081 |
| 1024 | 41.11/48.68 | 7.66/8.57 | 37.32/36.33 | 86.09/93.58 | 0.084/0.091 |
| 512 | 20.01/21.19 | 3.65/4.69 | 19.38/18.89 | 43.04/44.77 | 0.084/0.087 |
| 256 | 10.42/10.87 | 2.33/3.40 | 9.19/9.69 | 21.94/23.95 | 0.086/0.094 |
| 128 | 6.52/5.92 | 1.94/2.97 | 4.59/4.75 | 13.06/13.64 | 0.102/0.107 |
| 64 | 2.76/3.46 | 1.68/2.76 | 2.01/2.46 | 6.45/8.67 | 0.101/0.135 |
| 32 | 1.82/1.46 | 1.64/2.74 | 1.14/1.45 | 4.59/5.65 | 0.144/0.177 |
| PWD Num | Writing (ms) | Computation (ms) | Reading (ms) | Total (ms) | Time/Num |
|---|---|---|---|---|---|
| 4096 | 206.03/160.76 | 26.62/30.38 | 142.46/136.48 | 375.11/327.62 | 0.092/0.080 |
| 2048 | 100.22/83.14 | 13.57/16.04 | 76.18/69.55 | 189.97/168.72 | 0.093/0.082 |
| 1024 | 53.23/42.41 | 7.01/9.39 | 38.72/38.31 | 98.95/90.11 | 0.097/0.088 |
| 512 | 27.11/21.50 | 3.96/5.86 | 18.84/19.85 | 49.91/47.21 | 0.097/0.092 |
| 256 | 13.27/11.82 | 1.86/3.83 | 9.73/9.24 | 24.86/24.89 | 0.097/0.097 |
| 128 | 6.40/6.83 | 1.24/3.18 | 4.97/4.65 | 12.61/14.66 | 0.099/0.115 |
| 64 | 4.14/4.27 | 1.09/2.96 | 3.29/2.51 | 8.51/9.75 | 0.133/0.152 |
| 32 | 1.58/3.17 | 927.20/2.80 | 1.30/1.36 | 930.08/7.32 | 29.065/0.229 |
| PWD Num | Writing (ms) | Computation (ms) | Reading (ms) | Total (ms) | Time/Num |
|---|---|---|---|---|---|
| 4096 | 306.64/156.27 | 26.21/33.56 | 149.90/141.93 | 482.75/331.76 | 0.118/0.081 |
| 2048 | 157.82/87.29 | 13.29/17.83 | 72.71/68.76 | 243.81/173.87 | 0.119/0.085 |
| 1024 | 77.60/44.14 | 6.81/11.12 | 37.96/36.17 | 122.37/91.43 | 0.120/0.089 |
| 512 | 38.20/23.95 | 3.58/7.38 | 18.45/18.42 | 60.22/49.75 | 0.118/0.097 |
| 256 | 20.67/13.35 | 1.99/5.72 | 9.15/9.51 | 31.81/28.58 | 0.124/0.112 |
| 128 | 9.95/8.26 | 1.01/4.69 | 4.74/4.83 | 15.69/17.78 | 0.123/0.139 |
| 64 | 4.77/6.04 | 714.70/4.36 | 2.12/2.33 | 721.59/12.72 | 11.275/0.199 |
| 32 | 3.60/4.83 | 606.70/4.16 | 1.12/1.28 | 611.42/10.27 | 19.107/0.321 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Eum, S.; Kim, H.; Song, M.; Seo, H. Optimized Implementation of Argon2 Utilizing the Graphics Processing Unit. Appl. Sci. 2023, 13, 9295. https://doi.org/10.3390/app13169295
Eum S, Kim H, Song M, Seo H. Optimized Implementation of Argon2 Utilizing the Graphics Processing Unit. Applied Sciences. 2023; 13(16):9295. https://doi.org/10.3390/app13169295
Chicago/Turabian StyleEum, Siwoo, Hyunjun Kim, Minho Song, and Hwajeong Seo. 2023. "Optimized Implementation of Argon2 Utilizing the Graphics Processing Unit" Applied Sciences 13, no. 16: 9295. https://doi.org/10.3390/app13169295
APA StyleEum, S., Kim, H., Song, M., & Seo, H. (2023). Optimized Implementation of Argon2 Utilizing the Graphics Processing Unit. Applied Sciences, 13(16), 9295. https://doi.org/10.3390/app13169295