Abstract
Decentralized databases have gained popularity in the last few years in different areas, such as: traceability, supply chains or finance. Leveraging this type of emerging technology will improve knowledge sharing, as well as the transparency and traceability of the data for digital systems. In a similar way, the characteristics are advertised by the centralized ledger technologies, which are manufactured by large cloud service providers such as Amazon. The present study analyzes the performance of two ledger technologies: BigchainDB (i.e., the decentralized blockchain database) and Amazon QLDB (i.e., the centralized ledger database with transparent and immutable characteristics). For the purposes of comparison, we have integrated these technologies into our traceability platform, which is called the Smart Tracking Platform (STP), and performed a series of experiments enabling us to acquire data for different metrics, such as CPU or memory usage for both the reading and writing operations. The findings of the present study show that QLDB has an overall better performance compared to BigchainDB, based on the metrics that have been considered. From the perspective of database ledger implementation, Amazon QLDB proved to be an integrated solution, easier to use, while BigchainDB comprises a more complex system to be implemented and developed, but is more flexible. Although both systems are almost ready to use solutions for local environments, when it comes to configuration and setting up the communication between nodes within a production environment, BigchainDB adds a layer of complexity from a DevOps perspective, while Amazon QLDB completely overcomes it. Depending on the area considered and the identified needs, both BigchainDB and Amazon QLDB can be considered as suitable solutions for a ledger database.
1. Introduction
Recently, ledger technology (LT) has become the focus point for industry, academia and research due to its potential to change the way in which things are organized and the way collaboration takes place within various domains such as supply chain, finance, healthcare, energy, telecommunications, etc.
The concept of a blockchain-backed ledger brings verifiability into domains where data immutability is paramount, and where the necessity to ensure data integrity (and subsequently identify tampering) is the core feature in various processes. In this field, the cryptographical approach is new and has enabled the implementation of various technologies, culminating in the emergence of ledger technology. Classification can now be based on the type of entities that can modify the ledger (only by adding data), the checking of the ledger being done by any entity that tries to do so.
In this regard, the ledger technology is classified as either centralized ledger technology (CLT) or decentralized ledger technology (DLT). In the first case, the data is transferred via a central node. This node has control over the entire ledger system, as it is the only node capable of adding the data to the ledger. The ledger must be stored in a central repository and, if necessary, access to it can be severely restricted.
In contrast, a decentralized ledger will have numerous nodes that are able to control and update the ledger’s data, creating a network of centralized ledgers. At each data update, all nodes will receive a new copy of the ledger, allowing them to remain in sync. Actualization will only be allowed if a majority (or all) of the nodes validate the transaction. Most nodes will be unable to alter the data (just as in a centralized ledger network).
As a result of the many advantages offered by these technologies, the number of companies interested in developing LT-based applications has increased in recent years. At present, there are many different LT-based databases on the market that can be used for this purpose. This fact raises several challenges in selecting the most suitable database for the desired application. Not all databases provide the same features or the specific characteristics required for a particular case. In order to assist developers in selecting the most appropriate database for a particular application, this paper presents the results of a comparative analysis of two LT-based databases (i.e., BigchainDB [1] and Amazon Quantum Ledger Database—QLDB [2]), by highlighting the advantages and disadvantages of each of these solutions. These databases have been chosen based on the fact that they have proven to be popular solutions for LT-based applications [3]. In this regard, these two databases were used by the authors to implement a traceability platform, called Smart Tracking Platform (STP) [4]. The platform’s capabilities require a mechanism to verify the status of tracked products across various physical locations, as well as status changes, in a decentralized manner. The requirements of the proposed traceability platform are best addressed by a system that is fast enough to provide traceability and auditing capabilities. A ledger-based approach seems to provide the best results in this regard. The objectives for evaluating the candidate solutions were to ensure some basic features and low overhead. Although more functionality is usually desired (even if only for future expansion capabilities), only these minimum requirements were considered in our experiment.
This paper is organized as follows. First, a literature review was conducted to evaluate the level of interest in the LT-based technologies and their impact on the market. Next, an overview of the ledger-based technologies was considered in order to analyze the opportunity for the utilization of the technology and the difficulties that can be unmasked in the implementation of solutions. A direct comparison of the two selected technologies is the first step, with the characteristics of the two databases under consideration being presented, as well as the benefits and drawbacks outlined in the literature for each of these solutions. The next section presents the results of the comparison between the BigchainDB and Amazon Quantum Ledger Database (QLDB) databases in terms of their execution performance. The following section discusses the limitations of the explored technologies, as well as the findings of the evaluations. At the moment the current study was carried out, no other paper comparing these two types of databases had been identified.
2. Literature Review
In order to provide a more comprehensive understanding of this research topic, we have reviewed the scientific literature based on the Web of Science, IEEE Explore, Scopus, ScienceDirect, Wiley, and Google Scholar scientific database. We have used search keywords, such as “centralized ledger” or “centralised ledger” and “decentralized ledger” or “decentralised ledger”, in order to identify the relevant research articles, studies and chapters. Table 1 presents the search queries in the explored databases that are limited to the title, abstract and keyword fields of scientific publications. There were no restrictions in terms of the publication dates.

Table 1.
Search queries in scientific databases.
The query results from each of the selected scientific databases are listed in Table 2 and have been graphically illustrated in Figure 1.
Table 2.
Number of papers found for each database.
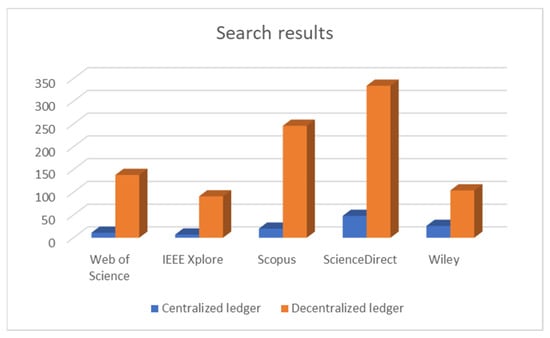
Figure 1.
Number of articles found in each of the selected scientific databases.
In order to search for grey literature (scientific literature that is produced outside of traditional publishing, distribution and indexing venues), we have used the Google Scholar database due to its broader coverage of articles and publications, including academic articles, theses/dissertations, conference proceedings, books or book chapters, unpublished materials (such as preprints), and other types of documents (i.e., non-academic articles) [5,6]. The number of publications indexed in the Google Scholar database referencing the term centralized/centralised ledger is 1260, while for decentralized/decentralised ledger, the number of scientific publications is 6540. Consequently, this fact proves an increased interest in these topics. However, given the fact that there are large differences in terms of the number of publications indexed in Google Scholar versus the number of scientific publications indexed in other databases, this database has not been given any consideration in this analysis.
The annual evolution of the number of scientific papers indexed in each of the selected databases referencing the above-mentioned keywords is shown in Table 3 and Table 4, as well as in Figure 2a,b.
Table 3.
Each database’s annual number of papers with “centralized/centralized ledgers” keywords.
Table 4.
Each database’s annual number of papers with “decentralized/decentralized ledgers” keywords.
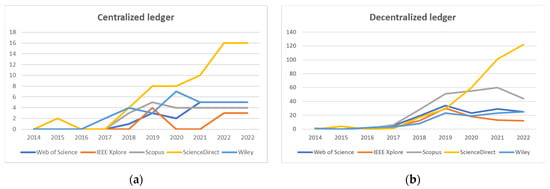
Figure 2.
(a) Evolutionary trend in the number of publications covering centralized ledgers; (b) Evolutionary trend in the number of publications covering decentralized ledgers.
Although academic literature investigating the industrial applications of centralized and decentralized ledgers has recently grown in volume ([7,8]), the findings have shown that the number of publications aimed at a better understanding of the use of these ledgers and their applications is still insignificant. The analysis of the above results indicates that, with the exception of the current year of 2022, there has been an increasing trend in the number of academic publications from ScienceDirect that reference the centralized and decentralized ledger. This trend reflects the scientific community’s growing interest and satisfies the industry’s needs.
However, the traditional approach of using databases is still an important component of today’s technological landscape. Moreover, there is competition between the LT-based technologies themselves, with both centralized and decentralized being used in the products that are based on the LT technology.
For example, paper [7] focuses on the uses of ledger databases as a traditional database manager. The authors review the Centralized Ledger Databases (CLD)-based centralized ledger technology and the permissioned blockchain technology-based decentralized ledger technology. They examine LedgerDB as a centralized ledger database and Hyperledger Fabric, FalconDB, BlockchainDB, ChainifyDB, BigchainDB, and Blockchain Relational Database as permissioned blockchain-based databases. In their paper, the authors discuss the strengths and weaknesses of the reviewed technologies and present a comparison of them.
Some researchers and practitioners have concentrated their research on applications based on centralized and/or decentralized ledger technologies. Thus, the research presented in [8] focuses on the role of centralized and decentralized ledgers in the money supply process. The authors conduct a SWOT analysis to identify the strengths, weaknesses, opportunities and threats of using both systems in finance. The authors reveal that in several aspects, “the strengths and opportunities of decentralized ledgers outweigh those of centralized ledgers”. However, “while decentralized ledgers are expected to disrupt finance and introduce unprecedented opportunities, centralized ledgers ensure the continuity of the current financial systems” [8].
Over time, the decentralized ledger technique, blockchain [9], has been used to implement numerous decentralized systems; for example, in payment systems, supply chain management, tracking and tracing, etc. Thus, various studies have demonstrated that the use of blockchain-based applications in supply chain networks can enhance product tracking and enable full product traceability [10,11,12,13]. Recently, blockchain has attracted attention to realize secure and robust data management systems for the Internet of Things (IoT) and Industrial Internet of Things (IIoT) [14]. Paper [15] demonstrates the use of a decentralized and immutable ledger, such as blockchain, as a common platform for companies in the logistics industry, along with the use of IoT sensor devices for tracking. Thus, the authors present a blockchain smart contract system that integrates the Internet of Things (IoT) technology to ensure product management in a logistics system, with a significant impact in improving security, speed, trust, and transparency for the data exchange that takes place in supply chains. In [16], the author evaluates the potential of blockchain technology in driving future IoT development towards the Ledger of Things.
Based on the use cases identified in the scientific literature reviewed, the ledger technology is a good fit for the STP platform. In the next section, the type of ledger technology best suited for implementation in traceability platforms will be analyzed.
3. Overview of Centralized and Decentralized Ledgers
Centralized and decentralized ledger databases are similar in that they store information; however, they differ in their functionality. In fact, these types of databases complement the functionality and features of a traditional database.
The main problem in the market-available implementation of the new cryptographical approaches to ledgers is mainly driven by market and regulatory inertia. Even if the distributed ledger is seen as one of the main disruptive technologies in various enterprise sectors [17], the introduction of this technology is slow and inconsistent. The main advantage of the DLT is the verification of transactions without a third-party service, which can be slow and costly in most cases, but also inflexible regarding the manner of accessing the verification service, which precludes the introduction of innovative products from the industry players. Moreover, this is placed at a lower cost than traditional approaches [18] but requires changes in the approach of the business towards the operational flows; changes that, in turn, require education for a proper understanding of the cryptological landscape and modifications of business operations, which also involve upfront costs. This produces low incentives for businesses to accept the changes.
On the regulatory front, the traditional approaches for the prevention of fraudulent transactions requires a well-documented, traceable, approach that often includes manual verifications (from human users, thus increasing the cost and the processing time) or certified tools and procedures [19]. The inadequate understanding of the new cryptological technologies prevents regulators and technology implementers using DLT and similar technologies on a large scale.
3.1. Overview of Centralized Ledgers
In the case of centralized ledgers, transactions are stored in a ledger under the control of a single entity. The physical infrastructure is usually co-located in the same location and the centralized node that controls the ledger is unique. The ledger trustee must maintain the ledger, record asset transfers and receive properly verified notifications [20].
Centralized ledgers are used as a combination of classical transactional technology (centralized recording and authorization/validation of the transactions) implemented using blockchain technology. This paradigm is close to traditional approach in accounting systems and offers an easier migration path from the perspective of enterprise users (being both familiar and regulated in sensitive industries such as finance and controlled research and development). In this instance, the control and validation of data is allowed via a single centralized node, which increases the cost and decreases the viability of the system (if the central node fails the entire system becomes non-functional because the system has a single point of failure), even if the entire system is backed-up (accounting for the downtime and the lost transaction that where in process of validation). Moreover, in this situation, the trust authority is set towards a single entity that controls the access to the validation mechanism and to the data. Even if the singular data (transaction) is immutable (owning to the cryptographical approach), the entire chain can be rebuilt if the trust agent wishes so, as no consensus and cross-validation is required [7]. A zero-trust approach is not possible in this context.
To summarize, the main drawbacks of this approach are its decreased usability, limited trust, limited privacy, the lack of verifiable immutability and the presence of a single point of failure. These concerns can be alleviated in a decentralized approach.
CLDs include LedgerDB, QLDB, Oracle BC Table, ProvenDB, and others. The findings of the QLDB evaluation will be presented in this paper.
3.2. Overview of Decentralized Ledgers
A decentralized ledger is defined in [21] as a set of nodes, each storing a local copy of the entire ledger. According to [22], decentralized ledgers are a specific data structure maintained by multiple parties via a consensus protocol, with each party preserving a copy of the ledger.
Decentralized ledgers can be roughly divided into two main categories: public ledgers and authorized ledgers [21]. Public ledgers are low-cost, secure, trusted and designed to support the decentralized record keeping of financial transactions (e.g., settlement payments) made within large groups of vendors who do not necessarily know or trust each other [23].
In the case of distributed ledger technology, the entities that collectively operate the distributed platform can use the authentication process in a decentralized manner. The platform’s resources are tamper-resistant (thus not allowing for hidden manipulation of data) and highly available (given the collectivist nature of the platform) [21]. The nodes form a decentralized database (the ledger) that does not depend on a single authority or point of validation. Instead, each node can add data (digital transactions of various types, although limitations do apply to the size of the data block involved in the transaction) to their local ledger, after validation. Each added transaction will then be part of the new validation process for new transactions, ensuring the immutability of the old transactions. The nodes are cryptographically signed and cross-validated, thus allowing them to be used in a zero-trust manner (unsecure environments where malicious actors can try to alter given data) or in unstable environments (generating faults in the network, crashing nodes etc.), generally recognized as unpredictable Byzantine faults [24]. In this case, we can define decentralized ledgers as a specific data structure maintained by multiple parties via a consensus protocol, with each party holding a copy of the ledger [22].
In this approach, given that the nodes can store different versions of the ledger (accounting for the internal states of the faulted nodes), inconsistencies can be solved via various mechanisms, the most common being the consensus [7]. Depending on the ledger network architecture, the nodes that are involved in consensus finding can be a selection of the available nodes (in permissioned DLT protocols), while in other protocols, all nodes can be used in finding consensus.
The transparency of the public ledgers for all system participants constitutes a critical feature [25,26]. As a result, the public ledger transactions are immutable, transparent and visible to all entities [27]. In contrast, adding and reading transaction records in authorized ledgers is restricted to specifically designated parties [28]. Authorized ledgers are also known as private blockchains because they frequently require the participant’s authentication and authorization for the permission level of blockchain participants [29].
3.3. Comparison of the Decentralized Ledger, Centralized Ledger and Traditional Database
According to [7], the decentralized and centralized ledger technologies, when compared to databases, can be considered less efficient due to the fact that most of them are not aimed at replacing the traditional database technologies, even if they are capable of doing so. Therefore, in order to use any of these technologies, analysis is essential to determine whether they meet the requirements of the system specification [30].
Table 5 below provides a comparative analysis of the decentralized ledger, the centralized ledger and the traditional database in order to support practitioners and researchers in choosing the best solution to adopt when implementing a specific application. Both the quantitative and qualitative criteria have been taken into consideration for this analysis.
Table 5.
Comparison of decentralized ledger, centralized ledger and traditional database [7,8,25,30].
4. Comparison between BigchainDB and QLDB
Ledger-based technologies have been developed in a variety of market segments. Consequently, taking a broad classification into account, the use of ledger technologies could fall into the following categories: for individual or low-volume use, for the small and medium-sized enterprise (SME) field, and for the large enterprise field ([31,32,33,34,35]). As the profits generated on the individual or small business level (e.g., up to 20–50 employees) are generally low, the first segment is generally less targeted by major technology developers. In contrast, there are stringent regulations in the high-end enterprise field regarding product quality, product capabilities, as well as the functionalities that must be integrated and the methods by which these are ensured (including the fiscal responsibility). Thus, various technology manufacturers frequently target the mid-enterprise field, either to impose a specific platform that will bring financial benefits or to test various technologies before launching them in the high-end enterprise field [36]. Open-source products also have a hidden cost of technological development, which is easier to justify in cases of the individual or small-scale enterprise systems. It is more difficult to justify for the high-end systems. Furthermore, products are either standalone or packaged as software as a service (SaaS).
Within this category, QLDB is a reputable manufacturer’s (Amazon) offering that also provides integrated support for banking, technology, and services—medical, financial, etc.—via its verifiable, serverless, centralized distributed ledger technology cryptographic system.
In contrast, there are also offerings in this specialized area that allow self-hosting in a centralized or decentralized manner, which can be adjusted to local conditions due to the fact that it is an open source, it has permissive licensing conditions, and it is directly managed by customers without other third parties. BigchainDB is one of the most well-known systems of its kind.
As mentioned in [37], Gartner highlights four common factors in the field of blockchain projects led by many companies or consortia:
- “The majority of industry (or consortia) participants need a distributed ledger where every participant has access to the same (single) source of truth.
- Once written to the ledger, the data is immutable and cannot be deleted or updated.
- A cryptographically and independently verifiable audit trail is needed to satisfy the use case, for example to prove the provenance or state of an asset.
- The various participants in the blockchain consortia all have a vested interest in its success; and there is no single entity in direct control of all activities” [37].
These features, which are difficult to achieve based on traditional technologies, are very appealing to users who want to use blockchain technology and distributed ledgers.
The technologies examined in the present paper cover some of the features proposed in [38]. The chosen platforms, such as QLDB and BigChainDB, are not the major players in the industrial market, according to a study of the market for popular databases technologies in use in various medium-level enterprises, which states that QLDB covers only 0.01% of the market (e.g., the Slintel study from 2022 focused on the clients of 68 mid-enterprises (Slintel 2022 study: https://www.slintel.com/tech/database, accessed on 4 December 2022)), while BigChainDB covers under 0.01% of the market (e.g., the Enlyft study from 2022 focused on the clients of 22 mid-enterprises (Enlyft 2022 study: https://enlyft.com/tech/products/bigchaindb, accessed on 4 December 2022)). Thus, they do cover one of its significant components—the database systems based on ledger technology—despite the fact that QLDB relies less on distributed ledger technologies to ensure traceability in comparison with BigchainDB. The written data for the presented components are immutable and cannot be modified without invalidating the ledger, ensuring the second requirement of the list. The third requirement is met by both of the studied technologies due to the fact that traceability is implemented similarly in both cases using blockchain technologies. However, in the case of the fourth characteristic, QLDB is a proprietary technology that Amazon, as the organization that designed it, is primarily interested in, whilst other market participants are less so. BigchainDB, on the other hand, is an open, adaptable technology that can be used by a wide range of entities for a variety of other purposes. It also provides real decentralization across distributed ledgers, which expands the field’s potential applications.
QLDB is best suited for use in cases in which a trusted authority is acknowledged by all participants, when centralization is not an issue as such. On the other hand, when there is no trusted authority and centralization is an issue, blockchain structures (blockchains) are optimal.
BigchainDB has been built on distributed databases with blockchain functionality [39], which is considered one of the most secure technologies available at present, as shown in [1]: “with high throughput, low latency, powerful query functionality, decentralized control, immutable data storage and built-in asset support, BigchainDB is similar to a database with blockchain characteristics”. Consequently, BigchainDB benefits from the advantages of modern distributed databases, such as high transaction rates, low latency, indexing, and structured data querying, and those of the blockchain, such as decentralized control, tamper-proofing, and traceability [40]. Furthermore, BigchainDB is powered by MongoDB, one of the most popular NoSQL databases, which has some benefits such as high throughput, massive data storage capabilities, linear scaling in capacity with the number of nodes, full-featured NoSQL query language support, efficient query, and rights management [3]. As BigchainDB is based on a distributed database by adding blockchain features, and not by extending blockchain technology, some of the disadvantages of blockchain, such as, the full replication of nodes, have been avoided. We have opted for this database because it is open source, it has drivers for Java, Python and JavaScript, and also allows running a single node on any virtual machine.
Amazon QLDB is a blockchain-based solution that provides the functionality of a centralized distributed ledger database. A cryptographically verifiable transaction log is one of the database’s key features. Other blockchain-based features include immutable data and transparency.
Table 6 compares BigchainDB and QLDB based on various relevant criteria for the selection of the best database to use in developing an application.
Table 6.
Comparison of BigchainDB and QLDB [7,39,40,41].
Analysis was conducted in [42] in order to demonstrate the average writing response time for different centralized (MongoDB) and various decentralized solutions (HL-Sawtooth, HLF-Fabric, BigchainDB, HLGF-Burrow). In general, there is a significant difference between MongoDB (centralized) and the Blockchain platforms (decentralized). The writing latency indicates that the blockchain-based systems are slower, with BigchainDB being a middle-of-the-road performer. Regarding memory consumption and CPU utilization, usage is significantly higher for the distributed blockchain platforms that use the Proof of Stake (PoS) consensus mechanisms (such as HLGF-Burrow), however, this imposes higher resource consumption and time overheads compared to the other platforms. Both Hyperledger Fabric and BigchainDB use Raft (newer versions migrated to Kafka) [7] and Byzantine Fault Tolerant (BFT), respectively, and Hyperledger Sawtooth is configured to use Proof of Elapsed Time (PoET). It seems that PoS requires more compute power and memory consumption than Raft, BFT or PoET. As a general conclusion of this study, the PoET Blockchain, HL-Sawtooth solution was the most efficient in terms of average response time, CPU and memory consumption, tested in an IoT-based experiment. One limitation of the study is the lack of data from centralized & managed ledger databases such as QLDB or Google BigQuery [43].
5. Case Study
The present paper highlights the use of centralized and decentralized ledgers for the implementation of a traceability platform, entitled Smart Tracking Platform (STP) [4], that enables users to track and trace assets along value chains.
In order to develop a track and trace application, the database technology that best fits the specific requirements must be established. The examination of the scientific literature revealed a scarcity of relevant data for selecting the best solution for the proposed application in terms of performance and cost. In recent years, distributed ledger technology has been regarded as one of the most disruptive technologies. However, as some studies have pointed out, this technology is not the best solution for all problems. For example, in [43], the authors examined the track-and-trace activities in supply chains to identify the instances where the distributed ledger technology could be used. Thus, based on the examined case studies, the authors concluded that distributed ledger technology is only required in extreme cases, such as when data immutability is mandatory, and all companies that have been directly associated with a dataset have been willing to delete it. A distributed ledger can provide value in some situations, such as in tracking external needs. The authors advise that other options, such as digital signatures, should be investigated in these cases. The paper also identified some cases when distributed ledger technology is considered ineffective, such as for hardware tracking and tracing within a company, as well as the tracking and tracing strictly for internal purposes. The present paper has considered alternatives to distributed ledger technology for the implementation of a traceability platform, which enables SMEs from various industries to track and trace assets across value chains. In some industries, transparency is considered an advantage for building trust around the stakeholders, for example, in the medical sector or non-profit organizations dedicated to charitable causes. In STP, we have considered integrating both a decentralized and a centralized solution. The decentralized solution (BigchainDB) is intended to be used by organizations that seek to achieve an advanced level of transparency, free from a central authority, and the centralized (QLDB) solution is intended to provide transparency across their value chain with a central authority. Traceability and product tracking in an Information Technology (IT) company has served as the case study for the evaluation of the comparison criteria taken into account.
A first step was to identify the specific challenges (SC) of the track and trace service that the proposed platform should address, such as:
- SC1. Transparency—having in view that different supply chain partners manage different sources of data, there is a need for transparency in terms of the product information to be tracked within a supply chain.
- SC2. Inconsistencies—the presence of multiple, isolated data sources managed by various individual organizations along the supply chain can result in discrepancies, the reconciliation of which can be resource-consuming (e.g., time, financial, human).
- SC3. Quality—product quality can be affected by the lack of real-time tracking capabilities of the organizations involved in the supply chain (e.g., scaling, monitoring, and easy setup).
- SC4. Data accuracy and integrity (Immutability)—unauthorized data tampering is not allowed. Any alterations must be detected.
- SC5. Data privacy and security—open-source solutions that can be peer-reviewed are often trusted, as compared to closed sources solutions.
- SC6. Decentralization—the transfer of authority from the organization, as the owner of the data, to the stakeholders.
- SC7. Audits—the use of different data sources can lead to difficult, time-consuming audits.
STP is a tool for tracking and tracing assets across different value chains. It is designed to be used by different types of organizations, such as SMEs, large companies, or non-profit entities, from different industries. One of the core features of STP is the ability to transfer traceability and value chain data to a decentralized or centralized ledger by providing the end-users with the possibility of making specific data publicly and securely available. The system architecture of the solution is described in the following section, while Table 7 presents the manner in which our solution addresses the above specific challenges.
Table 7.
BigchainDB and QLDB features against the specific challenges.
6. Experimental Evaluation
This section presents a comparative experimental evaluation of the two selected databases, BigchainDB and Amazon Quantum Ledger Database (QLDB). Figure 3 illustrates the workflow of the performed experiments.
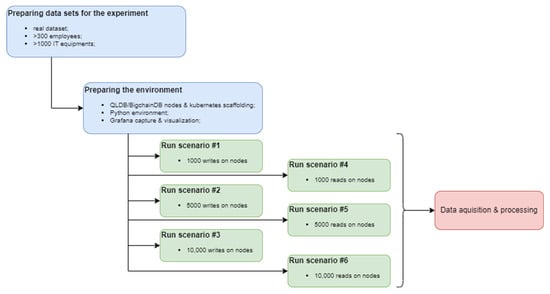
Figure 3.
Flow diagram of the experimental evaluation.
As part of the experimental evaluation, STP integrations of BigchainDB and QLDB were used in order to test the performance of both solutions regarding latency and resource usage (see Figure 4 and Figure 5). Our STP case study has been configured to track and trace the IT equipment in an IT and C organization with more than 300 employees and 1000 pieces of equipment used across multiple departments.
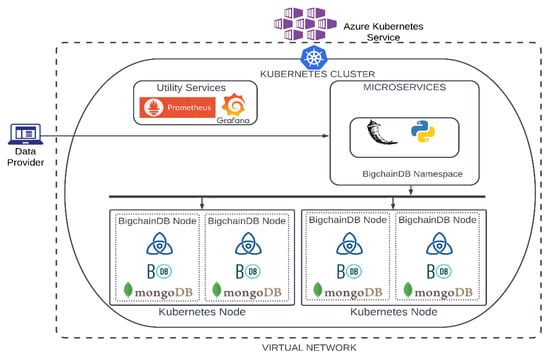
Figure 4.
High-level architecture of the prototype interacting with BigchainDB.
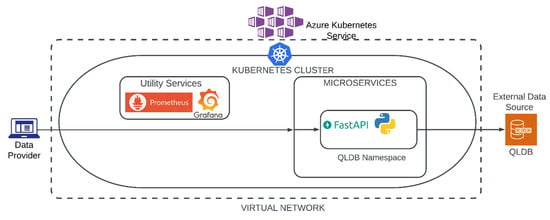
Figure 5.
High-level architecture of our prototype interacting with QLDB.
6.1. Environment
The present experiment was designed to monitor and compare the average execution times, as well as the CPU utilization and memory usages for reading and writing for both Amazon Quantum Ledger Database (QLDB) and BigchainDB technologies. The execution time is defined as the total time it takes until the dataset provided in the request is created and stored in the database, as it is for QLDB. In contrast, in BigchainDB, the execution time is computed by measuring the time necessary for the data to be stored in all MongoDB instances inside every node (this implies that the exact measurement logic is applied for the other performance indicators). A total of four nodes have been configured, as each set of two runs in a Kubernetes cluster. Grafana is the data visualization tool that has been used, and the query interaction was done via Prometheus Query Language (PromQL), a functional query language provided by Prometheus, which is a tool for data monitoring and collecting. The interaction with BigchainDB was possible due to the Python driver supported by the official documentation. In this case, a direct query interaction is not available; nonetheless, if one wishes to query documents manually, this can be done through the nodes’ MongoDB instance that they have access to.
As there are not many direct alternatives in terms of architecture, structure and functionality to BigchainDB, one of the main reasons for using QLDB as an alternative is the similarity between what a single node of BigchainDB does and the AWS candidate. The main area of interest refers to the immutability, transparency, verifiability, and persistency of data history.
The interaction with QLDB was ensured by using the Python driver provided by the official documentation and, essentially, by executing queries in a similar manner to traditional database, using PartiQL (a SQL-compatible query access solution used by Amazon in QLDB) as an interrogation language. The focus was on two significant operations: data reading and writing.
For both approaches, two types of functions were built: one for reading and one for writing data based on what every driver has to offer, whereas every pair of parts has been used with their specific Application Programming Interface (API) endpoints based on which the requests were made.
In order to interact with the functions required for reading and writing the data, there is a need for a software interface (API) to be set in place. For each of the two cases, there are different APIs to facilitate communication between the distinct interfaces. As far as the QLDB solution is concerned, a more modern approach was preferred, based on the use of FastAPI, which is a relatively new Python framework for building web applications. On the other hand, in terms of the BigchainDB solution, we adopted a classical approach that uses a classic Python micro-framework named Flask. Its primary benefits are its high flexibility and a resilient learning curve. Below, we have presented the components of the system used for this study.
The operating system used is Ubuntu 20.04. Some OS level dependencies need to be installed first, such as the following:
- python3.8 and python3.8-venv (virtual environment);
- pip3 (python package management tool);
- python3-dev (header files and a static library);
- libssl-dev (SSL and TLS cryptographic protocols);
- libffi-dev (Foreign Function Interface library);
- docker engine, daemon, and docker-compose.
6.2. BigchainDB
The BigchainDB nodes (see Figure 4) are synchronized based on the use of Azure Kubernetes Service and Helm (based on Kubernetes manifests). Kubernetes’ manifests are built using declarative programming, by bringing the cluster to the state desired by the user through manifest files (YAML or JSON). They describe services, applications, configurations, etc. Helm is a technology used to manage and configure a Kubernetes Cluster that abstracts the manifest.
To configure the nodes of BigchainDB, we used the StatefulSet type, which creates and maintains functional nodes. On each node, there is a BigchainDB Server (http://docs.bigchaindb.com/projects/server/en/latest/, accessed on 16 November 2022), an instance of Tendermint (https://tendermint.com/, accessed on 17 November 2022), and an example of Nginx; the same applies for the MongoDB database. To avoid losing the data in case of a node reset, we employed Persistent Volumes, together with Persistent Volume Claims and the Storage Class (https://learn.microsoft.com/en-us/azure/aks/concepts-storage, accessed on 16 November 2022). The latter connects to an Azure API (provisioner: kubernetes.io/azure-disk) and automatically creates Azure disks for storage. The connection between the nodes is made through services such as ClusterIP (https://www.ibm.com/docs/en/cloud-private/3.2.0?topic=networking-kubernetes-service-types, accessed on 17 November 2022). The moment the cluster is started, a script is run that makes the exchange between the public keys.
6.3. Amazon QLDB
As far as the tests are concerned, a QLDB instance was set up (see Figure 5). In this case, the tables Assets and Test were created; the latter was primarily used to make the requests. The tables have been created by using the Python driver, and the following function that receives the name of the table intended for creation as a parameter, and the default transaction executor:
@staticmethod
def __create_table(transaction_executor, table_name):
transaction_executor.execute_statement(f”Create TABLE {table_name}”)
Both solutions were compared based on the collected vital performance indicators and the metrics to determine the best option for them. As far as the BigchainDB is concerned, each node has been tracked in order to compare the performances with QLDB and to observe the performance when comparing them.
The measurements were made by running a bash script that made the requests automatically. It is worth mentioning that the requests were made sequentially. Therefore, the total duration increased as the number of requests grew.
The script executes the following simple function, which is made up of a while loop that runs until the lower bound, which is incremented after each request. When it reaches the value of the upper bound, inside the loop there is a decisional statement composed of an if/else statement that ensures the call of the proper request, based on its type. This approach was chosen due to the uniqueness of the data inserted in BigchainDB/QLDB. Thus, we are guaranteed that each data has a unique id.
- 1:
- displaying the script’s starting time
- 2:
- while lower_bound <= upper_bound
- 3:
- if the request is of type GET
- 4:
- making a call to the url for reading data
- 5:
- else if the request is of type POST
- 6:
- data <- “{ id: lower_bound }” # stringified json object
- 7:
- making a call to the url for inserting the specified data
- 8:
- end if
- 9:
- lower_bound <- lower_bound + 1
- 10:
- end while
- 11:
- displaying the script’s ending time
6.4. Results
Prior to running the tests, we prepared three scenarios for both platforms, BigchainDB and QLDB (Table 8).
Table 8.
Scenarios for the comparison experiment.
The data inserted into the decentralized databases refer to the traceability logs, which have been retrieved from the Smart Tracking Platform databases after running the test pilots. Each insert has an approximate size of 0.204 KB.
The color mapping for the following charts is presented in Table 9.
Table 9.
Color mapping.
6.4.1. Case 1—1000 Inserts
We noticed that the peak usage of the CPU is at 0.1% for Node 1, while the values fluctuate based on every individual node that we have, between 0.05 at its lowest on Node 2 (see Figure 6), while QLDB is a little under 0.02% (see Figure 7). The same scenario applies to the memory usage, where Node 1 is over 300 MB and Node 2 is at 225–250 MB (see Figure 8), while QLDB thrives with an approximate constant value of 45 MB (see Figure 9).
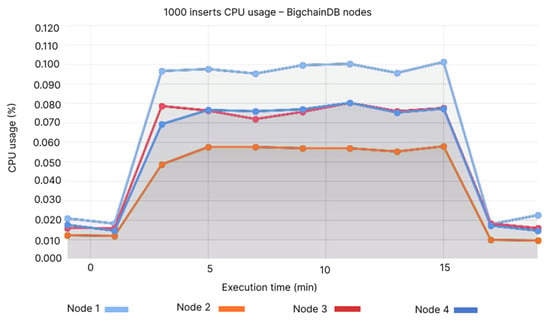
Figure 6.
1000 inserts CPU usage—BigchainDB nodes.
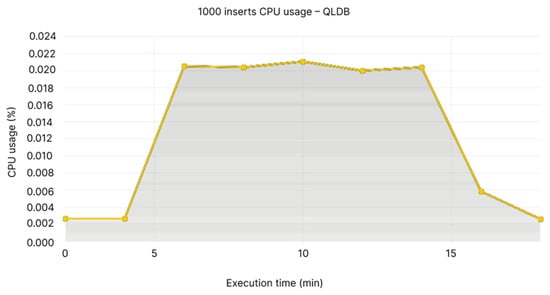
Figure 7.
1000 inserts CPU usage—QLDB.
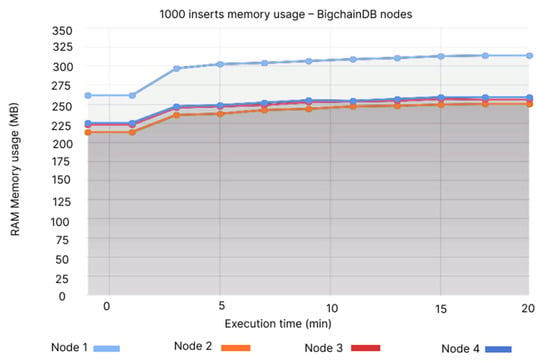
Figure 8.
1000 inserts memory usage—BigchainDB.
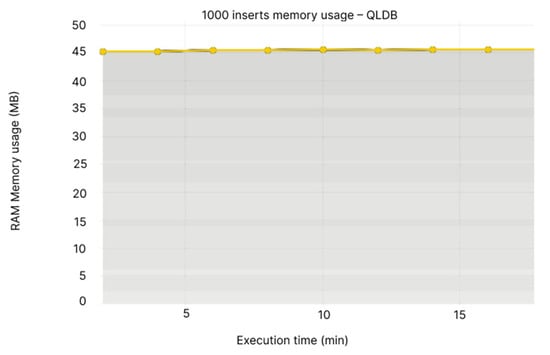
Figure 9.
1000 inserts memory usage—QLDB.
The CPU usage for each of the nodes is:
- Node 1: 0.09–0.1%, Node 2: 0.05–0.06%, Node 3: 0.06–0.07%, Node 4: 0.06–0.07%
The memory utilization for each node:
- Node 1: 300–325 MB, Node 2: 200–225 MB, Node 3: 225–275 MB, Node 4: 225–275 MB.
6.4.2. Case 2—5000 Inserts
The uttermost CPU usage is 0.1–0.11% for the first node, whereas the other values range between the minimum value at Node 2—0.05% (see Figure 10), and in QLDB’s case, between 0.018–0.022% (see Figure 11).
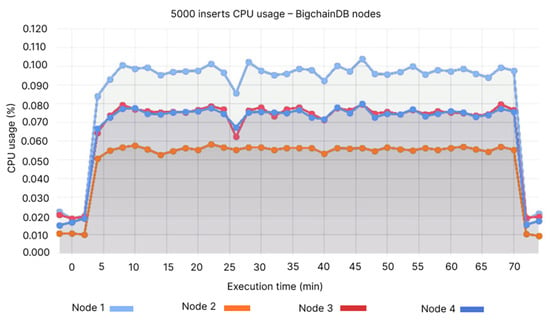
Figure 10.
5000 inserts CPU usage—BigchainDB nodes.
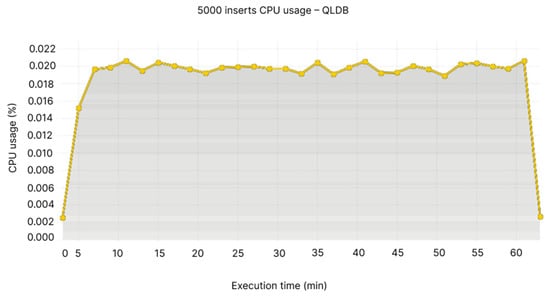
Figure 11.
5000 inserts CPU usage—QLDB.
In comparison with Node 1, which uses between 300 and 450 MB and seems to increase with time, and Node 2 with a more flattened increased slope at 225–300 MB (see Figure 12), QLDB maintains the memory usage at a low level of 45–50 MB (see Figure 13).
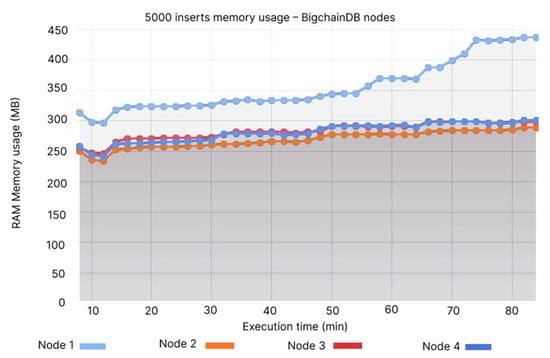
Figure 12.
5000 inserts memory usage—BigchainDB nodes.
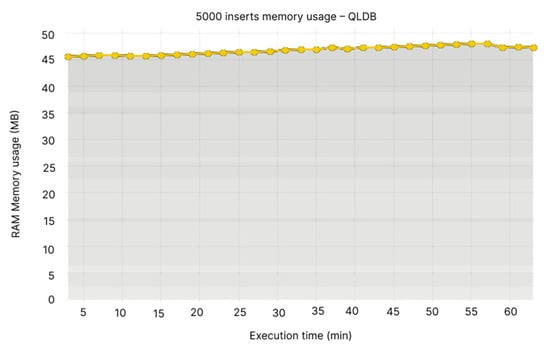
Figure 13.
5000 inserts memory usage—QLDB.
The CPU usage for each of the nodes is as follows:
- Node 1: 0.09–0.1%, Node 2: 0.05–0.06%, Node 3: 0.06–0.07%, Node 4: 0.06–0.07%
The memory utilization for each node is as follows:
- Node 1: 300–325 MB, Node 2: 200–225 MB, Node 3: 225–275 MB, Node 4: 225–275 MB
6.4.3. Case 3—10,000 Inserts
In this case, the maximum value has been reached for both technologies, the CPU usage for the first node being 0.9–0.11%, and the other values ranging between this value and the lowest value for Node 2—0.04% (see Figure 14), and for QLDB, between 0.0175–0.0225% (see Figure 15).
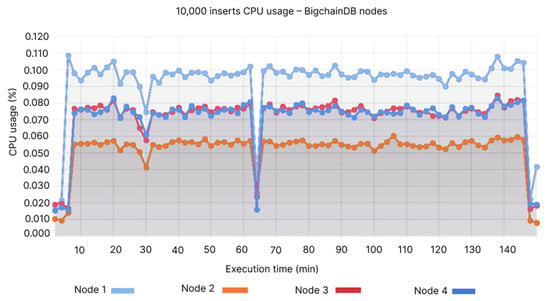
Figure 14.
10,000 inserts CPU usage—BigchainDB nodes.
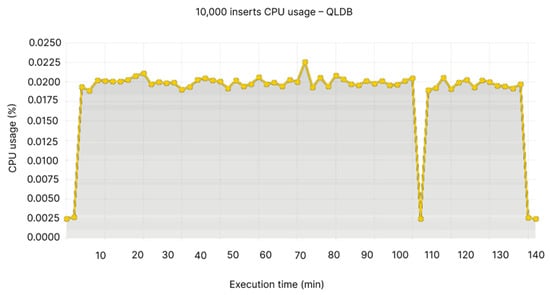
Figure 15.
10,000 inserts CPU usage—QLDB.
It can be noted that, while Node 1 appears to be the most resource hungry, which uses 450–550 MB, whereas the other nodes have values ranging between 300 and 350 MB (see Figure 16), the memory usage for QLDB remains the same between 45–50 MB (see Figure 17).
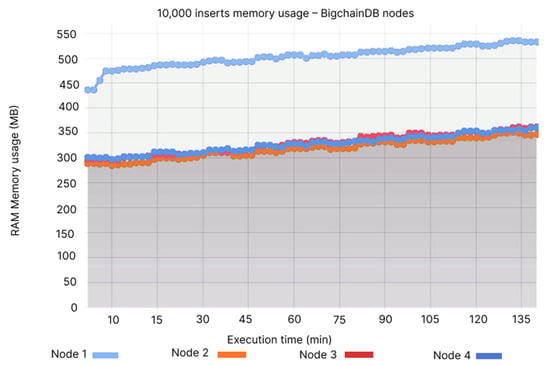
Figure 16.
10,000 inserts memory usage—BigchainDB nodes.
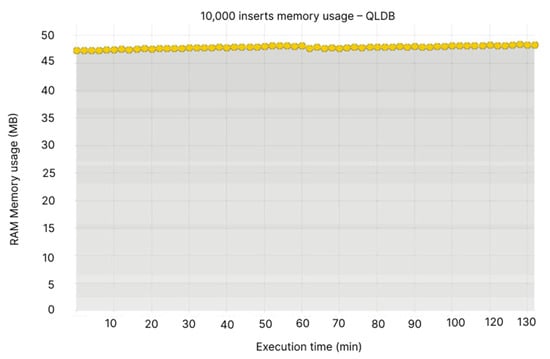
Figure 17.
10,000 inserts memory usage—QLDB.
The CPU usage for each of the nodes is as follows:
- Node 1: 0.09–0.11%, Node 2: 0.05–0.06%, Node 3: 0.07–0.08%, Node 4: 0.07–0.08%
The memory utilization for each node is as follows:
- Node 1: 450–550 MB, Node 2: 275–350 MB, Node 3: 275–375 MB, Node 4: 275–375 MB
6.4.4. Case 4—1000 Reads
Similar to the insert cases for BigchainDB, the CPU usage for Node 1 is of approximately 0.06% (see Figure 18), while QLDB’s CPU usage fluctuates around 0.012% (see Figure 19). In terms of memory, Node 1 registers the highest usage of 450-475 MB (See Figure 20), while QLDB’s memory usage is almost constant, ranging between 45 and 50 MB (See Figure 21).
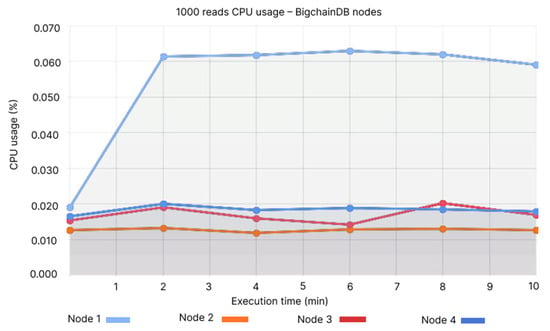
Figure 18.
1000 reads CPU usage—BigchainDB nodes.
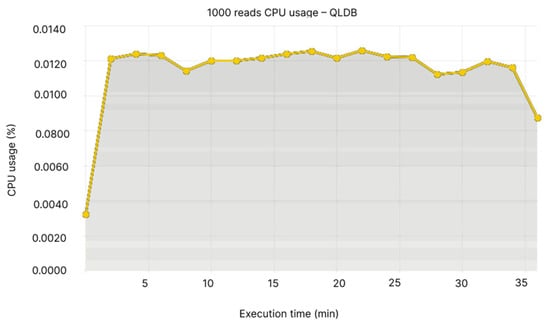
Figure 19.
1000 reads CPU usage—QLDB.
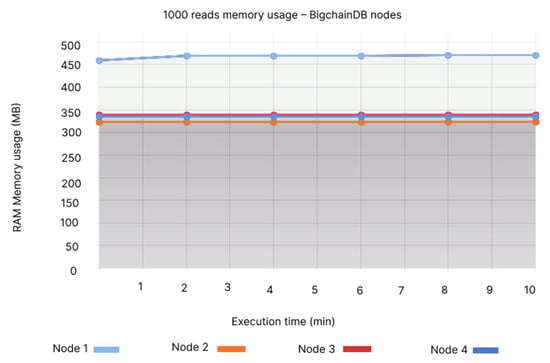
Figure 20.
1000 reads memory usage—BigchainDB nodes.
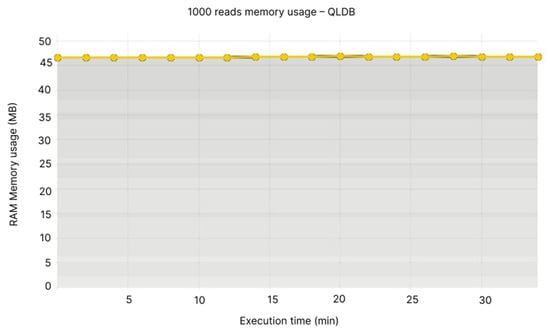
Figure 21.
1000 reads memory usage—QLDB.
The CPU usage for each of the nodes is as follows:
- Node 1: 0.06%, Node 2: 0.01–0.02%, Node 3: 0.01–0.02%, Node 4: 0.01–0.02%
The memory utilization for each node is as follows:
- Node 1: 430–450 MB, Node 2: 300–335 MB, Node 3: 300–335 MB, Node 4: 300–335 MB
6.4.5. Case 5—5000 Reads
When comparing CPU usage, BigchainDB has registered a value of 0.06% (see Figure 22), while QLDB’s CPU usage fluctuates around 0.012%, with some local maximum and minimum (see Figure 23).
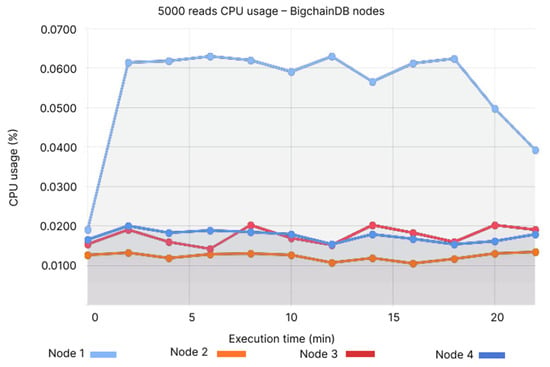
Figure 22.
5000 reads CPU usage—BigchainDB nodes.
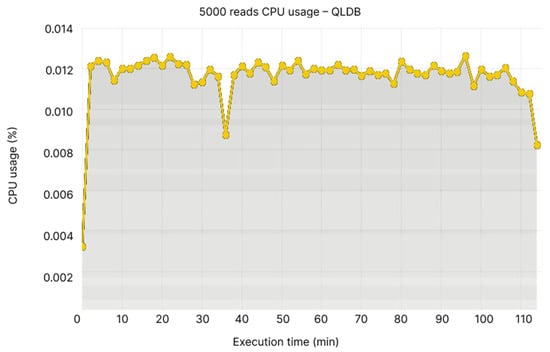
Figure 23.
5000 reads CPU usage—QLDB.
Node 1 of the BigchainDB has the highest usage in terms of memory, at 450–500 MB (see Figure 24), while QLDB’s memory usage fluctuations are almost inexistant, ranging between 45–50 MB (see Figure 25).
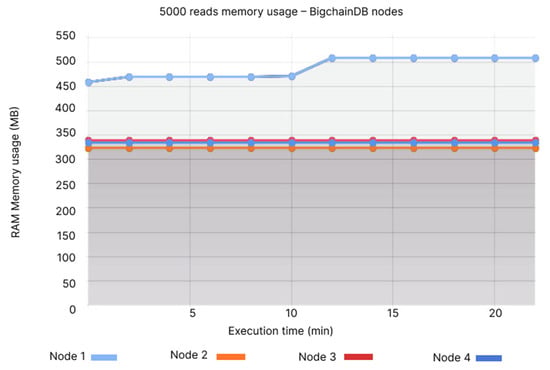
Figure 24.
5000 reads memory usage—BigchainDB nodes.
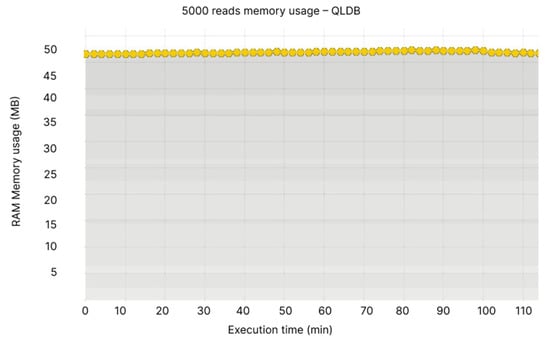
Figure 25.
5000 reads memory usage—QLDB.
The CPU usage for each of the nodes is as follows:
- Node 1: 0.055–0.063%, Node 2: 0.01–0.02%, Node 3: 0.01–0.02%, Node 4: 0.01–0.02%
The memory utilization for each node is as follows:
- Node 1: 430–480 MB, Node 2: 300–335 MB, Node 3: 300–335 MB, Node 4: 300–335 MB
6.4.6. Case 6—10,000 Reads
In this experiment, BigchainDB’s CPU usage is approximately 0.06, with some significant fluctuations (see Figure 26), while QLDB’s CPU usage is around 0.012% and similarly to BigchainDB, it has bigger fluctuations and spikes (see Figure 27).
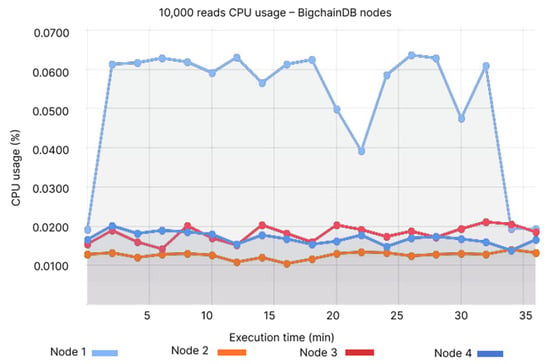
Figure 26.
10,000 reads CPU usage—BigchainDB nodes.
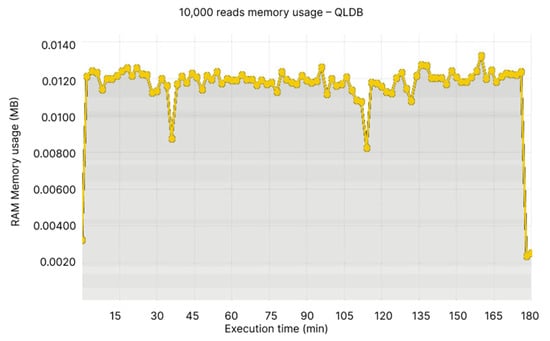
Figure 27.
10,000 reads CPU usage—QLDB.
When analysing the memory usage, we notice that Node 1 of BigchainDB has the highest usage, reaching 450–500MB, while the other nodes have an almost constant memory usage ranging between 300–350 MB (see Figure 28). QLDB’s memory usage fluctuations are insignificant, ranging between 45–50 MB (see Figure 29).
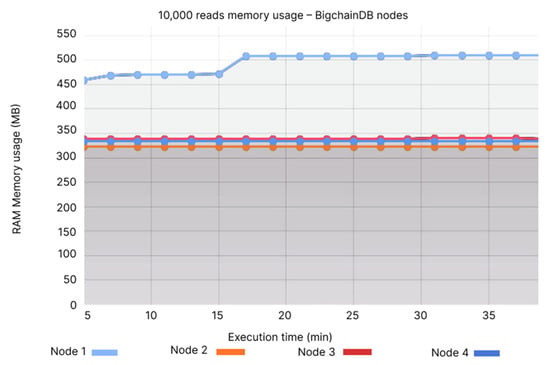
Figure 28.
10,000 reads memory usage—BigchainDB nodes.
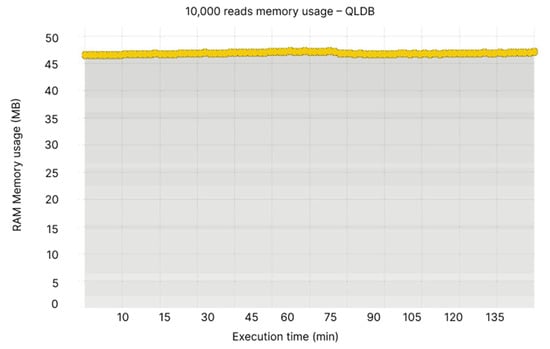
Figure 29.
10,000 reads memory usage—QLDB.
The CPU usage for each of the nodes is as follows:
- Node 1: 0.04–0.065%, Node 2: 0.01–0.02%, Node 3: 0.01–0.02%, Node 4: 0.01–0.02%
The memory utilization for each node is as follows:
- Node 1: 430–480 MB, Node 2: 300–335 MB, Node 3: 300–335 MB, Node 4: 300–335 MB
7. Discussion and Conclusions
A total number of 12 tests were executed against the compared tools BigchainDB and QLDB. Table 10 and Figure 30 and Figure 31 show the results of the experiments. Within this table, the maximum values have been highlighted in green and the minimum values in blue.
Table 10.
Results of the experiments.
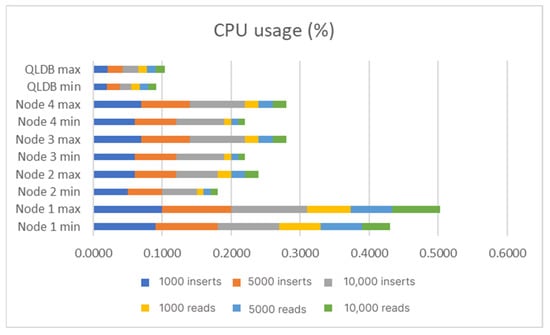
Figure 30.
CPU usage (%).
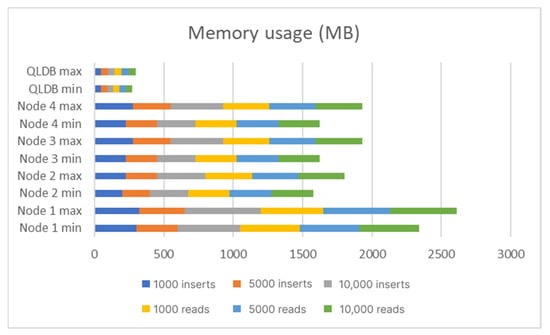
Figure 31.
Memory usage (MB).
In Case 1, with 1000 inserts, the QLDB uses 78% less CPU and 85% less memory than Node 1 of BigchainDB (the most consuming node), and 63.3% less CPU and 82% less memory than the least consuming node. In Case 2, with 5000 inserts, QLDB has 80% less CPU and 76% less memory than Node 1 of BigchainDB (the most consuming node), and 63.6% less CPU and 74% less memory than the other nodes. Case 3 (10,000 inserts) demonstrates the peak performance for the QLDB inserts. In the worst-case scenario for BigchainDB, QLDB uses 80% less CPU and 90.6% less memory than Node 1 of BigchainDB, and 63.6 less CPU and 85.5% memory, in comparison with the other three nodes.
In Case 4, with 1000 reads, QLDB has 80% less CPU and 90% less memory than Node 1 of BigchainDB and 7.7% less CPU and 85.3% less memory than the least consuming node. In Case 5 (5000 reads), QLDB uses 80% less CPU and 90.1% less memory than Node 1 of BigchainDB (the most consuming node), and 4% less CPU and 85.5% less memory than the other nodes.
Running Case 6 (10,000 reads) reveals that QLDB has 80.3% less CPU and 90.5% less memory than Node 1 of BigchainDB (the most consuming node), and 4.1% less CPU and 85.8% less memory than the other nodes.
As far as each insert case is concerned, QLDB excels in both memory usage and CPU utilization. At its maximum, the CPU utilization is of 0.0255%, while the memory usage is below 50 MB. It is a fact that BigchainDB would be more resource-consuming, due to its distributed nature, because it has to write the same data multiple times, depending on how many nodes the network comprises. Nevertheless, the nodes do not use the same number of resources. Some use up to half the resources that the other nodes do. The performance indicators of BigchainDB are 0.11% in CPU utilization and almost 550 MB of memory, both at their maximum values.
Amazon QLDB manages to keep the memory usage constant during the requests and at a low level. Although the numbers are not significant, as such, particularly if we consider the computation power of today’s computers, in some instances BigchainDB uses as much as 4–5 times the memory and 4–5 times the CPU that QLDB uses.
Similarly, as far as the reading cases are concerned, QLDB excels in every example, particularly in memory usage, by being almost constant, and having the same values for both the reading and inserting of the data (45–50 MB). In terms of the CPU usage, in all the provided examples, the value oscillates around 0.012%.
BigchainDB also uses a low CPU percentage, which is around 0.06% and is more memory intensive than QLDB, at a maximum of 500 MB.
In terms of the performance indicators for reading and inserting operations for each technology, the reading values are almost half the inserting values and exactly as they should be.
The two parameters we used when conducting the current study—CPU and RAM consumption—were selected due to the straightforwardness of their record and the useful information they provide about the system’s performance. Whilst there are other additional qualitative parameters that could be considered, including data security and privacy, or ease of use, in this case the quantitative technical analysis is considered to be the most crucial. In addition, it is straightforward to estimate the processing performance for each scenario based on the analyzed parameters.
Nonetheless, we consider that aspects related to security and privacy need to be briefly examined for the two databases analyzed in the current paper.
In the case of QLDB, AWS and the user share security responsibilities ([44,45]). AWS is responsible for protecting the infrastructure that runs the selected services, and third-party auditors test and verify its effectiveness on a regular basis as an added layer of security. Generally, it is recommended to set up accounts with AWS IAM (Identity and Access Management) and add extra layers of security such as MFA, SSL/TSL, activity logging via AWS CloudTrail, AWS encryption solutions, and using advanced managed security services for data protection (e.g., Amazon Macie). In the case of the user, responsibility is determined by the services used, as well as factors such as data sensitivity and project requirements.
In a decentralized system such as BigchainDB, the security of each node and the aggregate security across the entire network are extrinsic, which means that the security rules governing confidentiality, availability, and integrity exist outside of the core network design. For instance, if all the nodes have weak security rules, the network is vulnerable to breaches. In contrast, even if a small fraction of the network nodes adheres to reasonable security standards, the network as a whole can withstand attacks. To enhance each node’s security and privacy regarding the data traffic, all of the stored data needs to be encrypted at rest and in a transparent manner to BigchainDB, MongoDB, and Tendermint, and all data needs to be encrypted in transit and to enforce the use of HTTPS for the HTTP API and Websocket API. This can be achieved by using Nginx.
What is noteworthy for the BigchainDB’s reading cases is that, for reading operations, the CPU utilization is always at its highest only for the primary node, while for all the other nodes it reaches values close to those registered by QLDB, but still with 4–4.1% more consumption.
For inserting data, QLDB does not exceed 50 MB in terms of memory utilization, while BigchainDB’s memory utilization has an almost linear growth, being proportional to the number of inserts that are made.
Overall, BigchainDB’s CPU utilization, has greater fluctuations than QLDB, meaning it has more local minimums and maximums, as can be observed in case 3 (10,000 inserts), where BigchainDB has five local peaks, while in the same scenario, QLDB has only two.
Furthermore, analyzing the use of the same technology (BigchainDB) in two separate instances (case 1 and case 3), we can see that for a small number of requests, such as in case 1, the CPU utilization during the inserts is almost constant, with no significant fluctuations. In case 3, however, we register sharp fluctuations.
The conclusion of this study shows that QLDB has an overall better performance compared to BigchainDB based on the metrics that have been considered (CPU and memory usage) (see Figure 32 and Figure 33).
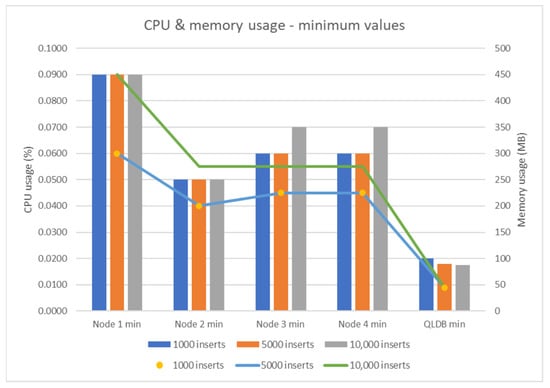
Figure 32.
CPU and memory usage—minimum values.
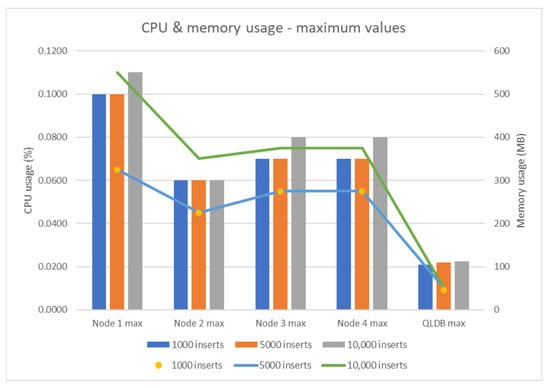
Figure 33.
CPU and memory usage—maximum values.
From the perspective of database ledger implementation, Amazon QLDB proved to be an integrated solution and easier to use, whilst BigchainDB involves a complex system to be implemented and developed, but with the advantage of being more flexible. Although both systems are almost ready-to-use solutions for local environments, when it comes to configuring and setting up the communication between nodes within a production environment, BigchainDB adds a layer of complexity from a DevOps perspective, while Amazon QLDB completely overcomes this issue. Depending on the area considered and the identified needs, both BigchainDB and Amazon QLDB can be considered as suitable solutions for a ledger database.
7.1. Summary, Limitations and Conclusions
The present paper is intended for both industrial and research readers. Given the variety of databases that can be used to develop an LT-based solution to a specific problem, in practice, selecting the most appropriate database is difficult. The decision-making process in this regard is influenced by several factors, including the specific context.
In this paper, the use of two popular databases was compared, with an analysis of the findings obtained. This benchmarking study introduced a track and trace application that allows supply chain partners to manage (and securely exchange) information needed to ensure traceability using decentralized and centralized ledgers.
The analysis of the results of the experiments presented in this paper can be helpful to practitioners in making the best decision on the use of a specific database for the development of a specific LT-based application. Researchers can also use the analysis presented in this material to select the database that would be best suited for experiments, such as testing and validating certain theories.
However, this paper has some limitations that will be addressed in future research, the most significant of which is the limited number of experiments and operations performed. QLDB is provided as a service (SaaS) for the organizations accessing it (an advantage for compliance with the local legislative framework), with centralized functioning. BigchainDB allows another approach, which is more convenient in some cases, for example, self-hosting (with assurance of data ownership, but also in-house assurance of legal compliance) with distributed traceability via nodes retaining the distributed records.
Finally, the experiment presents only two of the currently available options. With the growing interest in blockchain technologies and their applications in traceability, new platforms that match the features of the two described platforms are emerging.
Although the results of the experiments with QLDB have shown a better performance for certain criteria, depending on the context and the specific requirements of the applications to be developed, many users will undoubtedly find BigchainDB appealing as well.
7.2. Future Work
This study can be expanded with a cost comparison between the two technologies, BigchainDB and QLDB. In addition, a performance comparison improvement can be made by gradually increasing the number of distributed nodes while testing.
Furthermore, the sequentially made requests can be replaced with parallelized ones. In addition, a larger, sequential payload can be sent to measure the behavior of both technologies. The study can be expanded even further by sending larger parallel payloads and studying how the conglomerate of requests that holds large amounts of data affects the performance indicators of BigchainDB and QLDB.
A third solution may be added; another blockchain database, e.g., CassandraDB, or even a pure blockchain technology, would be more suitable for this study as we could compare different yet adjacent solutions that derive from the same base infrastructure.
Author Contributions
Conceptualization, S.L., P.C. and C.E.T.; methodology, C.E.T. and O.G.; software, P.C. and S.L.; writing—original draft preparation, S.L., P.C., C.E.T. and O.G.; writing—review and editing, O.G., C.O.T. and G.P.; review and supervision, P.C. and C.E.T.; funding acquisition, C.O.T. and C.E.T. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the project “119722/Centru pentru transferul de cunoștințe către întreprinderi din domeniul ICT—CENTRIC, Contract subsidiar 15568/01.09.2020, Smart Tracking Platform (STP)”, contract no. 5/AXA 1/1.2.3/G/13.06.2018, cod SMIS 2014+ 119722 (ID P_40_305).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data used to support the findings of this study are available from the corresponding author upon request.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
| API | Application Programming Interface |
| BFT | Byzantine Fault Tolerant |
| CLT | Centralized Ledger Technology |
| CLD | Centralized Ledger Database |
| CPU | Central Processing Unit |
| DB | Database |
| DevOps | combination of software development (Dev) and IT operations (Ops) |
| DLT | Decentralized Ledger Technology |
| IIOT | Industrial Internet of Things |
| IoT | Internet of Things |
| IT | Information Technology |
| JSON | JavaScript Object Notation |
| LT | Ledger Technology |
| NoSQL | non-SQL; non-relational database |
| PoET | Proof of Elapsed Time |
| PoS | Proof of Stake |
| QLBD | Quantum Ledger Database |
| SC | Specific Challenges |
| SME | Small and Medium Enterprise |
| SQL | Structured Query Language |
| STP | Smart Tracking Platform |
| YAML | Human-friendly data serialization language |
References
- BigchainBD. BigchainDB GmbH, 2020. Available online: https://www.bigchaindb.com/ (accessed on 15 September 2022).
- AWS. Amazon Web Services. Available online: https://aws.amazon.com/qldb/ (accessed on 5 September 2022).
- Wang, Y.; Hsieh, C.H.; Li, C. Research and Analysis on the Distributed Database of Blockchain and Non-Blockchain. In Proceedings of the IEEE International Conference on Cloud Computing and Big Data Analysis (ICCCBDA), Chengdu, China, 10–13 April 2020. [Google Scholar]
- ASSIST Software Smart Tracking Platform. 2022. Available online: https://assist-software.net/project/smart-tracking-platform (accessed on 20 August 2022).
- Martín-Martín, A.; Orduna-Malea, E.; Thelwall, M.; López-Cózar, E.D. Google Scholar, Web of Science, and Scopus: A systematic comparison of citations in 252 subject categories. J. Informetr. 2018, 12, 1160–1177. [Google Scholar] [CrossRef]
- Haddaway, N.R.; Collins, A.M.; Coughlin, D.; Kirk, S. The role of Google Scholar in evidence reviews and its applicability to grey literature searching. PLoS ONE 2015, 10, e0138237. [Google Scholar] [CrossRef]
- Fekete, D.; Kiss, A. A Survey of Ledger Technology-Based Databases. Future Internet 2021, 13, 197. [Google Scholar] [CrossRef]
- Rejeb, A.; Rejeb, K.; Keogh, J.G. Centralized vs. decentralized ledgers in the money supply process: A SWOT analysis. Quant. Financ. Econ. 2021, 5, 40–66. [Google Scholar] [CrossRef]
- Nakamoto, S. Bitcoin: A Peer-to-Peer Electronic Cash System. Decentralized Business Review. 21260. 2008. Available online: https://bitcoin.org/bitcoin.pdf (accessed on 29 November 2022).
- Agi, M.A.; Jha, A.K. Blockchain technology in the supply chain: An integrated theoretical perspective of organizational adoption. Int. J. Prod. Econ. 2022, 247, 108458. [Google Scholar] [CrossRef]
- Babich, V.; Hilary, G. OM Forum—Distributed ledgers and operations: What operations management researchers should know about blockchain technology. Manuf. Serv. Oper. Manag. 2020, 22, 223–240. [Google Scholar] [CrossRef]
- Sahoo, S.; Kumar, S.; Sivarajah, U.; Lim, W.M.; Westland, J.C.; Kumar, A. Blockchain for sustainable supply chain management: Trends and ways forward. Electron. Commer. Res. 2022. [Google Scholar] [CrossRef]
- Lu, Q.; Xu, X. Adaptable blockchain-based systems: A case study for product traceability. IEEE Softw. 2017, 34, 21–27. [Google Scholar] [CrossRef]
- Toyoda, K.; Shakeri, M.; Chi, X.; Zhang, A.N. Performance evaluation of ethereum-based on-chain sensor data management platform for industrial IoT. In Proceedings of the 2019 IEEE International Conference on Big Data (Big Data), Los Angeles, CA, USA, 9–12 December 2019; pp. 3939–3946. [Google Scholar]
- Augusto, L.; Costa, R.; Ferreira, J.; Jardim-Gonçalves, R. An application of Ethereum smart contracts and IoT to logistics. In Proceedings of the 2019 International Young Engineers Forum (YEF-ECE), Costa da Caparica, Portugal, 10 May 2019; pp. 1–7. [Google Scholar]
- Nguyen, K.Q. Ledger of Things-Future Technology for Value Creation. In Proceedings of the 2019 International Conference on System Science and Engineering (ICSSE), Dong Hoi, Vietnam, 20–21 July 2019; pp. 405–409. [Google Scholar]
- Erdenebold, T.; Rho, J.; Hwang, Y. Blockchain Reference Model and Use Case for Supply Chains within Enterprise Architecture. J. Inf. Technol. Archit. 2019, 16, 1–10. [Google Scholar]
- Bokolo, A.J. Distributed Ledger and Decentralised Technology Adoption for Smart Digital Transition in Collaborative Enterprise. In Enterprise Information Systems; Taylor & Francis: Abingdon, UK, 2021; pp. 1–34. [Google Scholar] [CrossRef]
- Greeshma, R.N.; Shoney, S. BlockChain Technology. Centralised Ledger to Distributed Ledger. Int. Res. J. Eng. Technol. (IRJET) 2017, 4, 2823–2827. [Google Scholar]
- Zetzsche, D.; Buckley, R.; Arner, D. The Distributed Liability of Distributed Ledgers: Legal Risks of Blockchain; University of Illinois Law Review: Urbana, IL, USA, 2017. [Google Scholar]
- Markus, I.; Xu, L.; Subhod, I.; Nayab, N. Decentralized Ledger based Access Control for Enterprise Applications. In Proceedings of the IEEE International Conference on Blockchain and Cryptocurrency, Seoul, Republic of Korea, 14–17 May 2019. [Google Scholar]
- Xu, Z.; Zou, C. What Can Blockchain Do and Cannot Do? China Econ. J. 2021, 14, 4–25. [Google Scholar] [CrossRef]
- Camera, G. A Perspective on Electronic Alternatives to Traditional Currencies. Sver. Riksbank Econ. Rev. 2017, 1, 126–148. [Google Scholar]
- Huang, B.; Peng, L.; Zhao, W.; Chen, N. Workload-based randomization byzantine fault tolerance consensus protocol. High-Confid. Comput. 2022, 2, 100070. [Google Scholar] [CrossRef]
- Fan, C.; Ghaemi, S.; Khazaei, H.; Musilek, P. Performance Evaluation of Blockchain Systems: A Systematic Survey. IEEE Access 2020, 8, 126927–126950. [Google Scholar] [CrossRef]
- Duke, A. What Does the CISG Have to Say about Smart Contracts: A Legal Analysis. Chic. J. Int. Law 2019, 20, 141. [Google Scholar]
- Yang, X.; Zhang, Y.; Wang, S.; Yu, B. LedgerDB: A Centralized Ledger Database for Universal Audit and Verification. Comput. Sci. Proc. VLDB Endow 2020, 13, 3138–3151. [Google Scholar] [CrossRef]
- Azgad-Tromer, S. Crypto Securities: On the Risks of Investments in Blockchain-Based Assets and the Dilemmas of Securities Regulation. Am. Univ. Law Rev. 2018, 68, 69. [Google Scholar]
- Lafarre, A.; van der Elst, C. Blockchain Technology for Corporate Governance and Shareholder Activism; European Corporate Governance Institute (ECGI); Law Working Paper No. 390/2018; SSRN eJournal: Rochester, NY, USA, 2018. [Google Scholar]
- Chowdhury, M.J.M.; Colman, A.; Kabir, M.A.; Han, J.; Sarda, P. Blockchain versus database: A critical analysis. In Proceedings of the 2018 17th IEEE International Conference on Trust, Security and Privacy in Computing and Communications/12th IEEE International Conference on Big Data Science and Engineering (TrustCom/BigDataSE), New York, NY, USA, 1–3 August 2018; pp. 1348–1353. [Google Scholar]
- Mayer, J.; Niemietz, P.; Trauth, D.; Bergs, T. How Distributed Ledger Technologies affect business models of manufacturing companies. Procedia CIRP 2021, 104, 152–157. [Google Scholar] [CrossRef]
- Amazon QLDB vs. MongoDB Comparison. Available online: https://www.peerspot.com/products/comparisons/amazon-qldb_vs_mongodb (accessed on 6 December 2022).
- BigchainDB. Available online: https://discovery.hgdata.com/product/bigchaindb (accessed on 14 November 2022).
- Spasov, E. Enterprise Blockchain’s Growing Impact on the Startup & SME Ecosystem. INDUSTRIA Digital Everything. Available online: https://www.industria.tech/blog/enterprise-blockchains-growing-impact-on-the-startup-and-sme/ (accessed on 12 December 2022).
- RMaiya. Is DLT the Answer to the Recovery of Micro, Small and Medium Enterprises? The Global Treasurer, 2022. Available online: https://www.theglobaltreasurer.com/2022/09/13/is-dlt-the-answer-to-the-recovery-of-micro-small-and-medium-enterprises/ (accessed on 18 November 2022).
- Singanamalla, S.; Mehra, A.; Chandran, N.; Lohchab, H.; Chava, S.; Kadayan, A.; Bajpai, S.; Heimerl, K.; Anderson, R.; Lokam, S. Telechain: Bridging Telecom Policy and Blockchain Practice. In Proceedings of the ACM SIGCAS/SIGCHI Conference on Computing and Sustainable Societies (COMPASS), Seattle, WA, USA, 29 June–1 July 2022; ACM: New York, NY, USA, 2022. [Google Scholar]
- Gartner. 21 January 2019. Available online: https://blogs.gartner.com/avivah-litan/2019/01/21/amazons-qldb-challenges-permissioned-blockchain/ (accessed on 16 September 2022).
- Research & Market. Global Blockchain in Telecoms Industry 2022–2026 Featuring Profiles of Accenture, Amazon, Bigchaindb, Blockcypher, ClearX Blockchain Technologies, IBM, Intel, and Oracle among Other Leading Players. 2022. Available online: https://www.prnewswire.com/news-releases/global-blockchain-in-telecoms-industry-2022-2026-featuring-profiles-of-accenture-amazon-bigchaindb-blockcypher-clearx-blockchain-technologies-ibm-intel-and-oracle-among-other-leading-players-301503182.html (accessed on 23 October 2022).
- BigchainDB 2.0: The Blockchain Database”, BigchainDB GmbH Berlin Germany, May 2018. Available online: https://www.bigchaindb.com/whitepaper/bigchaindb-whitepaper.pdf (accessed on 23 November 2022).
- McConaghy, T.; Marques, R.; Müller, A.; de Jonghe, D. BigchainDB. 8 June 2016. Available online: https://gamma.bigchaindb.com/whitepaper/bigchaindb-whitepaper.pdf (accessed on 18 August 2022).
- Makris, A.; Kontopoulos, I.; Psomakelis, E.; Xyalis, S.; Theodoropoulos, T.; Tserpes, K. Performance Analysis of Storage Systems in Edge Computing Infrastructures. Appl. Sci. 2022, 12, 8923. [Google Scholar] [CrossRef]
- Fokaefs, M.; Rasolroveicy, M. Performance Evaluation of Distributed Ledger Technologies for IoT data registry: A Comparative Study. In Proceedings of the World Conference on Smart Trends in Systems, Security and Sustainability, London, UK, 27–28 July 2020. [Google Scholar]
- Straubert, C.; Sucky, E. How Useful Is a Distributed Ledger for Tracking and Tracing in Supply Chains? A Systems Thinking Approach. Logistics 2021, 5, 75. [Google Scholar] [CrossRef]
- Security in Amazon QLDB. Available online: https://docs.aws.amazon.com/qldb/latest/developerguide/security.html (accessed on 14 December 2022).
- Shared Responsibility Model. Available online: https://aws.amazon.com/compliance/shared-responsibility-model/ (accessed on 14 December 2022).
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).