
Resource Profiling and Performance Modeling for Distributed Scientific Computing Environments



Abstract
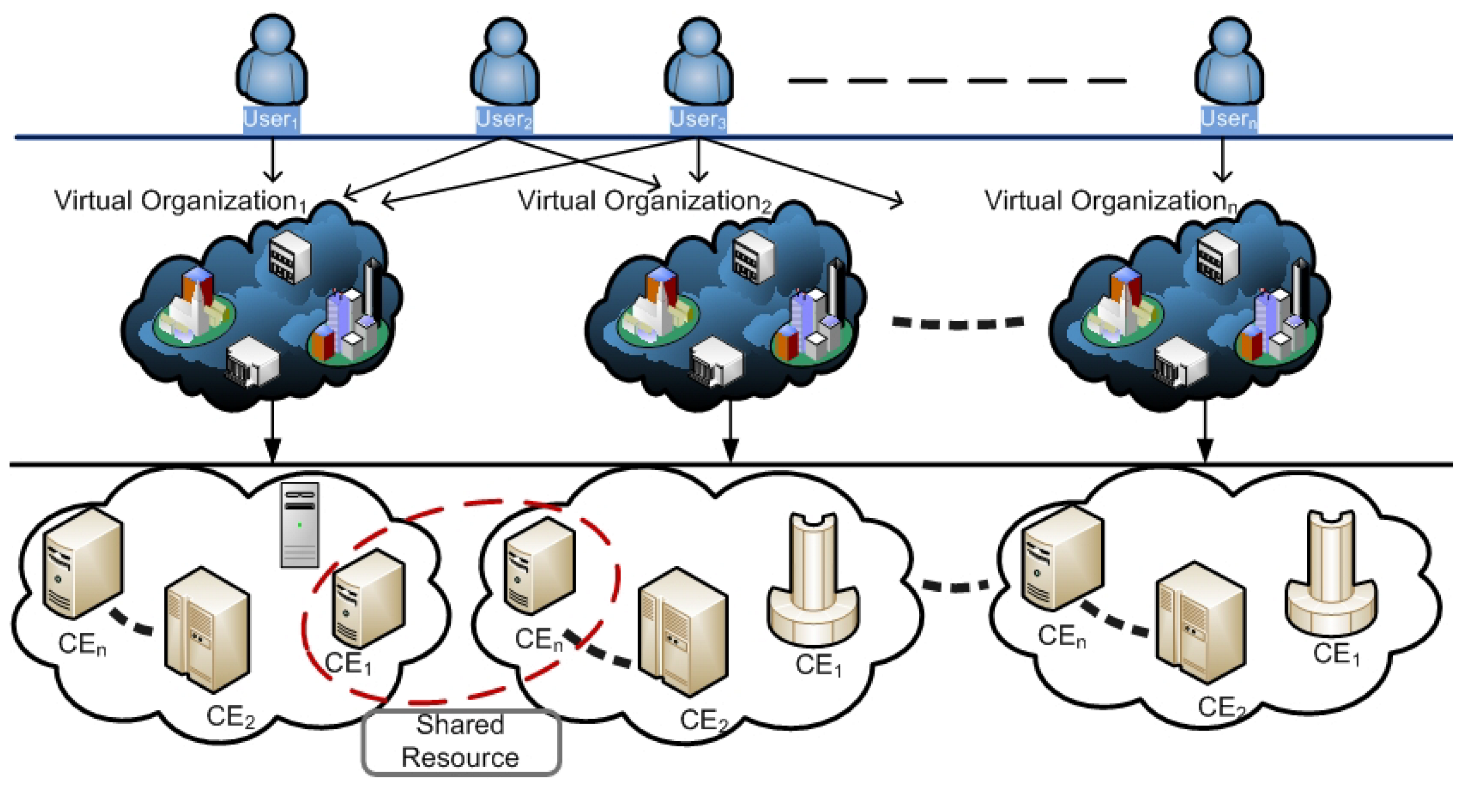
1. Introduction
- Design of novel resource profiling and prediction models including Adaptive Filter-based Online Linear Regression (AFOLR) and Adaptive Filter-based Moving Average (AFMV) by effectively employing linear combination of past predicted values and recent profiled data
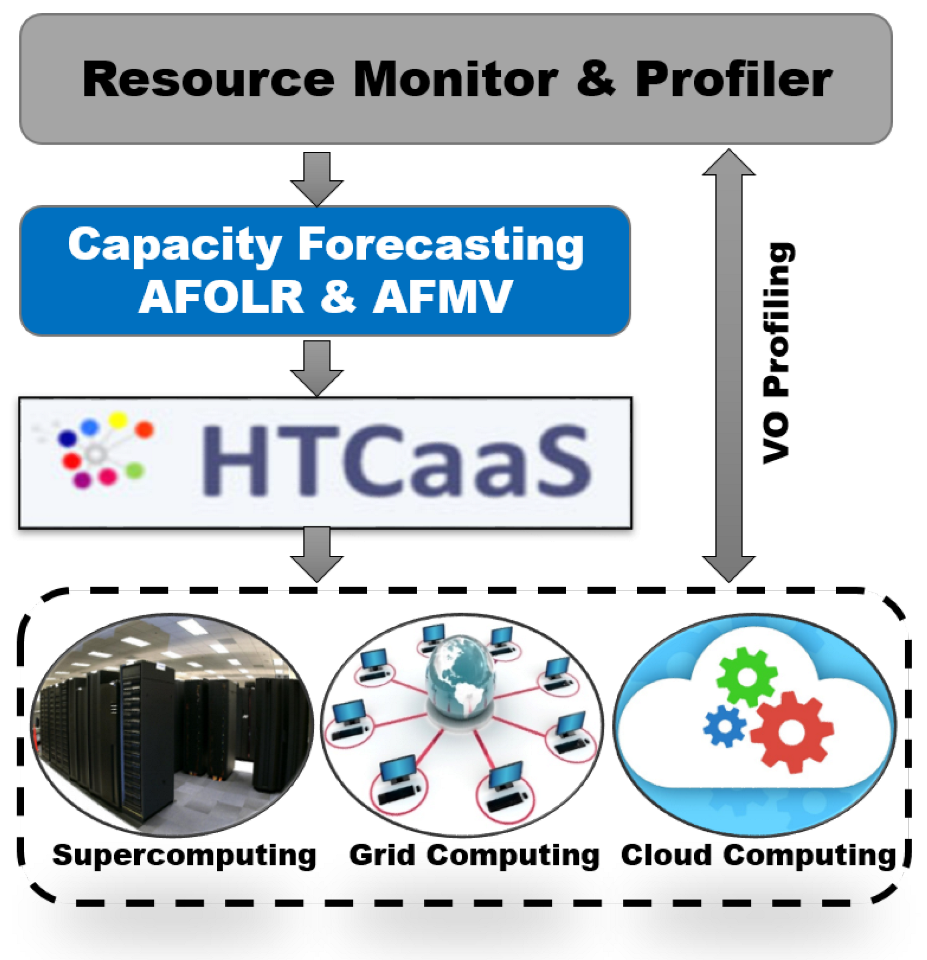
- Implementation of our proposed schemes on top of SCOUT system which can periodically profile and manage information of distributed scientific computing environments
- Application of the proposed scheme and policies to a real large-scale international and interdisciplinary computing environment for running many-tasks
- Comprehensive evaluation results of AFOLR and AFMV models including quantitative analysis and microbenchmark experiments for Many-Task Computing (MTC) workloads
2. Background and Related Research Work
2.1. Background Study
2.2. Related Work
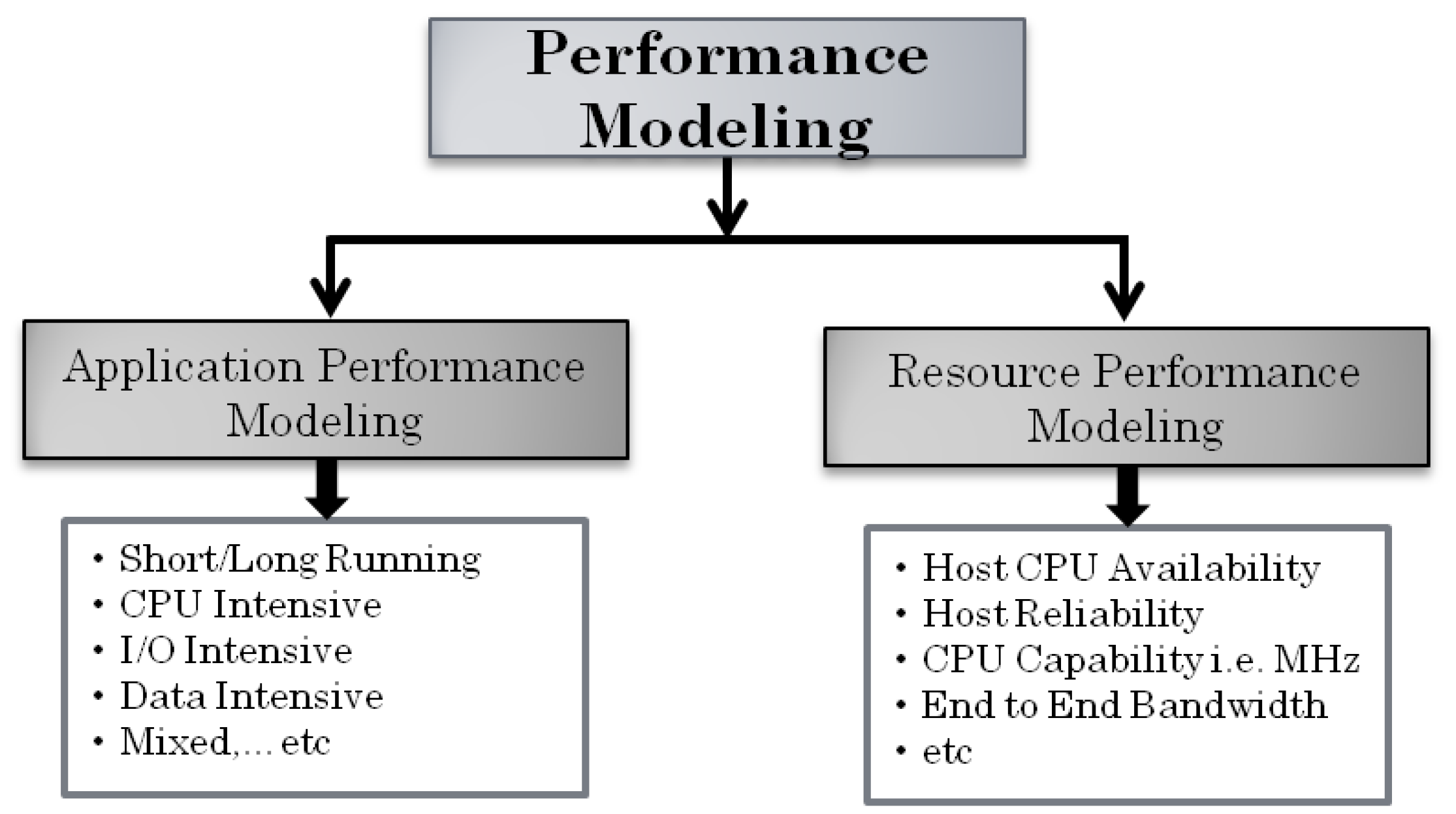
3. Resource Profiling and Performance Modeling
3.1. Resource Profiling and Forecasting Process
3.2. Resource Profiling and Prediction Models
3.2.1. Online Linear Regression (OLR)
| Algorithm 1: Online Linear Regression (OLR). |
 |
3.2.2. Moving Average (MV)
3.2.3. Adaptive Filter-Based Online Linear Regression (AFOLR)
| Algorithm 2: Adaptive Filter-based Online Linear Regression (AFOLR). |
 |
3.2.4. Adaptive Filter-Based Moving Average (AFMV)
| Algorithm 3: Adaptive Filter-based Moving Average (AFMV) |
 |
4. Evaluation
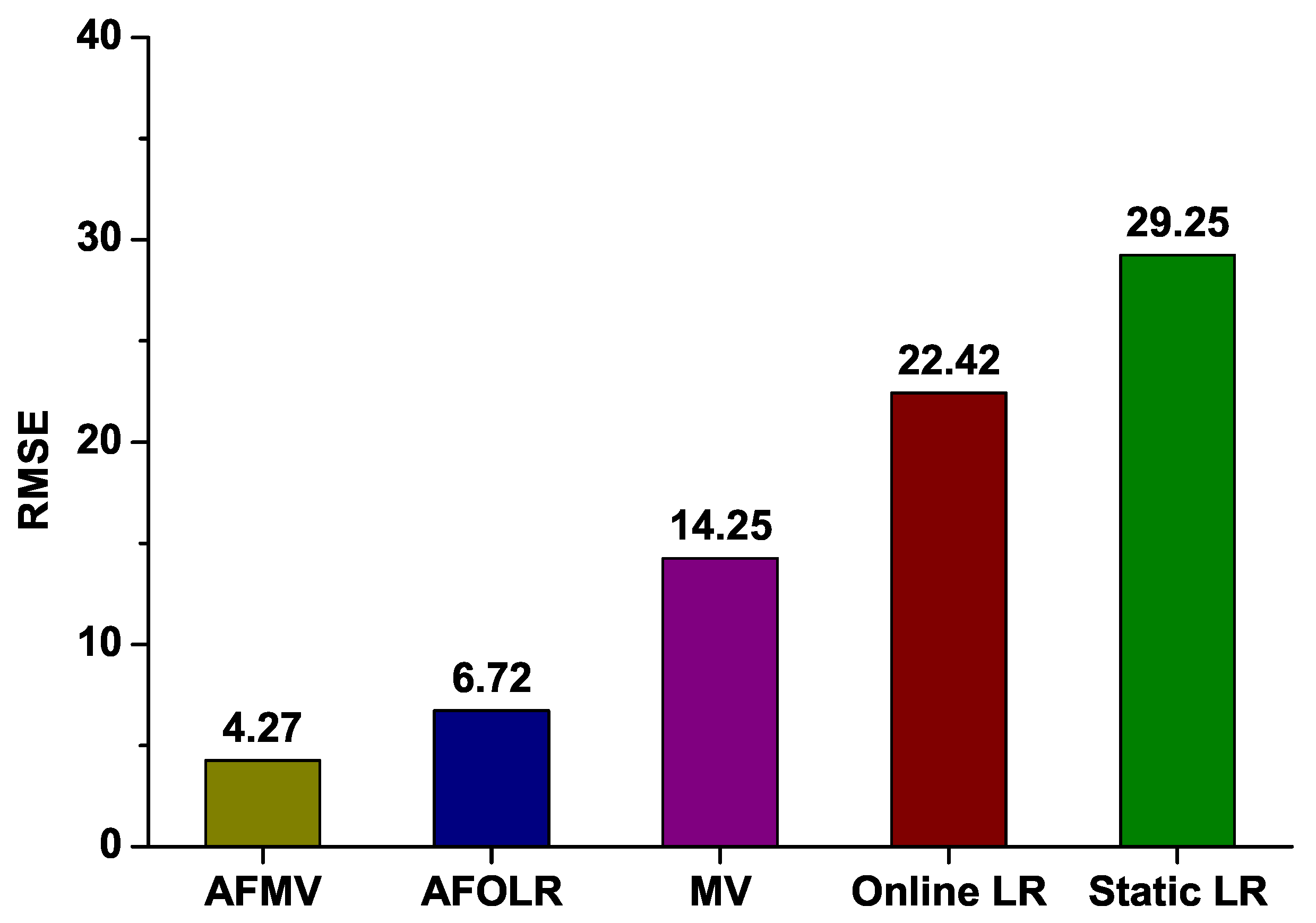
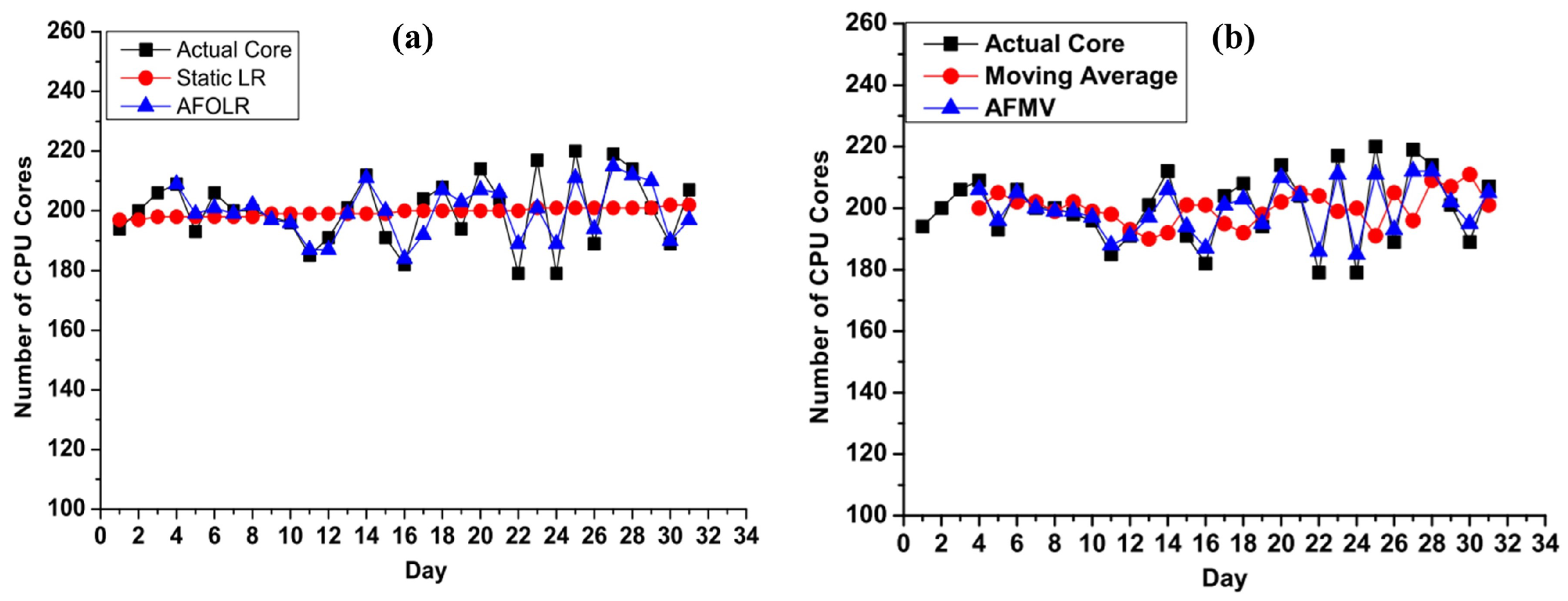
4.1. Quantitative Model Evaluation
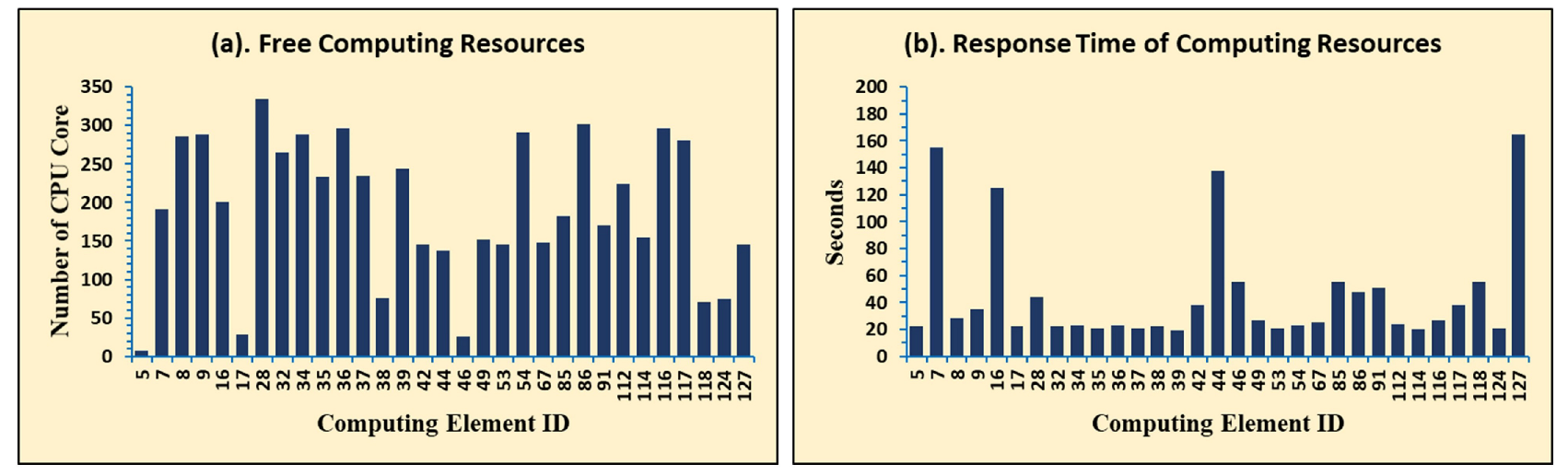
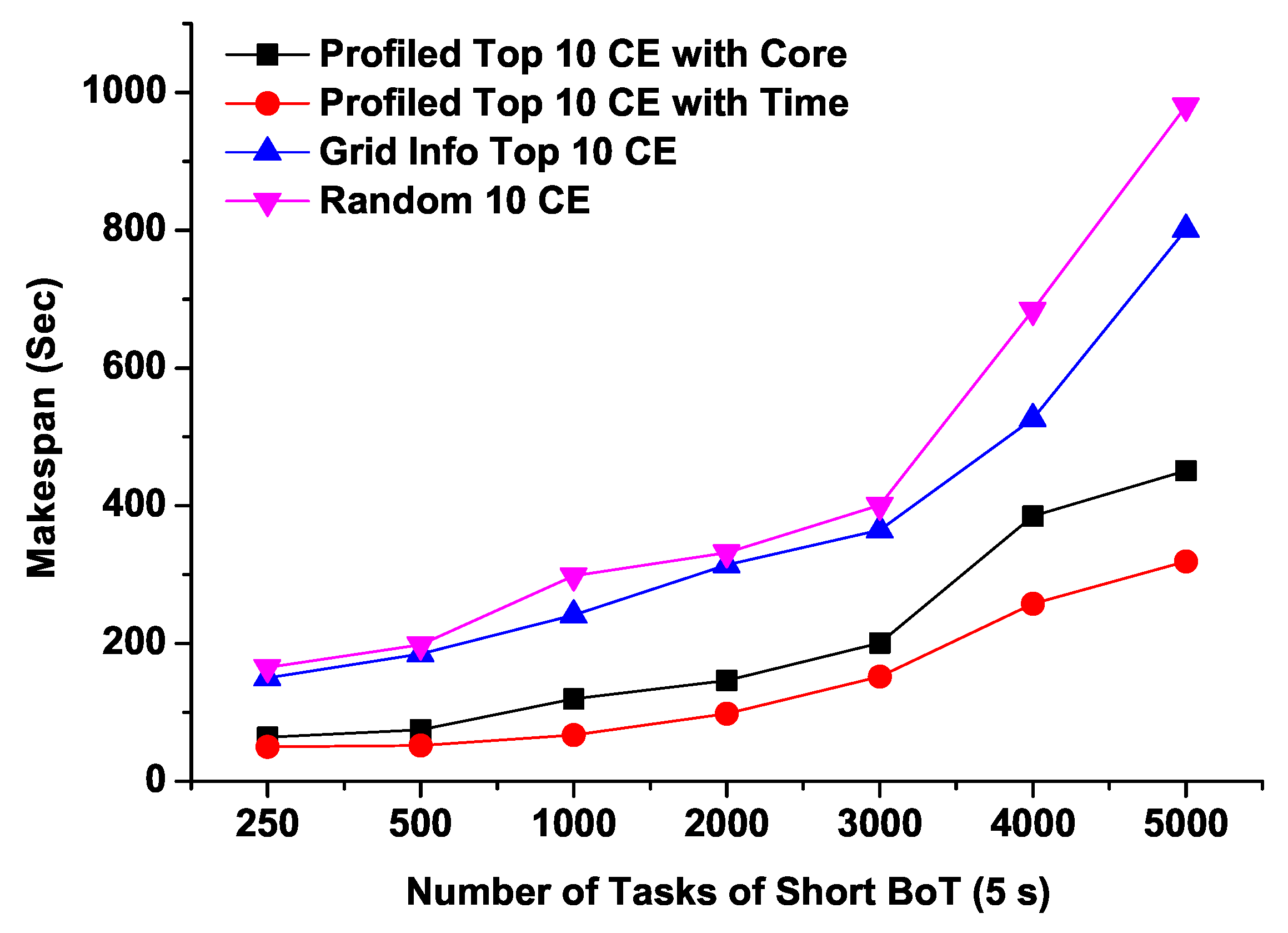
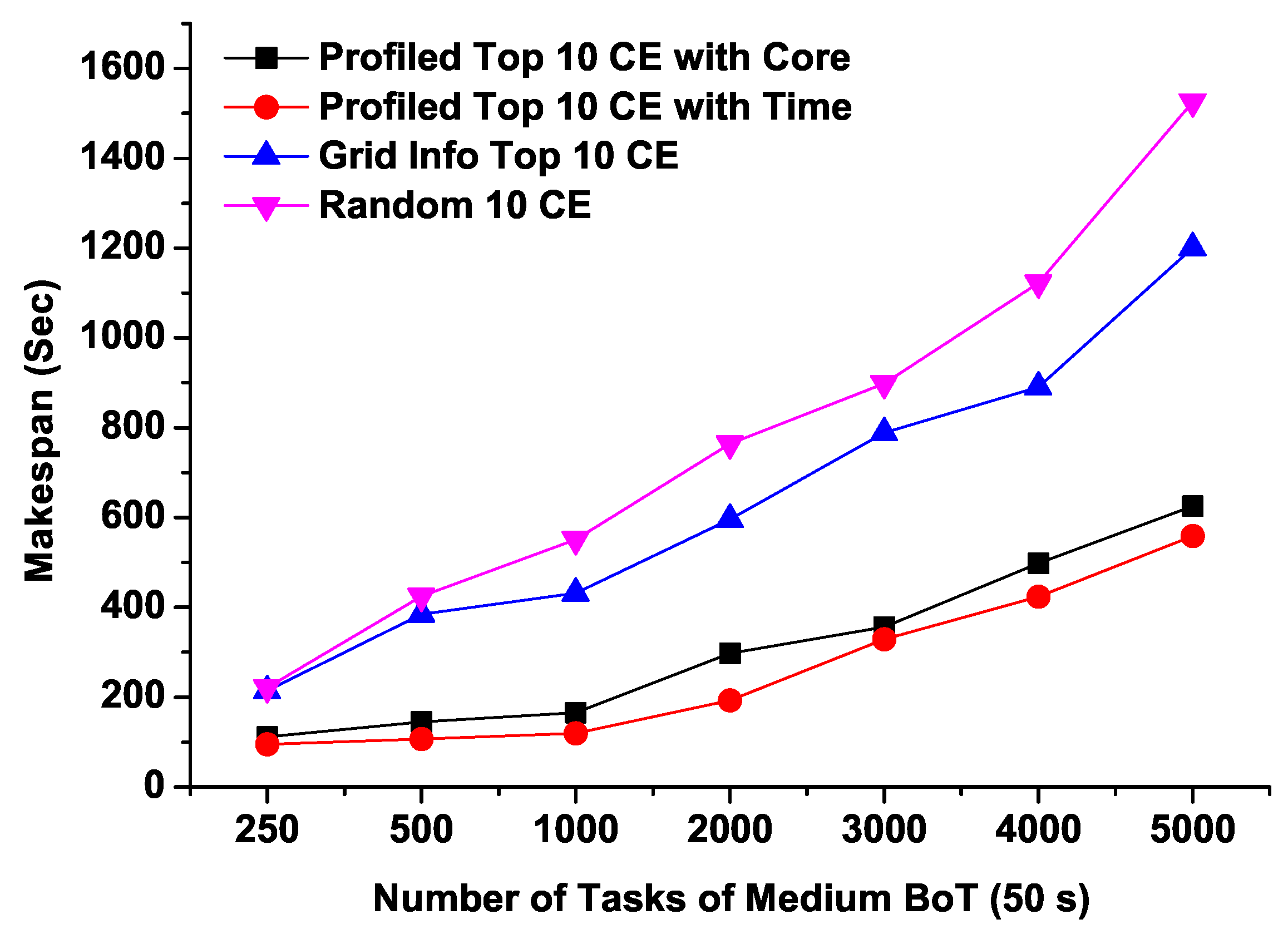
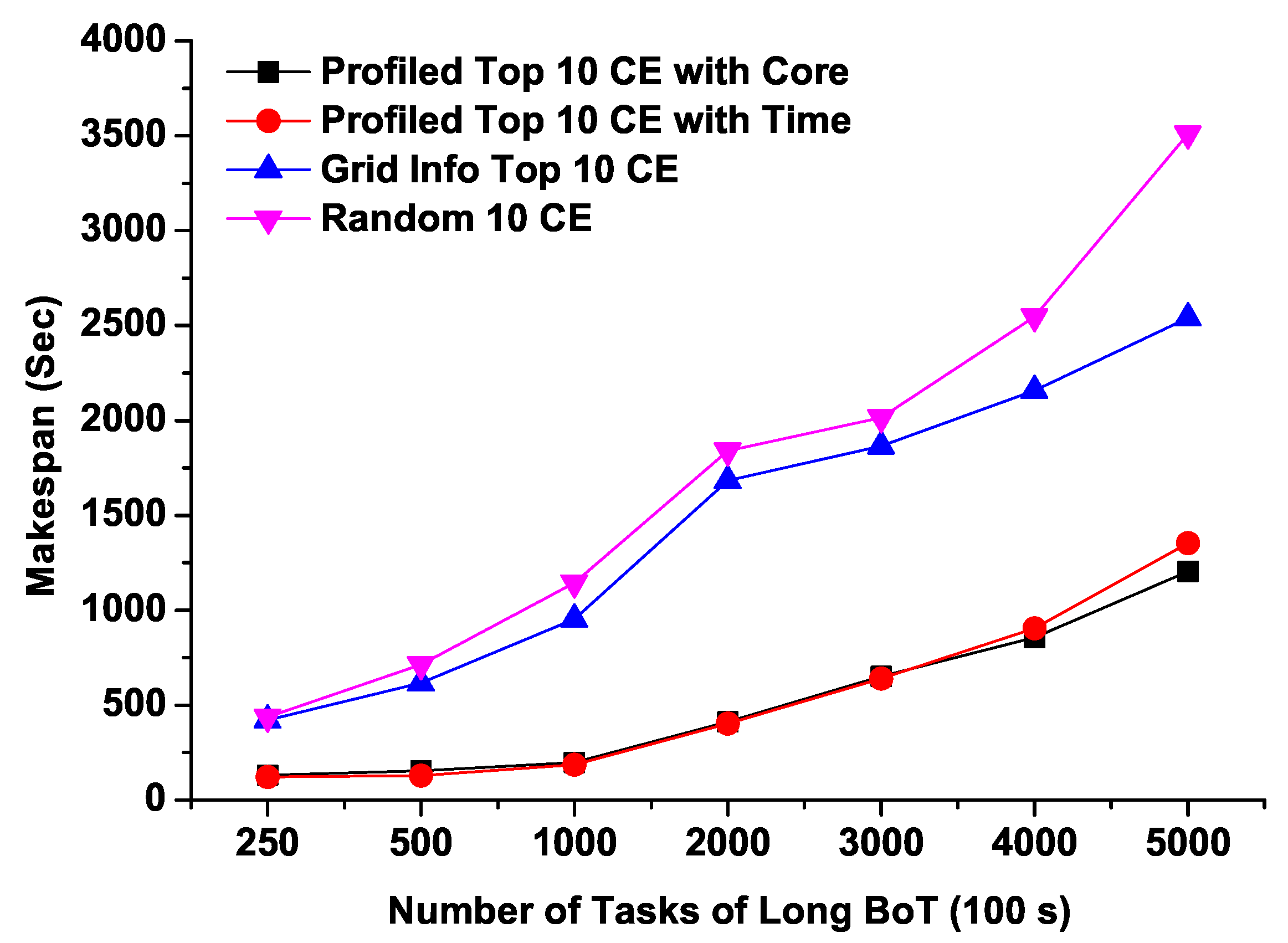
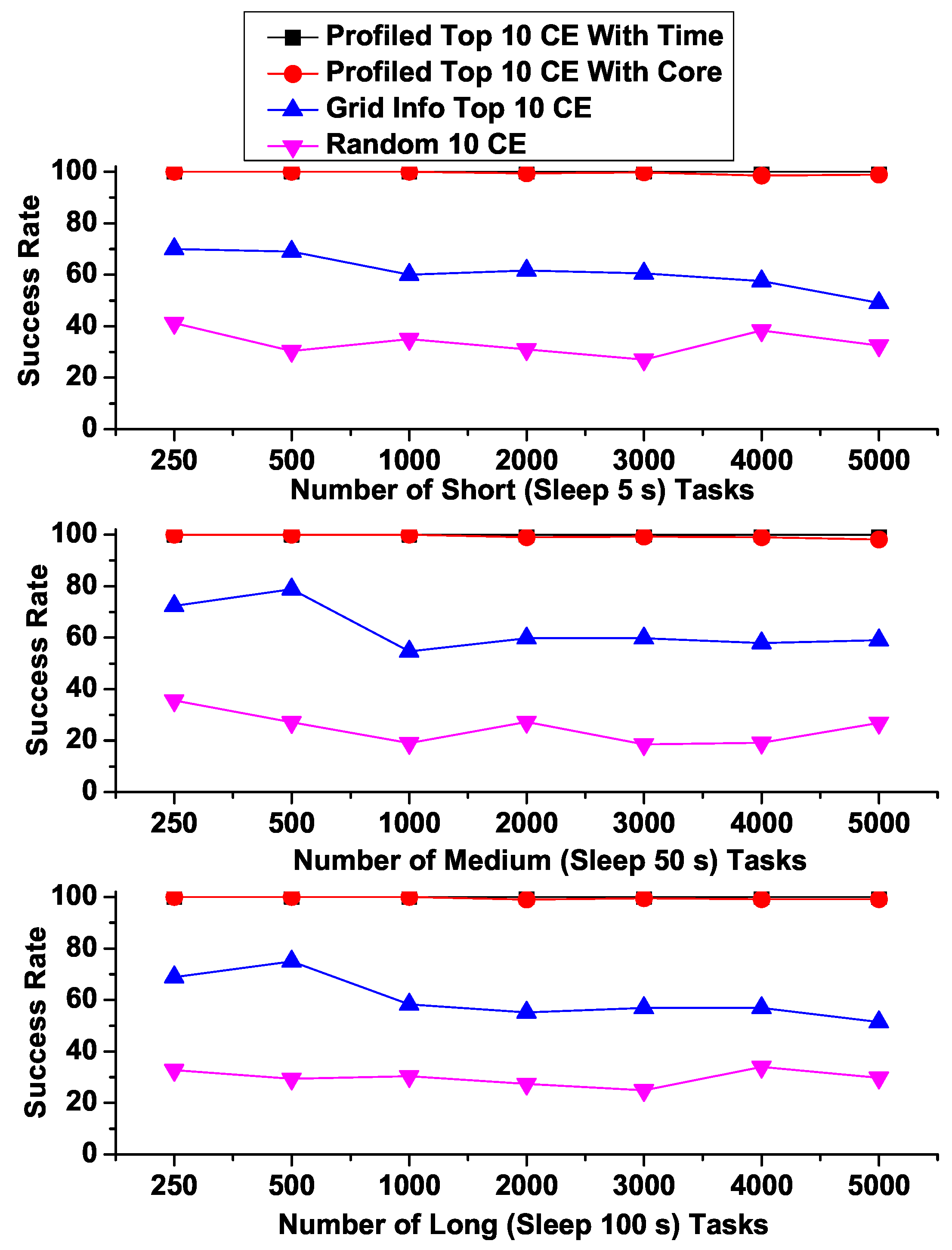
4.2. Microbenchmark Experiments
- Profiled Top 10 CE with Core: Top 10 CEs based on model predicted maximum available free CPU cores (i.e., best 10 CEs based on our proposed models that are expected to show maximum number of free CPU cores)
- Profiled Top 10 CE with Time: Top 10 CEs based on model predicted minimum response time (i.e., best 10 CEs based on our proposed model that are expected to show minimum response times)
- Grid Info Top 10 CE: Top 10 CEs based on the number of free CPU cores provided by the Grid Information Service which is an existing conventional monitoring service in VOs.
- Random 10 CE: Randomly selected 10 CEs (i.e., simply a collection of 10 CEs that are randomly selected)
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Xu, L.; Qiao, J.; Lin, S.; Qi, R. Task Assignment Algorithm Based on Trust in Volunteer Computing Platforms. Information 2019, 10, 244. [Google Scholar] [CrossRef]
- EGI: Advanced Computing for Research. Available online: https://www.egi.eu/ (accessed on 1 December 2021).
- Rodero, I.; Villegas, D.; Bobroff, N.; Liu, Y.; Fong, L.; Sadjadi, S.M. Enabling interoperability among grid meta-schedulers. J. Grid Comput. 2013, 11, 311–336. [Google Scholar] [CrossRef]
- Raicu, I.; Foster, I.; Zhao, Y. Many-Task Computing for Grids and Supercomputers. In Proceedings of the Workshop on Many-Task Computing on Grids and Supercomputers (MTAGS’08), Austin, TX, USA, 17 November 2008. [Google Scholar]
- Raicu, I.; Foster, I.; Wilde, M.; Zhang, Z.; Iskra, K.; Beckman, P.; Zhao, Y.; Szalay, A.; Choudhary, A.; Little, P.; et al. Middleware support for many-task computing. Clust. Comput. 2010, 13, 291–314. [Google Scholar] [CrossRef]
- Field, L.; Spiga, D.; Reid, I.; Riahi, H.; Cristella, L. CMS@ home: Integrating the Volunteer Cloud and High-Throughput Computing. Comput. Softw. Big Sci. 2018, 2, 2. [Google Scholar] [CrossRef]
- Anderson, D.P. BOINC: A platform for volunteer computing. J. Grid Comput. 2019, 18, 99–122. [Google Scholar] [CrossRef]
- Sanjay, H.; Vadhiyar, S. Performance modeling of parallel applications for grid scheduling. J. Parallel Distrib. Comput. 2008, 68, 1135–1145. [Google Scholar] [CrossRef]
- Qureshi, M.B.; Dehnavi, M.M.; Min-Allah, N.; Qureshi, M.S.; Hussain, H.; Rentifis, I.; Tziritas, N.; Loukopoulos, T.; Khan, S.U.; Xu, C.Z.; et al. Survey on grid resource allocation mechanisms. J. Grid Comput. 2014, 12, 399–441. [Google Scholar] [CrossRef]
- Hossain, M.A.; Vu, H.T.; Kim, J.S.; Lee, M.; Hwang, S. SCOUT: A Monitor and Profiler of Grid Resources for Large-Scale Scientific Computing. In Proceedings of the 2015 International Conference on Cloud and Autonomic Computing (ICCAC), Boston, MA, USA, 21–25 September 2015; pp. 260–267. [Google Scholar]
- Hossain, M.A.; Nguyen, C.N.; Kim, J.S.; Hwang, S. Exploiting resource profiling mechanism for large-scale scientific computing on grids. Clust. Comput. 2016, 19, 1527–1539. [Google Scholar] [CrossRef]
- The Biomed Virtual Organization. Available online: http://lsgc.org/biomed.html (accessed on 17 December 2021).
- Entezari-Maleki, R.; Trivedi, K.S.; Movaghar, A. Performability evaluation of grid environments using stochastic reward nets. IEEE Trans. Dependable Secur. Comput. 2014, 12, 204–216. [Google Scholar] [CrossRef]
- Forestiero, A.; Mastroianni, C.; Spezzano, G. A Multi-agent Approach for the Construction of a Peer-to-Peer Information System in Grids. In Self-Organization and Autonomic Informatics (I); IOS Press: Amsterdam, The Netherlands, 2005. [Google Scholar]
- Ramachandran, K.; Lutfiyya, H.; Perry, M. Decentralized resource availability prediction for a desktop grid. In Proceedings of the 2010 10th IEEE/ACM International Conference on Cluster, Cloud and Grid Computing (CCGrid), Melbourne, Australia, 17–20 May 2010; pp. 643–648. [Google Scholar]
- Shariffdeen, R.; Munasinghe, D.; Bhathiya, H.; Bandara, U.; Bandara, H.D. Adaptive workload prediction for proactive auto scaling in PaaS systems. In Proceedings of the 2016 2nd International Conference on Cloud Computing Technologies and Applications (CloudTech), Marrakech, Morocco, 24–26 May 2016; pp. 22–29. [Google Scholar]
- Smith, W.; Foster, I.; Taylor, V. Predicting application run times with historical information. J. Parallel Distrib. Comput. 2004, 64, 1007–1016. [Google Scholar] [CrossRef]
- Seneviratne, S.; De Silva, L.C.; Witharana, S. Taxonomy and Survey of Performance Prediction Systems for the Distributed Systems Including the Clouds. In Proceedings of the 2021 IEEE International Conferences on Internet of Things (iThings) and IEEE Green Computing & Communications (GreenCom) and IEEE Cyber, Physical & Social Computing (CPSCom) and IEEE Smart Data (SmartData) and IEEE Congress on Cybermatics (Cybermatics), Melbourne, Australia, 6–8 December 2021; pp. 262–268. [Google Scholar]
- Seneviratne, S.; Witharana, S.; Toosi, A.N. Adapting the machine learning grid prediction models for forecasting of resources on the clouds. In Proceedings of the 2019 Advances in Science and Engineering Technology International Conferences (ASET), Dubai, United Arab Emirates, 26 March–10 April 2019; pp. 1–6. [Google Scholar]
- Dinda, P.A.; O’hallaron, D.R. Host load prediction using linear models. Clust. Comput. 2000, 3, 265–280. [Google Scholar] [CrossRef]
- Javadi, B.; Kondo, D.; Vincent, J.M.; Anderson, D.P. Discovering statistical models of availability in large distributed systems: An empirical study of seti@ home. IEEE Trans. Parallel Distrib. Syst. 2011, 22, 1896–1903. [Google Scholar] [CrossRef]
- Anderson, D.P.; Cobb, J.; Korpela, E.; Lebofsky, M.; Werthimer, D. SETI@home: An Experiment in Public-Resource Computing. Commun. ACM 2002, 45, 56–61. [Google Scholar] [CrossRef]
- Padhye, V.; Tripathi, A. Resource Availability Characteristicsand Node Selection in CooperativelyShared Computing Platforms. IEEE Trans. Parallel Distrib. Syst. 2014, 25, 1044–1054. [Google Scholar] [CrossRef]
- PlanetLab: An Open Platform for Developing, Deploying, and Accessing Planetary-Scale Services. Available online: https://www.planet-lab.org/ (accessed on 3 December 2021).
- Rood, B.; Lewis, M.J. Grid resource availability prediction-based scheduling and task replication. J. Grid Comput. 2009, 7, 479–500. [Google Scholar] [CrossRef]
- Wolski, R.; Spring, N.T.; Hayes, J. The network weather service: A distributed resource performance forecasting service for metacomputing. Future Gener. Comput. Syst. 1999, 15, 757–768. [Google Scholar] [CrossRef]
- Verma, M.; Gangadharan, G.; Narendra, N.C.; Vadlamani, R.; Inamdar, V.; Ramachandran, L.; Calheiros, R.N.; Buyya, R. Dynamic resource demand prediction and allocation in multi-tenant service clouds. Concurr. Comput. Pract. Exp. 2016, 28, 4429–4442. [Google Scholar] [CrossRef]
- Cameron, D.; Casey, J.; Guy, L.; Kunszt, P.; Lemaitre, S.; McCance, G.; Stockinger, H.; Stockinger, K.; Andronico, G.; Bell, W.; et al. Replica management services in the european datagrid project. In Proceedings of the UK e-Science All Hands Meeting 2004, Nottingham UK, 31 August–3 September 2004. [Google Scholar]
- Faerman, M.; Su, A.; Wolski, R.; Berman, F. Adaptive performance prediction for distributed data-intensive applications. In Proceedings of the 1999 ACM/IEEE Conference on Supercomputing, Portland, OR, USA, 13–19 November 1999; p. 36-es. [Google Scholar]
- Nudd, G.R.; Kerbyson, D.J.; Papaefstathiou, E.; Perry, S.C.; Harper, J.S.; Wilcox, D.V. PACE—A toolset for the performance prediction of parallel and distributed systems. Int. J. High Perform. Comput. Appl. 2000, 14, 228–251. [Google Scholar] [CrossRef]
- Desprez, F.; Quinson, M.; Suter, F. Dynamic Performance Forecasting for Network-Enabled Servers in a Heterogeneous Environment. Ph.D. Thesis, INRIA, Le Chesnay-Rocquencourt, France, 2001. [Google Scholar]
- Kumar, J.; Singh, A.K. Workload prediction in cloud using artificial neural network and adaptive differential evolution. Future Gener. Comput. Syst. 2018, 81, 41–52. [Google Scholar] [CrossRef]
- Bi, J.; Li, S.; Yuan, H.; Zhou, M. Integrated deep learning method for workload and resource prediction in cloud systems. Neurocomputing 2021, 424, 35–48. [Google Scholar] [CrossRef]
- Song, B.; Yu, Y.; Zhou, Y.; Wang, Z.; Du, S. Host load prediction with long short-term memory in cloud computing. J. Supercomput. 2018, 74, 6554–6568. [Google Scholar] [CrossRef]
- Gul, F.; Mir, I.; Abualigah, L.; Sumari, P.; Forestiero, A. A Consolidated Review of Path Planning and Optimization Techniques: Technical Perspectives and Future Directions. Electronics 2021, 10, 2250. [Google Scholar] [CrossRef]
- Hellerstein, J.L.; Diao, Y.; Parekh, S.; Tilbury, D.M. Feedback Control of Computing Systems; Wiley Online Library: Hoboken, NJ, USA, 2004. [Google Scholar]
- Rho, S.; Kim, S.; Kim, S.; Kim, S.; Kim, J.S.; Hwang, S. HTCaaS: A Large-Scale High-Throughput Computing by Leveraging Grids, Supercomputers and Cloud. In Proceedings of the Research Poster at IEEE/ACM International Conference for High Performance Computing, Networking, Storage and Analysis (SC12), Salt Lake City, UT, USA, 10–16 November 2012. [Google Scholar]
- Kim, J.S.; Rho, S.; Kim, S.; Kim, S.; Kim, S.; Hwang, S. HTCaaS: Leveraging Distributed Supercomputing Infrastructures for Large-Scale Scientific Computing. In Proceedings of the 6th ACM Workshop on Many-Task Computing on Clouds, Grids, and Supercomputers (MTAGS’13) Held with SC13, San Francisco, CA, USA, 2–7 July 2013. [Google Scholar]
- Rawlings, J.O.; Pantula, S.G.; Dickey, D.A. Applied Regression Analysis: A Research Tool; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2001. [Google Scholar]
- Raicu, I.; Zhao, Y.; Dumitrescu, C.; Foster, I.; Wilde, M. Falkon: A Fast and Light-weight tasK executiON framework. In Proceedings of the 2007 ACM/IEEE conference on Supercomputing (SC’07), Reno, NV, USA, 10–16 November 2007. [Google Scholar]
- Raicu, I.; Zhang, Z.; Wilde, M.; Foster, I.; Beckman, P.; Iskra, K.; Clifford, B. Towards Loosely-Coupled Programming on Petascale Systems. In Proceedings of the 2008 ACM/IEEE conference on Supercomputing (SC’08), Austin, TX, USA, 15–21 November 2008. [Google Scholar]
- Tchier, F.; Ali, G.; Gulzar, M.; Pamučar, D.; Ghorai, G. A New Group Decision-Making Technique under Picture Fuzzy Soft Expert Information. Entropy 2021, 23, 1176. [Google Scholar] [CrossRef] [PubMed]
- Ali, G.; Ansari, M.N. Multiattribute decision-making under Fermatean fuzzy bipolar soft framework. Granul. Comput. 2022, 7, 337–352. [Google Scholar] [CrossRef]
- Ali, G.; Alolaiyan, H.; Pamučar, D.; Asif, M.; Lateef, N. A novel MADM framework under q-rung orthopair fuzzy bipolar soft sets. Mathematics 2021, 9, 2163. [Google Scholar] [CrossRef]
- Rao, V.S.; Srinivas, K. Modern drug discovery process: An in silico approach. J. Bioinform. Seq. Anal. 2011, 2, 89–94. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Resource Type | Related Study |
|---|---|
| CPU load | Dinda et al. [20], Smith et al. [17], Verma et al. [27] |
| Host Machine/Node | NWS [26], Javadi et al. [21], Padhye et al. [23], SCOUT [10] |
| Network Bandwidth | NWS [26], EDG ROS [28], Faerman et al. [29] |
| Memory | FACE [30], FAST [31] |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hossain, M.A.; Hwang, S.; Kim, J.-S. Resource Profiling and Performance Modeling for Distributed Scientific Computing Environments. Appl. Sci. 2022, 12, 4797. https://doi.org/10.3390/app12094797
Hossain MA, Hwang S, Kim J-S. Resource Profiling and Performance Modeling for Distributed Scientific Computing Environments. Applied Sciences. 2022; 12(9):4797. https://doi.org/10.3390/app12094797
Chicago/Turabian StyleHossain, Md Azam, Soonwook Hwang, and Jik-Soo Kim. 2022. "Resource Profiling and Performance Modeling for Distributed Scientific Computing Environments" Applied Sciences 12, no. 9: 4797. https://doi.org/10.3390/app12094797
APA StyleHossain, M. A., Hwang, S., & Kim, J.-S. (2022). Resource Profiling and Performance Modeling for Distributed Scientific Computing Environments. Applied Sciences, 12(9), 4797. https://doi.org/10.3390/app12094797