
Task-Aware Feature Composition for Few-Shot Relation Classification

Abstract
:1. Introduction
- We propose a task embedding learning module for capturing task-specific information.
- Two methods are proposed for utilizing task-specific information to guide feature composition dynamically for each meta-task.
- Our proposed method is a plug-and-play module that can be easily incorporated into existing methods and show significant improvements.
2. Related Work
2.1. Relation Classification
2.2. Metric-Based Few-Shot Learning
3. Task Definition
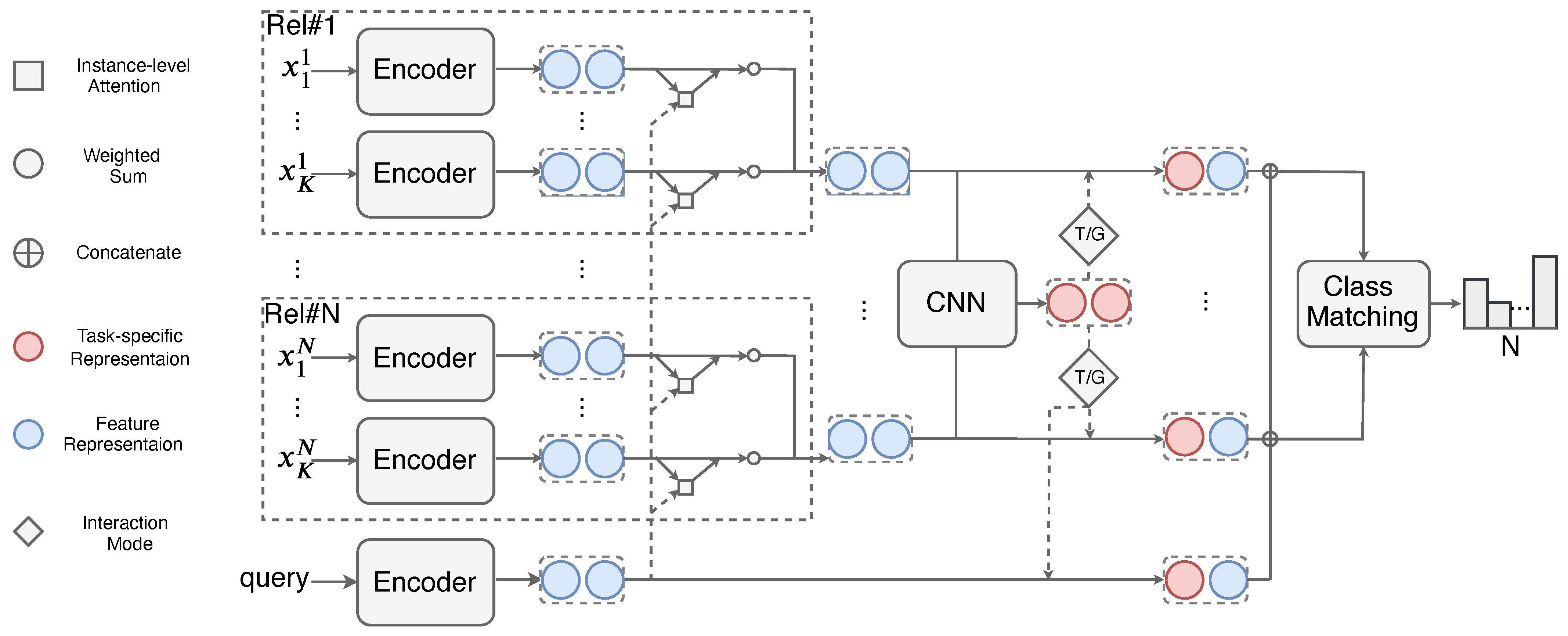
4. Methodology
- Context Encoder. Given a query or support instance and its mentioned entity pairs, we employ a context encoder similar to the MLMAN [12] to encode an instance into sentence representation.
- Relation Prototypes and Task Embedding Module. Taking the query and support sentence representations as input, by computing the match degrees between query and support representations and using the degrees as weights to combine support representations, we can obtain a prototype for each relation. After obtaining relation prototypes, we treat them as a whole and place a CNN encoder on top of them to extract task-specific representations, which are depicted as task embeddings.
- Task-aware Feature Composition. Based on the task-specific representation, we further propose two different guiding modes to dynamically refine and compose task-aware feature representations for each meta-task. Our guiding modes are based on a task-gated mechanism and gated feature combination, respectively.
- Class Matching. Once the task-specific information is incorporated into the composed query representation and prototypes, these feature representations are then used as input and fed to a matching module to measure the relationship between query and class prototypes.
4.1. Context Encoder
4.2. Relation Prototypes
4.3. Task-Aware Feature Composition
4.4. Class Matching
5. Experiments
5.1. Experiments on FewRel1.0 (General Domain)
5.1.1. Dataset and Evaluation Metrics
5.1.2. Baselines
- Finetune(CNN). Using a convolution neural network as the basic sentence encoder and Softmax as the classifier, the model is trained with a traditional supervised learning method. During the test, the sentence encoder parameters are fixed, and the classifier’s parameters are fine-tuned with a few supporting sentences in the test data.
- Finetune(PCNN). The training method used is the same as Finetune (CNN), except that the sentence encoder is changed to the piecewise pooled convolution neural network encoder (PCNN) proposed by Zeng et al. [32].
- kNN(CNN). Adopting CNN as the basic encoder and Softmax as the classifier and training the model using the traditional supervised method. In the test phase, the sentence representations of support and query sentences are acquired through the CNN encoder. Then, the sentence representations are clustered using the K-nearest neighbor algorithm.
- kNN(PCNN). The core idea is the same as kNN(CNN), except that the encoder used is PCNN.
- Meta Network. A meta-network [23] utilizes a high-level meta-learner on top of the traditional classification model.
- GNN [23]. This work considers each support sentence or query sentence as a node in the graph and employs a graph neural network to propagate the information between nodes.
- SNAIL [23]. A meta-learning model that utilizes temporal convolutional neural networks and attention modules for fast learning.
- Proto [23]. This work assumes there exists prototype embedding for each support class, and for each class, they average all support sentence representations in the class as the class prototype, then compute the distance between query and class prototypes.
- Proto-HATT [10]. Incorporating a hybrid attention mechanism into a prototypical framework.
- HAPN [33]. It proposes word-level, feature-level, and instance-level attention to obtain a more discriminative prototype of each class.
- MLMAN [12]. The basic encoder we used in our paper; it iteratively utilizes matching information between query and support sentences to refine the feature representations.
- BERT-PAIR [11]. A pretraining-based model pairs each query instance with all the supporting instances and sends the concatenated sequence to the BERT classification model to obtain the two instances’ score expressing the same relation.
- CTEG [25]. A model equipped with an entity-guided attention mechanism and confusion-aware training strategy to learn to decouple easily confused relations.
5.1.3. Results and Discussions
5.2. Experiments on FewRel2.0 (Cross Domain)
5.2.1. Datasets
5.2.2. Baselines
- Proto-ADV (CNN) [11]. Adopting the prototypical network as the basic architecture, then using adversarial training to remedy the huge domain gap;
- Proto (BERT) [11]. Using BERT as the sentence encoder and does not use adversarial training strategy;
- Proto-ADV (BERT) [11]. Using BERT as the sentence encoder and employing adversarial training;
- BERT-PAIR [11]. Using BERT sequence classification model to predict whether two instances express the same relation or not.
5.2.3. Results and Discussions
5.3. Adapting TFC into Existing Frameworks
5.4. The Impact of Word Embeddings
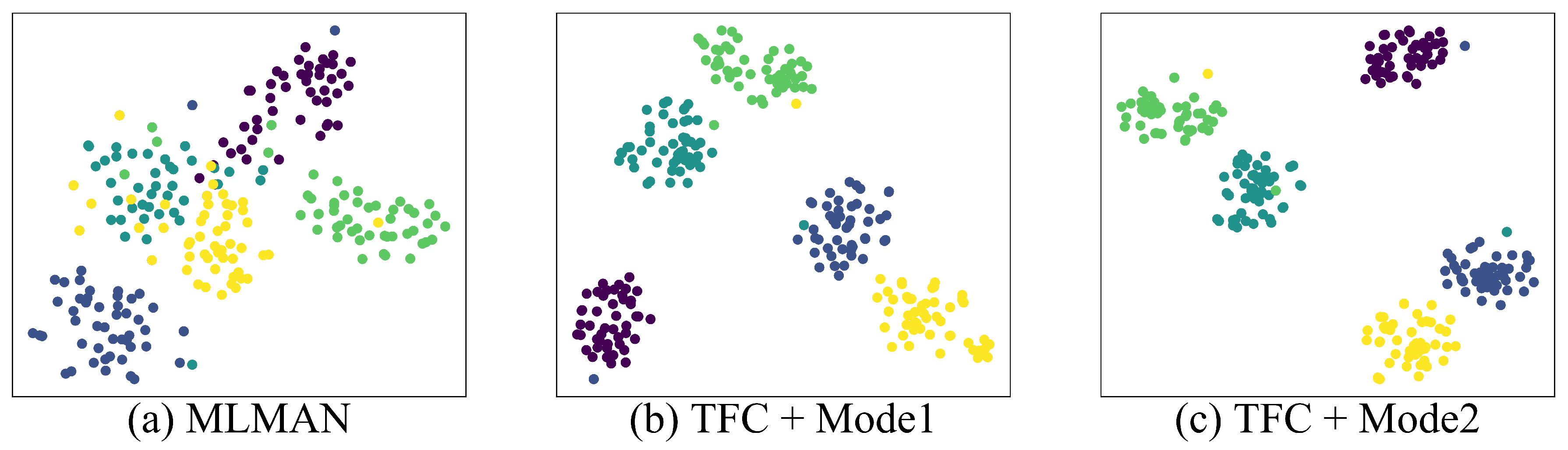
5.5. Feature Visualization Learned by TFC
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Yu, M.; Gormley, M.R.; Dredze, M. Combining word embeddings and feature embeddings for fine-grained relation extraction. In Proceedings of the 2015 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Denver, CO, USA, 31 May–5 June 2015; pp. 1374–1379. [Google Scholar]
- Gormley, M.R.; Yu, M.; Dredze, M. Improved relation extraction with feature-rich compositional embedding models. arXiv 2015, arXiv:1505.02419. [Google Scholar]
- Shi, G.; Feng, C.; Huang, L.; Zhang, B.; Ji, H.; Liao, L.; Huang, H.Y. Genre separation network with adversarial training for cross-genre relation extraction. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 1018–1023. [Google Scholar]
- Yin, R.; Li, K.; Zhang, G.; Lu, J. A deeper graph neural network for recommender systems. Knowl.-Based Syst. 2019, 185, 105020. [Google Scholar] [CrossRef]
- Zeng, D.; Liu, K.; Lai, S.; Zhou, G.; Zhao, J. Relation classification via convolutional deep neural network. In Proceedings of the 25th International Conference on Computational Linguistics, COLING 2014, Dublin, Ireland, 23–29 August 2014; pp. 2335–2344. [Google Scholar]
- Lin, Y.; Shen, S.; Liu, Z.; Luan, H.; Sun, M. Neural relation extraction with selective attention over instances. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Berlin, Germany, 7–12 August 2016; pp. 2124–2133. [Google Scholar]
- Zhang, T.; Subburathinam, A.; Shi, G.; Huang, L.; Lu, D.; Pan, X.; Li, M.; Zhang, B.; Wang, Q.; Whitehead, S.; et al. Gaia-a multi-media multi-lingual knowledge extraction and hypothesis generation system. In Proceedings of the Text Analysis Conference Knowledge Base Population Workshop, Gaithersburg, MD, USA, 13–14 November 2018. [Google Scholar]
- Yuan, C.; Huang, H.; Feng, C.; Liu, X.; Wei, X. Distant Supervision for Relation Extraction with Linear Attenuation Simulation and Non-IID Relevance Embedding. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 7418–7425. [Google Scholar]
- Snell, J.; Swersky, K.; Zemel, R. Prototypical networks for few-shot learning. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 4077–4087. [Google Scholar]
- Gao, T.; Han, X.; Liu, Z.; Sun, M. Hybrid attention-based prototypical networks for noisy few-shot relation classification. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 6407–6414. [Google Scholar]
- Gao, T.; Han, X.; Zhu, H.; Liu, Z.; Li, P.; Sun, M.; Zhou, J. FewRel 2.0: Towards more challenging few-shot relation classification. arXiv 2019, arXiv:1910.07124. [Google Scholar]
- Ye, Z.X.; Ling, Z.H. Multi-Level Matching and Aggregation Network for Few-Shot Relation Classification. arXiv 2019, arXiv:1906.06678. [Google Scholar]
- Oreshkin, B.; López, P.R.; Lacoste, A. Tadam: Task dependent adaptive metric for improved few-shot learning. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 3–8 December 2018; pp. 721–731. [Google Scholar]
- Xu, M.; Wong, D.F.; Yang, B.; Zhang, Y.; Chao, L.S. Leveraging local and global patterns for self-attention networks. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 3069–3075. [Google Scholar]
- Liu, Y.; Meng, F.; Zhang, J.; Xu, J.; Chen, Y.; Zhou, J. Gcdt: A global context enhanced deep transition architecture for sequence labeling. arXiv 2019, arXiv:1906.02437. [Google Scholar]
- Nguyen, T.H.; Grishman, R. Relation extraction: Perspective from convolutional neural networks. In Proceedings of the 1st Workshop on Vector Space Modeling for Natural Language Processing, Denver, CO, USA, 5 June 2015; pp. 39–48. [Google Scholar]
- Zhang, Y.; Zhang, G.; Zhu, D.; Lu, J. Scientific evolutionary pathways: Identifying and visualizing relationships for scientific topics. J. Assoc. Inf. Sci. Technol. 2017, 68, 1925–1939. [Google Scholar] [CrossRef]
- Shi, G.; Feng, C.; Xu, W.; Liao, L.; Huang, H. Penalized multiple distribution selection method for imbalanced data classification. Knowl.-Based Syst. 2020, 196, 105833. [Google Scholar] [CrossRef]
- Bouraoui, Z.; Camacho-Collados, J.; Schockaert, S. Inducing relational knowledge from BERT. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 7456–7463. [Google Scholar]
- Loureiro, D.; Jorge, A. Language modelling makes sense: Propagating representations through wordnet for full-coverage word sense disambiguation. arXiv 2019, arXiv:1906.10007. [Google Scholar]
- Soares, L.B.; FitzGerald, N.; Ling, J.; Kwiatkowski, T. Matching the blanks: Distributional similarity for relation learning. arXiv 2019, arXiv:1906.03158. [Google Scholar]
- Vinyals, O.; Blundell, C.; Lillicrap, T.; Wierstra, D. Matching networks for one shot learning. Adv. Neural Inf. Process. Syst. 2016, 26, 3630–3638. [Google Scholar]
- Han, X.; Zhu, H.; Yu, P.; Wang, Z.; Yao, Y.; Liu, Z.; Sun, M. Fewrel: A large-scale supervised few-shot relation classification dataset with state-of-the-art evaluation. arXiv 2018, arXiv:1810.10147. [Google Scholar]
- Geng, X.; Chen, X.; Zhu, K.Q.; Shen, L.; Zhao, Y. MICK: A Meta-Learning Framework for Few-shot Relation Classification with Small Training Data. arXiv 2020, arXiv:2004.14164. [Google Scholar]
- Wang, Y.; Bao, J.; Liu, G.; Wu, Y.; He, X.; Zhou, B.; Zhao, T. Learning to Decouple Relations: Few-Shot Relation Classification with Entity-Guided Attention and Confusion-Aware Training. arXiv 2020, arXiv:2010.10894. [Google Scholar]
- Deng, T.; Ye, D.; Ma, R.; Fujita, H.; Xiong, L. Low-rank local tangent space embedding for subspace clustering. Inf. Sci. 2020, 508, 1–21. [Google Scholar] [CrossRef]
- Esposito, M.; Damiano, E.; Minutolo, A.; De Pietro, G.; Fujita, H. Hybrid query expansion using lexical resources and word embeddings for sentence retrieval in question answering. Inf. Sci. 2020, 514, 88–105. [Google Scholar] [CrossRef]
- Kim, Y. Convolutional neural networks for sentence classification. arXiv 2014, arXiv:1408.5882. [Google Scholar]
- Huang, Z.; Xu, W.; Yu, K. Bidirectional LSTM-CRF models for sequence tagging. arXiv 2015, arXiv:1508.01991. [Google Scholar]
- Liang, Y.; Meng, F.; Zhang, J.; Xu, J.; Chen, Y.; Zhou, J. A Novel Aspect-Guided Deep Transition Model for Aspect Based Sentiment Analysis. arXiv 2019, arXiv:1909.00324. [Google Scholar]
- Li, H.; Eigen, D.; Dodge, S.; Zeiler, M.; Wang, X. Finding task-relevant features for few-shot learning by category traversal. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 1–10. [Google Scholar]
- Zeng, D.; Liu, K.; Chen, Y.; Zhao, J. Distant supervision for relation extraction via piecewise convolutional neural networks. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; pp. 1753–1762. [Google Scholar]
- Sun, S.; Sun, Q.; Zhou, K.; Lv, T. Hierarchical Attention Prototypical Networks for Few-Shot Text Classification. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 476–485. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C.D. Glove: Global vectors for word representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- Petroni, F.; Rocktäschel, T.; Lewis, P.; Bakhtin, A.; Wu, Y.; Miller, A.H.; Riedel, S. Language models as knowledge bases? arXiv 2019, arXiv:1909.01066. [Google Scholar]
- Van der Maaten, L.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
| Model | 5-Way 1-Shot | 5-Way 5-Shot | 10-Way 1-Shot | 10-Way 5-Shot |
|---|---|---|---|---|
| Finetune (CNN) | 44.21 | 68.66 | 27.30 | 55.04 |
| Finetune (PCNN) | 45.64 | 57.86 | 29.65 | 37.43 |
| kNN (CNN) | 54.67 | 68.77 | 41.24 | 55.87 |
| kNN (PCNN) | 60.28 | 72.41 | 46.15 | 59.11 |
| Meta Network | 64.46 | 80.57 | 53.96 | 69.23 |
| GNN | 66.23 | 81.28 | 46.27 | 64.02 |
| SNAIL | 67.29 | 79.40 | 53.28 | 68.33 |
| Proto | 69.20 | 84.79 | 56.44 | 75.55 |
| Proto-HATT | - | 90.12 | - | 83.05 |
| HAPN | - | 91.02 | - | 84.16 |
| MLMAN | 82.98 | 92.66 | 75.59 | 87.29 |
| BERT-PAIR | 88.32 | 93.22 | 80.63 | 87.02 |
| CTEG | 88.11 | 95.25 | 81.29 | 91.33 |
| TFC (BERT) | 86.31 | 92.97 | 78.13 | 87.01 |
| TFC+Mode 1 (BERT) | 89.71 | |||
| 95.42 | 82.31 | 89.33 | ||
| TFC+Mode 2 (BERT) | 89.76 | 95.13 | 82.81 | 92.76 |
| Model | 5-Way 1-Shot | 5-Way 5-Shot | 10-Way 1-Shot | 10-Way 5-Shot |
|---|---|---|---|---|
| Proto-ADV (CNN) | 42.21 | 58.71 | 28.91 | 44.35 |
| Proto (BERT) | 40.12 | 51.50 | 26.45 | 36.93 |
| Proto-ADV (BERT) | 41.90 | 54.74 | 27.36 | 37.40 |
| BERT-PAIR | 56.25 | 67.44 | 43.64 | 53.17 |
| TFC+Mode 1 | 67.33 | 79.86 | 54.31 | 69.35 |
| TFC+Mode 2 | 67.12 | 78.13 | 54.86 | 70.36 |
| Model | 5-Way 1-Shot | 5-Way 5-Shot | 10-Way 1-Shot | 10-Way 5-Shot |
|---|---|---|---|---|
| GNN | 70.21 | 81.25 | 49.22 | 67.29 |
| GNN+Mode 1 | 72.48 | 82.12 | 54.67 | 69.10 |
| GNN+Mode 2 | 72.13 | 82.35 | 55.44 | 69.01 |
| Proto | 75.25 | 86.02 | 59.37 | 77.18 |
| Proto+Mode 1 | 75.97 | 87.49 | 61.28 | 78.03 |
| Proto+Mode 2 | 75.62 | 87.33 | 61.41 | 78.22 |
| Proto (BERT) | 78.31 | 89.18 | 63.51 | 78.77 |
| Proto (BERT)+Mode 1 | 80.22 | 88.60 | 65.73 | 79.22 |
| Proto (BERT)+Mode 2 | 80.03 | 89.79 | 65.92 | 79.83 |
| Model | 5-Way 1-Shot | 5-Way 5-Shot | 10-Way 1-Shot | 10-Way 5-Shot |
|---|---|---|---|---|
| TFC+Mode 1 (BERT) | 83.27 | 91.13 | 68.58 | 81.11 |
| TFC+Mode 1 (WE) | 80.73 | 89.26 | 64.30 | 79.15 |
| TFC+Mode 2 (BERT) | 83.33 | 91.13 | 69.02 | 80.37 |
| TFC+Mode 2 (WE) | 80.71 | 89.17 | 63.97 | 79.32 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Deng, S.; Shi, G.; Feng, C.; Wang, Y.; Liao, L. Task-Aware Feature Composition for Few-Shot Relation Classification. Appl. Sci. 2022, 12, 3437. https://doi.org/10.3390/app12073437
Deng S, Shi G, Feng C, Wang Y, Liao L. Task-Aware Feature Composition for Few-Shot Relation Classification. Applied Sciences. 2022; 12(7):3437. https://doi.org/10.3390/app12073437
Chicago/Turabian StyleDeng, Sinuo, Ge Shi, Chong Feng, Yashen Wang, and Lejian Liao. 2022. "Task-Aware Feature Composition for Few-Shot Relation Classification" Applied Sciences 12, no. 7: 3437. https://doi.org/10.3390/app12073437
APA StyleDeng, S., Shi, G., Feng, C., Wang, Y., & Liao, L. (2022). Task-Aware Feature Composition for Few-Shot Relation Classification. Applied Sciences, 12(7), 3437. https://doi.org/10.3390/app12073437