4.4. Result Analysis
Firstly, we ran our method on different data sets (CIFAR-10, single class images in CIFAR-10 and Align CelebA) to check its efficiency in generation results.
Table 1 shows that we have obtained different results (measured with FID) when we performed the experiments with stable
and restart
(
means the learning rate in discriminator). In the experiments, we used the same DCGAN structure but different inputs. In the first row, the input is the whole CIFAR-10, and the input in the last row is Align Celeba. We also checked the availability of our method in single class images in CIFAR-10 and present them in other rows. From the results in
Table 1, we could see that the performance of the DCGAN trained with restart learning rate has shown different degrees of improvement on multi-category data (shown in the first row and the last row) and single-category data in CIFAR-10 (shown in the other rows). We also presented the corresponding visual results in
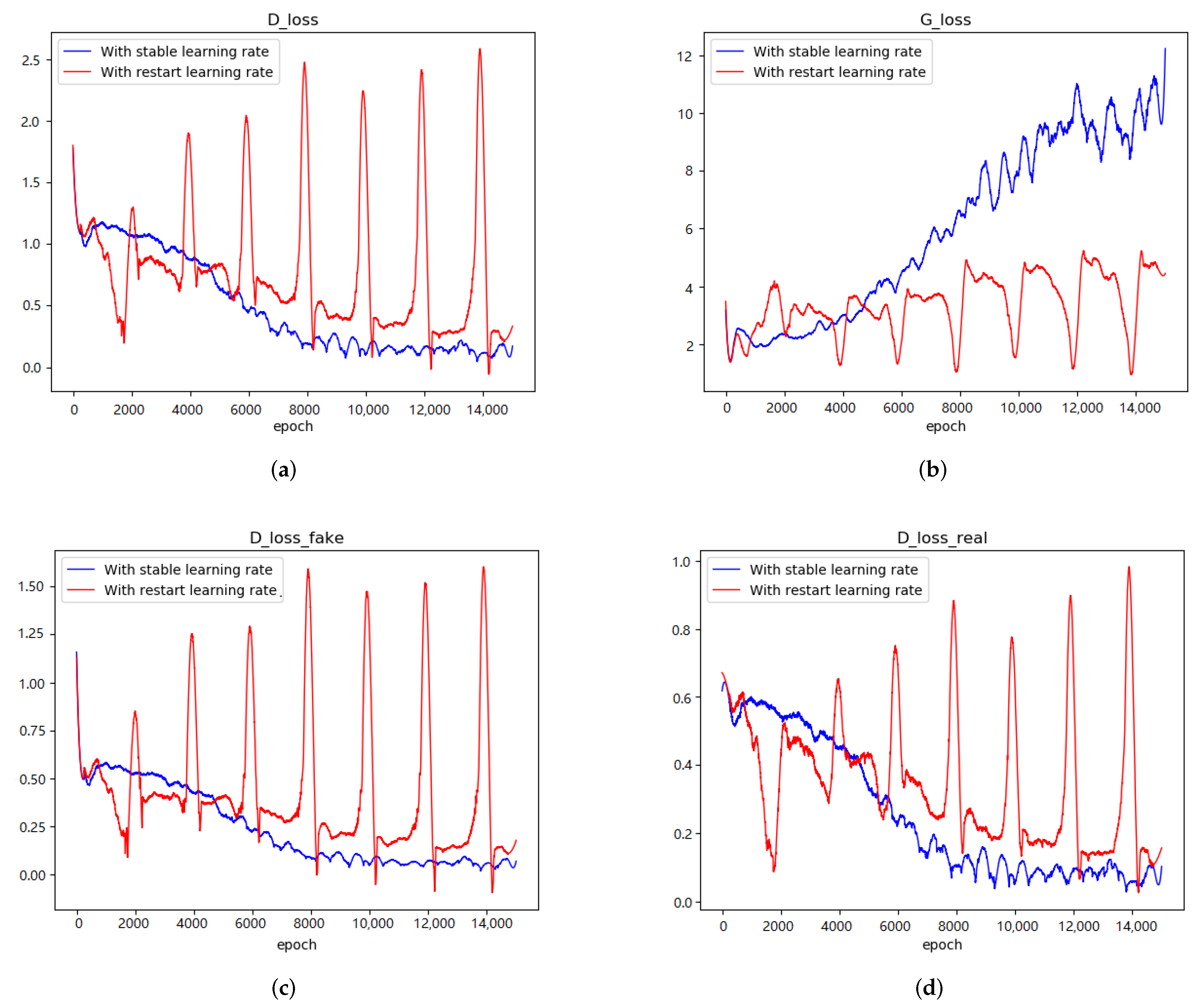
Figure 3: when we trained DCGAN with stable
on CIFAR-10, there are blurred parts in (a), while (b) has exhibited higher image resolution; on Align Celeba, almost all the faces in (c) are distorted and the use of Restart
could decrease the faces distortion (shown in (d) of
Figure 3). In conclusion, the plunge of Restart
is beneficial to GAN in terms of generation ability. In the next experiments, we will see whether these improvements come from the improvement of networks stability.
Table 2 shows the generated results (measured by FID score) by various GANs on CIFAR-10. We performed these experiments in different GANs for two purposes: (1) SNGAN and WGAN-GP are typical GANs to stable the training process, so we want to compare our method with SNGAN and WGAN-GP; (2) as our method only affects learning rate, we also want to check if it can improve the performance in SNGAN and WGAN-GP.
Note that when we performed the experiments in
Table 1, we tried to train models sufficiently (total updates = 100 k) with apposite learning rate value. However in the experiments of
Table 2, what we want to prove is that our restart schedule could improve the performance in various GANs despite of different initial learning rates and training steps. So we have different parameter settings for experiments in
Table 1 and experiments in the DCGAN model of
Table 2.
The learning rate for GANs training is usually around
(or
), and a large learning rate always causes oscillation over training steps. In
Table 2, when we set stable
to be
(or
), the more steps we take, the worse results we obtain in DCGAN and SNGAN (i.e., column 1 of
Table 2), which indicates the oscillation. Application of the restart learning rate in discriminator will avoid the oscillation problem effectively and brings more meaning for gradients for training, even though the maximum of Restart
is also set to be
(i.e., the column 2 of
Table 2).
When we set learning rate to be a relatively small value
, the restart learning rate could still promote the performance of DCGAN and SNGAN (shown in column 3 and column 4 of
Table 2). In practice,
is usually our choice for training process. Thus, under this value, we run experiments of each GAN five times to calculate its average and standard deviation of FID to check the impact of our proposed method on stability.
When we use stable
, WGAN-GP performed well in both cases (i.e.,
and
) which means WGAN-GP stabilizes training process efficiently while the use of restart
in it lead to worse results (i.e., line 5 and line 6 of
Table 2). We think there are two reasons: (1) WGAN-GP has already stable the training, hence periodical restart learning rate brings interference (can be indicated by the standard deviation of FID). (2) The reason why the restart learning rate is effective in DCGAN and SNGAN is that it avoids the disappearance of
, while the loss in the discriminator of WGAN-GP depends on Earth Mover (EM) distance which is continuous and differentiable till optimality. Bold numbers in
Table 2 means the best results in three GANs respectively. WGAN-GP with stable
(FID = 59.245) and DCGAN with restart
(FID = 58.735) have obtained the highest comparable performance in 40k iterations.
Table 2 shows that restart
is beneficial to DCGAN and SNGAN (with low average FID and comparable standard deviation value) but is not available for WGAN-GP. Exploring the deep reason why restart learning rate is useful or useless in various GAN frameworks is one of our future research directions.
Table 3 records the time spent for DCGAN and WGAN-GP to reach the best results (shown in bold) in
Table 2. As we have mentioned in the above paragraph, DCGAN with this restart
and WGAN-GP with stable
have comparable results in 40k iterations while DCGAN with this restart
spent less time. The reason why WGAN-GP with stable
cost more time is that it needs to calculate penalty in every iteration. We also note that the restart schedule does not bring too many calculations (compare line 1 and line 2 of
Table 3). All in all, the restart learning rate improves the generation performance of DCGAN without too much computational complexity and it is meaningful for GANs training. DCGAN with restart
is a reasonable choice for GANs generation work.
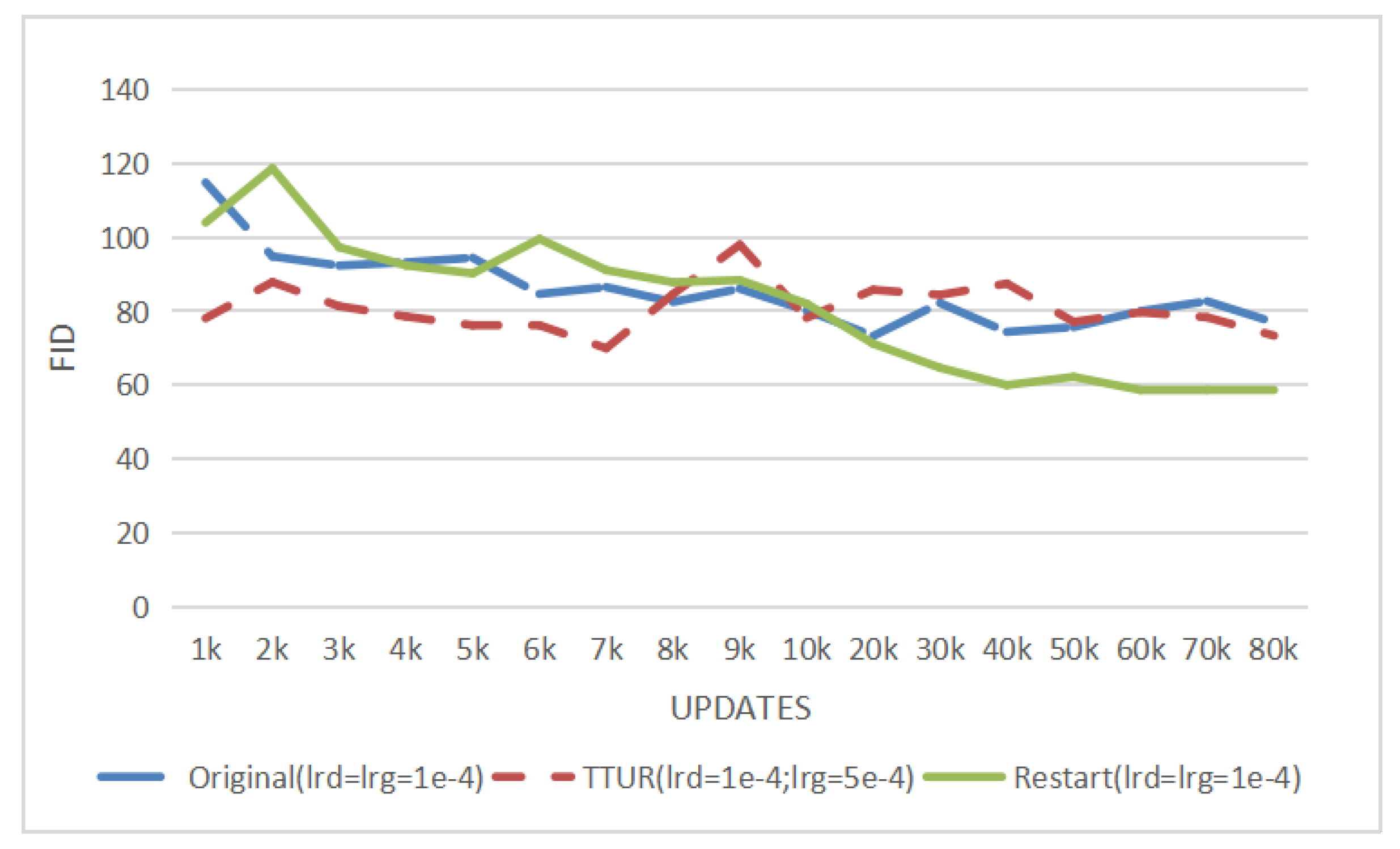
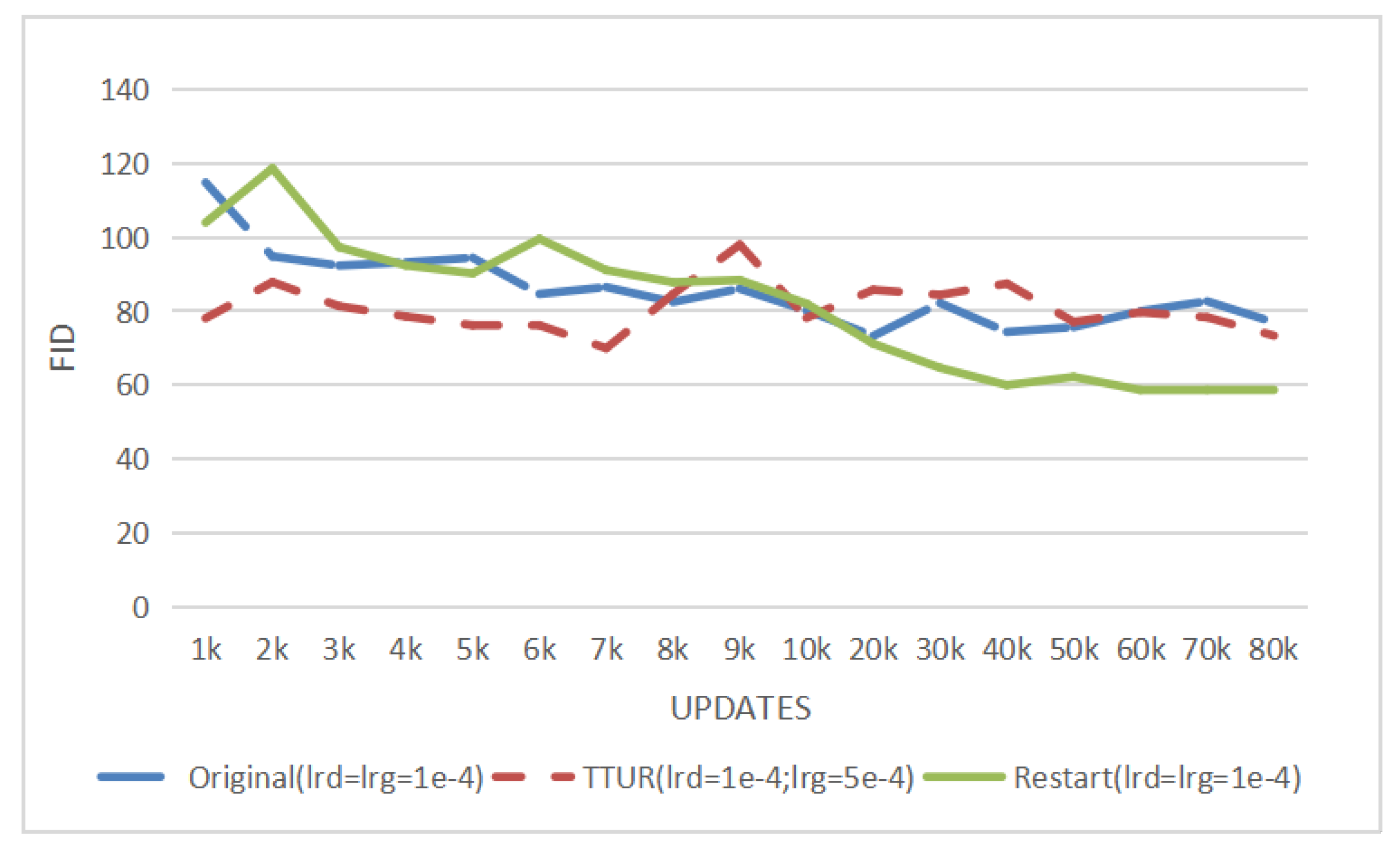
We also compare our method with the Two Time-Scale Update Rule [
24]. In
Figure 4, ‘Original’ means the DCGAN model in [
2], ‘TTUR’ means DCGAN trained by a Two Time-Scale Update Rule [
24], and ‘Restart’ means our method proposed in this paper. For fairness, the learning rate and updates settings of Original and TTUR are the same as settings in
Table 1 of [
24]. In our proposed method (‘Restart’ in
Figure 4), the learning rate of the generator is the same as ‘Original’ while the maximum learning rate of the discriminator is also equal to
. In
Figure 4, compared with the round-trip fluctuation of DCGAN with original learning rates, the FID results indicate that the DCGAN trained with TTUR decreases steadily and outperforms the original DCGAN in 80k updates. However, the DCGAN with our method obtained the highest performance and converges faster than the other two methods.
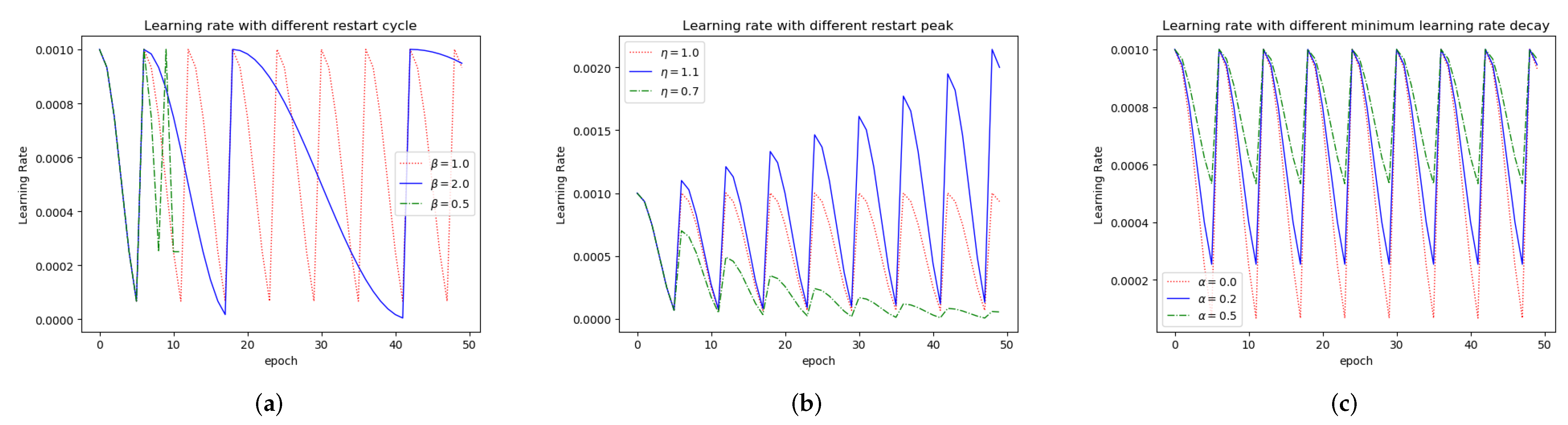
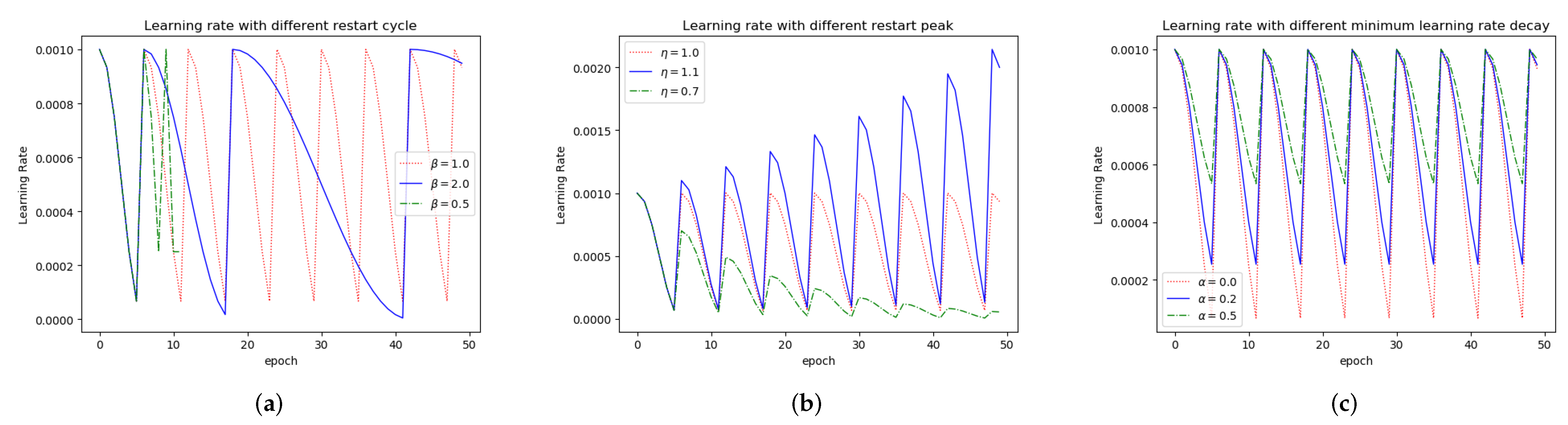
In order to analyze our method in detail, we have further explored the influence of four important parameters in the method on the experiment results and which are shown in the following parts. The four parameters are
(cycle length control coefficient),
(peak value control coefficient),
(the baseline of amplitudes), and
P (the number of steps in the first cycle), respectively. As we have discussed in
Section 2.2, the line of
Figure 1a shows the convergence of
D which will influence the final output. Therefore, we have investigated the influence of our method in two ways: (1) the convergence of loss of
D and (2) the result in terms of FID. Besides that, we consider the modification of the parameter settings that can prevent the fast convergence of
D and ensure the effectiveness during the training process.
In the ablation study of four parameters (, , , and P), we always explore the impact of different values of a parameter when the other three parameters remain unchanged. Based on the analysis of generated results (FID score), we select three representative values to see their impact on the discriminator loss curves.
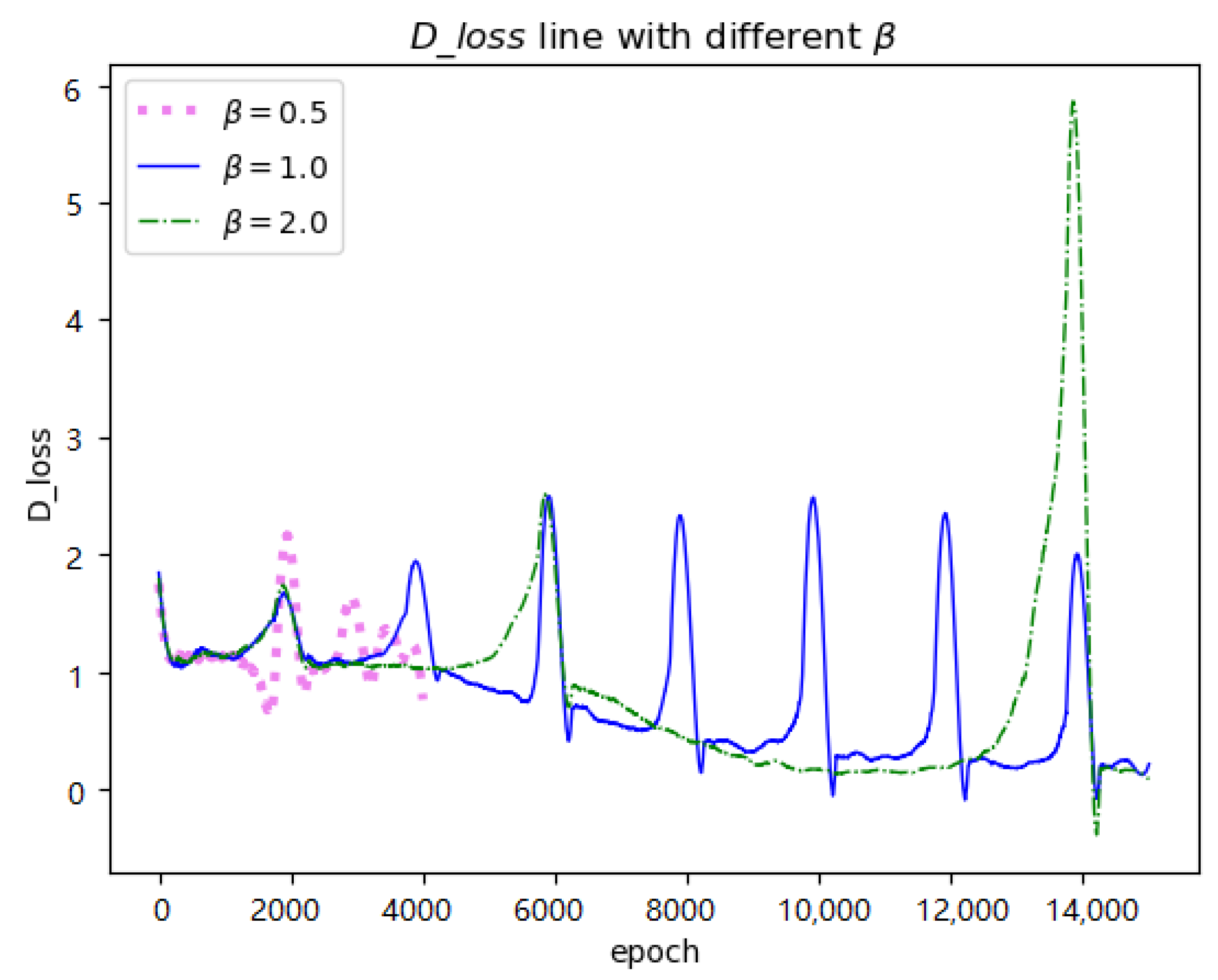
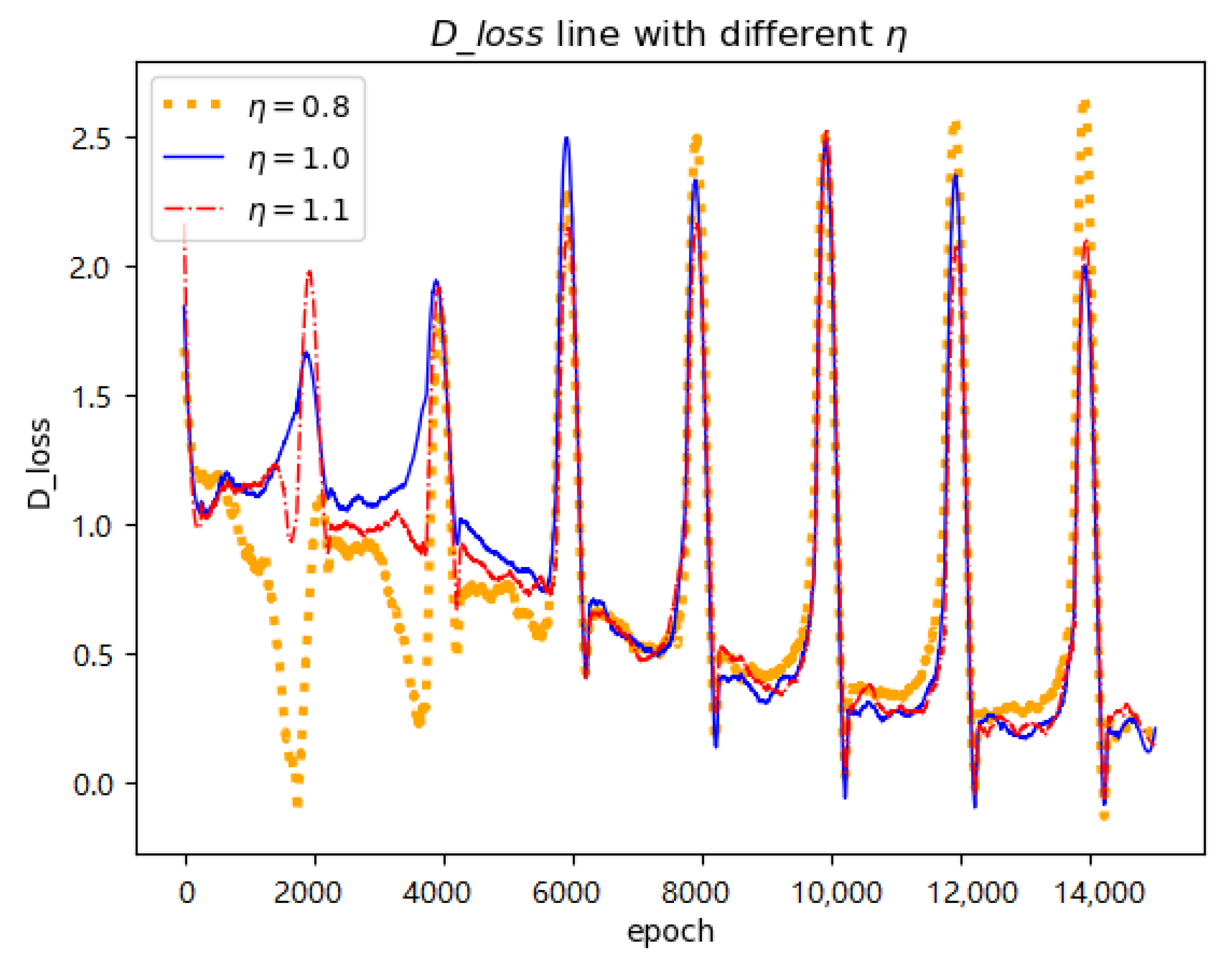
Table 4 gives different values related to the cycle length control coefficient
(row 6 in Algorithm 1) and
Figure 5 shows three corresponding
D loss lines.
defines the multiple of the current period length relative to the previous one. According to the update formula of period length (
),
with a value less than 1.0 (i.e., row 1 in
Table 4) shortens the length of a period. When the training process can not run properly, ‘NaN’ situation can occur (pink line in
Figure 5). ‘NaN’ represents that the program produces none value. Conversely, a large value (i.e., row 5 and 6 in
Table 4) may cause heavy disturbance as shown in the green line of
Figure 5 due to the sudden increase of the learning rate in the next period. However, this disturbance will not lead to heavy worse results (i.e., FID score in row 5) because of fast convergence. As shown in
Table 4, restart learning rate with
performs most effectively (i.e., row 2). However, at the same time, we also note that when we take values between 1.0 and 2.0 for
, the differences among them are small (i.e., row 3, row 4, and row 5). Even if
is taken as 3.0, the corresponding FID only increases by 3.806 compared with the smallest distance in row 2. In conclusion, we analyze that the value of
has little effect on the experimental results, but the values between 1.0 and 2.0 are more conducive for us to obtain satisfying results.
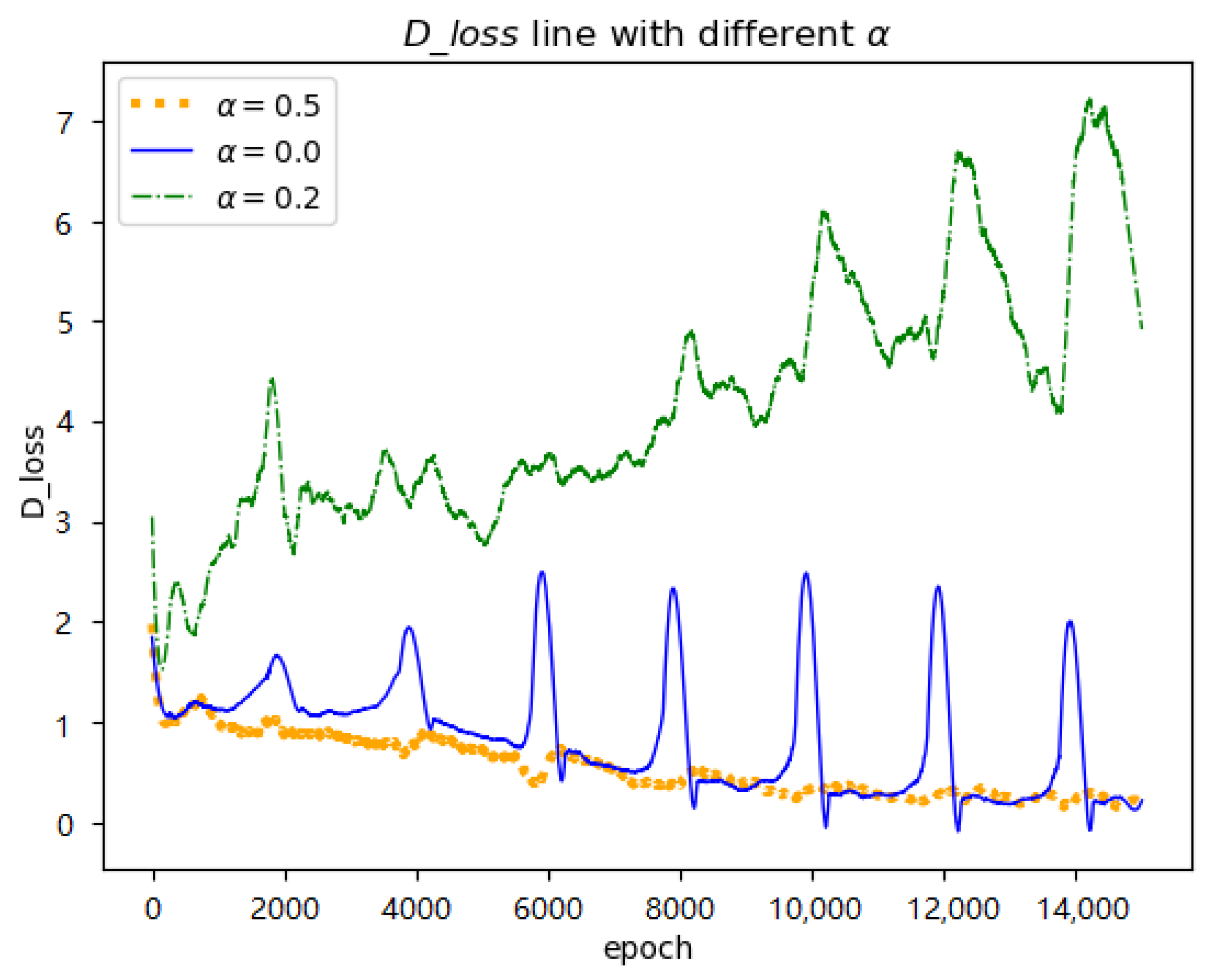
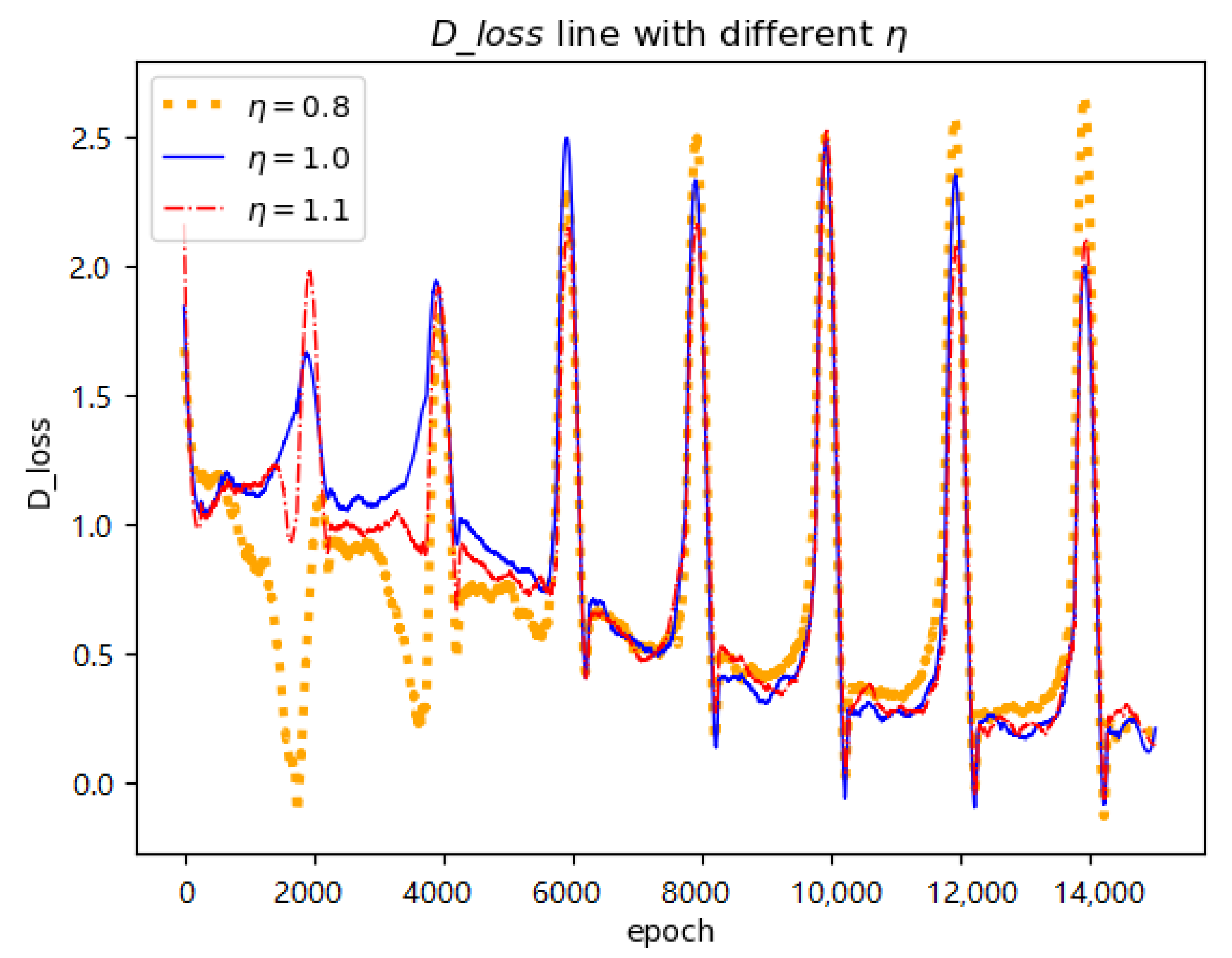
is the multiple of the current peak value relative to the previous one (note line 5 in Algorithm 1). We also set different values to parameter
(
Table 5). We have observed that
makes the peak value cumulative as the epoch increases (orange line in
Figure 6), and the increasing fluctuation is not conducive to the convergence of the whole training process. Additionally, larger values lead to worse results (compare row 5 and row 6 in
Table 5). However, values set to 1.0 or slightly less than 1.0 are beneficial for generated results (i.e., rows 2,3, and 4). For example, blue line and red line in
Figure 6 provide more gentle restart for training process.
exhibited the optimal result as shown in the third row of
Table 5 (corresponding FID=63.793). In conclusion, we can see that values slightly less than 1.0 are suitable for parameter
.
is the minimum value that the learning rate can decay to (shown in line 5 of Algorithm 1). When
is 0.0, it means there is no baseline, and the learning rate could decrease to zero to provide no gradient for updating (it is obvious that we need gradients for training GANs). In this way, we set its values between 0.0 and 1.0 to be the baseline of learning rate to explore its impact. When
is slightly greater than 0.0, the corresponding generated results are more improved than those of
(i.e., row 2, 3, 4 in
Table 6).
has obtained the optimal performance and the representative line in
Figure 7 shows the highest
D loss. Thus, the following conclusions can be inferred: appropriate increase
D loss can effectively prevent the disappearance of
D loss, so as to make GAN generate improved results. However, excessive values can lead to an increase in FID scores (i.e., row 5, 6 in
Table 6). Additionally, we also noted that the value
makes
D loss nearly disappearing (orange line in
Figure 7). We conjecture that it is because the range (1.0 to 0.5) of the learning rate is limited, which is contrary to our original intention for restart. All in all, we consider
to be most suitable for our method.
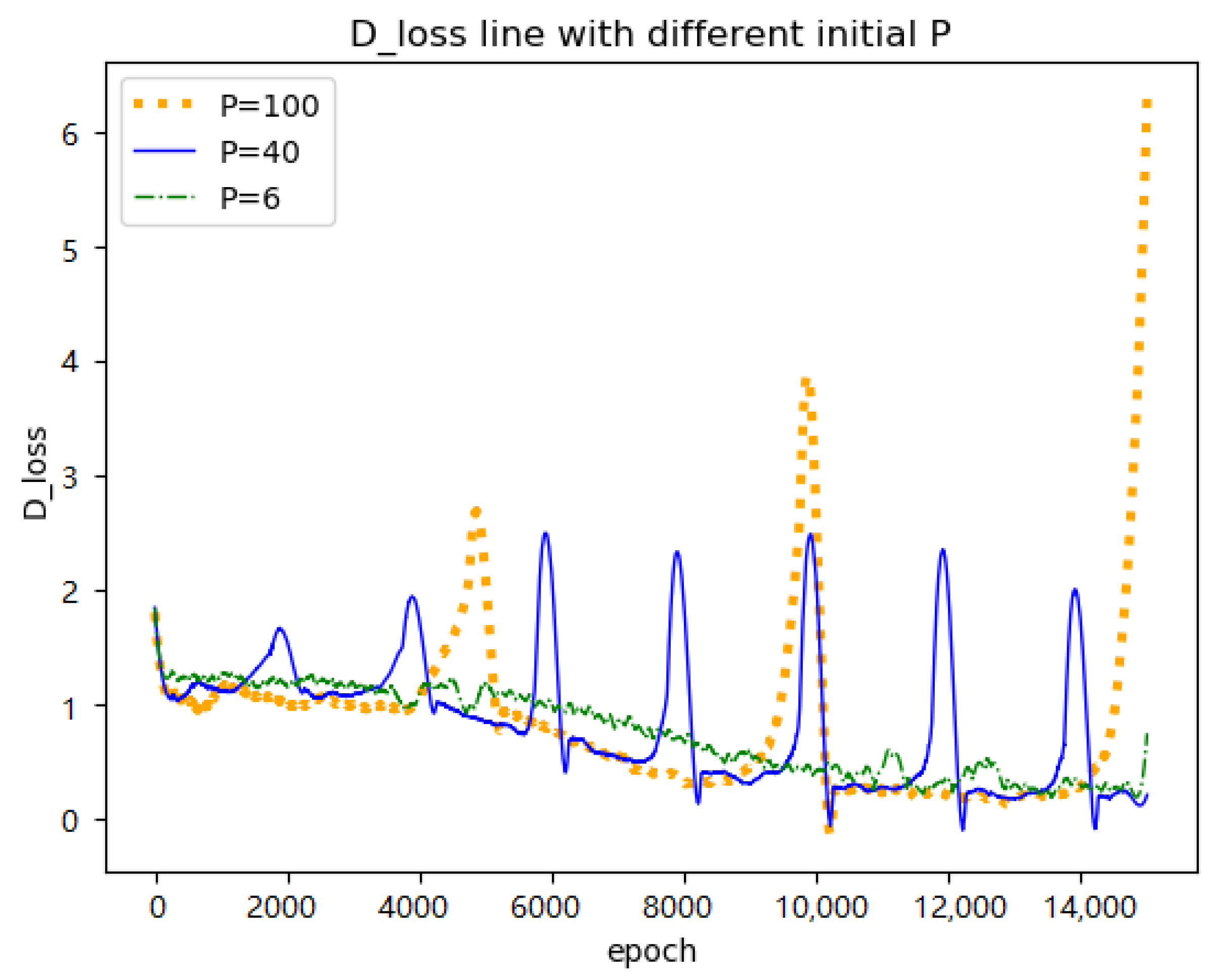
P is updated by
in the algorithm (line 6 in Algorithm 1).
P is the initial number of steps in the first cycle. As was previously discussed,
to be 1.0 or slightly greater than 1.0 is a moderate choice for training GANs. Hence too small values of
P (i.e., rows 1, 2, and 3 in
Table 7) provide limited steps to find potential optima. When the value of
P is too large, the period in the loss curve is too long, and the sudden increase of learning rate at the beginning of the next period will bring too high fluctuations to the training process (the orange line in
Figure 8). Heavy fluctuation makes the optimization of the previous cycle meaningless which is shown with underperformed generated results (i.e., rows 5 and 6 in
Table 7). When the initial value of
P is set to 40, it allows the restart learning rate to exercise its full performance and exhibits the satisfactory results (the blue line in
Figure 8 and the row 4 in
Table 7).
Overall, appropriate parameter selection is essential for demonstrating the functionality of our new method. Especially, it is shown that appropriate tuning of
and
significantly improves the performance. Through various experiments, we found the setting of parameters (
= 1.0,
= 0.8,
= 0.2,
P = 40) which gives satisfiable results. It also could be further explained that remarkable
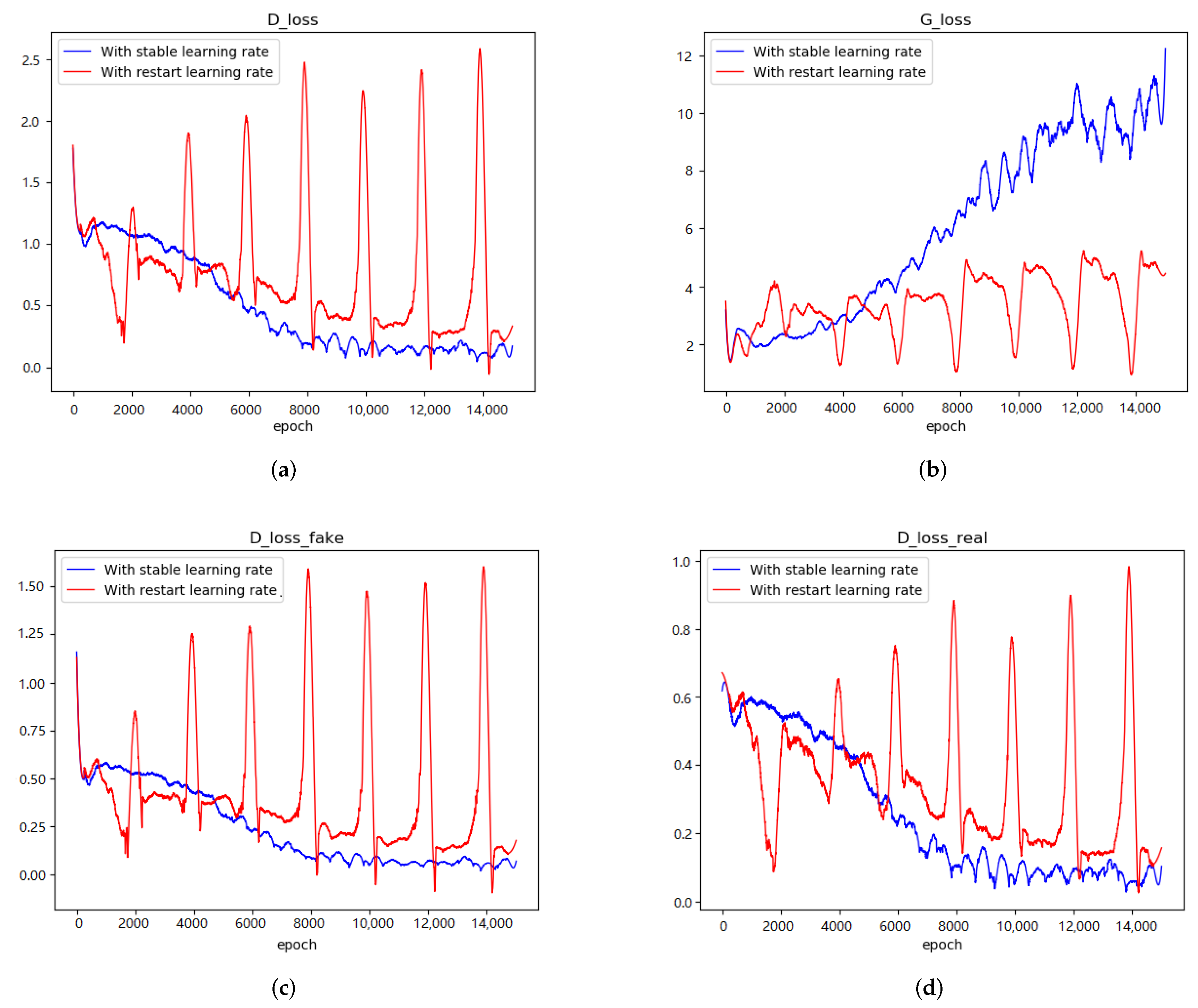
performance corresponds to low FID results. Restart learning prevents the fast disappearance of
(
Figure 1a) and the rapid growth of
(
Figure 1b). As explained above, preventing the rapid decline in the loss of the discriminator can effectively improve the performance of GAN, and restarting learning is an effective way for achieving the above-mentioned functions.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}