
An Effectively Finite-Tailed Updating for Multiple Object Tracking in Crowd Scenes


Abstract
:1. Introduction
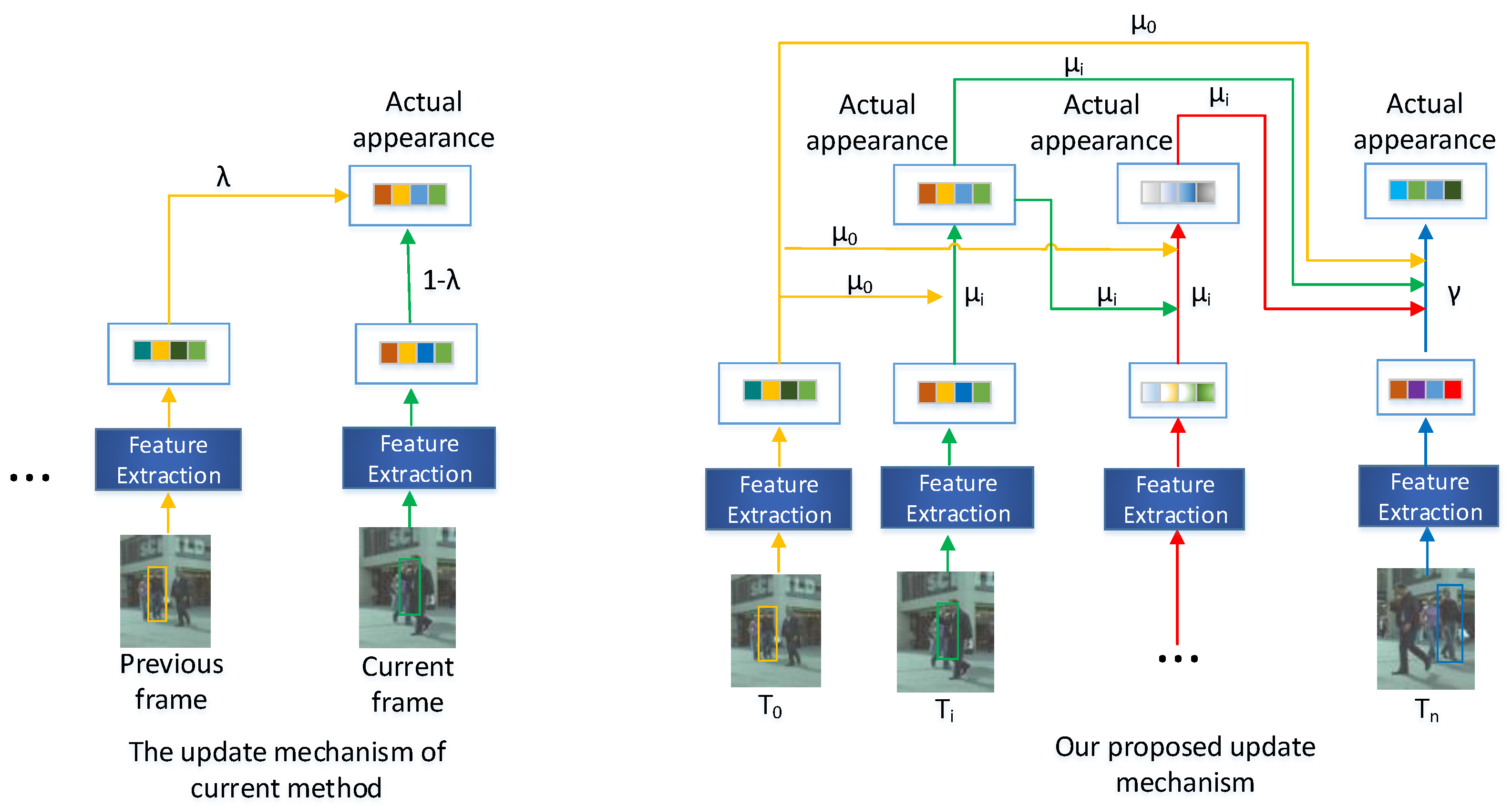
- We propose an effective and flexible appearance update mechanism, named finite-tailed updating (FTU), which combines the object’s historical accumulated appearance templates in multiple earlier frames with its Re-ID feature in the current frame to improve the identification performance of the object in the current frame.
- We propose an effective MOT solution that can obtain better performance than the state-of-the-art methods. The experimental results have shown that our tracker outperforms the state-of-the-art methods on MOT Challenge Benchmark.
2. Related Work
2.1. Multi-Object Tracking Framework
2.2. Update Object Appearance Template
3. Problem Formulation and the Approach
3.1. Revisiting FairMOT
3.1.1. Backbone Network
3.1.2. Object Detection Branch
3.1.3. Object-Embedding Branch
3.1.4. Updating the Motion Model
3.1.5. Updating the Appearance Model
3.2. The Proposed Updating Scheme
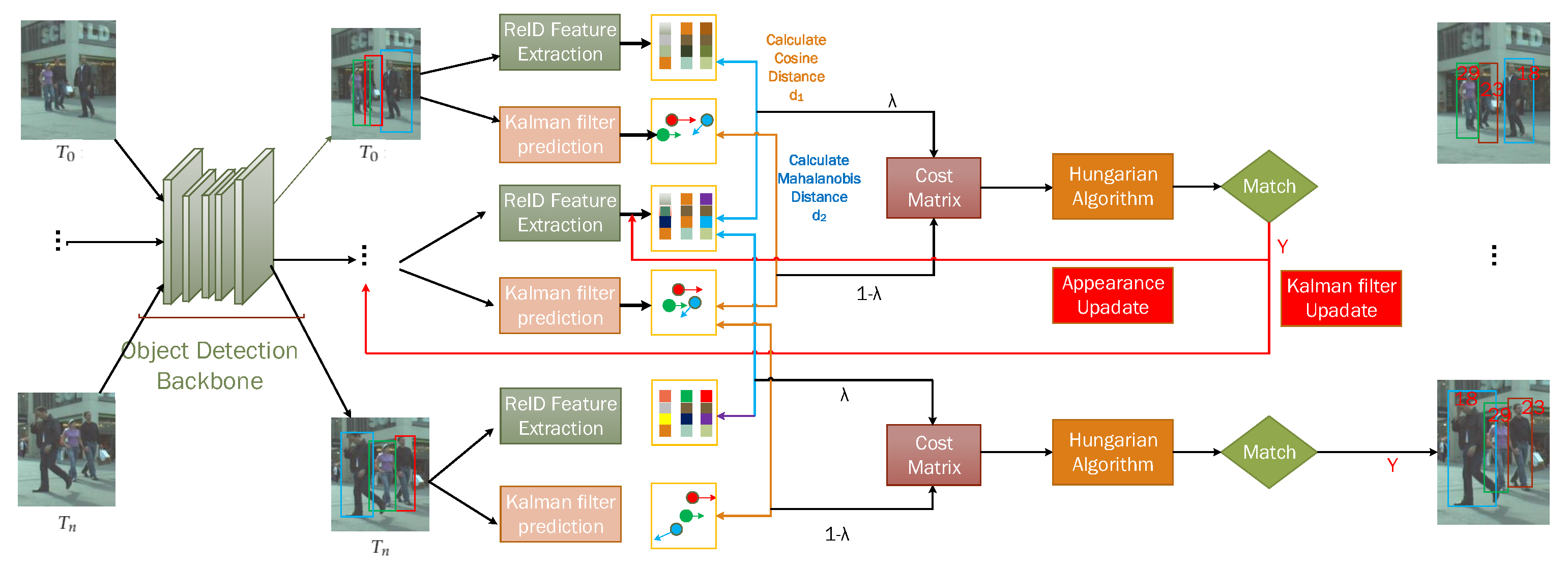
3.3. The Architecture of the Proposed MOT Framework
4. Experiment
4.1. Experimental Setting
4.2. Comparison with State-of-the-Art Methods
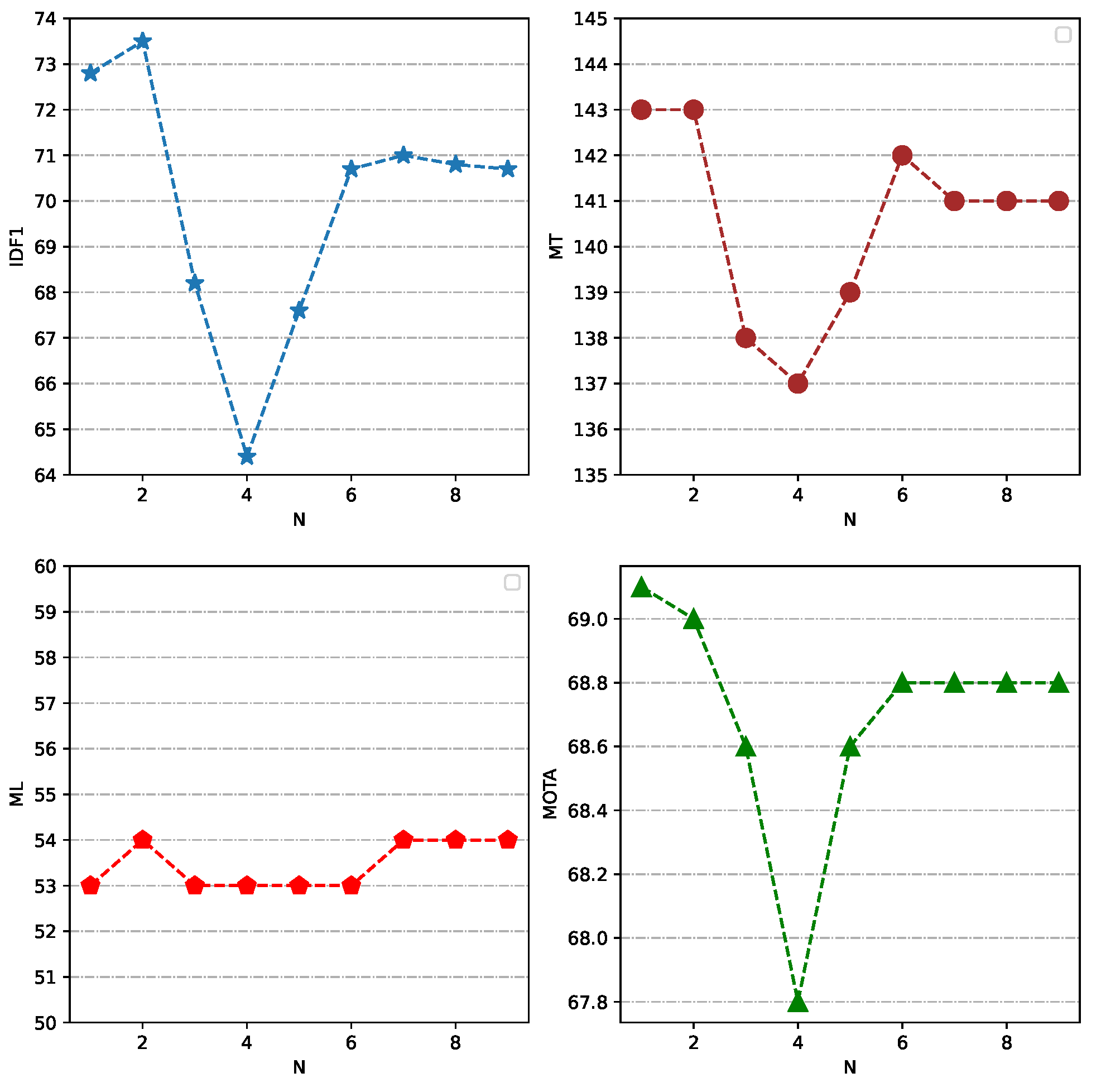
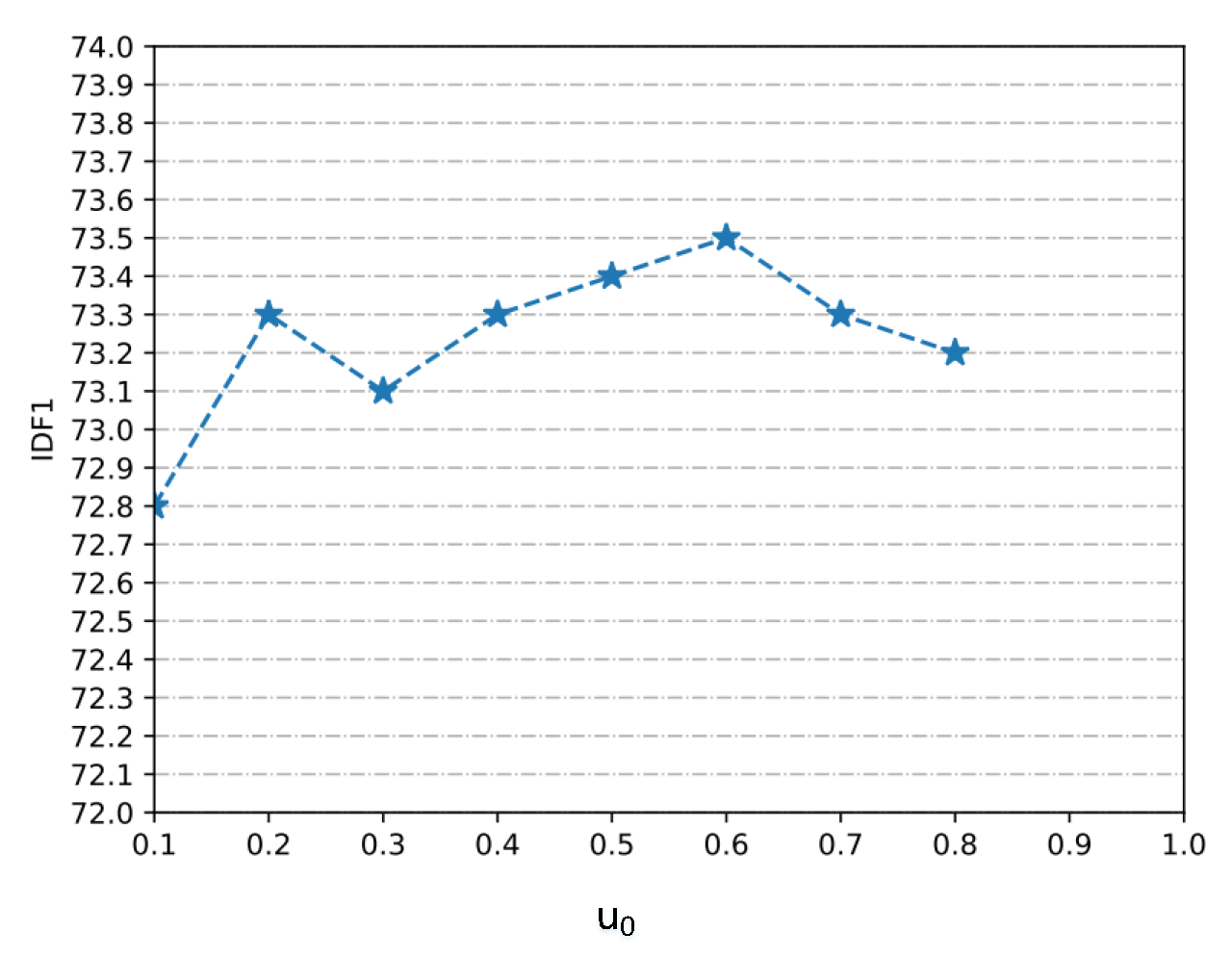
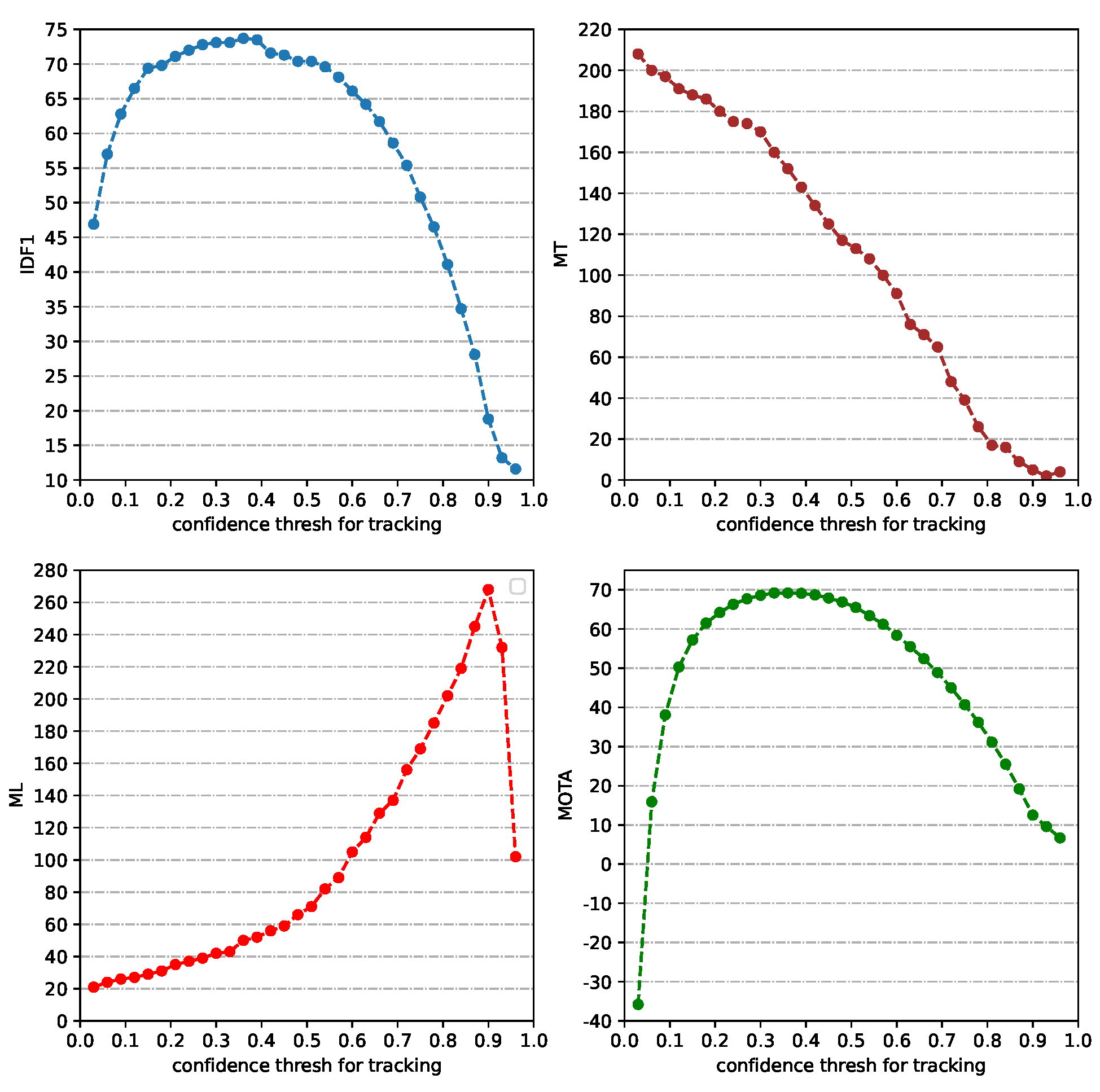
4.3. Hyperparameter Comparison and Analysis Experiments
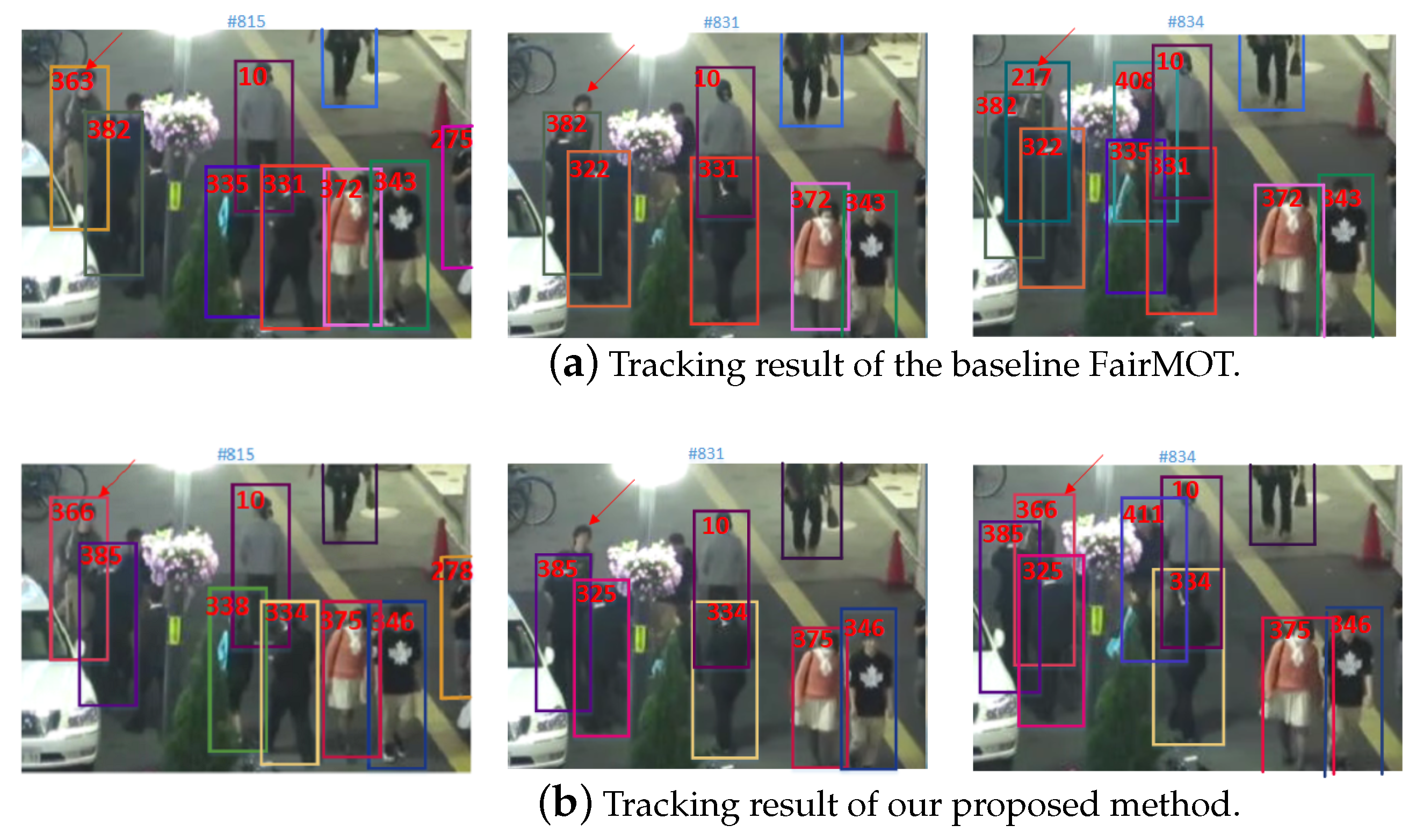
4.4. Comparison to Baseline Method FairMOT
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Luo, W.; Xing, J.; Milan, A.; Zhang, X.; Liu, W.; Kim, T.-K. Multiple object tracking: A literature review. Artif. Intell. 2020, 293, 103448. [Google Scholar] [CrossRef]
- Yu, F.; Li, W.; Li, Q.; Liu, Y.; Shi, X.; Yan, J. Poi: Multiple object tracking with high performance detection and appearance feature. In European Conference on Computer Vision (ECCV); Springer: Berlin/Heidelberg, Germany, 2016; pp. 36–42. [Google Scholar]
- Bochinski, E.; Eiselein, V.; Sikora, T. High-speed tracking-by-detection without using image information. In Proceedings of the 2017 14th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Lecce, Italy, 29 August–1 Septemebr 2017; pp. 1–6. [Google Scholar]
- Hornakova, A.; Henschel, R.; Rosenhahn, B.; Swoboda, P. Lifted disjoint paths with application in multiple object tracking. In Proceedings of the International Conference on Machine Learning (ICML), Vienna, Austria, 12–18 July 2020; pp. 4364–4375. [Google Scholar]
- Tokmakov, P.; Li, J.; Burgard, W.; Gaidon, A. Learning to track with object permanence. arXiv 2021, arXiv:2103.14258. [Google Scholar]
- Zhou, X.; Koltun, V.; Krähenbühl, P. Tracking objects as points. In European Conference on Computer Vision (ECCV); Springer: Berlin/Heidelberg, Germany, 2020; pp. 474–490. [Google Scholar]
- Tian, B.; Yao, Q.; Gu, Y.; Wang, K.; Li, Y. Video processing techniques for traffic flow monitoring: A survey. In Proceedings of the 2011 14th International IEEE Conference on Intelligent Transportation Systems (ITSC), Washington, DC, USA, 5–7 October 2011; pp. 1103–1108. [Google Scholar]
- Brown, M.; Funke, J.; Erlien, S.; Gerdes, J.C. Safe driving envelopes for path tracking in autonomous vehicles. Control Eng. Pract. 2017, 61, 307–316. [Google Scholar] [CrossRef]
- Kuhn, H.W. The hungarian method for the assignment problem. Nav. Res. Logist. Q. 1955, 2, 83–97. [Google Scholar] [CrossRef] [Green Version]
- Blackman, S.S. Multiple hypothesis tracking for multiple target tracking. IEEE Aerosp. Electron. Syst. Mag. 2004, 19, 5–18. Available online: https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=1263228 (accessed on 11 January 2004). [CrossRef]
- Welch, G.; Bishop, G. An Introduction to the Kalman Filter. Chapel Hill, NC, USA. 1995. Available online: https://perso.crans.org/club-krobot/doc/kalman.pdf (accessed on 17 September 1997).
- Choi, W. Near-online multi-target tracking with aggregated local flow descriptor. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 3029–3037. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 91–99. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Kim, C.; Li, F.; Ciptadi, A.; Rehg, J.M. Multiple hypothesis tracking revisited. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 4696–4704. [Google Scholar]
- Wojke, N.; Bewley, A.; Paulus, D. Simple online and realtime tracking with a deep association metric. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 Septemebr 2017; pp. 3645–3649. [Google Scholar]
- Pang, B.; Li, Y.; Zhang, Y.; Li, M.; Lu, C. Tubetk: Adopting tubes to track multi-object in a one-step training model. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 6308–6318. [Google Scholar]
- Park, Y.; Dang, L.M.; Lee, S.; Han, D.; Moon, H. Multiple object tracking in deep learning approaches: A survey. Electronics 2021, 10, 2406. [Google Scholar] [CrossRef]
- Chen, H.; Cai, W.; Wu, F.; Liu, Q. Vehicle-mounted far-infrared pedestrian detection using multi-object tracking. Infrared Phys. Technol. 2021, 115, 103697. [Google Scholar] [CrossRef]
- Bergmann, P.; Meinhardt, T.; Leal-Taixe, L. Tracking without bells and whistles. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 941–951. [Google Scholar]
- Wang, Z.; Zheng, L.; Liu, Y.; Li, Y.; Wang, S. Towards real-time multi-object tracking. In European Conference on Computer Vision (ECCV); Springer: Berlin/Heidelberg, Germany, 2020; pp. 107–122. [Google Scholar]
- Huang, W.; Zhou, X.; Dong, M.; Xu, H. Multiple objects tracking in the uav system based on hierarchical deep high-resolution network. Multimed. Tools Appl. 2021, 80, 13911–13929. [Google Scholar] [CrossRef]
- Zhou, X.; Wang, D.; Krähenbühl, P. Objects as points. arXiv 2019, arXiv:1904.07850. [Google Scholar]
- Gao, Y.; Hu, Z.; Yeung, H.W.F.; Chung, Y.Y.; Tian, X.; Lin, L. Unifying temporal context and multi-feature with update-pacing framework for visual tracking. IEEE Trans. Circuits Syst. Video Technol. 2019, 30, 1078–1091. Available online: https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=8660578 (accessed on 28 April 2020). [CrossRef]
- Yang, T.; Chan, A.B. Learning dynamic memory networks for object tracking. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 152–167. [Google Scholar]
- Choi, J.; Kwon, J.; Lee, K.M. Visual tracking by reinforced decision making. arXiv 2017, arXiv:1702.06291v1. [Google Scholar]
- Zhang, Y.; Wang, C.; Wang, X.; Zeng, W.; Liu, W. Fairmot: On the fairness of detection and re-identification in multiple object tracking. Int. J. Comput. Vis. 2021, 129, 3069–3087. [Google Scholar] [CrossRef]
- Yu, F.; Wang, D.; Shelhamer, E.; Darrell, T. Deep layer aggregation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 2403–2412. [Google Scholar]
- Ess, A.; Leibe, B.; Schindler, K.; Gool, L.V. A mobile vision system for robust multi-person tracking. In Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Anchorage, AK, USA, 23–28 June 2008; pp. 1–8. [Google Scholar]
- Zhang, S.; Benenson, R.; Schiele, B. Citypersons: A diverse dataset for pedestrian detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 3213–3221. [Google Scholar]
- Dollár, P.; Wojek, C.; Schiele, B.; Perona, P. Pedestrian detection: A benchmark. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Miami, FL, USA, 20–25 June 2009; pp. 304–311. [Google Scholar]
- Milan, A.; Leal-Taixé, L.; Reid, I.; Roth, S.; Schindler, K. Mot16: A benchmark for multi-object tracking. arXiv 2016, arXiv:1603.00831. [Google Scholar]
- Xiao, T.; Li, S.; Wang, B.; Lin, L.; Wang, X. Joint detection and identification feature learning for person search. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 3415–3424. [Google Scholar]
- Zheng, L.; Zhang, H.; Sun, S.; Chandraker, M.; Yang, Y.; Tian, Q. Person re-identification in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1367–1376. [Google Scholar]
- Bernardin, K.; Stiefelhagen, R. Evaluating multiple object tracking performance: The clear mot metrics. EURASIP J. Image Video Process. 2008, 2008, 1–10. Available online: https://link.springer.com/content/pdf/10.1155/2008/246309.pdf (accessed on 23 April 2008). [CrossRef] [Green Version]
- Lin, T.-Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In European Conference on Computer Vision (ECCV); Springer: Berlin/Heidelberg, Germany, 2014; pp. 740–755. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Stadler, D.; Beyerer, J. Improving multiple pedestrian tracking by track management and occlusion handling. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 10958–10967. [Google Scholar]
- Yang, J.; Ge, H.; Yang, J.; Tong, Y.; Su, S. Online multi-object tracking using multi-function integration and tracking simulation training. Appl. Intell. 2021, 2021, 1–21. [Google Scholar] [CrossRef]
- Brasó, G.; Leal-Taixé, L. Learning a neural solver for multiple object tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 6247–6257. [Google Scholar]
- Dai, P.; Weng, R.; Choi, W.; Zhang, C.; He, Z.; Ding, W. Learning a proposal classifier for multiple object tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 2443–2452. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Tracker | MOTA↑ (%) | IDF1↑ (%) | HOTA↑ | MT↑ (%) | ML↓ (%) |
|---|---|---|---|---|---|---|
| MOT16 | FairMOT [27] | 74.9 | 72.8 | - | 44.7 | 15.9 |
| TMOH [38] | 63.2 | 63.5 | 50.7 | 27.0 | 31.0 | |
| mfi_tst [39] | 59.9 | 58.7 | 46.9 | 24.1 | 30.8 | |
| MPNTrack [40] | 58.6 | 61.7 | 48.9 | 27.3 | 34.0 | |
| LPC_MOT [41] | 58.8 | 67.6 | 51.7 | 27.3 | 35.0 | |
| Tracktor++v2 [20] | 54.4 | 52.5 | 42.3 | 19.0 | 36.9 | |
| Ours | 74.4 | 73.7 | 60.2 | 46.1 | 15.2 | |
| MOT17 | FairMOT [27] | 73.7 | 72.3 | - | 43.2 | 17.3 |
| TMOH [38] | 62.1 | 62.8 | 50.4 | 26.9 | 31.4 | |
| mfi_tst [39] | 60.1 | 58.8 | 47.2 | 26.0 | 27.2 | |
| MPNTrack [40] | 58.8 | 61.7 | 49.0 | 28.8 | 33.5 | |
| LPC_MOT [41] | 59.0 | 66.8 | 51.5 | 29.9 | 33.9 | |
| Tracktor++v2 [20] | 56.3 | 55.1 | 44.8 | 21.1 | 35.3 | |
| Ours | 73.1 | 73.0 | 59.7 | 45.0 | 16.8 | |
| MOT20 | FairMOT [27] | 61.8 | 67.3 | - | 68.8 | 7.6 |
| TMOH [38] | 60.1 | 61.2 | 48.9 | 46.7 | 17.8 | |
| mfi_tst [39] | 59.3 | 59.1 | 47.1 | 41.1 | 17.3 | |
| MPNTrack [40] | 57.6 | 59.1 | 46.8 | 38.2 | 22.5 | |
| LPC_MOT [41] | 56.3 | 62.5 | 49.0 | 40.9 | 17.8 | |
| Tracktor++v2 [20] | 52.6 | 52.7 | 42.1 | 29.4 | 26.7 | |
| Ours | 59.7 | 67.8 | 54.0 | 66.5 | 7.7 |
| Backbone | MOTA↑ (%) | IDF1↑ (%) | IDs↓ | AP↑ | TPR↑ |
|---|---|---|---|---|---|
| ResNet-34 | 63.7 | 67.4 | 427 | 75.2 | 90.8 |
| ResNet-50 | 63.8 | 67.9 | 506 | 75.8 | 92 |
| ResNet-34-FPN | 64.5 | 70.2 | 367 | 77.9 | 94.3 |
| HRNet-W18 | 67.6 | 74.5 | 317 | 80.7 | 94.8 |
| DLA-34 | 69.0 | 73.5 | 304 | 81.4 | 94.3 |
| Backbone | Dim | MOTA↑(%) | IDF1↑ (%) | IDs↓ | FPS↑ |
|---|---|---|---|---|---|
| DLA-34 | 512 | 68.6 | 73.9 | 314 | 18.68 |
| DLA-34 | 256 | 68.5 | 72.5 | 339 | 19.91 |
| DLA-34 | 128 | 69.0 | 73.5 | 304 | 20.29 |
| DLA-34 | 64 | 69.2 | 72.8 | 299 | 21.27 |
| Dataset | Tracker | MOTA↑ (%) | IDF1↑ (%) | HOTA↑ | MT↑ (%) | ML↓ (%) |
|---|---|---|---|---|---|---|
| MOT16 | FairMOT [27] | 74.9 | 72.8 | - | 44.7 | 15.9 |
| Ours | 74.4 | 73.7 | 60.2 | 46.1 | 15.2 | |
| MOT17 | FairMOT [27] | 73.7 | 72.3 | - | 43.2 | 17.3 |
| Ours | 73.1 | 73.0 | 59.7 | 45.0 | 16.8 | |
| MOT20 | FairMOT [27] | 61.8 | 67.3 | - | 68.8 | 7.6 |
| Ours | 59.7 | 67.8 | 54.0 | 66.5 | 7.7 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, B.; Liang, D.; Li, L.; Quan, R.; Zhang, M. An Effectively Finite-Tailed Updating for Multiple Object Tracking in Crowd Scenes. Appl. Sci. 2022, 12, 1061. https://doi.org/10.3390/app12031061
Xu B, Liang D, Li L, Quan R, Zhang M. An Effectively Finite-Tailed Updating for Multiple Object Tracking in Crowd Scenes. Applied Sciences. 2022; 12(3):1061. https://doi.org/10.3390/app12031061
Chicago/Turabian StyleXu, Biaoyi, Dong Liang, Ling Li, Rong Quan, and Mingguang Zhang. 2022. "An Effectively Finite-Tailed Updating for Multiple Object Tracking in Crowd Scenes" Applied Sciences 12, no. 3: 1061. https://doi.org/10.3390/app12031061
APA StyleXu, B., Liang, D., Li, L., Quan, R., & Zhang, M. (2022). An Effectively Finite-Tailed Updating for Multiple Object Tracking in Crowd Scenes. Applied Sciences, 12(3), 1061. https://doi.org/10.3390/app12031061