





A Low-Latency Fair-Arbiter Architecture for Network-on-Chip Switches


Abstract
1. Introduction
2. Related Works and Analyses
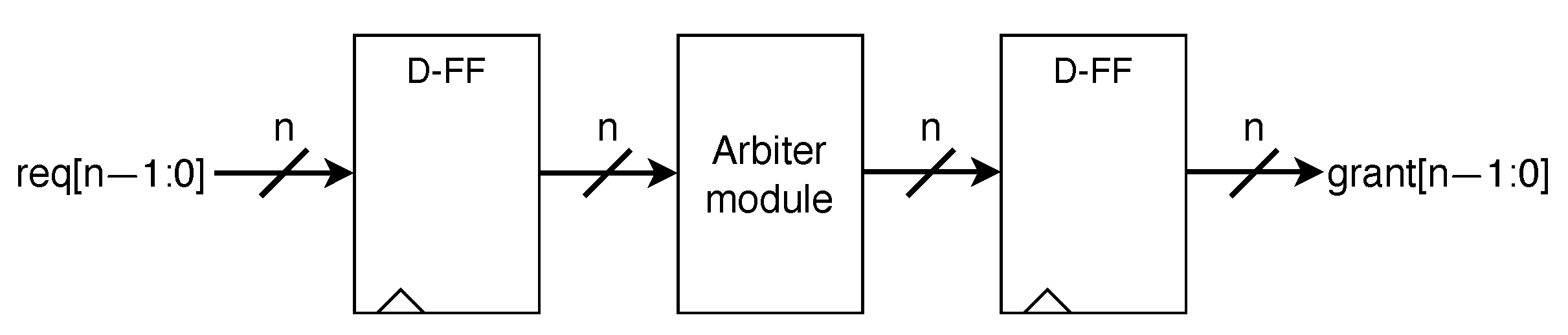
3. Fair Switch Arbiter
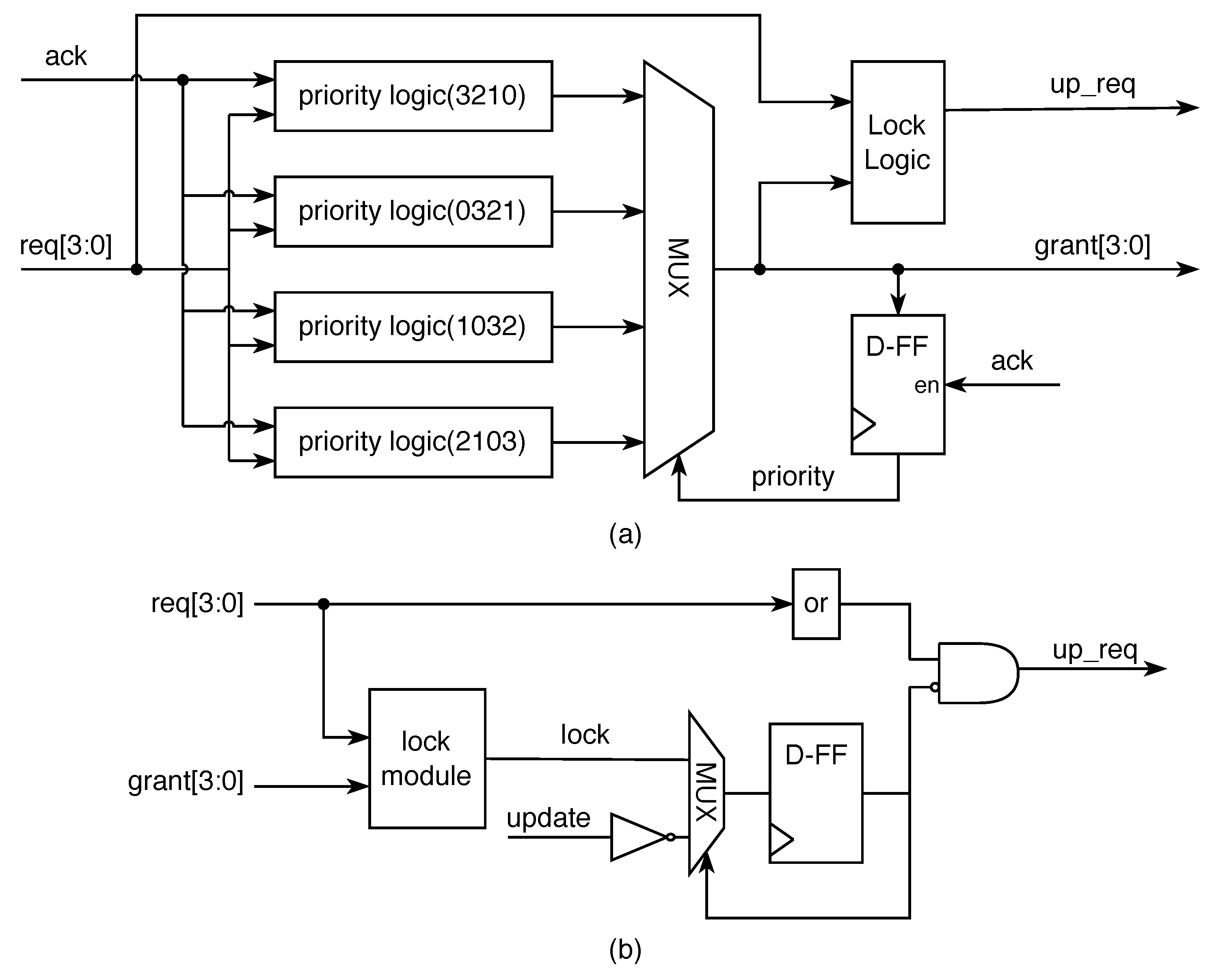
3.1. Fair Round-Robin Arbiter Scheme
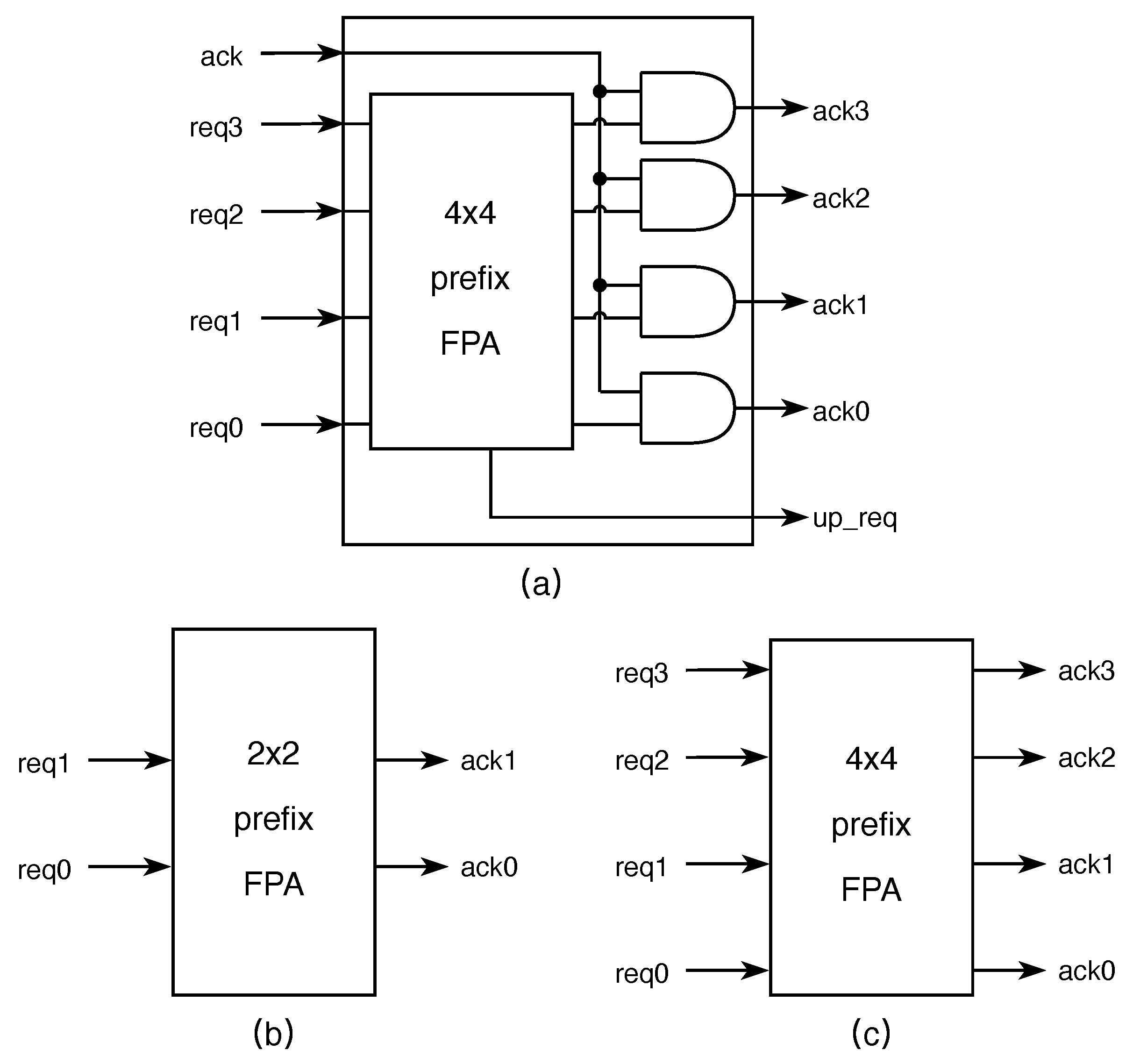
3.2. Round-Robin Arbiter Tree
4. Implementation and Experiment
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Chakravarthi, V.S. A Practical Approach to VLSI System on Chip (SoC) Design; Springer: Berlin/Heidelberg, Germany, 2020. [Google Scholar]
- Swarbrick, I.; Gaitonde, D.; Ahmad, S.; Gaide, B.; Arbel, Y. Network-on-Chip Programmable Platform in VersalTM ACAP Architecture. In Proceedings of the 2019 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, Seaside, CA, USA, 24–26 February 2019; Association for Computing Machinery: New York, NY, USA, 2019; pp. 212–221. [Google Scholar]
- Dimitrakopoulos, G.; Psarras, A.; Seitanidis, I. Microarchitecture of Network-on-Chip Routers; Springer: New York, NY, USA, 2015. [Google Scholar]
- Soundari, D.; Ganesh, M.S.; Raman, I.; Karthick, R. Enhancing network-on-chip performance by 32-bit RISC processor based on power and area efficiency. Mater. Today Proc. 2021, 45, 2713–2720. [Google Scholar] [CrossRef]
- Das, T.S.; Ghosal, P.; Chatterjee, N. Virtual circuit switch based orderly delivery of packets in adaptive NoC routing. In Proceedings of the 12th International Workshop on Network on Chip Architectures, Columbus, OH, USA, 13 October 2019; pp. 1–6. [Google Scholar]
- Aweya, J. Switch/Router Architectures: Shared-Bus and Shared-Memory Based Systems; IEEE Series on Mobile & digital Communication; Wiley: Hoboken, NJ, USA, 2018. [Google Scholar]
- Dananjayan, P.; Vanga, K.R. Low Latency NoC Switch using Modified Distributed Round Robin Arbiter. J. Eng. Sci. Technol. Rev. 2021, 14, 76–84. [Google Scholar]
- Karol, M.; Hluchyj, M.; Morgan, S. Input Versus Output Queueing on a Space-Division Packet Switch. IEEE Trans. Commun. 1987, 35, 1347–1356. [Google Scholar] [CrossRef]
- Mohtavipour, S.M.; Mollajafari, M.; Naseri, A. A novel packet exchanging strategy for preventing HoL-blocking in fat-trees. Clust. Comput. 2020, 23, 461–482. [Google Scholar] [CrossRef]
- Papaphilippou, P.; Sano, K.; Adhi, B.A.; Luk, W. Efficient Queue-Balancing Switch for FPGAs. In Proceedings of the 2021 International Conference on Field-Programmable Technology (ICFPT), Auckland, New Zealand, 6–10 December 2021; pp. 1–5. [Google Scholar]
- Gangwar, A.; Sreedharan, R.; Prasad, A.; Agarwal, N.K.; Gade, S.H. Topology Agnostic Virtual Channel Assignment and Protocol Level Deadlock Avoidance in a Network-on-Chip. In Proceedings of the 2021 58th ACM/IEEE Design Automation Conference (DAC), San Francisco, CA, USA, 5–9 December 2021; pp. 61–66. [Google Scholar]
- Guo, Y.; Zheng, H.; Wang, J.; Xiao, S.; Li, G.; Yu, Z. A Low-Cost and High-Throughput Virtual-Channel Router with Arbitration Optimization. In Proceedings of the 2019 IEEE International Conference on Integrated Circuits, Technologies and Applications (ICTA), Chengdu, China, 13–15 November 2019; pp. 75–76. [Google Scholar]
- Avani, P.; Agrawal, S. Efficient Dynamic Virtual Channel Architecture for NoC Systems. In Proceedings of the 2018 International Conference on Advances in Computing, Communications and Informatics (ICACCI), Bangalore, India, 19–22 September 2018; pp. 2502–2507. [Google Scholar]
- Papaphilippou, P.; Meng, J.; Gebara, N.; Luk, W. Hipernetch: High-Performance FPGA Network Switch. ACM Trans. Reconfigurable Technol. Syst. (TRETS) 2021, 15, 1–31. [Google Scholar] [CrossRef]
- Mei, L.C.; Qiao, L.F.; Chen, Q.H.; Yang, L.; Yang, J. A Packet Dispatching Scheme with Load Balancing Based on iSLIP for Satellite Onboard CIOQ Switches. In Lecture Notes in Electrical Engineering, Proceedings of the International Conference in Communications, Signal Processing, and Systems; Springer: Berlin/Heidelberg, Germany, 2016; pp. 77–85. [Google Scholar]
- Han, K.E.; Song, J.; Kim, D.U.; Youn, J.; Park, C.; Kim, K. Grant-Aware Scheduling Algorithm for VOQ-Based Input-Buffered Packet Switches. ETRI J. 2018, 40, 337–346. [Google Scholar] [CrossRef]
- Gupta, P.; McKeown, N. Designing and implementing a fast crossbar scheduler. IEEE Micro 1999, 19, 20–28. [Google Scholar] [CrossRef]
- Mirhosseini, A.; Sadrosadati, M.; Aghamohammadi, F.; Modarressi, M.; Sarbazi-Azad, H. BARAN: Bimodal Adaptive Reconfigurable-Allocator Network-on-Chip. ACM Trans. Parallel Comput. 2019, 5, 1–29. [Google Scholar] [CrossRef]
- Chao, H.; Lam, C.; Guo, X. A fast arbitration scheme for terabit packet switches. In Proceedings of the Seamless Interconnection for Universal Services, Global Telecommunications Conference, GLOBECOM’99, (Cat. No.99CH37042), Rio de Janeiro, Brazil, 5–9 December 1999; Volume 2, pp. 1236–1243. [Google Scholar]
- Khan, A.A.; Mir, R.N.; Din, N.U. Adaptive hybrid arbiter design for real-time traffic-aware scheduling. Circuit World 2021, 48, 185–203. [Google Scholar] [CrossRef]
- Shin, E.S.; Mooney, V.J.; Riley, G.F. Round-Robin Arbiter Design and Generation. In Proceedings of the 15th International Symposium on System Synthesis, Kyoto, Japan, 2–4 October 2002; Association for Computing Machinery: New York, NY, USA, 2002; pp. 243–248. [Google Scholar]
- Monfared, J.R.; Mousavi, A. Design and simulation of nano-arbiters using quantum-dot cellular automata. Microprocess Microsyst. 2020, 72, 102926. [Google Scholar] [CrossRef]
- Zheng, S.Q.; Yang, M. Algorithm-Hardware Codesign of Fast Parallel Round-Robin Arbiters. IEEE Trans. Parallel Distrib. Syst. 2007, 18, 84–95. [Google Scholar] [CrossRef]
- Ahmed, A.B.; Fujiki, D.; Matsutani, H.; Koibuchi, M.; Amano, H. AxNoC: Low-power Approximate Network-on-Chips using Critical-Path Isolation. In Proceedings of the 2018 Twelfth IEEE/ACM International Symposium on Networks-on-Chip (NOCS), Torino, Italy, 4–5 October 2018; pp. 1–8. [Google Scholar]
- Monemi, A.; Ooi, C.Y.; Palesi, M.; Marsono, M.N. Ping-lock round robin arbiter. Microelectron. J. 2017, 63, 81–93. [Google Scholar] [CrossRef]
- Turko, T.; Uhring, W.; Dadouche, F.; Fesquet, L. An Asynchronous Fixed Priority Arbiter for High througput Time Correlated Single Photon Counting Systems. In Proceedings of the 2018 25th IEEE International Conference on Electronics, Circuits and Systems (ICECS), Bordeaux, France, 9–12 December 2018; pp. 765–768. [Google Scholar]
- Thakur, G.; Sohal, H.; Jain, S. Design and Analysis of High-Speed Parallel Prefix Adder for Digital Circuit Design Applications. In Proceedings of the 2020 International Conference on Computational Performance Evaluation (ComPE), Shillong, India, 2–4 July 2020; pp. 095–100. [Google Scholar]
- van Pinxten, J.; Geilen, M.; Hendriks, M.; Basten, T. Parametric Critical Path Analysis for Event Networks With Minimal and Maximal Time Lags. IEEE Trans.-Comput.-Aided Des. Integr. Circuits Syst. 2018, 37, 2697–2708. [Google Scholar] [CrossRef]
- Gayathri, S.; Taranath, T.C. RTL synthesis of case study using design compiler. In Proceedings of the 2017 International Conference on Electrical, Electronics, Communication, Computer, and Optimization Techniques (ICEECCOT), Mysuru, India, 15–16 December 2017; pp. 1–7. [Google Scholar]
- Virtex-7 XT VC709 Connectivity Kit. Available online: https://docs.xilinx.com/v/u/en-US/ug966-v7-xt-connectivity-getting-started (accessed on 1 December 2022).
- Taraate, V. ASIC and FPGA Synthesis. In Advanced HDL Synthesis and SOC Prototyping; Springer: Berlin/Heidelberg, Germany, 2019; pp. 159–172. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Priority | State | Priority Order |
|---|---|---|
| 4’b0001 | 00 | |
| 4’b0010 | 01 | |
| 4’b0100 | 10 | |
| 4’b1000 | 11 |
| Arbiter | Critical Path | Arbiter Logic Gate (N = 256) | Fariness |
|---|---|---|---|
| PPA | 16 | unfair | |
| SA | 15 | unfair | |
| PRRA | 35 | fair | |
| IPRRA | 20 | fair | |
| PLA | 15 | fair | |
| FSA | 14 | fair |
| Port Number | PPA [19] (Unfair) | SA [21] (Unfair) | PRRA [23] | IPRRA [23] | PLA [25] | FSA |
|---|---|---|---|---|---|---|
| N = 4 | 0.15 | 0.14 | 0.20 | 0.20 | 0.19 | 0.14 |
| N = 8 | 0.21 | 0.20 | 0.26 | 0.25 | 0.24 | 0.21 |
| N = 16 | 0.27 | 0.23 | 0.34 | 0.30 | 0.28 | 0.23 |
| N = 32 | 0.34 | 0.29 | 0.40 | 0.36 | 0.33 | 0.26 |
| N = 64 | 0.42 | 0.35 | 0.46 | 0.40 | 0.37 | 0.28 |
| N = 128 | 0.50 | 0.37 | 0.54 | 0.48 | 0.43 | 0.33 |
| N = 256 | 0.61 | 0.41 | 0.58 | 0.53 | 0.50 | 0.37 |
| N = 512 | 0.68 | 0.45 | 0.67 | 0.61 | 0.54 | 0.42 |
| Average | 100% | 76% | 108% | 98% | 90% | 70% |
| Port Number | PPA [19] Unfair | SA [21] Unfair | PRRA [23] | IPRRA [23] | PLA [25] | FSA |
|---|---|---|---|---|---|---|
| N = 4 | 342 | 402 | 341 | 366 | 318 | 404 |
| N = 8 | 827 | 958 | 785 | 783 | 865 | 1076 |
| N = 16 | 1694 | 1930 | 1534 | 1540 | 1903 | 2015 |
| N = 32 | 3288 | 3844 | 2582 | 2864 | 3765 | 3713 |
| N = 64 | 6773 | 7722 | 5346 | 5977 | 7331 | 6936 |
| N = 128 | 13,052 | 15,559 | 10,255 | 10,793 | 14,135 | 13,761 |
| N = 256 | 25,113 | 30,826 | 21,121 | 21,482 | 28,231 | 26,704 |
| N = 512 | 50,319 | 60,844 | 40,891 | 41,940 | 54,470 | 52,608 |
| Average | 100% | 120% | 81% | 85% | 109% | 105% |
| Frequency | PPA [19] | SA [21] | PRRA [23] | IPRRA [23] | PLA [25] | FSA |
|---|---|---|---|---|---|---|
| 250 MHz | (3.6 ns) | (3.5 ns) | (3.9 ns) | (3.7 ns) | (3.7 ns) | (3.4 ns) |
| 300 MHz | (3.3 ns) | (3.2 ns) | (3.3 ns) | (3.1 ns) | (3.3 ns) | (3.1 ns) |
| 400 MHz | (2.3 ns) | (2.4 ns) | (2.3 ns) | (2.4 ns) | (2.4 ns) | (2.4 ns) |
| Port Number | PPA [19] | SA [21] | PRRA [23] | IPRRA [23] | PLA [25] | FSA |
|---|---|---|---|---|---|---|
| N = 4 | 7/11 | 8/12 | 7/12 | 7/12 | 10/11 | 6/11 |
| N = 8 | 21/23 | 22/28 | 18/24 | 20/24 | 25/23 | 27/24 |
| N = 16 | 49/47 | 48/56 | 48/48 | 48/48 | 57/47 | 65/48 |
| N = 32 | 104/95 | 106/116 | 96/96 | 93/96 | 127/95 | 122/96 |
| N = 64 | 215/191 | 204/232 | 199/192 | 201/192 | 257/191 | 231/192 |
| N = 128 | 432/384 | 449/468 | 393/384 | 389/384 | 532/384 | 447/384 |
| N = 256 | 883/767 | 836/936 | 859/768 | 839/769 | 1102/767 | 904/768 |
| Avg(LUT) | 100% | 97% | 94% | 93% | 123% | 105% |
| Avg(FF) | 100% | 122% | 100% | 100% | 100% | 100% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Luo, J.; Wu, W.; Xing, Q.; Xue, M.; Yu, F.; Ma, Z. A Low-Latency Fair-Arbiter Architecture for Network-on-Chip Switches. Appl. Sci. 2022, 12, 12458. https://doi.org/10.3390/app122312458
Luo J, Wu W, Xing Q, Xue M, Yu F, Ma Z. A Low-Latency Fair-Arbiter Architecture for Network-on-Chip Switches. Applied Sciences. 2022; 12(23):12458. https://doi.org/10.3390/app122312458
Chicago/Turabian StyleLuo, Jifeng, Wenqi Wu, Qianjian Xing, Meiting Xue, Feng Yu, and Zhenguo Ma. 2022. "A Low-Latency Fair-Arbiter Architecture for Network-on-Chip Switches" Applied Sciences 12, no. 23: 12458. https://doi.org/10.3390/app122312458
APA StyleLuo, J., Wu, W., Xing, Q., Xue, M., Yu, F., & Ma, Z. (2022). A Low-Latency Fair-Arbiter Architecture for Network-on-Chip Switches. Applied Sciences, 12(23), 12458. https://doi.org/10.3390/app122312458