Abstract
A new two-parameter power Zeghdoudi distribution (PZD) is suggested as a modification of the Zeghdoudi distribution using the power transformation method. As a result, the PZD may have increasing, decreasing, and unimodal probability density function and decreasing mean residual life function. In addition, other properties are presented, such as moments, order statistics, reliability measures, Bonferroni and Lorenz curves, Gini index, stochastic ordering, mean and median deviations, and quantile function. Following this, a section is devoted to the related model parameters which are estimated using the maximum likelihood estimation method, the weighted least squares and least squares methods, the maximum product of spacing method, the Cramer–von Mises method, and the right-tail and left-tail Anderson–Darling methods, and the Nikulin–Rao–Robson test statistic is considered. A simulation study is conducted to assess these methods and to investigate the distribution properties with right-censored data. The applicability of the proposed model is studied based on three real data sets of failure times, bladder cancer patients, and glass fiber data with a comparison with such competitors as the gamma, xgamma, Lomax, Darna, power Darna, power Lindley, and exponentiated power Lindley models. According to several established criteria, the comparative findings are overwhelmingly favorable to the suggested model.
1. Introduction
Ref. [1] investigated the characteristics of the Lindley distribution (LD) in great depth. According to [2], there are some circumstances in which the LD may not be appropriate from a theoretical or applied point of view. Due to this, ref. [2] introduced the power Lindley (PL) distribution, a more adaptable distribution, using a power transformation method. Ref. [2] showed that based on the values of the parameters, the hazard function of the PL distribution can rise, decrease, or decrease–increase–decrease. Some of the other distributions that have been suggested utilizing the power transformation method are the power Shanker distribution by [3], the power Ishita and Aradhana distributions by [4], and the power Rama and Garima distributions by [5,6]. The power Ishita distribution is proposed by [7], the power Sujatha distribution is considered by [8], and the power Prakaamy distribution is proposed by [9]. In addition, ref. [10] suggested the power half-logistic distribution, ref. [11] introduced the power binomial exponential distribution, ref. [12] proposed the power length-biased Suja distribution, ref. [13] discussed a novel three-parameter distribution known as the power Darna distribution (PDD), ref. [14] offered the power XLindley distribution, and ref. [15] proposed the power-modified Kies-exponential distribution. All of the power-transformed distributions are shown to be more adaptable than their respective baseline distributions, and more effective for analyzing complicated data structures in various spheres of life.
Ref. [16] provided a novel lifetime distribution with one parameter for modeling lifetime data from engineering and medical science, known as Zeghdοudi distribution (ZD), with a cumulative distribution function (cdf) given by
and a survival function defined as
The probability density function (pdf) of the ZD is
and its hazard function has the form
The ZD has the mean , variance coefficient of skewness , and coefficient of kurtosis .
According to [16], the maximum likelihood (MLE) and method of moment (MOM) estimators of the distribution parameter have the same forms as
where .
The accuracy of the parametric distributions is tested using several statistical methods. Numerous fresh initiatives are investigated to address these problems. Based on the well-known Kaplan and Meyer estimators, refs. [17,18] recommended a new form of the Chi-squared test for randomly censored actual data. Then, for the accelerated loss distributions, ref. [19] assumed certain nonparametric adjustments for the Kolmogorov-Smirnov statistic (KSS), Anderson–Darling statistic (ADS), and Cramer–von Mises statistic (KVMS). A different Chi-squared GOF test statistic is recently presented and demonstrated by [20] for the correct censored data. For distributional validation using right-censored approaches, Bagdonavicius and Nikulin’s (B-N) is the most current Chi-squared GOF test statistic in use.
The B-N GOF test and a new modified Chi-square GOF test are both utilized in this research to provide a censored maximum likelihood estimation for the right-censored validation. The results are checked for accuracy using a modified GOF statistical test on the right-censored actual data set. A modified GOF test that is based on the censored maximum likelihood estimators on the initial data is able to recover the information loss, whereas the grouped data have a Chi-square distribution. The modified criteria tests’ components are attained. Finally, the filtered technique is demonstrated with real-world data set applications for validation.
To the best of our knowledge, this paper is the first to suggest the power Zeghdoudi distribution, which offers more precision and flexibility for fitting actual data than some of the competitors considered in this study. The following sections make up the article: The density and cumulative distribution functions of the PZD are provided in Section 2 with graphical representations. The statistical properties of the PZD and related measures are described in Section 3. Various estimation techniques are presented in Section 4 and some simulations are given in Section 5. Applications of three actual real data sets in engineering and medical sciences are provided in Section 6. Closing observations and recommendations for further works are formulated in Section 7.
2. The Power Zeghdοudi Distribution
In this section, based on the same power transformation considered by [2], a random variable X is said to have a power Zeghdοudi distribution with parameters and if its survival function is given by
Figure 1 involves some plots of the survival function of the PZD for some distribution parameters. We can note that the survival function of the PZD has many shapes, such as decreasing–constant (, ) and decreasing (, ), which are heavy-tailed to the right.
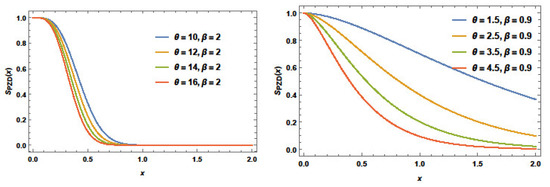
Figure 1.
Plots of the PZD survival function for different parameter values.
Hence, from (3) the corresponding cdf of PZD is given by
It is clear that for , the PZD reduces to the ZD. Plots of the PZD cdf for some selections of and are presented in Figure 2. It is noted that the cdf shapes of the PZD vary with the distribution parameter values.
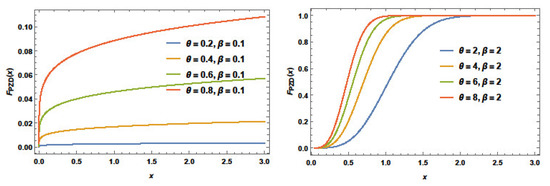
Figure 2.
Plots of the cdf of PZD for selected values of and .
The pdf of the PZD can be obtained by taking the derivative of as
Different PZD pdf plots are given in Figure 3 with various parameters. The suggested distribution pdf is asymmetric, unimodal, semi-symmetric (,), increasing–decreasing (,), skewed to the left (,), and skewed to the right (,), according to the parameter’s values.

Figure 3.
Pdf plots of the PZD with various values of parameters.
The Mode PZD
The logarithm of the PZD pdf given in Equation (4) is
The first derivative of this equation with respect to x is
Let to obtain the mode of the distribution as
3. Statistical Properties
In this section, some of the main statistical properties of the PZD are derived and some simulations are provided.
3.1. Moments
The rth moment about the origin of the PZD is defined as
and hence the mean of the distribution is
The inverse moment of the PZD is
While kurtosis of a random variable measures the degree of tail heaviness, skewness of a random variable measures the degree of long-tail. The coefficient of skewness , coefficient of variation , and coefficient of kurtosis of the PZD are given, respectively, by
where
Table 1 gives the mean , standard deviation , , , and of the PZD for various selections of the parameters.

Table 1.
Values of for the PZD for selected parameters.
The results in Table 1 indicate that the distribution is skewed to the right for these parameter value selections, with relatively small values of skewness. In addition, it is noted that the mean and variance values are decreasing as one parameter’s values are increasing for a fixed value of the other parameter.
3.2. Order Statistics
Let be a random sample selected from PZD with cdf (4) and pdf (5) and be its order statistics; then, the pdf of the ith order statistic, , is given by
For and m in (12), the pdfs of the smallest and largest order statistics, respectively, are given by
and
Figure 4 represents the three-dimensional plots of the minimum and maximum pdfs with , and .
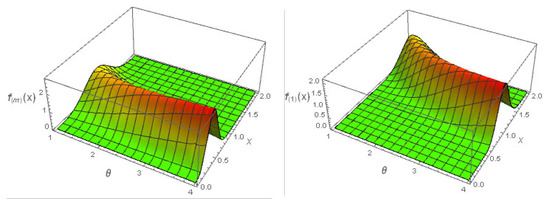
Figure 4.
Three-dimensional plots of maximum and minimum pdf of the PZD for .
3.3. Reliability Measures
The reliability and hazard functions of any lifetime equipment are the fundamental tools for analyzing aging and associated features. The conditional probability of failure, assuming it has lasted up to time , is represented by the hazard function. The hazard, reversed hazard rate, and odds functions of the PZD are given, respectively, by
Plots of the hazard, reversed hazard rate, and odds functions of the PZD are illustrated in Figure 5, Figure 6, and Figure 7, respectively.
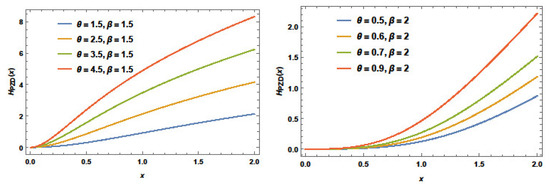
Figure 5.
The hazard function plots of PZD for various values of parameters.
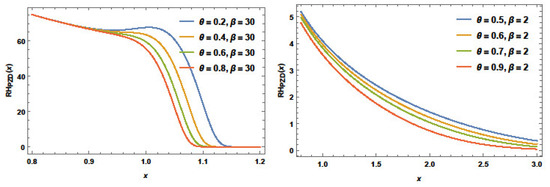
Figure 6.
The RHF plots of PZD for various values of parameters.
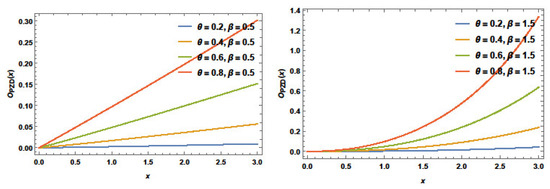
Figure 7.
The odds function plots of PZD for selected values of parameters.
Mean residual life (MRL) is crucial in demography, reliability, and survival analysis. The mean residual life function of PZD is defined as
MRL plots of the PZD for some particular parameters are offered in Figure 8. This figure reveals that the MRL for PZD is decreasing for these values with different behavior decreasing–constant and decreasing .
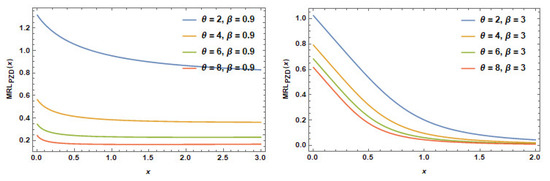
Figure 8.
The MRL plots of PZD for selected values of .
Remark 1.
It is to be noted that.
3.4. Mean and Median Deviations
The mean deviations from the mean and median, which are both essential measurements of the scatter in the population, are defined as
and
where and m is the population median.
3.5. Quantile Function and Stochastic Ordering
In this section, the quantile function and stochastic ordering are presented and discussed.
3.5.1. Quantile Function
Let given in (4). The quantile function, say , defined by , is the root of the equation
Table 2 presents some quantile values for some choices of p where the real and positive roots are assigned. It can be noted that the values are increasing in p.
Table 2.
Values for some selected values of p.
3.5.2. Stochastic Ordering
To define the stochastic ordering, a random variable X is smaller than a random variable Y in the following:
- (1)
- Mean residual life order , if for all t.
- (2)
- Likelihood ratio order , if decreases for all t.
- (3)
- Hazard rate order , if for all t.
- (4)
- Stochastic order , if for all t.
Remark 2.
.
Theorem 1.
Letandbe two random variables. If (,), or (with), then, and thus,and.
Proof.
Let and . Therefore,
For simplification, we have
Thus,
To this end, if (, ), or ( with ), then This shows that , and according to Remark 2, the theorem is proved. □
3.6. Some Curves and Gini Index
Assume that X is a continuous random variable with a non-negative, twice-differentiable cumulative distribution function. The Bonferroni curve of the random variable X is defined as
and , and the Lorenz curve is given as
The Gini index of the PZD can be expressed as
4. Methods of Estimation and Test
As is well known, the properties of maximum likelihood estimators are not always verified for small samples. Therefore, in recent years, classical and new estimation methods have been developed. One purpose of this work is to investigate different methods to estimate the unknown distribution parameters of the new model, such as maximum likelihood estimation (MLE), ordinary least square (LS), weighted least square (WLS), maximum product of spacing (MPS), Cramer–von Mises estimation (CME), and Anderson–Darling estimation (ADE) methods based on the empirical function distribution. In addition, the Nikulin–Rao–Robson test is considered in this section.
4.1. The MLE
Because of their properties, the maximum likelihood estimators are preferred in providing the values of the unknown parameters. Considering to be a random sample following the with parameters , the log-likelihood function becomes
The maximum likelihood estimators and of the unknown parameters and respectively, can be obtained from the following nonlinear score equations as
Hence,
In addition,
The simultaneous solution of the above likelihood equations constitutes the MLEs of and . However, analytical solutions are not feasible. Therefore, using R Core Team [21] software, we approximated the solution to the aforementioned normal equations. In addition, we have
and
4.2. Methods of LS and WLS
As the explicit forms of the maximum likelihood estimators cannot be obtained every time, some other methods are developed to overcome this problem. The LS and the WLS are well-known methods used for estimating unknown parameters [22]. Here, we consider these two approaches for estimating the unknown parameters of the . Let be the ordered observations obtained from a sample of size from the . By calculating the minimum of the function
with respect to and respectively, the LS estimates and can be obtained by setting , while we can obtain the estimates and by setting The following equations can be solved to yield these estimates as well as
where
4.3. Method of Maximum Product of Spacing
According to [23], and based on the differences among the values of the cdf at successive data points, the maximum product of spacing is an estimation method as interesting as that of MLE. Moreover, ref. [24] concluded that the estimator method outperforms all the other estimator methods.
The uniform spacings can be defined using a random sample of size n from a distribution with cdf as follows:
where and . The estimates denoted by and maximize the function with respect to the unknown parameters and as
or by solving the subsequent equations
where and are given earlier. For more details on this method, see [25].
4.4. Cramer–Von Mises and Anderson–Darling Methods
In recent years, some authors have used classical GOF statistics such as Cramer–von Mises and Anderson–Darling statistics to derive the estimators of the unknown parameters. Ref. [26] used these methods for the binomial-exponential 2 distributions, while [27] evaluated the process capability index for normal distribution. Aside from these methods and using this approach, we propose the use of the Pearson Chi-square statistic where the estimators noted are obtained by calculating the minimum of with respect to the unknown parameters.
Ref. [28] and later [29] showed that the Cramer–von Mises estimates based on the distance of Cramer–von Mises GOF statistics are the least biased compared to the other estimators. For calculation purposes, ref. [29] gives the formula for this statistic, where the estimators ensure its minimum concerning the unknown parameters, where
They also can be gained as the solution of the subsequent equations:
The Anderson–Darling estimation method is based on the classical Anderson and Darling goodness-of-fit statistic test proposed by [30]. This statistic is essentially used to fit data to a theoretical hypothesized model When the parameters are unknown, they can be estimated by , which minimize the statistic given in the form
which is equivalent to canceling the first derivatives of this function with respect to and . For more details on this method, see [29]. In their paper, ref. [31] showed that the estimation method gives the most efficient estimators. As is known, the Anderson–Darling statistic gives more weight to the tails of the distribution, so for right- or left-tailed distributions, the right tail ( and left tail ( can be considered for estimating the unknown parameters, as in [27,31,32].
The estimators of and denoted by , , respectively, are found by minimizing the equation given by
or
Similarly, the estimators denoted by , are acquired by minimizing the equation
or
with respect to the unknown distribution parameters. For more about the Anderson–Darling estimators, see [27,31,32]. Conversely, ref. [33] demonstrated that the minimum-distance estimation method is a highly competitive method compared to the estimation. In addition, ref. [24] confirmed the superiority of this method.
4.5. The Nikulin–Rao–Robson Test
The probability distribution used to describe any phenomenon is very important in this analysis. Since the twentieth century, researchers have continued to develop techniques to validate the different models. In addition to the classical procedures, we considered in this work a criteria test statistic based on the Nikulin–Rao–Robson statistic (NRR) to fit data to the . The great interest of the NRR statistic is that it recovers all the information lost while grouping data. Based on the MLE on initial data, this statistic introduced by [34,35] is a modification of the well-known Chi-square Pearson statistic . For testing the null hypothesis , given by
According to the above, the sample belongs to the parametric family with unknown parameters, and consists in grouping data into equiprobable intervals ..., where
such as
If represents the number of observed grouping into these intervals , and the vector is given by
The NRR statistic is defined as
where and are the estimated information matrices on non-grouped and grouped data, respectively, and is the vector of the ML estimators on initial data. The components of the vector and the matrix are
where represents the number of parameters. The distribution of is a Chi-square with degrees of freedom. To construct the test statistic corresponding to the PZD we calculated the ML estimators the limit intervals , and the derivatives for our model.
Then, after computing the estimated information matrices and , we obtained the statistic for the distribution. This method is used to construct GOF test statistics for some generalized models; for examples see [36,37,38,39].
5. Simulations
In this section, we investigate the performance of the estimation procedures used in this paper. To that end, we generated samples with different sizes ( , and from the model, and then computed the different estimators and their mean square errors (MSE) (values in brackets) for the unknown parameters using R statistical software when and . The results are given by sample size in Table 3.
Table 3.
Estimators’ values of and with different estimation methods.
Based on Table 2, it can be noted that the bias and MSE values of different estimators decrease as the sample size increases. For example, when with and , the MLE values are and , respectively. In addition, for the same case of , , and , the values of the LSE are and respectively. In general, we can say that the LSE method performs better than other methods up to , while the MLE is the best one for in terms of the MSE.
6. Applications
The analysis of three real data sets is considered to show the usefulness of the proposed distribution in modeling different phenomena and the performances of the methods used to determine the unknown parameters. In addition to the traditional model selection techniques, we calculated the statistic to prove that the proposed model fits some data sets better than some commonly used alternative distributions, such as:
- -
- The xgamma distribution suggested by [40] with pdf given by
- -
- Gamma distribution with pdf given by
- -
- Lomax distribution with pdf given by
- -
- Darna distribution proposed by [41] with pdf given by
- -
- Power Darna distribution introduced by [13] with pdf given by
- -
- Power Lindley distribution proposed by [2] with pdf defined as
- -
- Exponentiated power Lindley distribution (EPLD) offered by [42] with pdf given by
6.1. First Data: Failure Times of Devices
The first real data set refers to the failure times of 50 items put under a life test. It is generally known that this data set displays bathtub behavior of the hazard rate function [43]. This data set has been analyzed by many authors. The data are 0.1, 1.0, 1.0, 1.0, 2.0, 3.0, 82.0, 83.0, 84.0, 6.0, 7.0, 11.0, 36.0, 40.0, 45.0, 12.0, 18.0, 18.0, 21.0, 18.0, 0.2, 1.0, 1.0, 18.0, 18.0, 32.0, 45.0, 47.0, 63.0, 63.0, 67.0, 67.0, 50.0, 55.0, 60.0, 67.0, 67.0, 72.0, 85.0, 85.0, 85.0, 85.0, 75.0, 79.0, 82.0, 84.0, 84.0, 85.0, 86.0, 86.0. Figure 9 displays the density, total time on test transform (TTT), probability–probability (P–P) plot, and quantile–quantile (Q–Q) plot of the PZD for the failure times data.
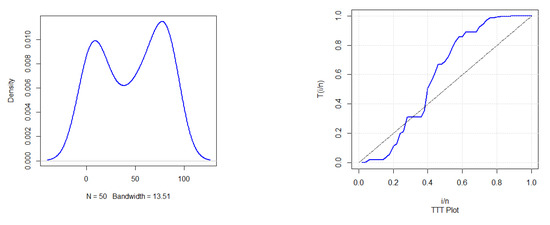
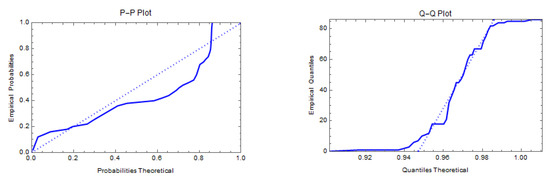
Figure 9.
The density, TTT, P–P, and Q–Q plots of the PZD for the failure times data.
Table 4 represents the values of the parameter estimators for the hypothesized distribution obtained by the different methods, and Kolmogorov–Smirnov (KS) and the corresponding p-values. Because it is established by the simulation study that the methods give the best results.
Table 4.
Different parameter estimators for failure times data.
As the maximum likelihood parameter estimators for the competing distributions are required to calculate their corresponding NRR test statistic , the MLE values are calculated and given in Table 5.
Table 5.
ML parameter estimates for the alternative distributions based on failure times data.
To distinguish between the proposed model and its alternatives, we used classical criteria for model selection, and the NRR statistics with the corresponding values are summarized in Table 6.
Table 6.
Values of criteria statistics for model selection based on failure times data.
From Table 6, we can see that the smallest values of the different criteria for model selection are obtained for the PZD, which confirms that the proposed PZD model describes these data better than all the alternatives.
6.2. Second Data: Remission Times
The second case addressed the lengths of remission times (in months) of 128 bladder cancer patients who are randomly selected, as reported by [44]. The data observations are 0.08, 4.87, 6.94, 8.66, 2.09, 3.48, 13.11, 23.63, 0.20, 13.80, 25.74, 0.50, 2.23, 3.52, 4.98, 6.97, 9.02, 3.88, 5.32, 7.39, 10.34, 13.29, 0.40, 2.26, 9.22, 2.46, 3.64, 5.09, 7.26, 0.51, 2.54, 14.76, 26.31, 0.81, 3.70, 5.17, 7.28, 9.47, 14.24, 25.82, 9.74, 2.62, 3.82, 5.32, 2.69, 4.23, 5.41, 7.62, 7.32, 10.06, 14.77, 32.15, 2.64, 14.83, 34.26, 4.33, 5.49, 7.66, 0.90, 5.34, 7.59, 10.66, 15.96, 2.69, 4.18, 36.66, 12.05, 10.75, 16.62, 43.01, 5.41, 7.63, 11.25, 17.14, 79.05, 17.12, 46.12, 4.40, 5.85, 8.26, 1.26, 2.83, 1.35, 2.87, 5.62, 1.19, 2.75, 4.26, 7.87, 11.64, 4.34, 5.71, 7.93, 11.79, 17.36, 1.40, 3.02, 18.10, 1.46, 11.98, 19.13, 12.02, 2.02, 3.31, 1.76, 3.25, 12.03, 20.28, 2.02, 4.50, 6.25, 8.37, 4.51, 6.54, 8.53, 3.36, 6.76, 8.65, 12.63, 22.69, 12.07, 21.73, 3.57, 5.06, 7.09, 2.07, 3.36, 6.93. Figure 10 represents the density, TTT, P–P, and Q–Q plots of the PZD for the 128 bladder cancer patients’ data. Various parameter estimators based on cancer patients’ data are summarized in Table 7.
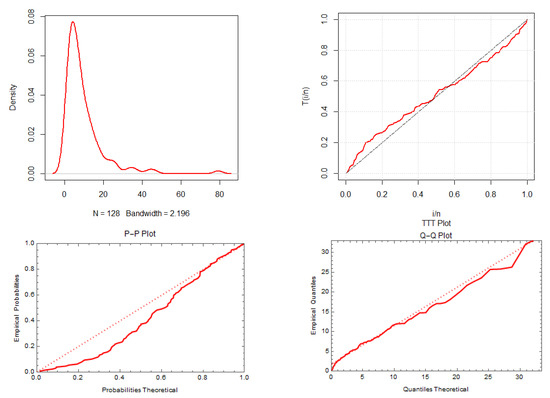
Figure 10.
The density, TTT, P–P, and Q–Q plots of the PZD for bladder cancer patients’ data.
Table 7.
Different parameter estimators for cancer patients’ data.
As the ML parameter estimators for the competing distributions are needed to compute their corresponding NRR test statistic , the MLE values are calculated and given in Table 8.
Table 8.
ML parameter estimates for the alternative distributions based on cancer patients’ data.
To show that this model can also describe this type of data, we used all classical criteria for model selection and the modified Chi-square NRR. All of the corresponding values are computed and given in Table 9.
Table 9.
Values of criteria statistics for model selection based on cancer patients’ data.
From Table 9, we can see that the smallest values of the different criteria for model selection are obtained for the PZD, which confirms that the proposed model describes these data better than all the alternatives considered here.
6.3. Third Data: Strengths of 1.5 cm Glass Fibers
We then considered the data set representing the strengths of 1.5 cm glass fibers. The data set is also analyzed by [45,46]. The data are 0.55, 0.93, 1.25, 1.36, 1.49, 1.52, 1.58, 1.61, 1.64, 1.68, 1.73, 1.81, 2.00, 0.74, 1.04, 1.27, 1.39, 1.49, 1.53, 1.59, 1.61, 1.66, 1.68, 1.76, 1.82, 2.01, 0.77, 1.11, 1.28, 1.42, 1.50, 1.54, 1.60, 1.62, 1.66, 1.69, 1.76, 1.84, 2.24, 0.81, 1.13, 1.29, 1.48, 1.50, 1.55, 1.61, 1.62, 1.66, 1.70, 1.77, 1.84, 0.84, 1.24, 1.30, 1.48, 1.51, 1.55, 1.61, 1.63, 1.67, 1.70, 1.78, 1.89. Figure 11 represents the density, TTT, P–P, and Q–Q plots of the PZD for the glass fiber data.
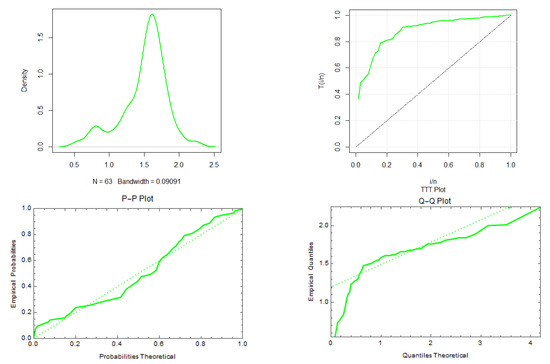
Figure 11.
The density, TTT, P–P, and Q–Q plots of the PZD with glass fiber data.
Table 10 represents the values of the parameter estimators for the hypothesized distribution PZD obtained by the different methods and the corresponding p-values.
Table 10.
Different parameter estimators with glass fiber data.
As the maximum likelihood parameter estimators for the competing distributions are needed to compute their corresponding NRR test statistic Y2, the MLE values are calculated and given in Table 11.
Table 11.
ML parameter estimates for the alternative distributions with glass fiber data.
To show that this model can also describe this type of data, we used all classical criteria for model selection and the modified chi-square NRR. All the corresponding values are computed and given in Table 12.
Table 12.
Values of criteria statistics for model selection with glass fiber data.
7. Conclusions and Suggestions
The power transformation approach is used in this research to generalize the Zeghdoudi distribution of one parameter to a power Zeghdoudi distribution of two parameters. Some statistical properties, including moments, reliability functions, order statistics, Bonferroni and Lorenz curves, Gini index, stochastic ordering, quantile function, and mean and median deviations are derived. Numerous estimation techniques are considered, such as the maximum likelihood estimation, least squares, weighted least squares, maximum product of spacing methods, the Cramer–von Mises method, and the right-tail and left-tail Anderson–Darling estimation methods. A simulation study is carried out to assess these estimation approaches and determine the distribution properties. Three actual data sets are examined and fitted and the Anderson–Darling and Nikulin–Rao–Robson test statistics are considered for the novel PZD to investigate the distribution’s applicability in different fields compared with the gamma, xgamma, Lomax, Darna, power Darna, power Lindley, and exponentiated power Lindley models. It is found that PZD often performs better than other distributions in fitting the three data sets considered in this study. In addition, the MSE values of different proposed estimators decrease for increased values of the sample size. Future work could include bivariate extensions, transmutation extensions, discrete extensions, and additional regression models. In addition, the PZD parameters can be estimated using the ranked set sampling method and some of its modifications. See [47] for stratified median ranked set sampling and [48] for double percentile ranked set samples.
Author Contributions
Conceptualization, A.I.A.-O.; Methodology, K.A. and A.I.A.-O.; Software, K.A. and A.I.A.-O.; Formal analysis, K.A.; Investigation, K.A., A.I.A.-O. and R.A.; Data curation, K.A.; Writing—original draft, K.A., A.I.A.-O. and R.A.; Writing—review & editing, A.I.A.-O. and R.A.; Funding acquisition, R.A. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
The data used in this study are available within the paper.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Ghitany, M.E.; Atieh, B.; Nadarajah, S. Lindley distribution and its application. Math. Comput. Simul. 2008, 78, 493–506. [Google Scholar] [CrossRef]
- Ghitany, M.; Al-Mutairi, D.K.; Balakrishnan, N.; Al-Enezi, L. Power Lindley distribution and associated inference. Comput. Stat. Data Anal. 2013, 64, 20–33. [Google Scholar] [CrossRef]
- Shanker, R.; Shukla, K.K. Power Shanker distribution and its application. Turk. Klin. Biyoistatistik 2017, 9, 175–187. [Google Scholar] [CrossRef]
- Shanker, R.; Shukla, K.K. A two-parameter power Aradhana distribution with properties and application. Indian Soc. Ind. Appl. Math. 2018, 9, 210–220. [Google Scholar] [CrossRef]
- Abebe, B.; Tesfay, M.; Eyob, T.; Shanker, R. A two-parameter power Garima distribution with properties and applications. Annal. Biostat. Biomed. Appl. 2019, 1, 515. [Google Scholar]
- Abebe, B.; Tesfay, M.; Eyob, T.; Shanker, R. A two-parameter power Rama distribution with properties and applications. Biom. Biostat. Int. J. 2019, 8, 6–11. [Google Scholar]
- Shukla, K.K.; Shanker, R. Power Ishita distribution and its application to model lifetime data. Stat. Transit. New Ser. 2018, 19, 135–148. [Google Scholar] [CrossRef]
- Shanker, R.; Shukla, K.K. A two-parameter power Sujatha distribution with properties and application. Int. J. Math. Stat. 2019, 20, 11–22. [Google Scholar]
- Shukla, K.K.; Shanker, R. Power Prakaamy distribution and its applications. Int. J. Comput. Theor. Stat. 2020, 7, 25–36. [Google Scholar]
- Krishnarani, S. On a power transformation of half-logistic distribution. J. Probab. Stat. 2016, 2016, 2084236. [Google Scholar] [CrossRef]
- Habibi, M.; Asgharzadeh, A. Power binomial exponential distribution: Modeling, simulation and application. Commun. Stat.-Simul. Comput. 2018, 47, 3042–3061. [Google Scholar] [CrossRef]
- Al-Omari, A.; Alhyasat, K.; Ibrahim, K.; Abu Bakar, M. Power length-biased Suja distribution: Properties and application. Electron. J. Appl. Stat. Anal. 2019, 12, 429–452. [Google Scholar]
- Al-Omari, A.I.; Aidi, K.; Alsultan, R. Power Darna distribution with right censoring: Estimation, testing, and applications. Appl. Sci. 2022, 12, 8272. [Google Scholar] [CrossRef]
- Meriem, B.; Gemeay, A.M.; Almetwally, E.M.; Halim, Z.; Alshawarbeh, E.; Abdulrahman, A.T.; Hussam, E. The Power XLindley Distribution: Statistical Inference, Fuzzy Reliability, and COVID-19 Application. J. Funct. Spaces 2022, 2022, 9094078. [Google Scholar] [CrossRef]
- Afify, A.Z.; Gemeay, A.M.; Alfaer, N.M.; Cordeiro, G.M.; Hafez, E.H. Power-Modified Kies-Exponential Distribution: Properties, Classical and Bayesian Inference with an Application to Engineering Data. Entropy 2022, 24, 883. [Google Scholar] [CrossRef]
- Messaadia, H.; Zeghdoudi, H. Zeghdoudi distribution and its applications. Int. J. Comput. Sci. Math. 2018, 9, 58–65. [Google Scholar] [CrossRef]
- Habib, M.; Thomas, D. Chi-square goodness-if-fit tests for randomly censored data. Ann. Stat. 1986, 14, 759–765. [Google Scholar] [CrossRef]
- Hollander, M.; Pena, E.A. A chi-squared goodness-of-fit test for randomly censored data. J. Am. Stat. Assoc. 1992, 87, 458–463. [Google Scholar] [CrossRef]
- Galanova, N.; Lemeshko, B.Y.; Chimitova, E. Using nonparametric goodness-of-fit tests to validate accelerated failure time models. Optoelectron. Instrum. Data Process. 2012, 48, 580–592. [Google Scholar] [CrossRef]
- Bagdonavicius, V.; Nikulin, M. Chi-squared goodness-of-fit test for right censored data. Int. J. Appl. Math. Stat. 2011, 24, 30–50. [Google Scholar]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2020. [Google Scholar]
- Swain, J.J.; Venkatraman, S.; Wilson, J.R. Least-squares estimation of distribution functions in Johnson’s translation system. J. Stat. Comput. Simul. 1988, 29, 271–297. [Google Scholar] [CrossRef]
- Cheng, R.C.H.; Amin, N.A.K. Estimating parameters in continuous univariate distribution with a shifted origin. J. R. Stat. Soc. 1983, 45, 394–403. [Google Scholar] [CrossRef]
- Al-Mofleh, H.; Afify, A.Z. A generalization of Ramos-Louzada distribution: Properties and estimation, properties and estimation. arXiv 2019, arXiv:1912.08799v1. [Google Scholar]
- Cheng, R.C.H.; Stephens, M.A. A goodness-of-fit test using Moran’s statistic with estimated parameters. Biometrika 1989, 76, 385–392. [Google Scholar] [CrossRef]
- Bakouch, H.S.; Dey, S.; Ramos, P.L.; Louzada, F. Binomial-exponential 2 distribution: Different estimation methods with weather applications. TEMA 2017, 18, 233–251. [Google Scholar] [CrossRef]
- Saha, M.; Dey, S.; Yadav, A.S.; Ali, S. Confidence intervals of the index Cpk for normally distributed quality characteristics using classical and Bayesian methods of estimation. Braz. J. Probab. Stat. 2021, 35, 138–157. [Google Scholar] [CrossRef]
- MacDonald, P.D.M. Comment on an estimation procedure for mixtures of distributions” by choi and bulgren. J. R. Stat. Society. Ser. B (Methodol.) 1971, 33, 326–329. [Google Scholar]
- Boos, D.D. Minimum distance estimators for location and goodness of fit. J. Am. Stat. Assoc. 1981, 76, 663–667. [Google Scholar] [CrossRef]
- Anderson, T.W.; Darling, D.A. Asymptotic Theory of Certain “Goodness of Fit” Criteria Based on Stochastic Processes. Ann. Math. Statist. 1952, 23, 193–212. [Google Scholar] [CrossRef]
- Rodrigues, G.C.; Louzada, F.; Ramos, P.L. Poisson–exponential distribution. different methods of estimation. J. Appl. Stat. 2018, 45, 128–144. [Google Scholar] [CrossRef]
- ZeinEldin, R.A.; Ahsan ul Haq, M.; Hashmi, S.; Elsehety, M. Alpha power transformed inverse Lomax distribution with different methods of estimation and applications. Complexity 2020, 2020, 1860813. [Google Scholar] [CrossRef]
- Akgül, F.G. Comparison of the estimation methods for the parameters of exponentiated reduced Kies distribution. J. Nat. Appl. Sci. 2018, 22, 1209–1216. [Google Scholar]
- Nikulin, M.S. Chi-square test for continuous distributions with location and scale parameters. Teor. Veroyatnostei Primen. 1973, 18, 583–591. [Google Scholar]
- Rao, K.C.; Robson, D.S. A Chi-square statistic for goodness-of-fit tests within the exponential family. Commun. Stat. 1974, 3, 1139–1153. [Google Scholar] [CrossRef]
- Goual, H.; Seddik-Ameur, N. Chi-squared type test for the AFT-generalized inverse Weibull distribution. Commun. Stat.-Theory Methods 2014, 43, 2605–2617. [Google Scholar] [CrossRef]
- Seddik-Ameur, N.; Aidi, K. Chi-square tests for generalized exponential distributions with censored data. Electron. J. Appl. Stat. Anal. 2016, 9, 371–384. [Google Scholar]
- Tilbi, D.; Seddik-Ameur, N. Chi-squared goodness-of-fit tests for the generalized Rayleigh distribution. J. Stat. Theory Pract. 2017, 11, 594–603. [Google Scholar] [CrossRef]
- Treidi, W.; Seddik-Ameur, N. NRR statistic for the extension Weibull distribution. Glob. J. Pure Appl. Math. 2016, 12, 2809–2818. [Google Scholar]
- Sen, S.; Maiti, S.S.; Chandra, N. The Xgamma distribution: Statistical properties and application. J. Mod. Appl. Stat. Methods 2016, 15, 774–788. [Google Scholar] [CrossRef]
- Al-Omari, A.I.; Shraa, D. Darna distribution: Properties and application. Electron. J. Appl. Stat. Anal. 2019, 12, 520–541. [Google Scholar]
- Ashour, S.K.; Eltehiwy, M.A. Exponentiated power Lindley distribution. J. Adv. Res. 2015, 6, 895–905. [Google Scholar] [CrossRef]
- Aarset, M.V. How to identify a bathtub hazard rate. IEEE Trans. Reliab. 1987, 36, 106–108. [Google Scholar] [CrossRef]
- Lee, E.T.; Wang, J.W. Statistical Methods for Survival Data Analysis, 3rd ed.; Wiley: New York, NY, USA, 2003. [Google Scholar]
- Bourguignon, M.; Silva, R.B.; Cordeiro, G.M. The Weibull G family of probability distributions. J. Data Sci. 2014, 12, 53–68. [Google Scholar] [CrossRef] [PubMed]
- Smith, R.L.; Naylor, J.C. A Comparison of maximum likelihood and Bayesian estimators for the three-parameter Weibull distribution. Appl. Stat. 1987, 36, 358–360. [Google Scholar] [CrossRef]
- Ibrahim, K.; Syam, M.; Al-Omari, A.I. Estimating the population mean using stratified median ranked set sampling. Appl. Math. Sci. 2010, 4, 2341–2354. [Google Scholar]
- Jemain, A.A.; Al-Omari, A.I. Double percentile ranked set samples for estimating the population mean. Adv. Appl. Stat. 2006, 6, 261–276. [Google Scholar]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).