

Research on Short Video Hotspot Classification Based on LDA Feature Fusion and Improved BiLSTM

Abstract
1. Introduction
- Data collection. Taking short videos containing Carya cathayensis as the main research object and TikTok platform as the main carrier, researchers crawled 16,282 comments data and built datasets based on them, enriching the research on the comment data of TikTok platform.
- A feature fusion method based on the combination of LDA topic model and Word2Vec word vector is presented. Based on the word vector, this method integrated the topic features of the text, expanded the feature representation of the information of comments, and solved the problem that the sparse feature representation of short text is not obvious to some extent.
- Construct a hot spot classification model based on BiLSTM-self-attention. Self-attention mechanism and BiLSTM were combined to extract features of comment information. Self-Attention can reduce the dependence of external parameters and make the model focus on the features of the text itself. The combination facilitated the extraction of more important features for classification.
- Comparative experiment. The LDA-BiLSTM-self-attention model proposed in this paper (hereinafter referred to as LBSA model) was compared with convolutional neural network (CNN), LSTM, gated recurrent unit (GRU), BiLSTM, CNN-LSTM, GRU-CNN, LDA-CNN, LDA-BiLSTM, CNN-self-attention, BiLSTM-self-attention, and other models. Experimental results demonstrate that the proposed model can extract features more accurately and achieve a better classification effect.
2. Related Work
2.1. Short Video Research
2.2. Topic Models
2.3. Deep Learning Models
3. Models and Improvements
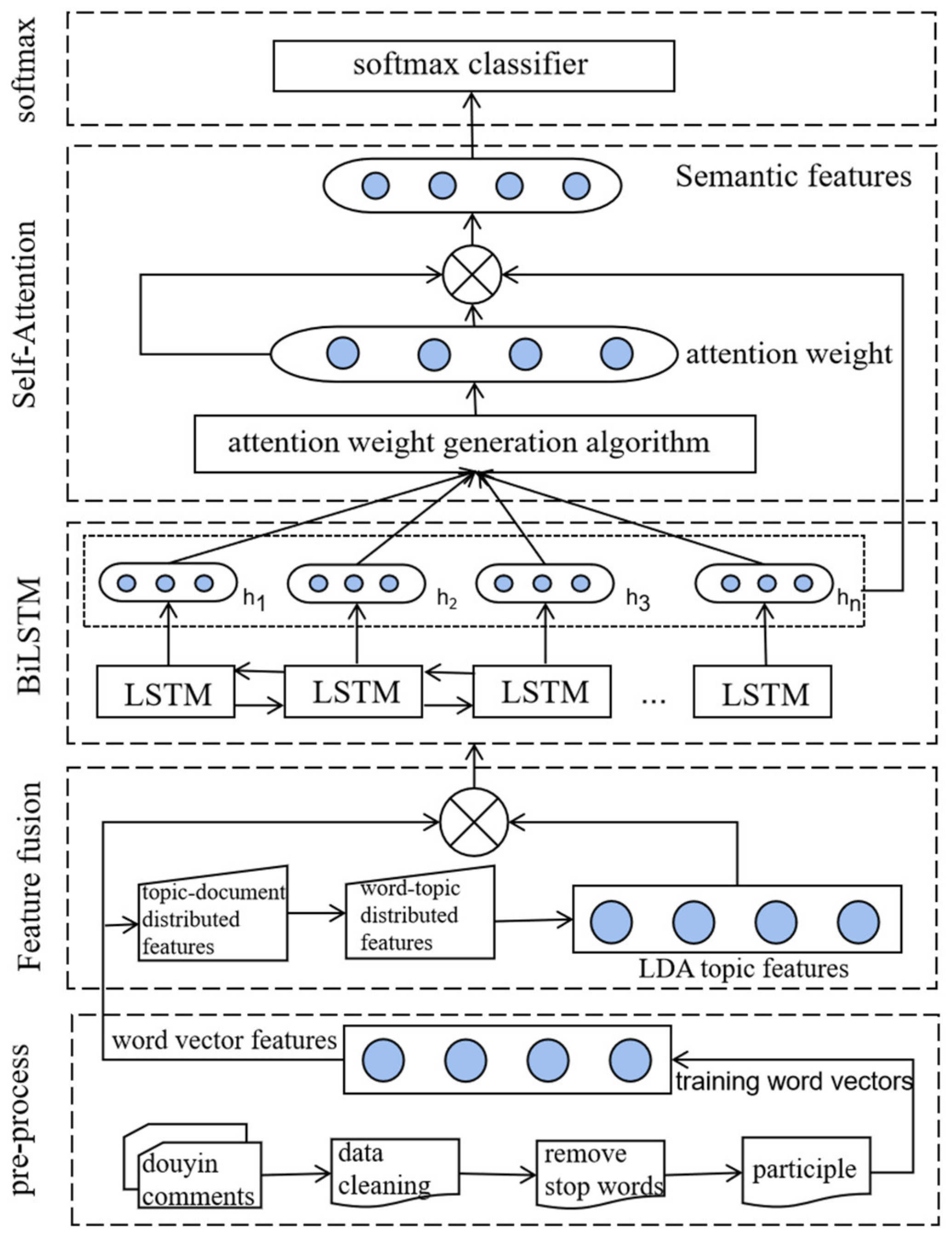
3.1. Overall Model Framework
3.2. Feature Fusion Method Based on LDA Topic Model
3.2.1. LDA Topic Model
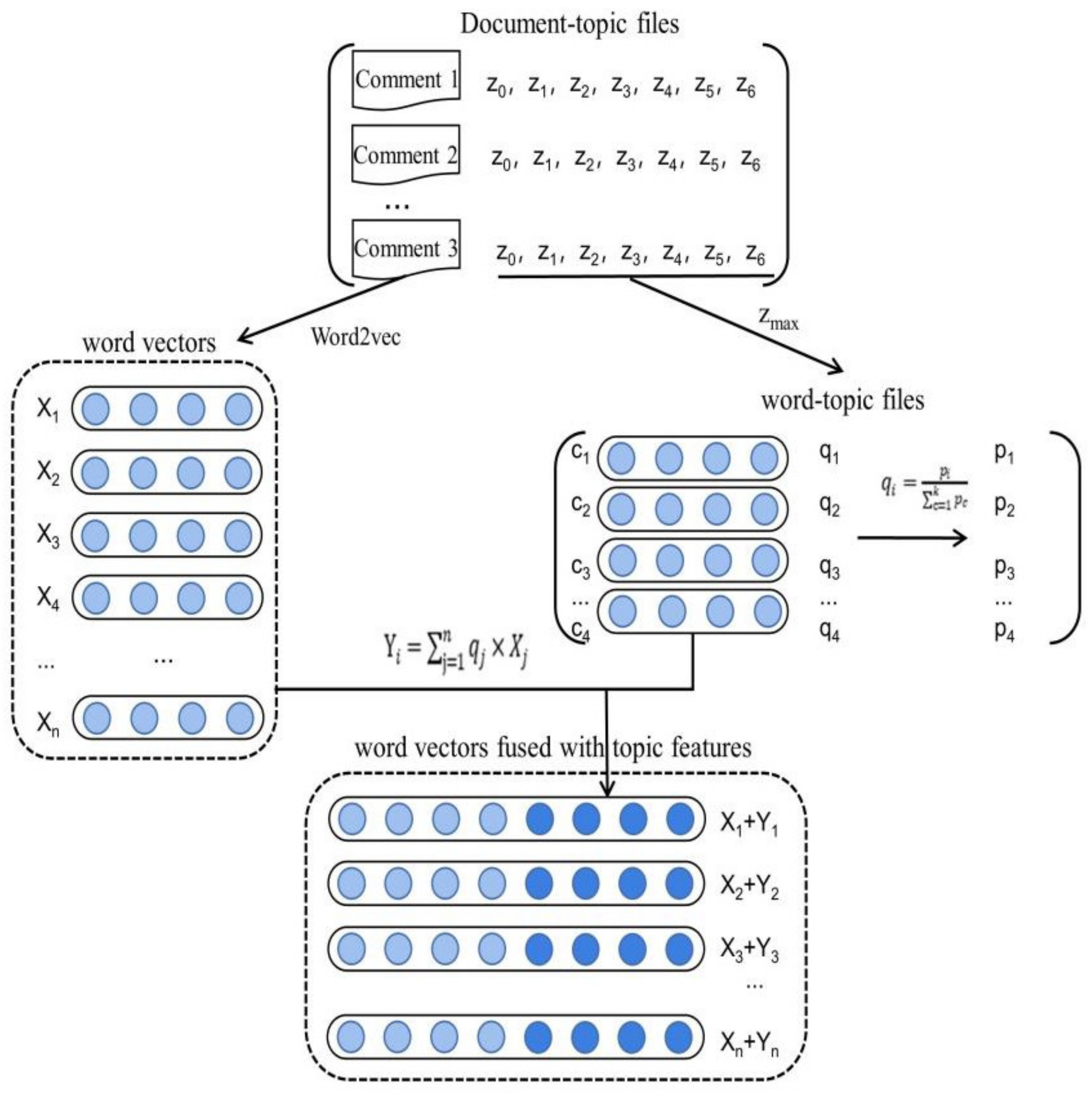
3.2.2. Fusion Method of Word Vector and LDA Topic Model
3.3. BiLSTM
3.4. Self-Attention
3.5. Softmax
4. Experiments and Results
4.1. Evaluation Indicators
4.2. Data Acquisition and Processing
4.3. Splitting Words
4.4. Training Word Vectors
4.5. Topic Classification
4.5.1. Optimal Topic Number Confirmation
4.5.2. Classification Tags
4.5.3. Topic Feature Integration
4.6. Experimental Results
4.6.1. Comparison of Model Results
4.6.2. Impact of Feature Fusion on the Model
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Douyin Data Report. Available online: https://xw.qq.com/amphtml/20220111A0AWP600 (accessed on 11 January 2022).
- Qi, J.; Xun, L.; Zhou, X.; Li, Z.; Liu, Y.; Cheng, H. Micro-blog user community discovery using generalized SimRank edge weighting method. PLoS ONE 2018, 13, e0196447. [Google Scholar] [CrossRef]
- Wu, D.; Yang, R.; Shen, C. Sentiment word co-occurrence and knowledge pair feature extraction based LDA short text clustering algorithm. J. Intell. Inf. Syst. 2020, 56, 1–23. [Google Scholar] [CrossRef]
- Cheng, F.E.I.; Seo, L.J. The Impact of the Educational Influencer Characteristics of the Short Video App Tik Tok on the Intention to Purchase Online Knowledge Content. J. Brand Des. Assoc. Korea 2021, 19, 77–94. [Google Scholar]
- Jiaheng, Z.; Choi, K. The Effect of Tourism Information Quality of TikTok on Information Reliability and Visit Intention: Focusing on Moderating Effects of Homogeneity. Northeast. Asia Tour. Res. 2022, 18, 1–21. [Google Scholar]
- Li, Z.X.; Zhang, S.M.; Bin Liu, H.; Wu, Q.T. Study on the Factors Influencing Users’ Purchase Intention on Live-Streaming E-Commerce Platforms: Evidence from the Live-Streaming Platform of TikTok. J. China Stud. 2021, 24, 25–49. [Google Scholar] [CrossRef]
- Gao, L.; Wang, H.; Zhang, Z.; Zhuang, H.; Zhou, B. HetInf: Social Influence Prediction With Heterogeneous Graph Neural Network. Front. Phys. 2022, 9, 787185. [Google Scholar] [CrossRef]
- Hong, L.; Yin, J.; Xia, L.-L.; Gong, C.-F.; Huang, Q. Improved Short-video User Impact Assessment Method Based on PageRank Algorithm. Intell. Autom. Soft Comput. 2021, 29, 437–449. [Google Scholar] [CrossRef]
- Shao, D.; Li, C.; Huang, C.; An, Q.; Xiang, Y.; Guo, J.; He, J. The short texts classification based on neural network topic model. J. Intell. Fuzzy Syst. 2022, 1–13. [Google Scholar] [CrossRef]
- Luo, L.-X. Network text sentiment analysis method combining LDA text representation and GRU-CNN. Pers. Ubiquitous Comput. 2019, 23, 405–412. [Google Scholar] [CrossRef]
- Tan, X.; Zhuang, M.; Lu, X.; Mao, T. An Analysis of the Emotional Evolution of Large-Scale Internet Public Opinion Events Based on the BERT-LDA Hybrid Model. IEEE Access 2021, 9, 15860–15871. [Google Scholar] [CrossRef]
- Shao, D.; Li, C.; Huang, C.; Xiang, Y.; Yu, Z. A news classification applied with new text representation based on the improved LDA. Multimedia Tools Appl. 2022, 81, 21521–21545. [Google Scholar] [CrossRef]
- Wang, B.; Huang, Y.; Yang, W.; Li, X. Short text classification based on strong feature thesaurus. J. Zhejiang Univ. Sci. C Comput. Electron. 2012, 13, 649–659. [Google Scholar] [CrossRef]
- Zhou, W.; Wang, H.; Sun, H. A Method of Short Text Representation Based on the Feature Probability Embedded Vector. Sensors 2019, 19, 3728. [Google Scholar] [CrossRef]
- Wang, J.; Li, Y.; Shan, J.; Bao, J.; Zong, C.; Zhao, L. Large-Scale Text Classification Using Scope-Based Convolutional Neural Network: A Deep Learning Approach. IEEE Access 2019, 7, 171548–171558. [Google Scholar] [CrossRef]
- Jang, B.; Kim, M.; Harerimana, G.; Kang, S.U.; Kim, J.W. Bi-LSTM Model to Increase Accuracy in Text Classification: Combining Word2vec CNN and Attention Mechanism. Appl. Sci. 2020, 10, 5841. [Google Scholar] [CrossRef]
- Yu, S.; Liu, D.; Zhu, W.; Zhang, Y.; Zhao, S. Attention-based LSTM, GRU and CNN for short text classification. J. Intell. Fuzzy Syst. 2020, 39, 333–340. [Google Scholar] [CrossRef]
- Xie, J.; Chen, B.; Gu, X.; Liang, F.; Xu, X. Self-Attention-Based BiLSTM Model for Short Text Fine-Grained Sentiment Classification. IEEE Access 2019, 7, 180558–180570. [Google Scholar] [CrossRef]
- Zhao, J.; Lin, J.; Liang, S.; Wang, M. Sentimental prediction model of personality based on CNN-LSTM in a social media environment. J. Intell. Fuzzy Syst. 2021, 40, 3097–3106. [Google Scholar] [CrossRef]
- Deng, L.; Ge, Q.; Zhang, J.; Li, Z.; Yu, Z.; Yin, T.; Zhu, H. News Text Classification Method Based on the GRU_CNN Model. Int. Trans. Electr. Energy Syst. 2022, 2022, 1–11. [Google Scholar] [CrossRef]
- Yang, J.; Zou, X.; Zhang, W.; Han, H. Microblog sentiment analysis via embedding social contexts into an attentive LSTM. Eng. Appl. Artif. Intell. 2021, 97, 104048. [Google Scholar] [CrossRef]
- Wu, P.; Li, X.; Ling, C.; Ding, S.; Shen, S. Sentiment classification using attention mechanism and bidirectional long short-term memory network. Appl. Soft Comput. 2021, 112, 107792. [Google Scholar] [CrossRef]
- Liu, G.; Guo, J. Bidirectional LSTM with attention mechanism and convolutional layer for text classification. Neurocomputing 2019, 337, 325–338. [Google Scholar] [CrossRef]
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent dirichlet allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Principe, V.A.; Vale, R.G.D.S.; de Castro, J.B.P.; Carvano, L.M.; Henriques, R.A.P.; Lobo, V.J.d.A.e.S.; Nunes, R.D.A.M. A computational literature review of football performance analysis through probabilistic topic modeling. Artif. Intell. Rev. 2022, 55, 1351–1371. [Google Scholar] [CrossRef]
- Korenčić, D.; Ristov, S.; Šnajder, J. Document-based topic coherence measures for news media text. Expert Syst. Appl. 2018, 114, 357–373. [Google Scholar] [CrossRef]
- Mimno, D.M.; Wallach, H.M.; Talley, E.; Leenders, M.; McCallum, A. Optimizing Semantic Coherence in Topic Models. In Proceedings of the 2011 Conference on Empirical Methods in Natural Language Processing, Edinburgh, UK, 27–31 July 2011. [Google Scholar]
- Yan, D.; Mei, X.; Yang, X.; Zhu, P. Research on Microblog Text Topic Clustering Based on the Fusion of Topic Model and Word Embedding. J. Mod. Inf. 2021, 41, 67–74. [Google Scholar] [CrossRef]
- Tang, H.; Wei, H.; Wang, Y.; Zhu, H.; Dou, Q. Text Semantic Enhancement Method Combining LDA and Word2vec. Comput. Eng. Appl. 2022, 58, 135–145. [Google Scholar]
- Du, J.; Vong, C.-M.; Chen, C.L.P. Novel Efficient RNN and LSTM-Like Architectures: Recurrent and Gated Broad Learning Systems and Their Applications for Text Classification. IEEE Trans. Cybern. 2020, 51, 1586–1597. [Google Scholar] [CrossRef]
- Zeng, Y.; Zhang, R.; Yang, L.; Song, S. Cross-Domain Text Sentiment Classification Method Based on the CNN-BiLSTM-TE Model. J. Inf. Process. Syst. 2021, 17, 818–833. [Google Scholar]
- Li, W.; Qi, F.; Tang, M.; Yu, Z. Bidirectional LSTM with self-attention mechanism and multi-channel features for sentiment classification. Neurocomputing 2020, 387, 63–77. [Google Scholar] [CrossRef]
- Wang, Y.; Zhu, L. Research on improved text classification method based on combined weighted model. Concurr. Comput. Pr. Exp. 2020, 32, 5140. [Google Scholar] [CrossRef]
- Chehal, D.; Gupta, P.; Gulati, P. RETRACTED ARTICLE: Implementation and comparison of topic modeling techniques based on user reviews in e-commerce recommendations. J. Ambient. Intell. Humaniz. Comput. 2021, 12, 5055–5070. [Google Scholar] [CrossRef]
- Chuang, J.; Manning, C.D.; Heer, J. Termite: Visualization Techniques for Assessing Textual Topic Models. In Proceedings of the International Working Conference on Advanced Visual Interfaces, Capri Island, Italy, 21–25 May 2012. [Google Scholar]
- Sievert, C.; Shirley, K.E. LDAvis: A method for visualizing and interpreting topics. In Proceedings of the Workshop on Interactive Language Learning, Visualization, and Interfaces at the Association for Computational Linguistics, Baltimore, MD, USA, 27 June 2014. [Google Scholar]
- Dave, V.; Singh, S.; Vakharia, V. Diagnosis of bearing faults using multi fusion signal processing techniques and mutual information. Indian J. Eng. Mater. Sci. 2020, 27, 878–888. [Google Scholar] [CrossRef]
- Bolourchi, P.; Moradi, M.; Demirel, H.; Uysal, S. Feature Fusion for Classification Enhancement of Ground Vehicle SAR Images. In Proceedings of the 2017 UKSim-AMSS 19th International Conference on Computer Modelling & Simulation (UKSim), Cambridge, UK, 5–7 April 2017; pp. 111–115. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Before the Segmentation of Words | After the Segmentation of Words |
|---|---|
| Do you have pecans without their skins on | Pecans without skin |
| You have many varieties. Can you mix them? I’ll buy a few pounds | many varieties mix a few pounds |
| I’ve bought it many times. It’s delicious | bought many times delicious |
| The order has been placed. When will it be delivered | Have ordered delivery |
| I placed an order, hoping to buy the same as yours. Don’t be disappointed | placed an order hope buy disappointed |
| I just wanted to buy nuts, and when is it live? | want buy nuts live |
| Parameter | Parameter Value |
|---|---|
| Hyperparameter α | 50/k |
| Hyperparameter β | 0.01 |
| number of iterations I | 30 |
| Number of Topics k | 7 |
| Topic | Top 10 Probability Words | Tags | Number of Documents | Percentage (%) |
|---|---|---|---|---|
| Topic 0 | Buy, order, hope, delicious, beat, delivery, support, want, have, received | Buy | 1358 | 16.4 |
| Topic 1 | Money, 1catty, gram, pot, block, 100, net weight, yuan, catty, sell | Weight | 1492 | 18.1 |
| Topic 2 | Delicious, buy, good, very, nice, really, repo, pecan, bought, really | Delicious | 1309 | 15.8 |
| Topic 3 | Eat, pecan, buy, like, original taste, fragrant, taste, too sweet, want, salt and pepper | Taste | 1098 | 13.3 |
| Topic 4 | Peel, eat, no, desiccant, like, no, shell, jar, difficult, hand | Hand Peeled | 900 | 10.9 |
| Topic 5 | Walnut, pecan, buy, this year, eat, small, new goods, broken, Lin ‘an, old goods | Quality | 945 | 11.4 |
| Topic 6 | Price increase, expensive, buy, 99, too expensive, price, a little, now, yuan, before | Price | 11.41 | 13.8 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, L.; Dai, D.; Liu, H.; Yuan, Y.; Ding, L.; Xu, Y. Research on Short Video Hotspot Classification Based on LDA Feature Fusion and Improved BiLSTM. Appl. Sci. 2022, 12, 11902. https://doi.org/10.3390/app122311902
Li L, Dai D, Liu H, Yuan Y, Ding L, Xu Y. Research on Short Video Hotspot Classification Based on LDA Feature Fusion and Improved BiLSTM. Applied Sciences. 2022; 12(23):11902. https://doi.org/10.3390/app122311902
Chicago/Turabian StyleLi, Linhui, Dan Dai, Hongjiu Liu, Yubo Yuan, Lizhong Ding, and Yujie Xu. 2022. "Research on Short Video Hotspot Classification Based on LDA Feature Fusion and Improved BiLSTM" Applied Sciences 12, no. 23: 11902. https://doi.org/10.3390/app122311902
APA StyleLi, L., Dai, D., Liu, H., Yuan, Y., Ding, L., & Xu, Y. (2022). Research on Short Video Hotspot Classification Based on LDA Feature Fusion and Improved BiLSTM. Applied Sciences, 12(23), 11902. https://doi.org/10.3390/app122311902