
A Forwarding Latency Optimization Method for Software Data Plane Based on Spin-Polling


Abstract
:1. Introduction
- We conduct a series of experiments, and the experimental results show that the forwarding latency of the software data plane has a specific relationship with the system load and the batch size of the batch processing mechanism. The batch size is not always the larger, the better.
- We analyze the characteristics of the forwarding latency of the software data plane based on spin-polling at different loads by a simple model.
- We propose a forwarding latency optimization scheme for the software data plane based on the spin-polling mechanism. First, we calculate the CPU utilization of the software data plane according to the number of cycles the CPU spends on the valuable task. Then, based on the CPU utilization calculated in real-time, the scheme optimizes the forwarding latency of the software data plane at different loads by controlling the Tx queues and dynamically adjusting the Tx batch size.
- We build a primary software data plane using Data Plane Development Kit (DPDK) on a Dell R740 server and implemented our proposed scheme on it. In addition, we give a detailed evaluation of our scheme, including a comparison with the original software data plane and Smart Batching [19].
2. Related Work
2.1. Software Data Plane
2.2. Spin-Polling Mechanism
2.3. Batch Processing Mechanism
3. Motivation
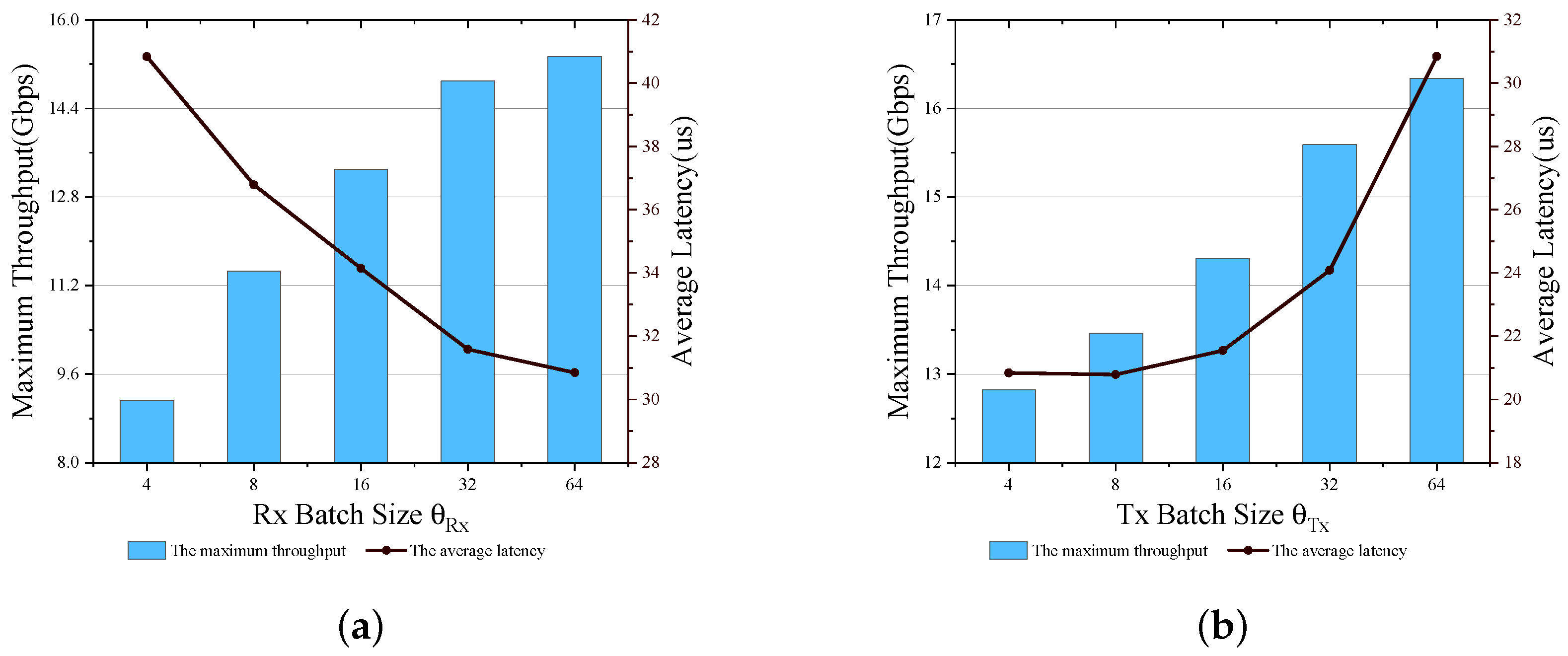
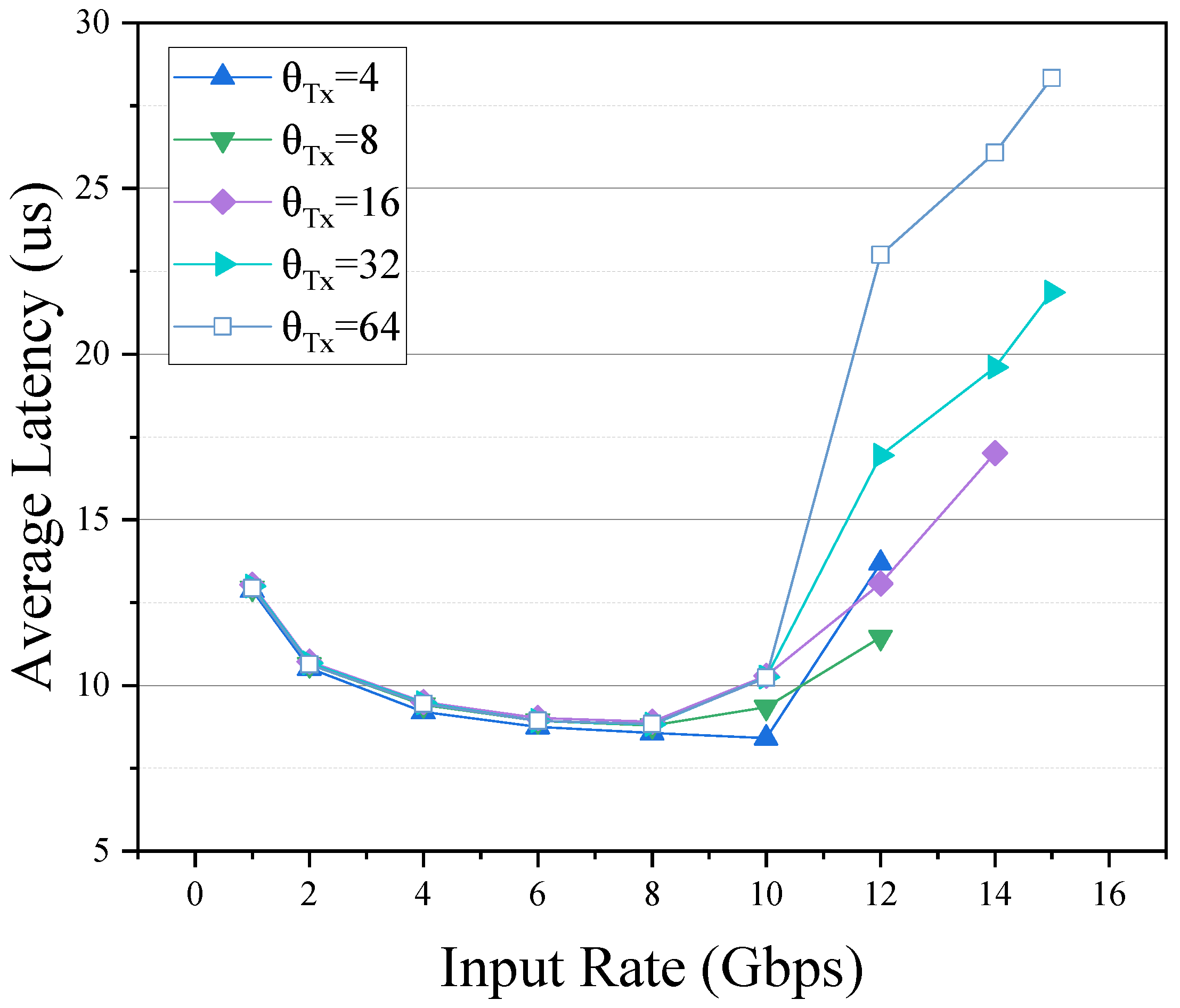
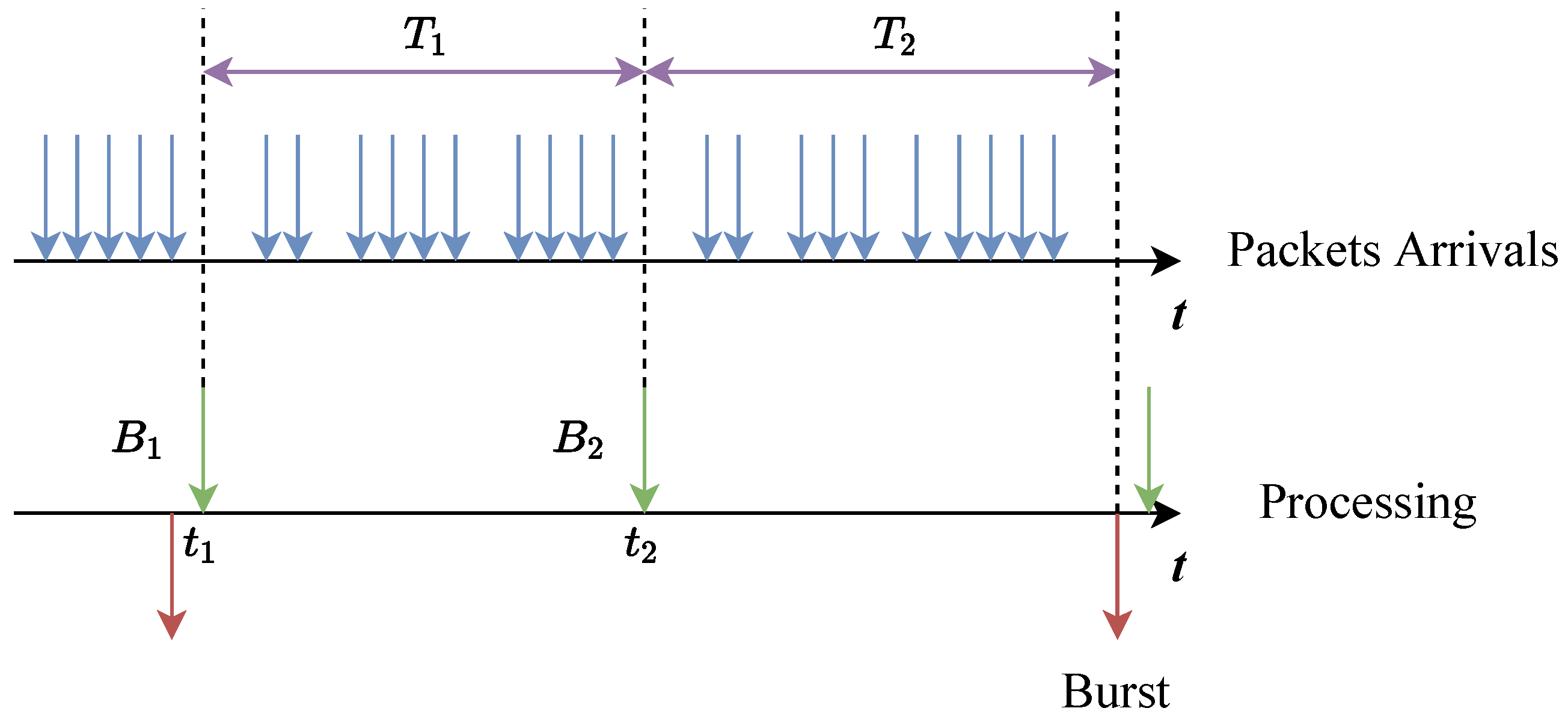
3.1. Static Batch Size
3.2. The Effects of Batch Processing Mechanisms
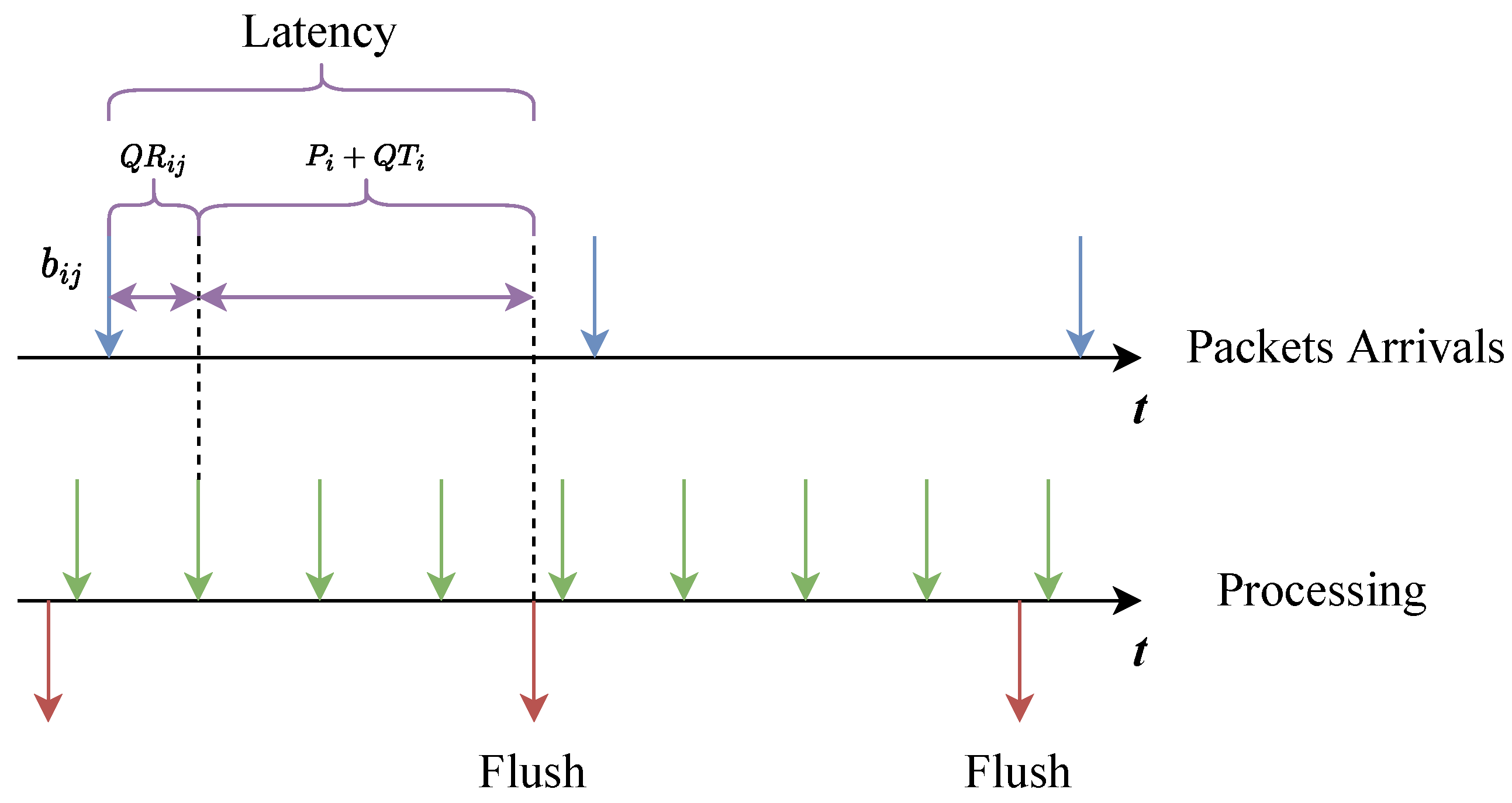
4. Model Analysis
5. Design and Implementation
5.1. Feasibility of Packet Forwarding Latency Optimization
| Algorithm 1: CPU Utilization |
 |
5.2. Latency Optimization Strategy
5.2.1. Single Rx Queue
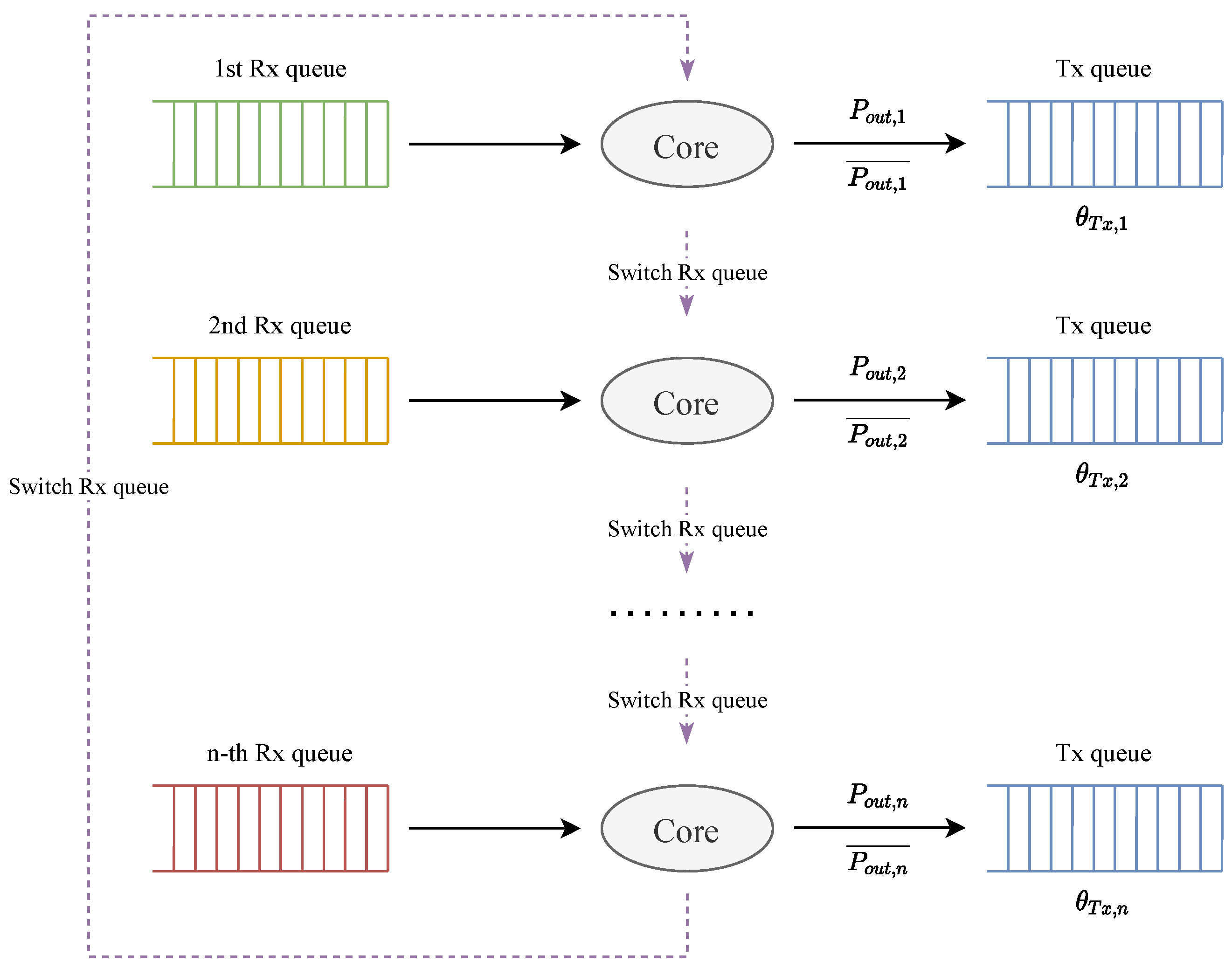
5.2.2. Multiple Rx Queues
5.3. Two-State Finite State Machine
6. Evaluation
6.1. The Selection of Observation Time
6.2. The Selection of Threshold
6.3. Comparison with Other Schemes
6.4. Multiple Queue Evaluation
7. Conclusions and Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- DPDK: Data Plane Development Kit. Available online: https://www.dpdk.org/ (accessed on 25 July 2022).
- Wang, J.; Cheng, G.; You, J.; Sun, P. SEANet: Architecture and Technologies of an On-Site, Elastic, Autonomous Network. J. Netw. New Media 2020, 6, 1–8. [Google Scholar]
- Rawat, D.B.; Reddy, S.R. Software Defined Networking Architecture, Security and Energy Efficiency: A Survey. IEEE Commun. Surv. Tutor. 2017, 19, 325–346. [Google Scholar] [CrossRef]
- Masoudi, R.; Ghaffari, A. Software Defined Networks: A Survey. J. Netw. Comput. Appl. 2016, 67, 1–25. [Google Scholar] [CrossRef]
- Open vSwitch. Available online: http://www.openvswitch.org/ (accessed on 25 July 2022).
- Golestani, H.; Mirhosseini, A.; Wenisch, T.F. Software Data Planes: You Can’t Always Spin to Win. In Proceedings of the ACM Symposium on Cloud Computing, Santa Cruz, CA, USA, 20–23 November 2019; ACM: New York, NY, USA, 2019; pp. 337–350. [Google Scholar] [CrossRef]
- Lim, H.; Han, D.; Andersen, D.G.; Kaminsky, M. MICA: A Holistic Approach to Fast In-Memory Key-Value Storage. In Proceedings of the 11th USENIX Symposium on Networked Systems Design and Implementation, Seattle, WA, USA, 2–4 April 2014; p. 17. [Google Scholar]
- Marinos, I.; Watson, R.N.; Handley, M. Network Stack Specialization for Performance. In Proceedings of the 2014 ACM Conference on SIGCOMM, Chicago, IL, USA, 17–22 August 2014; pp. 175–186. [Google Scholar] [CrossRef]
- Jeong, E.; Woo, S.; Jamshed, M.; Jeong, H.; Ihm, S.; Han, D.; Park, K. mTCP: A Highly Scalable User-Level TCP Stack for Multicore Systems. In Proceedings of the 11th USENIX Symposium on Networked Systems Design and Implementation, Seattle, WA, USA, 2–4 April 2014; p. 15. [Google Scholar]
- Kalia, A.; Andersen, D. Datacenter RPCs Can Be General and Fast. In Proceedings of the 16th USENIX Symposium on Networked Systems Design and Implementation, Boston, MA, USA, 26–28 February 2019; p. 17. [Google Scholar]
- Peter, S.; Li, J.; Zhang, I.; Ports, D.R.K.; Woos, D.; Krishnamurthy, A.; Anderson, T.; Roscoe, T. Arrakis: The Operating System Is the Control Plane. ACM Trans. Comput. Syst. 2016, 33, 1–30. [Google Scholar] [CrossRef]
- Belay, A.; Prekas, G.; Kozyrakis, C.; Klimovic, A.; Grossman, S.; Bugnion, E. IX: A Protected Dataplane Operating System for High Throughput and Low Latency. In Proceedings of the 11th USENIX Symposium on Operating Systems Design and Implementation, Broomfield, CO, USA, 6–8 October 2014; p. 18. [Google Scholar]
- Prekas, G.; Kogias, M.; Bugnion, E. ZygOS: Achieving Low Tail Latency for Microsecond-scale Networked Tasks. In Proceedings of the 26th Symposium on Operating Systems Principles, Shanghai, China, 28–31 October 2017; pp. 325–341. [Google Scholar] [CrossRef]
- Ousterhout, A.; Fried, J.; Behrens, J.; Belay, A.; Balakrishnan, H. Shenango: Achieving High CPU Efficiency for Latency-sensitive Datacenter Workloads. In Proceedings of the 16th USENIX Conference on Networked Systems Design and Implementation, Boston, MA, USA, 26–28 February 2019; p. 18. [Google Scholar]
- Kaffes, K.; Belay, A.; Chong, T.; Mazieres, D.; Humphries, J.T.; Kozyrakis, C. Shinjuku: Preemptive Scheduling for Msecond-Scale Tail Latency. In Proceedings of the 16th USENIX Conference on Networked Systems Design and Implementation, Boston, MA, USA, 26–28 February 2019; p. 16. [Google Scholar]
- Dalton, M.; Schultz, D.; Adriaens, J.; Arefin, A.; Gupta, A.; Fahs, B.; Rubinstein, D.; Zermeno, E.C.; Rubow, E.; Docauer, J.A.; et al. Andromeda: Performance, Isolation, and Velocity at Scale in Cloud Network Virtualization. In Proceedings of the 15th USENIX Symposium on Networked Systems Design and Implementation, Renton, WA, USA, 9–11 April 2018; p. 16. [Google Scholar]
- Honda, M.; Lettieri, G.; Eggert, L.; Santry, D. PASTE: A Network Programming Interface for Non-Volatile Main Memory. In Proceedings of the 15th USENIX Symposium on Networked Systems Design and Implementation, Renton, WA, USA, 9–11 April 2018; p. 18. [Google Scholar]
- Klimovic, A.; Litz, H.; Kozyrakis, C. ReFlex: Remote Flash ≈ Local Flash. In Proceedings of the Twenty-Second International Conference on Architectural Supportfor Programming Languages and Operating Systems, Xi’an, China, 8–12 April 2017; pp. 345–359. [Google Scholar] [CrossRef]
- Miao, M.; Cheng, W.; Ren, F.; Xie, J. Smart Batching: A Load-Sensitive Self-Tuning Packet I/O Using Dynamic Batch Sizing. In Proceedings of the 2016 IEEE 18th International Conference on High Performance Computing and Communications, IEEE 14th International Conference on Smart City, IEEE 2nd International Conference on Data Science and Systems (HPCC/SmartCity/DSS), Sydney, Australia, 16 December 2016; pp. 726–733. [Google Scholar] [CrossRef]
- Lange, S.; Linguaglossa, L.; Geissler, S.; Rossi, D.; Zinner, T. Discrete-Time Modeling of NFV Accelerators That Exploit Batched Processing. In Proceedings of the IEEE INFOCOM 2019-IEEE Conference on Computer Communications, Paris, France, 29 April–2 May 2019; pp. 64–72. [Google Scholar] [CrossRef]
- Das, T.; Zhong, Y.; Stoica, I.; Shenker, S. Adaptive Stream Processing Using Dynamic Batch Sizing. In Proceedings of the ACM Symposium on Cloud Computing—SOCC ’14, Seattle, WA, USA, 3–5 November 2014; pp. 1–13. [Google Scholar] [CrossRef] [Green Version]
- Cerovic, D.; Del Piccolo, V.; Amamou, A.; Haddadou, K.; Pujolle, G. Fast Packet Processing: A Survey. IEEE Commun. Surv. Tutor. 2018, 20, 3645–3676. [Google Scholar] [CrossRef]
- Kim, J.; Huh, S.; Jang, K.; Park, K.; Moon, S. The Power of Batching in the Click Modular Router. In Proceedings of the APSYS ’12: Proceedings of the Asia-Pacific Workshop on Systems, Seoul, Korea, 23–24 July 2012; p. 6. [Google Scholar]
- Barroso, L.A.; Hölzle, U. The Case for Energy-Proportional Computing. Computer 2007, 40, 33–37. [Google Scholar] [CrossRef]
- McKeown, N.; Anderson, T.; Balakrishnan, H.; Parulkar, G.; Peterson, L.; Rexford, J.; Shenker, S.; Turner, J. OpenFlow: Enabling Innovation in Campus Networks. SIGCOMM Comput. Commun. Rev. 2008, 38, 69–74. [Google Scholar] [CrossRef]
- Li, S.; Hu, D.; Fang, W.; Ma, S.; Chen, C.; Huang, H.; Zhu, Z. Protocol Oblivious Forwarding (POF): Software-Defined Networking with Enhanced Programmability. IEEE Netw. 2017, 31, 9. [Google Scholar] [CrossRef]
- Bosshart, P.; Daly, D.; Gibb, G.; Izzard, M.; McKeown, N.; Rexford, J.; Schlesinger, C.; Talayco, D.; Vahdat, A.; Varghese, G.; et al. P4: Programming Protocol-Independent Packet Processors. ACM SIGCOMM Comput. Commun. Rev. 2014, 44, 87–95. [Google Scholar] [CrossRef]
- Kim, H.J.; Lee, Y.S.; Kim, J.S. NVMeDirect: A User-Space I/O Framework for Application-specific Optimization on NVMe SSDs. In Proceedings of the 8th USENIX Conference on Hot Topics in Storage and File Systems, Denver, CO, USA, 20–21 June 2016; p. 5. [Google Scholar]
- Yang, Z.; Liu, C.; Zhou, Y.; Liu, X.; Cao, G. SPDK Vhost-NVMe: Accelerating I/Os in Virtual Machines on NVMe SSDs via User Space Vhost Target. In Proceedings of the 2018 IEEE 8th International Symposium on Cloud and Service Computing (SC2), Paris, France, 18–21 November 2018; pp. 67–76. [Google Scholar] [CrossRef]
- Begin, T.; Baynat, B.; Artero Gallardo, G.; Jardin, V. An Accurate and Efficient Modeling Framework for the Performance Evaluation of DPDK-Based Virtual Switches. IEEE Trans. Netw. Serv. Manag. 2018, 15, 1407–1421. [Google Scholar] [CrossRef]
- Han, S.; Jang, K.; Park, K.; Moon, S. PacketShader: A GPU-Accelerated Software Router. In ACM SIGCOMM Computer Communication Review; ACM: New York, NY, USA, 2010; p. 12. [Google Scholar]
- Rizzo, L. Netmap: A Novel Framework for Fast Packet I/O. In Proceedings of the USENIX ATC ’12: USENIX Annual Technical Conference, Boston, MA, USA, 12–15 June 2012; USENIX Association: Berkeley, CA, USA, 2012; p. 12. [Google Scholar]
- PF_RING. 2011. Available online: https://www.ntop.org/products/packet-capture/pf_ring/ (accessed on 25 July 2022).
- OpenOnload. 2022. Available online: https://github.com/Xilinx-CNS/onload (accessed on 25 July 2022).
- PACKET_MMAP. Available online: https://www.kernel.org/doc/Documentation/networking/packet_mmap.txt (accessed on 25 July 2022).










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Environment | Information |
|---|---|
| CPU | Intel Xeon Silver 4216 CPU @2.10 GHz |
| NIC | Intel Ethernet Connection E810 Series |
| DPDK Version | 21.11.1(LTS) |
| Ixia Network Version | 8.30 |
| Notation | Description |
|---|---|
| The number of packets in small batch | |
| The time interval between and | |
| The number of packets received by the CPU at one time | |
| m | The number of times the CPU receives packets between packets forwarding |
| N | The polling counter threshold |
| The residence time of packets on the data plane | |
| P | The time taken by CPUs to process packets |
| The queuing time of packets in Tx queues | |
| The queuing time of packets in Rx queues | |
| The time interval for CPU polling when no packets arrive |
| CPU Utilization | |
|---|---|
| 4 | 82.04% |
| 8 | 64.2% |
| 16 | 63.11% |
| 32 | 63.54% |
| 64 | 63.62% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tang, X.; Zeng, X.; Song, L. A Forwarding Latency Optimization Method for Software Data Plane Based on Spin-Polling. Appl. Sci. 2022, 12, 8758. https://doi.org/10.3390/app12178758
Tang X, Zeng X, Song L. A Forwarding Latency Optimization Method for Software Data Plane Based on Spin-Polling. Applied Sciences. 2022; 12(17):8758. https://doi.org/10.3390/app12178758
Chicago/Turabian StyleTang, Xinxin, Xuewen Zeng, and Lei Song. 2022. "A Forwarding Latency Optimization Method for Software Data Plane Based on Spin-Polling" Applied Sciences 12, no. 17: 8758. https://doi.org/10.3390/app12178758
APA StyleTang, X., Zeng, X., & Song, L. (2022). A Forwarding Latency Optimization Method for Software Data Plane Based on Spin-Polling. Applied Sciences, 12(17), 8758. https://doi.org/10.3390/app12178758