1. Introduction
Currently, the Dennard scaling law [
1] and Moore’s law [
2] are gradually coming to an end, and the agile development of hardware has brought new opportunities to people [
3]. Currently, the prosperity of Artificial Intelligence and the Internet of Things (AIoT) brings an amount of demand for chips from AIoT devices [
4]. Unlike other devices, such as personal computers and smartphones, AIoT devices in different applications require totally different chips that meet the latency, power, and area needed. Moreover, AIoT devices in different applications have various requirements of latency, power, and area, showing that some devices are more sensitive to power than latency and area, while some devices are more sensitive to area. In other words, the demand for chips from AIoT devices varies and is fragmented.
Therefore, the rapid construction of scene-specific systems-on-chips (SoCs) in the emerging AIoT field is promising [
5]. With the development of hardware description languages (HDLs), such as Chisel [
6] on Scala, ClaSH [
7] on Haskell, and PyRTL [
8] on Python, engineers can design hardware in a parameterized and reusable way, which can accelerate the construction of custom SoCs. Moreover, there are a few template-based chip design methods that aim to rapidly construct chips by adjusting the circuit modules and the parameters. FabScalar [
9] was developed by Niket K et al. for automatically composing synthesizable register-transfer-level (RTL) designs of arbitrary cores within a canonical superscalar template. The template defines canonical pipeline stages and interfaces among them. A canonical pipeline stage library (CPSL) provides many implementations of each canonical pipeline stage that differ in their superscalar width and depth of subpipelining. An RTL generation tool uses a template and CPSL to automatically generate the overall core of a desired configuration. Rocket Chip [
10], proposed by Krste et al., is an open-source SoC design generator that emits synthesizable RTL. It leverages Chisel to compose a library of sophisticated generators for cores, caches, and interconnects into an integrated SoC. Rocket Chip generates general-purpose processor cores that use the open RISC-V ISA and provides both an in-order core generator (Rocket) and an out-of-order core generator (BOOM). For SoC designers interested in utilizing heterogeneous specialization for added efficiency gains, Rocket Chip supports the integration of custom accelerators in the form of instruction set extensions, coprocessors, or fully independent novel cores. Moreover, Rocket Chip has been taped out (manufactured) eleven times and yielded functional silicon prototypes capable of booting Linux. Sizhuo Zhang et al. presented a framework called composable modular design (CMD) [
11] to facilitate the design of out-of-order processors. In CMD, the interface methods of modules provide instantaneous access and perform atomic updates to the state elements inside the module. Modules are composed together by atomic rules that call interface methods of different modules. The atomicity properties of interfaces in CMD ensure composability when selected modules are selectively refined.
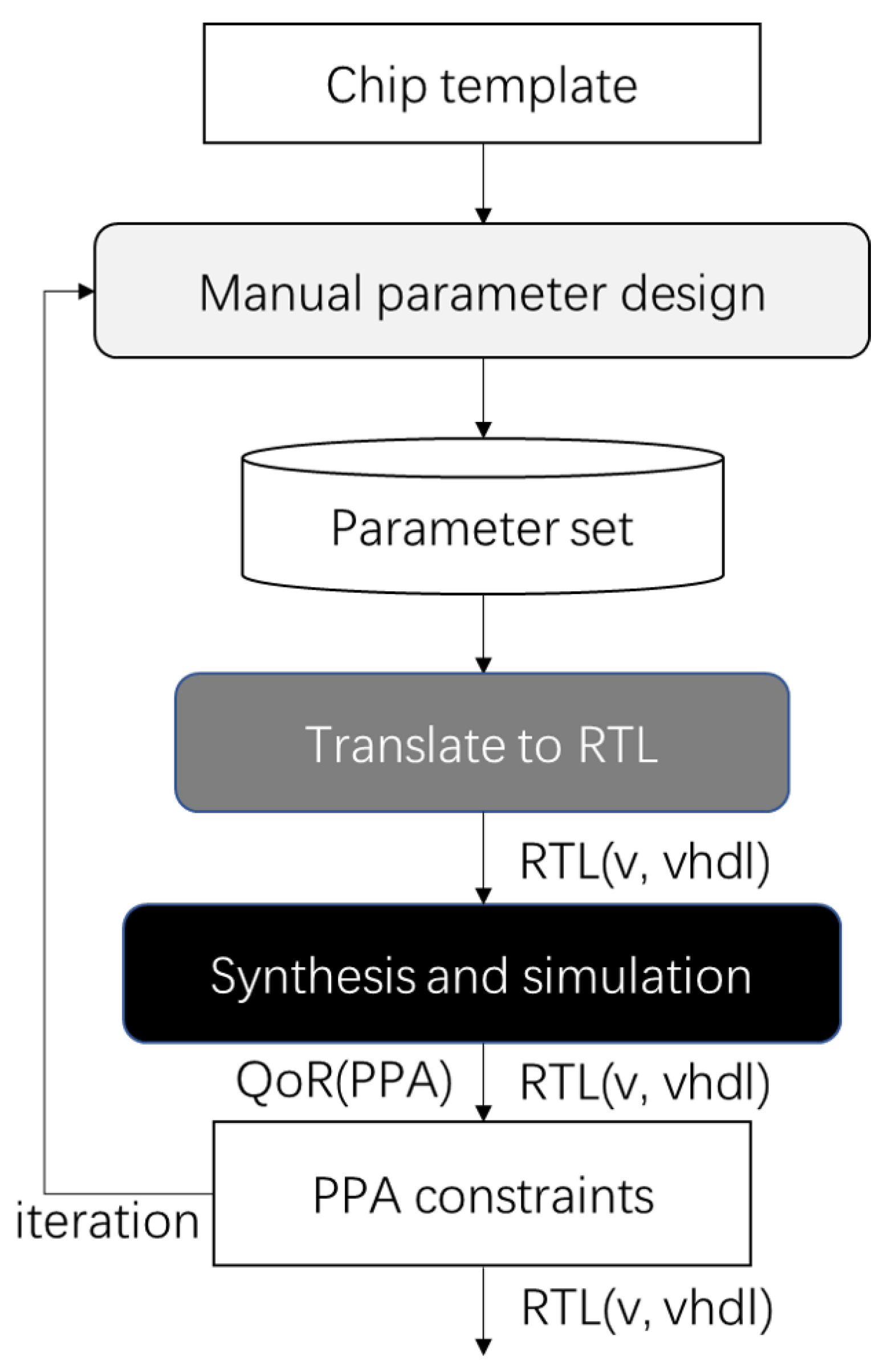
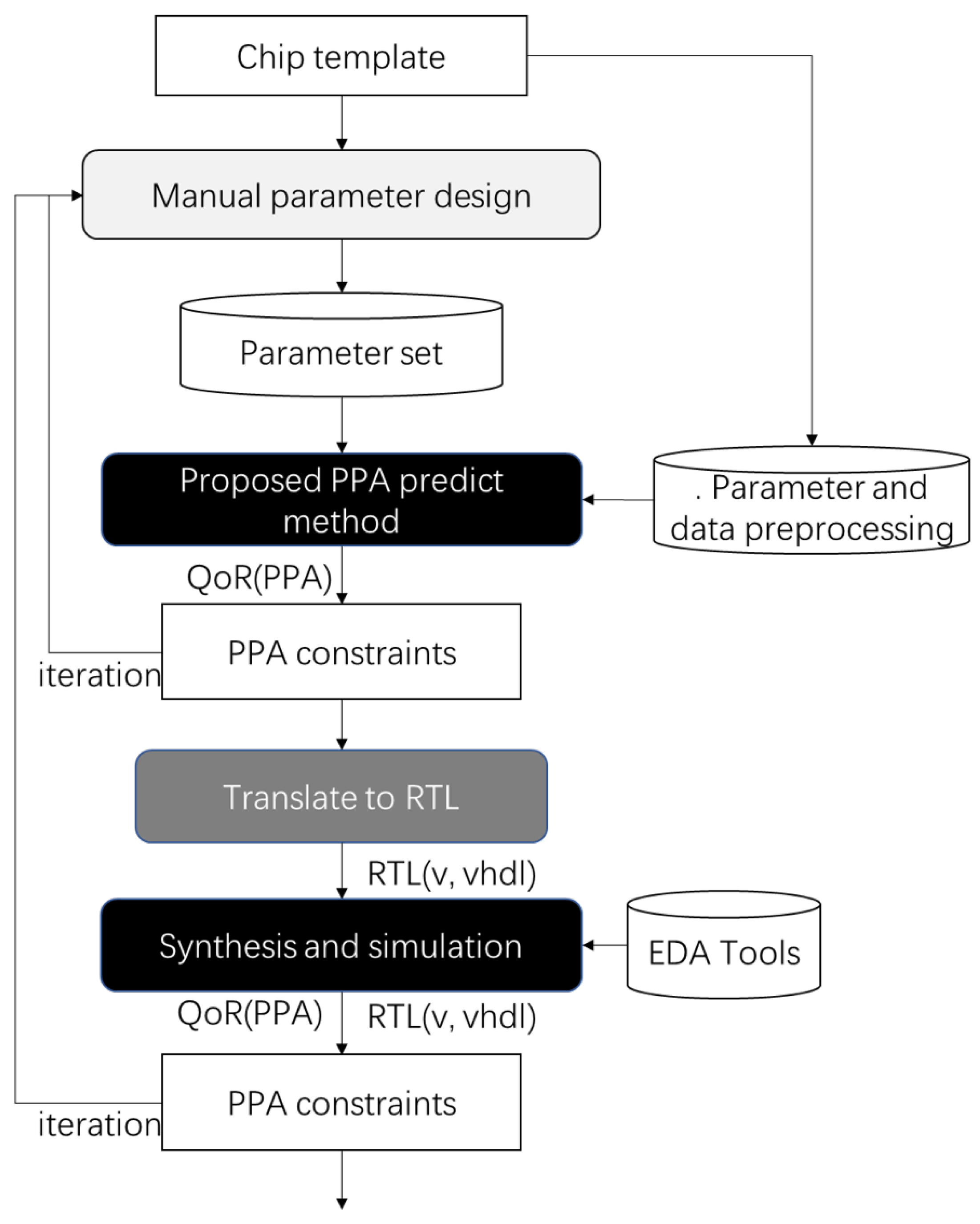
The designs of the methods mentioned are compiled into RTL, which can be run on FPGAs or synthesized using standard ASIC design flows. However, existing chip template-based design methods still use synthesis and simulation to obtain the quality of results (QoR) regarding performance, power, and area (PPA) for parameter set design space exploring (DSE), as shown in
Figure 1. However, iteration of the parameter set DSE via synthesis and simulation flows is time-consuming. Based on this, this study proposes a rapid and accurate PPA prediction for template-based chip design methods. First, a preprocess for template-based methods obtains the influence of each parameter of the templates on the PPA. Moreover, a PPA prediction model based on multivariate linear regression (ML-PM) is proposed to fit the multiparameter influence on the PPA via a single parameter effect. However, ML-PM does not consider the laws on processor performance. Therefore, a multivariate nonlinear regression prediction model (MNL-PM) based on Amdahl’s law is introduced to improve the accuracy of the PPA estimation.
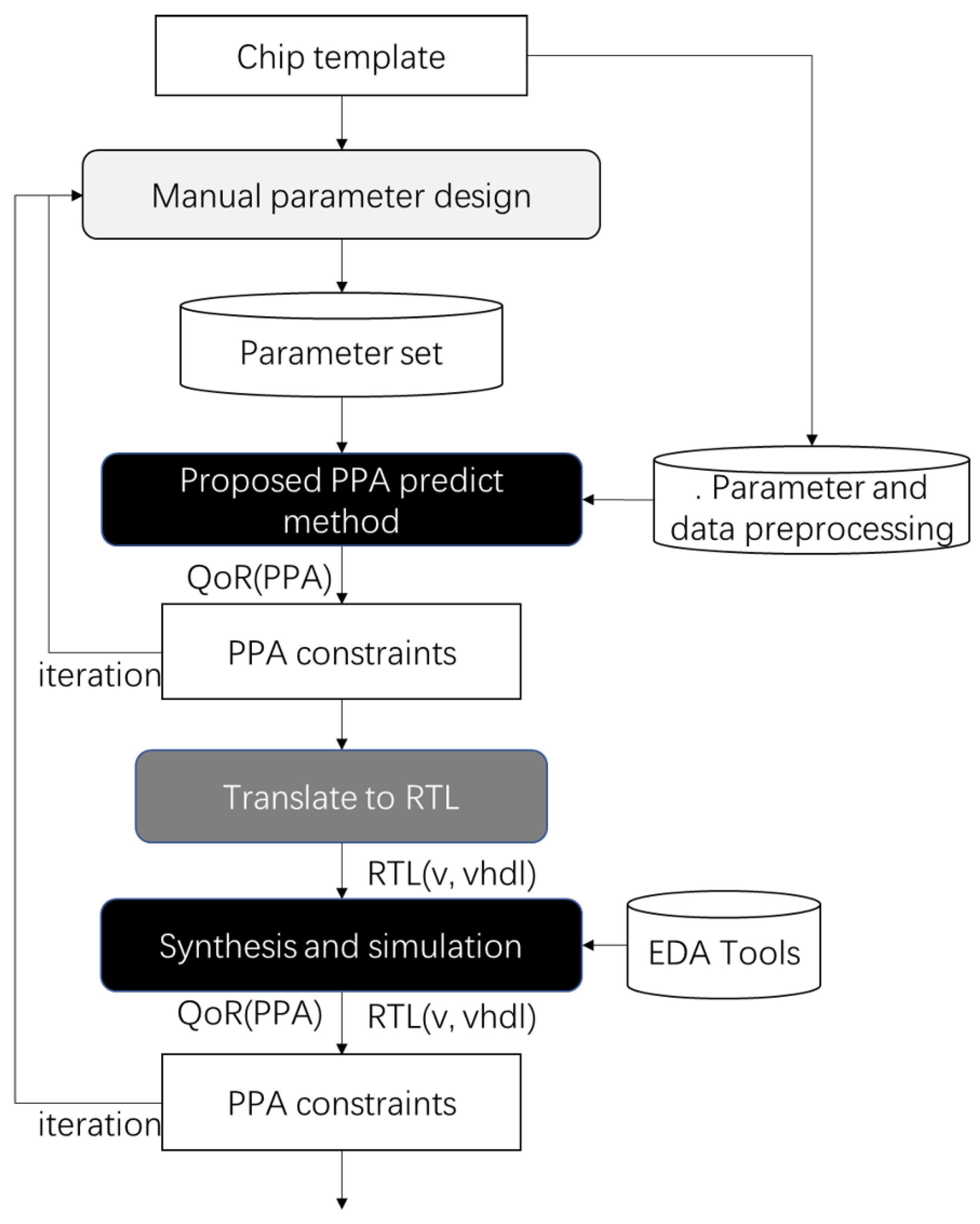
As shown in
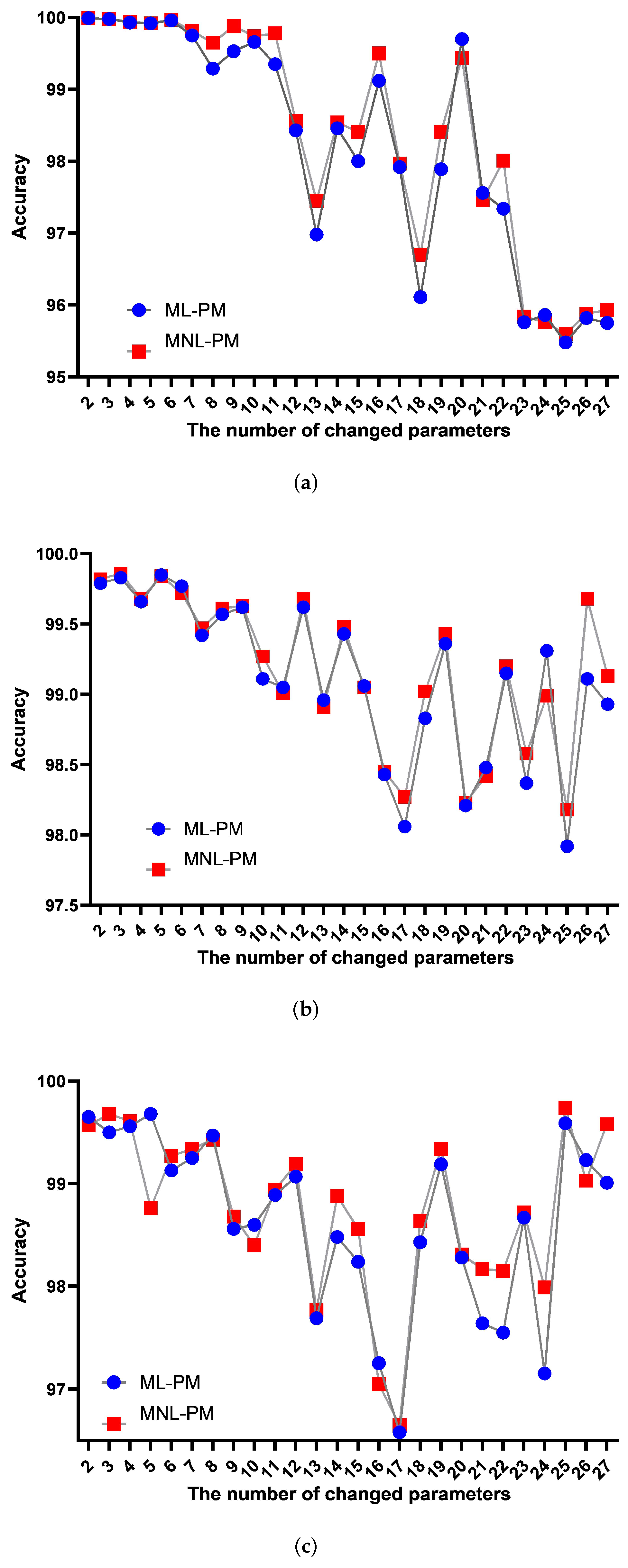
Figure 2, the proposed method replaces the synthesis and simulation process to reduce the time cost during the parameter design process. An empirical evaluation of the method shows that the PPA prediction for template-based chip design methods can reach 98.60%, 99.19%, and 98.53% accuracy on performance, power, and area, respectively, when compared with a PPA generated via synthesis and simulation flows. To the best of our knowledge, there is no previous work on fast and accurate PPA prediction on HDL design from template-based processor design methods. We believe that the proposed method is a novel and interesting design point in the space of solutions to the agile chip design problem. The main contributions of this work can be summarized as follows:
The PPA prediction model, ML-PM is proposed to achieve the PPA prediction via the parameter set, in which there are alters for normal multivariate linear regression model.
The PPA prediction model, MNL-PM based on Amdahl’s law is introduced as to improve the accuracy of the PPA estimation.
The iteration process of the parameters set DSE has been improved with the proposed PPA prediction model, which is time thrifty.
To the best of our knowledge, there is no previous work on fast and accurate PPA prediction on HDL design from template-based processor design methods. We believe that the proposed method is a novel and interesting design point in the space of solution to the agile chip design problem.
2. Related Work
As the AIoT grows, there are demands on processors that have different PPA requirements for various scenarios. Therefore, it is critical to design an AIoT process that meets the PPA needs in the short term. Template-based processor design methods, built on parameterized HDLs, aim to build chip architecture rapidly. However, these methods still require synthesis and simulation flows to obtain the PPA reports and find the proper parameter set, which takes a long time. Based on this, this study proposes a PPA prediction method that leverages the heavily parameterized features of template-based processor design methods to accelerate the iteration of parameter set design.
2.1. Parameterized HDLs
Traditional HDLs have a very long learning curve, even for experienced engineers. To solve this problem, new HDL designs focus on reusable and parameterized characteristics. Based on Python, PyRTL’s goal is to provide an alternative between these two extremes by enabling programmers to directly specify their hardware designs in a language they already know. MyHDL [
12] and PyMTL [
13] are also Python-based hardware design tools. MyHDL is built around generators and decoders; the semantics of this embedded language are close to Verilog and allow asynchronous logic and higher-level modeling. Much like traditional HDLs, however, only a structural “convertible subset” of the language can be automatically synthesized into real hardware. Chisel is an elaborate through-execution hardware design language. With support for signed types, named hierarchies of wires, and a well-designed control structure, Chisel is a powerful tool used in some great research projects, including OpenRISC [
14]. ClaSH is a hardware description embedded DSL in Haskell. ClaSH also provides an approach suitable for both combinational and synchronous sequential circuits and allows the transformation of these high-level descriptions to low-level synthesizable Verilog HDL.
2.2. Template-Based Chip Design Methods
Niket K et al. develop a toolset, called FabScalar, for automatically composing synthesizable RTL designs of arbitrary cores within a canonical superscalar template. The template defines canonical pipeline stages and interfaces among them. A canonical pipeline stage library (CPSL) provides many implementations of each canonical pipeline stage that differ in their superscalar width and depth of subpipelining. Rocket Chip, proposed by Krste A et al., is an open-source System-on-Chip design generator that emits synthesizable RTL. It leverages the Chisel hardware construction language to compose a library of sophisticated generators for cores, caches, and interconnects into an integrated SoC. Rocket Chip generates general-purpose processor cores that use the open RISC-V ISA and provides both an in-order core generator (Rocket) and an out-of-order core generator (BOOM). For SoC designers interested in utilizing heterogeneous specialization for added efficiency gains, Rocket Chip supports the integration of custom accelerators in the form of instruction set extensions, coprocessors, or fully independent novel cores. Sizhuo Zhang et al. present a framework called composable modular design (CMD) to facilitate the design of out-of-order processors. CMD designs can also be compiled into RTL, which can be run on FPGAs or synthesized using standard ASIC design flows. The atomicity properties of interfaces in CMD ensure composability when selected modules are selectively refined. Template-based chip design methods focus on the rapid construction of chips; therefore, modular and parameterized template design is the key point.
2.3. PPA Prediction for HLS
The relation between the knobs and the PPA for HLS design is a black box; therefore, machine learning is widely used for PPA prediction in HLS design to accelerate the design process. A. Mahapatra et al. proposed a machine-learning-based simulated annealer method for high-level synthesis design space exploration in 2014 [
15]. To foresee the correlation between power consumption and HLS-based applications at an early design stage, Zhe Lin et al. introduced HL-Pow [
16], a power modeling framework for FPGA HLS based on state-of-the-art machine learning techniques. HL-Pow incorporates an automated feature construction flow to efficiently identify and extract features that exert a major influence on power consumption, simply based upon HLS results, and a modeling flow that can build an accurate and generic power model applicable to a variety of designs with HLS. Moreover, W. Rhett Davis et al. presented models for fast and accurate PPA prediction that can reduce the manual optimization iterations with EDA tools in 2021 [
17]. They investigated techniques to automate PPA optimization using evolutionary algorithms. For PPA prediction, a baseline model is trained on a known design using Latin hypercube sample runs of an EDA tool, and transfer learning is then used to train the model for an unseen design. With transfer learning, the same accuracy was achieved on a different (unseen) design in only 15 runs, indicating the viability of transfer learning to generalize PPA models. However, PPA prediction for HLS is usually used for prototype design and algorithm verification, while HDLs are preferred for chip tape-out in the industry [
1]. On the one hand, HLS approaches promise to raise the level of abstraction and compile regular C/C++ functions into logic elements. There is still no clear way to develop an optimized design without prior hardware engineering experience. Moreover, the parameters for HLS are 3 kinds of knobs, which cannot control circuit details such as the ways cache numbers. On the other hand, PPA prediction methods based on machine learning require large samples for training. Therefore, we propose a rapid and accurate PPA prediction method for HDL designs from template-based chip design methods. On the one hand, there is a describable relation between the parameters of an HDL design and its PPA. The circuit details can be directly controlled by modifying the HDL codes. However, the proposed PPA prediction method requires a few samples to estimate the PPA.
Table 1 shows a comparison among the proposed method and the best machine learning model, XGBoost [
18], for HLS PPA prediction, which is mentioned in [
17].
3. PPA Prediction Method
The proposed method aims to rapidly estimate accurate PPA based on the parameter set of a certain chip design in the early stage of design, which can accelerate the process of proper parameter set design. The method contains two parts: one is the preprocess for a template-based method, and the other is a prediction model for the PPA estimation of the parameter set. In this study, a template-based method, Rocket Chip, is chosen as an example.
3.1. Parameter and Data Preprocessing
As the proposed method aims to predict the PPA of the parameter set for template-based methods, it is critical to determine the correlation among parameters and the design space of the parameter set. In Rocket Chip, for instance, a single core is mainly dependent on the parameters of modules, including the Core, Cache, BTB, and BTB’s submodule, BHT. First, only one of the parameters with correlations is selected as their representative. In this way, 27 parameters are selected as the parameter set. Second, to determine the design space of the parameter set, the value range of each parameter is designed, as shown partly in
Table 1, as follows.
For a bool-type parameter, there is only one optional value, and the default value is negated, except for the original value.
For an int-type parameter, there are two situations. For the first situation, there are two optional values except the original value of itself. Moreover, these three values form a proportional sequence with a common ratio of 2. As in the real design process, the parameters such as the size of memory are changed at a ratio of 2. Moreover, the default values will be the smallest, the middle, or the largest among these three values depending on the analysis of the existing designs in Rocket Chip. For other situations, the default values of these parameters are 0 and are still 0 in the existing designs in Rocket Chip. Then, 1 is set as another optional value of these parameters, similar to the rule for a bool-type parameter.
Moreover, the proposed method requires the individual influence of each parameter on the PPA to calculate the PPA prediction. Therefore, the bold value in
Table 2 is designed as the base parameter set, and each parameter is changed one at a time which are set as changed parameter sets to obtain the individual influence on PPA of each parameter. Specifically, the rules to set the values of the base parameters are that for int-type parameters with 3 optional values, the middle values are chosen, and for int-type parameters with value range, 0 and 1 values and bool-type parameters, the set value depends on the existing designs in Rocket Chip. Moreover,
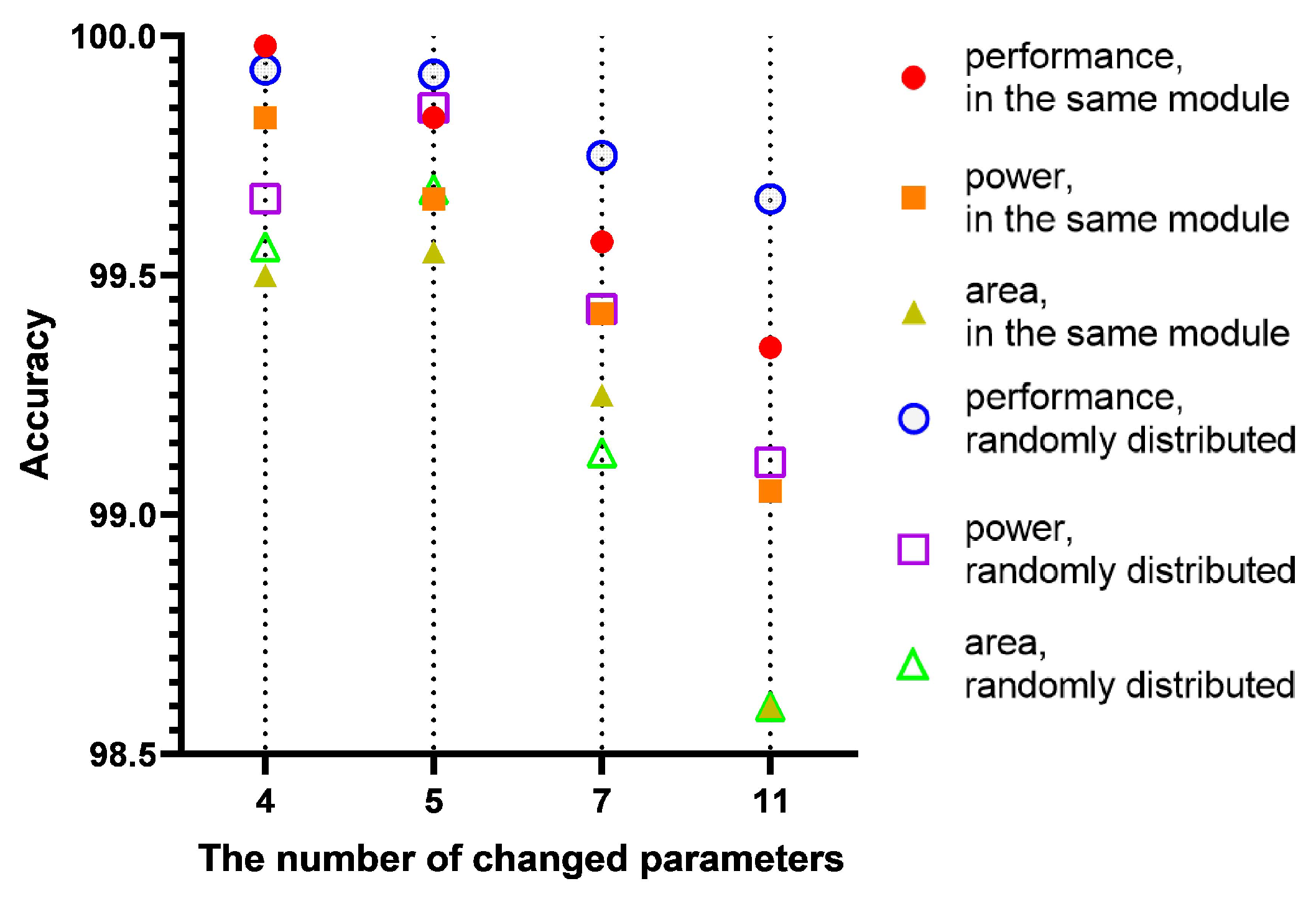
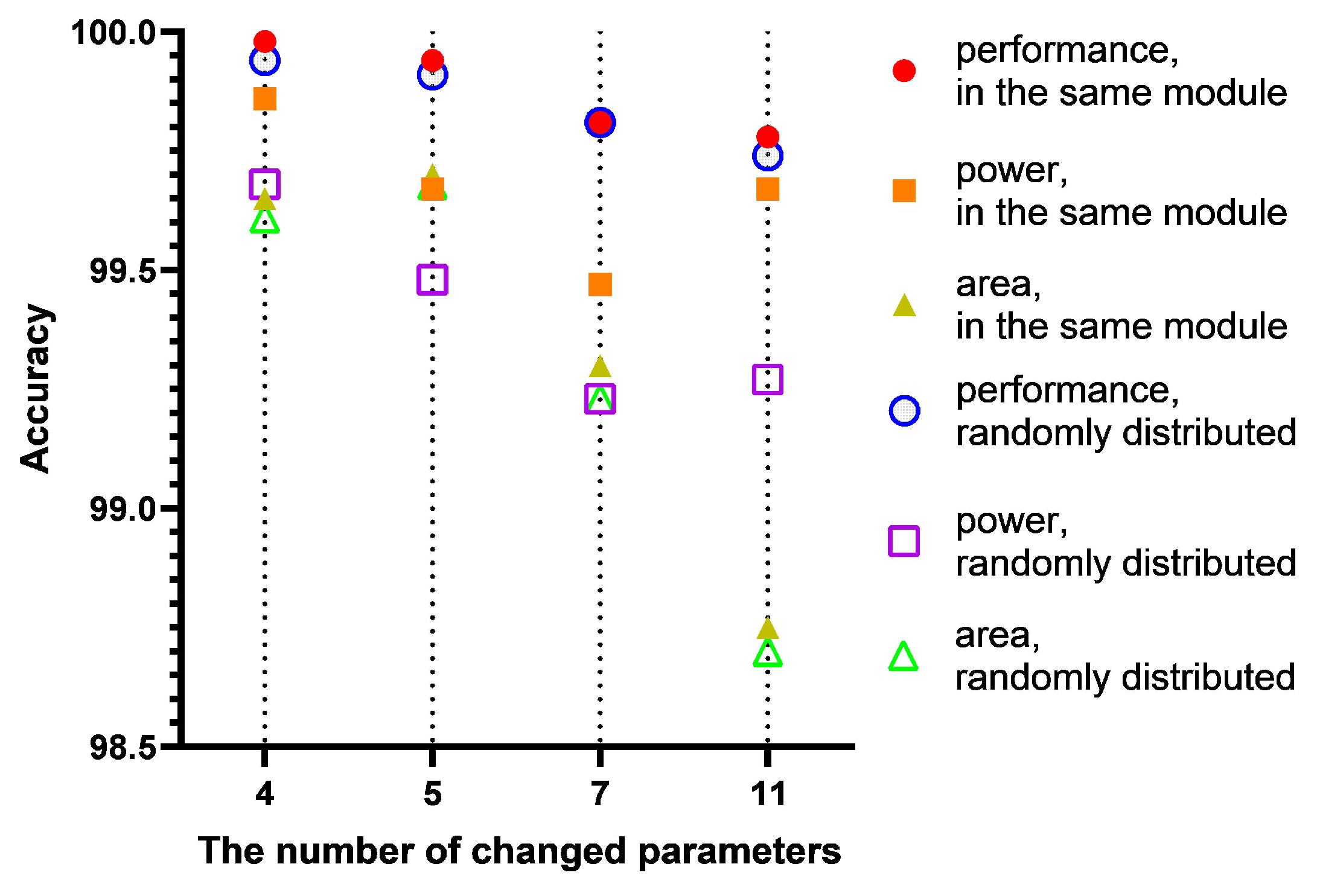
Table 3 shows an instance of changed sets partly. In this way, there are only 42 parameter set samples with PPA needed, and the PPA of the parameter set with the design space of 3.918 × 1010 is predictable.
3.2. Prediction Model Derivation
Having the effect of each parameter of the parameter set on PPA is not enough to predict the PPA of a certain parameter set design. Moreover, the relationship between the multifactor influence and a single-factor effect on the same system is a black box. Therefore, multivariate regression is utilized to fit the multiparameter influence on the PPA via a single parameter effect. The PPA estimate of the parameter set can be calculated via this method and the PPA samples of each parameter. In this study, the fit model is built separately based on a weight model and Amdahl’s law.
3.2.1. Multivariate Linear Regression Prediction Model
To build the ML-PM, we assume that each parameter is independent and has three individual weights for performance, power, and area. In detail, for each parameter
,
, this paper assumes that there are weight
,
, and
, for performance, power, and area specifically, while
,
, and
. Taking performance (
) for instance,
is the performance value of the base parameter set. And
will turn to
and fellow equation holding when one parameter
is modified to other value in its value range.
In the Equation (
1),
is the influence rate of the modified parameter
on
. And the change rate S can be represented as Equation (
3), when multiple parameters
,
are modified.
Although neither the
nor the
are known, the values of
and
are already known in the former preprocess, therefore,
and
can be replaced via
as the Equation (
4) below.
Based on the Equations (3) and (4), the change rate S can be calculated via available information, as the Equation (
6) below.
And
can be calculated as Equation (
6), when multiple parameters
,
are modified.
As the Equations (7) and (8) show separately, the power
and the area
can be calculated in the same way.
3.2.2. Multivariate Nonlinear Regression Prediction Model
Inspired via Amdahl’s law [
19], the MNL-PM is proposed to estimate the PPA. Amdahl’s law provides the maximum theoretical speedup achievable by a system which reflects the influence of each part in one system to the whole system at the same time. In detail, for each parameter
,
, the proposed method assumes that there are rates
,
, and
, each for its proportion in performance, power, and area, while
,
, and
and
,
,
. Taking performance (
) from PPA for instance,
, the value of the baseline’s performance, will turn to
and fellow equations holding when parameter
,
is modified to other value in its value range.
In the Equation (
9),
is the change rate and
is the change rate of the modified
. And the change rate
S can be represented as Equation (
11), when multiple parameters
,
are modified.
Although neither the
nor the
are known, the values of
and
are already known in the former preprocess. And
can directly expressed via
and
, as the Equation (
14) below.
Based on the Equations (11) and (12), the change rate S can be calculated via available information, as the Equation (
13) below.
And
S can be calculated as Equation (
14), when multiple parameters
,
are modified.
As the Equations (15) and (16) show separately, the power (
) and the area (
) can be calculated in the same way





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}