
A Novel Approach for Send Time Prediction on Email Marketing


 ,
,  , , and
, , and 
Abstract
1. Introduction
2. Predictive Approaches for Sending Marketing Campaigns
2.1. Predictive Approaches Based on Regression Classifiers
2.2. Predictive Approaches Based on Classification Classifiers
2.3. Predictive Approaches Based on a Mixture of Regression and Classification Classifiers
2.4. Summary of the Predictive Approaches
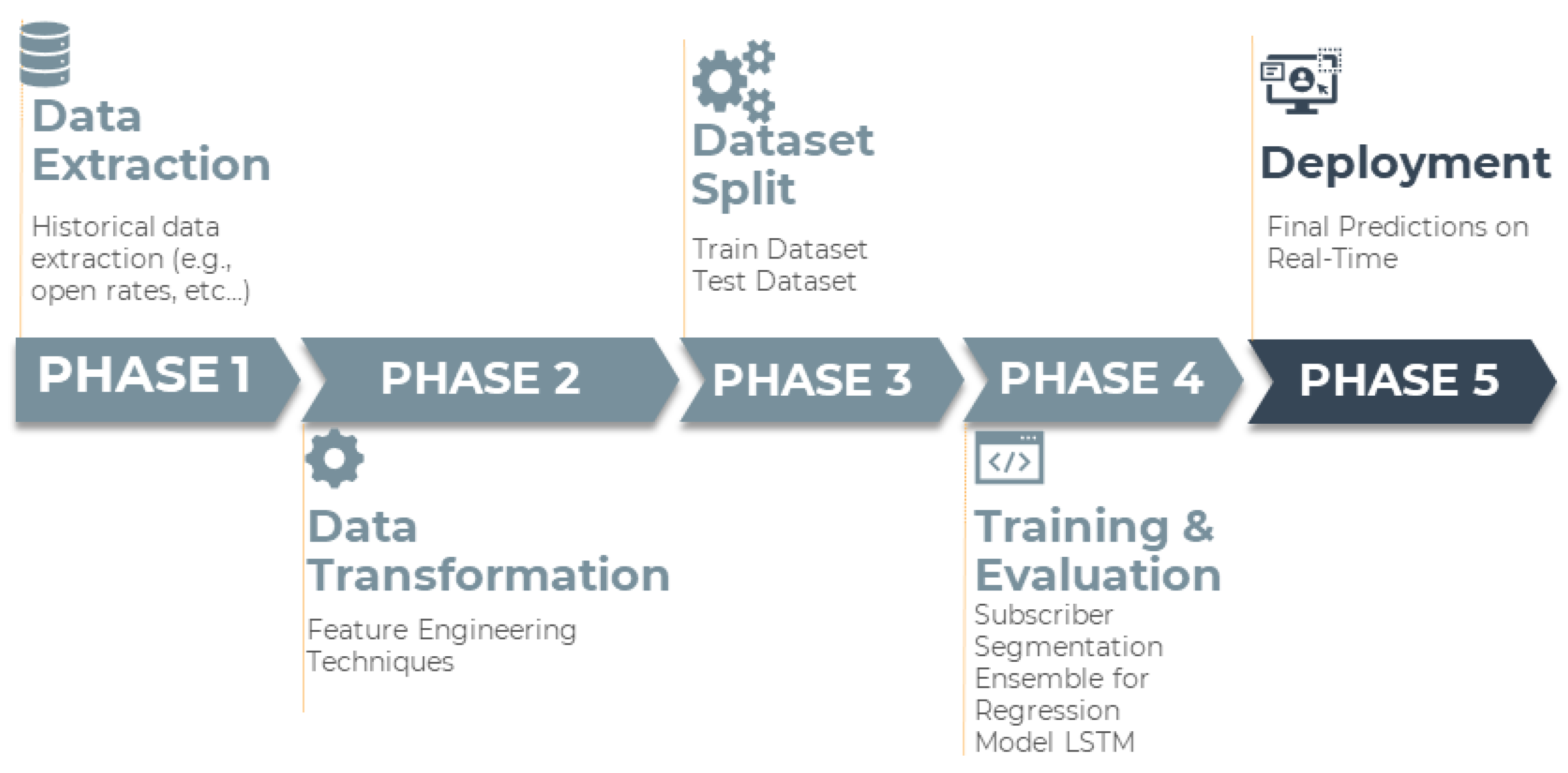
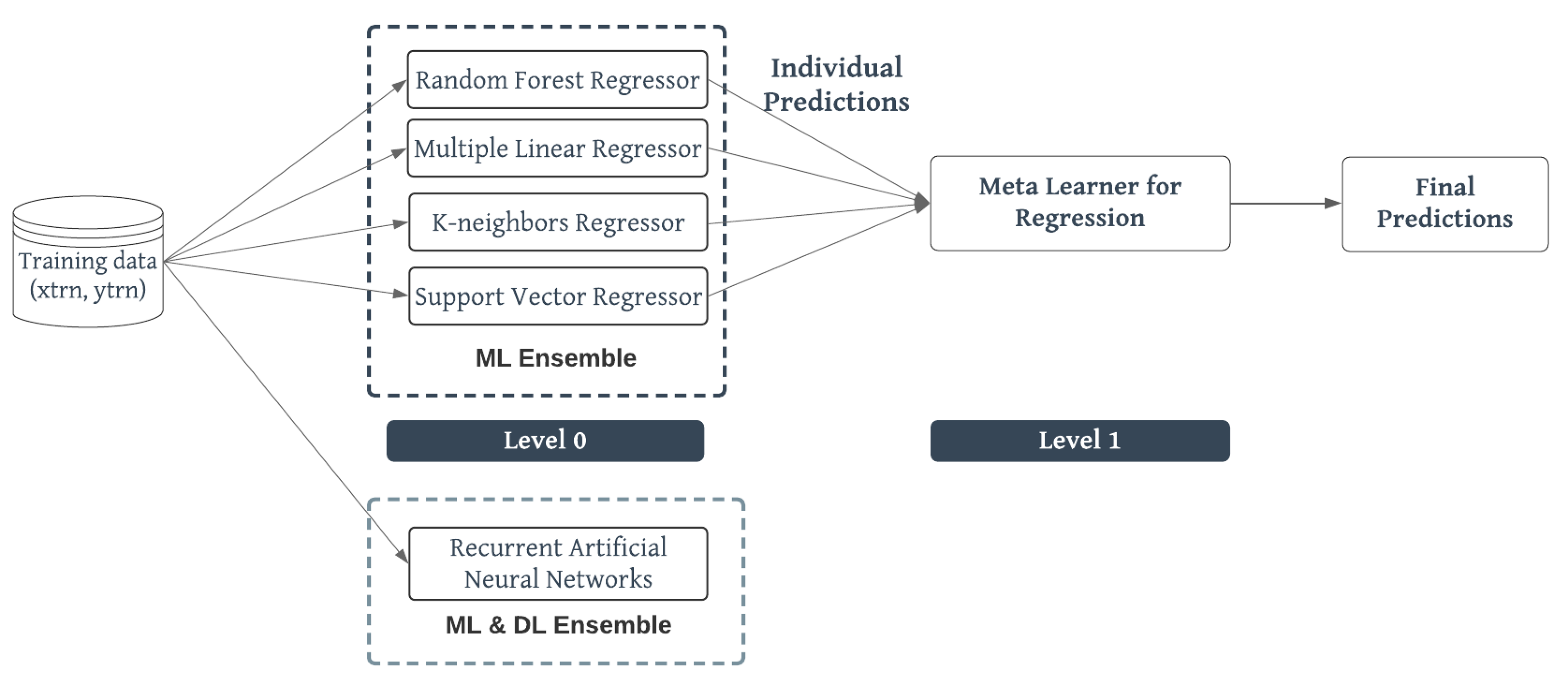
3. Methodology
| Algorithm 1 The Stacking algorithm. |
| procedure Input |
| procedure Output |
| Step 1: Learn all first-level regressors |
| for n = 1 to N do |
| end for |
| Step 2: Based on individual predictions create a new dataset |
| for i = 1 to m do |
| where Xtrn = |
| end for |
| Step 3: Learn the second-level regressor (meta-learner) |
| return H |
| end procedure |
| end procedure |
4. Computational Study
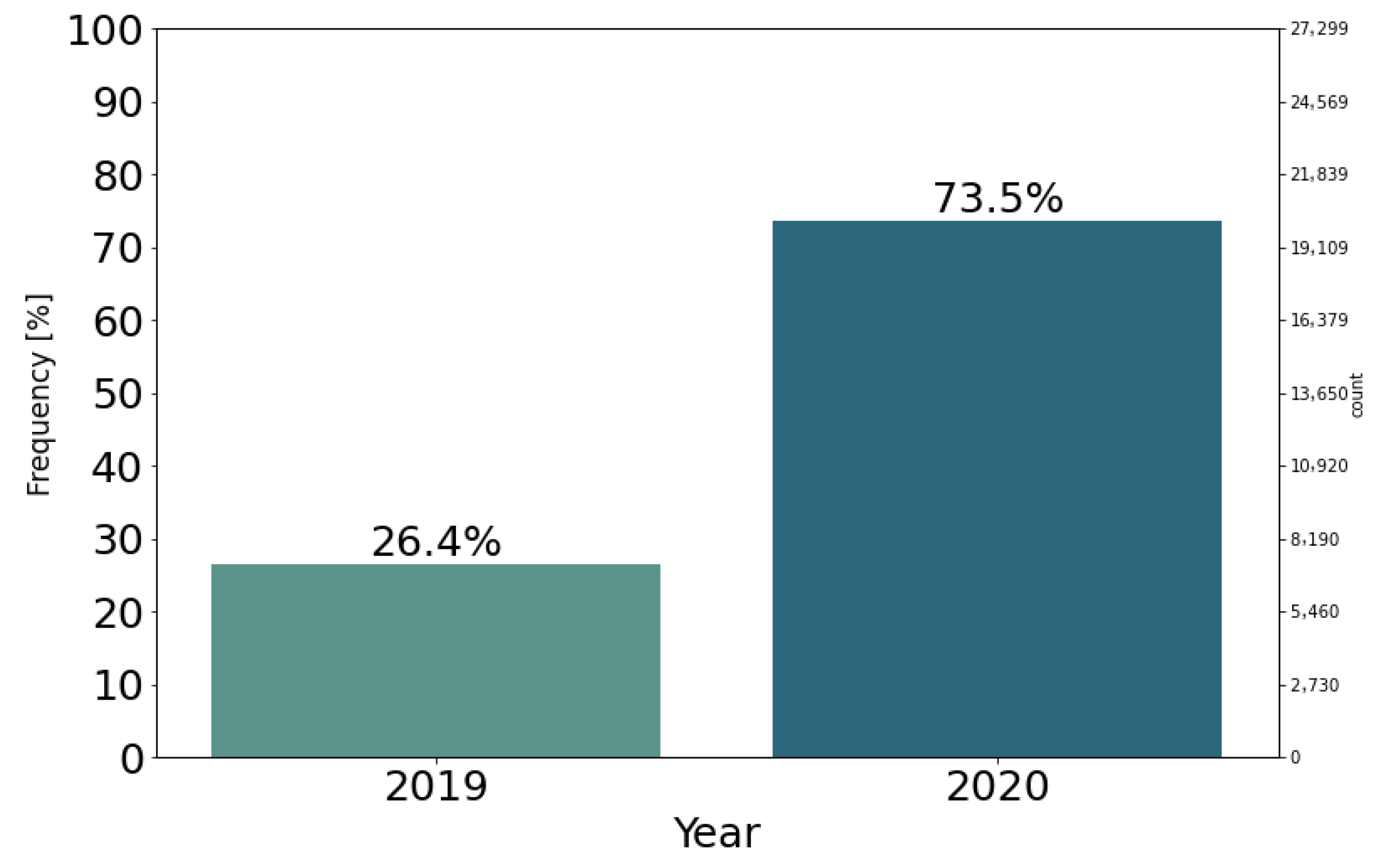
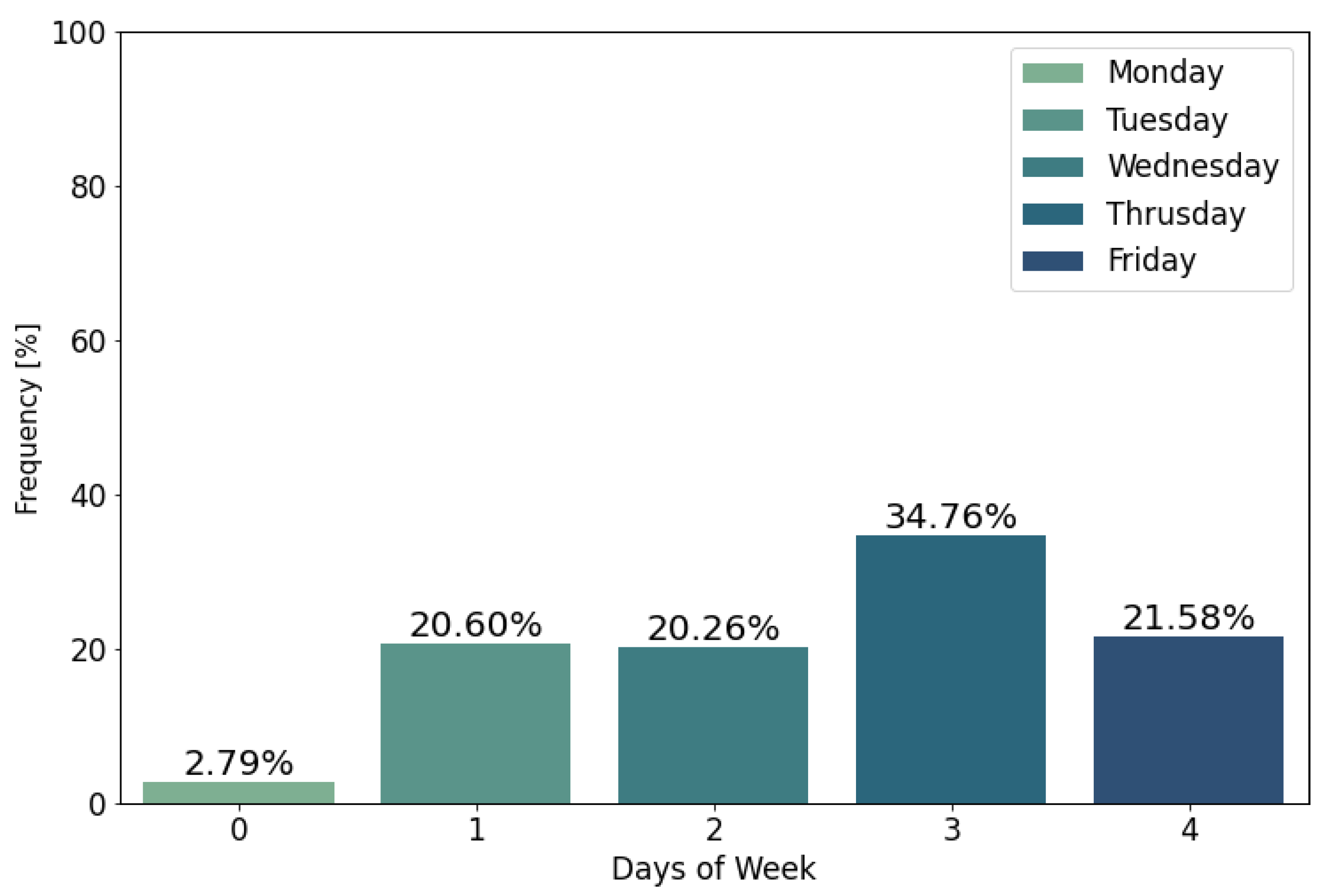
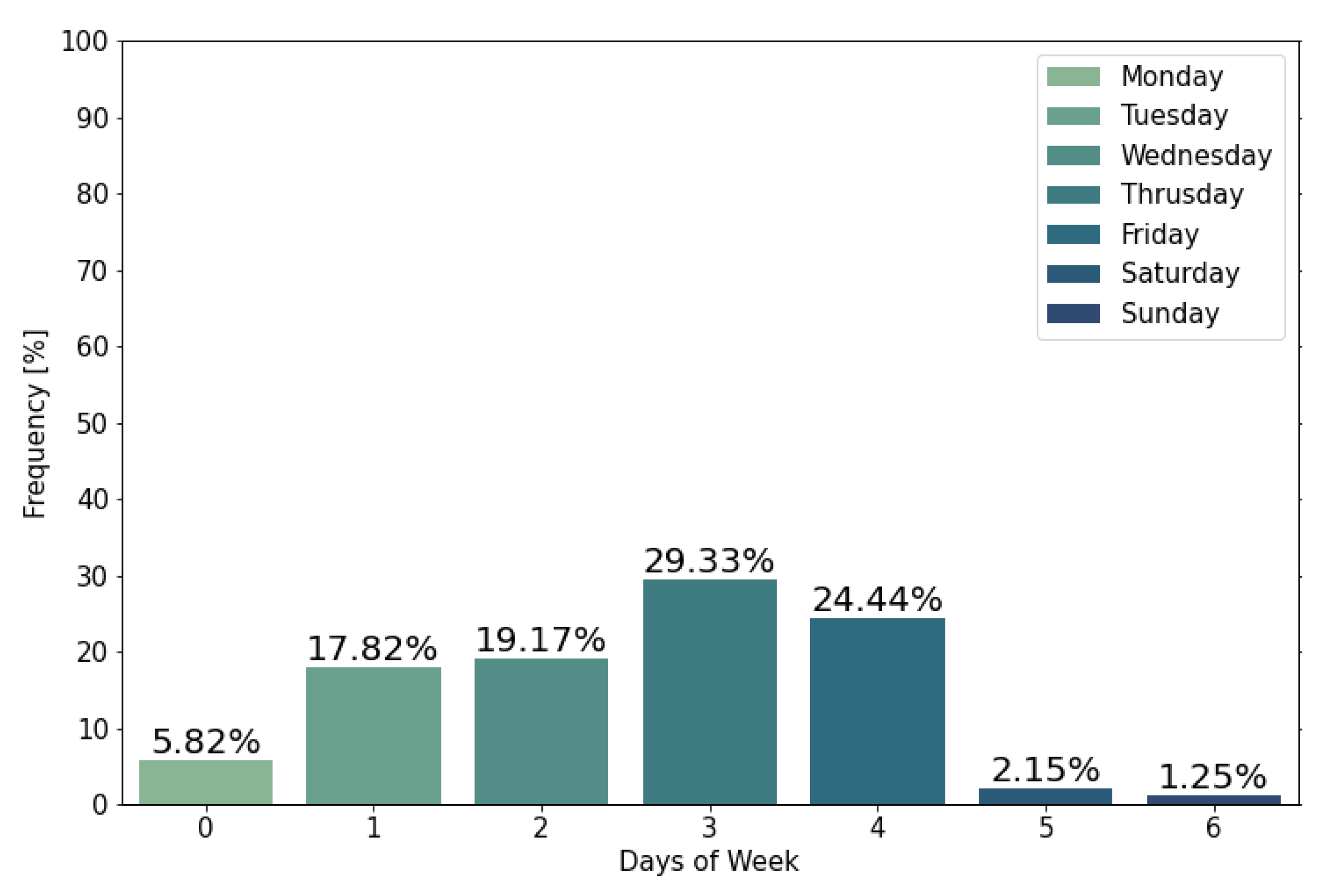
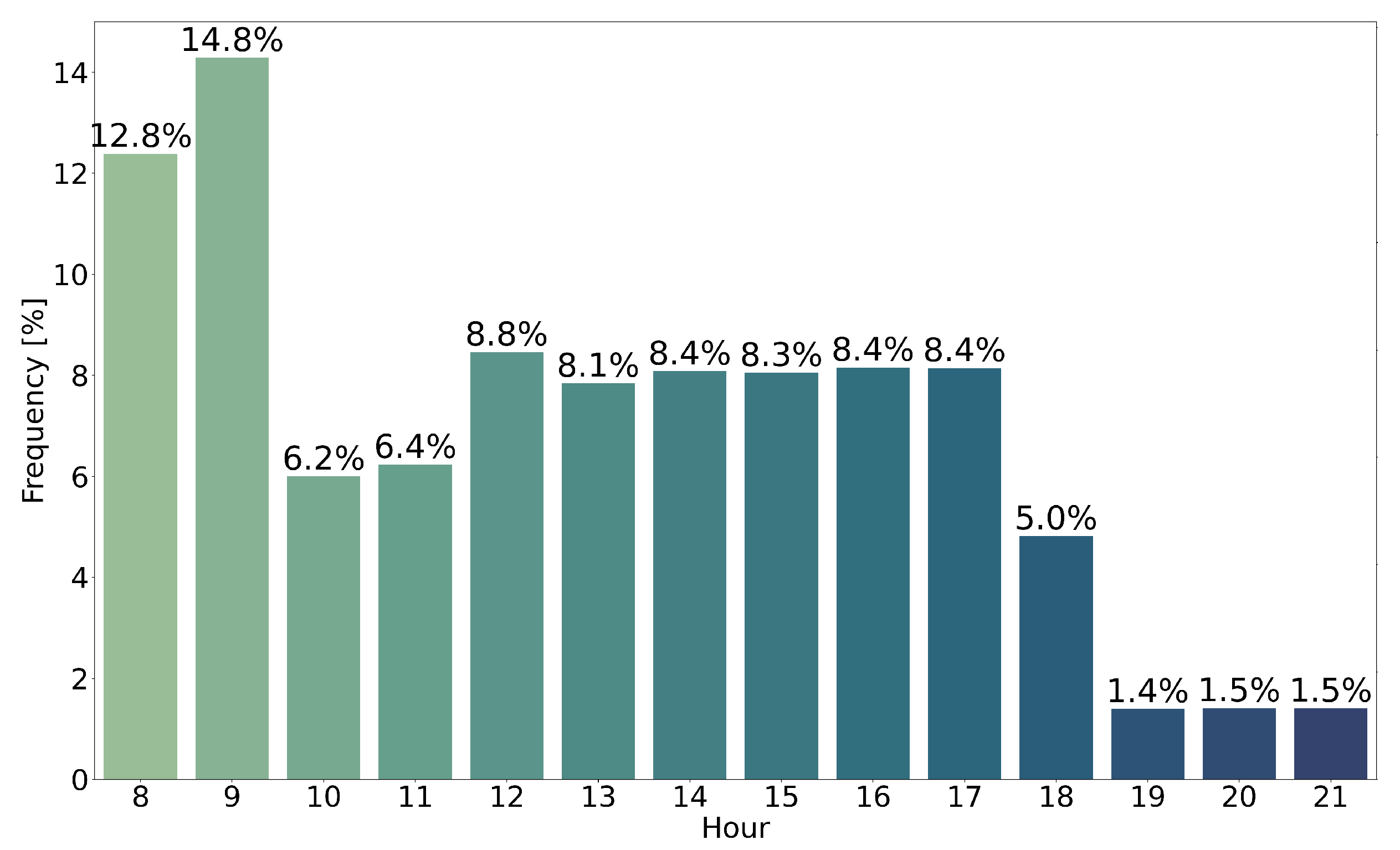
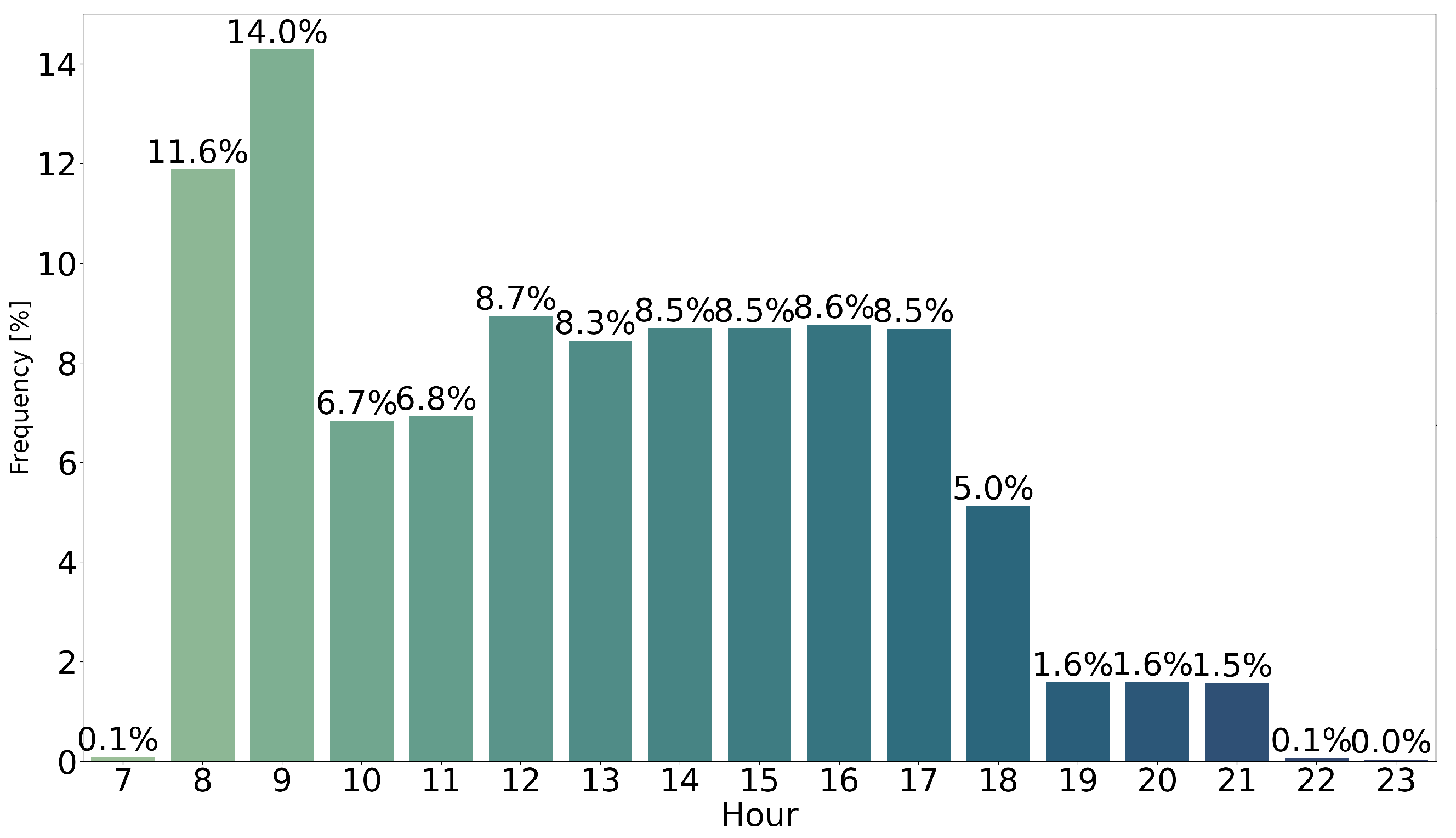
4.1. Data Analysis
- uid: the subscriber identification;
- action: the action that a subscriber will take (opening or clicking on an email);
- campaign: the campaign identification;
- time: the action timestamp (sending, opening or clicking on an email);
- destination: the channel of communication through which marketing campaigns are delivered;
- sendTimes: the time of when an email communication is sent to a subscriber (measured as a timestamp);
- timeAction: the time at which an action occurs (measured as a timestamp);
- emailDomain: the domain of the email (e.g., Hotmail, Gmail, etc.);
- city: the city associated with the subscriber’s location;
- region: the region associated with the subscriber’s location;
- country: the country associated with the subscriber’s location;
- ops: the operating system used by the subscriber (e.g., Windows, macOS, etc.);
- equip: the equipment used by the subscriber (e.g., smartphone, tablet, etc.);
- weekDaySendTimes: the day of the week an email campaign is sent to a subscriber;
- yearSendTimes: the year an email campaign is sent to a subscriber;
- monthSendTimes: the month an email campaign is sent to a subscriber;
- hourSendTimes: the hour an email campaign is sent to a subscriber;
- minuteSendTimes: the minute an email campaign is sent to a subscriber;
- WeekDayTimeAction: the day of the week a subscriber action occurred;
- yearTimeAction: the year a subscriber action occurred;
- monthTimeAction: the month a subscriber action occurred;
- hourTimeAction: the hour a subscriber action occurred;
- minuteTimeAction: the minute a subscriber action occurred.
4.2. Experimental Results
4.3. Discussion
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
References
- Deshmukh, S. Study On Artificial Intelligence in Marketing. Int. J. Adv. Innov. Res. 2019, 6, 112–116. [Google Scholar]
- Abakouy, R.; En-naimi, E.M.; Haddadi, A.E.; Lotfi, E. Data-Driven Marketing: How Machine Learning Will Improve Decision-Making for Marketers. In Proceedings of the 4th International Conference on Smart City Applications, Casablanca, Morocco, 2–4 October 2019; Association for Computing Machinery: New York, NY, USA, 2019. [Google Scholar] [CrossRef]
- Jonru, G.; Manrci, O. Highly Effective Techniques That Work Well In Email Marketing. Pardox J. 2020, 1. Available online: https://www.lantenay.com/index.php/pardox/article/view/31 (accessed on 1 July 2022).
- Thomas, J.S.; Chen, C.; Iacobucci, D. Email Marketing as a Tool for Strategic Persuasion. J. Interact. Mark. 2022, 57, 377–392. [Google Scholar] [CrossRef]
- Fariborzi, E.; Zahedifard, M. E-mail Marketing: Advantages, Disadvantages and Improving Techniques. Int. J. e-Educ. e-Bus. e-Manag. e-Learn. 2012, 2, 232. [Google Scholar] [CrossRef]
- Rysavy, M.D.; Michalak, R.; Daly, B. Library marketing: Sending text messages and emails to online library users during COVID-19. J. Libr. Adm. 2021, 61, 358–365. [Google Scholar] [CrossRef]
- Goic, M.; Rojas, A.; Saavedra, I. The effectiveness of triggered email marketing in addressing browse abandonments. J. Interact. Mark. 2021, 55, 118–145. [Google Scholar] [CrossRef]
- van Rijn, J. DMA National Client Email Report 2015. 2015. Available online: www.emailmonday.com/dma-national-client-email-report-2015/ (accessed on 16 December 2020).
- Salesforce. Fourth Annual State of Marketing: Insights and Trends from 3.500 Global Marketing Leaders. 2015. Available online: www.salesforce.com/content/dam/web/en_us/www/assets/pdf/datasheets/salesforce-research-fourth-annual-state-of-marketing.pdf (accessed on 17 December 2020).
- Forsey, C. The Ultimate List of Email Marketing Stats for 2020. 2020. Available online: blog.hubspot.com/marketing/email-marketing-stats (accessed on 17 December 2020).
- Bump, P. Why Consumers Subscribe and Unsubscribe from Email [New Data]. 2020. Available online: blog.hubspot.com/marketing/why-consumers-subscribe-to-email (accessed on 17 December 2020).
- Monitor, C. The New Rules of Email Marketing. 2020. Available online: www.campaignmonitor.com/resources/guides/email-marketing-new-rules (accessed on 17 December 2020).
- Vangelov, N. Digital Marketing and Outdoor Advertising in Smart Cities. Smart Cities Reg. Dev. (SCRD) J. 2022, 6, 81–91. [Google Scholar]
- Huang, M.H.; Rust, R.T. A framework for collaborative artificial intelligence in marketing. J. Retail. 2022, 98, 209–223. [Google Scholar] [CrossRef]
- Sukarsa, I.M.; Buana, P.W.; Arynasta, I.P.K. Software as a Service: Design and Build Lower Usage Cost Email Marketing for Hospitality Industry. Sci. J. Inform. 2020, 7, 189–202. [Google Scholar]
- Monitor, C. What are KPIs in Email Marketing? 2020. Available online: www.campaignmonitor.com/resources/knowledge-base/what-are-kpis-in-email-marketing (accessed on 23 December 2020).
- Paulo, M.; Miguéis, V.; Pereira, I. Leveraging email marketing: Using the subject line to anticipate the open rate. Expert Syst. Appl. 2022, 207, 117974. [Google Scholar] [CrossRef]
- iPULLRANK. Machine Learning for Marketers—A Comprehensive Guide to Machine Learning. 2020. Available online: assets.ctfassets.net/j5zy0n17n2ql/2D4mX8PjV6iC6i8cIuSCwk/23a4ebb99a6e9d5a82b2f03e1262f39d/ml-whitepaper.pdf (accessed on 18 December 2020).
- Gharaei, N.; Bakar, K.A.; Hashim, S.Z.M.; Pourasl, A.H.; Butt, S.A. Collaborative mobile sink sojourn time optimization scheme for cluster-based wireless sensor networks. IEEE Sens. J. 2018, 18, 6669–6676. [Google Scholar] [CrossRef]
- Ayvaz, D.; Aydoğan, R.; Akçura, M.T.; Şensoy, M. Campaign participation prediction with deep learning. Electron. Commer. Res. Appl. 2021, 48, 101058. [Google Scholar] [CrossRef]
- Schaeffer, S.E.; Sanchez, S.V.R. Forecasting client retention—A machine-learning approach. J. Retail. Consum. Serv. 2020, 52, 101918. [Google Scholar] [CrossRef]
- Sarkar, M.; De Bruyn, A. LSTM response models for direct marketing analytics: Replacing feature engineering with deep learning. J. Interact. Mark. 2021, 53, 80–95. [Google Scholar] [CrossRef]
- AT INTERNET. Lead. 2021. Available online: www.atinternet.com/en/glossary/lead/ (accessed on 8 April 2021).
- Deligiannis, A.; Argyriou, C.; Kourtesis, D. Building a Cloud-based Regression Model to Predict Click-through Rate in Business Messaging Campaigns. Int. J. Model. Optim. 2020, 10, 26–31. [Google Scholar] [CrossRef]
- Goldberg, Y. A Primer on Neural Network Models for Natural Language Processing. J. Artif. Intell. Res. 2016, 57, 345–420. [Google Scholar] [CrossRef]
- Deligiannis, A.; Argyriou, C.; Kourtesis, D. Predicting the Optimal Date and Time to Send Personalized Marketing Messages to Repeat Buyers. Int. J. Adv. Comput. Sci. Appl. 2020, 11, 90–99. [Google Scholar] [CrossRef]
- Naik, N. Choice of effective messaging protocols for IoT systems: MQTT, CoAP, AMQP and HTTP. In Proceedings of the 2017 IEEE International Systems Engineering Symposium (ISSE), Vienna, Austria, 11–13 October 2017; pp. 1–7. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. XGBoost. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016. [Google Scholar] [CrossRef]
- Paralic, J.; Kaszoni, T.; Mačina, J. Predicting suitable time for sending marketing emails. In Information Systems Architecture and Technology, Proceedings of the 40th Anniversary International Conference on Information Systems Architecture and Technology—ISAT 2019, Wrocław, Poland, 15–17 September 2019; Springer International Publishing: Cham, Switzerland, 2020; pp. 189–196. [Google Scholar]
- Zhang, J. Dive into Decision Trees and Forests: A Theoretical Demonstration. arXiv 2021, arXiv:2101.08656. [Google Scholar]
- Reis, I.; Baron, D.; Shahaf, S. Probabilistic Random Forest: A Machine Learning Algorithm for Noisy Data Sets. Astron. J. 2018, 157, 16. [Google Scholar] [CrossRef]
- Mohanapriya, M.; Jayabalan, L. Comparative study between decision tree and knn of data mining classification technique. J. Phys. Conf. Ser. 2018, 1142, 012011. [Google Scholar] [CrossRef]
- Conceição, A.; Gama, J. Main Factors Driving the Open Rate of Email Marketing Campaigns. In Proceedings of the International Conference on Discovery Science, Split, Coratia, 28–30 October 2019; Springer International Publishing: Cham, Switzerland, 2019; pp. 145–154. [Google Scholar] [CrossRef]
- Friedman, J.H. Greedy function approximation: A gradient boostingmachine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Luo, X.; Nadanasabapathy, R.; Zincir-Heywood, A.N.; Gallant, K.; Peduruge, J. Predictive Analysis on Tracking Emails for Targeted Marketing. In Proceedings of the International Conference on Discovery Science, Banff, AB, Canada, 4–6 October 2015; Japkowicz, N., Matwin, S., Eds.; Springer International Publishing: Cham, Switzerland, 2015; pp. 116–130. [Google Scholar]
- Joachims, T. Text categorization with Support Vector Machines: Learning with many relevant features. In Proceedings of the Machine Learning: ECML-98, Chemnitz, Germany, 21–23 April 1998; Nédellec, C., Rouveirol, C., Eds.; Springer: Berlin/Heidelberg, Germany, 1998; pp. 137–142. [Google Scholar]
- Sinha, M.; Vinay, V.; Singh, H. Modeling Time to Open of Emails with a Latent State for User Engagement Level. In Proceedings of the Eleventh ACM International Conference on Web Search and Data Mining, Los Angeles, CA, USA, 5–9 February 2018; pp. 531–539. [Google Scholar]
- Fox, J. Cox proportional-hazards regression for survival data. In An R and S-PLUS Companion to Applied Regression; Sage Publications, Inc.: Thousand Oaks, CA, USA, 2002. [Google Scholar]
- Glazier, S.W. Sequential Survival Analysis with Deep Learning. Master’s Thesis, Brigham Young University, Provo, UT, USA, 2019. [Google Scholar]
- Singh, H.; Sinha, M.; Sinha, A.R.; Garg, S.; Banerjee, N. An RNN-Survival Model to Decide Email Send Times. arXiv 2020, arXiv:2004.09900. [Google Scholar]
- Singh, H.; Sinha, M.; Sinha, A.; Garg, S.; Banerjee, N. Determining Strategic Digital Content Transmission Time Utilizing Recurrent Neural Networks and Survival Analysis; Adobe Inc.: San Jose, CA, USA, 2019. [Google Scholar]
- Piersma, N.; Jonker, J.J. Determining the optimal direct mailing frequency. Eur. J. Oper. Res. 2004, 158, 173–182. [Google Scholar] [CrossRef]
- Scikit Learn. Scikit-Learn Machine Learning in Python. 2020. Available online: https://scikit-learn.org/stable/ (accessed on 27 January 2022).
- Wu, H.; Cai, Y.; Wu, Y.; Zhong, R.; Li, Q.; Zheng, J.; Lin, D.; Li, Y. Time series analysis of weekly influenza-like illness rate using a one-year period of factors in random forest regression. BioSci. Trends 2017, 11, 2017. [Google Scholar] [CrossRef]
- Bandyopadhyay, G.; Chattopadhyay, S. Single hidden layer artificial neural network models versus multiple linear regression model in forecasting the time series of total ozone. Int. J. Environ. Sci. Technol. 2007, 4, 141–149. [Google Scholar] [CrossRef]
- Al-Qahtani, F.; Crone, S. Multivariate k-nearest neighbour regression for time series data—A novel algorithm for forecasting UK electricity demand. In Proceedings of the International Joint Conference on Neural Networks, Dallas, TX, USA, 4–9 August 2013; pp. 1–8. [Google Scholar] [CrossRef]
- Kunapul, G. Ensemble Methods for Machine Learning. 2020. Available online: https://www.manning.com/books/ensemble-methods-for-machine-learning (accessed on 3 January 2022).
- Brownlee, J. Regression Metrics for Machine Learning. 2021. Available online: https://machinelearningmastery.com/regression-metrics-for-machine-learning/ (accessed on 3 January 2022).
- Müller, J.M.; Pommeranz, B.; Weisser, J.; Voigt, K.I. Digital, Social Media, and Mobile Marketing in industrial buying: Still in need of customer segmentation? Empirical evidence from Poland and Germany. Ind. Mark. Manag. 2018, 73, 70–83. [Google Scholar] [CrossRef]
- Christy, A.J.; Umamakeswari, A.; Priyatharsini, L.; Neyaa, A. RFM ranking–An effective approach to customer segmentation. J. King Saud Univ. Comput. Inf. Sci. 2021, 33, 1251–1257. [Google Scholar] [CrossRef]
- Jonker, J.J.; Piersma, N.; Van den Poel, D. Joint Optimization of Customer Segmentation and Marketing Policy to Maximize Long-Term Profitability. Expert Syst. Appl. 2004, 27, 159–168. [Google Scholar] [CrossRef][Green Version]
- Optideia. Lifetime Value. 2020. Available online: https://www.optimizely.com/optimization-glossary/lifetime-value/ (accessed on 11 June 2021).
- Sun, Z.H.; Zuo, T.Y.; Liang, D.; Ming, X.; Chen, Z.; Qiu, S. GPHC: A heuristic clustering method to customer segmentation. Appl. Soft Comput. 2021, 111, 107677. [Google Scholar] [CrossRef]
- Li, Y.; Chu, X.; Tian, D.; Feng, J.; Mu, W. Customer segmentation using K-means clustering and the adaptive particle swarm optimization algorithm. Appl. Soft Comput. 2021, 113, 107924. [Google Scholar] [CrossRef]
- Tsagkanos, A. Stock market development and income inequality. J. Econ. Stud. 2017, 44, 87–98. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Features Implemented by the Models | |||||
|---|---|---|---|---|---|
| Paper | Open Rates | Click-through Rates | Time Intervals | Email Info. | Profile Info. |
| Deligiannis et al. [26] | ✓ | ✓ | |||
| Deligiannis et al. [24] | ✓ | ✓ | ✓ | ||
| Singh et al. [40] | ✓ | ✓ | ✓ | ✓ | ✓ |
| Paralic et al. [29] | ✓ | ✓ | |||
| Conceição et al. [33] | ✓ | ✓ | |||
| Sinha et al. [37] | ✓ | ✓ | |||
| Singh et al. [41] | ✓ | ✓ | |||
| Luo et al. [35] | ✓ | ✓ | ✓ | ✓ | |
| Piersma et al. [42] | ✓ | ✓ | |||
| R | MAE | MSE | RMSE | |
|---|---|---|---|---|
| Random Forest | 0.840 | 0.328 | 1.572 | 1.254 |
| Linear Regression | 0.312 | 1.621 | 6.748 | 2.598 |
| KNN | 0.898 | 0.166 | 1.171 | 1.082 |
| SVR | −0.048 | 2.052 | 8.786 | 2.964 |
| LSTM | 0.271 | 1.702 | 6.831 | 2.614 |
| ML Ensemble (stacking) | 0.91 | 0.204 | 1.051 | 1.025 |
| ML & DL Ensemble | 0.640 | 1.159 | 3.430 | 1.852 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Araújo, C.; Soares, C.; Pereira, I.; Coelho, D.; Rebelo, M.Â.; Madureira, A. A Novel Approach for Send Time Prediction on Email Marketing. Appl. Sci. 2022, 12, 8310. https://doi.org/10.3390/app12168310
Araújo C, Soares C, Pereira I, Coelho D, Rebelo MÂ, Madureira A. A Novel Approach for Send Time Prediction on Email Marketing. Applied Sciences. 2022; 12(16):8310. https://doi.org/10.3390/app12168310
Chicago/Turabian StyleAraújo, Carolina, Christophe Soares, Ivo Pereira, Duarte Coelho, Miguel Ângelo Rebelo, and Ana Madureira. 2022. "A Novel Approach for Send Time Prediction on Email Marketing" Applied Sciences 12, no. 16: 8310. https://doi.org/10.3390/app12168310
APA StyleAraújo, C., Soares, C., Pereira, I., Coelho, D., Rebelo, M. Â., & Madureira, A. (2022). A Novel Approach for Send Time Prediction on Email Marketing. Applied Sciences, 12(16), 8310. https://doi.org/10.3390/app12168310