Abstract
Speech Emotion Classification (SEC) relies heavily on the quality of feature extraction and selection from the speech signal. Improvement on this to enhance the classification of emotion had attracted significant attention from researchers. Many primitives and algorithmic solutions for efficient SEC with minimum cost have been proposed; however, the accuracy and performance of these methods have not yet attained a satisfactory point. In this work, we proposed a novel deep transfer learning approach with distinctive emotional rich feature selection techniques for speech emotion classification. We adopt mel-spectrogram extracted from speech signal as the input to our deep convolutional neural network for efficient feature extraction. We froze 19 layers of our pretrained convolutional neural network from re-training to increase efficiency and minimize computational cost. One flattened layer and two dense layers were used. A ReLu activation function was used at the last layer of our feature extraction segment. To prevent misclassification and reduce feature dimensionality, we employed the Neighborhood Component Analysis (NCA) feature selection algorithm for picking out the most relevant features before the actual classification of emotion. Support Vector Machine (SVM) and Multi-Layer Perceptron (MLP) classifiers were utilized at the topmost layer of our model. Two popular datasets for speech emotion classification tasks were used, which are: Berling Emotional Speech Database (EMO-DB), and Toronto English Speech Set (TESS), and a combination of EMO-DB with TESS was used in our experiment. We obtained a state-of-the-art result with an accuracy rate of 94.3%, 100% specificity on EMO-DB, and 97.2%, 99.80% on TESS datasets, respectively. The performance of our proposed method outperformed some recent work in SEC after assessment on the three datasets.
1. Introduction
SEC occupies an important position in affective computing and plays a cogent role in human relationships. Psychologically, there is no better way: a relationship can neither be initiated nor sustained without adequate communication. However, communication takes place in many ways (verbal and non-verbal), but auditory speech communication has been the hub for all other forms. It is the nucleus to which all other means of human interaction revolve [1]. One major factor that determines human decisions is emotion [2,3]. Whether on an inter-personal or intra-personal basis, emotion influences why human beings act or react the way they act, informs their judgment, and even sometimes molds their opinions. Classification of emotion through human speech, therefore, is the act of recognizing emotional content from speech [4] as depicted in Figure 1. The growth of human–computer interaction in the last decade cannot be unconnected to SEC [5,6]. Apart from wider application in major fields and sub-fields, SEC is reshaping the nearby future next revolution of human–machine interaction as it is attracting the vast majority of researchers worldwide. Mental disorders and depression-related diseases have been drawing great benefit from SEC coupled with the acceleration of patient treatment [7].
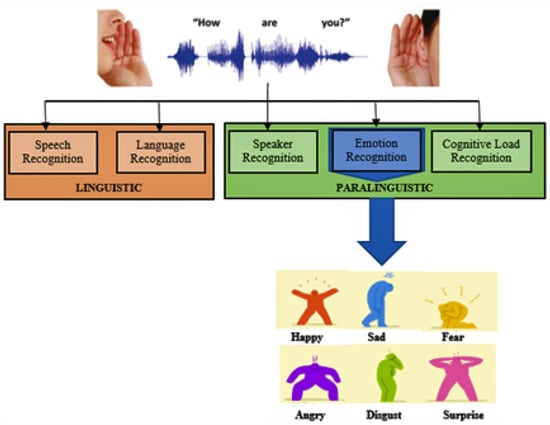
Figure 1.
Emotion Classification Framework.
However, the curiosity of why speech emotion classification has been experiencing high processing cost and increased memory consumption with less accuracy has remained a great question among researchers today [8]. Presently, one lingering challenge identified so far is the lack of a sufficient annotated speech dataset, but then, several models have been proposed to mitigate this challenge and improve accuracy, as was obtainable in [9] using Surrey Audio-Visual Expressed Emotion (SAVEE), Ryerson Multimedia Laboratory (RML), and eNTERFACE’05 as the speech corpus. A 3D convolutional neural network (CNN) model with fully connected layers was developed for SEC. They attained a state-of-the-art performance, but the huge features [10] extracted without a corresponding feature selection method applied before actual classification tends to increase computational [11] complexity and reduce the accuracy rate.
By way of improving on the previous study, we proposed a novel and robust deep transfer learning approach for speech emotion classification with feature selection techniques. Transfer learning leverages on knowledge acquired from the source task and implements it on the target task [12]. It reduces computational complexity as it requires no training before its usage. Not all features from speech signals carry emotional content, and this is the reason why many models’ failed to attain an optimal result. There is a need for a mechanism to subject extracted speech features [13,14] (spatial) to selection techniques for effectively identifying discriminating features that can increase accuracy while reducing computational cost.
Main Contributions
The specific contributions of this work are:
- Applying an optimized deep transfer learning for feature extraction using the pretrained model on ImageNet.
- Adopting an efficient feature selection technique for selecting a discriminative feature for optimal classification of emotion, because not all features from a speech signal carry paralinguistic information relevant to accurate emotion classification.
- Reducing misclassification of emotion and computational cost, while achieving state-of-the-art and improving accuracy on three speech datasets with two different classifiers.
- Systematic performance evaluation and critical comparison of the model with other methods, which indicates a high efficiency of deep transfer learning with feature selection for SEC.
The remaining part of this work is arranged as follows. Related work with some useful background concepts is presented in Section 2. Section 3 deals with the proposed methodology of the work. In Section 4, the experimental flow with exact results achieved was presented. Section 5 presents the discussion of the obtained results and comparison with recent works that have been published. A conclusion with recommendation for future work is given in Section 6.
2. Literature Review and Related Works
From a psychological point of view, Refs. [15,16], human emotions are categorized into six major groups, which fall under positive and negative emotion, respectively. However, this can also be sub-divided into valence or arousal. Valence emotion determines the extent to which emotion is either positive or negative, while arousal indicates the level of intensity. The description of these basic enotions are shown in Table 1. These emotions goes through the process of vectorization in speech data processing (encoding) before emotional features extraction and classification can be performed.

Table 1.
Basic Emotion Description.
For more than half a decade, several deep transfer learning techniques rooted in deep convolutional neural network (DCNN) have been applied in speech recognition with the utmost focus on emotion classification from speech. Transfer learning minimized computational cost while maintaining an accurate extraction of features from speech signals [17,18]. Despite several outstanding records of successful application of convolutional neural network (CNN), the SEC domain is still facing the intense challenge of optimal performance with minimal complexity. As the literature is saturated with many of the applications of deep transfer learning techniques for an improved performance in speech emotion classification, this work has reviewed some published works.
Obviously, the recent advancement in Artificial Intelligence and affective computing has conspicuously made the deep transfer learning model very popular in major fields, such as image segmentation, visual objects recognition systems, facial emotion recognition systems, age and gender estimation, and speech recognition systems, which is due to its extraordinary performance in prediction and low error rate.
Vryzas et al. [19] applied a pretrained DCNN-based transfer learning for speech emotion classification. A multi-user speech dataset was used in training their model, while fine tuning took place on the speaker-dependent speech emotion dataset. The first 11 layers of the model that served in feature learning were frozen from being trained according to the structural setup of the model with utmost the aim of fine-tuning the model on the target’s dataset input. Mustaqeem and Kwon, Ref. [20] investigated the possibility of adopting a double stream approach of CNN and DCNN for extracting spectral and spatial features for an improved performance in SEC. Aside from the fusion of dual features techniques, considerable effort was made by applying a feature selection algorithm for the effective classification of emotion. Mustaqeem and Kwon Ref. [21] proposed an attention-based convolutional neural network with a fully connected layer trained in an end-to-end manner for the effective classification of speech emotion. An optimized DNN was proposed by Aouani and Ayed, Ref. [22] for real-time speech emotion classification. The optimization was carried out using stochastic gradient descent.
Learning the most salient features from a speech spectrogram image through a light-weight CNN model for an improved performance in SEC was presented by Anvarjon et al. [23]. The model was also trained in an end-to-end mode, with an enhanced pooling strategy and fewer parameters. A deep transfer learning model that is based on AlexNet with correlation-based feature selection techniques was presented by Farooq et al. [24] in order to investigate the overall impact of the feature selection algorithm on speech emotion classification. Haider et al. [25] evaluated three different feature selection techniques, namely, Relief feature Infinite Latent Feature Selection, and a generalized Fisher score for speech emotion recognition, along with the recently proposed automatic feature selection method. They employed three datasets from three different languages to affirm that higher accuracy can only be achieved through a reduced feature set.
Zhang et al. [26] adopted transfer learning using a pretrained model on ImageNet (AlexNet) to extract segment-level features and an attention mechanism for learning emotionally rich features. Their model also combine Bi-directional Long Short-Term Memory (BiLSTM) for effective speech emotion classification using two different datasets (EMO-DB and IEMOCAP). Feng and Chaspari Ref. [27] proposed a transfer learning technique with distance loss for speech emotion classification. They fine-tuned a siamese nueral network in order to achieve a state-of-the-art result. An experiment was carried out on the eNTERFACE, RAVDESS, and CREMA-D datasets, respectively. Spectrogram features generated from speech signals were augmented in Padi et al. [28] and fed as input into a transfer learning model (ResNet) with a significant pooling layer (statistics) for speech emotion classification. They prevented overfitting and improved classification accuracy in spectrogram augmentation techniques.
Joshi et al. [29] proposed a deep neural network BiLSTM for emotion classification using a cross dataset that was rooted in EEG (electroencephalography). Out of the three datasets (DEAP, SEED, IDEA) used in their work, two were for training, while one (IDEA) was for testing the performance of their proposed method. Four classifiers (SVM, KNN, MLP and Deep RNN) were trained with four speech features (Hjorth parameters, DE, LF-DE and PSD), and the results of their experiments indicated that DNN parameters optimization can positively enhance the performance of the emotion classification system. In addition, the deep BiLSTM model improved emotion recognition from EGG through the extraction of discriminative features and temporal dependencies of speech samples. However, the datasets utilized were insufficient for a typical Deep BiLSTM network model learning, which eventually hampered the accuracy (59%) recorded. The most popular datasets used within the speech emotion domain consist of synthetic data because of the difficulty and security issues associated with real-world speech-based datasets. However, Blumentals and Salimbajevs [30] carried out a speech emotion classification task using a real-world dataset (from phone calls). In their work, a deep learning network made up of two LSTM layers and fully connected layers with an Adam optimizer for back propagation was utilized. Their model was first tested on three popular datasets which included IEMOCAP, RAVDESS and TESS with accuracy of 60.4% and 86.02% before the real-world data obtained from a call center was used. The real dataset was based on Lavitian Language, and a model accuracy of 52.48% was recorded. It very evident from this work that the result is lower than state-of-the-art; moreover, the testing accuracy on the real-world dataset used was not stated.
Really, it is very cumbersome to build a standardized speech corpus for emotion recognition, and this is a major difficulty confronting speech-based emotion classification tasks. Some of these deep learning methods adopted so far require extensive training, which in most cases increases computational cost. However, the accuracy of speech emotion classification must need to be improved upon, as proposed in our study. Additionally, determining which set of features carries emotional information through the feature selection algorithm can lessen misclassification and increase model performance. In Table 2, a summary of the reviewed literature is given.
Table 2.
Summary of Related Works.
3. Methods and Techniques
A unique approach of DNN-NCA-MLP (Deep transfer learning with Neighborhood Component Analysis and Multi-Layer Perceptron) for speech emotion classification is introduced. At first, our proposed method carried out preprocessing on a raw speech signal to generate suitable input (Mel-spectrogram) for the model. The structural framework of the proposed model is shown in Figure 2 below. The input image generated from the audio signal is fed into the pretrained DCNN model for robust utterance-level [31] features extraction. Thereafter, a feature selection technique is applied to carefully determine relevant and pertinent features for the accurate classification of emotion with the chosen classifier at the top layer of the model.
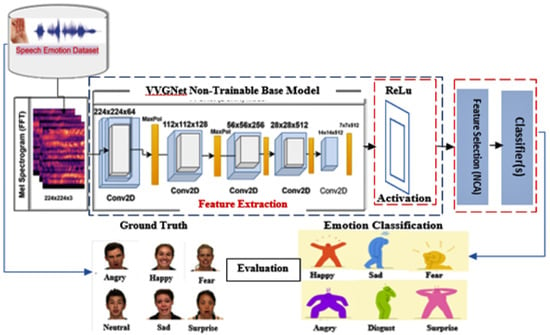
Figure 2.
Structure of the Proposed Model.
3.1. Speech Data Pre-Processing
Any successful SEC model begins with speech database preparation. Most speech emotion corpus are influenced by speakers’ age, gender and cultural background, among others. It then becomes necessary to diligently carry out adequate preparation of the dataset. Unlike other image processing sub-fields, applying transfer learning to a speech-based task requires substantive data preprocessing in order to make the input image suitable for the deep learning network. Specifically, speech signals carry information such as the sampling ratio, frequency and speed that must be enhanced before their usage for training and the corresponding feature map.
The required input to our proposed model is log mel-spectrogram. This is extracted from the speech signal. Mel-spectrogram has proven to be efficient and rich in emotional content for speech emotion classification. In generating the mel-spectrogram, a series of operations such as pre-emphasis, framing and windowing must need to be performed. The speech signal is first subjected to pre-emphasis for amplification of the frequency. Because of the continuous nature of the speech signal, framing is performed to disintegrate the signal into a fixed-length size, after which a hamming window of 20 ms size function is applied on the frame with 10 ms shift, as computed in Equation (1)
where M represents the window size for the hamming function w(n).
The mel-filter bank used in this work is 40, while the sample rate is 16 kHz and FFT (Fast Fourier Transform) is 512. A speech signal (x) of length (N) can be converted into a signal in the frequency domain (X) using the FFT technique as computed in Equation (2). The size of FFT corresponds to the size of the last convolution layer of our pretrained model. FFT is adopted [32] in generating the complete mel-spectrogram of the speech sample. As part of preprocessing, the mel-spectrogram generated using FFT is resized to the input specification (size) of our proposed model, which is 224 × 224 × 3. This represents the size (height × width) and the number of channels, respectively.
where x(r) represents a signal, W represents an N-point window function and h = 0, 1, 2, …, N− 1.
3.2. Feature Extraction with Deep Convolutional Neural Network
This section gives the detail performance of our proposed model with respect to feature learning from the original input mel-spectrogram. An utterance level feature is extracted using VGGNet (Visual Graphics Group Network) as the base model for the deep transfer learning model. As shown in Figure 2, the model consists of five, 2D convolutional layers in series of 224 × 224 × 3, 112 × 112 × 128, 56 × 56 × 256, 28 × 28 × 512 and 14 × 14 × 512 kernel size. Altogether, four pooling layers were used, with the last pooling layer having a size of 7 × 7 × 512. A dropout layer and two dense layers with ReLu (Reactivation Linear Unit) were used as the topmost level of the feature extraction segment. The dropout layer is a hyperparameter that can be used to prevent overfitting [33], and ReLu is the activation function. The pretrained model also carries an internal linear activation unit. The model is properly fine-tuned in order to extract all features (global and spatial) before the selection of high-level features in the next section. We utilized sparse-categorical cross-entropy and an Adams optimization algorithm in compiling our model.
The number of trainable parameters for our model is obtained from the fully connected layers (dense layer), because our base model does not need training. The dense layer consists of a total number of neurons from the current layer () and previous layer (). The product of these two mini parameters plus one (bias term) gives the value for the dense layer, which represents the total number of trainable parameters for our model. For instance, the single dense layer of our model (Desnse-1), ; therefore, total parameters = .
3.3. Neighborhood Component Analysis (NCA) Feature Selection
After the extraction of features with the DCNN segment of our proposed model, it is necessary to select relevant features in order to prevent misclassification and increase the accuracy of the entire model. Feature selection [34] occupies a significant position in this work, as it determines the level of performance. Many models other than the proposed model could have yielded an optimal result in speech emotion classification, but the absence of an appropriate feature selection algorithm incapacitated those models. It is very essential to know that huge features from speech data can be extracted, but not all these features are relevant [35] for emotion classification. The more irrelevant the features in the classifier, the greater the likelihood of misclassification and reduction in the accuracy and efficiency of the SEC model. However, even though feature selection is important, a careful choice of which feature selection techniques perform best and under which condition is another dicey question. The choice must be made depending on the model architectural framework. In this work, NCA, a feature selection method based on distance, has been chosen for selecting discriminative features and its performance in maximizing classification accuracy. The normalized equation for computing the NCA feature selection for a multi-class SEC problem is given in Equation (3).
where n is the number of observations, denotes the feature vectors, {1, 2, …, c} denotes class labels of emotional features, and c is the number of emotional class labels. To simplify, the goal is to provide relevant features (from the feature extraction segment of the model) for the classifier f: {1, 2, …, c}, which takes a feature vector and makes classification f(x) for the ground truth (label) y of x. The NCA algorithmic [36] procedure is defined in Algorithm 1.
| Algorithm 1: NCA Feature Selection Procedure |
| 1: procedure NCAFS (T, , , , ) ⊳ T: set of training,: initial step length, : kernel width, : parameter for regularization, : small positive integer constant; |
| 2: Initialization: … |
| 3: while |
| 4: for … do |
| 5: Compute and using with respect to (2) and (3) |
| 6: for … do |
| 7: |
| 8: t = t + 1 |
| 9: |
| 10: |
| 11: |
| 12: |
| 13: else |
| 14: |
| 15: wend |
| 16: |
| 17: return |
3.4. Classifiers
The classifiers [4] employed in this work are Multi-Layer Perceptron (MLP) and Support Vector Machine (SVM). For a multi-class problem such as SEC, the choice of an efficient classifier after feature selection is crucial. The classifier is found at the top-most layer of our proposed model. The fully connected layer and softmax function in the normal pretrained model have been replaced with two different classifiers for an improvement performance of speech emotion classification.
3.4.1. Multi-Layer Perceptron
The Multi-Layer Perceptron classifier is a feedforward neural network model that has three nodes of input, output and hidden layers [37]. Depending on the implementation, MLP can take one or more hidden layers, but in this work, one hidden layer is used for all the datasets (TESS, EMO-DB and TESS-EMO-DB). The input layers consist of a certain number of neurons which represent the total number of features from the feature selector. TESS has 2280 neurons and EMO-DB has 240 neurons. The output layer represents the actual number of emotional categories as present in the ground label of speech samples. The sigmoid activation function is used for our MLP classifier in determining the output of the neuron. After each iteration, the weights of the connections are continuously adjusted as part of the MLP’s training process.
3.4.2. Support Vector Machine
SVM is a sort of classifier that builds a hyperplane and optimizes the margin between the two classes in order to achieve classification purpose [38]. It has been proven to be efficient in many classification tasks. In this work, SVM is utilized as a second classifier too, and the result obtained is compared with our own MLP.
4. Experimental Result and Analysis
4.1. Emotion Datasets
We tested our proposed model on three datasets, which are TESS, EMO-DB and TESS-EMO-DB (hybridized) consisting of two languages (English and German).
4.1.1. TESS
Many researchers have used the Toronto Emotional Speech Set, a publicly accessible speech emotion database, to classify emotions. The speech samples were captured in 2010 at Northwestern University Auditory Laboratory [39]. Two actresses were requested to recite a few of the 200 words during the impromptu event, and their voices were recorded. During the scene, seven different emotions were recorded (happy, angry, fear, disgust, pleasant, surprise, sad and neutral). There are 2800 files in all that show human emotion.
4.1.2. EMO-DB
Seven acted emotional states are represented in the EMO-DB speech dataset: anger, disgust, boredom, joy, sadness, neutral, and fear. Ten actors who are natural German speakers contributed 535 emotional utterances in the German language. It was initiated by the ICS, Technical University, Berlin, German [40]. Five of them are actresses who are women, while the other five are actors who are men. The speech files are 3 s long on average, and they were initially collected at a sampling rate of 48 kHz before being resampled to 16 kHz.
4.1.3. TESS-EMO-DB
The combination of the two datasets, a formed and hybridized dataset, in our model yielded different results. Unlike the seven emotions in the two separate speech corpus, six emotions were used for classification.
4.2. Experiment Setup
In this work, the experiment was conducted on a Python 3.9 environment with an Intel Core i7 processor, 8 GB of RAM, and a 64-bit operating system. Additionally, other third-party libraries and deep learning tools (such as Tensorflow, Numpy, and audio processing) were used. Since our model’s input layer needs to be 224 × 224 × 3, preprocessing of the audio sample was initially necessary. The speech signal had to be converted to a log-mel spectrogram and resized to fit the model’s specifications. The mel spectrogram feature was extracted from the original audio data using the FFT method. The dataset is then divided into a training and testing set at a ratio of 80:20. The data for the test and training sets were both standardized to pixel values between 0 and 1. The basic implementation parameters used are shown in Table 3.
Table 3.
Implementation Parameters.
5. Result and Discussion
The result obtained in this work proved the efficiency of our proposed model. In the first stage of our experiment, we carried out training of the additional (topmost) layers of the feature extraction segment of our proposed model, which comprises a dropout layer, two dense layers, and an activation function, since all layers of our based transfer learning network are non-trainable. We obtained a significant accuracy and loss curve (94%, 14%) after training and validation was carried out with the dataset as indicated in Figure 3.
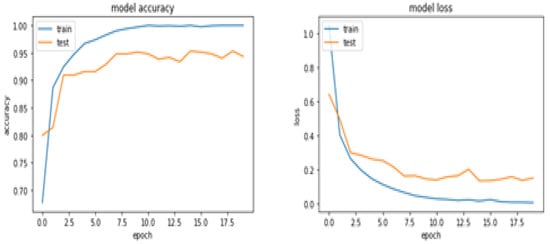
Figure 3.
Proposed model’s accuracy and loss performance curves for both training and validation.
A normalized confusion matrix which depicts a holistic insight of various results obtained from our experiments with different classifiers is shown in Figure 3, Figure 4 and Figure 5, respectively. Looking at the confusion matrix, for the TESS dataset with the MLP classifier, 100% accuracy was recorded for angry, disgust, fear and happy emotion, while the surprise emotion yielded the lowest accuracy of 89%, and others were above 90%. With the SVM classifier, the minimum accuracy increased to 90%.
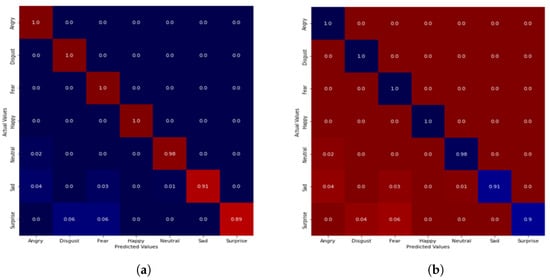
Figure 4.
Confusion matrix of emotion classification on TESS dataset. (a) DCNN-NCA-MLP. (b) CNN-NCA-SVM.
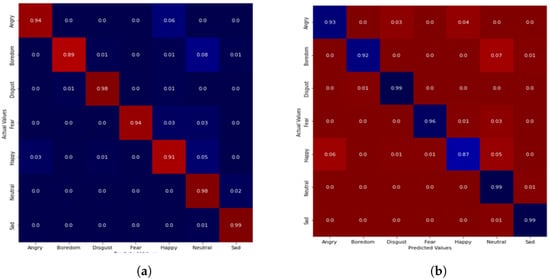
Figure 5.
Confusion matrix of emotion classification on the EMO-DB dataset. (a) DCNN-NCA-MLP. (b) CNN-NCA-SVM.
On the EMO-DB dataset, our model achieved 94%, 89%, 98%, 94%, 91%, 98% and 99% accuracy in classification for angry, boredom, disgust, fear, happy, neutral and sad emotion using the MLP classifier. When SVM was introduced, there was a slight improvement in recognition accuracy, as the three emotions (disgust, neutral and sad) recorded 99% accuracy while the happy emotion recorded the lowest accuracy of 87%. As with the combined dataset of TEES-EMO-DB, the highest accuracy of 99% was recorded for the sad, neutral and disgust emotions with the MLP classifier, while the happy emotion recorded the lowest accuracy of 87%, as depicted in Figure 6. For the SVM classifier, only the sad emotion produced the highest accuracy of 99%, while others were 90% and above.
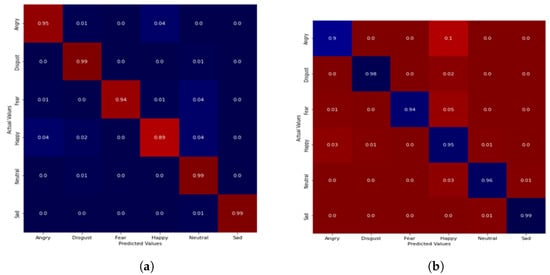
Figure 6.
Confusion matrix of emotion classification on TESS-EMODB dataset. (a) DCNN-NCA-MLP. (b) CNN-NCA-SVM.
As we analyze further, the classification report comprising accuracy, F1-score, specificity and sensitivity evaluation metrics was employed in order to fully grasp how efficient our proposed method performed in its discriminatory ability to learn features for speech emotion classification. As shown in Table 4, we achieved the highest accuracy of 97.2% on the TESS dataset with the SVM classifier, while the lowest accuracy of 94.3% was recorded from the EMO-DB dataset with the MLP classifier. The highest specificity and sensitivity of 100% was recorded with experiments on the two datasets for both classifiers, while 98.8% specificity was recorded on the combined dataset.
Table 4.
Performance Evaluation.
As with F1-score, we achieved a state-of-the-art result of 94.4%, 95.7% and 97%, respectively after evaluation on the three datasets. A return of operating curve (ROC) was adopted to present the graphical outlook of classification results of six emotions from the hybrid dataset. The ROC analysis result for six emotions on the combined dataset is illustrated in Figure 7. On the curve, each class represents an emotion: angry, sad, disgust, happy, fear and neutral with class 0 to 5, respectively. From the curve, the highest classification performance of Average Area Under the Curve (AUC) of 98% was achieved on classes 3 and 5 (neutral and disgust), while class 4 (fear) yielded the lowest AUC of 50%. However, none of the classes gave a classification outcome that is below the threshold (black dotted line). A chart indicating performance classification of emotion is also illustrated in Figure 8. The bars in represent experiments with MLP and SVM classifiers. From the chart, with SVM, five emotions comprising disgust, fear, happy, neutral and sad yielded accuracy results above 90%, while five emotions (sad, neutal, fear, disgust and angry) also yielded 90% and above accuracy.
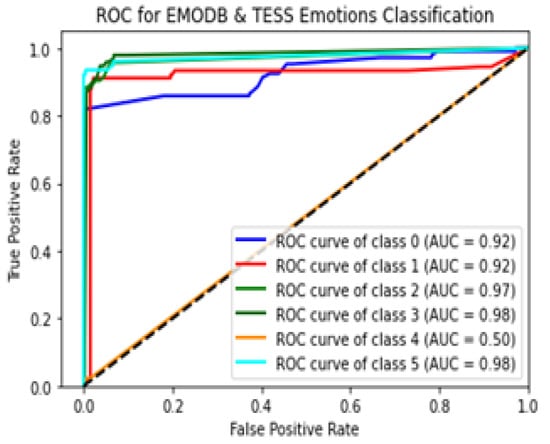
Figure 7.
ROC curve of classification.
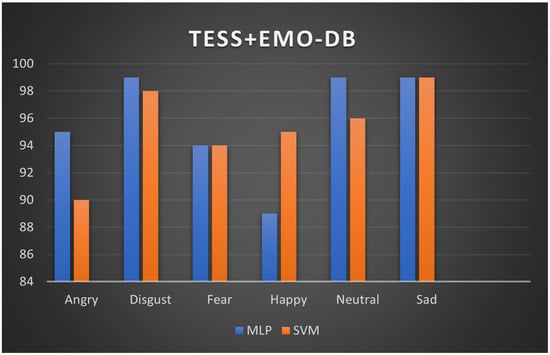
Figure 8.
Performance chart on TESS-EMODB with the two classifiers.
5.1. Performance Evaluation
The accuracy, specificity, and unweighted average recall (UAR) of our model are presented in Table 4. While accuracy measures the ratio of true emotion classified to all emotional classes in the dataset, specificity measures the ratio of actual emotion to predicted emotion. The evaluation result in this table showed the outcome of our work when a separate experiment using another classification algorithm (Random Forest) was conducted. The performance of our proposed method was compared with other studies in recent times, as indicated in Table 5, and our approach outperformed all of them in speech emotion classification. Additionally, a drastic reduction in complexity (at feature extraction and selection level) has been achieved, while the accuracy of emotion classification has been increased in our model as against what is obtained in the literature [2,38,39,40,41,42].
Table 5.
Performance Evaluation.
5.2. Performance Comparison
Our proposed model outperformed other existing methods when evaluated on the TESS and EMO-DB datasets, as shown in Table 3.
6. Conclusions and Future Work
In this work, a deep transfer learning approach with a feature selection algorithm that can select relevant features for speech emotion classification from a pool of extracted features through a deep convolutional neural network has been presented. It is obvious after a series of experiments have been carried out that the proposed method has improved accuracy and reduced the rate of misclassification as well as computational complexity using state-of-the-art emotional speech corpora. In achieving an optimum performance, the mel-spectrogram was extracted from raw speech signals through preprocessing and FFT. Thereafter, the mel-spectrogram was reshaped to match the requirement of the DCNN model for feature extraction. NCA feature selection was then applied in selecting the most salient and discriminating features that are relevant to emotion classification while reducing the workload of the classifier. With few hyperparameter tunning, our model achieved significant improvement in accuracy compared to existing methods as we carried out our experiment on the TESS, EMO-DB and combined (TESS+EMO-DB) dataset using two classifiers (MLP and SVM). Overall accuracies of 97.20%, 94.82% and 95.77% were obtained after we examined our method on TESS, EMO-DB and TESS+EMO-DB. The work has indicated that the proposed model is efficient for speech emotion classification. However, future experiments can be conducted using the cross-language speech corpus and testing with other classifiers to see their performance. We are also looking forward to adopting LSTM as an additional layer to our pretrained neural network and utilizing a multiple feature selection algorithm for an improved performance.
Author Contributions
Conceptualization, S.A. and S.V.; Methodology, S.A.; Software, S.A.; Validation, S.V.; Formal analysis, S.V.; Investigation, S.A.; Resources, S.V.; Data curation, S.A.; Writing—original draft preparation, S.A.; Writing—review and editing, S.V. All authors have read and agreed to the published version of the manuscript.
Funding
This research did not receive any funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Pusarla, A.N.; Singh, B.A.; Tripathi, C.S. Learning DenseNet features from EEG based spectrograms for subject independent emotion recognition. Biomed. Signal Process. Control 2022, 12, 74. [Google Scholar] [CrossRef]
- Krishnan, P.; Joseph, A.; Rajangam, V. Emotion classification from speech signal based on empirical mode decomposition and non-linear features. Complex Intell. Syst. 2021, 7, 1919–1934. [Google Scholar] [CrossRef]
- Jiang, W.; Wang, Z.; Jin, J.S.; Han, X.; Li, C. Speech emotion recognition with heterogeneous feature unification of deep neural network. Electronics 2019, 19, 2730. [Google Scholar] [CrossRef]
- Lieskovská, E.; Jakubec, M.; Jarina, R.; Chmulík, M.; Olave, M. A review on speech emotion recognition using deep learning and attention mechanism. Electronics 2021, 10, 1163. [Google Scholar] [CrossRef]
- Van, L.; Le Dao, T.; Le Xuan, T.; Castelli, E. Emotional Speech Recognition Using Deep Neural Networks. Sensors 2022, 22, 1414. [Google Scholar] [CrossRef]
- Topic, A.; Russo, M. Emotion recognition based on EEG feature maps through deep learning network. Eng. Sci. Technol. Int. J. 2021, 24, 1442–1454. [Google Scholar] [CrossRef]
- Moine, C.L.; Obin, N.; Roebel, A. Speaker attentive speech emotion recognition: Proceedings of the Annual Conference of the International Speech Communication Association. Interspeech 2021, 1, 506–510. [Google Scholar] [CrossRef]
- Sattar, R.; Bussoauthor, C. Emotion Detection Problem: Current Status, Challenges and Future Trends Emotion Detection Problem. In Shaping the Future of ICT: Trends in Information Technology, Communications Engineering, and Management: Global Proceedings Repository—American Research Foundation; ICCIIDT: London, UK, 2020. [Google Scholar]
- Hajarolasvadi, N.; Demirel, H. 3D CNN-based speech emotion recognition using k-means clustering and spectrograms. Entropy 2019, 22, 479. [Google Scholar] [CrossRef]
- Wang, Y.; Boumadane, A.; Heba, A. A Fine-tuned Wav2vec 2.0/HuBERT Benchmark for Speech Emotion Recognition, Speaker Verification and Spoken Language Understanding. arXiv 2021, arXiv:2111.02735. [Google Scholar]
- Luna-Jiménez, C.; Kleinlein, R.; Griol, D.; Callejas, Z.; Montero, J.; Fernández-Martínez, F. A Proposal for Multimodal Emotion Recognition Using Aural transformer on RAVDESS. Appl. Sci. 2022, 12, 327. [Google Scholar] [CrossRef]
- Bashath, S.; Perera, N.; Tripathi, S.; Manjang, K.; Dehmer, M.; Streib, F.E. A data-centric review of deep transfer learning with applications to text data. Inf. Sci. 2022, 585, 498–528. [Google Scholar] [CrossRef]
- Aggarwal, A.; Srivastava, A.; Agarwal, A.; Chahal, N.; Singh, D.; Alnuaim, A.A.; Alhadlaq, A.; Lee, H. Two-Way Feature Extraction for Speech Emotion Recognition Using Deep Learning. Sensors 2022, 22, 2378. [Google Scholar] [CrossRef]
- Badshah, A.M.; Rahim, N.; Ullah, N.; Ahmad, J.; Muhammad, K.; Lee, M.Y.; Kwon, S.; Baik, S.W. Deep features-based speech emotion recognition for smart affective services. Multimed. Tools Appl. 2019, 78, 5571–5589. [Google Scholar] [CrossRef]
- Cowen, A.S.; Keltner, D. Self-report captures 27 distinct categories of emotion bridged by continuous gradients. Proc. Natl. Acad. Sci. USA 2017, 38, E7900–E7909. [Google Scholar] [CrossRef] [PubMed]
- Oaten, M.; Stevenson, R.J.; Case, T.I. Disgust as a disease-avoidance mechanism. Psychol. Bull. 2009, 135, 303–321. [Google Scholar] [CrossRef]
- Elshaer, M.E.A.; Wisdom, S.; Mishra, T. Transfer Learning from Sound Representations for Anger Detection in Speech. arXiv 2019, arXiv:1902.02120. [Google Scholar]
- Nguyen, D.; Sridharan, S.; Nguyen, D.T.; Denman, S.; Tran, S.N.; Zeng, R.; Fookes, C. Joint Deep Cross-Domain Transfer Learning for Emotion Recognition. arXiv 2020, arXiv:2003.11136. [Google Scholar]
- Vryzas, N.; Vrysis, L.; Kotsakis, R.; Dimoulas, C. A web crowdsourcing framework for transfer learning and personalized Speech Emotion Recognition. Mach. Learn. Appl. 2021, 6, 100–132. [Google Scholar] [CrossRef]
- Mustaqeem; Kwon, S. Optimal feature selection based speech emotion recognition using two-stream deep convolutional neural network. Int. J. Intell. Syst. 2021, 36, 5116–5135. [Google Scholar] [CrossRef]
- Mustaqeem; Kwon, S. Att-Net: Enhanced emotion recognition system using lightweight self-attention module. Appl. Soft Comput. 2021, 102, 107101. [Google Scholar] [CrossRef]
- Aouani, H.; Ayed, Y.B. Speech Emotion Recognition with deep learning. Procedia Comput. Sci. 2021, 176, 251–260. [Google Scholar] [CrossRef]
- Anvarjon, T.; Mustaqeem; Kwon, S. Deep-net: A lightweight CNN-based speech emotion recognition system using deep frequency features. Sensors 2020, 20, 5212. [Google Scholar] [CrossRef] [PubMed]
- Farooq, M.; Hussain, F.; Baloch, N.; Raja, F.; Yu, H.; Bin-Zikria, Y. Impact of feature selection algorithm on speech emotion recognition using deep convolutional neural network. Sensors 2020, 20, 6008. [Google Scholar] [CrossRef]
- Haider, F.; Pollak, S.; Albert, P.; Luz, S. Emotion recognition in low-resource settings: An evaluation of automatic feature selection methods. Comput. Speech Lang. 2020, 65, 101–119. [Google Scholar] [CrossRef]
- Zhang, H.; Gou, R.; Shang, J.; Shen, F.; Wu, Y.; Dai, G. Pre-trained Deep Convolution Neural Network Model With Attention for Speech Emotion Recognition. Front. Physiol. 2021, 12, 643202. [Google Scholar] [CrossRef] [PubMed]
- Feng, K.; Chaspari, T. A Siamese Neural Network with Modified Distance Loss For Transfer Learning in Speech Emotion Recognition. arXiv 2006, arXiv:2006.03001. [Google Scholar]
- Padi, S.; Sadjadi, S.O.; Sriram, R.D.; Manocha, D. Improved Speech Emotion Recognition using Transfer Learning and Spectrogram Augmentation. In Proceedings of the 2021 International Conference on Multimodal Interaction (ICMI ’21), Montréal, QC, Canada, 18–22 October 2021; Association for Computing Machinery: New York, NY, USA, 2021; pp. 645–652. [Google Scholar] [CrossRef]
- Joshi, V.; Ghongade, R.; Joshi, A.; Kulkarni, R. Deep BiLSTM neural network model for emotion detection using cross-dataset approach. Biomed. Signal Process. Control 2022, 73, 103407. [Google Scholar] [CrossRef]
- Blumentals, E.; Salimbajevs, A. Emotion Recognition in Real-World Support Call Center Data for Latvian Language. In Proceedings of the ACM IUI Workshops 2022, Helsinki, Finland, 22 March 2022. [Google Scholar]
- Yao, Z.; Wang, Z.; Liu, W.; Liu, Y.; Pan, J. Speech emotion recognition using fusion of three multi-task learning-based classifiers: HSF-DNN, MS-CNN and LLD-RNN. Speech Commun. 2021, 120, 11–19. [Google Scholar] [CrossRef]
- Atila, O.; Şengür, A. Attention guided 3D CNN-LSTM model for accurate speech based emotion recognition. Appl. Acoust. 2021, 182, 108260. [Google Scholar] [CrossRef]
- Uddin, M.Z.; Nilsson, E.G. Emotion recognition using speech and neural structured learning to facilitate edge intelligence. Eng. Appl. Artif. Intell. 2020, 94, 103775. [Google Scholar] [CrossRef]
- Akçay, M.B.; Oğuz, K. Speech emotion recognition: Emotional models, databases, features, preprocessing methods, supporting modalities, and classifiers. Speech Commun. 2020, 166, 56–76. [Google Scholar] [CrossRef]
- Zhang, S.; Li, C. Research on Feature Fusion Speech Emotion Recognition Technology for Smart Teaching. Hindawi Mob. Inf. Syst. 2022, 2022, 7785929. [Google Scholar] [CrossRef]
- Yang, W.; Wang, K.; Zuo, W. Neighborhood component feature selection for high-dimensional data. J. Comput. 2022, 7, 162–168. [Google Scholar] [CrossRef]
- Ba’abbad, I.; Althubiti, T.; Alharbi, A.; Alfarsi, K.; Rasheed, S. A Short Review of Classification Algorithms Accuracy for Data Prediction in Data Mining Applications. J. Data Anal. Inf. Process. 2021, 9, 162–174. [Google Scholar] [CrossRef]
- Wanni, T.; Gunawan, T.; Qadri, S.; Kartiwi, M.; Ambikairajah, E. A Comprehensive Review of Speech Emotion Recognition Systems. IEEE Access 2021, 9, 47795–47814. [Google Scholar] [CrossRef]
- Dupuis, K.; Kathleen Pichora-Fuller, M. Recognition of emotional speech for younger and older talkers: Behavioural findings from the toronto emotional speech set. Can. Acoust.-Acoust. Can. 2012, 39, 182–183. [Google Scholar]
- Burkhardt, F.; Paeschke, A.; Rolfes, M.; Sendlmeier, W. A database of German emotional speech. In Proceedings of the 9th European Conference on Speech Communication and Technology, Lisbon, Portugal, 4–8 September 2012; pp. 1517–1520. [Google Scholar] [CrossRef]
- Praseetha, V.M.; Vadivel, S. Deep learning models for speech emotion recognition. J. Comput. Sci. 2021, 14, 1577–1587. [Google Scholar] [CrossRef]
- Venkataramanan, K.; Rajamohan, H.R. Emotion Recognition from Speech. Audio Speech Process. 2021, 1–14. [Google Scholar] [CrossRef]
- Meng, H.; Yan, T.; Yuan, F.; We, H. Speech Emotion Recognition from 3D Log-Mel Spectrograms with Deep Learning Network. IEEE Access 2019, 7, 125868–125881. [Google Scholar] [CrossRef]
- Mustaqeem; Kwon, S. Clustering-Based Speech Emotion Recognition by Incorporating Learned Features and Deep BiLSTM. IEEE Access 2020, 36, 79861–79875. [Google Scholar] [CrossRef]
- Yahia Cherif, R.; Moussaouni, A.; Frahta, N.; Berimi, M. Effective speech emotion recognition using deep learning approaches for Algerian dialect. In Proceedings of the International Conference of Women in Data Science at Taif University, WiDSTaif, Taif, Saudi Arabia, 30–31 March 2021; pp. 1–6. [Google Scholar] [CrossRef]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).