
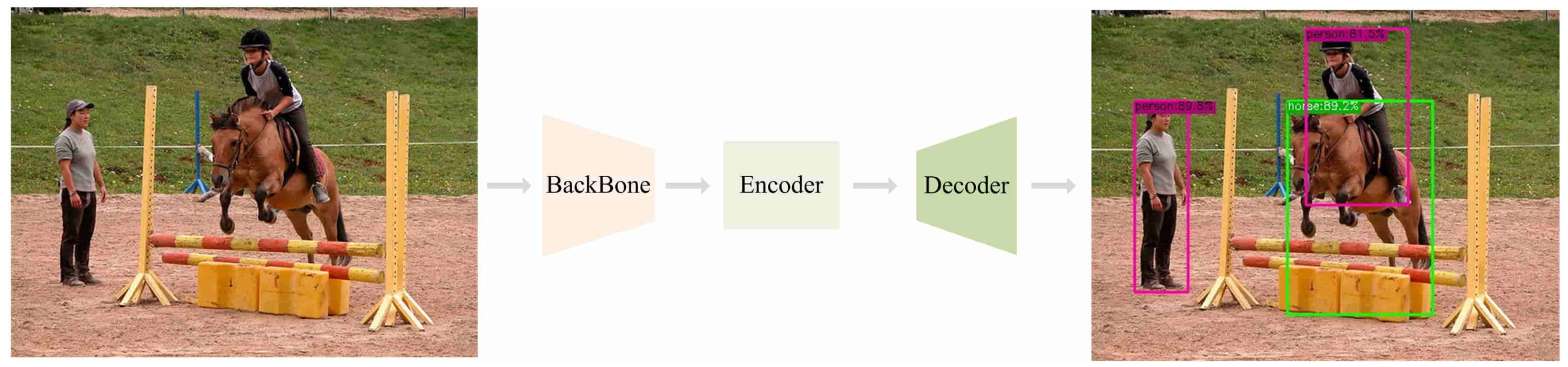
An Intelligent Weighted Object Detector for Feature Extraction to Enrich Global Image Information




Abstract
:1. Introduction
- The images input to neural networks are often multiscale, so object detectors cannot achieve the desired performance. Even two-stage object detection algorithms have difficulty in extracting finer-grained features;
- The deep convolutional layer integrates the features extracted from the bottom convolutional layer, so the deeper the network is, the richer the global feature information, but more convolutional layers result in the loss of more detailed information;
- Higher-level features correspond to larger receptive fields and can obtain global information about the instance, such as pose. Lower-level features retain better location information and can provide finer details. It is a constant problem in object detection to adopt an effective feature fusion method to fuse the semantic information between different layers.
- Replacing the common 3 × 3 convolutional approach in the backbone network CSPdarknet53 to extract features of images with fewer parameters, making the backbone network more efficient in extracting features;
- Designing local extracted feature modules so that different regions on the feature map receive the attention of different convolution kernels to extract fine-grained features;
- Introducing a global feature extraction module in the deep convolutional layer in which the semantic correlation of any two points in the feature map is calculated, thereby weakening the feature points with insufficient semantic information, compensating for the lack of global information ignored by the convolutional operation, and providing richer global feature information for the later layers or the final detection;
- In the feature fusion part of the model, multiscale fusion can assist the model for better performance detection, while giving weights to different layers of the model, i.e., adding a simple self-learning attention mechanism that makes the model focus more on the feature layers with a larger proportion of weights;
- This paper proposes a new method to enhance the dimension of the channel, which reuses the generated feature map and retains more original information about the image without using convolution.
2. Related Work
3. System Model and Definitions
3.1. GhostNet
3.2. Non-Local Neural Networks
4. Our Proposed Intelligent Weighted Object Detector
4.1. Overall Structure of the Model
4.2. Internal Structure of the Model
- Local extraction feature module: local-feature extractorThe local-feature extractor performs chunking and feature processing on the input feature maps; the specific structure is shown in Figure 5, where the 3 × 3 is the deep convolution. The feature map of the lower layer is rich in detailed information, and considering that the feature map near the initial input end experiences fewer convolution layers, there will be too much noise, meaning that the detailed information of the deep feature map is lost, so the feature extraction module of the local image is added to the middle layer in the backbone network. In the local-feature extractor, the feature map is chopped to obtain four patches of the same size , where , indicating four patches. After passes through the depthwise convolution, BN layer, and activation layer sequentially, it is returned to the size of according to the position of the original patch before chunking. In the local-feature extractor, the local image receives the attention of a single convolution, and the whole feature map no longer shares the same convolution kernel parameters, facilitating the extraction of detailed information in the image. This is be helpful for the detection of small objects;
- Global feature extraction module: non-local blockThe specific structure of the non-local block is shown in Figure 6. In the non-local block, the input feature map first undergoes 1 × 1 convolution for channel adjustment and dimensional spreading; then, the correlation between any pixel point of the feature map and other pixel points is calculated. Finally, the features at each location are weighted using this correlation.As shown in Figure 6, the exchange process in the global feature module is presented in Algorithm 1;
- GhostModuleConvIn GhostModuleConv, the feature map passes through a filter of size 3 × 3, step size 2, and convolution number C to obtain ; then, is sent to depthwise convolution to obtain and the final is obtained by concatenating the obtained and ;
- Reuse feature mapsInspired by GhostNet, which generates redundant feature maps when the feature maps go through multiple convolutional layers, and the fact that generating redundant maps causes the problem of computational redundancy, the idea of feature map reuse is proposed. The feature map reuse equation (5) is as follows.where is the feature map that has been generated in the network and has the same dimensions and size as the input feature map . When the number of channels of the output feature map is twice that of the input feature map, channel concatenation of the input feature map with can reduce the convolutional up-dimensioning operation for deeper feature maps with higher dimensionality. Thus, reusing feature maps can effectively avoid the dimensionality increase operation using 1 × 1 convolution and reduce a large number of convolution parameters.
Algorithm 1 Transformation algorithm in the global feature extraction module Input: Feature map
Output: Global semantic information-rich feature maps- 1:
- According to , , use the embedding weights and in and to perform weight transformation on x to obtain , , aiming to reduce the number of channels and computation. Use the linear embedding function for information exchange to obtain ;
- 2:
- Reshape the output in Step 1 to obtain , ;
- 3:
- According to embedded Gaussian , after transposing in Step 2, the similarity is calculated by matrix multiplication with to obtain ;
- 4:
- The output in Step 3 is softmax operated in the last dimension; then, perform the reshape operation with after matrix multiplication to obtain ;
- 5:
- A convolutional kernel of size 1 × 1 and number C adjusts the output of Step 4 to the size of the channel when it enters the non-local block.
- YOLOXFPNThe specific process of adding weights to the final output feature maps for dark3, dark4, and dark5 in YOLOXFPN is shown in Figure 7.To ensure that the divisor is not zero, . Before adding fusion, it is necessary to ensure that the fused feature maps have the same size. Therefore, is necessary to resize the feature maps, including adjusting the number of channels and the size of the feature maps.
5. Performance Analysis
5.1. Experimental Environment and Data Set
5.2. Experimental Evaluation Indicators
- Average Precision: Abbreviated as AP, this is used to measure the detection effectiveness of the model on each object class and is calculated as follows:Equation (8) represents the sum of the area enclosed between the PR curves and the horizontal coordinates of each category, where P is the accuracy of the object category , and . R is the object category’s recall rate , and , where is the number of correctly predicted categories in a picture, is the number of incorrectly predicted categories, and is the number of categories not predicted. The average of the values of each category obtained in Equation (8) is the final . IOU (intersection over union) represents the ratio of intersection and merge between the prediction box and ground truth box, so represents the accuracy of the model when the IOU ratio threshold is 50;
- Frames per second: Abbreviated as FPS, this is used to measure the speed of model detection. The calculation in Equation (9) is shown below.where is the computation time of the model, i.e., the average time it takes for an image to be computed by the model;
- Model parameters and model computational complexity: This metric is found by inputting the same batch of images to the model and using the model weight calculation package profile in the Pytorch framework to calculate the parameter amount and calculation complexity of the model. The former unit is MB, and the larger the latter value, the more complex the model.
5.3. Experimental Results and Analysis
5.3.1. Ablation Experiments on the PASCAL VOC Dataset
5.3.2. Comparative Experiments on the PASCAL VOC Dataset
5.3.3. Experimental Results on TACO Dataset and NEU-CLS Dataset
5.4. Engineering Applications
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wang, X.; Li, Q.; Xiong, N.; Pan, Y. Ant Colony Optimization-Based Location-Aware Routing for Wireless Sensor Networks. Int. Conf. Wirel. Algorithms 2008, 5258, 109–120. [Google Scholar]
- Wan, R.; Xiong, N.; Loc, N. An energy-efficient sleep scheduling mechanism with similarity measure for wireless sensor networks. Hum.-Centric Comput. Inf. Sci. 2018, 8, 18. [Google Scholar] [CrossRef] [Green Version]
- Lu, Y.; Wu, S.; Fang, Z.; Xiong, N.; Yoon, S.; Park, D.S. Exploring finger vein based personal authentication for secure IoT. Future Gener. Comput. Syst. 2017, 77, 149–160. [Google Scholar] [CrossRef]
- Gao, K.; Han, F. Connected Vehicle as a Mobile Sensor for Real Time Queue Length at Signalized Intersections. Sensors 2019, 19, 2059. [Google Scholar] [CrossRef] [Green Version]
- Jiang, Y.; Tong, G.; Yin, H.; Xiong, N. A Pedestrian Detection Method Based on Genetic Algorithm for Optimize XGBoost Training Parameters. IEEE Access 2019, 7, 118310–118321. [Google Scholar] [CrossRef]
- Yan, L.; Sheng, M.; Wang, C.; Gao, R.; Yu, H. Hybrid neural networks based facial expression recognition for smart city. Multimed. Tools Appl. 2022, 81, 319–342. [Google Scholar] [CrossRef]
- Xiao, Y.; Tian, Z.; Yu, J.; Zhang, Y. A review of object detection based on deep learning. Multimed. Tools Appl. 2020, 79, 23729–23791. [Google Scholar] [CrossRef]
- Selukar, M.; Jain, P.; Kumar, T. A device for effective weed removal for smart agriculture using convolutional neural network. Int. J. Syst. Assur. Eng. Manag. 2022, 13, 397–404. [Google Scholar] [CrossRef]
- Zhang, H.; Wang, Y.; Dayoub, F.; Sünderhauf, N. VarifocalNet: An IoU-aware Dense Object Detector. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 8510–8519. [Google Scholar]
- Zhou, X.; Koltun, V.; Krähenbühl, P. Probabilistic Two-Stage Detection. arXiv 2021, arXiv:2103.07461. [Google Scholar]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z. YOLOX: Exceeding YOLO Series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Zhu, X.; Su, W.; Lu, L.; Li, B. Deformable DETR: Deformable Transformers for End-to-End Object Detection. arXiv 2021, arXiv:2010.04159. [Google Scholar]
- Zhu, X.; Lyu, S.; Wang, X.; Zhao, Q. TPH-YOLOv5: Improved YOLOv5 Based on Transformer Prediction Head for Object Detection on Drone-captured Scenarios. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision Workshops (ICCVW), Montreal, BC, Canada, 11–17 October 2021; pp. 2778–2788. [Google Scholar]
- Yang, Z.; Liu, S.; Hu, H.; Wang, L.; Lin, S. RepPoints: Point Set Representation for Object Detection. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 9656–9665. [Google Scholar]
- Mittal, P.; Singh, R.; Sharma, A. Deep learning-based object detection in low-altitude UAV datasets: A survey. Image Vis. Comput. 2020, 104, 104046. [Google Scholar] [CrossRef]
- Yan, L.; Fu, J.; Wang, C.; Ye, Z.; Chen, H.; Ling, H. Enhanced network optimized generative adversarial network for image enhancement. Multimed. Tools Appl. 2021, 80, 14363–14381. [Google Scholar] [CrossRef]
- Huang, G.; Liu, S.; Van der Maaten, L.; Weinberger, K.Q. CondenseNet: An Efficient DenseNet Using Learned Group Convolutions. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2752–2761. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Howard, A.; Sandler, M.; Chen, B.; Wang, W. Searching for MobileNetV3. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 1314–1324. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6848–6856. [Google Scholar]
- Ma, N.; Zhang, X.; Zheng, H.; Sun, J. ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design. In Proceedings of the European Conference on Computer Vision 2018, Munich, Germany, 9 October 2018; pp. 122–138. [Google Scholar]
- Tan, M.; Le, Q.V. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. arXiv 2019, arXiv:1905.11946. [Google Scholar]
- Tan, M.; Le, Q.V. EfficientNetV2: Smaller Models and Faster Training. arXiv 2021, arXiv:2104.00298. [Google Scholar]
- Zhang, H.; Wu, C.; Zhang, Z. ResNeSt: Split-Attention Networks. arXiv 2020, arXiv:2004.08955. [Google Scholar]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J. GhostNet: More Features From Cheap Operations. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 1577–1586. [Google Scholar]
- Yang, L.; Jiang, H.; Cai, R.; Wang, Y.; Song, S.; Huang, G.; Tian, Q. CondenseNet V2: Sparse Feature Reactivation for Deep Networks. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 3568–3577. [Google Scholar]
- Han, D.; Yun, S.; Heo, B.; Yoo, Y. Rethinking Channel Dimensions for Efficient Model Design. arXiv 2020, arXiv:2007.00992. [Google Scholar]
- Wang, G.; Yuan, Y.; Chen, X.; Li, J. Learning Discriminative Features with Multiple Granularities for Person Re-Identification. In Proceedings of the 26th ACM International Conference on Multimedia, New York, NY, USA, 15 October 2018; pp. 274–282. [Google Scholar]
- Hu, H.; Zhang, Z.; Xie, Z.; Lin, S. Local Relation Networks for Image Recognition. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 3463–3472. [Google Scholar]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local Neural Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7794–7803. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G. End-to-End Object Detection with Transformers. arXiv 2020, arXiv:2005.12872. [Google Scholar]
- Chen, Y.; Dai, X.; Chen, D.; Liu, M.; Dong, X.; Yuan, L.; Liu, Z. Mobile-Former: Bridging MobileNet and Transformer. arXiv 2021, arXiv:2108.05895. [Google Scholar]
- Yang, Z.; Li, Z.; Jiang, X.; Gong, Y.; Yuan, Z.; Zhao, D.; Yuan, C. Focal and Global Knowledge Distillation for Detectors. arXiv 2022, arXiv:2111.11837. [Google Scholar]
- Sun, J.; Shen, Z.; Wang, Y.; Bao, H.; Zhou, X. LoFTR: Detector-Free Local Feature Matching with Transformers. arXiv 2021, arXiv:2104.00680. [Google Scholar]
- Sun, P.; Zhang, R.; Jiang, Y.; Kong, T.; Xu, C.; Zhan, W.; Tomizuka, M.; Li, L.; Yuan, Z.; Wang, C.; et al. Sparse R-CNN: End-to-End Object Detection with Learnable Proposals. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 14449–14458. [Google Scholar]
- Lin, T.-Y.; Dollár, P.; Girshick, R.; He, K. Feature Pyramid Networks for Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J. Path Aggregation Network for Instance Segmentation. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Zhao, Q.; Sheng, T.; Wang, Y.; Tang, Z. M2Det: A Single-Shot Object Detector Based on Multi-Level Feature Pyramid Network. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January 2019; pp. 9259–9266. [Google Scholar]
- Liu, S.; Huang, D.; Wang, Y. Learning Spatial Fusion for Single-Shot Object Detection. arXiv 2019, arXiv:1911.09516. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. EfficientDet: Scalable and Efficient Object Detection. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 10778–10787. [Google Scholar]
- Guo, C.; Fan, B.; Zhang, Q.; Xiang, S.; Pan, C. AugFPN: Improving Multi-scale Feature Learning for Object Detection. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 2592–12601. [Google Scholar]
- Zhang, D.; Zhang, H.; Tang, J.; Wang, M.; Hua, X.; Sun, Q. Feature Pyramid Transformer. In Proceedings of the 16th European Conference on Computer Vision(ECCV), Glasgow, UK, 23–28 August 2020; pp. 323–339. [Google Scholar]
- Chen, Q.; Wang, Y.; Yang, T.; Zhang, X.; Cheng, J.; Sun, J. You Only Look One-level Feature. arXiv 2021, arXiv:2103.09460. [Google Scholar]
- Krishna, H.; Jawahar, C.V. Improving Small Object Detection. In Proceedings of the 2017 4th IAPR Asian Conference on Pattern Recognition (ACPR), Nanjing, China, 26–29 November 2017; pp. 340–345. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2999–3007. [Google Scholar]
- Zhou, X.; Wang, D.; Krähenbühl, P. Objects as Points. arXiv 2019, arXiv:1904.07850. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Environmental Conditions |
|---|---|
| Operating System | CentOS 7.5 |
| GPU | NVIDIA Tesla V100 |
| Deep Learning Framework | PyTorch 1.7 |
| Method | AP(%) | Parameters | GFLOPs |
|---|---|---|---|
| YOLOX-S [11] | 76.75 | 9.0 M | 26.8 |
| +GhostModuleConv | 77.88 | 8.17 M | 24.82 |
| +Local-feature extractor | 78.06 | 8.17 M | 24.83 |
| Dark4 | Dark5 | Method | (%) | (%) | Parameters |
|---|---|---|---|---|---|
| ✓ | +Non-local block +R.W | 77.86 77.98 | - 82.5 | 8.75 M 8.49 M | |
| ✓ | +Non-local block +R.W | 78.35 78.33 | - 82.6 | 8.44 M 7.70 M | |
| ✓ | ✓ | +Non-local block +R.W | - 78.23 | - 83.1 | 9.49 M 8.75 M |
| VOC 2007 Test | YOLOX-S | YOLOX-S | YOLOX-S |
|---|---|---|---|
| aeroplane | 89.2 | 89.7 | 89.5 |
| bicycle | 89.1 | 89.8 | 88.5 |
| bird | 79.0 | 82.3 | 82.1 |
| boat | 75.9 | 77.7 | 77.4 |
| bottle | 73.0 | 73.5 | 72.2 |
| bus | 87.3 | 87.8 | 86.6 |
| car | 89.5 | 89.5 | 89.7 |
| cat | 86.6 | 87.3 | 87.9 |
| chair | 67.1 | 67.9 | 69.8 |
| cow | 87.0 | 88.9 | 87.5 |
| diningtable | 78.9 | 79.2 | 80.6 |
| dog | 84.9 | 86.1 | 85.2 |
| horse | 88.3 | 90.0 | 89.2 |
| motorbike | 88.0 | 89.0 | 87.8 |
| person | 86.6 | 86.7 | 86.8 |
| pottedplant | 62.0 | 61.1 | 61.6 |
| sheep | 81.9 | 85.1 | 85.3 |
| sofa | 78.4 | 79.6 | 79.7 |
| train | 84.7 | 86.3 | 86.9 |
| tvmonitor | 81.4 | 83.7 | 83.4 |
| Model | Backbone | Size | Params. (M) | FPS | mAP | mAP |
|---|---|---|---|---|---|---|
| EfficientDet-D1 [40] | Efficient-B1 | 640 | 6.56 | 13 | 72.7 | 51.3 |
| YOLOv3 [45] | Efficient-B1 | 416 | 41.1 | 25 | 78.0 | 44.5 |
| Retinanet [46] | ResNet50 | 600 | 37.97 | 34 | 78.9 | 51.5 |
| Centernet [47] | ResNet50 | 512 | 32.67 | 62 | 76.5 | 48.7 |
| YOLOv5-S [13] | CSPDarknet53 | 640 | 7.3 | 90 | 80.9 | 57.7 |
| YOLOX-S [11] | CSPDarknet53 | 640 | 9.0 | 63 | 81.9 | 60.4 |
| YOLOX-S | Improved CSPDarknet53 | 640 | 8.75 | 51 | 83.1 | 61.6 |
| YOLOX-S | Improved CSPDarknet53 | 640 | 8.92 | 48 | 82.9 | 61.6 |
| TACO | YOLOX-S | YOLOX-S |
|---|---|---|
| clear plastic bottle | 77.0 | 87.0 |
| plastic bottle cap | 60.4 | 72.0 |
| drink can | 75.9 | 79.6 |
| other plastic | 34.0 | 35.4 |
| plastic film | 46.3 | 55.1 |
| other plastic wrapper | 62.6 | 63.9 |
| unlabeled litter | 16.7 | 20.2 |
| cigarette | 15.4 | 26.4 |
| 48.5 | 54.9 | |
| 32.2 | 37.0 |
| NEU-CLS | YOLOX-S | YOLOX-S |
|---|---|---|
| crazing | 34.4 | 40.0 |
| inclusion | 71.3 | 74.0 |
| patches | 82.7 | 89.4 |
| pitted surface | 58.9 | 64.0 |
| rolled in scale | 56.7 | 52.6 |
| scratches | 84.8 | 85.5 |
| 64.8 | 67.6 | |
| 31.1 | 33.6 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yan, L.; Li, K.; Gao, R.; Wang, C.; Xiong, N. An Intelligent Weighted Object Detector for Feature Extraction to Enrich Global Image Information. Appl. Sci. 2022, 12, 7825. https://doi.org/10.3390/app12157825
Yan L, Li K, Gao R, Wang C, Xiong N. An Intelligent Weighted Object Detector for Feature Extraction to Enrich Global Image Information. Applied Sciences. 2022; 12(15):7825. https://doi.org/10.3390/app12157825
Chicago/Turabian StyleYan, Lingyu, Ke Li, Rong Gao, Chunzhi Wang, and Neal Xiong. 2022. "An Intelligent Weighted Object Detector for Feature Extraction to Enrich Global Image Information" Applied Sciences 12, no. 15: 7825. https://doi.org/10.3390/app12157825
APA StyleYan, L., Li, K., Gao, R., Wang, C., & Xiong, N. (2022). An Intelligent Weighted Object Detector for Feature Extraction to Enrich Global Image Information. Applied Sciences, 12(15), 7825. https://doi.org/10.3390/app12157825