Author Contributions
Conceptualization, S.-S.L. and O.-W.K.; methodology, S.-S.L.; software, S.-S.L.; validation, S.-S.L.; formal analysis, S.-S.L. and O.-W.K.; investigation, S.-S.L.; resources, S.-S.L.; data curation, S.-S.L.; writing—original draft preparation, S.-S.L.; writing—review and editing, O.-W.K.; visualization, S.-S.L.; supervision, O.-W.K.; project administration, O.-W.K.; funding acquisition, O.-W.K. All authors have read and agreed to the published version of the manuscript.
Figure 1.
Baseline encoder-decoder network architecture.
Figure 1.
Baseline encoder-decoder network architecture.
Figure 2.
SpecAugment applied to spectrogram. The sections to which frequency masking was applied [, + ) and time masking was applied [, + ) are shown in gray.
Figure 2.
SpecAugment applied to spectrogram. The sections to which frequency masking was applied [, + ) and time masking was applied [, + ) are shown in gray.
Figure 3.
Flow chart of the proposed method.
Figure 3.
Flow chart of the proposed method.
Figure 4.
Proposed method applied to base input spectrogram. The section to which the proposed method was applied is shown in gray.
Figure 4.
Proposed method applied to base input spectrogram. The section to which the proposed method was applied is shown in gray.
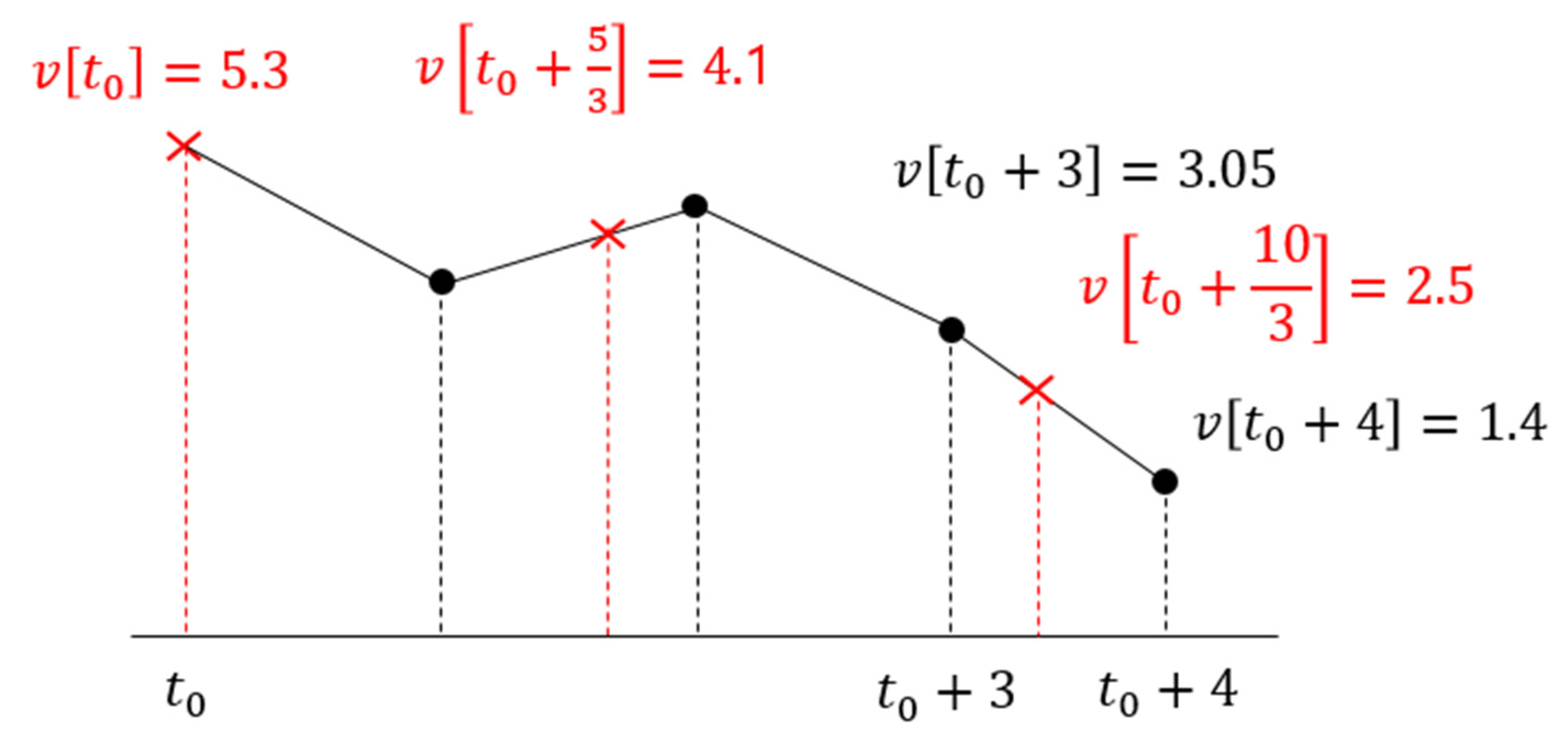
Figure 5.
Method of calculating replacement frames. The red cross indicates replacement frame values and the black bullet indicates original frame values when , respectively.
Figure 5.
Method of calculating replacement frames. The red cross indicates replacement frame values and the black bullet indicates original frame values when , respectively.
Figure 6.
WER results of WSJ database according to augmented frame range. The horizontal axis denotes the maximum augmentation range and the vertical axis denotes WER.
Figure 6.
WER results of WSJ database according to augmented frame range. The horizontal axis denotes the maximum augmentation range and the vertical axis denotes WER.
Figure 7.
Validation loss of WSJ (a) and LibriSpeech (b) databases by epoch. The horizontal axis denotes the number of epochs and the vertical axis denotes validation loss.
Figure 7.
Validation loss of WSJ (a) and LibriSpeech (b) databases by epoch. The horizontal axis denotes the number of epochs and the vertical axis denotes validation loss.
Figure 8.
Comparison of the attention alignments with the encoder feature index on x-axis and the outputs on y-axis for the same utterance. We note that speech frames are subsampled by 4:1 for encoder input of Transformer. (a) Original data; (b) speed perturbation (speed = 1.1); (c) FrameAugment (, , ); (d) FrameAugment (, , ).
Figure 8.
Comparison of the attention alignments with the encoder feature index on x-axis and the outputs on y-axis for the same utterance. We note that speech frames are subsampled by 4:1 for encoder input of Transformer. (a) Original data; (b) speed perturbation (speed = 1.1); (c) FrameAugment (, , ); (d) FrameAugment (, , ).
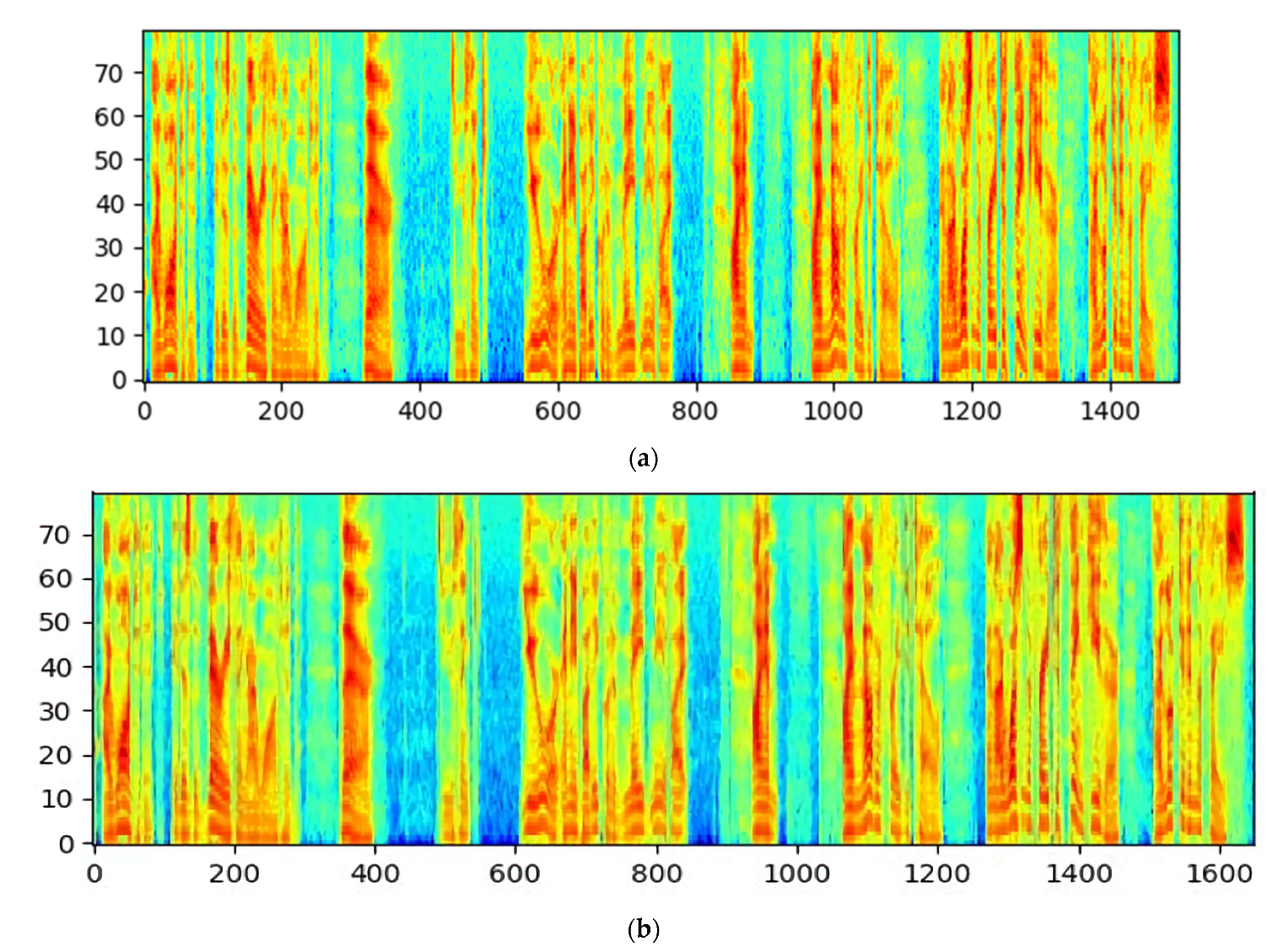
Figure 9.
Comparison of the spectrograms with frame index on x-axis and feature index on y-axis. The length of the utterance increases due to FrameAugment. (a) Original spectrogram; (b) spectrogram with FrameAugment (, , ).
Figure 9.
Comparison of the spectrograms with frame index on x-axis and feature index on y-axis. The length of the utterance increases due to FrameAugment. (a) Original spectrogram; (b) spectrogram with FrameAugment (, , ).
Figure 10.
Attention loss of the training data (a) and validation data (b) of the LibriSpeech database. The horizontal axis denotes the number of epochs, and the vertical axis denotes . We note that 3-fold speed perturbation means 3 times the original training data.
Figure 10.
Attention loss of the training data (a) and validation data (b) of the LibriSpeech database. The horizontal axis denotes the number of epochs, and the vertical axis denotes . We note that 3-fold speed perturbation means 3 times the original training data.
Table 1.
WER (%) results of WSJ database according to the maximum augmentation range when .
Table 1.
WER (%) results of WSJ database according to the maximum augmentation range when .
| Number of Repetitions | Dev93 | Eval92 |
|---|
| 0 | 0 | 7.88 | 5.02 |
| 100 | 1 | 7.81 | 4.78 |
| 2 | 7.35 | 4.86 |
| 200 | 1 | 7.27 | 4.45 |
| 2 | 7.51 | 4.91 |
| 300 | 1 | 7.66 | 5.07 |
| 2 | 7.27 | 4.43 |
| 400 | 1 | 7.55 | 4.27 |
| 2 | 7.20 | 5.05 |
| 500 | 1 | 7.03 | 4.75 |
| 2 | 6.97 | 5.00 |
| 600 | 1 | 7.25 | 4.73 |
| 2 | 7.31 | 5.12 |
| 700 | 1 | 7.49 | 4.50 |
| 2 | 7.26 | 4.92 |
Table 2.
WER (%) results of LibriSpeech database according to the maximum augmentation range when .
Table 2.
WER (%) results of LibriSpeech database according to the maximum augmentation range when .
| Dev-Clean | Test-Clean |
|---|
| 0 | 6.62 | 7.33 |
| 200 | 6.71 | 7.44 |
| 400 | 6.74 | 7.37 |
| 600 | 6.28 | 7.01 |
| 800 | 6.46 | 7.12 |
| 1000 | 6.31 | 6.95 |
| 1200 | 6.26 | 6.96 |
| 1400 | 6.61 | 7.16 |
Table 3.
WER (%) results of WSJ database according to frame rate when .
Table 3.
WER (%) results of WSJ database according to frame rate when .
| Dev93 | Eval92 |
|---|
| 0 | 7.88 | 5.02 |
| 0.9–1.1 | 7.03 | 4.75 |
| 0.7–1.3 | 7.38 | 4.82 |
| 0.7, 1.0, 1.3 | 7.07 | 4.87 |
| 0.5–1.5 | 7.24 | 4.94 |
| 0.5, 1.0, 1.5 | 7.04 | 4.70 |
Table 4.
WER (%) results of LibriSpeech database according to frame rate when .
Table 4.
WER (%) results of LibriSpeech database according to frame rate when .
| Dev-Clean | Test-Clean |
|---|
| 0.9–1.1 | 6.26 | 6.96 |
| 0.7–1.3 | 5.95 | 6.60 |
| 0.7, 1.0, 1.3 | 6.15 | 6.62 |
| 0.5–1.5 | 6.06 | 6.68 |
| 0.5, 1.0, 1.5 | 5.93 | 6.74 |
Table 5.
WER (%) results according to the maximum augmentation range. For the flexible case, the ratio was 0.7 and the frame rate range was 0.5–1.5 in the proposed method.
Table 5.
WER (%) results according to the maximum augmentation range. For the flexible case, the ratio was 0.7 and the frame rate range was 0.5–1.5 in the proposed method.
| Database | | Dev93/Dev-Clean | Eval92/Test-Clean |
|---|
| WSJ | 0 | 7.88 | 5.02 |
| Fixed ) | 7.24 | 4.94 |
| Flexible | 6.89 | 4.68 |
| LibriSpeech | 0 | 6.62 | 7.33 |
| Fixed ( | 6.06 | 6.68 |
| Flexible | 6.14 | 6.63 |
Table 6.
WER (%) results of WSJ database according to data augmentation methods.
Table 6.
WER (%) results of WSJ database according to data augmentation methods.
| Data Augmentation | Dev93 | Eval92 |
|---|
| None | 7.88 | 5.02 |
| SpecAugment | 7.23 | 4.87 |
| Speed perturbation | 7.24 | 4.93 |
| Proposed method | 6.89 | 4.68 |
Table 7.
WER (%) results of LibriSpeech database according to data augmentation methods.
Table 7.
WER (%) results of LibriSpeech database according to data augmentation methods.
| Data Augmentation | Dev-Clean | Test-Clean |
|---|
| None | 6.62 | 7.33 |
| SpecAugment | 6.23 | 6.96 |
| Speed perturbation | 6.10 | 6.74 |
| Proposed method | 6.14 | 6.63 |
Table 8.
WER (%) results of LibriSpeech database when incrementally combined with the previous data augmentation methods.
Table 8.
WER (%) results of LibriSpeech database when incrementally combined with the previous data augmentation methods.
| Data Augmentation | Dev-Clean | Test-Clean |
|---|
| SpecAugment | 6.23 | 6.96 |
| +Speed perturbation | 5.83 | 6.26 |
| +Proposed method | 5.53 | 6.01 |












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}