
Sign Language Gesture Recognition with Convolutional-Type Features on Ensemble Classifiers and Hybrid Artificial Neural Network


Abstract
:1. Introduction
- The usage of numerical image features obtainable from a convolutional neural network, with classifiers other than artificial neural networks for acquiring stellar accuracy values, in this case, ensemble models such as random forest and XGBoost.
- A neoteric method to obtain features from an image with binary robust invariant scalable keypoints on hand edges.
- The inception of a hybrid artificial neural network architecture that exploits both original image data and edge image data to augment classification performance on sign gestures compared to a single artificial neural network.
2. Related Work
3. Datasets and Methods
3.1. Datasets
3.2. Methodology
3.2.1. Feature Extraction
3.2.2. Dimensionality Reduction-Principal Component Analysis
3.2.3. Classification-Ensemble Methods
Random Forest
XGBoost
3.2.4. Classification-Neural Networks
Artificial Neural Network(ANN)
Hybrid ANN
Convolutional Neural Network (CNN)
4. Results
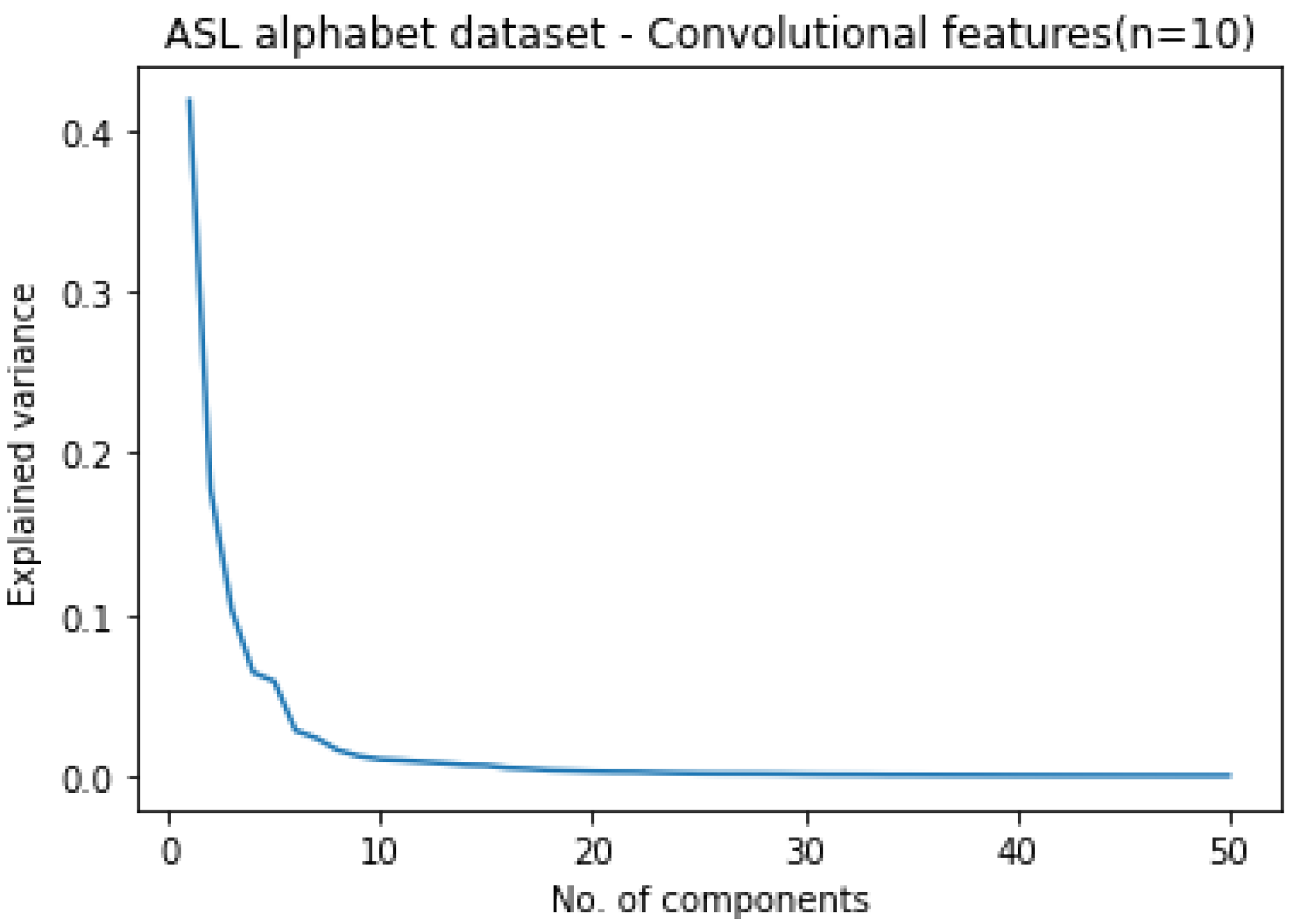
4.1. Principal Component Analysis (PCA)
4.2. Sign Recognition Accuracies: Ensemble Methods
4.3. Sign Recognition Accuracies: Neural Networks
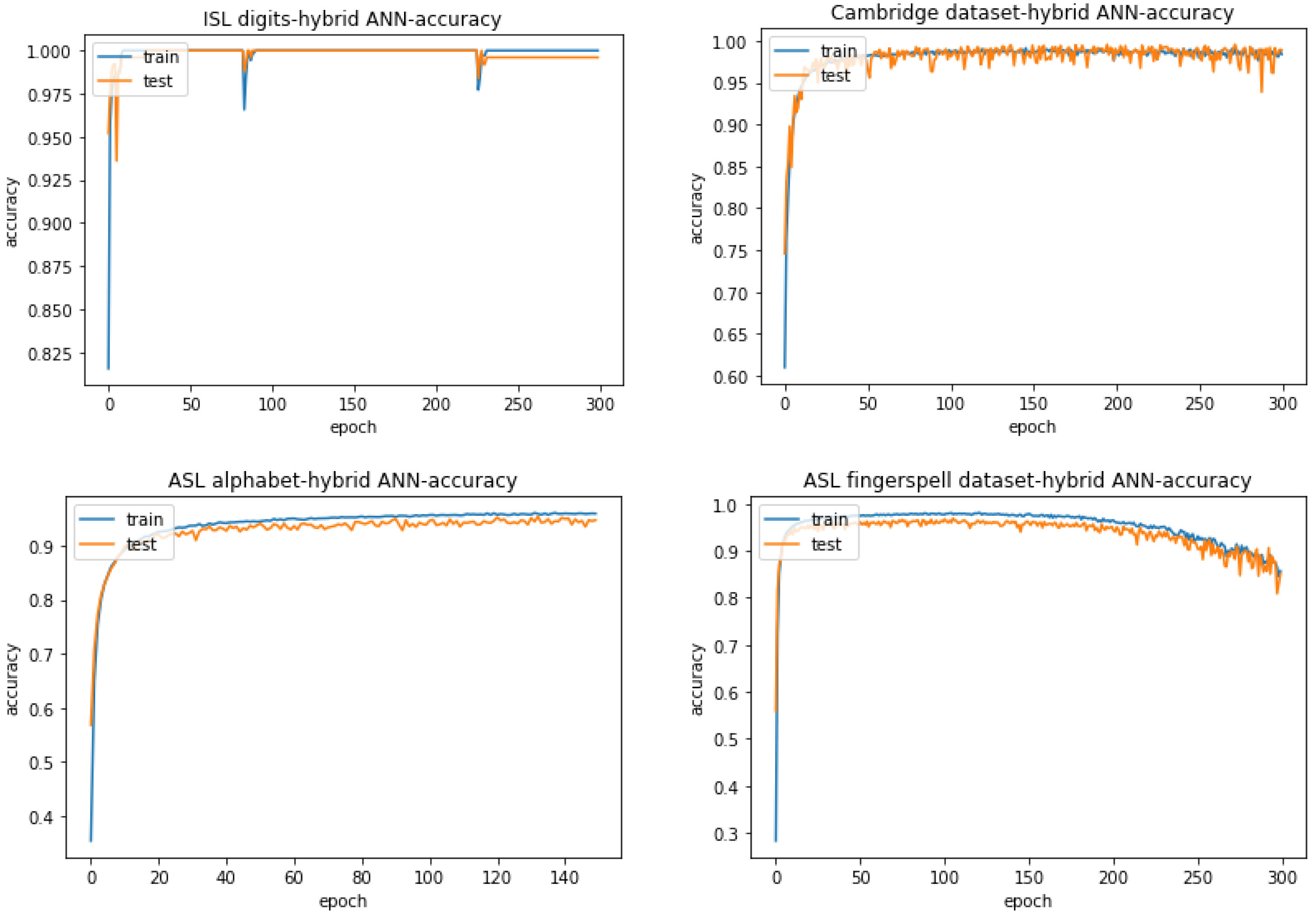
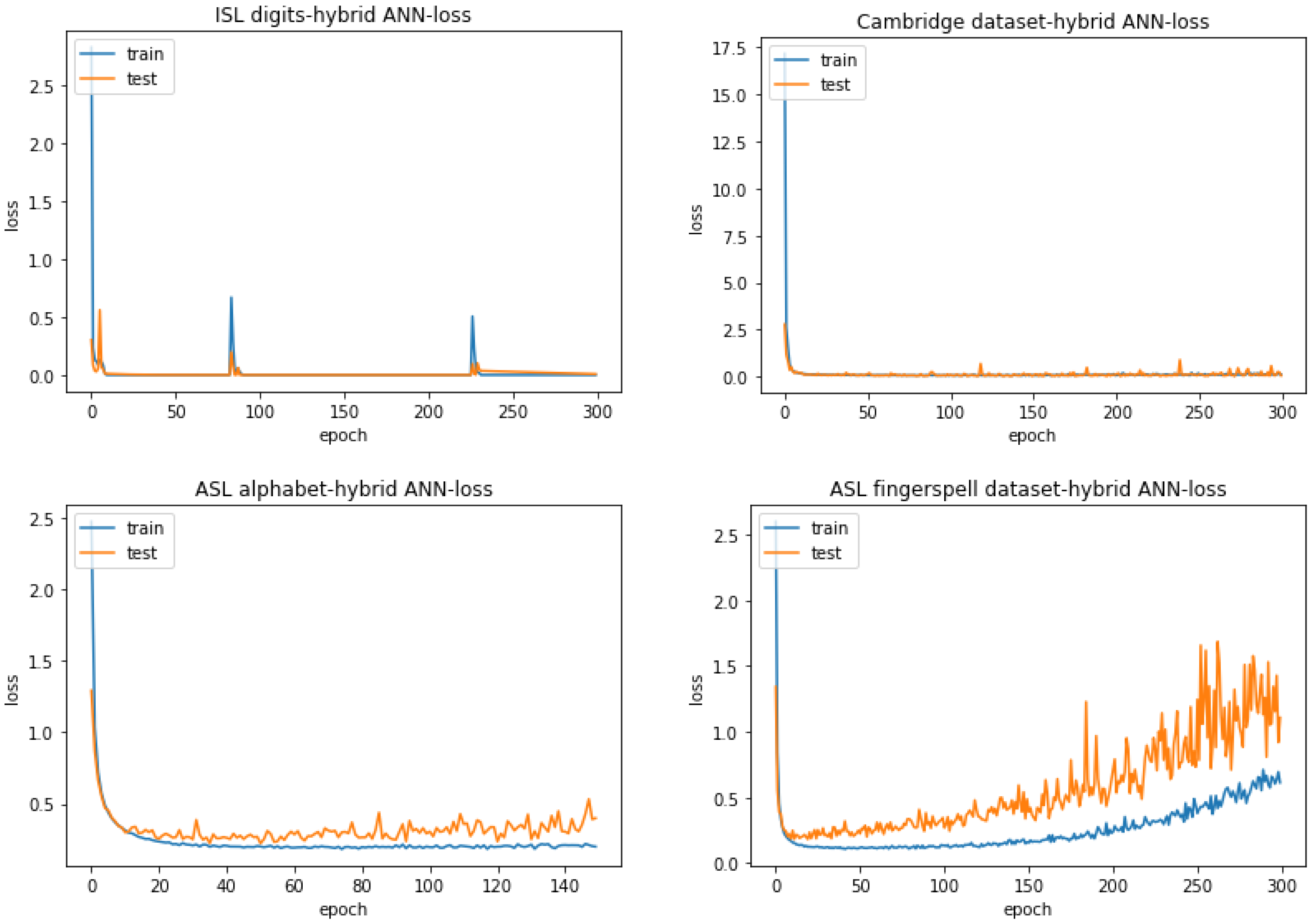
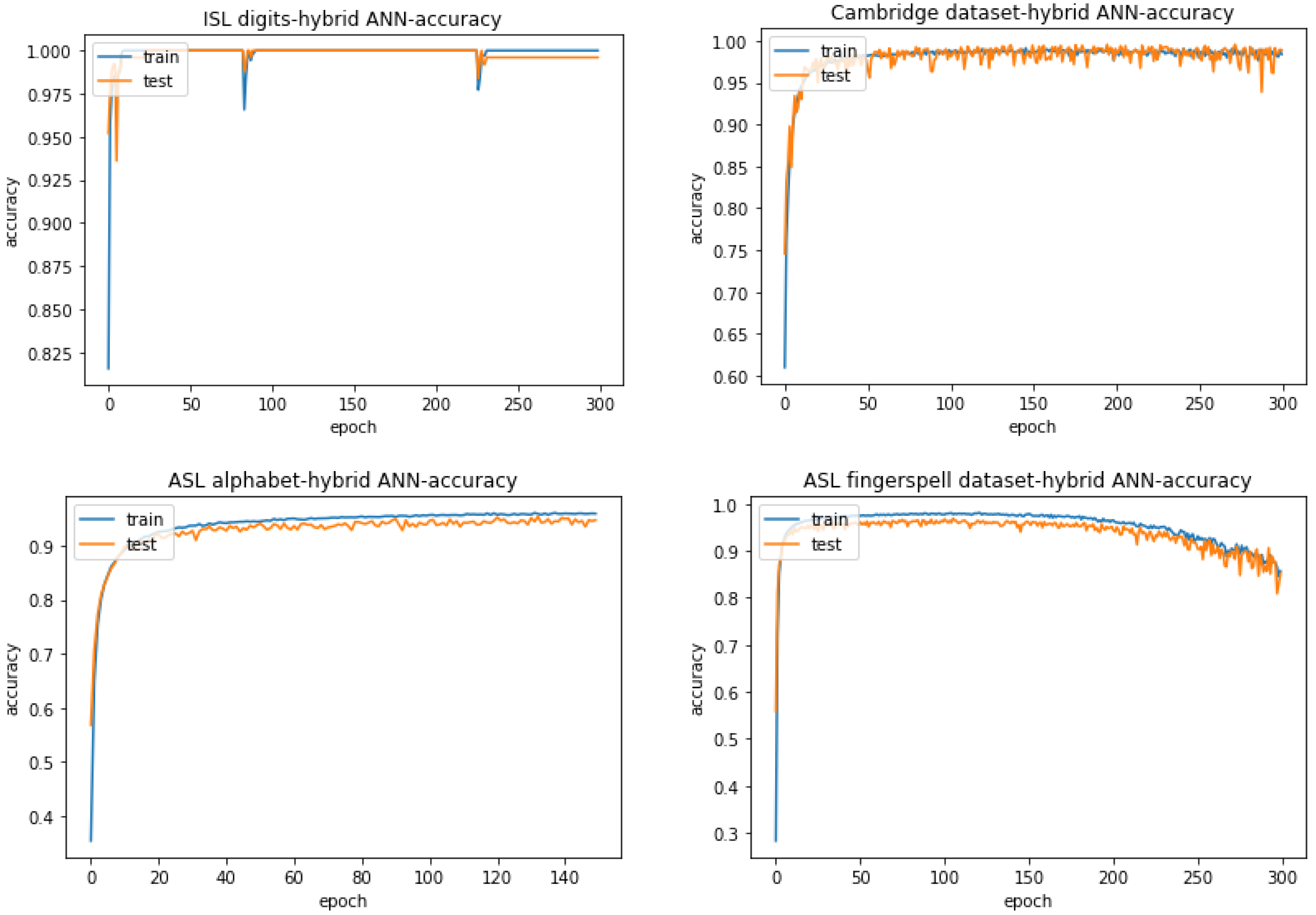
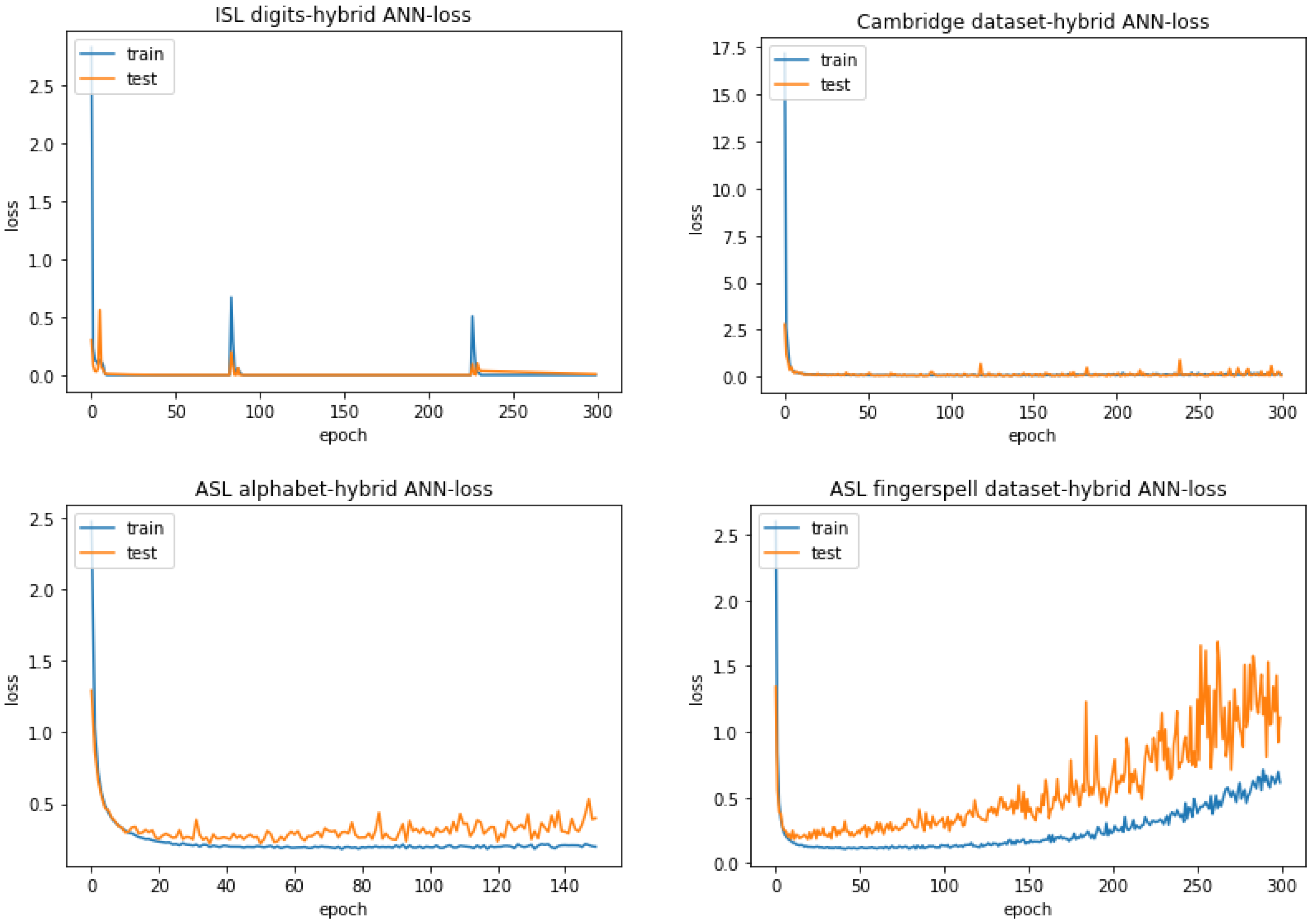
4.3.1. Hybrid ANN
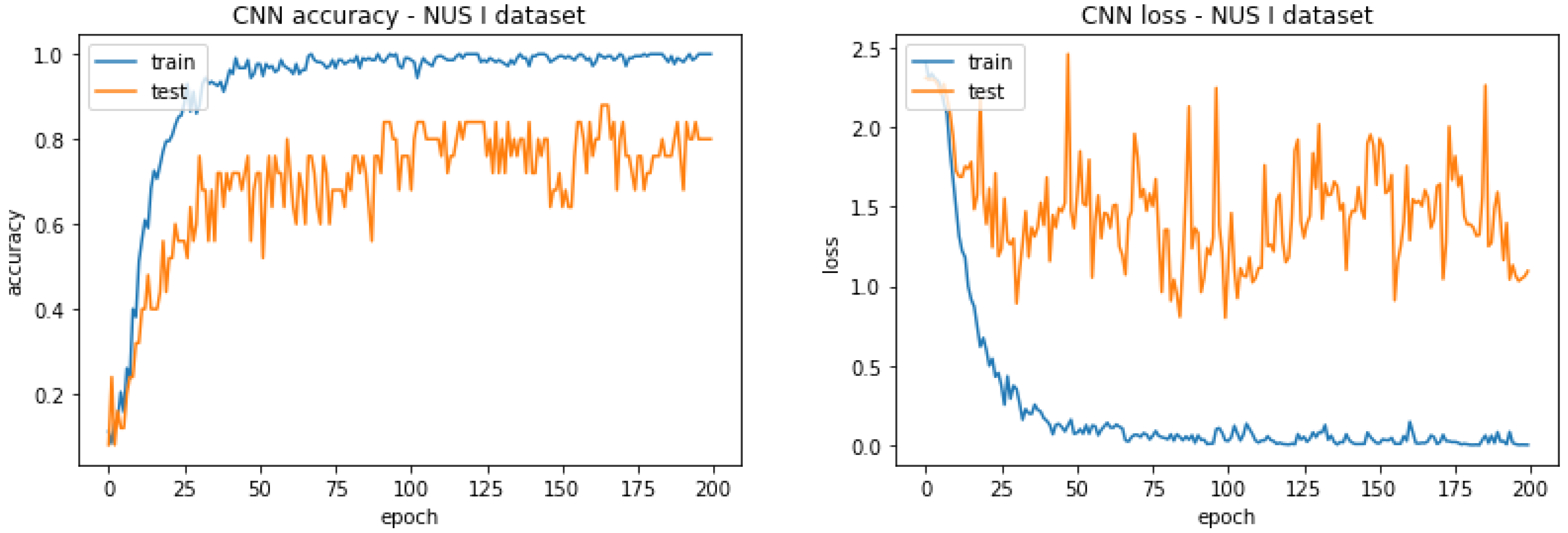
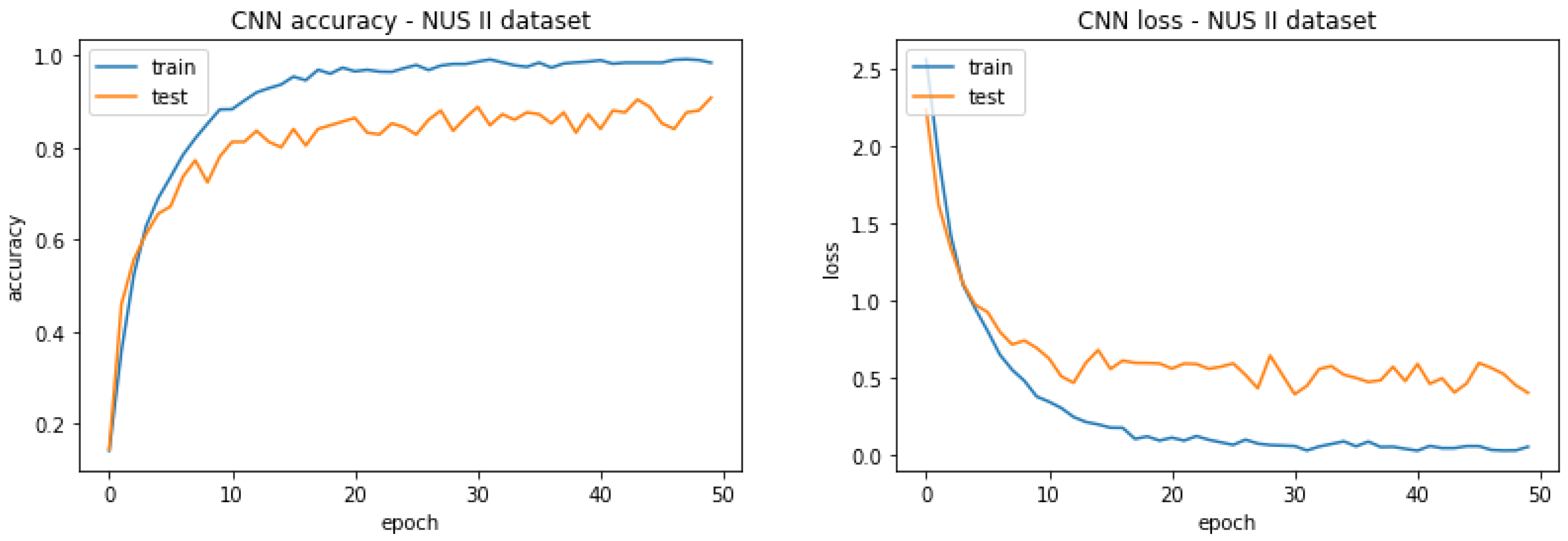
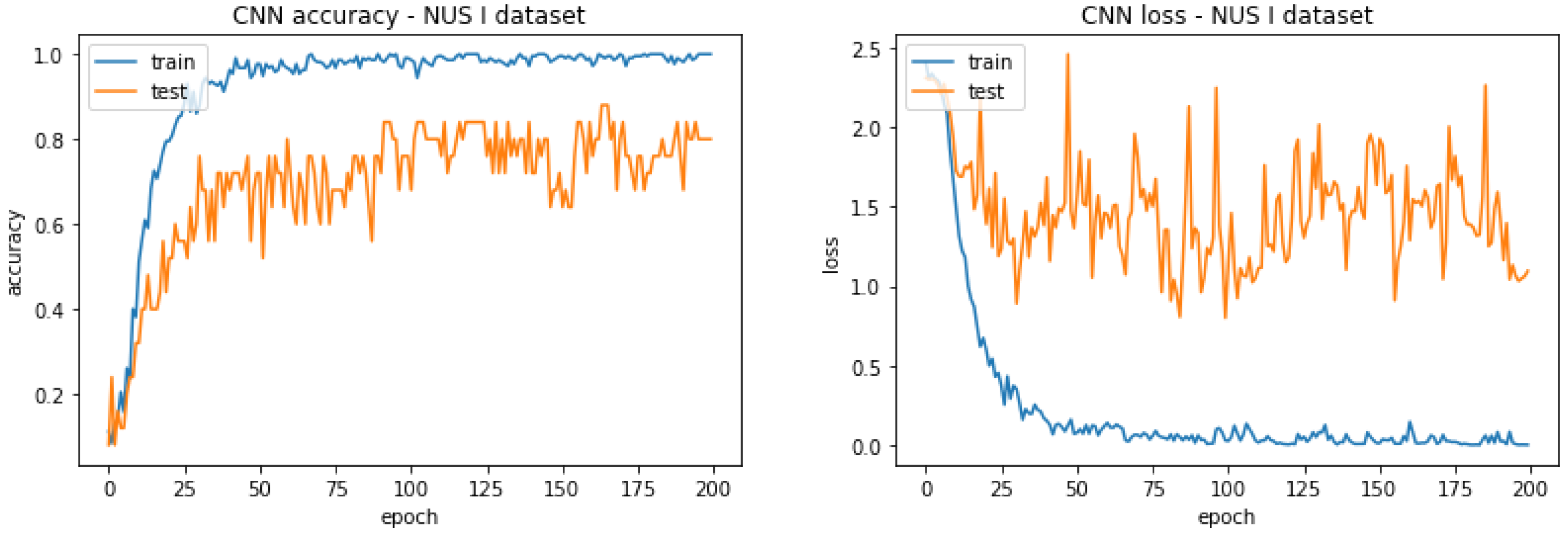
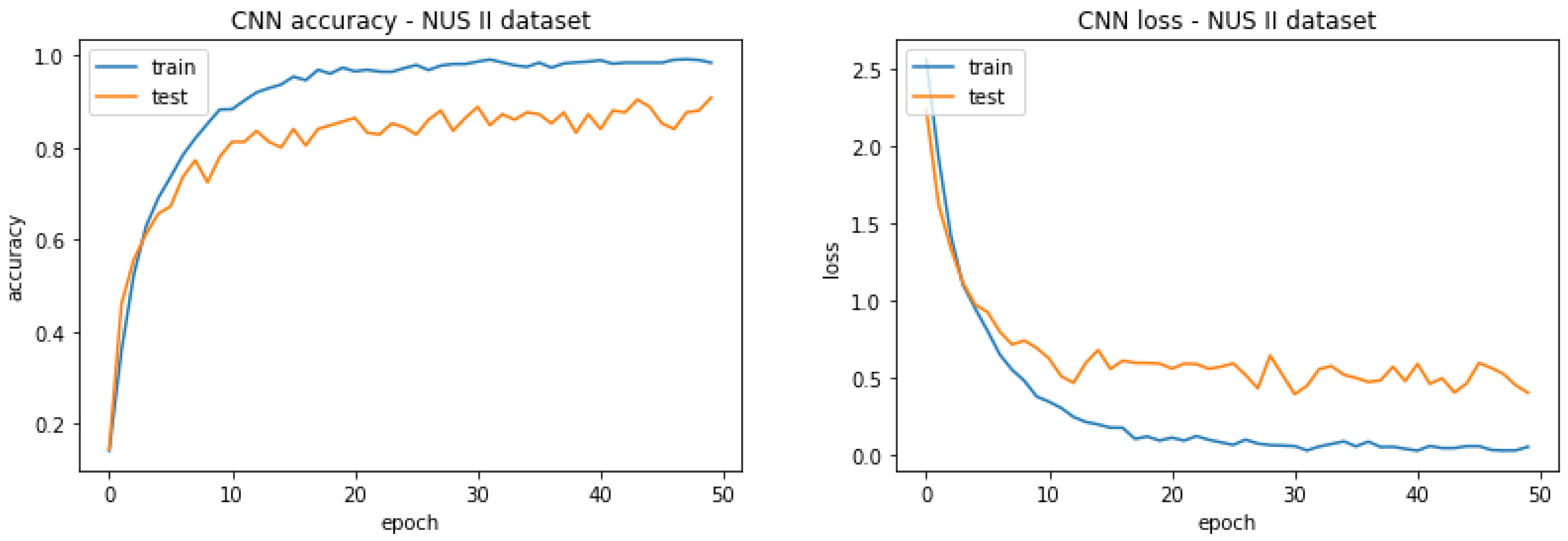
4.3.2. Convolutional Neural Networks (CNN)
4.4. Leave-One-Out-Accuracy
- Consider User A. To find the leave-one-out-accuracy for this user, the model under consideration is trained on the remaining users and tested on User A.
- This process is repeated for all users. The mean accuracy for all the users gives the leave-one-out-accuracy for the entire dataset.
4.5. Comparison with Base Paper Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| ASL | American Sign Language |
| NUS | National University of Singapore |
| ISL | Indian SIgn Language |
| CNN | Convolutional Neural Network |
| RGB | Red-Green-Blue |
| BRISK | Binary Robust Invariant Scalable Keypoints |
| PCA | Principal Component Analysis |
| ANN | Artificial Neural Network |
| ReLU | Rectified Linear Unit |
References
- Understanding Random Forest. Available online: https://towardsdatascience.com/understanding-random-forest-58381e0602d2 (accessed on 17 May 2022).
- A Gentle Introduction to XGBoost for Applied Machine Learning. Available online: https://machinelearningmastery.com/gentle-introduction-xgboost-applied-machine-learning/ (accessed on 17 May 2022).
- A Comprehensive Guide to Convolutional Neural Networks—The ELI5 Way. Available online: https://towardsdatascience.com/a-comprehensive-guide-to-convolutional-neural-networks-the-eli5-way-3bd2b1164a53 (accessed on 17 May 2022).
- Image Edge Detection Operators in Digital Image Processing. Available online: https://www.geeksforgeeks.org/image-edge-detection-operators-in-digital-image-processing/ (accessed on 17 May 2022).
- Artificial Neural Network. Available online: https://en.wikipedia.org/wiki/Artificial_neural_network (accessed on 17 May 2022).
- Sagayam, K.M.; Andrushia, A.D.; Ghosh, A.; Deperlioglu, O. Recognition of Hand Gesture Image Using Deep Convolutional Neural Network. Int. J. Image Graph. 2021, 21, 2140008–2140022. [Google Scholar] [CrossRef]
- Hurroo, M.; Walizad, M.E. Sign Language Recognition System using Convolutional Neural Network and Computer Vision. Int. J. Eng. Res. Technol. 2020, 9, 59–64. [Google Scholar]
- Aly, W.; Aly, S.; Almotairi, S. User-Independent American Sign Language Alphabet Recognition Based on Depth Image and PCANet Features. IEEE Access 2019, 7, 123138–123150. [Google Scholar] [CrossRef]
- Gattupalli, S.; Ghaderi, A.; Athitsos, V. Evaluation of Deep Learning based Pose Estimation for Sign Language Recognition. In Proceedings of the 9th ACM International Conference on Pervasive Technologies Related to Assistive Environments, Corfu Island, Greece, 29 June–1 July 2016. [Google Scholar]
- Thalange, A.; Dixit, S.K. COHST and Wavelet Features Based Static ASL Numbers Recognition. Procedia Comput. Sci. 2016, 92, 455–460. [Google Scholar] [CrossRef] [Green Version]
- Huang, J.; Zhou, W.; Zhang, Q.; Li, H.; Li, W. Video-based Sign Language Recognition without Temporal Segmentation. In Proceedings of the 32nd AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; pp. 2257–2264. [Google Scholar]
- Cui, R.; Liu, H.; Zhang, C. Recurrent Convolutional Neural Networks for Continuous Sign Language Recognition by Staged Optimization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1610–1618. [Google Scholar]
- Gangrade, J.; Bharti, J.; Mulye, A. Recognition of Indian Sign Language Using ORB with Bag of Visual Words by Kinect Sensor. IETE J. Res. 2020, 1–15. [Google Scholar] [CrossRef]
- Raheja, J.L.; Mishra, A.; Chaudhary, A. Indian sign language recognition using SVM. Pattern Recogn. Image Anal. 2016, 26, 434–441. [Google Scholar] [CrossRef]
- Thang, P.Q.; Dung, N.D.; Thuy, N.T. A Comparison of SimpSVM and RVM for Sign Language Recognition. In Proceedings of the International Conference on Machine Learning and Soft Computing, Ho Chi Minh, Vietnam, 13–16 January 2017; pp. 98–104. [Google Scholar]
- Kumara, B.M.; Nagendraswamy, H.S.; Chinmayi, R.L. Spatial Relationship Based Features for Indian Sign Language Recognition. Int. J. Comput. Commun. Instrum. Eng. 2016, 3, 8. [Google Scholar]
- Shivashankara, S.; Srinath, S. American Sign Language Recognition System: An Optimal Approach. Int. J. Image Graph. Sign. Process. 2018, 10, 18–30. [Google Scholar]
- Pansare, J.R.; Ingle, M. Vision-based approach for American Sign Language recognition using Edge Orientation Histogram. In Proceedings of the International Conference on Image, Vision and Computing, Portsmouth, UK, 3–5 August 2016; pp. 86–90. [Google Scholar]
- MediaPipe Hands. Available online: https://google.github.io/mediapipe/solutions/hands.html (accessed on 12 May 2022).
- Euclidean Distance. Available online: https://en.wikipedia.org/wiki/Euclidean_distance (accessed on 17 May 2022).
- Skin Color Code: For All Skin Tone Color Types. Available online: https://huebliss.com/skin-color-code/ (accessed on 12 May 2022).
- Canny Edge Detection. Available online: https://docs.opencv.org/4.x/da/d22/tutorial_py_canny.html (accessed on 12 May 2022).
- Sobel, vs. Canny Edge Detection Techniques: Step by Step Implementation. Available online: https://medium.com/@haidarlina4/sobel-vs-canny-edge-detection-techniques-step-by-step-implementation-11ae6103a56a (accessed on 12 May 2022).
- Leutenegger, S.; Chli, M.; Siegwart, R.Y. BRISK: Binary Robust invariant scalable keypoints. In Proceedings of the International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2548–2555. [Google Scholar]
- Multicollinearity. Available online: https://en.wikipedia.org/wiki/Multicollinearity (accessed on 17 May 2022).
- Orthogonal Transformation. Available online: https://mathworld.wolfram.com/OrthogonalTransformation.html (accessed on 17 May 2022).
- XGBoost Documentation. Available online: https://xgboost.readthedocs.io/en/stable/ (accessed on 27 June 2022).
- Overfitting. Available online: https://www.ibm.com/cloud/learn/overfitting (accessed on 17 May 2022).
- Intuition of Adam Optimizer. Available online: https://www.geeksforgeeks.org/intuition-of-adam-optimizer/ (accessed on 27 June 2022).
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1026–1034. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Paper | Problem Statement | Dataset | ML/DL Models Used | Results |
|---|---|---|---|---|
| Sagayam, K.M. et al. [6] | Devise a hand-gesture recognition model using a well-tuned deep CNN without using hybrid processes such as image pre-processing, segmentation and classification | Cambridge Hand Gesture Dataset | Methodology
| Accuracy—96.66% Sensitivity—85% Specificity—98.12% |
| Aly, W. et al. [8] | Devise a user-independent recognition system that exploits depth information of RGB images to learn features using PCA for classifying the sign gestures | ASL Finger Spelling dataset | Methodology
| Accuracy
|
| Gangrade, J. et al. [13] | Devise a system to recognize signs in a cluttered environment invariant of scaling, rotation and lighting | Self-generated ISL digits 0–9, NUS Dataset I and II | Methodology
| Accuracy-ISL digits
|
| Size | No. of Classes | Samples per Class | Test Size | |
|---|---|---|---|---|
| ASL alphabet | 72,000 | 24 | 3000 | 20% |
| ASL finger-spelling dataset | 65,774 | 24 | >2600 | 20% |
| Cambridge hand gesture dataset | 63,188 | 9 | >6000 | 20% |
| NUS I dataset | 240 | 10 | 24 | 10.4% |
| NUS II dataset | 2000 | 10 | 200 | 12.5% |
| ISL digits | 2000 | 10 | 200 | 12.5% |
| Input: | Sign Images Annotated with Labels |
|---|---|
| 1: | Extract numerical features from sign images: |
| Hand coordinates–3D coordinates of hand joints; | |
| Convolutional features–features obtained from a CNN after convolution and pooling operations; | |
| Convolutional features + finger angles–convolutional features from a CNN along with cosine of angles between the fingers; | |
| CNN features on hand edges–convolutional features on sign images whose background is removed and only hand edges are retained; | |
| CNN features on BRISK–convolutional features on hand edges retained sign images that are infused with BRISK keypoints; | |
| 2: | Perform dimensionality reduction on convolutional-related features: |
| PCA–dimensionality reduction through orthogonal transformation; | |
| 3: | Apply random forest and XGBoost on hand coordinates and all PCA-applied convolutional-type features; |
| 4: | Apply neural networks on the features: |
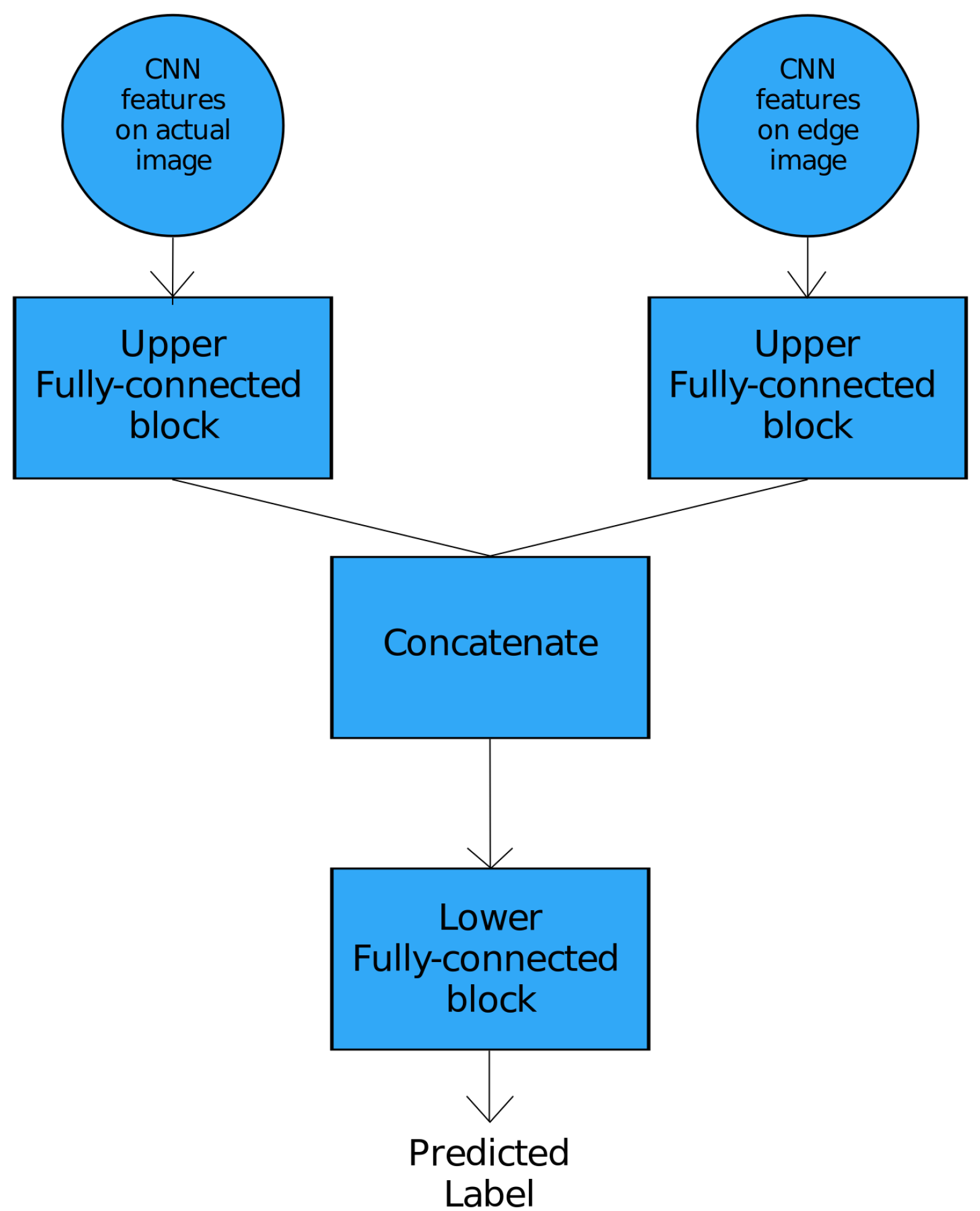
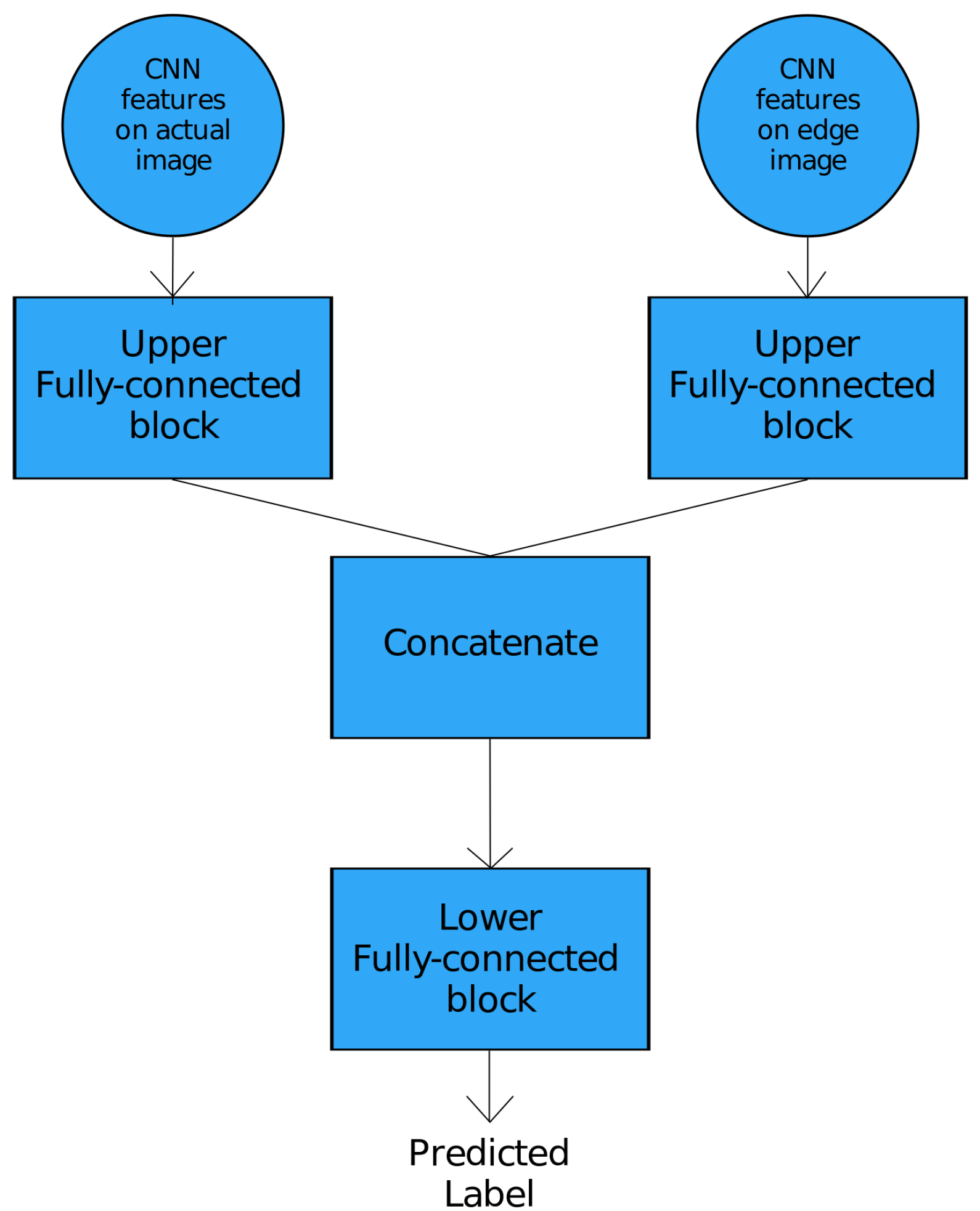
| Hybrid ANN–applied on convolutional features and CNN features on hand edges; | |
| CNN–applied directly on NUS I and II datasets; | |
| ANN–applied on hand coordinates extracted from ASL finger-spelling dataset for testing leave-on-out-accuracy. | |
| Output: | Predicted label of sign images. |
| Operation | Kernel | Stride | Filters | Pool | Activation |
|---|---|---|---|---|---|
| Conv2D | 3 × 3 | 1 × 1 | 64 | ||
| Conv2D | 3 × 3 | 1 × 1 | 64 | ||
| MaxPooling2D | 1 × 1 | 2 × 2 | |||
| Conv2D | 3 × 3 | 1 × 1 | 128 | ReLU | |
| Conv2D | 3 × 3 | 1 × 1 | 128 | ReLU | |
| MaxPooling2D | 1 × 1 | 19 × 19 | |||
| Flatten |
| Feature | Extraction Steps |
|---|---|
| Hand coordinates | 1: Initialize Mediapipe [19] hands object; 2: Pass the hand gesture image to the object; 3: The location of 21 hand joints in a 3D coordinate space are returned with each of them in the form of a 3-tuple as follows: |
| Convolutional features | 1: Feed the sign gesture image to the CNN described in Table 4; 2: The convolutional features are obtained as a flattened 1D feature vector after passing through convolutional layers and pooling layers. |
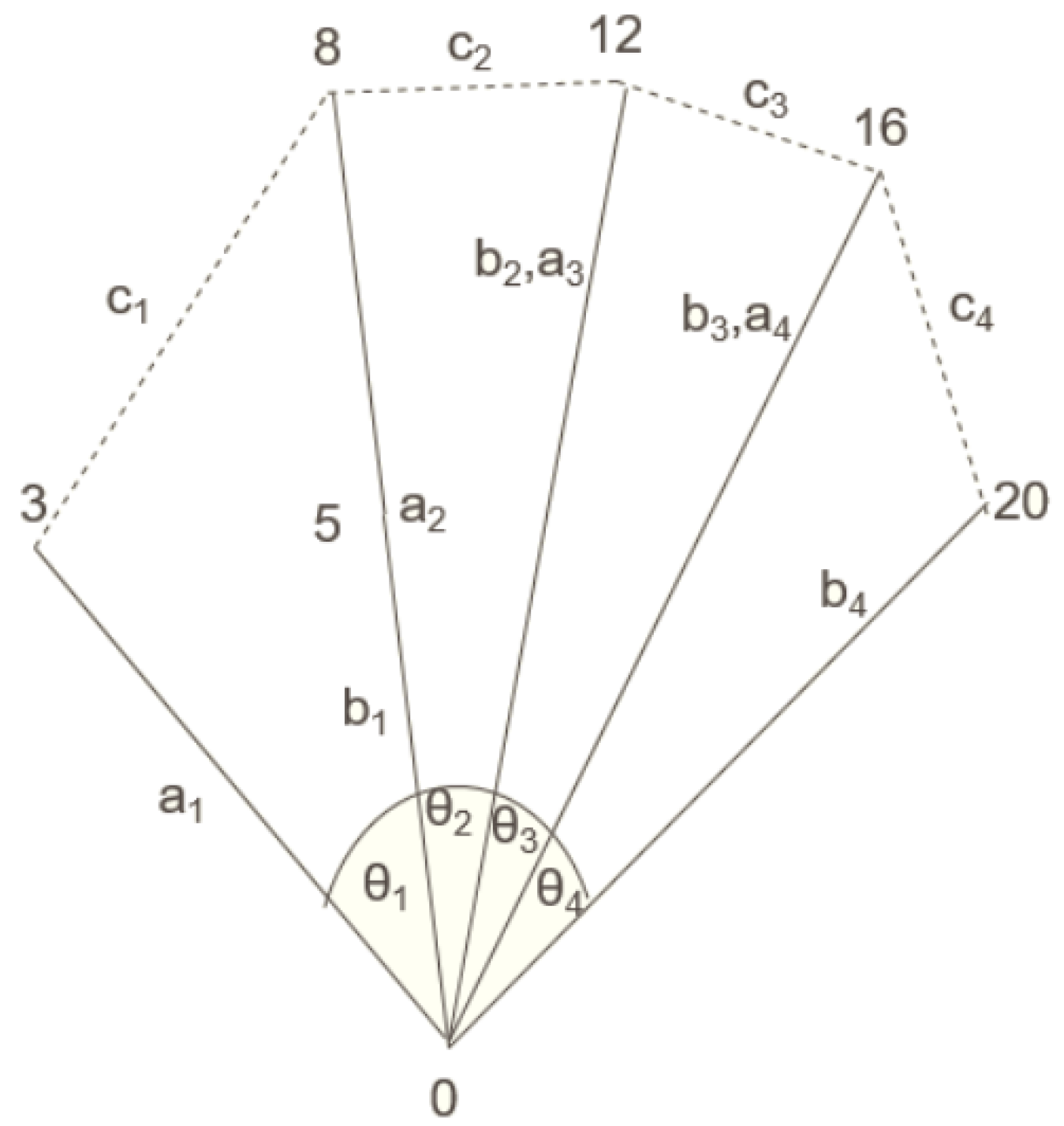
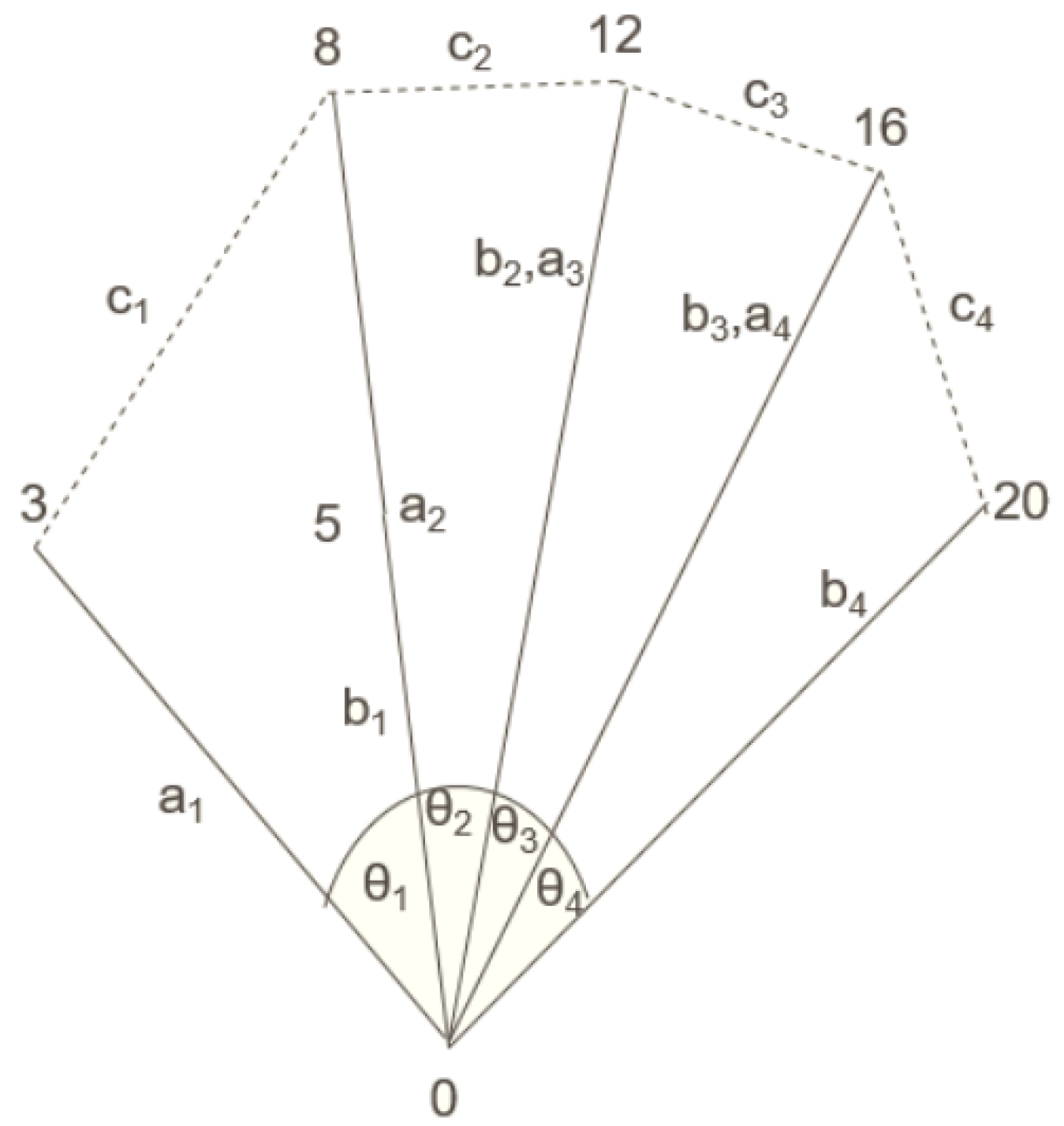
| Convolutional features + finger angles | 1: Obtain the hand coordinates 0, 3, 5, 8, 12, 16 and 20 using Mediapipe [19] as shown in Figure 2 to calculate the finger angles; 2: The Euclidean distances [20] , where i = 1 to 4 are calculated in three dimensions; 3: The four finger angles as depicted in Figure 2 are calculated using the law of cosines for triangles which is as follows: |
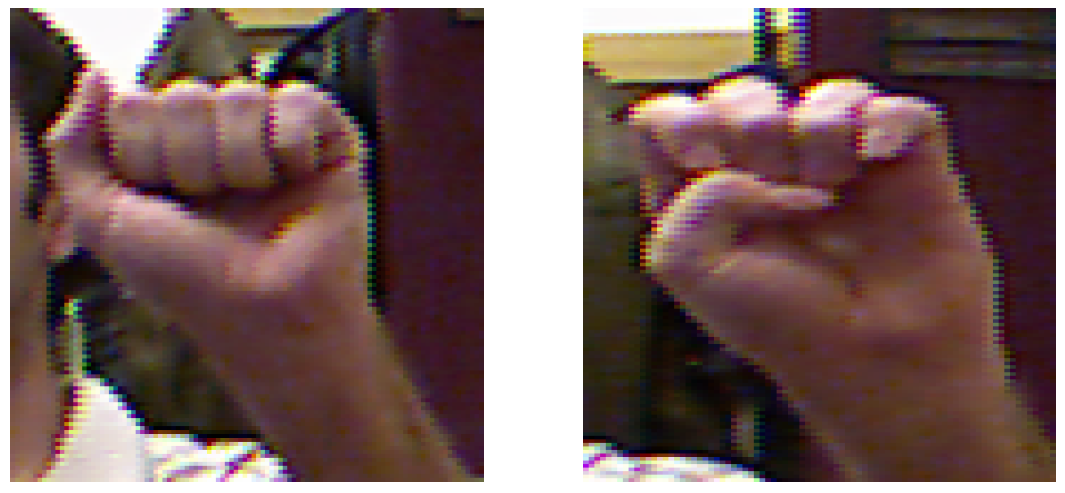
| CNN features on hand edges | 1: Initialize a skin-mask with the real skin tone color scheme [21] but decrease the lower bound to capture darker skin tones as well as skin tones under insufficient lighting; 2: Perform a bitwise AND between the skin mask and the input image to segment the hand region from the background; 3: Denoise the hand-segmented image using median blur; 4: Apply Canny filter [22] on the denoised image to retain only the hand edges; 5: The CNN described in Table 4 is used to extract features from the edge image. |
| CNN features on BRISK image | 1: Initialize a BRISK object; 2: Using the object, detect BRISK keypoints in the edge image obtained in the previous feature; 3: Pass this keypoint-infused image through the CNN described in Table 4. |
| Ensemble Technique | Implementation Steps |
|---|---|
| Random Forest, XGBoost | 1: Split the dataset into training and testing sets; 2: Initialize Random Forest classifier with 100 decision trees and XGBoost classifier with default parameterization of xgboost [27] library in python; 3: Fit the classifiers on the training sets; 4: Evaluate accuracy on the testing set using the trained classifiers. |
| Neural Network | Implementation Steps |
|---|---|
| ANN, hybrid ANN, CNN | 1: Construct the neural network as per the architectures specified in Section 3.2.4; 2: Split the dataset into training and testing sets; 3: Compile the neural network using a categorical cross entropy loss function and an Adam optimizer [29]; 4: Perform one-hot encoding on the dependent variable of the training and testing sets 5: Train the neural network on the training set with the testing set as the validation data. |
| Upper Fully-Connected Block | ||
|---|---|---|
| Neural Network Layer | No. of Neurons | Activation Function |
| Dense | 64 | ReLU |
| Dense | 64 | ReLU |
| Dense | No. of CNN features after PCA | Linear |
| Lower Fully-Connected Block | ||
| Neural Network Layer | No. of Neurons | Activation Function |
| Dense | 64 | ReLU |
| Dense | 64 | ReLU |
| Dense | No. of classes | Softmax |
| ASL Alphabet | ASL Finger-Spelling Dataset | Cambridge Hand Gesture Dataset | NUS I Dataset | NUS II Dataset | ISL Digits | |
|---|---|---|---|---|---|---|
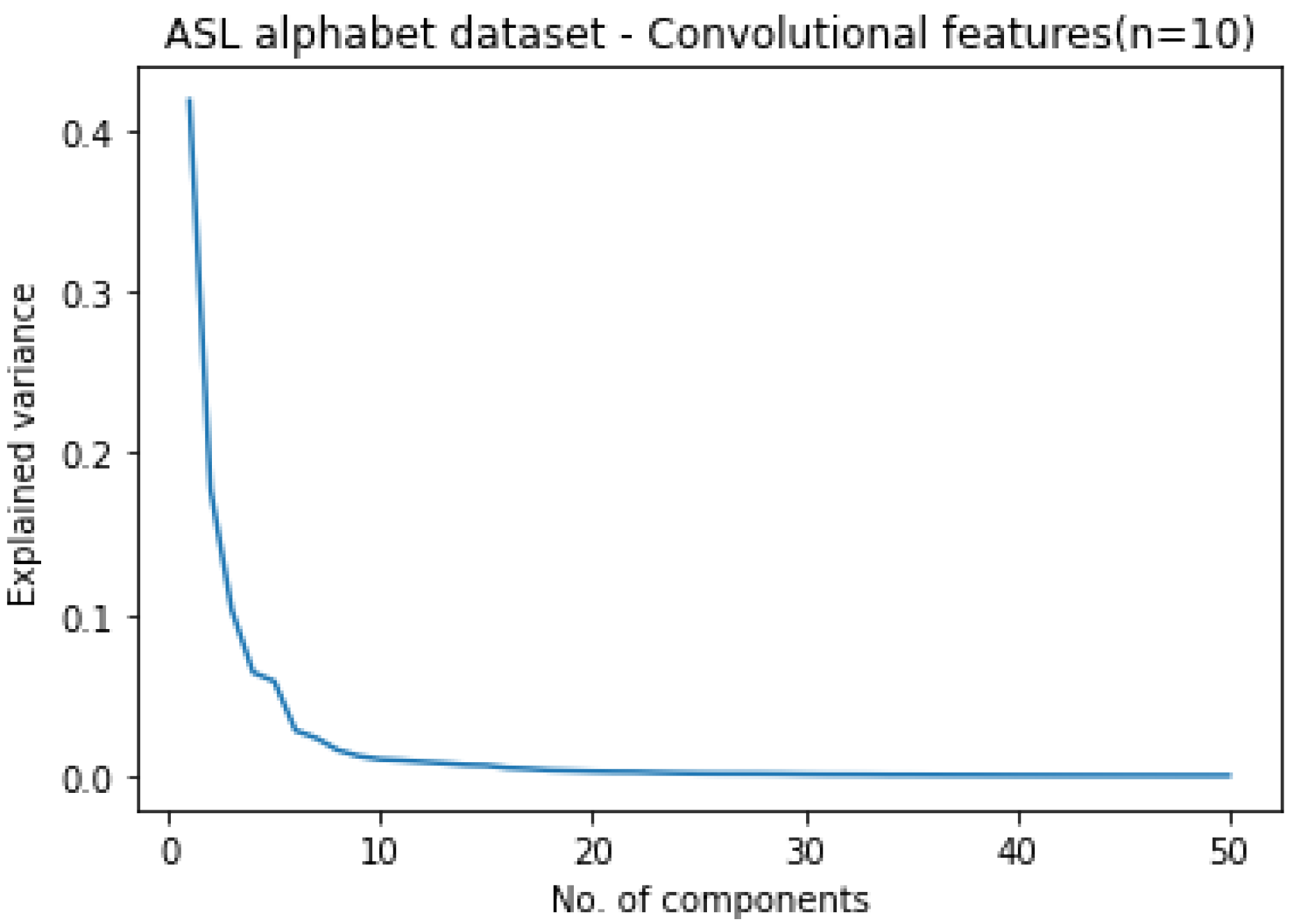
| Convolutional features | 10 | 10 | 10 | 10 | 10 | 5 |
| Convolutional features + finger angles | 10 | 10 | 10 | 10 | 10 | 5 |
| CNN features on hand edges | 15 | 5 | 15 | 10 | 20 | 5 |
| CNN features on BRISK | 15 | 15 | 15 | 10 | 15 | 15 |
| ASL Alphabet | ASL Finger-Spelling Dataset | Cambridge Hand Gesture Dataset | NUS I Dataset | NUS II Dataset | ISL Digits | |
|---|---|---|---|---|---|---|
| Hand coordinates + Random Forest | 98.063% | 98.967% | 98.626% | 80.000% | 97.200% | 100.000% |
| Hand coordinates + XGBoost | 98.647% | 99.136% | 98.789% | 80.000% | 97.200% | 99.602% |
| Convolutional features + PCA + Random Forest | 97.188% (n = 10) | 96.663% (n = 60) | 99.549% (n = 10) | 56.000% (n = 20) | 68.000% (n = 50) | 98.000% (n = 5) |
| Convolutional features + PCA + XGBoost | 93.847% (n = 10) | 96.556% (n = 60) | 96.669% (n = 10) | 52.000% (n = 10) | 68.800% (n = 50) | 96.000% (n = 5) |
| Convolutional features + finger angles + PCA + Random Forest | 96.806% (n = 10) | 96.391% (n = 60) | 99.243% (n = 10) | 60.000% (n = 20) | 71.200% (n = 40) | 96.016% (n = 5) |
| Convolutional features + finger angles + PCA + XGBoost | 93.901% (n = 10) | 96.121% (n = 60) | 96.711% (n = 10) | 52.000% (n = 20) | 64.000% (n = 40) | 95.219% (n = 5) |
| CNN features on hand edges + PCA + Random Forest | 95.306% (n = 60) | 90.901% (n = 60) | 99.565% (n = 15) | 52.000% (n = 20) | 65.600% (n = 50) | 98.800% (n = 5) |
| CNN features on hand edges + PCA + XGBoost | 93.729% (n = 60) | 90.422% (n = 60) | 99.391% (n = 15) | 56.000% (n = 20) | 66.400% (n = 50) | 98.800% (n = 5) |
| CNN features on BRISK + PCA + Random Forest | 88.993% (n = 60) | 79.506% (n = 15) | 98.093% (n = 15) | 64.000 (n = 20) | 49.200% (n = 15) | 96.400% (n = 15) |
| CNN features on BRISK + PCA + XGBoost | 86.229% (n = 60) | 78.449% (n = 60) | 92.807% (n = 15) | 60.000% (n = 10) | 40.400% (n = 50) | 96.000% (n = 15) |
| ISL Digits | Cambridge Hand Gesture Dataset | ASL Alphabet | ASL Finger-Spelling Dataset |
|---|---|---|---|
| 100.000% | 99.533% | 95.368% | 96.883% |
| NUS I Dataset (Batch Size = 5) | NUS II Dataset (Batch Size = 16) |
|---|---|
| 80.000% | 90.800% |
| User A | User B | User C | User D | User E | Average Accuracy | |
|---|---|---|---|---|---|---|
| Hand coordinates + Random Forest | 85.472% | 85.695% | 93.436% | 85.588% | 92.222% | 88.483% |
| Hand coordinates + XGBoost | 87.916% | 88.780% | 94.789% | 87.276% | 92.387% | 90.230% |
| Hand coordinates + ANN | 92.611% | 90.687% | 95.028% | 91.689% | 92.676% | 92.538% |
| Paper | Dataset | Test Size | Paper Technique | Proposed Technique |
|---|---|---|---|---|
| Sagayam, K.M. et al. [6] | Cambridge hand gesture dataset | 20% | 96.66% (CNN Classification) |
|
| ||||
| ||||
| Aly, W. et al. [8] | ASL finger-spelling dataset | leave-one-out-accuracy |
|
|
|
| |||
| Gangrade, J. [13] | Self-generated ISL digits | 250 |
|
|
|
| |||
| ||||
| ||||
| NUS I dataset | 25 |
|
| |
|
| |||
| ||||
| NUS II dataset | 250 |
|
| |
|
| |||
|
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jana, A.; Krishnakumar, S.S. Sign Language Gesture Recognition with Convolutional-Type Features on Ensemble Classifiers and Hybrid Artificial Neural Network. Appl. Sci. 2022, 12, 7303. https://doi.org/10.3390/app12147303
Jana A, Krishnakumar SS. Sign Language Gesture Recognition with Convolutional-Type Features on Ensemble Classifiers and Hybrid Artificial Neural Network. Applied Sciences. 2022; 12(14):7303. https://doi.org/10.3390/app12147303
Chicago/Turabian StyleJana, Ayanabha, and Shridevi S. Krishnakumar. 2022. "Sign Language Gesture Recognition with Convolutional-Type Features on Ensemble Classifiers and Hybrid Artificial Neural Network" Applied Sciences 12, no. 14: 7303. https://doi.org/10.3390/app12147303
APA StyleJana, A., & Krishnakumar, S. S. (2022). Sign Language Gesture Recognition with Convolutional-Type Features on Ensemble Classifiers and Hybrid Artificial Neural Network. Applied Sciences, 12(14), 7303. https://doi.org/10.3390/app12147303