
An FPGA Based Energy Efficient DS-SLAM Accelerator for Mobile Robots in Dynamic Environment


 ,
,  and
and 
Abstract
1. Introduction
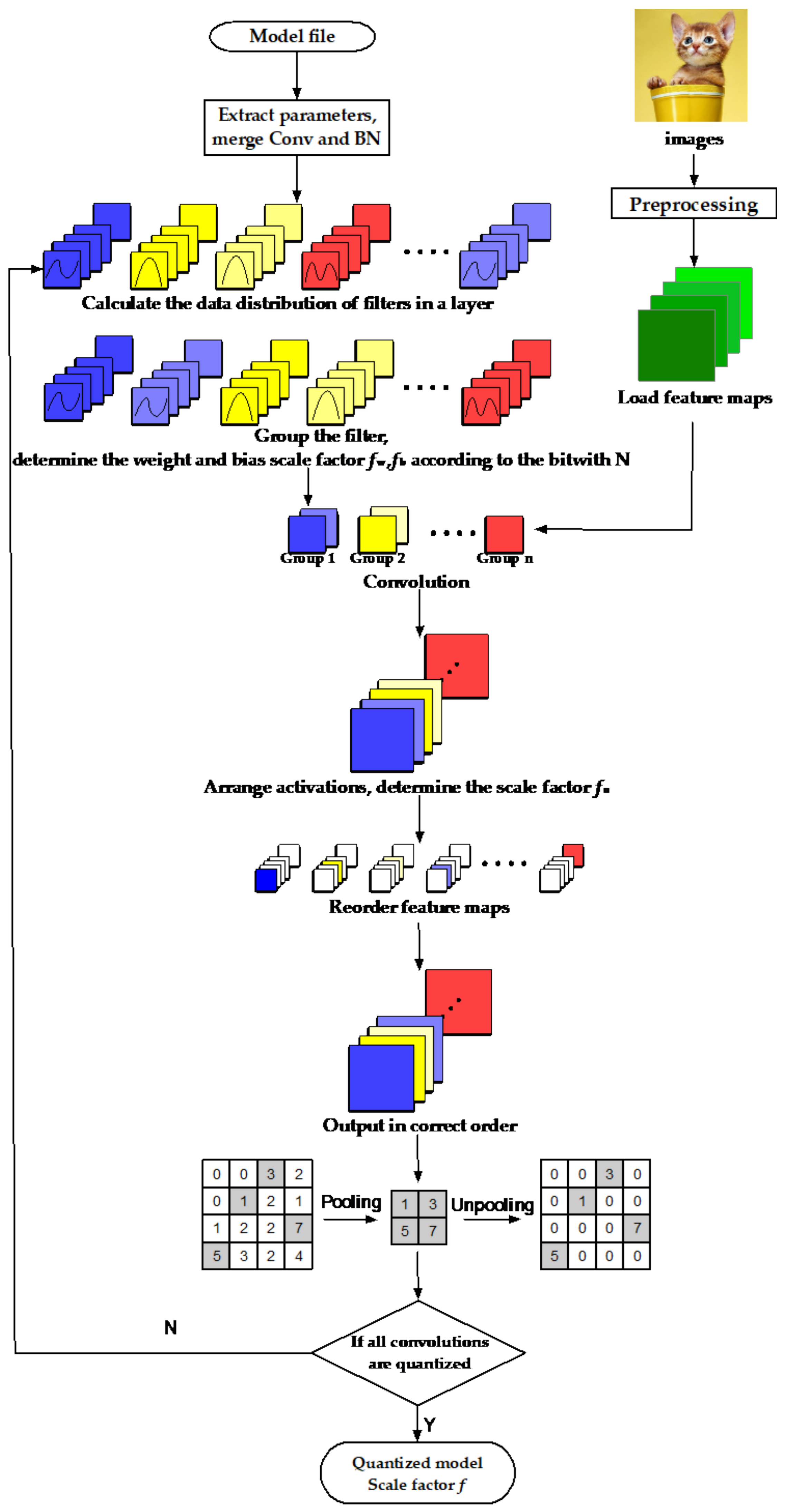
- The quantization strategy of combining convolution and batch normalization into one operation and grouping convolution filters with different data distribution is proposed to solve the problem of the large model and long execution time of a semantic segmentation network.
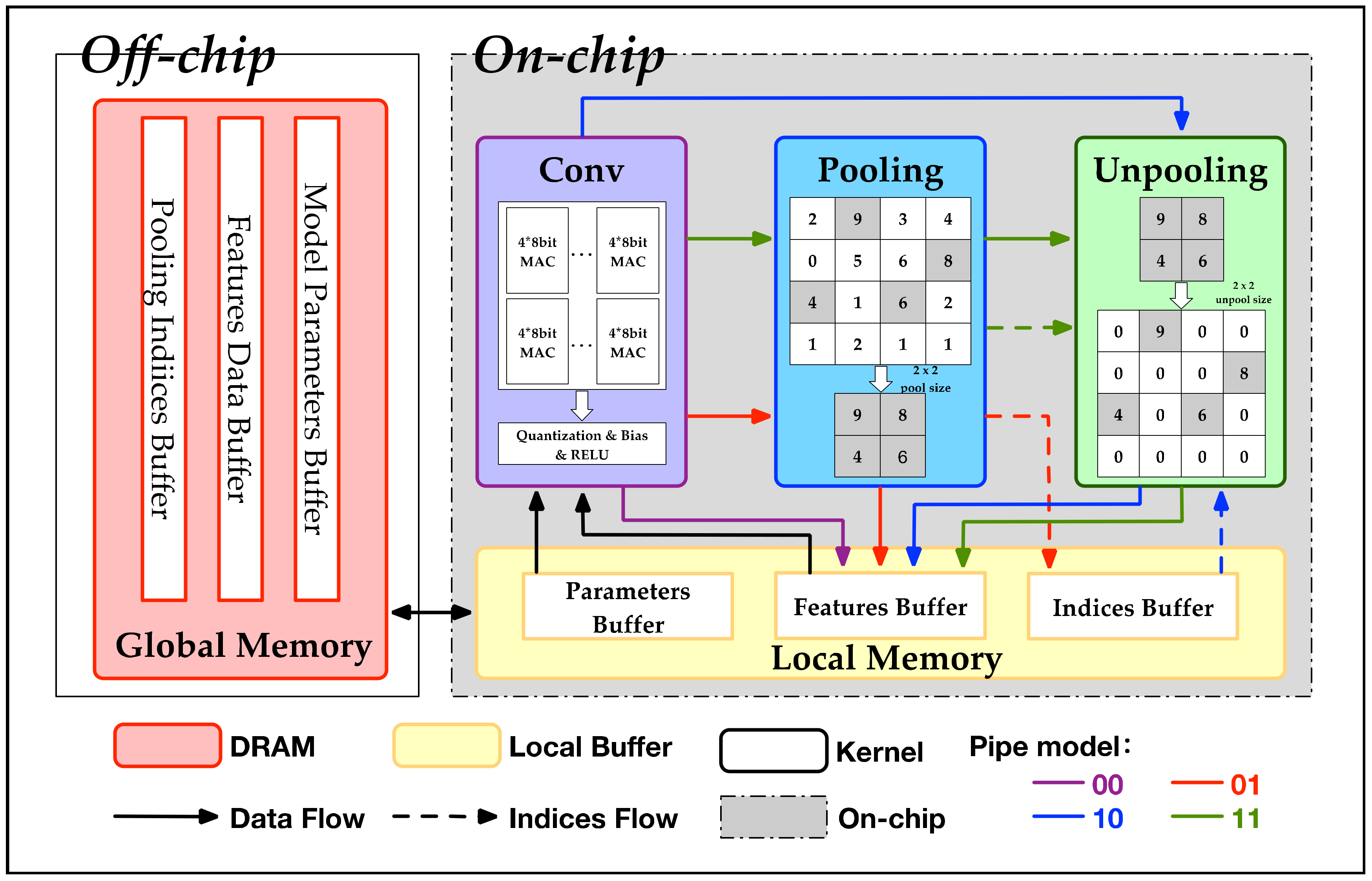
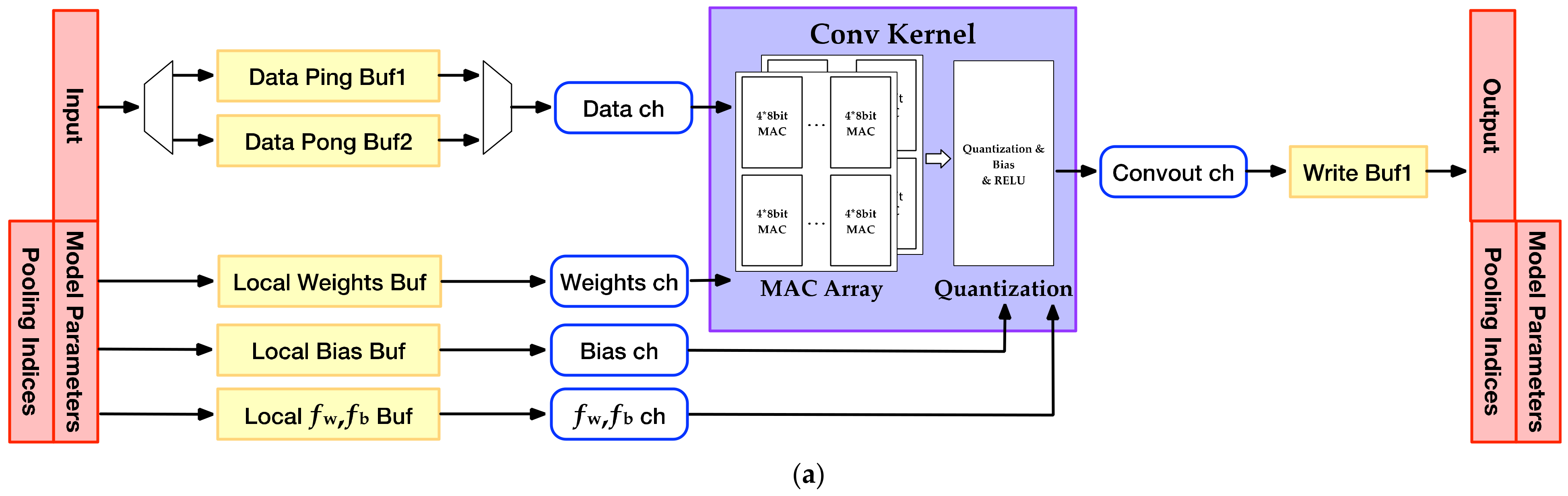
- A function configurable pipeline design method and a multi-level memory access optimization scheme for the convolutional Encoder-Decoder architecture of semantic segmentation networks is put forward.
- The high energy-efficient hardware acceleration solution of the DS-SLAM algorithm on a heterogeneous computing platform is proposed, which can be utilized for the functional module to provide mobile robots with autonomous localization.
2. Related Work
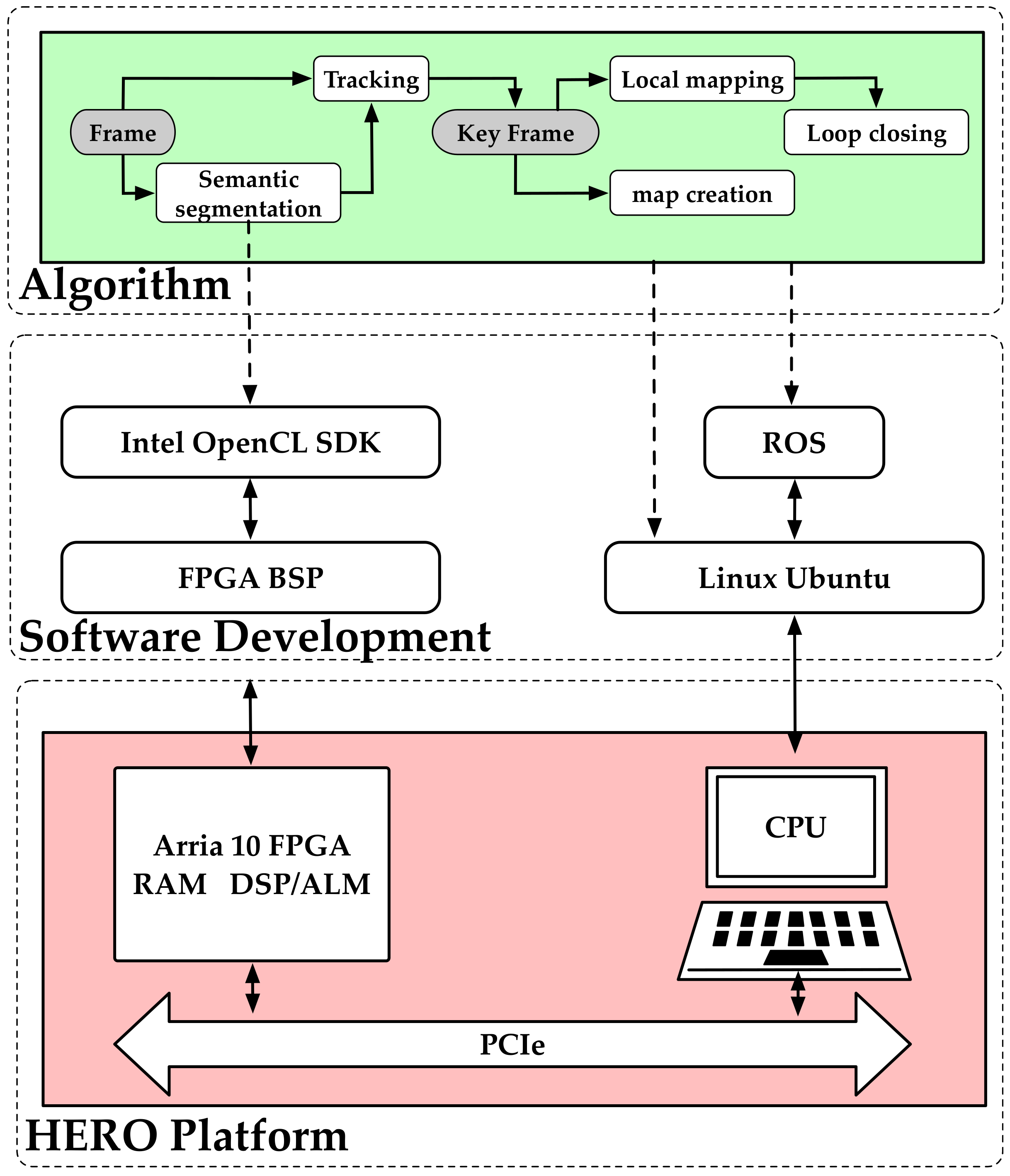
3. Algorithm Implementation
3.1. DS-SLAM Overview
3.2. Quantization Strategy
4. Proposed Method
4.1. Arria 10 FPGA Description
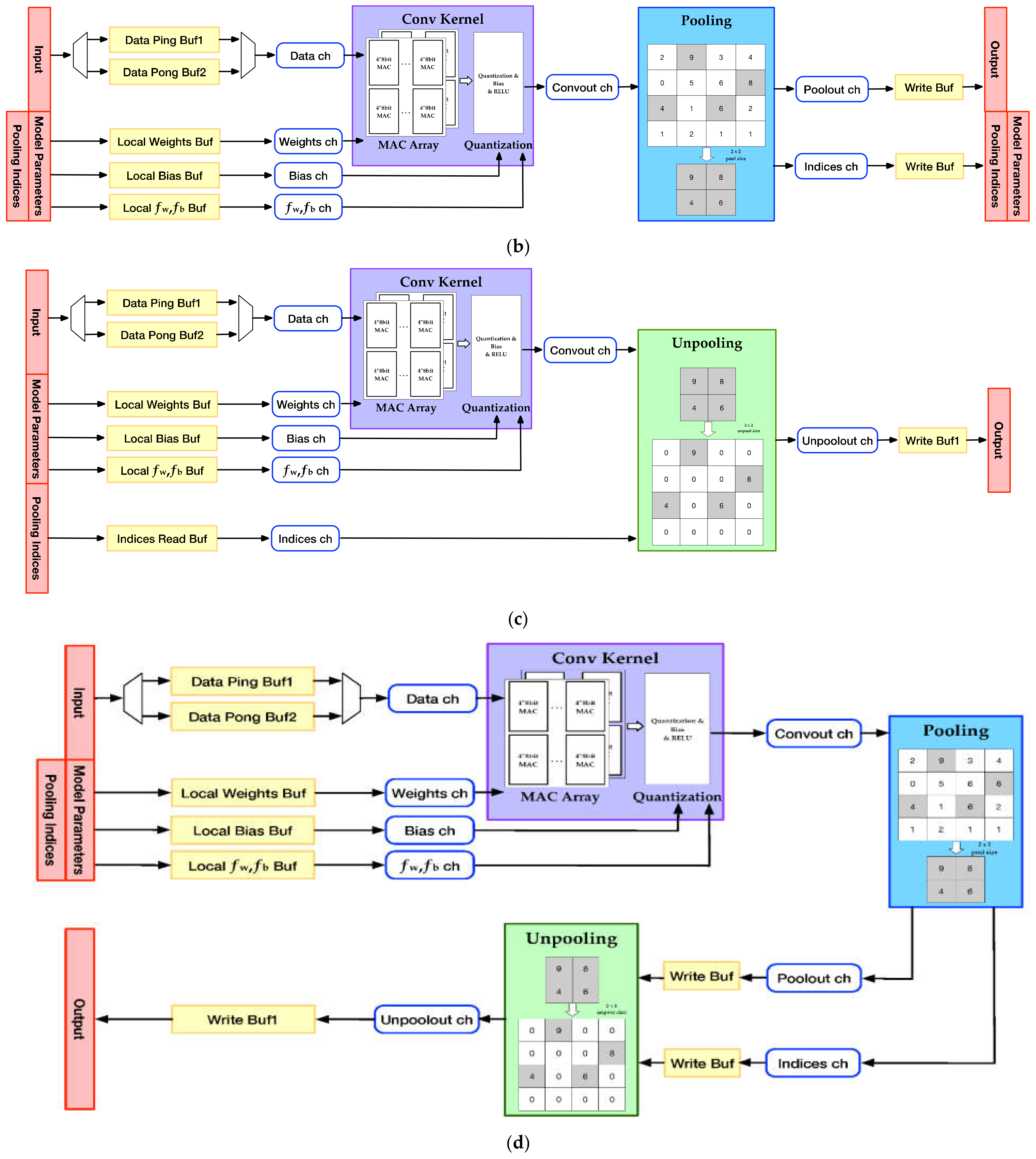
4.2. Accelerator Architecture
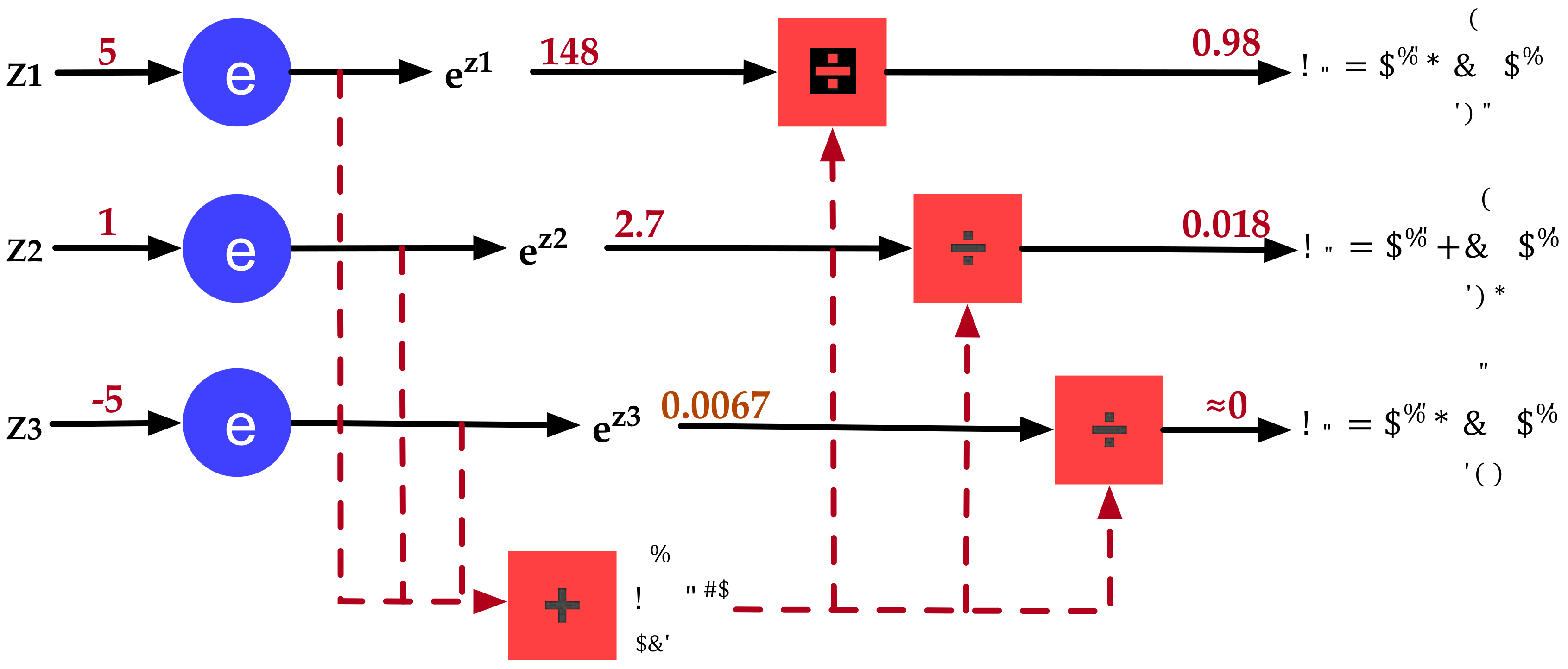
4.3. Softmax Optimization
5. Experimental Results
5.1. HERO Platform Description
5.2. Performance Evaluation
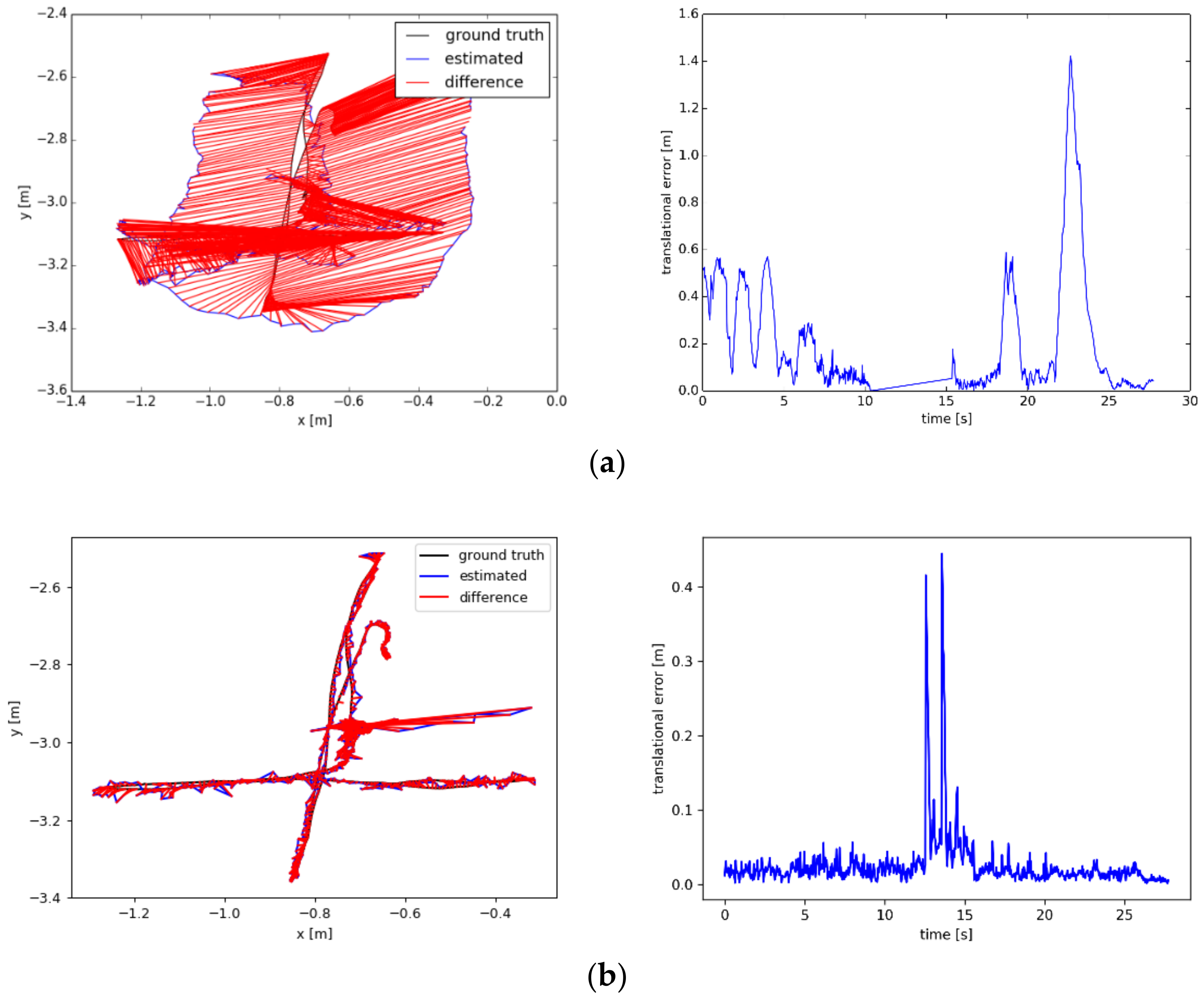
5.3. Accuracy Analysis
6. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Song, S.; Choi, D.; Hur, J.; Lee, M.; Park, Y.J.; Kim, J. Development and application of Mobile Robot system for Marking Process in LNGC cargo tanks. In Proceedings of the 2009 ICCAS-SICE, Fukuoka, Japan, 18–21 August 2009; pp. 2636–2638. [Google Scholar]
- Saitoh, M.; Takahashi, Y.; Sankaranarayanan, A.; Ohmachi, H.; Marukawa, K. A mobile robot testbed with manipulator for security guard application. In Proceedings of the 1995 IEEE International Conference on Robotics and Automation, Nagoya, Japan, 21–27 May 2002; Volume 3, pp. 2518–2523. [Google Scholar]
- Murphy, R. Human–Robot Interaction in Rescue Robotics. IEEE Trans. Syst. Man. Cybern. Part C Appl. Rev. 2004, 34, 138–153. [Google Scholar] [CrossRef]
- Dunbabin, M.; Marques, L. Robots for Environmental Monitoring: Significant Advancements and Applications. IEEE Robot. Autom. Mag. 2012, 19, 24–39. [Google Scholar] [CrossRef]
- Bapna, D.; Rollins, E.; Murphy, J.; Maimone, E.; Whittaker, W.; Wettergreen, D. The Atacama Desert Trek: Outcomes. In Proceedings of the 1998 IEEE International Conference on Robotics and Automation (Cat. No. 98CH36146), Leuven, Belgium, 20 May 2002; Volume 1, pp. 597–604. [Google Scholar]
- Rollins, E.; Luntz, J.; Foessel, A.; Shamah, B.; Whittaker, W. Nomad: A Demonstration of the Transforming Chassis. In Proceedings of the IEEE International Conference on Robotics and Automation, Leuven, Belgium, 20 May 1998; pp. 611–617. [Google Scholar]
- Kimon, P.V. Classification of UAVs. In Handbook of Unmanned Aerial Vehicles; Kimon, P.V., George, J.V., Eds.; Springer: Dordrecht, The Netherlands, 2015. [Google Scholar]
- Mei, Y.; Lu, Y.H.; Hu, Y.C. A case study of mobile robot’s energy consumption and conservation techniques. In Proceedings of the International Conference on Advanced Robotics, Seattle, WA, USA, 18–20 July 2005. [Google Scholar]
- Yu, C.; Liu, Z.; Liu, X. Ds-slam: A semantic visual slam towards dynamic environments. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 1168–1174. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Mur-Artal, R.; Tardos, J.D. Orb-slam2: An open-source slam system for monocular, stereo and rgb-d cameras. IEEE Trans. Robot. 2017, 33, 1255–1262. [Google Scholar] [CrossRef]
- Zhang, C.; Li, P.; Sun, G. Optimizing FPGA-based Accelerator Design for Deep Convolutional Neural Networks. In Proceedings of the ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, Monterey, CA, USA, 22–24 February 2015; pp. 161–170. [Google Scholar]
- Qiu, J.; Wang, J.; Yao, S. Going Deeper with Embedded FPGA Platform for Convolutional Neural Network. In Proceedings of the ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, Monterey, CA, USA, 21–23 February 2016; pp. 26–35. [Google Scholar]
- Khronos Group. OpenCL-The Open Standard for Parallel Programming of Heterogeneous Systems. Available online: http://www.khronos.org/opencl (accessed on 10 December 2020).
- Shi, X.; Cao, L.; Wang, D. HERO: Accelerating Autonomous Robotic Tasks with FPGA. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018. [Google Scholar]
- Tertei, D.T.; Piat, J.; Devy, M. FPGA design of EKF block accelerator for 3D visual SLAM. Comput. Electr. Eng. 2016, 55, 123–137. [Google Scholar] [CrossRef]
- Boikos, K.; Bouganis, C.-S. Semi-dense SLAM on an FPGA SoC. In Proceedings of the 2016 26th International Conference on Field Programmable Logic and Applications (FPL), Lausanne, Switzerland, 29 August–2 September 2016; pp. 1–4. [Google Scholar]
- Abouzahir, M.; Elouardi, A.; Latif, R.; Bouaziz, S.; Tajer, A. Embedding SLAM algorithms: Has it come of age? Robot. Auton. Syst. 2018, 100, 14–26. [Google Scholar] [CrossRef]
- Liu, R.; Yang, J. Eslam: An energy-efficient accelerator for realtime orb-slam on fpga platform. In DAC; ACM: New York, NY, USA, 2019; p. 193. [Google Scholar]
- Han, S.; Mao, H.; Dally, W.J. Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman coding. arXiv 2015, arXiv:1510.00149. [Google Scholar]
- Everingham, M.; Eslami SM, A.; Van Gool, L. The pascal visual object classes challenge: A retrospective. Int. J. Comput. Vis. 2015, 111, 98–136. [Google Scholar] [CrossRef]
- Intel Corporation. Intel Arria 10 Device Overview. Available online: https://www.intel.com/content/www/us/en/programmable/documentation/sam1403480274650.html (accessed on 10 December 2020).
- Yu, M.; Huang, H.; Liu, H.; He, S.; Qiao, F.; Luo, L.; Xie, F.; Liu, X.-J.; Yang, H. Optimizing FPGA-based Convolutional Encoder-Decoder Architecture for Semantic Segmentation. In Proceedings of the 2019 IEEE 9th Annual International Conference on CYBER Technology in Automation, Control, and Intelligent Systems (CYBER), Guangzhou, China, 29 July–2 August 2019; pp. 1436–1440. [Google Scholar]
- Huang, H. EDSSA: An Encoder-Decoder Semantic Segmentation Networks Accelerator on OpenCL-Based FPGA Platform. Sensors 2020, 20, 3969. [Google Scholar] [CrossRef] [PubMed]
- Sturm, J.; Engelhard, N.; Endres, F. A benchmark for the evaluation of rgb-d slam systems. In Proceedings of the 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, Vilamoura-Algarve, Portugal, 7–12 October 2012; pp. 573–580. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Module | ORB Feature Extraction | Moving Consistency Check | Semantic Segmentation | |
|---|---|---|---|---|
| Thread | Tracking | Tracking | Semantic segmentation | |
| Platform | Intel Core i7-6800K CPU | Intel Core i7-6800K CPU | Intel Core i7-8750H CPU | NVIDIA Quadro P4000 GPU |
| Time (ms) | 9.37 | 29.5 | 2582 | 37.6 |
| ALMS | Registers | M20Ks | DSPs | |
|---|---|---|---|---|
| Utilization | 24% | 12% | 63% | 100% |
| Software Implementations | Our Work | Improvements (vs. CPU) | ||
|---|---|---|---|---|
| Platform | i7-8750H CPU | i7-6800K CPU + P4000 GPU | HERO | - |
| Power | 45W | 245 W | 35 W | 22.2% |
| Execution time of semantic segmentation | 2582 ms | 37.6 ms | 155 ms | 94.0% |
| Execution time of the whole DS-SLAM | 2600 ms | 59.4 ms | 190 ms | 92.7% |
| Frame rate | 0.38 fps | 16.8 fps | 5.3 fps | 13× |
| Energy efficiency | 0.008 fps/W | 0.068 fps/W | 0.151 fps/W | 18× |
| Sequences | ORB-SLAM2 | DS-SLAM | Our Work | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| RMSE | Mean | Median | S.D. | RMSE | Mean | Median | S.D. | RMSE | Mean | Median | S.D. | |
| Fr3_walking_xyz | 0.7521 | 0.6492 | 0.5857 | 0.3759 | 0.0247 | 0.0186 | 0.0151 | 0.0161 | 0.0316 | 0.0176 | 0.0129 | 0.0262 |
| Fr3_walking_static | 0.3900 | 0.3554 | 0.3087 | 0.1602 | 0.0081 | 0.0073 | 0.0067 | 0.0036 | 0.0078 | 0.0069 | 0.0063 | 0.0035 |
| Fr3_walking_rpy | 0.8705 | 0.7425 | 0.7059 | 0.4520 | 0.4442 | 0.3768 | 0.2835 | 0.2350 | 0.5031 | 0.4276 | 0.3066 | 0.2646 |
| Fr3_walking_half | 0.4863 | 0.4272 | 0.3964 | 0.2290 | 0.0303 | 0.0258 | 0.0222 | 0.0159 | 0.0292 | 0.0250 | 0.0214 | 0.0151 |
| Fr3_sitting_static | 0.0087 | 0.0076 | 0.0066 | 0.0043 | 0.0065 | 0.0055 | 0.0049 | 0.0033 | 0.0060 | 0.0052 | 0.0046 | 0.0030 |
| Sequences | ORB-SLAM2 | DS-SLAM | Our Work | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| RMSE | Mean | Median | S.D. | RMSE | Mean | Median | S.D. | RMSE | Mean | Median | S.D. | |
| Fr3_walking_xyz | 0.4124 | 0.3110 | 0.2465 | 0.2684 | 0.0333 | 0.0238 | 0.0181 | 0.0229 | 0.0459 | 0.0275 | 0.0198 | 0.0367 |
| Fr3_walking_static | 0.2162 | 0.0905 | 0.0155 | 0.1962 | 0.0102 | 0.0091 | 0.0082 | 0.0048 | 0.0115 | 0.0104 | 0.0099 | 0.0048 |
| Fr3_walking_rpy | 0.4249 | 0.2825 | 0.1487 | 0.3166 | 0.1503 | 0.0942 | 0.0457 | 0.1168 | 0.1903 | 0.1076 | 0.0436 | 0.1570 |
| Fr3_walking_half | 0.3550 | 0.2161 | 0.0774 | 0.2810 | 0.0297 | 0.0256 | 0.0226 | 0.0152 | 0.0414 | 0.0363 | 0.0335 | 0.0198 |
| Fr3_sitting_static | 0.0095 | 0.0083 | 0.0073 | 0.0046 | 0.0078 | 0.0068 | 0.0061 | 0.0038 | 0.0089 | 0.0079 | 0.0071 | 0.0042 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, Y.; Luo, L.; Yin, S.; Yu, M.; Qiao, F.; Huang, H.; Shi, X.; Wei, Q.; Liu, X. An FPGA Based Energy Efficient DS-SLAM Accelerator for Mobile Robots in Dynamic Environment. Appl. Sci. 2021, 11, 1828. https://doi.org/10.3390/app11041828
Wu Y, Luo L, Yin S, Yu M, Qiao F, Huang H, Shi X, Wei Q, Liu X. An FPGA Based Energy Efficient DS-SLAM Accelerator for Mobile Robots in Dynamic Environment. Applied Sciences. 2021; 11(4):1828. https://doi.org/10.3390/app11041828
Chicago/Turabian StyleWu, Yakun, Li Luo, Shujuan Yin, Mengqi Yu, Fei Qiao, Hongzhi Huang, Xuesong Shi, Qi Wei, and Xinjun Liu. 2021. "An FPGA Based Energy Efficient DS-SLAM Accelerator for Mobile Robots in Dynamic Environment" Applied Sciences 11, no. 4: 1828. https://doi.org/10.3390/app11041828
APA StyleWu, Y., Luo, L., Yin, S., Yu, M., Qiao, F., Huang, H., Shi, X., Wei, Q., & Liu, X. (2021). An FPGA Based Energy Efficient DS-SLAM Accelerator for Mobile Robots in Dynamic Environment. Applied Sciences, 11(4), 1828. https://doi.org/10.3390/app11041828