Self-Attention Network for Human Pose Estimation

Abstract
:1. Introduction
- (1)
- We propose a simple yet surprisingly effective self-attention approach (SAN) which exploits long-range dependency between feature maps. It can increase representation power and performance of convolution operators.
- (2)
- We design a joint learning framework to enable usage of mixed 2D and 3D data such that the model can output both 2D and 3D poses and enhance generalization. As a by-product, our approach generates high quality 3D poses for images in the wild.
- (3)
2. Related Work
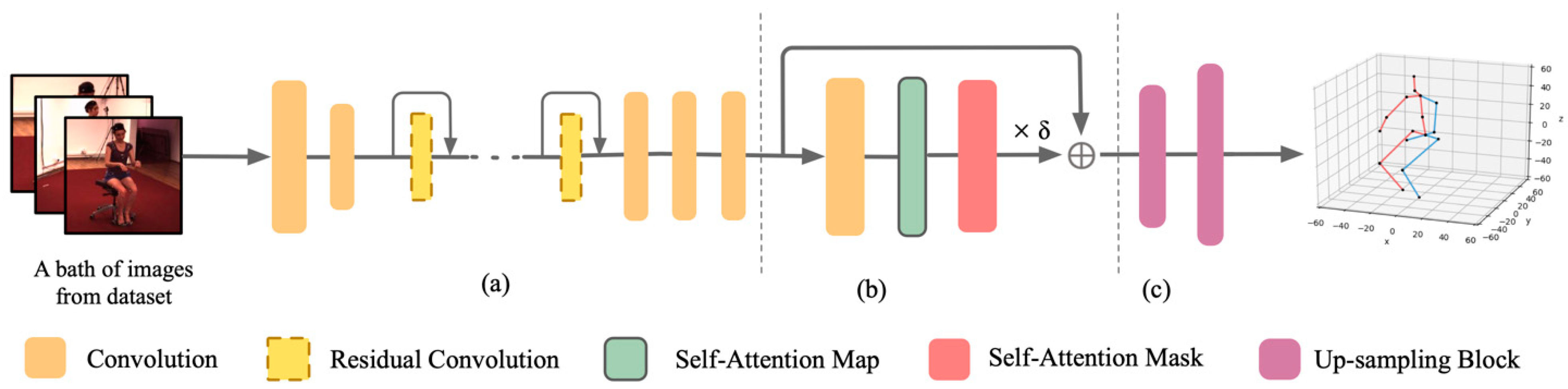
3. Model Architecture
3.1. Overview
3.2. Backbone and Upsampling Block Design
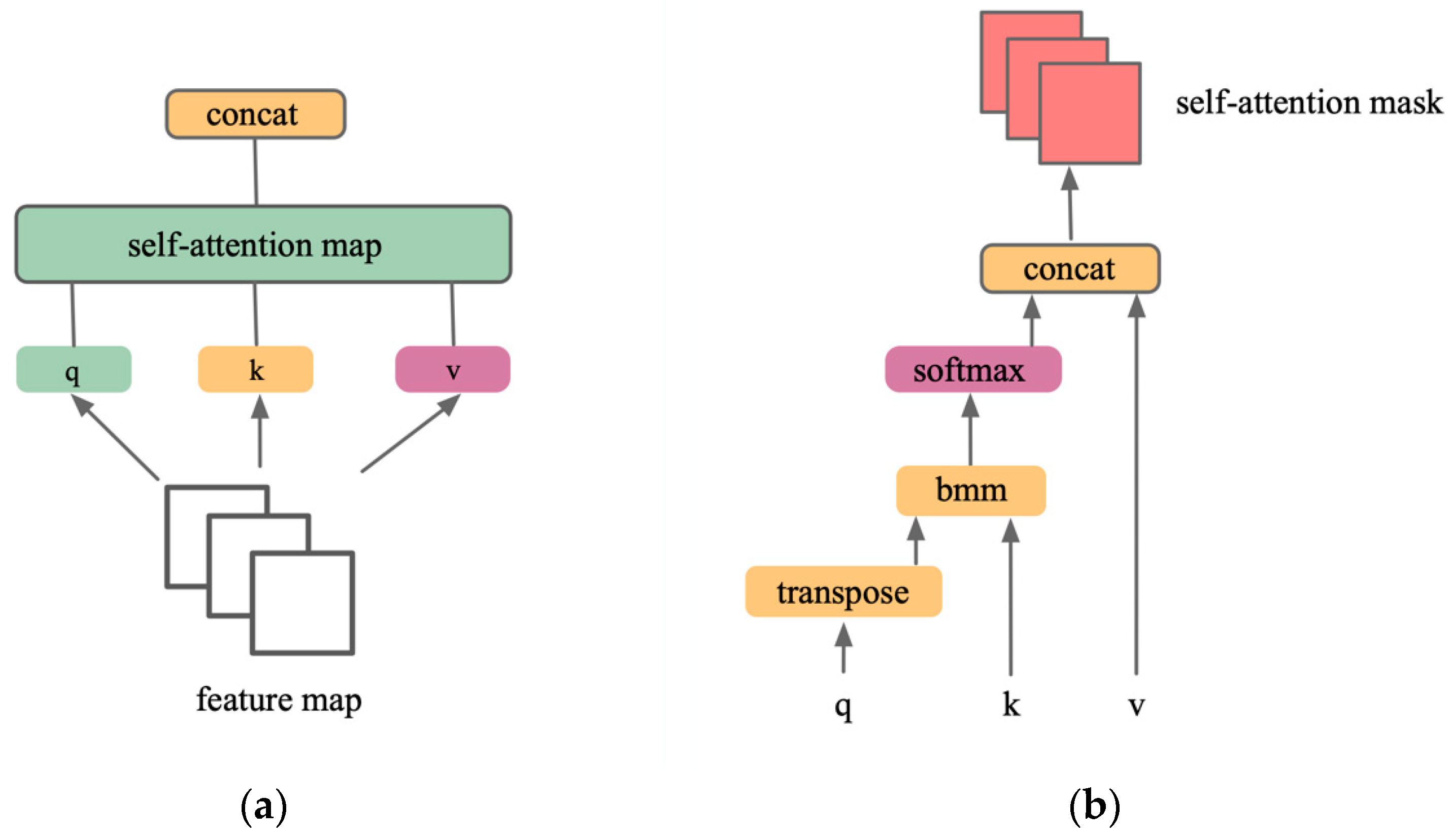
3.3. Self-Attention Network Design
3.4. Joint Learning for 2D and 3D Data
3.5. Training and Data Processing
4. Experiment
4.1. Dataset and Evaluation Metrics
4.2. Experiments on 3D Pose of Human3.6M
4.2.1. Ablation Study

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| (a) Protocol#1: reconstruction error (MPJPE). | ||||||||||||||||
| Protocol#1 | Direct. | Discuss | Eating | Greet | Phone | Pose | Purch. | Sitting | SittingD. | Smoke | Photo | Wait. | Walk | WalkD. | WalkT. | Avg. |
| CoarseToFine [17] | 67.4 | 71.9 | 66.7 | 69.1 | 72.0 | 65.0 | 68.3 | 83.7 | 96.5 | 71.7 | 77.0 | 65.8 | 59.1 | 74.9 | 63.2 | 71.9 |
| Zhou et al. [20] | 54.8 | 60.7 | 58.2 | 71.4 | 62.0 | 53.8 | 55.6 | 75.2 | 111.6 | 64.2 | 65.5 | 66.1 | 63.2 | 51.4 | 55.3 | 64.9 |
| Fang et al. [26] | 50.1 | 54.3 | 57.0 | 57.1 | 66.6 | 53.4 | 55.7 | 72.8 | 88.6 | 60.3 | 73.3 | 57.7 | 47.5 | 62.7 | 50.6 | 60.4 |
| CompositionalHP [15] | 52.8 | 54.8 | 54.2 | 54.3 | 61.8 | 53.6 | 71.7 | 86.7 | 61.5 | 67.2 | 53.1 | 53.4 | 61.6 | 47.1 | 53.4 | 59.1 |
| SemanticGCN [16] | 47.3 | 60.7 | 51.4 | 60.5 | 61.1 | 47.3 | 68.1 | 86.2 | 55.0 | 67.8 | 49.9 | 61.0 | 60.6 | 42.1 | 45.3 | 57.6 |
| RepNet+T+M [27] | 49.1 | 63.3 | 48.6 | 56.0 | 57.4 | 50.4 | 62.0 | 75.4 | 77.4 | 57.2 | 69.9 | 53.5 | 57.7 | 37.6 | 38.1 | 56.9 |
| Propagating-LSTM [28] | 43.8 | 51.7 | 48.8 | 53.1 | 52.2 | 52.7 | 44.6 | 56.9 | 74.3 | 56.7 | 74.9 | 66.4 | 47.5 | 68.4 | 45.5 | 55.8 |
| Habibie et al. [19] | 46.1 | 51.3 | 46.8 | 51.0 | 55.9 | 43.9 | 48.8 | 65.8 | 81.6 | 52.2 | 59.7 | 51.1 | 40.8 | 54.8 | 45.2 | 53.4 |
| Ci et al. [18] | 46.8 | 38.8 | 44.7 | 50.4 | 52.9 | 49.6 | 46.4 | 60.2 | 78.9 | 51.2 | 68.9 | 50.0 | 40.4 | 54.8 | 43.3 | 52.7 |
| Li et al. [29] | 43.8 | 48.6 | 49.1 | 49.8 | 57.6 | 45.9 | 48.3 | 62.0 | 73.4 | 54.8 | 61.5 | 50.6 | 43.4 | 56.0 | 45.5 | 52.7 |
| Pavllo et al. [30] | 47.1 | 50.6 | 49.0 | 51.8 | 53.6 | 49.4 | 47.4 | 59.3 | 67.4 | 52.4 | 61.4 | 49.5 | 39.5 | 55.3 | 42.7 | 51.8 |
| Guo et al. [31] | 43.4 | 50.2 | 48.5 | 43.0 | 50.6 | 52.4 | 63.8 | 81.1 | 43.5 | 61.4 | 45.2 | 43.7 | 55.1 | 36.9 | 43.5 | 51.8 |
| IntegralHP [7] | 47.5 | 47.7 | 49.5 | 50.2 | 51.4 | 43.8 | 46.4 | 58.9 | 65.7 | 49.4 | 55.8 | 47.8 | 38.9 | 49.0 | 43.8 | 49.6 |
| Ours | 43.7 | 44.0 | 47.8 | 48.4 | 50.2 | 43.4 | 46.0 | 55.0 | 70.9 | 47.2 | 52.9 | 44.9 | 39.4 | 50.6 | 44.1 | 48.6 |
| (b) Protocol#2: reconstruction error after rigid alignment with the ground truth (PA-MPJPE), where available. | ||||||||||||||||
| Protocol#2 | Direct. | Discuss | Eating | Greet | Phone | Pose | Purch. | Sitting | SittingD. | Smoke | Photo | Wait. | Walk | WalkD. | WalkT. | Avg. |
| Wandt et al. [32] | 53.0 | 58.3 | 59.6 | 66.5 | 72.8 | 56.7 | 69.6 | 78.3 | 95.2 | 66.6 | 71.0 | 58.5 | 63.2 | 57.5 | 49.9 | 65.1 |
| Guo et al. [31] | 37.8 | 38.9 | 49.7 | 44.7 | 47.3 | 38.9 | 58.5 | 83.6 | 52.1 | 62.6 | 40.0 | 43.2 | 54.2 | 34.5 | 39.6 | 48.8 |
| CompositionalHP [15] | 42.1 | 44.3 | 45.0 | 45.4 | 51.5 | 43.2 | 41.3 | 59.3 | 73.3 | 51.0 | 53.0 | 44.0 | 38.3 | 48.0 | 44.8 | 48.3 |
| Fang et al. [26] | 38.2 | 41.7 | 43.7 | 44.9 | 48.5 | 40.2 | 38.2 | 56.5 | 64.4 | 47.2 | 55.3 | 44.3 | 36.7 | 49.5 | 41.7 | 45.7 |
| Propagating-LSTM [28] | 37.4 | 38.9 | 45.6 | 42.6 | 48.5 | 39.9 | 39.2 | 53.0 | 68.5 | 51,5 | 54.6 | 38.4 | 33.2 | 55.8 | 37.8 | 45.7 |
| Hossian et al. [33] | 35.7 | 39.3 | 44.6 | 43.0 | 47.2 | 38.3 | 37.5 | 51.6 | 61.3 | 46.5 | 54.0 | 41.4 | 34.2 | 47.3 | 39.4 | 44.1 |
| Li et al. [29] | 35.5 | 39.8 | 41.3 | 42.3 | 46.0 | 36.9 | 37.3 | 51.0 | 60.6 | 44.9 | 48.9 | 40.2 | 33.1 | 44.1 | 36.9 | 42.6 |
| Pavlakos [34] | 34.7 | 39.8 | 41.8 | 38.6 | 42.5 | 38.0 | 36.6 | 50.7 | 56.8 | 42.6 | 47.5 | 39.6 | 32.1 | 43.9 | 39.5 | 41.8 |
| Ours | 39.7 | 38.7 | 43.8 | 42.2 | 43.3 | 38.5 | 42.1 | 50.6 | 65.9 | 42.2 | 46.1 | 39.8 | 33.3 | 44.1 | 38.8 | 40.6 |
4.2.2. Quantitative Results
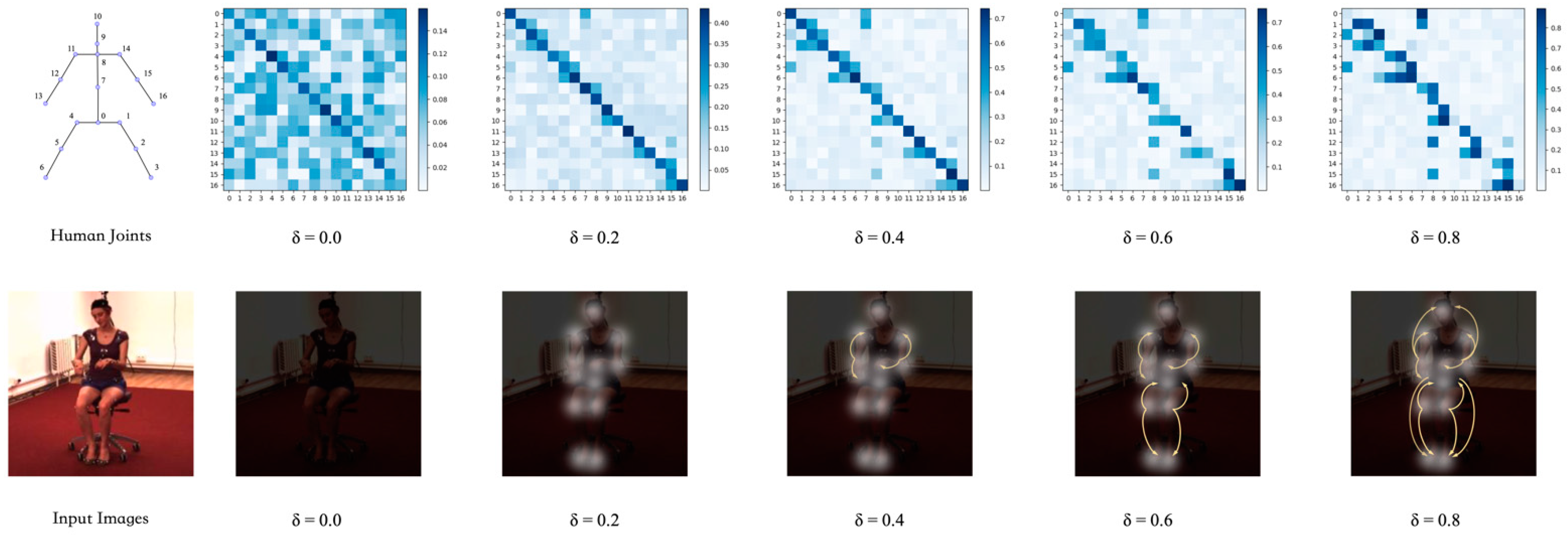
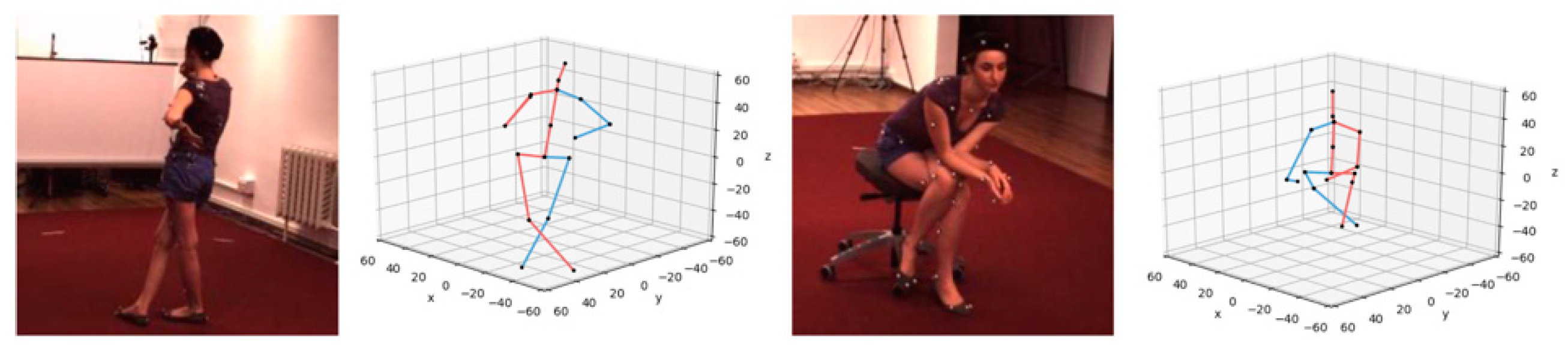
4.2.3. Qualitative Results
4.3. Experiment on 2D Pose of MPII and COCO
4.3.1. Quantitative Results
4.3.2. Qualitative Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Li, B.; Dai, Y.; Cheng, X.; Chen, H.; Lin, Y.; He, M. Skeleton based action recognition using translation-scale invariant image mapping and multi-scale deep CNN. In Proceedings of the 2017 IEEE International Conference on Multimedia & Expo Workshops (ICMEW), Hong Kong, China, 10–14 July 2017; pp. 601–604. [Google Scholar]
- Luvizon, D.C.; Picard, D.; Tabia, H. 2D/3D Pose Estimation and Action Recognition Using Multitask Deep Learning. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5137–5146. [Google Scholar]
- Li, B.; He, M.; Dai, Y.; Cheng, X.; Chen, Y. 3D skeleton based action recognition by video-domain translation-scale invariant mapping and multi-scale dilated CNN. Multimed. Tools Appl. 2018, 77, 22901–22921. [Google Scholar] [CrossRef]
- Li, B.; Chen, H.; Chen, Y.; Dai, Y.; He, M. Skeleton boxes: Solving skeleton based action detection with a single deep convo-lutional neural network. In Proceedings of the 2017 IEEE International Conference on Multimedia & Expo Workshops (ICMEW), Hong Kong, China, 10–14 July 2017; pp. 613–616. [Google Scholar]
- Insafutdinov, E.; Andriluka, M.; Pishchulin, L.; Tang, S.; Levinkov, E.; Andres, B.; Schiele, B. ArtTrack: Articulated Multi-Person Tracking in the Wild. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1293–1301. [Google Scholar]
- Chen, Y.; Tian, Y.; He, M. Monocular human pose estimation: A survey of deep learning-based methods. Comput. Vis. Image Underst. 2020, 192, 102897. [Google Scholar] [CrossRef]
- Sun, X.; Xiao, B.; Wei, F.; Liang, S.; Wei, Y. Integral Human Pose Regression. In Proceedings of the Constructive Side-Channel Analysis and Secure Design; Springer: Berlin/Heidelberg, Germany, 2018; pp. 536–553. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is All you Need. In Proceedings of the Conference and Workshop on Neural Information Processing Systems (NIPS), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Ionescu, C.; Papava, D.; Olaru, V.; Sminchisescu, C. Human3.6M: Large Scale Datasets and Predictive Methods for 3D Human Sensing in Natural Environments. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 1325–1339. [Google Scholar] [CrossRef] [PubMed]
- Andriluka, M.; Pishchulin, L.; Gehler, P.; Schiele, B. 2D Human Pose Estimation: New Benchmark and State of the Art Analysis. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 3686–3693. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common objects in context. In Computer Vision—ECCV ECCV Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2014; pp. 740–755. [Google Scholar]
- Newell, A.; Yang, K.; Deng, J. Stacked Hourglass Networks for Human Pose Estimation. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 11–14 October 2016; pp. 483–499. [Google Scholar]
- Chu, X.; Yang, W.; Ouyang, W.; Ma, C.; Yuille, A.L.; Wang, X. Multi-context Attention for Human Pose Estimation. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5669–5678. [Google Scholar]
- Sun, G.; Ye, C.; Wang, K. Focus on What’s Important: Self-Attention Model for Human Pose Estimation. arXiv 2018, arXiv:1809.08371. [Google Scholar]
- Sun, X.; Shang, J.; Liang, S.; Wei, Y. Compositional Human Pose Regression. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2621–2630. [Google Scholar]
- Zhao, L.; Peng, X.; Tian, Y.; Kapadia, M.; Metaxas, D.N. Semantic Graph Convolutional Networks for 3D Human Pose Re-gression. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 3425–3435. [Google Scholar]
- Pavlakos, G.; Zhou, X.; Derpanis, K.G.; Daniilidis, K. Coarse-to-Fine volumetric prediction for single-image 3d human pose. In Proceedings of the IEEE Proc. International Conference on Computer Vision and Pattern Recognition (CVPR), Venice, Italy, 21–26 July 2017; pp. 1263–1272. [Google Scholar]
- Ci, H.; Wang, C.; Ma, X.; Wang, Y. Optimizing Network Structure for 3D Human Pose Estimation. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 2262–2271. [Google Scholar]
- Habibie, I.; Xu, W.; Mehta, D.; Pons-Moll, G.; Theobalt, C. In the Wild Human Pose Estimation Using Explicit 2D Features and Intermediate 3D Representations. In Proceedings of the International Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 10905–10914. [Google Scholar]
- Zhou, X.; Huang, Q.X.; Sun, X.; Xue, X.; Wei, Y. Towards 3D Human Pose Estimation in the Wild: A Weakly-Supervised Ap-proach. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 398–407. [Google Scholar]
- Dabral, R.; Mundhada, A.; Kusupati, U.; Afaque, S.; Sharma, A.; Jain, A. Learning 3D Human Pose from Structure and Motion. In Proceedings of the Constructive Side-Channel Analysis and Secure Design; Springer: Berlin/Heidelberg, Germany, 2018; pp. 679–696. [Google Scholar]
- Ye, L.; Rochan, M.; Liu, Z.; Wang, Y. Cross-Modal Self-Attention Network for Referring Image Segmentation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 10494–10503. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. arXiv 2015, arXiv:1512.03385. [Google Scholar]
- Li, S.; Chan, A.B. 3d human pose estimation from monocular images with deep convolutional neural network. In Proceedings Asian Conference on Computer Vision (ACCV); Springer: Berlin/Heidelberg, Germany, 2014; pp. 332–347. [Google Scholar]
- Yao, Y.; Ren, J.; Xie, X.; Liu, W.; Liu, Y.-J.; Wang, J. Attention-Aware Multi-Stroke Style Transfer. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 1467–1475. [Google Scholar]
- Fang, H.; Xu, Y.; Wang, W.; Liu, X.; Zhu, S.C. Learning Pose Grammar to Encode Human Body Configuration for 3D Human Pose Estimation. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), New Orleans, LA, USA, 2–7 February 2018; Volume 32. No. 1. [Google Scholar]
- Chu, W.T.; Pan, Z.W. Semi-Supervised 3D Human Pose Estimation by Jointly Considering Temporal and Multiview Infor-mation. IEEE Access 2020, 8, 226974–226981. [Google Scholar] [CrossRef]
- Lee, K.; Lee, I.; Lee, S. Propagating LSTM: 3D Pose Estimation Based on Joint Interdependency. In Proceedings of the Constructive Side-Channel Analysis and Secure Design; Springer: Berlin/Heidelberg, Germany, 2018; pp. 123–141. [Google Scholar]
- Li, C.; Lee, G.H. Generating Multiple Hypotheses for 3D Human Pose Estimation with Mixture Density Network. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 9879–9887. [Google Scholar]
- Pavllo, D.; Feichtenhofer, C.; Grangier, D.; Auli, M. 3D Human Pose Estimation in Video with Temporal Convolutions and Semi-Supervised Training. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 7745–7754. [Google Scholar]
- Guo, Y.; Chen, Z. Absolute 3D Human Pose Estimation via Weakly-supervised Learning. In Proceedings of the 2020 IEEE International Conference on Visual Communications and Image Processing (VCIP), Macau, China, 1–4 December 2020; pp. 273–276. [Google Scholar]
- Wandt, B.; Rosenhahn, B. RepNet: Weakly Supervised Training of an Adversarial Reprojection Network for 3D Human Pose Estimation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 7774–7783. [Google Scholar]
- Hossain, M.R.I.; Little, J.J. Exploiting Temporal Information for 3D Human Pose Estimation. In Proceedings of the Constructive Side-Channel Analysis and Secure Design; Springer: Berlin/Heidelberg, Germany, 2018; pp. 69–86. [Google Scholar]
- Pavlakos, G.; Zhou, X.; Daniilidis, K. Ordinal Depth Supervision for 3D Human Pose Estimation. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7307–7316. [Google Scholar]
- Xiao, B.; Wu, H.; Wei, Y. Simple Baselines for Human Pose Estimation and Tracking. In Proceedings of the Constructive Side-Channel Analysis and Secure Design; Springer: Berlin/Heidelberg, Germany, 2018; pp. 472–487. [Google Scholar]
- Tang, W.; Yu, P.; Wu, Y. Deeply Learned Compositional Models for Human Pose Estimation. In Proceedings of the Constructive Side-Channel Analysis and Secure Design; Springer: Berlin/Heidelberg, Germany, 2018; pp. 197–214. [Google Scholar]
- Yang, S.; Yang, W.; Cui, Z. Pose Neural Fabrics Search. arXiv 2019, arXiv:1909.07068. [Google Scholar]
- Sun, K.; Xiao, B.; Liu, D.; Wang, J. Deep high-resolution representation learning for human pose estimation. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 5686–5696. [Google Scholar]
- Huo, Z.; Jin, H.; Qiao, Y.; Luo, F. Deep High-resolution Network with Double Attention Residual Blocks for Human Pose Estimation. IEEE Access 2020, 8, 1. [Google Scholar] [CrossRef]
- Jun, J.; Lee, J.H.; Kim, C.S. Human Pose Estimation Using Skeletal Heatmaps. In Proceedings of the 2020 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), Auckland, New Zealand, 7–10 December 2020; pp. 1287–1292. [Google Scholar]
- Tang, Z.; Peng, X.; Geng, S.; Zhu, Y.; Metaxas, D.N. CU-Net: Coupled U-Nets. In Proceedings of the British Machine Vision Conference (BMVC), Newcastle, UK, 3–6 September 2018. [Google Scholar]
- Tang, Z.; Peng, X.; Geng, S.; Wu, L.; Zhang, S.; Metaxas, D. Quantized Densely Connected U-Nets for Efficient Landmark Localization. In Proceedings of the Constructive Side-Channel Analysis and Secure Design; Springer: Berlin/Heidelberg, Germany, 2018; pp. 348–364. [Google Scholar]
- Ning, G.; Zhang, Z.; He, Z. Knowledge-Guided Deep Fractal Neural Networks for Human Pose Estimation. IEEE Trans. Multimedia 2018, 20, 1246–1259. [Google Scholar] [CrossRef]
- Zhang, W.; Fang, J.; Wang, X.; Liu, W. Efficientpose: Efficient human pose estimation with neural architecture search. arXiv 2020, arXiv:2012.07086. [Google Scholar]


| Method | Network | Input Size | 2D Data | SAN | MPJPE |
|---|---|---|---|---|---|
| a | ResNet-50 | - | × | 67.5 | |
| b | ResNet-50 | MPII | × | 62.2 | |
| c | ResNet-50 | MPII | √ | 57.9 | |
| d | ResNet-50 | MPII COCO | √ | 53.1 | |
| e | ResNet-50 * | MPII COCO | √ | 51.9 | |
| f | ResNet-152 * | MPII COCO | × | 49.6 | |
| g | ResNet-152 * | MPII COCO | √ | 48.6 |
| Model | Params | Flops | MPJPE |
|---|---|---|---|
| ResNet-50 | 34M | 14.10G | 62.2 |
| ResNet-50+SAN | 39M | 14.43G | 57.9 |
| Method | Head | Shoulder | Elbow | Wrist | Hip | Knee | Ankle | Average |
|---|---|---|---|---|---|---|---|---|
| SimpleBaseline-152 [35] | 97.0 | 95.9 | 90.3 | 85.0 | 89.2 | 85.3 | 81.3 | 89.6 |
| DLCM [36] | 95.6 | 95.9 | 90.7 | 86.5 | 89.9 | 86.6 | 82.5 | 89.8 |
| StackedHourglass [12] | 98.2 | 96.3 | 91.2 | 87.1 | 90.1 | 87.4 | 83.6 | 90.0 |
| PoseNFS [37] | 97.9 | 95.6 | 90.7 | 86.5 | 89.8 | 86.0 | 81.5 | 90.2 |
| HRNet-W32 [38] | 97.1 | 95.9 | 90.3 | 86.4 | 89.1 | 87.1 | 83.3 | 90.3 |
| CA+SA [39] | 97.1 | 96.0 | 90.7 | 86.4 | 89.4 | 86.8 | 83.3 | 90.4 |
| PRAB [39] | 97.1 | 96.2 | 90.7 | 86.4 | 89.8 | 86.9 | 83.3 | 90.5 |
| SkeletalHeatmap [40] | - | - | - | - | - | - | - | 90.6 |
| CU-Net [41] | 97.4 | 96.2 | 91.8 | 87.3 | 90.0 | 87.0 | 83.3 | 90.8 |
| DU-Net [42] | 97.6 | 96.4 | 91.1 | 87.3 | 90.4 | 87.3 | 83.8 | 91.0 |
| KnowledgeGuided [43] | 98.1 | 96.3 | 92.2 | 87.8 | 90.6 | 87.6 | 82.7 | 91.2 |
| MultiContext [13] | 98.5 | 96.3 | 91.9 | 88.1 | 90.6 | 88.0 | 85.0 | 91.5 |
| Ours | 98.7 | 96.6 | 92.4 | 88.2 | 91.1 | 88.9 | 84.8 | 91.7 |
| Method | |||||
|---|---|---|---|---|---|
| Integral-H1 [7] | 66.3 | 88.4 | 74.6 | 62.9 | 72.1 |
| Integral-I1 [7] | 67.8 | 88.2 | 74.8 | 63.9 | 74.0 |
| EfficientPose-B [44] | 70.5 | 91.1 | 79.0 | 67.3 | 76.2 |
| EfficientPose-C [44] | 70.9 | 91.3 | 79.4 | 67.7 | 76.5 |
| PoseNFS-MobileNet [37] | 67.4 | 89.0 | 73.7 | 63.3 | 74.3 |
| PoseNFS-ResNet [37] | 70.9 | 90.4 | 77.7 | 66.7 | 78.2 |
| Ours | 71.8 | 91.5 | 79.8 | 66.9 | 78.0 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xia, H.; Zhang, T. Self-Attention Network for Human Pose Estimation. Appl. Sci. 2021, 11, 1826. https://doi.org/10.3390/app11041826
Xia H, Zhang T. Self-Attention Network for Human Pose Estimation. Applied Sciences. 2021; 11(4):1826. https://doi.org/10.3390/app11041826
Chicago/Turabian StyleXia, Hailun, and Tianyang Zhang. 2021. "Self-Attention Network for Human Pose Estimation" Applied Sciences 11, no. 4: 1826. https://doi.org/10.3390/app11041826
APA StyleXia, H., & Zhang, T. (2021). Self-Attention Network for Human Pose Estimation. Applied Sciences, 11(4), 1826. https://doi.org/10.3390/app11041826